






摘要
电信领域的问答任务在文献中仍相对未被充分研究,主要是由于该领域的快速变化和标准的不断演变。本文提出了一种专门为电信领域设计的检索增强生成(Retrieval-Augmented Generation, RAG)框架,重点关注由3GPP文档组成的数据集。该框架引入了二分K均值聚类技术,按内容组织嵌入向量,从而更高效地进行信息检索。通过利用这种聚类技术,系统预选与用户查询最相似的子集簇,增强了检索信息的相关性。为了降低推理时的计算成本,该框架使用了小型语言模型进行测试,结果表明其准确率达到phi-2模型的66.12%和phi-3微调模型的72.13%,同时减少了训练时间。
[算法]
检索增强生成, 3GPP文档, 二分K均值, 小型语言模型
1 引言
大规模语言模型(LLMs)通过提供更好的文本理解和生成能力,已经革新了许多行业。这些模型,如Microsoft的phi-2 , 在数十亿参数的大数据集上进行了训练,能够深入捕捉语言细微差别和通用知识。LLMs的应用范围从自动化行政任务到个性化辅助,展示了其在许多领域的巨大创新潜力 。
尽管它们具有多功能性,但在高度专业化的领域如电信领域,LLM模型往往缺乏足够的特定数据训练,导致面对需要深度专业知识的问题时,回答不准确或不足。为克服这些限制,需要采用微调和检索增强生成(RAG)等专业化技术。
微调涉及对现有LLM在专门数据集上的重新训练。这一过程调整模型权重,使其预测更符合特定领域的知识和术语 。通过反复暴露于专业数据,模型可以捕捉到初始训练中不存在的相关模式和细微差别。这种方法提高了模型对特定领域查询提供准确和适当答案的能力。
RAG是另一种用于提高LLM准确性的强大技术。RAG通过结合文本生成与信息检索,将外部数据集成到查询上下文中 。这主要通过两个组件实现:一个检索模型在外部数据库中搜索相关文档,以及一个生成模型使用这些文档生成情境化答案 。这种方法扩展了模型的知识库,并确保答案更准确且基于最新的领域特定背景。
