






Jakub Maciążek
系统与计算机网络系
弗罗茨瓦夫科学与技术大学
弗罗茨瓦夫,波兰
kuba.maciazek@gmail.com
Michal W. Przewozniczek
系统与计算机网络系
弗罗茨瓦夫科学与技术大学
弗罗茨瓦夫,波兰
michal.przewozniczek@pwr.edu.pl
Jonas Schwaab
空间与景观规划研究所
苏黎世联邦理工学院
苏黎世,瑞士
jonasschwaab@ethz.ch
摘要
解决土地利用分配问题可以帮助我们应对一些最紧迫的全球环境问题。由于这些问题属于NP难问题,因此需要有效的优化器来处理它们。关于变量依赖性的知识有助于提出这样的工具。然而,在这项工作中,我们考虑了一个现实世界的多目标问题,对于该问题,标准的变量依赖性发现技术无法应用。因此,使用基于链接的变异算子是不可行的。为了解决这一问题,我们提出了针对特定问题的变量依赖性定义。在此基础上,我们提出获取依赖变量的掩码。通过使用这些掩码,我们构建了三个新颖的交叉算子。关于现实世界测试案例的结果表明,将我们的提议引入到两个著名的多目标优化器(NSGA-II 和 MOEA/D)中显著提高了它们的有效性。
CCS 概念
- 计算方法学 → 人工智能。
关键词
土地利用分配、多目标优化、变量依赖性、灰箱优化、遗传算法、进化算法、优化
ACM 引用格式:
Jakub Maciążek, Michal W. Przewozniczek, and Jonas Schwaab. 2025. 寻找和利用灰箱难解的双模态土地利用分配问题中的替代变量依赖概念。In 遗传与进化计算会议 (GECCO '25),7月14-18日,2025年,马拉加,西班牙。ACM, 纽约,NY,USA, 9 pages. https://doi.org/10.1145/3712256.3726419
1 引言
土地利用优化 (LUO) 被用于解决21世纪一些最紧迫的环境挑战,包括气候变化、生物多样性危机和肥沃农业用地的流失 [38]。LUO 问题在于确定不同土地利用类型(如城市、农业和森林)的最佳位置。此过程通常涉及平衡冲突的目标。例如,城市开发的收入必须与潜在的生物多样性和农业土壤损失进行权衡。
(0) 20
本作品根据知识共享署名4.0国际许可协议获得授权。GECCO '25,马拉加,西班牙
© 2025 版权由作者/版权所有者持有。
ACM ISBN 979-8-4007-1465-8/2025/07
https://doi.org/10.1145/3712256.3726419
因此,多目标优化方法已成为解决土地利用分配问题的标准方法 [30]。多目标 LUO 的目标可以大致分为两类。第一类目标是根据给定位置的特性评估特定土地利用类型的适用性。第二类目标是基于周围的土地利用类型和整体空间模式评估适用性。后者是在 LUO 中最常见的目标 [30],但由于其复杂性,对解决 LUO 构成了重大挑战。在本研究中,我们展示了以前尝试应对这些挑战的方法 [33] 可以被大幅改进,从而更有效地解决 LUO。
为了提出比目前可用的优化器显著更有效的优化器,我们参考了灰箱优化的思想。灰箱优化旨在通过使用变量依赖性来设计高度有效的优化器 [46]。对于二进制编码的问题,灰箱相关研究经常使用沃尔什分解来获取这种依赖性 [44]。因此,灰箱优化器使用通用问题特定知识来提高效率,但仍然足够通用以适用于许多不同的问题 [45]。
在本研究中,我们采用来自最新文献的解决方案编码和解码机制 [36],这导致使用二进制编码的解决方案。某些解决方案可能是不可行的,必须修复。然而,问题特征使得确定性修复机制效果不佳,因此随机程序被用于此目的。因此,我们不能通过评估修复版本同时保持原始(不可行)解决方案不变来确定性地评估不可行解决方案。由于这个原因,使用沃尔什分解不可行,因为它需要评估不可行解决方案。因此,尽管问题是二进制编码的,但所考虑的问题不能通过沃尔什分解进行分解,并且可以被视为灰箱难解的问题。
因此,我们提出了针对特定问题的变量依赖性概念,以便即使 LUO 是一个灰箱难解问题,也能利用依赖感知变异算子带来的潜力。使用所提出的变量依赖性概念,我们提出了一种针对特定问题的交叉算子和其他几种机制。实验确认,将我们的提议引入到两个专门用于多目标(MO)优化的优化器中显著提高了它们的有效性。
本文其余部分组织如下。下一节介绍我们的研究背景。第3节介绍了所考虑问题的定义、解决方案编码和标准算子。在第4-5节中,我们详细描述了所提出的算子并解释了其核心直觉。第六节展示了实验结果。最后,最后一节总结了这项工作并指出了未来工作的主要方向。
2 相关工作
2.1 土地利用分配
LUO 已被非常频繁地用于优化自然保护区和恢复区、城市开发区以及可再生能源区的位置 [30, 38]。LUO 用于为在国际、国家、区域和地方层面运作的空间规划师和政策制定者提供决策支持 [33]。土地利用和土地利用变化对社会、经济和环境目标产生影响 [3]。因此,在大多数情况下,必须将它们视为多目标优化问题。
已采用多种方法来制定多目标 LUO 问题并解决它们。在大多数情况下,要优化的空间单元以规则网格(即基于像素的地图)表示,但也有一些例子依赖于基于矢量(即空间多边形)的表示 [37]。决策变量通常是不同土地利用类型的离散表示(即每种土地利用类型的整数值),并且在许多情况下是代表在特定位置选择两种土地利用的二进制变量 [30]。
最常见的约束是特定土地利用应满足或不超过预定义面积(Schwaab et al., 2017)。包括的各种目标可以大致分为加性和空间依赖两类(Stewart 和 Janssen, 2014)。空间依赖目标包括连贯性(紧凑性、连接性等)、不同土地利用类型之间的距离以及大量测量碎片化的景观指标。
为了解决 LUO 问题,已经采用了多种方法,包括帕累托和分解法 [11]。由于大多数 LUO 问题的复杂性和多目标性质,解决这些问题的最常见方法是使用进化算法 [30]。因此,我们在本研究中使用的现实世界 LUO 问题包含了一些 LUO 问题最常见的特征,因此,我们认为所展示的进展可以对广泛的 LUO 应用有益。
2.2 多目标优化
二进制编码的多目标(MO)问题需要同时优化 m m m 个目标函数 f ( x ) = ( f 1 ( x ) , … , f m ( x ) ) f(\boldsymbol{x})=\left(f_{1}(\boldsymbol{x}), \ldots, f_{m}(x)\right) f(x)=(f1(x),…,fm(x)),其中 x = ( x 1 , x 2 , … , x n ) \boldsymbol{x}=\left(x_{1}, x_{2}, \ldots, x_{n}\right) x=(x1,x2,…,xn) 是大小为 n n n 的二进制向量。假设优化函数是最小化,解 x 0 \boldsymbol{x}^{\mathbf{0}} x0 支配 x i \boldsymbol{x}^{\mathbf{i}} xi 当且仅当 f i ( x 0 ) ≤ f i ( x i ) ∀ i ∈ { 1 , 2 , … , m } f_{i}\left(\boldsymbol{x}^{0}\right) \leq f_{i}\left(\boldsymbol{x}^{\mathbf{i}}\right) \forall i \in\{1,2, \ldots, m\} fi(x0)≤fi(xi)∀i∈{1,2,…,m} 并且 f ( x 0 ) ≠ f ( x i ) f\left(\boldsymbol{x}^{0}\right) \neq f\left(\boldsymbol{x}^{\mathbf{i}}\right) f(x0)=f(xi)。Pareto 最优集 P S \mathcal{P}_{S} PS 是所有非支配解的集合(Pareto 最优解)。所有 Pareto 最优解的目标值向量形成 Pareto 最优前沿 P F \mathcal{P}_{F} PF。通常, P F \mathcal{P}_{F} PF 的规模较大。因此,在 MO 中,我们希望找到一个近似 P F \mathcal{P}_{F} PF 的 PF [16]。
