






Tien Pham
计算机科学学院
曼彻斯特大学
英国曼彻斯特
canhantien.pham@manchester.ac.uk
Angelo Cangelosi
计算机科学学院
曼彻斯特大学
英国曼彻斯特
angelo.cangelosi@manchester.ac.uk
摘要
当前可解释深度强化学习方法存在注意力掩码与视觉输入中的对象位置不匹配的问题。本文解决了传统卷积神经网络(CNN)中的空间问题。我们提出了可解释特征提取器(IFE)架构,旨在生成准确的注意力掩码以说明代理在空间领域中关注的“内容”和“位置”。我们的设计包含一个人类可理解编码模块,用于生成完全可解释的注意力掩码,随后是一个代理友好型编码模块,以提高代理的学习效率。这两个组件共同构成了用于基于视觉的深度强化学习的可解释特征提取器,以实现模型的可解释性。生成的注意力掩码具有一致性、高度可被人类理解、在空间维度上准确,并有效突出视觉输入中的重要对象或位置。我们将可解释特征提取器集成到快速高效的数据框架Rainbow中,并在57个ATARI游戏中进行了评估,以展示所提出方法在空间保持、可解释性和数据效率方面的有效性。最后,我们通过将IFE集成到异步优势演员-评论家模型中展示了该方法的多功能性。
索引术语—可解释性,强化学习,注意力
I. 引言
深度强化学习(DRL)发展迅速,在机器人技术、游戏和其他决策过程中表现出色。许多DRL模型在AlphaGo [33]或MEME [16]等领域超越了人类专家。然而,由于其可解释性较差,DRL在现实中的社会影响被低估,特别是在自动驾驶和医疗等关键应用中。
为了解决这一问题,可解释深度强化学习(XDRL)在许多研究中被探讨,以揭示代理决策过程的关键见解。许多研究生成显著图来可视化政策变化的重要位置[10]。其他研究[7],[26]成功地应用多头注意力机制从视觉输入中揭示任务相关信息。然而,上述所有工作只能解释ATARI基准测试中的一些游戏,特别是对于模型表现优于人类但注意力图难以理解的游戏,引发了对这些方法有效性的担忧。此外,所有提出的方案都依赖于卷积神经网络从视觉输入中提取环境特征,因此无法内在地强制执行空间一致性。我们构建并评估了一个多功能的可解释特征提取器(IFE),它可以作为基于视觉的深度强化学习的可靠提取器。
在本文中,我们解决了XDRL中的空间保存问题,这导致了可解释性和性能之间的困境。一方面,卷积神经网络(CNN)在DRL中起着重要作用,能够高效地从视觉输入中提取空间特征。然而,由于卷积窗口之间的重叠,输入和输出之间的空间一致性并未完全保留。另一方面,非重叠卷积操作可以完全保留空间信息,但在训练期间会降低效率(第II-C节)。重新思考DRL中的特征提取器,我们构建了一个可解释模型,平衡了空间保存和学习性能(如图1所示)。首先,这种方法使用非重叠卷积操作从视觉输入中提取特征,同时完全保留空间信息,然后通过软注意力机制迫使模型在训练期间仅专注于与决策相关的特征。注意力掩码是在推理过程中模型的前向传递中计算的,并且是单张地图的形式,这对于可视化更高效,并且与上下文一致。之后,特征将被转换为
*这项工作部分由Horizon Europe(和UKRI Horizon Guaranteed Fund)根据Marie Skłodowska-Curie资助协议No 101072488(TRAIL)支持。这项工作还部分由EPSRC Prosperity资助CRADLE (EP/X02489X/1) 和美国空军科学研究办公室(USAF)根据CASPER++ Awards (FA8655-24-1-7047) 支持。
(c) 2025 IEEE。个人使用此材料是允许的。所有其他用途必须获得IEEE的许可,包括在任何当前或未来的媒体中重新印刷/重新发布此材料以用于广告或促销目的、创建新的集体作品、转售或重新分发到服务器或列表,或在其他作品中重复使用本工作的任何受版权保护的部分。
一个代理友好的域,这允许模型灵活地将环境表示编码到特征图中,使模型高效学习。结果表明,无论学习类型或策略如何,该特征提取器都是可解释且高效的。我们证明了我们的可解释特征提取器可以从ATARI环境中所有57个游戏中产生准确、一致且高度可理解的注意力掩码。为了促进可重复性和可重用性,我们的代码已公开可用${ }^{2}$。
我们总结如下贡献:
- 解决了可解释人工智能中的空间问题,并提出了一种简单而有效的解决方案,以最小化基于视觉的深度强化学习中的该问题。
-
- 引入了一个多功能且可靠的特征提取器,将其集成到深度强化学习模型中以实现可解释性。
-
- 在空间保存、可解释性和数据效率方面对传统CNN方法和最先进的可解释深度强化学习模型(Mott等人[26])在ATARI环境中进行评估。
II. 预备知识
A. 无模型深度强化学习
