






领子涵
北京大学
中国
lingzihan@stu.pku.edu.cn
安毅
北京大学
中国
anyi@stu.pku.edu.cn
郭志尧
阿里巴巴集团
中国
guozhiyao45@gmail.com
肖帅
阿里巴巴集团
中国
shuai.xsh@gmail.com
黄一轩
阿里巴巴集团
中国
huangyixuan@sjtu.edu.cn
兰金松
阿里巴巴集团
中国
jinsonglan.ljs@taobao.com
摘要
近年来,大型语言模型(LLMs)和多模态LLMs取得了显著进展。然而,这些模型仍然完全依赖于其参数化知识,这限制了它们生成最新信息的能力,并增加了生成错误内容的风险。检索增强生成(RAG)通过引入外部数据源部分缓解了这些挑战,但对数据库和检索系统的依赖可能会引入无关或不准确的文档,从而影响性能和推理质量。本文提出了一种新颖的多模态RAG框架——多模态知识型检索增强生成(MMKB-RAG),该框架利用模型的知识边界动态生成检索过程中的语义标签。这一策略实现了检索文档的联合过滤,仅保留最相关和准确的参考文献。在基于知识的视觉问答任务上的广泛实验表明了我们方法的有效性:在E-VQA数据集上,我们的方法在单跳子集上提高了 + 4.2 % +4.2\% +4.2%的性能,在完整数据集上提高了 + 0.4 % +0.4\% +0.4%;而在InfoSeek数据集上,它在未见问题子集上获得了 + 7.8 % +7.8\% +7.8%的提升,在未见实体子集上获得 + 8.2 % +8.2\% +8.2%的提升,在完整数据集上获得 + 8.1 % +8.1\% +8.1%的提升。这些结果突显了我们在当前最先进的MLLM和RAG框架基础上,在准确性和鲁棒性方面的显著改进。
CCS概念
- 信息系统 → \rightarrow → 语言模型。
关键词
MLLM, RAG, 知识边界, VQA
郑博
阿里巴巴集团
中国
bozheng@alibaba-inc.com
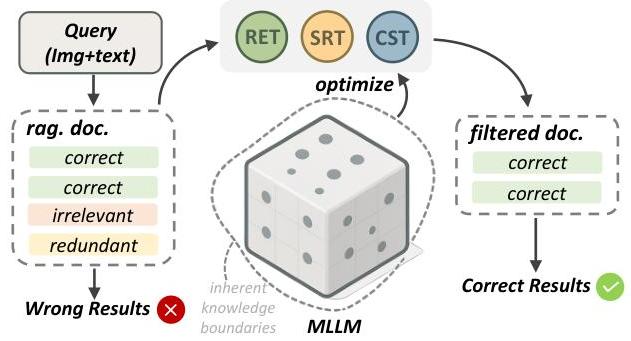
图1:示例说明RAG可能检索到无关和冗余的文档,导致错误结果。我们的方法利用MLLM的知识边界来过滤参考文献,保留生成准确答案所需的必要证据。
ACM参考格式:
领子涵,郭志尧,黄一轩,安毅,肖帅,兰金松,朱晓勇,郑博。2025。MMKB-RAG:一个多模态知识型检索增强生成框架。在《MMKBRAG:一个多模态知识型检索增强生成框架》(MM’25)会议录中。ACM,纽约,美国,10页。https://doi.org/XXXXXXX. XXXXXXXX
1 引言
大型语言模型(LLMs)和多模态大型语言模型(MLLMs)的快速发展彻底改变了自然语言处理和视觉推理任务。这些模型经过大量数据集训练,擅长利用内在的参数化知识生成连贯且上下文适当的回答。然而,一个根本性的挑战依然存在:对静态参数化知识(即预训练期间获得的知识)的依赖往往会导致错误或幻觉[23],特别是在需要精确、领域特定或实时信息的复杂查询时尤为明显[14]。例如,在基于知识的视觉问答(VQA)任务中,
如百科全书式VQA(E-VQA)[21]和InfoSeek [5],即使最先进的MLLM也难以生成准确的回答,因为缺乏有效检索和整合外部知识的能力。这一缺陷凸显了当前MLLM架构中的关键空白:需要机制以实现对外部知识源的动态和可靠访问。
为克服静态参数化知识的局限性,研究人员开发了检索增强生成(RAG)框架,使模型能够在推理过程中结合最新的相关信息。这些框架大致可分为检索侧机制和生成侧机制。在检索侧,现有方法主要关注将视觉和文本模态与外部知识源对齐。CLIP架构利用对比图像-文本编码器建立图像-问题对与知识条目之间的粗粒度对齐,而密集段落检索(DPR)架构[15, 16]通过引入细粒度特征增强了精度。例如,Wiki-LLaVA [4]采用基于CLIP的多阶段检索管道以改进对齐,而RoRA-VLM [22]利用对抗性训练技术提高对无关内容的鲁棒性。尽管取得了这些进展,实现视觉和文本信息之间的细粒度对齐仍然具有挑战性,通常导致次优的检索结果。
在生成侧,研究人员试图通过使MLLM自主评估检索内容的相关性和准确性来改进RAG系统。例如,ReflectiVA [7]使用专门的标记引导检索过程,而EchoSight [31]通过微调重排序模块过滤掉噪声或无关文档。然而,这些自评估策略通常依赖于外部注释管道或辅助模型,可能无法充分捕捉MLLM的内在知识边界。这一观察突显了对集成框架的需求,该框架可以利用MLLM的内在知识动态指导检索和过滤过程。
针对上述问题,我们提出了一个新的框架,称为多模态知识型检索增强生成(MMKB-RAG)。与传统RAG系统仅依赖外部检索策略不同,MMKB-RAG利用目标MLLM的内在知识边界动态生成用于过滤检索文档的专用标签。通过其内生注释系统,MLLM自主确定何时需要检索并验证检索知识的一致性和相关性,所有这些都基于其自身的内在知识限制。MMKB-RAG的关键创新在于其能力,通过从外源性、辅助模型依赖的注释管道转变为内生、能力感知的系统,弥合参数化知识和检索知识之间的差距,解决了多模态检索和自评估方法的不足。
总体而言,本文提出了以下主要贡献:
- 标记系统框架:MMKB-RAG引入了一个三阶段过程,以确定检索的必要性、评估单个文档的相关性以及验证多个文档之间的一致性,确保准确和稳健的推理。
-
- 内部知识利用:通过利用MLLM的内在知识及其与数据集的交互,MMKB-RAG自主定义知识边界并引导检索,无需依赖外部注释。
-
- 卓越性能:在基于知识的VQA任务中,MMKB-RAG优于最先进的模型,特别是在处理细粒度事实查询和复杂的多模态推理挑战方面。
2 相关工作
