






刘沛
1
,
2
{ }^{1,2}
1,2,刘欣
2
{ }^{2}
2,姚若宇
2
{ }^{2}
2,刘俊明
1
{ }^{1}
1,孟思远
1
{ }^{1}
1,王鼎
1
∗
{ }^{1 *}
1∗,马军
23
∗
{ }^{23 *}
23∗
1
{ }^{1}
1 上海人工智能实验室
2
{ }^{2}
2 香港科技大学(广州)
3
{ }^{3}
3 香港科技大学
pliu061@connect.hkust-gz.edu.cn wangding@pjlab.org.cn jun.ma@ust.hk
摘要
尽管检索增强生成(RAG)通过外部知识增强了大语言模型(LLMs),但传统的单智能体RAG在解决需要跨异构数据生态系统协调推理的复杂查询时仍存在根本限制。我们提出了HM-RAG,一种新颖的分层多智能体多模态RAG框架,开创了动态知识合成的协作智能。该框架由三层架构组成,包含专门的智能体:分解智能体通过语义感知的查询重写和模式引导的上下文增强,将复杂查询分解为上下文连贯的子任务;多源检索智能体使用可插拔模块针对矢量、图和基于网络的数据库进行并行、特定模态的检索;决策智能体通过一致性投票整合多源答案,并通过专家模型细化解决检索结果中的差异。通过结合文本、图关系和网络衍生证据,该架构实现了全面的查询理解,与基线RAG系统相比,在ScienceQA和CrisisMMD基准测试中,回答准确性提高了 12.95 % 12.95 \% 12.95%,问题分类准确性提高了 3.56 % 3.56 \% 3.56%。值得注意的是,HM-RAG在零样本设置下在这两个数据集上建立了最先进的结果。其模块化架构确保了新数据模态的无缝集成,同时保持严格的数据治理,标志着在解决RAG系统中多模态推理和知识合成的关键挑战方面取得了重大进展。代码可在https://github.com/ocean-luna/HMRAG获得。
关键词
检索增强生成 (RAG),多模态表示,多智能体系统,多源RAG
1 引言
在一个数据快速激增的时代,从异构来源高效检索相关信息已成为现代信息系统的基本支柱 [14]。多模态检索系统通过整合文本、图像、向量化数据和基于网络的内容,正成为电子商务、医疗保健和科学研究等领域不可或缺的工具 [59]。这些系统使用户能够跨多种模态导航不同数据类型,从而获取可操作的见解。然而,尽管近年来取得了显著进展,多模态检索仍然面临重大挑战。复杂性源于需要协调多样化的查询类型、数据格式的异质性和
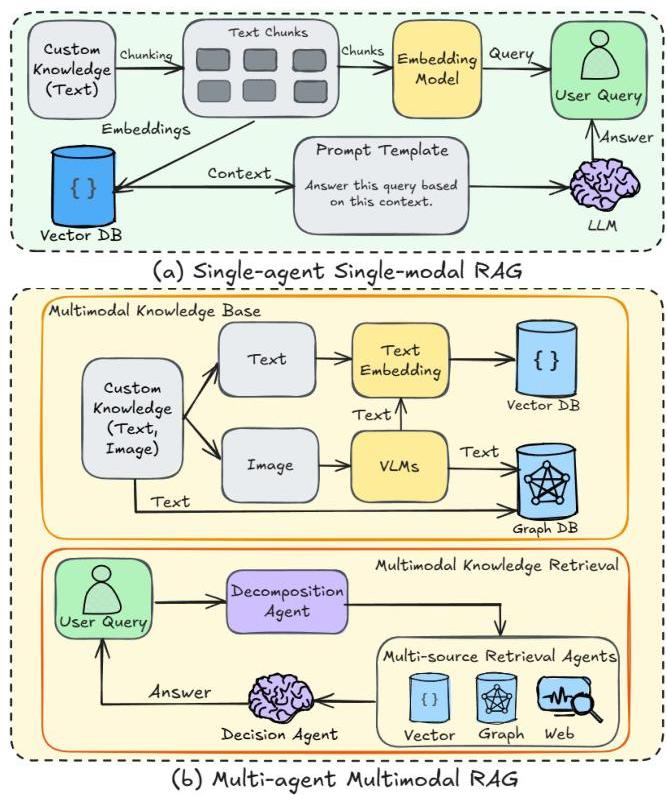
图1:(a) 单智能体单模态 RAG 和 (b) 多智能体多模态 RAG 的比较。多智能体多模态 RAG 通过将它们转换为向量和图数据库来处理多模态数据。它利用跨向量、图和基于网络的数据库进行多源检索,实现更全面和高效的信息检索。这种高级方法允许多智能体多模态 RAG 在处理复杂查询和多样化数据类型时达到卓越性能,使其与功能有限的单智能体单模态 RAG 区分开来。
检索任务的不同目标,所有这些都需要复杂的解决方案来弥合数据表示与用户意图之间的差距。
检索技术的演变历史上一直围绕单模态架构展开,其中查询和检索机制在单一预定义模态内运行 [3, 33]。尽管基于文本的检索增强生成 (RAG) 系统在处理语言信息方面表现出强大的性能 [43],但其无法处理视觉内容促使了
图像基础的 RAG 方法的发展 [7, 25, 41]。然而,当前的多模态实现面临着关键瓶颈:虽然图像基础的 RAG 系统在视觉内容处理方面表现出色,但它们通常无法在视觉元素和文本上下文之间建立一致的跨模态关联。这种局限性在多模态问答中尤为突出,系统必须将视觉感知与文本语义相结合以生成相关响应。
最近,基于图的检索框架被提出,通过构建知识图谱来增强文本依赖关系的建模,代表性的有 GraphRAG [12] 和 LightRAG [18]。这些方法进一步扩展到处理多模态输入 [37],利用图结构准确捕捉跨模态关系。尽管取得这些进展,基于图的方法仍面临固有的权衡:虽然它们能有效捕获高层次的模态交互,但往往牺牲了细粒度信息保真度。这在需要精确文本段落检索的情境下成为一个问题,因为图建模固有的抽象过程模糊了对细致分析至关重要的细粒度文本细节。
与此同时,另一个关键挑战在于调和不同模态的互补优势 [13, 15, 31]。文本模态擅长编码细粒度的语义细节和概念关系,而视觉模态相比之下能够捕捉空间上下文并促进空间关系的理解。当前特定模态的系统 [33, 54] 在跨模态综合方面表现出关键局限性,产生的检索结果要么过于专注于文本精度,要么局限于视觉模式识别。这种模态隔离在异构数据环境中创造了系统漏洞,缺乏跨模态对齐协议的风险可能导致检索操作过程中关键信息的丢失。例如,在以文本为中心的系统中,视觉查询无法将概念问题映射到说明性元素,而在以视觉为导向的框架中,密集文本查询缺乏词汇消歧机制。这些架构缺口突显了亟需能够和谐细粒度语义细节与跨模态上下文一致性的框架。
为应对这些挑战,我们引入了分层多智能体检索增强生成 (HM-RAG),这是一种通过协调多智能体协作增强多模态检索的新颖框架。HM-RAG 采用三层次架构,RAG 流程中有专门的智能体运行。分解智能体分析查询意图并动态重写请求以确保跨模态兼容性。多源检索智能体通过轻量级多模态检索并行获取知识,涵盖矢量、图和基于网络的数据源。最后,决策智能体通过领域特定验证策略合成和精炼候选响应,以确保准确性和一致性。这种分层设计通过结构化的智能体交互系统地编排文本-图像证据集成,实现分层推理。与传统方法不同,HM-RAG 结合查询分解、并行化信息检索和专家指导的答案精炼,以实现高效且上下文相关的响应。我们的贡献总结如下:
- 我们提出了一种新型模块化分层框架,将查询处理模块化为基于智能体的组件,这促进了可扩展且高效的多模态检索。
-
- 我们实现了多源即插即用检索集成,提供跨多样数据源的无缝连接。通过有效地将查询路由到矢量、图和基于网络的检索智能体,我们的方法确保了在处理异构数据环境时的灵活性和效率,简化了复杂的信息检索过程。
-
- 我们采用了专家指导的精炼过程,通过最少的专家监督确保响应质量的操作效率和上下文精度。
-
- 我们通过在基准数据集上的广泛实验展示了 HM-RAG 的有效性,结果在 ScienceQA 和 CrisisMMD 基准上达到了最先进的性能。
2 相关工作
2.1 检索增强生成
RAG 系统已经显著发展以增强其多模态推理能力 [16, 20, 33, 47]。最初,基于文本的 RAG 系统将大型语言模型 (LLMs) 与外部文本知识集成在一起,通过检索相关文本片段改进问答性能 [4, 27, 57]。然而,随着视觉丰富的文档变得越来越普遍,仅基于文本系统的局限性变得明显,促使了基于图像的 RAG 方法的发展 [5, 6, 38, 46]。尽管这些方法旨在为大型视觉语言模型 (VLMs) 检索视觉内容,但由于检索过程大多独立,他们在有效整合文本和图像模态方面遇到了挑战,阻碍了对其相互关系的深入理解。
为应对这些挑战,基于图的 RAG 系统应运而生,利用结构化的知识表示来捕捉跨模态和模态内的语义关系 [9, 18, 28, 44]。这些系统利用向量空间嵌入和拓扑关系来建模复杂的文档结构,使得检索出语义连贯的上下文超越简单的文本片段 [12, 42, 53]。基于图的 RAG 系统特别擅长理解文本和图像之间的关系,以及提取文本本身的关系 [37]。然而,当前的 RAG 实现通常依赖于单源检索,限制了其处理需要同时处理向量、图和基于网络数据库的复杂查询的能力 [19]。这种局限性在需要私有数据检索和实时更新的应用中尤其显著,缺乏集成的多源检索能力会导致不完整或过时的信息。为了充分利用每种数据模态的优势并满足动态和异构数据环境的需求,RAG 系统必须进化以支持协调的多源检索和综合。
2.2 RAG 中的智能体
RAG 已成为通过将检索机制与生成模型集成来执行知识密集型任务的关键范式,显著增强了语言模型的能力。然而,传统的 RAG 实现通常依赖于难以处理多模态查询的静态管道 [8, 48]。最近的基于智能体的 RAG 架构通过提高系统模块化和操作灵活性解决了这些限制 [11, 21, 29]。面向智能体的方法将查询处理分解为专门的组件,如语义解析、跨模态检索和上下文感知生成,允许有针对性的优化同时保持整体适应性。PaperQA [32] 通过利用学术文献生成基于证据的响应,减少了科学应用中的幻觉现象,体现了这一点。
在此基础上,像 FLARE [30] 这样的主动 RAG 方法通过预见性检索引入时间动态性,增强了扩展文本生成的性能。尽管取得了这些进展,多模态集成的挑战依然存在。新兴的动态 RAG 方法 [49, 50] 提出了实体感知增强策略,动态纳入检索到的实体表示,解决了上下文窗口限制的同时保持语义连贯性。我们的 HM-RAG 框架通过利用 LLMs 的语义理解的分层多智能体架构综合了这些创新。此设计实现了动态查询适应和多模态检索,为跨各种数据模态的复杂信息检索和生成任务提供了优化的解决方案。通过整合这些进步,HM-RAG 解决了多模态推理和知识综合的关键挑战,为更强大和灵活的 RAG 系统铺平了道路。
