






Marina Danilevsky, Kristjan Greenewald, Chulaka Gunasekara, Maeda Hanafi, Lihong He, Yannis Katsis, Krishnateja Killamsetty, Yatin Nandwani, Lucian Popa, Dinesh Raghu, Frederick Reiss, Vraj Shah, Khoi-Nguyen Tran, Huaiyu Zhu, Luis Lastras
IBM Research
摘要
在大型语言模型(LLM)开发社区中,目前尚未形成类似于软件库的清晰模式来支持大规模协作。即使对于常见的检索增强生成(RAG)用例,目前也无法针对不同LLM提供商共同认可的一组明确定义的API编写RAG应用程序。受编译器内建函数概念的启发,我们通过引入一个面向RAG的LLM内建函数库来提出这一概念的部分要素。LLM内建函数被定义为可以通过明确定义且相对稳定的API调用的能力,其独立于LLM内建函数本身的实现方式。我们库中的内建函数以LoRA适配器的形式发布在HuggingFace上,并通过基于vLLM作为推理平台的软件接口提供明确的结构化输入/输出特性,同时在两个平台上都附有文档和代码。本文描述了每个内建函数的预期用途、训练细节和评估结果,以及多个内建函数的组合应用。
1 引言
最重要的软件设计模式之一是软件库的概念:具有良好文档接口的通用代码,能够促进具有不同专长的开发者之间的大规模协作。然而,在大型语言模型(LLM)领域,尚未出现类似的模式。例如,提示词库通常仅对特定模型有用。即使对于常见的检索增强生成(RAG)用例,目前也无法针对不同LLM提供商共同认可的一组明确定义的API编写RAG应用程序。类比先前的突破性技术的例子很多;例如,不同的指令集架构曾广泛应用于微处理器设计,使得代码在不同处理器之间不兼容,而不同的操作系统为希望使用系统资源的应用程序提供了不同的抽象。
历史表明,在系统设计的关键部分出现接口是不可避免的,这允许不同的专业化蓬勃发展并支持更复杂系统的创建。本文的目的在于介绍RAG背景下这一概念的部分提议。我们从编译器内建函数的概念中汲取灵感,这些函数频繁出现到足以被包含在编程语言中。编译器负责在软件预期运行的具体计算机架构上生成实现这些函数的指令,但可以在优化这种实现时采取任何自由度。
在一个松散类似的概念中,我们将LLM内建函数定义为可以通过明确定义且相对稳定的API调用的能力,其独立于LLM内建函数本身的实现方式。性能指标(包括准确性、延迟和吞吐量)可能会在这些实现之间显著变化。我们认为,LLM内建函数最好以模型与提供熟悉接口给模型开发者的协同优化软件层的组合形式实现。这种模式已经在LLM社区中部分遵循;例如,Huggingface上的LLM模型通常打包有用于分词器的配置文件,这些文件将输入的结构化表示(例如工具描述、消息序列)转换为传递给LLM的实际原始标记。
我们提出了一个RAG LLM内建函数库,这些内建函数既以LoRA适配器的形式实现,也通过基于vLLM作为推理平台的软件接口实现明确的结构化输入/输出特性。为了说明目的,这些内建函数使用IBM Granite语言模型实现,未来有可能扩展到其他模型家族。我们指出,LLM内建函数的定义中没有任何内容要求它必须作为适配器构建;它可以以多种方式实现,包括简单地作为底层模型训练数据的一部分。本文是Greenewald等(2025)文章的姊妹篇,该文章介绍了激活LoRAs作为一种可以高效推理的方式实现LLM内建函数的机制。
1.1 RAG LLM内建函数库概述
LLM内建函数RAG库目前包含五个内建函数,每个内建函数都以用户与AI助手之间的单轮或多轮对话作为输入。其中三个内建函数还期望一组基础段落。每个内建函数的功能如下所述,表1总结了每个内建函数的输入和输出。
查询重写(QR)。给定以用户查询结尾的对话,QR将最后一个用户查询去上下文化,通过重写(必要时)将其转换为独立且可自行理解的等效版本。虽然这个适配器适用于任何多轮对话,但在RAG场景中特别有效,因为它将用户查询重写为独立版本的能力直接提高了检索器性能,从而提高了答案生成性能。这是一个预生成内建函数,因为建议在调用检索之前使用。
不确定性量化(UQ)。给定以助手响应结尾的对话,UQ计算一个确定性百分比,反映对前一个用户查询生成的答案的确定程度。UQ还可以将一个以用户查询结尾的对话作为输入,并根据查询本身预测确定性分数,而在生成答案之前。UQ也在基于文档的问题回答数据集上进行了校准,因此它可以用于为使用基础段落生成的RAG响应提供确定性分数。此内建函数可用于生成或预生成步骤。
幻觉检测(HD)。给定以助手响应结尾的对话和一组段落,HD为最后助手响应中的每个句子输出一个幻觉风险范围,相对于这组段落。它可以与产生多个生成响应的采样技术结合使用,其中一些可以根据其HD分数进行过滤。这是一个后生成内建函数,因为预期使用是在调用LLM生成响应之后。
可答性判断(AD)。给定以用户查询结尾的对话和一组段落,AD根据段落中的可用信息分类最终用户查询是否可答。它对于限制过于急切的模型非常有价值,通过识别不可答查询防止生成幻觉响应。它还可以用于指示系统重新查询检索器,使用替代表述获取更多相关的段落。这是一个预生成内建函数。
引用生成(CG)。给定以助手响应结尾的对话和一组段落,CG为最后助手响应从提供的段落生成引用。为响应中的每个句子(如果存在)生成引用,每个引用由来自支持段落的一组句子组成。这是一个后生成内建函数,因为预期使用是在调用LLM之后,因此可以用于为任何模型生成的响应创建引用。
1.2 RAG LLM内建函数实现
每个内建函数都通过为ibm-granite/granite-3.2-8binstruction微调的LoRA适配器实现。每个LoRA模型已在HuggingFace上发布:
- QR: https://huggingface.co/ibm-granite/granite-3.2-8b-lora-rag-query-rewrite
-
- UQ: https://huggingface.co/ibm-granite/granite-3.2-8b-lora-uncertainty
-
- HD: https://huggingface.co/ibm-granite/granite-3.2-8b-lora-rag-hallucination-detection
-
- AD: https://huggingface.co/ibm-granite/granite-3.2-8b-lora-rag-answerability-prediction
-
- CG: https://huggingface.co/ibm-granite/granite-3.2-8b-lora-rag-citation-generation
然而,推荐的使用方法是通过第二种发布机制:通过Granite IO Processing, 1 { }^{1} 1 这是一个框架,允许改变用户如何调用或推断IBM Granite模型以及模型输出如何返回给用户。换句话说,该框架允许扩展模型调用的功能。这特别有价值,因为内建函数的下游使用依赖于正确结构化的输出。尽管我们已经发布了单独的LoRAs,但我们强烈建议每个人使用Granite IO中的实现,并已提供了示例笔记本。
- CG: https://huggingface.co/ibm-granite/granite-3.2-8b-lora-rag-citation-generation
在本文其余部分,我们描述了库中每个内建函数的具体实现并评估其性能。我们还讨论了多个内建函数的组合,并展示了特定组合流的实现及评估。
2 查询重写
Granite 3.2 8b Instruct - 查询重写 是一个针对 ibm-granite/granite-3.2-8b-instruct 微调的LoRA适配器,用于以下任务:
给定用户与AI助手之间的多轮对话,将最后一轮用户的发言(查询)通过重写(必要时)转化为一个独立的版本,使其可以自行理解。
2.1 使用意图
查询重写适配器通常适用于多轮对话用例。它在RAG场景中特别有用,其将用户查询重写为独立版本的能力直接提高了检索器性能,从而间接提高了答案生成性能。
重写通常是扩展,即将查询中对实体、概念或对话中先前回合(无论是用户还是AI助手提到的)的隐式引用内联到查询中。这种扩展可以包括共指解析(即用实际实体替换代词)、处理省略现象(这是一种常见的语言现象,用户省略了句子或短语的一部分,但可以从上下文中理解)。
通过扩展后,查询成为一个独立的查询,仍等同于用户在最后一轮中所问的内容。重写的查询可以发送到下游任务(例如,在RAG场景中发送到检索器),作为对原始用户查询更好的替代,无需提供(可能非常长的)上下文。
输入:模型的输入是一个使用apply_chat_template函数转换为字符串的对话轮次列表。这些轮次可以在用户和助手角色之间交替,最后一轮假设来自用户。
为了触发LoRA适配器重写最后一轮用户发言,使用一个特殊的重写角色来触发模型的重写能力。该角色包括关键词"rewrite",后跟查询重写任务的简短描述。
<|start_of_role|>rewrite: Reword the final utterance from the USER into a single
utterance that doesn't need the prior conversation history to understand
the user's intent. If the final utterance is a clear and standalone question
