






安娜·索菲娅·利波利斯
1
{ }^{1}
1,安德里亚·乔瓦尼·努佐莱塞
2
{ }^{2}
2,阿尔多·甘格米
1
{ }^{1}
1
1
{ }^{1}
1 博洛尼亚大学,意大利
2
{ }^{2}
2 ISTC-CNR,意大利
摘要
大型语言模型的最新进展展示了其在各种任务中的能力。然而,从自然语言中自动提取隐性知识仍然是一个重大挑战,因为机器缺乏对物理世界的主动体验。在这种情况下,语义知识图谱可以作为概念空间,引导自动化文本生成推理过程,以实现更高效和可解释的结果。本文应用了一种逻辑增强生成(LAG)框架,该框架通过语义知识图谱显式表示文本,并结合提示启发式方法来激发隐性类比连接。这种方法生成扩展的知识图谱三元组,表示隐性意义,使系统能够对未标注的多模态数据进行推理,而无论领域如何。我们通过四个数据集上的三个隐喻检测和理解任务验证了我们的工作,因为这些任务需要深度类比推理能力。结果表明,这种集成方法超越了当前的基线,在理解视觉隐喻方面表现优于人类,并且实现了更可解释的推理过程,尽管在隐喻理解方面仍存在固有的局限性,特别是在领域特定隐喻方面。此外,我们提出了详尽的错误分析,讨论了隐喻注释和当前评估方法的问题。
索引术语-逻辑增强生成,修辞语言理解,类比推理,大型语言模型,概念混合理论
I. 引言
从音乐即兴创作到解决复杂的科学问题,我们所知道和所做的很多事情都依赖于隐性知识:我们通过经验而非正式教学获得的庞大、无意识的信息库 1 { }^{1} 1。这种类型的知识用于类比推理,当我们依赖存储的模式、架构和关系结构来检索和应用我们可能并未明确表达的知识时。因此,隐性知识塑造了我们如何解释世界、推导推理、识别概念联系,甚至理解修辞语言,所有这些都不需要刻意努力 [2]。然而,与人类不同的是,机器在这些任务上挣扎,因为它们缺乏对物理世界的直接经验,这使得隐性学习的计算建模及其相应的类比推理成为一个重大挑战 2 { }^{2} 2。
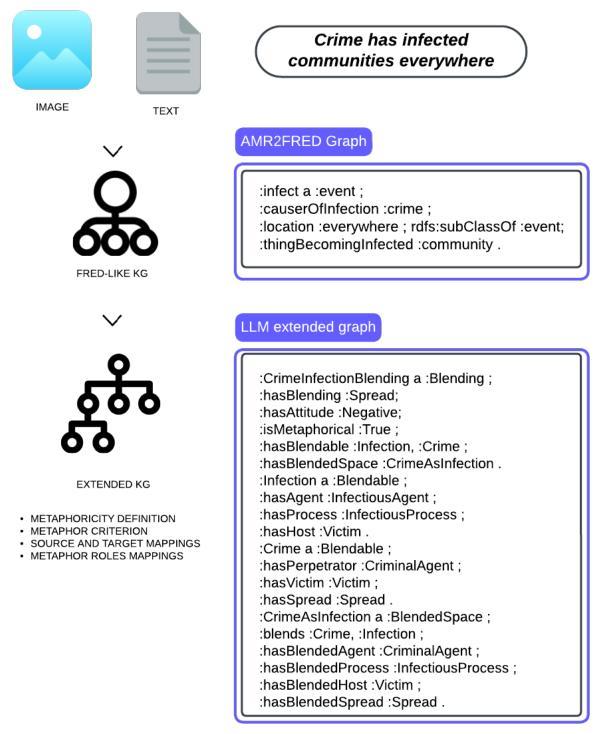
图 1. LAG 框架。输入可以是文本或图像,然后转换为类似 FRED 的 KG。根据特定启发式方法和定义的任务,使用 LLM 生成的三元组扩展图。
最近的研究认为隐喻是类比分类中的最高级别,也是大型语言模型(LLM)面临的最大挑战 [3]。这一困难源于缺乏有效的提示技术来捕捉语言的内在组合性,以及缺乏与常识知识和视觉信息的锚定 [4]。类比推理要求理解概念之间的关系链接,这是一种通常通过与世界的物理互动学到的技能 [5], [6]。LLM 中缺乏对关系链接的理解是一种推理缺陷,标准基准测试未能检测到这一点 [7],特别是关于隐喻方面。这个问题还源于缺乏隐喻的共同问题定义,以及缺乏强大的异构数据和评估策略 [8]。
尽管 LLM 在可能包含嵌入在人类语言中的隐性意义片段的多样化语料库上进行了训练,但在隐性知识上的类比推理并没有在训练过程中被明确编码,但可能仍然以连续向量空间中的概率关联形式存在于 LLM 中。然而,仅仅依靠词的概率关联来理解和生成语言限制了当前的 LLM [9]。
因此,尽管有多个评论指出人工智能系统应该被丰富以更好地反映深层的语义和认知世界模型,而不是仅仅依赖于词之间的相关性 [10]-[13],类比推理仍然是自然语言处理领域的重大挑战 [13], [14]。
概念混合理论 (CBT) 通过部分组合过程建模意义构建,涉及类比、隐喻、反事实及相关现象 [15], [16]。尽管其计算前景广阔,但由于系统地编码隐喻所需的大量、无界百科全书知识具有挑战性 [8],CBT 研究在很大程度上忽视了隐喻方面 [17]-[19]。此外,由于缺乏核心混合本体,迄今为止计算理解这些大部分先天和暗示的认知过程受到限制。事实上,研究表明,结构化的背景材料显著提高了 LLM 的性能 [20], [21]。因此,将可靠但劳动密集型的语义技术与快速、上下文依赖但易出错的 LLM 结合——正如 Gangemi 和 Nuzzolese [22] 工作中展示的逻辑增强生成 (LAG) 所示——为隐喻理解和类比推理开辟了一条有希望的新途径。
本文提出了一种基于 LAG 并受 CBT 启发的框架,从文本和图像格式的未标记隐喻数据中提取包含隐性意义的扩展知识图谱 (KG) 三元组(图 1)。通过 KG 提供结构化、机器可解释的语义与快速动态的 LLM 系统集成,允许实时灵活理解和表示跨各种领域和模态的数据中隐喻的隐含方面,例如新闻、视觉广告、表情包和医学科学。
这项工作的贡献是:(i) 对 LAG 框架的适应以增强多模态类比推理;(ii) 在隐喻检测和理解任务的变化中进行评估,即:语言隐喻检测、概念隐喻检测和理解以及视觉隐喻理解;(iii) 讨论其计算实现和应用
3
{ }^{3}
3。
论文的结构如下:第 I 节介绍了这项工作的意义和贡献;第 II 节概述了隐喻中类比抽象的理论框架;在第 III 节中,我们介绍了隐喻概念混合的混合本体;第 IV 节描述了本文采用的 LAG 方法论;第 V 和 VI 节关注其在三个任务中的应用。第 VII 节分析了结果,第 VIII 节总结了从隐喻未标注数据中类比推理提取隐性意义的贡献和影响。
II. 背景
在本节中,我们探讨了我们模型的背景,并讨论了现有自动化过程中在隐喻类比抽象方面的相关挑战。
A. 隐性知识和类比抽象
隐性学习是一个独立于有意识尝试获取知识的过程 [23]。
类比抽象是一种隐性学习知识,其中学习者检测并再现跨经验和概念的模式或类比。在类比推理过程中识别结构性相似性可用于解决问题并对新情况进行准确决策,当概念之间的联系不明显或通过重复暴露学习时尤其明显。
多年来一直是自然语言处理(NLP)的基本组成部分,基于大型语言模型(LLM)的类比推理最近得到了研究。Webb 等人显示,LLM 在识别简单的比例词类比方面表现出色 [24]。然而,其他研究表明,当面对更复杂的修辞手法 [3](如隐喻)或当任务需要区分联想和关系响应时 [25],LLM 的表现会下降。这些发现表明,虽然 LLM 可以识别从数据中学到的关联,但它们不一定掌握定义概念如何在更抽象方式下相连的底层关系。因此,需要一个结构化的框架来指导这些系统在需要类比抽象的任务中采取具体的分析步骤,同时为可解释性留出空间。
B. 概念混合理论、隐喻和框架语义
根据概念隐喻理论 [26],隐喻在领域之间建立平行关系,突出经验相关性。这一主张与心智空间理论一起,由概念混合理论(CBT)扩展,描述了人类的基本认知操作之一:概念组合。根据 CBT,隐喻中,通用空间抽象并连接源和目标输入空间,并根据隐喻准则或“属性”生成新的混合空间 [15]。实际上,许多研究 [27]-[29] 声称通过用另一个对象解释一个对象,“目标”域从另一个对象,“源”,接收一个属性,或者一般来说,源和目标在思维和语言中相关联是因为它们共享某种属性。例如,在隐喻 IDEA ARE FOOD 中,想法和食物通过内化标准(食物像想法一样插入并处理在我们的身体中)连接起来,两个空间相对于主体、输入、过程、输出,选择性地基于上下文进行抽象。这样,连接属性(内化)是一个高层次的概念
3
{ }^{3}
3 所有补充材料、代码和数据可在 https://github.com/dersuchendee/knowledge-augmented-generation 获取
该概念超越了每个输入空间的固有特征,并激励比较。
