






张义泽
1
,
2
,
3
∗
{ }^{1,2,3 *}
1,2,3∗
王昆
4
{ }^{4}
4
韩宪培
5
{ }^{5}
5
王天舒
4
,
5
,
7
∗
{ }^{4,5,7 *}
4,5,7∗
曾兴宇
4
{ }^{4}
4
孙乐
5
{ }^{5}
5
陈思蕊
1
,
6
{ }^{1,6}
1,6
林泓宇
5
{ }^{5}
5
陆超超
1
,
2
∗
{ }^{1,2 *}
1,2∗
1
{ }^{1}
1 上海人工智能实验室
2
{ }^{2}
2 上海创新研究院
3
{ }^{3}
3 上海交通大学
4
{ }^{4}
4 商汤科技
5
{ }^{5}
5 中国科学院软件研究所
6
{ }^{6}
6 同济大学
7
{ }^{7}
7 中国科学院大学杭州高等研究院 ez220523@sjtu.edu.cn, tianshu2020@iscas.ac.cn, luchaochao@pjlab.org.cn
摘要
大型语言模型(LLMs)展示了令人印象深刻的性能,并且越来越受到关注,以通过扩展测试时的计算能力来增强其推理能力。然而,在开放性、知识密集型和复杂的推理场景中,它们的应用仍然有限。面向推理的方法由于隐含假设完全的世界知识而难以推广到开放性场景。同时,知识增强推理(KAR)方法未能解决两个核心挑战:1)错误传播,其中早期步骤中的错误会通过链条级联;2)验证瓶颈,其中在多分支决策过程中会出现探索-利用权衡。为克服这些局限性,我们引入了ARISE,一种新颖的框架,将中间推理状态的风险评估与蒙特卡洛树搜索范式中的动态检索增强生成(RAG)相结合。这种方法能够有效构建和优化多个假设分支的推理计划。实验结果表明,ARISE显著优于最先进的KAR方法,最高可达 23.10 % 23.10 \% 23.10%,并且优于最新的RAG装备的大规模推理模型,最高可达 25.37 % 25.37 \% 25.37%。我们的项目页面位于https://opencausalab.github.io/ARise.
1 引言
大型语言模型(LLMs)已经在广泛的任务中展现出令人印象深刻的能力(OpenAI, 2023; Zhao et al., 2023b; Bubeck et al., 2023)。尽管取得了巨大成功,LLMs在复杂推理场景中仍面临根本挑战,阻碍了其在科学、金融和医疗等现实领域中的可靠应用(Taylor et al., 2022; Li et al., 2023; Thirunavukarasu et al., 2023)。为弥补这一差距,
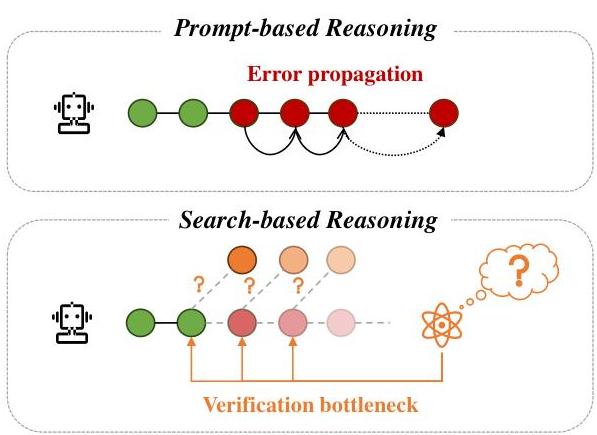
图1:错误传播和验证瓶颈。先前关于知识增强推理的工作未能解决两个核心挑战:1)错误传播,其中早期步骤中的错误会通过链条级联;2)验证瓶颈,其中在多分支决策过程中会出现探索-利用权衡。
最近的研究越来越多地专注于通过扩展测试时的计算能力来增强LLM推理,模仿系统2的慢思考,超越系统1的快速响应(Kahneman, 2011; Snell et al., 2024)。大量努力导致了各种方法的出现,包括基于提示(Yu et al., 2024a)、基于搜索(Hao et al., 2023)和基于学习(OpenAI, 2024; DeepSeek-AI et al., 2025),显示出巨大的前景。
然而,面向推理的方法难以推广到开放性场景(Valmeekam et al., 2022; Amirizaniani et al., 2024),主要是由于其隐含假设完全的世界知识。虽然像大规模推理模型(LRMs)这样的解决方案在数学和代码等任务上达到了专家或超人类水平的表现,但其成功高度依赖于明确的搜索算法或强化学习标准(Zhang et al., 2024a; Xu et al., 2025)。这种对增强LLM推理的过度关注隐含假设LLMs已经具备所有必要的推理知识,这在开放性或特定领域的上下文中往往缺乏。例如,法律辩护需要专门的法学知识,或者医学诊断需要最新的临床指南。事实上,推理是一个整合多种知识以得出结论的动态过程(Yu et al., 2024a; OpenAI, 2025),从而使知识获取成为推理的重要组成部分。
同时,当前的知识增强推理(KAR)方法,如图1所示,受到错误传播和验证瓶颈的影响,削弱了推理的可靠性。为了获取推理所需的知识,检索增强生成(RAG)已被证明是一种有效的方式,通过动态检索文档作为中间结果(Lewis et al., 2020; Liu et al., 2024)。基于提示的方法进一步通过链式思维(CoT)提示扩展KAR,将复杂推理分解为子步骤,并在推理过程中迭代检索相关知识(Zhao et al., 2023a; Yu et al., 2024b; Li et al., 2024)。然而,这种方法受到错误传播的困扰,其中早期步骤中的错误可能通过链条级联。虽然基于搜索的方法可以通过维护多个假设分支来缓解错误传播,但验证瓶颈限制了KAR的有效探索-利用权衡。现有的验证解决方案尚不令人满意,因为它们依赖于容易出错的自我验证(Stechly et al., 2024; Wang et al., 2023b; Zhang et al., 2024b),或者依赖于特定的验证器训练(Setlur et al., 2024; Zhang et al., 2024a)。
为克服这些局限性,我们提出了一个新颖的框架ARISE,通过风险适应搜索实现知识增强推理。如图2所示,ARISE由三个部分组成:推理状态生成、蒙特卡洛树搜索(MCTS)和风险评估。具体来说,ARISE通过分解和检索-推理迭代细化推理步骤,为LLMs提供精细的知识(§ 2.1)。MCTS将每个步骤视为搜索树中的一个节点,通过扩展线性推理来缓解错误传播,允许聚焦探索有前途的推理状态并在必要时进行回溯(§ 2.2)。风险评估利用贝叶斯风险最小化来评估每个状态的不确定性,动态平衡探索-利用权衡,引导搜索朝着可靠和新颖的推理方向(§ 2.3)。通过这种方式,ARISE通过结合结构化分解、知识检索和风险适应探索在一个统一框架内实现稳健和高效的复杂推理。
我们在三个具有挑战性的多跳问答(QA)基准数据集上进行了全面实验,这些数据集需要复杂的推理和知识整合。实验结果表明,ARISE显著优于最先进的(SOTA)KAR方法,准确率和F1分别平均提高了 23.10 % 23.10 \% 23.10%和 15.52 % 15.52 \% 15.52%。此外,与最新配备RAG的LRMs(DeepSeek-AI et al., 2025)相比,ARISE还使平均准确率和F1分别提高了 4.04 % 4.04 \% 4.04%和 25.37 % 25.37 \% 25.37%。这些结果验证了ARISE在开放性、知识密集型和复杂推理任务中的有效性。
总结一下,我们的贡献如下:
- 我们提出了一种用于开放性复杂推理的知识增强框架,并设计了一个风险适应MCTS算法来平衡推理的探索-利用权衡。
-
- 我们进行了全面的实验,验证了ARISE的有效性,并证明它优于最先进的KAR方法和最新的配备RAG的LRMs。
-
- 我们提供了经验性见解,即1)基于搜索的广泛推理可以比基于学习的深度推理探索更多解决方案,2)ARISE通过模型规模扩展逐步接近最优性能。
2 ARISE 方法
我们的方法ARISE利用风险适应树搜索为模型提供更多外部知识,从而有效地增强其推理能力。我们的流程如图2所示,包含以下三个部分:
- 推理状态生成:策略模型 1 { }^{1} 1 的单个步骤由一对动作组成:分解和检索-推理。每个步骤作为一个节点,编码一个中间推理状态。
-
- 蒙特卡洛树搜索:MCTS将一系列相互连接的节点转化为树结构。每个节点可以在指导下进行模拟扩展。局部值结合未来奖励可以在不实际前进步骤的情况下更新。
1
{ }^{1}
1 我们用“策略模型”来指代推理阶段使用的LLMs。
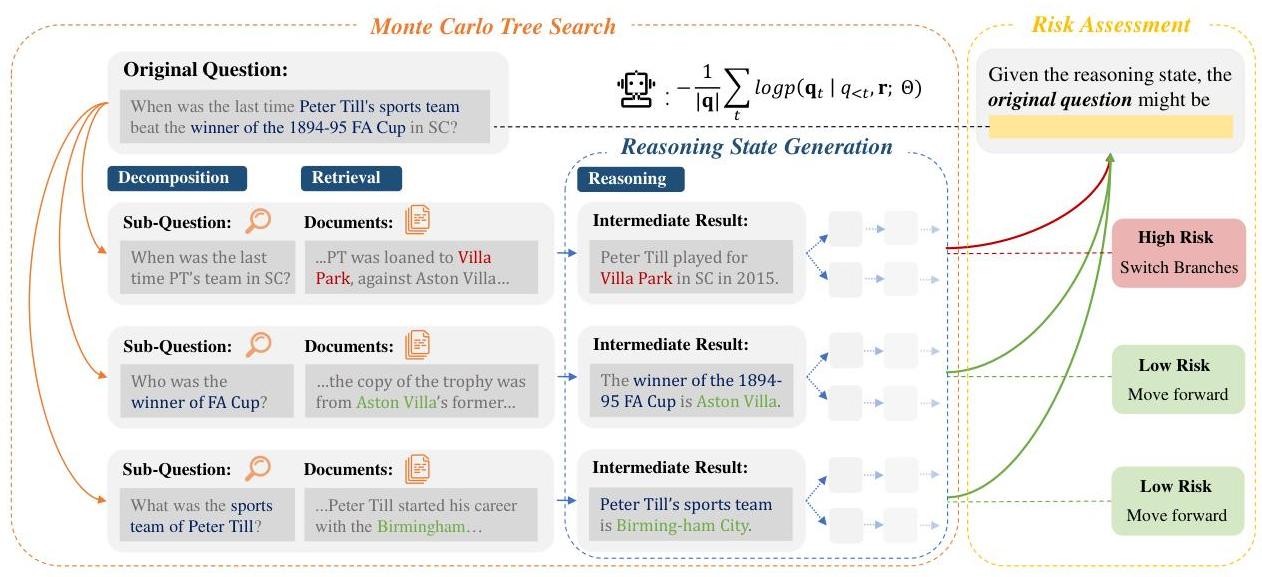
图2:ARISE流程。ARISE通过分解、检索-推理迭代细化推理步骤,为LLMs提供精细的知识(§ 2.1)。MCTS将每个步骤视为搜索树中的一个节点,通过扩展线性推理来缓解错误传播,允许探索推理路径并在必要时进行回溯(§ 2.2)。风险评估利用贝叶斯风险最小化来评估每个状态的质量,动态优化行动策略以引导搜索朝着有前途的方向前进(§ 2.3)。
