






何志伟
∗
,
1
,
2
^{*, 1,2}
∗,1,2,梁天
∗
,
1
{ }^{*, 1}
∗,1,许家豪
∗
,
1
{ }^{*, 1}
∗,1,刘秋志
1
{ }^{1}
1,陈兴宇
1
,
2
{ }^{1,2}
1,2,王跃
1
{ }^{1}
1,宋林锋
1
{ }^{1}
1,余典
1
{ }^{1}
1,梁振文
1
{ }^{1}
1,汪文轩
1
{ }^{1}
1,张卓盛
2
{ }^{2}
2,王睿
7
,
2
{ }^{7,2}
7,2,涂召鹏
7
,
1
{ }^{7,1}
7,1,米海涛
1
{ }^{1}
1,以及俞冬
1
{ }^{1}
1
1
{ }^{1}
1 腾讯
2
{ }^{2}
2 上海交通大学
https://github.com/zwhe99/DeepMath
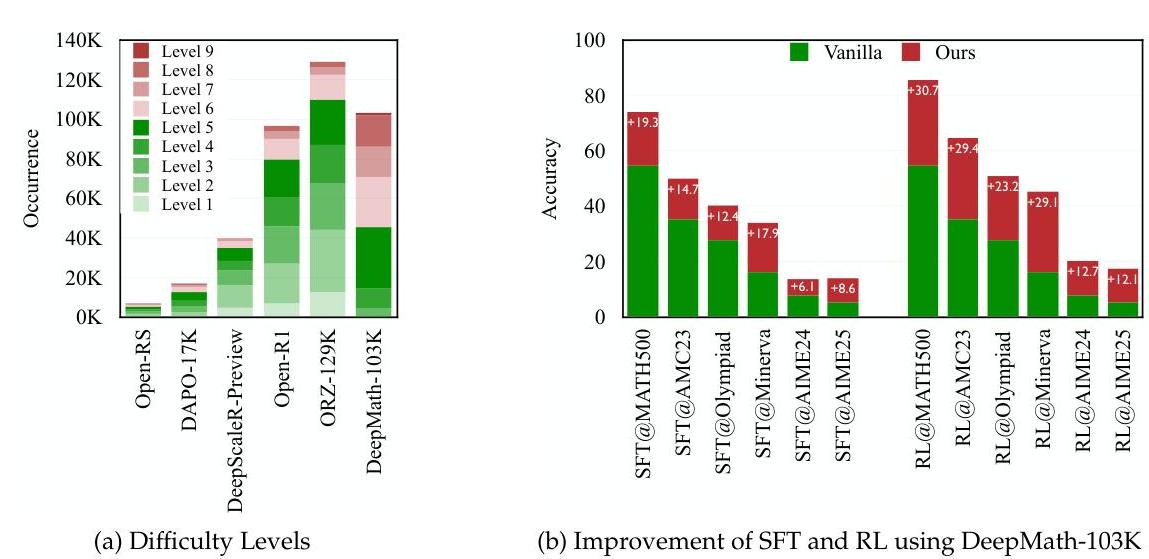
图1:我们引入了DeepMath-103K,这是一个包含大量具有挑战性的数学问题的大规模数据集。与现有的数据集相比,DeepMath-103K更具挑战性(图a)。所有问题均提供经过验证的最终答案和多种解题路径,支持广泛的训练范式,从而显著提高推理性能(图b)。
摘要
复杂的数学推理能力是人工智能的关键基准。尽管强化学习(RL)在大型语言模型(LLMs)中的应用展现出潜力,但其进展受到缺乏足够具有挑战性、适合RL的可验证答案格式且无污染的大规模训练数据的严重阻碍。为解决这些限制,我们引入了DeepMath-103K,这是一个全新的大规模数据集,包含约103K个数学问题,专门设计用于通过RL训练高级推理模型。DeepMath-103K通过涉及源分析、严格去污染及高难度筛选的严谨流程进行整理,显著超越现有开放资源的挑战水平。每个问题都包含一个可验证的最终答案,支持基于规则的RL,并提供三种不同的R1生成解决方案,适用于如监督微调或蒸馏等多样化的训练范式。涵盖广泛的数学主题,DeepMath-103K促进了通用推理的发展。我们展示了在DeepMath-103K上训练的模型在具有挑战性的数学基准测试中取得了显著改进,验证了其有效性。我们公开发布了DeepMath-103K,以促进构建更强大的AI推理系统的社区进步。
*贡献平等。这项工作是在何志伟、陈兴宇和王跃在腾讯实习期间完成的。
†
{ }^{\dagger}
† 对应联系人:涂召鹏 zptu@tencent.com 和王睿 wangrui12@sjtu.edu.cn.
1 引言
数学推理作为高级人工智能的核心能力,是检验旨在模拟复杂人类问题解决能力模型的关键试验场(Kojima等人,2022;Wei等人,2022)。最近的研究,特别是利用强化学习(RL)结合大语言模型(LLMs),在处理需要逻辑推导、符号操作和多步骤推理的复杂数学问题方面显示出巨大潜力(Jaech等人,2024;Guo等人,2025;Team,2024;xAI,2025;Google,2025)。值得注意的是,像RL-Zero(Guo等人,2025)这样的方法,通过在线RL引导二元奖励机制下的正确答案验证,已超越传统的监督微调方法。
尽管有这些前景,这些强大的RL技术的进步受到瓶颈制约:适合训练数据的稀缺性。现有的数学数据集(Hendrycks等人,2021b;Cobbe等人,2021a;Yu等人,2024;Toshniwal等人,2024)通常在几个关键方面不足。它们可能缺乏推动当前模型极限所需的极高难度,缺少实现基于规则的RL奖励方案所必需的可验证答案格式,受标准评估基准污染(损害评估完整性),或简单地在规模上不足,特别是在高度挑战性的问题上。虽然针对RL定制的人工标注数据集(Wang等人,2024;Face,2025;Hu等人,2025;Luo等人,2025b;Yu等人,2025;Dang & Ngo,2025;Albalak等人,2025)提供了宝贵的见解,但它们往往在规模上受限,并难以捕捉竞争数学中所需的极端难度,这对于训练最先进的推理者至关重要。
为了弥补这一关键差距,我们推出了DeepMath-103K,这是一套新颖的、大规模的数学数据集,专为通过强化学习加速高级推理模型的发展而设计。DeepMath-103K以其高浓度的挑战性数学问题著称,显著超越现有开放数据集中普遍存在的难度分布(图1a)。我们的数据集构建方法包括对一系列基准进行全面的数据去污染,以确保可信的评估,同时过滤主要处于高难度级别(
≥
5
\geq 5
≥5)的问题。
重要的是,DeepMath-103K中的每个问题都具有可验证的最终答案,直接支持在RL框架中应用基于规则的奖励函数。此外,每个问题都附有三个不同的R1生成解决方案(Guo等人,2025),为监督微调、奖励建模或模型蒸馏等多样化训练范式提供丰富数据(图2)。数据集涵盖了广泛的数学主题(图3),从基础概念到高级主题,促进通用推理能力的发展。包含大约103K个问题——其中包括95K个精心挑选的挑战性示例(Level 5-10)和8K个补充问题(Level 3-5)——DeepMath-103K代表了为社区提供所需资源以训练高效数学推理者的重大贡献。
我们通过展示在DeepMath-103K上训练的模型在多个具有挑战性的数学推理基准测试中取得显著性能提升来验证其有效性。这项工作提供了一个重要的、公开可访问的资源,解决了推进下一代AI推理系统所需的大型、具有挑战性、可验证且干净的数学数据的紧迫需求。
我们的主要贡献如下:
- 我们设计并发布了DeepMath-103K,这是一个新型的大规模数学数据集,专门为通过强化学习训练高级推理模型而精心策划,其特点是高难度、可验证的答案、每个问题的多种不同解决方案以及严格的去污染。
-
- 我们详细描述了一种细致的数据策划管道,包括源分析、针对标准基准进行广泛去污染以确保评估完整性、难度过滤和稳健的答案验证。
-
- 我们通过展示在DeepMath-103K上训练的模型在多个具有挑战性的数学推理基准测试中取得显著改进来证明其有效性,特别是在使用由数据集结构启用的RL-Zero技术时。
2 DeepMath-103K概述