在电信行业中,应用专业化的LLM尤为重要 。该行业以其复杂性和对特定术语的需求为特点。专业化的LLM可以显著减少获取关键信息的时间,提高回答的准确性,并确保符合国际标准。这使得操作更加高效,能够迅速满足行业的技术需求。
本文提出了一种针对电信行业的LLM模型专业化的新方法。它使用了TeleQnA数据集 , 该数据集专门用于评估LLM的电信知识。数据集包含从各种来源提取的10,000个问题和答案,包括标准规范和研究论文,确保覆盖所需的知识。目标是开发一种能够回答关于3GPP(第三代合作伙伴计划)第18版标准问题的模型。
本提案在于将微调与聚类技术相结合,特别是二分K均值 , 进一步提高模型的准确性和相关性。二分K均值用于对相似数据进行分组,识别对电信解释和分析至关重要的模式和趋势。实验结果展示了显著改进,突显了此方法在适应高度专业领域中的有效性。
2 相关工作
最近的研究探讨了LLM在电信领域的应用,展示了其在多个数据集中增强行业各方面潜力的可能性。然而,许多研究未能解决由嵌入向量表示的知识优化搜索过程。例如,Telco-RAG 介绍了利用LLM处理电信数据集问答任务的概念,但缺乏对其管道中具体组件(如基于嵌入的检索、语义搜索和响应生成)如何贡献整体性能改进的清晰说明。这一差距凸显了进一步研究优化LLM中搜索和检索机制的必要性,以增强其在电信应用中的能力。
例如,TelecomRAG 受限于其管道的局限性,无法解决电信行业中普遍存在的关键性能问题,如广泛使用的缩写和首字母缩略词。这种忽视可能导致处理该领域数据时的效率低下和不准确。相比之下,这项工作旨在处理可能对LLM分析构成挑战的用户输入。所提出的框架包含了一个文本预处理步骤,增强了提示,确保文本生成更准确可靠。这种预处理增强了LLM理解并生成有意义响应的能力,从而改善了问答任务的整体性能。
