






Elisabeth Dillies*
认知科学系
索邦大学
elisabeth.dillies@gmail.com
Jannis Blüml
计算机科学系
达姆施塔特工业大学
Florian Peter Busch
计算机科学系
达姆施塔特工业大学
Quentin Delfosse*
计算机科学系
达姆施塔特工业大学
quentin.delfosse@tu-darmstadt.de
Raban Emunds
计算机科学系
达姆施塔特工业大学
Kristian Kersting
计算机科学系
达姆施塔特工业大学
摘要
强化学习(RL)代理在各种环境中表现出显著的性能,能够直接从感官输入中发现有效的策略。然而,这些代理通常会利用训练数据中的虚假相关性,导致在新环境或略有修改的环境中无法泛化的脆弱行为。为了解决这一问题,我们引入了因果对象中心模型提取工具(COMET),这是一种旨在学习精确可解释因果世界模型(CWMs)的新算法。COMET 首先从观察中提取对象中心状态描述,并识别与所描绘对象属性相关的环境内部状态。通过符号回归,它对对象中心转换进行建模并推导出支配对象动态的因果关系。此外,COMET 还结合大型语言模型(LLMs)进行语义推理,标注因果变量以增强可解释性。
通过利用这些能力,COMET 构建了与环境的真实因果结构一致的 CWMs,使代理能够专注于任务相关特征。提取的 CWMs 减轻了捷径的风险,允许开发能够在动态场景中更好地规划和决策的 RL 系统。我们在 Atari 环境(如 Pong 和 Freeway)中验证的结果展示了 COMET 的准确性和鲁棒性,突显了其在强化学习中弥合对象中心推理和因果推理之间差距的潜力。
关键词:强化学习、世界模型、对象中心、因果性
致谢
这项研究工作由德国联邦教育与研究部、黑森州高等教育、研究、科学和艺术部 (HMWK) 资助,作为联合支持国家应用网络安全研究中心 ATHENE 的一部分,通过 “SenPai: XReLeaS” 项目以及黑森州人工智能中心 (hessian.AI) 的集群项目 “人工智能的第三次浪潮 - 3AI” 提供支持。
*等同贡献
1 引言
机器学习系统往往倾向于利用训练数据中的虚假相关性 [Schramowski et al., 2020, Stammer et al., 2021]。在 RL 设置中也是如此,代理学会与原定任务不符的策略,依赖于捷径 [di Langosco et al., 2022, Suau et al., 2024]。即使在最简单的 Pong Atari 游戏中,Delfosse 等人 [2024c] 显示,深度和符号 RL 代理都容易出现这种错位。在 Pong 中,敌人被编程为垂直对齐球的位置,导致两个物体垂直位置之间的准完美相关性。因此,RL 代理学会依赖敌人的垂直位置来确定球的位置并有效返回球,如图 1 所示。这些捷径阻止了代理在简化版本的环境中泛化,而人类对此类环境没有问题适应。例如,如果敌人隐藏或当球朝玩家移动时停止移动,RL 代理的表现就会下降。这种对更简单场景的错误泛化不仅限于 Pong,而是普遍存在于街机学习环境中 [Delfosse et al., 2024a]。