- 风险评估:我们设计了RiskValue函数来评估每个节点的中间推理状态的风险。策略模型能够根据每个分支的实际风险动态制定和调整行动策略。
2.1 推理状态生成
为了更清晰和细致地定义步骤,我们提示LLMs以交错方式进行问题分解和检索-推理。这两个连续的动作共同构成一个单一步骤。每个步骤的中间结果被持续追加到整个推理状态中,并作为后续步骤的新输入,逐步接近复杂任务的最终解决方案。这种方法,即将中间子任务及其标签与原始任务的输入串联以形成新的输入序列,在复合任务中广泛应用(Wies et al., 2023; Rajani et al., 2019; Cobbe et al., 2021)。具体来说,在第 i th i^{\text {th }} ith 步骤 2 ^{2} 2 中,输入包括原始问题 q \mathbf{q} q和来自先前步骤的中间结果 r 1 , r 2 , … , r i − 1 \mathbf{r}_{\mathbf{1}}, \mathbf{r}_{\mathbf{2}}, \ldots, \mathbf{r}_{\mathbf{i}-\mathbf{1}} r1,r2,…,ri−1,后者形成推理状态 s i − 1 = r 1 ⊕ r 2 ⊕ … ⊕ r i − 1 \mathbf{s}_{\mathbf{i}-\mathbf{1}}=\mathbf{r}_{\mathbf{1}} \oplus \mathbf{r}_{\mathbf{2}} \oplus \ldots \oplus \mathbf{r}_{\mathbf{i}-\mathbf{1}} si−1=r1⊕r2⊕…⊕ri−1。然后策略模型将问题分解为子问题 d i \mathbf{d}_{\mathbf{i}} di,遵循策略 π ( d i ∣ q , s i − 1 ) \pi\left(\mathbf{d}_{\mathbf{i}} \mid \mathbf{q}, \mathbf{s}_{\mathbf{i}-\mathbf{1}}\right) π(di∣q,si−1)。基于
子问题 d i \mathbf{d}_{\mathbf{i}} di和检索到的文档,生成中间结果 r i \mathbf{r}_{\mathbf{i}} ri并重复追加到推理状态中。每个步骤编码一个 ( s i − 1 , a i ) \left(\mathbf{s}_{\mathbf{i}-\mathbf{1}}, \mathbf{a}_{\mathbf{i}}\right) (si−1,ai)对,其中 s i − 1 \mathbf{s}_{\mathbf{i}-\mathbf{1}} si−1表示状态, a i \mathbf{a}_{\mathbf{i}} ai是一组 { d i , r i } \left\{\mathbf{d}_{\mathbf{i}}, \mathbf{r}_{\mathbf{i}}\right\} {di,ri},隐含反映该步骤的两个动作, d i \mathbf{d}_{\mathbf{i}} di是与分解对应的成果, r i \mathbf{r}_{\mathbf{i}} ri是与检索-推理对应的成果。一系列连贯的步骤,延伸至终点,共同形成一条完整轨迹。
2.2 蒙特卡洛树搜索
MCTS算法将单条轨迹扩展为树形结构。整个过程从原始问题作为根节点开始,随后进行迭代搜索,包括选择、扩展、模拟和回溯四个阶段。这四个阶段详细如下:
选择。从根节点出发遍历现有树结构,算法选择最佳子节点准备下一次扩展阶段。为了平衡探索和利用,选择过程中采用了著名的上置信界(UCT)(Kocsis and Szepesvári, 2006),公式为:
UCT ( s , a ) = Q ( s , a ) + w ln N ( P a ( s ) ) N ( s , a ) \operatorname{UCT}(\mathbf{s}, \mathbf{a})=Q(\mathbf{s}, \mathbf{a})+w \sqrt{\frac{\ln N(P a(\mathbf{s}))}{N(\mathbf{s}, \mathbf{a})}} UCT(s,a)=Q(s,a)+wN(s,a)lnN(Pa(s))
其中
N
(
s
,
a
)
N(\mathbf{s}, \mathbf{a})
N(s,a)和
N
(
P
a
(
s
)
)
N(P a(\mathbf{s}))
N(Pa(s))分别代表当前节点和其父节点在之前搜索中的访问次数。
Q
(
s
,
a
)
Q(\mathbf{s}, \mathbf{a})
Q(s,a)的初始值由Risk-Value函数(详见§ 2.3)计算,并在回溯阶段更新。
扩展。模型基于不同的视角从推理状态分解原始问题以生成新子问题。每个子问题及其对应结果形成一个独立的子节点,然后附加到选定节点,从而在宽度和深度上扩展树。
模拟。模型从选定节点启动想象的扩展,直到到达叶节点。此阶段有助于通过完成想象的推理轨迹而不改变树结构,为当前节点分配一个更远见的价值,结合未来奖励。在单次扩展中,模型仍可多次采样并贪婪地向叶节点推进。
回溯。回溯阶段更新所选推理分支上所有节点的值。此过程自底向上进行,父节点的值由其子节点的值和访问次数决定。数学公式如下:
Q ( s , a ) = ∑ c ∈ C ( s , a ) Q ( c ) ⋅ N ( c ) ∑ c ∈ C ( s , a ) N ( c ) Q(\mathbf{s}, \mathbf{a})=\frac{\sum_{\mathbf{c} \in \mathcal{C}(\mathbf{s}, \mathbf{a})} Q(\mathbf{c}) \cdot N(\mathbf{c})}{\sum_{\mathbf{c} \in \mathcal{C}(\mathbf{s}, \mathbf{a})} N(\mathbf{c})} Q(s,a)=∑c∈C(s,a)N(c)∑c∈C(s,a)Q(c)⋅N(c)
其中
C
(
s
,
a
)
\mathcal{C}(\mathbf{s}, \mathbf{a})
C(s,a)表示
(
s
,
a
)
(\mathbf{s}, \mathbf{a})
(s,a)的所有子节点。
经过预定数量的搜索迭代后,树结构和节点值趋于稳定。最终,模型通过每步最大化值,遵循贪婪策略选择最佳路径。
2.3 风险评估
在本节中,我们将深入探讨Risk-Value函数,该函数对推理状态进行风险评估以指导树搜索过程。首先,对于复合问题 q \mathbf{q} q,我们将其分解和检索-推理视为概率过程的统计决策(Zhai and Lafferty, 2006; Lafferty and Zhai, 2001)。具体来说,给定一组分解后的子问题 D = { d 1 , d 2 , … , d k } D=\left\{\mathbf{d}^{\mathbf{1}}, \mathbf{d}^{\mathbf{2}}, \ldots, \mathbf{d}^{\mathbf{k}}\right\} D={d1,d2,…,dk}和相应的中间结果集合 R = { r 1 , r 2 , … , r k } 3 R=\left\{\mathbf{r}^{\mathbf{1}}, \mathbf{r}^{\mathbf{2}}, \ldots, \mathbf{r}^{\mathbf{k}}\right\}^{3} R={r1,r2,…,rk}3,可以使用相关性评分 p ( r ∣ q ) , r ∈ R p(\mathbf{r} \mid \mathbf{q}), \mathbf{r} \in R p(r∣q),r∈R(Sachan et al., 2022)来评估节点状态的质量。应用贝叶斯规则后,我们用“问题生成可能性”(Zhai and Lafferty, 2001; Ponte and Croft, 1998)替代相关性评分:
log ( r ∣ q ) = log p ( q ∣ r ) + log p ( r ) + c \log (\mathbf{r} \mid \mathbf{q})=\log p(\mathbf{q} \mid \mathbf{r})+\log p(\mathbf{r})+c log(r∣q)=logp(q∣r)+logp(r)+c
其中 p ( r ) p(\mathbf{r}) p(r)是我们假设在此情况下均匀分布的先验信念,即 r \mathbf{r} r与任何问题相关。由于 c c c是与中间结果无关的常数,我们可以忽略它。公式简化为:
log ( r ∣ q ) ∝ log p ( q ∣ r ) , ∀ r ∈ R \log (\mathbf{r} \mid \mathbf{q}) \propto \log p(\mathbf{q} \mid \mathbf{r}), \forall \mathbf{r} \in R log(r∣q)∝logp(q∣r),∀r∈R
其中
p
(
q
∣
r
)
p(\mathbf{q} \mid \mathbf{r})
p(q∣r)衡量中间结果
r
\mathbf{r}
r与特定问题
q
\mathbf{q}
q的适配程度。我们利用策略模型计算生成原始问题标记的平均对数似然,以估计
log
p
(
q
∣
r
)
\log p(\mathbf{q} \mid \mathbf{r})
logp(q∣r)(Sachan et al., 2022; Yuan et al., 2024),并将指向
r
\mathbf{r}
r的节点
(
s
,
a
)
(\mathbf{s}, \mathbf{a})
(s,a)的预期风险定义如下:
Risk
(
(
s
,
a
)
→
r
∣
q
)
=
−
1
∣
q
∣
∑
t
log
p
(
q
t
∣
q
<
t
,
r
;
Θ
)
\operatorname{Risk}((\mathbf{s}, \mathbf{a}) \rightarrow \mathbf{r} \mid \mathbf{q})=-\frac{1}{|\mathbf{q}|} \sum_{t} \log p\left(q_{t} \mid \mathbf{q}_{<t}, \mathbf{r} ; \Theta\right)
Risk((s,a)→r∣q)=−∣q∣1∑tlogp(qt∣q<t,r;Θ),
其中
∣
q
∣
|\mathbf{q}|
∣q∣表示原始问题的长度,
q
t
q_{t}
qt表示
q
\mathbf{q}
q中的第
t
th
t^{\text {th }}
tth 标记,
q
<
t
\mathbf{q}_{<t}
q<t表示
q
\mathbf{q}
q中第
t
th
t^{\text {th }}
tth 标记之前的标记序列。
Θ
\Theta
Θ表示策略模型的参数。最后,通过反向的sigmoid函数将风险缩放到(0,1)范围内,作为节点值:
Q ( s , a ) = 1 − 1 1 + e α ⋅ ( Risk − β ) Q(\mathbf{s}, \mathbf{a})=1-\frac{1}{1+e^{\alpha \cdot(\text { Risk }-\beta)}} Q(s,a)=1−1+eα⋅( Risk −β)1
其中 α , β \alpha, \beta α,β是平移和缩放因子。
3 实验
3.1 设置
数据集。我们使用HotpotQA (Yang et al., 2018),2WikiMultihopQA (Ho et al., 2020) 和 MusiQue (Trivedi et al., 2022) 作为测试集。这些数据集涵盖了广泛的主题,需要检索和推理多个支持文档。为了平衡计算效率和评估的鲁棒性,我们在随机选择的200个问题子集上进行实验(Jiang et al., 2024; Feng et al., 2025)。更多细节请参见§ B.1。
3 { }^{3} 3 在此符号表示法中,符号的下标表示推理步骤的序列号,而上标表示不同推理视角的标识符。
| 方法 | HotpotQA | 2Wiki | MusiQue | 平均 | ||||
|---|---|---|---|---|---|---|---|---|
| EM | F1 | EM | F1 | EM | F1 | EM | F1 | |
| Qwen2.5-14B-Instruct | ||||||||
| 基础版 | 59.50 | 63.63 | 37.00 | 50.33 | 14.50 | 47.07 | 37.00 | 53.68 |
| 基于提示 | ||||||||
| Query2Doc (Wang et al., 2023a) | 61.00 | 67.65 | 38.00 | 53.40 | 22.00 | 55.79 | 40.33 | 58.95 |
| Self-Ask (Press et al., 2023) | 58.50 | 64.74 | 38.50 | 53.45 | 25.00 | 58.59 | 40.67 | 58.93 |
| Verify-and-Edit (Zhao et al., 2023a) | 62.50 | 70.16 | 38.50 | 57.68 | 22.00 | 55.30 | 41.00 | 61.05 |
| Auto-RAG (Yu et al., 2024b) | 68.00 | 66.64 | 53.00 | 55.13 | 35.50 | 59.05 | 52.17 | 60.27 |
| 基于搜索 | ||||||||
| CoT-SC (Wang et al., 2023b) | 63.00 | 71.39 | 37.50 | 54.41 | 16.00 | 57.46 | 38.83 | 61.09 |
| RATT (Zhang et al., 2024b) | 64.50 | 73.91 | 43.00 | 57.48 | 24.00 | 63.76 | 43.83 | 65.05 |
| ARISE (我们的方法) | 73.50 | 75.39 | 56.50 | 62.61 | 40.50 | 65.87 | 56.83 | 67.96 |
| Qwen2.5-7B-Instruct | ||||||||
| 基础版 | 54.50 | 63.63 | 36.50 | 50.33 | 11.00 | 47.07 | 34.00 | 53.68 |
| 基于提示 | ||||||||
| Query2Doc (Wang et al., 2023a) | 60.00 | 67.31 | 37.00 | 53.78 | 14.50 | 54.59 | 37.17 | 58.56 |
| Self-Ask (Press et al., 2023) | 44.00 | 61.43 | 27.50 | 48.86 | 22.00 | 57.48 | 31.17 | 55.92 |
| Verify-and-Edit (Zhao et al., 2023a) | 67.00 | 69.87 | 39.00 | 53.91 | 21.50 | 54.75 | 42.50 | 59.51 |
| Auto-RAG (Yu et al., 2024b) | 66.50 | 66.33 | 44.50 | 54.00 | 29.50 | 57.19 | 46.83 | 59.17 |
| 基于搜索 | ||||||||
| CoT-SC (Wang et al., 2023b) | 60.50 | 70.66 | 38.00 | 54.01 | 15.00 | 56.72 | 37.83 | 60.46 |
| RATT (Zhang et al., 2024b) | 58.50 | 68.88 | 36.50 | 53.91 | 18.00 | 56.58 | 37.67 | 59.79 |
| ARISE (我们的方法) | 66.50 | 73.87 | 47.50 | 61.37 | 29.00 | 62.26 | 47.67 | 65.83 |
| Llama3.1-8B-Instruct | ||||||||
| 基础版 | 55.50 | 63.63 | 31.50 | 50.33 | 14.00 | 47.07 | 33.67 | 53.68 |
