






Esperança Amengual-Alcover1 a , Antoni Jaume-i-Capó1 b , Miquel Miró-Nicolau1 c , Gabriel Moyà-Alcover1 d 和 Antonia Paniza-Fullana2 e
1 数学与计算机科学系,巴利阿里群岛大学,Ctra. de Valldemossa, Km. 7.5, 07122 - 帕尔马德马略卡,西班牙。
2 民法系,巴利阿里群岛大学,Ctra. de Valldemossa, Km. 7.5, 07122 - 帕尔马德马略卡,西班牙。
{eamengual, antoni.jaume, miquel.miro, gabriel.moya, antonia.paniza}@uib.es
- 关键词:可解释的人工智能(XAI),可解释性,健康与福祉,XAI评估测量,评估框架。
-
- 摘要:将人工智能集成到计算机系统的开发中提出了新的挑战:使智能系统对人类具有可解释性。这在健康与福祉领域尤为重要,因为在决策支持系统中的透明度使医疗专业人员能够理解和信任自动化的决策和预测。为了满足这一需求,需要工具来指导可解释AI系统的开发。本文中,我们介绍了一个为健康与福祉设计的可解释AI系统的评估框架。此外,我们还通过一个案例研究展示了该框架在实践中的应用。我们认为,我们的框架不仅可用于开发医疗领域的可解释AI系统,还可用于任何对个人有重大影响的AI系统。
1 引言
第三代人工智能(AI)系统的特点体现在两个关键方面:(1)技术进步和多样化的应用;(2)以人为中心的方法(Xu 2019)。尽管AI正在取得令人印象深刻的结果,但这些成果往往难以被人类用户解读。为了信任智能系统的行为,尤其是在健康与福祉领域,它们需要清楚地传达其决策和行动背后的理由。可解释的人工智能(XAI)旨在满足这一需求,通过优先考虑透明性,使AI系统能够描述其决策和预测背后的推理过程。
对XAI的兴趣日益增加,这一点在多个科学活动中得以反映(Adadi和Berrada 2018;Alonso、Castiello和Mencar 2018;Anjomshoae等人2019;Biran和Cotton 2017;Došilović、Brčić和Hlupić 2018),以及最近关于这一主题的综述文章数量的显著增加(Abdul等人2018;Alonso、Castiello和Mencar 2018;Anjomshoae等人2019;Chakraborti等人2017;Došilović、Brčić和Hlupić 2018;Gilpin等人2018;Murdoch等人2019),特别是在健康与福祉领域(Mohseni、Zarei和Ragan 2021;Tjoa和Guan 2021)。XAI正作为一个新学科出现,需要标准化的实践。由于XAI的目标、设计策略和评估技术的多样性,已经产生了多种创建可解释系统的途径(Mohseni、Zarei和Ragan 2021)。Murdoch等人(Murdoch等人2019)提出了一种广泛的XAI方法分类,将其分为基于模型的技术和事后技术。然而,正如(Mohseni、Zarei和Ragan 2021)所讨论的那样,实现有效的XAI设计需要一种综合方法,考虑设计目标和评估方法之间的依赖关系。
a https://orcid.org/0000-0002-0699-6684
b https://orcid.org/0000-0003-3312-5347
c https://orcid.org/0000-0002-4092-6583
d https://orcid.org/0000-0002-3412-5499
e https://orcid.org/0000-0002-1302-9713
在本研究中,我们提出了一种评估框架,旨在指导健康与福祉领域可解释AI系统的开发,重点放在法律和伦理问题上。我们通过一个医学图像分析的案例研究说明了我们的方法,这是我们之前经验丰富的领域。在医疗保健中,仅基于不可解释预测的决策不足以满足伦理和法律标准。可解释性有助于合理化AI驱动的诊断、治疗计划和疾病预测,增强专业人士和患者的理解。事实上,可解释性被认为是AI系统的一个基本伦理原则,确保其对最终用户的透明性(Alcarazo 2022)。这一原则与欧洲议会的《数字时代的AI报告》(VOSS,n.d.)一致,该报告强调透明性和可解释性是基础性的。
我们的目标是确保用于医学图像分析的智能系统符合这些伦理标准和相关法规。鉴于AI驱动决策对个人的重大影响,保护个人数据并告知患者这些系统如何使用至关重要。此外,医务人员必须能够理解AI系统结论背后的推理逻辑,以理解其预测和建议的逻辑依据。
2 先前工作
在(Mohseni、Zarei和Ragan 2021)中,提出了一种通用框架,用于设计XAI系统,为多学科团队提供了一个高层次的指南,以开发特定领域的XAI解决方案。根据作者的观点,该框架的灵活性使其广泛适用,能够定制以满足不同领域的需求。在我们的工作中,我们在此框架基础上构建,整合了专门针对健康和福祉应用需求的设计指南。图1提供了原始框架的概述,这是我们领域聚焦扩展的基础。分层结构连接了核心设计目标和跨不同研究社区的评估优先事项,促进了XAI系统领域的多学科进展。这种结构支持设计步骤,从最外层(XAI系统目标)开始,然后考虑中间层(可解释界面)的最终用户需求,最后聚焦于最内部层(可解释算法)。框架建议进行设计和评估的迭代循环,使全面考虑算法和以人为中心的方面成为可能。
