本文提供了一种简单的方法来快速将选中文本转换为大写或小写,并介绍了如何设置快捷键以提高效率。通过使用文本编辑器的内置功能,您可以轻松实现文本格式的快速调整,从而提升工作或学习的生产力。
本文提供了一种简单的方法来快速将选中文本转换为大写或小写,并介绍了如何设置快捷键以提高效率。通过使用文本编辑器的内置功能,您可以轻松实现文本格式的快速调整,从而提升工作或学习的生产力。
陈科肇
功能
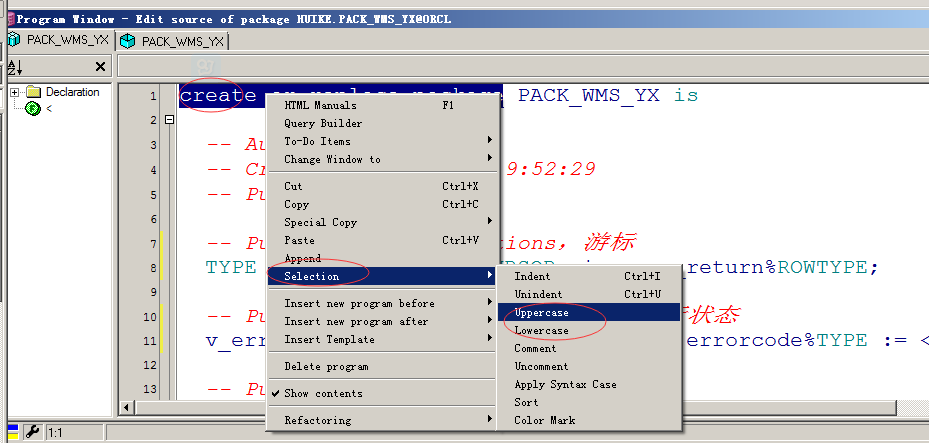
选中你需要转换的文字,右键->Selection->Uppercase或Lowercase,即大写或小写.
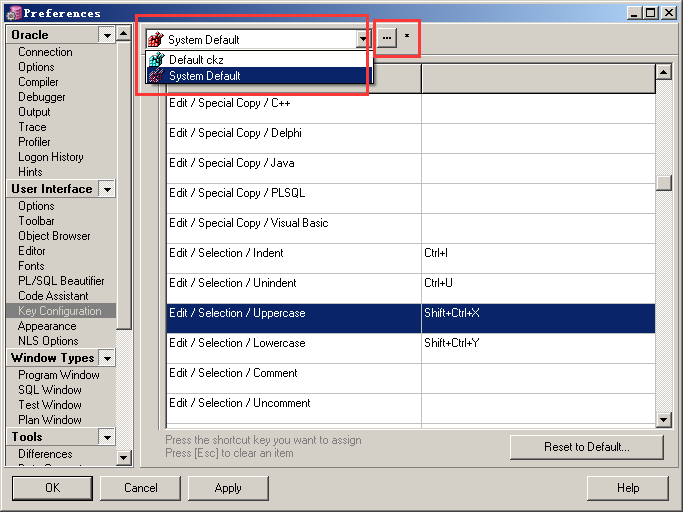
设置大小写快捷键
在工具栏,Tools->Preferences,在User Interface选项->Key Configuraction,然后在列表中的Item找到Edit/Session/Uppercase或Edit/Session/Lowercase,选中,按上你键盘的键来设置快捷键。
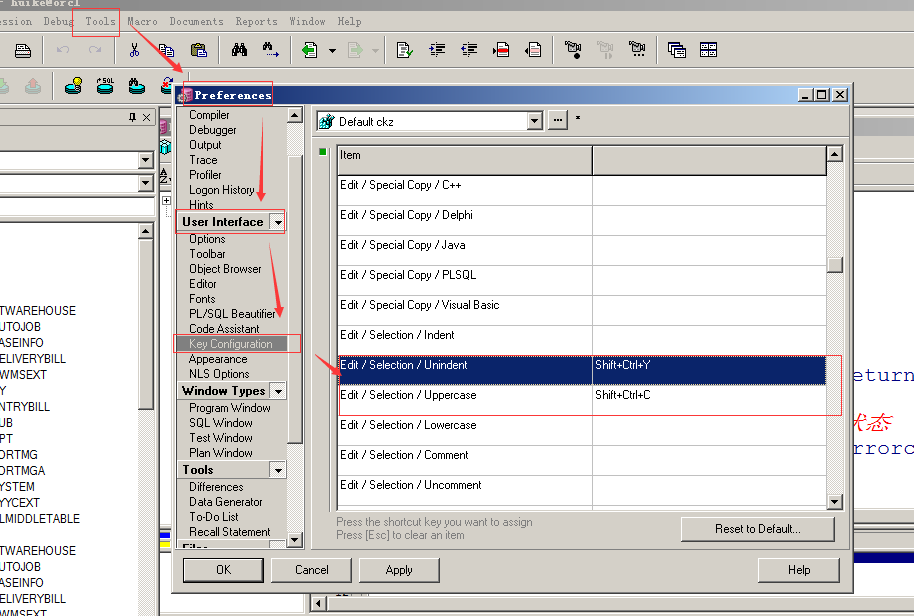
最后,点击Apply,即可!
你也可以设置其它的快捷键…
选中你需要转换的文字,右键->Selection->Uppercase或Lowercase,即大写或小写.
在工具栏,Tools->Preferences,在User Interface选项->Key Configuraction,然后在列表中的Item找到Edit/Session/Uppercase或Edit/Session/Lowercase,选中,按上你键盘的键来设置快捷键。
最后,点击Apply,即可!
你也可以设置其它的快捷键…
 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言