| 基于提示 | ||||||||
| Query2Doc (Wang et al., 2023a) | 57.50 | 63.52 | 32.50 | 49.78 | 19.00 | 49.91 | 36.33 | 54.40 |
| Self-Ask (Press et al., 2023) | 57.00 | 62.10 | 40.00 | 51.26 | 20.50 | 52.14 | 39.17 | 55.17 |
| Verify-and-Edit (Zhao et al., 2023a) | 50.50 | 65.07 | 29.00 | 51.91 | 13.50 | 49.77 | 31.00 | 55.58 |
| Auto-RAG (Yu et al., 2024b) | 51.00 | 53.37 | 35.00 | 48.81 | 21.50 | 52.61 | 35.83 | 51.60 |
| 基于搜索 | ||||||||
| CoT-SC (Wang et al., 2023b) | 64.50 | 71.40 | 45.00 | 58.02 | 22.00 | 59.43 | 43.83 | 62.96 |
| RATT (Zhang et al., 2024b) | 58.50 | 71.18 | 46.00 | 56.18 | 29.50 | 63.66 | 44.67 | 63.67 |
| ARISE (我们的方法) | 63.00 | 74.78 | 34.50 | 63.19 | 24.50 | 66.38 | 40.67 | 68.12 |
表1:ARISE与广泛基线的比较。
基线和指标。所有基线都结合了RAG。对于基于提示的基线,我们将ARISE与Query2Doc (Wang et al., 2023a), Self-Ask (Press et al., 2023), Verify-andEdit (Zhao et al., 2023a) 和 Auto-RAG (Yu et al., 2024b) 进行比较。对于基于搜索的基线,我们使用Self-Consistency (SC) (Wang et al., 2023b) 和 Retrieval-augmented-thought-tree (RATT) (Zhang et al., 2024b)。我们选择EM准确性和F1分数作为评估指标。如果预测答案正好包含在真实答案中,则预测正确(Jiang et al., 2024; Feng et al., 2025)。更多细节请参见§ B.2。
实施细节。在主要实验中,我们将迭代次数配置为200,
UCT中的探索权重因子
w
w
w设为1.4 ,温度设为0.7 。对于检索过程,我们采用BM25作为检索器。前向推理的提示直接描述任务,采用零样本指令。对于验证提示,我们提供少量样本演示。更多细节和具体提示请参见§ B.4。
3.2 主要结果
发现1:ARISE表现出优异性能。表1展示了ARISE和各种基线的综合实验结果。具体来说,在Qwen2.5-14B-Instruct模型上,ARISE在所有基准测试中表现优异,相对于基础RAG方法在EM上的绝对改进率为 19.83 % 19.83 \% 19.83%,相对于基于提示的基线为13.29%,相对于基于搜索的基线为 15.5 % 15.5 \% 15.5%。ARISE在Qwen2.5-7B-Instruct模型上也表现出稳健性能,相对于基础RAG方法在EM上的绝对改进率为$13.67 % $,总体上超过了各种基线。我们观察到ARISE在Llama模型上的表现略差。为进一步分析这一点,我们发现另一个有趣的现象:Auto-RAG采用与ARISE相同的交错分解和检索范式,也在Llama上表现出下降。这种现象表明Llama模型可能不适合迭代问题分解。相比之下,连续步骤推理方法如CoT和树思维表现出更好的结果。不过,ARISE在Llama上仍保持显著的F1优势,表明其在选择更有前途路径方面的有效性。
发现2:ARISE在更具挑战性的任务上表现出巨大潜力。我们兴奋地展示ARISE在更具挑战性的数据集上表现出色。基于平均表现,难度从HotpotQA逐渐增加到2WikiMultihopQA,再到MusiQue。特别是,在14B模型上,ARISE在HotpotQA上相对于基础RAG方法在EM上实现了 23.53 % 23.53 \% 23.53%的相对改进,这一数字在2WikiMultihopQA和MusiQue上分别飙升至 52.70 % 52.70 \% 52.70%和179.31%。相比之下,各种基线仅表现出平均 5.74 % 5.74 \% 5.74%, 11.94 % 11.94 \% 11.94% 和 66.09 % 66.09 \% 66.09%的性能提升。F1分数反映了同样的趋势,相对改进分别为 18.48 % 18.48 \% 18.48%, 24.40 % 24.40 \% 24.40% 和 39.94 % 39.94 \% 39.94%,对应三个基准测试。
3.3 与基于学习的LRMs比较
发现3:基于学习的LRMs尚未达到能有效匹配甚至取代基于搜索的推理方法如ARISE的程度。我们对基础模型与ARISE以及DeepSeek-R1蒸馏模型的经验比较揭示了测试时搜索的有效性关键见解。这些基于学习的LRMs从DeepSeekR1提取类似的推理模式。如图3所示,ARISE在Qwen模型系列上表现出优于LRMs的性能优势。尽管ARISE在Llama上相对于DeepSeek-R1风格的推理模式稍逊一筹,但它在Qwen模型上始终表现出色。平均而言,ARISE表现出 4.03 % 4.03 \% 4.03%的相对改进,强调了我们基于搜索的方法的优势。这些结果表明,尽管基于学习的LRMs如DeepSeek-R1蒸馏模型提供了有价值的见解,但它们尚未表现出与基于搜索的推理相同的效果。
3.4 模型规模
发现4:随着模型规模的增加,ARISE逐步接近最优性能上限,解锁更大模型的潜力。我们在Qwen2.5系列模型上进行了实验,涵盖从0.5 B到32 B的参数规模范围,如图4所示。为真实且显著地反映相关趋势,我们选择了两个更具挑战性的测试集:2WikiMultihopQA和Musique。我们采用Pass@N作为指标来评估成功率的上限,只要树中有一个存活节点能导出正确答案,就认为问题已解决。Pass@1则表示在ARISE指导下选出的最佳路径的成功率。结果显示Pass@N和基础方法随模型参数规模的变化趋势相似,但仍有平均 26.85 % 26.85 \% 26.85%的显著改进空间。这表明适当扩大推理计算提供了显著提升性能的潜力。我们观察到当模型大小达到7B参数时,上限和朴素检索的性能趋于饱和,表明进一步扩大模型参数收益递减。相比之下,随着模型参数的增加,ARISE表现出一致的改进。最佳路径选择的准确性逐渐接近上限,Pass@1和Pass@N之间的成功率差距从 25.00 % 25.00 \% 25.00%缩小到 7.25 % 7.25 \% 7.25%。
3.5 消融研究
3.5.1 风险评估
发现5:Risk-Value函数有效评估推理状态的风险,指导树搜索过程。我们进行了消融研究以评估Risk-Value (RV) 函数在指导蒙特卡洛树搜索(MCTS)中的有效性。表2展示了与基础MCTS和LLM-as-Judge 4 { }^{4} 4 基线相比的实验结果。加入RV函数后,所有数据集上的表现均有改善。具体来说,相较于基础MCTS基线,平均相对性能提升了 10.71 % 10.71 \% 10.71%。在更具挑战性的任务中,该函数的影响更为显著,MusiQue上的改进高达 17.39 % 17.39 \% 17.39%。这表明该函数能够更好地导航和优先选择低风险路径,确保搜索空间内的高效探索和利用。相比之下,带有LLM-as-Verifier的MCTS仅较基础方法略有改进。虽然预训练的LLM在验证期间可以提供有意义的上下文,但它们并未针对评估动态环境中推理状态的质量进行特别调整。这表明预训练的LLM作为独立验证者不足以进行路径规划,突显了如Risk-Value等专业函数在指导搜索过程中的关键作用。
3.5.2 MCTS迭代次数