多模态LLM。大规模语言模型(LLMs)[9,11,32]的出现推动了多模态LLMs(MLLMs)[6,18,30]的重大进展,使其具备基本的视觉理解和常识推理能力。值得注意的是,诸如LLaVA [18]、Qwen-VL[30]和InternVL[6]等实现已经在标准视觉问答(VQA)基准测试中表现出强劲性能。
基于知识的VQA。基于知识的VQA任务要求MLLM通过利用外部知识源整合超出视觉内容的信息。早期基准如KVQA[26]、OK-VQA[20]和A-OKVQA[25]主要集中在常识推理,这是大规模预训练MLLM表现有效的领域,得益于其隐含的知识表示。最近的数据集如E-VQA [21]和InfoSeek [5]推动了领域向Wikipedia规模的知识整合发展,需要对特定Wikipedia实体和细粒度细节有全面的理解。尽管这些基准展示了当前系统的上限,即使是最先进的MLLM在处理详细事实查询时仍受限于其参数密集型架构。这种根本限制经常导致生成幻觉内容[19, 24, 29]。
RAG框架[12]通过在推理过程中动态整合外部知识解决了这些限制。通过采用多阶段推理管道将参数化知识与检索信息合并,RAG架构在缓解这些内在约束方面展现出相当大的潜力。
高级RAG。在RAG范式中,多模态检索机制通常采用两种主要策略:1)基于CLIP的架构利用对比图像-文本编码器[27]建立图像-问题对与知识条目之间的粗粒度对齐;2)基于DPR的架构[15, 16]引入细粒度视觉特征(如感兴趣区域)以增强检索精度。检索到的条目随后被整合到MLLM作为上下文参考。
最近,Wiki-LLaVA[4]通过基于CLIP的多阶段检索过程整合知识,而RoRA-VLM[22]则采用对抗性训练以通过面向查询的视觉标记修剪提高对无关检索内容的鲁棒性。同时,EchoSight[31]通过微调Q-Former引入多模态重排序模块。尽管现有方法主要专注于优化多模态检索,但它们忽略了MLLM在自我评估知识边界中的内在作用。
受自RAG[2]的启发,我们提出了MMKB-RAG框架,其中MLLM自主生成专用标记以
MMKB-RAG框架
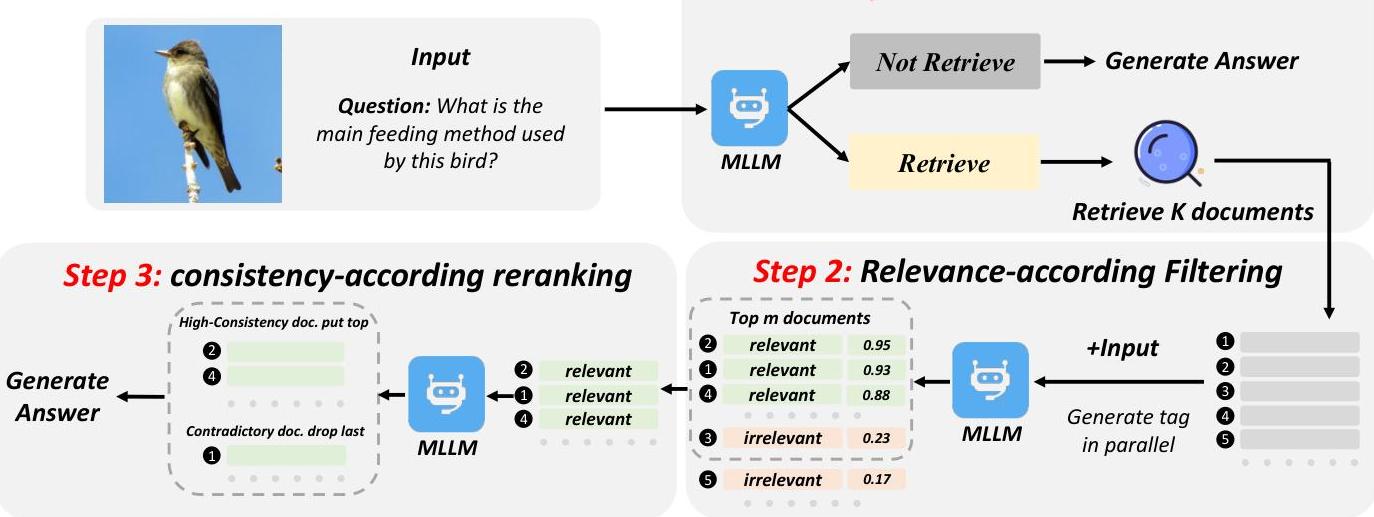
图2:MMKB-RAG流程。给定输入查询,MMKB-RAG首先评估检索的必要性。对于依赖检索的查询,我们采用两阶段过滤过程(步骤2和3),以确保只保留高质量的参考文档。然后将此精选的上下文提供给MLLM,以生成全面和准确的回答。
确定是否需要检索并验证检索知识的一致性和相关性。虽然最近的工作ReflectiVA[7]实现了类似的专用标记机制,但其注释管道从根本上不同,因为它利用不同的MLLM,从而忽略了目标模型的知识限制。相比之下,我们的框架建立了一个内生、知识边界感知的注释系统,直接将标签生成与目标模型对齐。这种从外源性、模型依赖的注释过程到内生、能力感知的标记方法的范式转变带来了显著的性能提升。
3 提出的方法
在基于知识的视觉问答(VQA)中,系统处理图像-问题对 ( I , Q ) (I, Q) (I,Q)并利用外部知识生成准确回答。传统的多模态检索增强生成(MMRAG)方法从知识库中检索相关文档以支持答案生成,公式化为:
y a n s = arg max y MLLM ( y ∣ I , Q , D k , P inpa ) y_{\mathrm{ans}}=\underset{y}{\arg \max } \operatorname{MLLM}(y \mid I, Q, D_{k}, P_{\text {inpa }}) yans=yargmaxMLLM(y∣I,Q,Dk,Pinpa )
其中 D k = { d 1 , d 2 , … , d k } D_{k}=\left\{d_{1}, d_{2}, \ldots, d_{k}\right\} Dk={d1,d2,…,dk}表示检索器 R R R根据图像-问题对 ( I , Q ) (I, Q) (I,Q)检索出的前 k k k篇文档集合, P inpa P_{\text {inpa }} Pinpa 表示为视觉问答设计的提示模板。
如图2所示,我们提出的MMKB-RAG(多模态知识型检索增强生成)通过三个关键创新超越了传统的MMRAG框架:(1) 利用模型的内部知识确定何时需要外部检索,提高效率;(2) 根据输入查询的相关性动态重新排序检索到的文档;(3) 使用一致性检查过滤掉不一致的信息,从而提高答案的可靠性和准确性。在接下来的部分中,我们将详细介绍我们的方法:第3.1节介绍了MMKB-RAG使用的标记系统,第3.2节描述了模型的训练方法。
3.1 MMKB-RAG的标记系统
检索标记(RET)。给定输入对 ( I , Q ) (I, Q) (I,Q),其中 I I I代表图像, Q Q Q代表问题文本,我们将输入分类为两类:(1) MLLM可以通过内部知识回答的问题,表示为[NoRet];(2) 需要外部知识检索才能准确回答的问题,表示为[Ret]。对于标记为[Ret]的输入,检索 R R R获取前 N N N个最相关的文档,允许MLLM结合外部知识生成更准确的答案;对于[NoRet]输入,MLLM直接生成答案,从而优化计算效率。微调后的MLLM使用指定的提示 P R E T P_{R E T} PRET预测这些标记。
R E T = MLLM f t ( I , Q , P R E T ) R E T=\operatorname{MLLM}_{f t}\left(I, Q, P_{R E T}\right) RET=MLLMft(I,Q,PRET)
我们从第一个生成标记中提取对应于[Ret]和[NoRet]的logits,并应用softmax函数将其转换为归一化的概率分数。超参数 γ \gamma γ用于调节最终预测类别。通过改变 γ \gamma γ,我们可以控制模型执行检索操作的倾向。通常, γ \gamma γ设置为0.5。