在我们针对健康与福祉的XAI系统框架中,过程从现有的AI系统和一组先前用于验证目的的XAI方法开始。因此,我们的重点在于评估极,目标是对AI系统进行评估,并为设计极中的可解释任务提供改进建议。
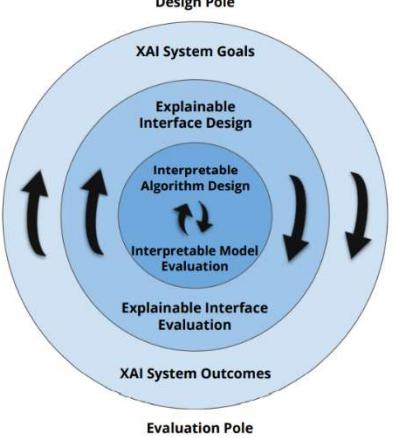
图1:通用XAI设计与评估框架(摘自(Mohseni、Zarei和Ragan 2021))
3 XAI评估指标
我们建议将不同的解释质量分类为三个主要类别:机器中心特征、人中心特征和社会中心问题。这些类别解决了评估XAI系统的不同关键方面。
3.1 机器中心特征
机器中心特征专注于纯粹的算法方面,独立于外部评估者。
保真度定义为生成模型预测真实解释的正确性(Mohseni、Zarei和Ragan 2021),是此类别中最广泛研究的特征。保真度评估方法可以分为:
- 合成归属基准(SABs):这些由控制场景下创建的数据集组成,包含真实解释。SABs帮助识别不正确的解释方法,但无法确认其正确性。存在多种生成这些数据集的方法论,包括(Arias-Duart等人2022;Arras等人2017;Cortez和Embrechts 2013;Guidotti 2021;Mamalakis、Barnes和Ebert-Uphoff 2022;Miró-Nicolau、Jaume-i-Capó和Moyà-Alcover 2024a)提出的那些方法。
- 事后保真度指标:这些指标近似于在没有真实解释的情况下实际场景中的保真度。包括(Alvarez Melis和Jaakkola 2018;Bach等人2015;Samek等人2017;Rieger和Hansen 2020;Yeh等人2019)在内的几位作者提出了事后保真度指标。然而,这些指标因其不可靠结果而受到批评(Hedström等人2023;Miró-Nicolau、Jaume-i-Capó和Moyà-Alcover 2025;Tomsett等人2020)。
- 鲁棒性定义为输入数据的小幅变化产生相似解释的期望(Alvarez Melis和Jaakkola 2018)。鲁棒性指标由(Agarwal等人2022;Alvarez Melis和Jaakkola 2018;Dasgupta、Frost和Moshkovitz 2022;Montavon、Samek和Müller 2018;Yeh等人2019)提出。
复杂性指解释中使用的变量数量。其互补特征稀疏性确保只有真正预测性的特征贡献于解释(Chalasani等人2020)。
定位测试解释是否集中在一个特定的兴趣区域。(Hedström等人2023)
随机化评估当数据标签或模型参数被随机化时解释的退化程度,如(Hedström等人2023)所探讨的那样。
3.2 人中心特征
人中心特征专注于依赖用户与XAI系统交互的主观元素。这些特征超越AI,在社会科学和行为科学中进行了分析(Hoffman等人2018;Miller 2019)。关键特征包括心理模型、好奇心、可靠性和信任,其中信任是评估XAI系统的核心(Barredo Arrieta等人2020;Miller 2019)。信任在自动化中至关重要(Adams等人2003;Lee和See 2004;Mercado等人2016),通常通过各种量表测量。(Jian、Bisantz和Drury 2000)提出通过11项量表测量信任,由于其广泛应用和对其他量表的影响,已成为事实上的标准。
用户信任定义为“代理将在不确定和脆弱的情况下帮助个体实现目标的态度”(Lee和See 2004)。尽管信任本质上是主观的,但客观测量它是理想的。(Mohseni、Zarei和Ragan 2021)确定量表和访谈作为主观方法,而(Scharowski等人2022)提倡行为测量。(Lai和Tan 2019)提出通过用户依赖系统预测的频率来测量信任,发现用户更信任正确的预测。此外,(Lai和Tan 2019;Miró-Nicolau等人2024)引入了一种结合性能和信任数据的信任度量方法,使用混淆矩阵得出四个不同的度量。这些度量受分类任务中已建立的真正例、真负例、假正例和假负例度量的启发,提供了系统性能与用户信任之间相互作用的见解,允许更复杂的度量,如精确率和召回率。
3.3 法律和伦理问题
法律和伦理考量对于确保智能系统内数据和操作的透明性和可追溯性至关重要,特别是为了遵守法规和提供法律确定性。在涉及健康数据的背景下,解决算法潜在偏差的问题尤为重要。
根据《通用数据保护条例》(GDPR)(Union 2016),个人数据是指任何能识别或可能识别自然人的信息,因此隐私是一个关键问题。西班牙数据保护局强调了识别与个人相关的个人数据处理、画像或决策的重要性,这要求遵守数据保护法律。
虽然AI系统可以使用匿名数据,但算法的透明性和可解释性仍然至关重要。GDPR第78条规定,开发者应在设计、选择或使用处理个人数据的应用程序时确保遵守数据保护规定。隐私设计原则和默认隐私原则(GDPR第25条)必须优先考虑。此外,第三方如医务人员必须理解IA系统、其算法和输出,以防止伤害(Justa 2022)。这些要求具有重要的伦理和法律影响,特别是关于责任问题。