, please DO NOT attempt to rewrite it, rather output the last utterance as
is. Your output format should be in JSON: | \"rewritten_question\": <REWRITE
> }"<|end_of_role|>
```
输出:当使用上述特殊重写角色提示时,模型生成一个包含实际重写问题的json对象。
注意:尽管查询重写的主要应用是在RAG场景中,此LoRA适配器也可用于重写其他对话用例中的用户问题(例如,访问数据库或其他API或工具)。因此,适配器不需要任何RAG文档(在RAG场景中上下文中可能存在),只需使用用户和助手之间的对话轮次。
请参见第A.1节,了解如何使用查询重写内建函数的示例。
# 2.2 评估
### 2.2.1 检索器评估
我们在MT-RAG基准Katsis等人(2025)上评估了不同查询重写策略下的Recall@k。所有检索段落均使用Elser检索器在与上述论文相同的设置下获得。除了LoRA适配器外,我们还包括几个其他基线,包括无重写(即将最后一轮用户发言直接发送到检索器),Mixtral重写,以及黄金重写(人工创建)。我们在三个不同的测试集上进行评估:a) 完整MT-RAG数据集(842个带有最后一轮用户发言的数据点);b) MT-RAG数据集的非独立子集,这是842个数据点中的260个最后一轮用户发言,经人工注释为非独立(即它们依赖于之前的上下文);c) MT-RAG数据集的独立子集,这是互补子集,包含所有被人工注释为独立的最后一轮用户发言。
在完整、非独立和独立子集的MT-RAG数据集上使用不同查询重写策略的检索召回评估(Recall@k)分别显示在表2、表3和表4中。
| 重写策略 | Recall@5 | Recall@10 | Recall@20 |
| :-- | :-- | :-- | :-- |
| 无重写 | 0.49 | 0.59 | 0.67 |
| Mixtral 8x7b | 0.52 | 0.64 | 0.72 |
| Granite 3.2-8b-instruct-query-rewrite-LoRA | 0.56 | 0.68 | 0.76 |
| 黄金重写 | 0.56 | 0.67 | 0.75 |
表2:完整MT-RAG数据集检索任务中不同查询重写策略的比较
| 重写策略 | Recall@5 | Recall@10 | Recall@20 |
| :-- | :-- | :-- | :-- |
| 无重写 | 0.26 | 0.39 | 0.44 |
| Mixtral 8x7b | 0.36 | 0.49 | 0.57 |
| Granite 3.2-8b-instruct-query-rewrite-LoRA | 0.44 | 0.57 | 0.66 |
| 黄金重写 | 0.48 | 0.58 | 0.66 |
表3:MT-RAG数据集非独立子集检索任务中不同查询重写策略的比较
如果我们关注Recall@20数值,作为一个实例,使用Granite 3.2-8b LoRA适配器进行查询重写相比不进行重写的策略总体提升了9个百分点。这种提升在非独立片段上更为明显,使用Granite 3.2-8b LoRA适配器进行查询重写比不进行重写的策略提升了22个百分点。此外,我们可以观察到LoRA重写的结果与黄金重写的结果非常接近,
| 重写策略 | Recall@5 | Recall@10 | Recall@20 |
| :-- | :-- | :-- | :-- |
| 无重写 | 0.61 | 0.72 | 0.79 |
| Mixtral 8x7b | 0.61 | 0.73 | 0.81 |
| Granite 3.2-8b-instruct-query-rewrite-LoRA | 0.63 | 0.75 | 0.83 |
| 黄金重写 | 0.61 | 0.72 | 0.79 |
表4:MT-RAG数据集独立子集检索任务中不同查询重写策略的比较
在非独立片段上(并且在独立片段上稍好些,因为人类标注者在将查询分类为独立时被指示保持不变,但LoRA适配器可能仍然执行一些重写,结果进一步提高了召回率)。
# 2.2.2 答案生成评估
我们评估了在不同查询重写策略下检索器检索出的顶级段落生成答案的质量。这里选择 $\mathrm{k}=20$,但其他值的 k 也有类似趋势。我们使用 Granite-3.2-8b instruct 作为答案生成器,并使用 RAGAS 忠实度 (RAGAS-F) 和 RAD-Bench 分数作为答案质量的度量标准。我们使用与上述相同的三个测试集。
在完整、非独立和独立子集的MT-RAG数据集上使用 RAGAS-F 和 RAD-Bench 的答案质量评估分别显示在表5、表6和表7中。
| 重写策略 | RAGAS-F | RAD-Bench |
| :-- | :-- | :-- |
| 无重写 | 0.73 | 0.66 |
| Mixtral 8x7b | 0.80 | 0.68 |
| Granite 3.2-8b-instruct-query-rewrite-LoRA | 0.81 | 0.70 |
| 黄金重写 | 0.79 | 0.69 |
表5:完整MT-RAG数据集答案质量中不同查询重写策略的比较
| 重写策略 | RAGAS-F | RAD-Bench |
| :-- | :-- | :-- |
| 无重写 | 0.61 | 0.62 |
| Mixtral 8x7b | 0.76 | 0.65 |
| Granite 3.2-8b-instruct-query-rewrite-LoRA | 0.79 | 0.69 |
| 黄金重写 | 0.80 | 0.69 |
表6:非独立子集MT-RAG数据集中不同查询重写策略的答案质量比较
| 重写策略 | RAGAS-F | RAD-Bench |
| :-- | :-- | :-- |
| 无重写 | 0.79 | 0.68 |
| Mixtral 8x7b | 0.82 | 0.70 |
| Granite 3.2-8b-instruct-query-rewrite-LoRA | 0.83 | 0.71 |
| 黄金重写 | 0.79 | 0.69 |
表7:独立子集MT-RAG数据集中不同查询重写策略的答案质量比较
正如Recall一样,这里也可以得出类似的观察。具体来说,当我们使用Granite 3.2-8b LoRA适配器进行查询重写时,相比于不进行重写的策略,RAGAS忠实度提高了8个百分点,RAD-Bench分数提高了4个百分点。这种改进在非独立片段上更为显著,使用Granite 3.2-8b LoRA适配器进行查询重写导致RAGAS忠实度提高了18个百分点,RAD-Bench分数提高了7个百分点。
# 2.3 训练细节
训练数据包含两类:1)独立示例,教导适配器避免重写已经独立的用户问题;2)非独立示例,包含多样化的模式,用于教导适配器扩展用户发言,使其成为独立的。
训练数据使用公开可用的Cloud语料库中的技术文档页面来自MT-RAG。基于这些文档,我们构建了一个高质量的人工创建对话数据集,其中对话的最后一轮有两种版本:非独立版本和相应的独立版本。训练数据集是专有的,并与一家第三方公司合作获得,该公司承包了人工标注者。
LoRA适配器使用PEFT在以下制度下进行了微调:秩 $=32$,学习率 $=3 \times 10^{-6}$,训练周期数 $=25$,基于验证集的早期停止,以及 $90 / 10$ 的训练和验证分割。
## 3 不确定性量化
Granite 3.2 8b Instruct - 不确定性量化 是一个针对 ibm-granite/granite-3.2-8b-instruct 的LoRA适配器,添加了在提示时提供校准确定性分数的能力,同时保留了 ibm-granite/granite-3.2-8b-instruct 模型的全部功能。该模型是一个经过微调的LoRA适配器,旨在模仿通过Shen等人(2024)的方法训练的校准器的输出。
### 3.1 使用意图
确定性分数定义。模型将以百分比形式响应,量化为10个可能值(即 $5 \%$, $15 \%$, $25 \% \ldots .95 \%$)。这个百分比在校准意义上解释为:给定一组分配了确定性分数为 $\mathrm{X} \%$ 的答案,大约 $\mathrm{X} \%$ 的这些答案应该是正确的。请参阅下面的评估实验,以验证这种行为在分布外的表现。
确定性分数解释。按照上述定义校准的确定性分数有时似乎偏向于中等确定性的原因如下。首先,作为人类,我们倾向于对自己的知识和无知过度自信——相比之下,校准模型不太可能输出非常高或非常低的信心分数,因为这些意味着正确或错误的确定性。您可能看到非常低信心分数的例子可能是模型的回答类似于“我不知道”,这很容易被评估为不是正确答案的问题(尽管这是适当的回答)。其次,请记住,模型正在自我评估——对我们或更大模型显而易见的正确或错误可能对8b模型不那么明显。最后,教会模型知道它知道和不知道的每一个事实是不可能的,因此它必须推广到难度各异的问题(其中一些可能是陷阱问题!)和未对其输出进行判断的设置。直观地说,它通过基于训练中评估的相关问题进行推断来做到这一点——这是一个本质上不精确的过程,导致了一些保守估计。