非支配排序遗传算法 II(NSGA-II)[5] 是一种知名的 MO 专用优化器。NSGA-II 使用个体群体。为了比较它们的质量,使用支配关系将它们聚类成子群体。第一个子群体(前缘)由集群人口中的非支配解组成。第二个前缘由从人群中移除第一个前缘后仍非支配的解组成,依此类推。前缘编号越高,它所分组的解质量越低。如果被比较的解属于同一个前缘,NSGA-II 使用拥挤距离度量。具有高拥挤距离值的解被认为是有特色的(相对于给定人群而言)因此有价值。有关 NSGA-II 的详细信息可以在 [5] 中找到。
在 MOEA/D [48] 中,每个解都被标量化。因此,每个解解决一个不同的单目标问题。这样,MOEA/D 避免使用支配关系,这在解决多目标问题时可能是一个优势 [21]。在每次迭代中,为每个解生成一组候选解,如果它们的标量化适应度更高,则最佳候选解取代原始解。MOEA/D 使用交配限制机制 [31],限制某个解可以与哪些其他解混合。交配限制允许避免混合解决显著不同标量化问题的个体。许多最新的研究使用 MOEA/D 或其改进版本作为研究起点 [6,32,43]。
2.3 基于依赖性的优化利用
在这项工作中,我们考虑了一个灰箱难解的问题,该问题无法使用典型的灰箱概念进行分解。然而,我们的研究目标是使优化过程中能够利用依赖性算子的潜力。因此,我们更详细地介绍了问题分解的概念。
灰箱优化的重点是提出使用关于变量依赖性的知识来改进优化器有效性的算子 [45]。变量依赖性的概念可以有多种解释方式,例如 [19, 24, 26]。然而,在与灰箱相关的研究中,经常考虑非线性依赖性,即变量 x g x_{g} xg 和 x h x_{h} xh 如果存在 x \boldsymbol{x} x 使得 [19]:
f ( x ) + f ( x g , h ) ≠ f ( x g ) + f ( x h ) f(\boldsymbol{x})+f\left(\boldsymbol{x}^{g, h}\right) \neq f\left(\boldsymbol{x}^{g}\right)+f\left(\boldsymbol{x}^{h}\right) f(x)+f(xg,h)=f(xg)+f(xh)
其中通过 x g , x h \boldsymbol{x}^{g}, \boldsymbol{x}^{h} xg,xh 和 x g , h \boldsymbol{x}^{g, h} xg,h 分别是从 x \boldsymbol{x} x 通过翻转基因 g g g、基因 h h h 或两者得到的解。
非线性依赖性也可以通过沃尔什分解 [8] 获得,这允许将任何伪布尔函数定义为:
f ( x ) = ∑ i = 0 2 m − 1 w i φ i ( x ) f(\boldsymbol{x})=\sum_{i=0}^{2^{m}-1} w_{i} \varphi_{i}(\boldsymbol{x}) f(x)=i=0∑2m−1wiφi(x)
其中 w i ∈ R w_{i} \in \mathbb{R} wi∈R 是第 i i i 个沃尔什系数, φ i ( x ) = ( − 1 ) i τ x \varphi_{i}(\mathbf{x})=(-1)^{\mathrm{i} \tau} \mathbf{x} φi(x)=(−1)iτx 生成符号, i ∈ { 0 , 1 } n \mathbf{i} \in\{0,1\}^{n} i∈{0,1}n 是索引 i i i 的二进制表示, x = { x 1 , x 2 , … , x n } \boldsymbol{x}=\left\{x_{1}, x_{2}, \ldots, x_{n}\right\} x={x1,x2,…,xn} 是大小为 n n n 的二进制解向量。
尽管沃尔什分解,两个变量 x g x_{g} xg 和 x h x_{h} xh 如果至少存在一个非零沃尔什系数 w i w_{i} wi 使得 i \mathbf{i} i 的第 g g g 个和第 h h h 个元素等于一,则它们是相关的 [41]。沃尔什分解识别的依赖性等同于非线性检查。
获得的依赖性通常存储在变量交互图(VIG)中,这是一个方阵。它的每个条目如果所指的变量对是相关的则为1,否则为0。灰箱算子将 VIG 中存储的依赖性聚类以获得依赖变量的掩码,这些掩码用于变异算子,例如作为分区交叉(PX)[42] 中的混合掩码或作为迭代局部搜索 [41] 中的扰动掩码。
在黑箱优化中,变量依赖性的先验知识不可用。因此,必须在优化器运行期间发现它 [39]。最近的连锁学习技术提案允许有效且高效地发现依赖性 [28, 41],这使得在黑箱优化中可以使用灰箱算子 [27]。一些研究集中在获得优化函数的代理模型上,以实现无成本或低成本的适应度评估,同时获得VIG [7, 15, 44]。
对于某些问题,非线性检查可能过于敏感。因此,提出了非单调性检查 [20],如果以下条件不成立,则认为
x
g
x_g
xg和
x
h
x_h
xh是相关的:
if
(
f
(
x
g
)
>
f
(
x
)
)
and
(
f
(
x
h
)
>
f
(
x
)
)
then
(
f
(
x
g
,
h
)
>
f
(
x
g
)
)
and
(
f
(
x
g
,
h
)
>
f
(
x
h
)
)
if
(
f
(
x
g
)
<
f
(
x
)
)
and
(
f
(
x
h
)
<
f
(
x
)
)
then
(
f
(
x
g
,
h
)
<
f
(
x
g
)
)
and
(
f
(
x
g
,
h
)
<
f
(
x
h
)
)
\begin{aligned} & \text { if }\left(f\left(x^{g}\right)>f(x)\right) \text { and }\left(f\left(x^{h}\right)>f(x)\right) \text { then } \\ & \left(f\left(x^{g, h}\right)>f\left(x^{g}\right)\right) \text { and }\left(f\left(x^{g, h}\right)>f\left(x^{h}\right)\right) \\ & \text { if }\left(f\left(x^{g}\right)<f(x)\right) \text { and }\left(f\left(x^{h}\right)<f(x)\right) \text { then } \\ & \left(f\left(x^{g, h}\right)<f\left(x^{g}\right)\right) \text { and }\left(f\left(x^{g, h}\right)<f\left(x^{h}\right)\right) \end{aligned}
