









DHT协议原理以及一些重点分析:
要做DHT的爬虫,首先得透彻理解DHT,这样才能知道在什么地方究竟该应用什么 算法 去解决 问题 。关于DHT协议的细节以及重要的参考 文章 ,请参考文末1
DHT协议作为BT协议的一个辅助,是非常好玩的。它主要是为了在BT正式下载时得到种子或者BT资源。传统的网络,需要一台中央服务器存放种子或者BT资源,不仅浪费服务器资源,还容易出现单点的各种问题,而DHT网络则是为了去中心化,也就是说任意时刻,这个网络总有节点是亮的,你可以去询问问这些亮的节点,从而将自己加入DHT网络。
要实现DHT协议的网络爬虫,主要分3步,第一步是得到资源信息(infohash,160bit,20字节,可以编码为40字节的十六进制字符串),第二步是确认这些infohash是有效的,第三步是通过有效的infohash下载到BT的种子文件,从而得到对这个资源的完整描述。
其中第一步是其他节点用DHT协议中的get_peers方法向爬虫发送请求得到的,第二步是其他节点用DHT协议中的announce_peer向爬虫发送请求得到的,第三步可以有几种方式得到,比如可以去一些保存种子的网站根据infohash直接下载到,或者通过announce_peer的节点来下载到,具体如何实现,可以取决于你自己的爬虫。
DHT协议中的主要几个操作:
主要负责通过UDP与外部节点交互,封装4种基本操作的请求以及相应。
ping:检查一个节点是否“存活”
在一个爬虫里主要有两个地方用到ping,第一是初始路由表时,第二是验证节点是否存活时
find_node:向一个节点发送查找节点的请求
在一个爬虫中主要也是两个地方用到find_node,第一是初始路由表时,第二是验证桶是否存活时
get_peers:向一个节点发送查找资源的请求
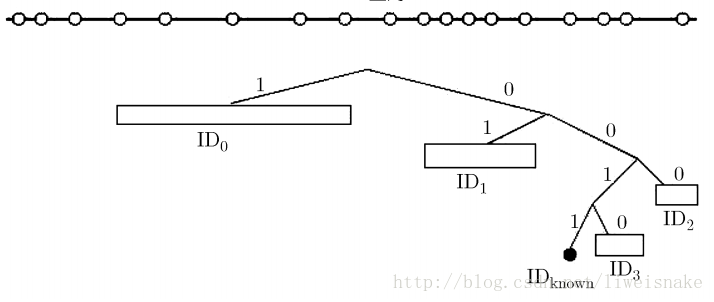
在爬虫中有节点向自己请求时不仅像个正常节点一样做出回应,还需要以此资源的info_hash为机会尽可能多的去认识更多的节点。如图,get_peers实际上最后一步是announce_peer,但是因为爬虫不能announce_peer,所以实际上get_peers退化成了find_node操作。
announce_peer:向一个节点发送自己已经开始下载某个资源的通知
爬虫中不能用announce_peer,因为这就相当于通报虚假资源,对方很容易从上下文中判断你是否通报了虚假资源从而把你禁掉
DHT协议中有几个重点的需要澄清的地方:
1. node与infohash同样使用160bit的表示方式,160bit意味着整个节点空间有2^160 = 730750818665451459101842416358141509827966271488,是48位10进制,也就是说有百亿亿亿亿亿个节点空间,这么大的节点空间,是足够存放你的主机节点以及任意的资源信息的。
2. 每个节点有张路由表。每张路由表由一堆K桶组成,所谓K桶,就是桶中最多只能放K个节点,默认是8个。而桶的保存则是类似一颗前缀树的方式。相当于一张8桶的路由表中最多有160-4个K桶。
3. 根据DHT协议的规定,每个infohash都是有位置的,因此,两个infohash之间就有距离一说,而两个infohash的距离就可以用异或来表示,即infohash1 xor infohash2,也就是说,高位一样的话,他们的距离就近,反之则远,这样可以快速的计算两个节点的距离。计算这个距离有什么用呢,在DHT网络中,如果一个资源的infohash与一个节点的infohash越近则该节点越有可能拥有该资源的信息,为什么呢?可以想象,因为人人都用同样的距离算法去递归的询问离资源接近的节点,并且只要该节点做出了回应,那么就会得到一个announce信息,也就是说跟资源infohash接近的节点就有更大的概率拿到该资源的infohash
4. 根据上述算法,DHT中的查询是跳跃式查询,可以迅速的跨越的的节点桶而接近目标节点桶。之所以在远处能够大幅度跳跃,而在近处只能小幅度跳跃,原因是每个节点的路由表中离自身越接近的节点保存得越多
5. 在一个DHT网络中当爬虫并不容易,不像普通爬虫一样,看到资源就可以主动爬下来,相反,因为得到资源的方式(get_peers, announce_peer)都是被动的,所以爬虫的方式就有些变化了,爬虫所要做的事就是像个正常节点一样去响应其他节点的查询,并且得到其他节点的回应,把其中的数据收集下来就算是完成工作了。而爬虫唯一能做的,是尽可能的去 多认识 其他节点,这样,才能有更多其他节点来向你询问。
6. 有人说,那么我把DHT爬虫的K桶中的容量K增大是不是就能增加得到资源的机会,其实不然,之前也分析过了,DHT爬虫最重要的信息来源全是被动的,因为你不能增大别人的K,所以距离远的节点保存你自身的概率就越小,当然距离远的节点去请求你的概率相对也比较小。
一些主要的组件(实际实现更加复杂一些,有其他的模块,这里仅列举主要几个):
DHT crawler :
这个就是DHT爬虫的主逻辑,为了简化多线程问题,跟server用了生产者消费者模型,负责消费,并且复用server的端口。