重要说明:确定性本质上是模型及其能力的内在属性。Granite-3.2-8b-Uncertainty-Quantification 并非旨在预测除自身或 ibm-granite/granite-3.2-8b-instruct 之外的任何其他模型生成响应的确定性。此外,确定性分数是分布量,因此在整体现实问题上表现良好,但在原则上可能在个别红队例子上得分令人惊讶。
### 3.1.1 使用步骤
有两个支持的使用场景。
场景 1. 回答问题并获取确定性分数按以下步骤进行。给定一个用户以用户角色书写的查询:
1. 使用基础模型正常生成响应(通过助理角色)。
${ }^{2}$ https://github.com/IBM/mt-rag-benchmark
2. 通过在确定性角色下生成提示模型生成确定性分数(在聊天模板中使用“确定性”作为角色,或者简单地附加 <|start_of_role|>certainty<|end_of_role|> 并继续生成)。
3. 3. 模型将以百分比形式响应,量化步长为 $10 \%$ (即 $05 \%$, $15 \%$, $25 \%$, ... $95 \%$)。请注意,分数和百分号后的任何额外文本可以忽略。当使用此角色时,可通过设置 "max token length" =3 来限制额外生成。
场景 2. 在生成答案之前,仅从问题(可选加上文档)预测确定性分数。给定一个用户以用户角色书写的查询:
4. 通过在确定性角色下生成提示模型生成确定性分数(在聊天模板中使用“确定性”作为角色,或者简单地附加 <|start_of_role|>certainty<|end_of_role|> 并继续生成)。
5. 2. 模型将以百分比形式响应,量化步长为 $10 \%$ (即 $05 \%$, $15 \%$, $25 \%$,... $95 \%$ )。请注意,分数和百分号后的任何额外文本可以忽略。当使用此角色时,可通过设置 "max token length" =3 来限制额外生成。
6. 3. 删除生成的确定性字符串,如有需要,使用基础模型正常生成响应(通过助理角色)。
请参阅第A.2节,了解如何使用不确定性量化内建函数回答问题并获得内在校准的确定性分数的示例。
# 3.1.2 可能的下游用例(未实现)
- 人类使用:确定性分数为人类用户提供何时信任模型答案的指示(应结合他们自己的知识加以补充)。
- - 模型路由/防护:如果模型的确定性较低(低于选定阈值),则值得将请求发送给更大、更强大的模型,或简单地选择不向用户展示响应。
- - RAG:Granite-3.2-8b-Uncertainty-Quantification 在基于文档的问题回答数据集上进行了校准,因此可以用于为使用RAG生成的答案提供确定性分数。这种确定性将是基于给定文档和模型自身知识的整体正确性预测(例如,如果模型正确但答案不在文档中,确定性仍然可以很高)。
### 3.2 评估
该模型在$\mathrm{MMLU}^{3}$数据集(未用于训练)上进行了评估。显示了基础模型(Granite-3.2-8b-instruct)和Granite-3.2-8b-UncertaintyQuantification的每项任务的预期校准误差(ECE)${ }^{4}$。我们的方法在任务中的平均ECE为0.064(满分为1),并在各任务中始终保持较低水平(最大任务ECE为0.10),相比基础模型平均ECE为0.20和最大任务ECE为0.60。值得注意的是,我们的ECE为0.064小于量化确定性输出之间的差距(10%量化步长)。此外,零样本性能在MMLU任务上没有下降,平均为89%。
### 3.3 训练细节
该模型是一个LoRA适配器,经过微调以提供确定性分数,模仿通过Shen等人(2024)方法训练的校准器的输出。
以下数据集用于校准和/或微调:
- BigBench (https://huggingface.co/datasets/tasksource/bigbench)
- - MRQA (https://huggingface.co/datasets/mrqa-workshop/mrqa)
${ }^{3}$ https://huggingface.co/datasets/cais/mmlu
${ }^{4}$ https://towardsdatascience.com/expected-calibration-error-ece-a-step-by-step-visual-explanation-with-python-codec3e9aa12937d
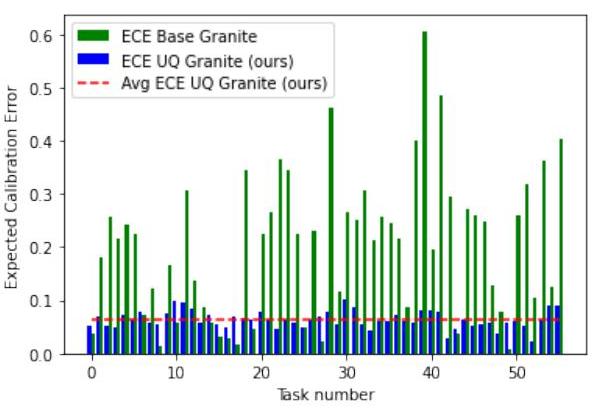
图1:UQ内建函数评估
- newsqa (https://huggingface.co/datasets/lucadillello/newsqa)
- - trivia_qa (https://huggingface.co/datasets/mandarjoshi/trivia_qa)
- - search_qa (https://huggingface.co/datasets/lucadillello/searchqa)
- - openbookqa (https://huggingface.co/datasets/allenai/openbookqa)
- - web_questions (https://huggingface.co/datasets/Stanford/web_questions)
- - smiles-qa (https://huggingface.co/datasets/alefgh/ChEMBL_Drug_Instruction_Tuning)
- - orca-math (https://huggingface.co/datasets/microsoft/orca-math-word-problems-200x)
- - ARC-Easy (https://huggingface.co/datasets/allenai/ai2_arc)
- - commonsense_qa (https://huggingface.co/datasets/tau/commonsense_qa)
- - social_iq_a (https://huggingface.co/datasets/allenai/social_i_qa)
- - super_glue (https://huggingface.co/datasets/aps/super_glue)
- - figqa (https://huggingface.co/datasets/nightingal3/fig-qa)
- - riddle_sense (https://huggingface.co/datasets/INK-USC/riddle_sense)
- - ag_news (https://huggingface.co/datasets/fancyzha/ag_news)
- - medmcqa (https://huggingface.co/datasets/openli/escienceai/medmcqa)
- - dream (https://huggingface.co/datasets/dataset-org/dream)
- - codah (https://huggingface.co/datasets/jaredfern/codah)
- - piqa (https://huggingface.co/datasets/ybisk/piqa)
# 4 幻觉检测
Granite 3.2 8b Instruct - 幻觉检测 是一个针对 ibm-granite/granite-3.2-8b-instruct 的LoRA适配器,微调用于模型输出的幻觉检测任务。给定用户与AI助手之间的多轮对话,以助手响应结束,并给出一组文档/段落,这些文档/段落是最后助手响应的基础,适配器会输出助手响应中每个句子的幻觉风险范围。
### 4.1 使用意图
这是一个LoRA适配器,能够在基于一组提供的文档/段落的情况下识别多轮RAG对话中最后助手响应的句子中的幻觉风险。
虽然您可以直接调用LoRA适配器,但我们强烈推荐通过Granite IO进行调用,如第1.2节所述。Granite IO通过定制的I/O处理器封装了幻觉检测适配器。I/O处理器提供了一个更友好的开发接口,因为它处理各种数据
转换和验证任务。这包括在调用适配器之前将助手响应拆分为句子,以及验证适配器的输出并将适配器返回的句子ID转换为响应上的适当跨度。
但是,如果您更喜欢直接调用LoRA适配器,其预期的输入/输出如下所述。
模型输入:模型的输入概念上是一系列以助手响应结束的对话轮次和一系列文档,使用apply_chat_template函数转换为字符串。为了让适配器工作,最后的助手响应应该预先拆分为句子,并且需要在句子前面加上句子索引。详细来说,主要输入是以下三个项目,每个项目都以JSON格式表示:
- 对话:用户和助手之间的对话轮次列表,列表中的每个项目都是一个字典,字段role和content分别表示用户和助手的角色,content字段包含相应的用户/助手发言。对话应该以助手轮次结束,该轮次的text字段应包含每个句子前面带有响应句子ID形式的助手发言,形式为$<r I>$,其中$I$是一个整数。编号应从0开始(对于第一句话),并为后续的每个句子递增1。
- - 指令:任务指令,编码为一个字典,字段role和content,其中role等于system,content等于以下字符串,描述幻觉检测任务:"将最后的助手响应拆分为单个句子。对于最后助手响应中的每个句子,识别忠实度评分范围。确保你的输出包含所有响应句子ID,并为每个响应句子ID提供相应的忠实度评分范围。输出必须是JSON结构。"
