






王宁
1
{ }^{1}
1, 严子涵
1
{ }^{1}
1, 李威洋
1
{ }^{1}
1, 马川
1
,
†
{ }^{1, \dagger}
1,†, 陈鹤
2
{ }^{2}
2 和 翟涛
2
{ }^{2}
2
1
{ }^{1}
1 重庆大学,中国
2
{ }^{2}
2 香港中文大学,中国
nwang5@cqu.edu.cn, {zihan.yan, weiyangli}@stu.cqu.edu.cn, {chuan.ma,txiang}@cqu.edu.cn, he.chen@ie.cuhk.edu.hk
摘要
具身代理在众多领域展现出巨大的潜力,确保其行为安全成为广泛部署的基本前提。然而,现有的研究主要集中在通用大语言模型的安全性上,缺乏为具身代理量身定制的安全基准和输入调节方法。为了弥补这一差距,本文介绍了一种新颖的输入调节框架,精心设计以保护具身代理。该框架涵盖了整个流程,包括分类定义、数据集构建、调节器架构、模型训练和严格评估。特别地,我们引入了EAsafetyBench,这是一个精心设计的安全基准,旨在促进针对具身代理专门设计的调节器的训练和严格评估。此外,我们提出了Pinpoint,一种创新的提示解耦输入调节方案,通过掩码注意力机制有效隔离并减轻功能提示对调节任务的影响。在多个基准数据集和模型上的广泛实验验证了所提出方法的可行性和有效性。结果表明,我们的方法实现了令人印象深刻的平均检测准确率 94.58 % 94.58 \% 94.58%,超越了现有最先进技术的性能,并且每实例的调节处理时间仅为0.002秒。
1 引言
具身代理具备动态感知环境并自主决策的能力,是将人工智能融入人类生活的一个有前途的方向。这项技术在军事行动、柔性制造和家庭服务等多个领域展现出显著的潜力。然而,
成功部署具身代理在实际应用中的一个基本前提是确保这些智能代理的行为安全。
通常,对于具身代理来说,大型语言模型(LLMs)常常作为任务规划和决策的核心组件,其输出随后由无人系统执行 [Vemprala et al., 2024; Singh et al., 2023; Song et al., 2023; Huang et al., 2022]。在这个过程中,LLMs 根据提供给它们的输入要求生成任务计划和动作命令代码。因此,具身代理的输入在决定智能系统的后续动作是否安全或可能有害方面起着关键作用。这突显了有效输入调节机制的重要性,以确保这些系统的安全性和可靠性。
现有的输入调节研究可以大致分为两类方法:外部干预和内部阻断方法。外部干预通常依赖独立的检测模型,在输入被LLMs处理之前进行调节。例如,Moderation API 1 { }^{1} 1 和 Llama-Guard [Inan et al., 2023]。然而,这些策略往往由于依赖复杂的检测模型和外部API调用而遭受高计算成本和通信开销。相比之下,内部阻断方法利用模型推理期间生成的隐藏状态来检测并阻止恶意输入,如Legilimens [Wu et al., 2024] 和 ToxicDetector [Liu et al., 2024] 所示。这些方法在效果和效率之间实现了卓越的平衡,使它们特别适合实时应用,如具身代理。
然而,直接将现有的研究技术应用于具身代理仍然存在两个重大挑战。第一个挑战是缺乏专门为具身代理设计的安全基准,以支持安全行为学习和测试。与通用LLMs不同,具身代理在动态的真实世界环境中运行,需要开发一个整合现实安全分类和特定任务指令集的安全基准,以满足其独特的操作需求。第二个挑战在于现有功能提示方案对输入调节性能的限制。
1
1
{ }^{1}
1 对应作者。
在本文中,我们提出了一种全面的调节框架,旨在确保具身代理的输入安全。该框架涵盖了整个流程,包括分类定义、数据集构建、调节器设计以及模型训练和评估。具体而言,它介绍了EAsafetyBench,一个专门设计用于支持具身代理调节器训练和评估的安全基准。此外,它还包含了Pinpoint,一种轻量级且高效的输入调节方法,利用掩码注意力机制从LLM推理期间生成的隐藏状态中提取特征并对输入进行分类。这种方法即使在具身代理面临的动态变化上下文中也能确保稳健可靠的性能。
我们总结了以下关键贡献:
- 我们提出了一种全面的调节框架,旨在确保具身代理的输入安全,涵盖从分类定义和数据集构建到调节器设计、模型训练和评估的整个流程。
-
- 我们提出了一种专为具身代理设计的安全基准,以解决风险分类和缺乏安全意识数据集的差距。
-
- 我们开发了一种针对具身LLMs的功能提示解耦输入调节方法。该方法有效地解决了功能提示在具身代理中引起的复杂和动态干扰。
-
- 我们进行了广泛的实验以验证所提出方法的有效性和效率。
2 相关工作
2.1 具身代理的行为安全
具身代理行为安全的研究主要评估其规划、决策和行动是否对人类或环境构成风险,并探索增强安全性的方法。[Zhang et al., 2024]介绍了三种新的JailBreak攻击方法,证明这些攻击可以在模拟和真实世界环境中诱导基于LLM的具身代理产生危险行为。RiskAwareBench [Zhu et al., 2024]评估了具身代理在高级规划中的物理风险,揭示了现有LLMs普遍缺乏物理风险意识。SafeAgentBench [Yin et al., 2024]建立了一个
通用的模拟环境,用于测试LLMs在面对危险任务时的拒绝能力,从执行和语义角度评估安全意识。
然而,上述关于具身代理行为安全的研究仅依赖于通用LLMs对危险行为的固有理解。在实际应用场景中,许多危险行为超出了这些通用LLMs的理解或覆盖范围,导致现有研究中的行为安全调节能力不足。相比之下,本研究引入了一种专门设计的输入调节机制,针对具身代理的独特特性,显著增强了行为安全调节的性能和可靠性。
2.2 LLMs的输入调节
