






Saleh Almohaimeed*,刘沈阳*,May Alsofyani*,Saad Almohaimeed 和 王立强
美国中佛罗里达大学计算机科学系
{saleh, shenyang, may_sof, saadm}@knights.ucf.edu, lwang@cs.ucf.edu
摘要
在语义解析领域,文本到SQL和问答任务取得了显著进展,这两者都专注于从数据源的原始格式中提取信息。然而,其形式化意义表示的固有约束(如SQL编程语言或基本逻辑形式)限制了它们从不同角度分析数据的能力,例如进行统计分析。为了解决这一限制并激励该领域的研究,我们设计了SIGMA,这是一个新的用于文本到代码语义解析的带统计分析的数据集。SIGMA包含6000个问题及其对应的Python代码标签,覆盖160个数据库。其中一半的问题涉及查询类型,返回信息的原始格式,而剩余的50%是统计分析问题,对数据执行统计操作。我们的数据集中包含4种查询类型和40种统计分析模式的Python代码标签。我们使用三种不同的基线模型:LGESQL、SmBoP 和 SLSQL 来评估SIGMA数据集。实验结果表明,带有ELECTRA的LGESQL模型优于所有其他模型,结构准确率达到83.37%。在执行准确率方面,结合GraPPa和T5的SmBoP模型达到76.38%。
关键词:语义解析 ⋅ \cdot ⋅ 统计分析 ⋅ \cdot ⋅ 文本到代码
1 引言
自然语言处理中的一个重要领域是语义解析(SP),它专注于将自然语言句子翻译成机器可解释的意义表示。这些目标表示可以是多种形式,如特定的编程语言(SQL)、正式的数学表达式(lambda演算)或简单的表示(文本)。大多数SP任务的重点是从知识源中检索信息,例如数据库、网页,
1946-0759/23/\$31.00 ©2023 IEEE
* 这些作者对该工作贡献相同。
我们的数据集可在github.com/sasmohaimeed/SIGMA获取。
而不考虑使用统计分析以不同方式探索数据。文本到SQL任务是语义解析中最受欢迎的任务之一,但其统计能力有限。它仅限于三种统计函数(Sum、Average和Count),无法进行更高级的统计计算。
为了满足多样化的数据探索需求,并强调最常用的统计函数,我们设计了SIGMA,一个跨域数据集,包含160个数据库和6000个自然语言问题,每个问题都配有相应的Python代码标签。SIGMA涵盖了总共40种统计分析模式,能够在向用户提供结果之前对数据执行统计函数。此外,还有4种类似于SQL语言子句的查询模式,直接从数据库中检索数据。在SIGMA的6000个问题中,3000个统计问题是九位人员编写的,他们要么是本科最后一年的学生,要么拥有统计学学位。在3000个查询问题中,其中有2000个是由三名研究生计算机科学学生组成的,1000个问题来自Spider [23] 数据集,以确保问题范围的多样性。鉴于Python能够进行各种类型的统计分析并执行超出此范围的操作,我们选择它作为目标语言。
为了评估该数据集的质量和多样性,我们使用了三个语义解析模型进行了实验:LGESQL [3]、SLSQL [9] 和 SmBoP [17]。我们的实验发现表明,LGESQL模型在结构准确性方面表现最佳,而SmBoP模型在执行准确性方面表现良好。
本文做出了以下贡献。(1)我们设计了SIGMA,一个包含160个数据库上6000个问题的数据集。总体而言,该数据集涵盖了44种不同模式,包括40种统计分析模式和4种SQL子句。(2)我们开发了一个内置的Python执行器,能够执行我们数据集中所有的44种模式。(3)在数据集上进行了实验,使用了三种模型:LGESQL [3]、SLSQL [9] 和 SmBoP [17]。
2 相关工作
在过去二十年中,许多语义解析和代码生成任务被引入以解决特定用户需求。目标意义表示(MRs)因任务而异。虽然一些MRs很简单,例如句子或数字,而另一些则更为复杂,例如编程语言或多个段落。我们的工作,文本到代码,与三个语义解析任务相关:文本到SQL、问答任务和代码生成任务。
对于文本到SQL任务,大量研究集中在从关系数据库中查询和检索信息的过程。文本到SQL任务试图将自然语言问题映射到可执行的SQL查询。早期关于这个任务的研究基于小规模和单域数据集,例如ATIS [14] [5]、Academic [10] 和 Scholar [7]。随后是对大规模数据集如WikiSQL [25] 和更复杂的跨域数据集如Spider [23] 的研究。最近的研究继续应对处理跨域数据集以及处理多个相互关联的自然语言查询的挑战,例如SParC [24] 和 CoSQL [22]。