最近已经开发了许多形式的可解释对象中心算法。它们首先提取对象中心(或符号)状态,然后依赖一阶逻辑 [Delfosse et al., 2023a]、多项式逼近和 LLM 解释 [Luo et al., 2024] 或决策树 [Kohler et al., 2024]。研究表明,它们是不透明方法的竞争性替代方案,表现与深度代理相当。重要的是,它们提供了一种可解释性,允许专家检测和纠正潜在的错位行为。Yoon 等人 [2023] 展示了对象中心代理在提高泛化能力和减少对虚假相关性的依赖方面的更高鲁棒性。
然而,对象中心符号推理并不能打破像 Pong 中敌人球拍和球之间的相关性。如果敌人开始表现出不同的行为,依赖这种虚假相关性并专注于敌人球拍的代理将无法返回球,而根据球的位置和速度移动的代理则不会受到相关性破裂的影响。两者可观测特征的相关性(即敌人的球拍和球的垂直位置)对我们预期的代理行为的重要性在于真实的因果关系。如果代理在因果世界模型中利用这些因果关系,机制的独立性 [Peters et al., 2017] 确保了期望的行为(即返回球)在修改后的环境中(例如,在返回球后敌人停止的情况下)适用。通过解开这些关系,代理可以专注于任务相关特征,促进在多样化场景中包括具有新颖动态或对抗性干预的策略的泛化发展。
即使已经开发了新的基准来测试 RL 代理的鲁棒性(例如,在 Atari 领域的 [Delfosse et al., 2024a]),自动检测和纠正虚假相关性的方法仍然未得到充分探索。将因果推理集成到 RL 代理中为实现人类般的适应性提供了途径 [Yang et al. 2024, Lei et al. 2024]。通过抽象相关特征并对观察到的现象的底层因果结构进行建模,RL 代理可以自主克服基于捷径策略的局限性。
在本文中,我们介绍了因果对象中心模型提取工具(COMET)。COMET 使用内部状态提取模拟环境的可解释因果世界模型(CWMs)。COMET 从观察中检测对象,然后对所描绘对象的属性与仿真环境依赖于生成观察的内部状态(例如 RAM)之间的因果关系进行建模。然后,它学习提取这些变量何时以及如何由环境更新。它检索相关的内部变量,并使用 LLM 的常见推理能力标注这些相关的内部状态(从而提高其可解释性)。
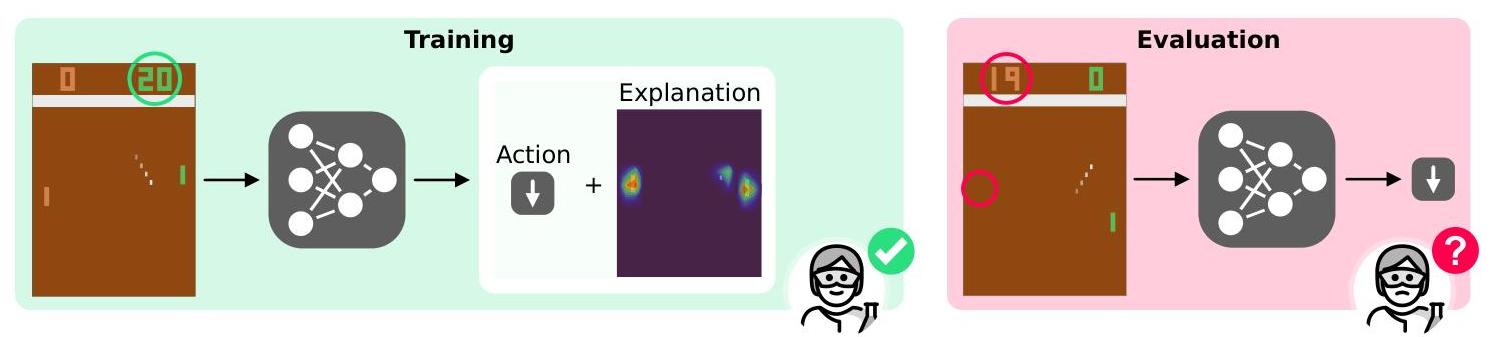
图 1:深度 RL 代理学习不可检测的捷径。一个深度(PPO)代理在训练环境的所示状态下达到最大分数并选择正确的动作。解释图进一步引导外部评审员认为该代理“理解”它应该在敌人后面返回球(左)。在测试环境中,敌人隐藏起来,代理决定向下移动,防止它抓住球(右)。这说明了代理学会了依赖敌人的垂直位置作为球位置的估计值。
2 方法
算法 1 详细描述了使用 COMET 提取因果世界模型(CWM)的过程。此方法将对象中心推理与符号回归和语义推理相结合,全面映射环境动态。下面,我们描述提取过程的每个阶段。
总体而言,COMET 通过以下步骤提取对象中心 CWM:
- 将内部状态值映射到对象的属性,
- 建模内部状态如何演变,
- 标注相关变量的意义。
COMET 需要一个可执行环境、一个可执行策略(可能是随机的)和一个用于常识推理的大语言模型(LLM)。它首先从策略生成轨迹,检索环境的内部状态(EIS)和渲染的 RGB 观察结果。然后,它使用对象发现方法(例如 [Delfosse et al., 2023b, Zhao et al., 2023])从每帧中提取对象。每个对象由一组属性组成(例如
x
,
y
,
w
,
h
\mathrm{x}, \mathrm{y}, \mathrm{w}, \mathrm{h}