3 方法论
我们介绍了 HM-RAG,这是一个解决 RAG 系统复杂挑战的新框架。如图 2 所示,HM-RAG 特点是创新的多智能体、多模态架构,具有用于信息提取和多源检索的专门智能体。给定一个自然语言问题 q q q 和参考文档 D \mathcal{D} D,RAG 从 D \mathcal{D} D 中检索语义相关的内容,将其与生成语言模型集成以产生严格基于 D \mathcal{D} D 的答案。这种方法推进了多模态问答和多智能体 RAG 能力。以下章节详细阐述了 HM-RAG 的架构设计。通过这个系统描述,我们阐明了框架如何有效集成和利用多模态信息和多源检索,最终导致 RAG 应用的准确性提升。
3.1 多模态知识预处理
本节重点介绍多模态数据处理,旨在将文本数据和视觉图像转换为向量和图数据库表示形式以增强检索操作。我们的方法使用 VLM 将视觉信息转码为文本表示形式,随后与原始文本语料库集成以共同构建向量和图数据库。
3.1.1 多模态文本知识生成。传统的以实体为中心的多模态知识提取方法依赖于预定义的类别边界,限制了其识别新视觉概念的能力。我们利用 BLIP-2 的框架 [34] 来利用预训练 VLM 的开放词汇潜力。基于通用的视觉到语言转换范式:
T o = D blip2 ( f align ( E blip2 ( I o ) ) ) T_{o}=\mathcal{D}_{\text {blip2 }}\left(f_{\text {align }}\left(\mathcal{E}_{\text {blip2 }}\left(I_{o}\right)\right)\right) To=Dblip2 (falign (Eblip2 (Io)))
其中视觉编码器 E blip2 \mathcal{E}_{\text {blip2 }} Eblip2 从输入图像 I o I_{o} Io 中提取特征,跨模态对齐模块 f align f_{\text {align }} falign 桥接视觉与语言语义。我们的框架通过利用原始文本数据的情境细化机制解决了机器生成描述过度简化的关键限制,特别是针对 BLIP-2 输出过于浓缩且缺乏视觉特异性的问题。
这一过程分为三个协同阶段。通过已建立的架构 [10, 22, 39] 进行分层视觉编码,生成补丁嵌入 V t ∈ R d n × N p V_{t} \in \mathcal{R}^{d_{n} \times N_{p}} Vt∈Rdn×Np。跨模态交互,其中可学习查询 Q t ∈ R d q × L q Q_{t} \in \mathcal{R}^{d_{q} \times L_{q}} Qt∈Rdq×Lq 通过缩放点积注意力关注视觉特征,动态加权空间语义相关性。情境感知文本生成,融合先前描述 T o i , t T_{o}^{i, t} Toi,t 的潜在文本特征与跨模态表示进行自回归解码。此阶段的情境细化增强了语义对齐,显著减少最终输出 T o T_{o} To 的描述模糊性和词汇稀疏性。
由此形成的多模态文本知识库通过系统集成原始文本输入与生成的文本化实现。
T m = Concate ( T , T o ) T_{m}=\operatorname{Concate}\left(T, T_{o}\right) Tm=Concate(T,To)
其中
T
T
T 对应源文本语料库,
T
m
T_{m}
Tm 表示通过异构融合过程形成的多模态文本聚合。
3.1.2 多模态知识图谱构建。我们通过协同增强的 VLM 描述与基于 LLM 的结构化推理建立多模态知识图谱 (MMKG)。基于 VLM 生成的精细化视觉描述
T
o
T_{o}
To,可选地与外部文本知识
T
T
T 融合,我们采用 LightRAG 框架 [18] 实现高效的多跳推理和动态知识集成:
G = LightRAG ( T o , T ) G=\operatorname{LightRAG}\left(T_{o}, T\right) G=LightRAG(To,T)
LightRAG 通过混合提取策略处理多模态输入。实体-关系提取:专用函数 f f f 将输入分解为实体 E = { e 1 , ⋯ , e n } E=\left\{e_{1}, \cdots, e_{n}\right\} E={e1,⋯,en} 和关系三元组 R = { ( h i , r i , t i ) } R=\left\{\left(h_{i}, r_{i}, t_{i}\right)\right\} R={(hi,ri,ti)},其中 h , t ∈ E h, t \in E h,t∈E 表示头/尾实体, r ∈ R r \in R r∈R 表示关系。双层推理增强:双尺度检索机制 Retrieve g l o b a l + l o c a l _{g l o b a l+l o c a l} global+local 在推理期间动态获取相关三元组;全局检索识别主题集群,局部提取专注于实体特定连接。
所构建的 MMKG
G
=
(
E
,
R
)
G=(E, R)
G=(E,R) 将知识形式化为三元组
(
h
,
r
,
t
)
(h, r, t)
(h,r,t),其中实体包括来自
T
0
T_{0}
T0 的视觉概念
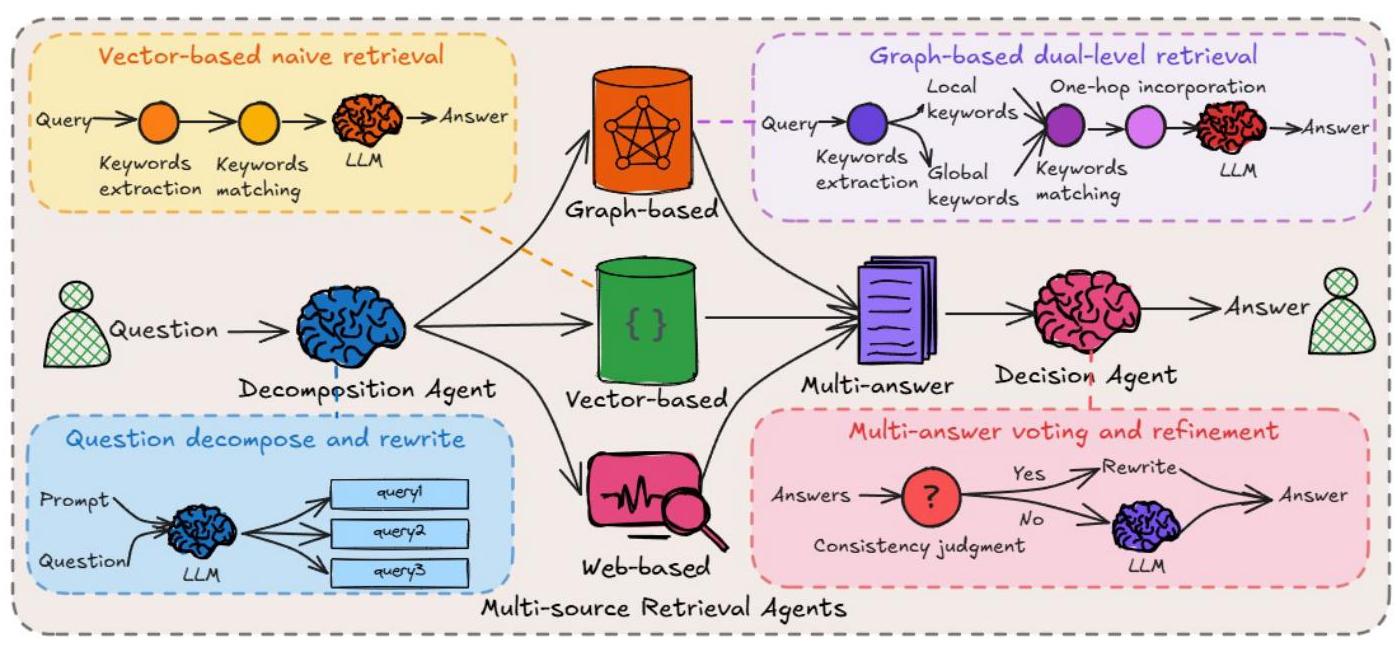
图2:HM-RAG概述。一个多智能体多模态框架分为三个阶段运行:首先,分解智能体使用LLM将问题重写并分解为若干子查询。其次,多源检索智能体根据需要从向量、图和基于网络的来源检索前-k个相关文档。最后,决策智能体提供投票机制和细化过程以生成最终答案。
和来自
T
T
T 的文本知识。至关重要的是,在图构建过程中嵌入视觉数据存储位置,实现跨模态接地。此架构建立了一个双向知识增强框架:语言模型通过嵌入在
G
G
G 中的视觉-语义关系实现视觉上下文推理,而视觉语言模型通过持续的多模态集成动态更新知识嵌入,有效通过表示一致性约束缓解幻觉概率。
3.2 分解智能体用于多意图查询
分解智能体是所提框架的关键组件,旨在将复杂、多意图的用户查询分解为连贯且可执行的子任务。该智能体解决了传统系统的一个关键限制,这些系统通常难以处理需要跨多个数据源联合推理的复合查询。通过利用分层解析机制,分解智能体识别用户查询的底层结构并将它们分解为原子单元,每个单元针对特定的数据模态或检索任务。
所提框架分为两个阶段,均由特定任务的LLM提示策略驱动。必要性判断分解。智能体首先确定输入问题 Q Q Q 是否包含多个意图,使用二元决策提示指令LLM将其分类为单意图或多意图。如果输出是多意图,则 Q Q Q 进入分解。否则,直接返回问题 Q Q Q。意图分解。LLM使用结构化提示将 Q Q Q 分解为候选子问题 q = { q 1 , ⋯ , q n } q=\left\{q_{1}, \cdots, q_{n}\right\} q={q1,⋯,qn},灵感来源于[35]:“根据其意图,将原问题的推理步骤分解为2到3个简单且逻辑连接的子问题,同时保留原问题的关键字。”
3.3 多源即插即用检索智能体
我们提出了一种模块化多智能体检索框架,通过标准化接口动态组合异构多模态搜索策略。通过将检索功能解耦为三个专门的智能体——基于向量的检索智能体、基于图的检索智能体和基于网络的检索智能体——系统实现了领域无关的适应性,同时确保了在多样化搜索场景中的互操作性。每个智能体都遵循统一的通信协议,实现了向量语义搜索、图拓扑探索和实时网络检索能力的无缝集成。此设计允许每个检索智能体作为即插即用组件运行,确保它们可以轻松集成或替换而不影响整个系统性能。这种模块化不仅增强了灵活性,还维持了特定任务的优化目标,使框架高度适应各种应用和数据模态。
3.3.1 细粒度信息的基于向量的检索智能体。此智能体利用朴素检索架构 [18] 高效搜索非结构化文本语料库。给定用户查询
q
q
q,系统首先使用编码器计算其语义嵌入
h
q
h_{q}
hq
E
text
\mathcal{E}_{\text {text }}
Etext :
h q = E text ( q ) h_{q}=\mathcal{E}_{\text {text }}(q) hq=Etext (q)
其中 h q ∈ R d h_{q} \in \mathbb{R}^{d} hq∈Rd 表示查询在 d d d 维向量空间中的嵌入。
接下来,系统使用余弦相似度计算查询嵌入 h q h_{q} hq 和所有文档嵌入 h j h_{j} hj 之间的语义相似度:
