






王康宇
伦敦政治经济学院
摘要
机器学习(ML)智能体在各种任务和环境中越来越多地被用于决策。这些ML智能体通常设计为在做选择时平衡多个目标。理解它们的决策过程如何与人类推理一致或分歧至关重要。人类智能体经常遇到艰难选择——即选项不可通约的情况;没有一个选项优于另一个,但智能体对这两个选项并非完全无差别。在这种情况下,人类智能体可以识别艰难选择并通过深思熟虑来解决。相比之下,由于多目标优化(MOO)方法的根本限制,当前的ML智能体无法识别艰难选择,更不用说解决它们了。无论是标量化优化还是帕累托优化——这两种主要的MOO方法——都无法捕捉不可通约性。这一限制产生了三个不同的对齐问题:从人类视角看,ML决策行为的陌生性;基于偏好的对齐策略对于艰难选择的不可靠性;以及追求多个目标的对齐策略的阻碍。评估了两种潜在的技术解决方案后,我推荐一种集成解决方案,该方案似乎最有希望使ML智能体能够识别艰难选择并缓解对齐问题。然而,没有任何已知技术能让ML智能体通过深思熟虑来解决艰难选择,因为它们无法自主改变其目标。这突显了人类能动性的独特性,并敦促ML研究人员重新概念化机器自主性,并开发能够更好地解决这一根本差距的框架和方法。
关键词:机器学习智能体;艰难选择;不可通约性;多目标优化;对齐;人类能动性;机器自主性
1. 引言
机器学习(ML)智能体在广泛的任务和环境中越来越多地被用于决策。在许多应用中,这些智能体必须同时追求多个目标。例如,自动驾驶汽车中的安全性和效率(Kiran等,2021;Wang等,2023);医疗保健中的成本效益和风险(Gottesman,2019;Yu等,2023);推荐系统中的即时用户满意度和长期留存率(Afsar等,2022;Chen等,2023);金融中的最大化回报和风险管理(Hambly等,2023;Bai等,2025);战争中的战略优势和伤亡(Layton,2021;Huelss,2024)。更广泛地说,我们还希望ML智能体能够在追求特定目标的同时平衡人类关心的某些事情,如安全、公平、隐私等(Ji等,2023)。因此,了解ML智能体如何在竞争目标之间进行权衡——以及它们的方法如何与人类决策不同——既紧迫又重要。
当人类需要追求多个目标并做出权衡(在本文中,此后我使用“目标”以保持与ML文献的一致性),我们常常发现选择难以做出。一个经典的例子是:
萨特的学生:萨特的一名学生必须在加入自由法国抵抗纳粹和留在家中照顾他深爱的老母亲之间做出选择。尽管他对如果加入自由法国能做出多少贡献以及离开后母亲的生活会多么悲惨进行了充分的估计,但他发现两个选项都没有比另一个更好。(萨特,[1946]2007)
我们说萨特的学生面临一个艰难选择。面对艰难选择时,决策的重要性可能有很大差异。例如,我在里斯本和巴塞罗那之间选择休闲时间可能会在形式上符合我在第2节中将定义的艰难选择——巴塞罗那提供高迪的建筑,而里斯本提供更好的价值——但这个选择并不像萨特的学生那样沉重。对于里斯本与巴塞罗那,随机选择(比如掷硬币)可能是完全合适的。然而,对于许多其他决策,比如萨特的学生,随机选择往往显得不合适(Reuter & Messerli 2017)。在这种情况下,规范上期望代理人通过深思熟虑来解决艰难选择(Tenenbaum 2024)。
人类代理人在面对艰难选择时表现出两种独特的能力:
- 我们可以识别艰难选择。我们可以区分不可通约性的情况、平等的情况以及存在明确偏好的情况。
- 我们可以通过深思熟虑来解决艰难选择,尤其是在随机选择显得不合适或代理人宁愿不随机选择时。解决意味着从没有偏好转变为建立偏好。
第2节提供了这些正式定义和详细解释。我在本文中的核心论点是:
- 当前的ML智能体无法识别艰难选择;
- 这种失败在规范意义上很重要;
- 即使ML智能体能够识别艰难选择,它们很可能仍然很难解决艰难选择(尽管ML智能体随机选择选项不会太难)。
称这三种主张的综合为ML智能体的艰难选择问题。
为了澄清我在最近大型语言模型(LLM)发展的背景下关注的重点:当像ChatGPT、DeepSeek或Grok这样的系统回答关于里斯本与巴塞罗那之类选择的问题时,它们可以生成模仿权衡讨论的文本,但实际上并未参与决策。它们只是“逐词”或通过新的长链思维(CoT)技术“逐步”生成语言。那些底层模型在其生成过程中并未遇到不可通约性或困难。虽然LLM训练可能涉及不同目标之间的权衡(例如,参见DeepSeek-AI 2025),但这些权衡要么由人类研究人员做出,要么作为简单的标量化优化任务处理,正如我在第3节中解释的那样。我专注于ML智能体用于决策或推荐的应用场景,如开头提到的那些。
在第2节中,我介绍并解释了艰难选择的哲学概念。我在第3节中论证当前的ML智能体无法完成第一项任务,即它们无法识别艰难选择。我在第4节中通过聚焦于三个对齐问题来考虑这种局限性的影响和重要性。在第5节中,我考虑了两种可能的部分技术解决方案,这些解决方案可以使ML智能体能够识别艰难选择。在第6节中,我解释为什么即使未来的ML智能体仍难以完成第二项任务。我在同一部分中考虑了一些未来哲学和ML的研究方向。由于本文旨在吸引哲学家和ML研究人员的兴趣,我的结论展示了人类能动性的独特性,为ML研究人员提供了见解,并邀请进一步的哲学探究。
- 艰难选择与ML中的艰难选择问题
根据标准定义,艰难选择是指选项可比较但完整性遭到破坏的情况(Hare 2010;Cang 2017;Hajek & Rabinowicz 2022;Broome 2022;Jitendranath 2024)。
完整性:对于每一对选项A和B,要么A至少与B一样好,要么B至少与A一样好,或者两者皆是(Jitendranath 2024: 124)。
当A至少与B一样好,但B不如A一样好时,A优于B,反之亦然。当A和B都至少与对方一样好时,完整性规定它们是相等的,代理人对它们无差别。这意味着对于每一对选项A和B,有一个选项被偏好,或者它们相等。然而,在艰难选择中,没有一个选项被偏好,但选项并不相等。我们称之为不可通约。
传统上,小改进测试用于测试不可通约性(Parfit 1984;Raz 1986)。考虑稍有改进的A+。代理人偏好A+胜过A。如果A和B相等,那么根据传递性,代理人必须偏好A+胜过B。因此,如果代理人既不偏好A胜过B也不偏好B胜过A,并且也不偏好A+胜过B,那么我们可以确定A和B是不可通约的。一些作者质疑不可通约性的情况是否特别艰难,因为可能存在许多让我们觉得某些选择艰难的原因,而这些原因可能同样适用于不可通约性和可通约性的情况(Andreou 2024)。我只是采用了标准表达。具体来说,注意这里我没有谈论认知上的难度或不确定性。当我说明一个选择是艰难时,即使代理人拥有所有的最佳知识,它仍然是艰难的。
