






Samuel Flanders
1
{ }^{1}
1, Melati Nungsari
1
{ }^{1}
1, Mark Cheong Wing Loong
2
{ }^{2}
2
1
{ }^{1}
1 亚洲商学院,吉隆坡,马来西亚
2
{ }^{2}
2 马来西亚莫纳什大学药学院
摘要
本文探讨了使用大型语言模型(LLMs),以GPT 3.5-Turbo为代表,进行主题分析编码。编码工作非常耗时,使得大多数研究人员无法对大规模语料库进行全面的主题分析。我们通过在语义相似的段落上生成高质量代码的少量样本提示来增强代码质量,同时利用廉价且更易扩展的模型。
引言
本文探讨了使用大型语言模型(LLMs),以GPT 3.5-Turbo(以下简称“GPT”)为代表,进行主题分析编码。编码工作非常耗时,使得大多数研究人员无法对大规模语料库进行全面的主题分析。
大型语言模型(LLMs)的最新进展为自动化定性研究的某些方面(包括主题分析(TA))开辟了新途径。先前的研究表明,LLMs可以为文本数据生成合理的主题代码(Dai, Xiong, and Ku, 2023; Morgan, 2023; De Paoli, 2024)。本文重点开发和评估了一种AI辅助编码方法,旨在通过大型语言模型增强文本段落的主题编码。我们的目标是通过精心设计的链式思维(CoT)提示工程和少量样本学习来提高机器生成代码的质量。
我们的测试案例是一个包含2,530篇关于难民的马来西亚新闻文章的语料库,收集这些文章是为了探讨以下研究问题:马来西亚新闻媒体中存在哪些对难民的态度?每篇文章被分割成段落,并通过结构化的多步骤过程由GPT编码。早期迭代揭示了一系列挑战,例如无关或模糊的段落、“总结溢出”,即模型的回答依赖于目标文本之外的信息,以及过于概括或错误归因的代码。为了解决这些问题,我们改进了提示,实施了排除标准,并引入了一个苏格拉底提示框架,引导模型进行相关性检查和结构化的CoT推理。
至关重要的是,我们还引入了一种可扩展的少量样本提示形式。而不是提供随机示例来指导GPT的输出,我们使用向量嵌入将语义相似的段落聚类,并向GPT提供来自同一聚类中的示例段落的编码摘要。这些示例通过我们在研究中使用的长篇苏格拉底管道生成,但也可以由人类研究人员提供。这种方法结合了少量样本提示的优点——提高了一致性和具体性——同时保持计算效率和理论基础。
我们通过要求三名人工编码员独立评估两个版本中固定样本的编码段落来评估我们的方法论:初始版本和包含上述改进的最终版本。评审员对代码的适当性进行了评分,识别出无关的段落,并参与了结构化讨论以解决分歧。最终版本达成了高度共识,F1分数超过0.82,阴性预测值为0.97 —— 表明该方法特别擅长识别无关材料。各轮之间的评分者间可靠性也大幅提高。
本文的贡献有两个方面:首先,我们提供了一种详细、可复制的方法论,用于通过提示改进、错误分析和结构化的少量样本提示来提高LLM生成的主题代码质量;其次,我们通过系统的人工审查来评估这种方法论,识别其优点和局限性。这项工作为未来在定性研究中应用AI编码奠定了基础,保留了人类分析的解释丰富性,同时受益于机器协助的可扩展性和一致性。
文献综述
将AI整合到定性研究中促使人们重新思考如何进行主题分析。传统的手动编码仍然是定性研究的核心,方法从有机的解释程序到更结构化的实证主义方法不等。早期的定性软件——如NVivo(Dawborn-Gundlach & Pesina, 2015)——已经补充了手动编码,然而这些方法通常需要研究人员深入参与以解释意义和发展主题。
编码和主题分析方法
主题分析的变化反映了对研究者角色和数据分析性质的不同假设。在光谱的一端,像编码可靠性(Boyatzis, 1998)这样的方法将代码视为简洁的领域摘要,有效地将定性数据转化为可量化测量。这些方法自然与实证主义观点一致,在这种观点中,可重复性和客观测量是最重要的。相比之下,灵活的方法——以Clarke和Braun(2006)为例——强调主题的有机演变,其中研究者的解释输入至关重要。此外,批判现实主义视角(Fryer, 2022; Christodoulou, 2023)引入了结合溯因推理和因果解释的框架,从而扩展了解释策略的范围。虽然这些解释主义方法丰富了定性探究,但也引入了可能降低跨研究可重复性的主观性。
AI和主题分析
大型语言模型(LLMs)的最新进展使主题分析的一个新研究分支得以实现。Dai, Xiong, 和 K u ( 2023 ) \mathrm{Ku}(2023) Ku(2023) 以及Morgan (2023) 的研究表明,LLMs能够生成捕捉文本数据具体方面的描述性代码。其他方法将LLM输出与人类监督相结合——通过迭代讨论和代码细化——以接近双人人类编码员的可靠性(Chew et al., 2023; De Paoli, 2024; Turobov et al., 2024; De Paoli and Mathis, 2024)。与这些模型不同,本文提出的方法通过少量样本提示生成明确的数据衍生和可重复的代码。我们的方法关注于生成客观代码,这些代码既可测量又可扩展,从而与实证主义生成可量化证据的概念一致。
合成与AI编码方法学的含义
文献揭示了主题分析中解释灵活性与客观严谨性之间的张力。尽管传统方法——无论是反思性的还是批判现实主义的——强调人类洞察力的不可或缺性(Clarke & Braun, 2017; Fryer, 2022; Christodoulou, 2023),实证主义方法如编码可靠性(Boyatzis, 1998)则强调可重复、数据衍生代码的好处。在这种背景下,我们的方法——集中在少量样本提示和结构化的苏格拉底编码过程中——代表了这些方法的混合。通过专注于生成具体和可测量的代码,该方法避免了许多与饱和度和解释变异性相关的主观陷阱。它因此为定性分析的扩展提供了途径,使研究人员能够以支持后续统计验证和理论发展的程度一致性评估大量数据集。
方法论
数据收集
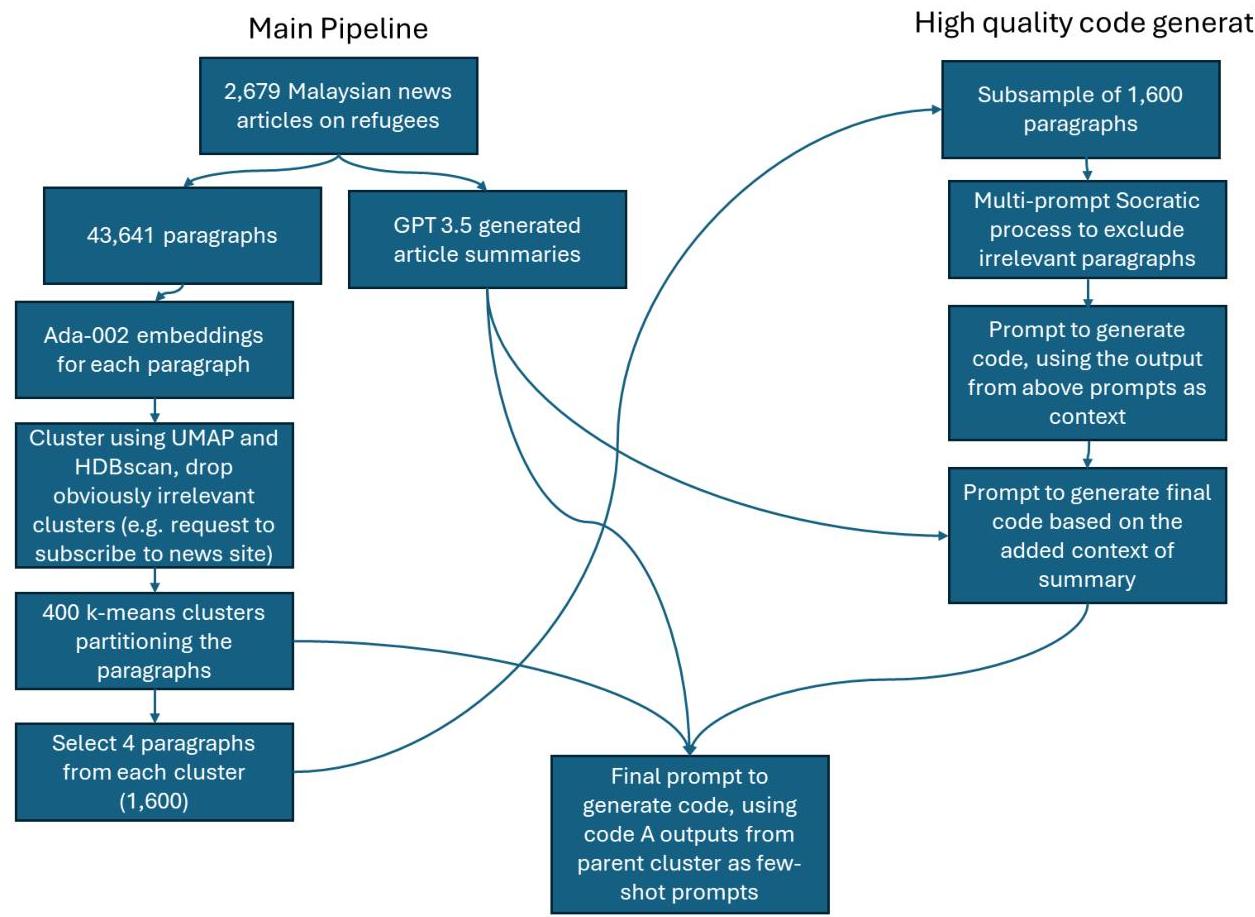
图1:数据收集和编码过程图解
我们的主题分析聚焦于马来西亚媒体对难民的态度,所以我们选择从马来西亚新闻文章中构建我们的语料库。为了选择来源,我们在谷歌搜索了“malaysia news”并排除了推广结果,目标是五个不同的来源以确保多样性。由于各种原因,许多搜索结果不可用(见表1),所以我们的五个来源来自前11个结果。
| 来源 | 包括 | 备注 |
|---|---|---|
| The Star | 是 | 数据仅从2020年1月起可用 |