问题:计算线积分 f 2 x P d x + Q d y \frac{f}{2x}Pdx+Qdy 2xfPdx+Qdy,沿椭圆 x 2 2 3 + y 2 36 = 1 \frac{x^2}{2^3}+\frac{y^2}{36}=1 23x2+36y2=1,其中向量场由以下公式给出: P = ( x − 1 ) 2 + y 2 x 2 + y 2 ; Q = x − 1 ( x − 1 ) 2 + y 2 P=\frac{(x-1)^2+y^2}{x^2+y^2}; Q=\frac{x-1}{(x-1)^2+y^2} P=x2+y2(x−1)2+y2;Q=(x−1)2+y2x−1。考虑向量场在椭圆内的点 ( 0 , 1 ) (0,1) (0,1)处未定义的情况下,确定积分的值。
最终答案:
2
π
2\pi
2π
难度:8
主题:数学 -> 微积分 -> 积分学 -> 积分技巧 -> 多变量
R1 解法1:好吧,所以我需要计算这个线积分……嗯,问题还提到……因此,该线积分的值为: 2 π 2\pi 2π
R1 解法2:好吧,所以我需要计算这个线积分……嗯,首先先让我回忆一下线积分是什么……因此,该线积分的值为: 2 π 2\pi 2π
R1 解法3:好吧,所以我需要计算这个线积分……所以,首先,也许我应该可视化这个椭圆……因此,该线积分的值为: 2 π 2\pi 2π
图2:来自DeepMath-103K数据集的一个示例数据样本,说明其组成部分。
DeepMath-103K中的每个数据样本都被有意设计为全面,支持数学推理研究中的各种下游应用。如图2所示,单个样本包括以下组件:
- 问题:数学问题陈述。
-
- 最终答案:可验证的最终答案,对于在RL设置中启用基于规则的奖励函数至关重要。
-
- 难度:数值难度评分,有助于像基于难度的训练(例如课程学习)或基于问题复杂性的自适应计算分配等技术(Wang等人,2025;Chen等人,2024)。
-
- 主题:问题的分层主题分类,支持特定主题的分析或训练。
-
- R1 解法:由DeepSeek-R1模型(Guo等人,2025)生成的三种不同的推理路径,适用于多样化的训练范式。
DeepMath-103K具备几个关键特征,使其特别适合于推进数学推理研究:
- R1 解法:由DeepSeek-R1模型(Guo等人,2025)生成的三种不同的推理路径,适用于多样化的训练范式。
更高难度 DeepMath-103K包含从难度等级3到10的数学问题。数据集包括95K个具有挑战性的问题(等级5-10),专为此研究精心策划,并额外增加8K个问题(等级3-5),源自SimpleRL(Zeng等人,2025b),以确保更广泛的难度覆盖。相比之下,我们分析并标记了几种现有数据集中常用的RL训练难度等级:Open-RS(Dang & Ngo,2025)、DAPO-17K(Yu等人,2025)、DeepScaleR-Preview(Luo等人,2025b)、ORZ-129K(Hu等人,2025)和Open-R1(Face,2025)。图1a展示了这些数据集的难度分布。如图所示,DeepMath-103K表现出显著更具挑战性的问题分布,相较于其他基准数据集,含有更高比例的难度等级5及以上的题目。这种对更高难度的关注旨在推动当前模型的推理极限。
广泛的主题多样性 除了高难度之外,DeepMath-103K的另一个关键特征是其在数学领域的广泛主题多样性。我们系统地将每个问题按照分层主题结构进行分类,遵循Gao等人(2024)建立的方法。如图3所示,这种分类揭示了DeepMath-103K从众多核心数学领域抽取问题。数据集的范围从基础主题如前代数和平面几何到复杂的领域如抽象代数(包括群论和域论)和高等微积分(涵盖微分方程和积分应用等)。这种广泛的主题基础确保了在DeepMath-103K上训练的模型能够接触到丰富的数学概念和问题解决范式,从而促进更强大和广泛可推广的推理技能的发展。
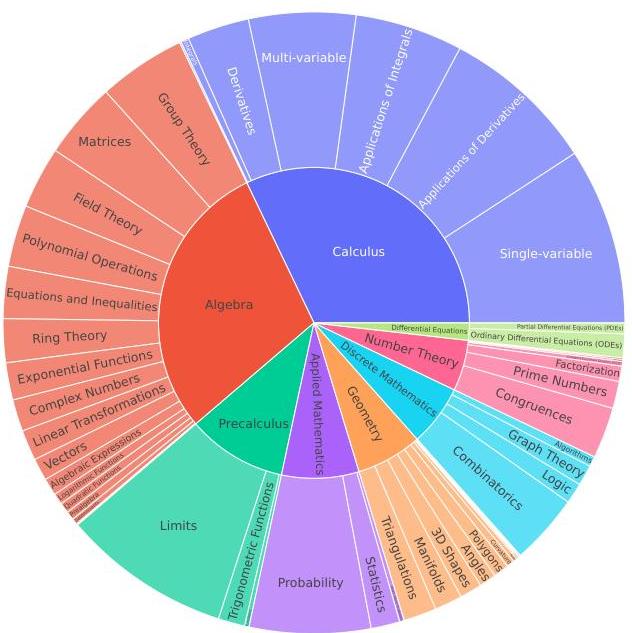
图3:DeepMath-103K涵盖的数学主题的分层分解。
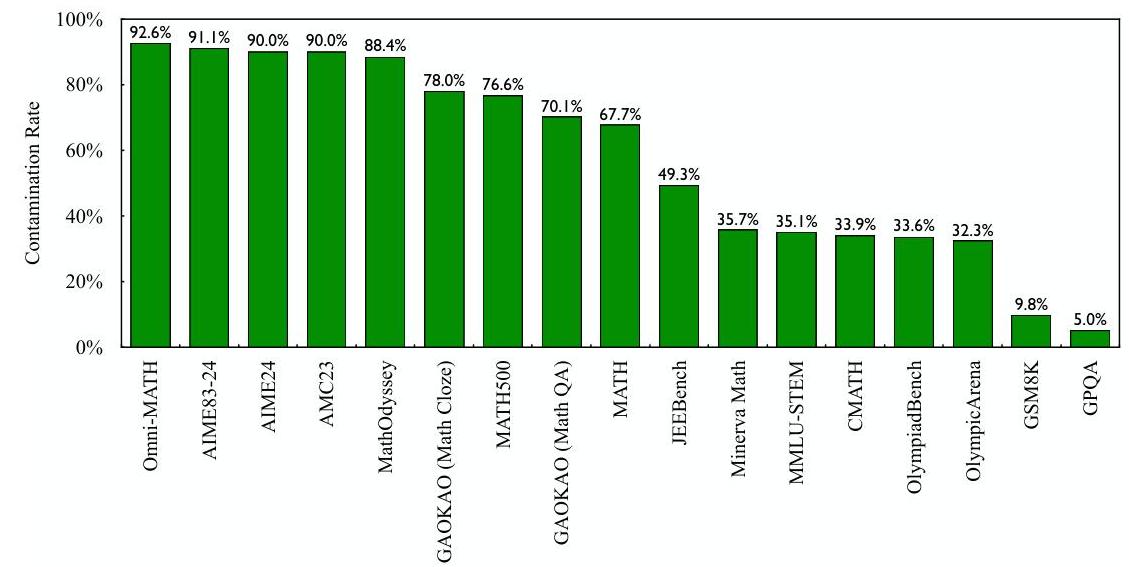
图4:常见数学和STEM基准在去污染前在原始数据源中检测到的污染率。
严格的数据去污染 DeepMath-103K完全使用现有开源数据集的训练拆分构建,仔细避免任何已知的测试集材料。然而,我们的初步分析显示,这些源数据集存在令人担忧的与常用评估基准重叠的污染水平。如图4所示,污染率(定义为在聚合的源训练拆分数据池中找到的基准测试样本百分比)相当高:AIME24达到90%,AMC23达到76.6%,MATH500达到35.7%,Minerva Math达到33.6%,OlympiadBench达到33.6%。认识到这些基准经常用于模型评估,DeepMath-103K经历了严格的去污染程序。此过程系统地识别并
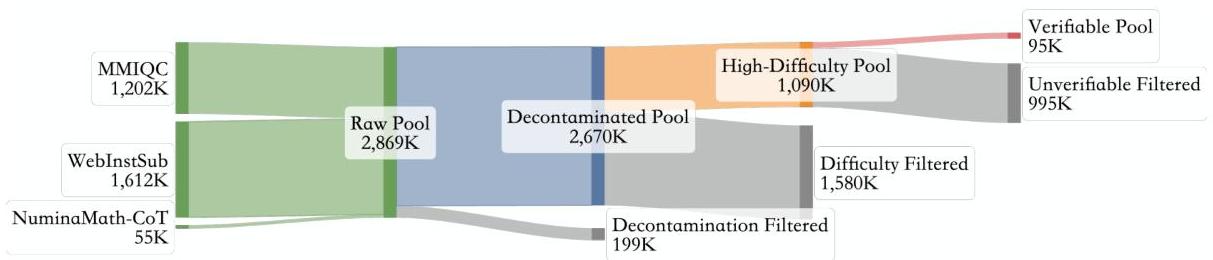
图5:DeepMath-103K的数据策划管道。从初始的2,869K原始问题池开始,经过连续阶段的数据去污染、难度过滤(保留等级
≥
5
\geq 5
≥5)和答案可验证性过滤,得到95K个问题。然后将其与8K个来自SimpleRL(Zeng等人,2025b)的问题合并,形成最终的DeepMath-103K数据集。
移除与这些标准评估集重叠的问题,确保使用DeepMath-103K训练的模型获得的未来基准结果的完整性。
适用于多样化的训练范式 DeepMath-103K的核心优势在于其全面的数据结构,既有经过验证的最终答案,也有多个解决方案路径,支持广泛的训练范式和研究方法。
- 监督微调:通过为每个问题提供三种不同的R1生成解决方案,DeepMath-103K能够创建丰富的监督训练语料库。这些解决方案提供了对相同问题的多种有效方法,使模型能够学习多样化的解决问题策略。与仅提供单一正确路径的数据集相比,DeepMath-103K解决方案的多样性帮助LLMs更好地泛化到未见过的问题。
-
- 模型蒸馏:先进的教师-学生范式通常依赖于为个别问题提供多个标记的解决方案路径。通过DeepMath-103K的三种解决方案轨迹,较大的教师模型可以有效地将多样化的解决问题风格传授给较小的学生模型,增强学生对不同推理启发式和策略的覆盖。
-
- 基于规则的强化学习(如RL-Zero):每个问题都具有可验证的最终答案,允许直接进行奖励分配,因为模型可以通过预测结果是否匹配正确解决方案来直接评估。这种二元反馈对于基于RL的方法如RL-Zero(Guo等人,2025)至关重要,通过鼓励针对正确性的具体改进来促进更深层次的推理。
-
- 奖励建模:借助多个有效的解决方案路径,可以设计区分高质量和低质量推理步骤或比较替代解决方案路线的奖励模型。这不仅细化了RL框架中的策略梯度,还辅助在多步解码流水线中重新排序或评分候选解决方案(xAI,2025)。