《电信RAG》的作者 优化了RAG管道的内部参数,特别是在索引检索方面,展示了显著的效率提升。然而,它仍然依赖于内容的原始结构,没有提供替代的搜索知识表示的方法。相比之下,本工作深入研究了内容的聚类技术,按内容分组嵌入,而不考虑其初始结构。这种方法允许在嵌入空间内更高效的搜索,增强了信息检索过程的整体性能和有效性。
3 方法论
为了使LLM模型在回答电信领域规格问题时更加专业,我们实施了几项关键步骤。本文使用的文档来自TeleQnA数据集,该数据集编译了3GPP系列文档的问答格式,带有选择题答案。


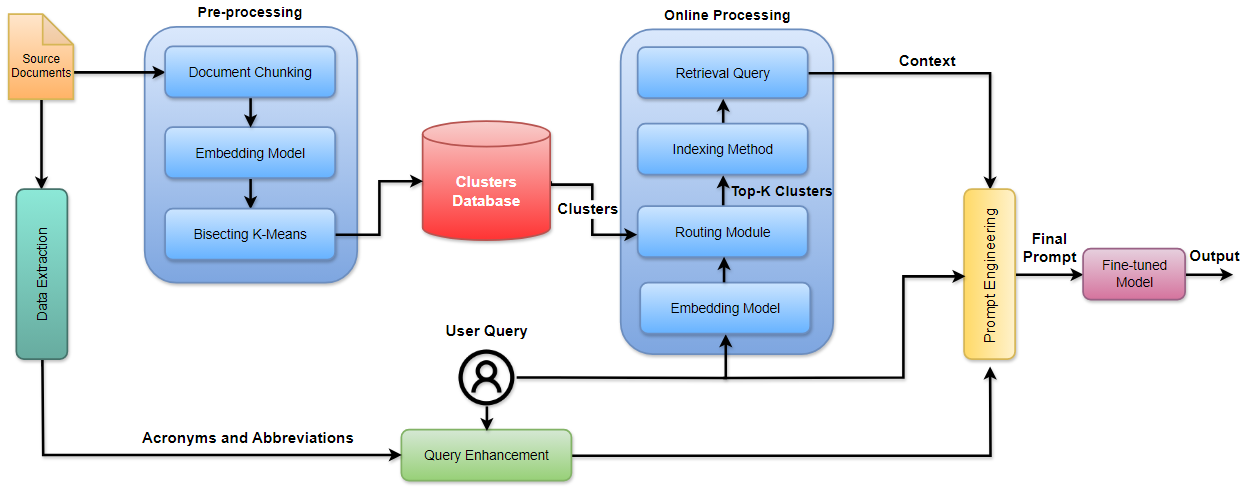
算法1展示了整个过程,分为两部分:第一部分仅处理一次以创建簇,第二部分每次处理新的用户查询。
![]()
![]()
![]()
高度 .4pt

![]()
![]()
3.1 查询增强
在电信领域,许多单词、缩写和术语难以理解 。像phi-2这样的语言模型通常用一般数据进行训练,因此可能无法理解3GPP标准文档中的特定技术术语。
在3GPP网站上,我们可以找到有价值的信息来增强查询,了解这些术语的含义。这些文档包含详细的和专业的信息,因此有必要教导这些术语给语言模型,帮助它们正确理解和使用这些信息。
在检索信息并传递给LLM生成答案之前,查询增强的过程。
查询增强的过程包括从3GPP文档中提取定义和缩写,并将这些含义纳入查询中。为此,我们创建了两个词典:一个是技术术语词典,另一个是缩略词词典。技术术语词典包括诸如“系统网络”之类的短语定义,而缩略词词典提供了如“5G”等术语的含义。这些资源用于扩展查询并在检索相关信息时提供更好的上下文。图 1 展示了使用上述技术的查询增强过程的一个例子。
3.2 文档文本预处理
3GPP第18版规范的文本被分割成不同大小的块,以便进行详细和准确的分析。将文本分割成块是自然语言处理中的常见做法,因为它有助于处理和分析大量文本数据 。选择了两种块大小配置进行测试:500和250个字符。这些值的选择基于 中展示的结果,证明这种划分大小能有效提高选定模型的准确性,如图 2 所示。
