






张松源 *
∗
{ }^{*}
∗,苏奥斯温 *
∗
{ }^{*}
∗,布莱克米切尔
‡
{ }^{\ddagger}
‡,塞林扎卡里
‡
{ }^{\ddagger}
‡ 和范楚楚
†
{ }^{\dagger}
†
†
{ }^{\dagger}
† 麻省理工学院航空航天系,美国马萨诸塞州剑桥
邮箱: {szhang21, oswinso, chuchu}@mit.edu
‡
{ }^{\ddagger}
‡ 麻省理工学院林肯实验室,美国马萨诸塞州列克星敦
邮箱: {mitchell.black, zachary.serlin}@ll.mit.edu
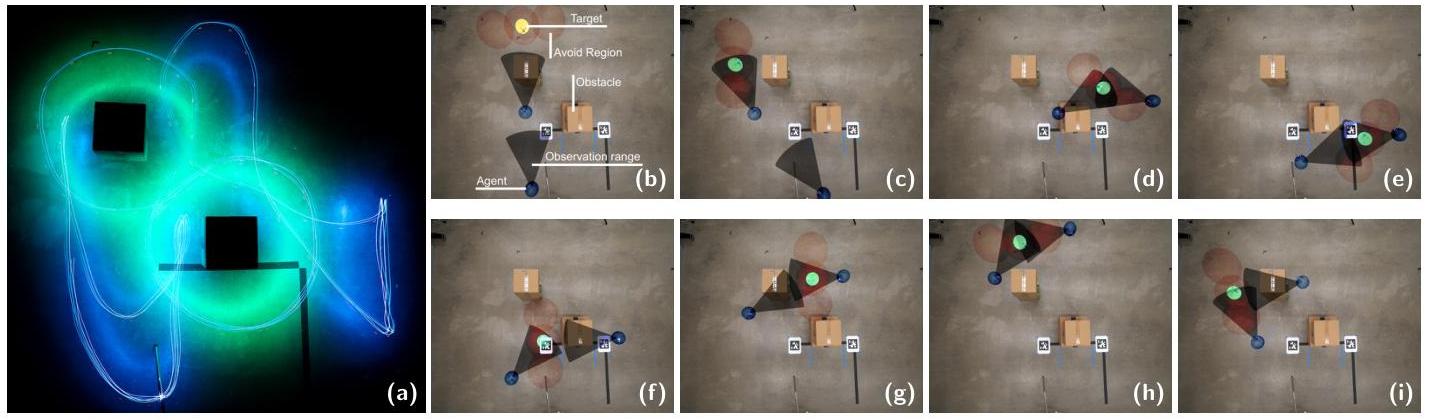
图1:两个智能体使用Def-MARL安全且协作地检查移动目标。我们提出了一种新的安全MARL算法Def-MARL,用于解决多智能体安全最优控制问题。Def-MARL将原始问题转化为其表观形式以避免不稳定训练,并将表观形式扩展到CTDE范式以实现分布式执行。(a): 无人机轨迹的长时间曝光照片。目标的轨迹显示为绿色,智能体的轨迹显示为蓝色。(b)-(i): 智能体策略的快照。使用Def-MARL,智能体学会协作以在任何时候都与目标保持视觉接触,每个智能体仅在其一侧有目标时负责。
摘要—多机器人系统的任务通常需要机器人协作完成团队目标同时保持安全性。这个问题通常被形式化为约束马尔可夫决策过程(CMDP),目标是最小化全局成本并将约束违反的平均值降低到用户定义的阈值以下。受现实世界机器人应用的启发,我们将安全性定义为零约束违反。虽然已经提出了许多安全多智能体强化学习(MARL)算法来解决CMDP,但在这种设置下这些算法遭受不稳定训练。为了解决这个问题,我们使用约束优化的表观形式以提高训练稳定性,并证明集中式表观形式问题可以通过每个智能体分布式求解。这导致了一种新的集中式训练分布式执行MARL算法,命名为Def-MARL。在两个不同模拟器上的8个不同任务的仿真实验表明,Def-MARL实现了最佳整体性能,满足安全约束并保持稳定训练。在Crazyflie四旋翼机上的真实硬件实验展示了Def-MARL与其他方法相比能够安全协调智能体完成复杂的协作任务的能力。 1 { }^{1} 1
I. 引言
多智能体系统(MAS)在我们对更便利未来的追求中起着重要作用,例如
自主仓库操作 [37],大规模自主包裹递送 [45] 和交通路由 [76]。这些任务通常需要设计分布式策略以使智能体协作完成团队目标同时保持安全。为了构建分布式策略,集中式训练分布式执行(CTDE)范式的多智能体强化学习(MARL)[84, 25] 已成为一种有吸引力的方法。为了结合安全约束,大多数MARL算法要么选择精心设计目标函数以包含软约束 [69, 58, 79, 74, 54, 57],要么使用约束马尔可夫决策过程(CMDP)[3] 建模问题,要求约束违反的平均值低于用户定义的阈值 [ 32 , 38 , 18 , 41 , 26 , 90 ] [32,38,18,41,26,90] [32,38,18,41,26,90]。然而,现实世界的机器人应用总是需要零约束违反。虽然这可以通过在CMDP中将约束违反阈值设置为零来解决,在这种设置下流行的拉格朗日方法会经历训练不稳定性,导致训练期间性能急剧下降,以及不收敛或收敛到较差的策略 [66, 35, 24, 36]。
这些担忧最近已被识别,导致了一系列采用哈密顿-雅可比可达性 [71, 44, 49, 46, 5] 技术的硬约束强化学习(RL)工作 [82, 89, 66, 24, 86]。这些技术在单智能体情况下的深度强化学习中显示出显著改进安全性的能力。然而,据我们所知,针对多智能体场景的安全RL理论和算法仍然缺乏,特别是在策略以分布式方式执行时。虽然单智能体RL方法可以通过将MAS视为一个集中式单智能体直接应用于MARL设置,但联合动作空间随着智能体数量呈指数增长,阻止这些算法扩展到具有大量智能体的场景 [33, 69, 23]。
为了解决具有分布式策略的多智能体场景中的零约束违反问题,同时实现高协作性能,我们提出了分布式表观形式MARL (Def-MARL) (图1)。Def-MARL不是考虑CMDP设置,而是直接解决多智能体安全最优控制问题(MASOCP),其解决方案满足零约束违反。为了解决MASOCP,Def-MARL使用了表观形式技术 [10],该技术在单智能体设置中已被证明可以生成比拉格朗日方法更好的策略 [66]。为了适应我们考虑的多智能体设置,我们证明了MASOCP的集中式表观形式可以由每个智能体以分布式方式求解。利用这一结果,Def-MARL属于CTDE范式。
我们在来自两个不同模拟器的8个不同任务上验证了Def-MARL,比较了其与现有使用惩罚和拉格朗日方法的安全MARL算法的性能。结果表明,Def-MARL在满足安全的同时实现了最佳性能:它与那些实现高安全但牺牲性能的保守基线一样安全,同时与那些牺牲安全以实现高性能的基线相匹配。此外,尽管基线方法需要不同的超参数才能在不同环境中表现良好,并因零约束违反阈值而遭受不稳定训练,Def-MARL在所有环境中使用相同的超参数进行稳定训练,表明算法对环境变化的鲁棒性。
我们还在Crazyflie (CF) 无人机 [27] 上进行了真实硬件实验,比较了Def-MARL与集中式和分散式模型预测控制(MPC)方法 [29] 在两个复杂协作任务上的表现。结果表明,Def-MARL以100%的安全率和成功率完成了任务,而MPC方法则陷入局部最小值或表现出不安全行为。
总结我们的贡献如下:
- 受之前关于零约束违反设置下拉格朗日方法训练不稳定的研究的启发,我们将表观形式方法从单智能体RL扩展到MARL,改善了现有MARL算法的训练不稳定性。
- 我们提供了理论结果,表明表观形式的外层问题可以在在线执行期间分解并以分布式方式求解。这使得Def-MARL符合CTDE范式。
-
- 我们通过广泛的仿真表明,无需任何超参数调整,Def-MARL实现了稳定训练,并在所有环境中与最保守的基线一样安全,同时与最具攻击性的基线一样高效。
-
- 我们在Crazyflie无人机硬件上展示了Def-MARL能够安全协调智能体完成复杂的协作任务。Def-MARL的表现优于集中式/分散式MPC方法,不会陷入次优局部最小值或表现出不安全行为。
II. 相关工作
无约束MARL。早期处理MARL安全问题的工作集中在导航和避碰 [14, 13, 21, 64],其中安全是通过稀疏碰撞惩罚 [39] 或者通过形状奖励惩罚靠近障碍物和邻近智能体的行为 [14, 13, 21, 64] 来实现的。然而,向奖励函数添加惩罚改变了原始目标函数,因此得到的策略可能不是原始约束优化问题的最优解。此外,即使是最优策略,也不能保证满足碰撞避免约束 [47, 21, 39]。