s j = h q T h j ∥ h q ∥ ∥ h j ∥ , ∀ j ∈ [ 1 , M ] s_{j}=\frac{h_{q}^{T} h_{j}}{\left\|h_{q}\right\|\left\|h_{j}\right\|}, \quad \forall j \in[1, M] sj=∥hq∥∥hj∥hqThj,∀j∈[1,M]
其中 j ∈ [ 1 , M ] j \in[1, M] j∈[1,M], M M M 为文档总数。相似度得分 s j s_{j} sj 衡量每个文档与查询的接近程度,构成排名检索文档的基础。
基于相似度得分,系统检索前- k k k 最相关的文档:
R k = { c 1 , ⋯ , c k } s.t. s 1 ≥ s 2 ≥ ⋯ ≥ s k \mathcal{R}_{k}=\left\{c_{1}, \cdots, c_{k}\right\} \quad \text { s.t. } \quad s_{1} \geq s_{2} \geq \cdots \geq s_{k} Rk={c1,⋯,ck} s.t. s1≥s2≥⋯≥sk
其中 R k \mathcal{R}_{k} Rk 表示前- k k k 检索上下文集,确保仅使用最相关的信息进行后续处理。
随后,语言模型通过受限解码生成答案 A o \mathcal{A}_{o} Ao:
A o = P ( q , R k ) = Concate ( q , Context , { c 1 , ⋯ , c k } ) \mathcal{A}_{o}=\mathcal{P}\left(q, \mathcal{R}_{k}\right)=\operatorname{Concate}\left(q, \operatorname{Context},\left\{c_{1}, \cdots, c_{k}\right\}\right) Ao=P(q,Rk)=Concate(q,Context,{c1,⋯,ck})
其中 P \mathcal{P} P 表示生成过程,将查询 q q q、检索上下文 { c 1 , ⋯ , c k } \left\{c_{1}, \cdots, c_{k}\right\} {c1,⋯,ck} 和附加上下文信息串联以生成最终答案。
具体而言,给定查询 q 和检索上下文 R k \mathcal{R}_{k} Rk 生成令牌序列 y 的条件概率被建模为:
p ( y ∣ q , R K ) = ∏ t = 1 T p l m ( y t ∣ y < t , q , R K ) p\left(y \mid q, \mathcal{R}_{K}\right)=\prod_{t=1}^{T} p_{l m}\left(y_{t} \mid y_{<t}, q, \mathcal{R}_{K}\right) p(y∣q,RK)=t=1∏Tplm(yt∣y<t,q,RK)
其中 p l m p_{l m} plm 表示语言模型自回归生成过程中令牌的条件概率,确保生成的答案在上下文中具有一致性。
此外,注意力机制明确将检索内容纳入生成过程:
Attention ( Q , K , V ) = softmax ( Q [ h q ; H R ] T d k ) [ h q ; H R ] \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q\left[h_{q} ; H_{\mathcal{R}}\right]^{T}}{\sqrt{d_{k}}}\right)\left[h_{q} ; H_{\mathcal{R}}\right] Attention(Q,K,V)=softmax(dkQ[hq;HR]T)[hq;HR]
其中
H
R
∈
R
K
×
d
H_{\mathcal{R}} \in \mathbb{R}^{K \times d}
HR∈RK×d 堆叠检索块的嵌入,
[
h
q
;
H
R
]
[h_{q} ; H_{\mathcal{R}}]
[hq;HR] 将查询嵌入与检索块嵌入串联,增强了模型聚焦相关信息的能力。为了确保生成答案的可靠性,约束强制 top-
p
=
1.0
p=1.0
p=1.0 和温度为 0 ,确保基于最高概率标记的确定性解码。这最小化了幻觉风险并确保事实准确性。
3.3.2 图形关系信息检索代理。此代理利用 LightRAG 的图遍历能力解决多跳语义查询 [18]。给定输入查询
q
q
q,代理通过 LightRAG 的联合注意力机制动态检索实体和关系,构造情境感知子图
G
q
⊆
G
G_{q} \subseteq G
Gq⊆G。子图定义为:
G q = { ( h , r , t ) ∣ LightRAG graph ( q , h , r , t ) > τ } G_{q}=\left\{(h, r, t) \mid \operatorname{LightRAG}_{\text {graph }}(q, h, r, t)>\tau\right\} Gq={(h,r,t)∣LightRAGgraph (q,h,r,t)>τ}
其中 LightRAG graph 通过跨模态注意力对齐查询嵌入与图三元组表示计算相关性分数,确保只有高度相关的三元组包含在子图中。
为高效解决复杂查询,代理采用平衡效率和全面性的分层搜索策略。首先,代理优先检索与查询相关的实体的本地1跳邻居,使用关系特定的注意力权重。这确保首先检索直接连接的实体和关系,为进一步探索提供基础。其次,代理通过迭代消息传递识别跨模态路径,全局扩展搜索。这允许代理探索超出直接邻居的更深层次语义关系,丰富检索信息。
此外,该框架是一个双层检索框架,通过三阶段检索过程将图结构化知识与向量表示集成。首先,框架对输入查询 q q q 进行语义分解,提取本地关键词 q j q_{j} qj 和全局关键词 q g q_{g} qg。此步骤捕获细粒度和高层次的语义信息。其次,框架执行混合图-向量匹配。优化的向量数据库将 q j q_{j} qj 与实体属性对齐,同时将 q g q_{g} qg 映射到知识图 G = ( V , E ) G=(\mathcal{V}, \mathcal{E}) G=(V,E) 中的关系模式。这种混合方法确保考虑显式实体属性和潜在关系语义。
最后,为增强检索完整性,框架执行高阶上下文扩展。检索子图扩展以包括检索节点和边的一跳邻居:
A g = { v i ∈ V ∧ ( v i ∈ N o ∨ v i ∈ N e ) } \mathcal{A}_{g}=\left\{v_{i} \in \mathcal{V} \wedge\left(v_{i} \in \mathcal{N}_{o} \vee v_{i} \in \mathcal{N}_{e}\right)\right\} Ag={vi∈V∧(vi∈No∨vi∈Ne)}
其中
N
o
\mathcal{N}_{o}
No 和
N
e
\mathcal{N}_{e}
Ne 分别表示检索节点和边的一跳邻居。此步骤确保检索子图保留结构完整性,同时捕获更广泛的上下文关系。最终答案
A
g
\mathcal{A}_{g}
Ag 使用
A
g
=
\mathcal{A}_{g}=
Ag=
LLM
(
A
g
)
\operatorname{LLM}\left(\mathcal{A}_{g}\right)
LLM(Ag) 生成,使用轻量级 LLM。
3.3.3 基于网络的检索代理用于实时信息。网络检索组件在信息检索和自然语言生成之间起到关键桥梁作用,显著增强生成文本的语义保真度和事实依据。我们的工作利用Google Serper API。系统通过参数化API请求向Google搜索引擎获取知识。对于输入查询
q
q
q,检索过程形式化为:
R = Google ( q ; θ search ) \mathcal{R}=\operatorname{Google}\left(q ; \theta_{\text {search }}\right) R=Google(q;θsearch )
其中 θ search \theta_{\text {search }} θsearch 指定搜索配置参数。我们采用设置 θ search = { \theta_{\text {search }}=\left\{\right. θsearch ={ num results = k , language = en, type = \left._{\text {results }}=k, \text { language }=\text { en, type }=\right. results =k, language = en, type = w e b } \left.w e b\right\} web}。API返回结构化结果 A w = { a i } i = 1 k \mathcal{A}_{w}=\left\{a_{i}\right\}_{i=1}^{k} Aw={ai}i=1k,每个结果包含标题、摘要、URL 和位置排名元数据。