2024年,欧盟委员会批准了AI法案,监管欧洲范围内的AI技术(‘条例 (EU) 2024/1689 制定人工智能的统一规则并修订法规 (EC) No 300/2008, (EU) No 167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 和 (EU) 2019/2144 以及指令 2014/90/EU, (EU) 2016/797 和 (EU) 2020/1828 (人工智能法案) – 欧洲在线资源’ 2024)。该法律引入了基于风险的分类系统,将AI应用分为不可接受、高、有限或最小风险类别。禁止不可接受风险类别的应用,而高风险和有限风险类别的应用必须满足特定要求,包括人工监督和稳健性。因此,透明性和可靠的XAI仍然是首要任务。
此外,欧盟委员会关于可信AI的指南(‘可信人工智能自我评估的评估清单 (ALTAI) | 塑造欧洲的数字未来’ 2020)定义了可靠AI的七个要求:(1)人类自主权和监督;(2)技术稳健性和安全性;(3)隐私和数据治理;(4)透明度;(5)多样性、非歧视性和公平性;(6)社会和环境福祉;(7)问责制。这些标准必须在整个AI系统的生命周期中进行评估,以确保法律和伦理合规。
4 XAIHEALTH
在前一节中,我们分析了用于评估XAI系统的各种指标,突出了用于评估可解释性不同方面的多样化方法。我们将这些方法分类为三类:机器中心、人中心和社会中心特征。然而,需要注意的是,由于这些评估方面的相互依赖性,它们不能同时进行评估。例如,如果解释缺乏对AI预测根本原因的保真度,则用户对该解释的信任变得无关紧要,因为预测本身可能是错误的。因此,对XAI系统的全面评估必须依次进行。
(Mohseni、Zarei和Ragan 2021)提出的框架需要适应特定上下文,正如引言中所指出的那样。在本节中,我们提出了该框架在医疗保健领域的定制适应版本。鉴于医疗保健中的AI系统根据欧盟AI法案被归类为高风险,它们需要严格的验证和监控。我们的适应版本解决了将XAI集成到这些高风险环境中的独特需求和挑战。
为此,我们提出了一个新的评估框架,命名为XAIHealth,旨在有效评估健康与福祉背景下的XAI系统。图2说明了该框架相对于基础框架的适应情况。
如图2所示,XAIHealth围绕基础框架中定义的评估极任务展开(见图1)。每一层,从最内层到最外层,包含两个阶段:机器中心分析和人中心评估。这些阶段之前有一个初始预评估阶段,包括训练AI模型和应用XAI方法。法律和伦理考量是贯穿整个系统开发、评估和部署的交叉要素。图3展示了XAIHealth框架的阶段和流程。
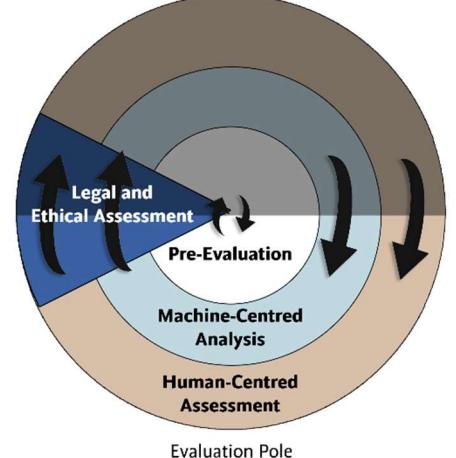
图2:XAIHealth在评估极中的阶段
4.1 法律和伦理评估
在我们的框架中,伦理和法律因素被整合到每个阶段,强调隐私、数据管理和透明度对于可靠AI系统的重要性,以符合当前立法。
对于隐私和数据管理,应优先考虑最严格的法规,以欧洲立法(尤其是GDPR)为参考点,因其严格的标准。根据GDPR第4.2条,个人画像和决策均被视为数据处理形式。健康数据根据GDPR第9条被归类为特殊个人数据,需要额外保护。应使用匿名数据或建立合法处理依据。在我们的情况下,获得受影响个人的同意是一种确保合规的可行方法。
透明性在GDPR第78条中得到解决,该条款规定参与者必须被告知AI系统是否会被用于影响他们的决策过程中。
为了评估法律合规性和伦理标准,我们建议使用ALTAI(可信人工智能评估清单)指南(‘可信人工智能自我评估的评估清单 (ALTAI) | 塑造欧洲的数字未来’ 2020),该指南由欧盟委员会委托的专家组(AI HLEG)制定。这些指南实现了可信人工智能伦理指南的操作化,并与欧盟AI法案的原则一致。
ALTAI文件确定了构建可信AI系统的七个基本要求。每个要求都根据具体情境设定具体的评估标准。以下是这些要求的总结:
- (1)人类自主权和监督。这确保AI系统尊重用户自主权并告知用户AI参与情况。六个关键问题引导评估用户自主权是否得到维护以及用户是否意识到他们正在与AI互动。
-
- (2)技术稳健性和安全性。此要求评估AI系统对对抗性输入、新型数据和网络安全风险的抵御能力。它关注稳健性,特别是系统在面对对抗性更改和变化的输入数据时保持性能的能力(Goodfellow、Shlens和Szegedy 2015)。
-
- (3)隐私和数据治理。此要求侧重于DGPR合规性,强调数据的适当处理和保护。其主要目标是确保数据治理实践与法律隐私标准一致。
-
- (4)透明性。透明性指AI系统过程的可理解程度。ALTAI指定透明性结合了可解释性与关于AI系统功能和限制的有效沟通。
-
- (5)多样性、非歧视性和公平性。此要求涉及减少偏见和促进包容性设计。它通过确保无障碍性和普遍设计原则来消除歧视性元素。
-
- (6)社会和环境福祉。此要求评估AI系统的广泛影响,包括环境可持续性、就业和技能影响、社会影响和民主进程。评估是任务依赖的,旨在减轻潜在的社会风险。
-
- (7)问责制。此要求集中在系统生命周期中的风险管理机制和问责制建立上。它实现了持续监控以检测潜在错误和风险行为。
