







rule-placement algorithm概述
主要介绍了一种规则放置算法(rule-placement algorithm)以达到“One Big Switch”的抽象。由于switch容量有限,将所有规则放入一组switch 集群中,以抽象成一个 big switch。
- input:①端点策略(end-point policy)和②路由策略(routing policy),以及③网络拓扑(network topology)和④交换机容量
- synthesize by:规则放置算法(rule-placement algorithm)
- output:规则(forwarding rule)
其中:
- Network topology:
- location (loc) 端口
- exposed locations 与外界相连的端口
- ingress loc (入口) 和 egress loc (出口)
某个流F最终到哪个出口端点O(网络交通的终点)
Endpoint policy (E):
- 一个端点策略就是一组相同源端口(入口)的规则集。其形式r:dst ip = 00∗, ingress = H1 : Permit, egress = H2
- a prioritized list of rules E :[r1, …, rm] ,其中m = ||E||
规则集由大到小分为:整个端点规则E——>划分成部分不重叠的流空间(flow space)D i ——>打包到switch的规则集E q (用在Path algorithm的cover阶段)
- 其中Di(Ei)是怎么来?——>通过路径策略确定Di
- 为方便描述分别定义为:整块矩形E;大矩形D i (E i );小矩形E q
- Routing policy (R):
- R(loc1, loc2, pkt) = s i 1 s i 2 …s i k ,其中s i 1 s i 2 …s i k 就是一条路径(path)
- (?)packet和path的关系?
Our rule-placement algorithm helps raise the level of abstraction for SDN by shielding programmers from the details of distributing rules across switches.
让控制平台管理规则的放置,而不需要应用程序或程序员来实现。他们只需要定义高水平的策略。
- 注:不存在规则依赖问题,因为一组有依赖的规则都全部放入一组交换机集群中——one big switch
rule-placement algorithm分析
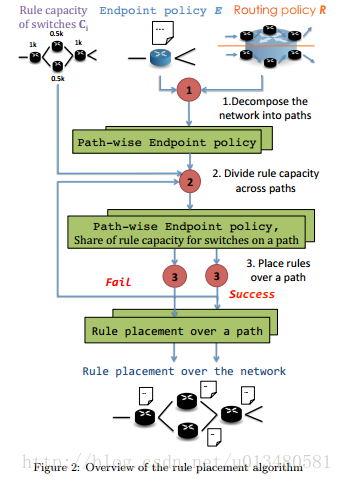
算法分为三个阶段:
- Decomposition (component 1):将问题分解成多条路径
- Resource allocation (component 2):估计每条路径上的交换机总容量,LP问题
- Path algorithm (component 3):在每条路径上安装对应的端点策略E i
一、Decomposition
we decompose the general rule-placement problem into smaller sub-problems.
输入条件:implementing {E, R} as implementing the routing policy R and a union of endpoint policies over the paths.
- 通过routing policy可以找出所有τ个路径。
- a union of endpoint policies是某个源端口的端点策略E
过程:E划分——>由P i 给出流空间 D i (相当于分割成实际部分规则集E i (部分规则空间))——>映射到 P i 在分配
More formally, we can associate path P i with a flow space D i (i.e., all packets that use P i belong to D i )and the projection E i of the endpoint policy on D i
首先,在E(整个规则集中)划出一块相应的流空间D i 给一条对应的路径,相当于大矩形E i 。——>按什么方式划分?怎么对应?
怎么划分?
- 由路径策略Pi确定Di
- 根据路径策略Pi的数据包包头划出规则空间D i 。如二维规则,提取指定的src_ip和dst_ip部分组成D i
- 注意任意两个不相同的规则空间总是不相交的
- 确定D
i
后,可以分别找到E中所有对应的实际部分规则集E
i
,如下图所示
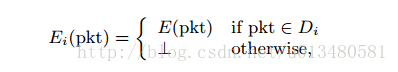
怎么对应路径?首先Ei在路径中已经确定。再怎么确定路径P i 是否合适?
- 涉及到阶段二,如下
二、Resource allocation
①The goal of “allocation” phase is to find a global rule-space allocation,such that it is feasible to find rule placements for all paths.
②the feasibility of a rule-space allocation depends primarily on the total amount of space allocated to a path, rather than the portion of that space allocated to each switch.
③we estimate the threshold value for the L i -hop path P i with endpoint policy E i .
我们首先定义一个阈值η作为估计D
i
中的规则数量:η=α
i
||E
i
||。
其中α
i
是P
i
长度的线性比值。
可知,影响规则空间的两个因素:
- The size of endpoint policy ||E i ||
- The path length L i :每个switch都需要至少一个小矩形,小矩形越多开销越大
rule-space allocation分为两步:
- 估计D i 中的规则数量:η=α i ||E i ||
- 通过LP,判断这条路径P i 是否合适
LP问题:
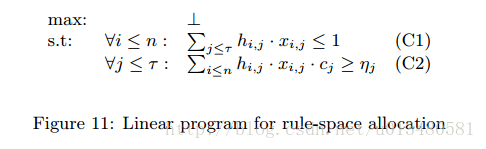
- 每个节点switch i 在所有路径P j 上的容量之和不超过100%
- 每条路径P j 的所有switch i 之和要≥η j
- i代表节点,j代表路径
- X i, j 代表switch中可用容量占比。如交换机容量C 4 =1000,X 4, 3 =0.4,则表示在P 3 上S 4 中可以放最多400个规则。
当检测失败时,增大η i ,再重新执行LP
三、Path algorithm(path-wise endpoint policy)
概述:
- 对于每一条路径,该算法分别(并行)将一块规则(小矩形)放入路径上的某个switch
- 每个规则在路径上只需要一个(i.e. 每个packet在路径上只需要执行一次的r.a)——>规则在路径上可以灵活地移动
- 注意放置规则之前,路径上的每个节点(switch)都要安放一条默认规则(优先级最低),用于当packet没有相对应规则(i.e. packet不在D i 中)时,转发到路径的下一跳节点
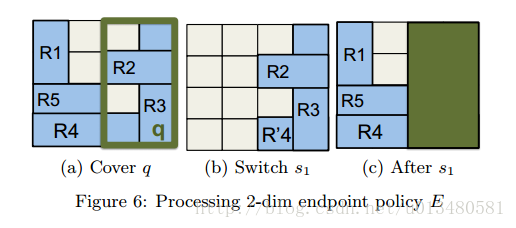
该算法分为三步:
- Cover:在打矩形中找到小矩形E q 。如何找?
- Pack:将大矩形和小矩形重叠部分的规则打包到switch
- Replace:用一条新规则(优先级最高)qFwd = (q, Fwd)代替小矩形中的规则集
注意两点:
- 放入的实际规则总是不少于E i 的规则集
- 规则放入switch不能有遗漏
接上,如何找小矩形?——>
如何找到最好的candidate rectangles?即在大矩形E
i
(这里不是整块矩形E)中找到第一次需要pack的小矩形?
——>转换成两个子问题:怎么选择小矩形?;如何找到小矩形?
(1)问题1:Rectangle selection
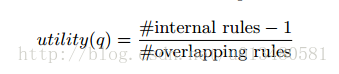
- internal rules是完全与q重叠
- overlapping rules是部分与q重叠
- 规则数量相同,选择utility最优的
(2)问题2:Top-Down search
- To limit the search space, our algorithm avoids searching too deeply,
preferring larger rectangles over smaller ones. - we only consider those rectangles q such that there exists no rectangle q¹ which satisfies both of the following two conditions:(i) q is inside q¹ and (ii) E q¹ can be packed in the switch. We call these q the maximal feasible predicates.
- q规则数量要满足≤switch的容量c i
- 搜索的矩形块由大到小,直到收缩到规则的边
补充:一维规则的放置
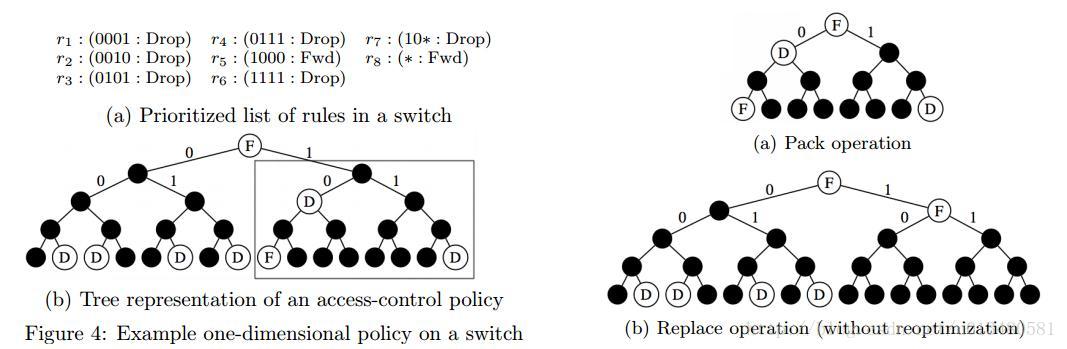
- If the root of this subtree has no action, the root inherits the action of its lowest ancestor(即4b图中矩形中的根节点r.a取自他的上一层节点)
- 算法是贪心的。每次pack的subtree subject(矩形内)都是逼近switch容量的
☆(3)算法伪代码:

- 2、找到所有≤d i 的最大可行矩形Q【Top-Down search 】
- 3、在Q中选出最好效率的q【Rectangle selection】
- 5和6、移除internal rules(注意:在新的E¹中不需要改overlapping的规则)。如下
- 7、在E¹添加新的规则qFwd = (q, Fwd)

算法优化
对一些不需要的数据包(丢弃操作的)还传入下一跳节点将会增加不必要的成本
充分利用入端口的switch容量
节点越靠前,权重越大转变打包顺序
This motivates us to reverse the order we place rules along a chain:here, we shall first pack the most refined rules at the last switch,and progressively pack the rules in upstream switches, making the ingress switch responsible for the biggest rules.
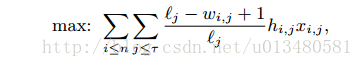
INCREMENTAL UPDATES
- Local Algorithm:不需要改变Path,只插入、删除、改变规则
- Global Algorithm:Path改变
Rule-Space Utilization
开销问题:额外规则的ovehead
- 定义:(C-||E i ||)/ ||E i || 其中,C为实际的规则数量
- 开销主要由LP问题和Path algorithm构成
- 多个路径的开销——一个规则在多个路径上(情况较少)
- 单个路径上的开销。随路径上节点数量的增加而线性增加
引用:
- Kang N, Liu Z, Rexford J, et al. Optimizing the “one big switch” abstraction in software-defined networks[C]// ACM Conference on Emerging NETWORKING Experiments and Technologies. ACM, 2013:13-24.
- Kang N, Reich J, Rexford J, et al. Policy transformation in software defined networks[C]// ACM SIGCOMM 2012 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication. ACM, 2012:309-310.















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