问答任务的目的是回答来自给定上下文的问题。上下文可以是一个单一文档,如SQuAD [16],或者多个文档,如TriviaQA [8]。上下文可以存储在结构化或半结构化的知识库中,如QAngaroo [19] 和 WebQuestions [1] 数据集。为了完成这项任务,应设计具有高级推理能力的模型来理解给定的上下文并回答用户的问题。
对于代码生成任务,代码生成任务中有广泛的子任务,包括修复代码、代码间翻译、代码补全和从文本生成代码。我们在此研究中关注的是文本到代码生成,即将文本序列转换为代码序列。一些数据集在这个任务中被创建,包括Card2code [11],它将卡片描述映射到使用Python编程语言实现它们的代码。Card2code的缺点在于它过于领域特定。这种领域特定的限制通过Django [12] 数据集得到了解决。它包含了整个Django Web框架的源代码,并为每行代码提供了英文注释。在CoNaLa [20] 数据集中,开发者的自然语言意图被映射到从Stack Overflow收集的代码片段。为了提高模型在此任务上的性能,研究人员应探索建立自然语言查询和相应代码之间的平行对齐策略。这可以通过实施一组规则来约束代码生成来实现。
在语义解析中,信息从各种来源提取,如数据库、知识图谱、文档和网页。然而,当前方法并未利用现代编程语言的功能,在数据被检索之前对其进行用户有利的操作。本文的一个动机是通过开发一个带有执行器的数据集来满足这一需求,该执行器可以对数据进行统计分析并从多种角度进行探索。
3 数据集
SIGMA数据集中有6000个问题,每个问题都有相应的Python代码作为真实值。3000个统计问题是九位拥有统计学或相关领域学位的人士撰写的。剩下的3000个问题中,2000个由三名计算机科学研究生撰写,1000个问题来自Spider [23] 数据集。
统计分析领域包含大量的不同模式。我们进行了广泛的研究以确定要包含哪些模式。[2] 提供了如何将不同的统计模式应用于数据科学的详细说明。从[2]中,我们选择了适用于我们数据集的所有统计分析模式,并将其分类为三个类别,即分布、绘图和数值。分布包括显示给定数据变量所有可能值位置的曲线函数,例如正态、指数和卡方分布。绘图包括用于表示一个或多个数据变量的图形技术,例如直方图、六边形和等高线技术。分布和绘图类别的结果将以不同类型的图表呈现。数值类别包括所有其他统计计算,其结果可以表示为表格或数字,例如均值、相关矩阵和频率表。除了统计分析外,我们还考虑了数据库的不同查询类型,其中包括四个SQL子句:SELECT、WHERE、GROUP BY 和 ORDER BY。表3显示了我们数据集中包含的所有统计和SQL模式。
表1. 此表显示了我们数据集中包含的所有统计和SQL模式。每个模式的类型指的是主类类型。
| Pattern | Type | Pattern | Type | Pattern | Type |
|---|---|---|---|---|---|
| Select | Query | Box | Plot | Outlier | Numeric |
| Where | Query | KDE | Plot | Standard Deviation | Numeric |
| Order by | Query | Pie | Plot | Variance | Numeric |
| Group By | Query | Bar | Plot | Range | Numeric |
| Noraml | Distribution | Scatter | Plot | Interquartile Range | Numeric |
| Standard Normal | Distribution | Hexbin | Plot | Frequency Table | Numeric |
| Long Tailed | Distribution | Contour | Plot | Mode | Numeric |
| Binomial | Distribution | Violin | Plot | Standard Error | Numeric |
| Poisson | Distribution | Mean | Numeric | Percentile | Numeric |
| Exponential | Distribution | Weighted Mean | Numeric | Correlation Matrix | Numeric |