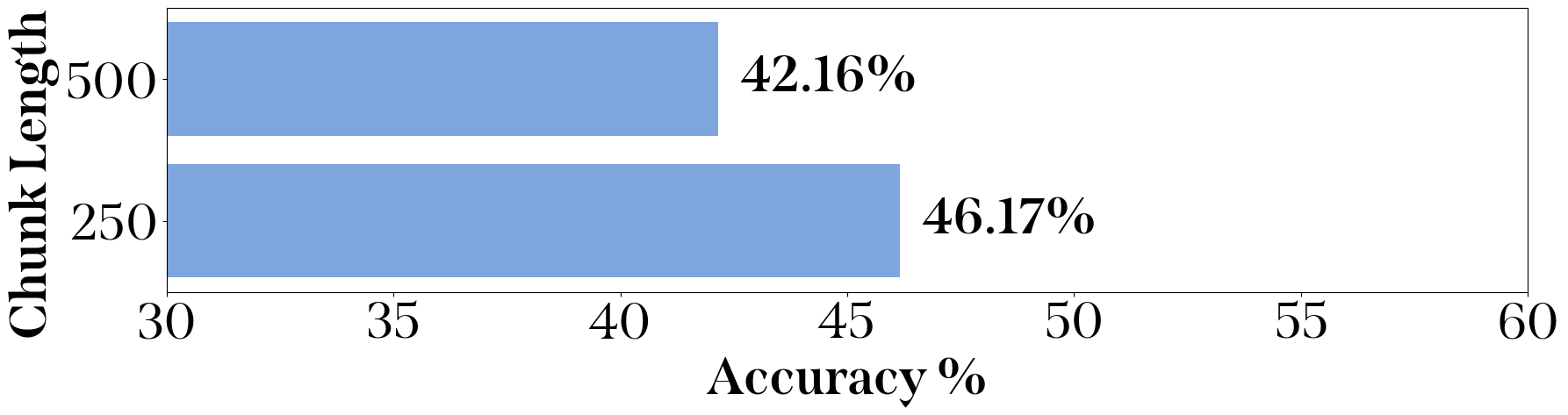
phi-2在不同块大小下的性能。
将文本分割成块后,每段文本被转换为嵌入,这是语言模型理解和使用数据的关键步骤。嵌入是文本的向量表示,将自然语言转化为机器学习模型可以处理的形式。本工作使用BAAI bge版本的大型英语模型 将块映射为数值向量,该模型以其在生成稳健和准确嵌入方面的高效性而闻名 。
3.3 RAG的聚类方法

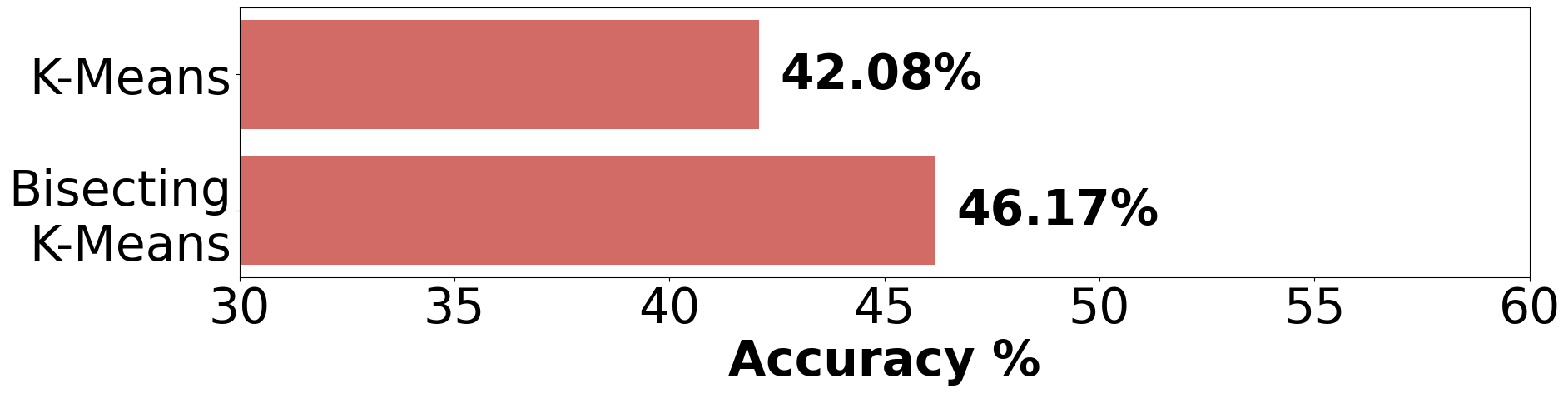
常规K均值和二分K均值聚类之间的性能差异,所有测试均使用phi-2模型。

SSE用于衡量簇内的变异性,通过计算每个数据点与簇中心的距离平方和来测量。SSE越低,簇内的数据越同质,表明数据分割质量越高。使用SSE可以识别哪些簇具有更大的内部变异性,因此应进一步细分以提高聚类的准确性。SSE的计算公式如下:

本工作中,嵌入被分为18个簇,将相似值的嵌入分组。这简化了识别具有相似特征的数据组的过程,并在文本生成期间促进了相关信息的检索。
3.4 路由模块
RAG路由模块通过从大量文档库中检索相关信息,增强了生成更准确和上下文相关响应的能力。该模块是必要的,因为它弥合了静态知识库和动态查询特定信息需求之间的差距,从而提高了生成内容的质量和相关性。
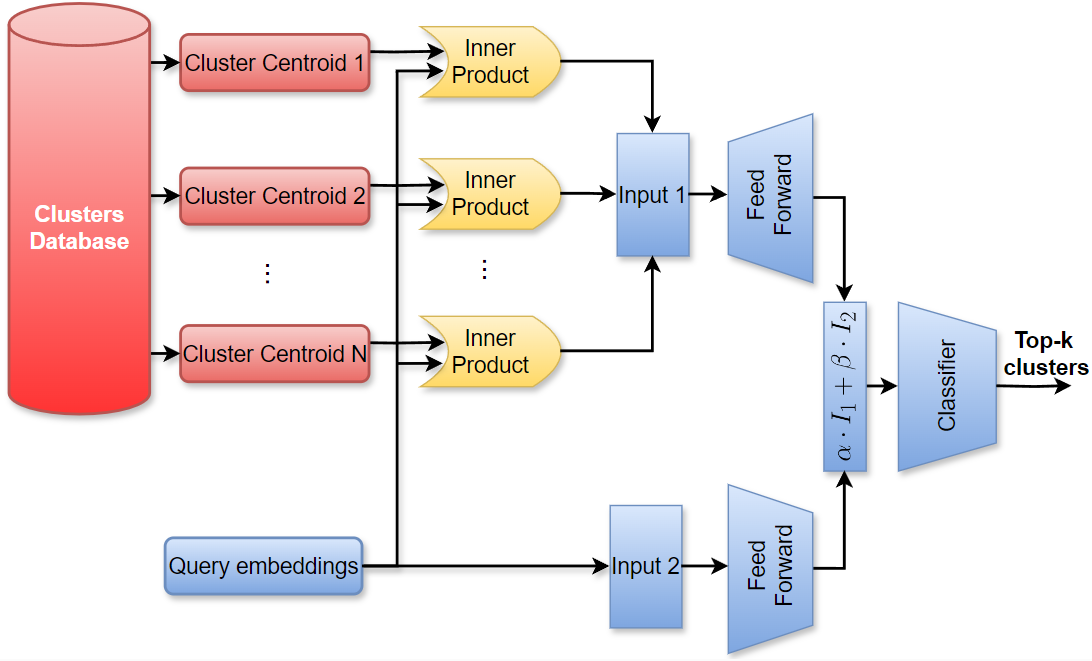
路由模块。




3.5 微调模型
采用了微调过程 1 来增强模型对上下文的理解并定制其响应以达到预期效果。根据可能的实际使用情况,选择了较小的模型。因此,选择了phi-2,因为它的大小允许我们对其进行微调并在小型设备上部署。
