




模型转换
每一个开源框架,都有自己的模型格式,MNN中支持,CAFFE,TensorFLow,ONNX等格式的网络结构转换成mnn格式。
为了方便大多都会将训练好的网络模型转成ONNX第三方通用的结构,这里主要分析mnn如何将ONNX的结构转换成自己支持的mnn格式。
模型转换的流程:
0. onnx结构
在此之前,需要先了解下onnx的结构。
onnx最外层是model,包含一些基础信息,onnx版本,来源框架/工具,来源工具版本等信息,当然还有最重要的计算图Graph(网络图结构)。
Model成员表
| 成员名称 | 解释 |
|---|---|
| ir_version | onnx版本 |
| opset_import | 模型的操作算计集合。必须支持集合中的所有算子,否则模型无法加载。 |
| producer_name | 模型来源框架或者工具,pytorch等 |
| producer_version | 来源工具版本 |
| domain | 表示模型名称空间或域的反向DNS名称,例如“org.onnx” |
| doc_string | 此模型的可读文档 |
| graph | 模型计算图以及权重参数 |
| metadata_props | metadata和名称的映射表 |
| training_info | 包含训练的一些信息 |
Graph成员表
| 成员名称 | 解释 |
|---|---|
| name | 模型计算图名称 |
| node | 计算图中的节点列表,基于输入/输出数据依赖性形成一个部分有序的计算图。它是拓扑顺序的。 |
| initializer | 一个tensor的列表。当与计算图中输入具有相同名称时,它将为该输入指定默认值。反之,它将指定一个常量值。 |
| doc_string | 此模型的可读文档 |
| input | 计算图中所有节点的输入 |
| output | 计算图所有节点的输出 |
| value_info | 用于存储非输入或输出值的类型和shape |
Node成员表
| 成员名称 | 解释 |
|---|---|
| name | 节点名称 |
| input | 节点输入,计算图输入,或者initializer或者其他节点的输出 |
| output | 节点的输出 |
| op_type | 算子操作类型 |
| domain | 算子的操作域, |
| attribute | 算子的一些信息,或者不会用于传播的常量 |
| doc_string | 可读的文档信息 |
Attribute的成员表
| 成员名称 | 解释 |
|---|---|
| name | 属性名称 |
| doc_string | 可读的文档信息 |
| type | 属性的类型,确定剩余字段中用于保存属性值的字段。 |
| f | 32位的浮点值 |
| i | 64位整数 |
| s | UTF-8字符串 |
| t | 一个tensor |
| g | 一个计算图 |
| floats | 浮点数组 |
| ints | 整型数组 |
| strings | 字符串数组 |
| tensors | tensor数组 |
| graphs | 计算图数组 |
1. 模型转换
先看模型转换的主要流程。
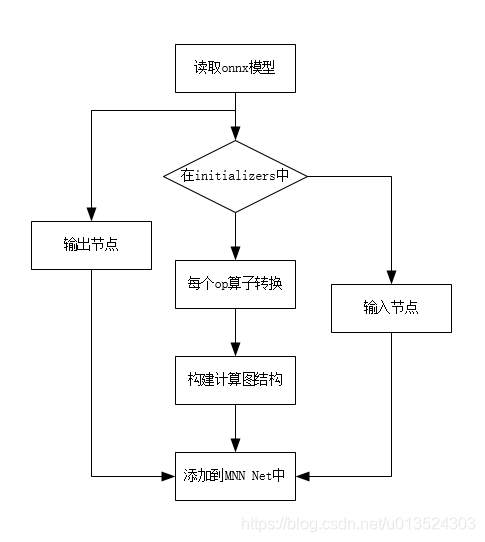
int onnx2MNNNet(const std::string inputModel, const std::string bizCode,
const common::Options& options, std::unique_ptr<MNN::NetT>& netT) {
onnx::ModelProto onnxModel;
// 读取onnx模型
bool success = onnx_read_proto_from_binary(inputModel.c_str(), &onnxModel);
DCHECK(success) << "read onnx model failed: " << inputModel;
LOG(INFO) << "ONNX Model ir version: " << onnxModel.ir_version();
const auto& onnxGraph = onnxModel.graph();
const int nodeCount = onnxGraph.node_size();
std::shared_ptr<OnnxTmpGraph> onnxTempGraph(new OnnxTmpGraph(&onnxGraph));
// op_name: name
// get mnn op pointer conveniently, then manipulate the mnn op
std::map<std::string, MNN::OpT*> mnnNodesMap;
// all tensors container
std::map<std::string, int> tensorsName;
// find the inputs which do not have initializer
// initializers是一个list,即是一个权重的tensor列表,并且每个元素都有明确的名字,和输出列表中的名字对应
const auto& initializers = onnxTempGraph->mInitializers;
// 模型中所有的输入和输出,包括最开始输入的图像以及每个结点的输入输出信息
const auto& inputs = onnxTempGraph->mInputs;
const auto& outputs = onnxTempGraph->mOutputs;
const auto& constantNodeToDelete = onnxTempGraph->mConstantNodeToDelete;
for (const auto& iter : inputs) {
bool notHaveInitializer = initializers.find(iter.first) == initializers.end();
// 找到不在initializers列表中的输入,从下面的代码可以看出,不在initializers中的是输入节点。
if (notHaveInitializer) {
netT->tensorName.push_back(iter.first);
tensorsName.insert(std::make_pair(iter.first, tensorsName.size()));
}
}
// 把没有initializers的输入节点添加到net中
for (const auto& iter : tensorsName) {
// here tensorsName are true Input node name
MNN::OpT* MNNOp = new MNN::OpT;