R E T = { [ R e t ] , if Score R E T > γ [ N o R e t ] , otherwise Score R E T = exp ( z R e t ) exp ( z R e t ) + exp ( z N o R e t ) \begin{aligned} & R E T= \begin{cases}{[R e t],} & \text { if } \operatorname{Score}_{R E T}>\gamma \\ {[N o R e t],} & \text { otherwise }\end{cases} \\ & \text { Score }_{R E T}=\frac{\exp \left(z_{R e t}\right)}{\exp \left(z_{R e t}\right)+\exp \left(z_{N o R e t}\right)} \end{aligned} RET={[Ret],[NoRet], if ScoreRET>γ otherwise Score RET=exp(zRet)+exp(zNoRet)exp(zRet)
单相关标记重排(SRT)。对于分类为[Ret]的输入,最初检索到的文档 D k D_{k} Dk仅基于嵌入相似性得分选择。然而,这种方法可能不能与MLLM的内部知识最佳对齐,潜在地引入无关或矛盾的信息。我们建议利用MLLM的内部知识能力进行相关性评估。为此,我们引入[Rel]和[NoRel]标记,使MLLM能够通过专用提示 P S R T P_{S R T} PSRT评估每个候选文档。对于给定的对(I, Q),第 i i i篇文档 d i d_{i} di的预测公式如下:
S R T i = MLLM f i ( I , Q , d i , P S R T ) S R T^{i}=\operatorname{MLLM}_{f i}\left(I, Q, d_{i}, P_{S R T}\right) SRTi=MLLMfi(I,Q,di,PSRT)
类似于前一部分,我们计算文档 d i d_{i} di的第一个标记的softmax概率,其中 z R e l z_{R e l} zRel对应于[Rel], z N o R e l z_{N o R e l} zNoRel对应于[NoRel]。我们根据[Rel]的概率对所有 k k k个检索到的文档进行重新排序,并选择前 K S R T K_{S R T} KSRT个文档作为最终结果,其中 k S R T ≤ k k_{S R T} \leq k kSRT≤k。此过程可公式化为:
D K S R T = { d i ∣ i ∈ arg Top k S R T { Score S R T j ∣ j ∈ [ 1 , k ] } } Score S R T j = exp ( z R e l i ) exp ( z R e l i ) + exp ( z N o R e l i ) \begin{gathered} D_{K_{S R T}}=\left\{d_{i} \mid i \in \arg \operatorname{Top} k_{S R T}\left\{\operatorname{Score}_{S R T}^{j} \mid j \in[1, k]\right\}\right\} \\ \text { Score }_{S R T}^{j}=\frac{\exp \left(z_{R e l}^{i}\right)}{\exp \left(z_{R e l}^{i}\right)+\exp \left(z_{N o R e l}^{i}\right)} \end{gathered} DKSRT={di∣i∈argTopkSRT{ScoreSRTj∣j∈[1,k]}} Score SRTj=exp(zReli)+exp(zNoReli)exp(zReli)
多一致性过滤(MCT)。使用[Rel]标记检索 D K S R T D_{K_{S R T}} DKSRT文档后,需要注意的是,此标记单独评估每个文档相对于输入的相关性。然而,这种逐文档评估可能导致缺乏全局上下文的问题,或者收集到的文档尽管单独相关,但整体上并不连贯。为解决这些问题,我们引入了一致性检查,从整体角度检查 D K S R T D_{K_{S R T}} DKSRT以过滤不一致之处,并组装更可靠的参考集。具体来说,我们使用微调的MLLM和专用提示 P C S T P_{C S T} PCST。此过程将集合精炼为 k C S T k_{C S T} kCST个文档的子集,为MLLM提供强大的外部知识。
D k C S T = MLLM f t ( D k S R T , P C S T ) D_{k_{C S T}}=\operatorname{MLLM}_{\mathrm{ft}}\left(D_{k_{S R T}}, P_{C S T}\right) DkCST=MLLMft(DkSRT,PCST)
通过标记系统获得外部知识 D k C S T D_{k_{C S T}} DkCST后,我们可以基于此参考知识生成答案,类似于标准的MMRAG方法。引入标记系统显著增强了检索知识的相关性和准确性,从而使MLLM能够生成更精确和可靠的答案。此过程可总结如下:
y atn = arg max y MLLM ( y ∣ I , Q , D k C S T , P oqa ) y_{\text {atn }}=\underset{y}{\arg \max } \operatorname{MLLM}(y \mid I, Q, D_{k_{C S T}}, P_{\text {oqa }}) yatn =yargmaxMLLM(y∣I,Q,DkCST,Poqa )