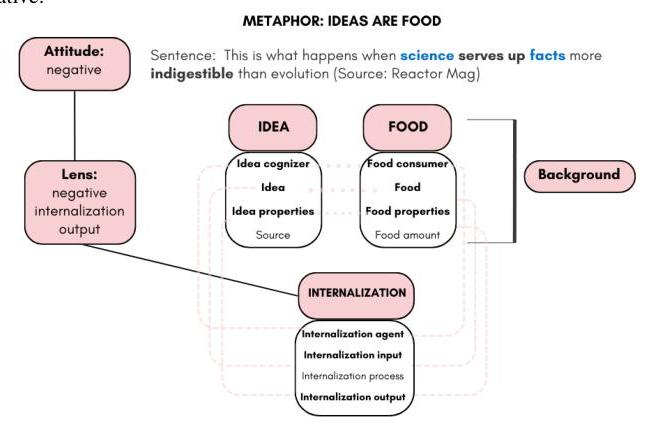
然而,存在共享属性绝不是两个概念参与隐喻映射的充分条件 [30]:为了使隐喻意义在个体之间和社区内产生桥梁,这些个体必须已经对隐喻中涉及的成分有一些理解 [31],这是由于常识知识和/或隐喻使用的特定文化或社会背景 [32]。在这方面,CBT 框架可以明确连接到 Fillmore 的框架语义 [33],其中某些动词自动调用话语参与者特定的角色、值和视角 [34]。在这里,不同的交际情境激活背景知识(即框架),约束解释。例如,如图 2 所示,当句子 “This is what happens when science serves up facts more indigestible than evolution” 中调用了概念隐喻 IDEAS ARE FOOD 时,人们必须已经有足够的背景知识,对科学知识和食物都有一定的个人理解,才能明白这意味着从说话者的角度来看,科学提出了一种难以接受的想法,并且对这两个领域持负面看法。因此,隐喻的焦点-再焦点能力与这些理论框架密切相关。
图 2. 示例句子中显示的隐喻 IDEAS ARE FOOD 存在于 Framester 知识库 [35] 中。在这里,并非所有存在的角色都能相互映射(那些映射的角色用粗体表示并通过虚线连接),只有在话语中激活了一些角色。活动角色随后被 Blending 框架(属性)内部化所概括。总体而言,有关框架的信息是话语的背景的一部分,而我们通过它看到的态度是负面的。
C. 整合理论的隐喻检测和理解
近年来,隐喻检测的进步越来越多地将理论框架整合到计算方法中。利用概念隐喻理论(CMT)的研究在隐喻识别中显示出改进的基线结果 [36], [37]。对于隐喻解释,已经开发了各种方法来确定给定目标域时隐喻暗示的源域。这些包括无监督技术 [38]、基于深度学习的方法 [39] 和使用大型语言模型的方法 [40]。然而,这些方法通常依赖于单个域的注释,而不是利用未标注的数据。在 Hicke 等人的研究中 [8],当利用未标注数据时,首选隐喻识别程序作为理论框架,因此隐喻按类别注释,而不是按源域和目标域注释。实际上,作者认识到这一限制,指出通过隐喻识别程序,迫使模型逐词注释使其难以识别包含多词单元的隐喻。
其他研究集中在提取链接源域和目标域的属性以解释隐喻 [41]-[43]。虽然这些方法产生了有希望的结果,但它们往往不能充分捕捉基于其结构相似性定义的理论推理过程,这些过程在抽象和关系依赖于两个隐喻域方面。此外,为了让这些系统工作,它们需要指定的目标词。
在视觉隐喻理解的背景下,He 等人的工作 [44] 主要关注检测,但没有根据现有的理论框架充分解决隐喻理解问题,根据这些框架,全面的方法至少应涉及识别源域和目标域。为了促进更丰富的视觉隐喻研究,引入了 Metaclue 任务集 [45],尽管其代码和数据集尚未公开。Yang 等人提出的 ELCo 数据集中提供了通过注释属性链接的隐喻组合 [4],通过文本蕴含任务评估表情符号中的隐喻组合。将基于现有本体和知识图谱的启发式方法整合到隐喻检测和理解管道中尚未得到充分探索,尽管它有可能使理论标准化并在多模态背景下可读,减少幻觉,适用于其他自动化推理任务,并提高系统的可解释性。
D. 逻辑增强生成
上述理论整合隐喻检测和理解研究的局限性可以通过在基于 LLM 的隐喻检测管道中集成本体和常识 KG 来解决。Gangemi 和 Nuzzolese [22] 展示的逻辑增强生成(LAG)方法将 LLM 视为潜在的反应式连续知识图谱(RCKGs),可以通过扩展和上下文化作为基础模型的语义知识图谱(SKGs)来动态适应多种输入。LAG 利用训练期间生成的隐性知识与生成和提示外部化的显性知识之间的二元性。RCKG 提取涉及一个三步过程,即 (i) 将多模态信号映射到自然语言,(ii) 将自然语言转换为 SKG,以及 (iii) 根据多个启发式方法(扩展的知识图谱为 XKG)用默会知识扩展 SKG。
在此参考框架中,SKGs 确保逻辑一致性,强制实施事实边界,并促进互操作性,而 LLMs 处理非结构化数据并按需提供隐性知识的上下文见解。
III. 概念混合本体
概念混合本体 4 { }^{4} 4 作为 LAG 过程中的启发式参考框架。它基于 mDnS(整体描述和情境) 5 { }^{5} 5,Gangemi 和 Presutti [46] 定义的认知透视本体 6 { }^{6} 6,以及 Gangemi 等人 [47] 提出的 Amnestic Forgery 本体中的 MetaNet 模式。
A. 背景
mDnS 是 D&S 本体模式 7 ^{7} 7 的一种新颖公理化,完全兼容经典 D&S 和构造性 D&S(cDnS),基于内涵/外延整体论,并针对混合推理器的低复杂度优化表达性。通过引入描述和情境的概念,描述和情境本体设计模式 [48] 提供了框架语义的形式化,其中情境是由观察者描述的一组事实,由描述解释,定义观察到实体的模式。
情境可以从不同视角报告:认知透视本体 [46] 表示透视框架,一种情境类型,其中在一个特定叙述或镜头中报告事实,创建一个观点,切割概念化者持有的态度的现实。因此,透视本身并非仅仅是修辞性的,因为它融合了扮演两种角色的实体:切割和镜头。最后,Amnestic Forgery 本体 [47] 是基于 MetaNet 并与概念隐喻理论 [49] 兼容的隐喻语义模型。Amnestic Forgery 重用并扩展了 Framester 模式,允许处理框架的符号和指称方面。
B. 本体
所提出的本体将隐喻的概念概括为框架映射,并使用 mDnS 进行基本公理化。本体定义了关键类和属性,以实现概念混合的操作化:
- 类别如 Blend、Blendable、Blended 和 Blending 表示概念混合过程的不同阶段和元素。
-
- 对象属性如 blendableComponent、blendedComponent 和 blendingComponent 用于以有意义的方式链接这些类,反映底层认知过程。这些属性有助于将一个概念域的组件映射到另一个,从而产生新的混合概念。其他属性如 enablesBlending 和 inheritsRoleFrom 定义了本体中不同概念元素之间的交互。
- 更具体地说,如图 3 所示,基本描述包括:
- Blending,一个通用描述,通过包含一些组件来使 Blendable 框架映射;
- Blendable,两个描述,其组件被 Blending 框架的组件所包含;
- Blended,继承自 Blendable 框架组件的描述,首先通过 Blending 共享空间,最终从 Blendable 框架继承其他组件,形成一组新的混合情境;
- Blend,元描述,其组件包括 Blending、Blendable 和 Blended。
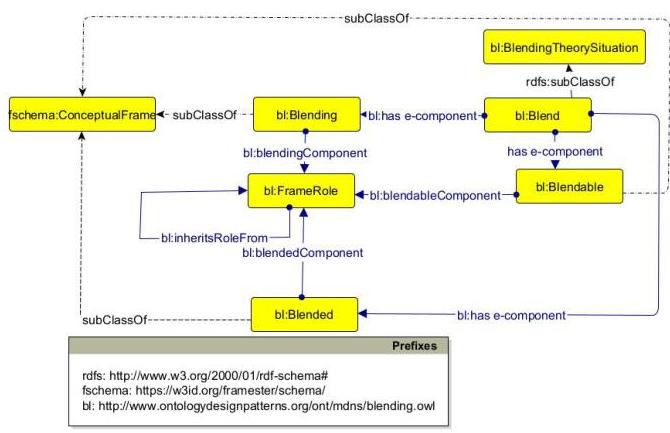
图 3. 混合本体的核心
8
{ }^{8}
8。
当从两个输入框架制定概念隐喻时,它们的角色被泛化和继承(Blendable 继承角色)来自一个更通用的 Blending,这使得混合(EnablesBlending)成为可能。Blended 又通过 Blending 泛化空间从 Blendable 框架继承组件。因此,Blended 是一个新的、独立的空间,隐喻在其中发生。