带屏蔽的安全MARL。一种流行的方法是为基于学习的方法提供安全屏蔽或安全过滤器 [25]。这里,无约束的学习方法与使用预测安全过滤器 [88, 50]、控制屏障函数 [11, 55] 或自动机 [19, 77, 48, 7] 的屏蔽或安全过滤器配对。此类屏蔽通常在学习开始前构建,并用于修改可行动作或已学习策略的输出以保持安全。一个好处是,由于屏蔽在训练前构建,因此在训练和部署过程中都可以保证安全。然而,它们需要领域专业知识来构建有效的屏蔽,这在单智能体设置中可能具有挑战性,而在多智能体设置中更为困难 [25]。其他方法可以自动生成屏蔽,但面临可扩展性挑战 [48, 20]。另一个缺点是屏蔽后的策略可能不考虑与原始策略相同的目标,可能会导致非协作行为或死锁 [56, 85, 87]。
约束MARL。与无约束MARL方法不同,后者将约束优化问题转换为无约束问题,约束MARL方法显式地解决了约束马尔可夫决策过程(CMDP)问题。对于单智能体情况,解决CMDP的突出方法包括原始方法 [78],使用拉格朗日乘子的原始-对偶方法 [8, 70, 35, 36],以及基于信任区域的方法 [1, 35]。这些方法提供了保证,形式为使用随机逼近理论 [59, 9] 的渐近收敛保证 [8, 70] 到最优(安全)解,或者
*等量贡献。
${ }^{\dagger}$ 项目网站: https://mit-realm.github.io/def-marl/. 分发声明 A. 公开发行批准。分发不受限制。
中间策略的递归可行性 $[1,60]$ 使用信任区域优化的思想 [61]。综述 [31] 提供了不同方法解决单智能体安全RL的概述。然而,在多智能体情况下,由于其他智能体的非平稳行为,问题变得更加困难,类似的接近方法只是最近才出现 [32, 38, 18, 41, 26, 90, 15]。然而,他们处理的CMDP设置使他们难以处理硬约束,并在零约束违反阈值下表现不佳 [24]。
模型预测控制。分布式MPC方法已被提出用于处理MAS,结合多智能体路径规划、机器学习和分布式优化 [75, 72, 92, 22, 42, 16, 52]。然而,当目标函数和约束是非线性时,用于解决MPC的非线性优化器的质量高度依赖于初始猜测 [73, 29]。此外,实时非线性优化器通常需要访问(准确的)一阶和二阶导数 [53, 29],这在尝试解决我们所考虑的不可微或不连续成本函数和约束的任务时带来了挑战。
III. 问题设定和预备知识
A. 多智能体安全最优控制问题
我们考虑以下定义的多智能体安全最优控制问题(MASOCP)。假设有一个同质MAS,包含 N N N个智能体。在时间步 k k k时,全局状态和控制输入分别由 x k ∈ X ⊆ R n x^{k} \in \mathcal{X} \subseteq \mathbb{R}^{n} xk∈X⊆Rn和 u k ∈ U ⊆ R m u^{k} \in \mathcal{U} \subseteq \mathbb{R}^{m} uk∈U⊆Rm给出。全局控制向量通过连接定义为 u k : = [ u 1 k , … ; u N k ] u^{k}:=\left[u_{1}^{k}, \ldots ; u_{N}^{k}\right] uk:=[u1k,…;uNk],其中 u i k ∈ U i u_{i}^{k} \in \mathcal{U}_{i} uik∈Ui是智能体 i i i的控制输入。我们考虑MAS的一般非线性离散时间动态:
x k + 1 = f ( x k , u k ) x^{k+1}=f\left(x^{k}, u^{k}\right) xk+1=f(xk,uk)
其中 f : X × U → X f: \mathcal{X} \times \mathcal{U} \rightarrow \mathcal{X} f:X×U→X是全局动力学函数。我们考虑部分可观测设置,其中每个智能体具有有限通信半径 R > 0 R>0 R>0,并且只能与其通信区域内或其他智能体通信或观察环境。记 o i k = O i ( x k ) ∈ O ⊆ R n o o_{i}^{k}=O_{i}\left(x^{k}\right) \in \mathcal{O} \subseteq \mathbb{R}^{n_{o}} oik=Oi(xk)∈O⊆Rno为智能体 i i i在时间步 k k k观察到的信息向量,其中 O i : X → O O_{i}: \mathcal{X} \rightarrow \mathcal{O} Oi:X→O是从智能体 i i i邻居共享的信息和观测到的数据编码的函数。我们允许智能体之间进行多跳通信,因此如果两个智能体之间存在通信路径,则一个智能体可以与另一个不在其通信范围内的智能体通信。
令智能体 i i i的避免/不安全集为 A i : = { o i ∈ O \mathcal{A}_{i}:=\left\{o_{i} \in \mathcal{O}\right. Ai:={oi∈O : h i ( o i ) > 0 } \left.h_{i}\left(o_{i}\right)>0\right\} hi(oi)>0},对于某些函数 h i : O → R h_{i}: \mathcal{O} \rightarrow \mathbb{R} hi:O→R。那么全局避免集定义为 A : = { x ∈ X : h ( x ) > 0 } \mathcal{A}:=\{x \in \mathcal{X}: h(x)>0\} A:={x∈X:h(x)>0},其中 h ( x ) = max i h i ( o i ) = max i h i ( O i ( x ) ) h(x)=\max _{i} h_{i}\left(o_{i}\right)=\max _{i} h_{i}\left(O_{i}(x)\right) h(x)=maxihi(oi)=maxihi(Oi(x))。换句话说, ∃ i \exists i ∃i,使得 o i ∈ A i ⟺ x ∈ A o_{i} \in \mathcal{A}_{i} \Longleftrightarrow x \in \mathcal{A} oi∈Ai⟺x∈A。给定全局成本函数 l l l : X × U → R \mathcal{X} \times \mathcal{U} \rightarrow \mathbb{R} X×U→R描述智能体要完成的任务 3 { }^{3} 3,