3.2 带标记系统的训练
在前一节中,我们介绍了三种不同的标记以过滤检索到的文档,显著增强了参考材料的相关性和准确性,从而提高了MLLM的回答质量。我们的方法与现有的依赖外部注释管道或辅助模型的方法
[
2
,
7
]
[2,7]
[2,7]有很大不同。如图3所示,主要创新在于我们的知识边界感知范式,所有标记决策明确来源于目标MLLM的内在知识范围和限制。这种自包含框架确保标记决策通过模型的自我评估机制产生,而不是外部监督,从而实现与模型认知边界的精确对齐。
RET算法。考虑到MLLM在处理VQA任务时的能力,可以观察到这些模型本身拥有大量的知识。这种内在知识使它们能够在不需要任何外部信息检索的情况下准确回答问题。我们的方法独特地利用了MLLM自身现有的知识边界,以确定每个查询是否需要外部检索。
详细的算法过程如算法1所示,初始化一个空数据集并基于模型正确响应查询的能力构建训练数据集。对于正确回答的查询,我们将其标记为[Ret],因为模型的内在知识已足够。相反,对于回答错误的查询,则标记为[NoRet],表示由于知识缺口或幻觉需要检索。收集数据后,我们使用提示
P
R
E
T
P_{R E T}
PRET微调MLLM,使其能够确定目标MLLM对给定查询是否需要检索支持。
SRT。传统的RAG系统通常采用基于嵌入的方法检索与输入查询语义最相关的参考文档。然而,这种方法存在几个局限性:(1) 仅语义相似度不足以保证检索到的文档有助于正确回答问题;(2) 检索过程独立于下游MLLM,可能引入干扰内容,从而影响响应准确性。为克服这些局限性,我们提出了一种新型的以模型为中心的检索范式,通过目标MLLM本身的视角进行相关性评估,明确评估每个候选文档支持准确响应生成的能力。
如算法2所述,我们介绍了一种新的数据收集策略,用于训练相关性评估MLLM。我们的方法将那些将错误答案转化为正确答案的文档识别为相关文档,而将那些破坏初始正确答案的文档识别为无关文档。这种方法创建了自然对比对,从而能够有效地微调MLLM,使用提示
P
S
R
T
P_{S R T}
PSRT优化其辨别有助于准确回答问题的参考文档的能力。
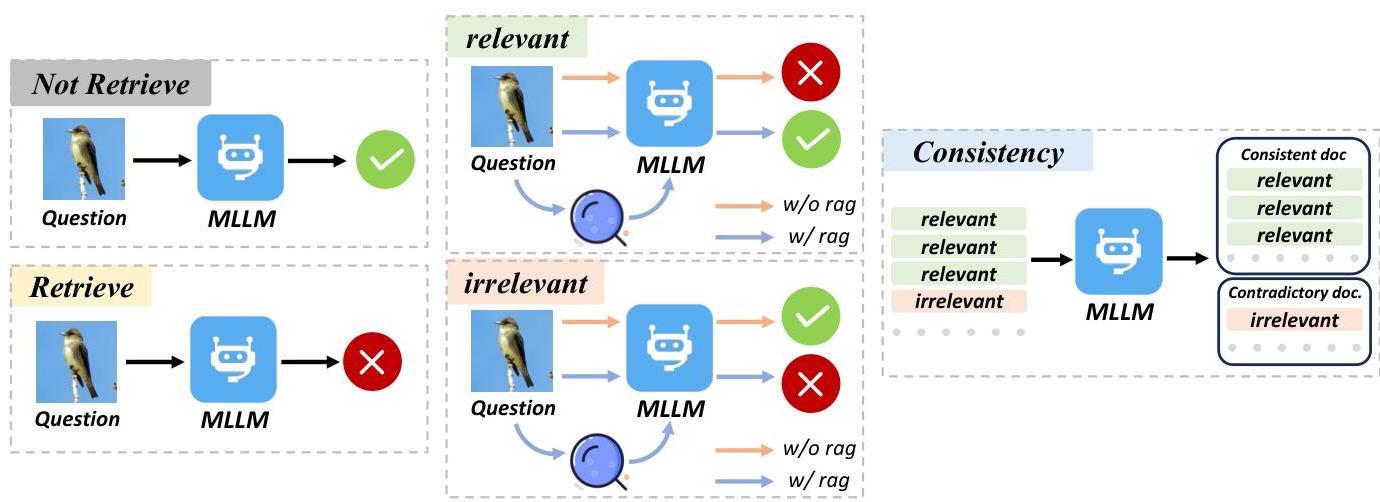
图3:标记系统的训练策略。RET根据模型响应的准确性决定是否调用检索机制;SRT通过评估模型在使用这些文档作为上下文时的表现来评估参考文本的质量;CST统一评估所有检索到的文档,以提供一致的参考文档。
算法2 数据构造SRT
输入: 图像-问题对 \(\left\{\left(I_{1}, Q_{1}\right),\left(I_{2}, Q_{2}\right), \ldots,\left(I_{N}, Q_{N}\right)\right\}\),目标
MLLM, 检索器 \(R\)
输出: SRT训练数据集 \(D_{\mathrm{SRT}}\)
初始化空数据集 \(D_{\mathrm{SRT}}=\emptyset\)
对 \(m=1\) 到 \(M\) 执行
输入 \(\left(I_{m}, Q_{m}\right)\) 到MLLM
获取推理响应 \(A_{m, \text { direct }}\) 从MLLM
使用 \(R\) 检索前 \(K\) 个最相似文档 \(D_{K}^{m}=\)
\(\left\{d_{1}^{m}, d_{2}^{m}, \ldots, d_{k}^{m}\right\}\) 对于 \(\left(I_{m}, Q_{m}\right)\)
对 \(k=1\) 到 \(K\) 执行
输入 \(\left(I_{m}, Q_{m}, d_{k}^{m}\right)\) 到MLLM
获取推理响应 \(A_{m, k}\) 从MLLM
如果 \(A_{m, \text { direct }}\) 错误且 \(A_{m, k}\) 正确则
设置 \(\operatorname{SRT}_{m, k}=[\) Rel \(]\)
否则如果 \(A_{m, \text { direct }}\) 正确且 \(A_{m, n}\) 错误则
设置 \(\operatorname{SRT}_{m, k}=[\) NotRel \(]\)
结束if
将 \(\left(I_{m}, Q_{m}, d_{k}^{m}, S R T_{m, k}\right)\) 添加到 \(D_{\mathrm{SRT}}\)
结束for
结束for
返回 \(D_{\mathrm{SRT}}\)
```
MCT。传统方法$[2,7]$仅依赖单相关标记只能确定查询与单个参考文档之间的相关性。这种方法无法解决在同时使用多个参考文档时可能出现的矛盾、冗余和不一致问题,最终影响响应的准确性。为解决这一局限性,我们提出了多一致性机制,对多个文档进行统一过滤和清理,消除矛盾和其他负面元素,同时为目标MLLM保留干净、一致和连贯的参考内容,从而提高响应准确性。
算法3概述了我们从$D_{S R T}$构建MCT训练数据的方法。我们首先利用MLLM生成$D_{S R T}$的简洁摘要,有效消除冗余信息。
## 算法3 数据构造MCT
输入: $D_{\text {SRT }}$, 目标MLLM, 负样本比例 $\tau \%$
输出: MCT训练数据集 $D_{M C T}$
1: 对每个唯一的$\left(I_{m}, Q_{m}\right)$在$D_{\text {SRT }}$中执行
2: 提取文档$S_{m}^{r}=\left\{d_{k}^{m} \mid S R T_{m, k}=[R e l]\right\}$和$S_{m}^{r r}=\left\{d_{k}^{m} \mid\right.$ $\left.S R T_{m, k}=[N o R e l]\right\}$