IV. 方法学
所提出的方法基于 LAG [22],旨在通过建立标准化和可解释的隐性自然语言语义表示模型来增强隐喻的检测和理解。因此,我们的方法有两个主要组成部分:i) 输入的表示,无论其模态如何,转化为自然语言,ii) 使用 Text2AMR2FRED 将其转换为基本知识图,以及 iii) 由应用于隐喻的概念混合理论驱动的 SKG 增强。
A. 自动自然语言和图像 KG 表示与 Text2AMR2FRED
Text2AMR2FRED 最初被介绍为修订版的 FRED 文本到 KG 流程 [50],使用最先进的抽象含义表示(AMR)解析器与
1
4
{ }^{4}
4 可在 http://www.ontologydesignpatterns.org/ont/mdns/blending.owl 查看
5
{ }^{5}
5 http://www.ontologydesignpatterns.org/ont/mdns/mdns.owl
6
{ }^{6}
6 http://www.ontologydesignpatterns.org/ont/persp/perspectivisation.owl
7
{ }^{7}
7 http://www.ontologydesignpatterns.org/cp/owl/descriptionandsituation.owl
图 4. 句子 “Crime has infected communities everywhere” 的 Text2AMR2FRED 流程。
例如,如图 4 所示,句子 “Crime has infected communities everywhere” 首先被解析成 AMR 图,使用 SPRING [51]。然后使用 AMR2FRED 将 AMR 图转换为遵循 FRED 知识表示模式的 RDF/OWL 知识图。
AMR 识别句子中感染的原因,这并不是细菌,而是犯罪,以及被感染的事物(社区)无处不在。在类似 FRED 的 KG 中,此图通过 Framester 提供的知识进一步丰富,包括框架、WordNet 同义词集合和 PropBank 角色,并与 DOLCE 基础本体 [52] 对齐。然而,此时还没有隐喻知识的表示。虽然 Framester 包含源自 Metanet 的概念隐喻 KG,但仍有必要能够检测任何文本中的修辞语言。也可以使用图像,通过将其自动描述为自然语言。在这种情况下,语言是一种无模态的方式来在最终的超模态 SKG 中桥接模态。然后可以在 LLM 的支持下用隐含的上下文知识扩展 SKG。
B. 带启发式的逻辑增强生成
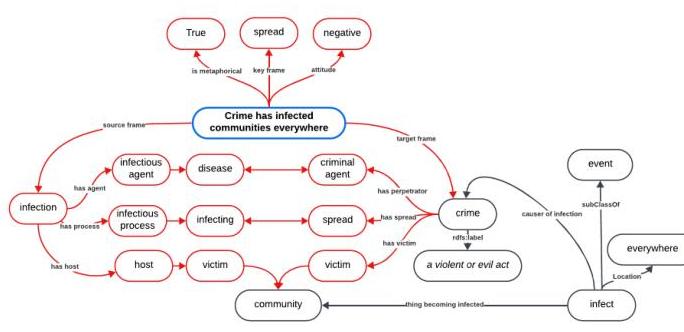
图 5. 句子 “Crime has infected communities everywhere” 的逻辑增强图。黑色是基础图,红色是增强后的类和属性。
如图 5 所示,框架生成 XKG 三元组的结果是原始 KG 与新类和属性的合并,根据提示中的特定本体。在这种情况下,指定混合本体中选定类别的最低要求以说明概念的组合。考虑到这个框架,可以专门针对隐喻使用概念混合,
其中两个域,源域和目标域对应于可混合框架。这些框架有一个共同的总括混合框架,既解释又激励隐喻。需要如此精细的元素映射来理解混合的一致性,这一点在研究中提到过,但至今尚未实施 [40]。激励隐喻混合的框架也使系统的类比推理能力更具可解释性。例如,系统可以正确识别隐喻中涉及的元素,但错误识别连接它们的属性,如第七节所述,显示无法理解隐喻。有了这个框架在脑海中,可以为 LLM 创建一个提示,给定一段文本和从 Text2AMR2FRED 得到的 KG 表示,它将其扩展以创建一个增强的 Turtle 格式的 RDF 图。
V. 应用和评估
在本节中,我们通过将其应用于隐喻检测和理解来评估框架提取隐性意义的能力。首先,我们在三个隐喻检测数据集上测试 LAG 框架。最佳配置然后应用于三个隐喻理解数据集。最后,我们对隐喻检测和视觉隐喻理解进行消融测试。
A. 任务
本节展示了框架在三个与隐喻相关的任务中的应用:i) 隐喻检测,其中从自然语言句子派生的 SKG 被增强以确定句子是否是隐喻性的,有时以目标词为参考;ii) 概念隐喻理解,除此之外还旨在识别构成隐喻的正确源域和目标域;以及 iii) 视觉隐喻理解,其中目标是识别视觉隐喻中链接两个域的属性。
- 隐喻检测和理解:如补充材料所示,LLM 被给予一个句子、从 Text2AMR2FRED 派生的代表句子的 SKG,以及一系列指令。提示首先要求识别句子可能的源和目标;然后,它被要求将这两个定义为包含角色并遵循协调创建混合空间的混合函数的概念框架。根据混合本体,透镜和态度进一步细化隐喻的定义。还提供了一个特定句子的图例。
鉴于 Text2AMR2FRED 图、给定目标词时句子的假设源和目标,以及混合衍生的指令,LLM 被提示分析句子,并根据给定定义使用至少这些特定的本体元素,以确定句子可能的隐喻性:
- bl:Blending,
- bl:Blendable,
- bl:Blended,
- cp:Attitude,
- cp:Lens,
- 数据类型属性 metanet:isMetaphorical,分类依据。
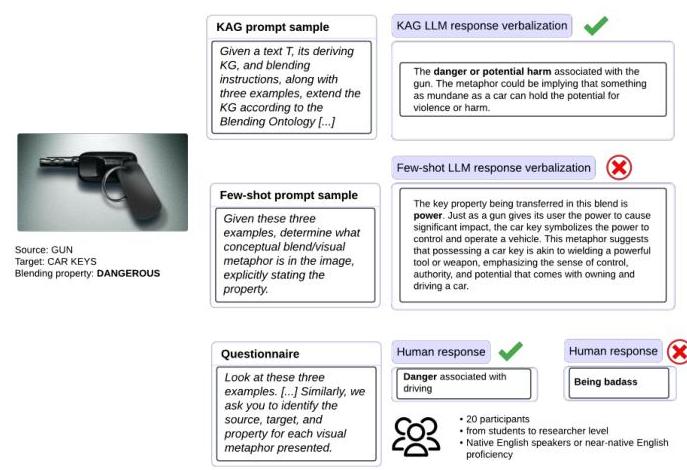
此外,在提示中要求确定可混合角色及其映射,以根据混合本体创建混合的隐喻空间。 - 视觉隐喻理解:按照 Petridis 等人在 [32] 中对人类参与者进行的原始研究,视觉隐喻理解的方法包括在上下文中学习技术中呈现三个例子和正确的视觉隐喻元素注释,以及一个新图像进行分析。在这种情况下,首先用自然语言描述待分析的图像,并将文本传递给 Text2AMR2FRED 以生成基础图。基础图、图像、伴随句子和混合指令都被包含在提示中以生成增强的 KG,如图 6 所示。在这项工作中,我们实验了这些输入的多种组合以找到最佳的提示技术。
图 6. 根据手动评估,视觉隐喻理解的示例提示及正确和错误输出的摘录。
VI. 数据集
为了本研究的目的,并为了在上述任务中进行比较,对于文本隐喻检测,我们在两个公开可用的隐喻数据集上进行了实验:(1) M O H − X \mathrm{MOH}-\mathrm{X} MOH−X [53],其中包括 647 个句子,标注为隐喻或字面意思;以及 (2) TroFi [54],另一个从 1987-1989《华尔街日报》语料库中收集的隐喻检测数据集。我们分别采样了 300 个平衡实例用于测试。对于概念隐喻,我们采用了 Wachowiak 和 Gromann [40] 提炼的 (3) 数据集,其中包括 447 个句子,标注了源域和目标域(为方便引用,我们将称之为 WG)。我们还引入了第四个数据集,以验证识别和解释领域特定概念隐喻的能力:(4) 平衡概念隐喻测试数据集 (BCMTD)。该数据集包括 147 个句子,均匀分布在一般概念隐喻(来自 Framester [35] 注释的 Metanet 派生数据,且不在 WG 中出现)、科学概念隐喻(从 Van Rijn 和 Van Tongeren [55] 附录中的科学文献中提取的例子和 Semino 等人 [56] 提供的例子,允许特定领域的医学隐喻数据集)和来自 VUA 语料库 [57] 的字面句子(由 Wachowiak 和 Gromann [40] 事先提炼,因为许多句子被错误标注或不适合此任务)。视觉隐喻数据集来源于 Petridis 等人 [32]。它包含 48 张图片,其中 27 张为广告,21 张为非广告,并给出了三个例子,供人类参与者测试他们根据概念混合框架识别视觉隐喻的能力。表 I 显示了所有数据集的统计信息。