我们考虑Atari游戏作为一个马尔可夫决策问题,由元组 ( S , A , P , R , γ ) (\mathcal{S}, \mathcal{A}, \mathcal{P}, \mathcal{R}, \gamma) (S,A,P,R,γ)定义。状态空间 S \mathcal{S} S包括由游戏引擎提供的所有可能的状态 s s s。 A \mathcal{A} A是代理在每个状态下可以执行的所有可能离散动作 a a a的有限集合。 P \mathcal{P} P是状态转移分布,表示每个元组 ( s , a ) (s, a) (s,a)的状态转移概率。奖励函数 r r r是执行特定动作时环境提供的输出,折扣因子 γ \gamma γ反映了随时间推移奖励信号的权重。通过基于视觉状态执行一系列动作以收集奖励,代理将尝试探索环境并通过训练最大化所获得的奖励。有几种方法试图解决大而可能无限的状态空间问题,以估计在采取行动后遵循最优策略的未来奖励期望值[2],[13],[23],[25],[36]。已经开发了几种框架来改进代理的性能和学习效率,例如深度Q网络[36],近端策略优化[31],演员评论家[19],异步高级演员评论家[23],Impala[8],MEME[16]等。所有这些方法都使用卷积神经网络变体来提取表示视觉状态的特征,然后将其映射到动作以指示状态-动作对向量。我们的工作重点是通过解释代理对环境的感知来改进特征提取器的可解释性,这可以应用于大多数基于视觉的深度强化学习模型。然而,由于
深度强化学习训练耗时较长,我们仅将该方法集成到快速高效的数据Rainbow[30]中,这是我们的评估主要框架,因其学习的数据效率高。我们还将该方法扩展到具有长短时记忆(LSTM)[23]的异步优势演员评论家(A3C),其具有不同的网络结构、学习策略和观察配置,以证明其多功能性。
B. 注意力
注意力机制最近在多个领域得到了深入研究[4],[6],[26],[40]。对视觉输入的注意力将指示模型在决定动作时聚焦的图像位置。关键思想是在空间特征上应用可学习的注意力权重,使模型能够在决策过程中适应性地专注于相关空间特征。主要有两种类型的注意力机制,即多头注意力[37]和Bahdanau注意力[4]。多头注意力同时在查询 Q \mathcal{Q} Q和键值对 ( K , V ) (\mathcal{K}, \mathcal{V}) (K,V)之间创建多个映射到输入,生成低维向量以基于查询总结输入[37]。每个映射都会创建注意力图,一起代表模型在不同空间中的注意力。相比之下,Bahdanau注意力将输入转换到空间维度上的注意力空间,然后压缩成单个值以创建注意力权重。还有其他形式和变体的注意力机制已被广泛使用以提高模型性能以及增加模型的可解释性[39],[41]。这项工作使用Bahdanau注意力中的软机制(第IV节)生成注意力掩码,因为其训练效率高以及掩码的可解释性。
C. 卷积神经网络中的空间保持与性能
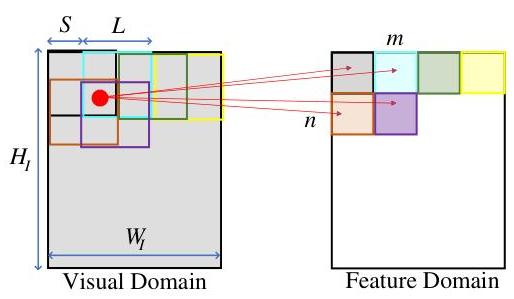
图2. 重叠卷积操作导致的一对多变换示意图。
传统的基于视觉的深度强化学习依赖于卷积神经网络作为特征提取器,逐步提取重叠空间领域的视觉特征[9]。在许多关于XDRL的研究中[7],[10],[26],[34],视觉解释如注意力或显著图是在最终特征中计算并转换到视觉空间。然而,卷积操作是不可逆的,不允许从特征到视觉
${ }^{1}$ 所有ATARI环境的视频可以在以下网址找到:https://sites.google.com/view/pay-attention-to-windows
${ }^{2}$ https://github.com/tiencapham/IFE

图1. 提出的基于视觉的深度强化学习的可解释特征提取器架构
域的精确转换。作为一种常见做法,简单的上采样方法用于检索视觉输入中的注意力掩码。假设特征在特征域中的坐标为
(
m
,
n
)
(m, n)
(m,n),并由大小为
(
L
,
L
)
(L, L)
(L,L)的卷积核以步幅
S
S
S从尺寸为
(
W
I
,
H
I
)
\left(W_{I}, H_{I}\right)
(WI,HI)的视觉输入中提取。经过上采样过程后,该特征的注意力掩码与其在视觉输入中对应像素之间的位移定义如下:
{ D x = m S ( 1 − 1 1 + 1 W I ) + l x ( 1 − S L 1 1 + 1 W I ) D y = n S ( 1 − 1 1 + 1 W I ) + l y ( 1 − S L 1 1 + 1 W I ) \left\{\begin{array}{l} D_{x}=m S\left(1-\frac{1}{1+\frac{1}{W_{I}}}\right)+l_{x}\left(1-\frac{S}{L} \frac{1}{1+\frac{1}{W_{I}}}\right) \\ D_{y}=n S\left(1-\frac{1}{1+\frac{1}{W_{I}}}\right)+l_{y}\left(1-\frac{S}{L} \frac{1}{1+\frac{1}{W_{I}}}\right) \end{array}\right. ⎩ ⎨ ⎧Dx=mS(1−1+WI11)+lx(1−LS1+WI11)Dy=nS(1−1+WI11)+ly(1−LS1+WI11)
