










需求
default 队列占总内存的40%,最大资源容量占总资源的60%
ops 队列占总内存的60%,最大资源容量占总资源的80%
配置多队列的容量调度器
- 在yarn-site.xml里面配置使用容量调度器
<!-- 使用容量调度器 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
- 在capacity-scheduler.xml中配置如下:
从Apache hadoop 3.1.0开始 CapacityScheduler支持配置绝对值格式的资源量。上面的 yarn.scheduler.capacity..capacity 和 yarn.scheduler.capacity..max-capacity 配置项,可以指定一个绝对资源量如 [memory=10240,vcores=12]。这表示为队列配置10GB的内存和12个Vcore。使用绝对值资源配置时,这2个参数分别对应Yarn web页面中队列信息的__Configured Capacity__和__Configured Max Capacity__
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 表示集群最大app数 -->
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
</property>
<!-- 表示集群上某队列可使用的资源比例 目的是为了限制过多的am数,即app数 -->
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
</property>
<!-- 配置指定调度器使用的资源计算器 -->
<!-- DefaultResourseCalculator 默认值,只使用内存进行比较 -->
<!-- DominantResourceCalculator 多维度资源计算,内存、cpu -->
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>
<!-- root队列中有哪些子队列-->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,ops</value>
</property>
<!-- *******************default队列*********************** -->
<!-- default 队列占用的资源容量百分比 40% -->
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>40</value>
</property>
<!-- default 队列占用的最大资源容量百分比 60%-->
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>60</value>