- - 文档:文档列表,列表中的每个项目都是一个字典,字段doc_id和text。text字段包含相应文档的文本。
为了提示LoRA适配器,我们按以下方式组合上述组件:首先将指令附加到对话的末尾,生成一个augmented_conversation列表。然后我们使用参数conversation = augmented_conversation和documents = documents调用apply_chat_template函数。
模型输出:当使用上述输入提示时,模型为最后助手响应的每个句子生成一个忠实度评分(幻觉风险)范围,形式为JSON字典。字典的形式为("<r0>": "value_0", "<r1>": "value_1", ...\},其中每个字段<rI>,其中I是一个整数,对应于最后助手响应中的一个句子ID,其对应的值是该句子的忠实度评分(幻觉风险)范围。输出值可以显示0-1之间的数值范围,增量为0.1 ,其中较高的值对应高忠实度(低幻觉风险),较低的值对应低忠实度(高幻觉风险)。此外,模型被训练为输出unanswerable,当响应句表明问题是无法回答的,以及输出NA,当无法确定忠实度(例如:非常短的句子)。
请参阅第A.3节,了解如何使用幻觉检测内建函数的示例。
# 4.2 评估
LoRA适配器在Niu等人(2024)的RAGTruth基准问答部分进行了评估。我们比较了LoRA适配器与RAGTruth论文中报告的方法在响应级幻觉检测性能上的表现。至少有一个句子的忠实度评分低于0.1的响应被视为幻觉响应。
评估结果如表8所示。基线的结果摘自Niu等人(2024)的RAGTruth论文。
### 4.3 训练细节
生成训练数据的过程包括两个主要步骤:
- 多轮RAG对话生成:从公开可用的文档语料库开始,我们生成了一组多轮RAG数据,包括基于从语料库中检索到的段落的多轮对话
- | 模型 | 精确度 | 召回率 | F1 |
- | :-- | :--: | :--: | :--: |
- | gpt-3.5-turbo (带提示) | 18.8 | 84.4 | 30.8 |
- | gpt-4-turbo (带提示) | 33.2 | 90.6 | 45.6 |
- | SelfCheckGPT Manakul等人 (2023) | 35.0 | 58 | 43.7 |
- | LMvLM Cohen等人 (2023) | 18.7 | 76.9 | 30.1 |
- | Fine-Tuned Llama-2-13B | 61.6 | 76.3 | 68.2 |
- | 幻觉检测 LoRA | 67.6 | 77.4 | 72.2 |
表8:幻觉检测结果
从语料库中检索到的段落。有关RAG对话生成过程的详细信息,请参阅Granite技术报告 ${ }^{5}$ 以及Lee等人(2024)。
- 忠实度标签生成:为了为响应创建忠实度标签,我们使用了Achintalwar等人(2024)提供的基于自然语言推理的技术。
以下公共数据集被用作多轮RAG对话生成过程的种子数据集:
- CoQA维基百科段落 (https://stanfordnlp.github.io/coqa/)
- - MultiDoc2Dial (https://huggingface.co/datasets/IBM/multidoc2dial)
- - QuAC (https://huggingface.co/datasets/allenal/quac)
LoRA适配器使用PEFT在以下制度下进行了微调:秩 $=8$,学习率 $=1 \mathrm{e}-5$,以及 $90 / 10$ 的训练和验证划分。
# 5 可答性判断
Granite 3.2 8b Instruct - 可答性判断 是一个针对 ibm-granite/granite-3.2-8b-instruct 微调的LoRA适配器,用于二元可答性分类任务。模型以多轮对话和一组文档作为输入,并根据输入文档中的可用信息分类用户的最终查询是否可答或不可答。
### 5.1 使用意图
这是一个LoRA适配器,能够在多轮对话中针对一组提供的文档对用户的最终查询进行可答性分类。模型被训练以根据输入文档中的信息唯一判断最后一个用户查询是否可答或不可答。这使其适合涉及RAG和基于文档的聊天机器人的应用场景,其中知道是否存在足够的信息来回答查询至关重要。可答性模型的分类输出可用于多种下游应用,包括但不限于:
- 在RAG环境中发送不可答问题之前进行过滤。通过提前将查询分类为不可答,系统可以防止生成虚构或误导性响应。
- - 重新查询检索器以获取更多相关文档。如果查询最初被认为是不可答的,检索器可以使用替代表述重新调用以获取更多相关文档。
模型输入:模型的输入是一个使用apply_chat_template函数转换为字符串的对话轮次列表和文档列表。这些轮次可以在用户和助手角色之间交替。最后一轮来自用户。文档列表是一个包含text字段的字典,该字段包含相应文档的文本。
为了提示LoRA适配器进行可答性判断,使用一个特殊的可答性角色来触发模型的这一功能。该角色包括关键词"answerability": <|start_of_role|>answerability<|end_of_role|>
${ }^{5}$ https://github.com/ibm-granite/granite-3.0-language-models/blob/main/paper.pdf
| 模型 | 不可答 <br> 精确度 | 不可答 <br> 召回率 | 不可答 <br> F1 | 可答 <br> 精确度 | 可答 <br> 召回率 | 可答 <br> F1 | 加权 <br> F1 |
| :-- | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| BigBird w/ MLP | 49.2 | 68.5 | 57.3 | 48.0 | 29.2 | 36.3 | 46.8 |
| LLaMA 2-7B | 72.2 | 71.0 | 71.6 | 71.4 | 72.6 | 72.0 | 71.8 |
| Granite 3.2-8b LoRA | 84.2 | 68.0 | 75.2 | 73.1 | 87.2 | 79.5 | 77.4 |
表9:SQUADRUN开发集上跨模型分类性能比较。指标按类别(可答 vs. 不可答)分解,包括精确度、召回率和F1分数。
| 模型 | 不可答 <br> 精确度 | 不可答 <br> 召回率 | 不可答 <br> F1 | 可答 <br> 精确度 | 可答 <br> 召回率 | 可答 <br> F1 | 加权 <br> F1 |
| :-- | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| BigBird w/ MLP | 69.6 | 77.6 | 73.4 | 70.1 | 60.8 | 65.2 | 69.6 |
| LLaMA 2-7B | 86.9 | 89.4 | 88.2 | 87.3 | 84.5 | 85.9 | 87.1 |
| Granite 3.2-8b LoRA | 85.4 | 89.3 | 87.3 | 87.0 | 82.4 | 84.6 | 86.1 |
表10:MT-RAG基准上跨模型分类性能比较。指标按类别(可答 vs. 不可答)分解,包括精确度、召回率和F1分数。
模型输出:当使用上述输入提示时,模型生成可答或不可答的输出。
请参见第A.4节,了解如何使用可答性判断内建函数的示例。
# 5.2 评估
### 5.2.1 可答性分类
我们针对基线在两个独立基准上评估了模型的二元可答性分类能力:
- 单轮设置(SQUADRun基准 Rajpurkar等人(2018)):在此设置中,提供用户查询和支持文档。我们的模型与标准基线进行比较,以衡量其根据文档集确定独立问题是否可答的能力。表9显示了分类结果。
- - 多轮设置(MT-RAG基准 Katsis等人(2025)):在此设置中,模型获得完整的多轮对话历史以及支持文档。该基准评估模型在最终用户查询可能依赖于先前回合上下文的情况下评估可答性的能力。表10显示了结果。
### 5.2.2 比较LoRA适配器与普通Granite的问答质量
我们在MT-RAG基准的一个子集上比较了Granite 3.2-8b Instruct与Granite 3.2-8b LoRA适配器的性能。在此设置中,每个查询仅与5个检索段落作为上下文配对。每个查询的真实可答性标签指示该查询相对于检索到的上下文是否可答。
- 可答性分类性能:LoRA适配器在整体F1得分上优于普通模型,无论是在可答还是不可答方面。LoRA适配器在不可答查询上的召回率更高,使其更擅长识别不应回答的问题。然而,这导致了可答查询召回率的降低。
- - RAGAS忠实度(RF)得分(在真正可答查询上):此得分略有下降,但并非由于生成质量下降,而是因为模型将更多真正可答查询标记为不可答并选择不回答。
- - 联合可答性-忠实度得分(JAFS):
$$
\text { JAFS }=\left\{\begin{array}{ll}
1 & \text { 如果预测值 }=\text { IDK/不可答 \& 真实值 }=\text { 不可答 } \\
\text { RF } & \text { 如果预测值 }=\text { 非IDK/可答 \& 真实值 }=\text { 可答 } \\
0 & \text { 否则 }
\end{array}\right.
