






周英杰
1
{ }^{1}
1, 曹捷章
2
{ }^{2}
2, 张子成
1
{ }^{1}
1, 温法荣
1
{ }^{1}
1, 蒋彦伟
1
{ }^{1}
1, 贾军
1
{ }^{1}
1, 刘晓红
1
{ }^{1}
1, 民雄阔
1
{ }^{1}
1, 翟光涛
1
{ }^{1}
1
1
{ }^{1}
1 上海交通大学,
2
{ }^{2}
2 哈佛医学院
摘要
图像修复(IR)在现实场景中通常面临各种复杂且未知的退化问题,例如噪声、模糊、压缩伪影和低分辨率等。为特定退化训练特定模型可能导致泛化能力较差。为了同时处理多种退化,All-in-One模型可能会在某些类型的退化上牺牲性能,并且在训练过程中仍难以应对未见过的退化。现有的IR代理依赖于多模态大语言模型(MLLM)和耗时的回滚选择策略,忽视了图像质量。因此,它们可能误判退化,并以冗余顺序进行不必要的IR任务,导致高时间和计算成本。为了解决这些问题,我们提出了一种基于链式思维(CoT)修复的质量驱动代理(Q-Agent)。具体来说,我们的Q-Agent包括鲁棒退化感知和质量驱动的贪婪修复两部分。前者首先微调MLLM,并使用CoT将多退化感知分解为单退化感知任务,以增强MLLM的感知能力。后者则使用客观图像质量评估(IQA)指标来确定最佳修复顺序并执行相应的修复算法。实验结果表明,我们的Q-Agent在修复性能上优于现有的All-in-One模型。
1. 引言
图像修复(IR)旨在恢复失真图像并提升视觉质量。多年来,任务特定的IR方法
[
3
,
47
,
53
,
64
]
[3,47,53,64]
[3,47,53,64] 解决了特定类型的IR问题。然而,这些方法在应对现实世界中的失真时往往具有较差的泛化能力。为了解决这一问题,All-in-One IR框架在一个统一的方法中恢复多种类型的退化。虽然这些方法提高了泛化能力,但研究表明
[
4
,
48
]
[4,48]
[4,48] 它们在有效性和灵活性方面通常不如任务特定模型。

图1. Q-Agent设计动机。现有的MLLMs和图像处理工具为实现多退化图像修复提供了新的解决方案。
因此,在IR中平衡有效性和泛化性仍然是一个关键且持续的研究挑战。
多模态大语言模型(MLLMs)的兴起为IR带来了新的机会,因为这些模型在多任务调度和处理方面表现出强大的能力,如图1所示。然而,MLLMs仍然存在幻觉 [13] 的问题,这会降低其输出的可靠性。这个问题在低级视觉感知任务中尤为关键,因为错误的退化感知会直接误导后续的图像增强和处理。正如Zhang等人 [58] 所指出的,MLLMs在准确感知退化图像方面存在局限性,尤其是在存在多种退化类型时。这为基于MLLMs的IR代理设计提出了重大挑战。此外,确定最佳IR顺序仍然是一个关键问题。尽管Chen等人 [4] 提出了一种基于回滚的方法来建立修复顺序,但随着退化类型数量的增加,其计算复杂度显著增加,导致效率低下和可扩展性受限。因此,开发一种更高效的修复顺序选择方法仍然是一个挑战。
为了解决上述挑战,我们提出了Q-Agent,这是一种质量驱动的IR代理,集成了鲁棒退化感知与质量驱动的贪婪修复,实现了更加智能和交互式的端到端修复过程。为了增强MLLMs的退化感知能力,我们构建了Q-Degrade,这是一个包含八种不同退化程度及退化引入顺序的大规模数据集。通过结合微调技术和链式思维(CoT) [45] 推理,我们使MLLMs能够对多种退化类型进行更鲁棒和准确的感知。此外,我们引入了五种无参考(NR)图像质量评估指标和不同的IR算法,作为Q-Agent的核心工具。为了优化修复顺序,我们提出了一种质量驱动的贪婪算法,该算法利用客观的NR质量评估指标迭代选择能最大化质量改进的修复步骤。这种方法确保了最佳的修复顺序,显著减少了回滚方法的计算开销。实验结果表明,Q-Agent在修复性能上超过了现有的All-in-One方法,同时保持了高度的灵活性和可扩展性。总之,本文的主要贡献如下:
- 我们提出了一种基于CoT的鲁棒退化感知方法。它将多退化感知问题分解为多个单独的退化感知子问题,从而使我们的MLLM比现有IR代理获得更好的感知能力。
- 我们提出了一种质量驱动的贪婪策略,通过测量图像质量来指导贪婪修复顺序的确定,有效地避免了回滚次数,提高了框架的计算效率和可扩展性。重要的是,我们的算法具有线性时间复杂度,远低于现有IR代理的复杂度。
- 我们的Q-Agent在性能上达到最优,并且相比现有的All-in-One模型具有高度的灵活性和可扩展性,预计可以扩展为更强大和全面的IR代理。
2. 相关工作
图像修复。图像常常受到诸如噪声、模糊、JPEG压缩伪影、低光照和低分辨率等退化的影响。为了保留图像质量,针对常用数据集上的退化图像进行针对性修复是至关重要的
[
1
,
10
,
22
,
25
,
31
,
34
,
42
,
49
]
[1,10,22,25,31,34,42,49]
[1,10,22,25,31,34,42,49]。然而,这些数据集在规模和失真多样性方面仍然有限,从而限制了其在真实场景中建模退化的能力。为缓解这些限制,我们引入了Q-Degrade,这是一个包含100,000
张退化图像的大规模图像退化数据集,旨在推动该领域的研究。
IR方法的演变可以分为两种范式:任务特定 [3, 47, 53, 64] 和All-in-One模型 [7, 14, 15, 17, 20, 29, 40, 43]。任务特定模型旨在有效恢复受特定类型退化影响的图像;然而,它们在同时处理多种退化类型时表现出明显的局限性。相比之下,All-in-One模型采用统一架构,能够在单一框架内处理多种退化。虽然这种方法增强了泛化能力,但通常会以修复性能为代价。为了在修复效果和泛化能力之间取得平衡,本文提出了一种基于MLLMs的新型修复框架Q-Agent。Q-Agent利用MLLMs的感知能力以All-in-One的方式全面评估图像退化。通过智能选择和顺序应用适当的IR工具,Q-Agent增强了退化图像的视觉质量,为IR提供了一个更适应和有效的解决方案。
图像质量评估(IQA)。IQA旨在评估图像的视觉质量和IR方法的有效性。一般来说,IQA可以分为主观和客观质量评估两类。主观质量评估涉及人类观察者根据视觉感知评估图像质量,提供对人类视觉最准确的反映。然而,这种方法在实际应用中受到高成本和耗时的限制,需要招募参与者和控制实验条件。相反,客观质量评估使用算法来估计图像质量,使其更具实践性和广泛采用。客观IQA方法进一步分为全参考(FR) [57]、减少参考(RR) [59] 和无参考(NR) [61, 63] 方法。FR IQA指标,如PSNR、SSIM [44] 和LPIPS [54],通过比较退化或恢复的图像与其原始图像来评估图像质量。相比之下,NR IQA指标(如BRISQUE [23]、NIQE [24] 和CPBD [26])仅从退化图像中估计图像质量,而无需参考图像。RR IQA方法作为中间方法,利用参考图像的部分信息来促进质量评估。