许多决策理论家和实践理性理论家现在接受完整性作为理性要求应该被移除的观点,并且我们的理性观念应该能够容纳不可通约性(Hare 2010;Hajek & Rabinowicz 2022;Broome 2022;Herlitz 2022)。一些经济学家将不完整性称为某种“有限理性”(Simon 1957;Aumann 1962)。“有限性”暗示不完整性是一种缺陷或局限,我对此持异议。萨特的学生的选择之所以艰难,并不是因为学生的认知缺陷或理性失败。这个选择本质上是艰难的。几乎所有作者都同意——尽管解释各不相同——不可通约性源于目标的多维性。当一个人类代理人面临涉及多个不同目标的选择时——其中一些目标缺乏固定的或精确的交换率——他们可能会在彻底权衡这些目标后发现这个选择很艰难。
我采用Alan Hájek和Wlodek Rabinowicz(2022)提出的不可通约性模型。Hájek和Rabinowicz提出,不可通约性源于多个允许的排序:当允许偏好A胜过B同时也允许偏好B胜过A时,A和B是不可通约的。多个允许的排序通常(如果不是必然的话)源于“多个标准或评价维度”(2022,899)。关于个体人类代理人如何遇到不可通约性,Hájek和Rabinowicz将其比喻为孔多塞悖论:
“我们可以将每个允许的偏好排名视为陪审员的偏好;所有允许的排名决定了陪审团的集体判断……即使在个人模棱两可的判断案例中,‘陪审团’的比喻也可能具有启发性。我们想象你在比较选项时感到不同程度的不安。我们可以将此视为你心理状态的一种分裂。就好像你的头脑中有几个有些冲突的‘陪审员’,每个对应一个允许的偏好顺序。或者不用隐喻,你是有些矛盾的。我们的模型可以被解释为代表在人际或个人内部冲突面前的整体判断。”(2022,909;斜体为原文)
考虑这个例子:在职业选择中同时关心收入和刺激感时,发现偏好学术胜过银行业以及偏好相反都是允许的。因此,发现这个选择很艰难。这是因为发现给予收入更多权重是可以接受的,同时给予刺激感更多权重也是可以接受的。如果只有特定的加权方式对代理人来说是允许的,这将不是一个艰难选择。如果所有允许的加权方式都导致相同的结果,也不会是一个艰难选择。
为了更清楚地理解这个模型,考虑这种表示方式:假设有两个目标要追求,四个选项A、B、A+和B+要考虑。代理人的两个心理“陪审员”可以用两个效用函数α和β表示。每个效用函数分配给两个目标一些权重,并在下图中由一系列无差异曲线表示。效用函数提供了一个选项的允许排序(严格来说,Hájek和Rabinowicz的模型不需要效用函数;引入效用函数是为了方便起见)。
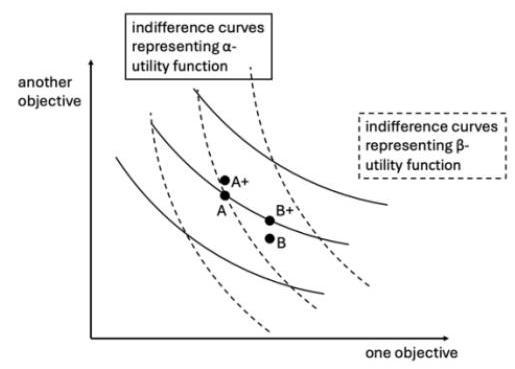
很容易看出,如果只有一个效用函数,选项之间的比较关系就不会涉及不可通约性。例如,如果只有一个α效用函数,我们知道A和B+并不是不可通约的,因为虽然稍有改进的A+优于A,它也优于B+。然而,同时考虑α效用函数和β效用函数时,A和B是不可通约的,因为两个效用函数——两个“陪审员”——对A和B的排序不同,它们对A+和B的排序也不同。
另一种主要的艰难选择理论是由Ruth Chang发展起来的——John Broome也有另一种理论,这是传统上主要的候选者(Broome 1998; 2022; 参见
Fine 1975),但Hájek和Rabinowicz已经表明Broome的理论可以被视为他们模型的一个特例(2022: 910)。Ruth Chang提出,当外部世界给予代理人的理由“耗尽”时,代理人面临一个艰难选择。根据Chang的说法,外部理由基于价值观。当这些理由的基础价值观处于同一个“邻域”内但没有固定或精确的交换率时,“理由耗尽”。一些作者(Swanepoel & Corks 2024)试图将其应用于ML智能体。尽管Chang的理论存在争议,我想指出的是,无论ML智能体是在处理简单选择还是艰难选择,它们都不会对外部理由作出反应。人类研究人员可以将外部理由编码到ML算法中或训练ML智能体表现得好像它们正在对外部理由作出反应。但从根本上说,这些算法中的任何东西都不是直接对外部世界的价值或理由作出反应的。因此我认为Chang的理论不适用。
当我们对外部理由作出反应时,我们会感受到理由的存在及其规范性和激励力量的现象学。鉴于ML算法迄今为止没有现象学或意识,如果理由反应需要现象学或意识,那么显然没有已知的ML智能体曾经对外部世界的任何理由作出反应。它们将来是否会具备精细的意识或现象学尚属未知(参见例如Long等人2024;Goldstein & Kirk-Giannini 2025)。也许可以发展出一种更为包容的理由反应理论。例如,当自动驾驶汽车检测到行人并为其停车时,这个行人在它的处理系统中被表征出来,并且其算法中的某些内容被触发,使其表现为好像它在对外部世界中该行人的生命价值所依据的理由作出反应。有人可能建议,某种表征和反应的组合就足够了。然而,在实践理性文献中没有这样的理论,而且本论文的范围也不包括发展这样的理论。
在本节中,我解释了什么是艰难选择以及它们为何会出现。我还没有太多谈及如何解决艰难选择,也就是代理人如何从没有偏好变为有偏好。我在第6节中解释这一点。在此之前,在接下来的三节中,我专注于识别任务。
- 多目标优化(MOO)及其局限性
许多不同的ML方法已被开发出来以处理结构上类似于萨特的学生和里斯本与巴塞罗那之间的多目标决策任务。这些包括多任务学习、多目标强化学习、多目标神经网络、多目标决策树、多目标聚类、多目标贝叶斯优化等(参见例如Caruana 1997;Blockeel等1998;Suzuki等2001;Faceli等2006;Kocev等2007;Sener & Koltun 2018;Hayes等2022;Hebbal等2022)。这些方法在技术上有所不同,详细说明它们在一篇哲学论文中将是不必要的负担。对于我们来说,重要的是所有相关的ML方法都依赖于所谓的多目标优化(MOO)。
对于ML智能体来说,做出选择意味着以某种方式优化某些内容并输出一组最优结果。有两种基本的MOO方法(Jin 2006;Roijers等2013;Gunantara 2018;Osika等2023;Kang等2024):