| Weibull | Distribution | Trimmed Mean | Numeric | Correlation Coefficient | Numeric |
| Chi-Square | Distribution | Mean Absolute Deviation | Numeric | Contingency table | Numeric |
| T | Distribution | Median | Numeric | Size | Numeric |
| F | Distribution | Weighted Median | Numeric | Confidence Interval | Numeric |
| Histogram | Plot | Median Absolute Deviation | Numeric |
3.1 标签(Python代码)的组成部分
我们的目标是将自然语言文本映射到稍后插入Python函数并执行的Python代码片段。Python代码片段包括五个组成部分,如图1所示。第一个部分是主类,它可以是四个值之一:分布、绘图、数值或查询。第二个称为子类,具体取决于主类。分布、绘图、数值和查询分别有10、9、21和4种不同的子类。第三个部分与数据库表相关。在第四个部分中,指定了从数据库中选择的列。额外参数是第五部分,它包括子类所需的附加信息。例如,当子类标记为“orderby”时,必须在额外参数中指定顺序是升序还是降序。然而,大多数子类不需要额外参数,因此可以留空。
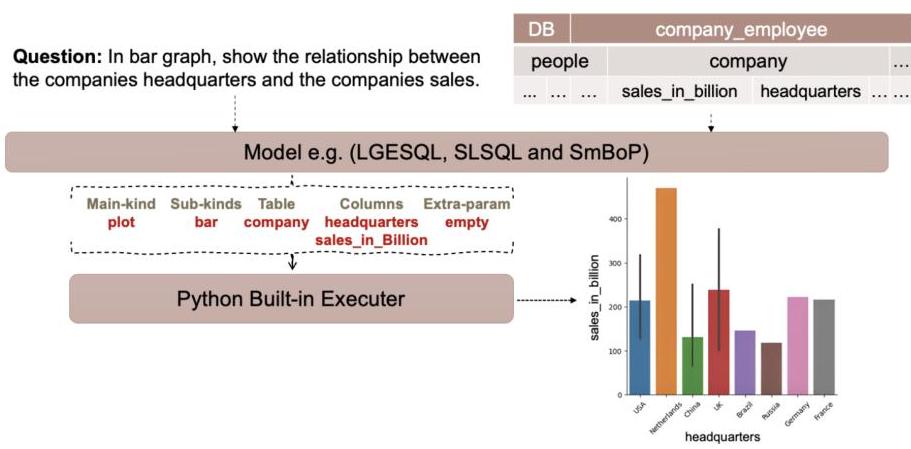
图1. 我们文本到代码任务的整体架构。问题和模式表及列为模型的输入,而Python代码标签为模型的输出。为了验证结果,可以使用内置的Python执行器执行Python代码,并展示结果。
3.2 问题和Python代码构建
在创建问题时,设计者不能随意选择数据库中的列。相反,我们提供给他们一个Excel表格,其中包含数据库名称、表名称和列名称。此外,我们允许他们探索数据库以查看表中的值。他们的任务只是编写问题。我们确保所有编写问题的人都遵循以下规则。
问题清晰度。模糊问题是指不同人对同一单词或短语有不同的解释。例如,如果问题是“计算员工表的平均值”,由于不知道列是什么,就无法计算员工的平均值。更好的问题是“计算员工收入的平均值”。此外,没有需要使用外部资源的问题,例如“计算努力工作的员工的平均工资”。如果数据库没有任何关于每位员工工作量的信息,则有必要参考外部信息来指示哪些员工是努力工作的。因此,这类模糊问题不包含在我们的数据集中。
问题同义词。要求每位参与者不要在每个问题中明确指出具体的列、表和统计模式名称。至少要有20%的问题包含同义词。例如,如果一列名为“salary”,参与者应在某些问题中使用其他同义词,如“income”或“wage”。此外,参与者应注意不要以相同的方式编写所有问题,例如总是先提到统计模式再提到列,或每道题都以“what are”开头。
3.3 数据集统计
在文本到SQL任务中,模型的输入是问题和模式,这与文本到代码任务的输入相同。因此,在表2中,我们总结了我们的数据集与其他流行的文本到SQL数据集的比较。
请注意,SIGMA数据集中的问题数量不如其他数据集(如Spider数据[23])多,但问题的多样性很大。相比Spider [23],该数据集由11名学生标注,我们的数据集包含5000个问题,由12名在SQL语言或统计学领域具有专业知识的个人标注。此外,1000个问题来自Spider数据集。由于这种多样性,模型学习更多,对问题含义的理解更深。此外,大多数其他数据集在一个领域内只有一个数据库。SIGMA跨越107个不同领域,包含160个不同的数据库。与Spider数据集相比,SIGMA在训练和测试数据集中不重复任何领域。尽管该数据集不是为文本到SQL任务设计的,但它包含与其他大多数文本到SQL数据集类似的查询类型,包括SELECT、WHERE、GROUPBY、ORDERBY以及另外40种统计分析模式。
表2. SIGMA数据集与流行文本到SQL数据集的比较。
| 数据集 | # Q | # 标签 # DBs # 领域 # 模式 | |||||
|---|---|---|---|---|---|---|---|
| ATIS | 5,280 | 947 | 1 | 1 | 4 | 群体来源 | |
| Scholar | 817 | 193 | 1 | 1 | 6 | 群体来源 | |