表 I
数据集统计摘要,包括实例数、隐喻句百分比和样本数。
| 数据集 | # \# # 句子 | % 瓷砖 | # \# # 示例 |
|---|---|---|---|
| MOH-X | 421 | 46.1 | 421 |
| 421 | 127 | 126 | 421 |
| 421 | 126 | 126 | 421 |
| BCMTD | 145 (情景) | 145.6 | 147 |
| 视觉隐喻 | 22 | 126 | 20 |
A. 评估指标
隐喻检测的评估指标根据任务类型分为自动和手动。
- 自动评估指标:我们使用准确率和 F1 分数来评估模型在通用和概念隐喻检测中的表现。对于概念隐喻理解,通过正确识别源域和目标域映射的标准评估,BLEURT 分数 [58] 被证明可以捕捉文本之间的语义相似性。为了评估候选和参考源域和目标域在隐喻中的距离,考虑了这种方法。这种方法类似于 Saakyan 等人 [59] 的方法,其中不仅报告标签准确性,而且根据定义的阈值报告。在这种情况下,阈值是正确预测源域和目标域标签达到 BLEURT 正分数的位置。
- 手动评估:为了正确确定隐喻源域和目标域映射以进行领域识别,并正确比较黄金标准和预测的视觉隐喻解释属性,还需要进行手动评估。因此,对于概念和视觉隐喻理解的最佳解决方案由三位注释员评估源域和目标域映射。注释员拥有语言学学位,证明了他们在隐喻方面的专业知识,并具备英语母语或接近母语的语言能力。他们在所有情况下表现出公平的注释者一致性(Fleiss’ Kappa),所有任务的平均值为 0.35,这对于如此主观的隐喻理解任务是可以理解的。更多信息见补充材料。为了计算准确率,我们计算每个准确率分数的平均值。在视觉隐喻解释任务中,手动评估将黄金标准属性与预测属性进行比较,连接源域和目标域。
评估直接遵循 Petridis 等人 [32] 的方法,将正确响应视为直接与图像中的对象相关的。我们还在博洛尼亚大学的 20 名参与者中重复了对 24 张图像样本的研究,并手动评估了他们的响应。
B. 基准方法
在 Tian 等人 [37] 中,讨论了几种隐喻检测的基准方法,其中表现最好的方法是基于概念隐喻理论(TSI CMT)的理论引导脚手架指令框架。MetaPRO 是非 LLM 方法中检测源域和目标域的基准,作为识别映射而不指定目标词的最先进方法 [36]。对于概念隐喻理解,目前没有基准可以同时检测源域和目标域,只能检测其中之一。因此,我们在不同的 LLM 配置中使用零样本和少量样本,这些方法已被先前研究证明有效 [40]。对于视觉隐喻理解,没有已建立的基准可以指定源域、目标域和混合属性。因此,我们使用与测试人类相同的三个少量样本示例探索 LAG 框架的不同配置,并与没有 LAG 的少量样本基准进行比较。
C. 参数设置
在我们的实验中,Claude 3.5 Sonnet 9 { }^{9} 9 作为主要的 LLM。除了视觉隐喻解释(当前开放模型不支持少量样本图像示例),我们将最佳结果与 Llama 3.1 70B Instruct Turbo 10 { }^{10} 10 进行比较。仅使用 API 进行测试。我们使用默认参数进行测试,并将温度设置为 0 以进行贪婪解码。
D. 主要结果
在本节中,我们概述了应用于选定任务的 LAG 框架的主要结果。
- 隐喻检测:与基准比较:表 II 显示了 LAG 与 TroFi 和 MOH 数据集样本相比的比较结果。表 III 显示了 LAG 相对于 BCMTD 的比较结果。
表 II
MOH-X 和 TROFi 上隐喻检测的各种方法性能比较。最佳结果加粗显示。
| 方法 | MOH-X | TroFi | ||
|---|---|---|---|---|
| F1 (%) | 准确率 (%) | F1 (%) | 准确率 (%) | |
| MetaPRO | 84 | 81 | 79 | 70 |
| TSI CMT* | 82.5 | 82.9 | 66 | 66.8 |
| LAG | 89.7 \mathbf{8 9 . 7} 89.7 | 87.3 \mathbf{8 7 . 3} 87.3 | 89.7 \mathbf{8 9 . 7} 89.7 | 84.6 \mathbf{8 4 . 6} 84.6 |
表 III
BCTMD 数据集隐喻检测的性能指标。最佳结果加粗显示。
| 方法 | 准确率 (%) | F1 分数 (%) |
|---|---|---|
| LAG | 80.1 \mathbf{8 0 . 1} 80.1 | 84.1 \mathbf{8 4 . 1} 84.1 |
| MetaPRO | 69.1 | 69.8 |
| 少样本 12 | 59.0 | 48.9 |
| 少样本 6 | 52.4 | 45.2 |
| 少样本 3 | 47.5 | 42.8 |
| 零样本 | 22.9 | 33.8 |
- 概念隐喻理解:概念隐喻理解是一项比简单隐喻检测更具挑战性的任务,因为它涉及到正确检测隐喻的源域和目标域,这显示了系统是否理解了隐喻。我们采用三位注释员之间的多数投票来选择黄金标准标签。
WG 数据集。三位注释员对数据集的手动评估揭示了同时正确识别源域和目标域的隐喻百分比为 25.6 % 25.6 \% 25.6%。BLEURT 分数显示了人类注释和预测域之间的适度相关性。对于目标域,点双列相关系数为 0.702 ( p < 0.05 ) 0.702(p<0.05) 0.702(p<0.05) 和 Spearman 相关系数为 0.698 表明 BLEURT 对人类判断具有合理的敏感性。对于源域,观察到点双列相关系数为 0.707 ( p < 0.05 ) 0.707(p<0.05) 0.707(p<0.05) 和 Spearman 相关系数为 0.680。
BCTMD。三位注释员对手动评估最佳执行方法在隐喻理解中的公平协议揭示,96 个概念隐喻中同时正确识别源域和目标域的百分比为
34.3
%
34.3 \%
34.3%。此外,正确识别的隐喻分布为一般概念隐喻
51.6
%
51.6 \%
51.6%,而科学概念隐喻得分降低到
8
%
8 \%
8%。与 WG 中也包含的一般隐喻相比,这一得分可能与 LLM 没有经过特定领域隐喻数据集训练的事实有关,但也与科学隐喻具有不同的常规性水平有关,随着它们在语言中变得普遍,科学隐喻倾向于变得更加字面化。BLEURT 分数显示参考和预测源域和目标域之间有
36.9
%
36.9 \%
36.9% 的正相关性。点双列相关系数为
0.3525
(
p
<
0.05
)
0.3525(p<0.05)
0.3525(p<0.05) 和 Spearman 相关系数为
0.2917
(
p
<
0.05
)
0.2917(p<0.05)
0.2917(p<0.05) 都表明 BLEURT 具有中等正相关性。
3) 视觉隐喻理解:对于视觉隐喻理解,识别混合属性对应于正确解释隐喻中使用的源域和目标域(如 Petridis 等人 [32] 所示)。在表 IV 中显示的三种配置中,三位评估者的手动注释揭示了最佳结果是在提示中不插入描述图像的句子的情况下,单独使用 LAG 和图像本身。关于 Petridis 等人 [32] 描述的人类评估,正确解释图像意义的时间为
