







flink 任务提交问题汇总
1. 提交flink自带任务WordCount.jar遇到的问题:
2. 提交flink 批处理任务时遇到的问题
3. flink定时任务,mysql连接超时问题
4. flink checkpoint 恢复失败
5. yarn 增加并行任务数量配置
6. 流处理flink程序在hadoop集群跑了一段时间莫名挂掉
1. 提交flink自带任务WordCount.jar遇到的问题:
问题描述:
最近在提交flink项目example下WordCount.jar批处理任务时遇到以下问题:
The main method caused an error: org.apache.flink.runtime.concurrent.FutureUtils$RetryException: Could not complete the operation. Number of retries has been exhausted.
之后就是拒绝连接等异常详细内容如下:
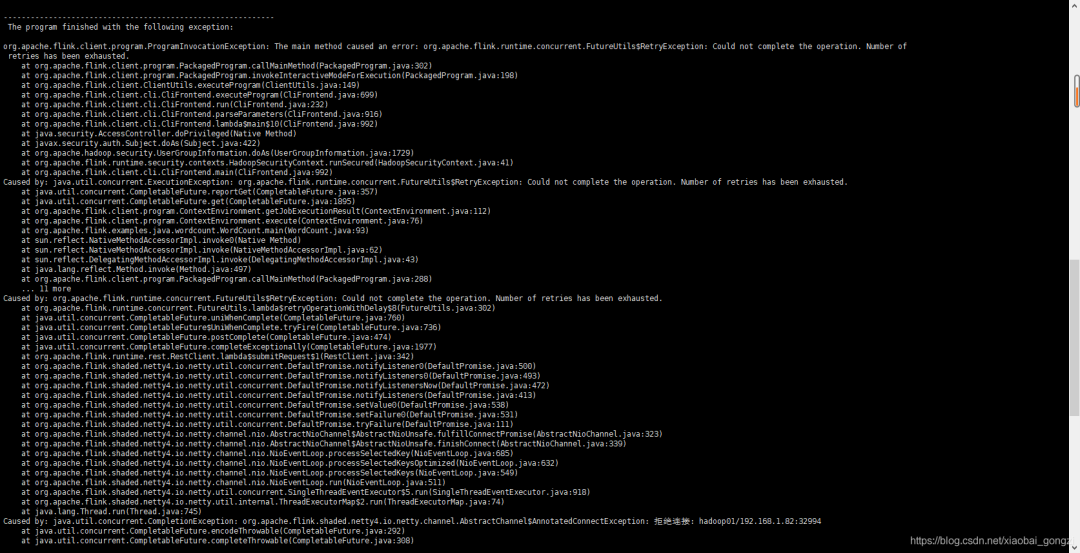
yarn 资源管理器,flink页面这样显示:

原因分析:
之后我重启了zk,hadoop,重新提交flink任务,但还是不行
之后看到flink页面的内容.Service temporarily unavailable due to an ongoing leader election. Please refresh,让我想到之前提交任务也遇到过这种情况。于是考虑了 以下两个问题:
1. 在yarn提交批处理任务的时候都是同一个任务,会不会产生冲突
2. 结果输出会不会冲突
在yarn提交任务是不可能冲突的,任务之间是独立的,所以排除了第一种情况,然后就是输出问题,我提交任务的时候都是在同一个文件输出,这时候问题就来了如果结果都输出到同一个文件那不就乱了,flink好像也预知了这样的问题,因此报了上面的错误
解决方案:
更改批处理的输出路径
如果你第一次是这样提交:
bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar -input hdfs://hadoop01:9000/test/word -output hdfs://hadoop01:9000/test/result1第二次就这样提交:
bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar -input hdfs://hadoop01:9000/test/word -output hdfs://hadoop01:9000/test/result22. 提交flink 批处理任务时遇到的问题
问题描述
最近写了一个flink批处理程序, 目的是读取hdfs文件,将文件数据写入到hbase
项目是在idea中开发的 pom 文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hdfs-flink</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<flink.version>1.11.2</flink.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>2.0.0-alpha1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>1.11.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.18</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.17</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.6</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- 指定模块打包-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<!--需要加入编译信息过滤,不然不知名错误-->
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.RSA</exclude>
<exclude>META-INF/*.DSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>xxx.Format</mainClass>
</transformer>
</transformers>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>将代码写完之后发现在idea中运行是没有问题,但是将项目打包后上传到集群,使用Job方式提交任务的时候报错,控制台的详细信息如下:
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/lib/flink/flink-1.11.2/lib/log4j-slf4j-impl-2.12.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/lib/hadoop/hadoop-3.1.4/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2021-02-24 13:52:11,153 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/usr/lib/flink/flink-1.11.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2021-02-24 13:52:11,179 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at hadoop01/192.168.1.82:8032
2021-02-24 13:52:11,306 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2021-02-24 13:52:11,372 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2021-02-24 13:52:11,372 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2021-02-24 13:52:11,410 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, slotsPerTaskManager=1}
2021-02-24 13:52:14,619 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1614083574571_0023
2021-02-24 13:52:14,653 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1614083574571_0023
2021-02-24 13:52:14,653 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2021-02-24 13:52:14,654 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
org.apache.flink.client.deployment.ClusterDeploymentException: Could not deploy Yarn job cluster.