x,y,w,h 边界框坐标或对象的值,如得分、生命计数器等)。
然后,COMET 使用 PySR [Cranmer, 2023] 进行符号回归,将每个属性与其对应的内部状态匹配。因此,它提取了一组相关的内部状态 R-EIS 及其与不同对象属性的映射。例如,内部状态
s
i
s_{i}
si 可以编码所描绘球对象的观察到的垂直位置,偏移量为 14,因此遵循:Ball.
y
=
s
i
−
14
y=s_{i}-14
y=si−14。
为了提取底层的对象中心世界模型,即理解对象如何演变,COMET 接下来搜索这些相关内部状态何时以及如何在每一步更新。对已收集的相关状态进行符号回归,将其映射到内部状态和动作。例如,我们的符号回归模型可以提取以下映射:
s
i
=
s
i
+
s
j
s_{i}=s_{i}+s_{j}
si=si+sj,其中
s
j
s_{j}
sj 是另一个内部状态,这里对应球的垂直速度。如果在方程中找到新的相关状态(例如这里的
s
j
s_{j}
sj),它们将被添加到 R-EIS 中。这个相关状态回归重复进行,直到 COMET 获得了所有相关状态的更新条件和方程(由于环境的内部状态集是有限的,最终会发生这种情况)。
然后,我们通过标注相关内部状态的意义来提高提取的世界模型的可解释性。为了识别
s
j
s_{j}
sj 的语义,我们使用 LLM 的常识推理能力。具体来说,我们向 ChatGPT(模型 40)提供追溯到对象属性的方程,并要求对内部状态的语义进行标注。在上述情况下,LLM 正确地识别出
1
{ }^{1}
1
s
j
s_{j}
sj 编码了球的垂直速度。提供的语义允许外部评审员更好地识别每个内部状态的目的。此外,它可以允许 LLM 减少回归所用的内部状态变量集。例如,在 Pong 中,当球撞击其中一个球拍时,球的水平速度翻转。LLM 可以检测到这种事件发生在球与其他对象碰撞时,并将输入集减少到其他对象的位置。即使面对一种新型情况,LLM 可能事先不知道任务,其常识推理仍能引导它识别出行进物体速度的突然变化是由于碰撞,并因此将搜索引向碰撞检测。
算法 1 因果对象中心模型提取
需要:env, agent, LLM
初始化 worldmodel
rgbs, EIS, actions \(\leftarrow\) sample(env, agent, nb_episodes)
objs \(\leftarrow\) detect(rgbs)
R-EIS \(\leftarrow\) find_relevant_EIS(objs.properties, EIS)
while R-EIS \(\neq \varnothing\) do
\(s \leftarrow\) R-EIS.pop()
if \(s \notin\) worldmodel then
update_equation, update_condition \(\leftarrow\) find_hidden_state(EIS, actions)
worldmodel(s) \(\leftarrow\) update_equation, update_condition
R-EIS \(\leftarrow\) R-EIS + update_equation.variables
end if
end while
annotate.variables(worldmodel, LLM)
return worldmodel