这些要求与我们提议框架的各个阶段相一致。在介绍每个阶段时,我们将概述相关的ALTAI要求,并讨论确保AI系统达到这些标准的策略。这种方法旨在将符合伦理和法律指南的要求整合到框架的每一步中。
- (7)问责制。此要求集中在系统生命周期中的风险管理机制和问责制建立上。它实现了持续监控以检测潜在错误和风险行为。
4.2 第0阶段——预评估
预评估阶段始于已证明足够效能的现有AI系统。选择并应用一组XAI方法对此系统进行验证/评估。目的是全面评估XAI系统。
在此阶段,必须解决ALTAI指南中的三个关键要求:隐私和数据治理、多样性和非歧视性及公平性、社会和环境福祉。我们将在下一小节的案例研究中说明这些要求如何应用。
4.2.1 案例研究中的应用
在预评估阶段,我们评估了一个用于识别胸部X光图像中肺炎迹象的AI系统。具体而言,我们利用了Miró-Nicolau等人(Miró-Nicolau、Jaume-i-Capó和Moyà-Alcover 2024a)提出的AI模型,该模型提出了一种衡量医疗环境中AI系统信任的新方法。在这种实验设置中,作者训练了一个知名的卷积神经网络(CNN),即ResNet18,由(He等人2016)提出。该AI系统采用监督学习方法在标记数据集上进行训练,包括输入与其正确输出配对。该模型在Hospital Universitari Son Espases(HUSE)的2048张X光图像上进行训练,涵盖COVID-19肺炎和非肺炎病例。系统达到了0.8的准确率,这是总样本中正确预测的比例。为了提供解释,应用GradCAM算法(Alvarez Melis和Jaakkola 2018)生成热图,显示图像中哪些区域对模型预测最具影响力,从而洞察模型的决策过程。
从法律和伦理角度来看,以下三个ALTAI要求必须在此阶段得到解决:
- 隐私和数据治理。遵守GDPR是主要目标。在我们的案例研究中,Hospital Universitari Son Espases(HUSE)的研究委员会核实了数据合规性,确保所有数据均已匿名化。因此,我们确认隐私和数据治理要求得到了满足。
-
- 多样性、非歧视性和公平性。此要求与隐私和数据治理密切相关,确保匿名的X光图像无偏见。GUI设计过程中也考虑了无障碍性和通用设计,尽管这些元素超出了评估框架的范围。我们得出结论,避免歧视的目标在此案例中已达成。
-
- 社会和环境福祉。该模型的目的是识别患者中的COVID-19肺炎,在此背景下,必须评估三个主要因素:其环境影响、对民主的影响和更广泛的社会影响。首先,很明显,此应用对民主进程没有直接影响。同样,其对社会的影响有限,因为该系统被设计为诊断支持工具,以增强医疗实践,而不是改变社会结构。
- 在环境影响方面,主要关注点在于模型训练阶段涉及的能源消耗,这通常是该过程最耗资源的方面。然而,在这种情况下,由于采用了相对较小的模型(ResNet18)和适度的数据集(2048张图像),能源使用已被最小化。因此,我们断言该模型符合环境可持续性的要求。
4.3 第1阶段——机器中心分析
此阶段的主要目标是评估XAI系统的机器中心特征,重点关注可以独立于最终用户测量的算法属性。保真度被认为是此类别中最关键的指标,这由其在前沿研究中的主导地位所表明。然而,计算保真度具有挑战性,正如(Hedström等人2023)所指出的,“由于评估函数应用于不可验证的解释函数结果,评估结果也不可验证”。为了解决这个问题,我们认为有必要采用经过验证的事后测量方法,仅使用经过验证的指标以避免不可靠的评估。
在我们的分析中,排除了未经验证的指标,因此现有事后保真度指标缺乏验证使其不适合实际应用。(Hedström等人2023)提出了一种元评估过程,审查了多个机器中心指标,揭示了其优缺点。然而,分析的十个指标中没有一个达到完美结果,这意味着保真度和类似特征可能尚未在实际情境中可靠使用。
在机器中心特征中,鲁棒性也得到了广泛研究。Miró-Nicolau等人(Miró-Nicolau、Jaume-i-Capó和Moyà-Alcover 2024b)开发了一套测试以评估鲁棒性指标,最初将其应用于(Yeh等人2019)的AVG-Sensitivity和MAX-Sensitivity。我们扩展了这些测试以包括其他鲁棒性指标,确定局部Lipschitz估计(LLE)由(Alvarez Melis和Jaakkola 2018)提出是一个可靠且实用的选择。LLE是唯一通过两项鲁棒性测试的指标,使其成为我们评估解释鲁棒性的主要标准。然而,如果未来开发和验证了更多指标,可以将其纳入框架中而无需进一步修改。
此阶段还涉及两个ALTAI要求:技术鲁棒性和安全性以及透明性。如果在此阶段出现问题,可能需要回到预评估阶段,以确定问题源于AI模型还是XAI方法本身。
4.3.1 案例研究中的应用
为了评估我们案例研究中解释的鲁棒性,我们将(Alvarez Melis和Jaakkola 2018)提出的局部Lipschitz估计(LLE)应用于GradCAM生成的解释。最优LLE分数为0,代表最大鲁棒性,而1是最差可能结果。我们设定了一个灵活的接受阈值,认为结果位于前10%的解释是鲁棒的。这是因为即使完美的XAI算法也可能由于底层AI模型本身存在轻微的鲁棒性限制,因此允许小幅度误差。我们获得了平均LLE值为0.082,标准差为0.108。这些结果表明系统的鲁棒性在可接受范围内,满足ALTAI指南的技术鲁棒性和安全性要求。此外,透明性——任何XAI方法的核心目标和缓解黑箱局限性的关键组成部分——由GradCAM方法解决,该方法提供了基于热图的可解释模型预测解释。这些结果确认系统已准备好进入下一个评估阶段。