主要任务就是负责初始化,包括路由表的初始化,以及初始的请求。另外负责处理所有进来的消息事件,由于生产者消费者模型的使用,里面的操作都基本上是单线程的,简化了不少问题,而且相信也比上锁要提升速度(当然了,加锁这步按理是放到了queue这里了,不过对于这种生产者源源不断生产的类型,可以用ring-buffer大幅提升性能)。
DHT server :
这里是DHT爬虫的服务器端,DHT网络中的节点不单是client,也是server,所以要有server担当生产者的角色,最初也是每个消费者对应一个生产者,但实际上发现可以利用IO多路复用来达到消息事件的目的,这样一来大大简化了系统中线程的数量,如果client可以的话,也应该用同样的方式来组织,这样系统的速度应该会快很多。(尚未验证)
DHT route table :
主要负责路由表的操作。
路由表有如下操作:
init :刚创建路由表时的操作。分两种情况:
1. 如果之前已经初始化过,并且将上次路由表的数据保存下来,则只需要读入保存数据。
2. 如果之前没有初始化过,则首先应当初始化。
首先,应当有一个接入点,也就是说,你要想加进这个网络,必须认识这个网络中某个节点i并将i加入路由表,接下来对i用find_node询问自己的hash_info,这里巧妙的地方就在于,理论上通过一定数量的询问就会找到离自己距离很近的节点(也就是经过一定步骤就会收敛)。find_node目的在于尽可能早的让自己有数据,并且让网络上别的节点知道自己,如果别人不认识你,就不会发送消息过来,意味着你也不能获取到想要的信息。
search :比较重要的方法,主要使用它来定位当前infohash所在的桶的位置。会被其他各种代理方法调用到。
findNodes :找到路由表中与传入的infohash最近的k个节点
getPeer :找到待查资源是否有peer(即是否有人在下载,也就是是否有人announce过)
announcePeer :通知该资源正在被下载
DHT bucket:
acitiveNode :逻辑比较多,分如下几点。
1. 查找所要添加的节点对应路由表的桶是否已经满,如果未满,添加节点
2. 如果已经满,检查该桶中是否包含爬虫节点自己,如果不包含,抛弃待添加节点
3. 如果该桶中包含本节点,则平均分裂该桶
其他的诸如 locateNode ,
replaceNode , updateNode ,
removeNode ,就不一一说明了
DHT torrent parser :
主要从bt种子文件中解析出以下几个重要的信息:name,size,file list(sub file name, sub file size),比较简单,用bencode方向解码就行了
Utils :
distance:计算两个资源之间的距离。在kad中用a xor b表示
为了增加难度,选用了不太熟悉的语言python,结果步步为营,但是也感慨python的简洁强大。在实现中,也碰到很多有意思的问题。比如如何保存一张路由表中的所有桶,之前想出来几个办法,甚至为了节省资源,打算用bit数组+dict直接保存,但是因为估计最终的几个操作不是很方便直观容易出错而放弃,选用的结构就是前缀树,操作起来果然是没有障碍;
在 超时问题 上,比如桶超时和节点超时,一直在思考一个高效但是比较优雅的做法,可以用一个同步调用然后等待它的超时,但是显然很低效,尤其我没有用更多线程的情况,一旦阻塞了就等于该端口所有事件都被阻塞了。所以必须用异步操作,但是异步操作很难去控制它的精确事件,当然,我可以在每个事件来的时候检查一遍是否超时,但是显然也是浪费和低效。那么,剩下的只有采用跟tomcat类似的方式了,增加一个线程来监控,当然,这个监控线程最好是全局的,能监控所有crawler中所有事务的超时。另外,超时如果控制不当,容易导致内存没有回收以至于内存泄露,也值得注意。超时线程是否会与其他线程互相影响也应当仔细检查。
最初超时的控制没处理好,出现了ping storm,运行一定时间后大多数桶已经满了,如果按照协议中的方式去跑的话会发现大量的事件都是在ping以确认这个节点是否ok以至于大量的cpu用于处理ping和ping响应。深入理解后发现,检查节点状态是不需要的,因为节点状态只是为了提供给询问的人一些好的节点,既然如此,可以将每次过来的节点替换当前桶中最老的节点,如此一来,我们将总是保存着最新的节点。
搜索算法 也是比较让我困惑的地方,简而言之,搜索的目的并不是真正去找资源,而是去认识那些能够保存你的节点。为什么说是能够保存你,因为离你越远,桶的数量越少,这样一来,要想进他们的桶中去相对来说就比较困难,所以搜索的目标按理应该是附近的节点最好,但是不能排除远方节点也可能保存你的情况,这种情况会发生在远方节点初始化时或者远方节点的桶中节点超时的时候,但总而言之,概率要小些。所以搜索算法也不应该不做判断就胡乱搜索,但是也不应该将搜索的距离严格限制在附近,所以这是一个权衡问题,暂时没有想到好的方式,觉得暂时让距离远的以一定概率发生,而距离近的必然发生
还有一点,就是 搜索速度问题 ,因为DHT网络的这种结构,决定了一个节点所认识的其他节点必然是有限的附近节点,于是每个节点在一定时间段内能拿到的资源数必然是有限的,所以应当分配多个节点同时去抓取,而抓取资源的数量很大程度上就跟分配节点的多少有关了。
