






Paul J. Pritz, Kin K. Leung
伦敦帝国理工学院计算机系,英国伦敦
摘要
在部分可观测环境中进行强化学习通常具有挑战性,因为它需要智能体学习对底层系统状态的估计。这些挑战在多智能体环境下进一步加剧,因为智能体同时学习并影响底层状态以及彼此的观测结果。我们提出使用对系统底层状态的学习信念来克服这些挑战,并实现完全去中心化的训练和执行的强化学习。我们的方法利用状态信息以自监督的方式预训练一个概率信念模型。由此产生的信念状态不仅捕获推断出的状态信息,还包含对此信息的不确定性,随后在基于状态的强化学习算法中使用,创建了一个用于部分可观测环境下合作多智能体强化学习的端到端模型。通过分离信念和强化学习任务,我们能够显著简化策略和价值函数的学习任务,并提高收敛速度和最终性能。我们在设计用于展示不同部分可观测变体的多样化部分可观测多智能体任务上评估了所提出的方法。
关键词:多智能体强化学习、部分可观测、信念状态、去中心化训练与去中心化执行
资金支持:本工作得到了DSTL SDS Continuation项目和EPSRC资助EP/Y037243/1的支持。
1. 引言
许多强化学习(RL)的实际应用本质上涉及多智能体系统,并且经常遭受不完整状态信息的影响,即底层系统状态的部分可见性。这种应用的典型例子包括无人机管理、物体搜索和交通控制 [[4], [19], [31]]。传统多智能体领域的做法试图通过在策略和价值函数架构中引入循环网络记忆来解决这一问题,并允许通信或假设训练期间所有数据集中可用。所有这些方法都有显著的缺点。首先,状态表示仅使用奖励作为信号进行学习,这并不能预测底层状态特征或环境动态。其次,这些表示中没有包含不确定性概念。第三,假设集中数据可用或允许通信在许多情况下可能是一个不现实的假设,或者需要大量的通信开销。训练阶段集中数据可用性的假设导致了集中训练、去中心化执行范式(CTDE)。通常,一个集中的批评者会处理所有智能体的观测结果甚至底层状态,然后为个别智能体策略提供学习信号 [[21]]。尽管这允许智能体以去中心化方式行动,但它对训练施加了强烈的限制,假设所有信息都可供集中批评者使用。
我们提出了一种框架,该框架不依赖于这个假设来进行策略学习,并有效地解决了部分可观测性问题。具体来说,我们提出了一种概率模型,从本地智能体历史中推断底层系统状态。这个信念模型使用条件变分自编码器 [[18]] 来推断状态并量化预测相关的不确定性。假设从环境中收集到了少量转换数据,我们的信念模型可以以自监督方式进行预训练,然后在下游RL任务中使用。我们假设,在此预训练阶段,完整的状态信息可以从环境中获得,以便进行自监督训练,但在随后的强化学习阶段则不可用。通过将表示学习任务与强化学习任务通过训练好的信念模型分开,我们能够使用更好的预测目标,即状态而非奖励,来进行表示学习方面,并仍然促进完全去中心化的强化学习。对于确切的模型规范,我们借鉴了单智能体领域 [[40]] 的最新进展,并将其适应于多智能体设置。
为了在多智能体RL设置中使用所提出的信念模型,我们提出了I2Q模型 [[15]] 的扩展,结合学到的信念状态来按智能体训练价值函数。理论上已证明I2Q在合作设置中即使智能体以去中心化方式同时训练也能收敛。因此,我们提出的方法遵循去中心化训练、去中心化执行范式(DTDE),并且在RL部分不依赖任何智能体间的通信。
为了评估我们的方法,我们提出了一组部分可观测多智能体领域,旨在以不同方式限制状态可观测性。具体来说,我们考虑了信息不对称、协调需求和记忆需求的场景。
2. 相关工作
多智能体强化学习(MARL)大致可分为集中训练、去中心化执行(CTDE)和去中心化训练、去中心化执行(DTDE)方法 [[9]]。在前者中,智能体使用共享信息(如共享状态)进行更新,然后在执行(测试)时丢弃这些信息,使每个智能体仅根据本地信息行动。后者方法将智能体可获取的信息限制为本地观测,无论是在训练还是执行过程中。除了这些MARL范式外,单智能体RL算法的多智能体改编仍因其简单性和在某些领域中的良好表现而受到欢迎 [[38], [44]]。接下来,我们将重点放在最近与部分可观测DTDE设置相关的工作上,即试图缓解MARL中由非平稳性和部分可观测性引起的问题 [[9]]。
2.1. MARL中的非平稳性
多个智能体同时学习会导致非平稳性问题。如果每个智能体都将其他智能体视为环境的一部分,那么从个体智能体的角度来看,随着其他智能体策略的演变,转移函数随时间变化,从而导致非平稳环境 [[25]]。这种移动目标问题也意味着单智能体RL算法在多智能体场景中分散训练时不再具有收敛保证。因此,CTDE作为一种流行范式出现,允许智能体在训练期间共享信息,同时保持独立执行 [[9]]。先前的多项研究提出了算法,其中集中批评者具有完全可见性,为分散执行者提供学习信号 [[8], [14], [21], [30], [32], [35]]。虽然这种集中训练方法通过联合集中训练解决了非平稳性问题,但也对状态和动作可见性做出了严格的假设。另一方面,采用DTDE方法的方法必须明确应对非平稳性。为此,Jiang和Lu [[15], [16]]、Lauer和Riedmiller [[20]]、Matignon等人 [[23]] 提出了适用于多智能体学习的Q学习变体,这些变体在合作设置中具有收敛保证。Jiang和Lu [[15]] 开发了一种基于状态-状态Q值的方法,而其他人则使用修改后的状态-动作Q值更新函数。其他方法将单智能体的策略基方法改编为多智能体领域 [[33], [36]]。集中和分散训练方案之间的差距通过维持对其他智能体策略的估计或将部分信息通过通信协议共享的方法来弥合 [[26], [46]]。通常,智能体学习交流状态或策略相关信息 [[7], [34], [37]] 或预测其他智能体的策略 [[10], [13], [27], [45]]。
2.2. 部分可观测性
部分可观测性在单智能体和多智能体强化学习环境中均带来了重大挑战。在单智能体RL中,最常用的部分可观测环境学习方法是基于使用循环网络处理观察历史 [[17]]。最近,基于变分目标的概率方法和信念模型获得了关注 [[11], [39], [40]]。这些模型通常通过学习一种分布来编码信念,该分布基于观察历史,能够预测未来的状态或奖励。在MARL中,部分可观测性带来的挑战因智能体之间潜在的信息不对称而进一步加剧 [[43]]。部分可观测MARL设置的理论框架要么是混合和竞争设置中的部分可观测马尔可夫博弈,要么是合作场景中的去中心化部分可观测马尔可夫决策过程(Dec-POMDP)[[1]]。
由于我们局限于合作设置,我们的分析将集中在这一领域的研究。几项先前的研究建议将为部分可观测单智能体RL设计的算法应用于多智能体领域。Gupta等人 [[12]] 提议将基于策略梯度的RL扩展到具有集中训练的多智能体问题。
沿袭类似思路,Wang等人 [[41]] 调查了Lowe等人 [[21]] 提出的MADDPG的递归版本,以应对集中批评者层面的部分可观测性。Diallo和Sugawara [[5]] 以及Park等人 [[28]] 也提出了应对部分可观测性的CTDE方法。虽然Diallo和Sugawara [[5]] 依赖于简单的集中Q值批评者,Park等人 [[28]] 提出了一种在集中训练的智能体间通信框架。
