







一文读懂StatefulSet以及实践攻略
目录
❤️ 摘要:本文详细介绍了Kubernetes中的StatefulSet概念和实际应用。文章通过比喻区分了有状态和无状态应用,并对比了StatefulSet与Deployment的不同之处。此外,还展示了StatefulSet的具体工作机制及其适用场景,包括数据库、分布式系统等。通过部署Redis集群的实际案例,演示了如何创建和管理StatefulSet,创建Headless Service、扩缩容及滚动更新等操作。通过本文,读者可以全面掌握StatefulSet的使用技巧,有效管理有状态应用。

1 概述
对于刚接触Kubernetes的初学者来说,可能不清楚Deployment 和 StatefulSet两者的区别,因为它可以用来管理 Pod。这篇文章为您理清什么是StatefulSet,结合前文《一文读懂Deployment以及实践攻略》让您可以适当选择和应用两者。
1.1 什么是有状态应用和无状态应用
在开始讲StatefulSet这个概念之前,我想先简单介绍一下什么是有状态应用和无状态应用。
关于有状态应用和无状态应用比喻为两个“服务员”。
有状态应用:记性好的服务员A
当你光顾一家餐厅,服务员A非常细心,会跟你打招呼,甚至记得您喜爱的座位和菜品。这就如有状态应用,它会保存用户的历史数据和会话状态。比如,购物车、登录信息等都保存在服务器端,每次你回来,服务员A都能准确无误地继续提供服务。
无状态应用:健忘的服务员B
现在你换了家餐厅,服务员B每次都要来问你要点什么。刚点完饮料,一会儿又过来问你是否要点餐。他完全不记得之前你说过什么,只记得你当下的需求。这就是无状态应用,每次请求都不依赖之前的会话状态,每个请求都是独立的,像是刚认识你一样。
1.2 什么是StatefulSet
在 Kubernetes 中,StatefulSet 是用于管理有状态应用的工作负载控制器。与无状态的 Deployment 相比,StatefulSet 适用于需要稳定标识、持久化存储以及有序启动和终止的应用场景,比如数据库、分布式缓存等。
1.3 StatefulSet 与 Deployment 的区别
StatefulSet 和 Deployment 在管理 Pod 的方式有以下主要区别:
| 特性 | StatefulSet | Deployment |
|---|---|---|
| Pod 标识 | 每个 Pod 有唯一的标识,并且稳定不变。 | Pod 是随机的,重启后名字会改变。 |
| 存储卷 | 每个 Pod 拥有独立的、持久的存储卷。 | 默认情况下,Pod 共享同一个存储卷。 |
| 启动和终止顺序 | 确保按序启动和删除。 | 并行启动和删除,无先后顺序。 |
| 用途 | 适合需要稳定存储和标识的有状态应用。 | 适合无状态的分布式应用。 |
1.4 StatefulSet 的工作机制
StatefulSet 具备以下特性:
- 稳定的网络标识:StatefulSet 为每个 Pod 分配一个唯一的标识符,如
web-0、web-1、web-2,这意味着每个 Pod 的名字、存储卷都会与它一一对应,不会因 Pod 重启而发生变化。同时每个 Pod 的 DNS 解析也是固定的,可以用podname-ordinal.servicename的形式来访问。 - 持久化存储:每个 Pod 在创建时会独立分配和绑定一个或多个的 PersistentVolume,用于保证数据不会因 Pod 重启而丢失。
- 有序部署与扩缩:StatefulSet 会按序(从
0到n)启动 Pods,并且扩展或缩减时也会按序进行。 - 优雅更新和终止:StatefulSet 在更新和终止时,也是确保有序和数据完整性。
1.5 适用场景
StatefulSet 适用于那些需要有状态的数据应用场景,比如:
- 数据库:如 MySQL、PostgreSQL 等,要求持久存储和稳定的网络标识。
- 分布式系统:如 Cassandra、ZooKeeper,需要有序部署和数据一致性。
- 有状态应用:如 Redis、Elasticsearch 等,需要在各个节点之间维护状态。
1.6 限制条件
StatefulSet的应用也有一些限制条件, 提前了解可以帮助我们在使用Kubernetes进行有状态应用的管理时,避免一些潜在的问题。