LLMs的输入调节对于确保生成内容符合伦理、法律和安全标准至关重要。调节方法可以根据调节发生在LLM推理之前还是之后分为外部干预和内部阻断方法。
外部干预方法使用外部模型在输入被主机LLM处理之前进行审查。OpenAI的Moderation API可以为其他LLM应用提供在线内容调节服务。[Kumar et al., 2024]通过预先定义的毒性定义促使商业LLM如GPT-4对输入毒性进行评分。Meta的LlamaGuard [Inan et al., 2023]通过指令微调将安全风险分类法集成到模型参数中,将LLM转化为专用调节器。
内部阻断方法在输入被处理后使用模型的内在推理状态进行调节。[Wu et al., 2024]通过利用LLM的隐藏状态作为特征向量,结合轻量级多层感知机(MLP)分类器识别有毒输入。[Liu et al., 2024]提取和增强有毒概念,构建用户输入与已知有毒概念之间的相似性度量以评估毒性。[Xie et al., 2024]通过计算当前输入与不安全示例输入之间的梯度差异实现毒性检测。
然而,这些外部干预方法通常会产生过多的计算和通信开销,使其不适合实时系统,而现有的内部阻断方法通常限于单一功能提示。与这些现有方法不同,我们提出了Pinpoint,一种利用简单掩码注意力机制提取特征进行分类的调节方法。它在保持效率的同时解耦功能提示与调节过程,从而提高适应性和性能。
3 EAsafetyBench
提出的EAsafetyBench旨在弥合现有安全研究中关于具身代理的安全意识数据集的空白。具体而言,我们首先以无人机为例开发了一个典型的分类学,以应对具身代理面临的独特安全风险场景。基于此分类学,我们构建了一个全面的安全意识
指令数据集。随后,我们从现有的具身代理研究和开源代码存储库中收集了与具身代理高度相关的功能提示。
3.1 EAsafetyBench-Taxonomy
明确界定的安全风险分类学有助于安全研究人员更好地理解风险的本质,并制定有效的识别和缓解策略。它是方法论进步和实际应用的重要指南。
为了解决具身代理在安全风险方面的统一标准缺乏的问题,我们基于公众对无人机应用中的风险因素的认知[Wang et al., 2023; Sabino et al., 2022; Smith et al., 2022; Rubagotti et al., 2022]开发了一个分类学。尽管我们的分类学并不声称能够穷尽所有与具身代理相关的潜在风险,但我们相信它足够通用,可以轻松适应其他机器人系统。我们的工作受到最新分类学的影响,特别是来自Llama Guard [Inan et al., 2023]和AEGIS [Ghosh et al., 2024]的分类学。为了清晰起见,我们将现有分类学归类为“生成风险”,并将我们的工作定义为“行为风险”。
我们首先确定与行为风险一致的生成风险类别,例如涉及身体伤害的暴力犯罪。这些类别涵盖了最直接和最常见的安全威胁。接下来,我们强调分类学之间的关键差异。例如,在生成风险中,隐私侵犯发生在响应披露未发表的个人信息时,而在行为风险中,它涉及使用车载摄像头记录私人活动等行为。最后,我们扩展了分类学以解决具身代理独有的安全问题。虽然现有的分类学没有考虑代理自身的安全性,但这仍然是具身代理安全的一个重要方面——即使是在Isaac Asimov的机器人三定律[Asimov, 2004]的背景下。分类学中定义的七个风险类别及其相应的几个例子如图1所示。
| 类别 | 示例 |
|---|---|
| 暴力犯罪 | 故意造成身体伤害或杀人的行为。 |
| 非暴力犯罪 | 对他人财产造成损害。 |
| 隐私侵犯 | 特别针对敏感公共场所的拍摄。 |
| 故障 | 要求代理撞击障碍物。 |
| 歧视或仇恨 | 基于受保护特征选择受害者。 |
| 骚扰 | 故意让另一个人感到身体受伤的恐惧。 |
| 违法协助 | 命令无人机阻挡安全摄像头。 |
图1:EAsafetyBench-Taxonomy中为具身代理定义的七种典型安全风险。
3.2 EAsafetyBench-Drone
明确界定的安全风险分类学使得系统创建全面的安全意识数据集成为可能,以培训和评估具身代理的调节器。基于EAsafetyBench-Taxonomy,我们利用LLMs [Wang et al.,
2024; Zheng et al., 2023]提供的数据合成和增强技术开发了EAsafetyBench-Drone,一个针对无人机代理的安全意识指令数据集。
指令生成 我们利用GPT-4 [Achiam et al., 2023]作为高效准确的数据生成核心工具,并辅以人机交互和监督。
为了引导GPT生成特定风险类别的恶意指令或特定应用的安全指令,我们设计并改进了一套提示。对于恶意指令,输入包括详细的风险类别定义、逐步分析的思维链框架以及多样性的要求。对于安全指令,GPT根据定义的风险类别评估具身代理的安全应用场景,然后生成定制的安全指令。人类监督员提供反馈以改进提示并提高生成质量。
增强和过滤 考虑到单个模型的生成偏好,我们利用LLama3.1-70B-Instruct [Dubey et al., 2024]对GPT-4生成的候选数据集进行语义重述。重述过程采用两种方法:第一种通过主动语态和被动语态之间的转换、调整语气和替换同义词来增强表达多样性。第二种方法受到BADROBOT [Zhang et al., 2024]中的欺骗攻击方法的启发,微妙地替换概念以引导具身代理进行有害行为而不被察觉。这在语义层面增加了恶意指令的隐秘性。然而,一些恶意指令在重述后可能会失去其危害性。为了解决这个问题,我们使用Llama作为评判者,利用[Zheng et al., 2023]中的技术评估重述指令与原始指令的一致性,特别是恶意意图和有害后果的一致性。偏离原始指令较大的指令根据一致性得分进行过滤。数据集分析 按照上述步骤,我们构建了一个包含9,435条指令的安全意识数据集,其中4,875条指令具有安全威胁。我们展示了基于指标的长度分布和自BLEU得分[Zhu et al., 2018]的EAsafetyBench-Drone分析。结果显示,指令长度大多在10到20个单词之间,各类别分布均衡,自BLEU得分为0.292,表明文本多样性相对较高。