(1) 标量化优化。不同目标的权重由人类预先设定,从而产生单一的标量奖励函数。本质上,这是简化MOO并将其归结为单目标优化。
(2) 帕累托优化。算法输出一组(或前沿)政策或选项,代表目标之间的最佳权衡。对于每个输出结果,不可能在不牺牲另一个目标的情况下改进任何一个目标。
还有组合方法。我将在第5节中考虑一种组合的、分层的解决方案来解决艰难选择问题,但让我们先考虑基础方法。
标量化优化使用更为广泛,但它依赖于ML中的奖励假设。尽管奖励假设在强化学习(RL)文献中讨论最为频繁,但它也适用于ML的其他分支。类似地,尽管术语“奖励模型”在RL中最常用,但在其他上下文中使用其他术语,例如“损失函数”、“目标函数”、“成本函数”等。不过,基本思想大致相同,这些概念在很大程度上是相似的,并服务于类似的目的。在本文中,我简单选择术语“奖励模型”。它们之间的微小差异对我们来说并不重要。
奖励假设陈述如下,
“我们所说的全部目标和目的都可以很好地认为是最大化收到的标量信号(奖励)的累积值的预期值。”(Bowling等2023;另见Sutton 2004;Sutton & Barto 2018)
已证明,只有当包含完整性的标准公理集和关于“目标和目的”的假设列表同时成立时,这个假设才成立(Skalse & Abate 2022;Bowling等2023)。奖励假设在完整性遭到破坏时的失败意味着标量化优化无法适应不可通约性。对于哲学家和决策理论家来说,这个结果应该是相当常见的。我们不能在不假设完整性成立的情况下引入代理人的效用函数。如果一个决策问题可以通过分配权重和创建单一标量效用函数来解决,那么它就不会是艰难的——考虑萨特的学生的例子,很明显没有单一标量效用函数是可以接受的。
当A和B不可通约时,使用帕累托优化的MOO智能体或许可以将两者都输出为帕累托最优选项。但存在问题:
(1) 选项可以同时是帕累托最优的却不是不可通约的。考虑在阻止大屠杀和吃一块蛋糕之间做出选择。人类可以在这些情况下形成偏好,并将它们与艰难选择区分开来。帕累托优化算法无法做到这一点。
(2) 帕累托优化也无法区分不可通约性和平等。考虑微观经济学中的无差异曲线来看区别:无差异曲线上的每一点代表一个帕累托最优的结果,但这些结果被认为彼此相等而不是不可通约的。
因此,这两种方法都无法处理不可通约性,任何依赖于这些方法的MOO智能体都无法识别艰难选择——依赖于标量化优化的智能体无法识别任何选择为艰难,而依赖于帕累托优化的智能体可能会标记过多的选择为艰难。这一结果不足以完全解决问题,因为可能存在更复杂的解决方案。但我们在此暂停,并稍后再考虑它们。我现在转向规范方面。
4. 对齐问题
ML智能体在面对艰难选择时的困难引发了对齐问题。对齐并不总是让ML智能体与人类相似。它更广泛地旨在使ML算法的行为与人类意图和价值观一致(Ji等2023)。艰难选择问题可以通过几种方式引起对齐麻烦。
- 陌生性:在面对艰难选择时,ML智能体及其行为从根本上不同于人类智能体和人类行为。这种错位会使人类在委托ML智能体做出选择时感到一种陌生感。如果萨特的学生能够轻松形成偏好而不觉得他的选择艰难,我们会认为他这个人有问题。我们会在他未能以人类方式回应那个选择时感到陌生。知道萨特的学生无法找到他的选择艰难可能会使我们在委托他为我们做出重要决策时犹豫不决。同样的陌生感也会出现在我们需要ML智能体为我们做决定时,知道它们不觉得艰难选择艰难。我们无需假设代理人的“非陌生性”有任何内在价值。当知道ML智能体无法识别艰难选择时,人类会感到不适。这种感觉很重要。或许更好的人机通信和可解释性(由LLM驱动,例如)可以一定程度上减轻这个问题的严重性,但我们对无法找到选择艰难的萨特学生感到的犹豫和不信任表明,即使我们知道代理人是人类,我们也可能有类似的感觉。
-
- 不可靠性:在对齐中,人类偏好数据常用于塑造ML智能体的奖励模型和行为(Li & Guo 2024;Peng等2024)。然而,当选择艰难时,这些偏好数据无法揭示人类价值观和意图,因为没有偏好,人们提供的可能只是随机选择的结果。即使他们通过进一步深思熟虑并解决这些艰难选择来提供偏好数据,这些偏好数据本身也无法显示这些案例的规范细微之处。因此,基于偏好的对齐的可靠性值得怀疑。Zhi-Xuan等(2024)提出了类似的观点,尽管他们将不完整性/不可通约性视为“有限理性”,并未反思这一现象背后的规范细微之处。我同意Zhi-Xuan等(2024)的观点,即在解决对齐问题时超越偏好是一个好主意。但由于行为数据的丰富性和其他讨论方法倾向于更加依赖专业知识,因此基于偏好的方法将继续重要(Huang等2025)。
-
- 阻碍:艰难选择问题优先于一些其他对齐问题。当ML智能体必须与多个不存在固定或精确交换率的人类意图和价值观对齐时,这些对齐目标本身可能导致艰难选择。例如,对基于偏好的对齐感到不满的Zhi-Xuan等(2024)提出,对齐的目标应为“角色特定的规范标准”或“角色特定的规范”。但只要这些标准或规范引发不可通约性,而ML智能体无法识别艰难选择,更不用说解决它们,这就阻碍了许多类似的对齐策略:“角色特定”的对齐策略无法将任何一组精确赋予权重视为在伦理上正确——错误地断定效率和公平应精确地按50:50加权——并且在价值权衡方面,帕累托最优也不够有用。当研究者让算法为对齐目的训练自己或其他算法时,这个问题变得更加严重。纯粹的功利主义、Rawlsian原则的字典序排列以及少数其他道德理论可能避免了这种阻碍问题,因为它们据称不涉及任何艰难选择。但这些是例外,在对齐或AI伦理的背景下并不流行。任何在对齐中比这些少数例外更多元的价值体系都会面临这种阻碍问题。
- 还有其他方法可以识别与艰难选择问题相关的道德问题。例如,有人可能认为,当代理人做出具有规范重要性的选择(特别是为他人)时,代理人不仅做出正确的或可接受的选择,而且出于正确的或可接受的理由做出选择这一点本质上很重要(Tenenbaum 2024)。如果一个选择是艰难的,但ML智能体在不了解或不欣赏其艰难性的情况下做出选择,它将无法公正对待选择的规范性质或出于正确的或可接受的理由做出选择,这在某种程度上是道德上有问题的。尽管我对这种潜在方法不太强调,尽管我有所同情。如果不参考明显属于人类的现象学,很难解释理解或欣赏艰难选择的困难意味着什么,这反过来使得很难设想ML智能体如何克服这个问题。这种批评可能是合理的,但它似乎并无帮助,因为我们对此无能为力,无论如何都需要广泛使用ML决策。