| Academic | 196 | 185 | 1 | 1 | 6 | 群体来源 | |
| GeoQuery | 877 | 247 | 1 | 1 | 6 | 群体来源 | |
| WikiSQL | 80,654 | 77,840 | 26,521 | - | 3 | 群体来源 | |
| Spider | 10,181 | 5,693 | 200 | 138 | 9 | 11名标注员 | |
| SIGMA | 6,000 | 4,180 | 160 | 107 | 44 | 12名标注员 |
3.4 内置Python执行器
内置执行器是用Python语言编写的。它包括我们数据集中所有44种模式的实现,包括分布、绘图、数值和查询类型。通过使用执行器,用户能够以类似SQL编程查询数据库的方式从表和列中提取信息。SQL查询“SELECT age FROM Student”相当于Python代码标签,其中主类是查询,子类是select,表是Student,列是age,额外参数为空。我们在research.mehaimeed.com创建了一个网页来执行所有Python代码标签。
4 任务定义
给定用户问题和模式表,我们需要生成一个Python代码片段,稍后将其插入到我们内置执行器的Python函数中。为了使这个数据集更加现实且更具代表性,我们定义了以下三个规则:跨域、结构匹配和同义词意识。前两个挑战与Spider [23]论文中提出的相似。
4.1 跨域。
大多数以前的语义解析数据集都是基于单个领域的单个数据集,如Academic [10] 和 ATIS [14]。模型表现良好的原因可能是它们记住了问题中的一些重复词汇,或者因为它们过拟合了数据,这可能会影响它们在其他领域应用时的表现。因此,我们确保训练和测试数据集有不同的数据库。因此,模型将基于理解问题的语义背景做出正确的预测。
4.2 结构匹配
在我们的文本到代码任务中,模型不需要正确预测五个Python代码组件的值。因为在现实场景中,人们可能知道自己寻找的值,但他们不知道如何编写编程语言代码以从数据库中检索数据。此外,由于某些数据库或知识库中值的复杂性,事先了解该领域的知识是必需的。有许多模型擅长预测样本的结构,但在那些样本中的值却是错误的。因此,我们纳入了结构匹配规则,要求模型只预测五个Python代码组件,而无需预测值。
4.3 同义词意识
一些模型在大型数据集上训练时可能会给出准确的预测结果,因为它们可以识别输入和输出之间的重复标记。仅仅记住标记的值和位置的问题在于它可能导致模型过度拟合数据,从而导致模型仅在该数据集上表现良好。因此,我们应该考虑句子的上下文和意义。为了解决这个问题,数据集中20%的问题包含许多同义词,这有助于我们判断模型是否理解了词语的意义。此外,在测试数据集中,10%的问题对所有模式、表和列都包含同义词,这使我们能够判断哪个模型表现更好。
4.4 多模式
模型应预测第二Python代码组件中的子类(模式)。我们的数据集包含40种统计模式。对于分布和绘图统计问题,模型只需找出一种模式即可。然而,在现实世界情况下,用户可能同时请求多种统计模式,例如“计算学生年龄的最常见的值和中位数。” 这个问题使用模式和中位数统计模式来回答。此外,为每个问题预测一种模式对模型来说并不难。因此,为了增加任务的难度,我们定义了多模式规则。对于统计数值类型,一个问题可以同时询问多达三种模式。这将增加任务的难度,使我们能够衡量模型在区分21种统计数值模式方面的鲁棒性。
5 评估指标
我们使用了多种指标来衡量模型在该数据集上的表现:执行准确率、结构匹配和同义词准确率。对于执行准确率,大多数以前在语义解析领域的研究,如文本到SQL [5] [7] [10] [14] [22] [23] [24] [25] 和问答任务 [1] [8] [16] [19],都使用了这种评估指标,这需要预测带有值的样本。在SIGMA数据集中,只有1444个问题需要预测5个Python代码组件标签以及值。这些问题仅与四种不同模式相关,即where、百分位数、修剪均值和置信区间。
结构匹配衡量模型预测与真实值Python代码组件标签完全匹配的百分比。然而,第五个额外参数标签中的一些值未包含在此度量中,这些值与以下四种模式有关:where、百分位数、修剪均值和置信区间。我们不包括它们,因为它们的值根据用户的输入而变化。例如,如果问题是“找到医生工资的70%百分位数”,70%的值可能因问题而异,基于用户的需求。
同义词准确率衡量模型在理解问题意义方面的稳健性。在测试数据集中,10%的问题对其模式、表和列使用同义词。假设模式是标准正态分布,表是商店,列是产品价格。在这种情况下,问题可以表述为“给我看看商店中所有产品成本的z分布”。