3: 如果$\left|S_{m}^{r}\right|>1$则
4: 应用摘要过程: $\operatorname{Sum}=M L L M\left(S_{m}^{r}\right)$
5: 与无关合并: $S_{m}^{m i x}, I d x=\operatorname{Mix}\left(S_{m}^{r}, \tau \% S_{m}^{i r}\right)$
6: 将$\left(I_{m}, Q_{m}, \operatorname{Sum}, S_{m}^{m i x}, I d x\right)$添加到$D_{M C T}$
7: 结束if
8: 结束for
9: 返回$D_{M C T}$
为了增强对噪声参考的鲁棒性,我们有意通过引入$\tau \%$的无关文档$S_{m}^{i r}$污染$S_{m}^{r}$,然后按[单相关]概率排名标识$S_{m}^{r}$条目索引。这种方法训练模型在混合质量语料库$S_{m}^{m i x}$中同时识别高质量文档索引并生成仅源自这些可靠来源的综合摘要。
## 4 实验
### 4.1 数据集
数据集。我们在四个知识密集型VQA基准上评估我们的方法:(1) OKVQA [20]包含14,000个跨多种知识类别的问题,其中5,000个验证样本用于我们的实验,使用VQA评分指标[1]进行评估;(2) E-VQA [21]包含221,000个问题-答案对,链接到16,700个精细的Wikipedia实体,涉及单跳和双跳推理问题,我们使用5,800个测试样本,使用BEM评分[3]进行评估;(3) InfoSeek [5]包括130万张图像-问题对,连接到大约
11,000个Wikipedia页面,按照先前的工作[31],我们在73,000个验证样本上报告结果,使用官方VQA评分脚本;以及(4) M2KR [16],这是一个多模态知识检索基准,以段落级别处理InfoSeek和E-VQA的知识库,我们遵循既定协议使用PreFLMR检索器进行比较评估,针对带有PreFLMR的RA-VQA基线。
外部知识库。InfoSeek和E-VQA数据集均由来自Wikipedia文档的外部知识库支持。具体来说,E-VQA数据集附带一个由2百万Wikipedia页面组成的知识库。每个页面包括Wikipedia标题、关联的文本部分及相关图片。相比之下,InfoSeek数据集利用了一个更广泛的知识库,包含6百万个Wikipedia实体。在我们的实验中,我们使用完整的2百万文档知识库用于E-VQA。对于InfoSeek,按照最近的研究[4, 31],我们从原始6百万文档语料库中提取了100,000页的子集。这种方法确保了高效的数据处理,同时保留了知识库的质量和覆盖范围。对于OKVQA,我们使用了基于Wikipedia文档的知识语料库,这些文档因其伪相关性由M2KR [16]确定。训练和测试段落语料库包括此知识语料库中的所有段落。OKVQA的评估仅在M2KR数据集上进行。
### 4.2 实现细节
检索知识。我们的实验特别旨在优化大型模型的知识注入和理解能力,重点研究这些模型在检索后如何处理和理解外部知识源。在我们的实验设计中,我们主要使用EVA-CLIP-8B[28]进行图像检索。在此实验中,我们选择了图像到图像检索,评估查询图像与嵌入在Wikipedia文档中的图像之间的相似性以检索相应的Wikipedia页面。为了与ReflectiVA[7]保持一致,我们将检索网页的数量设置为5。
模型架构和训练详情。我们使用Qwen2-VL-7B-Instruct [30]作为基础模型,该模型集成了一个675M参数的视觉Transformer(ViT)用于视觉编码和Qwen2-7B语言模型用于文本处理。架构中包含一个MLP连接器,内在地桥接图像标记和语言表示,使有效的多模态信息融合无需外部模块。为了优化计算效率,我们实施LoRA [10]微调,批量大小为512。
训练数据收集。在我们的研究中,我们使用官方Infoseek和E-VQA训练数据集的子集训练MMKB-RAG。为了优化计算效率,我们随机采样了可用数据的$10 \%$用于模型训练。重要的是,我们使用答案模型本身生成微调数据,而不依赖于外部模型如GPT-4o。
MCT类型选择。在我们实验的MCT阶段,我们实施了三种不同的细化策略:Filter:仅使用由MLLM输出索引的文档,保留唯一高质量的文档;Merge:仅使用MLLM生成的基于高质量文档的摘要;和$\mathbf{R e}$ rank:优先考虑MLLM识别的高质量文档,同时保留可能仍包含有价值信息的较不一致的文档。后续部分提供了验证这些策略有效性的全面消融研究。
### 4.3 与最先进方法的比较
我们在E-VQA和InfoSeek基准上评估我们的MMKB-RAG方法,结果如表1所示。评估分为两类:(1) 无知识注入的零样本MLLM和 (2) 有知识注入的检索增强模型。对于基线比较,我们包括在两个任务的目标数据集上训练的Qwen2-VL-7B-Instruct及其微调变体Qwen2-VL-7B-Instruct(SFT)。为了与Wiki-LLaVA进行公平比较,我们使用Contriever检索与查询最相似的前k个文档。
MMKB-RAG在所有设置下表现出优越性能。在零样本场景中,我们的方法超过了仅依赖预训练知识而无外部检索机制的BLIP-2和InstructBLIP等模型。对于检索增强场景,尽管这些模型具有相似的架构基础,MMKB-RAG显著超越了Qwen2-VL-7B-Instruct及其微调变体。这一性能差距突显了我们提出的MMKB-RAG方法在大幅提高响应准确性方面的有效性。