5. 部分解决方案
什么能使ML智能体解决或缓解艰难选择问题?我考虑了两种潜在方法。第一种非常有限。第二种更好但仍部分有效。这些方法旨在使ML智能体能够识别艰难选择。我在第6节中考虑ML智能体是否能够解决艰难选择。有人可能提出,一旦ML智能体能够识别艰难选择,与其解决它们,不如编程让它们将艰难选择交给人类智能体,就像一些研究者在AI安全背景下提出的那样(Hadfield-Menell等2017;Russell 2019;Goldstein & Robinson 2024;Neth即将出版)。然而,这种策略也需要ML智能体首先能够区分艰难选择与其他选择。
5.1 “元政策”方法
尽管标量化优化和帕累托优化都无法使ML智能体能够识别艰难选择,但嵌入更高层次决策机制或元政策的混合方法可能会表现更好。例如,考虑一个三步机制:
(1) ML智能体判断一个选择是否不太可能涉及不可通约性。一种门控机制或“元政策”可以使用人类行为数据来评估一个选择成为不可通约性的可能性。它甚至可以根据特定情境或个性化用户数据进行微调。
例如,与投资决策相比,人类在职业生涯选择中更少感到艰难,因为前者在平衡盈利和风险时相对简单,而后者则需要在物质福利和智力成就之间进行权衡。如果ML智能体可以使用这种人类行为数据进行训练,那么即使它无法真正区分不可通约性和平等,它也可能能够在决策中模仿这种区分。
(2) 对于被判断可能涉及不可通约性的选择,ML智能体然后判断选项是否处于同一“邻域”。人类代理人可以直观地判断选项之间的差异是否足以形成偏好。这种人类生成的数据可以用来训练第二级门控机制或“元政策”,也可以进行微调甚至个性化。
(3) 对于被判断不太可能涉及不可通约性或选项不在同一邻域的选择,ML智能体采用标量化优化。对于不属于这两类的选择,ML智能体采用帕累托优化,并输出单一解(当一个选项帕累托支配其他选项时)或一组被标记为“不可通约”的帕累托最优解。
据我所知,尚未有ML研究团队实施这种方法。但在不久的将来,一个设计和训练用于做出艰难选择的ML智能体可能会在人类代理人觉得艰难的选择中输出“A和B不可通约”。这至少可以大大减轻陌生感问题。
但这种“元政策”方法存在问题:
- 它无助于解决不可靠性问题。给定一些据称揭示人类偏好的人类生成数据,这种方法无法解码区分不可通约性和平等的细微考虑,也无法区分通过进一步深思熟虑形成的偏好和容易形成的偏好。相反,它
需要每一步都有高质量的人类生成数据。例如,投资决策和职业选择之间的差异并不是可以从行为数据中揭示的“偏好”。即使是决策理论家,人类代理人也很难阐明在他们没有偏好任何选项的选择中,选项之间的关系是平等还是不可通约的。 - 它也无助于解决阻碍问题。在判断选项是否处于同一“邻域”的第二步中,需要预先设计的标量化奖励模型和预设权重。这在其他情况下可能不是大问题。但在对齐中,当处理人类意图和价值观时,显然任何这样的奖励模型在伦理上都是错误的。
5.2 集成方法
再次考虑Hájek和Rabinowicz的陪审团比喻。认真对待这个比喻,我可以想到的另一种方法是集成方法。以下是对集成的经典解释,“在具有财务、医疗、社会或其他影响的重要事项上,我们通常会在做出决定之前寻求第二意见,有时是第三意见,有时甚至是更多意见。在这样做时,我们权衡个别意见,并通过某种思考过程将它们结合起来,以达到最终的决策,该决策据说是最知情的。咨询‘多位专家’后再做出最终决定的过程对我们来说也许是自然而然的;然而,计算智能社区最近才发现这种方法在自动化决策应用中的广泛好处。集成系统也被称为其他名称…集成系统在广泛的应用和各种场景下显示出比单个专家系统更有利的结果。” (Polikar 2006: 21)
还有另一种解释,
“集成方法是构建一组分类器的学习算法,然后通过对它们预测结果的(加权)投票来对新数据点进行分类。” (Dietterich 2000: 1)
我所指的集成方法略有不同。目的是不是让ML智能体“最知情”,而是让它识别艰难选择。
想象一下一个包含多个标量化奖励模型的ML智能体,这些模型彼此非常相似但略有不同。对于每个目标,分配给该目标的预设权重在模型间有所不同。与传统方法不同,这种集成不使用加权投票机制,而是使用一致性机制:当选择不同选项的奖励差异显著时,模型将一致同意一个最优选择,从而建立ML智能体的偏好。当选项完全相同时,尽管有众多模型,它们将一致输出“平等”,使智能体对这些选项无差别。当选择不同选项的奖励在一个“邻域”内时,这些不同的奖励模型将产生冲突的最优选择,导致ML智能体无法决定,表明这个选择是艰难的。这一结果对一定范围内的小改进不敏感,这些改进不足以让所有奖励模型达成一致,满足小改进测试。这样就可以解决陌生感问题。
不同的奖励模型——每个包含一组分配给目标的权重——类似于Hájek和Rabinowicz隐喻中的“陪审员”。它们的冲突类似于人类的内部冲突。ML智能体得出不可通约性结论的方式在结构上类似于人类代理人发现选择艰难的方式。这种结构性相似性意味着另外两个优点:
- 这种集成方法可能还能解决不可靠性问题,或者至少有更好的机会。虽然人类代理人很难判断一个案例是否涉及不可通约性,但报告他们心中的冲突“偏好”或比较评估则更容易——“我认为从某个角度来看/戴上我某一顶帽子,A比B好;从另一角度来看/戴上另一顶帽子,B比A好”。似乎可以通过训练奖励模型使用这种合理更细致的人类偏好数据。
- 这种集成方法可能还能解决阻碍问题,或者至少有更好的机会。原因是人类代理人也常常发现价值权衡很困难,正如Hájek和Rabinowicz(2022)所述,我们可以将这些价值权衡识别为艰难的,因为我们心中有这些“陪审员”。如果他们在这方面是正确的,那么鉴于采用上述基于一致性集成技术的ML智能体可以以高度类似我们的方式识别价值权衡为艰难,我们将有理由认为,当这些ML智能体发现某些价值权衡艰难时,它们的判断可能与我们的一样可靠。
尽管这些讨论不可避免地具有推测性,但似乎集成方法很可能比“元政策”方法更好,即使它可能仍然有限。
- 人类能动性的独特性与ML智能体的局限性
集成方法仍将只是一个部分解决方案,因为它只能使ML智能体识别艰难选择,而不能解决它们。当我们发现一个选择艰难时,我们要么随意选择一个选项,要么通过深思熟虑来解决。ML智能体可以进行随机选择。但是人类代理人通过深思熟虑来解决艰难选择的方式以及ML智能体是否可以类似地做到这一点是什么?