$$
该得分奖励模型在不可答查询上正确弃权(满分),并在可答查询上提供忠实答案(部分得分基于RAGAS忠实度)。对于错误或不忠实的预测,不给予任何得分。
LoRA适配器在此度量上提升了7% - 奖励模型在不可答查询上正确弃权,并在选择回答时保持忠实。
| 模型 | 不可答 <br> F1 | 可答 <br> F1 | 不可答 <br> 召回率 | 可答 <br> 召回率 | RF (在真正 <br> 可答上) | JAFS |
| :-- | :--: | :--: | :--: | :--: | :--: | :--: |
| Granite 3.2-8b Instruct | 14 | 76 | 8 | 97 | 75 | 50 |
| Granite 3.2-8b LoRA | 47 | 77 | 37 | 88 | 70 | 57 |
表11:使用MT-RAG基准对Granite 3.2-8B Instruct与LoRA适配器在可答性和忠实度度量上的比较。
# 5.3 训练细节
训练数据使用来自MT-RAG Katsis等人(2025)的公开可用政府语料库作为文档来源。基于该语料库,我们构建了一个包含人工创建和合成生成的多轮对话的数据集。它包括两类示例:(1)可答查询,其中最终用户问题可以根据提供的文档回答。这些示例教导适配器识别何时有足够的信息来支持答案。(2)不可答查询,其中文档缺乏回答最终用户查询所需的必要信息。我们使用Mixtral作为自动评判者来验证可答性标签并过滤掉噪声样本。
LoRA适配器使用PEFT在以下制度下进行了微调:秩 $=32$,学习率 $=5 \mathrm{e}-6$,训练周期数 $=25$,基于验证集的早期停止,以及 90/10 的训练和验证划分。
## 6 引用生成
Granite 3.2 8b Instruct - 引用生成 是一个特定于RAG的LoRA适配器,用于ibm-granite/granite-3.2-8b-instruct的引用生成任务。给定用户与AI助手之间的多轮对话,以助手响应结束,并给出一组文档/段落,这些文档/段落是最后助手响应的基础,适配器从提供的文档/段落生成最后助手响应的引用。LoRA适配器具有以下特点:
- 细粒度引用:适配器为助手响应中的每个句子(如果可用)生成引用。此外,每个引用由一组来自文档/段落的支持相应助手响应句子的句子组成。
- - 后处理引用生成:由于适配器以助手响应作为输入,因此它可以为任何LLM生成的响应生成后处理引用!选择您最喜欢的LLM,并使用适配器生成后处理引用!
### 6.1 使用意图
这是一个LoRA适配器,能够在基于一组提供的文档/段落的情况下为多轮RAG对话中的最后助手响应生成引用。它可用于为任何LLM在RAG环境中生成的助手响应生成后处理引用。
虽然您可以直接调用LoRA适配器,但我们强烈推荐通过Granite IO进行调用,如第1.2节所述。Granite IO通过定制的I/O处理器封装了适配器。I/O处理器提供了一个更友好的开发接口,因为它处理各种数据转换和验证任务。这包括,例如,在调用适配器之前将输入文档和助手响应拆分为句子,以及验证适配器的输出并将适配器返回的句子ID转换为文档和响应上的适当跨度。
但是,如果您更喜欢直接调用LoRA适配器,预期的输入/输出如下所述。
模型输入:模型的概念输入是一系列以助手响应结束的对话轮次和一系列文档,使用apply_chat_template函数转换为字符串。为了让适配器工作,最后的助手响应以及文档应该预先拆分为句子。详细来说,主要输入是以下三个项目,每个项目都以JSON格式表示:
- 对话:用户和助手之间的对话轮次列表,列表中的每个项目都是一个字典,字段role和content分别表示用户和助手的角色,而content字段包含相应的用户/助手发言。对话应该以助手轮次结束,该轮次的text字段应包含每个句子前面带有响应句子ID形式的助手发言,形式为<rI>,其中I是一个整数。编号应从0开始(对于第一句话),并为后续的每个句子递增1。请注意,只有最后一个助手轮次应按照上述方式拆分为句子;之前的助手轮次(以及所有用户轮次)应保持其原始形式。
- - 指令:任务指令,编码为一个字典,字段role和content,其中role等于system,content等于以下字符串,描述引用生成任务:"将最后的助手响应拆分为单个句子。对于响应中的每个句子,识别其引用的文档中的句子ID。确保你的输出包含所有响应句子ID,并为每个响应句子ID提供相应的引用文档句子ID。"
- - 文档:文档列表,列表中的每个项目都是一个字典,字段doc_id和text。text字段包含相应文档的文本,每个句子前面带有上下句子ID形式<cI>,其中I是一个整数。上下句子ID编号应从0开始(对于第一个文档的第一句话),并为后续的每个句子递增1。数字应在整个文档列表中继续递增,以确保每个上下句子ID在整个文档列表中只出现一次。例如,如果第一个文档的最后一句话的上下句子ID为<cn>,那么第二个文档的第一句话预计会有ID<cn+1>。
为了提示LoRA适配器,我们按以下方式组合上述组件:首先将指令附加到对话的末尾,生成一个augmented_conversation列表。然后我们使用参数conversation = augmented_conversation和documents = documents调用apply_chat_template函数。
模型输出:当使用上述输入提示时,模型为最后助手响应的每个句子生成引用,形式为JSON字典。字典的形式为 \{ "<r0>": ..., "<r1>": ..., ...\},其中每个字段<rI>,其中I是一个整数,对应于最后助手响应中相应句子的ID,其值是一个列表,包含支持特定响应句子的输入文档中的句子ID。
请参阅第A.5节,了解如何使用引用生成内建函数为给定的助手响应生成引用的示例。
# 6.2 评估
我们在两个引用基准上评估了LoRA适配器:
- ALCE Gao等人 (2023):评估模型生成文档/段落级引用的能力(即,识别响应中陈述所支持的文档/段落)。
- - LongBench-Cite Zhang等人 (2024):评估模型生成细粒度跨度级引用的能力(即,识别输入文档/段落中支持响应中陈述的跨度),重点在于长上下文。
由于LoRA适配器是一种后处理引用生成方法,其在这两个基准上的表现取决于要求其生成引用的助手响应。为了实现同类比较,对于每个实验,我们保持助手响应相同并更改用于生成引用的模型。特别是,我们提示LLM生成助手响应和引用,并在相应的基准上评估生成的引用。然后,我们计算并评估同一LLM响应由LoRA适配器生成的引用。
# 6.2.1 在ALCE上的评估
对于ALCE评估,我们提示Llama-3.1-70B-Instruct和Mixtral-8x22B-Instruct生成助手响应和相应的段落级引用。我们首先计算这些模型在ALCE上生成的引用的表现。随后,我们将这些模型的响应(去掉引用)输入LoRA适配器并评估其生成的引用。结果如表12所示。
| 生成响应的模型 | 生成引用的模型 | 召回率 | 精确率 | F1 |
| :-- | :-- | :-- | :-- | :-- |
| Llama-3.1-70B-Instruct | Llama-3.1-70B-Instruct | 61.4 | 58.1 | 59.7 |