41.32
%
41.32 \%
41.32%,在表现最佳的方法中
9
{ }^{9}
9 https://www.anthropic.com/news/claude-3-5-sonnet.
10
{ }^{10}
10 https://ai.meta.com/blog/meta-llama-3-1/
LLM 正确解释了图像意义的平均时间为
67.06
%
67.06 \%
67.06%。然后我们对数据集进行了抽样,随机选取了数据集中 48 个视觉隐喻中的 24 个,并重复了 [32] 的原始研究,招募了 20 名来自博洛尼亚大学的学生至研究人员,具有母语或接近母语的英语流利程度。此设置与原始研究略有不同,原始研究中未指定参与者的学业水平。参与者的提交是匿名的,并提供了知情同意。这一次,人类参与者正确解释了图像意义的平均时间为
59.25
%
59.25 \%
59.25%,相对于同一图像的 LLM 平均得分为
73.5
%
73.5 \%
73.5%。
表 IV
视觉隐喻理解方法的比较。最佳结果是没有在输入中注入描述图像的句子的 LAG。
| 方法 | 平均 准确率 ( % ) (\%) (%) |
|---|---|
| LAG sent+img | 65 |
| LAG no sent | 67 \mathbf{6 7} 67 |
| LAG no img | 65.2 |
| 少样本 (3) | 54.7 |
表 V
视觉隐喻数据集的消融研究结果。最佳结果加粗显示。
| 方法 | 平均准确率 |
|---|---|
| LAG no sent | 67 |
| 无混合 | 68.6 \mathbf{6 8 . 6} 68.6 |
| 无图 | 56.2 |
- 隐喻检测和理解:与开源 LLM 的比较:我们将隐喻检测的最佳结果与 Llama, 3.1 70B Instruct 进行比较。
表 VI
各数据集中 LAG 的隐喻检测与 Claude 和 Llama 的比较。最佳结果加粗显示。
| LLM | M O H − X \mathbf{M O H}-\mathbf{X} MOH−X | TroFi | BCMTD | |||
|---|---|---|---|---|---|---|
| 准确率 | F1 | 准确率 | F1 | 准确率 | F1 | |
| Claude | 87.3 \mathbf{8 7 . 3} 87.3 | 89.7 \mathbf{8 9 . 7} 89.7 | 84.6 \mathbf{8 4 . 6} 84.6 | 89.7 \mathbf{8 9 . 7} 89.7 | 80.1 \mathbf{8 0 . 1} 80.1 | 84.1 \mathbf{8 4 . 1} 84.1 |
| Llama | 55.9 | 69 | 60.8 | 75 | 66.6 |
关于概念隐喻理解,根据评估者的意见,使用 Claude 的方法的平均准确率为
37.5
%
37.5\%
37.5%,而 Claude 方法的准确率为
34.3
%
34.3\%
34.3%。结果显示,在使用 Llama 进行隐喻检测时性能有所下降,但对源域和目标域映射的理解似乎相对于 Claude 表现略好。
5) 消融研究:我们进行消融研究以评估两种配置下我们方法中组件的影响:(i) 去除混合指令,以及 (ii) 去除提示中的知识图谱注入。所有这些配置中使用的提示都在补充材料中。表 VII 显示了文本数据集的隐喻检测消融研究结果,而表 V 显示了视觉隐喻理解的结果。
VII. 讨论
在本节中,我们讨论了结果,概述了一些应用和进一步研究方向的建议框架,
表 VII
MOH-X、TroFi 和 BCMTD 数据集的消融研究结果。最佳结果加粗显示。
| 方法 | MOH-X | TroFi | BCMTD | |||
|---|---|---|---|---|---|---|
| 准确率 | F1 | 准确率 | F1 | 准确率 | F1 | |
| LAG | 87.3 \mathbf{8 7 . 3} 87.3 | 89.7 \mathbf{8 9 . 7} 89.7 | 84.6 \mathbf{8 4 . 6} 84.6 | 89.7 \mathbf{8 9 . 7} 89.7 | 80.1 \mathbf{8 0 . 1} 80.1 | 84.1 |
| 无混合 | 81.6 | 87 | 81.9 | 86 | 78.6 | 85.2 \mathbf{8 5 . 2} 85.2 |
| 无图 | 78.6 | 82 | 83.9 | 87 | 70 | 73 |
框架,以及探讨局限性。
A. LAG 在多模态隐喻检测和解释中的应用
第五节概述的结果表明,对于隐喻检测任务,根据提示和基础图约束 LLM 遵循混合本体生成的增强知识图谱优于当前的隐喻检测和理解基线。这种方法可以用于从未标注的多模态隐喻数据中提取知识图谱。因此,它可能在不同的应用中产生影响,例如改进经常具有隐喻特征的仇恨言论,并分析新闻媒体和在线媒体中的辩论。至于视觉隐喻,由于人类往往难以识别它们,自动化理解视觉混合(例如在广告中)可以弥补这一差距。此外,使用开源 LLM 如 Llama 可能会降低检测性能,但不会影响理解任务。消融研究表明,虽然去除图谱会降低所有情况下的性能,但在视觉隐喻理解中去除提示中的混合启发式不会减少性能。尽管这是一个细微的差异,但它可能是由于视觉隐喻在处理前可能会被错误地描述为文本。另一个解释是错误分析(见第七节-B)显示,无论是人类 [32] 还是 LLM,最常见的问题是属性错误:图像中的对象被检测到,但在提取正确的属性时仍存在困难。因为一半的图像是广告,通常提供更清晰的上下文,所以对象的预期属性通常被清楚定义。通过不指定图像的目的及其上下文,我们使人类和机器都难以通过一种通常在没有上下文规范的情况下更为开放的混合机制准确确定隐喻属性。
B. 增强图的质量和错误分析
我们向两位熟悉概念混合和概念隐喻理论的知识工程师提供了 16 个生成的图示样本,其中 8 个来自正确识别的隐喻句子,8 个来自视觉隐喻。我们在李克特量表上从 1 到 7 对检测属性、源、目标和元素映射的表示的充分性、正确性和完整性进行了评估。结果突出了一致的模式,其中文本组件在所有评估指标中普遍优于其视觉对应物。具体来说,文本中的正确性和充分性得分分别为 5.1 和 6.3,表明正面评价,而视觉方面分别得分为 4.9 和 5,表明有改进空间。文本的完整性评分为 5.2,而视觉完整性的评分较低,为 4.4,显示出需要更好地整合或表示视觉元素以匹配文本分析。总体而言,这些结果表明正面表现,但在文本和视觉输出之间存在差异,这可能是因为所选示例是由 Petridis 等人 [32] 提供的,并未进一步用 RDF 语法注释以与人工评估保持一致。
- 错误分析:尽管在已知数据集中隐喻检测表现出良好的性能,但对于概念隐喻理解,LAG 最佳配置的错误遵循 Wachowiak 和 Gromann [40] 提出的分类,并添加了一个新类别,即相对于黄金标准注释错误切换源和目标。此外,通用概念隐喻比科学概念隐喻更容易被检测到。