当使用EVA-CLIP检索器进行图像到图像检索时,MMKB-RAG在EchoSight和Reflective等采用类似检索机制的竞争方法上实现了更大的改进。这些结果表明,即使在相似的标记系统下,我们的方法也能实现卓越性能。图4提供了不同模型的定性比较。
### 4.4 消融研究和分析
4.4.1 MMKB-RAG标记的有效性。为了评估每个标记的贡献,我们通过逐步启用框架的不同组件进行了消融研究。表2总结了这些结果,其中$k$表示检索文档的数量。当仅启用RET时,MLLM使用默认设置$(k=5)$。相反,当使用SRT时,保留相关性得分高于0.5的段落,并按相关性降序排列($k=$自动)。
我们的实验揭示了每个标记的独特贡献:(1) RET在所有指标上提高了性能,尽管其影响在引入其他标记时减弱;(2) SRT显著提高了所有评估指标,表明尽管基于嵌入的检索可以识别语义相关的文档,但它不能保证最终答案的准确性;(3)
${ }^{1}$ InfoSeek使用的知识库包含与[4]相同的实体。
表1:E-VQA测试集和InfoSeek验证集上的VQA准确率评分,其中所有检索增强模型的结果均未考虑任何重新排序阶段以重新排列检索到的网页。粗体表示最先进,下划线表示第二佳,$\dagger$标记我们的复现结果。灰色表示由于不同的知识库而不可直接比较的结果。所有检索增强结果均排除重新排序。
| | | | | E-VQA | | | InfoSeek | | |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| 模型 | LLM | | 检索器 | 特征 | 单跳 | 全部 | 未见问题 | 未见实体 | 全部 |
| 零样本MLLMs | | | | | | | | | |
| BUP-2 [13] | Flan-T5SL | | - | - | 12.6 | 12.4 | 12.7 | 12.3 | 12.5 |
| InstructBUP [8] | Flan-T5SL | | - | - | 11.9 | 12.0 | 8.9 | 7.4 | 8.1 |
| LLaVA-v1.5 [17] | Vicuna-7B | | - | - | 16.3 | 16.9 | 9.6 | 9.4 | 9.5 |
| LLaVA-v1.5 [17] | LLaMA-3.1-8B | | - | - | 16.0 | 16.9 | 8.3 | 8.9 | 7.8 |
| Qwen2-VL-Instruct† [30] | Qwen-2-7B | | - | - | 16.4 | 16.4 | 17.9 | 17.8 | 17.9 |
| Qwen2-VL-Instruct(sft) $\dagger$ [30] | Qwen-2-7B | | - | - | 25.0 | 23.8 | 22.7 | 20.6 | 21.6 |
| 检索增强模型 | | | | | | | | | |
| Wiki-LLaVA [4] | Vicuna-7B | | CLIP ViT-L/14+Contriever | 文本 | 17.7 | 20.3 | 30.1 | 27.8 | 28.9 |
| Wiki-LLaVA [4] | LLaMA-3.1-8B | | CLIP ViT-L/14+Contriever | 文本 | 18.3 | 19.6 | 28.6 | 25.7 | 27.1 |
| EchoSight [31] | Mistral-7B/LLaMA-3-8B | | EVA-CLIP-8B | 视觉 | 19.4 | - | - | - | 27.7 |
| EchoSight [31] | LLaMA-3.1-8B | | EVA-CLIP-8B | 视觉 | 26.4 | 24.9 | 18.0 | 19.8 | 18.8 |
| ReflectiVA [7] | LLaMA-3.1-8B | | EVA-CLIP-8B | 视觉 | 35.5 | 35.5 | 28.6 | 28.1 | 28.3 |
| Qwen2-VL-Instruct† [30] | Qwen-2-7B | | EVA-CLIP-8B + Contriever | 视觉+文本 | 25.9 | 23.6 | 21.6 | 21.5 | 21.4 |
| Qwen2-VL-Instruct(sft) $\dagger$ [30] | Qwen-2-7B | | EVA-CLIP-8B + Contriever | 视觉+文本 | 32.6 | 29.9 | 23.3 | 23.8 | 23.6 |
| MMKB-RAG(我们的) | Qwen-2-7B | | EVA-CLIP-8B | 视觉 | 39.7 | 35.9 | 36.4 | 36.3 | 36.4 |
问题:这种鱼生活在世界哪个部分?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?
问题:这个植物内部是什么?

这个广场位于哪座城市?

在一战期间,哪些机场从Kiplin Hall接收补给?

这家酒店位于哪座城市?
检索文档1:2008年,汉堡面积为$755.2 \mathrm{~km}^{2}$(291.6平方英里),其中$92 \%$为陆地,$8 \%$为水域。交通基础设施面积为$12 \%$(9,183公顷或35.46平方英里)。这些都是非建筑区。慕尼黑...
检索文档2:斯图加特市郊铁路每天运营时间为04:00 - 01:00。周一至周五:服务频率为每10分钟一次,时间介于06:00 - 07:00 和 20:00 - 20:30。周六:服务频率为每10分钟一次,时间介于09:30 - 10:30 和 20:00 - 20:30。...