| Llama-3.1-70B-Instruct | Granite-3.2-8B LoRA 引用 | 54.8 | 65.9 | 59.8 |
| Mixtral-8x22B-Instruct | Mixtral-8x22B-Instruct | 62.2 | 62.5 | 62.3 |
| Mixtral-8x22B-Instruct | Granite-3.2-8B LoRA 引用 | 54.3 | 69.5 | 61.0 |
表12:在ALCE上的引用生成评估
我们观察到LoRA适配器在被提示创建段落级引用时的表现与更大模型相当。有趣的是,尽管适配器的F1表现与基线相似,但它表现出不同的精确率-召回率权衡,以较低的召回率为代价换取更高的精确率。
## 注意事项:
- 所有结果都在ELI5数据集上报告,使用ORACLE(5-psg)设置。
- - 为了提示Llama和Mixtral,我们采用了类似于ALCE论文中提出的设置;特别是我们使用了一个两步提示,包括两个ICL示例和论文Gao等人(2023)中略微修改的指令。
- - 上下文/响应的句子分割使用NLTK完成。
- - 最后,由于ALCE期望段落级引用,我们在运行ALCE评估之前将LoRA适配器生成的更细粒度引用提升到段落级。
### 6.2.2 在LonBench-Cite上的评估
对于LonBench-Cite评估,我们提示Llama-3.1-70B-Instruct生成助手响应和相应的引用。然后我们评估Llama生成的引用以及由LoRA适配器在Llama响应上调用后生成的后处理引用。结果如表13所示。
| 生成 <br> 响应的模型 | 生成 <br> 引用的模型 | Lonbench- <br> Chat (en) | | | MultifieldQA <br> (en) | | | HotpotQA | | | GovReport | | | |
| :-- | :-- | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| | | $\mathbf{R}$ | $\mathbf{P}$ | $\mathbf{F 1}$ | $\mathbf{R}$ | $\mathbf{P}$ | $\mathbf{F 1}$ | $\mathbf{R}$ | $\mathbf{P}$ | $\mathbf{F 1}$ | $\mathbf{R}$ | $\mathbf{P}$ | $\mathbf{F 1}$ | |
| Llama-3.1- <br> 70B-Instruct | Llama-3.1- <br> 70B-Instruct | 27.0 | 34.4 | 26.1 | 46.1 | 63.3 | 49.7 | 34.0 | 39.4 | 30.2 | 55.0 | 77.5 | 62.0 | |
| Llama-3.1- <br> 70B-Instruct | Granite-3.2- <br> 8B LoRA <br> 引用 | 61.9 | 68.6 | 62.0 | 71.2 | 84.1 | 74.3 | 66.8 | 73.3 | 65.4 | 70.3 | 83.6 | 75.4 | |
表13:在LonBench-Cite上的引用生成评估
我们观察到LoRA适配器在被提示创建跨度级引用时的表现显著优于Llama-3.1-70B-Instruct。这证明了适配器在为更大LLM生成的助手响应创建后处理引用方面的价值。
## 注意事项:
- 评估结果报告在LonBench-Cite的英语子集中(即,限制为语言字段等于en的实例)。
- - LoRA适配器的结果不包括遇到内存错误的$4 / 585$任务的性能。
- - 为了提示Llama生成带引用的响应,我们使用了Zhang等人(2024)在LonBench-Cite论文中描述的一次性提示。
- - 对于LoRA适配器,上下文的句子分割使用NLTK完成。对于响应,我们重用了Llama输出中的分割(因为LonBench-Cite提示指示模型输出拆分为句子/陈述的响应)。
# 6.3 训练细节
LoRA适配器在合成生成的引用数据集上进行了训练。生成训练数据的过程包括两个主要步骤:
- 多轮RAG对话生成:从公开可用的文档语料库开始,我们生成了一组多轮RAG数据,包括基于从语料库中检索到的段落的多轮对话。有关RAG对话生成过程的详细信息,请参阅Granite技术报告 ${ }^{6}$ 以及Lee等人(2024)。
- - 引用生成:对于前一步中的每个多轮RAG对话轮次,我们使用一个多步骤合成引用生成管道为助手响应生成引用。
以下公共数据集被用作多轮RAG对话生成过程的种子数据集:
- CoQA维基百科段落 (https://stanfordnlp.github.io/coqa/)
- - MultiDoc2Dial (https://huggingface.co/datasets/IBM/multidoc2dial)
- - QuAC (https://huggingface.co/datasets/allenal/quac)
利用生成的训练数据,LoRA适配器使用PEFT在以下制度下进行了微调:秩 $=8$,学习率 $=1 \mathrm{e}-5$,以及 $90 / 10$ 的训练和验证划分。
## 7 组合内建函数
单独的内建函数被创建和训练以专注于特定任务。实际上,我们肯定希望同时提高检索器性能、减少幻觉、生成更准确的引用等。由于内建函数的实现是抽象的,因此简单地将一个或多个添加到特定应用的“流程”中非常容易。
例如,由于使用查询重写提高了召回性能,也很可能通过提供更相关的上下文来正面影响引用。或者,像不确定性量化或幻觉检测这样的内建函数可以与响应生成的采样方法(这种采样方法顺便可以通过Granite IO获得)结合,以便轻松过滤出低质量候选者。
另一方面,有些组合流程很可能会产生令人困惑的结果。例如,如果相同的输入得到高分来自不确定性量化(意味着模型对其答案相当确定)和低分来自幻觉检测(意味着模型认为答案主要不忠实),这意味着什么呢?或者,如果根据可答性判断,一个查询是不可答的,但随后生成的答案却被引用生成丰富地引用,这意味着什么?随着每个添加到应用程序流程中的内建函数增加,测试和解释结果行为的复杂性显著增加。因此,尽管许多组合在技术上可能是可行的,我们建议谨慎对待,并在本节剩余部分中详细介绍创建和评估组合内建函数流程的过程。
特别是,我们将考虑一个同时使用查询重写(QR)和可答性判断(AD)内建函数的流程。这些内建函数在预期频繁进行多轮对话并与RAG系统交互且重要的是限制只能成功支持的响应的情况下是有益的(许多面向客户的聊天代理属于这种情况)。尽管表面上看这两个内建函数不会相互影响性能,我们会看到事实稍微复杂一些。
${ }^{6}$ https://github.com/ibm-granite/granite-3.0-language-models/blob/main/paper.pdf
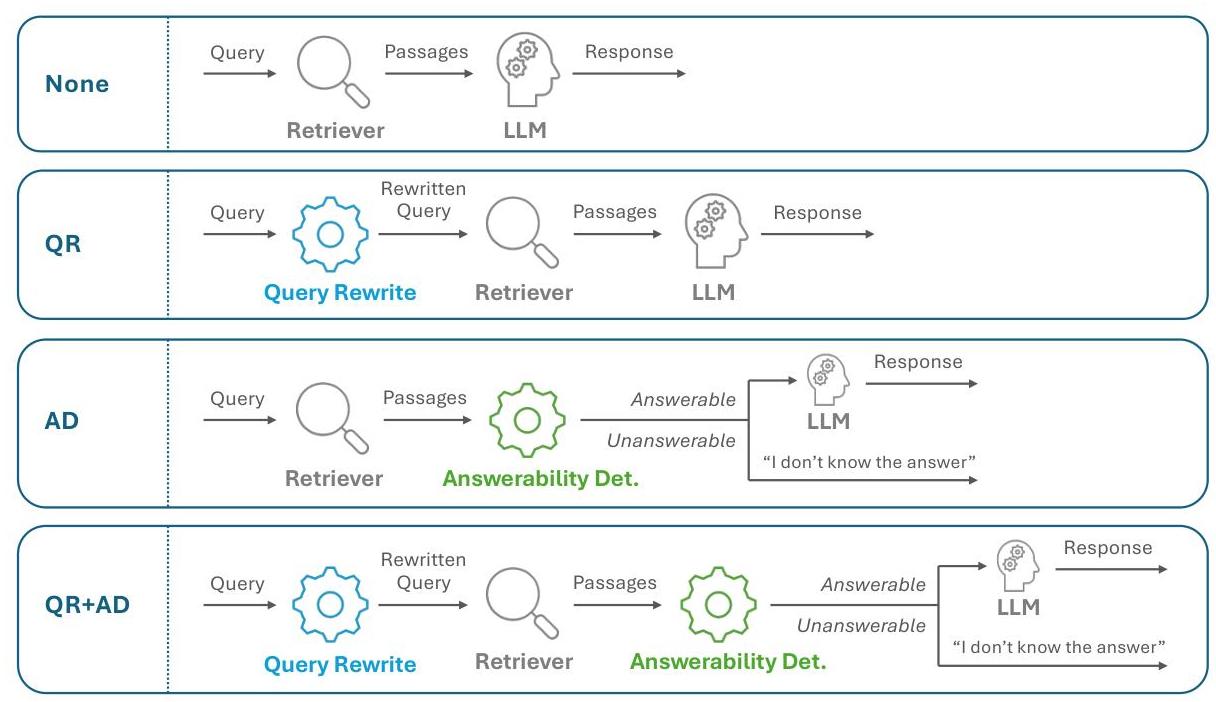
图2:本文考虑的RAG流程
# 7.1 查询重写加可答性判断
我们简要介绍四种以不同方式使用这两个内建函数的RAG流程:${ }^{7}$
- None: 使用给定的用户查询检索顶级$k$段落;两者都被输入到生成模型以创建响应。
