







最近跟风在学hadoop,原因很简单,只是想装个B而已。但是装B路途总是充满着坑,在这里记录一路的装B历程。
之前一直在看买的视频,看来看去,总感觉很特么简单,hadoop里的HDFS与MapReduce很好理解,但是动手实践起来,就是各种坑。
一个入门级的MapReduce包括一个Map,一个Reduce
Map主要用来清洗数据,根据具体的业务,指定key,每个key对应着相应的value,然后用Partitioner进行分区,分区后交给Reduce进行处理,在reduce里,每一个key对应着一系列的value集合
先上一个入门级的demo
Mapper类:
package com.mr;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WCMapper extends Mapper<LongWritable, Text, Text, DoubleWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] dataFields = line.split("\t");
String username = dataFields[0];
double income = Double.valueOf(dataFields[1]);
double expend = Double.valueOf(dataFields[2]);
double total = income-expend;
context.write(new Text(username),new DoubleWritable(total));
}
}
Reduce类:
package com.mr;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WCReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable> {
private DoubleWritable result = new DoubleWritable();
@Override
protected void reduce(Text username, Iterable<DoubleWritable> total,
Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
double sum = 0;
for (DoubleWritable d : total) {
sum += d.get();
}
result.set(sum);
context.write(username, result);
}
}
job类:
package com.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TestMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(TestMain.class);
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));//
//这里的args[0]参数对应着/count.txt 这里为hdfs文件系统根目录下的count.txt文件
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//submit
job.waitForCompletion(true);
}
}
上面的args[1]参数对应着/countanswer 这里将计算后的结果保存在hdfs文件系统根目录下的countanswer文件夹里,成功后hdfs会自动生成该文件夹,且该文件夹下有如下的文件:
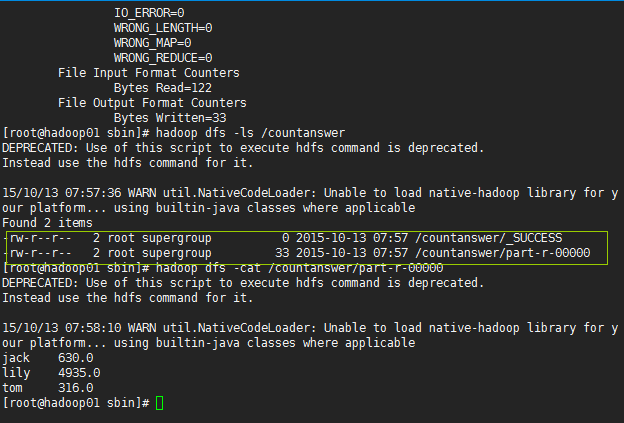
测试数据:
count.txt
tom 100 50 2015-10-11
jack 1000 500 2015-10-11
tom 1222 956 2015-10-11
jack 152 22 2015-10-11
lily 5555 620 2015-10-11eclipse将项目打成jar包,命名为count.jar
然后启动集群,我这里用的是为分布式,上传count.jar到 /home目录下,
然后在linux下输入:hadoop jar /home com.mr.TestMain /count.txt /countanswer
回车确定,出入如下结果:
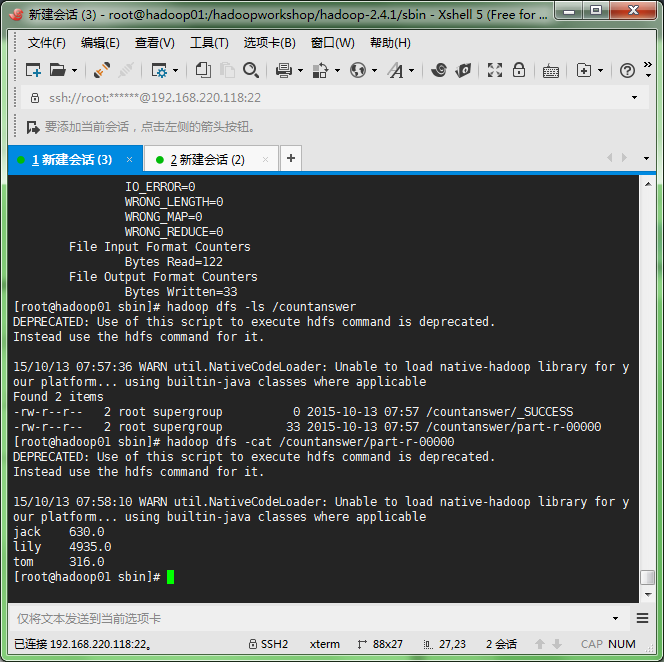















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