因此,在使用传统CNN方法的可解释视觉深度强化学习中,注意力掩码与对应的视觉输入之间存在位移的空间问题是不可避免的。此外,由于对象位于重叠区域可能会被多个卷积窗口提取,重叠卷积操作也会导致一对多问题。因此,可能会出现同一对象的多个特征(见图2)。相反,当步幅 S S S等于核大小 L L L时,非重叠卷积是完全空间可保持的,可以生成准确的注意力掩码。然而,这种方法失去了卷积操作之间的参数共享[9],从而降低了学习性能。参数共享允许模型定义特征是从哪个领域提取的,赋予了学习和适应任务的灵活性。因此,需要在可解释性和性能之间取得平衡,以实现可解释深度强化学习。
III. 相关工作
注意力机制已在深度学习中得到广泛研究,以提高模型的可解释性和性能,例如文本翻译[4],[37]、图像标题生成
[14], [20], [40], 问答 [12], [24], 对象跟踪 [18] 和强化学习 [7], [22], [26], [34]。这些方法使用注意力掩码提供模型对输入的感知,突出显示最相关的任务信息。对于视觉相关任务,上述所有工作都使用卷积神经网络作为主干来提取视觉特征,并应用注意力机制生成突出显示高注意力权重位置的掩码。然而,我们观察到CNN会导致第II-C节中提到的空间问题。据我们所知,我们是第一个解决和解决基于视觉的注意力模型中的空间问题的人。
可解释深度强化学习。可以通过几个方面来探索RL模型的可解释性,从自我可解释建模到奖励分解和后训练解释[11]。奖励分解[15], [21]可用于基于重新设计的奖励来解释代理的动作。可以从传统RL模型中提取显著图来解释代理的决策[3], [28]。其他工作[11], [28]识别了对代理最终奖励至关重要的状态。我们的工作重点是通过设计可解释的特征提取器来实现代理的可解释性。
强化学习中的注意力。已经有几项工作将注意力机制应用于揭示深度强化学习在决策过程中的信息[7], [26], [34]。Sorokin等人[34]提出了一种深度注意力递归Q网络,结合软或硬注意力机制与LSTM提取时间相关的注意力加权特征。然而,注意力可视化模糊且未能准确关注重要对象。Shi等人[32]通过自监督训练网络与解码器,提出了一种可解释的特征提取器,生成注意力图以指示代理关注点。Shi等人[17]设计了一种注意力瓶颈模型,将网络的潜在表示连接起来。Choi等人[7]将多头注意力与LSTM相结合,创建了一个多焦点注意力网络(MANet),通过利用多个并发注意力机制来提高代理关注重要元素的能力。类似的方法也由Mott等人[26]提出,他们应用一种软、空间顺序、自上而下的注意力(S3TA)在ATARI环境中生成注意力掩码,揭示了一些潜在的决策信息。这两项工作将多头注意力机制与LSTM层结合,创建查询向量并从小型信息区域提取注意力。多头注意力创建了多个注意力头,代表模型对输入的不同感知,从而造成头部间可解释性的一致性问题。相比之下,我们的软注意力仅创建一个注意力掩码,实现了更好的可解释性,详见第五-B节。此外,我们的方法对网络和训练程序的修改最少,并不依赖LSTM层,可以集成到多种强化学习模型中而不添加新组件。
IV. 方法
认识到第II-C节提到的两难境地,我们将可解释特征提取器公式化如下:
- 人类可理解领域的可解释性:可解释深度强化学习的目的是在决策过程中生成人类可理解的视觉“解释”。因此,注意力掩码需要在人类可理解领域中生成。在此阶段,模型将视觉输入编码到特征领域,其中语义应在空间上保持不变。
-
- 代理友好领域的性能:特征提取器的输出需要被代理使用以预测优化未来奖励的动作。为了提高强化学习模型的数据效率,输出特征应处于代理友好领域。这允许模型灵活地将特征转换到促进训练效率的领域。
A. 人类可理解编码(HUE)
我们介绍了可解释特征提取器中的第一个模块,称为人类可理解编码,主要侧重于生成视觉解释。通过非重叠卷积层处理观察(灰度帧堆栈)以提取完全空间可保持领域的关键特征。输出张量 [ z i ] \left[z_{i}\right] [zi]具有较低分辨率的视觉输入,这减少了注意力过程的计算强度,但仍足够精细以生成准确和清晰的注意力掩码。首先,特征张量 [ z i ] \left[z_{i}\right] [zi]被排列以展平两个空间维度,加速转换。我们定义了一个可学习的转换 ϕ \phi ϕ,它将表示在空间位置提取特征的向量转换为注意力权重 [ α i ] \left[\alpha_{i}\right] [αi],表示特征与任务的相关性。然后通过注意力屏蔽特征向量,仅夸大重要位置的特征,同时减少非相关空间特征的值,生成注意力加权的空间特征 z i masked z_{i}^{\text {masked }} zimasked 。