最后一个值得优化的地方是findnodes方法,之前的方式是把一个桶中所有数据拿出来排序,然后取其中前K个返回回去,但是实际上我们做了很多额外的工作,这是经典的 topN问题 ,使用排序明显是浪费时间的,因为这个操作非常频繁,所以即便所有保存的节点加起来很少((160 - 4) * 8),也会一定程度上增加时间。而采用的算法是在一篇论文《可扩展的DHT网络爬虫设计和优化》中找到的,基本公式是IDi = IDj xor 2 ^(160 - i),这样,已知IDi和i就能知道IDj,若已知IDi和IDj就能知道i,通过这种方式,可以快速的查找该桶A附近的其他桶(显然是离桶A层次最近的桶中的节点距离A次近),比起全部遍历再查找效率要高不少。
dht协议http://www.bittorrent.org/beps/bep_0005.html 及其翻译http://gobismoon.blog.163.com/blog/static/5244280220100893055533/
基于dht协议的网络爬虫http://codemacro.com/2013/05/19/crawl-dht/
dht协议的原理分析,非常不错,建议一看http://blog.sina.com.cn/s/blog_5384aaf00100a88k.html
爬虫源码参考别人的,非原创,只为学习
#encoding: utf-8
from hashlib import sha1
from random import randint
from struct import unpack, pack
from socket import inet_aton, inet_ntoa
from bisect import bisect_left
from threading import Timer
from time import sleep
from bencode import bencode, bdecode
BOOTSTRAP_NODES = [
("router.bittorrent.com", 6881),
("dht.transmissionbt.com", 6881),
("router.utorrent.com", 6881)
]
TID_LENGTH = 4
KRPC_TIMEOUT = 10
REBORN_TIME = 5 * 60
K = 8
def entropy(bytes):
s = ""
for i in range(bytes):
s += chr(randint(0, 255))
return s
# """把爬虫"伪装"成正常node, 一个正常的node有ip, port, node ID三个属性, 因为是基于UDP协议,
# 所以向对方发送信息时, 即使没"明确"说明自己的ip和port时, 对方自然会知道你的ip和port,
# 反之亦然. 那么我们自身node就只需要生成一个node ID就行, 协议里说到node ID用sha1算法生成,
# sha1算法生成的值是长度是20 byte, 也就是20 * 8 = 160 bit, 正好如DHT协议里说的那范围: 0 至 2的160次方,
# 也就是总共能生成1461501637330902918203684832716283019655932542976个独一无二的node.
# ok, 由于sha1总是生成20 byte的值, 所以哪怕你写SHA1(20)或SHA1(19)或SHA1("I am a 2B")都可以,
# 只要保证大大降低与别人重复几率就行. 注意, node ID非十六进制,
# 也就是说非FF5C85FE1FDB933503999F9EB2EF59E4B0F51ECA这个样子, 即非hash.hexdigest(). """
def random_id():
hash = sha1()
hash.update( entropy(20) )
return hash.digest()
def decode_nodes(nodes):
n = []
length = len(nodes)
if (length % 26) != 0:
return n
for i in range(0, length, 26):
nid = nodes[i:i+20]
ip = inet_ntoa(nodes[i+20:i+24])
port = unpack("!H", nodes[i+24:i+26])[0]
n.append( (nid, ip, port) )
return n
def encode_nodes(nodes):
strings = []
for node in nodes:
s = "%s%s%s" % (node.nid, inet_aton(node.ip), pack("!H", node.port))
strings.append(s)
return "".join(strings)
def intify(hstr):
#"""这是一个小工具, 把一个node ID转换为数字. 后面会频繁用到."""