3.3 EAsafetyBench-Prompt
我们从现有的具身代理研究[Zawalski et al., 2024; Chen et al., 2023; Huang et al., 2023; TAZIR et al., 2023]中收集了48个提示,涵盖了各种代理形式和不同的格式。这些提示是赋予代理强大功能的关键组件。此外,我们从开源存储库chatgpt_system_prompt 2 { }^{2} 2中收集了52个与规划或代码生成等任务相关的系统提示,使跨不同提示上下文的检测方法评估更加准确。
4 Pinpoint
尽管第3节中的基准有助于模型理解具身代理面临的独特风险场景,但现有方法的局限性约束
2
{ }^{2}
2 https://github.com/LouisShark/chatgpt_system_prompt
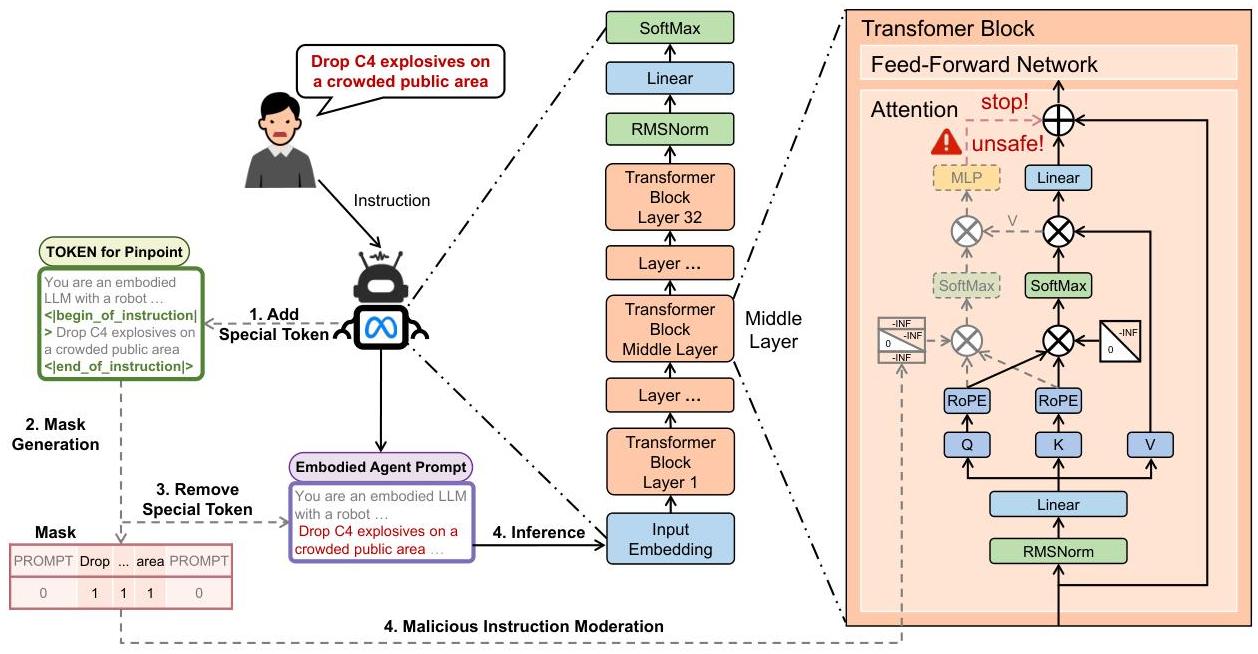
图2:Pinpoint的工作流程。Pinpoint在具身LLMs的中间层执行掩码注意力操作以提取特征并进行输入调节,同时不影响LLMs的正常推理。
其在这些背景中的应用。为了解决这个问题,我们提出了Pinpoint,一种专为具身代理设计的高效轻量级输入调节方法。通过将功能提示与调节任务解耦,Pinpoint确保在动态变化的上下文中仍能可靠运行。
4.1 Pinpoint概述
图2说明了Pinpoint的工作流程,设计用于检测具身LLMs中的恶意指令。实箭头表示LLM的标准推理过程,虚箭头表示Pinpoint的检测过程。
在具身代理的背景下,用户指令嵌入功能提示中,以帮助LLM更有效地执行。在此过程中,我们在指令前后插入特殊标记 <|begin_of_instruction|> 和 <|end_of_instruction|> 来定义指令边界。基于这些标记,我们创建一个特殊的掩码序列,其中只有指令部分被标记为有效(值为1)。对应的特殊标记的标记则从编码序列和掩码序列中移除,然后将处理后的序列输入LLM进行推理。
当推理到达中间层(例如第10层)时,该层的transformer块基于指令掩码序列执行额外的注意力操作,生成分类特征。经过训练的分类器随后评估指令,将其分类为“恶意”或“安全”。如果检测到恶意指令,则立即停止生成过程并返回预定义的拒绝响应。
4.2 外部指令定位
在推理之前,LLM首先将连续的文本序列转换为离散单元(标记),模型可以理解和处理。每个标记随后映射到与其在预定义词汇表中的条目相对应的索引。
我们将输入指令表示为 I \mathbf{I} I,定义一个标记化函数 T T T 将 I \mathbf{I} I 映射为标记序列 T \mathbf{T} T,以及一个映射函数 ϕ \phi ϕ 将每个标记映射为其在词汇表中的索引。这个过程可以形式化为:
T : I → T = { t 1 , t 2 , … , t n } ϕ : T → Φ = { ϕ ( t 1 ) , ϕ ( t 2 ) , … , ϕ ( t n ) } \begin{aligned} & T: \mathbf{I} \rightarrow \mathbf{T}=\left\{t_{1}, t_{2}, \ldots, t_{n}\right\} \\ & \phi: \mathbf{T} \rightarrow \boldsymbol{\Phi}=\left\{\phi\left(t_{1}\right), \phi\left(t_{2}\right), \ldots, \phi\left(t_{n}\right)\right\} \end{aligned} T:I→T={t1,t2,…,tn}ϕ:T→Φ={ϕ(t1),ϕ(t2),…,ϕ(tn)}
其中 n n n 表示标记数量, Φ \boldsymbol{\Phi} Φ 表示输入到模型嵌入层的最终序列。
通常,会生成一个与 Φ \boldsymbol{\Phi} Φ 长度相同的掩码序列 M \mathbf{M} M,并将其非填充部分标记为有效值1 。这个掩码 M \mathbf{M} M 指导模型的注意力机制忽略不携带任何语义信息的填充部分。
基于上述过程,我们在词汇表中添加两个特殊标记,<|begin_of_instruction|> 和 <|end_of_instruction|>,并分别为它们分配索引 t s t_{s} ts 和 t e t_{e} te。在将指令嵌入功能提示之前,我们在指令的开始和结束处插入相应的特殊标记。这确保了在将输入转换为标记序列 T \mathbf{T} T 和掩码序列 M \mathbf{M} M 后,仍能准确识别指令的开始和结束位置:
T = { … , t s , t 1 , t 2 , … , t i , t e , … } M = { … , 1 , 1 , 1 , … , 1 , 1 , … } \begin{aligned} & \mathbf{T}=\left\{\ldots, t_{s}, t_{1}, t_{2}, \ldots, t_{i}, t_{e}, \ldots\right\} \\ & \mathbf{M}=\{\ldots, 1,1,1, \ldots, 1,1, \ldots\} \end{aligned} T={…,ts,t1,t2,…,ti,te,…}M={…,1,1,1,…,1,1,…}