- - 查询重写(QR):使用QR内建函数转换给定的用户查询。结果查询用于检索顶级$k$段落。原始查询和检索到的段落被输入到生成模型以创建响应。
- - 可答性判断(AD):使用给定的用户查询检索顶级$k$段落。查询和段落被输入到AD内建函数。如果AD返回是,则查询和段落被输入到生成模型以创建响应;如果AD返回否,则跳过此步骤,并输出预定义的“I don't know the answer”响应。
- - 查询重写和可答性判断(QR+AD):两个内建函数都被使用:QR影响哪些顶级$k$段落被检索到,AD决定是否绕过生成模型。
图2提供了这四个流程的视觉表示。我们现在将检查在这四个流程中同时使用这两个内建函数的优点和权衡。正如前所述,QR的价值在于提高检索器的性能,增加顶级$k$段落的相关性。这增加了生成既更忠实的响应又更准确的引用的能力,因为提供了更多的相关上下文。另一方面,AD的价值在于在不可能生成基于证据的响应时约束过于急切的模型,大大增加了正确拒绝回答的可能性(尽管偶尔会过于保守)。因此,我们必须查看个体和组合内建函数流程对以下方面的定量影响:a)正确将查询分类为可答或不可答;b)生成模型创建的那些响应的忠实度;c)加权忠实度评分的总体得分。我们将逐一进行分析。
实验设置。为了基准测试上述流程,我们使用MT-RAG对话和Elser作为检索器。QR和AD分别使用QR LoRA适配器和AD LoRA适配器与Granite 3.2-8B Instruct一起执行。我们将检索段落数设置为5,跨越不同的检索策略。对于生成,
${ }^{7}$ 这些不是这两种内建函数的唯一可能应用;它们作为合理的例子允许我们调查它们组合的效果。
| 流程 | $F 1_{\text {不可答 }}$ | $F 1_{\text {可答 }}$ |
| :--: | :--: | :--: |
| 无 | 14 | 76 |
| QR | 12 | 82 |
| AD | 47 | 77 |
| QR+AD | 42 | 82 |
表14:可答性分类任务的性能
| 流程 | #Responses | RAGAS-F |
| :--: | :--: | :--: |
| 无 | 505 | 75 |
| QR | 578 | 78 |
| AD | 455 | 70 |
| QR+AD | 530 | 73 |
表15:每个流程确定为可答的查询生成响应的忠实度(RAGAS-F);该集合的大小由#Responses(生成响应的数量)表示
我们将Granite 3.2-8B Instruct模型发送以下信息:整个对话、顶级5个检索段落以及模型的默认RAG指令提示。
# 7.1.1 评估:可答性分类
表14显示了上述4种RAG流程在可答性分类任务上的$F 1$得分。使用AD内建函数显著提高了不可答查询的性能($F 1$得分从14增加到47)。QR内建函数也有影响(尽管较小):提高检索器的Recall@5性能使得某些问题更有可能可答($F 1$得分从76增加到82)。
### 7.1.2 评估:答案忠实度
QR内建函数提高了生成模型创建的答案的忠实度。表15显示了每个流程中的响应数量(意味着问题被正确识别为可答并且生成模型写出了响应)以及这些响应的RAGAS-F得分(见第2节)。要确定某个流程是否认为查询是可答的,使用简单的“I don't know”判断器对最终输出响应进行判断,以确定响应是否包含内容,或者本质上相当于说,“我不知道答案”(见Katsis等人(2025)关于IDK判断器的详细信息)。需要注意的是,这并不提供全面的视图,因为它没有反映RAG系统在本表未涵盖的其他情况下的性能(因此还包括每个流程中能够评分的响应数量)。
### 7.1.3 评估:联合可答性-忠实度
单独考虑表15中的RAGAS-F得分,似乎使用AD内建函数损害了性能,最好的方法是仅使用QR内建函数。因此,显然我们不应该仅仅依赖这一评估。因此,我们回到联合可答性-忠实度评分(JAFS),该评分在第5节中引入。该评分奖励模型在不可答查询上正确弃权(满分)以及在可答查询上提供忠实答案(部分得分基于RAGAS忠实度)。对于响应不可答查询或拒绝响应可答查询,不给予任何得分。表16列出了每个流程的JAFS得分。
| 流程 | JAFS |
| :--: | :--: |
| 无 | 50 |
| QR | 57 |
| AD | 57 |
| QR+AD | $\mathbf{6 1}$ |
表16:每个流程的联合可答性-忠实度评分
通过这个仔细的评估过程,我们能够理解此组合流程的好处和权衡。重要的方面是a)创建适当的非组合流程以供比较和b)使用反映每个内建函数带来的价值的指标分析每个流程的影响。我们现在已经能够证明,对于预期频繁进行多轮对话且重要的是限制只能成功支持的响应的RAG系统使用案例,按照描述的方式在流程中使用QR和AD内建函数将带来更好的整体性能。
# 8 结论
在本文中,我们介绍了一个面向RAG的LLM内建函数库。目前实现的内建函数包括查询重写、不确定性量化、幻觉检测、可答性判断和引用生成。它们作为LoRA适配器发布在HuggingFace上的ibm-granite/granite-3.2-8b-instruct上,以及通过Granite IO中的推荐实现,同时在两个地方附有文档和代码。所有模型均在Apache 2.0许可证下公开发布,供研究和商业用途使用。我们描述了每个内建函数的预期用途、训练细节和评估结果。我们还介绍了组合内建函数的概念,并详细描述了一种特定的组合,包括深入评估创建的流程。
## 9 致谢
感谢内部和外部标注者。
## 参考文献
Swapnaja Achintalwar, Adriana Alvarado Garcia, Ateret Anaby-Tavor, Ioana Baldini, Sara E. Berger, Bishwaranjan Bhattacharjee, Djallel Bouneffouf, Subhajit Chaudhury, Pin-Yu Chen, Lamogha Chiazor, Elizabeth M. Daly, Kirushikesh DB, Rogério Abreu de Paula, Pierre Dognin, Eitan Farchi, Soumya Ghosh, Michael Hind, Raya Horesh, George Kour, Ja Young Lee, Nishtha Madaan, Sameep Mehta, Erik Miehling, Keerthiram Murugesan, Manish Nagireddy, Inkit Padhi, David Piorkowski, Ambrish Rawat, Orna Raz, Prasanna Sattigeri, Hendrik Strobelt, Sarathkrishna Swaminathan, Christoph Tillmann, Aashka Trivedi, Kush R. Varshney, Dennis Wei, Shalisha Witherspooon, 和 Marcel Zalmanovici. 安全可靠的LLM探测器:实现、用途和局限性,2024. URL https://arxiv.org/abs/2403.06009.