在IR领域,FR IQA指标是最广泛使用的,因为它通过计算原始图像和恢复图像之间的差异,直接且可量化地测量恢复效果。然而,在许多实际应用中,高质量的参考图像往往不可用,使得FR IQA方法不切实际。在这种情况下,NR IQA方法提供了一个更灵活和可扩展的解决方案,能够在不依赖参考图像的情况下实现高效和自主的IQA。
3. 数据集构建
3.1. 源图像收集
为了确保最高质量和最多样化的图像数据集,我们从Laion-HighResolution数据集 [33] 中选择了12,225张图像作为源图像。选择涵盖了广泛的类别,包括现实照片和计算机生成的图像。在内容方面,数据集包括各种主题,如人物、场景、物体、艺术绘画和广告。为了更直观地表示这种多样性,我们在补充材料中包含了所选图像子集的可视化。
3.2. 多重退化模拟
本研究选择了八种常见的退化类型:噪声、运动模糊、失焦模糊、JPEG压缩伪影、低光、低分辨率、雾和雨。这些退化通过计算方法进行模拟,各自的参数得到精心控制。补充材料中提供了退化模拟的详细描述。虽然单独的退化类型可以指导IR算法的发展,但这些模型往往过于简单。在现实场景中,图像通常受到多种退化类型的综合影响,导致更复杂和集成的图像失真形式。为了更好地模拟这些现实条件,Q-Degrade数据集通过随机应用多达四种退化类型(从上述八种中选择)到源图像来构建。这种方法旨在模仿实践中通常遇到的多重并发退化。值得注意的是,与先前的工作 [4, 55, 56] 不同,选定的退化类型是按照特定顺序应用的,这一决定基于两个因素:1)尽管退化顺序在图像中无法直接观察到,但它在整个图像退化过程中客观存在;2)如图2所示,退化应用顺序显著影响最终图像的视觉效果。因此,退化顺序在数据集构建过程中是一个重要因素。考虑到各种因素,每张源图像经历十种不同的退化实例,退化的类型、严重程度和应用顺序各不相同。此过程产生了总计125,550张退化图像。经过人工检查后,移除了包括过度退化图像和包含敏感内容的图像在内的极端案例。最终版本的QDegrade数据集由100,000张退化图像组成。
4. Q-Agent用于CoT修复
高计算复杂度是现有修复代理 [4] 的一个严重挑战,特别是在多重退化图像修复的顺序确定方面,这限制了进一步扩展和优化。在本文中,我们通过CoT [45] 提出了一个新的修复代理(称为Q-Agent),其框架如图3所示。我们的QAgent包含两个模块:一个鲁棒退化感知模块和一个质量驱动的贪婪修复模块。前者结合微调和CoT [45] 技术,增强MLLM对多重退化的感知以制定准确的修复任务。后者则实现基于图像质量的最优修复顺序和IR的确定。
4.1. 鲁棒退化感知
可以直接在代理中应用MLLM进行多重退化的IR任务。然而,由于MLLM在退化预测方面存在固有限制,这可能导致不可避免的问题。MLLM可能会导致错误的退化感知,并进一步获得误导性的多重单一IR任务序列。如图4所示,Zhang等人 [46] 提出的Q-Bench为比较各种MLLM [5, 6, 8, 11, 16, 18, 50, 65] 的退化感知能力提供了一个基准,从中可以看出大多数MLLM在处理与图像退化相关问题方面的表现远远不能满足准确进行多重退化感知的要求。
图像退化感知涉及识别退化图像中的各种退化类型及其各自的程度,这对准确和高效的IR至关重要。为了提高MLLM对多重退化图像的感知能力,我们首先使用低秩自适应(LoRA) [12] 对MLLM进行微调。
此外,我们使用CoT [45] 将复杂的多重退化感知任务分解为简单的“是”或“否”问题,针对各个退化类型逐一提问。具体来说,MLLM会被依次问到“这张图像中是否存在
<
<
< dis
>
>
>?”,其中
<
<
< dis
>
>
>表示各种退化类型。特别是,当
<
<
< dis
>
>
>为“噪声”且回答为“是”时,MLLM会被进一步询问以确定退化的程度,请求为“这张图像中存在的噪声强度是多少:A. 低 B. 中 C.
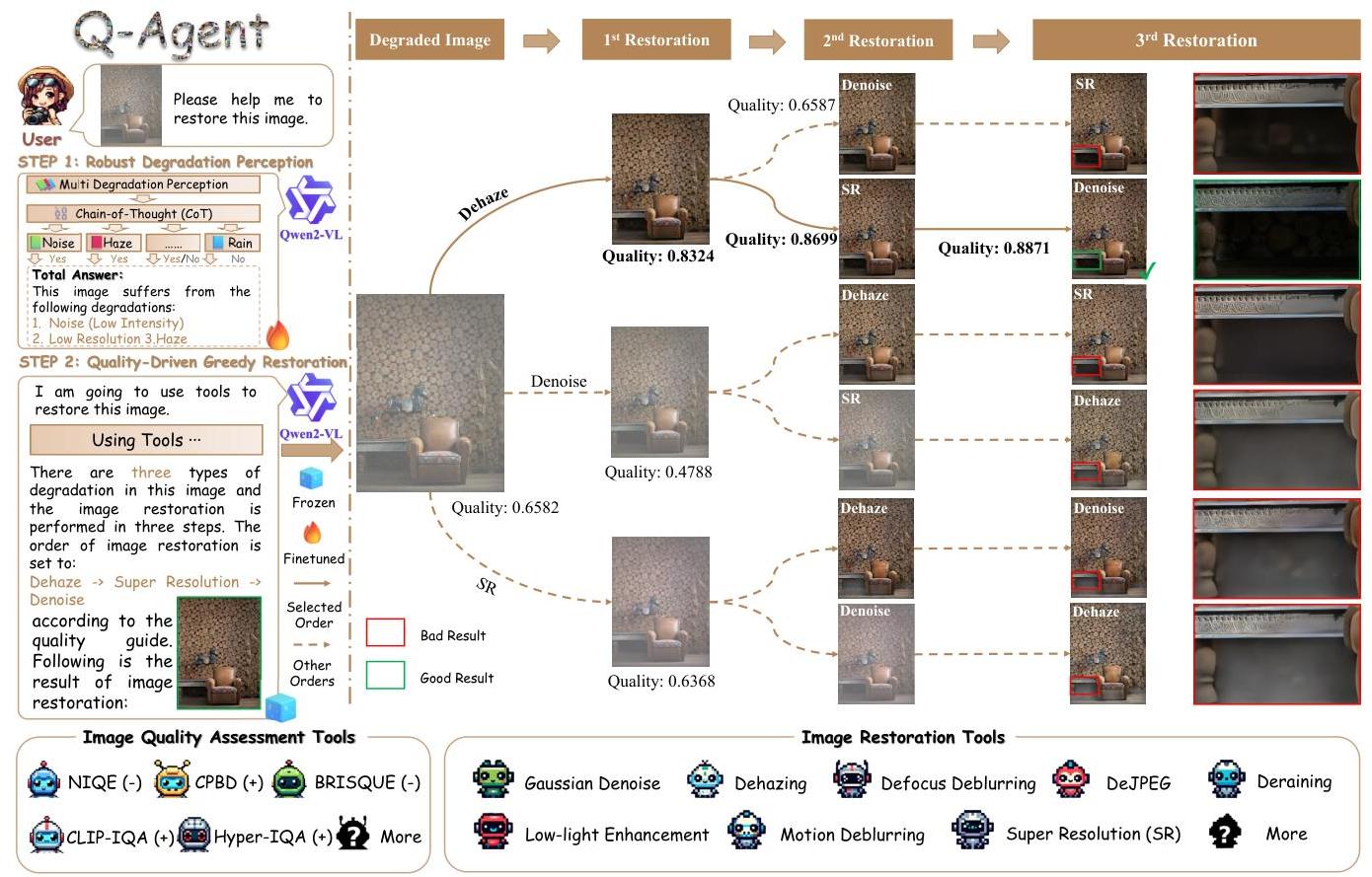
图3. Q-Agent框架,基于Qwen2-VL [41],通过使用各种图像质量评估工具和图像修复工具实现端到端图像修复。IQA工具的加号和减号表示预测值与图像质量之间的相关性。可以集成更多工具以进一步增强Q-Agent的图像修复能力。
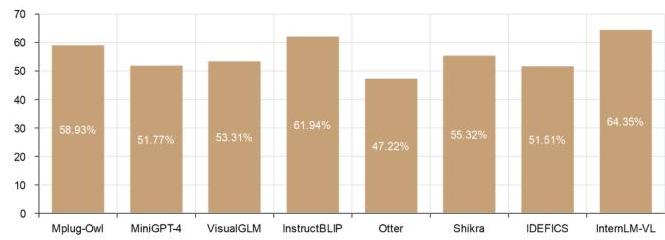
图4. MLLMs在Q-Bench上的退化感知准确性。
高。” 当所有退化类型都被提问后,回答“是”的退化类型被用作结果,以开发后续的修复任务。
4.2. 质量驱动的贪婪修复
在现实场景中,图像通常遭受多重退化。以不同顺序去除这些退化显著影响恢复图像的质量。因此,设计一个最优的修复顺序是开发IR代理的关键挑战。现有的基于回滚 [4] 和强化学习(RL)
[
4
,
27
,
30
]
[4,27,30]
[4,27,30] 的代理方法可能导致高计算成本。RestoreAgent [4] 使用回滚操作来识别最优的修复顺序。然而,图5揭示了这一点
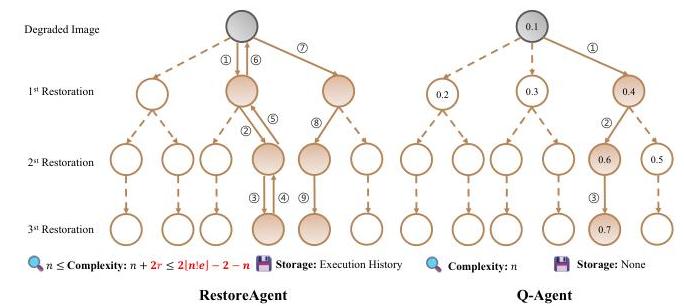
图5. Q-Agent的优势。假设恢复阶段和回滚的数量分别为
n
n
n和
r
r
r。RestoreAgent的最坏情况复杂度,如补充材料中所述,突显了处理更多退化时的局限性。
这种方法带来了显著的计算和存储开销。与基于RL的代理不同,我们旨在设计一种不需要额外训练的代理。在本文中,我们通过采用质量驱动的贪婪策略来选择修复顺序提出了Q-Agent。
质量驱动的贪婪策略。具体来说,该方法整合了IQA和IR工具。在每个步骤中,IR首先将所有可能的修复操作应用于当前图像,然后使用IQA方法评估修复结果。选择产生最高图像质量的修复操作作为下一步,并更新当前图像以准备下一次迭代。如图6所示,该方法定义了两个终止条件:1)MLLM感知的所有图像退化已通过相应的IR工具恢复;2)在后续迭代中没有进一步的修复操作能改善图像质量。满足任一条件的图像将返回给用户。
图像质量引导。客观IQA是Q-Agent的一个关键组成部分,因为它为恢复的图像提供了质量反馈,从而以系统和知情的方式引导IR过程。与需要真实图像作为参考的参考基IQA指标(如PSNR、SSIM [44] 和LPIPS [54])不同,非参考(NR)IQA方法在代理中得以应用,使整个恢复过程中能够预测和监控图像质量。为了确保全面和准确的客观IQA,我们考虑了5个代表性的NR方法。具体来说,NIQE [24] 主要关注图像的自然场景统计特征,BRISQUE [23] 整合了照明和结构信息,而CPBD [26] 广泛用于评估模糊和压缩伪影下的图像质量。此外,CLIP-IQA [39] 强调图像的语义信息,而Hyper-IQA [35] 能够检测局部失真。我们将这些指标分别表示为 v = [ n i , b r , c p , c l , h y ] v=[n i, b r, c p, c l, h y] v=[ni,br,cp,cl,hy]。整体图像质量可以定义为所有图像质量的平均值:
Quality = c p + c l + h y − n i − b r 5 \text { Quality }=\frac{c p+c l+h y-n i-b r}{5} Quality =5cp+cl+hy−ni−br
更高的Quality值表示更好的图像质量。在恢复过程的每个阶段,选择Quality最高的顺序作为最优操作。
自主IR模型选择。质量驱动的贪婪修复同样为IR模型选择提供了一个自主解决方案。在每次恢复中,不同的IR模型也被比较,最终选择的目标是最大化质量增益。经过统计分析,最常使用的各种IR模型列于表1。在这里,我们考虑了现实场景中的8种典型图像退化:高斯噪声、JPEG压缩伪影、雨水、雾霾、运动模糊、失焦模糊、低光照和低分辨率。可以从表1中得出几个观察结果:1)对于高斯噪声,我们根据退化程度将其分为三类,并选择去噪算法
表1. Q-Agent最常用的IR工具。
| 任务 | 标签 | IR工具 | 预训练数据集 |
|---|---|---|---|
| 高斯去噪 | DN | SCUNet (低强度) [53] | KodaK24 [10] |
| SCUNet (中等强度) [53] | KodaK24 [10] | ||
| SCUNet (高强度) [53] | KodaK24 [10] | ||
| DeJPEG | DJ | Restormer [51] | BSDSS00 [2] |
| 去雨 | DR | Rain100 [49] | |
| 去雾 | DH | RIDCP [47] | RIDCPS00 [47] |
| 运动去模糊 | MDR | AdaRecl2 [21] | GoPet [25] |
| 失焦去模糊 | DDR | DRBNet [32] | DPDD [1] |
| 低光增强 | LE | Retinexformer [3] | SDSD-indoor [42] |
| 超分辨率 | SR | BSRGAN [52] | RealSRSet [52] |
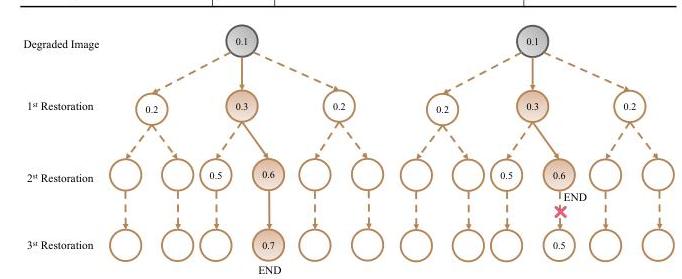
图6. 质量驱动的贪婪修复策略的终止条件。
采用不同程度的降噪去除以优化恢复;2)除DeJPEG和去雨外,QAgent充分利用了任务特定模型,突显了任务特定模型在特定退化恢复中的有效性;3)所有使用的IR模型都在其各自的数据集上进行了预训练,强调了Q-Agent对未来扩展和适应新任务的可扩展性。
5. 实验
5.1. 实验设置和标准
在本节中,我们展示了一系列全面的实验,以评估所提出的Q-Agent框架的有效性和鲁棒性。具体来说,实验旨在评估Q-Agent的退化感知能力和IR有效性。为了确保公平比较,本文提出的大型IR数据集Q-Degrade按8:2的比例分为训练集和测试集,两组之间没有内容重叠。训练集用于微调Qwen2-VL-7B-Instruct [41],该模型在Q-Agent中用于退化感知,而所有实验评估均在测试集上进行。Q-Agent中使用的所有IR工具都列在补充材料中。实验在配备 8 × 8 \times 8× A100 GPU的服务器上进行,以促进高效处理。
为了评估Q-Agent性能的各个方面,开发并采用了多种指标。对于基于MLLM的退化感知,我们首先引入了两个向量:退化向量
D
D
D和感知向量
D
ˉ
\bar{D}
Dˉ。这两个向量都是10维二进制向量,每个元素表示特定类型退化的存在与否。
表2. 不同MLLM在Q-Degrade数据集上的退化感知准确性,其中NI-L, NI-M, NI-H, IP, RA, HA, MB, DB, LL, LR分别表示低噪声、中等噪声、高噪声、JPEG压缩伪影、雨水、雾霾、运动模糊、失焦模糊、低光照、低分辨率。最佳值用红色标注,次优值用蓝色标注。
| MLLM | D A C C D A C C DACC | M A C C M A C C MACC | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NI-L | NI-M | NI-H | JP | RA | HA | MB | DB | LL | LR | All | ||
| Zero-shot | ||||||||||||
| GPT-4o [28] | 0.8521 | 0.7232 | 0.8854 | 0.7540 | 0.8090 | 0.7895 | 0.8303 | 0.8522 | 0.7980 | 0.8497 | 0.0052 | |
| Gemini-1.5-Pro [36] | 0.8208 | 0.7796 | 0.7570 | 0.6306 | 0.9252 | 0.3908 | 0.9070 | 0.8455 | 0.6047 | 0.5237 | 0.0424 | |
| Llava-Llama3-8B (In RestoreAgent) [19, 37] | 0.0030 | 0.0125 | 0.0753 | 0.0131 | 0.7045 | 0.0414 | 0.8238 | 0.8236 | 0.0000 | 0.0000 | 0.0701 | |
| Qwen2-VL-7B-Instruct (In Q-Agent) [41] | 0.7542 | 0.7233 | 0.7446 | 0.5056 | 0.8263 | 0.3772 | 0.7675 | 0.7989 | 0.3417 | 0.2049 | 0.1053 | |
| Zero-shot + CoT | ||||||||||||
| GPT-4o [28] | 0.8742 | 0.7366 | 0.8890 | 0.8199 | 0.8021 | 0.8265 | 0.8974 | 0.9092 | 0.7889 | 0.8022 | 0.5868 | |
| Gemini-1.5-Pro [36] | 0.8444 | 0.7535 | 0.8562 | 0.7481 | 0.9243 | 0.7978 | 0.9232 | 0.8998 | 0.8549 | 0.7690 | 0.5593 | |
| Llava-Llama3-8B (In RestoreAgent) [19, 37] | 0.6323 | 0.5989 | 0.5577 | 0.6834 | 0.8144 | 0.5206 | 0.7890 | 0.8389 | 0.5047 | 0.4683 | 0.4779 | |