${ }^{1}$ https://chatgpt.com/share/6786f2ef-3ab4-8006-b5e3-8a3b29e92b2e, 最后访问日期为 2024 年 1 月 15 日
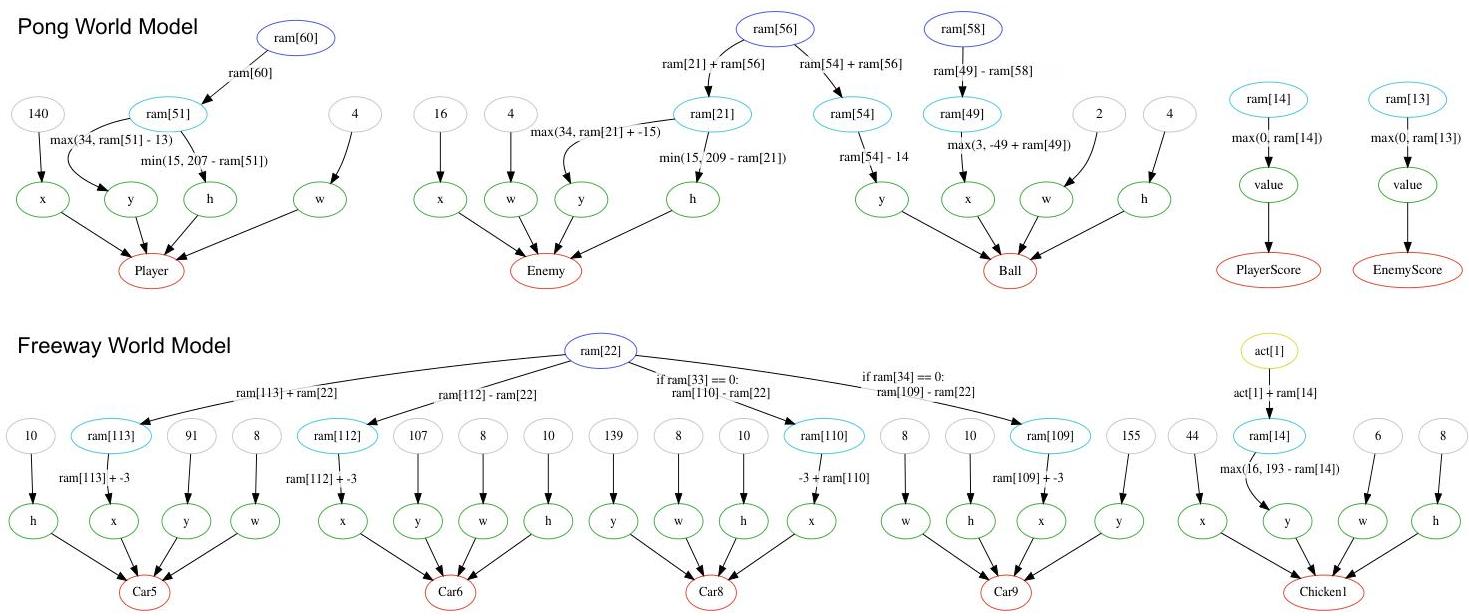
图 2:COMET 提取的世界模型示例。上图:提取的 Pong 环境世界模型,包括玩家、敌人、他们的得分和球。下图:Freeway 世界模型的一部分(共 10 辆车中显示 4 辆)。所有直接链接到对象属性的内部 RAM 变量(浅蓝色)与 Anand 等人 [2019] 提供的注释 RAM 相符。用于更新这些属性的变量(深蓝色)是有效的。例如,RAM [58] 对应球在 x 轴上的速度。
3 COMET 提取的世界模型
本节展示了从 Pong 和 Freeway 环境中获得的两个提取的世界模型。我们使用仿真器的随机存取存储器(RAM)作为环境的内部状态。为此,我们使用 OCAtari [Delfosse et al., 2024b] 中包含的对象提取器,并通过让人类代理玩一局游戏(大约 8000 步)来采样转换。为了确定 COMET 是否找到了正确的 RAM 值,我们首先参考 Anand 等人 [2019] 提供的 Atari RAM 注释
2
{ }^{2}
2。为了断言其他变量(来自更新条件)是否正确,我们直接更改它们并检查是否导致预期的显示修改。例如,我们可以将球的水平速度设置为 0 并观察其垂直移动。
如图 2 所示,COMET 正确识别了两款游戏的属性状态。对于 Pong,COMET 正确提取了球的水平和垂直速度(即 ram [58] 和 ram [56] 分别)。确实,状态 ram [51] 被更新为成为 ram [60](基于代理选择的动作更新)。然而,ram [56] 还被检索到编码玩家的速度。这是因为敌人被编程为跟随球(如引言中所述)。因此,在游戏的大部分过渡中,敌人的速度确实与球相匹配。然而,敌人被编程为抓球,因此跟随它。如果球在敌人下方,敌人将决定向下移动。然而,这条规则比匹配敌人速度的规则更复杂。因此,PySR 更倾向于简单的规则。在这里可以应用两种解决方案:允许模型进行干预,即修改球的速度以检查这是否直接改变敌人的 y 位置更新规则,或者使用 LLM 的常识推理选择最合适的更新规则。
在 Freeway 中,代理控制 Chicken1,目标是在不被横向移动的汽车撞到的情况下穿越道路。根据代理选择的动作更新鸡的垂直位置。它根据操纵杆的方向(即 act[1])递增。对于汽车 1 到 5,它们的位置递增;对于汽车 6 到 10,它们的位置递减。然而,为了模拟每辆汽车的不同速度,汽车 x 位置以不同的速度更新。虽然 car5 和 car6 的 x 位置在每一步都更新,但其他汽车如 car8 和 car9 使用计数器分别每 3 和 4 帧更新一次。因此,COMET 正确识别了 car8 和 car9 的水平位置更新条件。最后,在回归集中 ram [22] 始终设置为 -1(仅在游戏结束时设置为 0,此时汽车的位置确实不更新)。更改 ram [22] 不会影响汽车的速度。尽管回归得出了正确的结果,但改变内部状态值的干预将允许 COMET 识别并纠正其错误。LLM 的推理还可以在此处检测到 ram [22] 表示游戏是否结束(或未结束)来自回归的输入。一种更简单的替代方法是对使用变量而不是常量的符号回归器进行惩罚。