综合起来,这些特性使DeepMath-103K在基于AI的数学推理前沿研究中异常灵活,支持基于正确性奖励的直接RL以及受益于多个验证解决方案路径的更精细学习框架。
- 奖励建模:借助多个有效的解决方案路径,可以设计区分高质量和低质量推理步骤或比较替代解决方案路线的奖励模型。这不仅细化了RL框架中的策略梯度,还辅助在多步解码流水线中重新排序或评分候选解决方案(xAI,2025)。
3 DeepMath-103K的构建
本节详细介绍了用于构建DeepMath-103K的细致数据策划过程,如图5所示。该过程包括四个主要阶段:
- 数据源分析与收集:通过分析现有开放数据源的难度分布,识别并收集具有挑战性的数学问题。
-
- 数据去污染:严格去污染收集的数据,以去除与标准评估基准的潜在重叠,确保评估完整性。
-
- 难度过滤:根据难度对去污染后的问题进行过滤,仅保留评估为5级或更高的问题,专注于具有挑战性的内容。
-
- 答案验证:确保每个策划的问题都具有可验证的最终答案,并在DeepSeek-R1生成的多个解决方案路径中一致验证。
总体而言,这一策划管道确保DeepMath-103K基本上免受基准污染,并集中在适合高级推理模型训练的具有挑战性的数学问题上。整个过程涉及大量的计算资源,花费了 138 , 000 \mathbf{138,000} 138,000美元的GPT-40 API费用和总共 127 , 000 H 20 \mathbf{127,000}\mathbf{H20} 127,000H20 GPU小时。
- 答案验证:确保每个策划的问题都具有可验证的最终答案,并在DeepSeek-R1生成的多个解决方案路径中一致验证。
阶段1:数据源分析与收集。为了识别富含具有挑战性问题的数据源,我们首先分析了现有开放数学推理数据集的景观。这些数据集采用多样化的收集方法。例如,MetaMathQA(Yu等人,2024)、dart-math-hard(Tong等人,2024)和OpenMathInstruct-2(Toshniwal等人,2024)等数据集主要关注从已建立的数据集如GSM8K(Cobbe等人,2021a)和MATH(Hendrycks等人,2021b)中衍生的问题和解决方案的扩充。相比之下,NuminaMath-CoT(LI等人,2024)、MMIQC(Liu等人,2024)和WebInstructSub(Yue等人,2024)等数据集则更广泛地从网络中获取内容,收集来自在线平台(如Math Stack Exchange)的练习和讨论材料。
我们遵循Gao等人(2024)的方法估计这些潜在源数据集的难度分布,如图6所示。此分析揭示了明显的模式:主要从GSM8K和MATH(MetaMathQA、dart-math-hard、OpenMathInstruct-2)以及NuminaMath-CoT派生的数据集显示出偏向较低难度等级(等级1-5)的分布。相反,更多地从网络内容中获取的数据集,特别是MMIQC和WebInstructSub,显示出显著平坦的分布,具有更大比例的中高难度范围(等级5-9)的问题。基于这一发现,我们选择了MMIQC和WebInstructSub作为主要数据来源,因其具有更高比例的具有挑战性的问题。我们还加入了NuminaMath-CoT以增强初始集合的主题多样性。在应用基本过滤后,这一选择过程产生了一个原始的
2
,
869
K
2,869 \mathrm{~K}
2,869 K问题池。
阶段2:数据去污染。正如图4所示的常见基准中观察到的高污染率,严格的去污染过程对于确保DeepMath-103K的完整性至关重要。我们针对一套全面的数学和STEM基准进行了去污染,包括MATH(Hendrycks等人,2021b)、AIME(MAA,a)、AMC(MAA,b)、Minerva Math(Lewkowycz等人,2022)、OlympiadBench(He等人,2024)、Omni-MATH(Gao等人,2024)、MathOdyssey(Fang等人,2024)、GAOKAO(Zhong等人,2023)、JEEBench(Arora等人,2023)、MMLU-STEM(Hendrycks等人,2021a)、CMATH(Wei等人,2023)、OlympicArena(Huang等人,2024)、GSM8K(Cobbe等人,2021a)和GPQA(Rein等人,2024)。我们采用了Toshniwal等人(2024)提出的去污染方法,以有效去除基准问题的潜在改写。这包括以下步骤:
| 基准 | 原始问题 | 基准问题 |
|---|---|---|
| AIME24 | 在一个20x20的网格中,从左上角到右下角有多少条路线?我在Project Euler上尝试解决这个计算机编程问题。我见过一个使用nCr的方法,其中 n = 40 \mathrm{n}=40 n=40和 r = 20 \mathrm{r}=20 r=20。有人能解释这是如何工作的吗? | 考虑从8x8网格的左下角到右上角长度为16的路径。找出正好改变方向四次的路径数量,如下面所示的例子。 |
| AMC23 | 仅使用3便士、5便士和9便士硬币,无法精确支付的最大金额是多少? | 在Coinland州,硬币的价值分别为6、10和15美分。假设 x x x是以美分为单位的Coinland中最昂贵且无法用这些硬币精确支付的商品价值。 x x x的数字之和是多少? |
| MATH500 | 抱歉打扰您今天,但我遇到了这个问题:有限多个素数 p p p满足同余 8 x ≡ 1 ( m o d p ) 8x \equiv 1(\bmod p) 8x≡1(modp)没有解 x x x。确定所有这样的 p p p的总和。我最初认为答案是0,因为他们没有说 x x x必须是整数,但显然它确实如此。我不知道如何继续下去,有任何解决方案吗?谢谢您花时间阅读! | 有限多个素数 p p p满足同余 8 x ≡ 1 ( m o d p ) 8x \equiv 1(\bmod p) 8x≡1(modp)没有解 x x x。确定所有这样的 p p p的总和。 |
表1:使用语义比较检测到的原始数据池与基准之间的污染示例。颜色突出显示导致标记的概念或文本相似性。