Google Serper 框架通过三种主要操作模式在实际部署场景中表现出特别的有效性,每种模式都满足现代知识感知系统的关键需求。首先,实时事实验证模块通过神经记忆查询计算事实有效性评分。其次,带有归属意识的生成
协议确保通过双阶段注意力路由实现可追溯性。第三,自适应查询扩展机制通过差异术语加权解决词汇不匹配问题。
3.4 决策代理用于多答案细化
一致性投票。框架使用ROUGE-L和BLEU指标评估由基于向量、基于图和基于网络的检索系统生成的答案 { A n , A g , A w } \left\{\mathcal{A}_{n}, \mathcal{A}_{g}, \mathcal{A}_{w}\right\} {An,Ag,Aw} 之间的语义一致性。首先为每个答案生成摘要 { S u , S g , S w } \left\{\mathcal{S}_{u}, \mathcal{S}_{g}, \mathcal{S}_{w}\right\} {Su,Sg,Sw}。ROUGE-L 使用最长公共子序列(LCS)衡量关键信息的重叠,定义为:
R L = L C S ( S i , S j ) max { ∣ S i ∣ , ∣ S j ∣ } R_{L}=\frac{L C S\left(\mathcal{S}_{i}, \mathcal{S}_{j}\right)}{\max \left\{\left|\mathcal{S}_{i}\right|,\left|\mathcal{S}_{j}\right|\right\}} RL=max{∣Si∣,∣Sj∣}LCS(Si,Sj)
其中分子表示摘要之间的LCS长度,分母对其进行归一化。该指标强调保留关键事实信息的一致性。
BLEU 评估摘要之间n-gram匹配的局部精确度,定义为:
B L E U = exp ( ∑ n = 1 k w n log p n ) ⋅ min ( 1 , ∣ S j ∣ ∣ S i ∣ ) B L E U=\exp \left(\sum_{n=1}^{k} w_{n} \log p_{n}\right) \cdot \min \left(1, \frac{\left|\mathcal{S}_{j}\right|}{\left|\mathcal{S}_{i}\right|}\right) BLEU=exp(n=1∑kwnlogpn)⋅min(1,∣Si∣∣Sj∣)
其中 p n p_{n} pn 表示n-gram精确度, w n w_{n} wn 表示权重系数。该指标擅长检测术语或数值的精确匹配。
然后应用 R L R_{L} RL 和 B L E U B L E U BLEU 的加权融合,以平衡宏观层面的语义对齐与微观层面的细节一致性,衡量任何两个答案之间的相似性。如果成对相似性超过预定义阈值,则使用轻量级语言模型(LLM)细化结果以生成最终答案 A。如果相似性低于阈值,框架将继续进行专家模型细化。
专家模型细化。对于冲突的答案,框架使用 LLMs、多模态 LLMs(MLLMs)或基于 Cot 的语言模型(Cot-LMs)通过整合多源证据生成细化响应。LLM 或 MLLM 处理原始查询 q q q 和检索到的证据以生成最终答案 A \mathcal{A} A。此步骤作为专家指导,确保即使初始答案存在差异,最终响应在上下文中具有一致性和事实准确性。
4 实验
4.1 实验设置
数据集。我们在两个多模态推理基准上进行实验,涵盖不同的模态配置,包括复杂问答(ScienceQA)和危机事件分类(CrisisMMD)。
ScienceQA [40]。这是第一个大规模多模态基准,用于科学问答,涵盖3个核心学科(自然科学、社会科学和形式科学)。该数据集包含21,208个精心策划的实例,按26个主题、127个类别和379个不同的推理技能分层组织。每个实例结合文本问题与可选的视觉上下文(图表、图表或照片),平衡分为12,726个训练样本、4,214个验证样本和4,268个测试样本。
按照 LLaVA [36] 中建立的评估协议,我们报告所有测试样本的平均准确率,以评估模型在多模态理解和多步科学推理中的表现。值得注意的是,34.6% 的测试问题需要同时处理视觉和文本信息才能得出正确答案。
CrisisMMD [2]。该数据集呈现了一个具有挑战性的多模态集合,适用于灾难响应应用,包含约35,000条来自真实世界危机事件的社交媒体帖子,包含视觉和文本内容。它具有七个不同的灾难类别和四个精细的严重级别注释方案。其独特价值在于捕捉真实的用户生成内容,保留自然噪声模式和危机沟通中固有的复杂跨模态关系。这些特性使其特别适合评估零样本适应模型,因为在动态紧急场景中成功的表现直接与实际部署能力相关,而这些场景通常没有干净的数据和明确的模态对齐。
实现细节。我们利用 DeepSeek-R1-70B 进行动态图构建,并通过 Qwen2.5-7B 的参数适配框架优化 LightRAG 的混合检索机制,这与 VaLik [37] 一致。在决策细化过程中,我们使用 GPT-4o 处理 ScienceQA 数据集,并使用 GPT-4 分析 CrisisMMD 数据集。所有多模态推理工作流程都在单个 NVIDIA A800-80GB GPU 上运行,通过内存优化的并行化无缝支持图神经网络计算和检索增强生成任务的并发执行。
4.2 主要结果
在本节中,我们对 HM-RAG 进行系统评估,对比最先进的零样本 LLMs、VLMs 和 RAG 增强方法在多个基准上的表现。结果见表 1 和表 2,表明 HM-RAG 在所有比较方法中具有一致的优越性。
4.2.1 ScienceQA 结果。表 1 系统地量化了 HM-RAG 和现有零样本方法在 ScienceQA 数据集上的多模态问答性能。如表所示,HM-RAG 建立了最先进的平均准确率
93.73
%
93.73 \%
93.73%,分别超过了之前的最佳零样本 VLM 方法 LLaMA-SciTune 和 GPT-4o
4.11
%
4.11 \%
4.11% 和
2.82
%
2.82 \%
2.82%,并且显著优于单智能体 RAG 变体。与基于向量、基于图和基于网络的基线相比,HMRAG 分别实现了
12.95
%
12.95 \%
12.95%、
12.71
%
12.71 \%
12.71% 和
12.13
%
12.13 \%
12.13% 的绝对改进。在社会科学(SOC)任务的准确性方面观察到了显著的改进,相对于基于网络和基于图的基线分别达到了
24.38
%
24.38 \%
24.38% 和
20.65
%
20.65 \%
20.65% 的改进。该框架还超过了人类专家的表现
6.03
%
6.03 \%
6.03%。
4.2.2 CrisisMMD 结果。表 2 提供了在 CrisisMMD 基准上多模态理解能力的全面评估。我们的分析揭示了三个关键观察结果。首先,多模态增强的 LLMs 在所有任务中始终优于纯文本 LLMs 和专门的 VLMs。所提出的方法在平均准确率方面取得了最先进的表现
表 1:在 ScienceQA 数据集上的 Top-1 检索性能比较(准确率 %)。#P 表示可训练参数的数量。类别包括:NAT(自然科学)、SOC(社会科学)、LAN(语言科学)、TXT(文本上下文)、IMG(图像上下文)、NO(无上下文)、G1-6(1-6 年级)、G7-12(7-12 年级)。此处的比较基于 ScienceQA 排行榜上获得的最先进的零样本学习结果
1
{ }^{1}
1。
| 学习 | 模型 | #P | 科目 | 上下文模态 | 年级 | 平均 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NAT | SOC | LAN | TXT | IMG | NO | G1-6 | G7-12 | ||||
| 基线 | 人类 | - | 90.23 | 84.97 | 87.48 | 89.60 | 87.50 | 88.10 | 91.59 | 82.42 | 88.40 |
| 零样本 LLMs | ChatGPT [56] | - | - | - | - | - | - | - | - | - | 69.41 |
| GPT-3 (0-shot) [40] | 173B | 75.04 | 66.59 | 78.00 | 74.24 | 65.74 | 79.58 | 76.36 | 69.87 | 74.04 | |