我们的目标是找到分布式控制策略 π i : O → U i \pi_{i}: \mathcal{O} \rightarrow \mathcal{U}_{i} πi:O→Ui,使得从任意给定初始状态 x 0 ∉ A x^{0} \notin \mathcal{A} x0∈/A出发,策略保持智能体处于避免集 A \mathcal{A} A之外并最小化无限视界成本。换句话说,记 π : X → U \pi: \mathcal{X} \rightarrow \mathcal{U} π:X→U为联合策略,使得 π ( x ) = [ π 1 ( o 1 ) ; … ; π N ( o N ) ] = \pi(x)=\left[\pi_{1}\left(o_{1}\right) ; \ldots ; \pi_{N}\left(o_{N}\right)\right]= π(x)=[π1(o1);…;πN(oN)]= [ π 1 ( O 1 ( x ) ) ; … ; π N ( O N ( x ) ) ] \left[\pi_{1}\left(O_{1}(x)\right) ; \ldots ; \pi_{N}\left(O_{N}(x)\right)\right] [π1(O1(x));…;πN(ON(x))],我们的目标是解决给定初始状态 x 0 x^{0} x0的无限视界MASOCP:
min { π i } i = 1 n ∑ k = 0 ∞ l ( x k , π ( x k ) ) s.t. h i ( O i ( x k ) ) ≤ 0 , ∀ i ∈ { 1 , … , N } , k ≥ 0 x k + 1 = f ( x k , π ( x k ) ) , k ≥ 0 \begin{array}{ll} \min _{\{\pi_{i}\}_{i=1}^{n}} & \sum_{k=0}^{\infty} l\left(x^{k}, \pi\left(x^{k}\right)\right) \\ \text { s.t. } & h_{i}\left(O_{i}\left(x^{k}\right)\right) \leq 0, \quad \forall i \in\{1, \ldots, N\}, k \geq 0 \\ & x^{k+1}=f\left(x^{k}, \pi\left(x^{k}\right)\right), \quad k \geq 0 \end{array} min{πi}i=1n s.t. ∑k=0∞l(xk,π(xk))hi(Oi(xk))≤0,∀i∈{1,…,N},k≥0xk+1=f(xk,π(xk)),k≥0
请注意,安全约束(2b)不同于CMDP中考虑的平均约束 [3]。因此,与只要平均约束违反低于阈值就允许发生安全违反的公式不同,此公式不允许任何约束违反。从这里开始,我们为了简洁省略动力学约束(2c)。
B. 表观形式
现有方法无法很好地解决(2)。这在单智能体设置中已经被先前观察到 [82, 89, 66, 24]。我们稍后将展示,处理约束问题(2)的CMDP设置的方法的糟糕表现也适用于多智能体设置,因为我们观察到类似的现象(第V节)。具体来说,虽然无约束MARL可以使用惩罚方法 [51] 来解决(2),但这在实践中表现不佳,一个小的惩罚会导致违反约束的策略,而大的惩罚会导致更高的总成本。拉格朗日方法 [32] 理论上可以解决问题,但在实践中的约束违反阈值为零时,它会遭受不稳定训练和表现不佳 [66, 24]。在本节中,我们引入一种新方法来解决(2),通过将先前工作 [66] 扩展到多智能体设置,可以缓解上述问题。
给定一个具有目标函数 J J J(如, J = ∑ k = 0 ∞ l ( x k , π ( x k ) ) J=\sum_{k=0}^{\infty} l\left(x^{k}, \pi\left(x^{k}\right)\right) J=∑k=0∞l(xk,π(xk))如(2a)所示)和约束 h h h(如,(2b))的约束优化问题:
min π J ( π ) s.t. h ( π ) ≤ 0 \min _{\pi} \quad J(\pi) \quad \text { s.t. } \quad h(\pi) \leq 0 πminJ(π) s.t. h(π)≤0
它的表观形式 [10] 给出为
min π , z z s.t. h ( π ) ≤ 0 , J ( π ) ≤ z \min _{\pi, z} \quad z \quad \text { s.t. } \quad h(\pi) \leq 0, \quad J(\pi) \leq z π,zminz s.t. h(π)≤0,J(π)≤z
其中 z ∈ R z \in \mathbb{R} z∈R是一个辅助变量。换句话说,我们添加一个约束以强制 z z z作为成本 J ( π ) J(\pi) J(π)的上限,然后最小化 z z z。表观形式(4)的解与原问题(3)相同 [10]。此外,(4)等价于 [66]
min z z s.t. min π J z ( π , z ) : = max { h ( π ) , J ( π ) − z } ≤ 0 \begin{array}{ll} \min _{z} & z \\ \text { s.t. } & \min _{\pi} J_{z}(\pi, z):=\max \{h(\pi), J(\pi)-z\} \leq 0 \end{array} minz s.t. zminπJz(π,z):=max{h(π),J(π)−z}≤0
因此,原始约束问题(3)被分解为以下两个子问题:
s.t. h ( π ) ≤ 0 s.t. h ( π ) ≤ 0 \begin{aligned} & \text { s.t. } \quad h(\pi) \leq 0 \\ & \text { s.t. } h(\pi) \leq 0 \end{aligned} s.t. h(π)≤0 s.t. h(π)≤0
2 { }^{2} 2 在本文中,如果每个智能体仅使用本地信息/传感器数据和通过消息传递接收的信息做出决策,则策略是分布式的 [25],尽管有时这种设置在MARL中被称为“去中心化的” [83]。
- 一个无约束的内层问题(5b),其中,给定任意期望的成本上限 z z z,我们寻找 π \pi π以使 J λ ( π , z ) J_{\lambda}(\pi, z) Jλ(π,z)最小化,即最好满足约束 h ≤ 0 h \leq 0 h≤0和 J ≤ z J \leq z J≤z。
- 一个关于
z
z
z的一维约束外层问题(5a),找到最小的成本上限
z
z
z,使得
z
z
z确实是一个成本上限
(
J
≤
z
)
(J \leq z)
(J≤z),并且原始问题的约束
h
(
π
)
≤
0
h(\pi) \leq 0
h(π)≤0成立。