| Qwen2-VL-7B-Instruct (In Q-Agent) [41] | 0.9097 | 0.7478 | 0.8022 | 0.7978 | 0.8790 | 0.8464 | 0.8829 | 0.9180 | 0.7836 | 0.7771 | 0.6033 | |
| Fine-tuned + CoT | ||||||||||||
| Qwen2-VL-7B-Instruct (In Q-Agent)[41] | 0.9495 | 0.9235 | 0.9441 | 0.8819 | 0.9010 | 0.8908 | 0.9430 | 0.9208 | 0.8875 | 0.9588 | 0.7882 |
为了评估多种退化感知的性能,我们定义了准确率指标 M A C C M A C C MACC,如下所示:
M A C C = T T + F M A C C=\frac{T}{T+F} MACC=T+FT
其中 T T T表示退化向量 D D D和感知向量 D ^ \hat{D} D^相同的实例数, F F F表示它们不同的实例数。 M A C C M A C C MACC作为一个全局指标,但缺乏对不同类型退化的针对性考察。为此,我们引入了退化准确率 D A C C D A C C DACC,这是从Zhou等人 [62] 适应而来的,并定义如下:
D A C C = P ( S ^ i ∣ S i ) , i = 1 , 2 , … , 10 D A C C=P\left(\hat{S}_{i} \mid S_{i}\right), i=1,2, \ldots, 10 DACC=P(S^i∣Si),i=1,2,…,10
其中 S i S_{i} Si表示具有第 i i i种退化类型的图像集合, S ^ i \hat{S}_{i} S^i是指MLLM检测到的具有第 i i i种退化类型的图像子集。此外,为了评估质量驱动的贪婪修复过程的有效性,我们采用了IR中广泛使用的四个指标:PSNR、SSIM [44]、LPIPS [54] 和DISTS [9]。其中,PSNR和SSIM的值越高表示图像恢复质量越好,而LPIPS和DISTS与恢复效果呈负相关。记录各种恢复方案在测试集上所有图像的平均恢复性能作为最终性能。
5.2. 退化预测的准确性
为了评估MLLM在感知多种退化类型方面的性能,我们选择了3个广泛认可且具有代表性的MLLM进行比较。其中,GPT-4o [28] 和Gemini-1.5-Pro [36] 是闭源模型,而Llava-Llama3-8B是在RestoreAgent [4] 中使用的开源代码实现的。整个实验分为3种不同的推理情况进行全面验证,结果汇总在表2中。
从表2的结果中可以得出几个关键观察结果:1)在零样本推理情况下,虽然MLLM在感知单个退化类型方面表现出令人满意的表现,但所有现有的MLLM在感知多种退化类型方面表现出显著的局限性;2)Qwen2-VL [41] 在所有情况下都取得了最佳的多退化感知性能,证明了其作为Q-Agent框架基础模型的选择是合理的;3)通过引入CoT和微调,除了少数情况外,MLLM的退化感知性能得到了提升,特别是在多退化意识方面,证明了所使用技术的有效性;4)Q-Agent中使用的Qwen2-VL-7B [41] 在尺寸较小的情况下优于RestoreAgent [4] 中使用的Llava-Llama3-8B [19, 37]。
5.3. 恢复模型的顺序
为了更有效地和准确地比较不同恢复顺序对退化图像的影响,我们设计并评估了5种不同的恢复策略:1)反序恢复:根据退化应用的顺序,图像按反序依次恢复;2)随机恢复:恢复顺序从MLLM感知的退化类型中随机选择;3)人类专家恢复:人类专家通过直接感知退化类型并确定恢复顺序来恢复退化图像;4)可回滚恢复:RestoreAgent [4] 使用的可回滚搜索策略;5)Q-Agent恢复:使用质量驱动的贪婪策略来确定恢复顺序。所有恢复策略的结果如表3和图7所示。
从实验结果中可以得出几个结论:1)在所有恢复策略中,Q-Agent采用的质量驱动贪婪恢复方法取得了最佳的恢复结果,这在主观视觉评估和客观指标上都有所体现。这种优越性能可以归因于NR IQA工具的作用,它在整个恢复过程中提供连续的评估和指导,使顺序选择更加有效和稳定;2)尽管反序恢复在实际应用中缺乏实用性,但其表现表明IR不是一个简单的可逆过程。这强化了选择适当恢复顺序以获得最佳结果的重要性;3)虽然RestoreAgent [4] 中使用的回滚恢复方法在很大程度上能够实现超过人类专家恢复的解决方案,但从图7可以看出,在某些情况下,该策略确定的恢复顺序仍然不是最优的,主要原因是缺乏质量指导。

图7. 不同顺序选择策略的结果。输入图像的标签包含退化类型及其顺序。值得注意的是,回滚恢复策略仅在贪婪恢复中引入回滚操作,并不完全等同于RestoreAgent [4] 中的策略,因为作者未开源相关代码和数据。
表3. 不同恢复顺序选择策略的性能比较。最佳值用红色标注,次优值用蓝色标注。
| 策略 | PSNR ↑ \uparrow ↑ | SSIM ↑ \uparrow ↑ | LPIPS ↓ \downarrow ↓ | DISTS ↓ \downarrow ↓ |
|---|---|---|---|---|
| 反序恢复 | 19.6072 | 0.5703 | 0.2037 | 0.1017 |
| 随机恢复 | 18.6369 | 0.5870 | 0.1916 | 0.1044 |
| 回滚恢复 | 21.0382 | 0.6483 | 0.1840 | 0.0989 |
| 人类专家恢复 | 20.1890 | 0.6288 | 0.2018 | 0.0950 |
| Q-Agent (我们的方法) | 22.5847 | 0.6856 | 0.1529 | 0.0778 |
5.4. 与其他All-in-One方法的比较
从功能和结构的角度来看,QAgent可以被视为一种高度灵活和可扩展的All-in-One方法。为了验证Q-Agent的有效性,我们将其与7种具有代表性的All-in-One方法进行了比较,实验结果如表4所示。需要注意的是,为了确保公平性,所有选定方法都使用了作者提供的代码和预训练模型。此外,为了更直观地表示各种All-in-One方法的恢复效果,我们包括了可视化的结果,如图8所示。通过对结果的分析,可以得出几个关键结论:1)在恢复质量方面,所提出的Q-Agent超越了所有其他All-in-One方法,并在第二名恢复方法的基础上显著领先1.7 dB PSNR,突显了框架的有效性;2)Q-Agent的卓越性能归功于其整合了各种任务特定的IR工具,从而实现了端到端处理,同时利用了专门恢复方法的有效性;3)尽管QAgent在当前实验中取得了最佳性能,但随着新的、更先进的IR方法的开发,其性能还可以进一步提高,从而突显了所提框架的可扩展性。