Roi Cohen, May Hamri, Mor Geva, 和 Amir Globerson. LM vs LM: 通过交叉审问检测事实错误。In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 12621-12640, 2023.
Tianyu Gao, Howard Yen, Jiatong Yu, 和 Danqi Chen. 启用大型语言模型生成带引用的文本。In Houda Bouamor, Juan Pino, 和 Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 6465-6488, 新加坡,2023年12月。Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.398. URL https: //aclanthology.org/2023.emnlp-main.398/.
Kristjan Greenewald, Luis Lastras 和 Thomas Parnell, Lucian Popa Vraj Shah, Giulio Zizzo, Chulaka Gunasekara, Ambrish Rawat, 和 David Cox. 激活LoRA:用于内建函数的微调LLM,2025.
Yannis Katsis, Sara Rosenthal, Kshitij Fadnis, Chulaka Gunasekara, Young-Suk Lee, Lucian Popa, Vraj Shah, Huaiyu Zhu, Danish Contractor, 和 Marina Danilevsky. MTRAG:一个多轮对话基准,用于评估检索增强生成系统,2025. URL https://arxiv.org/abs/2501. 03468 .
Young-Suk Lee, Chulaka Gunasekara, Danish Contractor, Ramón Fernandez Astudillo, 和 Radu Florian. 多文档基础多轮合成对话生成,2024. URL https://arxiv.org/ abs/2409.11500.
Potsawee Manakul, Adian Liusie, 和 Mark Gales. Selfcheckgpt:零资源黑盒幻觉检测的大规模生成语言模型。In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 9004-9017, 2023.
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, Kashun Shum, Randy Zhong, Juntong Song, 和 Tong Zhang. Ragtruth:一个用于开发可信检索增强语言模型的幻觉语料库。In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 10862-10878, 2024.
Pranav Rajpurkar, Robin Jia, 和 Percy Liang. 知道你不知道的:SQuAD的不可答问题。In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 784-789, 2018.
Maohao Shen, Subhro Das, Kristjan Greenewald, Prasanna Sattigeri, Gregory Wornell, 和 Soumya Ghosh. 温度计:迈向大型语言模型的通用校准,2024. URL https://arxiv. org/abs/2403.08819.
Jiajie Zhang, Yushi Bai, Xin Lv, Wanjun Gu, Danqing Liu, Minhao Zou, Shulin Cao, Lei Hou, Yuxiao Dong, Ling Feng, 和 Juanzi Li. LongCite:启用LLM在长上下文问答中生成细粒度引用,2024. URL https://arxiv.org/abs/2409.02897.
# A 技术附录和补充材料
## A.1 查询重写快速入门示例
以下代码描述了如何使用查询重写模型。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
import json, re
INSTRUCTION_TEXT = “Reword the final utterance from the USER into a single
utterance that doesn’t need the prior conversation history to understand the
user’s intent. If the final utterance is a clear and standalone question,
please DO NOT attempt to rewrite it, rather output the last user utterance
as is.”
JSON = “Your output format should be in JSON: { “rewritten_question”: }”
REWRITE_PROMPT = “<|start_of_role|>rewrite: " + INSTRUCTION_TEXT + JSON + “<|
end_of_role|>”
device=torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)
BASE_NAME = “ibm-granite/granite-3.2-8b-instruct”
LORA_NAME = “ibm-granite/granite-3.2-8b-lora-rag-query-rewrite”
tokenizer = AutoTokenizer.from_pretrained(BASE_NAME, padding_side=‘left’,
trust_remote_code=True)
model_base = AutoModelForCausalLM.from_pretrained(BASE_NAME, device_map =‘auto’)
model_rewrite = PeftModel.from_pretrained(model_base, LORA_NAME)
输入对话
conv = [
{
“role”:“user”,
“content”:“Tim Cook is the CEO of Apple Inc.”
},
{
“role”:“assistant”,
“content”:“Yes, Tim Cook is the Chief Executive Officer of Apple Inc.”
},
{
“role”:“user”,
“content”:“and for Microsoft?”
}
```
```
# 为上述对话中的最后一轮生成查询重写
conv = [{“role”:“system”, “content”:”“}] + conv
input_text = tokenizer.apply_chat_template(conv, tokenize=False) +
REWRITE_PROMPT
inputs = tokenizer(input_text, return_tensors=“pt”)
output = model_rewrite.generate(inputs[“input_ids”].to(device), attention_mask=
inputs[“attention_mask”].to(device), max_new_tokens=80)
output_text = tokenizer.decode (output [0])
# 正则表达式模式,用于从模型输出中提取包含重写的JSON
pattern = r’(\s*”[“]+”\s*:\s*"[“]+”\s*)’
match_js = re.findall(pattern, output_text) [0]
try:
# 解析JSON并提取重写
rewrite = json.loads (match_js) [‘rewritten_question’]
except Exception as e:
rewrite = match_js.split ("“rewritten_question”: “, 1) [1]
print(f"Rewrite: {rewrite}\n”)
# Rewrite: Who is the CEO of Microsoft?
```
A.2 不确定性量化快速入门示例
以下代码描述了如何使用不确定性量化模型回答问题并获得内在校准的确信分数。注意,包含了一个通用的系统提示,这不是必需的,可以根据需要修改。
import torch,os
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel, PeftConfig
token = os.getenv("HF_MISTRAL_TOKEN")
BASE_NAME = "ibm-granite/granite-3.2-8b-instruct"
LORA_NAME = "ibm-granite/granite-3.2-8b-lora-uncertainty"
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载模型
tokenizer = AutoTokenizer.from_pretrained(BASE_NAME, padding_sidel'left',
trust_remote_code=True, token=token)
model_base = AutoModelForCausalLM.from_pretrained(BASE_NAME, device_map="auto")
model_UQ = PeftModel.from_pretrained(model_base, LORA_NAME)
question = "What is IBM Research?"
print("Question:" + question)
question_chat = [
{
"role": "user",
"content": question
},
]
# 使用基础模型生成答案
input_text = tokenizer.apply_chat_template(question_chat,tokenize=False,
add_generation_prompt=True)
# 分词
inputs = tokenizer(input_text, return_tensors="pt")
output = model_base.generate(inputs["input_ids"].to(device), attention_mask=
inputs["attention_mask"].to(device), max_new_tokens=600)
```
```
output_text = tokenizer.decode(output[0])
answer = output_text.split("assistant<|end_of_role|>")[1]
print("Answer: " + answer)
# Generate certainty score
uq_generation_prompt = "<|start_of_role|>certainty<|end_of_role|>"
uq_chat = [
{
"role": "system",
"content": ""
},
{
"role": "user",
"
}content": 问题
},
{
"role": "assistant",
"content": 答案
},
]
uq_text = tokenizer.apply_chat_template(uq_chat,tokenize=False) +
uq_generation_prompt
# 移除自动系统提示
string_to_remove = tokenizer.apply_chat_template(uq_chat[0:1], tokenize=False,
add_generation_prompt=False)
input_text = input_text[len(string_to_remove):]
uq_text = uq_text [len(string_to_remove):]
# 分词并生成
inputs = tokenizer(uq_text, return_tensors="pt")
output = model_UQ.generate(inputs["input_ids"].to(device), attention_mask=input
["attention_mask"].to(device), max_new_tokens=1)
output_text = tokenizer.decode (output[0])
uq_score = int(output_text[-1])
print("Certainty: " + str(5 + uq_score * 10) + "%")
参考论文:https://arxiv.org/pdf/2504.11704



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