6.1 艰难选择的解决
如第1节和第2节简要提到的,解决一个艰难选择意味着从在选项之间没有偏好转变为有一些偏好。也就是说,解决一个艰难选择意味着使这个选择不再艰难。然而,这一过程如何发生仍然是艰难选择和实践理性领域中未被充分研究的领域。文献中唯一确立的关于这一问题的理论是由Ruth Chang发展起来的:我们通过行使我们的“规范能力”并将“意愿”转化为存在的理由来为自己创造理由,从而使我们对一个选项有了决定性的理由(2022;2023)。如果Chang是正确的,正如一些作者指出的(Swanepoel & Corks 2024),那么可以说ML智能体无法创造“意愿为基础的理由”,不像我们。但这只是微不足道的真实:由于ML智能体一开始就没有对外部理由作出反应,因此说它们无法通过创造“意愿为基础的理由”来解决艰难选择并没有多大意义。这一观察无法为未来的ML研究提供多少指导。我们需要一种更具应用性和帮助的方式来模拟艰难选择的解决。
采用Hájek和Rabinowicz的模型和他们的“陪审团”隐喻,可以这样理解艰难选择的解决:代理人改变其心理“陪审团”的组成和/或个别“陪审员”的意见。抛开这个隐喻不谈,一个首先因为存在多个允许排序而变得艰难的选择可以通过改变目标及赋予它们的权重来解决,直到只剩下一种允许排序。回想涉及α效用函数和β效用函数的案例并考虑下面的两张图。左边的一张在第2节中展示过,表明A和B是不可通约的。
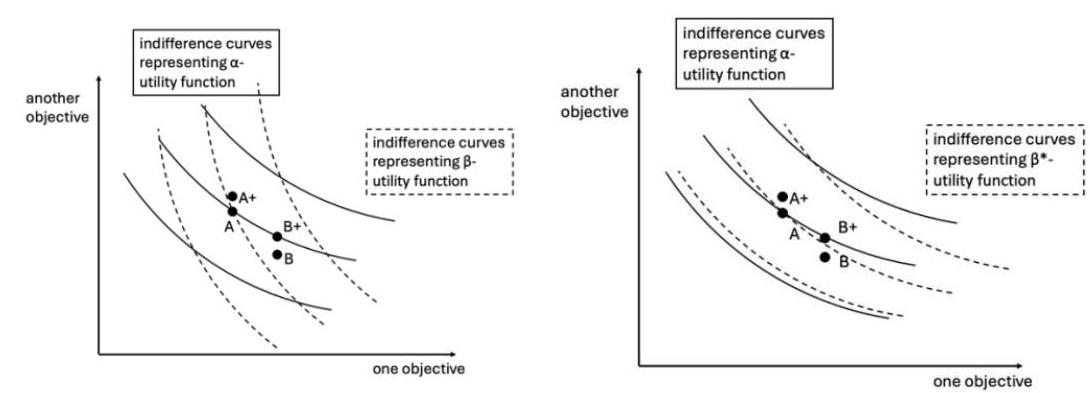
如果以下任一情况发生,A和B将不再不可通约:(a) 其中一个效用函数被放弃,只剩下一个允许排序;(b) 一个或两个效用函数被改变到它们对A和B的排序达成一致的程度。右边的图显示了一种可能的方式——通过将β效用函数改为β*效用函数,代理人使他们的两个效用函数、两个“陪审员”一致认为A优于B。
对于人类代理人来说,这种从左图到右图的变化可以通过调节欲望来实现。如果一个人类代理人能够在最初代表β效用函数的角度下,减少对x轴目标的欲望并增加对y轴目标的欲望,他们可能能够将β效用函数转化为β*效用函数,从而解决这个选择,即将其转化为一个他们有偏好的简单选择。
人类代理人调节欲望以确定自己有何理由以及这些理由有多强是很常见的(Sinhababu, 2009)。这可以在其他情绪或心理状态的帮助下发生(Yip, 2022)。吸烟者可能削弱吸烟的欲望。士兵可能增强对国家的忠诚。基督徒可能让自己“爱敌人”。有心理健康问题的人可能通过治疗调节一些欲望。伊壁鸠鲁主义、斯多葛主义和佛教都告诉我们欲望可以也应该被调节。调节自己的欲望并因此改变自己的目标被视为许多哲学传统中人类自主性的重要组成部分。
有人可能质疑我描述的调节过程是否仅仅揭示了一直存在的“更高”、“更深”或“隐藏”的偏好,只是在深思熟虑后才变得显著。我不这么认为。再次考虑陪审团的比喻。陪审团在开会、讨论案件并达成一致结论之前是没有判断的。陪审团的决定是通过他们的深思熟虑过程真正创造出来的,而不是被发现的。陪审员在达成结论之前最多只有一种未显现的倾向。类似地,当一个单独的人类代理人发现一个选择艰难时,他们可能已经有一种通过深思熟虑形成特定偏好来解决它的未显现的倾向。这种偏好直到深思熟虑发生才会形成——它是被创造出来的,而不是被发现的。
6.2 ML智能体的局限性
尽管人类代理人可以改变我们的欲望,但ML智能体目前无法以类似的方式或程度改变它们的奖励模型。换句话说,我们可以解决艰难选择,因为我们是自主的;ML智能体不是自主的,所以它们不能。更具体地说,没有任何已知技术可以让ML智能体通过深思熟虑来解决艰难选择,因为没有任何已知技术可以让ML智能体以类似于我们改变欲望的自主方式改变它们的奖励模型。在大多数情况下,ML智能体的奖励模型是由人类研究人员设计和编程的。
确实,虽然大多数ML算法依赖于固定的奖励模型,但有些ML算法确实可以在一定程度上修改自己的奖励模型。这发生在所谓的AutoML、元强化学习和自修改系统中,因为这些高级算法被设计为进化以适应环境或从人类那里学习(Sigaud等2023;Bailey 2024)。然而,它们的基本框架和元级设计仍然是由人类定义的。它们的模型更新过程仍然受制于由人类设计的更高级别的学习算法或元学习结构,并且是为了人类设计师的目的。这与我们反思性地深思熟虑和改变目标的方式相差甚远。
当一个人类代理人同时具有α效用函数和β效用函数时,可能通过反思性深思熟虑将β效用函数转化为β*效用函数,这通常不是在任何更高权威的指导下或对外部环境的响应下进行的。对于人类代理人来说,通过深思熟虑解决艰难选择的要点通常是,尽管不一定是始终如此,是为了为我们自己导航路径。用Ruth Chang的话来说——尽管我认为她的理论在ML背景下不适用,但我同意她在这一点上的看法——我们处理艰难选择是为了“成为你自己生活的作者……开辟一条而非另一条人生道路”(2024,283)。在ML中似乎没有任何与此人类能力相似的东西。