为了创建训练数据集,我们使用RAG为每个训练样本生成上下文。通过在训练过程中集成上下文,确保模型能够更好地利用相关外部信息,从而提高其理解并准确回答领域特定查询的能力,如 所示。具体来说,上下文与术语、定义、问题、选项、答案及答案解释连接在一起,使用Hugging Face的基础聊天模板,使模型更容易区分上下文、查询和响应,如图 5 所示。
训练文本示例。
还创建了一个单独的数据集,其中答案引用了3GPP文档中答案的具体部分。如果答案无法在上下文中找到,则明确指出未找到。该数据集用于微调更可靠的模型,因为有了引用,可以在文档中查找相应部分以确认答案。为了生成这个答案,将上下文、术语、缩写、问题、选项、答案及解释输入GPT-4 ,以提取最有价值的检索和文档,并在答案中引用它们。该数据集仅用于微调phi-2模型,并命名为增强响应,如图 7 所示。
4 结果
本节展示了该框架在应用于3GPP领域的LLM性能提升。所有微调实验都在配备8个vCPU、30 GB RAM和单个NVIDIA L4 GPU(24 GB VRAM)的机器上使用Hugging Face AutoTrain进行。
研究重点放在phi-2模型 2 上,因其体积较小且训练时间较短,优于Phi-3-4k-instruct ,如图 6 所示,而且在早期RAG测试中表现优于gemma-2-2b ,尽管它们的尺寸相似。开发完成后,另外两个模型也经过了整个流程的测试,分离增益以展示系统的各部分效果。
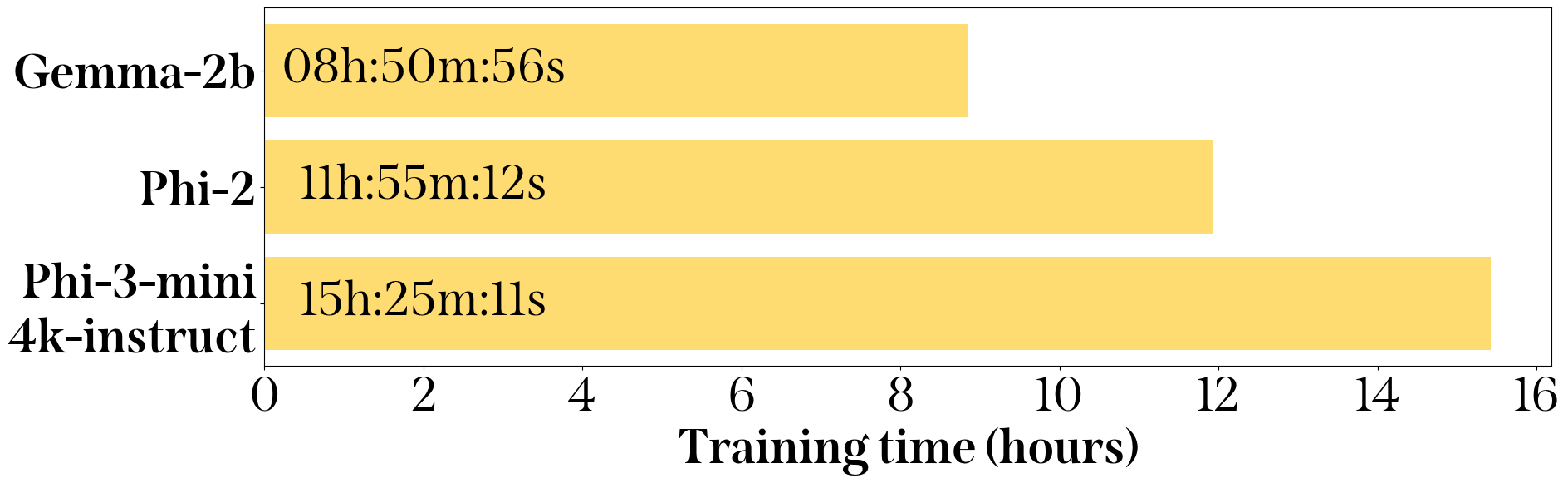
在8个vCPU、30GB RAM和1个L4 GPU(24GB VRAM)上使用Hugging Face AutoTrain微调模型所需的时间。
如图 7 所示,通过使用所描述的方法,获得了显著的准确率提升,相对于基础phi-2模型最高提升了34.4%,结合RAG和微调。此外,发现该技术还大幅提高了gemma-2-2b和Phi-3-4k-instruct模型的准确率,表明该方法的增益可能适用于其他模型,甚至更大规模的模型如Phi-3-mini-4k-instruct。