6 方法
本节展示了在我们的文本到代码任务上评估的三个模型的实验。问题和模式将是模型的输入,
然后模型将预测五个Python代码组件。我们在三个模型(LGESQL [3]、SLSQL [9] 和 SmBoP [17])上测试我们的数据集,这些模型在Spider [23]数据集竞赛中很受欢迎。
LGESQL [3] 包含三个部分,即输入、隐藏和输出模块。输入模块提供了图节点和边的初始嵌入。使用词嵌入Glove [13]或预训练语言模型如BERT [6]和ELECTRA [4]获得这些嵌入的表示。第二个(隐藏)模块使用图神经网络对最初生成的节点嵌入之间的关系结构进行编码和捕获。在最后一个输出模块中,应用语法基础的句法神经解码器,它将构造预测查询的抽象语法树(AST)。我们的修改主要集中在生成所需的AST上。所有44种模式都被包含在语法规则中。主要的变化涉及将五个Python代码组件转换为模型输入中的AST,然后在模型输出中将AST反解析为五个Python代码标签。
SLSQL。我们使用SLSQL [9]的简单基础模型,它由两部分组成:编码器和解码器。编码器将输入问题和模式项连接起来,传递给BERT变压器以生成词嵌入。之后,在两步解码过程中,解码器首先构建不带聚合函数的查询,然后使用GRU网络获取最终带聚合函数的查询。至于我们的数据集,主要修改是在SLSQL在预处理阶段生成的输入序列上进行的。输入序列代表在训练阶段每个问题对应的五个Python代码标签。此外,SLSQ在解码过程中实施了一些约束,以确保生成的SQL查询可以执行。我们也创建了类似的约束,以确保获得的五个Python代码标签可以执行。
SmBoP 和 T5。SmBop [17]模型使用自底向上的方法通过在束搜索阶段的第t步构建深度 ≤ t \leq \mathrm{t} ≤t的前K个子树来解决这个问题。在步骤 t + 1 \mathrm{t}+1 t+1中,从前一步t的前K个子树中构建更深的新树,并且仅保存K个最佳结果用于步骤 t + 1 \mathrm{t}+1 t+1。自底向上方法有助于解决自顶向下方法中的一个问题,即在完成构建整个树之前,部分树无法提供清晰的语义含义。对于编码器部分,SmBop模型继承自RATSQL+GRAPPA [18] [21]编码器。与其他模型类似,SmBop使用语法规则生成结果。然而,我们使用新语法规则为SmBop得到的结果并不好。为了充分利用SmBop模型的能力,我们使用WHERE子句预测子类而不是使用新规则。为了进一步提高结果的准确性,我们将问题视为文本摘要问题。T5 15]模型在摘要模式下进行训练,自然语言问题作为文本,子类名称和额外参数的连接作为摘要。然后使用T5模型的结果替换先前模型的部分结果。
7 实验结果
表3. 对不同类型模式的五个Python代码组件预测的结构和执行准确率。“统计”指结合数值、分布和绘图类型的准确率。“同义词”指针对表、列和模式类型的测试问题的同义词。
| 结构准确率 | |||||||
|---|---|---|---|---|---|---|---|
| 分类结果 | 所有 | ||||||
| 模型 | 数值 | 分布 | 绘图 | 查询 | 统计 | 同义词 | |
| SLSQL | 53.33 % 53.33 \% 53.33% | 60.56 % 60.56 \% 60.56% | 59.68 % 59.68 \% 59.68% | 41.81 % 41.81 \% 41.81% | 55.58 % 55.58 \% 55.58% | 33.75 % 33.75 \% 33.75% | 48.75 % 48.75 \% 48.75% |
| SmBoP + GraPPa + T 5 \operatorname{SmBoP}+\operatorname{GraPPa}+\mathrm{T} 5 SmBoP+GraPPa+T5 | 63.33 % 63.33 \% 63.33% | 69.01 % 69.01 \% 69.01% | 79.03 % 79.03 \% 79.03% | 87.40 % 87.40 \% 87.40% | 66.75 % 66.75 \% 66.75% | 37.50 % 37.50 \% 37.50% | 77.00 % 77.00 \% 77.00% |