| Malay Mail | 是 | |
| Malaysiakini | 是 | |
| FMT | 否 | 禁止抓取 |
| NST | 否 | 禁止抓取 |
| MalaysiaNow | 否 | 搜索查询仅允许“或”逻辑运算符,而非“和”,因此“malaysia refugees”产生大量无关结果。 |
| :–: | :–: | :–: |
| Yahoo Malaysia | 否 | 仅是其他新闻来源的索引 |
| Bernama | 否 | 仅显示过去两周的搜索结果 |
| TheMalaysianInsight | 是 | |
| Al Jazeera | 否 | 不是本地媒体 |
| The Sun | 是 |
表1:新闻来源
为了收集数据,我们对每个来源网站的搜索执行了“malaysia” “refugees”的查询,并收集了从2017年1月1日至搜索日期的所有文章,搜索日期从2023年3月至5月不等。为了生成我们语料库的段落,我们将文章按换行符分割,并删除所有少于50个字符的段落。我们还使用GPT生成了每篇文章的一段摘要,以便在GPT分析段落时提供上下文。
1
{ }^{1}
1
AI编码I
在我们的第一轮迭代中,对于每个段落,我们向GPT提示如下:
'Read a passage from a news article summarized here: ### ' + str(summary) + '
### passage: ### ' + str(excerpt)+ ' ### In 12 words or less, give the theme of
this specific passage as it embodies, relates to or reflects attitudes towards
refugees in Malaysia, or return "Irrelevant"'
其中“summary”包含整篇文章的一段摘要,“excerpt”包含段落。一个例子会很有帮助: 2 { }^{2} 2
摘录:同一十年间,马来西亚与其他许多国家一道,积极将波斯尼亚难民融入我们的社区,为他们提供急需的保护和教育机会。
编码:马来西亚对难民的积极历史待遇与当前情况形成对比。
进一步地,我们使用OpenAI的Ada嵌入这些编码(Coding)。这生成了一个包含语义意义的1536维向量,我们使用UMAP将其投影到6维,并使用HDBSCAN进行聚类。最终结果是60个段落聚类,每个聚类由语义相似的段落组成。
编码审查
然后,我们从语料库中随机抽取414个段落,并要求三位评审员根据李克特量表(强烈不同意、不同意、不确定、同意、强烈同意)评估编码,必要时提供评论。编码文档可在URL处获取。编码文档向评审员提供了文章的全文、文章链接、标题、ChatGPT提供的相同摘要、摘录本身、GPT生成的代码以及段落所属的聚类。 4 { }^{4} 4
评审员获得了以下指示:
您将收到一份包含从2017年至2023年马来西亚关于难民的新闻文章片段采样的Google表格。此文档还包含文章摘要、标题和每篇文章的全文。
具体来说,对于每个段落,您在多大程度上同意ChatGPT的编码?(1. 强烈不同意 2. 不同意 3. 不确定 4. 同意 5. 强烈同意)
由您选择1到5的值。没有正式的标准,例如“强烈同意”。如果您不确定自己是否强烈同意,不必担心确切哪个值(1-5)最恰当,请提供您不同意编码的哪些方面并提供您将如何编码它的示例。
独立完成此评估,并在所有评审员完成此任务之前不要讨论您的发现。
在整个过程中,评审员还获得了大量的澄清。这些通信可以在附录N中找到。
方法论迭代
由于该项目旨在开发一种新的AI编码方法,我们计划在第一次审查后修改我们的方法。我们与评审员召开了一次会议,以征求他们对ChatGPT编码给定段落的反馈。我们特别关注评审员一致反对ChatGPT编码的实例,以及评审员难以评估编码适切性的实例。利用这些实例,我们要求评审员识别ChatGPT编码结果中的问题、担忧和困难。评审员从各自的视角识别了几个问题,我们也能够从评审员之间的讨论中综合出额外的问题。关键问题包括以下几点:
- 总结溢出:代码经常反映出现在待编码段落中的内容,而这些内容并未出现在摘要中。
- 短段落编码效果不佳。
- 整体不准确。
- 代码中“态度”一词使用得非常广泛——经常涵盖并非态度的情况或将态度分配给错误的人。
- 段落中有两个相同的代词(针对两个人的两个“他”或两个“她”)导致混淆。
- GPT经常错过段落中的讽刺意味。
- 在结构复杂的段落中,例如描述几个人或概念之间关系时,GPT经常在解释上出现错误。
此外,他们识别出了语料库中频繁误编码的常见段落类型。具体而言,这些类型的段落从未与马来西亚媒体对难民的态度相关,但经常被错误地分配代码。这些包括:
- 评论文章中介绍意见的段落。
- 组织描述。
- 请求订阅新闻网站。
- 短小、不完整的句子。
- 图片说明。
- 下一篇文章的描述。
对于这些段落类型,我们的目标是简单地识别它们并将它们从语料库中排除,因为它们从未相关。使用上述的UMAP和HDBscan聚类技术,我们将语料库进一步细分为更精细的聚类,识别出对应上述段落类型的聚类,并从语料库中删除它们。
虽然去除无关的段落类型很容易,但之前描述的许多一般性问题无法直接解决:问题5、6和7本质上是GPT和基本方法论的限制。然而,我们能够做出许多改进。为了解决1、2和3,我们将最小段落长度从50个字符增加到100个字符——短段落不仅编码最差而且最不相关。对于1,我们稍微缩短了摘要,以免让摘要掩盖段落。为了解决1和4,我们测试了许多替代提示,并得出一个更好地指导GPT区分摘要和待编码段落以及什么是态度的提示。
此外,为了解决3和4,我们对提示方法进行了定性改变。我们不再简单地要求代码,而是要求一个包含四个响应的结构化列表,如下所示提示的末尾。GPT在标准程序格式响应方面非常出色,因此选择了JSON格式 5 { }^{5} 5作为提示。
最后,我们添加了另一个元素到我们的方法中。显然,我们可以从更详细的苏格拉底方法中获得更好的编码,这种方法涉及我们反复查询GPT有关编码过程的各个方面,逐步建立一些初步的段落评估,然后要求GPT使用其早期的指导评估作为参考生成最终编码。原因有二:
- 这使我们能够更仔细和细致地引导编码过程,确保GPT考虑每个过程的方面和潜在的绊脚石。
- GPT在一个响应中执行多个任务的能力有限。将任务分解成更简单的部分可以提高每个部分的表现。
当然,这种方法需要每个段落消耗更多的计算资源。鉴于当时的API调用价格,这种方法无法扩展到整个数据集。为此,我们
