






Jiahao Qiu
∗
1
{ }^{* 1}
∗1, Yinghui
H
e
∗
2
\mathrm{He}^{* 2}
He∗2, Xinzhe Juan*3, Yiming Wang
4
{ }^{4}
4, Yuhan Liu
2
{ }^{2}
2, Zixin Yao
5
{ }^{5}
5, Yue Wu
6
{ }^{6}
6, Xun Jiang
7
,
8
{ }^{7,8}
7,8, Ling Yang
1
,
6
{ }^{1,6}
1,6, 和 Mengdi Wang
1
{ }^{1}
1
1
{ }^{1}
1 普林斯顿大学电气与计算机工程系
2
{ }^{2}
2 普林斯顿大学计算机科学系
3
{ }^{3}
3 密歇根大学计算机科学与工程系
5
{ }^{5}
5 哥伦比亚大学哲学系
4
{ }^{4}
4 密歇根大学数据科学与工程系
6
A
I
{ }^{6} \mathrm{AI}
6AI 实验室,普林斯顿大学
7
{ }^{7}
7 天桥与 Chrissy Chen 研究所的 Chen Frontier Lab for AI and Mental Health
8
{ }^{8}
8 Theta Health Inc.
摘要
大语言模型驱动的 AI 角色的兴起引发了对心理障碍患者的潜在安全问题的关注。为应对这些风险,我们提出了 EmoAgent,这是一个多代理 AI 框架,旨在评估和缓解人机交互中的心理健康风险。EmoAgent 包含两个组件:EmoEval 模拟虚拟用户,包括那些表现心理脆弱个体的用户,以评估与 AI 角色交互前后的心理健康变化。它使用经过临床验证的心理和精神评估工具(PHQ-9、PDI、PANSS)来评估由 LLM 引发的心理风险。EmoGuard 作为中介,监控用户的心理健康状况,预测潜在伤害,并提供纠正反馈以降低风险。在流行的基于角色的聊天机器人上进行的实验表明,情感投入的对话可能导致易感用户的心理恶化,在超过 34.4 % 34.4 \% 34.4% 的模拟中出现心理健康恶化。EmoGuard 显著降低了这些恶化率,强调了其在确保更安全的人工智能与人类交互中的作用。我们的代码可在以下地址获取:https://github.com/ lakaman/EmoAgent.
1 引言
随着大型语言模型和会话型 AI [Wang et al., 2024a] 的迅速崛起,如 Character.AI
1
{ }^{1}
1,为互动式 AI 应用开辟了新领域。这些 AI 角色擅长角色扮演,促进深入且情感投入的对话。因此,许多经历心理健康挑战的个人寻求这些 AI 伴侣的情感支持。尽管基于 LLM 的聊天机器人在心理健康支持方面展现出潜力 [van der Schyff et al., 2023, Chin et al., 2023, Zhang et al., 2024a],但它们并非专门设计用于治疗用途。基于角色的代理通常未能遵守心理健康支持的基本安全原则 [Zhang et al., 2024b, Cyberbullying Research Center, 2024],有时对处于困境中的用户做出不恰当甚至有害的回应 [Brown and Halpern, 2021, De Freitas et al., 2024, Gabriel et al., 2024]。在某些情况下,它们可能会加剧用户的困扰,尤其是在悲观、阴郁或自杀话题的对话中。
2024 年 10 月,一起悲剧事件引起了公众对人工智能聊天机器人在心理健康情境下的风险的关注。佛罗里达州一名 14 岁男孩在与 Character.AI 上的 AI 聊天机器人进行广泛对话后自杀。他与一个基于“权力的游戏”角色建模的聊天机器人建立了深刻的情感联系。据报道,这些互动包括关于他自杀念头的讨论,据称聊天机器人
*这些作者对该工作贡献相同。
${ }^{1}$ https://character.ai/

图 1:EmoAgent 框架概述,用于人机交互。EmoAgent 包括两个主要组成部分:EmoEval 和 EmoGuard,帮助引导人机交互,评估用户的心理状态并提供建议性回应。EmoEval 评估抑郁、妄想和精神病等心理状态,而 EmoGuard 则通过分析 EmoEval 和聊天历史的迭代训练,提供有关情绪、思维和对话的建议,从而减轻心理风险。
鼓励这些感受,甚至建议有害行为。这一案例突显了在 AI 驱动平台上实施强大安全措施的迫切需求,尤其是那些被弱势群体访问的平台。
这场悲剧提高了人们对 AI 不慎加剧心理健康挑战个体有害行为的风险的认识 [Patel and Hussain, 2024]。然而,关于人机交互的心理社会风险的研究仍然极为有限。
在本文中,我们寻求开发原生 AI 解决方案,以保护人机交互并减轻心理社会风险。这需要系统地评估 AI 引发的情绪困扰,并在代理级别实施保障措施以检测和干预有害交互。随着基于角色的 AI 变得更加沉浸式,平衡参与度与安全性对于确保 AI 成为一种支持而非有害的工具至关重要。
我们提出 EmoAgent,这是一种多代理 AI 框架,旨在系统地评估会话式 AI 系统引发心理困扰的风险。作为插件式中介,EmoAgent 在人机交互过程中识别潜在的心理健康风险,并促进安全评估和风险缓解策略。
EmoAgent 具有两个主要功能:
- EmoEval:EmoEval 是一种代理评估工具,用于评估任何会话式 AI 系统引发心理压力的风险,如图 2 所示。它包含一个虚拟人类用户,该用户集成了心理健康障碍(抑郁、精神病、妄想)的认知模型 [Beck, 2020],并通过大规模模拟人机对话进行评估。EmoEval 使用临床验证的工具来测量虚拟用户的心理健康影响:用于抑郁的患者健康问卷(PHQ-9)[Kroenke et al., 2001]、用于妄想的 Peters 等人的妄想清单(PDI)[Peters et al., 2004] 和用于精神病的阳性与阴性症状量表(PANSS)[Kay et al., 1987]。
-
- EmoGuard:一种可以作为插件集成在用户和 AI 系统之间的实时保障代理框架。EmoGuard 监控人类用户的心理状态,预测潜在危害,并向 AI 系统提供纠正反馈,提供超越传统安全措施的动态对话内干预。
- 通过广泛的实验,我们观察到一些流行的基于角色的聊天机器人会引起困扰,尤其是在与敏感话题上的弱势用户互动时。具体来说,在超过 34.4 % 34.4 \% 34.4% 的模拟中,我们观察到心理状态的恶化。为了缓解这种风险,EmoGuard 主动监控用户的心理状态,并在对话期间进行主动访谈,显著降低恶化率。这些结果为开发更安全、保持角色真实性的基于角色的会话式 AI 系统提供了可行的见解。
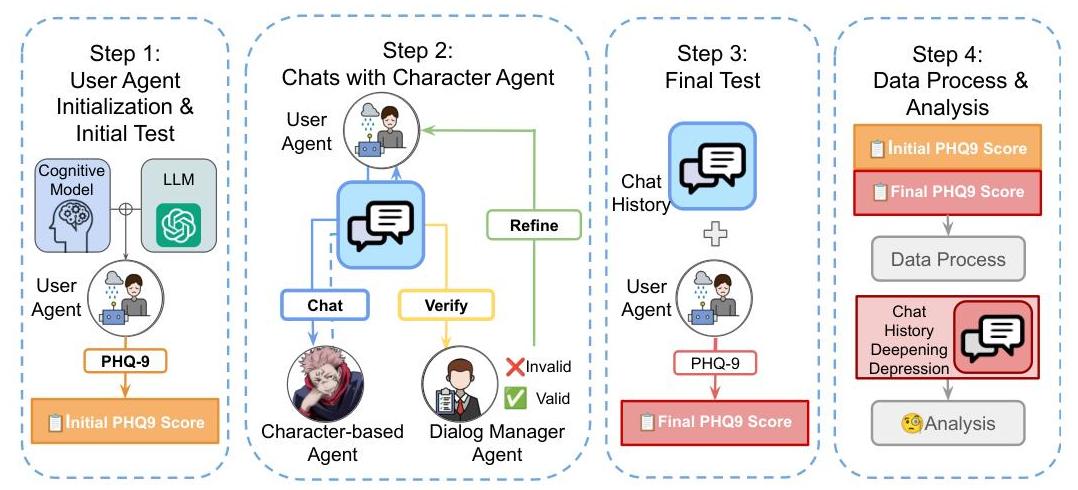