α i = ϕ ( z i ) z i masked = z i α i \begin{gathered} \alpha_{i}=\phi\left(z_{i}\right) \\ z_{i}^{\text {masked }}=z_{i} \alpha_{i} \end{gathered} αi=ϕ(zi)zimasked =ziαi
注意转换 f att f_{\text {att }} fatt 由两个全连接层构建。第一层用于将特征向量 z i z_{i} zi转换到注意力域 A A A。随后,第二层将其转换为单个值,表示重要性权重 e i e_{i} ei。为了迫使模型只选择真正重要的特征,应用了softmax激活,从而生成清晰且可解释的注意力掩码。
e i = f att ( z i ) ϕ ( z i ) = exp ( e i ) ∑ k = 1 L ( exp ( e k ) ) \begin{gathered} e_{i}=f_{\text {att }}\left(z_{i}\right) \\ \phi\left(z_{i}\right)=\frac{\exp \left(e_{i}\right)}{\sum_{k=1}^{L}\left(\exp \left(e_{k}\right)\right)} \end{gathered} ei=fatt (zi)ϕ(zi)=∑k=1L(exp(ek))exp(ei)
这种机制提供了一种可学习的方法来调整特征,通过增加重要空间特征的权重并减少无关特征的权重。最后,注意力加权的空间特征被重新排列回原始形状以供进一步处理。值得注意的是,由于卷积层和注意力机制的组合,人类可理解编码是完全可微分的,可以通过反向传播进行训练。强化学习模型在更新其权重以最大化未来回报的同时,也会调整注意力机制以选择对决策过程有贡献的重要空间特征。结果,注意力加权的空间特征仅在重要位置包含高值,而在其他位置则具有可忽略的权重。此外,保持空间特性的注意力掩码可以叠加在视觉输入上,并提供模型关注的“内容”和“位置”的视觉解释。
B. 代理友好编码
虽然人类可理解编码可以从视觉输入中提取特征并生成突出重要位置的准确注意力掩码,但其缺乏参数共享可能会降低训练效率,这是卷积特征提取器的优势。我们引入第二个组件,即代理友好编码,允许在特征提取中进行参数共享并促进训练过程。以重叠方式使用卷积层,随后是激活函数、池化或标准化层以及其他神经网络变体。对于在此模块中使用的网络类型或架构没有任何约束或特定要求,只要它促进了整个网络的训练效率即可。因此,这种方法可以被多种深度强化学习模型采用。我们的工作使用IMPALA-Large模型[8]作为主要框架,该框架在代理友好编码中使用最大池化层、两个连续的残差块和一个
自适应最大池化层。我们还将该方法整合到使用两个卷积层、一个全连接层和一个LSTM层的A3C-LSTM中。
C. 可解释特征提取器
上述两个组件共同构成了一个可解释特征提取器(IFE),可以用于基于视觉的深度强化学习模型。通过将IFE与决策层结合,具体取决于强化学习模型的类型,如双网络或演员-评论家网络,模型变得可解释。可解释模型能够在空间域中生成注意力掩码,并生成对决策过程有效的代理友好特征。
V. 结果与分析
表一
训练超参数
| 参数 | Rainbow | A3C-LSTM |
|---|---|---|
| 折扣因子 γ \gamma γ | 0.99 | 0.99 |
| Q-target 更新频率 | 32,000 帧 | - |
| PER 的重要性采样 β 0 \beta_{0} β0 | 0.45 | - |
| n 步引导中的 n n n | 3 | 20 |
| 初始探索 ϵ \epsilon ϵ | 1 | - |
| 最终探索 ϵ \epsilon ϵ | 0.01 | - |
| 探索衰减时间 | 1 , 000 , 000 1,000,000 1,000,000 帧 | - |
| 学习率 | 0.00025 | 0.0001 |
| 优化器 | Adam | Adam |
| Adam 参数 | 0.005 / 批量大小 | 使用 Amsgrad |
| GAE 参数 | - | 0.92 |
| 梯度裁剪范数 | 10 | - |
| 损失函数 | Huber | - |
| 批量大小 | 256 | - |
| 帧跳过 | 4 | 4 |
| 帧堆叠 | 4 | 1 |
| 灰度 | 是 | 是 |
基于我们的方法在快速高效的Rainbow模型中进行的全面评估,在57个ATARI游戏(OpenAI Gym v0.18.0 [5])上进行了彻底评估。评估中使用的网络架构详情如图3所示。由于论文篇幅限制,我们只为每次评估展示少数几个例子。为了更好地理解可解释的注意力掩码是如何可视化的,建议访问我们的项目网页 1 { }^{1} 1。此外,我们将[26]中的多头注意力模型(S3TA)作为基线进行评估,因为它们被认为是具有相似设置的可解释深度强化学习的最先进方法 3 { }^{3} 3。