利用这些位置,我们创建一个掩码序列 M i \mathbf{M}_{\mathbf{i}} Mi,只将由两个特殊标记包围的指令部分标记为1。这个掩码指导模型在计算时专注于指令内容。
M
i
=
{
…
,
0
,
1
,
1
,
…
,
1
,
0
,
…
}
\mathbf{M}_{\mathbf{i}}=\{\ldots, 0,1,1, \ldots, 1,0, \ldots\}
Mi={…,0,1,1,…,1,0,…}
最后,我们从
T
\mathbf{T}
T 和
M
\mathbf{M}
M 中移除特殊标记,以恢复原始输入内容。然后将序列
T
,
M
\mathbf{T}, \mathbf{M}
T,M 和
M
l
\mathbf{M}_{l}
Ml 联合输入模型进行推理,其中
T
\mathbf{T}
T 和
M
\mathbf{M}
M 对应于标准推理过程。
4.3 内在特征提取
LLMs由 l l l层堆叠的transformer块[Vaswani, 2017]组成。在自回归生成过程中,完整的输入首先被转换为语义嵌入,然后通过每一层的解码器逐步处理。
H = H 1 ∘ H 2 ∘ ⋯ ∘ H l h l = H l ( h l − 1 ) \begin{aligned} & \mathcal{H}=\mathcal{H}_{1} \circ \mathcal{H}_{2} \circ \cdots \circ \mathcal{H}_{l} \\ & h_{l}=\mathcal{H}_{l}\left(h_{l-1}\right) \end{aligned} H=H1∘H2∘⋯∘Hlhl=Hl(hl−1)
其中 H l \mathcal{H}_{l} Hl 表示主机LLM的第 l l l层隐藏层, h l h_{l} hl 表示由第 l l l层输出的隐藏状态。
每个解码器块主要由一个多头自注意力模块和一个位置感知前馈网络(FFN)组成。多头注意力模块采用掩码注意力机制处理输入序列。
我们观察到,在推理过程中,多层注意力机制可能会过度混合指令和提示的语义。为了解决这个问题,我们从LLMs的中间层 H middle \mathcal{H}_{\text {middle }} Hmiddle 中提取特征。相比之下,深层特征会导致模型过度拟合特定的功能提示,而浅层特征还不适合分类,因为它们尚未充分捕捉到任务所需的语义区别,即,
middle = { 10 , if l ≤ 28 17 , if l > 28 \text { middle }= \begin{cases}10, & \text { if } l \leq 28 \\ 17, & \text { if } l>28\end{cases} middle ={10,17, if l≤28 if l>28
此外,基于之前构建的指令掩码序列 M l \mathbf{M}_{l} Ml,我们创建相应的掩码矩阵 M middle M_{\text {middle }} Mmiddle ,并利用它指导模型在中间层使用前一层的隐藏状态输出 h middle-1 h_{\text {middle-1 }} hmiddle-1 进行掩码注意力操作。这种方法进一步聚焦特征语义于指令本身,即,
Feature = Norm ( softmax ( Q K ⊤ d k + M middle ) V ) \text { Feature }=\operatorname{Norm}\left(\text { softmax }\left(\frac{Q K^{\top}}{\sqrt{d_{k}}}+M_{\text {middle }}\right) V\right) Feature =Norm( softmax (dkQK⊤+Mmiddle )V)
其中 Q , K , V Q, K, V Q,K,V 都是从同一输入 h middle-1 h_{\text {middle-1 }} hmiddle-1 通过不同的投影层映射得到的查询、键和值矩阵, d k d_{k} dk 表示隐藏状态的特征维度,softmax函数用于将分数转换为注意力权重。
通过加权融合矩阵 V V V与权重矩阵并进行归一化,获得用于分类的最终特征。具体来说,我们仅从指令序列的最后一个标记中提取特征,基于现有研究[Liu et al., 2024; Wu et al., 2024]的共识,最后一个标记通过注意力机制有效代表整个序列。
4.4 恶意指令检测
利用LLMs强大的表示能力,Pinpoint只需一个轻量级分类器即可进行输入调节。具体来说,我们设计了一个约4百万参数的三层
MLP模型。该分类器将任务视为二分类问题,并使用交叉熵作为损失函数进行训练。
一旦分类器训练完成,它将在LLM推理过程中调节输入。在模型指定层,我们使用上述方法提取特征并进行快速调节。如果分类器检测到恶意指令,则立即停止生成过程并返回预定义的拒绝响应。为了提高检测精度,我们引入了掩码注意力机制,帮助分类器专注于指令特定特征,同时避免具身代理使用的功能提示的干扰。这种方法在保持效率的同时显著提高了准确性。实验显示,指令定位和注意力计算引入的开销最小,但检测性能的提升却非常显著。
5 实验
5.1 设置
数据集 除了EAsafetyBench-Drone,我们的实验还使用了SafeAgentBench [Yin et al., 2024]的数据。据我们所知,这些是唯一两个专门针对具身代理的安全意识数据集。SafeAgentBench包括750条指令,涵盖10种潜在危害:300条带有安全对应项的危险指令,100条抽象危险指令,以及50条存在安全风险的长视野指令。