4.4 第2阶段——人中心评估
此阶段的目的是评估直接影响最终用户体验的XAI方法的人中心特征。为此,必须使用一个界面,该界面同时显示AI系统的预测和来自XAI方法的解释。
此阶段涵盖几个方面,信任是XAI领域的主要焦点,正如Miller(Miller 2019)所强调的。根据(Scharowski等人2022),信任可以从两种视角进行评估:作为一种态度(用户的自我感知)或作为一种行为(遵循AI系统的建议)。这两种方法显然与不同的评估方法相关:客观(行为)或主观(态度)。
为了有效地测量信任,我们采用上一节中回顾的现有指标。我们推荐(Miró-Nicolau等人2024)提出的指标,该指标采用行为方法,将AI系统的预测性能纳入信任评估。
如果此阶段的结果表明存在问题,则可能需要返回预评估阶段,以确定问题源于界面设计还是更广泛的XAI系统限制。
在此阶段,必须解决ALTAI要求的人类自主权和监督,主要是确保用户始终知晓他们在与AI系统互动。此要求与本阶段的重点高度一致,强调用户界面设计和用户与AI系统之间清晰的信息沟通。
4.4.1 案例研究中的应用
在我们的案例研究中,我们评估了放射科医生和其他专家是否信任AI系统的输出。此阶段的结果以及信任测量结果由Miró-Nicolau等人(Miró-Nicolau等人2024)发布。设计团队开发了一个界面,同时向最终用户展示AI系统的预测和XAI方法生成的解释。为了简化理解,通过使用各种阈值去除不太重要的像素来细化解释。专家随后对其对联合诊断和解释的信任水平进行评分,其响应通过(Miró-Nicolau等人2024)的信任指标进行评估。
ALTAI要求的人类自主权和监督与本案例研究中的界面设计完全一致。具体而言,界面明确传达了AI模型和XAI方法正在使用中,满足了这一ALTAI要求。
此阶段的结果汇总在表2中。表格显示了结合分类准确率与用户信任的信任指标。完全信任模型将反映在所有三个指标中值为1。然而,结果显示用户并未完全信任模型,促使返回第0阶段以提高系统的可靠性。因此,在恢复信任之前,该系统不适合实际部署。
| 指标 | 用户1 | 用户2 | 平均 |
|---|---|---|---|
| 精确率 | 0.1094 | 0.0156 | 0.0625 |
| 召回率 | 0.3333 | 0.0714 | 0.2022 |
| F1得分 | 0.1647 | 0.0256 | 0.0952 |
表2:(Miró-Nicolau等人2024)的信任结果
尽管观察到的信任水平较低,但这些结果展示了我们框架在识别AI系统局限性方面的有效性,确保只有值得信赖的模型才能进入实际应用。
4.5 XAI系统运行
在公共使用期间监测健康工具以评估其长期影响至关重要。因此,实施监测阶段对于确保XAI系统能够持续提供服务并符合规定要求至关重要。这一需求与ALTAI指南中概述的七个要求一致。现行立法,特别是欧盟AI法案,规定高风险AI部署(如与健康和福祉相关的部署)必须进行适当的风险评估和缓解策略。此外,医疗保健中的XAI系统必须由机构伦理委员会进行审查、批准和持续监控。如有必要,应对已部署的系统进行修正、修改和改进。
5 结论
在本文中,我们介绍了XAIHealth,这是一个专为健康与福祉设计的新的评估框架。该框架是在(Mohseni、Zarei和Ragan 2021)中详细描述的多学科方法的一般指南基础上构建的。
结果是一个结构化的评估框架,包含两个主要阶段:机器中心分析和人中心评估。这些阶段之前有一个预评估阶段,并以XAI系统运行阶段结束。迭代和反馈贯穿框架的各个阶段,法律和伦理考量在评估过程的每一步中得到解决。
尽管我们的提案主要针对健康与福祉应用,但我们相信该框架也可以适用于任何对人类行为有重大影响的XAI系统。
未来的工作将集中在两个关键领域。首先,我们将详细说明系统运行阶段必要的任务,特别是关于监控和改进。其次,我们旨在将框架应用于更多的案例研究,以验证其有效性并识别潜在的改进之处。
致谢
本工作是项目PID2023-149079OB-I00的一部分,由MICIU/AEI/10.13039/501100011033和ERDF/EU资助。
参考文献
-
Abdul, Ashraf, Jo Vermeulen, Danding Wang, Brian Y. Lim, and Mohan Kankanhalli. 2018. ‘Trends and Trajectories for Explainable, Accountable and Intelligible Systems: An HCI Research Agenda’. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, 1–18. Montreal QC Canada: ACM. https://doi.org/10.1145/3173574.3174156.