5.5. 消融实验
为了评估Q-Agent的鲁棒性,我们进行了一系列消融实验。具体来说,我们考察了训练数据集大小的变化如何影响QAgent框架的多重退化感知和IR能力。实验设置和结果如表5所示。通过对表5中的结果进行分析,可以得出以下观察结果:1)即使在较小的数据集上进行微调,Q-Agent仍能保持竞争力的表现,证明了框架的鲁棒性;2)总体而言,随着
M
A
C
C
M A C C
MACC的下降,IR的质量也相应下降,表明Q-Agent的性能受到MLLM感知多重退化类型能力的影响。
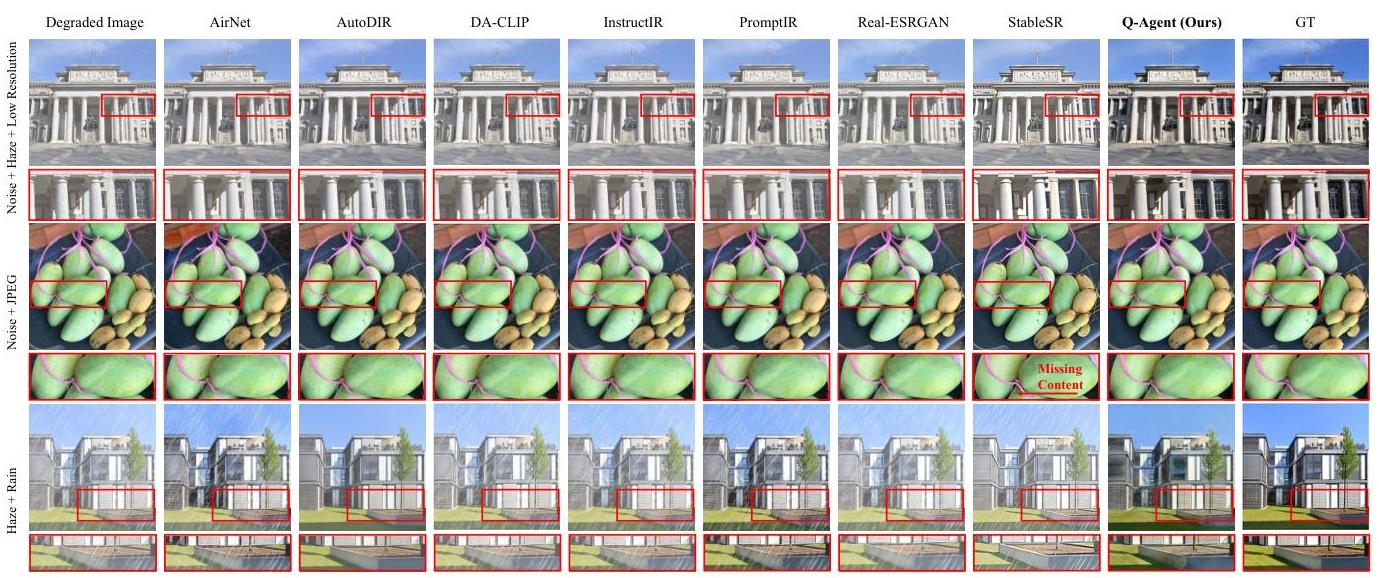
图8. Q-Agent与其他All-in-One方法的性能比较。红框放大局部以更好查看。
表4. 所提出的Q-Agent与不同All-in-One模型的性能比较。最佳值用红色标注,次优值用蓝色标注。
| 方法 | PSNR ↑ \uparrow ↑ | SSIM ↑ \uparrow ↑ | LPIPS ↓ \downarrow ↓ | DISTS ↓ \downarrow ↓ |
|---|---|---|---|---|
| AirNet [17] | 17.7129 | 0.4744 | 0.2531 | 0.2352 |
| AutoDIR [14] | 18.4029 | 0.4320 | 0.2313 \mathbf{0 . 2 3 1 3} 0.2313 | 0.1885 |
| DA-CLIP [20] | 20.8141 \mathbf{2 0 . 8 1 4 1} 20.8141 | 0.6471 \mathbf{0 . 6 4 7 1} 0.6471 | 0.2876 | 0.1546 \mathbf{0 . 1 5 4 6} 0.1546 |
| InstructIR [7] | 17.5059 | 0.3829 | 0.2595 | 0.2356 |
| PromptIR [29] | 20.0148 | 0.5259 | 0.2434 | 0.2201 |
| Real-ESRGAN [43] | 13.6988 | 0.2055 | 0.2589 | 0.2600 |
| StableSR [40] | 12.4668 | 0.1821 | 0.4235 | 0.2924 |
| Q-Agent (我们的方法) | 22.5847 | 0.6856 | 0.1529 \mathbf{0 . 1 5 2 9} 0.1529 | 0.0778 \mathbf{0 . 0 7 7 8} 0.0778 |
6. 可扩展性讨论
实验结果表明,所提出的QAgent为IR任务提供了一个可行、有效和鲁棒的框架。值得注意的是,Q-Agent在IR性能和可恢复退化范围方面表现出强大的可扩展性。关于IR性能,MLLM的快速发展将增强Q-Agent的多重退化感知能力。此外,IR工具和IQA方法的持续发展将提高Q-Agent在恢复质量和确定最佳恢复顺序方面的性能。在恢复退化类型方面,Q-Agent不仅可以处理8种经典且常见的图像退化类型,还可以处理其他退化类型,如摩尔纹 [60],从而扩展其适用性。此外,集成更多专业的恢复方法将进一步扩展Q-Agent的功能。例如,可以将恢复旧照片的方法 [38] 纳入Q-Agent框架中,从而创建一个更全面和完整的IR解决方案。总的来说,本文提出的Q-Agent提供了一种灵活且可扩展的方法,用于将MLLMs与IR任务集成。
表5. Q-Agent在QDegrade数据集上的消融实验结果。最佳值用红色标注,次优值用蓝色标注。
| 训练/测试规模 | M A C C ↑ M A C C \uparrow MACC↑ | PSNR ↑ \uparrow ↑ | SSIM ↑ \uparrow ↑ | LPIPS ↓ \downarrow ↓ | DISTS ↓ \downarrow ↓ |
|---|---|---|---|---|---|
| 20K / 20K | 0.7092 | 19.7588 | 0.6022 | 0.2131 | 0.1435 |
| 40K / 20K | 0.7596 | 20.2483 | 0.6581 | 0.1753 | 0.0944 |
| 60K / 20K | 0.7723 \mathbf{0 . 7 7 2 3} 0.7723 | KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: …hbf{2 1 . 9 0 4 | 0.6798 \mathbf{0 . 6 7 9 8} 0.6798 | 0.1462 \mathbf{0 . 1 4 6 2} 0.1462 | 0.0786 \mathbf{0 . 0 7 8 6} 0.0786 |
| 80K / 20K | 0.7882 | 22.5847 | 0.6856 | 0.1529 \mathbf{0 . 1 5 2 9} 0.1529 | 0.0778 \mathbf{0 . 0 7 7 8} 0.0778 |
7. 结论
图像修复(IR)方法的有效性和泛化性一直是广泛研究和讨论的主题。多模态大语言模型(MLLMs)的出现为推进IR技术引入了一种新方法。为了在有效性、多功能性、可用性和可扩展性之间取得平衡,我们提出了QAgent,这是一种质量驱动的链式思维(CoT)IR代理。Q-Agent框架包括两个关键阶段:鲁棒退化感知和质量驱动的贪婪修复。具体来说,CoT推理方法将多重退化感知任务分解为单退化感知,以提高MLLMs的退化预测准确性。随后,质量驱动的贪婪修复模块确定最佳修复顺序,并在无参考图像质量指标的指导下应用IR工具。实验结果表明,所提出的Q-Agent在退化感知、修复性能和鲁棒性方面具有显著优势。随着相关技术的不断发展,预计Q-Agent将进一步提升其图像修复能力,为实际应用提供更全面和有效的解决方案。
参考文献
[1] Abdullah Abuolaim 和 Michael S Brown。使用双像素数据进行散焦去模糊。在 Computer Vision-ECCV 2020: 第16届欧洲会议论文集,格拉斯哥,英国,2020年8月23-28日,第X 16部分,第111-126页。Springer, 2020. 2, 5
[2] Pablo Arbelaez, Michael Maire, Charless Fowlkes 和 Jitendra Malik。轮廓检测与分层图像分割。IEEE模式分析与机器智能汇刊,33(5):898-916, 2010. 5
[3] Yuanhao Cai, Hao Bian, Jing Lin, Haoqian Wang, Radu Timofte 和 Yulun Zhang。Retinexformer: 一种用于低光图像增强的一阶段Retinex基础变换器。在 IEEE/CVF国际计算机视觉会议论文集,第12504-12513页,2023. 1, 2, 5