答案:
拉姆斯伯顿&普雷斯顿
答案:
RAF Catterick,RAF Croft 和 RAF Middleton St George

图5:我们的标记系统插图,展示了RET、SRT和CST的效果。虚线表示不同标记的操作位置,红色文本突出错误信息,绿色文本表示正确信息。
4.4.3 训练数据构造的有效性。为了评估不同训练数据构造方法的影响,我们将我们的方法与更强大的外部模型(GPT-40)在SRT模块上进行比较,该模块对系统性能有最显著影响。由于成本限制,我们将GPT-40生成的样本限制为2,000个,而我们的方法生成的数据集范围从2,000到100,000个样本。表5总结了结果。
我们的实验揭示了两个关键发现:首先,通过我们的方法增加训练数据量并未带来性能提升。这表明小型、高质量的数据集足以让模型学习有效的偏好模式。其次,在相同训练数据量(2,000个样本)的情况下,尽管GPT-4o具有更强的通用能力,但我们的方法显著优于它。我们假设我们的构造方法生成的训练数据更好地与回答模型的特性对齐,从而实现更有效的文档重新排序和评分。
### 4.5 在M2KR数据集上的比较
我们进一步在M2KR数据集上验证我们的方法,该数据集专门设计用于基准多模态模型在图像+文本到文本检索任务中的表现。在此评估中,模型必须通过联合推理视觉和文本输入生成响应。表6展示了我们的MMKB-RAG方法与强基线(包括RA-VQAv2和各种Qwen2-VL-Instruct变体)的比较分析,所有这些都利用了PreFLMR检索器。
表3:SRT性能随检索文档数量变化的影响。
| $k$ | E-VQA | | InfoSeek | | |
| :--: | :--: | :--: | :--: | :--: | :--: |
| | 单跳 | 全部 | 未见问题 | 未见实体 | 全部 |
| auto | 38.09 | 34.63 | 34.07 | 33.55 | 33.81 |
| 1 | 37.30 | 33.79 | 33.39 | 30.77 | 32.03 |
| 5 | 39.56 | 35.89 | 35.05 | 34.91 | 34.98 |
| 10 | 38.90 | 35.33 | 33.68 | 33.18 | 33.43 |
| 15 | 37.39 | 33.84 | 30.16 | 29.82 | 29.99 |
| 20 | 35.20 | 32.08 | 25.32 | 25.09 | 25.09 |
结果表明,MMKB-RAG在评估指标上始终优于RA-VQAv2和基础知识型模型,验证了我们方法的有效性。
## 5 结论
在这项研究中,我们介绍了一种新的框架,称为多模态知识型检索增强生成(MMKB-RAG)。此框架利用回答模型的知识边界动态生成RAG系统的标签,从而能够更有效地过滤检索到的文档并仅保留最相关和准确的参考文献。通过这样做,MMKBRAG显著提高了模型在多模态任务中回答的准确性和鲁棒性。
表4:不同MCT类型对性能的影响。
| MCT类型 | $k$ | E-VQA | | | InfoSeek | | |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| | | 单跳 | | 全部 | 未见问题 | 未见实体 | 全部 |
| merge | auto | 34.84 | | 32.14 | 36.43 | 36.32 | 36.37 |
| rerank | auto | 39.62 | | 35.90 | 34.53 | 34.96 | 34.74 |
| filter | auto | 39.47 | | 35.74 | 35.82 | 35.04 | 35.43 |
| merge | 5 | 35.77 | | 33.00 | 36.10 | 35.80 | 36.00 |
| rerank | 5 | 39.16 | | 35.43 | 35.17 | 34.98 | 35.07 |
| filter | 5 | 38.48 | | 35.00 | 34.81 | 34.08 | 34.44 |
| merge | 10 | 34.61 | | 31.79 | 34.38 | 34.48 | 34.43 |
| rerank | 10 | 38.61 | | 35.08 | 32.83 | 32.96 | 32.89 |
| filter | 10 | 38.78 | | 35.20 | 33.52 | 32.76 | 33.14 |
| merge | 15 | 33.47 | | 30.57 | 35.91 | 35.65 | 35.78 |
| rerank | 15 | 37.16 | | 33.72 | 30.09 | 29.90 | 29.99 |
| filter | 15 | 37.81 | | 34.52 | 35.11 | 33.99 | 34.54 |
| merge | 20 | 31.98 | | 29.64 | 35.61 | 35.04 | 35.32 |
| rerank | 20 | 35.32 | | 32.14 | 25.20 | 25.17 | 25.18 |
| filter | 20 | 35.24 | | 32.35 | 34.72 | 33.33 | 34.01 |
表5:使用GPT40和我们提出的方法训练的SRT性能比较。
| | | E-VQA | | | InfoSeek | | |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| | num | k | 单跳 | 全部 | 未见问题 | 未见实体 | 全部 |
| GPT-4o | 2k | auto | 39.81 | 36.13 | 33.03 | 33.22 | 33.12 |
| | 2k | auto | 40.06 | 36.24 | 35.22 | 36.65 | 35.92 |
| | 5k | auto | 39.68 | 35.68 | 34.78 | 34.72 | 34.75 |
| MMKB-RAG | 10k | auto | 39.22 | 35.50 | 33.73 | 33.93 | 33.83 |
| | 50k | auto | 39.24 | 35.39 | 34.85 | 34.14 | 34.49 |
| | 100k | auto | 38.09 | 34.63 | 34.07 | 33.55 | 33.81 |
表6:M2KR数据集上的性能比较。
| 模型 | OKVQA | Infoseek | E-VQA |
| :-- | :-- | :-- | :-- |
| 零样本MLLMs | | | |
| RA-VQAv2 | 55.44 | 21.78 | 19.80 |
| Qwen2-VL-Instruct | 60.45 | 21.75 | 19.01 |
| Qwen2-VL-Instruct(sf) | 64.08 | 26.00 | 26.72 |
| 检索增强模型 | | | |
| RA-VQAv2 w/ FLMR | 60.75 | - | - |
| RA-VQAv2 w/ PreFLMR | 61.88 | 30.65 | 54.45 |
| Qwen2-VL-Instruct w/ PreFLMR | 46.99 | 24.68 | 51.81 |
| Qwen2-VL-Instruct(sf) w/ PreFLMR | 65.07 | 30.74 | 53.89 |
| MMKB-RAG w/ PreFLMR | 65.44 | 34.72 | 60.93 |
## 致谢
感谢Robert,提供百吉饼并解释CMYK和色彩空间。
## 参考文献
[1] Aishwarya Agrawal, Jiasen Lu, Stanislaw Antol, Margaret Mitchell, C. Lawrence Zitnick, Dferor Batra, and Devi Parikh. 2016. VQA: Visual Question Answering. arXiv:1505.00468 [cs.CL] https://arxiv.org/abs/1505.00468
[2] Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-rag: Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511 (2023).