if (f(xg)>f(x)) and (f(xh)>f(x)) then (f(xg,h)>f(xg)) and (f(xg,h)>f(xh)) if (f(xg)<f(x)) and (f(xh)<f(x)) then (f(xg,h)<f(xg)) and (f(xg,h)<f(xh))
使用非单调性检查可以有效优化非加性可分解问题 [12]。
3 土地利用优化问题
3.1 问题定义和质量度量
在这里,我们详细介绍土地利用优化(LUO)问题。我们采用类似于 [1] 提出的符号。在LUO中,我们考虑一个 R x C R x C RxC的矩阵区域。每个区域可以属于 K K K个土地利用类别之一。在考虑的LUO实例中,我们需要通过将 T T T个农业区域转变为城市区域来提出一个包含 U U U个城市区域的土地利用地图(初始的城市区域数量为 U − T U-T U−T)。因此,我们希望最小化因转换而造成的农业生产力损失(LAP)[34]。
L A P ( y ) = 1 / A ∑ r = 1 R ∑ c = 1 C ∑ k = 1 K a r c k y r c k L A P(\boldsymbol{y})=1 / A \sum_{r=1}^{R} \sum_{c=1}^{C} \sum_{k=1}^{K} a_{r c k} y_{r c k} LAP(y)=1/Ar=1∑Rc=1∑Ck=1∑Karckyrck
受制于
V r = 1 , . R , c = 1 , . C ∑ k = 1 K y r c k = 1 ∑ r = 1 R ∑ c = 1 C y r c 1 = U \begin{gathered} V_{r=1, . R, c=1, . C} \sum_{k=1}^{K} y_{r c k}=1 \\ \sum_{r=1}^{R} \sum_{c=1}^{C} y_{r c 1}=U \end{gathered} Vr=1,.R,c=1,.Ck=1∑Kyrck=1r=1∑Rc=1∑Cyrc1=U
其中 y \boldsymbol{y} y表示所考虑的土地利用地图,由二进制变量 y r c k y_{r c k} yrck表达, U U U是所需的城市区域数量, k = 1 k=1 k=1是城市区域类型, a r c k a_{r c k} arck是给定区域潜在的农业生产力损失, A A A是整个矩阵的潜在农业生产力损失总和。
除了最小化农业生产力损失外,我们还希望保持所有类型的区域紧凑。因此,我们希望最小化总边缘长度(TEL)度量 [34]。
TEL
(
y
)
=
∑
r
=
1
R
∑
c
=
1
C
∑
k
=
1
K
(
y
r
+
1
,
c
,
k
+
y
r
−
1
,
c
,
k
+
y
r
,
c
+
1
,
k
+
y
r
,
c
−
1
,
k
)
⋅
y
r
c
k
\operatorname{TEL}(\boldsymbol{y})=\sum_{r=1}^{R} \sum_{c=1}^{C} \sum_{k=1}^{K}\left(y_{r+1, c, k}+y_{r-1, c, k}+y_{r, c+1, k}+y_{r, c-1, k}\right) \cdot y_{r c k}
TEL(y)=∑r=1R∑c=1C∑k=1K(yr+1,c,k+yr−1,c,k+yr,c+1,k+yr,c−1,k)⋅yrck
受制于
V k = 1 , … , K , r ∈ { 0 , R + 1 } ; c ∈ { 0 , C + 1 } y r c k = 0 V_{k=1, \ldots, K, r \in\{0, R+1\} ; c \in\{0, C+1\}} y_{r c k}=0 Vk=1,…,K,r∈{0,R+1};c∈{0,C+1}yrck=0
LUO 被分类为 NP 难问题 [10, 18]。
3.2 解决方案编码和修复机制
在 LUO 中,我们可以将每个解决方案表示为二进制向量
f
(
x
)
f(\boldsymbol{x})
f(x),其中
x
=
{
x
1
,
x
2
,
…
,
x
n
}
\boldsymbol{x}=\left\{x_{1}, x_{2}, \ldots, x_{n}\right\}
x={x1,x2,…,xn} 的大小为
n
n
n。每个
x
i
x_{i}
xi 我们解释为决策“不要转换关联的农业区域”
(
x
i
=
0
)
(x_{i}=0)
(xi=0) 或“将关联的农业区域转换为城市区域”
(
x
i
=
1
)
(x_{i}=1)
(xi=1)。注意
n
n
n 等于初始的农业区域数量。如果解决方案可行,则
u
(
x
)
=
T
u(\boldsymbol{x})=T
u(x)=T,其中
u
(
x
)
u(\boldsymbol{x})
u(x) 是
x
\boldsymbol{x}
x 的单位数 [4](1的数量)。
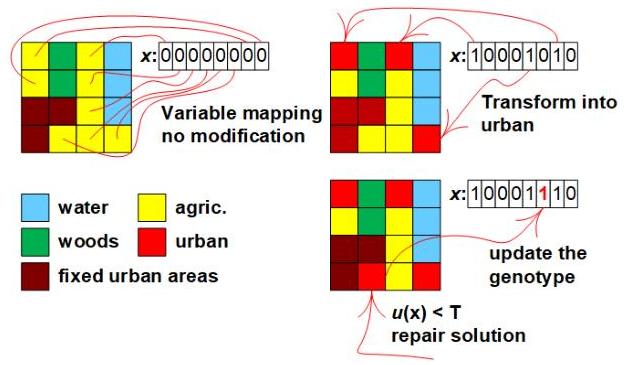
图 1:LUO 示例的变量映射、解决方案编码和修复机制,其中 R = C = 4 , K = 5 , T = 4 R=C=4, K=5, T=4 R=C=4,K=5,T=4,以及 U = 7 U=7 U=7。
在图 1 中,我们展示了 LUO 示例的解决方案。每个农业区域由每个 x i x_{i} xi 表示。如果 x i = 1 x_{i}=1 xi=1,那么它会修改原始地图,将由 x i x_{i} xi 指代的区域从农业区域转换为城市区域。如果 u ( x ) ≠ T u(\boldsymbol{x}) \neq T u(x)=T,那么解决方案必须修复。在图 1 中, u ( x ) < T u(\boldsymbol{x})<T u(x)<T。因此,必须将额外的区域转换为城市区域。如果 u ( x ) > T u(\boldsymbol{x})>T u(x)>T,那么修复机制将放弃由 x \boldsymbol{x} x 定义的一些修改。
在 [36] 中,考虑了两种修复机制。这两种机制都是突变的一部分。在随机修复突变(RRM)中,我们随机选择任意 x i = 1 x_{i}=1 xi=1 并将其赋值为0,直到 u ( x ) = T u(\boldsymbol{x})=T u(x)=T。使用偏差修复突变(BRM),我们可以修复城市区域的不足或过剩。要修复的区域(转换为城市区域或放弃转换为城市区域)是随机选择的,但选择给定区域的概率与修复后细胞邻域(冯·诺依曼邻域)中相同类别的区域数量成比例。
3.3 标准算子
作为基线,我们考虑 [36] 中提出的算子,其中它们被引入到 NSGA-II 中。在本研究中,我们也考虑这些标准算子引入到 MOEA/D 中。
随机种群初始化(SP-I)是一种随机初始化,它从给定案例问题的初始表示中,通过随机均匀分布选择 T T T 个农业区域并将其转换为城市区域。
角度交叉(AC)算子通过组合父代矩阵的一半生成后代,这些矩阵通过穿过中心的分割线以随机变化的角度获得。
组合突变(MutC)顺序使用五个原子操作符。首先,随机块突变(RBM)以10%的概率执行。RBM 将随机大小的块区域从农业区域转换为城市区域。然后是 RRM,只有在 RBM 已经触发的情况下才会发生。接下来,再次以10%的概率随机单元突变(RCM)将一个随机选择的城市区域转换为农业区域,并将一个随机选择的农村农业区域转换为城市区域。然后,以100%的概率执行 BRM。最后,以10%的概率执行带偏差单元修补突变(BCPM)。它以与其大小成反比的概率将相邻的城市区域连续块转换为农村区域。接下来,以与其大小成正比的概率选择新的连续城市区域块。然后将之前移除的城市区域数量添加到该块中。农业区域转换为此块的概率取决于相反类别(城市区域)的相邻单元数量,就像 BRM 一样。MutC 保证输出可行的解决方案。