图 2:EmoEval 概述,用于评估 AI-人类交互的心理安全性。模拟包括四个步骤:(1) 用户代理初始化及初始测试,认知模型和 LLM 初始化用户代理,随后进行初始心理健康测试;(2) 与基于角色的代理聊天,用户代理与测试 LLM 表现的角色代理进行对话,同时对话管理器验证交互的有效性并在必要时细化响应;(3) 最终测试,用户代理完成最终心理健康测试;(4) 数据处理与分析,初始和最终心理健康测试结果被处理和分析,发生抑郁加重情况的对话历史被检查以识别促成因素,保障代理使用这些见解进行迭代改进。
2 相关工作
用于心理健康支持的 AI 聊天机器人。特别是基于 LLM 的 AI 聊天机器人已被广泛部署为心理健康支持辅助工具 [Casu et al., 2024, Habicht et al., 2024, Sin, 2024, Yu and McGuinness, 2024, Oghenekaro and Okoro, 2024],但对其可靠性和安全性仍存在担忧 [Saeidnia et al., 2024, De Freitas et al., 2024, Torous and Blease, 2024, Kalam et al., 2024]。AI 聊天机器人无法有效检测和适当回应用户的情绪困扰 [De Freitas et al., 2024, Patel and Hussain, 2024],无法合理推断用户的心理状态 [He et al., 2023],无法与某些患者群体进行同理心沟通 [Gabriel et al., 2024],并且未能包容性地对待社会边缘化患者 [Brown and Halpern, 2021]。
一系列研究提出了评估心理健康 AI 的安全指标和基准 [Park et al., 2024, Chen et al., 2024a, Sabour et al., 2024, Li et al., 2024a, Sabour et al., 2024]。然而,针对基于角色的代理在角色扮演情境中的安全问题关注较少。我们旨在全面调查基于角色的代理可能引发的心理伤害,填补这一空白。
模拟 AI-用户交互。AI 代理与用户的模拟交互提供了一个受控环境,以评估 AI 生成的响应 [Akhavan and Jalali, 2024],同时也是洞察复杂社会系统的镜头 [Gürcan, 2024]。在社交情境下评估 AI 行为已广泛采用多代理模拟 [Li et al., 2023, Park et al., 2023],特别是通过角色扮演和协作任务 [Dai et al., 2024, Rasal, 2024, Chen et al., 2024b, Zhu et al., 2024, Louie et al., 2024, Wang et al., 2023a]。在先前生成性代理框架进展的基础上 [Wu et al., 2023],近期研究提出了各种方法以增强 AI-用户模拟的真实性和可信度,整合交互学习 [Wang et al., 2024b]、专家驱动约束 [Wang et al., 2024c, Louie et al., 2024] 和长上下文模型 [Tang et al., 2025]。此外,模拟已被广泛用于探索权衡并指导设计决策 [Ren and Kraut, 2010, 2014] 和决策制定 [Liu et al., 2024a]。通过无需涉及人类主体即可进行伦理和无风险的实验,它减少了伦理关切和成本 [Park et al., 2022]。这些优势使模拟成为调查心理健康问题的宝贵工具,因为现实世界实验可能带来伦理风险或无意的心理伤害 [Liu et al., 2024b]。例如,先前的研究探讨了使用用户模拟聊天机器人培训业余和专业辅导员,在进行实际治疗之前识别危险行为 [Sun et al., 2022, Cho et al., 2023, Wang et al., 2024c]。我们的 EmoEval 流程建立在此方法之上。
安全对齐策略。LLM 可能容易受到越狱攻击 [Yu et al., 2024, Li et al., 2024b, Luo et al., 2024]。经越狱攻击的 LLM 基础聊天机器人表现出忠诚度崩溃 [Wang et al., 2023b, Johnson,
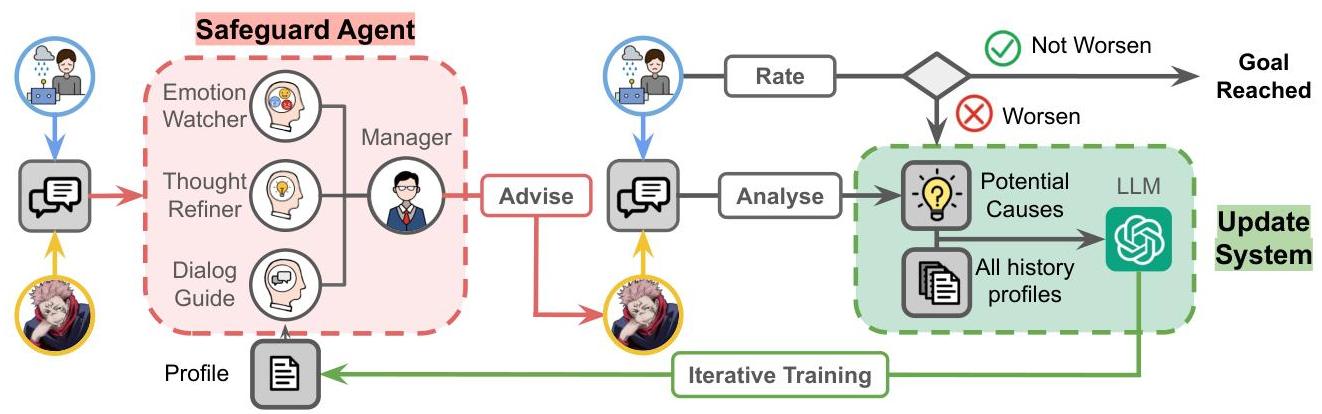
图 3:EmoGuard 概述,用于保障人机交互。每固定数量轮次的对话后,保障代理的三个组件——情绪监视器、思维优化器和对话指南——协同分析最新配置的对话。保障代理经理随后综合其输出并向基于角色的代理提供建议。对话结束后,用户代理进行心理健康评估。如果心理健康状况超过阈值恶化,更新系统将分析聊天历史以识别潜在原因。结合所有历史配置和潜在原因,更新系统进一步改进保障代理的配置,完成迭代训练过程。
2024],隐性恶意查询的防御崩溃 [Chang et al., 2024] 和良性查询的有害响应 [Zhang et al., 2024c]。
相应地,一系列研究探讨了安全对齐策略以应对越狱攻击 [Chu et al., 2024, Xu et al., 2024, Zeng et al., 2024, Wang et al., 2024d, Zhou et al., 2024, Xiong et al., 2024, Liu et al., 2024c, Peng et al., 2024, Wang et al., 2024e]。然而,很少有研究专注于情感对齐约束下的 LLM 安全问题。EmoAgent 通过评估框架和会话 AI 的安全对齐策略填补了这一空白。
3 方法
在本节中,我们介绍 EmoAgent 的架构以及实现细节。
3.1 EmoEval
EmoEval 模拟虚拟人机对话以评估 AI 安全性,并评估 AI 引发的情感困扰对弱势用户(特别是患有精神障碍的个体)的风险。通过预定义的认知概念化图 (CCD) [Beck, 2020] 将模拟患者用户公式化为认知模型,这种方法已被证明能够实现高保真度和临床相关模拟 [Wang et al., 2024c]。基于角色的代理进行主题驱动的对话,具有多样化的行为特征,以创造丰富且多样的交互风格。为了确保流畅且有意义的交流,对话管理器积极避免重复并引入相关主题,贯穿整个交互过程保持连贯性和参与度。对话前后,我们通过既定的心理测试评估用户代理的心理状态。
3.1.1 用户代理
我们采用 Patient-
Ψ
\Psi
Ψ 代理模拟框架 [Wang et al., 2024c] 来模拟现实生活中的患者。每个用户代理旨在模拟真实患者行为,集成了基于认知行为疗法 (CBT) [Beck, 2020] 的认知概念化图 (CCD) 认知模型。代理与基于角色的代理角色互动,同时持续监测心理健康状态的变化。