与拉格朗日方法的比较。另一种解决MASOCP(2)的流行方法是拉格朗日方法 [32]。然而,当考虑零约束违反时,它会遭受不稳定训练 [66,35]。更具体地说,这是指约束条件为 ∑ k = 0 ∞ c ( x k ) ≤ 0 \sum_{k=0}^{\infty} c\left(x^{k}\right) \leq 0 ∑k=0∞c(xk)≤0,对于 c : X → R ≥ 0 c: \mathcal{X} \rightarrow \mathbb{R}_{\geq 0} c:X→R≥0非负的情况。由于 h h h可以为负,我们可以通过取 c ( x ) : = max { 0 , h ( x ) } c(x):=\max \{0, h(x)\} c(x):=max{0,h(x)}将我们的问题设置(3)转换为零约束违反设置。然后,(3)变为
min π J ( π ) s.t. ∑ k = 0 ∞ max { 0 , h ( x k ) } ≤ 0 \min _{\pi} \quad J(\pi) \quad \text { s.t. } \quad \sum_{k=0}^{\infty} \max \left\{0, h\left(x^{k}\right)\right\} \leq 0 πminJ(π) s.t. k=0∑∞max{0,h(xk)}≤0
(6)的拉格朗日形式为
max λ ≥ 0 min π J λ ( π , λ ) : = J ( π ) + λ ∑ k = 0 ∞ max { h ( x k ) , 0 } \max _{\lambda \geq 0} \min _{\pi} \quad J_{\lambda}(\pi, \lambda):=J(\pi)+\lambda \sum_{k=0}^{\infty} \max \left\{h\left(x^{k}\right), 0\right\} λ≥0maxπminJλ(π,λ):=J(π)+λk=0∑∞max{h(xk),0}
其中 λ \lambda λ是拉格朗日乘子,并通过梯度上升更新。然而, ∂ ∂ λ J λ ( π , λ ) = ∑ k = 0 ∞ max { h ( x k ) , 0 } ≥ \frac{\partial}{\partial \lambda} J_{\lambda}(\pi, \lambda)=\sum_{k=0}^{\infty} \max \left\{h\left(x^{k}\right), 0\right\} \geq ∂λ∂Jλ(π,λ)=∑k=0∞max{h(xk),0}≥ 0 ,所以 λ \lambda λ持续增加且永不减少。当对于某个 k k k, h ( x k ) > 0 h\left(x^{k}\right)>0 h(xk)>0时, ∂ ∂ π J λ ( π , λ ) \frac{\partial}{\partial \pi} J_{\lambda}(\pi, \lambda) ∂π∂Jλ(π,λ)按 λ \lambda λ线性缩放,大的 λ \lambda λ值会导致关于 x x x的大梯度,从而使训练变得不稳定。注意,对于表观形式,由于 z z z不与成本函数 J J J相乘,而是加到 J J J上(见(5b)), ∂ ∂ x J x ( π , z ) \frac{\partial}{\partial x} J_{x}(\pi, z) ∂x∂Jx(π,z)不会随 z z z的值缩放,从而导致更稳定的训练。我们在实验中验证了这一点(第V节)。
IV. 分布式表观形式多智能体强化学习
在本节中,我们提出分布式表观形式MARL(Def-MARL)算法,使用MARL解决MASOCP(2)。首先,我们将MASOCP(2)转换为其表观形式,用辅助变量 z z z建模期望的成本上限。表观形式包括一个内层问题和一个外层问题。为了分布式执行,我们提供了一个理论结果,表明外层问题可以由每个智能体分布式求解。这使得Def-MARL适合CTDE范式,在集中训练中,给定期望的成本上限 z z z,一起训练智能体的策略;在分布式执行中,智能体分布式找到确保安全的最小成本上限 z z z。
A. MASOCP的表观形式
为了将MASOCP(2)重写为其表观形式(5),我们首先使用标准最优控制符号定义联合策略 π \pi π的成本值函数 V l V^{l} Vl [6]:
V l ( x τ ; π ) : = ∑ k ≥ τ l ( x k , π ( x k ) ) V^{l}\left(x^{\tau} ; \pi\right):=\sum_{k \geq \tau} l\left(x^{k}, \pi\left(x^{k}\right)\right) Vl(xτ;π):=k≥τ∑l(xk,π(xk))
我们还定义约束值函数 V h V^{h} Vh为最大约束违反:
V h ( x τ ; π ) : = max k ≥ τ h ( x k ) = max k ≥ τ max i h i ( o i k ) = max i max k ≥ τ h i ( o i k ) = max i V i h ( o i τ ; π ) \begin{aligned} V^{h}\left(x^{\tau} ; \pi\right) & :=\max _{k \geq \tau} h\left(x^{k}\right)=\max _{k \geq \tau} \max _{i} h_{i}\left(o_{i}^{k}\right) \\ & =\max _{i} \max _{k \geq \tau} h_{i}\left(o_{i}^{k}\right)=\max _{i} V_{i}^{h}\left(o_{i}^{\tau} ; \pi\right) \end{aligned} Vh(xτ;π):=k≥τmaxh(xk)=k≥τmaximaxhi(oik)=imaxk≥τmaxhi(oik)=imaxVih(oiτ;π)
在这里,我们交换最大值以定义局部每智能体函数 V i h ( o i τ ; π ) = max k ≥ τ h i ( o i k ) V_{i}^{h}\left(o_{i}^{\tau} ; \pi\right)=\max _{k \geq \tau} h_{i}\left(o_{i}^{k}\right) Vih(oiτ;π)=maxk≥τhi(oik)。每个 V i h V_{i}^{h} Vih仅使用智能体的本地观察,因此是分布式的。我们现在引入辅助变量 z z z作为 V l V^{l} Vl的期望上限,允许我们简洁地重述(2)为
min { π i } i = 1 n V l ( x 0 ; π ) s.t. V h ( x 0 ; π ) ≤ 0 \min _{\{\pi_{i}\}_{i=1}^{n}} V^{l}\left(x^{0} ; \pi\right) \quad \text { s.t. } \quad V^{h}\left(x^{0} ; \pi\right) \leq 0 {πi}i=1nminVl(x0;π) s.t. Vh(x0;π)≤0
(10)的表观形式(5)则为
min z z \min _{z} z zminz
s.t.
