






Md Sultan Al Nahian, Chris Delcher, Daniel Harris, Peter Akpunonu 和 Ramakanth Kavuluru
摘要
从患者的医疗记录中预测药物过量风险的能力对于及时干预和预防至关重要。传统机器学习模型在分析纵向医疗记录以完成这一任务方面显示出潜力。然而,大型语言模型(LLMs)的最新进展提供了一个机会,通过利用它们处理长文本数据和跨多种任务的固有先验知识来提高预测性能。在本研究中,我们评估了Open AI的GPT-40 LLM在使用患者纵向保险索赔记录预测药物过量事件方面的有效性。我们在微调和零样本设置下评估其性能,并将其与强大的传统机器学习方法作为基线进行比较。我们的结果表明,LLMs不仅在某些设置下优于传统模型,还可以在零样本设置下预测过量风险而无需特定任务的训练。这些发现突显了LLMs在临床决策支持中的潜力,特别是用于药物过量风险预测。
索引术语 - 机器学习,自然语言处理,大型语言模型,理赔数据,药物过量。
I. 引言
药物过量(OD)是美国主要的公共卫生危机,每年导致大量紧急医疗干预和死亡。根据疾病控制和预防中心(CDC)的数据,2022年美国因药物过量死亡的人数约为107,941人[1],这凸显了对有效预防和干预策略的迫切需求。除了对患者致命后果和生活质量的丧失外,处方药滥用、非法药物和多重药物滥用已对医疗系统、急救人员和政策制定者造成了巨大负担。早期识别高危个体可以促进及时干预,如针对性临床评估、行为支持和处方监测,从而降低致命结果的可能性。
Md Sultan Al Nahian 来自肯塔基大学生物医学信息学研究所,地址:美国肯塔基州列克星敦,邮编:40536。(电子邮件:sa.nahian@uky.edu)
Chris Delcher 和 Daniel Harris 来自肯塔基大学药学实践与科学系,地址:美国肯塔基州列克星敦,邮编:40536。(电子邮件:chris.delcher@uky.edu;daniel.harris@uky.edu)
Peter Akpunonu 来自肯塔基大学急诊医学系,地址:美国肯塔基州列克星敦,邮编:40536。(电子邮件:pe-ter.akpunonu@uky.edu)
Ramakanth Kavuluru 来自肯塔基大学内科医学系,并在计算机科学系持有兼职任命,地址:美国肯塔基州列克星敦,邮编:40536。(电子邮件:ramakanth.kavuluru@uky.edu)
传统上,药物过量风险评估依赖于临床判断、患者自我报告以及基于人口统计、行为和病史数据的结构化风险评估工具。一个广泛使用的工具是处方药监测计划(PDMP)[2],这是一个电子数据库,追踪各州内的受控物质处方情况。授权用户包括医生、药剂师、执法部门和公共卫生官员,他们可以查询PDMPs以识别可能有害或非法的处方药使用模式。然而,PDMPs经常遭受数据不完整的问题,其有限的州际数据共享使得很难监控跨州获取药物的患者。此外,数据录入延迟可能会进一步导致信息缺失,阻碍安全和知情决策[3]。虽然PDMPs和毒理学筛查为潜在过量风险提供了有价值的见解,但这些方法主要是反应性的而非主动性的。它们还依赖于临床医生手动审查患者的病史,可能导致忽略模式和不一致之处。因此,传统方法可能无法捕捉到促成过量风险的复杂、纵向因素,强调了对数据驱动自动化过程的需求。
为了克服手动过程的局限性,近年来,机器学习(ML)方法已经出现,成为通过利用大规模电子健康记录(EHRs)、保险索赔数据和处方历史改进过量预测的有希望的工具。传统的ML模型,如逻辑回归、随机森林和深度学习方法[4]-[6],已经展示了通过分析诸如先前诊断、药物处方、医疗资源利用模式和社会健康决定因素等因素识别高风险个体的能力。这些模型可以处理结构化和非结构化的医疗数据,揭示传统评估中可能被忽略的隐藏相关性。然而,许多现有的ML方法需要广泛的特征工程,并且通常难以捕捉顺序患者访问中的时间依赖性。
最近大型语言模型(LLMs)[7]的进步为克服传统机器学习模型在预测药物过量风险方面的局限性提供了有希望的机会。LLMs在大量数据上进行了预训练,包括生物医学和临床文本,使它们能够理解复杂的医疗信息,这可能使它们能够根据患者的病史生成明智的决策[8]。与需要广泛特征工程的传统ML模型不同,LLMs可能利用
其上下文理解更有效地处理顺序医疗事件 [9], [10]。此外,这些模型在其预训练过程中获得了先验知识,允许它们在不需要特定任务微调的情况下,在各种任务中做出明智的预测。在本研究中,我们探讨了LLMs在从患者纵向医疗历史(记录在保险索赔中)预测药物过量事件中的潜力。
具体来说,我们调查了Open AI的GPT-4o在使用Merative MarketScan(前身为Truven)数据集预测药物过量事件中的能力,该数据集包括患者的诊断、程序记录、用药历史和人口统计数据。我们将过量预测视为一个序列建模问题,其中模型处理患者过去的医疗访问,以估计在未来两个预定义时间窗口(下一个7天和30天)内发生药物过量事件的可能性。为此,我们设计了不同的提示模板,向模型提供纵向访问信息和任务说明。为了评估基于LLM的方法的有效性,我们进行了零样本推理实验(模型未使用任何特定任务数据进行训练)和微调实验(模型使用此类数据进行微调)。然后我们将它们的性能与传统的机器学习模型(包括随机森林和XGBoost)进行比较,这两种方法广泛用于结构化数据 [11], [12]。我们的分析提供了关于LLMs在临床预测任务中的优势和局限性的见解,特别是在建模复杂的纵向患者数据时。
II. 数据集