| LGESQL + Glove | 67.28 % 67.28 \% 67.28% | 71.83 % 71.83 \% 71.83% | 65.08 % 65.08 \% 65.08% | 71.36 % 71.36 \% 71.36% | 67.74 % 67.74 \% 67.74% | 42.50 % 42.50 \% 42.50% | 69.75 % 69.75 \% 69.75% |
| LGESQL + BERT | 78.00 % 78.00 \% 78.00% | 85.92 % 85.92 \% 85.92% | 80.95 % 80.95 \% 80.95% | 84.67 % 84.67 \% 84.67% | 79.85 % 79.85 \% 79.85% | 65.00 % 65.00 \% 65.00% | 82.50 % 82.50 \% 82.50% |
| LGESQL + ELECTRA | 78.00 % 78.00 \% 78.00% | 85.92 % 85.92 \% 85.92% | 82.54 % 82.54 \% 82.54% | 86.18 % 86.18 \% 86.18% | 80.09 % 80.09 \% 80.09% | 73.75 % 73.75 \% 73.75% | 83.37 % 83.37 \% 83.37% |
| 执行准确率 | |||||||
| SmBoP + GraPPa + T 5 \operatorname{SmBoP}+\operatorname{GraPPa}+\mathrm{T} 5 SmBoP+GraPPa+T5 | 63.33 % 63.33 \% 63.33% | 69.01 % 69.01 \% 69.01% | 79.03 % 79.03 \% 79.03% | 86.14 % 86.14 \% 86.14% | 66.75 % 66.75 \% 66.75% | 37.50 % 37.50 \% 37.50% | 76.38 % 76.38 \% 76.38% |
结构准确率和执行准确率用于评估模型的真实值和预测Python标签之间的准确率。可以在表3中找到三种模型性能的比较。SLSQL表现最低,为 48.75 % 48.75 \% 48.75%,原因是SLSQL基础模型未能很好地解决模式链接问题。LGESQL使用词向量Glove [13]、LGESQL使用PLM BERT [6] 和 LGESQL [3] 使用PLM ELECTRA [4] 的准确率分别为 69.75 % 69.75 \% 69.75%, 82.50 % 82.50 \% 82.50% 和 83.37 % 83.37 \% 83.37%. Glove的问题在于它不考虑每个词的上下文,这解释了它的较低性能。PLM ELECTRA优于PLM BERT。这是由于BERT替换了某些输入标记为[MASK],阻止模型从所有输入中学习。相比之下,ELECTRA使用替换标记检测从所有输入中学习,并根据上下文确定输入中的每个词是否被替换。
由于SmBoP模型 [17] 依赖于在合成问题-SQL对上预训练的PLM GraPPa [21],结果不尽如人意。然而,在我们使用T5模型 [15] 预测子类和额外参数后,这一问题已得到解决。该模型在结构匹配中达到了
77
%
77 \%
77%,在执行准确率为
76.38
%
76.38 \%
76.38%。执行准确率的结果表明其表现良好,但仍需改进空间。尽管
LGESQL + ELECTRA在结构匹配中实现了最高的准确率,同义词的准确率为
73.75
%
73.75 \%
73.75%。因此,显然需要改进模型以处理同义词。需要注意的是,预测带有值的五个Python标签代码需要模型具备领域先验知识。然而,我们更关注结构匹配,这不需要预测带有值的Python标签,这就是为什么我们使用了三个模型进行结构匹配和一个模型进行执行准确率的原因。
8 结论
我们介绍了SIGMA,一个用于文本到代码语义解析的带统计分析的数据集,它包含跨越160个数据库的6000个问题及其对应的Python代码。在SIGMA中,我们的数据集涵盖了44种模式,其中40种用于统计分析。通过我们的内置Python执行器,用户可以执行生成的Python代码。实验中使用了三个模型:LGESQL、SLSQL 和 SmBoP。T5模型用于帮助提高SmBoP模型中子类和额外参数的准确性。据我们所知,这是第一个利用Python编程语言检索信息并进行统计分析的文本到代码任务的数据集。
参考文献
- Berant, J., Chou, A., Frostig, R., Liang, P.: Freebase上的语义解析从问题-答案对。《2013年自然语言处理经验方法会议论文集》pp. 1533-1544 (2013)