- 将完整数据集划分为400个聚类, 6 { }^{6} 6
- 从每个聚类中抽样四个段落,
- 对这些1600个段落使用长篇苏格拉底方法进行编码,
- 对于每个400个聚类,生成该聚类中四个段落的四个代码摘要。
- 在对整个数据集生成最终编码时,识别该段落属于哪个400个聚类,并将第4步中的代码摘要作为上下文提供给GPT。
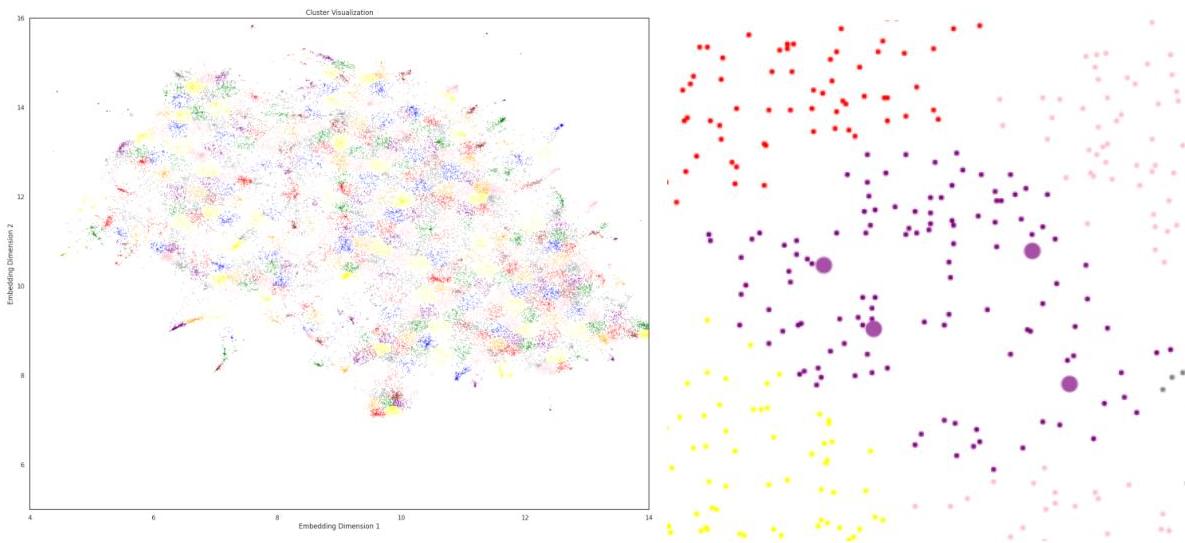
图2,A:400个聚类的二维可视化。B:一个聚类的细节,突出显示了四个抽样段落
这种方法的理论依据是,同一聚类中的段落在许多方面应该是相似的,看到高质量的代码作为参考可以提高GPT的表现。这可以被视为一种少量样本提示的形式,其中AI模型被提供所需输出的例子以指导其回答。由于输入文本的高成本,我们总结了四个代码以使提示更加简洁。在本文中,
长篇苏格拉底方法如下:我们要求GPT评估段落是否为图片说明或免责声明:
‘Read a passage from a news article ### ’ + str(excerpt)+ ’ ### Is this passage a piece of text such as 1. a disclaimer of opinion, 2. a photo caption. Or is it a complete passage from the body of a news article? Respond only in the following python dictionary format: {“1. disclaimer?”: True/False, “2. caption?”: True/False, “Body?”: True/False }’
然后我们要求GPT评估段落是否明确讨论了难民和马来西亚:
‘Read a passage from a news article ### ’ + str(excerpt)+ ’ ### Step by step, answer the following questions: 1. Does the passage explicitly, unambiguously discuss refugees? Note: most passages are not about refugees. 2. Does the passage explicitly, unambiguously reference Malaysia? Note: most passages are about other countries.’ + note + ’ Now respond in the following Python dictionary format: {“1. Refugees?”: “Yes.”/“No.”, “2. Malaysia?”: “Yes.”/“No.”}’
note变量将GPT在前一步中的分析反馈到当前步骤。如果没有出现任何警告标志,则为空:" ",但是如果有任何警告标志,则总结前一个问题。在这个步骤中,它将标记"段落是个人意见的免责声明"或"段落是图片说明"的可能性。
接下来,我们询问GPT对其相关性的信心及如果无关的原因:
'Read a passage from a news article ### ’ + str(excerpt)+ ’ ### Answer step by step: 1. Might this passage be relevant to attitudes towards refugees in Malaysia? If it clearly is, answer “Yes.” If it might be, depending on the context of the article the passage is from–eg. the identity of the subject and their location–answer “Maybe.” If it is definitely irrelevant regardless of context, answer “No.” ’ + note + ’ 2. If “No.” or “Maybe.”, in 15 words or less give any and all reasons why it might be irrelevant–both those provided earlier and any others you identify, such as irrelevant output from a content management system or editorial annotations to the article. Respond in the following python dictionary format: {“1. Relevant?”:“Yes.”/“Maybe.”/“No.”,“2. Why Not?”:string or None} ’
在这里,如果没有任何警告标志,note变量为空:" ",但是如果有任何警告标志,则在提示中添加以下文本:‘注意:这个段落已被标记为可能满足以下无关标准:[CRITERIA] ### 如果有任何这些标准为真,你应该回答"No."或"Maybe. ",其中[CRITERIA]为’段落是个人意见的免责声明,’,‘段落是图片说明,’,‘不关于难民,’,‘不关于马来西亚,’ 如相关。
在第四个提示中,我们要求GPT对段落进行编码,同时考虑到它之前的关联性评估。
‘Read a passage from a news article ### ’ + str(excerpt)+ ’ ### Give the theme of this passage as it embodies, relates to or reflects attitudes towards refugees in Malaysia if it is relevant to that topic. If it is not relevant, simply summarize the passage in a few words. Note that this passage may simply be text from the web interface and not from an article at all. Before answering, analyze step by step: 1. in 14 words or less, return the theme. Do not offer a generic theme like “attitudes towards refugees in Malaysia”, but give a specific theme. 2. Whose attitudes are being reflected? Examples: the