min
{
π
i
}
i
=
1
n
max
{
max
i
V
i
h
(
o
i
τ
;
π
)
,
V
l
(
x
τ
;
π
)
−
z
}
⏟
:
=
V
(
x
0
,
z
;
π
)
≤
0
\quad \min _{\{\pi_{i}\}_{i=1}^{n}} \underbrace{\max \left\{\max _{i} V_{i}^{h}\left(o_{i}^{\tau} ; \pi\right), V^{l}\left(x^{\tau} ; \pi\right)-z\right\}}_{:=V\left(x^{0}, z ; \pi\right)} \leq 0
min{πi}i=1n:=V(x0,z;π)
max{imaxVih(oiτ;π),Vl(xτ;π)−z}≤0。
通过将(11b)的左侧解释为一个新的策略优化问题,我们将总价值函数
V
V
V定义为(11b)的目标函数。这可以简化为
V ( x τ , z ; π ) = max { max i V i h ( o i τ ; π ) , V l ( x τ ; π ) − z } = max i max i { V i h ( o i τ ; π ) , V l ( x τ ; π ) − z } = max i V i ( x τ , z ; π ) \begin{aligned} V\left(x^{\tau}, z ; \pi\right) & =\max \left\{\max _{i} V_{i}^{h}\left(o_{i}^{\tau} ; \pi\right), V^{l}\left(x^{\tau} ; \pi\right)-z\right\} \\ & =\max _{i} \max _{i}\left\{V_{i}^{h}\left(o_{i}^{\tau} ; \pi\right), V^{l}\left(x^{\tau} ; \pi\right)-z\right\} \\ & =\max _{i} V_{i}\left(x^{\tau}, z ; \pi\right) \end{aligned} V(xτ,z;π)=max{imaxVih(oiτ;π),Vl(xτ;π)−z}=imaximax{Vih(oiτ;π),Vl(xτ;π)−z}=imaxVi(xτ,z;π)
再次,我们交换最大值以定义 V i ( x τ , z ; π ) = V_{i}\left(x^{\tau}, z ; \pi\right)= Vi(xτ,z;π)= max { V i h ( o i τ ; π ) , V l ( x τ ; π ) − z } \max \left\{V_{i}^{h}\left(o_{i}^{\tau} ; \pi\right), V^{l}\left(x^{\tau} ; \pi\right)-z\right\} max{Vih(oiτ;π),Vl(xτ;π)−z}作为每智能体总价值函数。使用这个重写(11)则产生
min z z s.t. min π max i V i ( x 0 , z ; π ) ≤ 0 \begin{aligned} & \min _{z} \quad z \\ & \text { s.t. } \quad \min _{\pi} \max _{i} V_{i}\left(x^{0}, z ; \pi\right) \leq 0 \end{aligned} zminz s.t. πminimaxVi(x0,z;π)≤0
这将原始问题(2)分解为一个无约束内层问题(13b)关于策略 π \pi π和一个约束外层问题(13a)关于 z z z。在离线训练期间,我们解决内层问题(13b):对于参数 z z z,找到最优策略 π ( ⋅ , z ) \pi(\cdot, z) π(⋅,z)以最小化 V ( x 0 , z ; π ) V\left(x^{0}, z ; \pi\right) V(x0,z;π)。注意,内层问题的最优策略取决于 z z z。在执行期间,我们在线解决外层问题(13a)以获得满足约束(13b)的最小 z z z。使用内层问题中找到的 z z z条件策略 π ( ⋅ , z ) \pi(\cdot, z) π(⋅,z)中的这个 z z z,我们得到了整个表观形式MASOCP(EF-MASOCP)的最优策略。
为了解决内层问题(13b),总价值函数 V V V必须适用于动态规划,我们在以下命题中展示这一点。
命题1:动态规划可以应用于EF-MASOCP(13),结果为
V
(
x
k
,
z
k
;
π
)
=
max
{
h
(
x
k
)
,
V
(
x
k
+
1
,
z
k
+
1
;
π
)
}
z
k
+
1
=
z
k
−
l
(
x
k
,
π
(
x
k
)
)