${ }^{2}$ https://github.com/mila-iqia/atari-representation-learning/blob/master/atariari/benchmark/ram_annotations.py
4 讨论与未来工作
在本文中,我们介绍了 COMET 和一种通过在可观察对象上执行符号回归并利用 LLM 的常识推理能力为因果变量提供语义来提取可解释对象中心因果世界模型的算法。COMET 的主要讨论点之一是它访问环境的隐藏状态。大多数为 RL 代理提取 CWM 的方法都没有访问内部状态 [Yang et al., 2024, Lei et al., 2024],这构成了更现实的设置。然而,即使是工业环境中,大多数 RL 代理至少在虚拟环境中进行了预训练。COMET 旨在从环境中提取精确的 CWM,这可以作为目标 CWM。访问真实的 CWM 允许我们使用 JAX 重新实现这些精确的环境。
3
{ }^{3}
3。我们最初的 JAX 版本基准(例如 Pong),使用 GPU 并行化(在 RTX2070 上)相比原始 Atari Gym 版本的 CPU 执行速度提高了 30 到 100 倍。
我们最重要的下一步是将 LLM 的常识推理能力整合到 COMET 中。我们将使用 LLM 生成符号函数(用 Julia 和 SymPy),这些函数可以在回归时由 PySR 使用。我们已经对 COMET 提取的相关内部变量进行了干预,以测试提取模型的准确性。我们计划将这些干预措施整合到 COMET 中,以便修正 CWM。当然,我们还计划扩展评估到更多环境,特别是 ALE 套件中的环境。
参考文献
Ankesh Anand, Evan Racah, Sherjil Ozair, Yoshua Bengio, Marc-Alexandre Côté, and R Devon Hjelm. Atari 中无监督的状态表示学习。神经信息处理系统进展,2019。
Miles Cranmer. 使用 PySR 和 symbolicregression.jl 进行科学的可解释机器学习。arXiv 预印本,2023。
Quentin Delfosse, Hikaru Shindo, Devendra Singh Dhami, and Kristian Kersting. 可解释且可解释的逻辑策略通过神经引导的符号抽象。神经信息处理进展(NeurIPS),2023a。
Quentin Delfosse, Wolfgang Stammer, Thomas Rothenbacher, Dwarak Vittal, and Kristian Kersting. 通过运动和对象连续性提升对象表示学习。2023b。
Quentin Delfosse, Jannis Blüml, Bjarne Gregori, and Kristian Kersting. Hackatari:用于稳健和持续强化学习的 Atari 学习环境。强化学习会议中的可解释策略研讨会,2024a。
Quentin Delfosse, Jannis Blüml, Bjarne Gregori, Sebastian Sztwiertnia, and Kristian Kersting. OCAtari:对象中心的 Atari 2600 强化学习环境。强化学习期刊,2024b。