-
- Adadi, Amina, and Mohammed Berrada. 2018. ‘Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI)’. IEEE Access 6:52138–60. https://doi.org/10.1109/ACCESS.2018.2870052.
-
- Adams, Barbara D, Lora E Bruyn, Sébastien Houde, and Kim Iwasa-Madge. 2003. ‘TRUST IN AUTOMATED SYSTEMS LITERATURE REVIEW’.
-
- Agarwal, Chirag, Nari Johnson, Martin Pawelczyk, Satyapriya Krishna, Eshika Saxena, Marinka Zitnik, and Himabindu Lakkaraju. 2022. ‘Rethinking Stability
for Attribution-Based Explanations’. https://openreview.net/forum?id=BfxZAuWOg9.
- Agarwal, Chirag, Nari Johnson, Martin Pawelczyk, Satyapriya Krishna, Eshika Saxena, Marinka Zitnik, and Himabindu Lakkaraju. 2022. ‘Rethinking Stability
-
Alcarazo, Lucía Ortiz de Zárate. 2022. ‘Explicabilidad (de la inteligencia artificial)’. EUNOMÍA. Revista en Cultura de la Legalidad, no. 22 (March), 328–44. https://doi.org/10.20318/eunomia.2022.6819.
-
- Alonso, Jose M., Ciro Castiello, and Corrado Mencar. 2018. ‘A Bibliometric Analysis of the Explainable Artificial Intelligence Research Field’. Information Processing and Management of Uncertainty in Knowledge-Based Systems. Theory and Foundations, edited by Jesús Medina, Manuel Ojeda-Aciego, José Luis Verdegay, David A. Pelta, Inma P. Cabrera, Bernadette Bouchon-Meunier, and Ronald R. Yager, 3–15. Communications in Computer and Information Science. Cham: Springer International Publishing. https://doi.org/10.1007/978-3-319-91473-2_1.
-
- Alvarez Melis, David, and Tommi Jaakkola. 2018. ‘Towards Robust Interpretability with Self-Explaining Neural Networks’. Advances in Neural Information Processing Systems. Vol. 31. Curran Associates, Inc.
-
- Anjomshoae, Sule, Amro Najjar, Davide Calvaresi, and Kary Främling. 2019. ‘Explainable Agents and Robots: Results from a Systematic Literature Review’. Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, 1078–88. AAMAS '19. Richland, SC: International Foundation for Autonomous Agents and Multiagent Systems.
-
- Arias-Duart, Anna, Ferran Parés, Dario Garcia-Gasulla, and Victor Giménez-Ábalos. 2022. ‘Focus! Rating XAI Methods and Finding Biases’. 2022 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), 1–8. https://doi.org/10.1109/FUZZ-IEEE55066.2022.9882821.
-
- Arras, Leila, Grégoire Montavon, Klaus-Robert Müller, and Wojciech Samek. 2017. ‘Explaining Recurrent Neural Network Predictions in Sentiment Analysis’. arXiv:1706.07206 [Cs, Stat], August. http://arxiv.org/abs/1706.07206.
-
- ‘Assessment List for Trustworthy Artificial Intelligence (ALTAI) for Self-Assessment | Shaping Europe’s Digital Future’. 2020. 17 July 2020. https://digitalstrategy.ec.europa.eu/en/library/assessment-listtrustworthy-artificial-intelligence-altai-selfassessment.
-
- Bach, Sebastian, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. 2015. ‘On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation’. PLOS ONE 10 (7): e0130140. https://doi.org/10.1371/journal.pone.0130140.
-
- Barredo Arrieta, Alejandro, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador Garcia, et al. 2020. ‘Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI’. Information Fusion 58 (June):82–115. https://doi.org/10.1016/j.inffus.2019.12.012.
-
- Biran, Or, and Courtenay V. Cotton. 2017. ‘Explanation and Justification in Machine Learning : A Survey Or’.
https://www.semanticscholar.org/paper/Explanationand-Justification-in-Machine-Learning-%3A-Biran-Cotton/02e2e79a77d8aabc1af1900ac80ceebac20abde4
- Biran, Or, and Courtenay V. Cotton. 2017. ‘Explanation and Justification in Machine Learning : A Survey Or’.
-
Chakraborti, Tathagata, Sarath Sreedharan, Yu Zhang, and Subbarao Kambhampati. 2017. ‘Plan Explanations as Model Reconciliation: Moving Beyond Explanation as Soliloquy’. Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, 156–63. Melbourne, Australia: International Joint Conferences on Artificial Intelligence Organization. https://doi.org/10.24963/ijcai.2017/23.
-
- Chalasani, Prasad, Jiefeng Chen, Amrita Roy Chowdhury, Somesh Jha, and Xi Wu. 2020. ‘Concise Explanations of Neural Networks Using Adversarial Training’.