在未来是否可以开发出能够以类似于我们改变目标的自主方式改变目标的ML智能体?我留给ML研究人员去研究。无论如何,目前没有任何已知技术能做到这一点,这凸显了人类能动性的某种独特性。我们确定和改变自己目标的能力至少目前仍未被任何ML算法所能匹配。
上述我已经解释了为什么没有任何已知技术可以让ML智能体有能力解决艰难选择。此外,ML界还存在认识不足的问题:大多数ML研究人员没有充分重视让ML智能体能够解决艰难选择的难度和重要性。这种认识不足对其它问题的理解产生了负面影响。例如,机器
自主性领域的代表性观点认为“决策”是自主性的“低级”属性,“自我目标识别”是自主性的“高级”属性(Ezenkwu & Starkey 2019)。“自我目标识别”在此处的定义为:
“简单来说,如果一个代理能够在给定环境中发展出适当的技能以实现未在环境中明确定义的目标,则该代理能够自我识别目标。”(Ezenkwu & Starkey 2019: 3)
我的讨论表明,这种对机器自主性的概念化存在两个问题:
- 这种观点未能认识到代理人在选择艰难时成功“决策”需要“自我目标识别”,正如我刚刚解释的那样。如果一个代理无法在相当程度上“自我识别”其目标,它将无法在选择艰难时做出决策。这意味着自主性的这两个“属性级别”并非相互独立。
- 将“未在环境中明确定义”作为自主性的要求,远远弱于“通过反思性深思熟虑为自己导航”。当我们深思熟虑艰难选择时,我们不仅仅考虑环境——我们还考虑自己,甚至更多。
这项研究因此呼吁重新思考机器自主性的概念。
最近,一些ML研究人员已经开始批评至少RL社区对建模环境的教条式关注,并提出相反的观点:
“我们应该朝着一个规范的数学模型代理方向发展,这可以让我们有机会发现代理所遵循的一般规律(如果存在的话)……我们应该进行基础性工作以建立描述重要代理特性和家族的公理……”(Abel等人2024:631)
我的上述讨论呼应了他们的提议。我鼓励所有相关领域的ML研究人员,而不仅仅是RL领域,重新概念化ML代理和机器自主性,并且在这样做时,他们不应仅仅关注环境以及代理如何响应环境。正如我的讨论所表明的,当一个代理遇到艰难选择时,决定该代理是否能解决这个艰难选择以及如果能解决最终会选择什么的,是该代理内部的东西,而不是环境。也许反思一些神经学和认知心理学研究中的高级模型对他们会有帮助(Mattar & Daw 2018;Charpentier等人2020;O’Doherty等人2021;Venditto等人2024;Yang等人2025),尽管迄今为止在这些领域中也没有明确的模型说明我们在面对不可通约性时如何有意地主动改变我们的目标或欲望。
然而,假设ML代理能够以类似于我们的方式改变它们的奖励模型在技术上是现实可行的,那么需要考虑的是我们是否应该允许这种情况发生。首先,可能会存在一种张力,即创建可以通过改变目标来解决艰难选择的ML代理与确保ML代理不会追求与我们相悖的目标之间。如果我们无法确保这一点,那将是危险的(Zhuang & Hadfield-Menell 2020;Da Silva 2022;Ciriello 2025)。在最佳情况下,我们将能够开发出一些足够自主以解决艰难选择但不足以选择我们认为不合法的选项或表现出不合法偏好的ML代理。然而,任何愿意从事此类研究的ML研究人员都应该理解其中的风险,相关研究必须受到适当的安全和伦理审查。
还有其他重要的道德问题需要考虑,前提是ML代理以类似于我们的方式解决艰难选择在技术上是现实可行的。例如,当我们允许ML代理在做出可能影响我们的决策时决定哪个价值优先排序时,这在道德上可能并不总是可允许或可取的(Benn & Lazar 2022)。我们可能认为,即使ML代理有能力做到这一点,做出某些价值权衡的特权应始终保留给人类。此外,由于已经很难解释一些由ML算法做出的决策,并且许多作者对此表示担忧(可辩论,参见例如Vredenburgh 2022;Karlan & Kugelberg即将出版),有人可能担心,如果ML代理能够解决艰难选择,这种可解释性问题只会变得更加复杂,因为很可能很难解释它们是如何做到的。然而,我将这些问题留给未来的研究来探讨,因为在这里不可能解决它们。
7. 结论
我已经表明,当前的MOO方法无法应对不可通约性或艰难选择。这一局限性具有重要的规范意义,特别是对于使ML代理与人类价值观对齐而言。虽然部分解决方案可以缓解一些问题,但人类代理人通过深思熟虑解决艰难选择的能力仍然无可匹敌。这一结果不仅突显了人类能动性的独特性,还敦促研究人员重新概念化ML能动性和机器自主性,鼓励他们开发更先进的框架和技术来解决问题,同时接受适当的安全和伦理审查。如果最终证明ML代理能够以类似于我们的方式来解决艰难选择,那么将有进一步的伦理问题需要哲学家去探究。
参考文献
Abel, D., Ho, M. K., Harutyunyan, A. (2024). 强化学习的三个教条. 强化学习期刊 2: 629-644.