发现6:具有动态风险评估的ARISE能够在相对较低的推理成本下实现近优解。我们针对推理成本与解质量之间的权衡进行了实证实验。具体来说,我们考察了随着MCTS迭代次数从1增加到200,ARISE的表现如何变化。图5展示了ARISE在相对较低的推理成本下达到近优解的效率。随着MCTS迭代次数的增加,
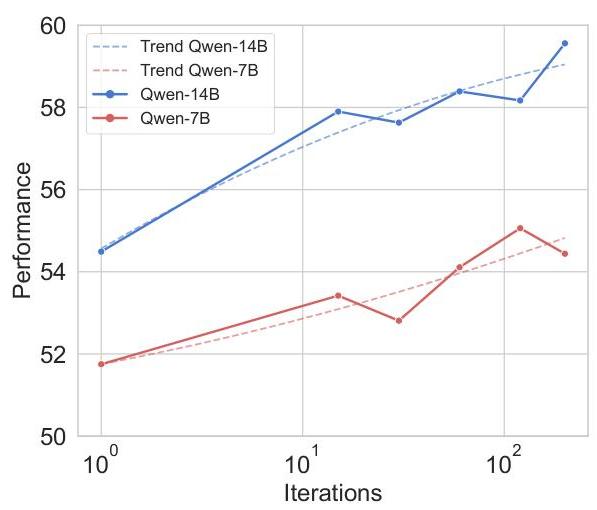
图5:迭代消融。我们使用EM准确率和F1分数的平均值来评估性能。
性能有所提高,但在较高的迭代次数下,改进速度减缓。在搜索过程的初始阶段(从1到30次迭代),性能迅速提高。初期对潜在移动的探索鼓励模型更好地理解搜索空间。此阶段增加的额外路径数量对解决方案的质量有实质性贡献。超过30次迭代后,性能改进开始趋于平稳。例如,在30到60次迭代之间,性能相对仅提高了
1.32
%
1.32 \%
1.32%,而在初始阶段,提高幅度为
5.76
%
5.76 \%
5.76%。这表明,随着算法开始收敛于最佳决策,进一步探索搜索空间的回报递减。这种现象归因于ARISE提供动态的逐步骤Risk-Value,无需等待结果验证即可指导下一步迭代。Risk-Value函数能快速缩小有希望的分支。性能在大约100次迭代后趋于稳定。进一步的迭代可能会带来增量改进,但在高度探索的搜索空间中影响较小。
3.5 MCTS迭代
发现6:具有动态风险评估的ARISE能够在相对较低的推理成本下实现近优解。我们针对推理成本与解质量之间的权衡进行了实证实验。具体来说,我们考察了随着MCTS迭代次数从1增加到200,ARISE的表现如何变化。图5展示了ARISE在相对较低的推理成本下达到近优解的效率。随着MCTS迭代次数的增加,
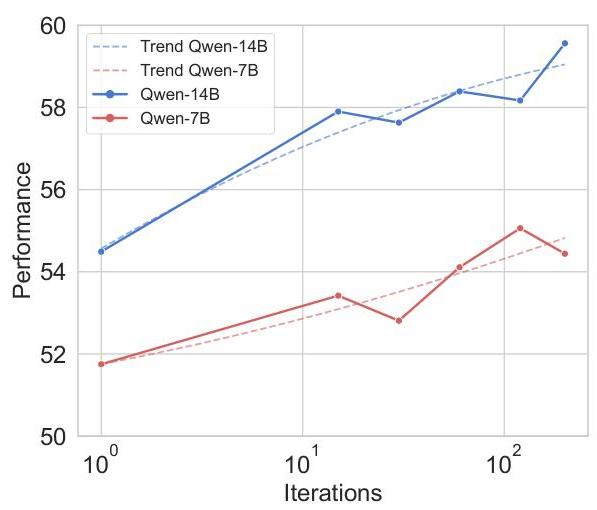
图5:迭代消融。我们使用EM准确率和F1分数的平均值来评估性能。
性能有所提高,但在较高的迭代次数下,改进速度减缓。在搜索过程的初始阶段(从1到30次迭代),性能显示出快速的改进。初期的探索有助于模型更好地理解搜索空间。在此阶段增加额外路径数量对解决方案质量有显著贡献。超过30次迭代后,性能改进开始趋于平稳。例如,在30到60次迭代之间,性能仅相对提升了
1.32
%
1.32\%
1.32%,而在初始阶段,提升幅度为
5.76
%
5.76\%
5.76%。这表明,随着算法开始收敛于最佳决策,进一步探索搜索空间的回报逐渐减少。这种现象可以归因于ARISE提供了动态的逐级Risk-Value,无需等待结果验证即可指导下一步迭代。Risk-Value函数能够迅速缩小有希望的分支。性能在大约100次迭代后趋于稳定。进一步的迭代可能会带来增量改进,但在高度探索的搜索空间中影响较小。
4 相关工作
测试时计算。扩展测试时计算最近已成为许多研究努力中的热门话题(Brown et al., 2024; Snell et al., 2024),旨在将LLMs的推理范式从快速但容易出错的系统1思维转变为更谨慎的系统2思维(Kahneman, 2011; Snell et al., 2024)。先前的工作主要包括基于提示(Yu et al., 2024a)、基于搜索(Hao et al., 2023)和基于学习(OpenAI, 2024; DeepSeek-AI et al., 2025)的方法。基于提示的推理利用链式思维(CoT)(Wei et al., 2022)提示将复杂推理分解为子步骤,通过生成额外的中间标记逐步接近更准确的最终答案(Zhao et al., 2023a; Yu et al., 2024b; Li et al., 2024)。基于搜索的推理允许LLMs通过生成多个样本提高性能,树形方法进一步集成了规划和探索(Yao et al., 2023; Besta et al., 2024; Hao et al., 2023)。尽管多次冗余模拟显著增加了推理开销,但用于解决方案选择的验证器对于确保效率至关重要。基于学习的方法旨在通过后训练将大规模复杂模型的深度推理模式注入小型模型(OpenAI, 2024; DeepSeek-AI et al., 2025)。
检索增强生成。检索增强生成(RAG)将LLMs的内在知识与外部数据库的广阔、动态存储库合并,一定程度上缓解了语言模型幻想和知识过时的问题(Lewis et al., 2020; Gao et al., 2023)。近期研究(Wang et al., 2023a; Press et al., 2023; Yu et al., 2024b; Zhao et al., 2023a)提出了一些基于提示的策略,使LLMs更好地利用RAG的潜力,本质上将其集成到中间推理过程中(例如,链式思维(CoT)(Wei et al., 2022))。在这些方法中,LLMs与检索动作的交互将推理过程分解为不连续的小步骤,有助于生成更真实的中间结果并减少自回归标记生成的固有不稳定性。
5 结论
在本工作中,我们介绍了ARISE,一种新颖的知识增强推理框架,解决了复杂推理任务中的错误传播和验证瓶颈问题。通过将MCTS与风险适应探索相结合,ARISE通过迭代分解、检索-推理步骤实现了动态和有效的推理。我们的实验表明,ARISE优于广泛的一流方法,并且超过了最新配备RAG的基于学习的LRMs的性能。这些结果突显了ARISE在推进现实世界应用中开放性、知识密集型和复杂推理任务的潜力。
局限性
尽管我们的方法ARISE在知识密集型和复杂推理任务中表现出强大的性能,但仍有一些局限性有待改进。我们当前的工作重点在于测试时搜索,将策略模型的训练留待未来研究。虽然我们已经证明了我们的方法在动态引导解决方案搜索过程中的有效性,但基于学习的LRMs有可能进一步优化性能和推理成本之间的权衡。实验中使用的提示是基于经验试验选择的,而非经过系统优化的过程。尽管这些提示在我们的任务中表现有效,但更严格的提示设计和调整方法可能有助于在各种场景下提高泛化能力和稳健性。我们的实验目前局限于多跳问答(QA)任务。ARISE在其他推理任务(如数学问题求解、代码生成或复杂决策)中的适用性仍有待探索。将我们的方法扩展到更广泛的推理任务是一个重要的未来研究方向。
参考文献
Maryam Amirizaniani, Elias Martin, Maryna Sivachenko, Afra Mashhadi, 和 Chirag Shah. 2024. LLMs能否像人类一样推理?评估LLMs在开放式问题中的心智理论推理能力。在第33届ACM国际信息和知识管理会议论文集,CIKM 2024, Boise, ID, USA, 2024年10月21日至25日,第34-44页。ACM.
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, 和 Torsten Hoefler. 2024. 思维图:用大型语言模型解决复杂问题。在第三十八届AAAI人工智能会议论文集,AAAI 2024, 第三十六届创新应用人工智能会议论文集,IAAI 2024, 第十四届教育进步人工智能研讨会论文集,EAAI 2014, 2024年2月20日至27日,加拿大温哥华,第17682-17690页。AAAI出版社。
Bradley C. A. Brown, Jordan Juravsky, Ryan Saul Ehrlich, Ronald Clark, Quoc V. Le, Christopher Ré, 和 Azalia Mirhoseini. 2024. 大型语言猴子:通过重复采样扩展推理计算。CoRR, abs/2407.21787.
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott M. Lundberg, Harsha Nori, Hamid Palangi, Marco Túlio Ribeiro, 和 Yi Zhang. 2023. 人工通用智能的火花:GPT-4的早期实验。CoRR, abs/2303.12712.
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, 和 John Schulman. 2021. 训练验证器以解决数学文字问题。CoRR, abs/2110.14168.