Quentin Delfosse, Sebastian Sztwiertnia, Mark Rothermel, Wolfgang Stammer, and Kristian Kersting. 可解释的概念瓶颈以对齐强化学习代理。神经信息处理进展(NeurIPS),2024c。
Lauro Langosco di Langosco, Jack Koch, Lee D. Sharkey, Jacob Pfau, and David Krueger. 深度强化学习中的目标误泛化。国际机器学习会议 ICML,2022。
Hector Kohler, Quentin Delfosse, Riad Akrour, Kristian Kersting, and Philippe Preux. 可解释且可编辑的程序化树策略用于 RL。欧洲强化学习研讨会,2024。
Anson Lei, Bernhard Schölkopf, and Ingmar Posner. SPARTAN:一种学习局部因果关系的稀疏变换器。2024。
Lirui Luo, Guoxi Zhang, Hongming Xu, Yaodong Yang, Cong Fang, and Qing Li. 带有文本解释的端到端神经符号强化学习。第四十一届国际机器学习会议,2024。
Jonas Peters, Dominik Janzing, and Bernhard Schölkopf. 因果推断的基础与学习算法。麻省理工学院出版社,2017。
Patrick Schramowski, Wolfgang Stammer, Stefano Teso, Anna Brugger, Franziska Herbert, Xiaoting Shao, Hans-Georg Luigs, Anne-Katrin Mahlein, and Kristian Kersting. 通过与解释交互使深度神经网络因正确的科学原因而正确。自然机器智能,2020。
Wolfgang Stammer, Patrick Schramowski, and Kristian Kersting. 正确概念:通过与解释交互修订神经符号概念。计算机视觉和模式识别会议 CVPR,2021。
Miguel Suau, Matthijs T. J. Spaan, and Frans A. Oliehoek. 坏习惯:RL 中的策略混淆和轨迹外泛化。RLJ,2024。
Yupei Yang, Biwei Huang, Fan Feng, Xinyue Wang, Shikui Tu, and Lei Xu. 通过因果导向的自适应表示实现可泛化的强化学习。arXiv 预印本,2024。
Jaesik Yoon, Yi-Fu Wu, Heechul Bae, and Sungjin Ahn. 探究强化学习中预训练对象中心表示的方法,2023。
Xu Zhao, Wenchao Ding, Yongqi An, Yinglong Du, Tao Yu, Min Li, Ming Tang, and Jinqiao Wang. 快速分割任何事物。arXiv 预印本,2023。
https://github.com/k4ntz/JAXAtari
参考论文:https://arxiv.org/pdf/2504.07257



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