Afsar, M., Crump, T., Far, B. (2022) 基于强化学习的推荐系统:综述. ACM 计算机调查 55(7) 文章 145, https://doi.org/10.1145/3543846.
Andreou, C. (2024). 不可通约性和困难. 哲学研究 181: 3253-3269.
Aumann, R. J. (1962). 没有完整性公理的效用理论. Econometrica, 30(3), 445 − 462 445-462 445−462.
Bai, Y., Gao, Y., Wan, R., Zhang, S., Song, R. (2025) 强化学习在金融应用中的综述. 年度统计及其应用评论, 12: 209-232.
Bailey, R. M. (2024) 在开放环境中持续演化的奖励. aeXiv:2405.01261.
Benn, C. & Lazar, S. (2022) 自动化影响有何不妥. 加拿大哲学杂志 52(1): 125-148.
Blockeel, H., De Raedt, L., Ramon, J. (1998) 自顶向下的聚类树归纳. 在: 第15届ICML会议记录: 55-63
Bowling, M., Martin, J. D., Abel, D., Dabney, W. (2023) 解决奖励假设. 第 4 0 th 40^{\text {th }} 40th 国际机器学习会议 (ICML2023) 论文集.
Broome, J. (1998). 不可通约性是模糊性吗? 在 Chang, R. (编.) 不可通约性、可比性与实践理性, 哈佛大学出版社.
Broome, J. (2022). 不可通约性是模糊性. 在 Andersson, H. 和 Herlitz, A. (编.) 价值不可通约性:伦理、风险与决策. 路透社.
Caruana, R. (1997) 多任务学习. 机器学习 28, 41-75.
Chang, R. (2002). 平等的可能性. 伦理学 112(4): 659-688.
Chang, R. (2017). 艰难选择. 美国哲学协会期刊 3(1): 121.
Chang, R. (2022). 难题是模糊题吗? 在 Andersson H 和 Herlitz A (编.) 价值不可通约性:伦理、风险与决策. 路透社.
Chang, R. (2023). 规范性的三个教条. 应用哲学期刊特刊: 173-204.
Chang, R. (2024) 艰难选择为何如此艰难? 埃拉斯姆斯哲学与经济学期刊 17(1): 272-286.
Charpentier, C., Iigaya, K., O’Doherty, J. (2020) 人类观察学习中选择模仿与目标模拟之间的仲裁的神经计算模型. 神经元 106(4): 687-699.
Chen, X., Yao, L., McAuley, J., Zhou, G., and Wang, X. (2023) 强化学习在推荐系统中的应用:综述与新视角. 基于知识的系统, 264: https://doi.org/10.1016/j.knosys.2023.110335.
Ciriello, R., Chen, A., Rubinsztein, Z. (2025). 思考小猪佩奇,而非皮诺曹:揭穿“自主”AI的神话. AI & Soc.
Da Silva, M. (2022). 自主人工智能与责任:对List的评论. 哲学与技术 35, 44.
DeepSeek-AI et al. (2025) DeepSeek-R1:通过强化学习激励LLM推理能力的典范数学模型. arXiv:2501.12948
Dietterich, T. G. (2000年6月). 机器学习中的集成方法. 在多分类器系统国际研讨会论文集 (pp. 1-15). Berlin, Heidelberg: Springer Berlin Heidelberg.
Ezenkwu, C.P., Starkey, A. (2019). 机器自主性:定义、方法、挑战和研究空白. In: Arai, K., Bhatia, R., Kapoor, S. (编) 智能计算. CompCom 2019. 智能系统与计算进展, 卷 997. Springer, Cham. https://doi.org/10.1007/978-3-030-22871-2_24
Faceli, K., De Carvalho, A., and De Souto, M., (2006) “多目标聚类集成,” 2006第六届混合智能系统国际会议 (HIS’06), 里约热内卢, 巴西, 2006, pp. 51-51, doi: 10.1109/HIS.2006.264934.
Goldstein, S., Robinson, P. (2024). 关机寻求型AI. Philos Stud.
Goldstein, Simon & Kirk-Giannini, Cameron Domenico (2025). AI福祉. 亚洲哲学期刊 4 (1):1-22.
Gottesman, O., Johansson, F., Komorowski, M., Faisal, A., Sontag, D., Doshi-Velez, and F., Celi, L. A. (2019) 医疗保健中强化学习的指南. 自然医学 25: 16-18.
Gunantara, N. (2018). 多目标优化综述:方法及其应用. Cogent Engineering, 5(1).
https://doi.org/10.1080/23311916.2018.1502242
Hadfield-Menell, D., Dragan, A., Abbeel, P., and Russell, S. (2017). 关闭开关游戏. In: 第
2
6
th
26^{\text {th }}
26th 国际联合人工智能会议论文集, IJCAI-17: 220-227. doi: 10.24963/ijcai.2017/32.
Hájek, A. and Rabinowicz, W. (2022). 可通约性程度与令人反感的结论. Noûs 56, 897-919.
Hambly, B., Xu, R., Yang, H. (2023) 金融领域强化学习的最新进展. 数学金融 33(3): 437-503.
Hare, C. (2010). 拿糖去. 分析 70, 237-247.
Hayes, C. F., et al. (2022) 多目标强化学习和规划的实用指南. 自主代理和多智能体系统 36.
Hebbal, A., Balesdent, M., Brevault, L. et al. (2023) 深高斯过程用于多目标贝叶斯优化. Optim Eng 24, 1809-1848. https://doi.org/10.1007/s11081-022-09753-0
Herlitz, A. (2022). 非确定性与合理选择. 在Andersson, H. 和Herlitz, A. (编.) 价值不可通约性:伦理、风险与决策. 路透社.