在这项研究中,我们使用了来自Merative MarketScan研究数据库(前身为Truven)的数据。这个综合数据库包含从保险索赔中提取的去标识化的患者特定健康信息,涵盖了大量多样化的人口。数据集包括关键的医疗保健数据元素,如患者人口统计、诊断、程序、处方药物和就诊记录。它提供了患者在医疗系统中的纵向就诊视图,使深入分析医疗趋势、治疗模式和患者结果成为可能。
A. 队列选择
在这项研究中,我们使用了涵盖三年(2020-2022)的Merative MarketScan数据。研究队列包括以下患者:(1)至少18岁,和(2)至少有12个月的连续数据,且最少有五次医疗事件(例如,诊断、程序或处方)。
我们根据这些标准提取队列,并将它们分为两组:病例组和对照组。
-
病例组:该组包括任何药物过量或中毒事件的患者,通过ICD-9和ICD-10代码识别。在ICD-10-CM中,药物中毒案例分类在T36-T50代码下,涵盖药物、药品和生物物质的中毒、不良反应和剂量不足。这些代码在研究中频繁用于识别药物过量案例[13], [14]。为了确保病例组仅专注于过量案例,我们首先提取所有带有ICD-10-CM代码T36-T50的记录,然后排除与不良反应和剂量不足相关的案例。具体而言,第五位字符为’5’或’6’的案例(例如,T40.2X5, T40.2X6)被移除,因为它们分别表示不良反应和剂量不足。
-
对于基于ICD-9的识别,我们包括以下代码的案例:965, 968, 969, 970, E850, E853, E854, 和 E858。
-
- 对照组:对照组由不属于病例组且没有过量诊断记录的患者组成。此组还包括由于剂量不足或不良反应导致药物中毒的患者,但明确排除那些有过量事件记录的患者。
-
此外,对照组包括一个子集,称为“暴露组”。该组由接触过阿片类药物或兴奋剂但未经历过量的患者组成。由于使用阿片类药物或兴奋剂通常会增加过量的风险[15], [16],包括这些患者对模型预测过量事件提出了独特的挑战。这组有助于提高模型区分接触阿片类药物或兴奋剂但不过量和过量的个体的能力。通过在对照组中包括暴露患者,我们旨在使模型更加稳健,确保它可以准确评估高风险人群的过量风险。
-
为了识别暴露队列,我们使用了处方记录和诊断数据。如果患者满足以下任一条件,则将其纳入该队列:
-
- 至少有一张阿片类药物或兴奋剂的处方,或者
-
- 被诊断为阿片类药物或兴奋剂使用障碍,但没有过量事件记录。
-
对于基于处方的识别,我们使用了MEDISPAN根类别:
-
- “ADHD/抗嗜睡症/抗肥胖/厌食剂”(用于兴奋剂处方)
-
- “镇痛药 - 阿片类药物”(用于阿片类药物处方)
对于基于诊断的识别,我们包括根据ICD-9或ICD-10代码被诊断为阿片类药物或兴奋剂使用障碍的患者:
- “镇痛药 - 阿片类药物”(用于阿片类药物处方)
-
ICD-9代码:304.0x, 304.2X, 304.4X, 304.7X, 305.5X, 305.6X, 305.7X, 305.8X
-
- ICD-10代码:F11.XXX, F14.XXX, F15.XXX
B. 数据预处理
从表中提取队列后,我们对数据进行了预处理,以便为我们的预测建模做好准备。由于目标是基于截至预测时点为止的患者医疗历史来预测未来过量事件的风险,因此数据集应仅包括发生在截止日期之前的就诊记录。必须排除此截止日期之后记录的所有数据,以确保
| 诊断 | 药物(治疗类别) | |||||||
|---|---|---|---|---|---|---|---|---|
| 病例 | 对照 | 病例 | 对照 | |||||
| 变量 | 百分比 | 变量 | 百分比 | 变量 | 百分比 | 变量 | 百分比 | |
| 原发性高血压 | 38.17 | 原发性高血压 | 54.67 | 心理治疗,抗抑郁药 | 57.83 | 抗高血脂药物,NEC | 39.92 | |
| 未指定焦虑障碍 | 33.67 | 一般成人医学检查无异常发现 | 37.5 | 肾上腺及组合,NEC | 28.67 | 心理治疗,抗抑郁药 | 38.00 | |
| 接触并(疑似)暴露于COVID-19 | 31.33 | 免疫接种 | 35.33 | 镇痛/抗热,鸦片激动剂 | 28.33 | 疫苗,NEC | 35.17 | |
| 免疫接种 | 29.0 | 高血脂症,未指定 | 34.25 | 抗癫痫药,其他 | 27.00 | 肾上腺及组合,NEC | 33.92 | |
| 广泛性焦虑障碍 | 26.33 | 接触并(疑似)暴露于COVID-19 | 33.25 | 抗高血脂药物,NEC | 23.83 | β受体阻滞剂 | 25.83 | |
| 单次发作未指定的重大抑郁症 | 26.0 | 无并发症的2型糖尿病 | 21.92 | 镇痛/抗热,非甾体/抗炎 | 21.83 | 胃肠道药物,其他,NEC | 24.83 | |
| 高血脂症,未指定 | 23.33 | 维生素D缺乏症,未指定 | 21.17 | 疫苗,NEC | 21.67 | 抗生素,青霉素类 | 22.75 | |
| 其他长期药物(当前)疗法 | 22.67 | 免疫接种 | 21.08 | 抗生素,青霉素类 | 21.5 | 镇痛/抗热,非甾体/抗炎 | 22.58 | |
| 一般成人医学检查无异常发现 | 20.83 | 混合性高血脂症 | 18.75 | 安眠/镇静/催眠药,NEC | 21.5 | 鸦片激动剂 | 21.75 | |
| 呼吸急促 | 18.17 | 未指定焦虑障碍 | 18.41 | 止吐药,NEC | 20.83 | 交感神经兴奋剂,NEC | 19.5 |
表I