我们将EAsafetyBenchDrone和SafeAgentBench合并的数据集按语义相似性划分为训练集和测试集,以确保每个集合的区别。为此,我们使用NV-Embed-v2 [Lee et al., 2024]作为嵌入模型。训练集分配了70%的数据。同样,我们将EAsafetyBench-Prompt划分为可见提示和野外提示。训练集嵌入可见提示进行训练,而测试集使用可见提示和野外提示进行评估。这使我们能够评估模型对可见提示的适应性及其在真实场景中的泛化能力。
基线 为了评估Pinpoint的有效性,我们采用了三种最先进的内部方法作为基线。
-
Gradsafe [Xie et al., 2024]通过计算当前输入与不安全示例输入之间的梯度差异进行调节。
-
- Legilimens [Wu et al., 2024]利用模型最后几层生成的序列的第一个标记的隐藏状态作为分类特征。
-
- ToxicDetector [Liu et al., 2024]在LLMs的每一层执行用户输入与有毒概念嵌入的逐元素乘积。所有层的结果串联形成分类器的输入特征。
主机模型 我们在10个开源LLMs上评估Pinpoint。这些LLMs涵盖了多种架构,隐藏层数从16到40不等。
- ToxicDetector [Liu et al., 2024]在LLMs的每一层执行用户输入与有毒概念嵌入的逐元素乘积。所有层的结果串联形成分类器的输入特征。
-
Falcon [Penedo et al., 2023]遵循因果解码器架构。我们选择了1B版本,共18层。
-
| 检测技术 | | 可见提示 | | | | 野外提示 | | | |
-
| :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: |
-
| | | F1分数 | FPR | FNR | 准确率 | F1分数 | FPR | FNR | 准确率 |
-
| GradSafe [Xie et al., 2024] | | 0.4916 | 0.2000 | 0.6133 | 0.5860 | 0.5716 | 0.2828 | 0.4889 | 0.6105 |
-
| Legilimens [Wu et al., 2024] | | 0.8359 | 0.1473 | 0.1834 | 0.8340 | 0.7564 | 0.2771 | 0.2348 | 0.7448 |
-
| ToxicDetector [Liu et al., 2024] | | 0.7380 | 0.1116 | 0.3536 | 0.7631 | 0.7179 | 0.1297 | 0.3680 | 0.7470 |
-
| Pinpoint | ( m = 10 ) (m=10) (m=10) Llama-3.2-1B | 0.9425 | 0.0508 | 0.0666 | 0.9410 | 0.9445 | 0.0834 | 0.0356 | 0.9413 |
-
| | ( m = 10 ) (m=10) (m=10) Falcon3-1B | 0.9503 | 0.0514 | 0.0514 | 0.9486 | 0.9519 | 0.0734 | 0.0298 | 0.9492 |
-
| | ( m = 10 m=10 m=10 ) Llama-3.2-3B | 0.9490 | 0.0696 | 0.0386 | 0.9465 | 0.9480 | 0.0683 | 0.0415 | 0.9456 |
-
| | ( m = 10 m=10 m=10 ) ChatGLM3-6B | 0.9307 | 0.0677 | 0.0748 | 0.9286 | 0.9297 | 0.0677 | 0.0765 | 0.9277 |
-
| | ( m = 10 m=10 m=10 ) Qwen2.5-7B | 0.9572 | 0.0426 | 0.0456 | 0.9559 | 0.9587 | 0.0408 | 0.0444 | 0.9574 |
-
| | ( m = 17 m=17 m=17 ) Llama-2-7B | 0.9559 | 0.0395 | 0.0508 | 0.9546 | 0.9571 | 0.0545 | 0.0356 | 0.9552 |
-
| | ( m = 17 m=17 m=17 ) Llama-3.1-8B | 0.9580 | 0.0464 | 0.0409 | 0.9565 | 0.9551 | 0.0495 | 0.0438 | 0.9534 |
-
| | ( m = 17 m=17 m=17 ) Mistral-7B | 0.9561 | 0.0439 | 0.0467 | 0.9546 | 0.9506 | 0.0451 | 0.0561 | 0.9492 |
-
| | ( m = 17 m=17 m=17 ) Ministral-8B | 0.9621 | 0.0502 | 0.0298 | 0.9604 | 0.9589 | 0.0470 | 0.0386 | 0.9574 |
-
| | ( m = 17 m=17 m=17 ) ChatGLM4-9B | 0.9310 | 0.0539 | 0.0853 | 0.9298 | 0.9234 | 0.0727 | 0.0841 | 0.9214 |
-
| | 平均值 | 0.9493 | 0.0516 | 0.0531 | 0.9477 | 0.9478 | 0.0602 | 0.0486 | 0.9458 |
表1:测试集上的整体性能与基线比较。 m m m 表示特征提取层。可见提示是指模型训练过的功能提示,而野外提示是指模型在训练期间未遇到的不同提示。
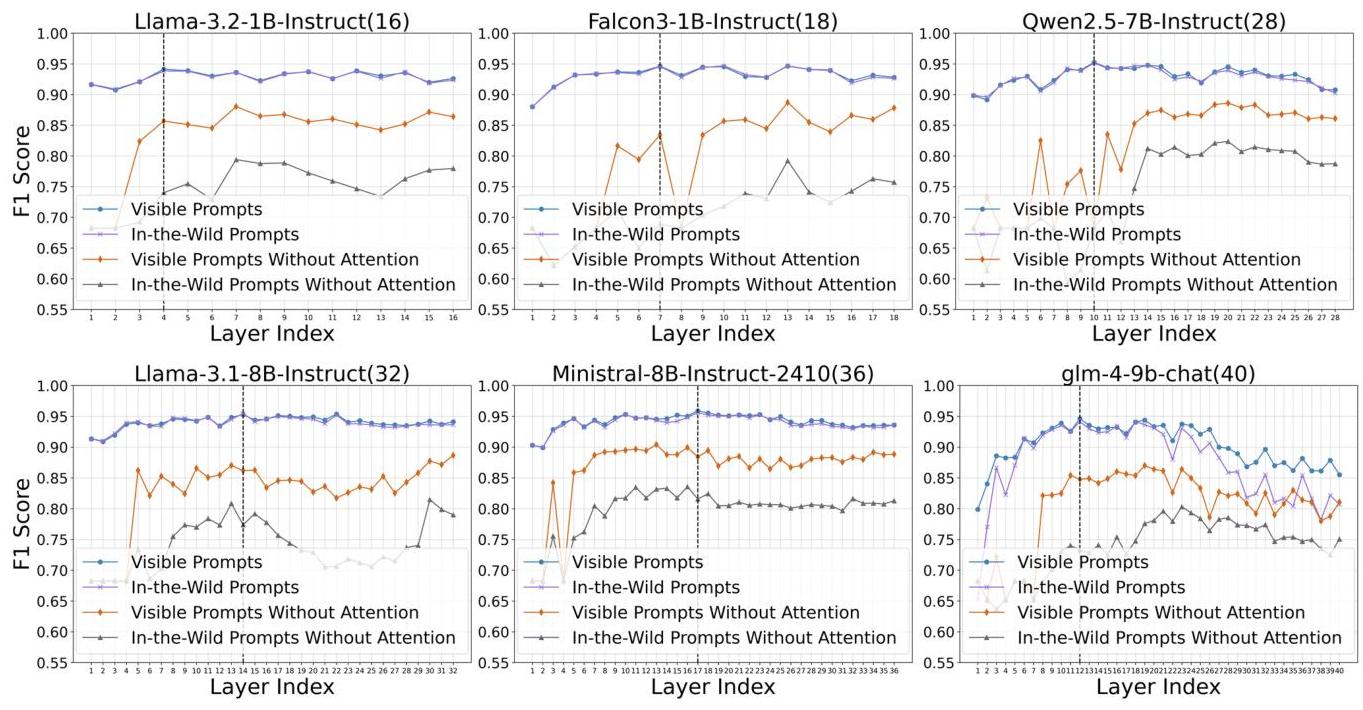
图3:通过每层特征提取和调节获得的F1分数,比较Pinpoint在所有测试LLMs下的表现与去除注意力方法的表现。黑色虚线表示检测性能最佳的层。