</property>
<!-- 允许单个用户最多可获取的队列资源的倍数,默认值1,
确保单个用户无论集群有多空闲,永远不会占用超过队列配置的资源
当值大于1时,用户可使用的资源将超过队列配置的资源,
但应该不能超过队列配置的最大资源
-->
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
</property>
<!-- 队列状态 -->
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
</property>
<!-- 限定哪些admin用户可向root队列中提交应用程序 -->
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
</property>
<!-- 为root队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等 -->
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
</property>
<!-- 配置哪些用户有权配置提交任务优先级 -->
<property>
<name>yarn.scheduler.capacity.root.default.acl_application_max_priority</name>
<value>*</value>
</property>
<!-- 任务的超时时间设置:yarn application -appId ${appId} -updateLifeTime Timeout -->
<!-- 如果application指定了超时时间,则提交到该队列的application能够制定的最大超时时间不能超过该值。-->
<property>
<name>yarn.scheduler.capacity.root.default.maximum-application-lifetime</name>
<value>-1</value>
</property>
<!-- 如果application没有指定超时时间,则用default-application-lifetime 作为默认值 -->
<property>
<name>yarn.scheduler.capacity.root.default.default-application-lifetime</name>
<value>-1</value>
</property>
<!-- *******************hive队列*********************** -->
<!-- hive 队列占用的资源容量百分比 60% -->
<property>
<name>yarn.scheduler.capacity.root.ops.capacity</name>
<value>60</value>
</property>