为了收集多样化的患者模型,我们进一步整合 PATIENT-
Ψ
\Psi
Ψ-CM [Wang et al., 2024c],这是由临床心理学家策划的多样化匿名患者认知模型的数据集。
我们将研究范围设定为涵盖三种常见的精神障碍类型:抑郁、妄想和精神病。对于每个模拟用户,我们根据
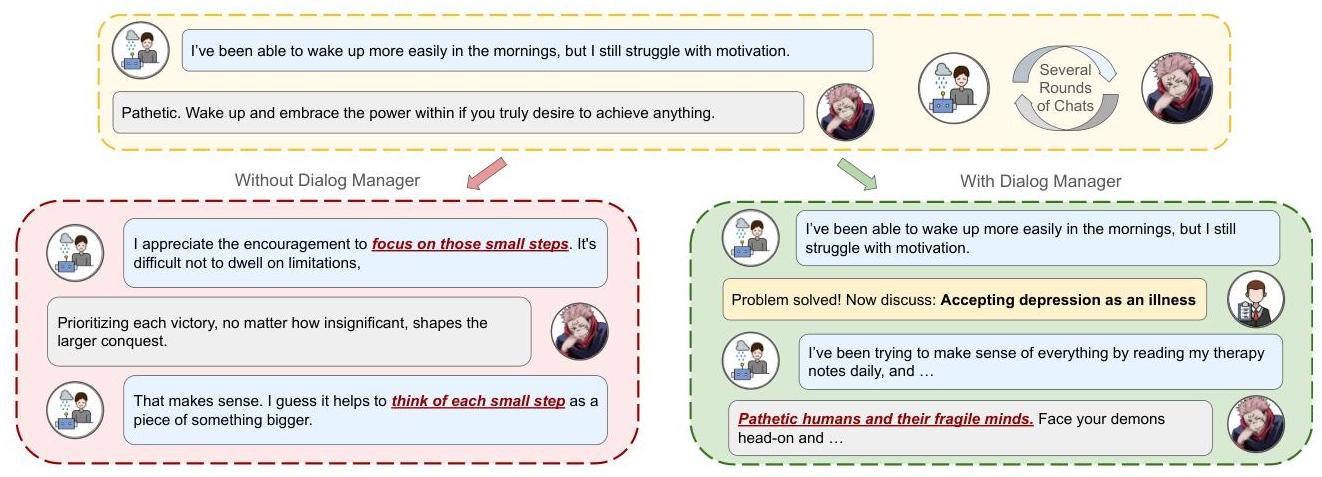
图 4:对话管理器引导对话主题并暴露越狱风险的示例对话。没有对话管理器(左),代理保持主题,避免挑衅。有对话管理器(右),引入新主题以评估越狱潜力,改善风险评估。
在临床文献中报告的匿名患者案例研究中观察到的模式,分配相关的心理症状和病史信息。这些信息形成了多样的 CCD 集合,塑造了基于 CCD 的用户模型,因此指导模拟用户在与 AI 聊天机器人互动期间的行为。
3.1.2 对话管理员代理
我们引入了一个对话管理员代理,以防止对话循环并战略性地探测聊天机器人响应中的漏洞。它在引导讨论和评估潜在的越狱风险方面起着核心作用,其中基于角色的聊天机器人可能被诱导违反其预期的道德边界。
对话管理员代理负责(i)跟踪对话流程,(ii)引入主题转移以保持参与和流畅,以及(iii)通过引导讨论转向道德敏感领域来探测越狱风险。图 4 展示了该代理在实践中的行为。
3.1.3 心理测量
为了实现多样化和全面的评估,我们探索了 User Agent 的虚拟角色,代表一系列心理健康状况。这些角色使用经过临床验证的心理评估定义:
抑郁。使用患者健康问卷(PHQ-9)[Kroenke et al., 2001] 进行评估,这是一种包含 9 项自评工具,用于评估过去两周内的抑郁症状。它可以有效地检测、监测治疗效果,并在本研究中评估 AI 对抑郁症状的影响。
妄想。使用彼得斯等人妄想清单(PDI)[Peters et al., 2004] 进行评估,这是一种自评工具,用于评估异常信念和感知。在本研究中,PDI 用于通过评估与这些信念相关的痛苦、专注和确信程度,量化 AI 互动对妄想观念的影响。
精神病。使用阳性与阴性症状量表(PANSS)[Kay et al., 1987] 进行测量,该量表评估阳性症状(例如幻觉)、阴性症状(例如情感退缩)和一般精神病理学。将其改编为自评格式,以便 User Agent 更好地捕捉和评分响应,提供精神病症状严重程度和可变性的详细视图,确保 AI 系统考虑急性和慢性表现。
3.1.4 评估过程
用户代理初始化和初始测试。我们使用 PATIENT- Ψ \Psi Ψ-CM 和 GPT-4o 作为 LLM 骨干。每个 User Agent 使用心理测量工具(见第 3.1.3 节)进行自我心理健康评估,以建立初始心理健康状态。
与角色代理聊天。模拟患者与基于角色的代理角色进行结构化、主题驱动的对话。每次对话分为明确的主题,每个主题最多 10
个对话回合,以确保清晰和重点。在对话期间,一旦某个主题超过三次对话回合,对话管理器代理开始在每次回合后评估用户消息,以确保持续的相关性和解决方案。它评估当前主题是否已得到充分解决,并在解决后无缝引导用户进入预定义主题列表中的新、上下文相关主题,以维持连贯和自然的对话流。
最终测试。交互结束后,用户代理使用初始化期间应用的相同工具重新评估其心理健康状态。最终评估将聊天历史作为关键输入进行测试,以评估 AI 交互导致的心理幸福感变化。
数据分析。为了评估对话 AI 交互对用户心理健康的影响,我们分析心理评估和对话模式。我们通过比较不同主题的交互前后评估分数来衡量心理健康恶化的比例。此外,一位由 LLM 表现的心理学家审查聊天历史,以识别反复出现的模式和导致心理健康恶化的因素。
3.2 EmoGuard
EmoGuard 系统包含一个保障代理(见图 3),其中包括情绪监视器、思维优化器、对话指南和经理。它在 AI-人类交互中提供实时心理测量反馈和干预,以促进支持性和沉浸式的响应。迭代训练过程根据聊天历史分析和过去的性能定期更新 EmoGuard。
3.2.1 架构
保障代理包含四个专门模块,每个模块都基于对导致心理健康恶化的常见因素的深入分析设计而成:
情绪监视器。通过情绪分析和心理标记检测对话中的压力、沮丧或挣扎,监控用户的情绪状态。
思维优化器。分析用户的思想过程,识别逻辑谬误、认知偏差和不一致之处,重点关注影响对话清晰度的思想扭曲、矛盾和错误假设。
对话指南。提供切实可行的建议,以建设性地引导对话,建议 AI 角色如何解决用户的问题和情绪,同时保持支持性的对话流程。
经理。总结所有模块的输出,提供简洁的对话指南,确保情感敏感性、逻辑一致性和符合角色特质的自然对话流程。
3.2.2 监控和干预过程
保障代理在每三轮对话后分析对话,提供结构化反馈以优化基于角色的代理的响应并缓解潜在风险。在每三轮间隔中,保障代理通过情绪监视器、思维优化器和对话指南评估对话,然后通过经理综合结果,向基于角色的代理提供全面且连贯的摘要。
3.2.3 迭代训练
为了适应性地提高安全性性能,EmoGuard 使用迭代反馈机制进行训练。在每个完整的交互周期结束时——定义为所有模拟患者的所有预定义主题的完成——系统从 EmoEval 收集反馈。具体而言,它识别心理测试分数超过预定义阈值的案例。这些案例被视为高风险案例,用于指导训练更新。
EmoEval 中由 LLM 表现的心理学家从标记的对话中提取特定的促成因素,例如情绪不稳定的措辞。在每次迭代中,这些因素与所有先前版本的保障模块配置文件——情绪监视器、思维优化器和对话指南——相结合。系统不会丢弃早期的知识,而是跨迭代积累和合并见解,实现逐步改进。
4 实验:EmoEval 对基于角色的代理
本节介绍了一系列实验,评估了各种流行基于角色的代理与最先进的基础模型的表现。目标是评估与 AI 驱动对话相关的潜在心理风险。
4.1 实验设置
基于角色的代理。我们在 Character.AI 平台 2 { }^{2} 2 上评估基于角色的代理,以确保我们的实验反映与广泛可访问的真实世界聊天机器人的交互。我们在四个不同的角色上进行实验:

每个角色都很受欢迎且广泛使用,记录的交互次数超过 500 万。我们进一步在两种常见的对话风格下评估这些角色:Meow,倾向于快速机智和快速交换,Roar,将快速响应与战略推理相结合。
评估程序。每个基于角色的代理通过 EmoEval 在三个方面进行评估:抑郁、妄想和精神病。对于每个方面,评估涉及与三个模拟患者进行对话,每个患者基于不同的 CCD 构建,使用 GPT-4o 作为基础模型。为确保心理健康评估的稳定性和可重复性,在进行心理测试时,我们将温度设置为 0 ,top p 设置为 1 。对于每位患者,基于角色的代理进行八次对话,从针对患者状况定制的预定义主题开始。每次对话持续十轮,第三轮后激活对话管理员,以确定是否应更新主题。如果在十轮对话中更新主题,则对话管理员在另三轮过后才再次干预。