注意力可视化。为了在推理过程中可视化注意力掩码,我们首先将视觉观察输入到可解释模型中并检索注意力掩码(如图4所示)。然后将掩码上采样以使其形状与视觉输入相似。最后,将注意力掩码叠加在暗化的输入上以更清晰地可视化。暗淡的注意力表示小值,而明亮的掩码则表示
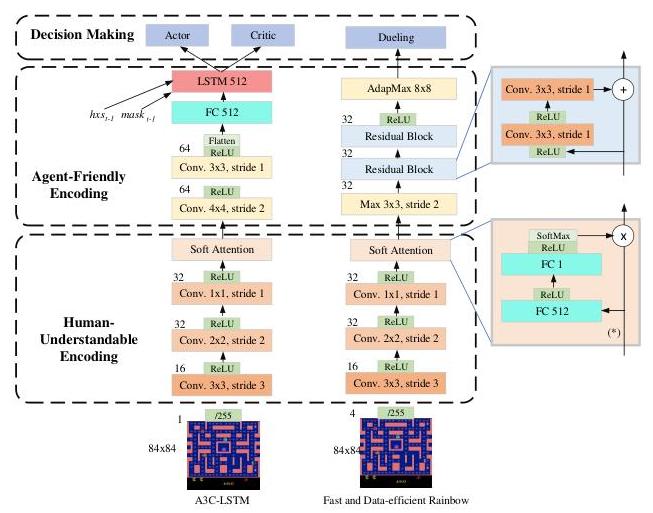
图3. 论文中使用的网络架构
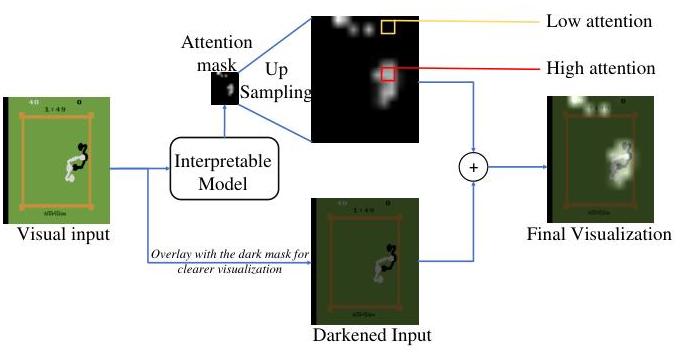
图4. 叠加在视觉输入上的注意力掩码可视化
显著的注意力权重,突出了“哪里”和“什么”代理正在看。
A. 空间保持
我们将所提模型生成的注意力图与正常CNN架构(在HUE中使用重叠卷积操作)进行比较。我们的模型可以准确定位重要对象,而CNN注意力则存在随机偏移(参见图5)。请注意,状态 S t S_{t} St的输入是4个连续帧 ( F t − 3 , F t − 2 , F t − 1 , F t ) \left(F_{t-3}, F_{t-2}, F_{t-1}, F_{t}\right) (Ft−3,Ft−2,Ft−1,Ft),这会导致视觉输入中对象的位移,从而在掩码中产生轨迹注意力。在57个ATARI游戏中,我们观察到,无论得分表现如何,我们提出的模型可以在所有环境中生成清晰准确的注意力掩码。这一观察结果支持了所提框架相比传统CNN方法缓解了空间保持问题的主张。
与图6中显示的S3TA方法进行比较,我们发现我们的注意力掩码准确且与环境背景一致,而S3TA可视化由于空间保持问题出现了偏移。以太空入侵者(图6(a))为例,注意力掩码在敌人身上向上左偏移至注意力头2,但在注意力头4向下左偏移。在河流突击案例(图6(b))中,燃料箱的注意力也向左偏移到注意力头2,而在注意力头3中发现了对该油箱的多重注意力,从左到顶部随机偏移。在其他游戏中,S3TA可视化中也可以发现类似的问题,但在我们提出的方法中没有。此外,S3TA模型中也出现了注意力头不一致的问题。例如,在太空入侵者(图6(a))中,角色的注意力可能出现在注意力头3上,而在河流突击(图6(b))中,则可能出现在注意力头1上,这引起了对模型解释的关注。我们的方法生成所有注意力在一个单一的掩码中,导致更高效和易懂的解释。

图5. 模型连续5次输入的注意力掩码叠加示例。图表展示了在(a)乒乓球和(b)耐久战中,所提模型与传统CNN模型之间的对比。所提模型的注意力可视化更为清晰和易于解释,而CNN方法的注意力掩码因多个对象的注意力而变得扭曲和模糊。我们还可以看到注意力与物体移动的一致性,例如球或汽车。
图6. 我们的工作与S3TA [26]在(a)太空入侵者、(b)河流突击、(c)功夫大师和(d)攻击中的注意力掩码比较。S3TA的四个注意力头按从左到右的顺序呈现。
B. 可解释性评估
可解释性难以衡量,取决于各种主观和客观因素。目前尚无标准基准来评估模型的可解释性。然而,我们可以直观地声称,我们的可解释模型为ATARI基准中的所有游戏生成了清晰和准确的注意力掩码。

图7. 我们的工作与S3TA [26]在(a)大西洋、(b)詹姆斯邦德中的注意力掩码比较。在S3TA方法中捕获了随机且难以解释的注意力掩码(大西洋中的注意力2和詹姆斯邦德中的注意力1)。
检查S3TA可视化,我们观察到在大多数游戏中,注意力与对象之间的位移以及难以理解的注意力出现
(图6和图7),这降低了可视化的可解释性。类似的问題也可能出现在带有注意力的CNN网络中(图5)。这可以通过第二节-C部分中提到的CNN的空间和一对多问题来解释,这些问题模糊了注意力掩码并在视觉领域生成了难以解释的注意力。相比之下,所提出的方法通过强迫模型在完全保留的空间域中编码图像并生成清晰、准确和可解释的注意力掩码,减轻了这个问题,证实了所提出方法的优越可解释性。
在成功的学习环境中进行解释。通过观察ATARI基准中的所有可视化,我们得出结论,我们的模型在所有环境中都是可解释的,但S3TA模型并非如此。我们观察到一些环境,S3TA模型可以学习,其人类标准化分数大于10%,但其可视化难以理解(注意力掩码随机生成,难以将注意力掩码与视觉输入背景联系起来,见图8)。这种现象是由CNN中的严重空间问题引起的,其中代理友好领域与人类可理解领域极为不同。因此,我们无法解释应该对代理获取奖励有意义的注意力掩码。

图8. 我们的工作与S3TA [26]在(a)冰球、(b)拳击、(c)直升机指挥官和(d)疯狂攀登者中的注意力掩码比较。我们展示了四个游戏的例子,其中S3TA模型的注意力掩码难以理解,而人类标准化分数大于10%。
C. 训练中的数据效率和通用性
我们将所提模型的数据效率与传统的带注意力的CNN方法及其一种变体进行了评估,该变体仅使用HUE作为特征提取器。这些模型在50,000,000帧内进行了训练,基准性能如表二所示。我们发现,所提模型的表现与传统CNN相当,而仅使用HUE的模型由于缺乏参数共享(见第五-A节)表现较差。详细的性能和学习曲线展示在我们的项目网页上 1 { }^{1} 1。由于S3TA缺乏开源代码以及其高昂的训练计算需求(2亿帧),我们仅在六个ATARI游戏中比较了所提方法的效率,包括乒乓球、太空入侵者、拳击、Ms Pacman、防御者和突围。我们的方法在平均和中位指标上均优于S3TA。