另一条MARL研究路径关注使用学习到的信念状态或嵌入来应对MARL领域中的部分可观测性。Mao等人 [[22]] 提出了一种模型,其中通过递归网络学习环境状态的嵌入版本,然后在智能体的策略中使用。其他方法利用变分模型要么在CTDE设置中学习关于环境状态的信念 [[47]],要么学习关于其他智能体的观测和策略的信念 [[24], [42]]。总体而言,很少有方法考虑DTDE设置中的部分可观测性,现有方法通常依赖于单智能体算法的变体。
3. 方法论
受单智能体RL中基于信念状态方法的启发,我们为部分可观测多智能体问题提出了一种表示学习模块 [[40]]。我们提出的方法与基于状态的Q学习 [[15]] 结合,并可用于完全去中心化的多智能体强化学习。基于本地智能体历史,我们的目标是学习关于底层系统状态的概率信念,这些信念作为下游RL任务的表示。使用这些信念,我们训练一组策略 πi(ai |oi , b(hi)),其中oi 是当前观测,b(hi) 是基于智能体i的历史hi 对系统状态的信念。为此,我们提出了一种两阶段学习过程。首先,我们为每个智能体预训练一个信念模型,假设可以访问从环境中收集的离线标记数据集。其次,在I2Q框架的一个变体中使用信念状态,以仅访问本地信息的方式去中心化地学习策略。
3.1. 前提条件
在本工作中,我们将自己限制在具有部分可观测性的合作多智能体场景中。因此,环境可以定义为去中心化的部分可观测马尔可夫决策过程(Dec-POMDP)[[1]]。Dec-POMDP由元组⟨S, O, A, R, P, W, γ⟩描述。在这个框架中,oi ∈ O 表示智能体可获得的部分观测,由全局系统状态s ∈ S派生,而ai ∈ A 表示智能体i采取的动作。每个智能体i ∈ N := {1, . . . , N} 可访问部分观测oi ,这是通过观测函数W(s) : S → O确定的。所有N个智能体的组合动作表示为联合动作a := ai∈N ∈ AN 。状态转移遵循概率分布P(s ′ |s, a) : S × AN × S → [0, 1]。在每一步,智能体根据奖励函数R(s, s′ ) : S × S → R 观察联合奖励。智能体的目标是学习一个联合策略π = Q i πi(ai |oi),以最大化联合回报G = P t γ t rt ,其中G是时间步t处预期折现未来奖励的总和,γ是折扣因子。
为了以去中心化方式训练一组合作智能体,我们建立在Jiang和Lu [[15]] 最近提出的MARL方法I2Q之上,该方法通过扩展Edwards等人的工作 [[6]] 解决了合作设置中的非平稳性问题。以下简要介绍他们的方法,并参考Jiang和Lu [[15]] 获取更详细的理论分析。Jiang和Lu [[15]] 显示,在确定性环境中,对理想转移概率P ∗ i (s ′ |s, ai) = P(s ′ |s, ai , π∗ −i (s, ai)) 进行Q学习的智能体将收敛到其个人最优策略。理想转移概率假定所有其他智能体的最佳行为和存在最优联合策略π ∗ (s) = arg maxa Q(s, a)。由于最优策略和转移概率事先未知,因此为每个智能体学习一个状态-状态值函数Qss i (s, s′ )
Q i s s ( s , s ′ ) = r + γ max s ′ ′ ∈ N ( s ′ ) Q i s s ( s ′ , s ′ ′ ) , Q_i^{ss}(s, s') = r + \gamma \max_{s'' \in \mathcal{N}(s')} Q_i^{ss}(s', s'')\,, Qiss(s,s′)=r+γs′′∈N(s′)maxQiss(s′,s′′),
其中N (s ′ ) 是下一状态的邻接集合。此函数可以从局部非平稳经验中学习,并学习等价于联合Q函数的值maxs ′ Qss i (s, s′ ) = maxa Q(s, a)。为了避免直接对邻接状态的最大化操作,这在大或连续状态环境中可能是不可行的,每个智能体随后通过最大化期望
E s , a i , s ′ [ λ Q i s s ( s , f i ( s , a i ) ) − ( f i ( s , a i ) − s ′ ) 2 ] … \mathbb{E}_{s,a_i,s'} \left[ \lambda Q_i^{ss}(s, f_i(s, a_i)) - (f_i(s, a_i) - s')^2 \right] \dots Es,ai,s′[λQiss(s,fi(s,ai))−(fi(s,ai)−s′)2]…
第一项鼓励具有高Qss值的下一个状态,第二项将它们约束在邻接状态的集合内。然后可以通过最小化以下表达式来学习状态-动作Q函数:
E s , a i , r ∼ D i [ ( Q i ( s , a i ) − r − γ max a i ′ Q ˉ i ( f i ( s , a i ) , a i ′ ) ) 2 ] … \mathbb{E}_{s, a_i, r \sim \mathcal{D}_i} \left[ \left( Q_i(s, a_i) - r - \gamma \max_{a'_i} \bar{Q}_i(f_i(s, a_i), a'_i) \right)^2 \right] \dots Es,ai,r∼Di[(Qi(s,ai)−r−γai′maxQˉi(fi(s,ai),ai′))2]…
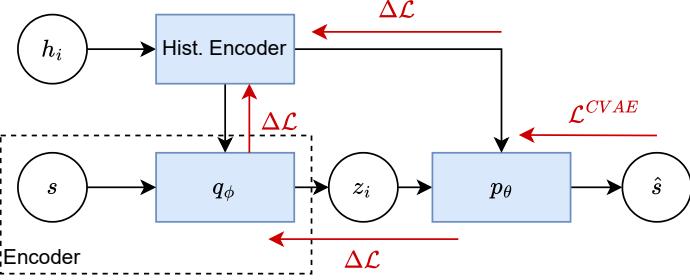
图1:CVAE架构,用于从本地历史中学习关于状态的信念。模型的编码器部分仅在预训练期间使用,并在RL部分中丢弃。所有模型组件均通过L CV AE损失进行训练。每个智能体维护自己的模型。
虽然这种方法允许完全去中心化的训练和执行,但Jiang和Lu [[15]] 关于环境做了几个假设。他们假设环境是确定性的、合作的,并且所有智能体共享并观察相同的状态。在本工作中,我们放松了关于共享状态的假设,而是假设一个部分可见的环境,其中在强化学习期间无法观察到真实的底层状态。我们方法的其他假设保持不变。
3.2. 自监督学习信念状态
为了对底层系统状态建模信念,我们提议在每个智能体级别使用条件变分自编码器(CVAE)[[18]]。为每个智能体单独训练模型不仅可以使RL训练完全去中心化,还可以让我们解决智能体之间可能存在的信息不对称问题。对于下游RL任务,我们希望为每个智能体找到一个分布p(s|hi),以从智能体的本地历史中估计系统状态。对于学习这些信念状态,我们假设可以访问从环境中预先收集的数据集,(s, {hi}i∈N ) ∼ D,其中hi 是智能体i在当前时间步之前的观察和动作历史。注意,为了便于说明,我们在所有公式中省略了时间步下标。我们进一步假设,对于给定的历史hi ,观察状态s是由潜变量zi 控制的 [[40]]。因此,底层系统状态可以建模为一个随机函数,该函数取决于hi 和zi
p ( s , h i , z i ) = p ( h i ) p ( z i ) p ( s ∣ h i , z i ) . p(s, h_i, z_i) = p(h_i)p(z_i)p(s|h_i, z_i)\ . p(s,hi,zi)=p(hi)p(zi)p(s∣hi,zi) .