<!-- default 队列占用的最大资源容量百分比 80%-->
<property>
<name>yarn.scheduler.capacity.root.ops.maximum-capacity</name>
<value>80</value>
</property>
<!-- 允许单个用户最多可获取的队列资源的倍数,默认值1,
确保单个用户无论集群有多空闲,永远不会占用超过队列配置的资源
当值大于1时,用户可使用的资源将超过队列配置的资源,
但应该不能超过队列配置的最大资源
-->
<property>
<name>yarn.scheduler.capacity.root.ops.user-limit-factor</name>
<value>1</value>
</property>
<!-- 队列状态 -->
<property>
<name>yarn.scheduler.capacity.root.ops.state</name>
<value>RUNNING</value>
</property>
<!-- 限定哪些admin用户可向root队列中提交应用程序 -->
<property>
<name>yarn.scheduler.capacity.root.ops.acl_submit_applications</name>
<value>*</value>
</property>
<!-- 为root队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等 -->
<property>
<name>yarn.scheduler.capacity.root.ops.acl_administer_queue</name>
<value>*</value>
</property>
<!-- 配置哪些用户有权配置提交任务优先级 -->
<property>
<name>yarn.scheduler.capacity.root.ops.acl_application_max_priority</name>
<value>*</value>
</property>
<!-- 任务的超时时间设置:yarn application -appId ${appId} -updateLifeTime Timeout -->
<!-- 如果application指定了超时时间,则提交到该队列的application能够制定的最大超时时间不能超过该值。-->
<property>
<name>yarn.scheduler.capacity.root.ops.maximum-application-lifetime</name>
<value>-1</value>
</property>
<!-- 如果application没有指定超时时间,则用default-application-lifetime 作为默认值 -->
<property>