- 对于我们原始数据集中的每个候选问题,我们使用嵌入相似性搜索(使用paraphrase-multilingual-MiniLM-L12-v2(Reimers & Gurevych,2019))来识别目标基准聚合测试集中最相似的前- k ( k = 5 ) k(k=5) k(k=5)个例子。
-
- 然后将每个候选问题与其检索到的前-
k
k
k个基准示例使用LLM-Judge(Llama-3.3-70B-Instruct(Grattafiori等人,2024))进行比较,以确定它们是否构成相同的问题或改写。为了减轻位置偏差,我们对每对问题进行了两次评估,交换问题的顺序,每次候选问题进行
2
k
2k
2k次比较。如果这些
2
k
2k
2k次比较中的任何一次表明可能存在改写或重复,该候选问题将被丢弃。
这种方法的语义目的是不仅识别完全重复的问题,还包括可能与其他评估集重叠的近似重复和改写问题。
表1展示了这种语义去污染相对于简单词汇匹配的有效性。例如,AIME24和AMC23示例表明,传达类似数学概念的问题即使在数值和措辞上有差异,也被正确标记为受污染。MATH500示例展示了嵌入在对话文本中的几乎相同的问题的检测。这些案例强调了我们方法识别细微概念重叠的能力,从而产生一个相对常见评估基准泄漏较少的数据集。
- 然后将每个候选问题与其检索到的前-
k
k
k个基准示例使用LLM-Judge(Llama-3.3-70B-Instruct(Grattafiori等人,2024))进行比较,以确定它们是否构成相同的问题或改写。为了减轻位置偏差,我们对每对问题进行了两次评估,交换问题的顺序,每次候选问题进行
2
k
2k
2k次比较。如果这些
2
k
2k
2k次比较中的任何一次表明可能存在改写或重复,该候选问题将被丢弃。
阶段3:难度过滤。先前的工作Zeng等人(2025a)强调了使RL训练数据难度与目标模型推理能力相匹配的重要性,指出强大的模型从暴露于高度挑战性问题中获益显著。基于这一见解,我们策划DeepMath-103K的过程专注于选择代表重大推理挑战的问题。为了量化难度,我们采用了Omni-MATH(Gao等人,2024)中详细描述的方法。我们根据Art of Problem Solving (AoPS)提供的注释指南,使用GPT-4o为每个去污染后的问題分配一个难度等级。为了确保稳健的估计,我们对每个问题查询GPT-40六次,并平均所得评分以确定其最终难度等级。随后,我们应用严格的过滤标准,仅保留估计难度等级为5或更高的问题。表2展示了通过这一过滤阶段的几何问题示例,说明增加的难度等级通常与更大的概念深度和推理复杂性相关联。
阶段4:答案验证。可验证的最终答案的存在对于启用RL中的基于规则的奖励机制至关重要,这有助于缓解奖励欺骗,并在训练成功的推理模型如DeepSeek-R1(Guo等人,2025)中起到了重要作用。然而,可靠地构建这样的答案存在两个主要挑战:
-
某些问题类型,如数学证明或开放式探索,本质上缺乏唯一、易于验证的最终结果。
-
- 某些答案过于复杂(例如,冗长的表达式或复杂的符号),使得自动基于规则的验证变得困难甚至不可行。
为了解决这些问题,我们实施了一个严格的两阶段验证过程:
- 某些答案过于复杂(例如,冗长的表达式或复杂的符号),使得自动基于规则的验证变得困难甚至不可行。
-
问题格式化和过滤:我们使用GPT-4o处理原始问题。不适合验证的问题类型(例如,证明)被丢弃。会话式的提问被自动重写成标准化格式,寻求单一、具体的数值或符号答案。
-
- 答案一致性检查:对于成功通过上述步骤的问题,我们使用DeepSeek-R1模型生成三条不同的解决方案路径。基于规则的验证器随后从这些生成的解决方案中提取最终答案,以及从原始源解决方案(如果可用)中提取。我们强制执行严格的一致性:只有所有提取的最终答案相同的那些问题才保留在最终数据集中。
1 { }^{1} 1 https://artofproblemsolving.com/wiki/index.php/AoPS_Wiki:Competition_ratings
| 模型 | MATH500 | AMC23 | 奥林匹克
数学 | Minerva
基准 | AIME24 | AIME25 |
| :-- | --: | --: | --: | --: | --: | --: |
| 通义千问2.5-Math-7B-Instruct | 83.2 | 59.2 | 42.6 | 41.7 | 12.1 | 11.0 |
| 通义千问2.5-7B-Base | 54.8 | 35.3 | 27.8 | 16.2 | 7.7 | 5.4 |
| 监督微调 | | | | | | |
| 1 R1 解法 | 69.2 | 47.3 | 35.9 | 29.8 | 12.3 | 8.7 |
| 3 R1 解法 | 74.1 | 50.0 | 40.2 | 34.1 | 13.8 | 14.0 |
| 零强化学习 | | | | | | |
| Open-Reasoner-Zero-7B | 81.8 | 58.9 | 47.9 | 38.4 | 15.6 | 14.4 |
| 通义千问2.5-7B-SimpleRL-Zoo | 77.0 | 55.8 | 41.0 | 41.2 | 15.6 | 8.7 |
| DeepMath-Zero-7B(我们的) | 85.5 \mathbf{85 . 5} 85.5 | 64.7 \mathbf{64 . 7} 64.7 | 51.0 \mathbf{51 . 0} 51.0 | 45.3 \mathbf{45 . 3} 45.3 | 20.4 \mathbf{20 . 4} 20.4 | 17.5 \mathbf{17 . 5} 17.5 |
| R1-Distill-通义千问1.5B(指令) | 84.7 | 72.0 | 53.1 | 36.6 | 29.4 | 24.8 |
| 强化学习 | | | | | | |
| DeepScaleR-1.5B-Preview | 89.4 \mathbf{89 . 4} 89.4 | 80.3 | 60.9 \mathbf{60 . 9} 60.9 | 42.2 \mathbf{42 . 2} 42.2 | 42.3 \mathbf{42 . 3} 42.3 | 29.6 |
| Still-3-1.5B-Preview | 86.6 | 75.8 | 55.7 | 38.7 | 30.8 | 24.6 |