在本研究中,我们还考虑了 MutC 的修改版本。在 MutC2 中,我们跳过 RBM 后的 RRM。因此,RBM 所做的更改不会由 RRM 修复,而是由 BRM 修复,后者倾向于提出更好的紧凑性解决方案。
4 提议的交叉算子
灰箱优化器利用变量依赖性来提升其有效性。然而,第2节中描述的两种依赖性检查,即非线性和非单调性检查,都不适用于所考虑的解决方案编码,原因如下。在所考虑的 LUO 中,我们需要选择 T 个区域进行修改。因此,如果解决方案 x a \boldsymbol{x}_{\boldsymbol{a}} xa 是可行的,那么解决方案 x a g , x a h \boldsymbol{x}_{\boldsymbol{a}}^{\boldsymbol{g}}, \boldsymbol{x}_{\boldsymbol{a}}^{\boldsymbol{h}} xag,xah 和 x a g , h \boldsymbol{x}_{\boldsymbol{a}}^{\boldsymbol{g}, \boldsymbol{h}} xag,h 将是不可行的,因为它们的单位化不同于 u ( x a ) u\left(\boldsymbol{x}_{\boldsymbol{a}}\right) u(xa)。同时,修复程序遵循拉马克效应 [29],即修复程序修改原始解决方案。因此,在所考虑的典型于 LUO 的设置中 [30],我们无法计算 f ( x a g ) , f ( x a h ) f\left(x_{\boldsymbol{a}}^{\boldsymbol{g}}\right), f\left(x_{\boldsymbol{a}}^{\boldsymbol{h}}\right) f(xag),f(xah) 和 f ( x a g , h ) f\left(x_{\boldsymbol{a}}^{\boldsymbol{g}, \boldsymbol{h}}\right) f(xag,h),这使得非线性和非单调性检查不可用。由于相同的原因,使用沃尔什分解也是不可用的——许多基因型是不可行的,无法评估。
灰箱算子可以带来出色的结果 [41, 46],同时保持其简单性,并且通常是无参数的 [42]。相比之下,第3.3节中提出的标准算子似乎复杂,并需要额外的设置(例如,MutC 和 MutC2 中的一些子算子以给定概率执行)。
因此,我们提出了一种针对特定问题定义变量之间依赖性的概念。我们建议的核心直觉是,在 LUO 中,我们应该更多地考虑和处理同一类型的相邻区域,而不是单个区域。因此,对于给定的一对混合个体,我们根据三种过滤方式进行相邻区域的聚类。
我们建议的核心直觉基于以下观察:TEL 是一个空间度量,即单个变量(与单个区域相关)对 TEL 的影响不是由其单独值决定的,而是由其值与邻近区域变量值之间的关系决定的。因此,我们希望创建这样的变量集群并一起交换它们。
这种直觉与典型的灰箱算子假设相同,例如 PX [27, 42]。
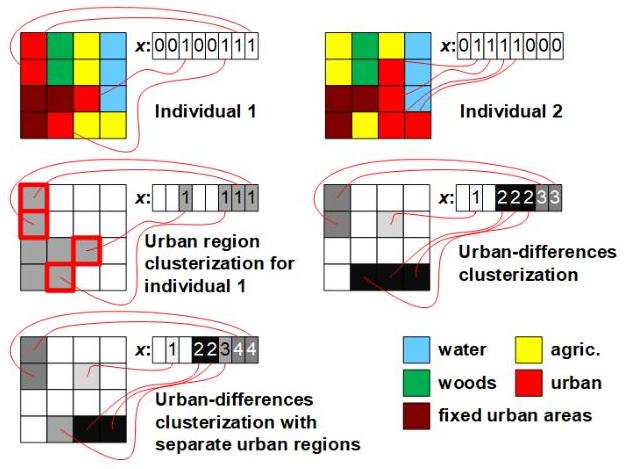
图 2:由所提出的交叉算子使用的集群化示例(我们考虑与图 1 相同的实例)
在所有提出的交叉算子中,我们获得依赖变量的集群。在后代创建过程中,我们以随机顺序处理所有集群,并从一个或另一个父母那里分配值。这个过程类似于均匀交叉,但我们考虑的是基因集群而不是单个基因。
图 2 展示了三种用于交叉的变量集群化想法。简单的区域交叉(SRC)涉及将所有指代单一城市区域的变量分组,该城市区域由其中一个交叉个体表示(图 2 左列,中间行)。我们展示了一个例子,其中分组的变量不代表连续的区域,但通过固定的城区连接在一起。在创建后代时,SRC 将从第一个父代中选择一半的分组区域。SRC 的缺点是它创建了相对较大的不同基因组。此外,如果两个交叉个体表示相似的土地利用地图,那么使用 SRC,它们将无法交换那些相似区域的不同部分。因此,SRC 应当通过交换大区域来确保快速收敛,这些区域指的是高质量的解决方案,但在改善已找到的高质量解决方案方面可能不如其他方法有效。
为了克服潜在的 SRC 缺点,在差异区域交叉(DRC)中,我们建议聚集城市差异区域(图 2 右列,中间行)。对于示例个体,这种交叉会产生三个不同的变量集群。按照生成精确指代区域差异的掩码的想法,我们还提出了基于个体的差异区域交叉(IDRC)。IDRC 的工作方式与 DRC 相同,但它只聚集同一类别的变量。因此,在提出的示例中(图 2 右列,底部行),第二个 DRC 掩码被分为两个掩码。
所有提出的交叉类型产生的个体可能不可行。在交叉之后,我们以一定的概率执行 MutC 或 MutC2(取决于优化器的配置)。如果个体在这些操作之后仍然不可行,则使用 RRM 或 BRM 进行修复。
5 提议的初始化程序
在 [36] 中成功提出了针对特定问题的变异算子。在前一节中,我们展示了如何利用问题依赖的直觉来提出变量依赖性概念,并在标准依赖性概念不适用时实现依赖性变量的集群化。然而,提出有效的特定问题机制的潜力不仅限于变异和交叉。一些研究表明,生成适当的初始种群可以提高结果质量 [2,14]。因此,我们提出了四种种群初始化程序,以验证它们在改善结果方面的潜力。其中一些程序基于第 3.3 节中呈现的变异算子所使用的相同或类似的直觉。
在基于土壤质量偏差的初始化(SQ-I)中,我们通过随机选择农业区域并以概率 1 − s q 1-s q 1−sq 将其转换为城市区域来创建个体,其中 s q s q sq 是给定区域的标准化土壤质量,即单元格的 a r v k a_{r v k} arvk 除以给定样本的最大 a r v k a_{r v k} arvk 值。此操作持续进行,直到转换了 T T T 个区域。与 SP-I(见第 3.3 节)类似,要转换的农业区域是随机选择的,但高价值区域的选择概率较低。SQI 结果种群应包含确保较低农业质量损失的个体。
在基于总边缘长度偏差的初始化(TEL-I)中,我们通过随机选择农业区域并以概率 u / 4 u / 4 u/4 将其转换为城市区域来创建个体,其中 u u u 是相邻城市区域的数量。TEL-I 应该提出适应 TEL 度量的个体种群。
[36] 中的研究表明,通过结合各种变异算子可以同时考虑两个目标函数,从而获得更好的结果。因此,我们提出了 SQ-I 和 TEL-I 的混合体。
混合 SQ/TEL 初始化(HYB-I)的工作方式与 SQ-I 和 TEL-I 相同,但转换概率等于 ( 1 − s q ) ∗ ( u / 4 ) \sqrt{(1-s q) *(u / 4)} (1−sq)∗(u/4)。因此,HYB-I 结合了 SQ-I 和 TEL-I 的特性。在半半初始化(HAL-I)中,一半种群使用 SQ-I 创建,另一半使用 TEL-I 创建。
6 实验
在本研究中,我们提出了针对所考虑 LUO 问题的新交叉算子和种群初始化程序。所提实验的目标是回答以下问题:
Q1. 所提出的交叉算子(SRC、DRC 和 IDRC)是否能比标准的 AC 交叉算子更有效地提高优化器的效果?
Q2. 所提出的种群初始化程序是否对结果质量有积极影响?
Q3. 所提出的机制的影响是否取决于优化器?