| DDCoT (GPT-3) [58] | 175B | 78.60 | 73.90 | 80.45 | 77.27 | 69.96 | 82.93 | 80.65 | 73.50 | 78.09 | |
| CoT GPT-3 + Doc [24] | 173B | - | - | - | - | - | - | - | - | 79.91 | |
| DDCoT (ChatGPT) [58] | 175B | 80.15 | 76.72 | 82.82 | 78.89 | 72.53 | 85.02 | 82.86 | 75.21 | 80.15 | |
| 零样本 VLMs | LaVIN-13B [56] | - | - | - | - | - | - | - | - | - | 77.54 |
| LLaMA-SciTune [23] | 7B | 84.50 | 94.15 | 82.91 | 88.35 | 83.64 | 88.74 | 85.05 | 85.60 | 86.11 | |
| LG-VQA (BLIP-2) [17] | - | - | - | - | - | - | - | - | - | 86.32 | |
| LG-VQA (CLIP) [17] | - | - | - | - | - | - | - | - | - | 87.22 | |
| LLaMA-SciTune [23] | 13B | 89.30 | 95.61 | 87.00 | 93.08 | 6.67 | 91.75 | 84.37 | 91.30 | 90.03 | |
| 零样本单智能体 RAG | 基于向量 [37] | 7B | 84.54 | 74.24 | 86.91 | 82.74 | 72.53 | 90.03 | 84.51 | 80.28 | 82.98 |
| 基于图 [37] | 7B | 84.15 | 75.14 | 87.64 | 82.99 | 73.18 | 89.69 | 84.40 | 80.95 | 83.16 | |
| 基于网络 | 7B | 83.79 | 72.89 | 91.82 | 81.09 | 70.55 | 94.01 | 85.98 | 79.30 | 83.59 | |
| GPT-4o [26] | - | 92.72 | 93.48 | 86.09 | 92.67 | 90.88 | 87.60 | 92.91 | 88.00 | 91.16 | |
| 零样本多智能体 RAG | HM-RAG | - | 94.36 | 90.66 | 94.91 | 93.79 | 89.94 | 96.03 | 94.42 | 92.49 | 93.73 |
表 2:在 CrisisMMD 数据集上的 Top-1 检索性能比较(准确率 %)。-I 表示指令调优变体。粗体表示最高值。任务 1 是二分类任务,而任务 2 和任务 2 合并是多分类任务。比较数据来源于 [37],这是 CrisisMMD 数据集上开创性的 LLM 基础工作。
| 方法 | #P | 任务 1 | 任务 2 | 任务 2 合并 | 平均 |
|---|---|---|---|---|---|
| 单模态 LLMs | |||||
| LLaMA-2 [51] | 7B | 62.32 | 18.32 | 21.45 | 34.03 |
| 13B | 63.80 | 21.82 | 33.15 | 39.59 | |
| 70B | 63.15 | 28.87 | 36.89 | 42.97 | |
| 7B | 65.04 | 44.52 | 45.33 | 51.63 | |
| Qwen2.5 [55] | 32B | 67.28 | 46.94 | 47.07 | 53.76 |
| 72B | 67.95 | 50.51 | 50.29 | 56.25 | |
| GPT-4 [1] | - | 66.83 | 47.25 | 49.44 | 54.51 |
| 多模态 VLMs | |||||
| Qwen2-VL [52] | 2B-I | 47.56 | 7.60 | 7.42 | 20.86 |
| 7B-I | 62.45 | 32.68 | 34.20 | 43.11 | |
| 72B-I | 65.80 | 47.21 | 48.28 | 53.76 | |
| LLaVA [36] | 7B | 54.00 | 28.01 | 30.61 | 37.54 |
| 13B | 60.58 | 20.14 | 23.44 | 34.72 | |
| 34B | 56.44 | 25.15 | 25.07 | 35.55 | |
| CLIP [45] | - | 43.36 | 17.88 | 20.79 | 27.34 |
| GPT-4o [26] | - | 68.20 | 47.58 | 49.55 | 55.11 |
| 单智能体 RAG | |||||
| 基于向量 [37] | 7B | 67.49 | 45.11 | 45.94 | 52.85 |
| 基于图 [37] | 7B | 68.90 | 50.02 | 50.69 | 56.54 |
| 多智能体 RAG | |||||
| HM-RAG | - | 72.06 | 51.50 | 52.09 | 58.55 |
58.55 % 58.55 \% 58.55%,比最强基线(GPT-4o)和仅文本变体(Qwen2.572B)分别绝对提高了 2.44 % 2.44 \% 2.44% 和 3.44 % 3.44 \% 3.44%,尽管只使用了 7B 参数。
其次,模型规模与性能增益表现出非线性相关。虽然 Qwen2.5-72B(仅文本)达到了 56.25 % 56.25 \% 56.25% 的平均准确率,我们的 7B 多模态增强变体获得了 2.3 % 2.3 \% 2.3% 的绝对改进,展示了优越的参数效率。这种趋势在各个模态中都存在,Qwen2-VL-72B-I(VLM)尽管参数数量相当,但表现仍比我们的方法差 4.79 % 4.79 \% 4.79%。
第三,多模态集成对任务性能有显著影响。我们的方法在平均准确率上比其仅文本和仅图变体分别提高了 5.7 % 5.7 \% 5.7% 和 2.01 % 2.01 \% 2.01%,这突显了多源推理的有效性。值得注意的是,任务 1 上的 72.06 % 72.06 \% 72.06% 准确率建立了一个新的基准,超过了 GPT-4o 3.86 % 3.86 \% 3.86%,展示了强大的视觉-文本对齐能力。
4.3 定性分析
我们提供了一个预测示例,如图 3 所示,以展示我们所提出模型的有效性。这个示例经过精心挑选,旨在展示模型处理复杂模式并做出准确选择的能力。对于希望了解更多案例的读者,附录 A 提供了一组更详细的示例。在给定示例中,由于数据库中没有与此问题相关的记录,所有多源检索代理都产生了错误结果。为应对这种情况,决策代理中的专家细化用于执行高水平思考以得出正确结果。这表明
1
{ }^{1}
1 https://scienceqa.github.io/leaderboard.html
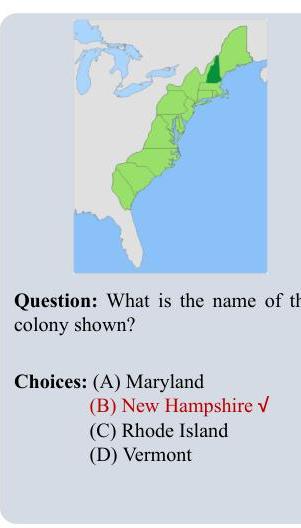
基于文本的
文档块… 由于我们从提供的块中没有直接信息,并且因为选项中没有任何明确回答为正确的,我们必须得出结论,基于…,答案是"FAILED:"。
答案:答案是 (D)。
基于图的
答案未在选项中提供,但根据知识库给出的上下文,它可能指的是列出的其中一个殖民地。由于没有提供额外的信息或上下文,我将声明,在没有足够细节来选择给定选项的情况下。
答案:答案是 (A)。
基于网络的
使用下面的地图,请将殖民地名称与… - Brainly/a它们的位置是:A 新罕布什尔州。B 马萨诸塞州殖民地。C 罗德岛殖民地。D 康涅狄格殖民地。E 纽约殖民地
https://brainly.com/question/13673860。答案:答案是 ©。
HMAgent
地图用较深的阴影突出新罕布什尔州,表明它是选定的殖民地。
答案:答案是 (B)。
图 3:案例研究:HM-RAG 与基线方法(基于向量、基于图和基于网络的检索代理)的比较。
表 3:在 ScienceQA 数据集上不同 HM-RAG 变体的性能比较。组件包括:VA(基于向量的检索代理),GA(基于图的检索代理),WA(基于网络的检索代理),和 DA(决策代理)。
| 代理配置 | NAT | SOC | LAN | TXT | IMG | NO | G1-6 | G7-12 | 平均 | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VA | GA | WA | DA | ||||||||||