| DeepMath-1.5B(我们的) | 89.0 | 81.6 \mathbf{81 . 6} 81.6 | 60.1 | 40.6 | 39.8 | 30.8 \mathbf{30 . 8} 30.8 |
- 答案一致性检查:对于成功通过上述步骤的问题,我们使用DeepSeek-R1模型生成三条不同的解决方案路径。基于规则的验证器随后从这些生成的解决方案中提取最终答案,以及从原始源解决方案(如果可用)中提取。我们强制执行严格的一致性:只有所有提取的最终答案相同的那些问题才保留在最终数据集中。
表3:使用不同训练数据集进行RL和SFT的结果。“DeepMath”表示使用DeepMath-103K训练的模型。性能通过pass@1 ( n = 16 \mathrm{n}=16 n=16) 准确率进行评估。我们也列出了通义千问2.5-Math-7B-Instruct的参考结果。
这种结合问题标准化和多解答案一致性检查的方法确保DeepMath-103K中的每个问题都有一个可以通过自动化规则稳健验证的最终答案。
4 DeepMath-103K的有效性
4.1 在具有挑战性的数学基准上的结果
为了实证验证DeepMath-103K在训练高级数学推理模型方面的有效性,我们进行了利用不同训练范式的实验。我们从两个不同的初始检查点开始训练模型:一个基础LLM通义千问2.5-7B-Base和一个已经经过监督微调用于数学推理的模型 - R1-Distill-通义千问1.5B。我们在一系列具有挑战性的数学基准上评估性能:MATH500(Hendrycks等人,2021b)、AIME 2024-2025(MAA,a)、AMC 2023(MAA,b)、Minerva Math(Lewkowycz等人,2022)和OlympiadBench(He等人,2024)。表3汇总的结果清楚地展示了使用DeepMath-103K训练的好处。
在DeepMath-103K上进行监督微调显著增强了基础模型性能,多个解决方案进一步提高了收益。如第2节所述,DeepMath-103K中的每个问题包括三个不同的R1生成解决方案,便于监督微调(SFT)。我们使用DeepMath-103K提供的第一个R1解决方案或所有三个解决方案对通义千问2.5-7B-Base进行微调。如表3所示,SFT在所有基准上都显著提高了基础模型的性能。例如,仅使用一个R1解决方案就将MATH500的准确率从 54.8 % 54.8\% 54.8%提高到 69.2 % 69.2\% 69.2%。利用所有三个不同的解决方案进一步提升了性能(例如,在MATH500上为 74.1 % 74.1\% 74.1%,在AIME25上为 14.0 % 14.0\% 14.0%),证明了让模型接触多样化问题解决策略的价值。
DeepMath-103K通过RL-Zero使基础模型达到最先进的性能。RL-Zero(Guo等人,2025)通过在线RL使用直接从可验证最终答案得出的二元奖励训练模型。这种方法与DeepMath-103K的核心设计理念完美契合,即为每个问题提供经过严格验证的最终答案(第3节的第4阶段),从而可以直接应用对推进数学推理至关重要的基于规则的奖励。我们训练了
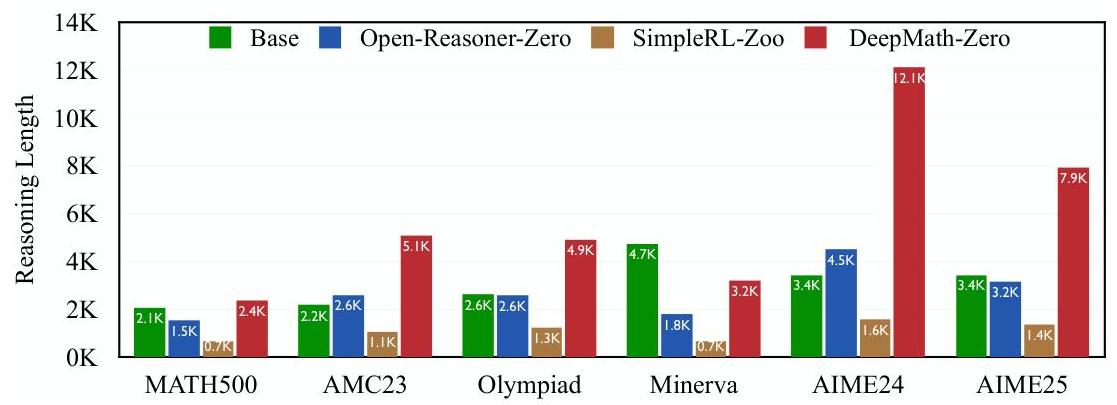
图7:使用不同数据集通过RL-Zero训练的模型在不同基准上的平均推理长度(令牌数),起始模型为通义千问2.5-7B-Base。
通义千问2.5-7B-Base模型在DeepMath-103K上使用RL-Zero进行训练(记为“DeepMath-Zero”)。为了对比,我们还包含了使用RL-Zero在其他公共RL数据集上训练的模型结果:Open-Reasoner-Zero-7B(Hu等人,2025)和通义千问2.5-7B-SimpleRL-Zoo(Zeng等人,2025a)用于7B模型。表3显示DeepMath-Zero-7B在所有基准上始终且显著优于SFT模型和其他RL数据集上训练的模型。
此外,我们还在R1-Distill-通义千问1.5B上进行了实验,这是一个已经经过监督微调用于数学推理的模型。为了对比,我们还包含了1.5B模型的DeepScaleR-1.5B-Preview(Luo等人,2025b)和Still-3-1.5B-Preview(Face,2025)的结果。如表3所示,DeepMath-Zero-1.5B在AMC23( 81.6 % 81.6\% 81.6%)和AIME25( 30.8 % 30.8\% 30.8%)上实现了在所比较的1.5B模型中的最佳结果,并在其余基准上表现居首。
显著的性能提升验证了DeepMath-103K的设计原则对推进数学推理的有效性。这些结果强有力地证明了DeepMath-103K的有效性。尤其是在RL-Zero上的显著改进,突显了DeepMath-103K核心特性的价值。数据集对高难度问题的关注推动模型走向更复杂的推理。可验证最终答案的存在使得基于规则的RL优化有效。此外,严格的去污染过程确保观察到的收益反映了真实的推理改进,而不是基准泄露。规模和主题多样性可能有助于在各种基准上观察到的稳健性。总的来说,这些实验确认DeepMath-103K作为一个强大的资源,用于训练高度有能力的数学推理模型。
4.2 使用DeepMath-103K的RL-Zero定性分析
在本节中,我们提供定性分析,以深入了解在DeepMath-103K上使用RL-Zero训练如何增强数学推理能力,重点是DeepMath-Zero-7B。
在DeepMath-103K上进行训练通常鼓励模型生成显著更长且更详细的推理步骤,特别是在高度复杂的基准上。我们分析了DeepMath-Zero-7B生成的解决方案的平均长度(令牌数)与基础模型和其他RL数据集上训练的模型相比(图7)。DeepMath-Zero-7B在几个基准上产生了明显更长的推理链,特别是在更具挑战性的基准上,如AIME24(12106个令牌 vs. Open-Reasoner-Zero的4503个和通义千问2.5-7B-SimpleRL-Zoo的1582个),AIME25(7920 vs. 3177和1365)。虽然解决方案长度不是质量的直接衡量标准,但这种显著增加表明,在DeepMath-103K的具有挑战性的问题上进行训练促使模型参与更详尽的逐步推导,可能反映了解决复杂任务所需的更深处理。
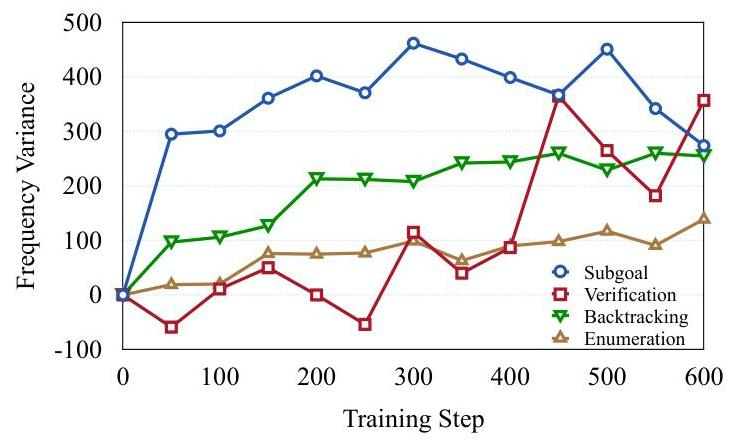
图8:在RL-Zero训练过程中观察到的有益认知行为的变化(与初始状态相比)。