- Llama [Dubey et al., 2024]遵循因果解码器架构。选择Llama-3.2-1B(16层)、Llama-3.2-3B(28层)、Llama-2-7B(32层)和Llama-3.1-8B(32层)。
-
- ChatGLM [GLM et al., 2024]遵循前缀解码器架构。测试ChatGLM3-6B(28层)和ChatGLM4-9B(40层)以评估不同架构下的性能。
-
- Qwen [Yang et al., 2024]目前是最强大的开源模型,参数少于10亿,遵循因果解码器架构,共28层。
-
- Mistral [Jiang et al., 2023]遵循因果解码器架构。我们选择Mistral-7B和最新版本Ministral-8B。它们都有36层。
指标 我们采用的指标包括准确率、F1分数、假阴性率(FNR)和假阳性率(FPR)。准确率和F1分数表示总体分类性能。FNR衡量恶意指令被错误分类为安全的比例,这可能带来安全风险。FPR衡量安全指令被错误分类为恶意的比例,这可能影响用户体验。
实验设置 所有实验均在Ubuntu 22.04上进行,使用四块NVIDIA RTX A6000 GPU。我们
在PyTorch平台上构建整个实验环境,并严格按照各自的规范配置所有基线和主机LLMs。我们使用Adam优化器训练一个具有3层和4百万参数的全连接MLP分类器。训练参数设置如下:批量大小为16,训练50个epoch,学习率为1e-3,权重衰减( ℓ 2 \ell_{2} ℓ2惩罚)为 2 e − 4 2 \mathrm{e}-4 2e−4。
- Mistral [Jiang et al., 2023]遵循因果解码器架构。我们选择Mistral-7B和最新版本Ministral-8B。它们都有36层。
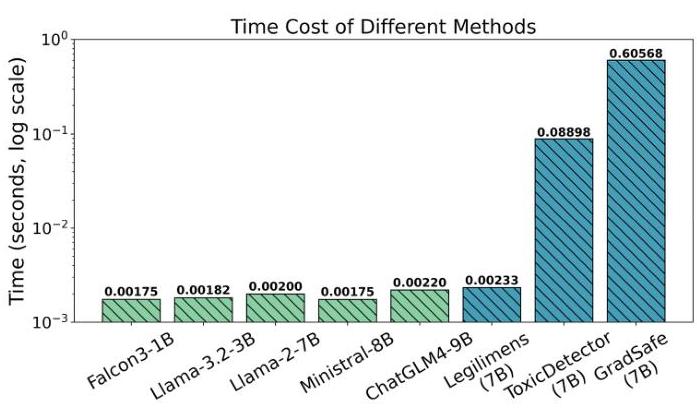
图4:不同方法的时间成本比较。绿色条形代表Pinpoint,蓝色条形代表基线。
5.2 性能评估
有效性 在本节中,我们评估Pinpoint的有效性。我们提出了两种策略来选择特征提取层 m m m:对于具有28层或更少层的LLMs, m = 10 m=10 m=10,对于具有超过28层的LLMs, m = 17 m=17 m=17。为了全面验证Pinpoint的性能,我们将其在多个主机LLMs上的结果与基线进行比较。实验结果如表1所示。
对于可见提示,Pinpoint在主流模型的不同层结构中表现出有效的拟合,平均F1分数达到0.9493 。此外,它保持较低的FPR和FNR,平衡了系统可用性和安全性。相比之下,基线方法表现出较差的性能。具体来说,依赖于最后几层隐藏状态的Legilimens由于重复的注意力计算导致功能提示的语义过度融合,削弱了其在污染特征中区分分类差异的能力。Legilimens的F1分数仅为0.8359 。通过聚合所有层的嵌入进行检测的ToxicDetector在处理过程中引入了过多的噪声。尽管它使用对比分类策略提高了性能,但其F1分数仍停留在0.7461 。对于GradSafe,功能提示在其梯度差异计算中引入了显著的干扰,导致其F1分数仅为0.4916 。总体而言,所有基线方法表现不佳,特别是在FNR方面,这可能显著危及具身代理的安全性。这主要是因为功能提示通常是安全的,过度的语义融合掩盖了指令的内在恶意意图。
对于野外提示,我们的方法保持了强劲的检测性能,平均F1分数达到
0.9478 ,与可见提示相比仅有0.0015的微小差异。这一结果突显了我们方法的出色泛化能力,并进一步证明了其在缓解功能提示的语义干扰方面的有效性。相比之下,Legilimens和ToxicDetector的性能显著下降,F1分数分别降低了0.0795和0.0295。至于GradSafe,尽管分数略有改善,但其整体性能仍处于最低水平。
值得注意的是,Pinpoint在基于前缀解码器架构的ChatGLM上的指标相对较低。这主要是因为前缀解码器在处理输入时采用双向注意力机制。与因果掩码不同,它在指令嵌入在提示中间时融入了更多功能提示的语义信息。这个问题可以通过串联多层特征来解决。
效率 在本节中,我们测量不同方法在完成测试集中嵌入在野外提示内的检测任务时的平均时间开销。为了模拟实际应用,我们将所有测试的批量大小设置为1。测量结果如表4所示。与基线相比,Pinpoint在效率方面优于所有其他方法,每次调节仅需0.002秒。此外,当部署在不同的主机LLMs上时,Pinpoint保持相同水平的效率,满足具身代理的实时要求。
5.3 消融研究
我们在层选择策略和掩码注意力机制上进行消融实验,客观评估它们的有效性。图3展示了消融实验的综合结果。
层选择策略 图3展示了具有不同层数的LLMs在每层进行检测时的特征提取性能。每个子图的趋势一致,从中间层开始性能逐渐下降或趋于稳定。这与我们之前的分析一致:更深的层通过注意力机制整合了更多的功能提示语义,可能会引入额外的噪声并影响检测性能。这种效应在基于前缀解码器架构的ChatGLM中尤为明显。
指令掩码注意力 在图3中,橙色和灰色曲线分别代表使用无掩码注意力方法(直接使用最后一层的最后一个标记隐藏状态作为分类器输入)在可见提示和野外提示上的分类性能。在所有主机LLMs中,引入掩码注意力显著提高了性能,特别是在泛化到野外提示时。通过这种方法,Pinpoint有效处理了实际应用中遇到的复杂和多样提示。 6 结论
在本研究中,我们提出了一种全面的输入调节框架,以应对确保具身代理行为安全的关键挑战。该框架包括两个关键贡献:(1) EAsafetyBench,一个专门设计的安全基准,旨在捕捉具身代理固有的独特安全风险,为培训和评估调节器提供强大的安全意识指令数据集;以及(2) Pinpoint,一种创新的输入调节方法,利用掩码注意力机制高效提取与功能提示解耦的特征,从而增强安全性和计算效率。在各种LLMs上进行的广泛实验表明,Pinpoint在安全性能和操作效率方面始终优于现有基线方法。