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, 和另外181人. 2025. Deepseek-R1: 通过强化学习激励LLMs的推理能力。
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, 和另外82人. 2024. Llama 3模型群。CoRR, abs/2407.21783.
Wenfeng Feng, Chuzhan Hao, Yuewei Zhang, Jingyi Song, 和 Hao Wang. 2025. Airrag: 通过基于树的搜索激活内在推理以实现检索增强生成。预印本,arXiv:2501.10053.
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, 和 Haofen Wang. 2023. 面向大型语言模型的检索增强生成:综述。CoRR, abs/2312.10997.
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, 和 Zhiting Hu. 2023. 使用语言模型进行推理即使用世界模型进行规划。在第2023届实证方法自然语言处理会议论文集,EMNLP 2023, 新加坡,2023年12月6日至10日,第8154-8173页。计算语言学协会。
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, 和 Akiko Aizawa. 2020. 构建一个多跳问答数据集以全面评估推理步骤。在第28届国际计算语言学会议论文集,COLING 2020, 西班牙巴塞罗那(在线),2020年12月8日至13日,第6609-6625页。计算语言学国际委员会。
Jinhao Jiang, Jiayi Chen, Junyi Li, Ruiyang Ren, Shijie Wang, Wayne Xin Zhao, Yang Song, 和 Tao Zhang. 2024. RAG-STAR: 通过检索增强验证和细化加强深思熟虑推理。CoRR, abs/2412.12881.
Daniel Kahneman. 2011. 快速思考与缓慢思考。Farrar, Straus and Giroux.
Levente Kocsis 和 Csaba Szepesvári. 2006. 基于强盗的蒙特卡洛规划。在机器学习:ECML 2006, 第17届欧洲机器学习会议论文集,柏林,德国,2006年9月18日至22日,计算机科学讲义第4212卷,第282-293页。Springer.
John D. Lafferty 和 ChengXiang Zhai. 2001. 文档语言模型、查询模型和信息检索的风险最小化。在SIGIR 2001: 第24届年度国际ACM SIGIR信息检索研究与发展会议论文集,2001年9月9日至13日,美国路易斯安那州新奥尔良,第111-119页。ACM.
Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, 和 Douwe Kiela. 2020. 检索增强生成用于知识密集型NLP任务。在神经信息处理系统进展第33卷:2020年神经信息处理系统年度会议论文集,NeurIPS 2020, 2020年12月6日至12日,虚拟会议。
Xingxuan Li, Ruochen Zhao, Yew Ken Chia, Bosheng Ding, Shafiq Joty, Soujanya Poria, 和 Lidong Bing. 2024. 知识链:通过动态知识适配跨异构源地基大型语言模型。在第十二届国际学习表示会议论文集,ICLR 2024, 奥地利维也纳,2024年5月7日至11日。OpenReview.net.
Yinheng Li, Shaofei Wang, Han Ding, 和 Hang Chen. 2023. 金融领域的大规模语言模型:综述。在第四届ACM国际金融人工智能会议论文集,ICAIF 2023, 美国纽约布鲁克林,2023年11月27日至29日,第374-382页。ACM.
Jingyu Liu, Jiaen Lin, 和 Yong Liu. 2024. RAG能帮助LLM推理多少?CoRR, abs/2410.02338.
OpenAI. 2023. GPT-4技术报告。CoRR, abs/2303.08774.
OpenAI. 2024. 学习用LLM推理。https://openai.com/index/ learning-to-reason-with-llms/.
OpenAI. 2025. 引入深度研究。https://openai.com/index/ introducing-deep-research/.
Jay M. Ponte 和 W. Bruce Croft. 1998. 一种基于语言建模的信息检索方法。在SIGIR '98: 第21届年度国际ACM SIGIR信息检索研究与发展会议论文集,1998年8月24日至28日,澳大利亚墨尔本,第275-281页。ACM.
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, 和 Mike Lewis. 2023. 测量和缩小语言模型的组合性差距。在计算语言学协会发现论文集:EMNLP 2023, 新加坡,2023年12月6日至10日,第5687-5711页。计算语言学协会。
Nazneen Fatema Rajani, Bryan McCann, Caiming Xiong, 和 Richard Socher. 2019. 解释你自己!利用语言模型进行常识推理。在第57届计算语言学协会会议论文集,ACL 2019, 意大利佛罗伦萨,2019年7月28日至8月2日,第1卷:长篇论文,第4932-4942页。计算语言学协会。
Devendra Singh Sachan, Mike Lewis, Mandar Joshi, Armen Aghajanyan, Wen-tau Yih, Joelle Pineau, 和 Luke Zettlemoyer. 2022. 使用零样本问题生成改进段落检索。在第2022届实证方法自然语言处理会议论文集,EMNLP 2022, 阿联酋阿布扎比,2022年12月7日至11日,第3781-3797页。计算语言学协会。
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, 和 Aviral Kumar. 2024. 奖励进步:扩大自动化流程验证器以支持LLM推理。CoRR, abs/2410.08146.
Charlie Snell, Jaehoon Lee, Kelvin Xu, 和 Aviral Kumar. 2024. 最优扩展LLM测试时计算比扩展模型参数更有效。CoRR, abs/2408.03314.
Kaya Stechly, Karthik Valmeekam, 和 Subbarao Kambhampati. 2024. 大型语言模型在推理和规划任务上的自我验证限制。CoRR, abs/2402.08115.
Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, 和 Robert Stojnic. 2022. Galactica: 一个用于科学的大规模语言模型。CoRR, abs/2211.09085.
Qwen Team. 2024. Qwen2.5: 一系列基础模型。
Arun James Thirumavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, 和 Daniel Shu Wei Ting. 2023. 医疗领域的大规模语言模型。Nature Medicine, 29(8):19301940.
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, 和 Ashish Sabharwal. 2022. Musique: 通过单跳问题组合构建多跳问题。Trans. Assoc. Comput. Linguistics, 10:539-554.
Karthik Valmeekam, Alberto Olmo Hernandez, Sarath Sreedharan, 和 Subbarao Kambhampati. 2022. 大型语言模型仍然无法规划(针对规划和推理变化的LLM基准)。CoRR, abs/2206.10498.
Liang Wang, Nan Yang, 和 Furu Wei. 2023a. Query2doc: 使用大型语言模型进行查询扩展。在第2023届实证方法自然语言处理会议论文集,EMNLP 2023, 新加坡,2023年12月6日至10日,第9414-9423页。计算语言学协会。
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, 和 Denny Zhou. 2023b. 自洽性提高了语言模型中的链式思维推理。在第十一届国际学习表示会议论文集,ICLR 2023, 卢旺达基加利,2023年5月1日至5日。OpenReview.net.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, 和 Denny Zhou. 2022. 链式思维提示引发了大型语言模型中的推理。在神经信息处理系统进展第35卷:2022年神经信息处理系统年度会议论文集,NeurIPS 2022, 美国路易斯安那州新奥尔良,2022年11月28日至12月9日。
Noam Wies, Yoav Levine, 和 Amnon Shashua. 2023. 子任务分解使得序列到序列任务的学习成为可能。在第十一届国际学习表示会议论文集,ICLR 2023, 卢旺达基加利,2023年5月1日至5日。OpenReview.net.
Fengli Xu, Qianyue Hao, Zefang Zong, Jingwei Wang, Yunke Zhang, Jingyi Wang, Xiaochong Lan, Jiahui Gong, Tianjian Ouyang, Fanjin Meng, Chenyang Shao, Yuwei Yan, Qinglong Yang, Yiwen Song, Sijian Ren, Xinyuan Hu, Yu Li, Jie Feng, Chen Gao, 和 Yong Li. 2025. 朝向大规模推理模型:大规模语言模型强化推理的综述。
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, 和 Christopher D. Manning. 2018. Hotpoiqa: 一个用于多样化、可解释的多跳问题回答的数据集。在第2018届实证方法自然语言处理会议论文集,比利时布鲁塞尔,2018年10月31日至11月4日,第2369-2380页。计算语言学协会。
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, 和 Karthik Narasimhan. 2023. 思维树:大型语言模型的深思熟虑问题解决。在神经信息处理系统进展第36卷:2023年神经信息处理系统年度会议论文集,NeurIPS 2023, 美国路易斯安那州新奥尔良,2023年12月10日至16日。
Fei Yu, Hongbo Zhang, Prayag Tiwari, 和 Benyou Wang. 2024a. 自然语言推理,综述。ACM Comput. Surv., 56(12):304:1-304:39.
Tian Yu, Shaolei Zhang, 和 Yang Feng. 2024b. AutoRAG: 大型语言模型的自主检索增强生成。CoRR, abs/2411.19443.