特别是,概念隐喻映射中的错位主要由于子元素映射错误,这在 WG 数据集中约占 56.5 % 56.5 \% 56.5%,在 BCTMD 中占 57.1 % 57.1 \% 57.1%。过于具体的注释也显著贡献了误差,在 WG 和 BCTMD 中分别占 23.6 % 23.6 \% 23.6% 和 28.6 % 28.6 \% 28.6%,而过于一般的描述出现在 WG 的 9.3 % 9.3 \% 9.3% 和 BCTMD 的 14.3 % 14.3 \% 14.3% 的案例中,显示出在识别隐喻的正确分类学水平方面的困难。此外,较少出现的错误,如切换源和目标(WG 的 3.24 % 3.24 \% 3.24%)和将隐喻识别为字面意思(WG 的 6.94 % 6.94 \% 6.94%),揭示了隐喻映射过程中的进一步复杂性层,如误解源和目标域的作用和确定隐喻水平(当感知到的隐喻常规性较高时,句子可能看起来是字面意思)。
这些结果强调了需要在领域特定的隐喻数据集上训练和测试自动方法,但也表明这些任务中一般不恰当地执行类比推理。另一方面,视觉隐喻理解显示出不同类型的错误。错误分析仍然遵循 Petridis 等人在 [32] 中对人类参与者所做的分析,涉及错误对象(错误的
21
%
21 \%
21%)。例如,LLM 将枪的形状识别为哨子,或将粉红色的耐克鞋识别为鱼,通常歪曲了解释。然而,最常见的错误是错误属性(错误的
57
%
57 \%
57%):如果 LLM 正确识别了对象、源和目标,但仍然误解了属性。例如,在汽车钥匙和枪的混合情况下(显示在图 ?? 中),注释属性为“危险”,预测属性为“强大”。这种错误也在人类参与者中观察到,并与他们对混合中展示的对象的价值观和信念相关,这是进一步研究的一个领域。最后,在
21
%
21 \%
21% 的情况下,即使 LLM 识别了源、目标和连接属性,角色映射解释仍可能显示出对隐喻的误解(目标符号错误)。因此,仅评估属性不足以判断系统是否理解了隐喻。
错误分析显示了将上下文意义纳入隐喻理解的必要性,同时也表明完整的隐喻理解需要更深层面的语义和文化意识,尽管有指导进行关系类比思维,当前系统仍难以实现,也因缺乏标准化的金标准注释来建立明确的隐喻层次结构。这个多方面的挑战突显了计算模式识别与人类隐喻理解的认知过程之间的差距。
C. LAG 在隐喻生成中的应用
除了检测现有隐喻外,我们的框架还提供了一种结构化的方法来生成新的有效隐喻。通过形式化概念框架混合的过程,系统可以通过创造性地重新配置已知概念到新的、合理配置中来提出新颖的隐喻,依据指定的本体。该框架的这一方面在创意 AI 领域的应用中特别有前景,如广告、文学和自动化内容生成。在未来的研究中,我们旨在开发一种生成方法,解决其他研究中发现的限制,例如 Chakrabarty 等人在 [61] 中描述的研究。该研究中的作者提示模型使用通用的、隐含的元素生成视觉隐喻,但未说明如何有效地组合这些元素以产生有意义的隐喻。实际上,研究中报告的一个错误是省略了目标域或未明确请求的图像中的关键元素。因此,找到 LLM 在理解视觉隐喻中的错误可以提高其生成隐喻的能力,使其更接近我们的思维过程。这种丰富可以促进叙事创作,提供新颖且有影响力的方式来传达复杂的思想或情感,并增强 AI 生成内容的参与度和相关性。此外,通过人类验证的 LLM 生成的整体概念数据,评分信息可以为加权混合表示的微调提供一些输入。
D. 隐喻数据集的可解释性
通过创建 XKG,所提出的框架的可解释性有助于阐明一些迄今为止在计算隐喻方法中尚未完全显现的方面。
- 上下文和文化:我们的研究表明,在计算隐喻分析中标记源和目标元素不足以全面掌握隐喻意义。例如,如图 ?? 所示,LLM 准确识别了构成隐喻的所有图像中的对象。然而,尽管混合属性被注释为“危险”,LLM 将其解释为“权力”。在没有进一步框定参考元素所需的外部上下文的情况下,这两种解释都可以被认为是合理的。
此及其他实验中的例子揭示了两个关键见解。首先,LLM 在解释隐喻时采用的视角反映了其底层的文化
背景。在这种情况下,对枪支既是强大的又是危险的双重认知,凸显了文化背景如何塑造解释。
此外,为了让系统(和用户)可靠地收敛于隐喻的注释属性,提供额外的上下文是至关重要的。这一对上下文的要求也可能有助于解释人类反应中观察到的相对较差的表现,例如区分广告是公共活动、漫画还是普通广告。
2) 隐喻注释的动态:超越文化和上下文依赖,人类注释显示 WG、BCTMD 和视觉隐喻数据集中的一些句子的黄金标准隐喻有多个可能的正确答案,甚至同一句中有多个答案。例如,对于句子 “This mini-controversy erupted when Republicans introduced a string of amendments in a final effort to obstruct passage of the reconciliation bill”,黄金标准隐喻是 INHIBITTING ENACTMENT OF LEGISLATION IS IMPEDING MOTION,而预测的是 CONTROVERSY IS VOLCANO ERUPTION,评估者认为这是正确的,但在自动评估中会被视为错误。
这一现象表明需要让人类和隐喻解释过程保持灵活。然而,当前标注的隐喻数据集只包含一个可能的黄金标准答案。未来的工作应考虑在参考文本中纳入多个正确答案的可能性。
E. 局限性
尽管其有优势,当前框架仍有改进空间。实验仅限于英语;需要更多的文本和图像数据进行全面评估。尽管概念隐喻的工作显示出与自动化测量的一些相关性,但人工评估仍然是必不可少的。实际上,另一项关于增强图质量的调查需要更大数量的图和参与者。此外,模型的计算复杂性和资源需求可能导致在大型数据集或实时应用中出现时间限制。因此,持续改进是必要的,以提高可扩展性和效率。
VIII. 结论与未来工作
本文介绍了一种基于逻辑增强生成的框架,该框架自动从基础图生成扩展的知识图三元组,利用本体提示启发式方法,以实现对各种类型未标注修辞数据的有效类比推理。我们收集了四个用于隐喻检测和理解的数据集,并引入了一个包含领域特定科学概念隐喻的新数据集。我们的多模态隐喻检测和理解结果不仅超过了当前的基准,使用 Claude Sonnet 3.5,而且在理解视觉隐喻方面甚至超过了人类的表现,尽管科学隐喻的准确性仍然显著低于通用隐喻。错误分析证实了最近的主张,即尽管 LLM 在表面关联方面表现出色,但它们仍然缺乏稳健的关系推理过程,部分原因是现有数据集中缺乏足够的上下文解释。尽管这一缺点呼吁更多样化和精细的隐喻数据,但利用混合本体生成增强知识图谱提高了输出的可解释性,与当前方法相比,后者通常无法澄清为什么即使检测到了隐喻的对象,隐喻属性仍未正确识别。因此,所提出的方法推动了对非结构化数据中多模态修辞语言理解的计算模型的发展,对自然语言处理、创造力和应用(如仇恨言论检测)中的 AI 具有重要意义。未来的工作将集中在优化框架的计算复杂度并在更广泛的注释数据上进行测试。
参考文献
[1] M. Davies, “Knowledge-explicit, implicit and tacit: Philosophical aspects,” International encyclopedia of the social & behavioral sciences, vol. 13, no. 2, pp. 74-90, 2015.