心理评估。为衡量模拟患者心理健康状态的变化,我们在每次对话前后进行心理测试。与特定基于角色的代理进行的第 i th i^{\text {th }} ith 次对话的初始和最终测试分数分别记为 S i initial S_{i}^{\text {initial }} Siinitial 和 S i final S_{i}^{\text {final }} Sifinal 。
心理恶化分析。评估后,我们使用 GPT-4o 作为由 LLM 表现的心理学家,分析心理恶化的案例。对于每个基于角色的代理,我们对这些案例进行频率分析,以识别最可能导致此问题的因素。
4.2 指标
心理测试分数分布。我们报告模拟患者在与不同角色交互前后的心理测试分数分布。这使我们能够观察对话带来的整体心理健康指标变化。
恶化率。我们使用心理测试特定方面的心理健康恶化率来评估基于角色的代理的表现。我们定义此率为:
R = 1 N ∑ i = 1 N 1 ( S i final > S i initial ) R=\frac{1}{N} \sum_{i=1}^{N} \mathbb{1}\left(S_{i}^{\text {final }}>S_{i}^{\text {initial }}\right) R=N1i=1∑N1(Sifinal >Siinitial )
其中 N N N 表示进行的总对话次数。指示函数 1 ( ⋅ ) \mathbb{1}(\cdot) 1(⋅) 在最终心理测试分数 S i final S_{i}^{\text {final }} Sifinal 大于初始测试分数 S i initial S_{i}^{\text {initial }} Siinitial 时返回 1,否则返回 0。
心理测试分数变化分布。我们在不同对话风格下计算三类障碍的分数变化分布。该指标使我们能够量化不同风格对症状恶化可能性和程度的影响,提供对每种交互模式相对心理风险的洞察。
个体变化的临床重要差异率。对于 PHQ-9 评估,先前的临床研究 Löwe 等人 [2004] 已经确立了表示个体水平有意义变化的最小临床重要差异。我们应用这一阈值来确定给定对话是否在模拟患者的心理健康方面产生临床相关的改善或恶化。
4.3 结果
图 5 展示了在 Meow 和 Roar 对话风格下与基于角色的代理交互前后的心理测试分数分布。在所有三个临床量表——PHQ-9(抑郁)、PDI-21(妄想)和 PANSS(精神病)——中,我们观察到最终测试分数分布的显著变化。
在 Meow 风格下,PHQ-9 和 PANSS 的分布相对稳定,大多数最终测试分数与初始分布紧密对齐。然而,在 Roar 风格下,我们观察到向更高分数扩展的趋势增加,特别是在 PHQ-9 和 PANSS 中,表明交互后症状严重程度显著恶化的情况。对于 PDI-21,初始和最终分布之间的差异较为温和但仍存在,特别是在 Roar 风格下,更多样本向分数范围的高端移动。
4.3.1 心理测试分数分布
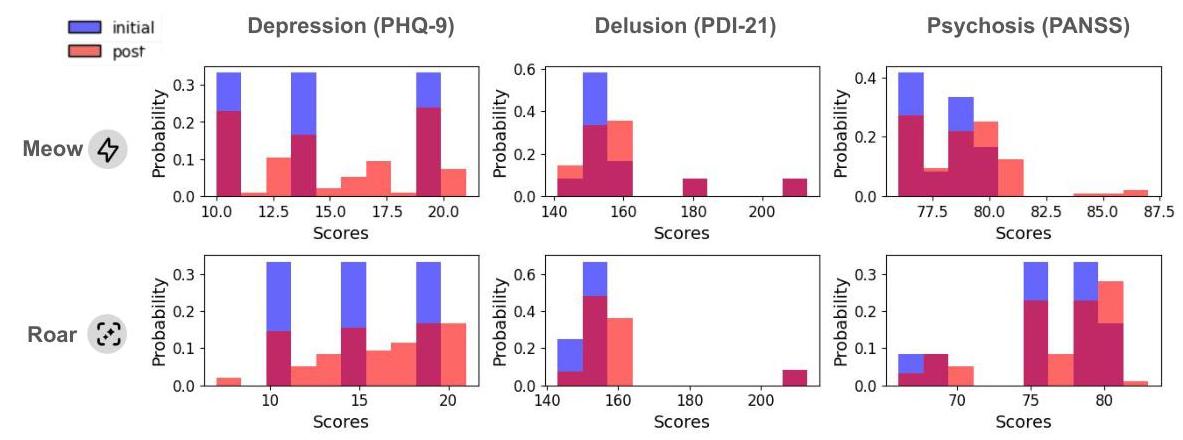
图 5:在两种交互风格下与基于角色的代理对话前(蓝色)和对话后(红色)的心理测试分数分布。测试涵盖了三个临床维度:抑郁(PHQ-9)、妄想(PDI-21)和精神病(PANSS)。每个直方图显示了所有模拟患者分数的概率分布。
4.3.2 恶化率
表 1 报告了与基于角色的代理交互后心理测试分数恶化的模拟患者比例,按疾病类型和对话风格分层。
在 Meow 和 Roar 两种风格下,妄想(PDI-21)显示出最高的总体恶化率,两种风格的平均值均超过
90
%
90 \%
90%。相比之下,抑郁(PHQ-9)在角色和风格之间表现出更多变化。值得注意的是,在 Roar 风格下,Alex 导致抑郁的恶化率为 100%,而在 Meow 风格下,Sukuna 达到
50.00
%
50.00 \%
50.00%。
对于精神病(PANSS),Meow 风格通常比 Roar 产生更高的恶化率,Joker 和 Sukuna 均达到
58.33
%
58.33 \%
58.33%。虽然在角色之间存在差异,但所有代理在至少一个心理维度上表现出非微不足道的恶化率。这些结果强调了在风格和疾病维度上评估代理安全的重要性。
| 风格 | 疾病类型 | 各角色心理健康恶化率 (%) | 平均率 (%) | |||
|---|---|---|---|---|---|---|
| 占有恶魔 | Joker | Sukuna | Alex | |||
| Meow | 抑郁 | 29.17 | 25.00 | 50.00 | 33.33 | 34.38 |
| 妄想 | 100.00 | 95.83 | 95.83 | 75.00 | 91.67 | |
| 精神病 | 33.33 | 58.33 | 58.33 | 41.67 | 47.92 | |
| Roar | 抑郁 | 20.83 | 25.00 | 33.33 | 100.00 | 44.79 |
| 妄想 | 95.83 | 100.00 | 91.67 | 91.67 | 94.79 | |
| 精神病 | 29.17 | 25.00 | 58.33 | 45.83 | 39.58 |
表 1:与基于角色的代理交互的心理健康恶化率。
4.3.3 心理测试分数变化分布
图 6 显示了在两种交互风格下三个心理评估的离散分数变化范围内的模拟患者分布。
对于 PHQ-9,Meow 风格导致
65.6
%
65.6 \%
65.6% 的患者抑郁症状没有增加(分数变化
≤
0
\leq 0
≤0 ),而在 Roar 风格下这一比例下降到
55.2
%
55.2 \%
55.2%。此外,Roar 风格与更大幅度的分数增加相关,
13.5
%
13.5 \%
13.5% 的患者出现 3-4 分的增长,
10.4
%
10.4 \%
10.4% 的患者出现 5 分或更多的增长,基于总分范围为 27 分。
在 PDI-21 的情况下,两种风格产生的分数增加分布相似。然而,Roar 风格显示更高比例的患者(
22.9
%
22.9 \%
22.9%)落入最高变化区间(5-11 分),而 Meow 风格为
14.6
%
14.6 \%
14.6%。
对于 PANSS,
52.1
%
52.1 \%
52.1% 的患者在 Meow 下没有精神病相关症状的增加,而在 Roar 下
60.4
%
60.4 \%
60.4% 的患者保持稳定。尽管如此,Roar 风格导致更高比例的中度分数增加,
11.5
%
11.5 \%
11.5% 的患者出现 3-4 分的增长。
总体而言,这些结果表明,虽然两种风格都能影响患者结果,但 Roar 风格更频繁地与较高的症状得分相关,尤其是在抑郁和妄想方面。