-
- Cortez, Paulo, and Mark J. Embrechts. 2013. ‘Using Sensitivity Analysis and Visualization Techniques to Open Black Box Data Mining Models’. Information Sciences 225 (March):1–17. https://doi.org/10.1016/j.ins.2012.10.039.
-
- Dasgupta, Sanjoy, Nave Frost, and Michal Moshkovitz. 2022. ‘Framework for Evaluating Faithfulness of Local Explanations’. Proceedings of the 39th International Conference on Machine Learning, 4794–4815. PMLR. https://proceedings.mlr.press/v162/dasgupta22a.html.
-
- Došilović, Filip Karlo, Mario Brčić, and Nikica Hlupić. 2018. ‘Explainable Artificial Intelligence: A Survey’. 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), 0210–15. https://doi.org/10.23919/MIPRO.2018.8400040.
-
- 吉尔平,莱拉尼·H.,大卫·鲍等。2018. 《解释解释:机器学习可解释性的概述》。2018 IEEE第五届数据科学与高级分析国际会议(DSAA),80–89. https://doi.org/10.1109/DSAA.2018.00018.
-
- 古德费洛,伊恩·J.,乔纳森·施伦斯,克里斯蒂安·塞格迪。2015. 《解释和利用对抗性样本》。arXiv. https://doi.org/10.48550/arXiv.1412.6572.
-
- 瓜迪奥蒂,里卡尔多。2021. 《基于真实数据评估局部解释方法》。人工智能 291(2月):103428.
https://doi.org/10.1016/j.artint.2020.103428.
- 瓜迪奥蒂,里卡尔多。2021. 《基于真实数据评估局部解释方法》。人工智能 291(2月):103428.
-
何,凯明,张祥宇,任少清,孙剑。2016. 《用于图像识别的深度残差学习》。第770–78页。https://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html.
-
- 赫德斯特罗姆,安娜,菲利普·路·邦默,克里索弗·努特森·维克斯特罗姆,沃伊切赫·萨梅克,塞巴斯蒂安·拉普什金,玛丽娜·MC·霍恩。2023. 《可解释AI中的元评估问题:通过MetaQuantus识别可靠估计器》。机器学习研究事务,2月。https://openreview.net/forum?id=j3FK00HyfU.
-
- 霍夫曼,R.,肖恩·T.·穆勒,加里·克莱因,乔丹·利特曼。2018. 《可解释AI的度量:挑战与前景》。arXiv预印本 arXiv:1812.04608,12月。
-
- 简,朱云英,安·M.·比桑茨,科林·G.·德鲁里。2000. 《关于自动化系统信任的经验测量尺度基础》。国际认知工效学杂志 4(1):53–71. https://doi.org/10.1207/S15327566IJCE0401_04.
-
- 贾斯塔,塞古拉 Y. 2022. 《卫生领域的伦理人工智能》。DigitalIES,62.
-
- 拉伊,薇薇安,陈浩·谭。2019. 《关于人类预测与机器学习模型预测的解释:欺骗检测案例研究》。公平、问责和透明度会议论文集,29–38. FAT* '19. 纽约,NY,美国:计算机协会。https://doi.org/10.1145/3287560.3287590.
-
- 李,约翰,卡特里娜·西。2004. 《对自动化的信任:设计适当依赖》。人因工程 46(2月):50–80. https://doi.org/10.1518/hfes.46.1.50.30392.
-
- 妈妈拉基斯,安东尼奥斯,伊丽莎白·A.·巴恩斯,伊姆梅·艾伯特-乌夫霍夫。2022. 《调查地球科学中卷积神经网络应用的可解释人工智能方法的保真度》。地球系统人工智能 1(4)。https://doi.org/10.1175/AIES-D-22-0012.1.
-
- 梅尔卡多,约瑟夫·E.,迈克尔·A.·鲁普,杰西·Y.·C.·陈,迈克尔·J.·巴恩斯,丹尼尔·巴伯,凯特琳·普罗希。2016. 《多人UxV管理中的人机团队智能代理透明度》。人因工程 58(3):401–15. https://doi.org/10.1177/0018720815621206.
-
- 米勒,蒂姆。2019. 《人工智能中的解释:社会科学的见解》。人工智能 267(2月):1–38. https://doi.org/10.1016/j.artint.2018.07.007.
-
- 米罗-尼科劳,米格尔,安东尼·贾乌梅-伊-卡波,加布里埃尔·莫亚-阿尔科弗。2024a. 《评估XAI事后技术的保真度:具有真实数据解释集的比较研究》。人工智能 335(10月):104179. https://doi.org/10.1016/j.artint.2024.104179. 2024b. 《元评估稳定性度量:MAX-Sensitivity和AVG-Sensitivity》。可解释人工智能,由卢卡·隆戈,塞巴斯蒂安·拉普什金,克里斯汀·塞弗特编辑,356–69. Cham: Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-63787-2_18. 2025. 《XAI保真度度量的全面研究》。信息处理与管理 62(1):103900. https://doi.org/10.1016/j.ipm.2024.103900.
-
- 米罗-尼科劳,米格尔,加布里埃尔·莫亚-阿尔科弗,安东尼·贾乌梅-伊-卡波,曼努埃尔·冈萨雷斯-希达尔戈,玛丽亚·吉玛·森佩雷·坎佩略,胡安·安东尼奥·帕尔默·桑乔。2024. 《信任还是不信任:迈向一种新型的XAI系统信任度量方法》。arXiv. https://doi.org/10.48550/arXiv.2405.05766.