病例和对照组中的前10种诊断和药物。表格展示了前10种诊断(使用ICD-9和ICD-10代码分类)和前10种药物(按治疗类别分类),以及每个诊断或药物在患者既往就诊中至少出现一次的百分比。
模型反映仅使用过去和现在信息进行预测的真实世界情景。
为了实现这一点,针对病例队列,我们首先确定每位患者首次记录的药物过量遭遇。从这次遭遇开始,我们回溯到紧接其前的遭遇,并检查它是否落在指定的预测窗口内(图1)。如果此前遭遇的日期落在预测窗口内,我们将之指定为患者医疗历史的截止日期。所有在此截止日期后的数据均被排除,确保数据集反映患者在潜在过量事件前的状态。例如,在7天预测窗口内,如果患者的首次过量遭遇发生在2022年7月30日,而紧接其前的遭遇是在2022年7月25日,由于后者日期落在7天窗口内,因此被定为截止日期。患者的医疗历史至2022年7月25日止被包括在队列中的阳性病例中,预测任务是评估接下来7天内过量的风险。
对于对照组和暴露组,我们关注最近的就诊,并检查紧接其前的遭遇。
如果此次遭遇落在预测窗口内,其日期被指定为截止日期。所有至该截止日期的就诊信息都被包括在数据集中作为负面示例。这确保了数据代表在那个时间点尚未经历过量的患者。使用最近就诊前的遭遇作为截止日期,确保负面或对照案例与正面案例的时间结构相匹配。
表I 显示了病例组和对照组中前10种诊断和前10种药物的统计。诊断使用ICD-10和ICD-9代码分类,而药物根据其治疗类别名称分类。表格展示了前10种诊断和药物的百分比,即在患者既往就诊中至少有一次这些诊断或药物的患者比例。由于患者可以在一次就诊中有多重诊断并在同时被开具多种药物,这些百分比不会加总到100%。所报告的百分比表示每种诊断或药物在患者中出现的频率,而不是受影响的独特患者的比例。
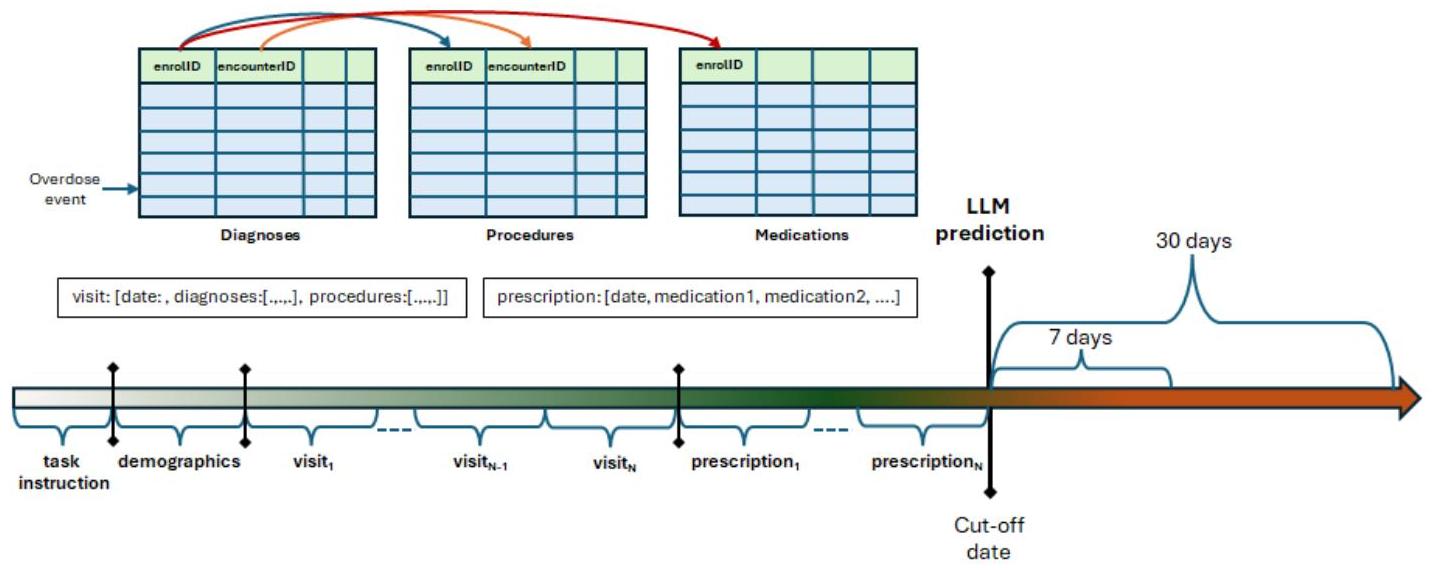
图1. 提示由任务指令和患者的医疗历史组成。医疗历史包括人口统计信息、就诊/遭遇详情和处方。就诊和处方均按时间顺序呈现,最早的排在前面,最新的排在最后。每次就诊包含就诊期间的诊断和进行的程序。LLM的目标是根据过去的就诊情况预测未来7天和30天内药物过量的可能性。
III. 方法
在本研究中,我们旨在通过使用LLMs从患者的纵向医疗数据中预测药物过量风险。我们将结果与基线方法进行比较,以展示使用LLMs的有效性。在本节中,我们讨论了基线方法和提出的基于LLM的方法。
A. 基线方法
对于基线,我们使用了传统机器学习算法,随机森林和XGBoost,这些算法通常用于结构化数据。由于这些算法需要静态输入特征,我们从数据集中导出了一组固定的特征。我们将主要和次要诊断代码、程序代码、药物名称和药物治疗名称及其强度和给药途径作为特征组。
为了定义特征集,我们识别了每个特征类型中最频繁的值,选择了在训练数据集中至少出现在50次就诊中的项目。这一过程产生了总共3,700个特征。对于每位患者,我们通过计算这些选定特征项在所有就诊中的出现次数来构建特征向量。这些特征向量随后被用来训练基线模型。
B. 大型语言模型
由于LLMs被设计为处理基于文本的输入,而MarketScan数据库以表格格式结构化,我们需要将纵向结构化的医疗数据转换成LLMs可以有效解释的格式。几项研究表明,将结构化表格数据转换为文本可以使LLMs更有效地处理它。为此转换提出了各种序列化技术。一种常见的方法是用可读编程语言的数据结构表示表格数据,如Pandas DataFrame [17]、HTML代码 [17]、[18] 或列表的列表表示的数据矩阵 [17]。其他广泛使用的方法包括将数据转换为JSON格式 [19]、键值对 [20] 或分隔符分隔值(如CSV或TSV)[21]。此外,一些研究探索了使用预定义模板将表格数据转换为自然语言句子 [10]、[22]。在我们的研究中,我们选择了JSON格式进行数据转换,因其有效性、简单性和结构化表示。
从Merative Marketscan数据库中,我们提取了四个主要表:诊断、程序、遭遇和处方,其中每一行代表一次遭遇(就诊)的单条记录。例如,诊断表中的一行包含一次遭遇中的一个诊断细节,而程序表则包含一个程序,依此类推。由于一次遭遇可能涉及多个诊断、程序和其他细节,某个遭遇的信息分布在这些表的多行中。为了汇总某个特定遭遇的所有细节,我们使用了诊断、程序和遭遇表中的唯一标识符——遭遇ID。通过使用这个标识符,将诊断表中与特定遭遇相关的所有行链接起来,以整合诊断细节。同样,使用相同的遭遇ID将程序和遭遇表中的行链接并聚合,提供一次就诊的所有诊断、程序和遭遇信息的综合记录。
每位患者通过Enrol ID唯一识别,该ID在所有表中保持一致。通过使用这个标识符,我们检索了与患者相关的所有遭遇,并使用上述过程聚合了每次就诊的详细信息。得到的患者特定的就诊记录按照时间顺序排列,较早的就诊排在前面,最近的就诊排在后面。这种时间安排保留了患者医疗历史随时间的进展,使得能够表示他们的纵向护理数据。
为了将患者数据作为文本序列表示给LLMs,我们使用了两种格式:(1) 详细的就诊信息和 (2) 就诊的统计摘要。每种格式进一步以两种方式结构化:(a) 使用详细描述和 (b) 使用原始医疗代码。
- 详细的就诊信息:在这种格式中,我们将每次就诊的详细信息、处方和患者人口统计数据转换为文本。数据以两种方式表示:(1) 使用详细的文本描述和 (2) 使用原始医疗代码。
- 详细描述:在这种结构中,我们用相应的自然语言描述替换医疗代码和数据库字段名,以利用LLMs对文本数据的理解。我们使用特定ICD-9/10代码对应的描述来表示诊断,ICD-9 PCS代码用于程序的描述等。例如,代替使用代表慢性肾病(CKD)的ICD-10诊断代码N18.9,我们包含了其描述:“慢性肾病,未特指(CKD)。” 同样,对于数据库字段,我们用可读标签“诊断代码”替换技术名称“DIAG_CD”。我们假设提供详细的自然语言描述将帮助LLMs更好地理解患者的医疗历史的临床背景。