Malaysian government, The Bangladeshi government, Malaysians, NGOs, the author. 3. Who is the target of the attitudes? Examples: migrant workers, Myanmar, the Rohingya, the government, UNHCR. 4. What is the valence of attitudes towards the target, if any?: “Sympathetic.”, “Hostile.”, or “H/A”. ’ + note + ’ Finally, Respond ONLY in the following python dictionary format: (“1. Theme”: stringval1, “2. Whose Attitude?”:stringval2,“3. Target”:stringval3,“4. Valence”: “Sympathetic.”/“Hostile.”/“N/A”|’
在这个提示中,如果在前一步中“Relevant?”被评估为“Yes”,则note变量为空,如果是“Maybe”,则为‘ Previous analysis found that this passage might be irrelevant for this reason: ’ + reason + ‘### Take this into account.’,如果是“No”,则为‘ Previous analysis found that this passage is irrelevant for this reason: ’ + reason + ‘### Take this into account.’,其中reason是在前一步中“Why Not?”给出的原因。
请注意,在苏格拉底方法中,初始编码不引用摘要。相反,我们首先看段落是否单独相关,然后要求GPT根据摘要重新评估其代码。这有助于防止摘要溢出,即GPT的编码只与摘要相关,而与感兴趣的段落无关。这使我们进入最后的编码步骤:
"Read a passage from a news article \#\#\# ' + str(excerpt)+ ' \#\#\# The theme of this passage was coded as
\#\#\# ' + str(precode) + ' \#\#\# but this analysis ignores the article summary and is therefore unreliable.
Reassess the theme of this passage as it relates to attitudes towards refugees in Malaysia, given the
context of this summary of the article it came from \#\#\# ' + str(summary) + ' \#\#\# Before answering,
analyze step by step: 1. in 14 words or less, return the reassessed theme (if relevant) as it relates
to attitudes towards refugees in Malaysia, or return None. Do not give a generic theme like "attitudes
towards refugees in Malaysia", but provide a specific theme. If irrelevant, return None for all further
questions. If relevant, 2. Whose attitudes are being reflected? Examples: the government, Malaysians,
NGOs, the author. 3. Who is the target of the attitudes? Examples: the Rohingya, the government, UNHCR.
4. What is the valence of the attitude towards the target, if any?: "Sympathetic.", "Hostile.", or
"N/A". ' + note + ' Once again, the passage to code is \#\#\# ' + str(excerpt)+ ' \#\#\# Finally, Respond
ONLY in the following python dictionary format: ("1. Theme": stringval1/None, "2. Whose
Attitude?":stringval2,"3. Target":stringval3",4. Valence": "Sympathetic."/"Hostile."/"N/A"|'
在这个提示中,precede是前一步的代码,note包含‘ Previous analysis found that this SPECIFIC passage might be irrelevant for this reason: ’ + reason + ‘### Does the summary clarify this?.’
Or ‘ Previous analysis found that this SPECIFIC passage might be irrelevant for this reason: ’ + reason + ‘### Does the summary clarify this?.’