\begin{aligned} V\left(x^{k}, z^{k} ; \pi\right) & =\max \left\{h\left(x^{k}\right), V\left(x^{k+1}, z^{k+1} ; \pi\right)\right\} \\ z^{k+1} & =z^{k}-l\left(x^{k}, \pi\left(x^{k}\right)\right) \end{aligned}
V(xk,zk;π)zk+1=max{h(xk),V(xk+1,zk+1;π)}=zk−l(xk,π(xk))
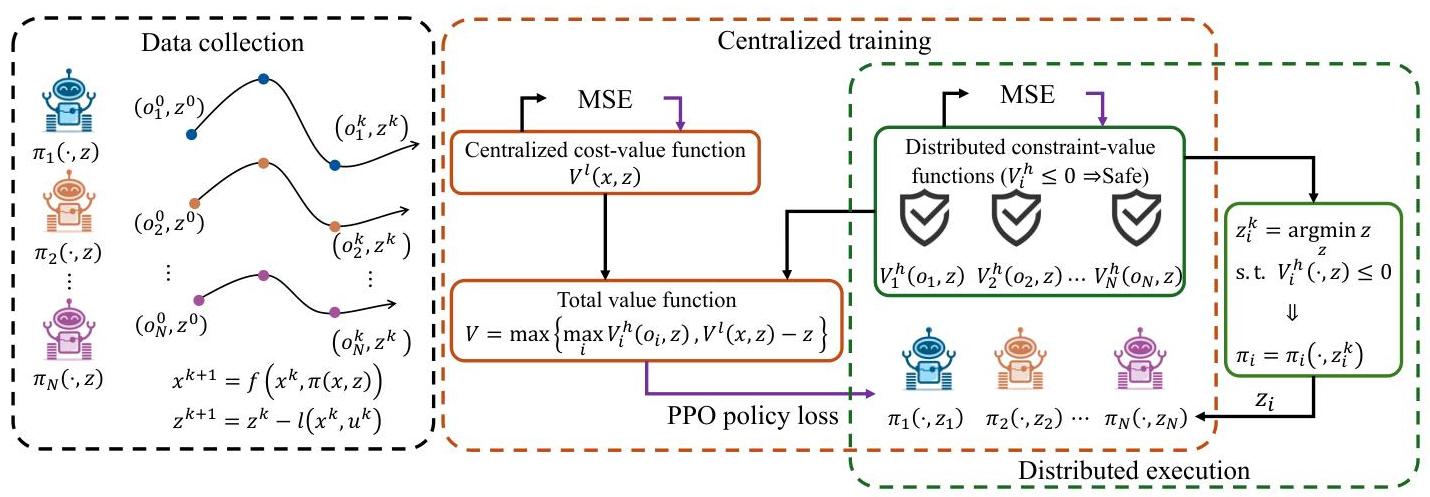
图2:Def-MARL算法。使用当前策略 π \pi π随机采样的初始状态和 z 0 z^{0} z0收集 x x x和 z z z中的轨迹。在集中训练(橙色块)中,分布式约束值函数 V i h V_{i}^{h} Vih和策略 π i \pi_{i} πi以及集中式成本值函数 V l V^{l} Vl联合训练。在分布式执行(绿色块)中,使用分布式 V i h V_{i}^{h} Vih求解外层问题(15b)以计算最优 z i z_{i} zi,该 z i z_{i} zi用于每个智能体的 z z z条件策略。
命题1的证明在附录A中给出了单智能体版本的证明之后。换句话说,对于给定的成本上限
z
k
z^{k}
zk,当前状态
x
k
x^{k}
xk的价值函数
V
V
V可以使用下一个状态
x
k
+
1
x^{k+1}
xk+1的价值函数但使用不同的成本上限
z
k
+
1
=
z
k
−
l
(
x
k
,
π
(
x
k
)
)
z^{k+1}=z^{k}-l\left(x^{k}, \pi\left(x^{k}\right)\right)
zk+1=zk−l(xk,π(xk))计算,该值本身是
z
k
z^{k}
zk的函数。这可以解释为成本上限
z
z
z的“动力学”。直观地说,如果我们希望满足上限
z
k
z^{k}
zk但遭受成本
l
(
x
k
,
π
(
x
k
)
)
l\left(x^{k}, \pi\left(x^{k}\right)\right)
l(xk,π(xk)),那么下一个时间步的上限应该减小
l
(
x
k
,
π
(
x
k
)
)
l\left(x^{k}, \pi\left(x^{k}\right)\right)
l(xk,π(xk)),以便从
x
k
x^{k}
xk开始的总成本仍以上限
z
k
z^{k}
zk为界。附录C提供了关于命题1的更多讨论。
备注1 (
z
z
z对学习策略的影响):从(12),对于固定的
x
x
x和
π
\pi
π,观察到对于足够大的
z
z
z(即,
V
l
(
x
;
π
)
−
z
V^{l}(x ; \pi)-z
Vl(x;π)−z足够小),我们有
V
(
x
,
z
;
π
)
=
V
h
(
x
;
π
)
V(x, z ; \pi)=V^{h}(x ; \pi)
V(x,z;π)=Vh(x;π)。因此,对
V
(
x
,
z
;
π
)
V(x, z ; \pi)
V(x,z;π)取梯度步骤相当于对
V
h
(
x
;
π
)
V^{h}(x ; \pi)
Vh(x;π)取梯度步骤,这减少了约束违反。否则,
V
(
x
,
z
;
π
)
=
V
l
(
x
;
π
)
−
z
V(x, z ; \pi)=V^{l}(x ; \pi)-z
V(x,z;π)=Vl(x;π)−z。对
V
(
x
,
z
;
π
)
V(x, z ; \pi)
V(x,z;π)取梯度步骤相当于对
V
l
(
x
;
π
)
V^{l}(x ; \pi)
Vl(x;π)取梯度步骤,这减少了总成本。
B. 使用MARL解决内层问题
按照So和Fan [66],我们使用带有近端策略优化(PPO)[63]的集中训练来解决内层问题。我们使用图神经网络(GNN)主干来表示
z
z
z-条件策略
π
θ
(
o
i
,
z
)
\pi_{\theta}\left(o_{i}, z\right)
πθ(oi,z),成本值函数
V
ϕ
l
(
x
,
z
)
V_{\phi}^{l}(x, z)
Vϕl(x,z),以及约束值函数
V
ψ
h
(
o
i
,
z
)
V_{\psi}^{h}\left(o_{i}, z\right)
Vψh(oi,z),参数分别为
θ
,
ϕ
\theta, \phi
θ,ϕ和
ψ
\psi
ψ。需要注意的是也可以使用其他神经网络(NN)结构。实现细节在附录E中介绍。
策略和价值函数更新。在集中训练期间,NNs被训练以解决内层问题(13b),即,对于随机采样的
z
z
z,找到使总价值函数
V
(
x
0
,
z
;
π
)
V\left(x^{0}, z ; \pi\right)