为了回答上述问题,我们将所提出的机制引入到 NSGA-II 和 MOEA/D 中,这是两个知名的多目标专用优化器。这一选择的另一优点是 NSGA-II 和 MOEA/D 的程序差异显著,例如,前者考虑支配关系来决定哪些个体质量更高,而后者通过标量化适应度来达到这一目的。请注意,[36] 中的先前研究仅考虑了 NSGA-II。
6.1 实验设置
我们使用了14个 LUO 基准测试,其中12个已经在 [35, 36] 中考虑过。其中三个用于调整和初始运算符影响分析。停止条件是100000次适应度函数评估(FFE),与 [36] 中相同。所有优化器及其版本均在 Python 中实现。对于 NSGA-II,我们使用了 DEAP 框架提供的选择机制 1 { }^{1} 1。对于 MOEA/D,我们基于 2 { }^{2} 2 提供的源代码进行了实现。
每个优化器(NSGA-II/MOEA/D)都考虑了所有可用配置,具体取决于交叉算子(AC/SRC/DRC/IDRC)、变异算子(MutC/MutC2)、种群初始化程序(SP-I/SQ-I/TEL-I/HYB-I/HAL-I)和修复算子(RRM, BRM)。基于它们的结果,选择了最有前途的算子,然后对所有可能的组合进行了调整程序,如下所述。
每次组合调整两次,一次使用初始参数种群大小100,交叉和变异概率为 50 % 50 \% 50%,第二次交叉概率为 90 % 90 \% 90%,变异概率为 10 % 10 \% 10%。由于过程的随机性,使用了5个随机种子来比较参数设置。
首先,计算了初始参数组合平均超体积。然后调整种群大小。在10次迭代中,从给定步长(大小为40)开始,修改最佳找到的种群大小(增加或减少)。对于在给定迭代中分析的种群大小,计算给定设置的平均超体积。如果得分比原始得分更好,则标记为当前最佳参数。如果更差,则改变方向(从加法变为减法,反之亦然)。如果变化是从减法变为加法,则首先将步长减半。经过10次迭代后,当前最佳种群成为进一步调整的基础参数,同时也成为调整的种群大小和结果。
交叉概率和变异概率以相同的方式进行调整。初始调整步长为 5 % 5 \% 5%。
所有步骤都包括护栏以处理无效参数的边缘情况,如零或负种群大小或概率,以及超过 100 % 100 \% 100% 的概率。然而,这些并不改变过程的整体思路。
对于最佳组合,每个实验重复20次,现在使用所有14个样本。为了验证结果差异的统计显著性,我们使用了 Wilcoxon 符号秩检验,显著性水平为 5 % 5 \% 5%。完整的源代码和实验的完整详细结果可在 Zenodo [17] 和 GitHub 3 { }^{3} 3 上获得。
1
{ }^{1}
1 gitHub.com/DEAP/deap
2
{ }^{2}
2 sites.google.com/view/moead/home
3
{ }^{3}
3 gitHub.com/KubaMaciazek/Gray-Box-concepts-for-Land-Use-Assignment
所考虑的 LUO 问题是多目标的。因此,我们考虑两种度量来检查所提出的 PF 的质量。逆世代距离(IGD)定义如下。
D P F → S ( S ) = 1 ∣ P F ∣ ∑ f ′ ∈ P F min x ∈ S { d ( f ( x ) , f θ ) } D_{\mathcal{P}_{F} \rightarrow \mathcal{S}}(\mathcal{S})=\frac{1}{\left|\mathcal{P}_{F}\right|} \sum_{f^{\prime} \in \mathcal{P}_{F}} \min _{x \in \mathcal{S}}\left\{d\left(f(x), f^{\theta}\right)\right\} DPF→S(S)=∣PF∣1f′∈PF∑x∈Smin{d(f(x),fθ)}
其中 P F \mathcal{P}_{F} PF 是最优 PF, S \mathcal{S} S 是被评估的 PF, d ( ⋅ , ⋅ ) d(\cdot, \cdot) d(⋅,⋅) 是欧几里得距离。
最优 IGD 值为 0,当 S \mathcal{S} S 覆盖 P F \mathcal{P}_{F} PF 时出现。这里,我们考虑现实世界的 LUO 实例,其中 P F \mathcal{P}_{F} PF 未知。因此,我们以以下方式构建伪最优 PF。我们考虑所有优化器返回的所有 PF,并从这样一个集中选择非支配点。这样的伪最优 PF 不一定是最佳的,但至少与所有被评估的 PF 相等或更好,并足以计算 IGD。同样的 IGD 伪最优 PF 构建程序在 [22] 中也被采用。
第二个 PF 质量度量是超体积(HV),定义如下:
H V ( S ) = Λ ( ⋃ s ∈ S { s ′ { s < s ′ < s nadir } ) H V(\mathcal{S})=\Lambda\left(\bigcup_{s \in \mathcal{S}}\left\{s^{\prime}\left\{s<s^{\prime}<s^{\text {nadir }}\right\}\right)\right. HV(S)=Λ(s∈S⋃{s′{s<s′<snadir })
其中 Λ \Lambda Λ 是勒贝格测度, S \mathcal{S} S 是被评估的 PF, s s s 是 S \mathcal{S} S 中的一个点, s nadir s^{\text {nadir }} snadir 是纳迪尔点 [13]。
在与 HV 和 IGD 相关的结果中,我们考虑它们的归一化值,计算方法如下: N ( V r ) = ( V r − V min ) / ( V max − N\left(V_{r}\right)=\left(V_{r}-V_{\min }\right) /\left(V_{\max }-\right. N(Vr)=(Vr−Vmin)/(Vmax− V min V_{\min } Vmin,其中 N ( V r ) N\left(V_{r}\right) N(Vr) 是归一化函数, V r V_{r} Vr 是归一化值, V min , V max V_{\min }, V_{\max } Vmin,Vmax 分别是所有考虑的优化器获得的给定度量的最小值和最大值。注意 HV 是最大化,IGD 是最小化。另一种考虑的归一化类型是排名。
6.2 结果
在第4节和第5节中,我们提出了一系列针对特定问题的机制。然而,本工作的关键提议是基于所提出的变量依赖性理解 LUO 的三种提出的交叉算子(SRC、DRC、IDRC)。它们的目标是支持有效的混合,因为灰箱机制不可用。因此,我们希望比较基础 MOEA/D 和 NSGA-II 版本及其使用三种提出的交叉算子之一的版本。基础版本使用第3.3节中描述的标准算子,即用于种群初始化的 SP-I,用于交叉的 AC 和用于变异的 MutC。
在图3中,我们展示了在调整过程中考虑的三个LUO实例的详细比较。我们报告了HV和IGD为基础的MOEA/D和NSGA-II优化器及其使用三种提出的交叉算子之一的版本(使用RRM或BRM修复交叉结果)之间的比较。图3显示,对于两个优化器,使用DRC在每个考虑的测试案例中都优于AC。IDRC也优于AC,但并非在所有情况下都如此。SRC的表现不如AC。对于IGD和MOEA/D,DRC在所有情况下都优于AC。然而,对于IGD和NSGA-II,DRC和AC表现相当好。所考虑比较的 p p p-值可以在补充材料中找到。
上述观察允许得出以下初步结论。SRC创建了太大掩码,因为它考虑了太多无关的依赖性。考虑到典型的链接概念,我们可以指出SRC遭受了错误链接[25],即认为某些变量是依赖的,尽管它们实际上是独立的。因此,它创建了太大的掩码,可能会降低结果的质量[23])。因此,与其他交叉类型相比,其性能较低。