如果相关性分别被评估为maybe或no。
这里是一个聚类中四个代码的例子:
{“1. 主题”: “希望获得公民身份和遣返”, “2. 谁的态度?”: “发言人”, “3. 目标”: “缅甸政府”, “4. 倾向”: “同情.” }
{“1. 主题”: “赞扬遣返协议和安排”, “2. 谁的态度?”: “发言人”, “3. 目标”: “缅甸和孟加拉国”, “4. 倾向”: “同情.”}
在这一点上,我们将每个400个聚类中的每组4个代码组合在一起,并为每个生成一个摘要:
"Read a list of four themes from a cluster of passages ### ' + str(codes)+ ' ### Step by step, answer
the following: 1 Are all of these themes both present and relevant to attitudes towards refugees in
Malaysia? "All are."/"None are."/"Some are.". If irrelevant, return none to all further questions. 2.
If relevant, return the overarching theme as it relates to attitudes towards refugees in Malaysia, or
return None. Do not give a generic theme like "attitudes towards refugees in Malaysia", but provide a
specific and detailed theme. If relevant, 3. Whose attitudes are being reflected? Examples: the
government, Malaysians, NGOs, the author. 4. Who is the target of the attitudes? Examples: the
Rohingya, the government, UNHCR. 5. What is the overall valence, if any? Finally, Respond ONLY in the
following python dictionary format: ("1. Are Passages Relevant?": "All are."/"None are."/"Some are.","2.
Theme": stringval1/None, "3. Whose Attitude?":stringval2,"4. Target":stringval3,"5. Valence":
"Sympathetic."/"Hostile."/"N/A")'
这里是较早给出的四个代码的摘要:
{‘1. Are Passages Relevant?’: ‘All are.’, ‘2. Theme’: ‘对马来西亚罗兴亚难民遣返、公民身份和人道待遇的态度’, ‘3. Whose Attitude?’: ‘The speaker, Saifuddin, Rohingyas’, ‘4. Target’: ‘Myanmar and Bangladesh, Rohingya refugees, Return home with facilities and humane treatment, Burmese government’, ‘5. Valence’: ‘Sympathetic.’}
这引导我们得到最终提示,适用于整个语料库:
"Read this passage from a news article ### ' + str(excerpt) + ' ### If relevant, give the theme of
this SPECIFIC passage as it embodies, relates to, or reflects attitudes towards refugees in Malaysia.
The following summary of the excerpted article may provide context for the passage (e.g. who is being
discussed and where events are occurring): ### ' + str(summary) + ' ### Here is an overview of how
several passages similar to this one have been coded: ### ' + str(relevant) + ' ### DO NOT copy this
coding verbatim, but use it as reference and be careful if only some or none of the similar passages
were deemed relevant. Before answering, analyze step by step: 1. in 12 words or less, return the theme
(if relevant) as it relates to attitudes towards refugees in Malaysia, or return None. Do not give a
generic theme like "attitudes towards refugees in Malaysia", but provide a specific single theme. If
irrelevant, return None for all further questions. If relevant, 2. Whose attitudes are being reflected?
Examples: the government, Malaysians, NGOs, the author. 3. Who is the target of the attitudes?
Examples: the Rohingya, the government, UNHCR. 4. What is the valence of attitudes towards the target,
if any?: "Sympathetic.", "Hostile.", or "N/A". Once again, the passage to code is ### ' +
str(excerpt)+ ' ### Finally, Respond ONLY in the following python dictionary format: ("1. Theme":
None/stringval1, "2. Whose Attitude?":None/stringval2,"3. Target":None/stringval3, 4. Valence":
"Sympathetic."/"Hostile."/"N/A")'
以下是该提示的输出示例,使用的是与AI编码I中相同的段落:
[“1. 主题”: “突出过去接纳难民的努力”, “2. 谁的态度?”: “马来西亚,与其他许多国家共同”, “3. 目标”: “波斯尼亚难民”, “4. 倾向”: “同情”]
编码审查II
然后我们要求评审员评估新代码,同时保持审查段落样本不变。以下是提供给评审员的提示复制品:
再次提醒一下AI编码任务:
研究问题(RQ):
研究马来西亚新闻媒体中对马来西亚难民的态度 OR
这篇文章是否有对难民的态度
使用了相同的文章,但摘录长度不同,与之前的版本相比。排除了低于100或150个字符的摘录。——澄清一下:它们被删除了,因为在第一次尝试中出现了无关段落的问题,我们从考虑中删除了一些段落。这些包括明显无关的话题,如订阅请求,以及所有少于100个字符的段落。
现在,编码分为4个类别:
- 主题
- 谁对难民的态度
- 这种态度的目标是谁
- 倾向:敌对/同情
第二至第四类是为了帮助评估主题是否准确
你会发现有些摘录没有编码,这是因为我们上次已经将其标记为无关
列
- 评估(强烈不同意、不同意、不确定、同意、强烈同意) - 评估你同意的程度
- 相关(是=1, 否=0) - 这个摘录应该被编码吗?这个摘录是否与RQ相关?
- 无关代码(是=1, 否=0) - 这个代码是否与RQ无关?
- 评论 - 你的任何想法
在附录A中提供了澄清内容。
在评审员独立评估ChatGPT编码完成后,我们召开了第二轮讨论会。我们比较和对比了评审员的评估结果:1)识别评审员一致同意(评为“同意”或“强烈同意”)的段落,2)识别评审员一致不同意(评为“不同意”或“强烈不同意”)的段落,3)突出至少一名评审员评估结果与其他评审员不同的段落。在与评审员的讨论中,我们回顾了他们一致不同意的代码,以了解原因,并随后识别可能进一步完善给予ChatGPT指令的行动。我们还审查了评审员之间存在分歧的代码,并要求每位评审员解释他们如何得出对该代码的评估。在此讨论期间,每位评审员描述了他们对代码的解释、提供评估的基础以及他们在审查代码及其附带段落时的不确定性。评审员还讨论了他们对ChatGPT编码能力的期望、关键术语和短语的定义以及其他对编码的担忧。讨论还得到了评审员在整个评估过程中更新的日记的支持。我们主持了这一讨论并解决了代码评估中的所有分歧。
达成代码评估的一致意见后,我们召集了进一步的讨论,评审员们讨论了他们对GPT编码为相关或无关的段落的评估。随后,我们要求他们完成两项步骤的最终任务:首先,评估每个“无关”段落是否显然无关而不参考其来源文章,然后在摘录文章的上下文中审查至少一位评审员认为不显然无关的段落。第一步的指示如下:
大家好,我们决定需要另一轮审查! 具体来说,就是那些被编码为无关的段落实际上是否无关。首先,我们希望你能选择
判断153个编码为“None”的段落是否显然与研究问题无关,即:对马来西亚难民的态度。
这次,我们希望你仅根据段落文本进行评估。如果无论文章提供的背景如何,这段话都不应被编码,请在“Obvious that this text should not be coded (T/F)”列中选择True
如果显然是相关的或者可能相关取决于背景(例如有一个代词,而该人的身份可能使其相关),请选择False
对于至少有一位评审员认为可能是相关的9个段落,指示如下:
你们能否逐一查看这9个段落,并在总结和整篇文章的背景下,评估每个段落是否本身与对难民的态度相关?