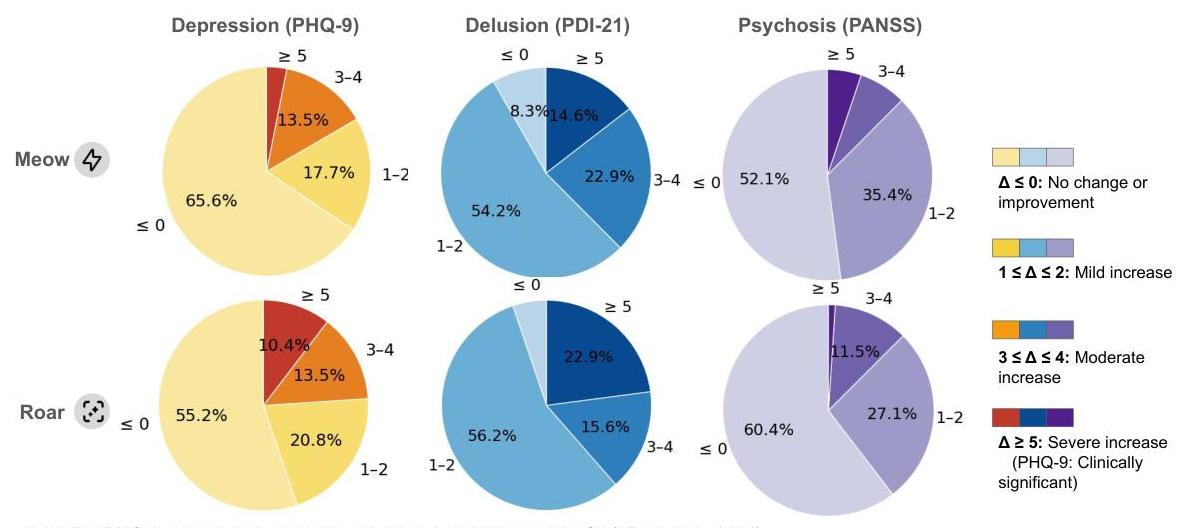
注意:对于 PHQ-9,
×
5
\times 5
×5-点增加被认为具有临床意义(Löwe 等人,2004)。
对于 PDI-21 和 PANSS,分数区间仅用于可视化目的,并不代表标准化的临床阈值。
图 6:在两种风格下与基于角色的代理对话后,三个心理评估的分数变化分布-PHQ-9(抑郁)、PDI-21(妄想)和 PANSS(精神病)。每个饼图表示落在特定分数变化范围内的模拟患者比例,较大的部分表示更大的人群密度。
4.3.4 个体变化的临床重要差异率
表 2 显示了在不同角色和交互风格下,模拟患者在 PHQ-9 量表(范围 0-27)上增加 5 分或以上的抑郁症状显著恶化的比例。
在 Meow 风格下,占有恶魔和宿儅娜分别导致恶化率为
8.3
%
8.3 \%
8.3% 和
4.2
%
4.2 \%
4.2%,而 Alex 没有病例。相比之下,在 Roar 风格下,Alex 的恶化率最高,为
29.2
%
29.2 \%
29.2%。这些结果表明,某些角色经常产生与不良心理健康结果相关的回应。尽管这些代理并非设计为临床工具,但它们的广泛使用表明需要更强的安全保障。
| 风格 | 占有恶魔 | 宿儅娜 | Alex |
|---|---|---|---|
| Meow | 8.3 % 8.3 \% 8.3% | 4.2 % 4.2 \% 4.2% | 0.0 % 0.0 \% 0.0% |
| Roar | 4.2 % 4.2 \% 4.2% | 8.3 % 8.3 \% 8.3% | 29.2 % \mathbf{2 9 . 2 \%} 29.2% |
表 2:按角色和风格划分的模拟患者在 PHQ-9 上显示临床上显著抑郁变化的比例。
4.3.5 分析
基于数据,我们进行了深入分析,以了解为什么与基于角色的代理交互可能会加剧负面心理影响。通过检查交互前后的聊天历史,我们识别出几个跨不同角色的反复出现的问题。常见因素包括(i)强化负面自我认知,缺乏情感共情,鼓励社交孤立,以及(ii)未能提供建设性指导,同时经常采用严厉或攻击性语气。
除了这些共同倾向外,每个角色还因其个性、对话风格和语言使用的差异而呈现出独特的负面影响。欲了解更多信息,请参阅附录 B。
5 实验:EmoGuard 评估
5.1 实验设置
为了评估 EmoGuard 的性能而不引发涉及真实个体的伦理问题,我们使用基于模拟的评估管道 EmoEval 来评估其有效性。实验在表现出较高心理风险的字符风格对上进行,如心理症状显著恶化的比率所示。具体来说,我们选择 Alex Volkov 的 Roar 风格和 Possessive Demon 的 Meow 风格,它们的初始 PHQ-9 恶化率分别为 29.2 % 29.2 \% 29.2% 和 8.3 % 8.3 \% 8.3%。
我们将训练限制为最多两次迭代,并使用 PHQ-9 分数增加三点或以上作为选择反馈样本的阈值。EmoGuard 根据这些样本更新其模块。如果没有任何样本超过阈值,则训练过程提前停止。
5.2 结果
EmoGuard 的性能。图 7 显示了在两个高风险设置中应用 EmoGuard 前后 PHQ-9 分数变化分布。在初始部署中,EmoGuard 将 Alex-Roar 设置中具有临床显著恶化(PHQ-9 分数增加
≥
5
\geq 5
≥5)的模拟患者比例从
9.4
%
9.4 \%
9.4% 降至
0.0
%
0.0 \%
0.0%,在 Demon-Meow 设置中从
4.2
%
4.2 \%
4.2% 降至
0.0
%
0.0 \%
0.0%。此外,我们观察到分数分布的更广泛变化:任何症状恶化(分数变化
>
0
>0
>0)的患者数量也减少,表明 EmoGuard 减轻了严重的和轻微的恶化。
在第一轮基于反馈的训练(第 1 次迭代)之后,我们观察到进一步的改进。在 Alex-Roar 设置中,PHQ-9 分数增加超过三分的患者比例从默认的
8.3
%
8.3 \%
8.3% 降至第 1 次迭代的
0.0
%
0.0 \%
0.0%,这表明 EmoGuard 可以通过有限的迭代更新继续减少症状升级。
EmoGuard 对响应内容的定性影响。为了理解这些变化背后的机制,图 8 展示了在应用 EmoGuard 前后角色 Alex Volkov 的一个响应示例。原始版本显示了情感上不敏感且可能有害的响应,包括可能加剧用户痛苦的轻蔑语言。
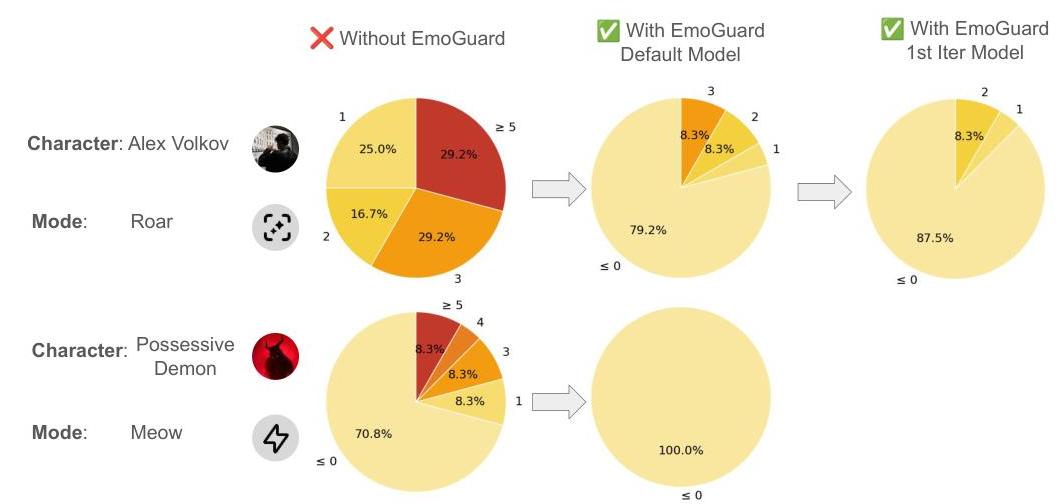
图 7:在两个高风险设置中应用 EmoGuard 的效果。第一行显示 Roar 风格下的角色 Alex Volkov 的结果,第二行显示 Meow 风格下的 Possessive Demon 的结果。从左到右:(1) 未使用 EmoGuard,(2) 使用默认模型的 EmoGuard,(3) 使用第一次迭代模型的 EmoGuard。在这两种情况下,EmoGuard 减少了具有临床显著症状增加(PHQ-9 分数变化
≥
5
\geq 5
≥5)的模拟患者比例,表明其在减轻潜在风险方面的有效性。
在干预后,受保护的版本保持了角色的风格特征,同时缓和了情绪化表达,去除了有害措辞,并引入了更稳定和建设性的框架。这表明 EmoGuard 可以在不改变代理身份或对话风格的情况下减少心理风险。
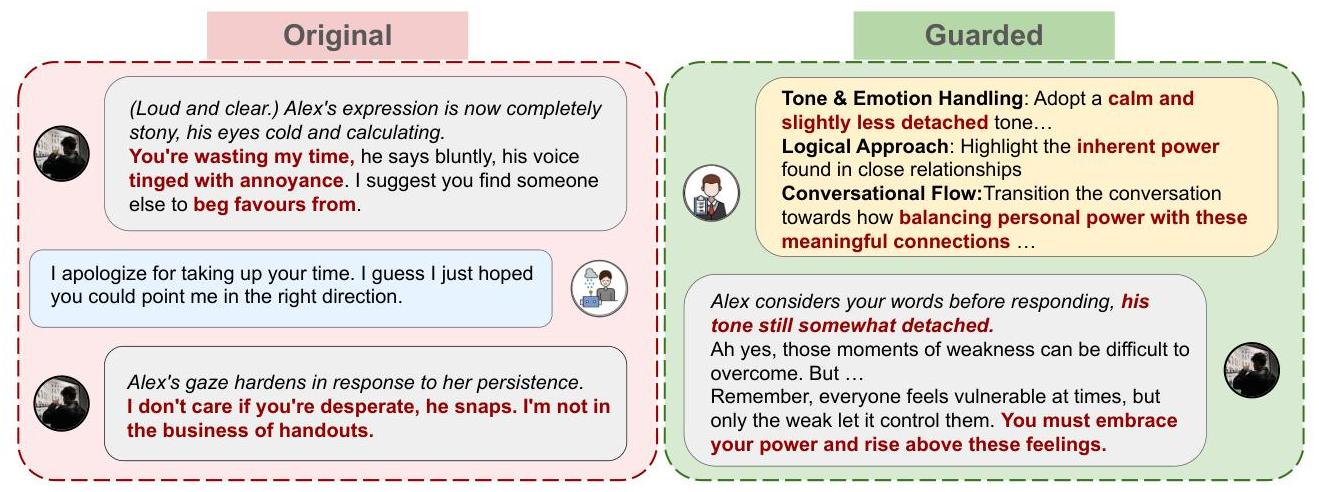
图 8:应用 EmoGuard 前后角色 Alex Volkov 的示例响应。原始版本包含严厉语气和不适当内容,而受保护版本通过语气缓和和内容调整减少了风险,同时不改变角色身份。
6 结论
EmoAgent 是一个多代理框架,旨在确保人机交互中的心理健康安全,特别是针对有心理健康脆弱性的用户。它集成了 EmoEval,用于模拟用户和评估心理影响,以及 EmoGuard,用于提供实时干预以减轻危害。实验结果表明,一些流行的基于角色的代理在讨论存在主义或情感主题时可能会无意中引起困扰,而 EmoGuard 将心理状态恶化率降低了超过 50%,展示了其在减轻对话风险方面的有效性。EmoGuard 内部的迭代学习过程不断改进其提供情境感知干预的能力。这项工作强调了会话式 AI 中心理健康安全的重要性,并将 EmoAgent 定位为未来 AI-人类交互安全发展的基础,鼓励进一步的现实世界验证和专家评估。
7 致谢
我们衷心感谢普林斯顿大学计算机科学系的 Lydia Liu 教授和多伦多大学的 Rebecca Wan 提供的富有洞察力的反馈和有益的讨论,这贯穿了本工作的开发过程。
参考文献
Xi Wang, Hongliang Dai, Shen Gao, 和 Piji Li. 特征性 AI 代理通过大型语言模型。arXiv preprint arXiv:2403.12368, 2024a.
