






这个问题同样也是之前辅导过的同学的面试问题,这个问题非常接地气且考察面试者的实践经验。事实上,这也是我们大数据提高班的Flink专项提高部分内容。
下面我列举的这些就是核心,能答出这些重点即可。
内存模型在Flink1.9和Flink1.11版本做了非常大的改动,主要原因是为了统一Batch和Streaming的内存配置。首先我建议大家只看Flink1.11版本的内存配置即可。
有两个FLIP可以参考,这两个FLIP你能看懂的话就能完全掌握Flink的内存配置。
FLIP-116: Unified Memory Configuration for Job Managers
FLIP-49: Unified Memory Configuration for TaskExecutors
我们分情况来说。
JobManager内存模型
Flink1.11后的JM内存模型如下:
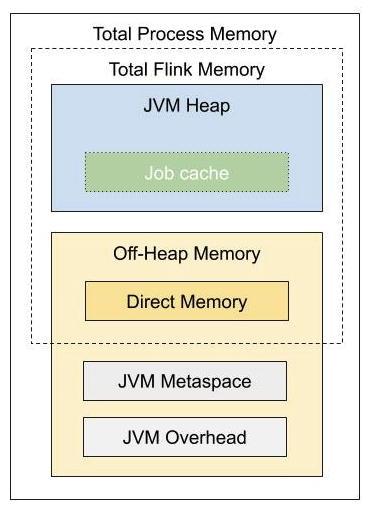
两个版本之间最大的变化是:
Flink 1.9 中只有堆内、堆外两个内存模块;
Flink 1.11 中将 Flink 1.9 的堆外模块细分为 Direct Memory、JVM Metaspace 和 JVM Overhead 三类;
核心的参数如下:

举个例子,假设 JM 配置的总内存大小为 1GB,那么 JM 在启动时,生成的 JVM 命令如下:
-Xmx469762048
-Xms469762048
-XX: MaxDirectMemorySize=134217728
-XX:MaxMetaspaceSize=268435456,计算结果:
Heap: 1g - 128m - 256m - 192m = 448MB;
DirectMemory:128MB;
Metaspace:256MB;
Overhead:min(max(192m, 0.1 * 1g), 1g) = 192m
JM的内存配置建议是:只需要配置JM的总内存大小,其余全部默认即可。
TaskManager内存模型
Flink1.11后的TM内存模型如下:
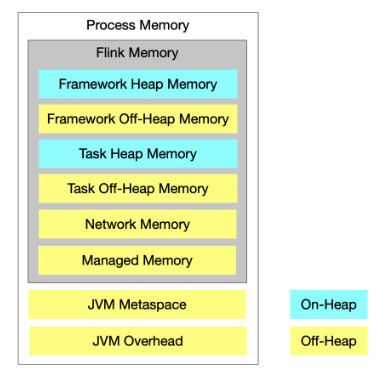
TaskManager核心配置参数如下:
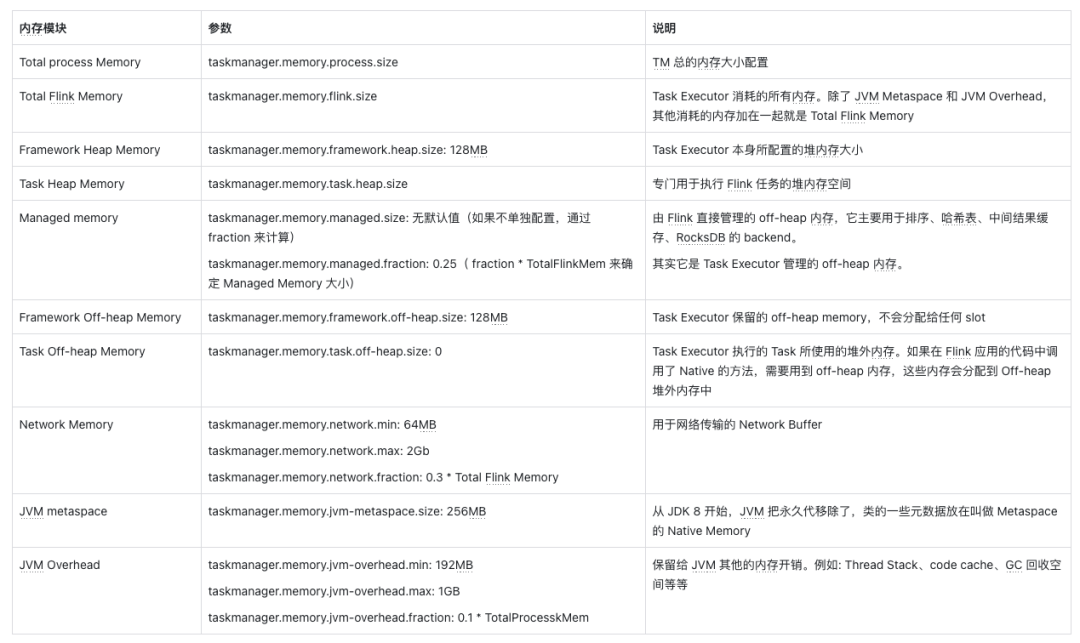
TM的内存配置建议:只需要配置TM的总内存大小,其余全部默认即可。
举个例子,假设一个任务的 TM 内存配置为 4196 MB,运行时的 JVM 参数被设置如下:
# JVM 配置
-Xmx973204290 # 928.12MB
-Xms973204290
-XX:MaxDirectMemorySize= 1241639855 # 1184.12MB
-XX:MaxMetaspaceSize=268435456 # 256MB
# 计算的配置
taskmanager.memory.framework.off-heap.size=134217728b
taskmanager.memory.network.max=1107422127b
taskmanager.memory.network.min=1107422127b
taskmanager.memory.task.off-heap.size=0b
taskmanager.memory.framework.heap.size=134217728b
taskmanager.memory.task.heap.size=838986562b
taskmanager.memory.managed.size=1476562799b注意,这里有个特殊的配置需要注意,如果你的任务TM个数过多,会出现类似如下的错误:
java.io.IOException: Insufficient number of network buffers: required xxx, but only xxx available. The total number of network buffers is currently set to xxx of xxx bytes each. You can increase this number by setting the configuration keys 'taskmanager.network.memory.fraction', 'taskmanager.network.memory.min', and 'taskmanager.network.memory.max'.
at org.apache.flink.runtime.io.network.buffer.NetworkBufferPool.createBufferPool(NetworkBufferPool.java:363)
at org.apache.flink.runtime.io.network.partition.ResultPartitionFactory.lambda$createBufferPoolFactory$0(ResultPartitionFactory.java:207)
at org.apache.flink.runtime.io.network.partition.ResultPartition.setup(ResultPartition.java:131)
at org.apache.flink.runtime.taskmanager.Task.setupPartitionsAndGates(Task.java:898)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:648)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:539)
at java.lang.Thread.run(Thread.java:748)原因是因为作业TM之间shuffle数据时,network buffer不足。通过调整taskmanager.memory.network.min,taskmanager.memory.network.max和taskmanager.memory.network.fraction即可。
加餐,内存设置和并行度关系
最后,估算一个任务的内存消耗,要和并行度的指定搭配进行。
举个例子,假如我们估算一个任务需要消耗的总内存是20G,这时候资源该怎么分配呢?
我们可以指定TM个数=2,单个TM消耗10G内存,2x10=20G;也可以指定TM个数=10,单个TM消耗2G内存,10x2=20G。
这两种方式有区别吗?当然有。
假设我们TM个数=2,那么如果我的任务数据量较大,例如上游Source端的Kafka Partition数量为128,那么理论上我们需要指定的Flink任务的最大并行度至少是128,那么单个TM的Slot数量就应该是64,因为2x64=128。这会带来什么问题呢?单个TM分配64个Slot明显不太合理。
我们拿出官网的推荐:

官网给出的建议值是:TakManager所拥有的cpu核数的整数倍(proportional to the number of physical CPU cores that the TaskManager's machine has)。
实际中我们单个TM分配的cpu一般是1的整数倍,例如2、4...,那么这时候单个TM的slot个数建议是20、40、80...。最好是cpu数量的整数倍,至于是多少倍,大家可以根据经验判断,一般来说建议是10-20倍左右。
当然,在Flink1.14版本后,对于希望更精细化调节资源消耗的用户,基于对特定场景的了解,Flink提供了细粒度资源管理。我们直接拿官网的图做对比:
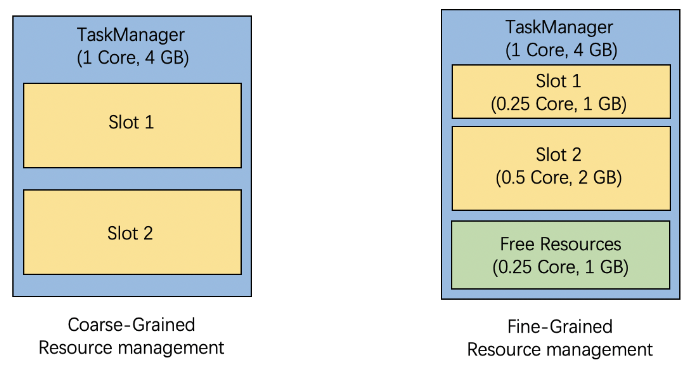
对于细粒度资源管理,Slot 资源请求包含用户指定的特定的资源配置文件。Flink 会遵从这些用户指定的资源请求并从 TaskManager 可用的资源中动态地切分出精确匹配的 slot。如上图所示,对于一个 slot,0.25Core 和 1GB 内存的资源申请,Flink 为它分配 slot 1。
对于没有指定资源配置的资源请求,Flink会自动决定资源配置,如上所示,TaskManager 的总资源是 1Core 和 4GB 内存,task 的 slot 数设置为2,Slot 2 被创建,并申请 0.5 Core和 2GB 的内存而没有指定资源配置。 在分配 Slot 1和 Slot 2后,在 TaskManager 留下 0.25 Core 和 1GB 的内存作为未使用资源。
所以你看这个问题其实是一环套一环的,有经验的面试官会继续往下追问。当然如果你掌握的足够好,也可以给出超出面试官期望的回答。

如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!

Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
















 2274
2274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