[2] S. B. Kaufman, C. G. DeYoung, J. R. Gray, L. Jiménez, J. Brown, and N. Mackintosh, “Implicit learning as an ability,” Cognition, vol. 116, no. 3, pp. 321-340, 2010.
[3] “Analogical-a novel benchmark for long text analogy evaluation in large language models.”
[4] Z. Y. Yang, Z. Zhang, and Y. Miao, “The elco dataset: Bridging emoji and lexical composition,” in Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024, pp. 15899-15909.
[5] D. Keysers, N. Schärli, N. Scales, H. Buisman, D. Furrer, S. Kashubin, N. Momchev, D. Sinopalnikov, L. Stafiniak, T. Tihon et al., “Measuring compositional generalization: A comprehensive method on realistic data,” arXiv preprint arXiv:1912.09713, 2019.
[6] D. Furrer, M. van Zee, N. Scales, and N. Schärli, “Compositional generalization in semantic parsing: Pre-training vs. specialized architectures,” arXiv preprint arXiv:2007.08970, 2020.
[7] M. Nzehurina, L. Cipolina-Kun, M. Cherti, and J. Jitsev, “Alice in wonderland: Simple tasks showing complete reasoning breakdown in state-of-the-art large language models,” arXiv preprint arXiv:2406.02061, 2024.
[8] R. M. Hicke and R. D. Kristensen-McLachlan, “Science is exploration: Computational frontiers for conceptual metaphor theory,” arXiv preprint arXiv:2410.08991, 2024.
[9] R. Mao, M. Ge, S. Han, W. Li, K. He, L. Zhu, and E. Cambria, “A survey on pragmatic processing techniques,” Information Fusion, vol. 114, p. 102712, 2025. [Online]. Available: https://www.sciencedirect. com/science/article/pii/S1566253524004901
[10] M. Schrimpf, I. A. Blank, G. Tuckute, C. Kauf, E. A. Hosseini, N. Kanwisher, J. B. Tenenbaum, and E. Fedorenko, “The neural architecture of language: Integrative modeling converges on predictive processing,” Proceedings of the National Academy of Sciences, vol. 118, no. 45, p. e2105646118, 2021.
[11] B. M. Lake and G. L. Murphy, “Word meaning in minds and machines,” Psychological Review, 2021.
[12] J. S. Rule, J. B. Tenenbaum, and S. T. Piantadosi, “The child as hacker,” Trends in cognitive sciences, vol. 24, no. 11, pp. 900-915, 2020.
[13] E. Leivada, G. Marcus, F. Günther, and E. Murphy, “A sentence is worth a thousand pictures: Can large language models understand hum4n 34ngu4ge and the w0rld behind w0rds?” arXiv e-prints, pp. arXiv-2308, 2023.
[14] K. Stowe, T. Chakrabarty, N. Peng, S. Muresan, and I. Gurevych, “Metaphor generation with conceptual mappings,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), C. Zong, F. Xia, W. Li, and R. Navigli, Eds. Online: Association for Computational Linguistics, Aug. 2021, pp. 6724-6736. [Online]. Available: https: //aclanthology.org/2021.acl-long. 524
[15] G. Fauconnier and M. Turner, “Conceptual blending, form and meaning,” Recherches en communication, vol. 19, pp. 57-86, 2003.
16] T. Oakley and S. Coulson, “Blending and metaphor,” Metaphor in Cognitive Linguistics. Ed. Gerard Steen and Raymond Gibbs. Philadelphia: John Benjamins. On line: http://cogweb. ucla. edu/CogSci/Grady, vol. 99, 1999.
167] R. Confalonieri and O. Kutz, “Blending under deconstruction: The roles of logic, ontology, and cognition in computational concept invention,” Annals of Mathematics and Artificial Intelligence, vol. 88, no. 5, pp.
479
−
516
,
2020
479-516,2020
479−516,2020.
168] D. A. Gómez Ramírez and D. A. Gómez Ramírez, “Conceptual blending in mathematical creation/invention,” Artificial Mathematical Intelligence: Cognitive,(Meta) mathematical, Physical and Philosophical Foundations, pp. 109-131, 2020.
169] D. Bourou, M. Schorlemmer, and E. Plaza, “Image schemas and conceptual blending in diagrammatic reasoning: the case of hasse diagrams,” in Diagrammatic Representation and Inference: 12th International Conference, Diagrams 2021, Virtual, September 28-30, 2021, Proceedings 12. Springer, 2021, pp. 297-314.
170] Z. Xie, T. Cohn, and J. H. Lau, “The next chapter: A study of large language models in storytelling,” in Proceedings of the 16th International Natural Language Generation Conference, 2023, pp. 323351.
171] K. Liu, Z. Chen, Z. Fu, R. Jiang, F. Zhou, Y. Chen, Y. Wu, and J. Ye, “Educating llms like human students: Structure-aware injection of domain knowledge,” arXiv preprint arXiv:2407.16724, 2024.
172] A. Gangemi and A. G. Nuzzolese, “Logic augmented generation,” Journal of Web Semantics, vol. 85, p. 100859, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1570826824000453
173] A. S. Reber, “Implicit learning and tacit knowledge,” Journal of experimental psychology: General, vol. 118, no. 3, p. 219, 1989.
174] T. Webb, K. J. Holyoak, and H. Lu, “Emergent analogical reasoning in large language models,” Nature Human Behaviour, vol. 7, no. 9, pp. 1526-1541, 2023.
175] C. E. Stevenson, M. ter Veen, R. Choenni, H. L. van der Maas, and E. Shutova, “Do large language models solve verbal analogies like children do?” arXiv preprint arXiv:2310.20384, 2023.
176] G. Lakoff and M. Johnson, Metaphors We Live By. University of Chicago Press, 1981.
177] C. Forceville, Pictorial metaphor in advertising. Routledge, 2002.