此外,发现使用增强响应训练的模型比非增强响应模型表现更差,如图 7 所示。尽管如此,该模型仍能有用,因为它能够将问题与3GPP文档关联起来,提供一个更好的起点来查找答案。
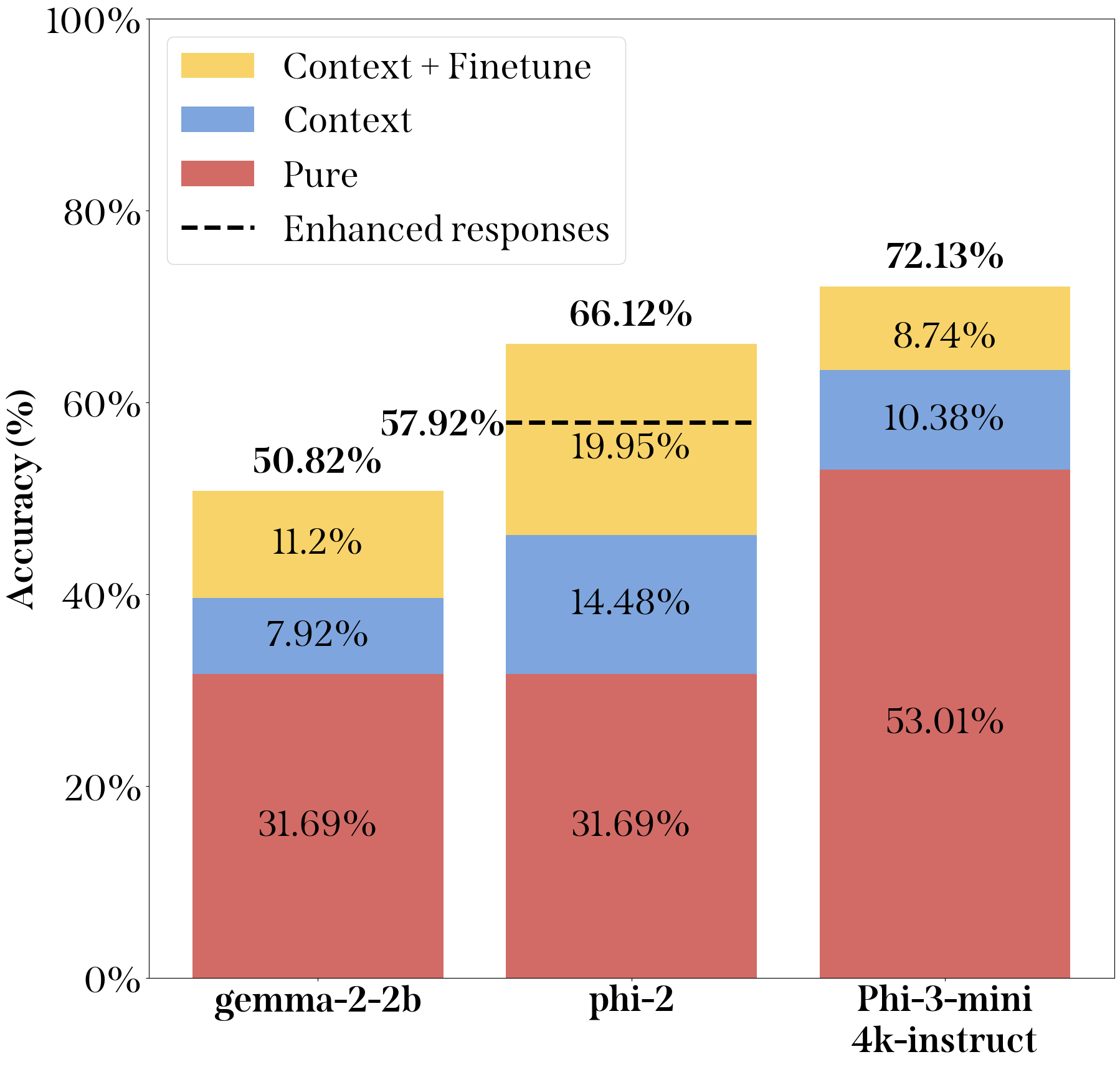
各模型按方法分开的性能提升。
5 未来工作
虽然所提出的框架在问答任务中展示了进步,但仍有许多机会可以进一步提升性能。未来的研究可以探索新型知识表示技术,如知识图谱,以提高信息检索和推理能力。此外,更加注重数据预处理,尤其是清理文档块后再将其转换为嵌入,可以显著提高输入数据的质量和相关性。此外,改进路由模块以输出更聚焦的簇选择,可能会带来更高效和准确的响应。最后,使用更大的语言模型如GPT-4可能会带来显著改进,前提是需要仔细评估以在模型大小、计算资源和性能增益之间找到最佳平衡。
6 结论
本文展示了在RAG架构中集成路由模块与聚类技术,显著提高了信息检索的效率和准确性。通过对3GPP源文档进行分块、嵌入和二分K均值聚类的预处理,系统有效地将大量数据组织成有意义的簇。这些簇存储在向量数据库中,为RAG模型快速访问和利用最相关信息提供了结构化的基础。
最终,这种RAG架构方法通过预处理阶段(按内容而不是源文档格式收集嵌入)和实时处理阶段(在可接受的时间内交付高准确性和上下文适当的响应),充分利用了两者的优势。实验结果显示,使用较小的LLM(如phi-2和phi-3)分别在电信文档中达到了66.12%和72.13%的准确率,而训练时间分别为不到12小时和16小时。
致谢
本工作得到了LASSE — 研究与发展中心在电信、自动化和电子领域 — 和Unicamp计算机网络实验室(LRC)的教授Carlos Alberto Astudillo Trujillo博士的指导、资助和支持。我们衷心感谢他们对本研究的支持。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