基于此生成模型,我们定义了一个编码器-解码器架构,以学习未观察到的系统状态的分布。这包括一个编码器,用于近似后验分布p(zi |s, hi) 为qϕ(zi |s, hi) 和一个解码器pθ(s|hi , zi),参数化为ϕ和θ。为了训练CVAE,我们最大化观察数据的条件对数似然log pθ(s|hi),使用证据下界(ELBO)[[18]]。这定义为
log p θ ( s ∣ h i ) ≥ E q ϕ ( z i ∣ s , h i ) [ log p θ ( s ∣ h i , z i ) + log p ( z i ) − log q ϕ ( z i ∣ s , h i ) ] . (1) \log p_{\theta}(s|h_i) \ge \mathbb{E}_{q_{\phi}(z_i|s,h_i)} \left[ \log p_{\theta}(s|h_i, z_i) + \log p(z_i) - \log q_{\phi}(z_i|s, h_i) \right]. \tag{1} logpθ(s∣hi)≥Eqϕ(zi∣s,hi)[logpθ(s∣hi,zi)+logp(zi)−logqϕ(zi∣s,hi)].(1)
拆分各项后,我们得到
log
p
θ
(
s
∣
h
i
)
≥
E
q
ϕ
(
z
i
∣
s
,
h
i
)
[
log
p
θ
(
s
∣
h
i
,
z
i
)
]
−
E
q
ϕ
(
z
i
∣
s
,
h
i
)
[
log
p
(
z
i
)
−
log
q
ϕ
(
z
i
∣
s
,
h
i
)
]
.
(2)
\begin{split} \log p_{\theta}(s|h_{i}) &\geq \mathbb{E}_{q_{\phi}(z_{i}|s,h_{i})} \left[ \log p_{\theta}(s|h_{i},z_{i}) \right] \\ &\quad - \mathbb{E}_{q_{\phi}(z_{i}|s,h_{i})} \left[ \log p(z_{i}) - \log q_{\phi}(z_{i}|s,h_{i}) \right]. \end{split} \tag{2}
logpθ(s∣hi)≥Eqϕ(zi∣s,hi)[logpθ(s∣hi,zi)]−Eqϕ(zi∣s,hi)[logp(zi)−logqϕ(zi∣s,hi)].(2)
上述右边的第二个期望是先验和学习后验之间的KL散度。因此,我们CVAE模型的损失函数变为
L i C V A E ( s ∣ h i ) = E q ϕ ( z i ∣ s , h i ) [ log p θ ( s ∣ h i , z i ) ] − D K L ( q ϕ ( z i ∣ s , h i ) ∣ ∣ p ( z i ) ) . (3) \mathcal{L}_i^{CVAE}(s|h_i) = \mathbb{E}_{q_\phi(z_i|s, h_i)} \left[ \log p_\theta(s|h_i, z_i) \right] - D_{KL}(q_\phi(z_i|s, h_i) || p(z_i)). \tag{3} LiCVAE(s∣hi)=Eqϕ(zi∣s,hi)[logpθ(s∣hi,zi)]−DKL(qϕ(zi∣s,hi)∣∣p(zi)).(3)
注意,在实践中,我们可以实例化这个模型的一个单一版本,如果所有智能体具有相同的观测,则在预训练后在智能体间共享。如果智能体之间的观测不同,则需要为每个智能体准备一个模型。编码器和解码器均由神经网络参数化,我们使用一个递归历史编码器,该编码器由编码器和解码器共享。可以在图 [1.] 中看到此模型的概述。
3.3. 学习价值函数 – Belief-I2Q
我们通过使用局部观测与之前学到的信念状态相结合进行训练。由于CVAE的解码器输出的是状态分布,我们通过从解码器的状态分布中抽取一系列独立同分布样本来表示它。对于每个智能体,我们从先验p(zi) 中抽取m个样本,用于解码器网络以获得sˆj ∼ pθ(sj |hi,j , zi,j )∀j < m。
算法1 信念模型预训练
输入:数据集Di = {s, hi} 当未收敛时重复采样s, hi ∼ Di L CV AE i (s|hi) = Eqϕ(zi|s,hi) [log pθ(s|hi , zi)] − DKL(qϕ(zi |s, hi)||p(zi)) 使用L CV AE 更新ϕ, θ 和历史编码器结束重复
这些样本包括均值和方差,并随后平均以使得
b
(
h
i
)
=
1
m
∑
j
s
^
j
.