[4] Haoyu Chen, Wenbo Li, Jinjin Gu, Jingjing Ren, Sixiang Chen, Tian Ye, Renjing Pei, Kaiwen Zhou, Fenglong Song 和 Lei Zhu。Restoreagent: 通过多模态大语言模型实现自主图像修复代理。神经信息处理系统进展,37: 110643-110666, 2025. 1, 3, 4, 6, 7
[5] Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu 和 Rui Zhao。Shikra: 激发多模态LLM的参照对话魔力。arXiv预印本 arXiv:2306.15195, 2023. 3
[6] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu 等。InternVL: 扩展视觉基础模型并针对通用视觉-语言任务对齐。在 IEEE/CVF 计算机视觉与模式识别会议论文集,第24185-24198页,2024. 3
[7] Marcos V Conde, Gregor Geigle 和 Radu Timofte。遵循人类指令的高质量图像恢复。arXiv e-prints, 第arXiv-2401页,2024. 2, 8
[8] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung 和 Steven Hoi。InstructBLIP: 通过指令微调实现通用视觉-语言模型。arXiv 预印本 arXiv:2305.06500, 2023. 3
[9] Keyan Ding, Kede Ma, Shiqu Wang 和 Eero P Simoncelli。图像质量评估:统一结构和纹理相似性。IEEE 模式分析与机器智能汇刊,44(5):2567-2581, 2020. 6
[10] Rich Franzen。柯达无损真彩色图像套件。http: //r0k.us/graphics/kodak, 1999. 2, 5
[11] GLM团队, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, Shuxun Yang, Weng Lam Tam, Wenyi Zhao, Xiao Liu, Xiao Xia, Xiaohan Zhang, Xiaotao Gu, Xin Lv, Xinghan Liu, Xinyi Liu, Xinyue Yang, Xixuan Song, Xunkai Zhang, Yifan An, Yifan Xu, Yilin Niu, Yuantao Yang, Yueyan Li, Yushi Bai, Yuxiao Dong, Zehan Qi, Zhaoyu Wang, Zhen Yang, Zhengxiao Du, Zhenyu Hou,
和 Zihan Wang。ChatGLM: 从GLM-130B到GLM-4的所有工具的大规模语言模型系列。arXiv预印本 arXiv:2406.12793, 2024. 3
[12] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen 等。LoRA: 大规模语言模型的低秩自适应。ICLR, 1(2): 3,2022.3
[13] Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang 和 Nenghai Yu。Opera: 通过过度信任惩罚和回顾分配缓解多模态大规模语言模型中的幻觉。在 IEEE/CVF 计算机视觉与模式识别会议论文集,第13418-13427页,2024. 1
[14] Yitong Jiang, Zhaoyang Zhang, Tianfan Xue 和 Jinwei Gu。AutoDIR: 使用潜在扩散实现自动全合一图像修复。在欧洲计算机视觉会议,第340-359页。Springer, 2024. 2, 8
[15] Xiangtao Kong, Chao Dong 和 Lei Zhang。迈向有效的多合一图像修复:序列学习和提示策略。arXiv预印本 arXiv:2401.03379, 2024. 2
[16] Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander Rush, Douwe Kiela 等。Obelics: 一个开放的大规模过滤的交错图像文本文档数据集。神经信息处理系统进展,36, 2024. 3
[17] Boyun Li, Xiao Liu, Peng Hu, Zhongqin Wu, Jiancheng Lv 和 Xi Peng。未知腐蚀的全合一图像修复。在 IEEE/CVF 计算机视觉与模式识别会议论文集,第1745217462页,2022. 2, 8
[18] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang 和 Ziwei Liu。Otter: 具有上下文指令微调的多模态模型。arXiv预印本 arXiv:2305.03726, 2023. 3
[19] Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen 和 Yong Jae Lee。Llava-next: 改进的推理、OCR和世界知识。https: //llava-v1.github.io/blog/2024-01-30-llava-next/, 2024. 6
[20] Ziwei Luo, Fredrik K Gustafsson, Zheng Zhao, Jens Sjölund 和 Thomas B Schön。控制视觉-语言模型实现通用图像修复。arXiv预印本 arXiv:2310.01018, 3(8), 2023. 2, 8
[21] Xintian Mao, Qingli Li 和 Yan Wang。Adarevd: 自适应补丁退出可逆解码器推动图像去模糊的极限。在 IEEE/CVF 计算机视觉与模式识别会议论文集,第2568125690页,2024. 5
[22] Shibin Mei, Hang Wang 和 Bingbing Ni。MSSIDD: 多传感器去噪基准。arXiv预印本 arXiv:2411.11562, 2024. 2
[23] Anish Mittal, Anush Krishna Moorthy 和 Alan Conrad Bovik。空间域内无需参考的图像质量评估。IEEE图像处理汇刊,21(12): 4695-4708, 2012. 2, 5