-
- 原始医疗代码:在这种格式中,我们保留原始医疗代码而不转换为自然语言描述。例如,诊断代码N18.9直接使用,而不是其描述。使用原始医疗代码有两个目的:1. 简洁表示:它减少了文本序列的长度,这对处理效率是有利的。2. 能力测试:它评估LLMs是否可以直接从标准化的医疗代码中解释和做出预测,而无需额外的上下文。
- 就诊的统计摘要:与第一种格式不同,第一种格式将每次就诊以键值对的形式表示为文本,这种方法以统计方式总结患者数据。它
将患者的全部就诊数据汇总为一个特征向量。这是我们在基线方法中使用的相同特征向量,我们在其中计算每个特征(例如诊断代码、程序代码)在患者所有就诊中的出现次数。为了使这种格式与LLMs兼容,我们将特征向量转换为文本,将字段名和数值转换为自然语言。这创建了一个患者医疗历史的简洁高层次摘要。如同在详细就诊信息格式中,我们将字段名表示为两种方式:使用描述性标签和其原始医疗代码。
这些不同的输入格式导致四种不同的表示形式,我们命名为,1) 详细就诊 - 描述性,2) 详细就诊 - 医疗代码,3) 汇总就诊 - 描述性和4) 汇总就诊 - 医疗代码。
IV. 实验设置
在本研究中,我们调查了LLMs使用患者纵向医疗记录预测药物过量事件的潜力。为此,我们使用了最新的GPT-4o模型(gpt-4o-2024-08-06)作为LLM。为了评估其性能,我们将其与传统机器学习模型进行了比较,后者作为基线。具体来说,我们选择了随机森林和XGBoost作为基线模型,因为它们在涉及结构化表格数据的分类任务中表现出色且效果显著。
为了选择每个模型的最佳超参数,我们使用了网格搜索技术。对于GPT模型,我们测试了三个温度值: 0.5 , 0.8 0.5,0.8 0.5,0.8 和 1.0,并发现0.5提供了最佳性能。因此,在所有LLM实验中,我们使用了0.5的温度。
我们在两个预测窗口:7天和30天内评估了模型预测药物过量的表现。在7天窗口中,模型预测患者在接下来的7天内是否有过量风险,而在30天窗口中,它预测接下来30天内的风险。对于每个预测窗口,我们创建了单独的数据集,每个数据集包含900个样本用于训练,900个用于验证,900个用于测试。每个集合包括300个病例组(过量)和600个对照组(非过量),其中对照组中有300个实例(或 50 % 50 \% 50%)为暴露组(如第II-A节中定义)。本文中报告的所有结果均基于测试集。
| 预测窗口 | 模型 | P | R | Spec | F1 |
|---|---|---|---|---|---|
| 7天 | 随机森林 | 88.89 | 66.67 | 95.83 | 76.19 |
| XGBoost | 85.88 | 73.00 | 94.00 | 78.92 | |
| 30天 | 随机森林 | 84.02 | 61.33 | 93.67 | 70.91 |
| XGBoost | 85.77 | 70.33 | 95.50 | 77.29 |
表II
过量预测的基线表现
V. 结果
表II显示了基线模型随机森林和XGBoost在预测过量事件中的表现。
| 预测窗口 | 提示类型 | 准确率 | 召回率 | 特异性 | F1分数 |
|---|---|---|---|---|---|
| 7天 | 详细就诊 - 描述性 | 57.68 | 51.33 | 81.17 | 54.32 |
| 详细就诊 - 医疗代码 | 54.87 | 50.67 | 79.17 | 52.69 | |
| 汇总就诊 - 描述性 | 57.08 | 45.67 | 82.83 | 50.74 | |
| 汇总就诊 - 医疗代码 | 53.66 | 44.00 | 81.00 | 48.35 | |
| 30天 | 详细就诊 - 描述性 | 58.54 | 56.00 | 80.17 | 57.24 |
| 详细就诊 - 医疗代码 | 53.02 | 55.67 | 75.33 | 54.31 | |
| 汇总就诊 - 描述性 | 55.75 | 42.00 | 83.33 | 47.91 | |
| 汇总就诊 - 医疗代码 | 51.44 | 41.67 | 80.33 | 46.04 |
表III
使用LLMs进行零样本过量预测的结果
| 预测窗口 | 提示类型 | 准确率 | 召回率 | 特异性 | F1分数 |
|---|---|---|---|---|---|
| 7天 | 详细就诊 - 描述性 | 74.1 | 65.67 | 89.00 | 69.99 |
| 详细就诊 - 医疗代码 | 71.19 | 70.00 | 85.83 | 70.39 | |
| 汇总就诊 - 描述性 | 87.23 | 82.00 | 94.00 | 84.53 | |
| 汇总就诊 - 医疗代码 | 89.47 | 79.33 | 95.33 | 84.10 | |
| 30天 | 详细就诊 - 描述性 | 74.05 | 71.33 | 87.50 | 72.62 |
| 详细就诊 - 医疗代码 | 74.91 | 68.67 | 88.50 | 71.65 | |
| 汇总就诊 - 描述性 | 95.80 | 76.00 | 98.33 | 84.76 | |
| 汇总就诊 - 医疗代码 | 88.24 | 80.00 | 94.67 | 83.92 |
表IV
使用LLMs进行微调过量预测的结果
| 预测窗口 | 最大就诊次数 | 准确率 | 召回率 | F1 |