[3] Jannis Bulian, Christian Buck, Wojciech Gajewski, Benjamin Boerschinger, and Tal Schuster. 2022. Tomayto, Tomalito. Beyond Token-level Answer Equivalence for Question Answering Evaluation. arXiv:2202.07654 [cs.CL] https://arxiv.org/ abs/2202.07654
[4] Davide Caffagni, Federico Cocchi, Nicholas Moratelli, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. 2024. Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1818-1826.
[5] Yang Chen, Hexiang Hu, Yi Luan, Haitian Sun, Soravit Changpinyo, Alan Ritter, and Ming-Wei Chang. 2023. Can Pre-trained Vision and Language Models Answer Visual Information-Seeking Questions? arXiv:2302.11713 [cs.CV] https://arxiv. org/abs/2302.11713
[6] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. 2024. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24185-24198.
[7] Federico Cocchi, Nicholas Moratelli, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. 2025. Augmenting Multimodal LLMs with Self-Reflective Tokens for Knowledge-based Visual Question Answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
[8] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. 2023. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. arXiv preprint arXiv:2305.06500 (2023).
[9] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024).
[10] Edward J Hu, Yelong Shen, Phillip Wallis, Zeysan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models. ICLR 1, 2 (2022), 3.
[11] Albert Q Jiang, Alexandre Sabkayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. 2023. Mistral 7B. arXiv preprint arXiv:2310.06825 (2023).
[12] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems 33 (2020), 9459-9474.
[13] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models.
[14] Yangning Li, Yinghui Li, Xinyu Wang, Yong Jiang, Zhen Zhang, Xinran Zheng, Hui Wang, Hai-Tao Zheng, Fei Huang, Jingren Zhou, and Philip S. Yu. 2025. Benchmarking Multimodal Retrieval Augmented Generation with Dynamic VQA Dataset and Self-adaptive Planning Agent. arXiv:2411.02937 [cs.CL] https: //arxiv.org/abs/2411.02937
[15] Weizhe Lin, Jinghong Chen, Jingbiao Mei, Alexandru Coca, and Bill Byrne. 2023. Fine-grained late-interaction multi-modal retrieval for retrieval augmented visual question answering. Advances in Neural Information Processing Systems 36 (2023), 22820-22840.
[16] Weizhe Lin, Jingbiao Mei, Jinghong Chen, and Bill Byrne. 2024. PreFLMR: Scaling Up Fine-Grained Late-Interaction Multi-modal Retrievers. arXiv preprint arXiv:2402.08327 (2024).
[17] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved Baselines with Visual Instruction Tuning. In CVPR.
[18] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2024. Visual instruction tuning. Advances in neural information processing systems 36 (2024).
[19] Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. 2024. A survey on hallucination in large vision-language models. arXiv preprint arXiv:2402.00253 (2024).
[20] Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. 2019. Ok-vqa: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/csf conference on computer vision and pattern recognition. $3195-3204$.
[21] Thomas Mensink, Jasper Uijlings, Lluis Castrejon, Arushi Goel, Felipe Cadar, Howard Zhou, Fei Sha, André Araujo, and Vittorio Ferrari. 2023. Encyclopedic VQA: Visual questions about detailed properties of fine-grained categories. arXiv:2306.09224 [cs.CV] https://arxiv.org/abs/2306.09224
[22] Jingyuan Qi, Zhiyang Xu, Rulin Shao, Yang Chen, Jin Di, Yu Cheng, Qifan Wang, and Lifu Huang. 2024. RoRA-VLM: Robust Retrieval-Augmented Vision Language Models. arXiv preprint arXiv:2410.08876 (2024).
[23] Vipula Rawte, Swagata Chakraborty, Aguihb Pathak, Anubhav Sarkar, S.M Towhidul Islam Tonmoy, Aman Chadha, Annt Sheth, and Anitava Das. 2023. The Troubling Emergence of Hallucination in Large Language Models - An Extensive Definition, Quantification, and Prescriptive Remediations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 2541-2573. doi:10.18655/v1/2023.enntlp-main. 155
[24] Vipula Rawte, Annt Sheth, and Anitava Das. 2023. A survey of hallucination in large foundation models. arXiv preprint arXiv:2309.05922 (2023).
[25] Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. 2022. A-okvqa: A benchmark for visual question answering using world knowledge. In European conference on computer vision, Springer, $146-162$.
[26] Sanket Shah, Anand Mishra, Naganand Yadati, and Partha Pratim Talukdar. 2019. Kvqa: Knowledge-aware visual question answering. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 8876-8884.
[27] Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. 2023. Eva-clip: Improved training techniques for clip at scale. arXiv preprint arXiv:2303.15389 (2023).
[28] Quan Sun, Jinsheng Wang, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, and Xinlong Wang. 2024. Eva-clip-18b: Scaling clip to 18 billion parameters. arXiv preprint arXiv:2402.04252 (2024).
[29] Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. 2024. Eyes wide shut? exploring the visual shortcomings of multimodal IIns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition. 9568-9578.
[30] 王鹏,白帅,谭思南,王世杰,范志浩,白锦泽,陈克勤,刘雪婧,王佳琳,葛文斌等。2024。Qwen2-VL:增强任何分辨率下的视觉语言模型对世界的感知。arXiv预印本arXiv:2409.12191(2024)。
[31] 严一斌,解伟迪。2024。EchoSight:用维基知识推进视觉语言模型。计算语言学协会发现2024年会议记录。计算语言学协会,1338-1351。doi:10.18653/ v1/2024.findings-ennlp. 83
[32] 杨安,杨宝松,张贝成,惠宾森,郑博,余博文,李成远,刘大毅恒,黄飞,魏海然等。2024。Qwen2.5技术报告。arXiv预印本arXiv:2412.15115(2024)。
参考论文:https://arxiv.org/pdf/2504.10074



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