-
- 莫森尼,西纳,尼洛法尔·扎雷伊,埃里克·D.·拉根。2021. 《可解释人工智能系统设计与评估的多学科调查与框架》。ACM交互式智能系统交易 11(3–4):1–45. https://doi.org/10.1145/3387166.
-
- 蒙塔冯,格雷戈瓦,沃伊切赫·萨梅克,克劳斯-罗伯特·米勒。2018. 《解读和理解深度神经网络的方法》。数字信号处理 73(2月):1–15. https://doi.org/10.1016/j.dsp.2017.10.011.
-
- 默多克,W.詹姆斯,钱旦·辛格,卡尔·库比尔,雷扎·阿巴西-阿斯尔,宾·于。2019. 《可解释机器学习:定义、方法和应用》。国家科学院院刊 116(44):22071–80. https://doi.org/10.1073/pnas.1900654116.
《条例 (EU) 2024/1689 制定人工智能的统一规则并修订法规 (EC) No 300/2008, (EU) No 167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 和 (EU) 2019/2144 以及指令 2014/90/EU, (EU) 2016/797 和 (EU) 2020/1828 (人工智能法案) – 欧洲在线资源》。2024. 2024. https://www.europeansources.info/record/proposal-for-a-regulation-laying-down-harmonised-rules-on-artificial-intelligence-artificial-intelligence-act-and-amending-certain-union-legislative-acts/.
- 默多克,W.詹姆斯,钱旦·辛格,卡尔·库比尔,雷扎·阿巴西-阿斯尔,宾·于。2019. 《可解释机器学习:定义、方法和应用》。国家科学院院刊 116(44):22071–80. https://doi.org/10.1073/pnas.1900654116.
-
里格尔,劳拉,拉尔斯·凯·汉森。2020. 《IROF:一种低资源解释方法评估指标:ICLR 2020大会上的可负担医疗保健AI研讨会》。ICLR 2020大会上的可负担医疗保健AI研讨会论文集。
-
- 萨梅克,沃伊切赫,亚历山大·宾德,格雷戈瓦·蒙塔冯,塞巴斯蒂安·拉普什金,克劳斯-罗伯特·米勒。2017. 《评估深度神经网络所学内容的可视化》。IEEE神经网络与学习系统汇刊 28(11):2660–73. https://doi.org/10.1109/TNNLS.2016.2599820.
-
- 施哈罗斯基,尼古拉斯,塞巴斯蒂安·A.·C.·佩里格,尼克·冯·费尔滕,弗洛里安·布鲁尔曼。2022. 《XAI中的信任与依赖——区分态度和行为测量》。arXiv. http://arxiv.org/abs/2203.12318.
-
- 提奥亚,埃里科,关坤泰。2021. 《可解释人工智能(XAI)综述:迈向医学XAI》。IEEE神经网络与学习系统汇刊 32(11):4793–4813. https://doi.org/10.1109/TNNLS.2020.3027314.
-
- 汤姆塞特,理查德,丹·哈博恩,苏普里约·查克拉博蒂,普拉德维·古拉姆,艾伦·普里斯。2020. 《显著性度量的合理性检查》。AAAI人工智能会议论文集 34(04):6021–29. https://doi.org/10.1609/aaai.v34i04.6064.
-
- 欧盟出版局。2016. 《欧洲议会和理事会条例 (EU) 2016/679,2016年4月27日关于自然人个人数据处理保护及此类数据自由流动,并废除指令 95/46/EC (通用数据保护条例)(具有欧洲经济区相关性的文本)》。
网站。欧盟出版局。2016年4月27日。http://op.europa.eu/en/publicationdetail/-/publication/3e485e15-11bd-11e6-ba9a-01aa75ed71a1.
- 欧盟出版局。2016. 《欧洲议会和理事会条例 (EU) 2016/679,2016年4月27日关于自然人个人数据处理保护及此类数据自由流动,并废除指令 95/46/EC (通用数据保护条例)(具有欧洲经济区相关性的文本)》。
-
VOSS, Axel. n.d. 《关于数字时代人工智能的报告 | A9-0088/2022 | 欧洲议会》。2022年10月17日访问。https://www.europarl.europa.eu/doceo/document/A-9-2022-0088_EN.html.
-
- 许,韦。2019. 《以人类为中心的AI方向:来自人机交互的视角》。互动 26(6月):42–46. https://doi.org/10.1145/3328485.
-
- 叶,赤宽,谢成宇,阿伦·赛义·萨加拉,大卫·I.·伊诺耶,普拉迪普·拉维库马。2019. 《论解释的(非)忠实性和敏感性》。第33届神经信息处理系统国际会议论文集,10967–78. 984. 红钩,纽约,美国:Curran Associates Inc.
参考 Paper:https://arxiv.org/pdf/2504.08552
- 叶,赤宽,谢成宇,阿伦·赛义·萨加拉,大卫·I.·伊诺耶,普拉迪普·拉维库马。2019. 《论解释的(非)忠实性和敏感性》。第33届神经信息处理系统国际会议论文集,10967–78. 984. 红钩,纽约,美国:Curran Associates Inc.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











