







RDD是Spark中的一个很基础,很核心的概念,其全称是弹性分布式数据集,这是一种全新的数据抽象模型。在Spark中处理数据,无论是用BDAS(伯克利数据分析栈)中的哪一个数据分析模型,最终都会将数据转化成基础的RDDs,将通过各种API定义的操作,解析成对于基础的RDD操作。这样一来通过一个底层的Spark执行引擎就可以满足各种计算模式。这也是Spark设计团队提出“one thing to rule them all”的底气所在。
比如,你在Spark集群中加载了了一个很大的文本数据,Spark就会将该文本抽象为一个RDD,这个RDD根据你定义的分区策略(比如根据hashkey)可以分为数个Partiton,这样你就可以对各个分区并行处理,从而提高效率。对于用户来说,你不需要考虑底层的RDD究竟是怎样的,只需要像在单机上那样操作就可以了。
RDD是一系列只读分区的集合,它只能从文件中读取并创建,或者从旧的RDD生成新的RDD,RDD的每一次变换操作都会生成新的RDD而不是在原来的基础上进行修改,这种组粒度的数据操作方式为RDD带来了容错和数据共享方面优势,但是在面对大数据集中频繁的小操作时,却显得效率低下。
下面说一下这样的RDD设计的优势:
很多时候我们需要在多个计算模型间进行数据共享。通常是各个计算模型各自为政,缺乏高效的数据共享原语。比如MapReduce实现数据共享就是将数据序列化到磁盘上。这样就会引入数据备份,磁盘I/O以及序列化,这就极大拖慢了数据处理的效率。而Spark由于采用了统一的RDD抽象模型,数据共享简单而直接。
容错机制是分布式系统中的一个很重要的概念,为了应对在数据处理过程中可能出现的各种数据丢失的情况,一般的解决方案就是复制备份,这也是最简单粗暴的方案。在RDD中却通过一种名为血统(lineage)的容错机制巧妙的避开了复制容错,具体的方案是:每一个RDD都要记住从初始数据到构建出自己的一系列操作,这一系列操作构成了一个有向无环图,这也是spark中的数据处理机制。因此,在计算过程中任何一个环节出现数据丢失都可以通过lineage快速进行恢复。
这些优势使得RDD拥有广泛的适用性,可以满足不同计算框架的需求。
RDD操作
对RDD的操作是通过一些列算子来完成的,这些算子可以分为两类,一类是Transformation算子,而另一类是action算子。
transformation算子可以称为变换算子,比如map,filter等。这类算子定义的是RDD之间的变换操作,这些算子不会再定义的时候立即执行,而是将操作记录下来,如果有多个Transformation算子,这些记录就形成了一个有向无环图。这个图也是数据容错的关键所在,如果出现数据丢失,只需要查找这个图就能根据丢失的RDD如何得来进行数据回复。
action算子可以称之为行动算子。比如reduce,collect等。这类操作一般作用是返回一个值(或数组)或者将数据持久化到磁盘中。当action算子出现的时候,才会真正的提交job,将之前的记录RDD变换的DAG转化成相应的DAG执行策略,DAG执行策略中有多个stage,每个stage中有多个task,这些task将被分发给各个执行器执行。这些都是属于spark架构中的内容本文就不细表了。
这里以一个简单的wordcount程序来进行说明:
def main(args: Array[String]){
val conf = new SparkConf()
val sc = new SparkContext(conf)
val line = sc.textFile(args(0))
val result = line.flatMap(_.split("[^a-zA-Z]+")).map((_, 1)).reduceByKey(_+_) <pre name="code" class="plain">result.saveAsTextFile(args(1)) 实现wordcount算法实际上只有一行:
val result = line.flatMap(_.split("[^a-zA-Z]+")).map((_, 1)).reduceByKey(_+_) result.saveAsTextFile(args(1)) 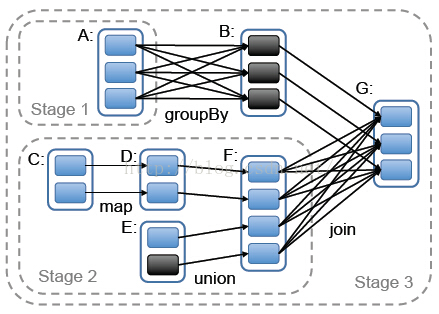
图中,每个实现框代表一个RDD,实线框中的有色矩形代表各个分区,黑色表示已经存于内存中的分区,RDD之间的连线表示RDD之间的依赖。
RDD原理
通过以上代码,再结合我们已有的编程知识,我们可以发现,RDD实际上是一个类(sc.textFile()方法返回一个RDD对象,然后用line接收这个对象)而这个RDD类中也定义了一系列的用于操作的方法,也就是我们上面介绍过的算子。
这个类为了实现对数据的操作,里面应该有以下属性:
1、分区信息,用于记录特定RDD的分区情况。
2、依赖关系,指向其父RDD
3、一个函数,用于记录父RDD到自己的转换操作。
4、划分策略和数据位置的元数据。
在DAG中这样的RDD就可以看做一个个节点,RDD中存储的依赖关系就是DAG的边。在Spark中,数据在物理上被划分为一个个block,这些block由blockmanager统一管理。
在设计RDD之间的依赖关系的时候,设计者将RDD之间的依赖关系分为两类:
1、窄依赖:一个父RDD的分区至多被一个子RDD的分区使用。比如map操作。
2、宽依赖:子RDD中存在多个RDD分区依赖于一个父RDD。比如join操作。
下图给出了两种依赖关系中父子分区的依赖关系(连线表示有依赖关系)
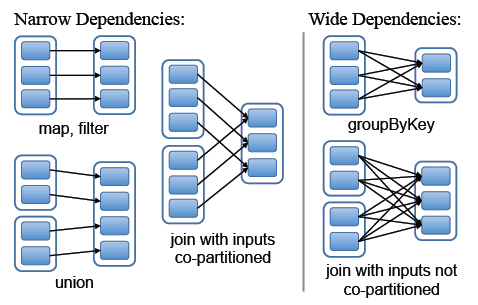
所以:窄依赖允许在单个节点上流水线的执行操作,如果出现某个分区数据失效,只需要重新计算单个分区。而宽依赖需要所有的父RDD可用,如果出现分区失效可能会导致整个RDD重新计算。
内存管理
Spark提供了三种持久化的存储策略:
为序列化的Java对象存于内存中、序列化后的数据存于内存中、序列化的数据存于磁盘中。
第一个选项的性能表现是最优秀的,因为可以直接访问在JAVA虚拟机内存里的RDD对象。在空间有限的情况下,第二种方式可以让用户采用比JAVA对象图更有效的内存组织方式,代价是降低了性能。 第三种策略适用于RDD太大难以存储在内存的情形,但每次重新计算该RDD会带来额外的资源开销。
对于有限可用内存,我们使用以 RDD 为对象的 LRU 回收算法来进行管理。当计算得到一个新的 RDD 分区,但却没有足够空间来存储它时,系统会从最近最少使用的 RDD 中回收其一个分区的空间。除非该 RDD 便是新分区对应的 RDD,这种情况下,Spark 会将旧的分区继续保留在内存,防止同一个 RDD 的分区被循环调入调出。这点很关键--因为大部分的操作会在一个 RDD 的所有分区上进行,那么很有可能已经存在内存中的分区将会被再次使用。















 499
499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