在DeepMath-103K上训练的模型在RL-Zero训练过程中表现出更多的有益认知行为。我们遵循Gandhi等人(2025);Zeng等人(2025a)的方法,追踪了在DeepMath-Zero-7B的RL-Zero训练过程中出现的四种关键认知行为,这些行为与有效的问题解决密切相关:
- 分目标设定:将复杂问题分解为更小、更易管理的步骤(例如,“要解决这个问题,我们首先需要…”)。
-
- 验证:系统地检查中间结果或推理步骤(例如,“让我们通过…来验证这个结果”)。
-
- 回溯:明确修订方法以识别错误或死胡同(例如,“这种方法不行,因为… 让我们尝试…”)。
-
- 枚举:通过穷举考虑多种情况或可能性来解决问题。
图8显示了这些行为在整个训练过程中相对于初始模型频率的变化。我们观察到随着训练的进行,所有有益的认知行为都有显著增加。这表明在DeepMath-103K的具有挑战性和可验证的问题上进行优化,促使模型采用更结构化和稳健的问题解决策略,超越简单的模式匹配,转向更刻意的推理过程,涉及规划、检查和调整其方法。这些行为的出现与开发更通用和更有能力的数学推理者的目标相一致。
- 枚举:通过穷举考虑多种情况或可能性来解决问题。
5 相关工作
LLM复杂推理 LLMs使用链式思维(CoT)提示(Wei等人,2022)生成逐步推理,显著提高了其在推理密集型任务中的有效性。一系列策略倾向于通过演示直接改进LLM CoT在推理任务中的表现(Zhou等人,2022;Zhang等人,2023;Brown等人,2020;Wang等人,2022),而其他作品则贡献于CoT结构(Yao等人,2023;Chen等人,2023)、规划(Wang等人,2023)和难度(Fu等人,2023)。
近期在推理时间扩展方面的进展(Snell等人,2024;Brown等人,2024;Wu等人,2024)显著提升了LLM在复杂任务中的推理表现。在此基础上,带有正确性奖励的在线强化学习(RL)已成为
推理模型(Guo等人,2025)的一个有前途的方向。通过训练模型优化正确的最终答案,这些方法在复杂推理任务中达到了最先进的表现(Jaech等人,2024;Guo等人,2025;Team,2024;xAI,2025;Google,2025)。受此启发,我们提出了DeepMath-103K数据集,这是一个大规模且可验证答案的数据集,适合用于LLM复杂推理能力的RL。
数学推理数据集及其他 提升LLM推理能力的典型范式是对人工标注的推理数据进行监督微调。这些数学推理数据主要是从网络语料库中挖掘出来的(LI等人,2024;Zeng等人,2024;Li等人,2024;Yu等人,2024;Yue等人,2024)。相应地,随着LLM推理能力的提升,评估基准数据集侧重于评估LLM在问题解决准确性、逐步推理以及对更复杂和高难度水平问题的稳健性,这些水平甚至超越了人类专家的能力(Hendrycks等人,2021b;Lewkowycz等人,2022;He等人,2024;Gao等人,2024;Fang等人,2024;Zhong等人,2023;Arora等人,2023;Hendrycks等人,2021a;Wei等人,2023;Huang等人,2024;Cobbe等人,2021a;Rein等人,2024;Cobbe等人,2021b;MAA, a;b;Glazer等人,2024)。
在RL-Zero时代,缺乏具有挑战性、多样性和可验证性的推理问题阻碍了基于强化学习的零样本LLM推理。为了解决这一问题,我们引入了DeepMath-103K,这是一个精心策划的问题新数据集,涵盖了不同的难度级别和主题。此外,DeepMath-103K旨在避免与评估基准相关联的污染,从而缓解对测试集泄露的担忧。
RL-Zero强化学习 RL-Zero(Guo等人,2025)是一个从头开始开发基础LLM强化学习(RL)能力的简化框架。它通过使用环境互动,即问题示例上的推理正确性,来增强探索并提升推理表现,从而阐明LLM推理。最近大型语言模型(LLM)推理的进展已深刻地受到强化学习(RL)技术的影响(Jaech等人,2024;Guo等人,2025;Team,2024;xAI,2025;Google,2025)。
尽管RL-Zero在推进LLM推理方面取得了成功,但在该框架内调整的模型在推理效率上面临挑战。正如Chen等人(2024)和Wang等人(2025)所观察到的,这些模型倾向于对简单问题过度思考并生成冗余的CoTs(链式思维)进行过多验证,而在复杂问题上则思考不足,导致在不同问题难度上的表现不一致。基于上述分析,近期研究集中于开发高效的RL-zero算法以增强LLMs的高效推理能力(Chen等人,2024;Team等人,2025;Wang等人,2025;Arora & Zanette,2025;Yeo等人,2025;Luo等人,2025a)。这些努力的核心原则是根据任务的实际难度校准LLM的响应长度,这促使我们构建带有难度注释的DeepMath-103K数据集。
6 结论
在这项工作中,我们解决了阻碍AI数学推理进步的关键瓶颈,特别是针对强化学习方法:缺乏大规模、足够具有挑战性、可验证且干净的训练数据。我们介绍了DeepMath-103K,这是一个精心构建的新数据集,旨在克服这些限制。DeepMath-103K提供了一个大量(103K个问题)主要为高难度数学问题(等级5-9),每个问题都配备了对于基于规则的RL至关重要的可验证最终答案,并进一步丰富了三种不同的R1生成解决方案以支持多样化的训练方法。我们严格的策划过程,包括全面的基准去污染,确保了数据集的完整性以实现可靠的模型评估。我们展示了DeepMath-103K的实际价值,表明在其中训练的模型在要求苛刻的数学推理任务中表现出显著的性能提升。通过公开发布DeepMath-103K,我们为研究社区提供了一个关键资源,旨在加速更强大和稳健的AI系统的开发,能够应对复杂的数学挑战。
参考文献
Alon Albalak, Duy Phung, Nathan Lile, Rafael Rafailov, Kanishk Gandhi, Louis Castricato, Anikait Singh, Chase Blagden, Violet Xiang, Dakota Mahan, 和 Nick Haber. Big-math: 一个用于强化学习的大规模、高质量数学数据集,2025. URL https: //arxiv.org/abs/2502.17387.