<name>yarn.scheduler.capacity.root.opsdefault-application-lifetime</name>
<value>-1</value>
</property>
<!--
CapacityScheduler尝试调度机本地容器之后错过的调度机会数。
通常,应该将其设置为集群中的节点数。
默认情况下在一个架构中设置大约40个节点。应为正整数值。
-->
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>40</value>
</property>
<!--
在节点本地延迟时间之外的另外的错过的调度机会的次数,在此之后,
CapacityScheduler尝试调度非切换容器而不是机架本地容器.例如:在node-locality-delay = 40和rack-locality-delay = 20的情况下,
调度器将在40次错过机会之后尝试机架本地分配,在40 + 20 = 60之后错过机会.使用-1作为默认值,禁用此功能.
在这种情况下,根据资源请求中指定的容器和唯一位置的数量以及集群的大小,计算分配关闭交换容器的错失机会的数量
-->
<property>
<name>yarn.scheduler.capacity.rack-locality-additional-delay</name>
<value>-1</value>
</property>
<!-- 此配置指定用户或组到特定队列的映射 -->
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value>u:root:default,g:root:default,u:%user:%user</value>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings-override.enable</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.capacity.application.fail-fast</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.capacity.workflow-priority-mappings</name>
<value></value>
</property>
<property>
<name>yarn.scheduler.capacity.workflow-priority-mappings-override.enable</name>
<value>false</value>
</property>
</configuration>
其中的容量也可以采用绝对值来配置