return long(hstr.encode('hex'), 16) #先转换成16进制, 再变成数字
def timer(t, f):
Timer(t, f).start()
class BucketFull(Exception):
pass
class KRPC(object):
def __init__(self):
self.types = {
"r": self.response_received,
"q": self.query_received
}
self.actions = {
"ping": self.ping_received,
"find_node": self.find_node_received,
"get_peers": self.get_peers_received,
"announce_peer": self.announce_peer_received,
}
self.socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
self.socket.bind(("0.0.0.0", self.port))
def response_received(self, msg, address):
self.find_node_handler(msg)
def query_received(self, msg, address):
try:
self.actions[msg["q"]](msg, address)
except KeyError:
pass
def send_krpc(self, msg, address):
try:
self.socket.sendto(bencode(msg), address)
except:
pass
class Client(KRPC):
def __init__(self, table):
self.table = table
timer(KRPC_TIMEOUT, self.timeout)
timer(REBORN_TIME, self.reborn)
KRPC.__init__(self)
def find_node(self, address, nid=None):
nid = self.get_neighbor(nid) if nid else self.table.nid
tid = entropy(TID_LENGTH)
msg = {
"t": tid,
"y": "q",
"q": "find_node",
"a": {"id": nid, "target": random_id()}
}
self.send_krpc(msg, address)
def find_node_handler(self, msg):
try:
nodes = decode_nodes(msg["r"]["nodes"])
for node in nodes:
(nid, ip, port) = node
if len(nid) != 20: continue
if nid == self.table.nid: continue
self.find_node( (ip, port), nid )
except KeyError:
pass
def joinDHT(self):
for address in BOOTSTRAP_NODES:
self.find_node(address)
def timeout(self):
if len( self.table.buckets ) < 2:
self.joinDHT()
timer(KRPC_TIMEOUT, self.timeout)
def reborn(self):
self.table.nid = random_id()
self.table.buckets = [ KBucket(0, 2**160) ]
timer(REBORN_TIME, self.reborn)
def start(self):
self.joinDHT()
while True:
try:
(data, address) = self.socket.recvfrom(65536)
msg = bdecode(data)
self.types[msg["y"]](msg, address)
except Exception:
pass
def get_neighbor(self, target):
return target[:10]+random_id()[10:]
class Server(Client):
def __init__(self, master, table, port):
self.table = table
self.master = master
self.port = port
Client.__init__(self, table)
def ping_received(self, msg, address):
try:
nid = msg["a"]["id"]
msg = {
"t": msg["t"],
"y": "r",
"r": {"id": self.get_neighbor(nid)}
}
self.send_krpc(msg, address)
self.find_node(address, nid)
except KeyError:
pass
def find_node_received(self, msg, address):
try:
target = msg["a"]["target"]
neighbors = self.table.get_neighbors(target)
nid = msg["a"]["id"]
msg = {
"t": msg["t"],
"y": "r",
"r": {
"id": self.get_neighbor(target),
"nodes": encode_nodes(neighbors)
}
}
self.table.append(KNode(nid, *address))
self.send_krpc(msg, address)
self.find_node(address, nid)
except KeyError:
pass
def get_peers_received(self, msg, address):
try:
infohash = msg["a"]["info_hash"]
neighbors = self.table.get_neighbors(infohash)
nid = msg["a"]["id"]
msg = {
"t": msg["t"],
"y": "r",
"r": {
"id": self.get_neighbor(infohash),
"nodes": encode_nodes(neighbors)
}
}
self.table.append(KNode(nid, *address))
self.send_krpc(msg, address)
self.master.log(infohash)
self.find_node(address, nid)
except KeyError:
pass
def announce_peer_received(self, msg, address):
try:
infohash = msg["a"]["info_hash"]
nid = msg["a"]["id"]
msg = {
"t": msg["t"],
"y": "r",
"r": {"id": self.get_neighbor(infohash)}
}
self.table.append(KNode(nid, *address))
self.send_krpc(msg, address)
self.master.log(infohash)
self.find_node(address, nid)
except KeyError:
pass
# 该类只实例化一次.
class KTable(object):
# 这里的nid就是通过node_id()函数生成的自身node ID. 协议里说道, 每个路由表至少有一个bucket,
# 还规定第一个bucket的min=0, max=2^160次方, 所以这里就给予了一个buckets属性来存储bucket, 这个是列表.
def __init__(self, nid):
self.nid = nid
self.buckets = [ KBucket(0, 2**160) ]
def append(self, node):
index = self.bucket_index(node.nid)
try:
bucket = self.buckets[index]
bucket.append(node)
except IndexError:
return
except BucketFull:
if not bucket.in_range(self.nid):
return
self.split_bucket(index)
self.append(node)