| × \times × | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 90.72 | 88.08 | 94.09 | 89.30 | 84.58 | 95.68 | 92.47 | 88.46 | 91.04 | |
| ✓ \checkmark ✓ | × \times × | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 91.21 | 87.96 | 94.73 | 90.32 | 85.62 | 95.61 | 92.22 | 90.05 | 91.44 | |
| ✓ \checkmark ✓ | ✓ \checkmark ✓ | × \times × | ✓ \checkmark ✓ | 88.99 | 84.81 | 90.27 | 88.17 | 83.09 | 91.78 | 89.46 | 86.62 | 88.45 | |
| ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | × \times × | 83.79 | 72.89 | 91.82 | 81.09 | 70.55 | 94.01 | 85.98 | 79.30 | 83.59 | |
| ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 94.36 | 90.66 | 94.91 | 93.79 | 89.94 | 96.03 | 94.42 | 92.49 | 93.73 |
我们模型在知情决策方面的熟练程度确保了相较于依赖单一检索机制的增强鲁棒性。
4.4 消融研究
表 3 在 ScienceQA 上通过受控消融研究系统评估了各个代理组件的贡献。关于框架设计出现了三个关键见解。首先,决策代理(DA)确立了自身作为最关键元素的地位,其移除引发了最显著的性能下降
10.82
%
10.82 \%
10.82%。该组件在合成多源决策方面尤为重要,正如当 DA 被禁用时,图像任务的准确性显著下降
21.56
%
21.56 \%
21.56%,社会推理任务的准确性下降
19.60
%
19.60 \%
19.60% 所证明的那样。其次,基于网络的检索代理(WA)展示了强大的集成能力。停用 WA 导致平均性能下降
5.63
%
5.63 \%
5.63%,对第 7-12 年级任务的影响更为明显,准确率下降
6.35
%
6.35 \%
6.35%。第三,完全集成的代理系统实现了峰值性能
93.73
%
93.73 \%
93.73%,比最佳消融配置高出显著的
2.44
%
2.44 \%
2.44%。此最优配置在所有任务类别中提供了持续的改进,特别是在多模态场景中,文本任务的改进为
3.70
%
3.70 \%
3.70%,图像任务的改进为
4.80
%
4.80 \%
4.80%。该框架还显示了优越的
处理复杂查询的能力,在7-12年级问题上达到了比基线高
2.64
%
2.64 \%
2.64% 的准确率。这些实证结果证实了架构在协调专门智能体以实现全面多模态推理方面的有效性。
5 结论
在本文中,我们介绍了 HM-RAG,这是一种新颖的分层多智能体多模态检索增强生成框架,旨在解决复杂多模态查询处理和知识综合的挑战。HM-RAG 开创性地通过整合专门用于查询分解、多源检索和决策细化的智能体,实现跨结构化、非结构化和基于图的数据进行动态知识综合。通过在 ScienceQA 和 CrisisMMD 基准上的广泛实验,HM-RAG 展示了在多模态问答和分类准确性方面的最先进的性能,相对于所有类别的基线方法都有显著改进。我们的工作通过有效解决多模态推理和知识综合的关键挑战,推动了 RAG 系统的发展,为在多样化应用领域中构建更强大和灵活的信息检索和生成系统铺平了道路。
参考文献
[1] Jeph Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Alterschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. GPT-4 技术报告。arXiv 预印本 arXiv:2303.08774 (2023).
[2] Firoj Alam, Ferda Ofil, and Muhammad Imran. 2018. CrisisMMD: 来自自然灾害的多模态 Twitter 数据集。在 Proceedings of the International AAAI Conference on Web and Social Media, Vol. 12.
[3] Abhijit Anand, Vinay Setty, Avishek Anand, et al. 2023. 使用LLM进行上下文感知查询重写的文本排序器。arXiv 预印本 arXiv:2308.16753 (2023).
[4] Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. 自我RAG:通过自我反思学习检索、生成和批判。arXiv 预印本 arXiv:2310.11511 (2023).
[5] Sukanya Bag, Ayushman Gupta, Rajat Kaushik, and Chirag Jain. 2024. 超越文本的BAG:增强BAG系统中的图像检索。在2024年电气、计算机和能源技术国际会议(ECECT)。IEEE, 1-4.
[6] Mirco Bonomo 和 Simone Bianco. 2025. 视觉BAG:无需微调扩展MLLM视觉知识。arXiv预印本arXiv:2501.10834 (2025).
[7] 陈战鹏, 徐诚进, 齐义忠, 国建. 2024. MLLM 是一个强大的重排序器:通过知识增强重排序和噪声注入训练推进多模态检索增强生成。arXiv预印本arXiv:2407.21439 (2024).
[8] 程宇恒, 张策尧, 张正文, 孟祥瑞, 洪思睿, 李文昊, 王子豪, 王泽浩, 王泽楷, 尹峰, 赵军华, 等. 2024. 探索基于大语言模型的智能体:定义、方法和前景。arXiv预印本arXiv:2401.03428 (2024).
[9] 董玉鑫, 王硕, 郑宏业, 陈家静, 张振鸿, 王赤航. 2024. 先进的带图结构的BAG模型:优化复杂的知识推理和文本生成。在2024年第5届计算机工程与智能通信国际研讨会(ISCEIC)。IEEE, 626-630.
[10] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, 等. 2020. 一张图片值得16x16个词:大规模图像识别的变压器。arXiv预印本arXiv:2010.11929 (2020).
[11] Gustavo de Aquino e Aquino, Nádila da Silva de Azevedo, Leandro Tounit Silva Okimoto, Leonardo Yuto Suzuki Camelo, Hendrio Luis de Souza Bragança, Rubens Fernandes, Andre Printez, Fabio Cardoso, Raimundo Gomes, Israel Gondres Torné. 2025. 从BAG到多智能体系统:LLM发展的现代方法调查。(2025).
[12] Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apuvva Mody, Steven Truttt, Dasha Metropolitansky, Robert Ouazawa Nees, Jonathan Larson. 2024. 从局部到全局:一种面向查询摘要的GraphBAG方法。arXiv预印本arXiv:2404.16130 (2024).
[13] Manuel Fayose, Hugues Sihille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, Pierre Colombo. 2024. ColPali:利用视觉语言模型高效文档检索。在第十三届国际学习表示会议.
[14] Matthias Fey, Weihua Hu, Kexin Huang, Jan Eric Lenssen, Rishahh Ranjan, Joshua Robinson, Rex Ying, Jiaxuan You, Jure Leskovec. 2023. 关系深度学习:关系数据库上的图表示学习。arXiv预印本arXiv:2312.04615 (2023).