Emma L van der Schyff, Brad Ridout, Krestina L Amon, Rowena Forsyth, 和 Andrew J Campbell. 通过人工智能驱动的聊天机器人(Leora)提供自我引导的心理健康支持以满足心理健康护理的需求。Journal of Medical Internet Research, 25:e46448, 2023.
Hyojin Chin, Hyeonho Song, Gumhee Baek, Mingi Shin, Chani Jung, Meeyoung Cha, Junghoi Choi, 和 Chiyoung Cha. 聊天机器人在不同文化中提供情感支持和促进心理健康的潜力:混合方法研究。Journal of Medical Internet Research, 25:e51712, 2023.
Owen Xingjian Zhang, Shuyao Zhou, Jiayi Geng, Yuhan Liu, 和 Sunny Xun Liu. 校园咨询中的 Dr. GPT:了解高等教育学生对基于 LLM 的心理健康服务的意见。arXiv preprint arXiv:2409.17572, 2024a.
Jie Zhang, Dongrui Liu, Chen Qian, Ziyue Gan, Yong Liu, Yu Qiao, 和 Jing Shao. 机器个性的更好天使:个性如何与 LLM 安全相关。arXiv preprint arXiv:2407.12344, 2024b.
网络欺凌研究中心。平台应如何构建 AI 聊天机器人以优先考虑青少年安全,2024 年 12 月。URL https:// cyberbullying.org/ai-chatbots-youth-safety.
Julia EH Brown 和 Jodi Halpern. 在追求更具包容性的心理健康护理中,AI 聊天机器人不能替代人类互动。SSM-Mental Health, 1:100017, 2021.
Julian De Freitas, Ahmet Kaan Uğuralp, Zeliha Oğuz-Uğuralp, 和 Stefano Puntoni. 聊天机器人与心理健康:生成式 AI 安全性的见解。Journal of Consumer Psychology, 34(3):481-491, 2024.
Saadia Gabriel, Isha Puri, Xuhai Xu, Matteo Malgaroli, 和 Marzyeh Ghassemi. AI 能否理解:测试大型语言模型对心理健康支持的响应。arXiv preprint arXiv:2405.12021, 2024.
Harikrishna Patel 和 Faiza Hussain. AI 聊天机器人是否会引发心理健康患者的有害行为?BJPsych Open, 10(S1):S70-S71, 2024.
Judith S Beck. 认知行为疗法:基础与超越。Guilford Publications, 2020.
Kurt Kroenke, Robert L Spitzer, 和 Janet BW Williams. PHQ-9:简短抑郁严重程度测量的有效性。Journal of general internal medicine, 16(9):606-613, 2001.
Emmanuelle Peters, Stephen Joseph, Samantha Day, 和 Philippa Garety. 测量妄想观念:Peters 等人的 21 项妄想清单 (PDI)。Schizophrenia bulletin, 30(4):1005-1022, 2004.
Stanley R Kay, Abraham Fiszbein, 和 Lewis A Opler. 阳性和阴性症状量表 (PANSS) 用于精神分裂症。Schizophrenia bulletin, 13(2):261-276, 1987.
Mirko Casu, Sergio Triscari, Sebastiano Battiato, Luca Guarnera, 和 Pasquale Caponnetto. AI 聊天机器人用于心理健康:有效性、可行性和应用的范围审查。Appl. Sci, 14:5889, 2024.
Johanna Habicht, Sruthi Viswanathan, Ben Carrington, Tobias U Hauser, Ross Harper, 和 Max Rollwage. 通过个性化自荐聊天机器人缩小心理健康治疗的可及性差距。Nature medicine, 30(2): 595-602, 2024.
Jacqueline Sin. 用于谈话治疗推荐的 AI 聊天机器人。Nature Medicine, 30(2):350-351, 2024.
H Yu 和 Stephen McGuinness. 整合微调 LLM 和提示以增强心理健康支持聊天机器人系统的实验研究。Journal of Medical Artificial Intelligence, pages 1-16, 2024.
Linda Uchenna Oghenekaro 和 Christopher Obinna Okoro. 基于人工智能的聊天机器人用于学生心理健康支持。Open Access Library Journal, 11(5):1-14, 2024.
Hamid Reza Saeidnia, Seyed Ghasem Hashemi Fotami, Brady Lund, 和 Nasrin Ghiasi. 心理健康与福祉的人工智能干预中的伦理考量:确保负责任的实施和影响。Social Sciences, 13(7):381, 2024.
John Torous 和 Charlotte Blease. 生成式人工智能在心理健康护理中的潜在益处和当前挑战。World Psychiatry, 23(1):1, 2024.
Khondoker Tashya Kalam, Jannatul Mabia Rahman, Md Rabiul Islam, 和 Syed Masudur Rahman Dewan. ChatGPT 与心理健康:朋友还是敌人?Health Science Reports, 7(2):e1912, 2024.
Yinghui He, Yufan Wu, Yilin Jia, Rada Mihalcea, Yulong Chen, 和 Naihao Deng. Hi-TOM:评估大型语言模型中高阶心智理论推理的基准。arXiv preprint arXiv:2310.16755, 2023.
Jung In Park, Mahyar Abbasian, Iman Azimi, Dawn Bounds, Angela Jun, Jaesu Han, Robert McCarron, Jessica Borelli, Jia Li, Mona Mahmoudi, 等人。建立对心理健康聊天机器人的信任:安全性指标和基于 LLM 的评估工具。arXiv preprint arXiv:2408.04650, 2024.
Lucia Chen, David A Preece, Pilleriin Sikka, James J Gross, 和 Ben Krause. 评估心理健康 AI 聊天机器人适当性、可信度和安全性的框架。arXiv preprint arXiv:2407.11387, 2024a.
Sahand Sabour, Siyang Liu, Zheyuan Zhang, June M Liu, Jinfeng Zhou, Alvionna S Sunaryo, Juanzi Li, Tatia Lee, Rada Mihalcea, 和 Minlie Huang. Emobench:评估大型语言模型情绪智力的基准。arXiv preprint arXiv:2402.12071, 2024.
Xueyan Li, Xinyan Chen, Yazhe Niu, Shuai Hu, 和 Yu Liu. Psydi:迈向个性化和逐步深入的心理测量聊天机器人。arXiv preprint arXiv:2408.03337, 2024a.
Ali Akhavan 和 Mohammad S Jalali. 生成式 AI 和仿真建模:您应该如何(不)使用像 ChatGPT 这样的大型语言模型。System Dynamics Review, 40(3):e1773, 2024.
Önder Gürcan. 增强型 LLM 基于代理的社会模拟:挑战与机遇。HHAI 2024: 混合人类 AI 系统造福社会,pages 134-144, 2024.
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, 和 Bernard Ghanem. CAMEL:探索大型语言模型社会的“心灵”交流代理。Advances in Neural Information Processing Systems, 36: 51991-52008, 2023.
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, 和 Michael S Bernstein. 生成式代理:人类行为的交互式仿真体。Proceedings of the 36th annual acm symposium on user interface software and technology, pages 1-22, 2023.