at org.apache.flink.yarn.YarnClusterDescriptor.deployJobCluster(YarnClusterDescriptor.java:431)
at org.apache.flink.client.deployment.executors.AbstractJobClusterExecutor.execute(AbstractJobClusterExecutor.java:70)
at org.apache.flink.api.java.ExecutionEnvironment.executeAsync(ExecutionEnvironment.java:973)
at org.apache.flink.client.program.ContextEnvironment.executeAsync(ContextEnvironment.java:124)
at org.apache.flink.client.program.ContextEnvironment.execute(ContextEnvironment.java:72)
at com.spaceon.hys.argos.set.Format.main(Format.java:66)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:288)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:198)
at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:149)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:699)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:232)
at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:916)
at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:992)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:992)
Caused by: org.apache.flink.yarn.YarnClusterDescriptor$YarnDeploymentException: The YARN application unexpectedly switched to state FAILED during deployment.
Diagnostics from YARN: Application application_1614083574571_0023 failed 4 times in previous 10000 milliseconds due to AM Container for appattempt_1614083574571_0023_000004 exited with exitCode: 1
Failing this attempt.Diagnostics: [2021-02-24 13:52:25.722]Exception from container-launch.
Container id: container_1614083574571_0023_04_000001
Exit code: 1
[2021-02-24 13:52:25.723]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
[2021-02-24 13:52:25.724]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
For more detailed output, check the application tracking page: http://hadoop01:8088/cluster/app/application_1614083574571_0023 Then click on links to logs of each attempt.
. Failing the application.
If log aggregation is enabled on your cluster, use this command to further investigate the issue:
yarn logs -applicationId application_1614083574571_0023
at org.apache.flink.yarn.YarnClusterDescriptor.startAppMaster(YarnClusterDescriptor.java:1021)
at org.apache.flink.yarn.YarnClusterDescriptor.deployInternal(YarnClusterDescriptor.java:524)
at org.apache.flink.yarn.YarnClusterDescriptor.deployJobCluster(YarnClusterDescriptor.java:424)
... 21 more
2021-02-24 13:52:26,086 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cancelling deployment from Deployment Failure Hook
2021-02-24 13:52:26,087 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at hadoop01/192.168.1.82:8032
2021-02-24 13:52:26,088 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Killing YARN application
2021-02-24 13:52:26,097 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Killed application application_1614083574571_0023
2021-02-24 13:52:26,097 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deleting files in hdfs://hadoop01:9000/user/root/.flink/application_1614083574571_0023.原因分析:
1. 从控制台的日志好像发现不了什么关键的问题,只是报了一个 Container 加载失败,然后让你去yarn的首页去查看日志,之后我也查看了相关日志信息,但都没有发现什么有价值的信息。
2. 于是考虑是不是自己jar包的问题,之后使用各种打包的方式都没能解决问题。
3. 最后就只能逐个排除出问题的jar包,最后发现去掉 hbase-client 的包后程序正常执行,经过查看hbase-client 的依赖发现 hbase-client 包里使用的hadoop相关的依赖都是2.8.x,但是我的hadoop集群是3.1.4 版本。于是判断可能是hadoop版本冲突了。
解决方案:
去除hbase-client的包里 hadoop 相关依赖,其中有些包在 hadoop-client 中是包含的,但是不能覆盖hbase-client里的,通过 maven-shade-plugin打包也是不能解决的
具体操作在 pom 文件修改hbase-client 依赖:
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.4.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-annotations</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
</exclusion>
</exclusions>
</dependency>3. flink定时任务,mysql连接超时问题
问题描述
前一天将flink任务提交到集群,第二天在web界面发现如下异常:
2021-07-01 09:11:40
com.mysql.cj.jdbc.exceptions.CommunicationsException: The last packet successfully received from the server was 63,745,201 milliseconds ago. The last packet sent successfully to the server was 63,745,201 milliseconds ago. is longer than the server configured value of 'wait_timeout'. You should consider either expiring and/or testing connection validity before use in your application, increasing the server configured values for client timeouts, or using the Connector/J connection property 'autoReconnect=true' to avoid this problem.