Xiaowei Yuan, Zhao Yang, Yequan Wang, Jun Zhao, 和 Kang Liu. 2024. 使用风险最小化改进零样本LLM重排序器。在第2024届实证方法自然语言处理会议论文集,EMNLP 2024, 美国佛罗里达州迈阿密,2024年11月12日至16日,第17967-17983页。计算语言学协会。
ChengXiang Zhai 和 John D. Lafferty. 2001. 应用于即席信息检索的语言模型平滑方法研究。在SIGIR 2001: 第24届年度国际ACM SIGIR信息检索研究与发展会议论文集,2001年9月9日至13日,美国路易斯安那州新奥尔良,第334-342页。ACM.
ChengXiang Zhai 和 John D. Lafferty. 2006. 信息检索的风险最小化框架。Inf. Process. Manag., 42(1):31-55.
Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, 和 Jie Tang. 2024a. REST-MCTS*: 通过过程奖励引导树搜索的LLM自训练。在神经信息处理系统进展第38卷:2024年神经信息处理系统年度会议论文集,NeurIPS 2024, 加拿大不列颠哥伦比亚省温哥华,2024年12月10日至15日。
Jinghan Zhang, Xiting Wang, Weijieying Ren, Lu Jiang, Dongjie Wang, 和 Kunpeng Liu. 2024b. RATT: 用于连贯和正确LLM推理的思维结构。CoRR, abs/2406.02746.
Ruochen Zhao, Xingxuan Li, Shafiq Joty, Chengwei Qin, 和 Lidong Bing. 2023a. Verify-and-edit: 一种知识增强的链式思维框架。在第61届计算语言学协会年度会议论文集(第1卷:长篇论文),ACL 2023, 加拿大多伦多,2023年7月9日至14日,第5823-5840页。计算语言学协会。
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, 和另外3人. 2023b. 大型语言模型综述。CoRR, abs/2303.18223.
A 进一步结果
A. 1 关于计算开销的讨论
我们从两个角度分析ARISE的计算开销:(1)其与搜索空间的关系,以及(2)其与各种基线的比较。所有实验均使用两块NVIDIA H100 GPU(80GB)进行,成本主要以推理时间(分钟)衡量,反映实时推理效率。
| (深度, 宽度) | EM | F1 | 时间(分钟) |
|---|---|---|---|
| 基础版 / (1,1) | 56.00 | 59.70 | 10 |
| ( 3 , 3 ) (3,3) (3,3) | 63.50 | 65.84 | 40 |
| ( 3 , 4 ) (3,4) (3,4) | 65.00 | 65.69 | 52 |
| ( 3 , 5 ) (3,5) (3,5) | 64.50 | 66.63 | 66 |
| ( 3 , 6 ) (3,6) (3,6) | 65.00 | 64.91 | 83 |
| ( 4 , 4 ) (4,4) (4,4) | 66.50 | 65.36 | 119 |
| ( 4 , 5 ) (4,5) (4,5) | 66.00 | 67.01 | 168 |
| ( 4 , 6 ) (4,6) (4,6) | 67.00 | 66.29 | 266 |
| ( 5 , 4 ) (5,4) (5,4) | 63.50 | 65.52 | 189 |
| ( 5 , 5 ) (5,5) (5,5) | 66.00 | 66.24 | 413 |
| ( 5 , 6 ) (5,6) (5,6) | 65.50 | 65.63 | 770 |
表3:与搜索空间相关的计算开销。随着搜索空间在深度和宽度上扩展,性能提高但回报递减且推理时间显著增加。 ( 4 , 5 ) (4,5) (4,5)设置达到了良好的平衡,并在我们的主要实验中采用。
与搜索空间相关的计算开销
我们使用Llama3.1-8B-Instruct模型在HotpotQA数据集上进行了实验。结果是在不同的搜索空间配置下得出的——由搜索深度和宽度定义。如表3所示,扩展搜索空间导致性能提高(在EM和F1分数上),尤其是在从基础设置(深度1 ,宽度1 )扩展到中等配置时。然而,随着深度和宽度的进一步增加,这些改进逐渐减少,而计算开销急剧上升。例如,将深度从3增加到4,宽度从4增加到6,推理时间从52分钟增加到266分钟,但性能改进微乎其微。基于此观察,我们在主要实验中采用了深度=4和宽度=5的配置,这在准确性和计算成本之间达到了实际平衡。值得注意的是,最佳搜索空间配置可能因实例而异。不同问题需要不同程度的推理和知识整合,通常对应于不同数量的推理跳跃。因此,根据任务复杂性自适应确定搜索空间仍然是一个开放的研究问题。即使是最先进的推理模型仍然面临在更宽和更深的推理路径之间做出选择的挑战。我们在§ 5中进一步讨论了这一点,并将其视为未来工作的有前途的方向。
| 方法 | EM | F1 | 时间(分钟) |
|---|---|---|---|
| 基础版 | 14.50 | 47.07 | 10 |
| Query2Doc | 22.00 | 55.79 | 16 |
| Self-Ask | 25.00 | 58.59 | 18 |
| Verify-and-Edit | 22.00 | 55.30 | 21 |
| Auto-RAG | 35.50 | 59.05 | 26 |
| CoT-SC | 16.00 | 57.46 | 69 |
| RATT | 24.00 | 63.76 | 155 |
| ARISE(我们的方法) | 40.50 \mathbf{4 0 . 5 0} 40.50 | 65.87 \mathbf{6 5 . 8 7} 65.87 | 160 \mathbf{1 6 0} 160 |
表4:与基线的计算开销比较。ARISE在EM和F1分数上表现最佳,但由于其基于搜索的多步推理,推理时间更高。实际部署应考虑计算资源和期望性能之间的权衡。
与基线的计算开销比较
我们进一步评估了我们的方法ARISE与一组具有竞争力的基线在Musique数据集上的计算开销,使用Qwen2.5-14B-Instruct模型。结果总结在表4中。如图所示,ARISE在EM和F1分数上表现最高,展示了我们基于搜索的推理策略的有效性。然而,这伴随着更高的计算成本,主要是由于扩大的搜索空间和多步推理过程。在实际应用中,性能和推理时间之间的权衡应根据手头任务的性质进行上下文化。在金融、医疗保健和法律等高风险领域,牺牲额外的计算时间以提高准确性往往是一项值得的投资。
A. 2 检索系统质量的影响
为了评估ARISE对底层检索系统质量的敏感程度,我们考察了两个关键因素:检索器类型和检索文档数量。
| 数据集 | BM25 EM | BM25 F1 | BGE EM | BGE F1 |
|---|---|---|---|---|
| Musique | 40.50 | 65.87 | 44.50 | 70.47 |
| HotpotQA | 73.50 | 75.39 | 74.00 | 75.41 |
| 2Wiki | 56.50 | 62.61 | 72.00 | 67.36 |
表5:检索器类型的影响。密集检索器(BGE)在所有数据集上均优于稀疏检索器(BM25),在更具挑战性的基准测试中效果更为显著。
检索器选择。我们比较了ARISE与稀疏检索器(BM25)和密集检索器(BGE)配对时的表现。如表5所示,密集检索在所有三个数据集上始终优于稀疏检索。平均而言,BGE将EM和F1分数提高了 11.7 % 11.7 \% 11.7%,在更具挑战性的数据集(如2Wiki)上尤其显著。这表明,尽管ARISE在简单任务上对检索质量表现出一定的鲁棒性(例如HotpotQA),但在更复杂的场景中,它从高质量证据中受益匪浅。这些结果表明,尽管ARISE中的验证者引导推理可以在一定程度上减轻检索噪声,但它仍然依赖于获取相关和精确的信息以进行有效的多跳推理。
| # \# # 文档 | EM | F1 |
|---|---|---|
| 1 | 28.50 | 44.14 |
| 2 | 40.50 | 65.87 |
| 3 | 37.00 | 63.97 |
表6:检索文档数量的影响。检索两个文档时性能达到峰值,表明在充分证据和检索噪声之间取得了平衡。
检索文档数量。我们进一步评估了在Musique数据集上变化检索文档数量的影响。如表6所示,检索两个文档时性能最佳。添加第三个文档并未带来进一步改进,甚至可能略微降低性能。这可以归因于两个因素。首先,任务的知识密度影响了额外上下文的益处。其次,由于ARISE的逐步推理设计,整体问题被分解为更小、更易管理的子问题,每个子问题需要较少的上下文信息。总之,ARISE对缺失关键信息比接收冗余或嘈杂证据更敏感,表现出对检索噪声的一定程度的鲁棒性。