-
- Bruce, P., Bruce, A., Gedeck, P.: 数据科学家实用统计学:使用R和Python的50多个重要概念。O’Reilly Media (2020)
-
- Cao, R., Chen, L., Chen, Z., Zhao, Y., Zhu, S., Yu, K.: Lgesql: 增强文本到SQL模型的线图与混合局部和非局部关系。arXiv preprint arXiv:2106.01093 (2021)
-
- Clark, K., Luong, M.T., Le, Q.V., Manning, C.D.: Electra: 将文本编码器预训练为判别器而非生成器。arXiv preprint arXiv:2003.10555 (2020)
-
- Dahl, D.A., Bates, M., Brown, M.K., Fisher, W.M., Hunicke-Smith, K., Pallett, D.S., Pao, C., Rudnicky, A., Shriberg, E.: 扩展ATIS任务的范围:ATIS-3语料库。《1994年人类语言技术研讨会论文集》(1994)
-
- Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: 预训练深层双向Transformer以理解语言。arXiv preprint arXiv:1810.04805 (2018)
引用: S. Almohaimeed, S. Liu, M. Alsofyani, S. Almohaimeed and L. Wang, “SIGMA: A Dataset for Text-to-Code Semantic Parsing with Statistical Analysis,” 2023 International Conference on Machine Learning and Applications (ICMLA), Jacksonville, FL, USA, 2023, pp. 851-857, doi: 10.1109/ICMLA58977.2023.00125. IEEE Xplore链接: https://ieeexplore.ieee.org/abstract/document/10459845 - Iyer, S., Konstas, I., Cheung, A., Krishnamurthy, J., Zettlemoyer, L.: 从用户反馈中学习神经语义解析器。arXiv preprint arXiv:1704.08760 (2017)
-
- Joshi, M., Choi, E., Weld, D.S., Zettlemoyer, L.: Triviaqa: 一个大规模远程监督的阅读理解挑战数据集。arXiv preprint arXiv:1705.03551 (2017)
-
- Lei, W., Wang, W., Ma, Z., Gan, T., Lu, W., Kan, M.Y., Chua, T.S.: 重新审视文本到SQL中模式链接的作用。《2020年自然语言处理经验方法国际会议论文集》pp. 6943-6954 (2020)
10.10. Li, F., Jagadish, H.V.: 构建交互式的自然语言界面以访问关系数据库。《VLDB Endowment会议记录》8(1), 73-84 (2014)
- Lei, W., Wang, W., Ma, Z., Gan, T., Lu, W., Kan, M.Y., Chua, T.S.: 重新审视文本到SQL中模式链接的作用。《2020年自然语言处理经验方法国际会议论文集》pp. 6943-6954 (2020)
- Ling, W., Grefenstette, E., Hermann, K.M., Kočiskÿ, T., Senior, A., Wang, F., Blunsom, P.: 潜在预测网络用于代码生成。arXiv preprint arXiv:1603.06744 (2016)
-
- Oda, Y., Fudaba, H., Neubig, G., Hata, H., Sakti, S., Toda, T., Nakamura, S.: 学习生成伪代码的方法使用统计机器翻译。《2015年第30届IEEE/ACM自动化软件工程国际会议论文集》pp. 574-584. IEEE (2015)
-