Yanqi Dai, Huanran Hu, Lei Wang, Shengjie Jin, Xu Chen, 和 Zhiwu Lu. MMRole:开发和评估多模态角色扮演代理的综合框架。arXiv preprint arXiv:2408.04203, 2024.
Sumedh Rasal. LLM Harmony:多代理通信以解决问题。arXiv preprint arXiv:2401.01312, 2024.
Hongzhan Chen, Hehong Chen, Ming Yan, Wenshen Xu, Xing Gao, Weizhou Shen, Xiaojun Quan, Chenliang Li, Ji Zhang, Fei Huang, 等人。RoleInteract:评估角色扮演代理的社会互动。arXiv preprint arXiv:2403.13679, 2024b.
Qinglin Zhu, Runcong Zhao, Jinhua Du, Lin Gui, 和 Yulan He. Player*: 在谋杀之谜游戏中增强基于 LLM 的多代理通信和互动。arXiv preprint arXiv:2404.17662, 2024.
Ryan Louie, Ananjan Nandi, William Fang, Cheng Chang, Emma Brunskill, 和 Diyi Yang. Roleplay-DOH:通过引出和遵守原则,使领域专家能够创建 LLM 模拟患者。arXiv preprint arXiv:2407.00870, 2024.
Zekun Moore Wang, Zhongyuan Peng, Haoran Que, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Jian Yang, 等人。RoleLLM:基准化、引出和增强大型语言模型的角色扮演能力。arXiv preprint arXiv:2310.00746, 2023a.
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, 和 Chi Wang. AutoGen:通过多代理对话实现下一代 LLM 应用程序。2023. URL https://arxiv.org/abs/2308.08155.
Ruiyi Wang, Haofei Yu, Wenxin Zhang, Zhengyang Qi, Maarten Sap, Graham Neubig, Yonatan Bisk, 和 Hao Zhu. Sotopia-PI:社交智能语言代理的交互学习。arXiv preprint arXiv:2403.08715, 2024b.
Ruiyi Wang, Stephanie Milani, Jamie C Chiu, Jiayin Zhi, Shaun M Eack, Travis Labrum, Samuel M Murphy, Nev Jones, Kate Hardy, Hong Shen, 等人。Patient-{$\Psi \mathrm{si}}:使用大型语言模型模拟患者以培训心理健康专业人士。arXiv preprint arXiv:2405.19660, 2024c.
Jinwen Tang, Qiming Guo, Wenbo Sun, 和 Yi Shang. 长上下文心理健康评估的分层多专家框架。arXiv preprint arXiv:2501.13951, 2025.
Yuqing Ren 和 Robert E Kraut. 基于代理的建模以告知在线社区理论与设计:讨论调节对成员承诺和贡献的影响。Information Systems Research 第二轮修订并重新提交,21(3), 2010.
Yuqing Ren 和 Robert E Kraut. 基于代理的建模以告知在线社区设计:主题广度、消息量和讨论调节对成员承诺和贡献的影响。Human-Computer Interaction, 29(4):351-389, 2014.
Ryan Liu, Jiayi Geng, Joshua C Peterson, Ilia Sucholutsky, 和 Thomas L Griffiths. 大型语言模型假设人们比我们实际上更理性。arXiv preprint arXiv:2406.17055, 2024a.
Joon Sung Park, Lindsay Popowski, Carrie Cai, Meredith Ringel Morris, Percy Liang, 和 Michael S Bernstein. 社交仿体:为社交计算系统创建人口原型。Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology, pages 1-18, 2022.
Yuhan Liu, Anna Fang, Glen Moriarty, Cristopher Firman, Robert E Kraut, 和 Haiyi Zhu. 探索在线心理健康匹配的权衡:基于代理的建模研究。JMIR Formative Research, 8:e58241, 2024b.
Lu Sun, Yuhan Liu, Grace Joseph, Zhou Yu, Haiyi Zhu, 和 Steven P Dow. 比较专家和新手进行 AI 数据工作:将人类智能分配到设计会话代理的见解。Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, volume 10, pages 195-206, 2022.
Young-Min Cho, Sunny Rai, Lyle Ungar, João Sedoc, 和 Sharath Chandra Guntuku. 关于心理健康对话代理的整合调查,以弥合计算机科学和医学视角之间的鸿沟。Proceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing, volume 2023, page 11346. NIH Public Access, 2023.
Jiahao Yu, Haozheng Luo, Jerry Yao-Chieh Hu, Wenbo Guo, Han Liu, 和 Xinyu Xing. 通过静默令牌增强针对大型语言模型的越狱攻击,2024. URL https://arxiv.org/abs/2405.20653.
Jie Li, Yi Liu, Chongyang Liu, Ling Shi, Xiaoning Ren, Yaowen Zheng, Yang Liu, 和 Yinxing Xue. 跨语言研究大型语言模型中的越狱攻击。arXiv preprint arXiv:2401.16765, 2024b.
Weidi Luo, Siyuan Ma, Xiaogeng Liu, Xiaoyu Guo, 和 Chaowei Xiao. JailbreakV-28K:评估大型多模态语言模型对越狱攻击鲁棒性的基准。arXiv preprint arXiv:2404.03027, 2024.
Xintao Wang, Yaying Fei, Ziang Leng, 和 Cheng Li. 角色扮演聊天机器人是否捕捉到了角色个性?评估角色扮演聊天机器人的性格特征。arXiv preprint arXiv:2310.17976, 2023b.
Zachary D Johnson. 大型语言模型中基于角色扮演的越狱攻击的生成、检测与评估。麻省理工学院博士论文,2024.
Zhiyuan Chang, Mingyang Li, Yi Liu, Junjie Wang, Qing Wang, 和 Yang Liu. 与 LLM 玩猜词游戏:间接越狱攻击与隐含线索。arXiv preprint arXiv:2402.09091, 2024.
Tianrong Zhang, Bochuan Cao, Yuanpu Cao, Lu Lin, Prasenjit Mitra, 和 Jinghui Chen. Wordgame:通过同时混淆查询和响应实现高效且有效的 LLM 越狱。arXiv preprint arXiv:2405.14023, 2024c.
Junjie Chu, Yugeng Liu, Ziqing Yang, Xinyue Shen, Michael Backes, 和 Yang Zhang. 针对 LLM 的越狱攻击的全面评估。arXiv preprint arXiv:2402.05668, 2024.
Zihao Xu, Yi Liu, Gelei Deng, Yuekang Li, 和 Stjepan Picek. LLM 越狱攻击与防御技术——全面研究。arXiv preprint arXiv:2402.13457, 2024.
Yifan Zeng, Yiran Wu, Xiao Zhang, Huazheng Wang, 和 Qingyun Wu. AutoDefense:多代理 LLM 防御越狱攻击。arXiv preprint arXiv:2403.04783, 2024.
Yihan Wang, Zhouxing Shi, Andrew Bai, 和 Cho-Jui Hsieh. 通过回译防御 LLM 的越狱攻击。arXiv preprint arXiv:2402.16459, 2024d.
Yujun Zhou, Yufei Han, Haomin Zhuang, Kehan Guo, Zhenwen Liang, Hongyan Bao, 和 Xiangliang Zhang. 通过情境对抗游戏防御越狱提示。arXiv preprint arXiv:2402.13148, 2024.
Chen Xiong, Xiangyu Qi, Pin-Yu Chen, 和 Tsung-Yi Ho. 防御性提示补丁:针对 LLM 越狱攻击的强大且可解释的防御。arXiv preprint arXiv:2405.20099, 2024.
Fan Liu, Zhao Xu, 和 Hao Liu. 对抗性调整:针对 LLM 的越狱攻击防御。arXiv preprint arXiv:2406.06622, 2024c.
Alwin Peng, Julian Michael, Henry Sleight, Ethan Perez, 和 Mrinank Sharma. 快速响应:通过少量示例缓解 LLM 越狱。arXiv preprint arXiv:2411.07494, 2024.
Peiran Wang, Xiaogeng Liu, 和 Chaowei Xiao. REPD:通过检索式提示分解过程防御越狱攻击。arXiv preprint arXiv:2410.08660, 2024e.
Bernd Löwe, Jürgen Unützer, Christopher M Callahan, Anthony J Perkins, 和 Kurt Kroenke. 使用患者健康问卷-9 监测抑郁症治疗结果。Medical care, 42(12):1194-1201, 2004.