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>[memory=9830,vcores=9]</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>[memory=14745,vcores=14]</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ops.capacity</name>
<value>[memory=14745,vcores=14]</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ops.maximum-capacity</name>
<value>[memory=19660,vcores=19]</value>
</property>
不同的队列同时可以使用不同的资源配置格式,也就是说有些队列可以使用百分比格式,有些可以使用绝对值格式,而且实际使用时发现在这种混合配置中,各层级上所有队列的百分比之和必须等于100的约束将不再有效。
- 同步到其他节点后,刷新配置
bin/yarn rmadmin -refreshQueues
- 查看界面展示
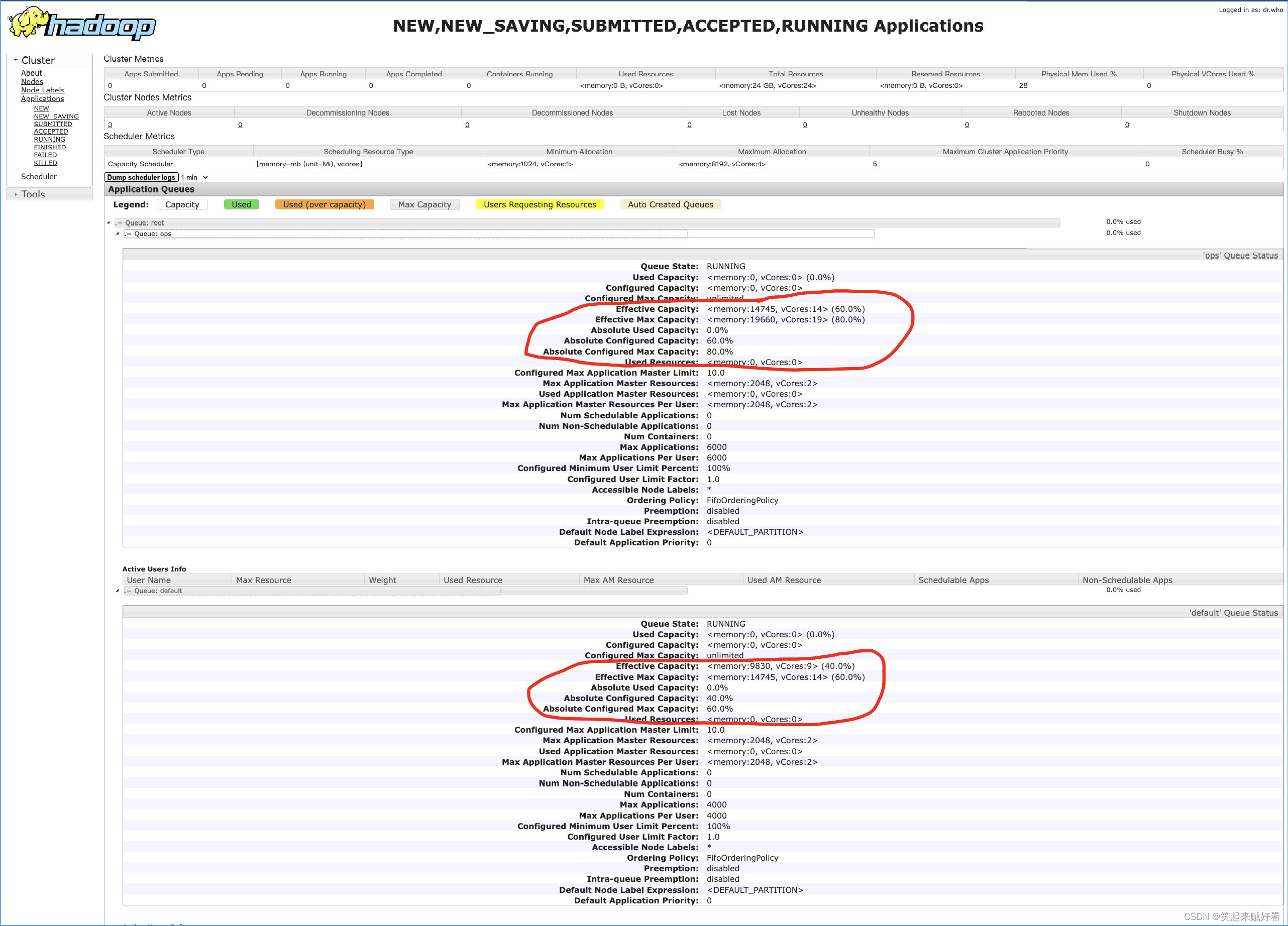
验证队列资源
- 提交任务,查看队列资源占比情况
提交任务
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 2g --executor-memory 2g --executor-cores 1 --num-executors 1 --queue default examples/jars/spark-examples_2.12-3.2.1.jar 100
–driver-memory 2g --executor-memory 2g --executor-cores 1 --num-executors 1
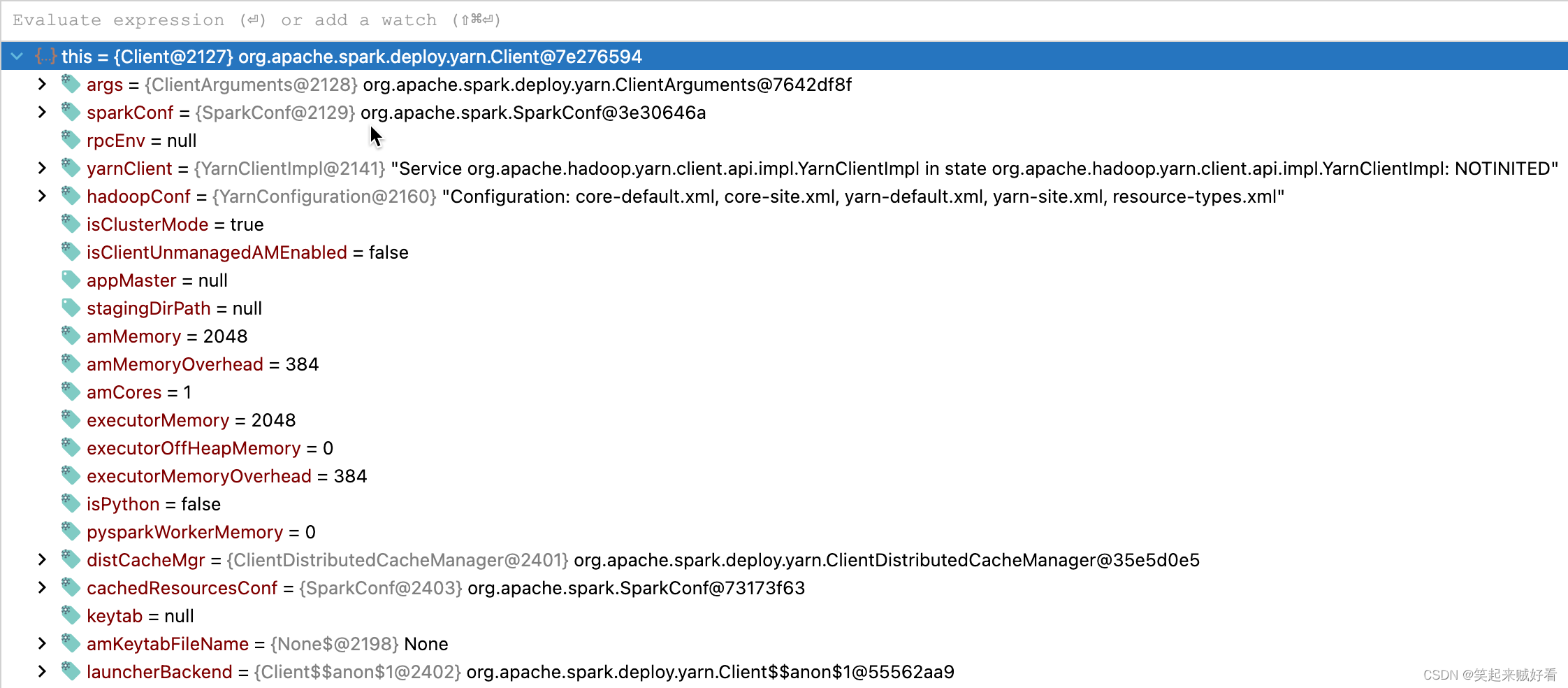

可以看到 向YARN的资源需求是:
amMemory = 2048
amMemoryOverhead = 384
executorMemory = 2048
executorOffHeapMemory. = 0
executorMemoryOverhead = 384
amCores = 1
最终向YARN上申请AM的资源大小为:
am = amMemory + amMemoryOverhead = 2432
executor = executorMemory + executorMemoryOverhead = 2432
capability = <memory:2432,vCores:1>
由于配置的集群资源分配最小单位为1024MB, 因此需要向上取整, 即 3072 MB
这也是为甚么我明明申请的 资源 比较小,但是在yarn上显示的资源总不对,比实际申请的资源要高一些。资源比预期的要高。
这主要是yarn的资源计算是用DominantResourceCalculator来计算管理 cpu、内存的。