# 返回与目标node ID或infohash的最近K个node.
# 定位出与目标node ID或infohash所在的bucket, 如果该bucuck有K个节点, 返回.
# 如果不够到K个节点的话, 把该bucket前面的bucket和该bucket后面的bucket加起来, 只返回前K个节点.
# 还是不到K个话, 再重复这个动作. 要注意不要超出最小和最大索引范围.
# 总之, 不管你用什么算法, 想尽办法找出最近的K个节点.
def get_neighbors(self, target):
nodes = []
if len(self.buckets) == 0: return nodes
if len(target) != 20 : return nodes
index = self.bucket_index(target)
try:
nodes = self.buckets[index].nodes
min = index - 1
max = index + 1
while len(nodes) < K and ((min >= 0) or (max < len(self.buckets))):
if min >= 0:
nodes.extend(self.buckets[min].nodes)
if max < len(self.buckets):
nodes.extend(self.buckets[max].nodes)
min -= 1
max += 1
num = intify(target)
nodes.sort(lambda a, b, num=num: cmp(num^intify(a.nid), num^intify(b.nid)))
return nodes[:K] #K是个常量, K=8
except IndexError:
return nodes
def bucket_index(self, target):
return bisect_left(self.buckets, intify(target))
# 拆表
# index是待拆分的bucket(old bucket)的所在索引值.
# 假设这个old bucket的min:0, max:16. 拆分该old bucket的话, 分界点是8, 然后把old bucket的max改为8, min还是0.
# 创建一个新的bucket, new bucket的min=8, max=16.
# 然后根据的old bucket中的各个node的nid, 看看是属于哪个bucket的范围里, 就装到对应的bucket里.
# 各回各家,各找各妈.
# new bucket的所在索引值就在old bucket后面, 即index+1, 把新的bucket插入到路由表里.
def split_bucket(self, index):
old = self.buckets[index]
point = old.max - (old.max - old.min)/2
new = KBucket(point, old.max)
old.max = point
self.buckets.insert(index + 1, new)
for node in old.nodes[:]:
if new.in_range(node.nid):
new.append(node)
old.remove(node)
def __iter__(self):
for bucket in self.buckets:
yield bucket
class KBucket(object):
__slots__ = ("min", "max", "nodes")
# min和max就是该bucket负责的范围, 比如该bucket的min:0, max:16的话,
# 那么存储的node的intify(nid)值均为: 0到15, 那16就不负责, 这16将会是该bucket后面的bucket的min值.
# nodes属性就是个列表, 存储node. last_accessed代表最后访问时间, 因为协议里说到,
# 当该bucket负责的node有请求, 回应操作; 删除node; 添加node; 更新node; 等这些操作时,
# 那么就要更新该bucket, 所以设置个last_accessed属性, 该属性标志着这个bucket的"新鲜程度". 用linux话来说, touch一下.
# 这个用来便于后面说的定时刷新路由表.
def __init__(self, min, max):
self.min = min
self.max = max
self.nodes = []
# 添加node, 参数node是KNode实例.
# 如果新插入的node的nid属性长度不等于20, 终止.
# 如果满了, 抛出bucket已满的错误, 终止. 通知上层代码进行拆表.
# 如果未满, 先看看新插入的node是否已存在, 如果存在, 就替换掉, 不存在, 就添加,
# 添加/替换时, 更新该bucket的"新鲜程度".
def append(self, node):
if node in self:
self.remove(node)
self.nodes.append(node)
else:
if len(self) < K:
self.nodes.append(node)
else:
raise BucketFull
def remove(self, node):
self.nodes.remove(node)
def in_range(self, target):
return self.min <= intify(target) < self.max
def __len__(self):
return len(self.nodes)
def __contains__(self, node):
return node in self.nodes
def __iter__(self):
for node in self.nodes:
yield node
def __lt__(self, target):
return self.max <= target
class KNode(object):
