









solr默认是不支持中文分词的,这样就需要我们手工配置中文分词器,在这里我们选用IK Analyzer中文分词器。
IK Analyzer下载地址:https://code.google.com/p/ik-analyzer/downloads/list
如图:
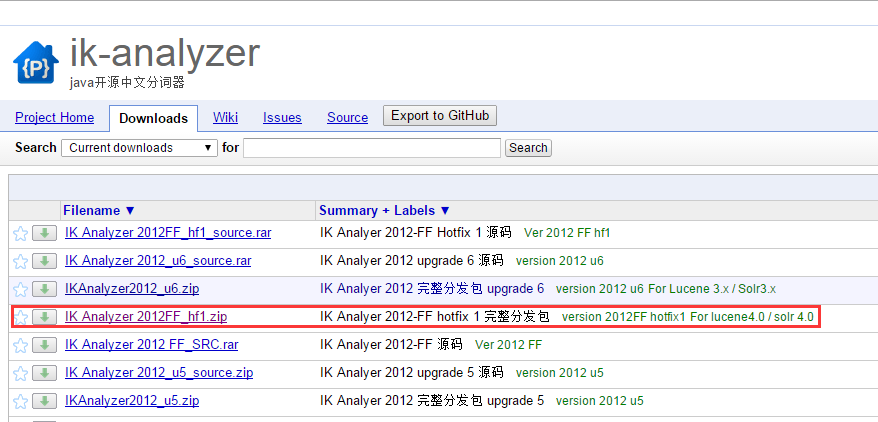
默认大家已经下载并解压了solr,在这里我们使用solr 4.10.4版本
试验环境centos 6.5 ,JDK1.7
整合步骤
1:解压下载的IK Analyzer_2012_FF_hf1.zip压缩包,把IKAnalyzer2012FF_u1.jar拷贝到solr-4.10.4/example/solr-webapp/webapp/WEB-INF/lib目录下
2:在solr-4.10.4/example/solr-webapp/webapp/WEB-INF目录下创建目录classes,然后把IKAnalyzer.cfg.xml和stopword.dic拷贝到新创建的classes目录下即可。
3:修改solr core的schema文件,默认是solr-4.10.4/example/solr/collection1/conf/schema.xml,添加如下配置
<fieldType name="text_ik" class="solr.TextField">
<!--索引时候的分词器-->
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<!--查询时候的分词器-->
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType> <fieldtype name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<!-- general -->
<field name="id" type="string" indexed="true" stored="true" multiValued="false" required="true"/>
<field name="name" type="text_ik" indexed="true" stored="true" multiValued="false" />
<field name="content" type="text_ik" indexed="true" stored="true" multiValued="true" />
<field name="_version_" type="long" indexed="true" stored="true"/>
4:启动solr,bin/solr start
5:进入solr web界面http://localhost:8983/solr,看到下图操作结果即为配置成功
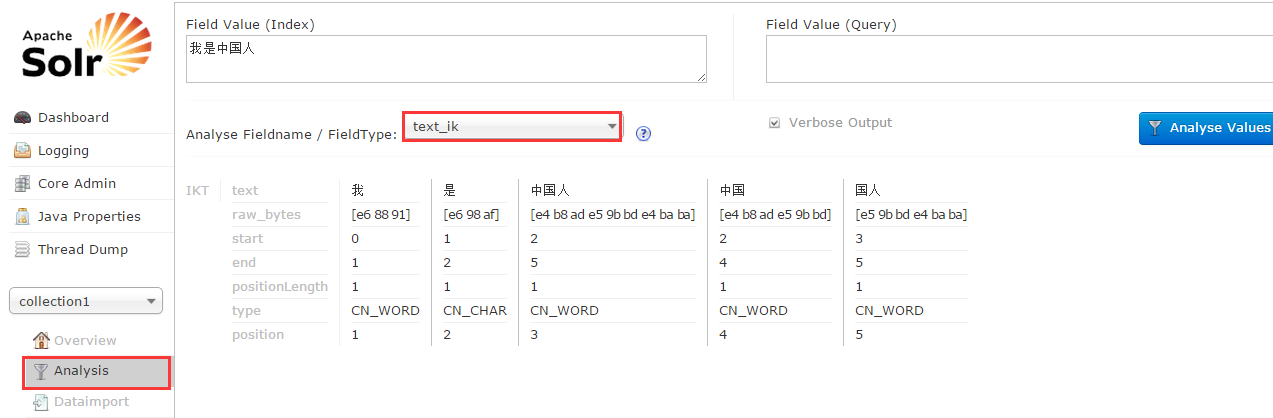
到现在为止,solr就和IK Analyzer中文分词器整合成功了。
但是,如果我想自定义一些词库,让IK分词器可以识别,那么就需要自定义扩展词库了。
操作步骤:
1:修改solr-4.10.4/example/solr-webapp/webapp/WEB-INF/classes目录下的IKAnalyzer.cfg.xml配置文件,配置如下
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>注意字典的格式,是一行写一个词
2:新建ext.dic文件(扩展字典),在里面添加如下内容(注意:ext.dic的编码必须是Encode in UTF-8 without BOM,否则自定义的词库不会被识别)
超人学院
3:新建stopword.dic(扩展停止词字典,即以该词为分界线分词),在里面添加
中国
中华人民

3:重启solr
4:在solr web界面进行如下操作,看到图中操作结果即为配置成功。
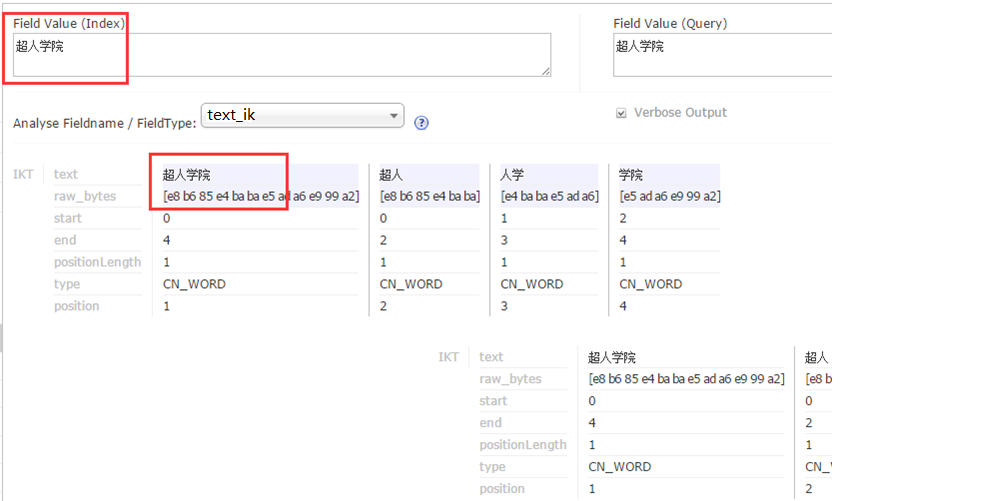
高亮显示我们会在下一篇文章中介绍















 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