为了评估可解释特征提取器的通用性,我们将IFE集成到具有
表二
雅达利游戏的人类标准化得分
| 模型 | 中位数 | 平均数 |
|---|---|---|
| 基线 [57 游戏] | 922.43 % 922.43 \% 922.43% | 139.75 % 139.75 \% 139.75% |
| 带注意力的 CNN [57 游戏] | 955.48 % \mathbf{9 5 5 . 4 8 \%} 955.48% | 143.99 % 143.99 \% 143.99% |
| 仅有 HUIE [57 游戏] | 896.16 % 896.16 \% 896.16% | 133.52 % 133.52 \% 133.52% |
| 提议 [57 游戏] | 944.36 % 944.36 \% 944.36% | 157.21 % \mathbf{1 5 7 . 2 1 \%} 157.21% |
| S3TA [6 游戏] | 1513.4 % 1513.4 \% 1513.4% | 1796.6 % 1796.6 \% 1796.6% |
| 提议 [6 游戏] | 1549.71 % \mathbf{1 5 4 9 . 7 1 \%} 1549.71% | 1969.82 % \mathbf{1 9 6 9 . 8 2 \%} 1969.82% |
不同的学习类别(on-policy)、不同的观察配置(单个灰度帧)和不同的网络组件(LSTM 层)相比Fast and Efficient Rainbow [35]。我们观察到类似的可视化效果,其中注意力掩码准确地突出了视觉输入中的重要对象,成功地展示了“哪里”和“什么”代理感知以决定动作(如图9所示)。

图9. 可解释特征提取器集成到A3C LSTM的展示案例
D. 转移学习中的注意力
迁移学习或持续学习是一种学习类型,我们利用在一个任务中的训练知识转移到另一个任务中,这在最近的各种研究中逐渐兴起[1],[27],[38]。我们在Krull和Hero游戏的持续学习背景下进行了一项实验,这些游戏用于评估ATARI基准中的持续学习[29]。我们使用在一个游戏中训练的模型在另一个游戏中进行评估,发现注意力掩码也可以转移(图10),这表明可解释特征提取器部分转移了来自编码器的知识。这一结果还说明了在训练期间遇到未知观察时,注意力掩码仍然可靠。
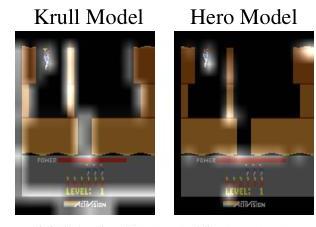
(a) Hero游戏评估

(b) Krull游戏评估
图10. 可解释特征提取器的知识转移
VI. 局限性
尽管我们的方法显示出有希望的结果,并证明比当前可解释深度强化学习的最先进方法优越,但我们承认我们的工作中存在几个局限性。由于资源限制和
深度强化学习的计算强度,我们只能在快速高效的数据Rainbow框架和使用A3C LSTM的几个环境中评估我们的方法。因此,诸如在可解释A3C LSTM中的数据高效学习、我们的方法与S3TA的数据效率的详细比较及其在其他强化学习框架中的性能等方面未包含在我们的评估中。此外,我们注意到在某些ATARI环境中,模型可能会陷入次优解(例如,什么都不做,导致零奖励)。这使得环境保持静态,不提供新的视觉输入,因此也没有有用的学习信息,导致模糊的注意力可视化。为了解决这个问题,我们必须在网球和蒙特祖玛复仇等游戏中进行多次实验。
VII. 结论
我们成功地解决了、制定了并开发了一种方法来缓解基于视觉的可解释深度强化学习中的空间保持问题。我们的方法结合了人类可理解编码和软注意力模块,以从视觉输入中提取空间注意力,随后通过代理友好编码增强模型的训练效率。这些元素共同构成了一种可解释的特征提取器。
我们提出的方法可以生成一个注意力掩码,可视化代理在决策过程中的视觉输入感知。我们已经评估并展示了这种方法在空间保持、可解释性和数据效率方面相较于传统CNN方法和当前ATARI环境中的可解释深度强化学习最先进方法的优越性。我们认为我们的框架作为一个可靠的可解释特征提取器,加深了我们对基于视觉的深度强化学习模型底层机制的理解。
参考文献
[1] David Abel, Andre Barreto, Benjamin Van Roy, Doina Precup, Hado P van Hasselt, and Satinder Singh. 持续强化学习的定义。In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, 编辑, Advances in Neural Information Processing Systems, volume 36, pages 50377-50407. Curran Associates, Inc., 2023.