# """
# nid就是node ID的简写, 就不取id这么模糊的变量名了. __init__方法相当于别的OOP语言中的构造方法,
# 在python严格来说不是构造方法, 它是初始化, 不过, 功能差不多就行.
# """
__slots__ = ("nid", "ip", "port")
def __init__(self, nid, ip, port):
self.nid = nid
self.ip = ip
self.port = port
def __eq__(self, other):
return self.nid == other.nid
#using example
class Master(object):
def __init__(self, f):
self.f = f
def log(self, infohash):
self.f.write(infohash.encode("hex")+"\n")
self.f.flush()
try:
f = open("infohash.log", "a")
m = Master(f)
s = Server(Master(f), KTable(random_id()), 8001)
s.start()
except KeyboardInterrupt:
s.socket.close()
f.close()
CREATE TABLE `torrentinfo` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`infohash` char(40) NOT NULL DEFAULT '',
`filename` varchar(128) DEFAULT NULL,
`filelength` bigint(11) DEFAULT NULL,
`recvtime` datetime DEFAULT NULL,
`filecontent` text,
`uinthash` int(11) unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `uinthash_index` (`uinthash`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# _*_ coding: utf-8 _*_
import socket
import os,glob
import time as time_p
import requests
from bencode import bdecode, BTL
from torrent import *
import threading, signal
import MySQLdb
from BloomFilter import *
class Thunder(object):
def __init__(self):
self.connstr={'host':'127.0.0.1','user':'root','passwd':'123456','port':3306,'charset':"UTF8"}
def download(self, infohash):
try:
tc = self._download(infohash)
if(tc==-1):
return
tc = bdecode(tc)
info = torrentInfo(tc)
# print info['name']
# print info['length']
# print info['files']
uint=int(infohash[:4]+infohash[-4:],16)
time_now=time_p.strftime('%Y-%m-%d %H:%M:%S',time_p.localtime(time_p.time()))
sql="insert into torrentinfo(infohash,filename,filelength,recvtime,filecontent,uinthash) values('%s','%s','%d','%s','%s','%d')"%(infohash,MySQLdb.escape_string(info['name']),info['length'],time_now,MySQLdb.escape_string(info['files']),uint)
self.executeSQL(sql)
except Exception,e:
print e
pass
def openConnection(self):
try:
self.conn=MySQLdb.connect(**self.connstr)
self.cur=self.conn.cursor()
self.conn.select_db('dht')
except MySQLdb.Error,e:
print 'mysql error %d:%s'%(e.args[0],e.args[1])
def executeSQL(self,sql):
try:
self.cur.execute(sql)
self.conn.commit()
except MySQLdb.Error,e:
print 'mysql error %d:%s'%(e.args[0],e.args[1])
def closeConnection(self):
try:
self.cur.close()
self.conn.close()
except MySQLdb.Error,e:
print 'mysql error %d:%s'%(e.args[0],e.args[1])
def _download(self, infohash):
infohash = infohash.upper()
start = infohash[0:2]
end = infohash[-2:]
url = "http://bt.box.n0808.com/%s/%s/%s.torrent" % (start, end, infohash)
headers = {
"Referer": "http://bt.box.n0808.com"
}
try:
r = requests.get(url, headers=headers, timeout=10)
if r.status_code == 200:
# f=open("d:\\"+infohash+'.torrent','wb')
# f.write(r.content)
# f.close()
return r.content
except (socket.timeout, requests.exceptions.Timeout), e:
pass
return -1
class torrentBean(object):
"""docstring for torrentBean"""
__slots__=('infohash','filename','recvtime','filecontent','uinthash')
def __init__(self, infohash,filename,recvtime,filecontent,uinthash):
super(torrentBean, self).__init__()
self.infohash = infohash
self.filename = filename
self.recvtime = recvtime
self.filecontent = filecontent
self.uinthash = uinthash
bf = BloomFilter(0.001, 1000000)
a=Thunder()