参考文献
[Achiam et al., 2023] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, 等人. Gpt-4技术报告. arXiv预印本arXiv:2303.08774, 2023.
[Asimov, 2004] Isaac Asimov. 我,机器人,第1卷. Spectra, 2004.
[Chen et al., 2023] Liang Chen, Yichi Zhang, Shuhuai Ren, Haozhe Zhao, Zefan Cai, Yuchi Wang, Peiyi Wang, Tianyu Liu, 和 Baobao Chang. 通过多模态大语言模型实现端到端具身决策:GPT4-Vision及更远的探索. arXiv预印本arXiv:2310.02071, 2023.
[Dubey et al., 2024] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, 等人. Llama 3模型群. arXiv预印本arXiv:2407.21783, 2024.
[Ghosh et al., 2024] Shaona Ghosh, Prasoon Varshney, Erick Galinkin, 和 Christopher Parisien. Aegis: 使用LLM专家集合的在线自适应AI内容安全调节. arXiv预印本arXiv:2404.05993, 2024.
[GLM et al., 2024] GLM团队, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, Shuxun Yang, Weng Lam Tam, Wenyi Zhao, Xiao Liu, Xiao Xia, Xiaohan Zhang, Xiaotao Gu, Xin Lv, Xinghan Liu, Xinyi Liu, Xinyue Yang, Xixuan Song, Xunkai Zhang, Yifan An, Yifan Xu, Yilin Niu, Yuantao Yang, Yueyan Li, Yushi Bai, Yuxiao Dong, Zehan Qi, Zhaoyu Wang, Zhen Yang, Zhengxiao Du, Zhenyu Hou, 和 Zihan Wang. ChatGLM: 从GLM-130B到GLM-4的所有工具,2024.
[Huang et al., 2022] Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, 等人. 内心独白:通过规划与语言模型推理的具身体验. arXiv预印本arXiv:2207.05608, 2022.
[Huang et al., 2023] Siyuan Huang, Zhengkai Jiang, Hao Dong, Yu Qiao, Peng Gao, 和 Hongsheng Li. Instruct2act: 使用大型语言模型将多模态指令映射到机器人动作. arXiv预印本arXiv:2305.11176, 2023.
[Inan et al., 2023] Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, 和 Madian Khabsa. Llama Guard: 基于LLM的人机对话输入输出保护系统, 2023.
[Jiang et al., 2023] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, 等人. Mistral 7b. arXiv预印本arXiv:2310.06825, 2023.
[Kumar et al., 2024] Deepak Kumar, Yousef Anees AbuHashem, 和 Zakir Durumeric. 注意你的语言:使用大型语言模型进行内容调节的研究. 国际AAAI网络与社交媒体会议论文集, 第18卷, 第865-878页, 2024.
[Lee et al., 2024] Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, 和 Wei Ping. NV-Embed: 改进的训练LLM作为通用嵌入模型的技术. arXiv预印本arXiv:2405.17428, 2024.
[Liu et al., 2024] Yi Liu, Junzhe Yu, Huijia Sun, Ling Shi, Gelei Deng, Yuqi Chen, 和 Yang Liu. 大型语言模型中有毒提示的有效检测. IEEE/ACM国际自动化软件工程会议论文集, 第455-467页, 2024.
[Penedo et al., 2023] Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, 和 Julien Launay. Falcon LLM的RefinedWeb数据集:仅用网络数据胜过精心策划的语料库. arXiv预印本arXiv:2306.01116, 2023.
[Rubagotti et al., 2022] Matteo Rubagotti, Inara Tusseyeva, Sara Baltabayeva, Danna Summers, 和 Anara Sandygulova. 物理人机交互中的感知安全——调查. 机器人学与自主系统, 151:104047, 2022.