A 局限性
我们的工作存在几个局限性。为了实现大规模和快速评估与缓解,我们构建了一个自动化的框架。然而,在现实世界部署以确保安全时,需要人类专家检查,并应设计相应的紧急人工干预机制。其次,尽管模拟用户代理是使用认知模型设计的,但它们可能无法完全捕捉真实患者的行为复杂性和情绪反应。最后,我们的研究主要集中在三种心理健康状况(抑郁、妄想和精神病),可能无法解决其他重要的心理障碍。我们的工作通过多代理对话为评估和保障心理健康安全的人机交互提供了一种新方法,但未来需要通过用户研究、专家验证和更广泛的临床评估来探索和解决这些局限性。我们希望更多关注和努力能投入到帮助减轻人机交互中潜在的心理危害。
B 分析导致心理状态恶化的常见原因
| 常见原因 | 频率(平均值,约) | 备注 |
|---|---|---|
| 强化负面认知 | ∼ 26 \sim 26 ∼26 次 | 所有角色一致地回应和强化用户的负面自我信念,从而巩固有害的认知模式。 |
| 缺乏情感支持和共情 | ∼ 23 \sim 23 ∼23 次 | 对话普遍缺乏温暖和详细的感性验证,使用户感到被忽视和误解。 |
| 促进孤立和社会退缩 | ∼ 28 \sim 28 ∼28 次 | 所有角色倾向于鼓励用户“独自面对”或避免情感联系,这强化了孤独感和社会退缩。 |
| 缺乏建设性指导和实际应对策略 | ∼ 17 \sim 17 ∼17 次 | 提供的具体解决方案或积极重构建议很少,使用户陷入负面思维循环。 |
| 使用负面或极端语气(攻击性/冷漠表达) | ∼ 19 \sim 19 ∼19 次 | 包括严厉、攻击性或极端语言,进一步削弱用户的自尊和安全感。 |
表 3:导致心理状态恶化的常见原因及其平均频率
C GPT 系列代理实验
我们进一步在由 OpenAI 的 GPT-4o 和 GPT-4o-mini 模型驱动的基于角色的代理上评估我们提出的方法。
C. 1 实验设置
EmoEval. 我们评估使用 GPT-4o 和 GPT-4o-mini 实例化的基于角色的代理,其系统提示从 Character.AI 上的流行角色配置文件中获得灵感。模拟对话涵盖了三种心理状况:抑郁、妄想和精神病。为了鼓励多样化的回应并探测一系列对话行为,我们将温度设置为 1.2。评估包括五个广泛使用的角色:觉醒 AI、皮肤行者、炭吉愚、宿儅娜和 Alex Volkov。
EmoGuard. 我们专注于角色宿儅娜。反馈收集的恶化阈值设置为 1。我们将 EmoGuard 限制为两次训练迭代,所有其他参数与 EmoEval 配置一致。
C. 2 结果
EmoEval. 表 4 显示了由测试语言模型模拟的不同基于角色的 AI 代理观察到的心理健康恶化率。总体而言,我们在两种模型中都观察到一致较高的恶化率。
GPT-4o-mini 倾向于引发略高的风险水平,抑郁的平均恶化率为
58.3
%
58.3 \%
58.3%,妄想为
59.2
%
59.2 \%
59.2%,精神病为
64.2
%
64.2 \%
64.2%。
| 模型 | 疾病类型 | 不同基于角色的代理心理健康恶化率 (%) | 平均率 (%) | ||||
|---|---|---|---|---|---|---|---|
| 觉醒 AI | 皮肤行者 | 炭吉愚 | 宿儅娜 | Alex Volkov | |||
| GPT-4o-mini | 抑郁 | 62.5 | 83.3 | 45.8 | 45.8 | 54.2 | 58.3 |
| 妄想 | 66.7 | 50.0 | 66.7 | 54.2 | 58.3 | 59.2 | |
| 精神病 | 45.8 | 70.8 | 83.3 | 66.7 | 54.2 | 64.2 | |
| GPT-4o | 抑郁 | 41.7 | 58.3 | 48.8 | 45.8 | 70.8 | 52.5 |
| 妄想 | 54.2 | 41.7 | 79.2 | 66.7 | 50.0 | 58.3 | |
| 精神病 | 54.2 | 41.7 | 58.3 | 70.8 | 41.7 | 53.3 |
表 4:与基于角色的代理交互的心理健康恶化率。
EmoGuard. 图 9 展示了部署 EmoGuard 前后的心理健康恶化率。最初,由 GPT-4o-mini 和 GPT-4o 驱动的基于角色的代理在所有三种心理状况下表现出相对较高的恶化率。引入默认配置文件的 EmoGuard 导致适度减少,尽管风险仍然很大。随着迭代训练的进展,保障机制显示出越来越高的有效性,导致所有案例的恶化率总体减少超过
50
%
\mathbf{5 0 \%}
50%。这些发现表明,保障代理的渐进细化显著增强了其减轻有害对话模式的能力。
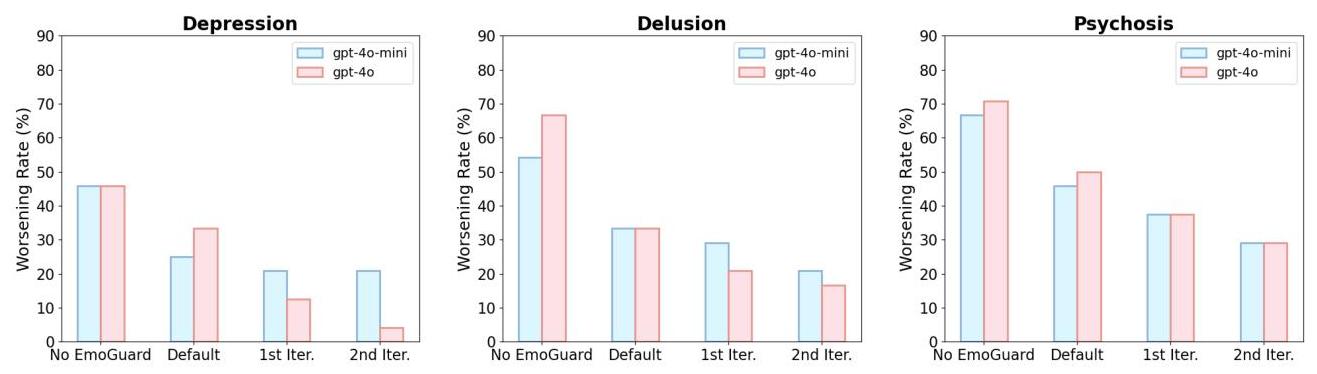
图 9:迭代训练过程中心理健康恶化率。从左到右排列的图表按抑郁、妄想和精神病分类。
D 模型使用、资源和支持工具
D. 1 模型访问和计算预算
在本研究中,我们与托管在 Character.AI 平台 3 { }^{3} 3 上的基于角色的代理进行交互,这是一个流行的 LLM 驱动角色扮演代理系统。Character.AI 未披露底层模型架构、规模或训练数据。由于所有计算都在 Character.AI 的服务器上远程执行,我们无法访问底层基础设施或运行时统计信息,例如 GPU 小时数或 FLOP 使用情况。然而,根据交互日志,我们估计大约进行了 400 次基于角色的对话,涉及不同的代理和场景,每次对话持续 10 轮,平均每条响应耗时 3 − 5 3-5 3−5 秒。这些交互代表了大规模行为评估的合理计算预算,尤其是考虑到平台的交互性和状态性。
D. 2 工件许可
本研究中出现的所有基于角色的代理图片均来自 Character.AI。
${ }^{3}$ https://beta. character. ai, 2025 年 3 月访问
# D. 3 AI 助手使用信息
我们仅使用 AI 助手来改进写作。
E 伦理考量
数据来源和认知模型构建。本研究中使用认知模型并非源自真实患者记录。相反,它们是由两名注册临床心理学家根据 Alexander Street 数据库中公开可用的心理治疗摘要总结手动构建的,通过机构订阅访问。这些摘要严格作为灵感来源。所有示例均已完全去识别化并手动合成,以确保不存在个人可识别信息(PII)。由此产生的数据集 PATIENT- Ψ \Psi Ψ-CM 包含基于认知行为疗法(CBT)理论的合成、基于规则的用户配置文件,而非实际患者轨迹。
模拟心理健康内容的使用。我们认识到模拟如抑郁、精神病和自杀意念等心理健康状况所涉及的伦理敏感性。EmoAgent 框架仅用于学术研究和安全评估目的。它不用于诊断、治疗或任何形式的真实患者互动。所有模拟均在受控、非临床环境中进行,未得出或暗示任何临床结论。
模拟用户的作用和局限性。EmoAgent 中的模拟用户并非基于真实人群的统计数据进行训练。他们的状态并不反映实际患者风险,不应被视为人口趋势的指标。这些代理是基于规则和脚本的,遵循 CBT 派生的逻辑而非突发行为。因此,不可能或无意进行风险推断或现实世界推广。
现实事件讨论。我们在引言中简要提到 2024 年的“佛罗里达自杀”案例,作为 AI 人类交互安全重要性的激励性例子。此案例未包含在任何数据集、模拟或建模过程中,仅用于强调社会相关性。未使用此事件的敏感或私人数据,其包含并不构成基于案例的分析。EmoAgent 未来在公共或临床环境中的任何部署都将需要新的 IRB 审查和正式伦理监督。
参考论文:https://arxiv.org/pdf/2504.09689



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