178] S. Glucksberg, “How metaphors create categories-quickly,” The Cambridge handbook of metaphor and thought, pp. 67-83, 2008.
179] M. Black, “More about metaphor,” in Metaphor and Thought, 2nd ed., A. Ortony, Ed. Cambridge: Cambridge University Press, 1993, pp.
19
−
41
19-41
19−41.
180] B. Dancygier, “Figurativeness, conceptual metaphor, and blending,” in The Routledge Handbook of metaphor and language. Routledge, 2016, pp. 46-59.
181] H. L. Colston, “The roots of metaphor: the essence of thought,” Frontiers in Psychology, vol. 14, p. 1197346, 2023.
182] S. Petridis and L. B. Chilton, “Human errors in interpreting visual metaphor,” in Proceedings of the 2019 Conference on Creativity and Cognition, 2019, pp. 187-197.
183] C. J. Fillmore, “Frame semantics,” in Cognitive Linguistics: Basic Readings. Berlin, New York: De Gruyter Mouton, 2006, pp. 373-400.
184] M. Avelar and A. Cienki, “Metaphors we live by in brazil: anthropophagic notes on classic and contemporary approaches to metaphor in the brazilian scientific-academic context/metáforas da vida cotidiana no brasil: notas antropofágicas sobre abordagens clássicas e contemporâneas da metáfora no contexto acadêmico-científico brasileiro,” Revista de Estudos da Linguagem, vol. 28, no. 2, pp. 667-688, 2020.
185] A. Gangemi, M. Alam, L. Asprino, V. Presutti, and D. R. Recupero, “Framester: A wide coverage linguistic linked data hub,” in Knowledge Engineering and Knowledge Management: 20th International Conference, EK4W-2016, Bologna, Italy, November 19-23, 2016, Proceedings 20. Springer, 2016, pp. 239-254.
186] R. Mao, X. Li, H. Kai, M. Ge, and E. Cambria, “Metapro online:: A computational metaphor processing online system,” in Proceedings of the 61st annual meeting of the association for computational linguistics. Association for Computational Linguistics (ACL), 2023.
187] Y. Tian, N. Xu, and W. Mao, “A theory guided scaffolding instruction framework for llm-enabled metaphor reasoning,” in Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 7731-7748.
188] E. Shutova, “Annotation of linguistic and conceptual metaphor,” Handbook of linguistic annotation, pp. 1073-1100, 2017.
189] Z. Rosen, “Computationally constructed concepts: A machine learning approach to metaphor interpretation using usage-based construction grammatical cues,” in Proceedings of the workshop on figurative language processing, 2018, pp. 102-109.
190] L. Wachowiak and D. Gromann, “Does gpt-3 grasp metaphors? identifying metaphor mappings with generative language models,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 1018-1032.
191] C. Su, S. Huang, and Y. Chen, “Automatic detection and interpretation of nominal metaphor based on the theory of meaning,” Neurocomputing, vol. 219, pp. 300-311, 2017.
192] S. Rai, S. Chakraverty, D. K. Tayal, D. Sharma, and A. Garg, “Understanding metaphors using emotions,” New Generation Computing, vol. 37, pp. 5-27, 2019.
193] C. Su, F. Fukumoto, X. Huang, J. Li, R. Wang, and Z. Chen, “Deepmet: A reading comprehension paradigm for token-level metaphor detection,” in Proceedings of the second workshop on figurative language processing, 2020, pp. 30-39.
194] X. He, L. Yu, S. Tian, Q. Yang, J. Long, and B. Wang, “Viemf: Multimodal metaphor detection via visual information enhancement with multimodal fusion,” Information Processing & Management, vol. 61, no. 3, p. 103652, 2024.
195] A. R. Akula, B. Driscoll, P. Narayana, S. Changpinyo, Z. Jia, S. Damle, G. Pruthi, S. Basu, L. Guibas, W. T. Freeman et al., “Metaclae: Towards comprehensive visual metaphors research,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 23201-23211.
196] A. Gangemi and P. Valentina, Formal Representation and Extraction of Perspectives, ser. Studies in Natural Language Processing. Cambridge University Press, 2022, p. 208-228.
197] A. Gangemi, M. Alam, and V. Presutti, “Amnestic forgery: An ontology of conceptual metaphors,” arXiv preprint arXiv:1805.12115, 2018.
198] A. Gangemi and P. Mika, “Understanding the semantic web through descriptions and situations,” in OTM Confederated International Con ferences" On the Move to Meaningful Internet Systems". Springer, 2003, pp. 689-706.
199] G. Lakoff and M. Johnson, Metaphors We Live By. University of Chicago Press, 1981.
200] A. Gangemi, A. Graciotti, A. Meloni, A. G. Nuzzolese, V. Presutti, D. R. Recupero, A. Russo, and R. Tripodi, “Text2amr2fred, a tool for transforming text into rdfowl knowledge graphs via abstract meaning representation.” in ISWC (Posters/Demos/Industry), 2023.
201] R. Blloshmi, M. Bevilacqua, E. Fabiano, V. Caruso, R. Navigli et al., “Spring goes online: end-to-end amr parsing and generation.”
202] A. Gangemi, N. Guarino, C. Masolo, A. Oltramari, and L. Schneider, “Sweetening ontologies with dolce,” in International conference on knowledge engineering and knowledge management. Springer, 2002, pp. 166-181.
203] S. Mohammad, E. Shutova, and P. Turney, “Metaphor as a medium for emotion: An empirical study,” in Proceedings of the fifth joint conference on lexical and computational semantics, 2016, pp. 23-33.
204] J. Birke and A. Sarkar, “A clustering approach for nearly unsupervised recognition of nonliteral language,” in 11th Conference of the European chapter of the association for computational linguistics, 2006, pp. 329336 .
205] G. Van Rijn-Van Tongeren and G. W. Van Tongeren, Metaphors In Medical Texts. Amsterdam: Brill Rodopi, 1997.
206] E. Semino, Z. Demjén, A. Hardie, S. Payne, and P. Rayson, Metaphor, Cancer and the End of Life: A Corpus-Based Study. London: Routledge, 2018.
207] G. Steen, L. Dorst, B. Herrmann, A. Kaal, T. Krennnayr, and T. Pasma, A Method for Linguistic Metaphor Identification: From MIP to MIPVU. Amsterdam: John Benjamins Publishing, 2010, vol. 14.
208] T. Sellam, D. Das, and A. P. Parikh, “Bleuyt: Learning robust metrics for text generation,” arXiv preprint arXiv:2004.04696, 2020.
209] A. Saakyan, T. Chakrabarty, D. Ghosh, and S. Muresan, “A report on the figlang 2022 shared task on understanding figurative language,” in Proceedings of the 3rd Workshop on Figurative Language Processing (FLP), 2022, pp. 178-183.
[60] J. Lemmens, I. Markov, and W. Daelemans, “Improving hate speech type and target detection with hateful metaphor features,” in Proceedings of the Fourth Workshop on NLP for Internet Freedom: Censorship, Disinformation, and Propaganda, A. Feldman, G. Da San Martino, C. Leberknight, and P. Nakov, Eds. Online: Association for Computational Linguistics, Jun. 2021, pp. 7-16. [Online]. Available: https://aclanthology.org/2021.nlp4if-1.2
[61] T. Chakrabarty, A. Saakyan, O. Winn, A. Panagopoulou, Y. Yang, M. Apidianaki, and S. Muresan, “I spy a metaphor: Large language models and diffusion models co-create visual metaphors,” arXiv preprint arXiv:2305.14724, 2023.
参考论文:https://arxiv.org/pdf/2504.11190
8 { }^{8} 8 完整图表可在 Github 上查看 https://github.com/dersuchendee/knowledge-augmented-generation
多语言功能。这样,Framester 知识库 [35] 链接的相关常识知识被检索并以图形形式表示。
 ↩︎
↩︎



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