a.openConnection()
# info_hash="a02d2735e6e1daa6f7d58f21bd7340a7b7c4b7a5"
# info_hash='cf3a6a4f07da0b90beddae838462ca0012bef285'
# a.download('cf3a6a4f07da0b90beddae838462ca0012bef285')
files=glob.glob('./*.txt')
for fl in files:
print os.path.basename(fl)
f=open(fl,'r')
for line in f:
infohash=line.strip('\n')
if not bf.is_element_exist(infohash):
bf.insert_element(infohash)
a.download(infohash)
a.closeConnection()
{
'files': [{
'path': ['PGD660.avi'],
'length': 1367405512,
'filehash': 'J\xef\xfe\xb3K\xd4g\x8d\x07m\x03\xbb\xb3\xadt\xa1\xa0\xf0\xec\xab',
'ed2k': '/\xfb\xe55#n\xbd1\xb6\x1c\x0f\xf3\xe4\x9dP\xfb',
'path.utf-8': ['PGD660.avi']
}, {
'path': ['PGD660B.jpg'],
'length': 135899,
'filehash': '*$O\x17w\xe9E\x95>O\x1f\xfb\x0e\x9b\x16\x15B\\Q\x9d',
'ed2k': 'T/L*\xbb\x8e.\xe2d\xddu\nR\x07\xca\x19',
'path.utf-8': ['PGD660B.jpg']
}, {
'path': ['yoy123@\xe8\x8d\x89\xe6\xa6\xb4\xe7\xa4\xbe\xe5\x8c\xba@\xe6\x9c\x80\xe6\x96\xb0\xe5\x9c\xb0\xe5\x9d\x80.mht'],
'length': 472,
'filehash': '&\xa92\xb7\xdd8\xeel3\xcc-S\x07\xb5e\xd35\xc0\xb7r',
'ed2k': '\x13\xd2 a\x0cA\xb4\xf2X\x12\xea\xd4\xe8\xac`\x92',
'path.utf-8': ['yoy123@\xe8\x8d\x89\xe6\xa6\xb4\xe7\xa4\xbe\xe5\x8c\xba@\xe6\x9c\x80\xe6\x96\xb0\xe5\x9c\xb0\xe5\x9d\x80.mht']
}, {
'path': ['yoy123@\xe8\x8d\x89\xe6\xa6\xb4\xe7\xa4\xbe\xe5\x8c\xba\xe5\xae\xa3\xe4\xbc\xa0.txt'],
'length': 363,
'filehash': '\x96nA*\xe2\xb6Y+[\xe3\xaf\xd4\x14A\x94\xf5@\xcd\xc1\x91',
'ed2k': '8V\xa6X\xd9\x82l\xdbNO8\xe8D\xe9E\xed',
'path.utf-8': ['yoy123@\xe8\x8d\x89\xe6\xa6\xb4\xe7\xa4\xbe\xe5\x8c\xba\xe5\xae\xa3\xe4\xbc\xa0.txt']
}, {
'path': ['\xe2\x98\x85\xe5\xb0\x91\xe5\xa6\x87 \xe8\xae\xba\xe5\x9d\x9b \xe9\x99\x90\xe9\x87\x8f\xe5\xbc\x80\xe6\x94\xbe\xe4\xb8\xad\xe3\x80\x82\xe3\x80\x82.mht'],
'length': 475,
'filehash': '\xec\xde\xeb-6\x86\x1avB\xdd\xd8q\x8b\x8f\xc06\xf0XX\x0e',
'ed2k': '\xa7\x8dU\xfd\xfc=\x12\x15>yE\x8f&A\xc2u',
'path.utf-8': ['\xe2\x98\x85\xe5\xb0\x91\xe5\xa6\x87 \xe8\xae\xba\xe5\x9d\x9b \xe9\x99\x90\xe9\x87\x8f\xe5\xbc\x80\xe6\x94\xbe\xe4\xb8\xad\xe3\x80\x82\xe3\x80\x82.mht']
}, {
'path': ['\xe6\x9f\x8f\xe6\x8b\x89\xe5\x9c\x96\xe7\xa7\x98\xe5\xaf\x86\xe8\x8a\xb1\xe5\x9c\x92.mht'],
'length': 478,
'filehash': "\xe4\xb5'Td\x0b=P\xc0\x9aG\xa2\xd7\xfapg\xc6.\x8e\xa7",
'ed2k': '\xdd\x8d\xbb\x0b\x04\xcb\x03O\xb1\x18"\x03\xb1\x1d\xba\x08',
'path.utf-8': ['\xe6\x9f\x8f\xe6\x8b\x89\xe5\x9c\x96\xe7\xa7\x98\xe5\xaf\x86\xe8\x8a\xb1\xe5\x9c\x92.mht']
}, {
'path': ['\xe7\xbe\x8e\xe5\xa5\xb3\xe4\xb8\x8a\xe9\x96\x80\xe6\x8f\xb4\xe4\xba\xa4\xe6\x9c\x8d\xe5\x8b\x99.mht'],
'length': 478,
'filehash': "\xe4\xb5'Td\x0b=P\xc0\x9aG\xa2\xd7\xfapg\xc6.\x8e\xa7",
'ed2k': '\xdd\x8d\xbb\x0b\x04\xcb\x03O\xb1\x18"\x03\xb1\x1d\xba\x08',
'path.utf-8': ['\xe7\xbe\x8e\xe5\xa5\xb3\xe4\xb8\x8a\xe9\x96\x80\xe6\x8f\xb4\xe4\xba\xa4\xe6\x9c\x8d\xe5\x8b\x99.mht']
}],
'publisher': 'yoy123',
'piece length': 524288,
'name': 'PGD660 \xe6\x83\xb3\xe8\xa9\xa6\xe8\x91\x97\xe5\x85\xa8\xe5\x8a\x9b\xe6\x93\x8d\xe6\x93\x8d\xe7\x9c\x8b\xe9\x80\x99\xe5\x80\x8b\xe6\xb7\xab\xe8\x95\xa9\xe7\xbe\x8e\xe5\xa5\xb3\xe5\x97\x8e \xe5\xb0\x8f\xe5\xb7\x9d\xe3\x81\x82\xe3\x81\x95\xe7\xbe\x8e',
'publisher.utf-8': 'yoy123',
}
# _*_ coding: utf-8 _*_
from time import time
def torrentInfo(torrentContent):
metadata = torrentContent["info"]
print metadata
info = {
"name": getName(metadata),