(4)
b(h_i) = \frac{1}{m} \sum_j \hat{s}_j \,. \tag{4}
b(hi)=m1j∑s^j.(4)
为了简化符号,我们将编码gi = g(oi , b(hi)) 定义为智能体i的拼接观测和信念状态。为了避免由状态-状态价值函数Qss引起的信用分配问题,该问题由多个观测可能映射到同一状态引起,我们将其留在观测空间中。因此,每个智能体学习三个函数:(1) Qss i , (2) fi(gi , ai), (3) Qi(gi , ai)。状态-状态价值函数被训练以最小化目标,
L i Q s s = E o i , a i , o i ′ , r ∼ D i [ ( Q i s s ( o i , o i ′ ) − r − γ Q ˉ i s s ( o i ′ , f i ( g i ′ , a i ∗ ) ) ) 2 ] , a i ∗ = arg max a i ′ Q i ( g i ′ , a i ′ ) . (5) \begin{split} \mathcal{L}_{i}^{Q^{ss}} = \mathbb{E}_{o_{i}, a_{i}, o_{i}', r \sim \mathcal{D}_{i}} \left[ \left( Q_{i}^{ss}(o_{i}, o_{i}') - r - \gamma \bar{Q}_{i}^{ss}(o_{i}', f_{i}(g_{i}', a_{i}^{*})) \right)^{2} \right], \\ a_{i}^{*} = \arg\max_{a_{i}'} Q_{i}(g_{i}', a_{i}'). \end{split} \tag{5} LiQss=Eoi,ai,oi′,r∼Di[(Qiss(oi,oi′)−r−γQˉiss(oi′,fi(gi′,ai∗)))2],ai∗=argai′maxQi(gi′,ai′).(5)
过渡函数fi通过最大化以下目标进行学习
L i f = E o i , a i , o i ′ ∼ D i [ λ Q i s s ( o i , f i ( g i , a i ) ) − ( f i ( g i , a i ) − o i ′ ) 2 ] . (6) \mathcal{L}_i^f = \mathbb{E}_{o_i, a_i, o_i' \sim \mathcal{D}_i} \left[ \lambda Q_i^{ss} \left( o_i, f_i(g_i, a_i) \right) - \left( f_i(g_i, a_i) - o_i' \right)^2 \right]. \tag{6} Lif=Eoi,ai,oi′∼Di[λQiss(oi,fi(gi,ai))−(fi(gi,ai)−oi′)2].(6)
由于我们仍然需要一个状态-动作价值函数来评估在环境中执行的动作,我们进一步为每个智能体训练Q函数Qi(gi , ai)。此价值函数Qi(gi , ai)通过最小化以下目标进行学习
L
i
Q
=
E
o
i
,
a
i
,
r
∼
D
i
[
(
Q
i
(
g
i
,
a
i
)
−
r
−
γ
max
a
i
′
Q
ˉ
i
(
g
(
f
i
(
g
i
,
a
i
)
,
b
(
h
i
′
)
)
,
a
i
′
)
)
2
]
,
(7)
\mathcal{L}_i^Q = \mathbb{E}_{o_i, a_i, r \sim \mathcal{D}_i} \left[ \left( Q_i(g_i, a_i) - r - \gamma \max_{a_i'} \bar{Q}_i(g(f_i(g_i, a_i), b(h_i')), a_i') \right)^2 \right], \tag{7}
LiQ=Eoi,ai,r∼Di[(Qi(gi,ai)−r−γai′maxQˉi(g(fi(gi,ai),b(hi′)),ai′))2],(7)
其中b(h ′ ) 是基于智能体历史扩展的下一个观测预测给出的信念状态,Q¯ i 是Qi 的目标网络。这三个函数(1) - (3)通过从环境中收集的经验迭代更新。我们学习价值函数的设置是对Jiang和Lu [[15]] 提出的I2Q的扩展,我们将其方法称为Belief-I2Q。
3.4. 架构与训练
我们将所有函数实现为神经网络,并以两阶段过程进行训练。首先,智能体使用随机滚动策略从环境中收集少量数据。在此期间,我们假设智能体可以访问真实状态信息,这些信息用于标记情节数据。为了学习第 [3.2节] 中概述的信念状态模型,我们使用递归历史编码器来处理智能体历史hi 。然后将编码作为输入传递给编码器和解码器网络pθ和qϕ,并联合训练这些网络以最小化(3)。
在信念模型预训练后,所有智能体网络初始化并在完全去中心化的方式下进行训练。Q函数和过渡函数随后通过从环境中收集的经验使用损失(5) - [(7)
4. 实验
4.1. 环境
为了评估我们的方法在部分可观测MARL设置中的有效性,我们构建了一系列网格世界环境。根据基于状态的Q学习的要求,所有研究的场景都是合作的,即智能体共享相同的奖励。我们使用的环境旨在测试我们的方法在不同类型的部分可观测性下的有效性,例如不对称信息、局部可见性和时间受限的可见性。
4.1.1. 场景1:多智能体神谕