[15] 高云帆, 熊云, 高欣雨, 贾康翔, 潘金林, 毕玉曦, 戴毅, 孙佳伟, 王浩芬, 王浩芬. 2023. 大语言模型的检索增强生成:综述。arXiv预印本arXiv:2312.10997 2 (2023).
[16] Jeanie Genesis 和 Frazier Keane. 2025. 整合知识检索与生成:NLP 中 BAG 模型的全面调查。(2025).
[17] Deepanway Ghosal, Navonil Majumder, Roy Ka-Wet Lee, Rada Mihalcea, Soujanya Poria. 2023. 语言引导的视觉问答:利用知识丰富的提示提升多模态语言模型。arXiv预印本arXiv:2310.20159 (2023).
[18] Guo Zirui, Xia Lianghao, Yu Yanhua, Ao Tu, Huang Chao. 2024. LightBAG: 简单快速的检索增强生成。arXiv预印本arXiv:2410.05779 (2024).
[19] Shailja Gupta, Rajesh Ranjan, Surya Narayan Singh. 2024. 检索增强生成 (RAG) 的全面调查:演变、当前状况和未来方向。arXiv预印本arXiv:2410.12837 (2024).
[20] Kelvin Guo, Kenton Lee, Zora Tung, Panopong Pasupat, Mingwei Chang. 2020. 检索增强语言模型预训练。在机器学习国际会议。PMLR, 3929-3938.
[21] Han Siwei, Peng Xia, Zhang Buiyi, Sun Tong, Li Yun, Zhu Hongtu, Yao Huaxiu. 2025. MDwcAgent: 用于文档理解的多模态多智能体框架。arXiv预印本arXiv:2503.13964 (2025).
[22] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. 2016. 图像识别的深度残差学习。在 IEEE 计算机视觉与模式识别会议论文集。770-778.
[23] Sameera Horawalavithana, Sai Murakoti, Ian Stewart, Henry Kvinge. 2023. SCTTONE: 对齐大型语言模型与科学多模态指令。arXiv预印本arXiv:2307.01139 (2023).
[24] Cheng-Yu Huach, Si-An Chen, Chun-Liang Li, Yaushisa Fujii, Alexander Ratner, Chen-Yu Lee, Ranjay Krishna, Tomas Pfister. 2023. 工具文档使大型语言模型能够零样本工具使用。arXiv预印本arXiv:2308.00675 (2023).
[25] 胡安文, 徐海阳, 叶继波, 颜明, 张亮, 张波, 李晨, 张吉, 秦晋, 黄飞, 等. 2024. mPLUG-DocOWI 1.5: 统一结构学习用于无OCR文档理解。arXiv预印本arXiv:2403.12895 (2024).
[26] Aaron Hurst, Adam Lerer, Adam P Groucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, 等. 2024. GPT-4s系统卡。arXiv预印本arXiv:2410.21276 (2024).
[27] Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, Edouard Grave. 2022. 少样本学习与检索增强语言模型。arXiv预印本arXiv:2208.03299 1, 2 (2022), 4.
[28] Cheonsu Jeong. 2024. 基于图智能体的方法增强基于知识的问答。知识管理研究 25, 3 (2024), 99-119.
[29] Cheonsu Jeong. 2024. 使用图的高级BAG系统实现方法的研究。arXiv预印本arXiv:2407.19994 (2024).
[30] Jiang Zhenghao, Xu Frank F, Gao Luyu, Sun Zhiqing, Liu Qian, DwivediYu Jane, Yang Yiming, Callan Jamie, Neuling Graham. 2023. 主动检索增强生成。arXiv预印本arXiv:2305.06983 (2023).
[31] Omar Khattab 和 Matei Zaharia. 2020. ColBERT: 通过上下文化晚期交互提高检索效率和效果的BERT。在第43届ACM SIGIR国际信息检索研究与发展会议论文集。39-48.
[32] Jakub Lala, Odhran O’Donoghue, Aleksandar Shtedritski, Sam Cox, Samuel G Rodrigues, Andrew D White. 2023. PaperQA: 科学研究的检索增强生成智能体。arXiv预印本arXiv:2312.07559 (2023).
[33] Patrick Lewis, Ethan Peres, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Nansan Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, 等. 2020. 检索增强生成用于知识密集型NLP任务。神经信息处理系统进展33 (2020), 9459-9474.
[34] 李俊楠, 李冬旭, Savarese Silvio, Hoi Steven. 2023. BLIP-2: 使用冻结图像编码器和大型语言模型引导的语言-图像预训练。在机器学习国际会议。PMLR, 1973019742.
[35] 李威杰, 王锦, 余良志, 张雪杰. 2025. 问题分解拓扑:通过信息检索增强大型语言模型以完成知识密集型任务。在第33届国际计算语言学会议论文集。2814-2833.
[36] 刘浩天, 李春远, 吴庆洋, 李永杰. 2023. 视觉指令调整。神经信息处理系统进展36 (2023),
34892
−
34916
34892-34916
34892−34916.
[37] 刘俊明, 孟思远, 高艳婷, 毛松, 蔡品龙, 颜国航, 陈轶荣, 晏子琳, 拜托石, 王顶. 2025. 对齐视觉到语言:用于增强LLMs推理的无文本多模态知识图谱构建。arXiv预印本arXiv:2503.12972 (2025).
[38] 刘佳旺, 陶叶, 王飞, 李辉, 秦兴工. 2025. SiQA: 基于RAG的结构化图像多模态问答模型。在ICASSP 2025-2025 IEEE国际声学、语音和信号处理会议(ICASSP)。IEEE, 1-5.
[39] 刘泽, 林昱彤, 曹跃, 胡汉, 魏一轩, 张征, 林 Stephen, 郭邦宁. 2021. 3win Transformer: 使用位移窗口的分层视觉Transformer。在IEEE/CVF国际计算机视觉会议论文集。10012-10022.
[40] 卢潘, Mishra Swaroop, 夏堂霖, 邱良, 常凯维, 祝松春, Tafjord Oyvind, Clark Peter, Ashwin Kalyan. 2022. 学会解释:通过思维链进行科学问答的多模态推理。神经信息处理系统进展35 (2022), 2507-2521.
[41] 洛楚维, 沈雨凡, 朱兆庆, 郑琦, 余智, 姚聪. 2024. LayoutLLM: 利用大型语言模型进行文档理解的布局指令调整。在IEEE/CVF计算机视觉与模式识别会议论文集。15630-15640.
[42] Costas Macromatis 和 George Karypis. 2024. GNN-RAG: 图神经检索用于大型语言模型推理。arXiv预印本arXiv:2405.20139 (2024).
[43] Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, Ajmal Mian. 2023. 大型语言模型的全面概述。arXiv预印本arXiv:2307.06435 (2023).
[44] Tyler Thomas Procko 和 Omar Ochoa. 2024. 图检索增强生成用于大型语言模型:调查。在2024年人工智能、科学、工程和技术会议(AIsSET)。IEEE, 166-169.
[45] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, 等. 2021. 学习可转移视觉模型的自然语言监督。在机器学习国际会议。PmLR, 8748-8763.
[46] Monica Riedler 和 Stefan Langer. 2024. 超越文本:为工业应用优化具有多模态输入的RAG。arXiv预印本arXiv:2410.21943 (2024).
[47] Tolga Jakar 和 Hakan Emekci. 2025. 最大化RAG效率:RAG方法的比较分析。自然语言处理 31, 1 (2025), 1-25.
[48] Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, Thomas Scialom. 2023. Toolformer: 语言模型可以自学使用工具。神经信息处理系统进展36 (2023), 68539-68551.
[49] Su Weihang, Tang Yichen, Ai Qingyao, Wu Zhijing, Liu Yiqun. 2024. DRAGIN: 基于大型语言模型实时信息需求的动态检索增强生成。arXiv预印本arXiv:2405.10081 (2024).
[50] Sabrina Toro, Anna V Anagnostopoulos, Susan M Bello, Kai Blumberg, Rhiannon Cameron, Leigh Carmody, Alexander D Diehl, Damion M Dooley, William D Duncan, Petra Fey, 等. 2024. 使用人工智能动态检索增强生成本体(DRAGON-AI)。生物医学语义杂志15, 1 (2024), 19.
[51] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajwal Bhargava, Shruti Bhoesale, 等. 2023. Llama 2: 开放基础和微调聊天模型。arXiv预印本arXiv:2307.09288 (2023).
[52] 王鹏, 白帅, Tan Sinan, 王世杰, 范志浩, 白金泽, 陈克勤, 刘雪婧, 王嘉琳, Ge Wenhin, 等. 2024. Qwen2-VL: 增强视觉语言模型在任意分辨率下的世界感知。arXiv预印本arXiv:2409.12191 (2024).