at com.mysql.cj.jdbc.exceptions.SQLError.createCommunicationsException(SQLError.java:174)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:64)
at com.mysql.cj.jdbc.ConnectionImpl.isReadOnly(ConnectionImpl.java:1412)
at com.mysql.cj.jdbc.ConnectionImpl.isReadOnly(ConnectionImpl.java:1390)
at com.mysql.cj.jdbc.ClientPreparedStatement.executeBatchInternal(ClientPreparedStatement.java:403)
at com.mysql.cj.jdbc.StatementImpl.executeBatch(StatementImpl.java:796)
at com.spaceon.hys.quality.function.sink.SinkQualityResult.invoke(SinkQualityResult.java:74)
at com.spaceon.hys.quality.function.sink.SinkQualityResult.invoke(SinkQualityResult.java:22)
at org.apache.flink.streaming.api.operators.StreamSink.processElement(StreamSink.java:56)
at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:161)
at org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:178)
at org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:153)
at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:67)
at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:351)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxStep(MailboxProcessor.java:191)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:181)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:566)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:536)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:721)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:546)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.mysql.cj.exceptions.CJCommunicationsException: The last packet successfully received from the server was 63,745,201 milliseconds ago. The last packet sent successfully to the server was 63,745,201 milliseconds ago. is longer than the server configured value of 'wait_timeout'. You should consider either expiring and/or testing connection validity before use in your application, increasing the server configured values for client timeouts, or using the Connector/J connection property 'autoReconnect=true' to avoid this problem.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:422)
at com.mysql.cj.exceptions.ExceptionFactory.createException(ExceptionFactory.java:61)
at com.mysql.cj.exceptions.ExceptionFactory.createException(ExceptionFactory.java:105)
at com.mysql.cj.exceptions.ExceptionFactory.createException(ExceptionFactory.java:151)
at com.mysql.cj.exceptions.ExceptionFactory.createCommunicationsException(ExceptionFactory.java:167)
at com.mysql.cj.protocol.a.NativeProtocol.send(NativeProtocol.java:572)
at com.mysql.cj.protocol.a.NativeProtocol.sendCommand(NativeProtocol.java:633)
at com.mysql.cj.protocol.a.NativeProtocol.sendCommand(NativeProtocol.java:130)
at com.mysql.cj.NativeSession.sendCommand(NativeSession.java:317)
at com.mysql.cj.NativeSession.queryServerVariable(NativeSession.java:1046)
at com.mysql.cj.jdbc.ConnectionImpl.isReadOnly(ConnectionImpl.java:1398)
... 18 more
Caused by: java.net.SocketException: Broken pipe
at java.net.SocketOutputStream.socketWrite0(Native Method)
at java.net.SocketOutputStream.socketWrite(SocketOutputStream.java:109)
at java.net.SocketOutputStream.write(SocketOutputStream.java:153)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.flush(BufferedOutputStream.java:140)
at com.mysql.cj.protocol.a.SimplePacketSender.send(SimplePacketSender.java:55)
at com.mysql.cj.protocol.a.TimeTrackingPacketSender.send(TimeTrackingPacketSender.java:50)
at com.mysql.cj.protocol.a.NativeProtocol.send(NativeProtocol.java:563)
... 23 more原因分析
因为在flink任务里有一个按天统计功能,通过flink的定时器完成每天输出一个统计结果,但是在初始化mysql连接的后,也就是启动flink任务后,过24小时才会有该链接的更新操作,但mysql默认的连接等待时长为8小时,在建立连接后过8小时候没有进行任何查询操作,mysql将自动关闭连接,这才导致mysql连接失效
解决方案
网上的解决方案大致两种
1. 更新mysql的配置,重新设置连接的等待时间

2. 连接加&autoReconnect=true属性(mysql5.x无效,亲测)
我是通过代码层来重新建立连接的
因为不想再去动mysql的默认配置,直接catch CommunicationsException ,若抛此异常表示连接断开了,然后重新建立连接
try {
execUpdate(value);
System.out.println("mysql 连接未断开更新");
}catch (CommunicationsException e){
connection = ConnectionUtil.getConnection();
execUpdate(value);
System.out.println("mysql 连接断开重连更新");
}4. flink checkpoint 恢复失败
异常信息:
org.apache.flink.util.StateMigrationException: For heap backends, the new state serializer must not be incompatible.