在这个环境中,我们采用了Wang等人[[40]] 提出的信息寻求问题并将其扩展到多智能体设置。智能体被随机放置在一个网格世界中,宝藏被放置在网格的三个角落。只有一个随机选择的宝藏会产生正奖励。步骤受到小步惩罚。宝藏的位置对智能体未知,但可以从位于网格剩余角落的神谕处查询。一旦查询,较高奖励字段的位置会在一个时间步内揭示。所有智能体共享相同的观测,并且除了正确的宝藏位置外,对整个网格具有完全可见性。状态始终包含正确的宝藏位置。观测是连续的,包括两个智能体的坐标以及一旦揭示后正确宝藏的位置。
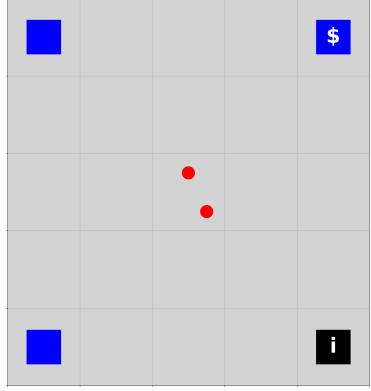
(a) 神谕环境的可视化。红色圆点代表智能体(从网格中心开始)。蓝色框代表宝藏位置,黑色框代表神谕。只有一个宝藏位置包含奖励。
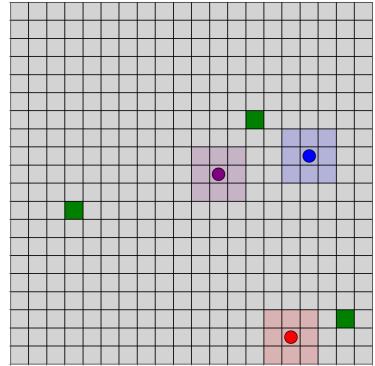
(b) 收集环境的可视化。绿色框代表随机放置的奖励场。彩色圆点是智能体,从网格上的随机位置开始。他们的可见半径由周围的阴影区域表示。
图2:神谕和收集环境。
有9个离散动作,其中8个动作让智能体向不同方向移动,一个是空动作。插图可见于图 [2a.]。
4.1.2. 场景2:收集任务
智能体再次被随机放置在一个网格世界中,它们的任务是从网格中收集一定数量的价值相等的宝藏。所有宝藏都产生相同的正奖励,而每一步都有一个小成本。每个智能体都有一个局部可见半径。在任何给定时间步,智能体可见的网格部分组合起来形成观测。当前不在任何智能体半径内的地图的所有区域均不可见。该环境的插图可见于图 [2b.]。智能体和奖励被编码为索引,观测和状态是离散的。状态由具有完全可见性的网格组成。智能体有五个离散动作可用,其中四个将它们移动到相邻字段,一个是空动作。
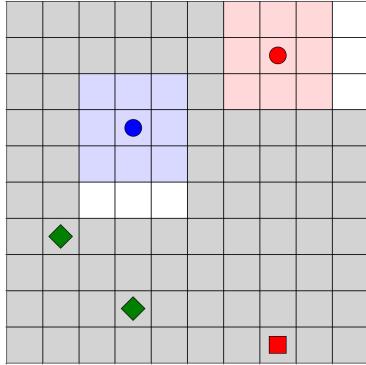
(a) 逃生室环境的可视化。智能体在情节开始时被随机放置在网格上。他们的可见半径由周围的阴影区域表示。钥匙由绿色菱形象征,出口由红色正方形表示。已经探索的区域标记为白色,而未探索的区域标记为灰色。
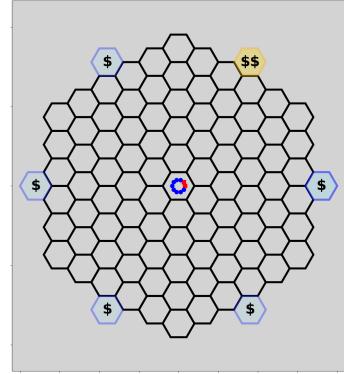
(b) 蜂巢环境的可视化。两个知情智能体(红色)和8个不知情智能体(蓝色)被放置在场地中心。知情智能体知道更高奖励场(橙色带$$符号)的位置。不知情智能体将所有六个奖励场视为同等价值。
图3:逃生室和蜂巢环境。
4.1.3. 场景3:多智能体逃生室
逃生室场景要求智能体收集散布在网格中的若干把钥匙,以解锁同样随机放置在网格中的出口。钥匙可以由任何智能体收集,出口在它们共同持有所有钥匙时可以解锁。只有解锁出口才会产生正奖励,而步骤和智能体之间的碰撞会产生负奖励。随着智能体在网格中移动,它们逐渐用其可见半径揭开网格。观测包含所有已探索的区域,并且一旦智能体离开已发现的区域,这些区域不会再次变得模糊。观测包含整个网格,物品有不同的整数表示,未发现的区域有默认值。该环境的可视化可以在图 [3a.] 中找到。状态包含完全揭示的网格。同样,有5个离散动作可用,包括移动到相邻字段和空动作。
4.1.4. 场景4:协调蜂巢
这个设置最初由Boos等人[[3]] 提出,将智能体置于六边形(蜂巢状)场地的中心。场地的六个角包含奖励场。其中两个奖励场产生更高的奖励,而其他所有奖励场产生相等的正奖励。此外,如果多个智能体到达同一个奖励场,会有乘法奖励。信息不对称引入了部分可观测性:只有10个智能体中的两个(知情)知道高奖励场的位置。因此,他们的任务是建立领导者-跟随者的动态,引导不知情的智能体到高奖励场[[2]]。观测由所有智能体的坐标位置和奖励场的位置表示。知情智能体还观察到两个高奖励场的位置,这些位置也被包含在状态中。7个可用动作为离散动作,包括移动到相邻六边形和空动作。该环境的可视化可见于图 [3b.]。
4.2. 实验设置和基准
我们将我们的方法Belief-I2Q与两种遵循DTDE范式的做法进行比较。我们的第一个基准是I2Q算法的递归版本(Rec.-I2Q)[[15]]。为了赋予该方法记忆能力,并使其能够在我们考虑的部分可观测环境中学习,我们为每个智能体实现了一个历史编码器,该编码器在每个智能体的Qss i 和Qi 函数之间共享。我们的第二个基准是递归版本的迟滞独立Q学习(Rec.-Hyst.-IQL)[[23]],同样使用每个智能体的历史编码器,该编码器由Q函数使用。与独立Q学习相比,迟滞Q学习对正面和负面经验应用不同的学习率。其想法是减少与低奖励相关的经验的权重,这可能是由其他智能体的行为造成的。迟滞Q学习的修改更新规则为Qi(oi , ai) ← Qi(oi , ai) + αψ for ψ > 0 和Qi(oi , ai) ← Qi(oi , ai) + βψ otherwise,其中ψ = r + γ maxa ′ Qi(o ′ i , a′ ) − Qi(oi , ai) 且α > β。这两种基线方法不利用单独学习的状态表示,而是遵循传统的使用递归网络从观察历史中学习的方法。基线和我们方法之间的一个关键区别在于,基线算法仅使用强化学习损失来学习环境表示,因为它们在训练Q函数时也将历史编码器作为一部分。由于我们所有的环境都有离散动作,我们直接使用学习到的Q函数作为行动策略。
完整的相应架构参数化可以在[附录A.]中找到。对于连续动作环境,该方法可以很容易地通过使用演员函数进行扩展。