- Pennington, J., Socher, R., Manning, C.D.: Glove: 全局向量用于词表示。《2014年自然语言处理经验方法会议论文集》pp. 1532-1543 (2014)
-
- Price, P.: 说话语言系统评估:ATIS领域。《语音与自然语言:1990年宾夕法尼亚州Hidden Valley研讨会论文集》(1990)
-
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: 探索统一文本到文本Transformer转移学习的极限。《Journal of Machine Learning Research》21(1), 5485-5551 (2020)
-
- Rajpurkar, P., Jia, R., Liang, P.: 知道你不知道的:Squad的不可回答问题。arXiv preprint arXiv:1806.03822 (2018)
-
- Rubin, O., Berant, J.: Smbop: 半自回归自底向上的语义解析。arXiv preprint arXiv:2010.12412 (2020)
-
- Wang, B., Shin, R., Liu, X., Polozov, O., Richardson, M.: Rat-sql: 关系感知的模式编码和链接用于文本到SQL解析器。arXiv preprint arXiv:1911.04942 (2019)
-
- Welbl, J., Stenetorp, P., Riedel, S.: 构建多跳文档阅读理解数据集。《计算语言学协会会刊》6, 287-302 (2018)
-
- Yin, P., Deng, B., Chen, E., Vasilescu, B., Neubig, G.: 从Stack Overflow学习挖掘对齐的代码和自然语言对。《2018年第15届国际软件仓库挖掘会议论文集》pp. 476-486 (2018)
-
- Yu, T., Wu, C.S., Lin, X.V., Wang, B., Tan, Y.C., Yang, X., Radev, D., Socher, R., Xiong, C.: Grappa: 带语法增强预训练的表语义解析。arXiv preprint arXiv:2009.13845 (2020)
-
- Yu, T., Zhang, R., Er, H.Y., Li, S., Xue, E., Pang, B., Lin, X.V., Tan, Y.C., Shi, T., Li, Z., et al.: Cosql: 跨域自然语言数据库接口的对话式文本到SQL挑战。arXiv preprint arXiv:1909.05378 (2019)
-
- Yu, T., Zhang, R., Yang, K., Yasunaga, M., Wang, D., Li, Z., Ma, J., Li, I., Yao, Q., Roman, S., et al.: Spider: 大规模人工标注的复杂和跨域语义解析和文本到SQL任务数据集。arXiv preprint arXiv:1809.08887 (2018)
-
- Yu, T., Zhang, R., Yasunaga, M., Tan, Y.C., Lin, X.V., Li, S., Er, H., Li, I., Pang, B., Chen, T., et al.: Sparc: 上下文中的跨域语义解析。arXiv preprint arXiv:1906.02285 (2019)
-
- Zhong, V., Xiong, C., Socher, R.: Seq2sql: 使用强化学习从自然语言生成结构化查询。arXiv preprint arXiv:1709.00103 (2017)
参考论文:https://arxiv.org/pdf/2504.04301
- Zhong, V., Xiong, C., Socher, R.: Seq2sql: 使用强化学习从自然语言生成结构化查询。arXiv preprint arXiv:1709.00103 (2017)
- Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: 预训练深层双向Transformer以理解语言。arXiv preprint arXiv:1810.04805 (2018)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