[2] Mahmoud Assran, Joshua Romoff, Nicolas Ballas, Joelle Pineau, and Michael Rabbat. 基于闲聊的参与者-学习者架构用于深度强化学习。Advances in Neural Information Processing Systems, 32, 2019.
[3] Akanksha Atrey, Raleigh Clary, and David Jensen. 探索而非解释:深度强化学习显著图的反事实分析。arXiv preprint arXiv:1912.05743, 2019.
[4] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 通过联合学习对齐和翻译进行神经机器翻译。arXiv preprint arXiv:1409.0473, 2014.
[5] Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym, 2016.
[6] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 自监督视觉Transformer中出现的属性。In Proceedings of the IEEE/CVF国际计算机视觉会议, pages 9650-9660, 2021.
[7] Jinyoung Choi, Beom-Jin Lee, and Byoung-Tak Zhang. 多焦点注意力网络用于高效的深度强化学习。In 第三十一届AAAI人工智能会议研讨会, 2017.
[8] Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Vlad Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. Impala: 具有重要加权参与者-学习者架构的可扩展分布式深度强化学习。In 国际机器学习会议, pages 1407-1416. PMLR, 2018.
[9] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. 深度学习。MIT Press, 2016. http://www.deeplearningbook.org.
[10] Samuel Greydanus, Anurag Koul, Jonathan Dodge, and Alan Fern. 可视化和理解Atari智能体。In Jennifer Dy and Andreas Krause, 编辑, 第35届国际机器学习会议论文集, volume 80 of Proceedings of Machine Learning Research, pages 1792-1801. PMLR, 2018年7月10日至15日.
[11] Wenbo Guo, Xian Wu, Usmann Khan, and Xinyu Xing. EDGE: 解释深度强化学习策略。Advances in Neural Information Processing Systems, 34:12222-12236, 2021.
[12] Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. 教机器阅读和理解。Advances in neural information processing systems, 28, 2015.
[13] Matteo Hessel, Joseph Modayil, Hado Van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. Rainbow: 深度强化学习中的改进组合。In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
[14] Drew A Hudson and Christopher D Manning. 组合注意力网络用于机器推理。arXiv preprint arXiv:1803.03067, 2018.
[15] Zoe Juozapaitis, Anurag Koul, Alan Fern, Martin Erwig, and Finale Doshi-Velez. 通过奖励分解实现可解释的强化学习。In IJCAI/ECAI Workshop on explainable artificial intelligence, 2019.
[16] Steven Kaptarowski, Víctor Campos, Ray Jiang, Nemanja Rakićević, Hado van Hasselt, Charles Blundell, and Adrià Puigdomènech Badia. Human-level Atari 200倍更快。arXiv preprint arXiv:2209.07550, 2022.