[53] 武军德, 朱久圆, 齐云丽, 陈景坤, 徐敏, Menolascina Filippo, Grau Vicente. 2024. 医疗图RAG: 通过图检索增强生成实现安全医疗大型语言模型。arXiv预印本arXiv:2408.04187 (2024).
[54] 彭霞, 朱康宇, 李浩然, 王天泽, 石伟家, 王盛, 张林军, James Zou, 姚华秀. 2024. MMed-RAG: 适用于医疗视觉语言模型的多功能多模态RAG系统。arXiv预印本arXiv:2410.13085 (2024).
[55] 杨安, 杨宝松, 张瑞臣, 惠斌元, 郑波, 余博文, 李成远, 刘大义衡, 黄飞, 魏浩然, 等. 2024. Qwen2.5技术报告。arXiv预印本arXiv:2412.15115 (2024).
[56] 杨晓翠, 吴文芳, 冯师, 王明, 王大令, 李阳, 孙启, 张一菲, 符小明, Foria Soujanya. 2023. MM-BigBench: 在多模态内容理解任务上评估多模态模型。arXiv预印本arXiv:2310.09036 (2023).
[57] 张天君, Patil Shishir G, Jain Naman, Shen Sheng, Zaharia Matei, Stoica Ion, Gonzalez Joseph E. 2024. RAFT: 适应特定领域的RAG语言模型。在第一次语言建模会议上.
[58] 郑哥, 杨斌, 唐佳瑾, 周洪宇, 杨思贝. 2023. DDCoT: 多模态推理中语言模型的职责分明链式思维提示。神经信息处理系统进展36 (2023),
5168
−
5191
5168-5191
5168−5191.
[59] Zhong Zhaijang 和 Davide Mottin. 2023. 增强知识的图机器学习用于药物发现:从精确到可解释性。在第29届ACM SIGKDD知识发现与数据挖掘国际会议论文集。
5841
−
5842
5841-5842
5841−5842.
A 预测示例
我们在图3中展示了额外的预测示例。此外,我们还包含了两个代表性问题,无论是否带有图像
基于文本的
物体的热能取决于它的质量和温度。温度最低的物体将具有最少的热能。在这种情况下,250克的水杯在温度为 14 ⋅ u 00 b 0 C 14 \cdot \mathrm{u} 00 \mathrm{b0C} 14⋅u00b0C 的情况下,具有提供的选项中最低的温度。
参考
\
n
[
D
C
]
\backslash n[\mathrm{DC}]
\n[DC]$ 这些物体除了温度外都是相同的(文件: chunk_65)。
答案:答案是 (B)。
基于图的
热能是与原子和分子运动相关的能量。分子和原子运动得越快,物体拥有的热能就越多。
物体的温度是衡量该物体内原子和分子平均动能的指标。因此,温度最低的物体拥有最少的热能。
答案:答案是 (B)。
基于文本的
实际上,这段文字使用了不同的修辞手法:一个公开的秘密,即某事在某些人中广为人知,但被主体否认。然而,这不是提供的选项之一,也不符合给定的修辞手法选择。
参考 \ n − ∣ [ D C ] \backslash n-\mid[\mathrm{DC}] \n−∣[DC] 上下文: N/A(没有直接适用于此上下文的具体文档块)。
答案:答案是 (B)。 × \times ×
基于图的
在所提供的上下文中,… 公开秘密是指广泛知晓但未公开承认或正式承认的事物。
虽然(A)矛盾结合了相互矛盾的术语(如“大虾”),并且(B)夸张涉及夸大,但两者都不能准确描述上下文中的短语。
参考:
n1. [KG] 遗传学研究表型作为基因型导致的特征,例如祖里的斑点外套。(文件: 2025-03-05 19:18:00)。
答案:答案是 (B)。 × \times ×
基于网络的
哪个物体拥有更多的热能?这些物体除了温度外都相同。一个100克的苹果汁杯在…
接口:https://www.gauthmath.com/solution/1805304034624517/Which-object-has-more-thermal-energy-The-objects-are-identical-except-for-their-\n.
答案:答案是 (B)。
HMAgent
温度测量物质的冷热程度。如果物质中的粒子减速,温度就会下降。现在物质既具有较少的热能,又具有较低的温度。所有三杯水的质量相同但温度不同。由于 14 \ u 00 b 0 C 14 \backslash u 00 b 0 \mathrm{C} 14\u00b0C 的水杯是最冷的,它具有最少的热能。
答案:答案是 (B)。
基于网络的
目前,当然,已经发现有必要对配给量进行调整(Squealer 总是说… KaTeX parse error: Undefined control sequence: \n at position 1: \̲n̲\n\#4 \mathrm{f… quiz/et.com/67 4788055#Seventh-grade-c5-classify-the-figure-of-speech-euphemism-hyperbole-oxymoron-paradox-flash-cards/。
答案:答案是 (A)。
HMAgent
文本使用了矛盾修饰法,即将两个看似矛盾的术语结合在一起。公开的秘密是一种矛盾,因为“公开”描述的是自由或公众已知的事情,而秘密是隐藏的。
答案:答案是 (A)。
图4:单模态问答比较。

问题:哪个更好地描述了戴恩特雨林生态系统?
选项:(A) 它全年降雨。它的土壤也缺乏养分。
\sqrt{ }
(B) 它有寒冷的冬天。它也有许多不同类型的生物。
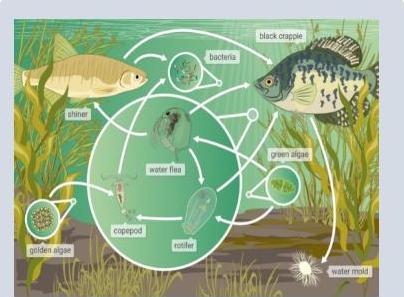
问题:以下哪种生物是这个食物网中的初级消费者?
选项:(A) 拷贝豆 \sqrt{ }
(B) 黑鲈
© 细菌
基于文本的
根据文档块提供的信息和上下文,澳大利亚东北部的戴恩特雨林生态系统更适合描述:“它全年降雨。它的土壤也缺乏养分。” 这与热带雨林的典型特征一致,而不是描述寒冷冬天和有限生物多样性的选项。
参考:
-[DC] 戴恩特雨林是澳大利亚东北部的一个热带雨林生态系统(文件: #daintree_rain_forest_context)。
答案:答案是 (A)。
基于图的
基于提供的上下文,我现在将生成一个全面的摘要关于… [KG] 基因是遗传的基本单位,携带生物指令用于特征和特性,并通过代代相传。
答案:答案是 (A)。
基于文本的
在食物网中,初级消费者是吃生产者(如植物)或其他初级消费者的生物。从给定的信息和小石城湖的上下文中,黑鲈鱼(选项 B)在生态系统模型中被列为消费者。这表明它以湖内较小的生物为食,使其成为初级消费者。 n\n参考:\n[DC] 以下是来自威斯康星州淡水湖生态系统的 Little Rock Lake 的食物网。(文件: Document_Chunk_3.
答案:答案是 (B)。 X
基于图的
根据提供的食物网,黑鲈鱼可能以小型生物如桡足类或浮游动物为食,使其在这个生态系统中成为初级消费者。\n\n答案: B. 黑鲈鱼n参考: n 1. [ K G ] \mathrm{n} 1 .[\mathrm{KG}] n1.[KG] 生态系统中的食物网分析(文件: KG_005)。
答案:答案是 (B)。 X
基于网络的
戴恩特雨林维基百科 \ u 3011 \ \backslash u 3011 \backslash \u3011\ n 戴恩特雨林,也被称为戴恩特,是澳大利亚昆士兰东北海岸的一个地区,距离…uff1a https://en.wikipedia.org/wiki/Daintree_Rainfor est.
答案:答案是 (A)。
HMAgent
它全年降雨。它的土壤也缺乏养分。
答案:答案是 (A)。
基于网络的
以下是来自威斯康星州淡水湖生态系统的 Little Rock Lake 的食物网。黑鲈鱼细菌银鱼绿色藻类水蚤 …n\n94fe\u63a5\uff1ahttps://www.gauth math.com/solution/1794627532113926.
答案:答案是 (A)。
HMAgent
细菌鲈鱼有箭头指向它来自水蚤、变形虫和银鱼。这些生物都不是生产者,所以黑鲈鱼不是初级消费者。
细菌有箭头指向它们来自水蚤和银鱼。水蚤和银鱼都不是生产者,所以它们也不是初级消费者。
答案:答案是 (A)。
图5:多模态问答比较。
参考论文:https://arxiv.org/pdf/2504.12330



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