4.3. 结果
为了确保可比性,我们为所有模型训练相同数量的情节,并在每个情节之后更新参数。我们对关键超参数进行了网格搜索,并报告了在此搜索中表现最佳的模型的结果。所有结果取三个随机种子的平均值,并报告这三个运行的均值和标准差。
我们的方法Belief-I2Q在所有领域中学习到强大的策略,除了HoneyComb环境外,通常优于基准解决方案。Rec.-I2Q和Rec.-Hyst.-IQL常常难以学习连贯的策略,并在某些领域中表现出转换问题。特别是,Belief-I2Q在Oracle、收集和逃生室环境中取得了更强的最终性能。我们还观察到Oracle和逃生室环境的收敛速度更快。虽然Belief-I2Q在收集环境中实现了更好的最终性能,但收敛速度比基准慢。我们推测这可能是由于该环境中相对复杂的信念状态,需要捕捉目前不在任何智能体半径内的地图的所有区域。这反过来可能会在智能体学会正确解释信念状态之前导致价值函数估计的高方差。
所评估的设置是为了反映部分可观测性的不同细微差别。Belief-I2Q在所有智能体都能从当前或过去的观察中推断底层系统状态的情况下表现特别好,而不依赖于其他智能体的学习策略来进行这种表示学习方面。为了使信念模型推断有用信息,未观察到的状态部分需要能够合理地从观察历史中预测出来。这一点似乎在Oracle、收集和逃生室环境中是可能的。我们推测,捕捉推断状态的不确定性的能力使智能体能够学习更好的策略。基准不具备这种能力,可能会在未观察到的状态部分尚不能准确预测时误导智能体。与提到的三种环境不同,HoneyComb环境引入了信息不对称,其中只有两个智能体可以访问底层状态的未观察元素。因此,不知情的智能体只能从其他(知情)智能体的运动模式中推断出高奖励场的位置。
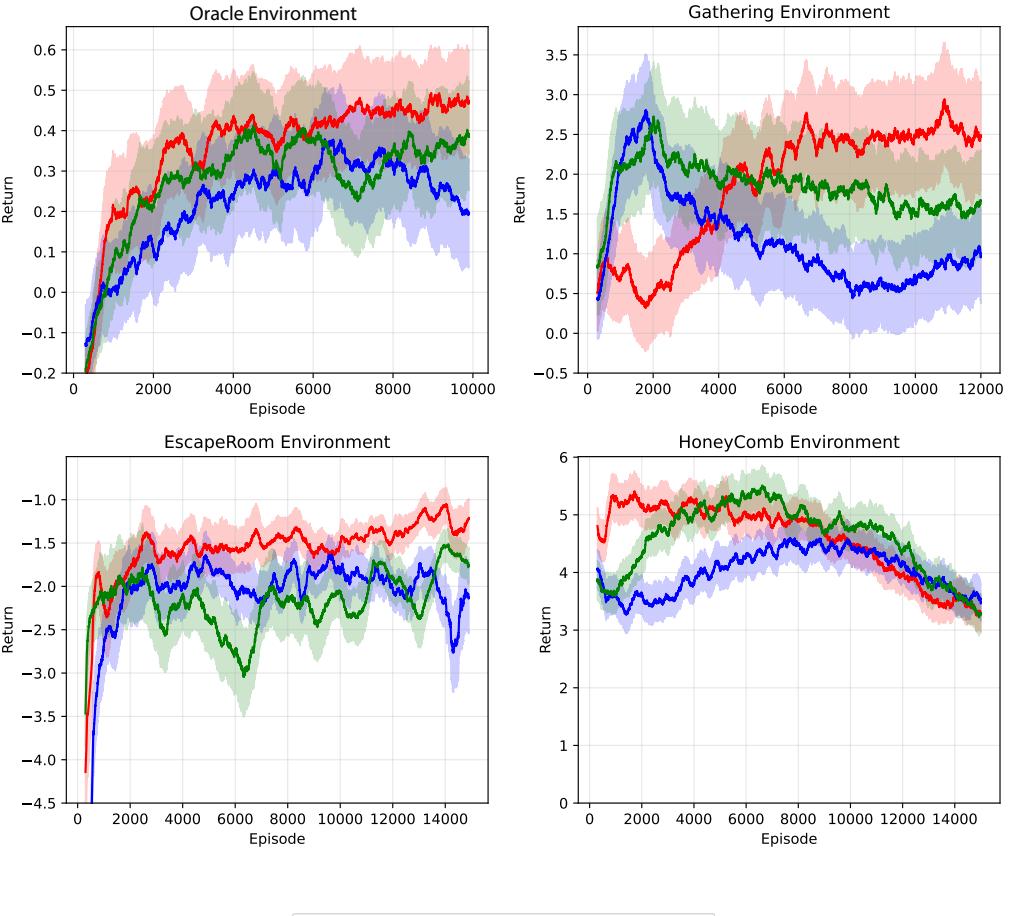
图4:我们的方法Belief-I2Q与递归基准I2Q和迟滞Q学习的评估结果对比。图表显示了每集的回报,经过100集平滑处理。结果取三个随机种子的平均值。阴影区域显示了随机种子间结果的标准差。
Belief-I2Q Rec.-Hyst.-IQL Rec.-I2Q
然而,由于信念模型是通过随机回放训练的,运动模式可能并不反映这种信息,因此无法建立领导者-跟随者动态。因此,在我们的结果中,我们观察到在这种环境下的表现相对较差。所选基准在这种情形下表现也不佳,表明它们也无法从知情智能体的运动模式中推断出有关底层状态的信息,以弥补这种信息不对称。
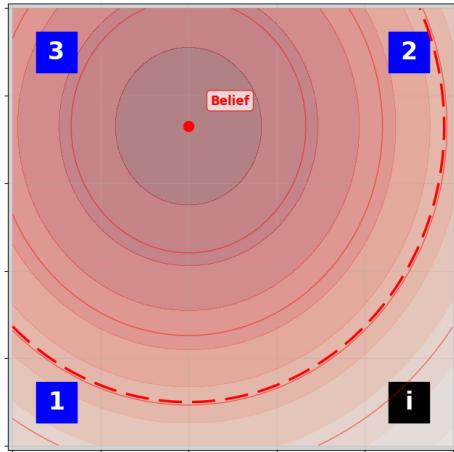
(a) 查询神谕前一时间步的信念状态。在这种情况下,信念状态没有分组,因为神谕尚未被查询,也没有关于正确盒子位置的信息可用。
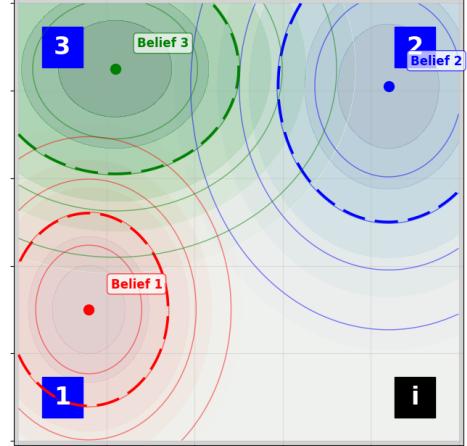
(b) 查询神谕后一时间步的信念状态。信念状态根据实际正确盒子的位置分组——信念1对应于正确盒子位于左下角(盒子1)的情况,依此类推。
图5:查询神谕前(左侧)和后(右侧)的信念状态可视化。信念模型的输出,均值和标准差在每个信念状态可视化中取100集的平均值。因此,绘制的标准差是信念模型跨样本的标准差的平均值,而不是样本均值的标准差。轮廓中的虚线代表一个标准差。对于此可视化,我们仅查询一个智能体的信念状态。
为了评估我们的信念模型的有效性,超越改进RL代理的策略性能,我们使用Oracle环境为例,对底层系统状态未观察部分的信念状态进行视觉检查。我们选择这个环境是因为形成准确信念状态所需的信息是在特定时刻揭示的,即查询神谕时,这样可以轻松进行查询前后的信念状态比较。对于其他环境,由于智能体在其周围探索时信念不断演变,这样的比较不容易完成。此外,在这种情况下,信念状态易于解释,因为奖励的真实位置被揭示,信念状态可以根据此信息分组。我们在图 [5.] 中展示了信念状态的可视化。在查询神谕之前(图 [5a) ]),信念状态显示出高方差,并不指向任何特定的宝藏位置更为可能。请注意,信念仍然大约捕捉到了盒子的平均位置,即均值大约在宝藏位置的中点。在查询神谕之后(图 [5b) ]),我们观察到信念状态清楚地区分了三个可能的宝藏位置。需要注意的是,此处用于比较的信念状态是在情节的几步之后收集的,即当其中一个智能体移动到神谕处查询时。因此,显示的信念状态可能受到了另一个智能体的任何探索的影响,该智能体可能已经移动到某个宝藏位置,排除或确认了它是正确的盒子。然而,这种可视化仍然提供了证据,表明Belief-I2Q可以有效地捕捉和表示环境的部分可观测方面。
5. 结论
我们提出了一种新的部分可观测多智能体强化学习方法,并在几种实验设置中进行了评估,这些设置展示了不同类型的部分可观测性。我们的实验结果揭示了所提出方法与该领域相关算法相比的有效性。通过在初始预训练阶段利用系统状态信息,我们能够在强化学习阶段完全去中心化训练和执行。我们的算法还可以轻松地与现有的策略梯度方法结合,通过使用学习到的Q函数作为批评者。未来的研究可以探索这一途径,并扩展应用到更大规模的问题。
参考文献
- [1] Daniel S Bernstein, Robert Givan, Neil Immerman, and Shlomo Zilberstein. 分散控制马尔可夫决策过程的复杂性。运筹学数学,27(4):819–840, 2002.