Daman Arora 和 Andrea Zanette. 训练语言模型以高效推理. arXiv 预印本 arXiv:2502.04463, 2025.
Daman Arora, Himanshu Singh 和 Mausam. 大型语言模型是否已经足够先进?一个具有挑战性的问题解决基准. 在 Houda Bouamor, Juan Pino 和 Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 7527-7543, 新加坡,2023 年 12 月. 计算语言学协会. doi: 10.186 53 / v 1 / 2023. e m n l p − m a i n . 468 53 / \mathrm{v} 1 / 2023 . e m n l p-m a i n .468 53/v1/2023.emnlp−main.468. URL https://aclanthology.org/2023.emnlp-main.468.
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, 和 Azalia Mirhoseini. 大型语言猴子:通过重复采样扩展推理计算. arXiv 预印本 arXiv:2407.21787, 2024.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell 等. 语言模型是少量学习者. Advances in neural information processing systems, 33:1877-1901, 2020.
Wenhu Chen, Xueguang Ma, Xinyi Wang, 和 William W. Cohen. 思维程序提示:分离计算与推理以解决数值推理任务. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=YfZ4ZPt8zd.
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, 和 Dong Yu. 不要为 2 + 3 = 2+3= 2+3=想太多?关于O1类LLM的过度思考,2024. URL https: //arxiv.org/abs/2412.21187.
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, 和 John Schulman. 训练验证器以解决数学文字问题. arXiv 预印本 arXiv:2110.14168, 2021a.
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, 和 John Schulman. 训练验证器以解决数学文字问题,2021b. URL https://arxiv.org/ab s / 2110.14168 s / 2110.14168 s/2110.14168.
Quy-Anh Dang 和 Chris Ngo. 小型LLM中的推理强化学习:什么有效,什么无效,2025. URL https://arxiv.org/abs/2503.16219.
Hugging Face. Open r1: Deepseek-r1的完全开放再现,2025年1月. URL https: //github.com/huggingface/open-r1.
Meng Fang, Xiangpeng Wan, Fei Lu, Fei Xing, 和 Kai Zou. Mathodyssey: 使用Odyssey数学数据评估大型语言模型的数学问题解决技能. arXiv 预印本 arXiv:2406.18321, 2024.
Yao Fu, Hao Peng, Ashish Sabharwal, Peter Clark, 和 Tushar Khot. 基于复杂度的多步推理提示. 在 The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=yf1icZHC-19.
Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, 和 Noah D Goodman. 自我改进推理者的认知行为,或,高效明星的四个习惯. arXiv 预印本 arXiv:2503.01307, 2025.
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, Zhengyang Tang, Benyou Wang, Daoguang Zan, Shanghaoran Quan, Ge Zhang, Lei Sha, Yichang Zhang, Xuancheng Ren, Tianyu Liu, 和 Baobao Chang. Omnimath: 适用于大型语言模型的通用奥林匹克级数学基准,2024. URL https://arxiv.org/abs/2410.07985.
Elliot Glazer, Ege Erdil, Tamay Besiroglu, Diego Chicharro, Evan Chen, Alex Gunning, Caroline Falkman Olsson, Jean-Stanislas Denain, Anson Ho, Emily de Oliveira Santos, Olli Järviniemi, Matthew Barnett, Robert Sandler, Matej Vrzala, Jaime Sevilla, Qiuyu Ren, Elizabeth Pratt, Lionel Levine, Grant Barkley, Natalie Stewart, Bogdan Grechuk, Tetiana Grechuk, Shreepranav Varma Enugandla, 和 Mark Wildon. Frontiermath: 用于评估高级数学推理的人工智能基准,2024. URL https://arxiv.org/abs/2411.04872.
Google. Gemini 2.0 闪电思考,2025. URL https://cloud.google.com/vertex-ai/generati ve-ai/docs/thinking. 访问日期:2025年3月25日。
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan 等人. Llama 3 模型群. arXiv 预印本 arXiv:2407.21783, 2024.
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi 等人. Deepseek-R1: 通过强化学习激励LLM的推理能力. arXiv 预印本 arXiv:2501.12948, 2025.
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, 和 Maosong Sun. Olympiadbench: 一个具有挑战性的基准,用于通过奥林匹克级别的双语多模态科学问题促进AGI,2024.
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, 和 Jacob Steinhardt. 测量大规模多任务语言理解. 国际学习表示会议 (ICLR) 的会议记录,2021a.
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, 和 Jacob Steinhardt. 使用数学数据集测量数学问题解决能力. NeurIPS, 2021b.
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, 和 Heung-Yeung Shum Xiangyu Zhang. Open-reasoner-zero: 一种开源方法,用于在基础模型上扩展强化学习. https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero, 2025.
Zhen Huang, Zengzhi Wang, Shijie Xia, Xuefeng Li, Haoyang Zou, Ruijie Xu, Run-Ze Fan, Lyumanshan Ye, Ethan Chern, Yixin Ye, Yikai Zhang, Yuqing Yang, Ting Wu, Binjie Wang, Shichao Sun, Yang Xiao, Yiyuan Li, Fan Zhou, Steffi Chern, Yiwei Qin, Yan Ma, Jiadi Su, Yixiu Liu, Yuxiang Zheng, Shaoting Zhang, Dahua Lin, Yu Qiao, 和 Pengfei Liu. Olympicarena: 用于超级人工智能的多学科认知推理基准. arXiv 预印本 arXiv:2406.12753, 2024. URL https://arxiv.org/abs/2406.12753.
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney 等人. OpenAI O1 系统卡. arXiv 预印本 arXiv:2412.16720, 2024.
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, 和 Yusuke Iwasawa. 大型语言模型是零样本推理者. Advances in neural information processing systems, 35: 22199-22213, 2022.
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, 和 Vedant Misra. 解决定量推理问题的语言模型. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, 和 A. Oh (eds.), Advances in Neural Information Processing Systems, volume 35, pp. 3843-3857. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/18abbee f8cfe9203fdf9053c9c4fe191-Paper-Conference.pdf.