| 条件 | 说明 | 案例 |
|---|---|---|
| 存储必须通过 PersistentVolume Provisioner 或管理员预先分配 | StatefulSet中的每个Pod需要持久化存储(PersistentVolume, PV),并且这种存储要么由存储类(StorageClass)和PersistentVolume Provisioner自动创建,要么由管理员提前手动分配。 | 运行一个MySQL集群时,如果不为每个Pod配置PersistentVolume,当Pod重启或迁移到其他节点时,数据可能会丢失。因此,管理员需要为每个Pod预先配置一个PV,或者让Kubernetes根据存储类自动为每个Pod创建动态PV。 |
| 删除或缩减StatefulSet不会删除相关的存储卷 | 当删除StatefulSet或缩减其规模时,Kubernetes不会自动删除与这些Pod关联的PersistentVolume。 | 运行一个Kafka集群时,每个Pod负责不同的分区日志存储。如果你意外缩减了StatefulSet规模或删除了它,Kafka集群的日志数据不会丢失,因为与Pod关联的存储卷(PersistentVolume)仍然存在,在重新启动StatefulSet时可以恢复这些数据。 |
| StatefulSet需要一个无头服务(Headless Service)来管理Pod的网络身份 | StatefulSet中的每个Pod都有一个唯一的、稳定的网络标识。这个标识是由无头服务(Headless Service)提供的,用户需要手动创建此服务,以确保每个Pod都有一个稳定的DNS名称,便于网络通信。 | 对于Cassandra数据库集群,无头服务确保每个Cassandra实例(Pod)都有一个唯一的网络标识,例如 cassandra-0.cassandra.default.svc.cluster.local,从而防止外部随意访问后端的Pod。 |
| StatefulSet不保证Pod删除时的顺序 | StatefulSet默认使用OrderedReady的Pod管理策略,在滚动更新时按照顺序进行Pod的升级。如果某个Pod在更新时无法成功启动,整个滚动更新过程可能会停滞,需要手动干预来恢复状态。 | 运行一个ZooKeeper集群时,您可能希望在缩减规模时按顺序关闭Pod,先关闭zookeeper-2,再关闭zookeeper-1,最后关闭zookeeper-0,以确保集群在缩减期间不会失效。通过手动缩减StatefulSet到0,你可以控制每个Pod按顺序终止。 |
| 滚动更新时可能会进入一个需要手动干预的破坏状态 | StatefulSet默认使用OrderedReady的Pod管理策略,在滚动更新时按照顺序进行Pod的升级。如果某个Pod在更新时无法成功启动,整个滚动更新过程可能会停滞,需要手动干预来恢复状态。 | 运行一个Elasticsearch集群时,如果在滚动更新期间某个Pod因为配置问题无法启动,整个更新过程将被卡住,导致集群无法继续运行。此时,你需要手动检查并删除失败的Pod或修复问题,才能继续滚动更新。 |
2 实践案例:部署有状态的 Redis 集群
我们将通过一个简单的例子来演示如何使用 StatefulSet 来部署一个有状态的 Redis 集群。
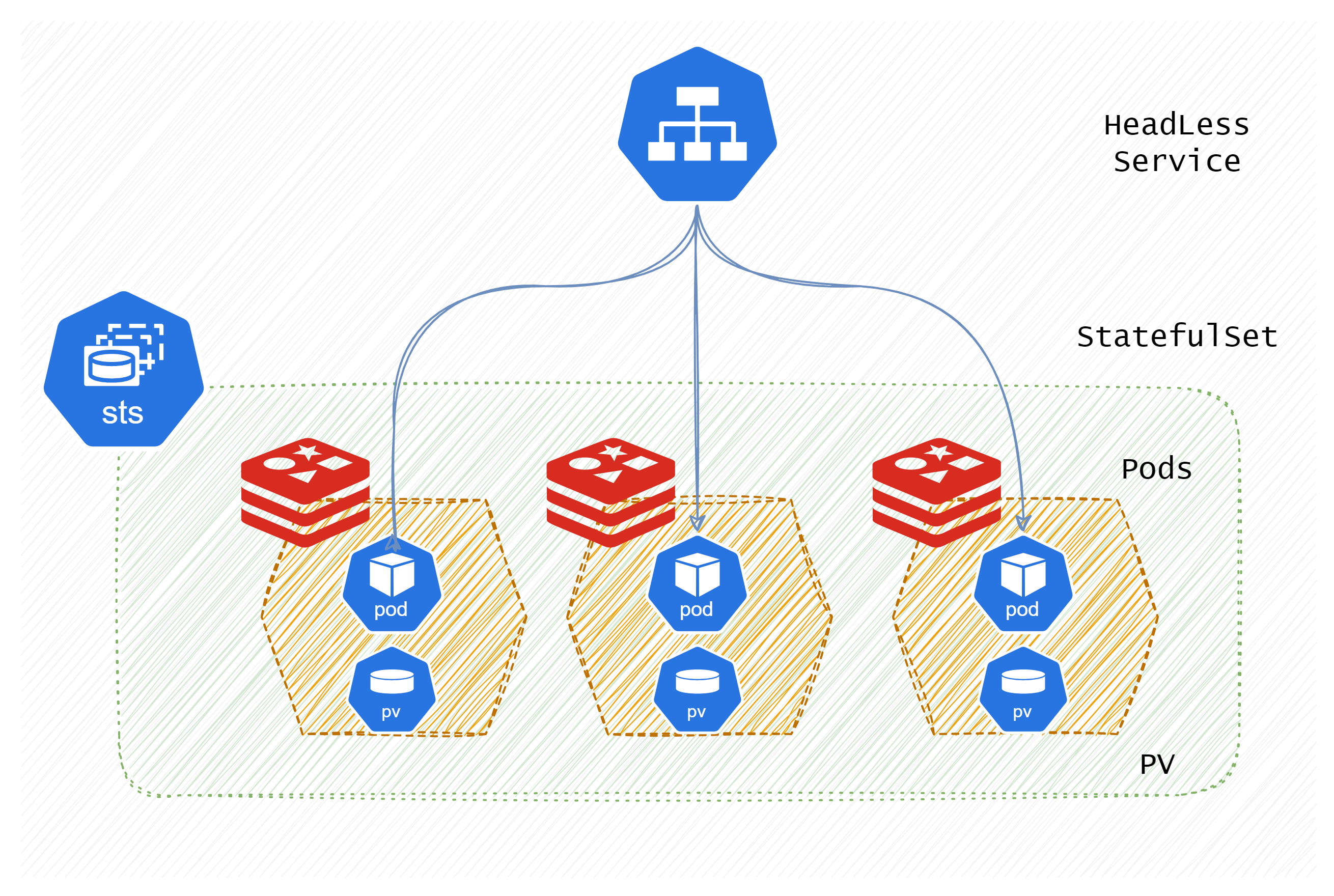
2.1 部署StatefulSet
2.1.1 定义 Redis StatefulSet
首先,我们定义一个 Redis StatefulSet的yaml,确保每个 Redis 节点有自己独立的存储,并且能够在重启后恢复。
编辑redis-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
# 定义StatefulSet名称
name: redis
spec:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1382
1382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