at org.apache.flink.runtime.state.heap.HeapKeyedStateBackend.tryRegisterStateTable(HeapKeyedStateBackend.java:230) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.runtime.state.heap.HeapKeyedStateBackend.createInternalState(HeapKeyedStateBackend.java:273) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.runtime.state.KeyedStateFactory.createInternalState(KeyedStateFactory.java:47) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.runtime.state.ttl.TtlStateFactory.createStateAndWrapWithTtlIfEnabled(TtlStateFactory.java:72) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.runtime.state.AbstractKeyedStateBackend.getOrCreateKeyedState(AbstractKeyedStateBackend.java:279) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.streaming.api.operators.StreamOperatorStateHandler.getOrCreateKeyedState(StreamOperatorStateHandler.java:245) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.getOrCreateKeyedState(AbstractStreamOperator.java:435) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.streaming.runtime.operators.windowing.WindowOperator.open(WindowOperator.java:240) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.streaming.runtime.tasks.OperatorChain.initializeStateAndOpenOperators(OperatorChain.java:291) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.streaming.runtime.tasks.StreamTask.lambda$beforeInvoke$0(StreamTask.java:479) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.runThrowing(StreamTaskActionExecutor.java:47) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.streaming.runtime.tasks.StreamTask.beforeInvoke(StreamTask.java:475) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:528) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:721) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:546) ~[preprocessing-flink-1.0.0-SNAPSHOT.jar:1.0.0-SNAPSHOT]
at java.lang.Thread.run(Thread.java:745) ~[?:1.8.0_65]解决方案
先看 cheackpoint 页面信息
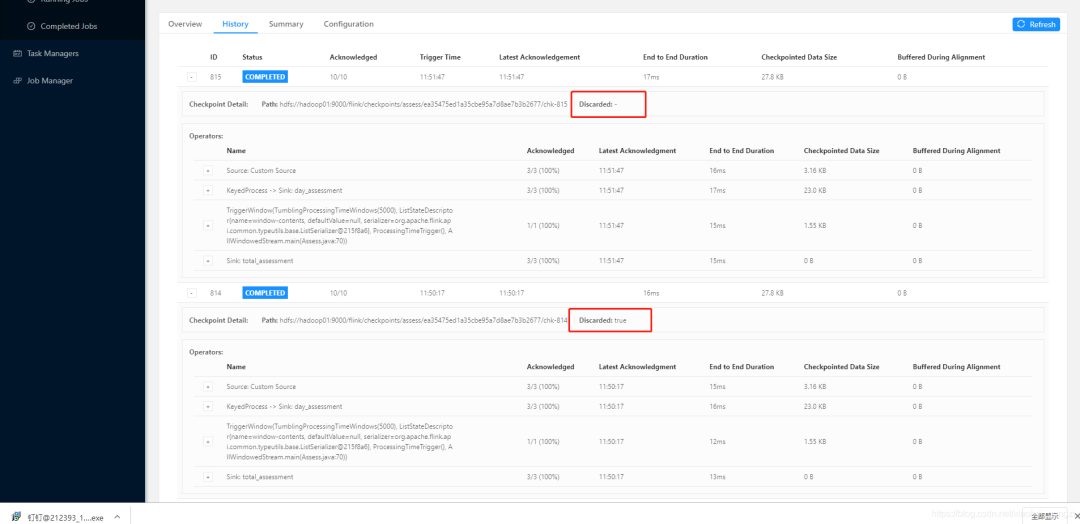
再查看hdfs,会发现只有最近的一条checkpoint被保留下来,所以恢复的参数必须是最后一条存在的checkpoint记录
/usr/lib/flink/flink/bin/flink run -d -m yarn-cluster -yjm 1024 -ytm 1024 -s hdfs://hadoop01:9000/flink/checkpoints/preprocess/60366092809bbc2b5785591f8014f759/chk-815 /usr/lib/flink/jars/test/xxx.jar5. yarn 增加并行任务数量配置
问题描述
由于项目的要求,需要在yarn集群运行三个以上的flink流处理程序,外加一部分批处理程序,今天测试的时候发现部署了三个flink流处理程序后,内存,cpu资源都没有占满还有大部分的空间,但是提交flink批处理程序的时候,批处理程序一直处于挂起状态,不执行,大概想了一下应该就是资源分配的问题
解决方案
修改hadoop配置文件:capacity-scheduler.xml