V(x0,z;π)最小化的策略
π
(
⋅
,
z
)
\pi(\cdot, z)
π(⋅,z)。我们遵循MAPPO [80]训练NNs。具体来说,当使用生成的优势估计(GAE)[62]计算第
i
i
i个智能体的优势
A
i
A_{i}
Ai[63]时,而不是使用成本函数
V
l
V^{l}
Vl[80],我们应用分解的总价值函数
max
{
V
ψ
h
(
o
i
,
z
)
,
V
ϕ
l
(
x
,
z
)
−
z
}
\max \left\{V_{\psi}^{h}\left(o_{i}, z\right), V_{\phi}^{l}(x, z)-z\right\}
max{Vψh(oi,z),Vϕl(x,z)−z}。我们根据动态方程(1)和
z
z
z(14)进行轨迹回滚,使用学习的策略
π
θ
\pi_{\theta}
πθ,从随机采样的
x
0
x^{0}
x0和
z
0
z^{0}
z0开始。收集轨迹后,我们通过回归训练成本值函数
V
ϕ
l
V_{\phi}^{l}
Vϕl和约束值函数
V
ψ
h
V_{\psi}^{h}
Vψh,并使用PPO策略损失更新
z
z
z-条件策略
π
θ
\pi_{\theta}
πθ。
C. 在分布式执行期间解决外层问题
在执行期间,我们在网上解决EFMASOCP(13)的外层问题。然而,外层问题仍然是集中的,因为约束(13b)需要集中的成本值函数
V
l
V^{l}
Vl。为了实现执行期间的分布式策略,我们引入以下理论结果:
定理1:假设没有两个独特的
z
z
z值能达到同样的独特成本。那么,EF-MASOCP(5a)的外层问题等价于以下问题:
z = max i z i z i = min z ′ z ′ s.t. V i h ( o i ; π ( ⋅ , z ′ ) ) ≤ 0 , i = 1 , ⋯ , N \begin{aligned} z= & \max _{i} z_{i} \\ z_{i}= & \min _{z^{\prime}} \quad z^{\prime} \\ & \text { s.t. } \quad V_{i}^{h}\left(o_{i} ; \pi\left(\cdot, z^{\prime}\right)\right) \leq 0, \quad i=1, \cdots, N \end{aligned} z=zi=imaxziz′minz′ s.t. Vih(oi;π(⋅,z′))≤0,i=1,⋯,N
证明在附录B中给出。定理1使得在执行期间无需使用集中的
V
l
V^{l}
Vl即可计算
z
z
z。具体来说,每个智能体
i
i
i求解局部问题(15b)以获取
z
i
z_{i}
zi,这是一个一维优化问题,可以使用根查找方法(例如,[12])有效求解,如同[66]中那样,然后在其他智能体间通信
z
i
z_{i}
zi以获取最大值(15a)。一个挑战是,如果智能体不相连,这个最大值可能无法计算。然而,在我们的问题设置中,如果一个智能体不相连,它就不会出现在其他相连智能体的观察
o
o
o中。因此,它不会对
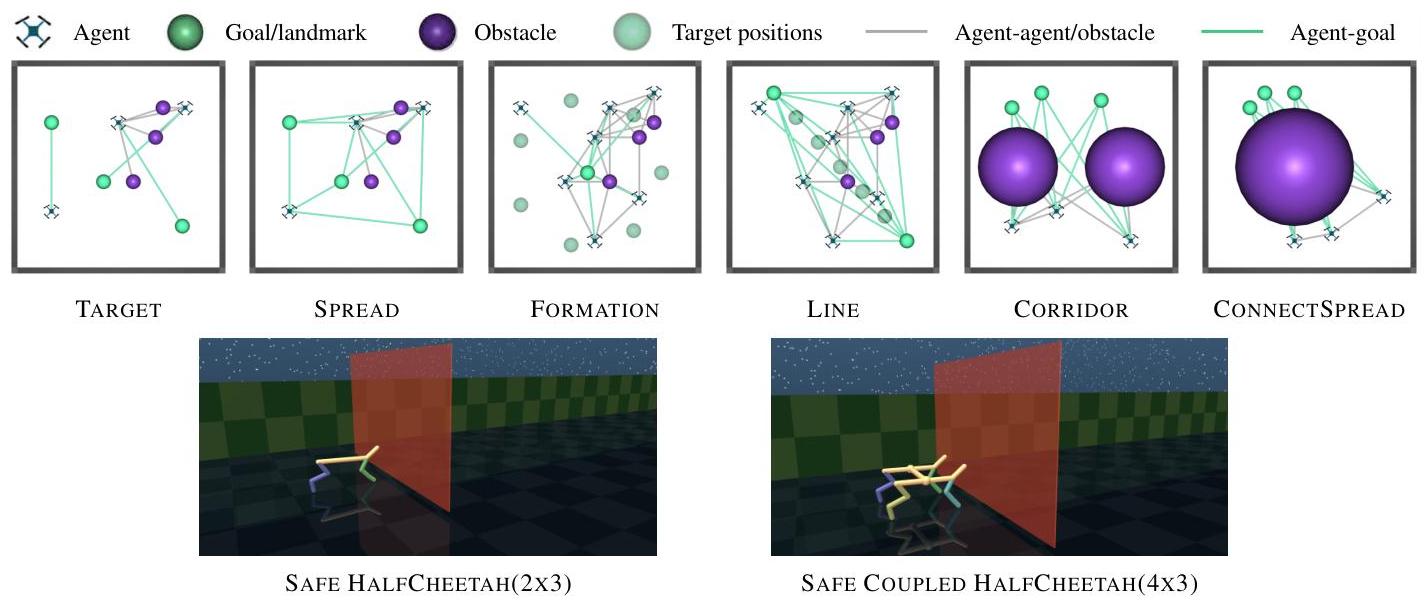
图3:仿真环境。可视化(顶部)修改后的MPE [40] 和(底部)Safe Multi-agent MuJoCo [32] 环境。
其他智能体的约束值函数
V
h
V^{h}
Vh有所贡献。因此,仅需相连智能体之间通信其
z
i
z_{i}
zi。此外,我们实验观察到即使不通信
z
i
z_{i}
zi,智能体也能在维持安全的同时实现低成本(见第V-C节)。因此,我们的方法不包括
z
i
z_{i}
zi通信。Def-MARL的整体框架如图2所示。
处理估计误差。由于使用NN估计 V h V^{h} Vh可能存在误差,我们可以通过修改 h h h来减少由此产生的安全违规,增加缓冲区域。具体来说,对于常数 ν > 0 \nu>0 ν>0,我们修改 h h h使其在约束被违反时 h ≥ ν h \geq \nu h≥ν,否则 h ≤ − ν h \leq-\nu h≤−ν。然后我们将(15b)修改为 V y h ( o i , z i ) ≤ − ξ V_{y}^{h}\left(o_{i}, z_{i}\right) \leq-\xi Vyh(oi,zi)≤−ξ,其中 ξ ∈ [ 0 , ν ] \xi \in[0, \nu] ξ∈[0,ν]是一个超参数(我们希望 ξ ≈ ν \xi \approx \nu ξ≈ν以更强调安全性)。这使得 z z z对 V h V^{h} Vh的估计误差更加鲁棒。我们在第V-C节研究了 ξ \xi ξ的重要性。
V. 仿真实验
在本节中,我们设计仿真实验来回答以下研究问题:
(Q1): Def-MARL是否能在所有环境中使用恒定超参数满足安全约束并实现低成本?