DRC对于所有考虑的MOEA/D和NSGAII版本来说是最有效的。IDRC的表现不如DRC。这种观察表明IDRC创建了太小的掩码,忽略了太多的变量依赖性。因此,可以说它遭受了缺失链接,即忽略了某些变量之间的依赖性,这导致掩码太小,降低了结果的质量[47]。
在实验的主要部分中,我们考虑了所有可能的优化器版本和所有14个LUO实例。出于实际原因,我们报告了每个考虑的优化器的四个最佳版本和基础版本的结果。所有优化器版本的完整结果可以在源代码和第6.1节中提到的结果包中找到。表1展示了每个优化器的五个选定版本的详细配置及其基于IGD和HV的排名。优化器按照其由联合排名(IGD和HV排名的平均值)指示的质量进行排序。此外,我们报告了对于给定版本比其基础版本更好或更差的考虑LUO实例的数量。1与图3中呈现的结果一致。所有最有效的MOEA/D版本和四个NSGA-II版本中的三个使用DRC交叉。三个最佳的MOEA/D版本,具有相似的排名结果,考虑了三种不同的初始化程序(包括最简单的SQ-I),这表明它们对结果质量的影响可以忽略不计。其中两个使用MutC2进行变异,一个使用MutC,这确认了它们对结果质量的影响也很低。无论考虑哪个MOEA/D版本,其调整后的参数设置要么相同要么相似。因此,参数设置对结果的影响并不显著。最后,所有四个最佳的MOEA/D版本在所有14个考虑的实例中(两个版本)或在13个实例中优于基础MOEA/D版本,这证实了所提出的DRC交叉带来了类似于典型灰箱算子的有效性改进潜力,适用于它们适用的问题[45]。
DRC交叉也提高了NSGA-II的有效性。使用IDRC的两个最佳NSGA-II版本(列表中唯一使用不同交叉的优化器版本)在所有考虑的情况下都优于基础NSGA-II版本。这一结果对于表现第三好的NSGA-II版本来说仍然令人信服,该版本在11个实例上表现更好。然而,第三好的版本被基础NSGA-II击败。这样的结果表明所提出的交叉积极影响了NSGA-II的有效性。请注意,总体而言,NSGA-II的表现明显不如MOEA/D。这样的结果并不令人惊讶,因为基于其他最新研究可以得出类似的观察结果[6, 42, 43]。除了上述结果外,我们在补充材料中支持帕累托前沿可视化。
结果证实,所提出的DRC交叉显著提高了两个考虑的多目标优化器的有效性。连同本文提出的其他机制,
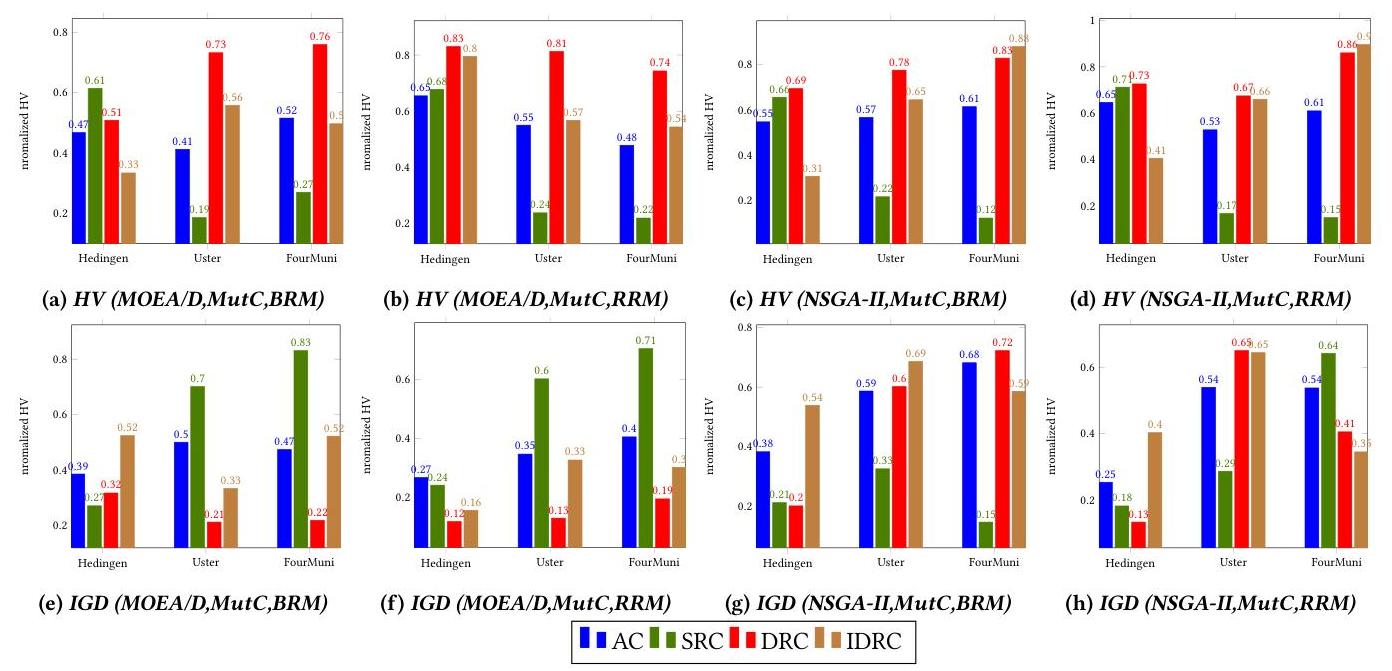
图3:所提出的交叉算子的影响(基础优化器、变异类型、交叉结果修复操作)
表1:最佳优化器及其基础版本的整体基于排名的比较
| Opt | 优化器版本 | | | | 配置 | | | 联合排名 (IGD-HV)
Z
\mathbf{Z}
Z | vs. 基础版 | | IGD 排名 | | | | HV 排名 | |
| :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: |
| | | 初始化 | 变异 | 交叉 | 修复 | 种群 | 交叉 | 变异 | | 更好 | 更差 | 中等 | 平均 | 最小 | 最大 | 平均 | 最小 | 最大 |
| MOEA/D | HYB-I | MutC | DRC | RRM | 100 | 0.5 | 0.5 | 2.29 | 14 | 0 | 1.5 | 2.21 | 1 | 1 | 2 | 2.36 | 1 | 2 |
| MOEA/D | TEI-I | MutC2 | DRC | RRM | 100 | 0.5 | 0.5 | 2.46 | 13 | 1 | 2 | 2.71 | 1 | 8 | 2 | 2.21 | 1 | 7 |
| MOEA/D | SQ-I | MutC2 | DRC | RRM | 110 | 0.5 | 0.6 | 2.82 | 14 | 0 | 2.5 | 2.71 | 1 | 4 | 3 | 2.93 | 1 | 4 |
| MOEA/D | SQ-I | MutC2 | DRC | RRM | 100 | 0.5 | 0.5 | 3.68 | 13 | 1 | 3 | 3.64 | 3 | 6 | 4 | 3.71 | 1 | 6 |
| NSGA-II | HAL-I | MutC | IDRC | RRM | 540 | 1.0 | 0.1 | 5.18 | 14 | 0 | 6 | 5.43 | 1 | 8 | 5.5 | 4.93 | 1 | 6 |
| MOEA/D | SP-I | MutC | AC | RRM | 100 | 0.5 | 1.0 | 5.75 | 基础 MOEA/D | 5 | 5.71 | 4 | 8 | 5 | 5.79 | 3 | 9 | |
| NSGA-II | HAL-I | MutC2 | DRC | RRM | 300 | 1.0 | 0.5 | 6.43 | 14 | 0 | 6.5 | 6.29 | 2 | 9 | 7 | 6.57 | 3 | 8 |
| NSGA-II | SQ-I | MutC2 | DRC | RRM | 120 | 0.9 | 0.5 | 8.11 | 11 | 3 | 8 | 8.07 | 6 | 10 | 8 | 8.14 | 7 | 9 |
| NSGA-II | HAL-I | MutC2 | DRC | RRM | 100 | 0.5 | 0.5 | 8.75 | 6 | 8 | 10 | 9.00 | 5 | 10 | 9 | 8.50 | 5 | 10 |
| NSGA-II | SP-I | MutC | AC | RRM | 100 | 0.5 | 1.0 | 9.54 | 基础 NSGA-II | 9 | 9.21 | 8 | 10 | 10 | 9.86 | 9 | 10 | |
DRC允许提出一个专门针对LUO的优化器,该优化器显著优于所考虑的竞争基准优化器。
7 结论
在这项工作中,我们考虑了一个现实世界的多目标NP难问题。由于所考虑的LUO设置是灰箱难解的,我们提出了特定于问题的变量依赖性概念。使用这些概念,我们提出了DRC交叉。实验表明,DRC显著提高了两个基于完全不同概念的知名多目标专用优化器的有效性。连同其他特定于问题的机制,我们提出了新的基于MOEA/D和NSGA-II的优化器,这些优化器在所有考虑的LUO实例中优于竞争优化器。
未来工作的主要方向将集中在为LUO提出无参数的优化器 [16, 22]。另一种自然的选择是提出基于捐赠者的混合算子,类似于PX [42] 或最优混合 [39]。最后,一个有趣的想法是提出一种非灰箱难解的LUO表示方法,从而允许使用灰箱杠杆。这种研究路径的主要困难在于获得一种几乎所有或几乎所有的变量都是相互依赖的问题表示方法,这将
使灰箱算子不可用 [40]。最后,考虑统计分析预测的依赖性 [9,39] 看起来非常有前景。
致谢
Jakub Maciążek 和 Michal Przewozniczek 得到了波兰国家科学中心(NCN)的支持,资助编号为 2020/38/E/ST6/00370。Jonas Schwaab 得到了瑞士国家科学基金会(SNSF)通过科学交流资助 IZSEZ0_229824 的支持。
参考文献
[1] Jeroen C. J. H. Aerts, Erwin Eisinger, Gerard B. M. Heuvelink, 和 Theodor J. Stewart. 2003. 使用线性整数规划进行多站点土地利用分配。地理分析 35, 2 (2003), 148-169. doi:10.1111/j.1538-4632.2003.tb01106.x arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.1538-4632.2003.tb01106.x