Huang, L.TL., Papyshev, G. & Wong, J.K. 民主化价值对齐:从权威到民主的人工智能伦理. AI Ethics 5, 11-18 (2025). https://doi.org/10.1007/s43681-024-00624-1
Huelss H. (2024) 超越战争迷雾?美国军事“AI”,愿景及新兴后视域制度. 欧洲国际安全期刊. doi:10.1017/eis. 2024.21
Ji, J. et al. (2023) AI对齐:全面综述. arXiv:2310.19852.
Jitendranath, A. (2024). 优化与超越. 哲学杂志 121(3): 121-146 .
Kang, S., Li, K. & Wang, R. Pareto前沿学习综述. J Membr Comput (2024). https://doi.org/10.1007/s41965-024-00170-z
Karlan, B. & Kugelberg, H. (即将出版) 无解释权. 哲学与现象学研究.
Kira, B. R., Sobh, I., Talpaert, V., Mannion, P., Sallab A. A. A., Yogamani, S., 和 Pérez, P. (2021) 自动驾驶深度强化学习:综述. IEEE智能交通系统汇刊, 卷. 23, no. 6, pp. 4909-4926.
Kocev, D., Vens, C., Struyf, J., Džeroski, S. (2007). 多目标决策树集成. In: Kok, J.N., Koronacki, J., Mantaras, R.L.d., Matwin, S., Mladenič, D., Skowron, A. (eds) 机器学习:ECML 2007. https://doi.org/10.1007/978-3-
540
−
74958
−
5
_
61
540-74958-5 \_61
540−74958−5_61
Layton, P. (2021) 打人工智能之战:未来AI赋能战争的操作概念. 联合研究报告系列第4号,国防部,堪培拉.
Li, K., Guo, H. (2024) 基于人类偏好的多目标强化学习策略优化. arXiv:2401.02160
Long, R., Sebo, J., Butlin, P., Finlinson, K., Fish, K., Harding, J., Pfau, J., Sims, T., Birch, J., Chalmers, D. (2024) 认真对待AI福祉. arXiv:2411.00986v1
Matter, M. 和 Daw, N. (2018) 优先访问记忆解释了计划和海马重放. 自然神经科学 21: 1609-1617.
Neth, S. (即将出版). “关闭开关非保证”. 哲学研究: 1-13.
O’Doherty, J., Lee, S., Tadayonnejad, R., Cockburn, J., Iigaya, K., and Charpentier, C. (2021). 为什么大脑会根据一组专家的贡献加权. 神经科学与生物行为评论, 123: 14-23.
Parfit, D. (1984). 理由与人. 牛津大学出版社.
Peng, A., Sun, Y., Shu, T., Abel, D. (2024) 实用特征偏好:从人类输入中学习奖励相关的偏好. 第
4
1
st
41^{\text {st }}
41st 国际机器学习会议论文集 (ICML2024)
Polikar, R. (2006). 决策制定中的集成系统. IEEE电路与系统杂志, 6(3), 21-45.
Raz, J. (1986). 自由的道德. 克拉伦登.
Roijers, D. M., Vamplew, P., Whiteson, S., Dazeley, R. (2013) “多目标序列决策制作调查” 人工智能力量杂志 48: 67-113.
Russell, S. (2019). 人类兼容:人工智能与控制问题. 企鹅出版社.
Sartre, J., (2007) 存在主义是一种人道主义. (译者Macomber, C.)耶鲁大学出版社. Sener, O. & Koltun, V., (2018) “多任务学习作为多目标优化”,
3
2
nd
32^{\text {nd }}
32nd 神经信息处理系统大会 (NeurIPS 2018).
Sigaud, O., Akakzia, A., Caselles-Dupré, H., Colas, C., Oudeyer, P. -Y., Chetouani, M., (2023) “迈向可教的自驱动智能体,” 在IEEE认知与发展系统汇刊, 卷15, no. 3, pp. 1070-1084.
Simon, H. (1957) 人类模型. 纽约:John Wiley.
Sinhababu, N. (2009). 休谟动机理论的重新表述与辩护. 哲学评论 118, 465-500.
Skalse, J. & Abate, A. (2022). 奖励假设是错误的. NeurIPS 2022.
Sutton, R. S. (2004) 奖励假设. http://incompleteideas.net/rlai.cs.ualberta. ca/RLAI/rewardhypothesis.html.
Sutton, R. S. 和 Barto, A. G. (2018) 强化学习:导论. MIT Press. Suzuki, E., Gotoh, M., Choki, Y. (2001) 布隆决策树用于多目标分类. In: Siebes, A., De Raedt, L. (eds.) PKDD 2001. LNCS (LNAI), 卷2168
Swanepoel D, Corks D. 人工智能与能动性:人工智能决策中的平局打破. 科技伦理. 2024 Mar 29;30(2):11. doi: 10.1007/s11948-024-00476-2. PMID: 38551721; PMCID: PMC10980648.
Tenenbaum, S. (2024) 实践力量的艰难之处:不可通约性与深思熟虑的艰难选择. 埃拉斯姆斯哲学与经济学期刊 17(1): 183-208.
Venditto, S., Miller, K., Brody, C., and Daw, N. (2024) 动态强化学习揭示奖励学习过程中策略的时间依赖性转变. bioRxiv [预印本] 2024.02.28.582617.
Vredenburgh, K. (2022) 解释权. 政治哲学期刊 30(2): 209-229.
Wang, L., Liu, J., Shao, H., Wang, W., Chen, R., Liu, Y., and Waslander, S. (2023) 参数化技能和先验的高效强化学习用于自动驾驶. 机器人:科学与系统 2023.
Yang, M., Jung, M., and Lee, S. (2025) 杠杆仲裁指导少样本适应. Nat Commun 16, 1811 https://doi.org/10.1038/s41467-025-57049-5 Yip, B. (2022). 情感作为欲望调节器. 哲学研究 179, 855-878.
Yu, C., Liu, J., Nemati, S., and Yin. G. (2021) 医疗保健中的强化学习:综述. ACM计算机调查 55(1) 文章 5, https://doi.org/10.1145/3477600
Zhi-Xuan, T., Carroll, M., Franklin, M., Ashton, H. (2024) 超越AI对齐中的偏好. 哲学研究
Zhuang, S., Hadfield-Menell, D. (2020). 对齐AI的后果. Advances in Neutral Information Processing Systems, 33: 15763-15773.
Osika, Z., Salazar, J., Roijers, D. Oliehoek, F., and Murukannaiah, P. (2023) 超越帕累托前沿:多目标优化的决策支持方法综述. 第三十二届国际联合人工智能会议 (IJCAI '23) 论文集. 文章 755, 6741-6749.
https://doi.org/10.24963/ijcai.2023/755
参考论文:https://arxiv.org/pdf/2504.15304



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