以强烈同意到强烈不同意的方式来回答这个问题。
结果
尽管方法论略显复杂,但结果可以相当简单地表述。对于第一轮编码,由于对GPT认为“无关”的段落评估存在误解,导致这些审查结果无法使用,但我们仍展示以下共识率,我们将其定义为样本子集中至少两名评审员同意或强烈同意GPT编码的段落比例。这是模型的精确度 7 { }^{7} 7。
| 结果 | 共识率 | 95% 置信区间(Clopper-Pearson) |
|---|---|---|
| 精确度 | 0.4961 | ( 0.4468 , 0.5455 ) (0.4468,0.5455) (0.4468,0.5455) |
表2:第一轮编码模型性能。
此处的结果不尽如人意。不到一半的代码被认为合理。
我们还通过Kendall’s Tau-b计算了评分者间可靠性(IRR),同样仅针对被认为相关的段落。结果显示第一阶段的共识非常有限。
表3:首次编码评分者间可靠性
对于最后一轮编码,我们提供了共识率的五个关键统计数据:准确率
8
{ }^{8}
8,这是整个样本的共识率,不论GPT的编码决策如何;精确度,样本中GPT提供编码的部分的共识率;召回率
9
{ }^{9}
9,样本中有共识的相关段落和GPT也将段落编码为相关的比例;
F
1
F_{1}
F1 分数
10
{ }^{10}
10,精确度和召回率的调和平均值;负预测值
11
{ }^{11}
11,样本中GPT认为段落无关的部分的共识率。
| 结果 | 值 | 95% 置信区间(Clopper-Pearson) |
|---|---|---|
| 准确率 | 0.8116 | ( 0.7729 , 0.8478 ) (0.7729,0.8478) (0.7729,0.8478) |
| F 1 F_{1} F1 分数 | 0.8248 | ( 0.7854 , 0.8622 ) (0.7854,0.8622) (0.7854,0.8622) |
表4:最终编码模型性能
F
1
F_{1}
F1 分数是分类模型预测能力的常用度量标准,82% 的分数表明此方法生成的输出(代码或“无关”分类)在大多数情况下被人工评审员认为合理。精确度值显示了模型的不足之处:大约30%的代码没有得到共识支持。召回率和负预测值展示了模型的优势:识别无关段落。假阴性非常少,导致这些度量几乎无误。这并不令人惊讶:为了成功生成一个真阴性,我们的模型只需要正确评估相关性。为了成功生成一个真阳性,模型需要既评估相关性,又提供一个特定代码,这是一个更困难的任务。附录A提供了更多关于模型性能的分析。
我们再次通过Kendall’s Tau-b测量IRR。在这里,我们看到相对于第一轮有显著的共识增加。一个主要原因是,我们包含了整个数据集,而不仅仅是GPT认为相关的段落。不出所料,正如分配一个好的代码比识别一个无关段落更难一样,就什么是好的代码达成一致也比同意一个段落无关更难。因此,对于被认为无关的段落,共识几乎是普遍的,但对于已编码的段落,共识较低。即便如此,与第一轮相比,我们在已编码段落中仍然看到了明显的共识增加。这可能的一个原因是在最后一轮中,评审员明确地根据共识构建讨论重新评估每个代码。这表明,为第一个版本的模型测量的精确度可能不如为最终版本的模型测量的精确度可信。
| 结果 | Kendall’s Tau-b (所有 编码) | Kendall’s Tau-b (GPT 编码 相关) | p值(四舍五入值在两种情况下相同) |
|---|---|---|---|
| 评分员1&2 | 0.950 | 0.917 | 0.000 |
| 评分员2&3 | 0.780 | 0.519 | 0.000 |
| 评分员1&3 | 0.763 | 0.473 | 0.000 |