-
- [2] Margarete Boos, Johannes Pritz, Simon Lange, and Michael Belz. 移动人群中的领导力。PLoS计算生物学,10(4): e1003541, 2014.
-
- [3] Margarete Boos, Johannes Pritz, and Michael Belz. 蜂巢范式在集体人类行为研究中的应用。Journal of Visualized Experiments, 143:e58719, 2019.
-
- <span id="p------
- age-17-0">[4] Jeancarlo Arguello Calvo and Ivana Dusparic. 异构多智能体深度强化学习用于交通灯控制。爱尔兰人工智能和认知科学会议论文集,第2–13页,2018年。
-
- [5] Elhadji Amadou Oury Diallo 和 Toshiharu Sugawara.
- ------ 在部分可观测环境下的对抗性多智能体协调与深度强化学习。2019 IEEE 第31届国际人工工具智能会议 (ICTAI),第198–205页,2019年。doi: 10.1109/ ICTAI.2019.00036.
-
- [6] Ashley Edwards, Himanshu Sahni, Rosanne Liu, Jane Hung, Ankit Jain, Rui Wang, Adrien Ecoffet, Thomas Miconi, Charles Isbell, 和 Jason Yosinski. 使用深度确定性动力学梯度估计 Q(s, s’)。在国际机器学习会议上,第2825–2835页。PMLR,2020年。
-
- [7] Jakob Foerster, Yannis M Assael, Nando de Freitas, 和 Shimon Whiteson. 使用深度多智能体强化学习进行通信的学习。在神经信息处理系统进展会议上,第2137–2145页,2016年。
-
- [8] Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Philip HS Torr, 和 Shimon Whiteson. 反事实多智能体策略梯度。在AAAI人工智能会议上,2018年。
-
- [9] Sven Gronauer 和 Klaus Diepold. 多智能体深度强化学习:综述。人工智能评论,55(2):895–943, 2022年。
-
- [10] Aditya Grover, Maruan Al-Shedivat, Jayesh Gupta, Yuri Burda, 和 Harrison Edwards. 学习多智能体系统中的策略表示。在国际机器学习会议上,第1802–1811页。PMLR,2018年。
-
- [11] Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Bernardo A Pires, 和 Rémi Munos. 神经预测信念表示。arXiv预印本 arXiv:1811.06407, 2018年。
-
- [12] Jayesh K Gupta, Maxim Egorov, 和 Mykel Kochenderfer. 使用深度强化学习的协作多智能体控制。在自主代理和多智能体系统会议:AAMAS 2017研讨会,最佳论文,巴西圣保罗,2017年5月8-12日,修订精选论文16,第66–83页。Springer,2017年。
-
- [13] Zhang-Wei Hong, Shih-Yang Su, Tzu-Yun Shann, Yi-Hsiang Chang, 和 Chun-Yi Lee. 面向多智能体系统的深度策略推理Q网络。arXiv预印本 arXiv:1712.07893, 2017年。
-
- [14] Shariq Iqbal 和 Fei Sha. 多智能体强化学习中的演员-注意力-批评者。在国际机器学习会议上,第2961–2970页,2019年。
-
- [15] Jiechuan Jiang 和 Zongqing Lu. I2Q: 完全去中心化的Q学习算法。神经信息处理系统进展,35: 20469–20481, 2022年。
-
- [16] Jiechuan Jiang 和 Zongqing Lu. 最优可能Q学习。arXiv预印本 arXiv:2302.01188, 2023年。
-
- [17] Peter Karkus, David Hsu, 和 Wee Sun Lee. QMDP-net: 部分可观测环境下规划的深度学习。神经信息处理系统进展,30, 2017年。
-
- [18] Diederik P Kingma 和 Max Welling. 自动编码变分贝叶斯。第二届国际表示学习会议,2014年。
-
- [19] Xiangyu Kong, Bo Xin, Yizhou Wang, 和 Gang Hua. 联合物体搜索的合作深度强化学习。IEEE计算机视觉与模式识别会议论文集,第1695–1704页,2017年。
-
- [20] Martin Lauer 和 Martin A Riedmiller. 合作多智能体系统中分布式的强化学习算法。在第十七届国际机器学习会议论文集中,第535–542页,2000年。
- [21] Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, 和 Igor Mordatch. 混合合作-竞争环境中的多智能体Actor-Critic。在神经信息处理系统进展会议论文集中,第6379–6390页,2017年。
-
- [22] Weichao Mao, Kaiqing Zhang, Erik Miehling, 和 Tamer Başar. 部分可观测合作多智能体强化学习中的信息状态嵌入。在2020年第59届IEEE决策与控制会议(CDC)论文集中,第6124–6131页。IEEE,2020年。
-
- [23] Laëtitia Matignon, Guillaume J Laurent, 和 Nadine Le Fort-Piat. 分散式强化学习中的迟滞Q学习:适用于合作多智能体团队的算法。在2007年IEEE/RSJ国际智能机器人与系统会议论文集中,第64–69页。IEEE,2007年。
-
- [24] Pol Moreno, Edward Hughes, Kevin R McKee, Bernardo Avila Pires, 和 Théophane Weber. 多智能体强化学习中的神经递归信念状态。arXiv预印本 arXiv:2102.02274, 2021年。
-
- [25] Frans A Oliehoek 和 Christopher Amato. 去中心化POMDPs的简明介绍。Springer, 2016年。
-
- [26] Afshin Oroojlooy 和 Davood Hajinezhad. 协作多智能体深度强化学习综述。应用智能,53(11): 13677–13722, 2023年。
-
- [27] Georgios Papoudakis, Filippos Christianos, 和 Stefano Albrecht. 部分可观测环境下的智能体建模用于深度强化学习。神经信息处理系统进展,34:19210–19222, 2021年。
-
- [28] Young Joon Park, Young Jae Lee, 和 Seoung Bum Kim. 具有近似模型学习的合作多智能体强化学习。IEEE Access, 8:125389–125400, 2020年。
-
- [29] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, 和 Adam Lerer. PyTorch中的自动微分。在NIPS-W, 2017年。
-