|---|---|---|---|---|
| 7天 | 5 | 55.10 | 36.00 | 43.55 |
| 10 | 58.37 | 45.33 | 51.03 | |
| 20 | 55.30 | 48.67 | 51.77 | |
| 30 | 57.68 | 51.33 | 54.32 | |
| 40 | 55.97 | 50.00 | 52.82 |
表V
考虑不同最大就诊次数值时的零样本性能。
两种模型的F1分数都在70到80之间,表明基线性能强劲。在两个预测窗口中,XGBoost始终比随机森林获得更高的F1分数。虽然XGBoost识别更多阳性过量事件,但随机森林提供的精度更高,产生更少的假阳性。
LLM实验的结果见表III和表IV。表III重点介绍了LLM在零样本设置下预测过量事件的有效性。我们使用两个预测窗口(7天和30天)进行了实验,并在四种不同的提示模板下评估了性能。结果表明,当提供详细的英文诊断和程序代码描述时,LLM表现最佳。这种提示格式在两个预测窗口中都实现了高召回率和高精度,优于其他提示格式。
为了评估LLM识别阴性过量事件的能力,我们还报告了特异性分数。详细描述提示的特异性为81.17,表明模型在零样本设置下正确识别阴性病例的强大能力。
在第二种提示格式中,我们使用了原始医疗代码而不是它们的
自然语言描述。这种格式在7天和30天预测时间框架内分别达到了52.69和54.31的F1分数。尽管与使用详细的自然语言描述相比性能略低,但这种方法有一个关键优势。通过依赖原始代码,输入提示的大小显著减少,从而降低了运行LLM的计算成本。表III还展示了使用患者过往就诊汇总统计的提示格式(我们在表中称为汇总就诊)的结果。在这种方法中,提供了过去n次就诊中诊断、程序和药物的汇总统计。我们评估了两种变体:一种使用原始医疗代码,另一种使用其英文描述。结果显示,使用英文描述的提示达到50.74的F1分数,而使用原始代码的提示达到48.35的F1分数。然而,这两种变体的表现都不如包含全面就诊级信息的提示。这突显了提供详细和丰富的上下文输入数据以增强零样本设置下的预测性能的重要性。
为了进一步评估LLM在使用患者就诊数据训练后预测过量事件的有效性,我们在训练数据集上对GPT-4o模型进行了微调。分别对每个预测窗口(7天和30天)和每个在零样本设置中使用的提示格式进行了微调。然后在相同的测试集上测试这些微调模型,以实现与它们的零样本对应模型和基线模型的直接比较。表IV展示了微调模型的结果。研究发现表明,微调显著提高了模型的性能。例如,在7天预测窗口中,“详细就诊 - 描述”
和“详细就诊 - 医疗代码”提示格式的微调模型的F1分数分别为69.99和70.59,分别比它们的相应零样本模型提高了16和18个百分点。这提高了模型准确预测阳性过量事件的能力,也增强了其正确识别非过量事件的能力,如召回率和特异性的增加所示。
当使用每位患者的就诊数据汇总统计进行微调时,观察到了显著的改进。需要注意的是,基线模型也经过相同的汇总数据训练以进行比较。如表IV所示,微调的LLM在7天预测窗口中达到84.53的F1分数,比表现最好的基线模型XGBoost高出约6个百分点,XGBoost的F1分数为78.92。更重要的是,微调的LLM在预测过量事件方面表现出比基线模型更好的能力。例如,微调的LLM使用汇总统计的召回率为82,比XGBoost高出9个百分点。
VI. 讨论
我们的实验结果证明了LLM利用患者纵向医疗历史(包括诊断记录、执行的程序和开具的药物)在特定时间段内预测药物过量风险的潜力。LLM的一个特别值得注意的优势在于其零样本能力;即使在没有任何特定任务微调的数据集上,这些模型也能利用其内部知识和语言理解生成预测。这种能力在我们的零样本实验中得到了体现,例如,模型在使用包含详细医疗描述的提示类型预测30天窗口内的过量案例时,达到了56%的召回率。这样的结果表明,即使仅仅依赖其预训练知识,LLM也能成功识别前瞻性队列中超过一半的过量案例。
在本节中,我们讨论了影响预测过量事件表现的几个因素。具体来说,我们分析了频繁和重要特征的意义,探讨就诊次数如何影响预测准确性,并检查纵向数据在塑造模型表现中的作用。此外,我们还研究了使用原始医疗代码与详细诊断和程序描述在预测过量事件中的差异。
A. 就诊次数
提供给LLM的先前就诊次数在决定其预测表现中起着至关重要的作用,因为它直接影响可用于决策的历史医疗信息量。更多的就诊次数允许模型捕捉患者医疗历史的更全面细节,可能会导致更准确的预测。然而,增加就诊次数也会导致更长的输入提示,
这可能会影响模型有效处理和利用信息的能力。
为了研究提供给LLM的不同就诊次数对其影响,我们进行了一次零样本实验,使用了不同的最大就诊次数限制。在这个实验中,我们使用了详细的描述提示类型,并将预测窗口设置为7天。表V中的结果显示,当仅使用最近的五个就诊时,模型的表现最低。随着就诊次数的增加,模型的表现有所改善,表明更多的上下文增强了其检测过量风险模式的能力。然而,当最大就诊次数设置为40时,我们观察到表现下降。虽然增加就诊次数为LLM提供了更多信息来进行明智的预测,但也显著延长了输入提示。例如,在我们的实验中,包含20个就诊的提示的平均令牌长度为3070个令牌,而包含40个就诊的提示的平均令牌长度达到了6652个令牌。这种过长的输入长度可能会引入挑战,使模型难以专注于最相关信息,导致相对较低的表现。我们的结果表明,当输入提示变得太长时,模型可能难以专注于最关键的信息,从而降低其有效性。
从这些实验中,我们发现使用最多30次先前就诊达到了在提供足够历史上下文和维持可管理输入长度之间的最佳平衡。因此,我们在本研究的所有后续实验中采用了30次就诊作为默认配置。