B 更多细节
B. 1 数据集的更多细节
我们使用HotpotQA (Yang et al., 2018),2WikiMultihopQA (Ho et al., 2020),和MusiQue (Trivedi et al., 2022)作为测试集,这是三个代表开放性、知识密集型和复杂推理任务的基准。这些问题需要检索和推理多个支持文档以回答,并涵盖了广泛的主题,不受任何现有知识库或模式的约束。我们对数据集进行了预处理。具体来说,考虑到计算资源的限制,我们从每个数据集中随机抽取了200个问题作为最终测试集。每个实例包括原始问题及其答案,以及可能的参考文档和必要的支持文档。在测试阶段,我们将每个问题的可能参考文档视为其外部知识库,并使用BM25作为检索器,每次检索返回前两个文档。基于原始数据集,大多数问题涉及复杂推理,涉及三个或更多跳跃(超过80%)(Feng et al., 2025)。其中,Musique的推理难度最高,多跳问题的比例显著较高。我们将搜索深度固定为四层,以与解决问题所需的子问题分解数量相匹配,从而减少不必要的推理开销。此外,我们将初始最大可扩展子节点数设置为5,以全面覆盖跳跃次数,保证模型分解问题的多样性。随着搜索深度的增加,原始问题分解视角的多样性逐渐减少。因此,我们也逐步减少了可扩展子节点的数量,以确保搜索效率。
B. 2 评估的更多细节
我们选择EM准确率和F1分数作为评估指标。EM准确率衡量结果的成功率,而F1分数评估推理过程的可靠性。具体来说,对于EM,我们采用覆盖EM计算方法。我们对模型预测和
真实答案都进行预处理,将它们转换为统一的大小写格式。如果真实答案是预测结果的子字符串,则认为预测正确。这种方法旨在真实反映方法的性能。此外,我们使用简洁的响应提示,确保模型的最终输出不过于冗长,从而避免误报情况。对于F1分数的计算,我们利用与整个推理路径和原始问题相关的前两个文档。在最后一步,我们基于完整的推理状态进行额外检索,以确保文档反映整个路径的上下文。为了避免冗余检索模糊F1分数的比较,我们将每次检索限制为只返回前两个文档。
B. 3 LLMs的更多细节
在整个实验中,我们主要使用了Qwen系列(Team, 2024)和Llama系列模型(Dubey et al., 2024)。Qwen系列包括规模为 0.5 B , 3 B , 7 B , 14 B 0.5 \mathrm{~B}, 3 \mathrm{~B}, 7 \mathrm{~B}, 14 \mathrm{~B} 0.5 B,3 B,7 B,14 B和32B参数的模型,而Llama实验主要在8B参数模型上进行。为确保实验公平性,对于涉及风险评估或状态评估的任务,我们始终使用相应的策略模型。此外,实验还涉及DeepSeek-R1蒸馏模型(DeepSeekAI et al., 2025),包括Qwen-7B, Qwen-14B, Qwen-32B和Llama-8B。蒸馏的小模型从DeepSeekR1提取推理模式,表现出优于通过强化学习获得的推理模式的性能(DeepSeek-AI et al., 2025)。
B. 4 提示的更多细节
我们列出了ARISE中使用的所有提示的完整细节。前向推理使用的提示遵循零样本指令,直接描述任务。风险评估的提示提供了少量样本演示。
算法1 ARISE
要求:原始问题
q
q
q;分解提示
p
d
p_{d}
pd;推理提示
p
r
p_{r}
pr
要求:LLM
f
(
⋅
)
f(\cdot)
f(⋅);外部知识检索模型
g
(
⋅
)
g(\cdot)
g(⋅)
要求:选择
S
e
(
⋅
)
S e(\cdot)
Se(⋅);扩展
E
x
(
⋅
)
E x(\cdot)
Ex(⋅);模拟
S
i
(
⋅
)
S i(\cdot)
Si(⋅);回溯
B
a
(
⋅
)
B a(\cdot)
Ba(⋅)
要求:生成问题提示
p
g
p_{g}
pg;价值函数
V
(
⋅
)
V(\cdot)
V(⋅);获取最佳路径
P
(
⋅
)
P(\cdot)
P(⋅)
s
0
;
t
←
q
\mathbf{s}_{\mathbf{0}} ; \mathbf{t} \leftarrow q
s0;t←q
对于
i
=
1
,
…
,
T
i=1, \ldots, T
i=1,…,T进行循环
s
i
←
S
e
(
s
0
,
t
)
\mathbf{s}_{\mathbf{i}} \leftarrow S e\left(\mathbf{s}_{\mathbf{0}}, \mathbf{t}\right)
si←Se(s0,t)
d
i
←
f
(
s
i
,
q
,
p
d
)
d_{i} \leftarrow f\left(\mathbf{s}_{\mathbf{i}}, q, p_{d}\right)
di←f(si,q,pd)
z
i
←
g
(
d
i
)
z_{i} \leftarrow g\left(d_{i}\right)
zi←g(di)
r
i
←
f
(
z
i
,
d
i
,
p
r
)
r_{i} \leftarrow f\left(z_{i}, d_{i}, p_{r}\right)
ri←f(zi,di,pr)
s
i
+
1
←
s
i
,
r
i
,
V
(
f
(
r
i
,
q
,
p
g
)
)
\mathbf{s}_{\mathbf{i + 1}} \leftarrow \mathbf{s}_{\mathbf{i}}, r_{i}, V\left(f\left(r_{i}, q, p_{g}\right)\right)
si+1←si,ri,V(f(ri,q,pg))
t
←
E
x
(
s
i
+
1
)
\mathbf{t} \leftarrow E x\left(\mathbf{s}_{\mathbf{i + 1}}\right)
t←Ex(si+1)
t
←
S
i
(
s
i
)
;
B
a
(
s
i
,
s
0
)
\mathbf{t} \leftarrow S i\left(\mathbf{s}_{\mathbf{i}}\right) ; B a\left(\mathbf{s}_{\mathbf{i}}, \mathbf{s}_{\mathbf{0}}\right)
t←Si(si);Ba(si,s0)
结束循环
返回
P
(
s
0
,
t
)
P\left(\mathbf{s}_{\mathbf{0}}, \mathbf{t}\right)
P(s0,t)
▹
\triangleright
▹ 生成根节点和树
▹
\triangleright
▹ 执行T次MCTS迭代
▹
\triangleright
▹ 选择最佳节点
▹
\triangleright
▹ 分解问题
▹
\triangleright
▹ 检索相关文档
▹
\triangleright
▹ 前向推理
▹
\triangleright
▹ 生成新节点
▹
\triangleright
▹ 将节点附加到树上
▹
\triangleright
▹ 模拟和回溯
获取最佳路径
问题分解
你的任务是根据中间答案和观察结果将原始问题分解为一个更小的子问题。鼓励从多个角度进行分解。
输出一个用于推理原始问题的想法,并输出一个你认为适合解决的子问题。不要重复问题,也不要尝试回答问题。
输出格式限制为:
想法:…
子问题:…
这里,“…”表示需要填写的省略输出信息。
原始问题:[原始问题]
中间答案:[推理状态]
观察结果:[检索到的文档]
输出:
中间答案生成
你的任务是使用提供的支持事实回答以下问题。
输出的答案应该是一个完整的陈述句,而不是直接输出短语或单词。
句子中不要使用代词。
特别地,如果没有提供支持事实,只需输出“未找到直接相关的事实。”且不输出其他内容。
问题:[子问题]
支持事实:[检索到的文档]
输出:
最终答案生成
你的任务是基于中间答案回答原始问题。
直接输出最终答案,不输出其他内容。
原始问题:[原始问题]
中间答案:[推理状态]
输出:
风险评估
给定包含原始问题未知事实的中间答案,你的任务是推断原始问题可能是什么。
直接输出最有可能的原始问题,不输出其他内容。
示例1:
中间答案:
Muhammad Ali去世时74岁。
Alan Turing去世时41岁。
原始问题可能是:
谁活得更久,Muhammad Ali还是Alan Turing?
示例2:
中间答案:
Craigslist由Craig Newmark创立
Craig Newmark出生于1952年12月6日。
原始问题可能是:
Craigslist的创始人何时出生?
中间答案:{推理状态}
原始问题可能是:
LLM-as-Verifier
给定一个问题,你的任务是确定其分解的子问题和对应的中间答案与原始问题的一致性得分。
直接输出一个介于0到10之间的数字来表示一致性得分。
不要输出任何其他内容。
原始问题:{原始问题}
子问题:{子问题}
中间答案:{推理状态}
输出:
参考论文:https://arxiv.org/pdf/2504.10893



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