MNNOp->name = iter.first;
MNNOp->type = MNN::OpType_Input;
MNNOp->main.type = MNN::OpParameter_Input;
auto inputParam = new MNN::InputT;
const auto it = inputs.find(iter.first);
DCHECK(it != inputs.end()) << "Input Paramter ERROR ==> " << iter.first;
const auto& tensorInfo = (it->second)->type().tensor_type();
const int inputDimSize = tensorInfo.shape().dim_size();
inputParam->dims.resize(inputDimSize);
for (int i = 0; i < inputDimSize; ++i) {
inputParam->dims[i] = tensorInfo.shape().dim(i).dim_value();
}
inputParam->dtype = onnxOpConverter::convertDataType(tensorInfo.elem_type()); // onnx数据类型转换成mnn的数据类型
inputParam->dformat = MNN::MNN_DATA_FORMAT_NCHW; // 数据格式为NCHW
MNNOp->outputIndexes.push_back(tensorsName[iter.first]);
MNNOp->main.value = inputParam;
mnnNodesMap.insert(std::make_pair(iter.first, MNNOp));
netT->oplists.emplace_back(MNNOp);
}
// onnx的节点导入到mnn的节点中
for (int i = 0; i < nodeCount; ++i) {
const auto& onnxNode = onnxGraph.node(i);
const auto& opType = onnxNode.op_type();
// name maybe null, use the first output name as node-name
const auto& name = onnxNode.output(0);
// TODO not to use constantNodeToDelete anymore
if (constantNodeToDelete.find(name) != constantNodeToDelete.end()) {
continue;
}
// 找到对应op类型的转换器
auto opConverter = onnxOpConverterSuit::get()->search(opType);
MNN::OpT* MNNOp = new MNN::OpT;
MNNOp->name = name;
MNNOp->type = opConverter->opType();
MNNOp->main.type = opConverter->type();
mnnNodesMap.insert(std::make_pair(name, MNNOp));
// convert initializer to be Constant node(op) 将权重转换为常量节点
for (int k = 0; k < onnxNode.input_size(); ++k) {
const auto& inputName = onnxNode.input(k);
const auto it = initializers.find(inputName);
if (it != initializers.end() && tensorsName.find(it->first) == tensorsName.end()) {
// Create const Op
MNN::OpT* constOp = new MNN::OpT;
constOp->type = MNN::OpType_Const;
constOp->main.type = MNN::OpParameter_Blob;
constOp->main.value = onnxOpConverter::convertTensorToBlob(it->second); // onnx的tensor转换为mnn的tensor
mnnNodesMap.insert(std::make_pair(inputName, constOp));
auto outputIndex = (int)netT->tensorName.size();
constOp->name = it->first;
constOp->outputIndexes.push_back(outputIndex);
tensorsName.insert(std::make_pair(it->first, outputIndex));
netT->tensorName.emplace_back(constOp->name);
netT->oplists.emplace_back(constOp);
}
}
// TODO, delete the run() args opInitializers 删除一些不在opInitializers中的节点。
std::vector<const onnx::TensorProto*> opInitializers;
for (int k = 0; k < onnxNode.input_size(); ++k) {
const auto& inputName = onnxNode.input(k);
const auto it = initializers.find(inputName);
if (it != initializers.end()) {
opInitializers.push_back(it->second);
}
}
// 执行算子转换
opConverter->run(MNNOp, &onnxNode, opInitializers);
netT->oplists.emplace_back(MNNOp);
const int outputTensorSize = onnxNode.output_size();
for (int ot = 0; ot < outputTensorSize; ++ot) {
netT->tensorName.push_back(onnxNode.output(ot));
tensorsName.insert(std::make_pair(onnxNode.output(ot), tensorsName.size())) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