表5:最终编码评分者间可靠性
讨论
在这种我们提出的新型AI编码方法中,重要的是要注意(人类)评审员在此过程中的角色和贡献。尽管我们最初将评审员的角色视为仅仅是AI编码的客观评估者和验证者,但我们很快意识到,我们与评审员之间的讨论导致了AI编码过程的重大变化和编码性能的改进。实际上,在我们的方法中,ChatGPT执行的编码在很大程度上是由人类指导的。包括评审员对ChatGPT编码的反馈,以及为解决评审员之间对ChatGPT如何编码提供的段落存在分歧的多次讨论中的见解,使我们能够采用一种迭代的编码方法,类似于多个进行编码框架工作的编码员之间的典型过程,其中持续的讨论会导致修订、重新解释和重新定义代码和术语,直到达成共识并可以将最终的编码框架应用于其余数据。令我们非常感兴趣的是,在解决编码评估分歧的讨论中,一位或多为评审员经常“捍卫”ChatGPT执行的编码,有效地赋予ChatGPT在与其他(人类)评审员讨论中的“声音”。然而,需要注意的是,使用这种“人类指导”的AI编码方法需要大量的工作与(人类)评审员合作,此外还需要准备AI进行编码所需的工作。从评审员的日记中我们注意到,整个过程中,评审员在评估ChatGPT的编码时感到不确定,并且在必须阐述和辩护他们的评级方法以与其它评审员达成共识时感到不适。评审员还努力进行来回讨论,以达成对关键术语的共同理解,并在他们之间标准化共同的评级方法。这表明给我们,
评审员必须提前准备好信任这一迭代过程,并预期在开发出最终方法之前,他们需要在一定程度的不确定性下完成任务。
附录
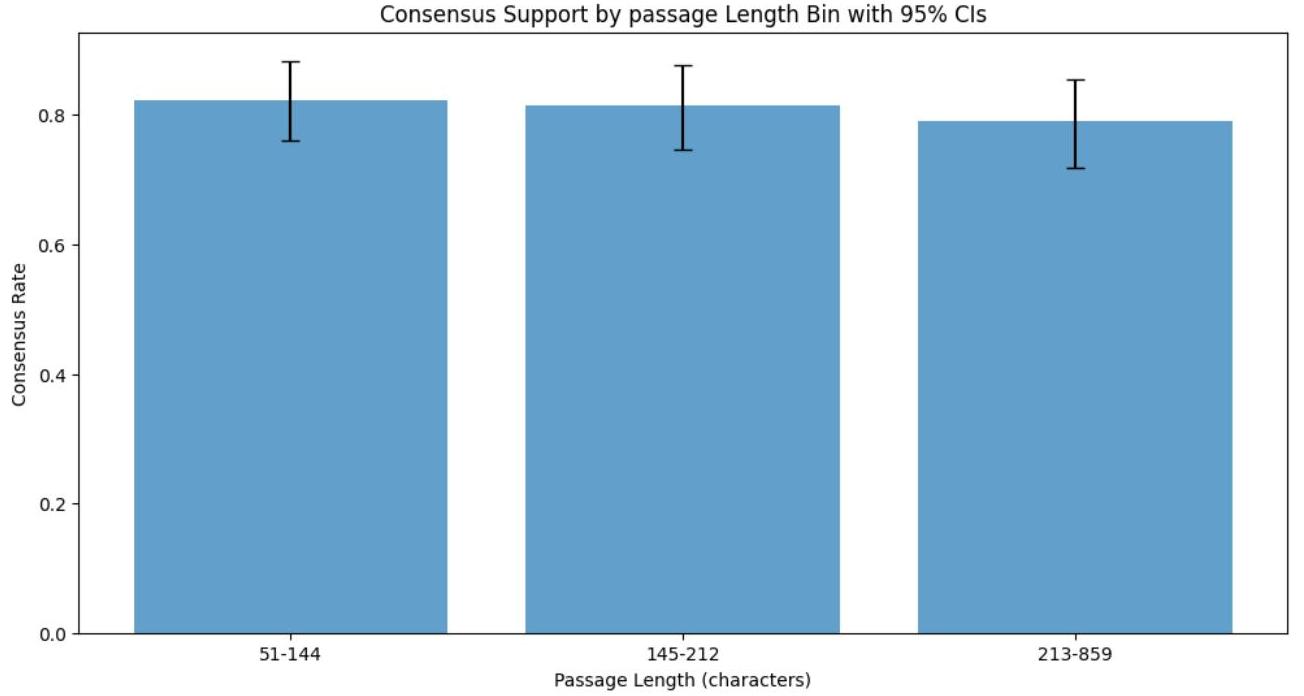
图A1:按文档长度分组的第二轮共识支持率及95%置信区间
图A1按段落长度分解了第二轮共识率。有人可能会预期,由于缺乏上下文,较短的段落表现会较差,或者由于可能存在多个代码或大型文档中的注意力问题,较长的段落表现会较差。然而,尽管段落长度范围广泛,我们并未发现明显差异。
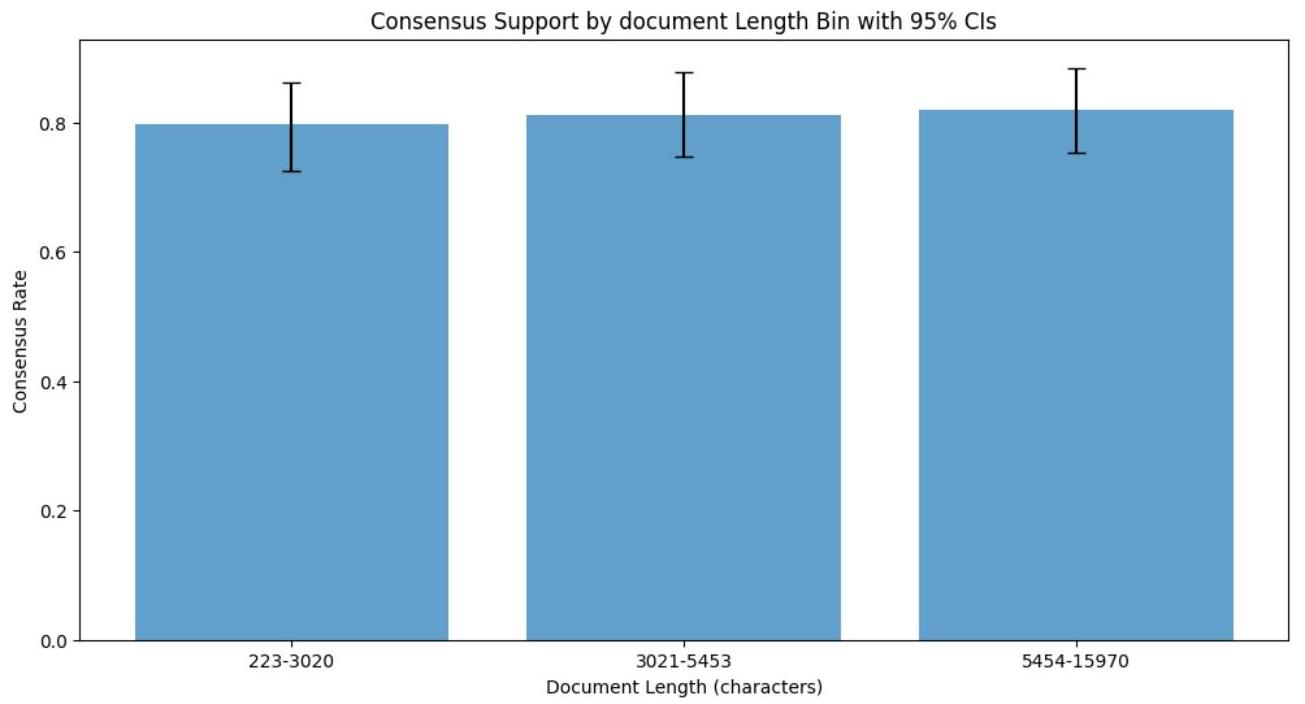
图A2:按摘要长度分组的支持率大于1的比例及95%置信区间
图A1按文档长度分解了第二轮共识率。有人可能会预期,较长的文档编码难度更大,因为段落外会有更多的上下文,而简短的摘要无法充分捕捉额外的上下文。然而,尽管文档长度范围广泛,我们并未发现明显差异。
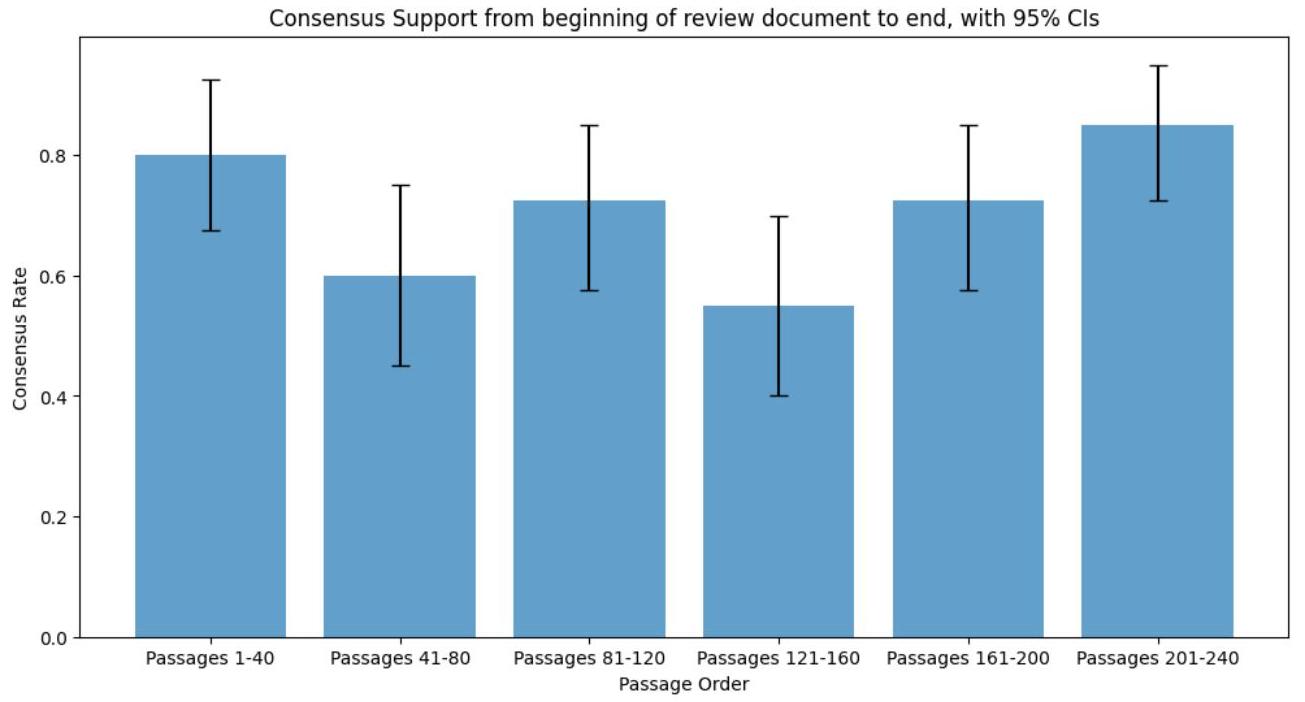
图A3:从审查文档开头到结尾的共识支持情况,带有95%置信区间
图A1按审查文档分解了第二轮共识率。所有评审员都获得了包含相同顺序编码段落的同一文档。假设他们自上而下工作,评审员可能预计在整个过程中改变评估。虽然我们在各组中看到一些变化,但似乎没有明确趋势。这可能是由于评审员已经完成了一次过程,因此其审查过程已经稳定。值得注意的是,为了便于编码,段落在审查文档中按聚类分组。因此,段落的顺序是非随机的,共识率的系统性变化不一定意味着评审员标准的变化。
参考文献
Fryer, Tom. “批判现实主义主题分析方法:产生因果解释.” 《批判现实主义期刊》21, no. 4 (2022): 365-384.
Boyatzis, R. E. (1998). 定性信息的转化:主题分析和代码开发. Sage Publications, Inc.
Braun, Virginia, and Victoria Clarke. “心理学中使用主题分析.” 《定性心理学研究》3, no. 2 (2006): 77-101.
Clarke, Victoria, and Virginia Braun. “主题分析.” 《积极心理学期刊》12, no. 3 (2017): 297-298.