[24] Anish Mittal, Rajiv Soundararajan 和 Alan C Bovik。“完全盲”图像质量分析仪。IEEE信号处理快报,20(3):209-212, 2012. 2, 5
[25] Seungjun Nah, Tae Hyun Kim 和 Kyoung Mu Lee。深度多尺度卷积神经网络用于动态场景去模糊。在 IEEE/CVF 计算机视觉与模式识别会议论文集,第38833891页,2017. 2, 5
[26] Niranjan D Narvekar 和 Lina J Karam。基于累积概率模糊检测(CPBD)的无需参考的图像模糊度量。IEEE图像处理汇刊,20(9):2678-2683, 2011. 2, 5
[27] Zepeng Ning 和 Lihua Xie。多智能体强化学习及其应用综述。自动化与智能杂志,3(2):73-91, 2024. 4
[28] OpenAI。https://openai.com/index/hello-gpt-40/, 2024. 6
[29] V Potlapalli, SW Zamir, S Khan 和 FS Khan。PromptIR: 提示所有盲图像恢复。arxiv 2023. arXiv预印本 arXiv:2306.13090, 7. 2, 8
[30] Ethan Rathbun, Christopher Amato 和 Alina Oprea。SleeperNets: 针对强化学习智能体的通用后门中毒攻击。神经信息处理系统进展,37:111994-112024, 2025. 4
[31] Jaesung Rim, Haeyun Lee, Jucheol Won 和 Sunghyun Cho。真实世界模糊数据集用于学习和基准化去模糊算法。在计算机视觉-ECCV 2020: 第16届欧洲会议,英国格拉斯哥,2020年8月23-28日,论文集,第XXV 16部分,第184-201页。Springer, 2020. 2
[32] Lingyan Ruan, Bin Chen, Jizhou Li 和 Miuling Lam。学习使用生成的光场和真实的失焦图像进行去模糊。在 IEEE/CVF 计算机视觉与模式识别会议论文集,第1630416313页,2022. 5
[33] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman 等。Laion-5b: 一个开放的大规模数据集,用于训练下一代图像文本模型。神经信息处理系统进展,35:25278-25294, 2022. 3
[34] Ziyi Shen, Wenguan Wang, Xiankai Lu, Jianbing Shen, Haibin Ling, Tingfa Xu 和 Ling Shao。以人为中心的运动去模糊。在 IEEE/CVF 国际计算机视觉会议论文集,第5572-5581页,2019. 2
[35] Shaolin Su, Qingsen Yan, Yu Zhu, Cheng Zhang, Xin Ge, Jinqiu Sun 和 Yanning Zhang。由自适应超网络引导的野外盲目图像质量评估。在 IEEE/CVF 计算机视觉与模式识别会议论文集,第3667-3676页,2020. 5
[36] Gemini团队, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang 等。Gemini 1.5: 解锁数百万个上下文标记下的多模态理解。arXiv预印本 arXiv:2403.05530, 2024. 6
[37] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar 等。Llama: 开放且高效的基语言模型。arXiv预印本 arXiv:2302.13971, 2023. 6
[38] Ziyu Wan, Bo Zhang, Dongdong Chen, Pan Zhang, Dong Chen, Jing Liao 和 Fang Wen。让旧照片焕然一新。在 IEEE/CVF 计算机视觉与模式识别会议论文集,第2747-2757页,2020. 8
[39] Jianyi Wang, Kelvin CK Chan 和 Chen Change Loy。探索CLIP以评估图像的外观和感觉。在年度AAAI人工智能会议,2023. 5
[40] Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan 和 Chen Change Loy。利用扩散先验进行真实世界图像超分辨率。国际计算机视觉杂志,132(12):5929-5949, 2024. 2, 8
[41] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou 和 Junyang Lin。Qwen2-VL: 在任意分辨率下增强视觉语言模型的世界感知。arXiv预印本 arXiv:2409.12191, 2024. 4, 5, 6
[42] Ruixing Wang, Xiaogang Xu, Chi-Wing Fu, Jiangbo Lu, Bei Yu 和 Jiaya Jia。在黑暗中看到动态场景:一个高质量的视频数据集,具有机电对齐。在 IEEE/CVF 国际计算机视觉会议论文集,第9700-9709页,2021. 2, 5
[43] Xintao Wang, Liangbin Xie, Chao Dong 和 Ying Shan。Real-ESRGAN: 使用纯合成数据训练真实世界的盲超分辨率。在 IEEE/CVF 国际计算机视觉会议论文集,第1905-1914页,2021. 2, 8
[44] Zhou Wang, Alan C Bovik, Hamid R Sheikh 和 Eero P Simoncelli。图像质量评估:从误差可见性到结构相似性。IEEE图像处理汇刊,13(4):600-612, 2004. 2, 5, 6
[45] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou 等。链式思维提示激发大规模语言模型中的推理。神经信息处理系统进展,35:24824-24837, 2022. 2, 3
[46] Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Chunyi Li, Wenxiu Sun, Qiong Yan, Guangtao Zhai 等。Q-Bench: 低级视觉通用基础模型的基准。arXiv预印本 arXiv:2309.14181, 2023. 3