- [30] Bei Peng, Tabish Rashid, Christian Schroeder de Witt, Pierre-Alexandre Kamienny, Philip Torr, Wendelin Böhmer, 和 Shimon Whiteson. FACMAC: 因子化多智能体集中策略梯度。神经信息处理系统进展,34:12208–12221, 2021年。
-
- [31] Huy Xuan Pham, Hung Manh La, David Feil-Seifer, 和 Aria Nefian. 无人机场覆盖的合作与分布式强化学习。arXiv预印本 arXiv:1803.07250, 2018年。
-
- [32] Tabish Rashid, Mikayel Samvelyan, Christian Schroeder, Gregory Farquhar, Jakob Foerster, 和 Shimon Whiteson. QMIX: 深度多智能体强化学习中的单调值函数分解。在国际机器学习会议论文集中,第4295–4304页,2018年。
-
- [33] Mikayel Samvelyan, Tabish Rashid, Christian Schroeder De Witt, Gregory Farquhar, Nantas Nardelli, Tim GJ Rudner, Chia-Man Hung, PhilipHS Torr, Jakob Foerster, 和 Shimon Whiteson. 星际争霸多智能体挑战。arXiv预印本 arXiv:1902.04043, 2019年。
-
- [34] Amanpreet Singh, Tushar Jain, 和 Sainbayar Sukhbaatar. 在大规模多智能体合作与竞争任务中学习何时进行通信。arXiv预印本 arXiv:1812.09755, 2018年。
-
- [35] Kyunghwan Son, Daewoo Kim, Wan Ju Kang, David Earl Hostallero, 和 Yung Yi. QTRAN: 通过变换进行因子化以实现合作多智能体强化学习。在国际机器学习会议论文集中,第5887–5896页。PMLR, 2019年。
-
- [36] Kefan Su 和 Zongqing Lu. 去中心化策略优化。arXiv预印本 arXiv:2211.03032, 2022年。
-
- [37] Sainbayar Sukhbaatar, Arthur Szlam, 和 Rob Fergus. 使用反向传播学习多智能体通信。神经信息处理系统进展,29, 2016年。
-
- [38] Ming Tan. 多智能体强化学习:独立智能体与合作智能体。在第十届国际机器学习会议论文集中,第330–337页,1993年。
-
- [39] Arun Venkatraman, Nicholas Rhinehart, Wen Sun, Lerrel Pinto, Martial Hebert, Byron Boots, Kris Kitani, 和 J Bagnell. 预测状态解码器:将未来编码到循环网络中。神经信息处理系统进展,30, 2017年。
-
- [40] Andrew Wang, Andrew C Li, Toryn Q Klassen, Rodrigo Toro Icarte, 和 Sheila A McIlraith. 部分可观测深度RL中的信念表示学习。在国际机器学习会议论文集中,第35970–35988页。PMLR, 2023年。
-
- [41] Rose E Wang, Michael Everett, 和 Jonathan P How. 部分可观测环境和有限通信下的R-MADDPG。arXiv预印本 arXiv:2002.06684, 2020年。
-
- [42] Ying Wen, Yaodong Yang, Rui Luo, Jun Wang, 和 Wei Pan. 多智能体强化学习中的概率递归推理。arXiv预印本 arXiv:1901.09207, 2019年。
-
- [43] Annie Wong, Thomas Bäck, Anna V Kononova, 和 Aske Plaat. 深度多智能体强化学习:挑战与方向。人工智能评论,56(6):5023–5056, 2023年。
-
- [44] Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, 和 Yi Wu. 合作多智能体游戏中的惊人的PPO有效性。神经信息处理系统进展,35:24611–24624, 2022年。
-
- [45] Yunpeng Zhai. 分散多智能体合作学习中的动态信念。在第三十二届国际人工智能联合会议(IJCAI)论文集中,第4772–4780页,2023年。
-
- [46] Kaiqing Zhang, Zhuoran Yang, 和 Tamer Başar. 多智能体强化学习:理论与算法的选择性概述。强化学习与控制手册,第321–384页,2021年。
-
- [47] Xianjie Zhang, Yu Liu, Hangyu Mao, 和 Chao Yu. 基于变分递归模型的共同信念多智能体强化学习。神经计算,513:341–350, 2022年。
附录A. 模型架构
附录A.1. Belief-I2Q
该实现包含多个元素,所有这些都由神经网络参数化。历史编码器在qϕ和pθ之间共享,实现为单层GRU,具有[64]个隐藏单元。编码器和解码器网络qϕ和pθ都实现为两层前馈MLP,大小为[64, 64],使用ReLu激活函数。编码器输出zi的大小为belief_dim,而解码器输出关于未观察状态特征和log-variance的信念,其维度由环境决定。zi和状态预测sˆ都被建模为高斯分布。Qss、f和Q函数由使用ReLu激活函数的三层前馈神经网络参数化,隐藏层大小为[128, 128, 128]。我们还为Qss和Q使用目标网络,每集更新τ = 0.005。我们对所有组件使用Adam优化器。
附录A.2. 基线
对于递归迟滞Q学习,我们将Q函数参数化为单层GRU,具有[64]个隐藏单元,随后是三个使用ReLu激活函数和[128, 128, 128]隐藏单元的线性层。我们为Q使用目标网络,每集更新τ = 0.005,并使用Adam优化器。
递归I2Q实现遵循[[15]]使用的版本。我们使用单层GRU,具有[64]个隐藏单元,在Qss和Q函数之间共享。Qss、f和Q函数由使用ReLu激活函数的三层前馈神经网络参数化,隐藏层大小为[128, 128, 128]。同样,我们为Qss和Q使用目标网络,每集更新τ = 0.005,并使用Adam优化器训练所有组件。
所有模型均使用PyTorch [[29]] 实现。
附录B. 超参数
所有模型都使用容量为10,000集的回放缓冲区进行训练,基于学习的Q值采用线性衰减epsilon的epsilon-greedy策略,初始值为ϵ = 0.6,并使用每集更新的目标网络,更新率为τ = 0.005。我们将Oracle、收集、EscapeRoom和HoneyComb环境的最大集长度分别限制为40、100、100和25步。基线使用批量大小为32集的数据,每集进行一次更新步骤。由于Belief-I2Q是基于单独转换进行训练的,我们调整了更新批量大小以反映这一点。我们对所有模型进行了网格搜索。我们在{0.001, 0.0003}范围内搜索Q、Qss、信念模型和f的学习率。我们还在{0.1, 0.3}范围内搜索f的λ参数,并在{8, 16, 32}范围内搜索zi的潜在维度。报告的结果反映了表现最佳的运行结果,平均取自3个随机种子。
参考 Paper:https://arxiv.org/pdf/2504.08417



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