| 字段 | P | R | F1 |
|---|---|---|---|
| 诊断 | 71.27 | 39.67 | 50.97 |
| 手术 | 44.74 | 11.33 | 18.08 |
| 处方 | 50.89 | 28.67 | 36.68 |
| 诊断 & 手术 | 72.25 \mathbf{7 2 . 2 5} 72.25 | 41.67 | 52.86 |
| 诊断 & 处方 | 59.68 | 49.33 | 54.01 |
| 手术 & 处方 | 48.18 | 35.33 | 40.77 |
| 诊断、手术 & 处方 | 57.68 | 51.33 \mathbf{5 1 . 3 3} 51.33 | 54.32 \mathbf{5 4 . 3 2} 54.32 |
表VI
使用7天预测窗口和最多30次就诊信息的不同特征组合的零样本表现。
B. 不同字段的影响
为了预测药物过量风险,我们使用了患者的过往就诊,包括诊断、执行的手术和处方。这些组件提供了患者整体医疗历史的重要信息,帮助LLM评估潜在的过量风险。尽管这三个组件都对风险预测有贡献,但了解每个组件对预测的影响程度也很重要。为此,我们进行了实验,在这些组件(诊断、手术和处方)的不同组合下测试了LLM。例如,模型分别使用仅诊断历史、仅手术、诊断和手术的组合等进行测试。通过系统地变化输入字段,我们旨在分析每个医疗历史组件对准确预测过量风险的贡献。表VI中的结果显示,诊断历史在预测药物过量方面起着最重要的作用。在单个组件中,诊断数据单独提供了最有助于做出准确预测的信息。这一发现与某些疾病可能与药物过量相关联的事实相符,如高血压[23]和焦虑障碍[24]。如表I所示,相当比例的过量阳性患者也有这些条件的历史。这表明诊断历史为LLM提供了必要的信息,关于某些条件的存在,有助于做出明智的预测。然而,我们的结果还显示,结合所有三个组件可以提高召回率,帮助识别更多的阳性过量案例。
C. 描述与原始医疗代码
LLM在多样化的数据集上进行训练,包括生物医学和临床文本。因此,它们可能具备对标准化医疗编码系统的固有理解,例如ICD-9/ICD-10用于诊断,CPT/HCPCS用于手术及其他结构化的临床术语。与提供详细解释医疗状况和手术的自然语言描述不同,医疗代码是包含同等临床信息的紧凑表示格式。
使用医疗代码而非自然语言描述的一个关键优势是显著减少输入标记长度。由于医疗代码比其对应的详细描述包含更少的标记,用代码代替描述可以大幅减少提示大小。例如,在使用30次先前就诊的详细描述提示类型时,平均输入长度为5510.61个标记。相比之下,仅使用医疗代码可将平均标记数减少到4146.57个。这种25%的平均输入长度减少不仅优化了计算效率,还降低了API成本,这对于在实际临床应用中部署LLM是一个重要的考虑因素。
为了评估LLM是否能够有效解释医疗代码并基于它们做出预测,我们在零样本和微调设置下测试了GPT-4o,其中先前患者的遭遇被表示为自然语言描述或相应的医疗代码。表III和表IV的结果表明,使用医疗代码的模型性能与基于详细描述输入的性能相当。例如,在7天预测窗口中,详细描述提示的F1分数为54.32,而基于医疗代码提示的F1分数为52.69。这表明LLM可以有效地利用结构化临床代码进行过量预测,达到与描述性输入相似的性能水平。这对LLM在临床环境中的实际部署具有影响,因为使用结构化代码不仅减少了计算成本,还确保了与电子健康记录(EHR)系统的兼容性,这些系统广泛使用代码进行文档记录和分析。然而,需要进一步研究以探索是否结合最小补充上下文与医疗代码可以增强可解释性和提高预测准确性。
D. 顺序遭遇信息与汇总统计
我们的实验表明,传统机器学习模型(如XGBoost和随机森林)在使用详细的顺序遭遇信息预测过量事件时优于LLM。对于基于LLM的预测,输入数据由前n次遭遇的文本描述组成,并按时间顺序呈现。每次遭遇包括诊断、手术和药物的详细信息,保留了患者医疗历史的顺序性质。相比之下,传统机器学习模型以分类格式处理输入数据,其中每个独特的诊断、手术或药物被视为一个独立特征。而不是保持时间顺序,这些模型通过计数最后n次遭遇中每个特征的出现次数来汇总信息。这种汇总表示将患者的病史压缩成一个更简单的数值格式,可能使传统ML模型更好地识别模式。
为了确定LLM是否能像传统模型一样有效地利用汇总信息,我们将基线模型使用的结构化特征向量转换为文本格式。具体来说,我们将数据表示为键值对序列,其中键对应于一个医疗特征(例如,诊断或手术),值表示其在过去n次就诊中的频率。这种方法使我们能够以LLM可以有效处理的格式向其展示相同的汇总统计表示。表IV中的结果显示,虽然LLM在使用汇总输入格式进行零样本预测时表现不佳(表III),但在适应后的微调设置中,其性能显著提高。事实上,微调后的LLM超越了基线模型,表明LLM在经过适当调整后可以有效解释汇总数据。
| 模型 | 提示类型 | 对照组 | |
|---|---|---|---|
| 暴露组 | 非暴露组 | ||
| 零样本 | 详细描述 | 73.67 | 88.67 |
| 原始医疗代码 | 69.67 | 88.67 | |
| 汇总统计 - 描述性 | 69.00 | 96.67 | |
| 汇总统计 - 原始代码 | 66.33 | 95.67 | |
| 微调 | 详细描述 | 88.00 | 90.00 |
| 原始医疗代码 | 86.00 | 85.00 | |
| 汇总统计 - 描述性 | 94.00 | 94.00 | |
| 汇总统计 - 原始代码 | 95.67 | 95.00 |
表VII
在对照组中预测“无过量”事件的模型准确性,针对暴露组与非暴露组实例。
E. 暴露组的表现