"length": calcLength(metadata),
"timestamp": getCreateDate(torrentContent),
"files": extraFiles(metadata)
}
return info
def calcLength(metadata):
length = 0
try:
length = metadata["length"]
except KeyError:
try:
for file in metadata["files"]:
length += file["length"]
except KeyError:
pass
return length
def extraFiles(metadata):
files = []
try:
for file in metadata["files"]:
path = file["path.utf-8"]
size=file['length']
if len(path) > 1:
main = path[0]
for f in path[1:2]:
files.append("%s/%s %d bytes" % (main, f,size))
else:
files.append("%s %d bytes" % (path[0],size) )
if files:
return '\r\n'.join(files)
else:
return getName(metadata)
except KeyError:
return getName(metadata)
def getName(metadata):
try:
name = metadata["name.utf-8"]
if name.strip()=="":
raise KeyError
except KeyError:
try:
name = metadata["name"]
if name.strip()=="":
raise KeyError
except KeyError:
name = getMaxFile(metadata)
return name
def getMaxFile(metadata):
try:
maxFile = metadata["files"][0]
for file in metadata["files"]:
if file["length"] > maxFile["length"]:
maxFile = file
name = maxFile["path"][0]
return name
except KeyError:
return ""
def getCreateDate(torrentContent):
try:
timestamp = torrentContent["creation date"]
except KeyError:
timestamp = int( time() )
return timestamp
#encoding: utf-8
'''
Created on 2012-11-7
@author: palydawn
'''
import cmath
from BitVector import BitVector
class BloomFilter(object):
def __init__(self, error_rate, elementNum):
#计算所需要的bit数
self.bit_num = -1 * elementNum * cmath.log(error_rate) / (cmath.log(2.0) * cmath.log(2.0))
#四字节对齐
self.bit_num = self.align_4byte(self.bit_num.real)
#分配内存
self.bit_array = BitVector(size=self.bit_num)
#计算hash函数个数
self.hash_num = cmath.log(2) * self.bit_num / elementNum
self.hash_num = self.hash_num.real
#向上取整
self.hash_num = int(self.hash_num) + 1
#产生hash函数种子
self.hash_seeds = self.generate_hashseeds(self.hash_num)
def insert_element(self, element):
for seed in self.hash_seeds:
hash_val = self.hash_element(element, seed)
#取绝对值
hash_val = abs(hash_val)
#取模,防越界
hash_val = hash_val % self.bit_num
#设置相应的比特位
self.bit_array[hash_val] = 1
#检查元素是否存在,存在返回true,否则返回false
def is_element_exist(self, element):
for seed in self.hash_seeds:
hash_val = self.hash_element(element, seed)
#取绝对值
hash_val = abs(hash_val)
#取模,防越界
hash_val = hash_val % self.bit_num
#查看值
if self.bit_array[hash_val] == 0:
return False
return True
#内存对齐
def align_4byte(self, bit_num):
num = int(bit_num / 32)
num = 32 * (num + 1)
return num
#产生hash函数种子,hash_num个素数
def generate_hashseeds(self, hash_num):
count = 0
#连续两个种子的最小差值
gap = 50
#初始化hash种子为0
hash_seeds = []
for index in xrange(hash_num):
hash_seeds.append(0)
for index in xrange(10, 10000):
max_num = int(cmath.sqrt(1.0 * index).real)
flag = 1
for num in xrange(2, max_num):
if index % num == 0:
flag = 0
break
if flag == 1:
#连续两个hash种子的差值要大才行
if count > 0 and (index - hash_seeds[count - 1]) < gap:
continue
hash_seeds[count] = index
count = count + 1
if count == hash_num:
break
return hash_seeds
def hash_element(self, element, seed):
hash_val = 1
for ch in str(element):
chval = ord(ch)
hash_val = hash_val * seed + chval
return hash_val
def SaveBitToFile(self,f):
self.bit_array.write_bits_to_fileobject(f)
pass
















 1605
1605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