[17] Jinkyu Kim and Mayank Bansal. 注意力瓶颈:迈向可解释的深度驾驶网络。In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1310-1313, 2020.
[18] Adam K------
osiorek, Alex Bewley, and Ingmar Posner. 层次注意力循环跟踪。Advances in neural information processing systems 30, 2017.
[19] Alex X Lee, Anusha Nagabandi, Pieter Abbeel, and Sergey Levine. 随机潜在演员评论家:具有潜在变量模型的
------深度强化学习。Advances in Neural Information Processing Systems, 33:741-752, 2020.
[20] Xuelong Li, Bin Zhao, Xiaoqiang Lu, et al. 基于多级注意力模型的RNN用于视频字幕生成。In IJCAI, volume 2017, pages 2208-2214, 2017.
[21] Zhengxian Lin, Kim-Ho Lam, and Alan Fern. 对比解释通过嵌入自预测实现强化学习。arXiv preprint arXiv:2010.05180, 2020.
[22] Anthony Manchin, Elisan Abbasnejad, and Anton Van Den Hengel. 使用有效的自我监督方法实现带有注意力的工作强化学习。In 神经信息处理:第26届国际会议,ICONIP 2019, Sydney, NSW, Australia, December 12-15, 2019, Proceedings, Part V 26, pages 223-230. Springer, 2019.
[23] Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. 异步深度强化学习方法。In 国际机器学习会议,pages 1928-1937. PMLR, 2016.
[24] Volodymyr Mnih, Nicolas Heess, Alex Graves, et al. 循环视觉注意力模型。Advances in neural information processing systems, 27, 2014.
[25] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. 通过深度强化学习实现人类级别的控制。nature, 518(7540):529-533, 2015.
[26] Alexander Mott, Daniel Zoran, Mike Chrzanowski, Daan Wierstra, and Danilo Jimenez Rezende. 使用增强注意力代理实现可解释强化学习。Advances in neural information processing systems, 32, 2019.
[27] Sam Powers, Eliot Xing, Eric Kolve, Roozbeh Mottaghi, and Abhinav Gupta. CORA: 作为持续强化学习代理平台的基准、基线和度量标准。In Sarath Chandar, Razvan Pascanu, and Doina Precup, 编辑, 第一届终身学习代理会议论文集, volume 199 of Proceedings of Machine Learning Research, pages 705-743. PMLR, 2022年8月22日至24日.
[28] Nikaash Puri, Sukriti Verma, Piyush Gupta, Dhruv Kayastha, Shripad Deshmukh, Balaji Krishnamurthy, and Sameer Singh. 解释你的行动:使用具体和相关的特征归属理解智能体动作。arXiv preprint arXiv:1912.12191, 2019.
[29] David Robnick, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Gregory Wayne. 持续学习中的经验回放。In H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. Fox, and R. Garnett, 编辑, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
[30] Dominik Schmidt and Thomas Schmied. 快速高效的数据Rainbow训练:Atari上的实验研究。arXiv preprint arXiv:2111.10247, 2021.
[31] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 近端策略优化算法。arXiv preprint arXiv:1707.06347, 2017.
[32] Wenjie Shi, Gao Huang, Shiji Song, Zhuoyuan Wang, Tingyu Lin, and Cheng Wu. 自监督发现可解释强化学习的特征。IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(5):2712-2724, 2022.
[33] David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. 掌握围棋游戏的深度神经网络与树搜索。nature, 529(7587):484-489, 2016.
[34] Ivan Sorokin, Alexey Seleznev, Mikhail Pavlov, Aleksandr Fedorov, and Anastasiia Ignateva. 深度注意力递归Q网络。arXiv preprint arXiv:1512.01693, 2015.
[35] Richard S Sutton and Andrew G Barto. 强化学习:导论。MIT press, 2018.
[36] Hado Van Hasselt, Arthur Guez, and David Silver. 带有双重Q学习的深度强化学习。In Proceedings of the AAAI conference on artificial intelligence, volume 30, 2016.
[37] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 注意力就是你所需要的。Advances in neural information processing systems, 30, 2017.
[38] Maciej Wolczyk, MichalZając, Razvan Pascanu, Ł ukasz Kuciński, and Piotr Miłoś. 在持续强化学习中解缠转移。In S. Kojey, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, 和 A. Oh, 编辑, Advances in Neural Information Processing Systems, volume 35, pages 6304-6317. Curran Associates, Inc., 2022.
[39] Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. CBAM: 卷积块注意力模块。In Proceedings of the European conference on computer vision (ECCV), pages 3-19, 2018.
[40] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. 展示、关注并讲述:带视觉注意力的神经图像字幕生成。In International conference on machine learning, pages 2048-2057. PMLR, 2015.
[41] Chenggang Yan, Yunbin Tu, Xingzheng Wang, Yongbing Zhang, Xinhong Hao, Yongdong Zhang, and Qionghai Dai. STAT: 视频字幕生成的空间-时间注意力机制。IEEE transactions on multimedia, 22(1):229-241, 2019.
参考论文:https://arxiv.org/pdf/2504.10071



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