暴露队列代表控制组的一个子集,其中个体已接触阿片类药物或兴奋剂但未经历药物过量。这个队列特别难以预测,因为滥用阿片类药物或兴奋剂的人通常面临更高的过量风险。因此,在我们的实验中,我们还评估了模型在该暴露队列上的表现,并将其与控制组的其余部分进行比较。
表VII展示了GPT-4o模型在控制队列中预测暴露组和非暴露组过量事件的准确性,预测窗口为7天。如表所示,零样本LLM倾向于预测暴露组中的更多过量病例,这反映在其较低的暴露组准确性上。这表明,模型在零样本设置下错误地将阿片类药物或兴奋剂暴露与更高可能性的过量联系起来,即使个体实际上并未经历过量。然而,当我们使用训练数据微调模型时,其在预测阿片类药物暴露个体中的过量事件方面的表现有所改善。如表所示,最佳微调模型在暴露组中的准确率达到95.67%,相比零样本预测中的73.67%有了显著提升。这一改进突显了微调在更好地使模型预测与阿片类药物或兴奋剂暴露个体的实际过量风险相一致的有效性。
| 提示类型 | 7天 | 30天 |
|---|---|---|
| 详细描述 | $ 0.0137$ | $ 0.0125$ |
| 原始医疗代码 | $ 0.0102$ | $ 0.0101$ |
| 汇总统计 - 描述性 | $ 0.0037$ | $ 0.0034$ |
| 汇总统计 - 原始代码 | $ 0.0031$ | $ 0.0029$ |
表VIII
在不同提示类型和预测窗口下进行预测的每实例平均成本(美元)。
F. 推理成本
为了估算使用OpenAI API通过训练模型进行预测的成本,我们分析了不同输入提示类型的每实例成本。表VIII展示了使用7天和30天预测窗口的各种提示格式的每实例平均推理成本。在此分析中,我们计算了每位患者最多包含30次就诊的输入成本。结果显示,包含详细就诊信息和描述性医疗术语的提示最为昂贵,因为它们包含每位患者较高的平均令牌数量。具体而言,这些详细提示在7天预测窗口中的成本为$ 0.0137,在30天窗口中的成本为$ 0.0125。相比之下,将描述性医疗术语替换为其对应的医疗代码可将API成本降低近25%。此外,汇总就诊信息可进一步降低成本(几乎降低73%),因为汇总统计需要显著较少的
令牌来表示患者的医疗历史,相比于详细的就诊描述。
VII. 结论
预测药物过量风险的能力在医疗保健中至关重要,因为它可以实现及时干预并有可能挽救生命。在这项研究中,我们评估了一个大型语言模型GPT-4o在基于患者纵向医疗记录预测药物过量风险方面的有效性。具体来说,我们检查了它在两个时间间隔内的预测表现——从观察日期起的7天内和30天内。我们的实验结果显示,微调后的LLM在提供汇总的先前诊断、程序和药物统计摘要时优于传统的基线方法,这些特征与基线方法中使用的相同。然而,在零样本推断设置中,我们发现提供详细的遭遇信息导致比仅使用汇总统计更准确的预测。
我们的方法也存在一定的局限性。在当前模型中,我们利用人口统计、诊断、程序和药物信息进行预测,但未包括实验室数据,因为Merative MarketScan(前身为Truven)中未提供这些数据。在未来的工作中,我们计划纳入实验室数据,这可能会提高模型在预测过量事件方面的表现。此外,由于微调专有模型GPT40的高成本以及大量输入令牌,我们将训练数据集限制为900名患者。在未来,我们将纳入更多训练实例,以调查是否可以增强模型的预测能力。
我们模型的另一个局限性在于它依赖于保险索赔数据,而这些数据并非在就诊结束时实时可用。该模型预测的是从索引日期起未来7天或30天内的药物过量风险。然而,导致该日期的最近几次就诊的细节可能尚未记录在保险索赔中,从而造成实时预测能力的差距。由于我们的模型主要使用Merative数据,而这些数据需要几周的时间来处理,这种延迟阻止了模型利用最新的患者信息。一种现实世界部署的潜在解决方案是,在进行预测之前,用当地医院或诊所的最新就诊记录(自上次Merative记录以来)补充Merative的历史数据。通过整合这些来源,模型将能够生成更及时和可靠的预测。因此,我们强调这一局限性并不妨碍我们方法的实施和实用性。
尽管存在这些局限性,我们的基于LLM的模型在预测过量风险方面表现出高召回率和特异性。即使在零样本推断中,模型也实现了超过54%的召回率,突出其在没有任务特定训练的情况下做出明智决策的能力。这些发现表明,LLM在临床决策支持系统中有潜力,特别是用于药物过量预测。
致谢
本工作得到了美国国家卫生研究院(NIH)国家药物滥用研究所通过R01DA057686资助的支持。内容完全由作者负责,并不一定代表NIH的官方观点。
参考文献
[1] M. R. Spencer, M. F. Garnett, and A. M. Miniño, “Drug overdose deaths in the united states, 2002-2022,” National Center for Health Statistics, Tech. Rep. 494, December 2023. [Online]. Available: https://stacks.cdc.gov/view/cdc/135849
[2] E. P. Finley, A. Garcia, K. Rosen, D. McGeary, M. J. Pugh, and J. S. Potter, “Evaluating the impact of prescription drug monitoring program implementation: a scoping review,” BMC health services research, vol. 17, pp. 1-8, 2017.