yarn.scheduler.capacity.maximum-am-resource-percent
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
#该值默认为0.1,将其修改为0.2
<value>0.2</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>该值的描述信息意为,群集中可用于运行应用程序主机的资源的最大百分比,即控制并发运行的应用程序的数量
根据应用场景适当的增大该值即可提高应用的并发数量
6. 流处理flink程序在hadoop集群跑了一段时间莫名挂掉
问题描述
一个左右前在hadoop集群跑了一个flink流处理任务,有一天检查的时候发现挂掉了,信息如下:

点进去
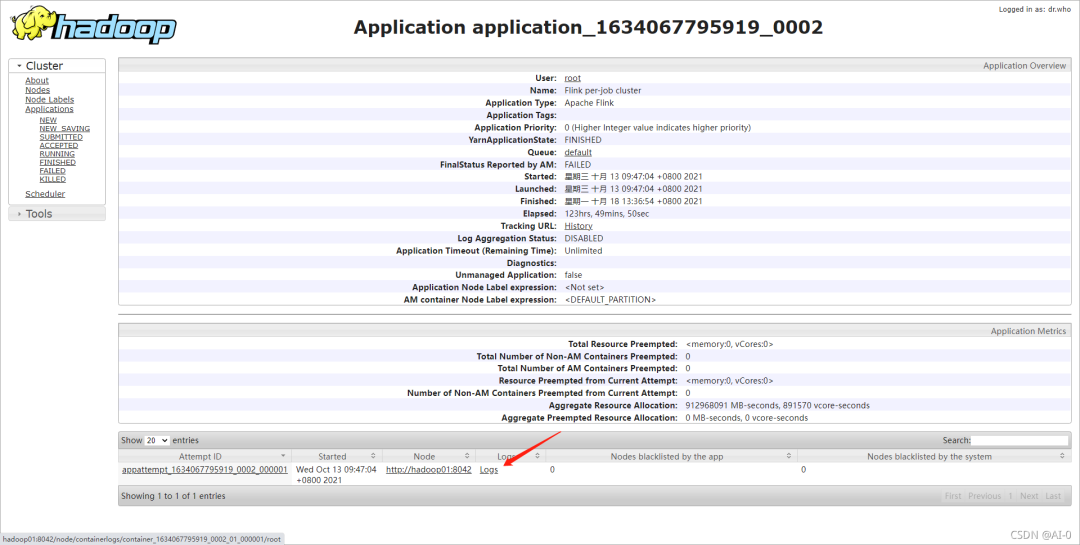
查看日志
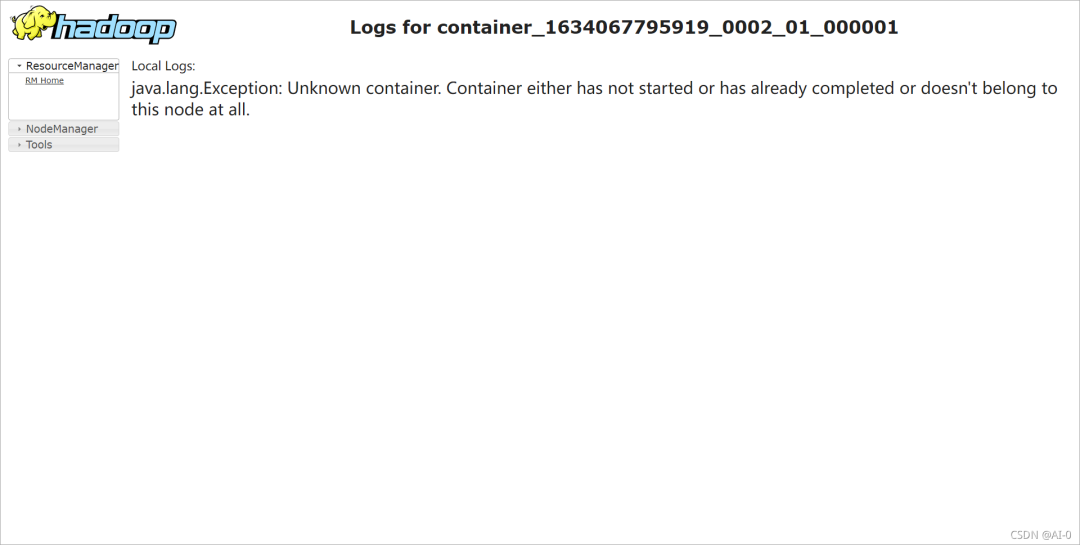
发现flink所有的运行日志随hadoop的容器消失了
原因分析
第一时间想到查看hadoop的日志,大概会有些帮助,进而定位问题,先后查看了namenode日志,datanode日志发现并无异常,然后查看nodemanager的日志时发现了端倪
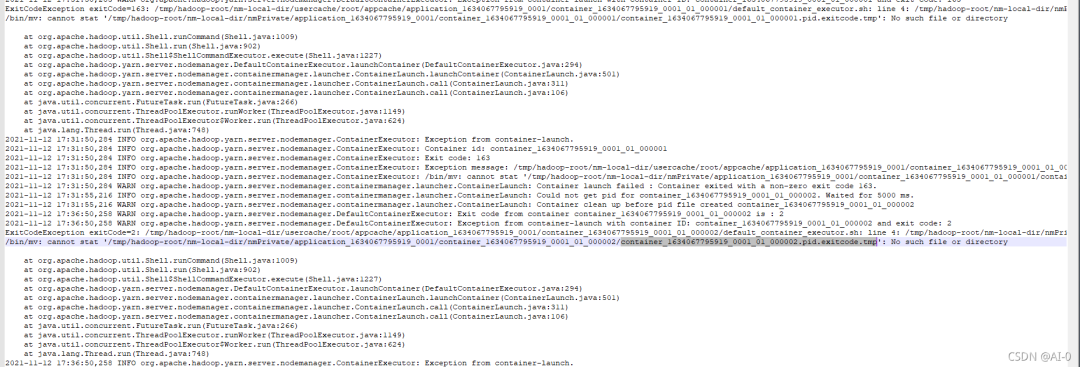
(由于日志文件比较大在linux终端查看不方便所以下载下来,使用Notepad++查看,查看时在hadoop任务界面找到任务失败的时间,下载该时间点的日志文件,就可以找到对应日志信息)
从日志信息可以发现,由于找不到进程id,所以容器直接关掉了退出了,于是根据日志进去查看了linux系统下的tmp目录,最后发现果然有/tmp/hadoop-root/*一系列目录,对于hadoop容器的进程id这么重要的东西怎么能放在/tmp目录呢,tmp目录众所周知在文件不修改的情况下,默认30天会被清理,那么问题大概就出现在这里了,运行flink任务的container 的进程id被系统清理了
解决方案
通过分析后,查看了一下hadoop临时目录的配置

可以发现用到该配置的地方竟然有13处之多,当然也包含了container的进程id的信息存放,因此只需将hadoop.tmp.dir的配置更改一下就可以了,更改时修改core-site.xml文件,添加该配置项,具体的目录根据自己系统空间去配置
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!


2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点














 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