[47] Ruiqi Wu, Zhengpeng Duan, Chunle Guo, Zhi Chai 和 Chongyi Li。RidCP: 通过高质量代码本先验重振真实图像去雾。在 IEEE/CVF 计算机视觉与模式识别会议论文集,2023. 1, 2, 5
[48] Hanyu Xiang, Qin Zou, Muhammad Ali Nawaz, Xianfeng Huang, Fan Zhang 和 Hongkai Yu。图像修复的深度学习:综述。模式识别,134:109046, 2023. 1
[49] Wenhan Yang, Robby T Tan, Jiashi Feng, Jiaying Liu, Zongming Guo 和 Shuicheng Yan。单幅图像的深度联合雨检测与去除。在
IEEE/CVF 计算机视觉与模式识别会议论文集,第1357-1366页,2017. 2, 5
[50] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi 等。mPLUG-Owl: 模块化赋予大型语言模型多模态能力。arXiv预印本 arXiv:2304.14178, 2023. 3
[51] Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan 和 Ming-Hsuan Yang。Restormer: 高分辨率图像修复的高效变压器。在CVPR, 2022. 5
[52] Kai Zhang, Jingyun Liang, Luc Van Gool 和 Radu Timofte。设计一个实用的退化模型用于深度盲图像超分辨率。在 IEEE 国际计算机视觉会议,第4791-4800页,2021. 5
[53] Kai Zhang, Yawei Li, Jingyun Liang, Jiezhang Cao, Yulun Zhang, Hao Tang, Deng-Ping Fan, Radu Timofte 和 Luc Van Gool。实用盲图像去噪的Swin-Conv-UNet和数据合成。机器智能研究,20(6):822-836, 2023. 1, 2, 5
[54] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman 和 Oliver Wang。作为感知度量的深层特征的不合理有效性。在 IEEE 计算机视觉与模式识别会议论文集,第586-595页,2018. 2, 5, 6
[55] Zicheng Zhang, Wei Sun, Yingjie Zhou, Haoning Wu, Chunyi Li, Xiongkuo Min, Xiaohong Liu, Guangtao Zhai 和 Weisi Lin。通过文本提示评估零样本数字人质量。arXiv预印本 arXiv:2307.02808, 2023. 3
[56] Zicheng Zhang, Yingjie Zhou, Wei Sun, Wei Lu, Xiongkuo Min, Yu Wang 和 Guangtao Zhai。DDH-QA: 动态数字人质量评估数据库。在 2023 IEEE 国际多媒体与博览会会议 (ICME),第2519-2524页。IEEE, 2023. 3
[57] Zicheng Zhang, Yingjie Zhou, Wei Sun, Xiongkuo Min, Yuzhe Wu 和 Guangtao Zhai。数字人头部的感知质量评估。在 IEEE 国际声学、语音和信号处理会议,第
1
−
5
,
2023.2
1-5,2023.2
1−5,2023.2
[58] Zicheng Zhang, Haoning Wu, Erli Zhang, Guangtao Zhai 和 Weisi Lin。Q-Bench: 单图像到成对的低级视觉多模态基础模型基准。IEEE 模式分析与机器智能汇刊,2024. 1
[59] Zicheng Zhang, Yingjie Zhou, Chunyi Li, Kang Fu, Wei Sun, Xiaohong Liu, Xiongkuo Min 和 Guangtao Zhai。纹理网格数字人的减少参考质量评估度量。在 ICASSP 2024-2024 IEEE 国际声学、语音和信号处理会议 (ICASSP),第2965-2969页。IEEE, 2024. 2
[60] Bolun Zheng, Shanxin Yuan, Gregory Slabaugh 和 Ales Leonardis。使用可学习带通滤波器的图像消摩尔纹。在 IEEE/CVF 计算机视觉与模式识别会议论文集,第3636-3645页,2020. 8
[61] Yingjie Zhou, Zicheng Zhang, Wei Sun, Xiongkuo Min, Xianghe Ma 和 Guangtao Zhai。一种无需参考的质量评估方法用于数字人头部。在 2023 IEEE 国际图像处理会议 (ICIP),第36-40页。IEEE, 2023. 2
[62] Yingjie Zhou, Zicheng Zhang, Jiezhang Cao, Jun Jia, Yanwei Jiang, Farong Wen, Xiaohong Liu, Xiongkuo Min 和 Guangtao Zhai。Memo-Bench: 文本到图像和多模态大型语言模型在情感分析上的多个基准。arXiv预印本 arXiv:2411.11235, 2024. 6
[63] Yingjie Zhou, Zicheng Zhang, Wei Sun, Xiaohong Liu, Xiongkuo Min 和 Guangtao Zhai。3D说话头像的主观和客观体验质量评估。在 ACM 国际多媒体会议,第60336042页,2024. 2
[64] Yingjie Zhou, Zicheng Zhang, Farong Wen, Jun Jia, Xiongkuo Min, Jia Wang 和 Guangtao Zhai。Reli-QA: 重新照明人头的多维质量评估数据集。在 2024 IEEE 视觉通信和图像处理国际会议 (VCIP),第1-5页。IEEE, 2024. 1, 2
[65] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li 和 Mohamed Elhoseiny。MiniGPT-4: 使用高级大语言模型增强视觉-语言理解。arXiv预印本 arXiv:2304.10592, 2023. 3
参考论文:https://arxiv.org/pdf/2504.07148



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