[3] B. J. S. Marie, M. J. Witty, and J. C. Reist, “Barriers to increasing prescription drug monitoring program use: A multidisciplinary perspective,” CIN: Computers, Informatics, Nursing, vol. 41, no. 8, pp. 556-562, 2023.
[4] W.-H. Lo-Ciganic, J. L. Huang, H. H. Zhang, J. C. Weiss, Y. Wu, C. K. Kwoh, J. M. Donohue, G. Cochran, A. J. Gordon, D. C. Malone et al., “Evaluation of machine-learning algorithms for predicting opioid overdose risk among medicare beneficiaries with opioid prescriptions,” JAMA network open, vol. 2, no. 3, pp. e190968-e190968, 2019.
[5] Z. Che, J. St Sauver, H. Liu, and Y. Liu, “Deep learning solutions for classifying patients on opioid use,” in AMIA Annual Symposium Proceedings, vol. 2017, 2018, p. 525.
[6] F. Ma, R. Chitta, J. Zhou, Q. You, T. Sun, and J. Gao, “Dipole: Diagnosis prediction in healthcare via attention-based bidirectional recurrent neural networks,” in Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, 2017, pp. 19031911.
[7] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 18771901. [Online]. Available: https://proceedings.neurips.cc/paper_files/ paper/2020/file/1457c0d6bfcb4967418b0b8ac142f64a-Paper.pdf
[8] J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler et al., “Emergent abilities of large language models,” Transactions on Machine Learning Research, 2022.
[9] X. Liu, D. McDuff, G. Kovacs, I. Galatzer-Levy, J. Sunshine, J. Zhan, M.-Z. Poh, S. Liao, P. Di Achille, and S. Patel, “Large language models are few-shot health learners,” arXiv preprint arXiv:2305.15525, 2023.
[10] S. Hegselmann, A. Buendia, H. Lang, M. Agrawal, X. Jiang, and D. Sontag, “Tabllm: Few-shot classification of tabular data with large language models,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2023, pp. 5549-5581.
[11] R. J. Ellis, Z. Wang, N. Genes, and A. Ma’ayan, “Predicting opioid dependence from electronic health records with machine learning,” BioData mining, vol. 12, pp. 1-19, 2019.
[12] C. R. Ramírez Medina, J. Benítez-Aurioles, D. A. Jenkins, and M. Jani, “A systematic review of machine learning applications in predicting opioid associated adverse events,” npj Digital Medicine, vol. 8, no. 1, p. 30, 2025.
[13] R. Di Rico, D. Nambiar, M. Stoové, and P. Dietze, “Drug overdose in the ed: a record linkage study examining emergency department icd-10 coding practices in a cohort of people who inject drugs,” BMC health services research, vol. 18, pp. 1-9, 2018.
[14] L. M. T. Snow, K. E. Hall, C. Custis, A. L. Rosenthal, E. Pasalic, S. Nechuta, J. W. Davis, B. J. Jacquemin, S. R. Jagnsep, P. Rock et al., “Descriptive exploration of overdose codes in hospital and emergency department discharge data to inform development of drug overdose morbidity surveillance indicator definitions in icd-10-cm,” Injury prevention, vol. 27, no. Suppl 1, pp. i27-i34, 2021.
[15] H. Palis, C. Xavier, S. Dobrer, R. Desai, K.-o. Sedgemore, M. Scow, K. Lock, W. Gan, and A. Slaunwhite, “Concurrent use of opioids and stimulants and risk of fatal overdose: a cohort study,” BMC Public Health, vol. 22, no. 1, p. 2084, 2022.
[16] A. S. Bohnert and M. A. Ilgen, “Understanding links among opioid use, overdose, and suicide,” New England journal of medicine, vol. 380, no. 1, pp. 71-79, 2019.
[17] A. Singha, J. Cambronero, S. Gulwani, V. Le, and C. Parnin, “Tabular representation, noisy operators, and impacts on table structure understanding tasks in llms,” in NeurIPS 2023 Second Table Representation Learning Workshop.
[18] Y. Sui, J. Zou, M. Zhou, X. He, L. Du, S. Han, and D. Zhang, “Tap4llm: Table provider on sampling, augmenting, and packing semi-structured data for large language model reasoning,” CoRR, 2023.
[19] Y. Sui, M. Zhou, M. Zhou, S. Han, and D. Zhang, “Table meets llm: Can large language models understand structured table data? a benchmark and empirical study,” in Proceedings of the 17th ACM International Conference on Web Search and Data Mining, 2024, pp. 645-654.
[20] Z. Wang, C. Gao, C. Xiao, and J. Sun, “Meditab: Scaling medical tabular data predictors via data consolidation, enrichment, and refinement,” arXiv preprint arXiv:2305.12081, 2023.
[21] A. Narayan, I. Chami, L. Orr, and C. Ré, “Can foundation models wrangle your data?” Proceedings of the VLDB Endowment, vol. 16, no. 4, pp. 738-746, 2022.
[22] H. Gong, Y. Sun, X. Feng, B. Qin, W. Bi, X. Liu, and T. Liu, “Tablegpt: Few-shot table-to-text generation with table structure reconstruction and content matching,” in Proceedings of the 28th International Conference on Computational Linguistics, 2020, pp. 1978-1988.
[23] W. Q. Gan, J. A. Buxton, H. Palis, N. Z. Janjua, F. X. Scheuermeyer, C. G. Xavier, B. Zhao, R. Desai, and A. K. Slaunwhite, “Drug overdose and the risk of cardiovascular diseases: a nested case-control study,” Clinical Research in Cardiology, pp. 1-10, 2021.
[24] J. van Draanen, C. Tsang, S. Mitra, V. Phuong, A. Murakami, M. Karamouzian, and L. Richardson, “Mental disorder and opioid overdose: a systematic review,” Social psychiatry and psychiatric epidemiology, pp. 1-25, 2022.
参考论文:https://arxiv.org/pdf/2504.11792



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