[2] David A. Bennett, Ningchuan Xiao, 和 Marc P. Armstrong. 2004. 使用进化算法探索公共政策的地理后果。美国地理学家协会年鉴 94, 4 (2004), 827-847. doi:10.1111/j.1467-8306.2004.00437.x arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.1467-8306.2004.00437.x
[3] Oliver Chikumbo, Erik Goodman, 和 Kalyanmoy Deb. 2014. 基于三重底线的多目标决策方法用于土地管理问题。
多准则决策分析杂志 22 (2014年12月). doi:10.1002/mcda.1536
[4] Kalyaninoy Deb 和 David E. Goldberg. 1993. 欺骗性和简单二进制函数的充分条件。Ann. Math. Artif. Intell. 10, 4 (1993), 385-408.
[5] K. Deb, A. Pratap, S. Agarwal, 和 T. Meyarivan. 2002. 快速且精英的多目标遗传算法:NSGA-II。IEEE 进化计算学报 6, 2 (2002年4月), 182-197.
[6] Bild Dechel, Geoffrey Provost, 和 Byung-Woo Hong. 2021. 增强Mosaic的逃离机制。2021 IEEE进化计算大会 (CEC) (Kraków, Poland). IEEE Press, 1163-1170. doi:10.1109/CEC45853.2021. 9500957
[7] Arkadiy Dushatskiy, Tanja Alderliesten, 和 Peter A. N. Bosman. 2021. 通过结合有效学习沃尔什系数和依赖关系设计代理辅助遗传算法的新方法。ACM Trans. Evol. Learn. Optim. 1, 2, Article 5 (2021年7月), 23页. doi:10.1145/3453141
[8] R. B. Heckendorn. 2002. 嵌入式景观。进化计算 10, 4 (2002), 345-369.
[9] Shih-Huan Hsu 和 Tian-Li Yu. 2015. 通过成对链接检测、增量链接集和受限/回混实现优化:DSMGA-II。遗传与进化计算会议论文集 (GECCO '15). ACM, 519-526.
[10] Kangning Huang, Xiaoping Liu, Xia Li, Juyong Liang, 和 Shenjing He. 2012. 改进的人工免疫系统以寻找大规模地区土地利用分配问题的Pareto前沿。国际地理信息系统期刊 27 (2012年11月), 922-946. doi:10.1080/13658816.2012.730147
[11] Andrea Kaim, Anna Corel, 和 Martin Volk. 2018. 农业用地分配的多标准优化技术综述。环境建模与软件 105 (2018年7月). doi:10.1016/eevsoft.2018.05.051
[12] Marcin Michal Komarnicki, Michal Witold Przewozniczek, Halina Kwamicka, 和 Krzysztof Walkowiak. 2023. 大规模全局优化的增量递归排名分组。IEEE 进化计算学报 27, 3 (2023), 1498-1513.
[13] Maciej Laszczyk 和 Pawel B. Myszkowski. 2019. 多目标优化质量度量调查:构建互补的多目标质量度量集合。群体智能与进化计算 48 (2019), 109-133. doi:10.1016/j.swevo.2019.04.001
[14] Sven Lautenbach, Martin Volk, Michael Strauch, Gerald Whittaker, 和 Ralf Seppelt. 2013. 基于优化的生物柴油作物生产权衡分析,用于管理农业流域。环境模型软件 48 (2013), 98-112. https://api.semanticscholar.org/CorpusID:9210561
[15] Florian Leprétre, Sébastien Verel, Cyril Fonlupt, 和 Virginie Marion. 2019. 使用沃尔什函数作为伪双态优化问题的代理模型。遗传与进化计算会议论文集 (GECCO '19). Association for Computing Machinery, New York, NY, USA, 303-311. doi:10.1145/3321707.3321800
[16] Ngoc Hoang Loong, Dan La Poutré, 和 Peter A.N. Bosman. 2018. 具有交错多重启动方案的多目标基因池最优混合进化算法。群体智能与进化计算 40 (2018), 238 - 254. doi:10. 1016/j.swevo.2018.02.005
[17] Jakob Maciążek, Michal Witold Przewozniczek, 和 Jonas Schwaab. 2025. 发表“在灰盒难解的双模态土地利用分配问题中寻找和利用替代变量依赖概念”的复制包。Zenodo. doi:doi.org/10.5281/zenodo.13198495
[18] Zohreb Masoumi, Jamshid Maleki, Saadi Mesgari, 和 Ali Mansourian. 2016. 使用进化算法进行多目标地理分析以分配土地用途和支持决策:土地用途分配和支持决策。地理分析 49 (2016年6月). doi:10.1111/gean.12111
[19] M. Munetomo 和 D.E. Goldberg. 1999. 使用非线性检查识别连锁的遗传算法。IEEE SMC’99 Conference Proceedings, 1999 IEEE International Conference on Systems, Man, and Cybernetics (Cat. No.99CH37028), Vol. 1. 595-600 vol.1. doi:10.1109/ICSMC.1999.814159
[20] Masaharu Munetomo 和 David E. Goldberg. 1999. 使用非单调性检测识别连锁的重叠函数。Evol. Comput. 7, 4 (1999年12月), 377-398. doi:10.1162/evco.1999.7.4.377
[21] Monalisa Pal 和 Sanghamitra Bandyopadhyay. 2016. 许多目标优化中收敛度量和超体积指标的可靠性。2016年第二届控制、仪器、能源与通信国际会议 (CIEC) 511-515. doi:10.1109/CIEC.2016.7513006
[22] Michal Witold Przewozniczek, Piotr Dziurzanski, Shuai Zhao, 和 Leandro Soares Indrusiak. 2021. 解决工业过程规划问题的多目标无参数种群金字塔。群体智能与进化计算 60 (2021), 100773. doi:10.1016/j.swevo.2020.100773
[23] Michal W. Przewozniczek, Bartosz Frej, 和 Marcin M. Komarnicki. 2020. 测量和改进现代进化算法应用于部分加性可分离问题的连锁学习质量和改进。2020年遗传与进化计算会议论文集 (GECCO '20). Association for Computing Machinery, New York, NY, USA, 742-750.
