







1. Bucket(分桶)数量设置不当带来的问题
问题描述:上线运行一段时间后,随着越来越多的数据增长,集群每次重启后一周左右,读写就会开始变得越来越慢,直到无法正常进行读写。
问题处理:
对数仓表的 Schema 的分析,发现有些表数据并不大,但是 Bucket 却设置的非常大
通过
show data from table命令列出所有表Bucket信息,大部分的Bucket设置不合理按照官方的建议将调整Bucket设置,调整后集群逐步恢复正常的读写
2. 关于 Partition 和 Bucket 的数量和数据量的建议
一个表的 Tablet 总数量等于 (Partition num * Bucket num)
数量原则:一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量
数据量原则:单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)
当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则
在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(
ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度
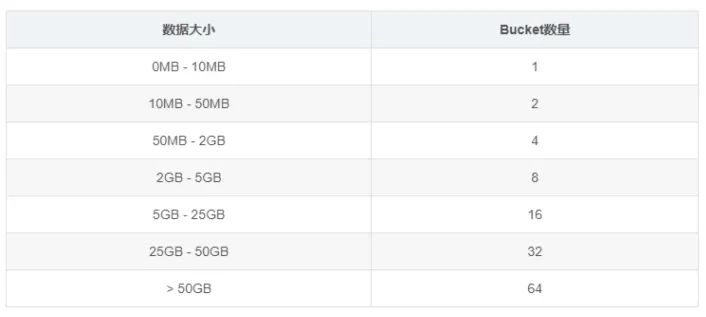
举一些例子:假设在有10台BE,每台BE一块磁盘的情况下。如果一个表总大小为 500MB,则可以考虑4-8个分片。5GB:8-16个分片。50GB:32个分片。500GB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。5TB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片
注:表的数据量可以通过 SHOW DATA 命令查看,结果除以副本数,即表的数据量
3. 分桶数不规范带来的问题
3.1 分桶数太多
Tablet是Apache Doris的最小物理存储单元,集群中的Tablet数量 = 分区数 * 分桶数 * 副本数。分桶数过多会造成FE元数据信息负载过高,从而影响导入和查询性能。一般发生在Apache Doris上线运行一段时间之后,随着越来越多数据的接入,数量的增长,集群运行一段时间后,读写就变得越来越慢,直到无法正常进行读写。
例如这个案例:打破数据孤岛,Apache Doris 助力纵腾集团快速构建流批一体数仓架构
3.2 分桶数太少
对于大表而言,分桶数太少会导致单个Tablet的文件占用空间远大于官方推荐的10GB上限范围,文件太大造成Apache Doris后台的Compaction进程变得缓慢,最后造成写入进程,如Broker Load导入失败。
例如这个案例:万亿数据秒级响应,Apache Doris 在360数科实时数仓中的应用
4. 分桶数规范
一个表的 Tablet 总数量等于 (Partition num * Bucket num)
数量原则:一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量
数据量原则:单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)
当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则
在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀
一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度
在数据量持续增长预期的情况下,可考虑以下分桶数:
5. 自动分桶
手动分桶对使用者有一定的要求:清楚当前数据量的大小并且对将来的数据量的增长有比较准确的预估。
这对非数据开发的小伙伴不太友好。
分桶数没有设置好,虽然可以通过重建分区,指定新分区的分桶数来解决,但毕竟带来了一定的运维工作。
自动分桶这个功能的出现带来了福音(仅限于分区表)。
注意:该功能要求使用 Apache Doris 1.2.2 及以上版本
5.1 建表语法
create table tbl1
(...)
[PARTITION BY RANGE(...)]
DISTRIBUTED BY HASH(k1) BUCKETS AUTO
properties(
"estimate_partition_size" = "10G"
)BUCKETS AUTO表示自动设置分桶数estimate_partition_size:可选参数,提供一个单分区初始数据量,根据这个数据量来计算出初始的分桶数,未指定的话会使用默认分桶数:10
自动分桶的功能还可以根据历史分区的数据量趋势预估未来分区的分桶数。
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!


2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点















 515
515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