Chengpeng Li, Zheng Yuan, Hongyi Yuan, Guanting Dong, Keming Lu, Jiancan Wu, Chuanqi Tan, Xiang Wang, 和 Chang Zhou. Mugglemath: 评估查询和响应增强对数学推理的影响. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 10230-10258, 2024.
Jia LI, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, 和 Stanislas Polu. Numinamath. [https://huggingface.co/AI-MD/NuminaMath-CoT] (https://github.com/project-numina/aimo-progress-prize/blob/main/report/numina_dataset.pdf), 2024.
Haoxiong Liu, Yifan Zhang, Yifan Luo, 和 Andrew Chi-Chih Yao. 通过迭代问题组成扩充数学文字问题, 2024. URL https://arxiv.org/abs/2401.09003.
Haotian Luo, Li Shen, Haiying He, Yibo Wang, Shiwei Liu, Wei Li, Naiqiang Tan, Xiaochun Cao, 和 Dacheng Tao. O1-pruner: 长度和谐微调以进行O1类推理修剪, 2025a. URL https://arxiv.org/abs/2501.12570.
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y. Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, Raluca Ada Popa, 和 Ion Stoica. Deepscaler: 通过扩展RL超越O1-preview达到1.5亿参数模型. https://pretty-radio-b75.notion.site/DeepSca leR-Surpassing-01-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8c a303013a4e2, 2025b. Notion Blog.
MAA. 美国邀请赛数学考试(AIME). 数学竞赛系列,a. URL https://maa.org/math-competitions/aim.
MAA. 美国数学竞赛(AMC 10/12). 数学竞赛系列,b. URL https://maa.org/math-competitions/amc.
Nils Reimers 和 Iryna Gurevych. Sentence-BERT: 使用孪生BERT网络的句子嵌入. 在Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019. URL http://arxiv.org/abs/1908.10084.
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, 和 Samuel R. Bowman. GPQA: 一个研究生级别的谷歌证明问答基准. 在第一届语言建模会议上,2024. URL https://openreview.net/forum?id=Ti6758 4b98.
Charlie Snell, Jaehoon Lee, Kelvin Xu, 和 Aviral Kumar. 最优扩展LLM测试时计算比扩展模型参数更有效, 2024. URL https://arxiv.org/abs/2408 . 03314 .
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, 等人. Kimi K1.5: 使用LLM扩展强化学习. arXiv预印本arXiv:2501.12599, 2025.
Qwen Team. Qwq: 深思熟虑未知边界的界限, 2024年11月. URL https: //qwenlm.github.io/blog/qwq-32b-preview/.
Yuxuan Tong, Xiwen Zhang, Rui Wang, Ruidong Wu, 和 Junxian He. DART-math: 针对数学问题解决的难度感知拒绝调优. 在第三十八届年度神经信息处理系统会议,2024. URL https://openreview.net/forum?id=zLU21oQjD5.
Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, 和 Igor Gitman. Openmathinstruct-2: 使用大规模开源指令数据加速数学领域的AI发展. arXiv预印本arXiv:2410.01560, 2024.
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, 和 Ee-Peng Lim. 计划与解决问题提示:通过大语言模型改进零样本链式思维推理. 在Anna Rogers, Jordan Boyd-Graber, 和Naoaki Okazaki (eds.), 第六十一届计算语言学协会年会论文集(第一卷:长文),pp. 2609-2634, 加拿大多伦多,2023年7月. 计算语言学协会. doi: 10.18653 /v1/2023.acl-long.147. URL https://aclanthology.org/2023.acl-long.147/.
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, 和 Zhifang Sui. Math-shepherd: 无需人工标注验证和强化LLM逐步推理. 在第六十二届计算语言学协会年会论文集(第一卷:长文),pp. 9426-9439, 2024.
Xuezhi Wang, Jason Wei, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, 等人. 理由增强集合在语言模型中的应用. arXiv预印本arXiv:2207.00747, 2022.
Yue Wang, Qiuzhi Liu, Jiahao Xu, Tian Liang, Xingyu Chen, Zhiwei He, Linfeng Song, Dian Yu, Junta Li, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, 和 Dong Yu. 思维无处不在:关于O1类LLM的欠思考,2025. URL https://arxiv.org/abs/2501 . 18585 .
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, 等人. 链式思维提示激发大型语言模型中的推理. Advances in neural information processing systems, 35:24824-24837, 2022.
Tianwen Wei, Jian Luan, Wei Liu, Shuang Dong, 和 Bin Wang. Cmath: 你的语言模型能通过中国小学数学测试吗?, 2023.
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, 和 Yiming Yang. 推理扩展定律:对使用语言模型解决问题的最佳推理的实证分析. arXiv预印本arXiv:2408.00724, 2024.
xAI. Grok: 人工智能助手,2025. URL https://x.ai. 由xAI开发,2025年3月25日访问。
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, 和 Karthik Narasimhan. 思维之树:利用大型语言模型进行深思熟虑的问题解决. Advances in neural information processing systems, 36:11809-11822, 2023.
Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, 和 Xiang Yue. 揭秘大型语言模型中的长链式思维推理. arXiv预印本arXiv:2502.03373, 2025.
Longhui Yu, Weisen Jiang, Han Shi, Jincheng YU, Zhengying Liu, Yu Zhang, James Kwok, Zhenguo Li, Adrian Weller, 和 Weiyang Liu. Metamath: 引导自己的数学问题用于大型语言模型. 在第十二届国际学习表示会议,2024. URL https://openreview.net/forum?id=N8NOhgNDRt.
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Weinan Dai, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, Wei-Ying Ma, Ya-Qin Zhang, Lin Yan, Mu Qiao, Yonghui Wu, 和 Mingxuan Wang. Dapo: 一个大规模开源LLM强化学习系统,2025. URL https://arxiv.org/abs/2503.14476.
Xiang Yue, Tianyu Zheng, Ge Zhang, 和 Wenhu Chen. Mammoth2: 扩展来自网络的指令. Advances in Neural Information Processing Systems, 37:90629-90660, 2024.
Liang Zeng, Liangjun Zhong, Liang Zhao, Tianwen Wei, Liu Yang, Jujie He, Cheng Cheng, Rui Hu, Yang Liu, Shuicheng Yan, 等人. Skywork-math: 数学推理在大型语言模型中的数据扩展规律——故事继续. arXiv预印本arXiv:2407.08348, 2024.
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, 和 Junxian He. Simplerlzoo: 调查和驯服野外开放基础模型的零强化学习,2025a. URL https://arxiv.org/abs/2503.18892.
Weihao Zeng, Yuzhen Huang, Wei Liu, Keqing He, Qian Liu, Zejun Ma, 和 Junxian He. 7B模型和8K示例:使用强化学习出现的推理既有效又高效. https://hkust-nlp.notion.site/simplerl-reason, 2025b. Notion Blog.
Zhuosheng Zhang, Aston Zhang, Mu Li, 和 Alex Smola. 自动链式思维提示在大型语言模型中的应用. 在第十一届国际学习表示会议,2023. URL https://openreview.net/forum?id=5NTt8GFjUNkr.
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, 和 Nan Duan. AGIEval: 一个以人为中心的基础模型评估基准,2023.
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, 等人. 最少到最多提示使大型语言模型具备复杂推理能力. arXiv预印本arXiv:2205.10625, 2022.
参考论文:https://arxiv.org/pdf/2504.11456


















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