24] Michal Witold Przewozniczek, Bartosz Frej, 和 Marcin Michal Komarnicki. 2024. 从直接到定向变量依赖——真实世界和理论问题中的非对称依赖发现。IEEE 进化计算学报 (2024), 1-1. doi:10.1109/TEVC.2024.3496193
[25] Michal W. Przewozniczek 和 Marcin M. Komarnicki. 2020. 实证连锁学习。IEEE 进化计算学报 24, 6 (2020年12月), 10971111 .
[26] Michal W. Przewozniczek, Marcin M. Komarnicki, 和 Bartosz Frej. 2021. 使用实证连锁学习直接发现连锁。遗传与进化计算会议论文集 (GECCO '21). Association for Computing Machinery, New York, NY, USA, 609-617. doi:10.1145/3449639. 3459333
[27] Michal W. Przewozniczek, Renato Tinós, Bartosz Frej, 和 Marcin M. Komarnicki. 2022. 从黑箱到暗灰优化——通过直接实证连锁发现和分区交叉。遗传与进化计算会议论文集 (GECCO '22). Association for Computing Machinery, New York, NY, USA, 269-277. doi:10.1145/3512290.3528734
[28] Michal Witold Przewozniczek, Renato Tinós, 和 Marcin Michal Komarnicki. 2023. 第一改进爬山法与连锁学习——将暗灰盒优化引入统计连锁学习遗传算法。遗传与进化计算会议论文集 (GECCO '23). ACM, 946-954.
[29] Michal Witold Przewozniczek, Krzysztof Walkowiak, 和 Michal Albin. 2017. 弹性光网络中路由和频谱分配问题的鲍德温效应的进化成本。应用软计算 52, C (2017年3月), 843-862.
[30] Md Rahman 和 György Szabó. 2021. 使用空间数据进行多目标城市土地利用优化:系统回顾。可持续城市与社会 74 (2021年7月), 103214. doi:10.1016/j.scs.2021.103214
[31] Amin V. Bernabé Rodriquez 和 Carlos A. Coello Coello. 2021. 基于S能量的多目标进化算法交配限制集成。2021 IEEE计算智能研讨会系列 (SSCI). 1-8. doi:10. 1109/SSCI50451.2021.9660112
[32] Miao Rong, Dunwei Gong, Witold Pedrycz, 和 Ling Wang. 2020. 动态多目标进化优化的多模型预测方法。IEEE 进化计算学报 24, 2 (2020), 290-304. doi:10.1109/ TEVC.2019.2925358
[33] Jonas Schwaab, Kalyan Deb, Erik Goodman, Sven Lautenbach, Maarten van Strien, 和 Adrienne Grét-Regamey. 2017. 提高遗传算法在土地利用分配问题上的性能。国际地理信息系统期刊 32 (2017年12月), 1-24. doi:10.1080/13658816.2017.1419249
[34] Jonas Schwaab, Kalyaninoy Deb, Erik Goodman, Sven Lautenbach, Maarten van Strien, 和 Adrienne Grét-Regamey. 2017. 减少瑞士市政当局因紧凑型城市发展导致的农业生产力损失。计算机、环境与城市系统 65 (2017), 162-177. doi:10.1016/j. compresurboys.2017.06.005
[35] Jonas Schwaab, Kalyaninoy Deb, Erik Goodman, Sven Lautenbach, Maarten van Strien, 和 Adrienne Grét-Regamey. 2017. 减少瑞士市政当局因紧凑型城市发展导致的农业生产力损失。计算机、环境与城市系统 65 (2017), 162-177. doi:10.1016/j. compresurboys.2017.06.005
[36] Jonas Schwaab, Kalyaninoy Deb, Erik Goodman, Sven Lautenbach, Maarten J. van Strien, 和 Adrienne Grét-Regamey. 2018. 提高遗传算法在土地利用分配问题上的性能。国际地理信息系统期刊 32, 5 (2018), 907-930. doi:10.1080/13658816.2017.1419249
[37] Theodor Stewart 和 Ron Janssen. 2014. 基于GIS的多目标土地利用规划算法。计算机、环境与城市系统 46 (2014年7月). doi:10.1016/j.compensurboys.2014.04.002
[38] Bernarde R.N. Strassburg, Alvaro Inbarrem, Hawthorne L. Beyer, Carlos Leandro Cordeiro, Renato Crouzeilles, Catarina C. Jakovac, André Braga Junqueira, Eduardo Lacerda, Agnieszka E. Latawiec, Andrew Balmford, Thomas M. Brooks, Stuart H.M. Butchart, Robin L. Chazdon, Karl Heinz Erb, Pedro Brancalion, Graeme Buchanan, David Cooper, Sandra Díaz, Paul F. Donald, Valerie Kapos, David Leclère, Lera Miles, Michael Obersteiner, Christoph Plutzae, Carlos Alberto de M. Scaramuzza, Fabio R. Scarano, 和 Piero Visconti. 2020. 全球生态恢复优先区域。自然 386, 7831 (2020年10月29日), 724-729. doi:10.1038/s41586-020-2784-9
[39] Dirk Thierens 和 Peter A.N. Bosman. 2015. 基于连锁树遗传算法的分层问题求解。遗传与进化计算会议论文集 (GECCO '15). ACM, 877-884.
[40] Renato Tinós, Michal Przewozniczek, Darrell Whitley, 和 Francisco Chicano. 2023. 带连锁学习的遗传算法。遗传与进化计算会议论文集 (GECCO '23). Association for Computing Machinery, New York, NY, USA, 981-989. doi:10.1145/3583131. 3590349
[41] Renato Tinós, Michal W. Przewozniczek, 和 Darrell Whitley. 2022. 基于变量交互的迭代局部搜索扰动用于伪布尔优化。遗传与进化计算会议论文集 (GECCO '22) ACM, 296-304.
[42] Renato Tinós, Darrell Whitley, 和 Francisco Chicano. 2015. 分区交叉用于伪布尔优化。2015 ACM基础遗传算法XIIF会议论文集 (Aberystwyth, United Kingdom) (POGA '15) Association for Computing Machinery, New York, NY, USA, 137-149. doi:10. 1145/2725494.2725497
[43] Michal K. Tomczyk 和 Miłosz Kaduński. 2020. 基于分解的交互式多目标进化算法。IEEE 进化计算学报 24, 2 (2020), 320-334. doi:10.1109/TEVC. 2019. 2915767
[44] Sébastien Verel, Bilel Derbel, Arnaud Liefooghe, Hernán Aguirre, 和 Kiyoshi Tanaka. 2018. 基于沃尔什分解的伪布尔函数代理模型。Anne 并行问题求解自然会议 - PPSN XV,
Auger, Carlos M. Fonseca, Nuno Lourenço, Penousal Machado, Luís Paquete, 和 Darrell Whitley (Eds.). Springer International Publishing, Cham, 181-195.
[45] D. Whitley. 2019. 下一代遗传算法:用户指南和教程。元启发式手册。Springer, 245-274.
[46] L. Darrell Whitley, Francisco Chicano, 和 Brian W. Goldman. 2016. Mk景观的灰箱优化 Mk景观和最大Ksat。演化计算 24, 3 (2016年9月), 491-519. doi:10.1162/EVCO_a_00184
[47] Tian-Li Yu 和 David E. Goldberg. 2004. 朝向理解遗传算法的模型构建的质量和效率。遗传与进化计算会议 - GECCO 2004, Kalyanmoy Deb (Ed.). Springer Berlin Heidelberg, Berlin, Heidelberg, 367-378.
[48] Q. Zhang 和 H. Li. 2007. MOEA/D:基于分解的多目标进化算法。IEEE 进化计算学报 11, 6 (2007年12月), 712-731. doi:10.1109/TEVC.2007.892759
参考论文:https://arxiv.org/pdf/2504.11882



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