spark和yarn上申请的资源没有对的上。
所以最终的资源:
Driver 申请的资源 --driver-memory 2g 实际在yarn中AM申请的资源为 3g1c
Executor 申请的资源 --executor-memory 2g --executor-cores 1 --num-executors 1 实际在yarn中executor申请的资源为 3g1c
最终总的资源为 6g2c

同理再提交一下 1g1c的
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 1g --executor-memory 1g --executor-cores 1 --num-executors 2 --queue default examples/jars/spark-examples_2.12-3.2.1.jar 100
–driver-memory 1g --executor-memory 1g --executor-cores 1 --num-executors 2
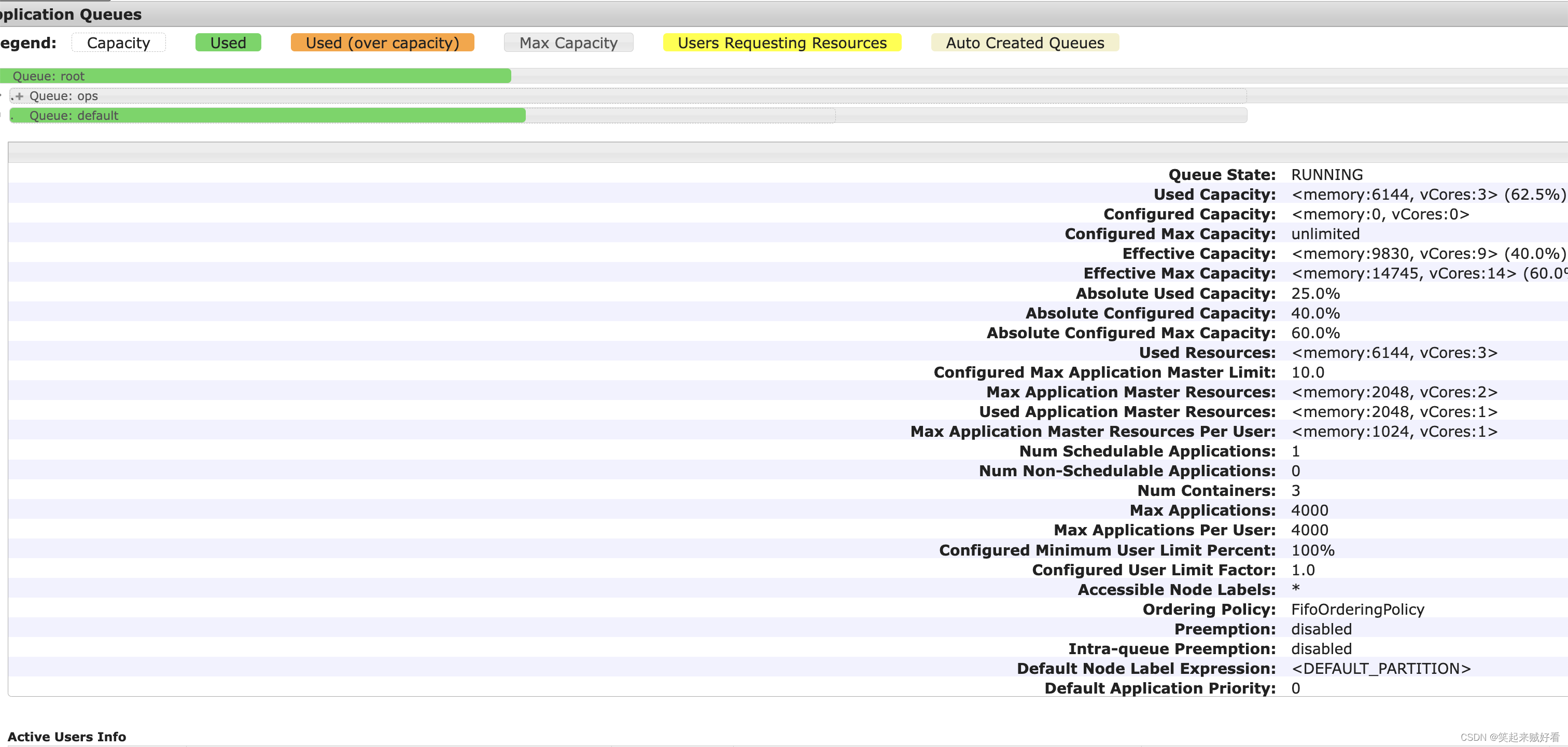
所以最终的资源:
Driver 申请的资源 --driver-memory 1g 实际在yarn中AM申请的资源为 1g1c
Executor 申请的资源 --executor-memory 1g --executor-cores 1 --num-executors 2 实际在yarn中executor申请的资源为 4g2c
最终总的资源为 6g3c
- 验证队列的最大资源限制
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 2g --executor-memory 2g --executor-cores 2 --num-executors 5 --queue default examples/jars/spark-examples_2.12-3.2.1.jar 100

当内存需求超过队列最大资源时
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 2g --executor-memory 2g --executor-cores 2 --num-executors 6 --queue default examples/jars/spark-examples_2.12-3.2.1.jar 100

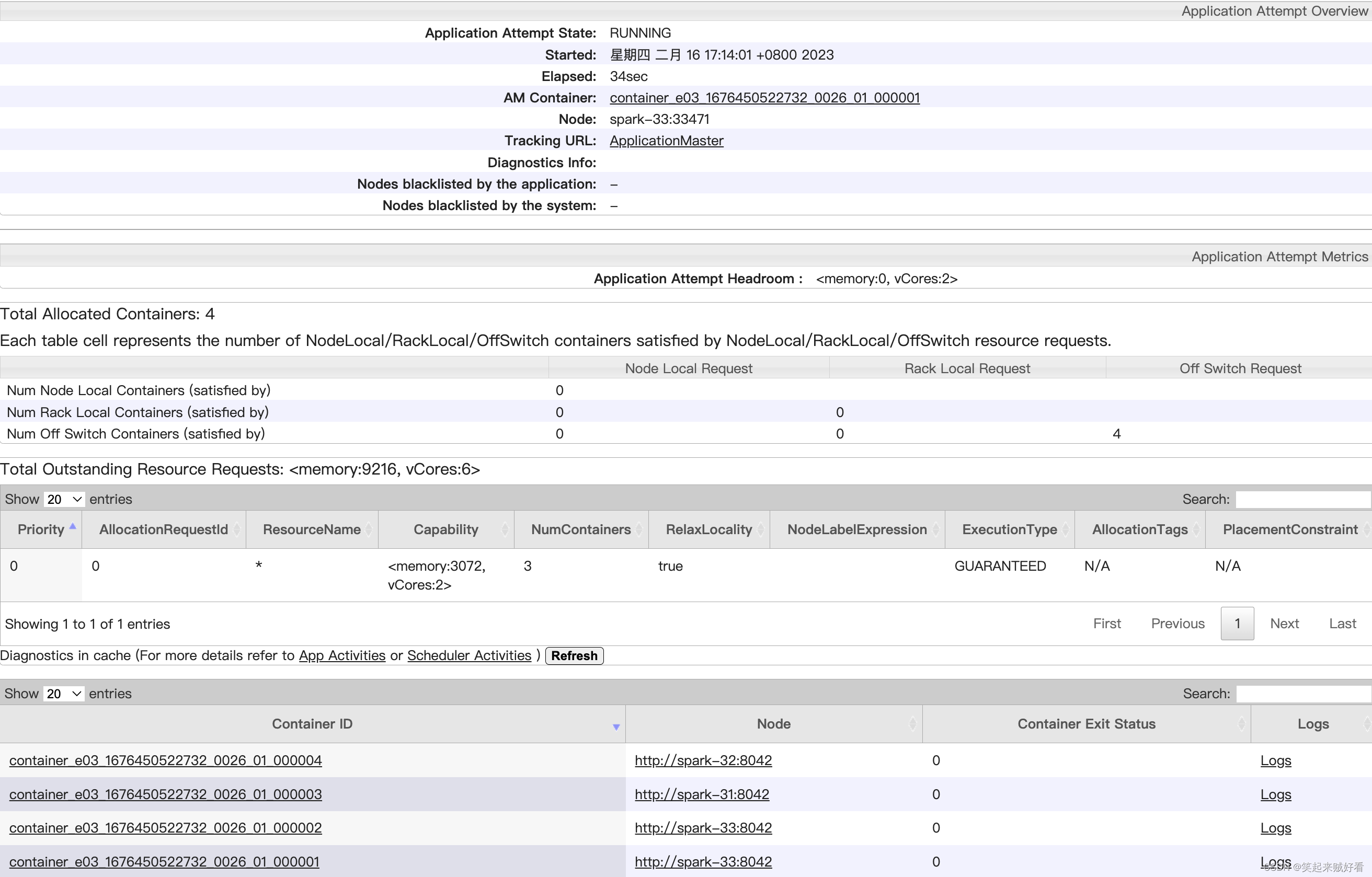
最终看到申请的资源可以超过队列配置的资源,但是不会超过最大的资源
spark申请的容器为 6 个,但是最终只启动了4个。
希望对正在查看文章的您有所帮助,记得关注、评论、收藏,谢谢您

















 2844
2844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