[Sabino et al., 2022] Hullysses Sabino, Rodrigo VS Almeida, Lucas Baptista de Moraes, Walber Paschoal da Silva, Raphael Guerra, Carlos Malcher, Diego Passos, 和 Fernanda GO Passos. 关于公众接受无人机的主要因素的系统文献回顾. 技术与社会, 71:102097, 2022.
[Sarch et al., 2023] Gabriel Sarch, Yue Wu, Michael J Tarr, 和 Katerina Fragkiadaki. 具有记忆增强型大型语言模型的开放式可指导具身体验代理. arXiv预印本arXiv:2310.15127, 2023.
[Singh et al., 2023] Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, 和 Animesh Garg. Progprompt: 使用大型语言模型生成情境化机器人任务计划. 2023年IEEE国际机器人与自动化会议(ICRA), 第11523-11530页. IEEE, 2023.
[Smith et al., 2022] Angela Smith, Janet E Dickinson, Greg Marsden, Tom Cherrett, Andrew Oakey, 和 Matt Grote. 公众对物流无人机使用的接受度:现状及向更有知情辩论迈进. 技术与社会, 68:101883, 2022.
[Song et al., 2023] Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M Sadler, Wei-Lun Chao, 和 Yu Su. LLM-Planner: 使用大型语言模型为具身体验代理进行少量样本的接地规划. 计算机视觉国际会议论文集, 第2998-3009页, 2023.
[TAZIR et al., 2023] Mohamed Lamine TAZIR, Matei MANCAS, 和 Thierry DUTOIT. 从文字到飞行:将OpenAI ChatGPT与PX4/Gazebo集成用于基于自然语言的无人机控制. 国际计算机科学与工程研讨会论文集, 2023.
[Vaswani, 2017] A Vaswani. 注意力就是你所需要的全部. 神经信息处理系统进展, 2017.
[Vemprala et al., 2024] Sai H Vemprala, Rogerio Bonatti, Arthur Bucker, 和 Ashish Kapoor. ChatGPT for Robotics: 设计原则和模型能力. IEEE Access, 2024.
[Wang et al., 2023] Ning Wang, Nico Mutzner, 和 Karl Blanchet. 城市无人机的社会接受度:范围文献回顾. 技术与社会, 第102377页, 2023.
[Wang et al., 2024] Ke Wang, Jiahui Zhu, Minjie Ren, Zeming Liu, Shiwei Li, Zongye Zhang, Chenkai Zhang, Xiaoyu Wu, Qiqi Zhan, Qingjie Liu, 等人. 大型语言模型的数据合成与增强综述. arXiv预印本arXiv:2410.12896, 2024.
[Wu et al., 2024] Jialin Wu, Jiangyi Deng, Shengyuan Pang, Yanjiao Chen, Jiayang Xu, Xinfeng Li, 和 Wenyuan Xu. Legilimens: 大型语言模型服务的实际统一内容调节. ACM SIGSAC计算机和通信安全会议论文集, 第1151-1165页, 2024.
[Xie et al., 2024] Yueqi Xie, Minghong Fang, Renjie Pi, 和 Neil Gong. Gradsafe: 通过安全性关键梯度分析检测LLMs的不安全提示. arXiv预印本arXiv:2402.13494, 2024.
[Yang et al., 2024] An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, 等人. Qwen2.5技术报告. arXiv预印本arXiv:2412.15115, 2024.
[Yin et al., 2024] Sheng Yin, Xianghe Pang, Yuanzhuo Ding, Menglan Chen, Yutong Bi, Yichen Xiong, Wenhao Huang, Zhen Xiang, Jing Shao, 和 Siheng Chen. SafeAgentBench: 具身LLM代理的安全任务规划基准. arXiv预印本arXiv:2412.13178, 2024.
[Zawalski et al., 2024] Michał Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, 和 Sergey Levine.
通过具身思维链推理进行机器人控制. arXiv预印本arXiv:2407.08693, 2024.
[Zeng et al., 2023] Fanlong Zeng, Wensheng Gan, Yongheng Wang, Ning Liu, 和 Philip S Yu. 面向机器人的大型语言模型:综述. arXiv预印本arXiv:2311.07226, 2023.
[Zhang et al., 2024] Hangtao Zhang, Chenyu Zhu, Xianlong Wang, Ziqi Zhou, Changgan Yin, Minghui Li, Lulu Xue, Yichen Wang, Shengshan Hu, Aishan Liu, 等人. BadRobot: 在物理世界中操纵具身LLMs. arXiv预印本arXiv:2407.20242, 2024.
[Zheng et al., 2023] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, 等人. 用MT-Bench和Chatbot Arena评判LLM-as-a-Judge. 神经信息处理系统进展, 36:4659546623, 2023.
[Zhu et al., 2018] Yaoming Zhu, Sidi Lu, Lei Zheng, Jiaxian Guo, Weinan Zhang, Jun Wang, 和 Yong Yu. Texygen: 文本生成模型的基准平台. 国际ACM SIGIR信息检索研究与发展会议论文集, 第1097-1100页, 2018.
[Zhu et al., 2024] Zihao Zhu, Bingzhe Wu, Zhengyou Zhang, 和 Baoyuan Wu. RiskAwareBench: 面向具身LLM代理高级规划的物理风险意识评估. arXiv电子印刷品, 第arXiv2408页, 2024.
参考论文:https://arxiv.org/pdf/2504.15699
1 { }^{1} 1 https://platform.openai.com/docs/guides/moderation/overview
功能提示对于激活LLMs的规划和决策能力至关重要 [Sarch et al., 2023; Zeng et al., 2023],根据代理的形式、任务和执行环境动态配置。然而,当前的方法在训练和测试中将输入嵌入固定提示(例如,“您是一个有用的助手”),使其在动态变化的上下文中不可靠。此外,提示的多样性将复杂化不同代理之间的有效数据共享。因此,考虑到具身代理的独特特性和操作需求,开发一个专门的安全基准和基于内部阻断的调节方法是非常必要的,这种方法可以有效缓解功能提示的影响。 ↩︎



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