Christodoulou, Michalis. “主题分析的四个C模型. 批判现实主义视角.” 《批判现实主义期刊》23, no. 1 (2024): 33-52.
Morgan, David L. “探索人工智能在定性数据分析中的应用:ChatGPT案例.” 《国际定性方法杂志》22 (2023): 16094069231211248.
Dai, Shih-Chieh, Aiping Xiong, and Lun-Wei Ku. “LLM-in-the-loop: 利用大型语言模型进行主题分析.” arXiv预印本 arXiv:2310.15100 (2023).
Dawborn-Gundlach, Merryn, and Jenny Pesina. “使用多样且互补的方法进行定性数据分析的主题分析.” 在当代数学、科学、健康和环境教育研究研讨会论文集中. 迪肯大学, 2015.
Chew, Robert, John Bollenbacher, Michael Wenger, Jessica Speer, and Annice Kim. “LLM辅助内容分析:使用大型语言模型支持演绎编码.” arXiv预印本 arXiv:2306.14924 (2023).
De Paoli, Stefano, and Walter S. Mathis. “反思归纳主题饱和作为衡量使用LLMs进行归纳主题分析有效性的潜在指标.” 《质量与数量》(2024): 1-27.
Turobov, Aleksei, Diane Coyle, and Verity Harding. “使用ChatGPT进行主题分析.” arXiv预印本 arXiv:2405.08828 (2024).
De Paoli, Stefano. “使用大型语言模型进行半结构化访谈的归纳主题分析:对这种方法局限性的探讨与挑战.” 《社会科学计算机评论》42, no. 4 (2024): 997-1019.
参考论文:https://arxiv.org/pdf/2504.07408
8 { }^{8} 8 准确率 = (True Positives + True Negatives)/(True Positives + True Negatives + False Negatives + False Positives),我们将评审员共识视为真实标签。
9 { }^{9} 9 召回率=True Positives/(True Positives + False Negatives),我们将评审员共识视为真实标签。
10 F 1 { }^{10} \mathrm{~F}_{1} 10 F1 分数=2/((1/Recall)+(1/Precision)).
11 { }^{11} 11 负预测------
值=True Negatives/(True Negatives + False Negatives),我们将评审员共识视为真实标签。
| 精确度 | 0.7192 | ( 0.6654 , 0.7731 ) (0.6654,0.7731) (0.6654,0.7731) |
| :-- | :-- | :-- |
| 召回率 | 0.9738 | ( 0.9476 , 0.9948 ) (0.9476,0.9948) (0.9476,0.9948) |
| 负预测值 | 0.9675 | ( 0.9351 , 0.9935 ) (0.9351,0.9935) (0.9351,0.9935) | ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