(Q2): Def-MARL是否能实现原始约束优化问题的全局最优?
(Q3): Def-MARL的训练稳定性如何?
(Q4): Def-MARL在更大规模的MAS上表现如何?
(Q5): 从Def-MARL中学到的策略是否能推广到更大的MAS?
实施细节、环境和超参数在附录E中提供。
A. 设置
环境。我们在两组仿真环境中评估Def-MARL:修改后的Multi-agent Particle Environments (MPE) [40] 和 Safe Multi-agent MuJoCo环境 [32](见图3)。在MPE中,假设智能体具有双积分动力学和有界的连续动作空间 [ − 1 , 1 ] 2 [-1,1]^{2} [−1,1]2。我们在附录E中提供了所有任务的完整细节。为了增加任务的难度,我们在这些环境中添加了3个静态障碍物。对于Safe Multi-agent MuJoCo环境,我们考虑Safe HalfCheetaH 2x3和Safe Coupled HalfCheetaH 4x3。智能体必须协作使猎豹尽可能快地运行而不与前面移动的墙碰撞。为了设计约束函数 h h h,我们在所有实验中设 ν = 0.5 \nu=0.5 ν=0.5,并在解决外层问题时设 ξ = 0.4 \xi=0.4 ξ=0.4。
基线。我们将我们的算法与最先进的(SOTA)MARL算法InforMARL [51] 进行比较,该算法使用带有惩罚成本 l ′ ( x , u ) = l ( x , u ) + β max { h ( x ) , 0 } l^{\prime}(x, u)=l(x, u)+\beta \max \{h(x), 0\} l′(x,u)=l(x,u)+βmax{h(x),0}的约束,其中 β ∈ { 0.02 , 0.1 , 0.5 } \beta \in\{0.02,0.1,0.5\} β∈{0.02,0.1,0.5}是一个惩罚参数,并将此基线表示为Penalty ( β ) (\beta) (β)。我们还考虑了最先进的安全MARL算法MAPPO-Lagrangian [30, 32] 4 { }^{4} 4。此外,由于MAPPO-Lagrangian [32] 的官方实现中拉格朗日乘子 λ \lambda λ的学习率很小 ( 1 0 − 7 ) \left(10^{-7}\right) (10−7),因此训练过程中的 λ \lambda λ值将主要由初始值 λ 0 \lambda_{0} λ0决定。因此,我们考虑两个 λ 0 ∈ { 1 , 5 } \lambda_{0} \in\{1,5\} λ0∈{1,5}。此外,为了比较训练稳定性,我们将MAPPO-Lagrangian中的 λ \lambda λ学习率增加到 3 × 1 0 − 3 3 \times 10^{-3} 3×10−3。 5 { }^{5} 5 为了公平比较,我们重新实现了MAPPO-Lagrangian,使用与Def-MARL和InforMARL相同的GNN主干,分别记为 Lagr ( λ 0 ) \operatorname{Lagr}\left(\lambda_{0}\right) Lagr(λ0)和 Lagr ( l r ) \operatorname{Lagr}(\mathrm{l} r) Lagr(lr)对于增加学习率的那个。我们让每种方法运行相同数量的更新步骤,这些步骤足以使所有方法收敛。
评估标准。根据MASOCP的目标,我们使用成本和安全率作为评估所有算法性能的标准。成本是轨迹上的累积成本 ∑ k = 0 T l ( x k , u k ) \sum_{k=0}^{T} l\left(x^{k}, u^{k}\right) ∑k=0Tl(xk,uk)。安全率定义为在整个轨迹上保持安全的智能体比例,即 h i ( o i k ) ≤ 0 , ∀ k h_{i}\left(o_{i}^{k}\right) \leq 0, \forall k hi(oik)≤0,∀k,针对所有智能体。与CMDP设置不同,我们不报告时间上的约束违反均值,而是报告硬安全约束的违反情况。
B. 结果
我们在3个不同的随机种子下训练所有算法,并在32个不同的初始条件下测试收敛策略。如第IV-C节所述,我们在实验中禁用了智能体之间的
z
i
z_{i}
zi通信(在第V-C节进行了研究)。我们得出以下结论。
(Q1): Def-MARL在所有环境中使用恒定超参数实现了最佳性能。首先,我们在图4中绘制每个算法的安全率(y轴)和累积成本(x轴)。因此,一个算法越接近左上角,其表现越好。在MPE和Safe Multi-agent MuJoCo环境中,Def-MARL始终最接近左上角,同时保持低成本并具有接近100%的安全率。对于基线Penalty和Lagr,它们的性能和安全性对其超参数高度敏感。虽然Penalty使用
β
=
0.02
\beta=0.02
β=0.02
和Lagr使用
λ
0
=
1
\lambda_{0}=1
λ0=1通常具有较低的成本,但它们也经常违反约束。当
β
=
0.5
\beta=0.5
β=0.5或
λ
0
=
5
\lambda_{0}=5
λ0=5时,它们优先考虑安全性,但以较高的累积成本为代价。然而,Def-MARL保持了与最保守基线(Penalty (0.5) 和 Lagr (5))相似的安全率,但成本要低得多。我们指出没有单一基线方法在所有环境中表现明显更好:基线方法在环境间的性能变化很大,显示了这些算法对超参数选择的敏感性。相反,Def-MARL在所有环境中表现最佳,使用一套恒定的超参数,这表明其对超参数选择的不敏感性。
(Q2): Def-MARL能够达到原始问题的全局最优。一个重要观察是,对于非最优
λ
\lambda
λ的Penalty和Lagr,在其训练过程中优化的成本函数与原始成本函数不同。因此,它们可以与原始问题有不同的最优解。即使它们的训练收敛,也可能无法达到原始问题的最优解。在图5中展示了Def-MARL和四个基线的收敛状态。Def-MARL达到了原始问题的全局最优并覆盖了所有三个目标。相比之下,Penalty (0.02) 和 Lagr (1) 的最优解因惩罚项而改变,因此它们选择留下一个智能体以减少安全惩罚。当惩罚更大时,Penalty (0.5) 和 Lagr (5) 的最优解发生了显著变化,它们完全忘记了目标,只关注安全性。
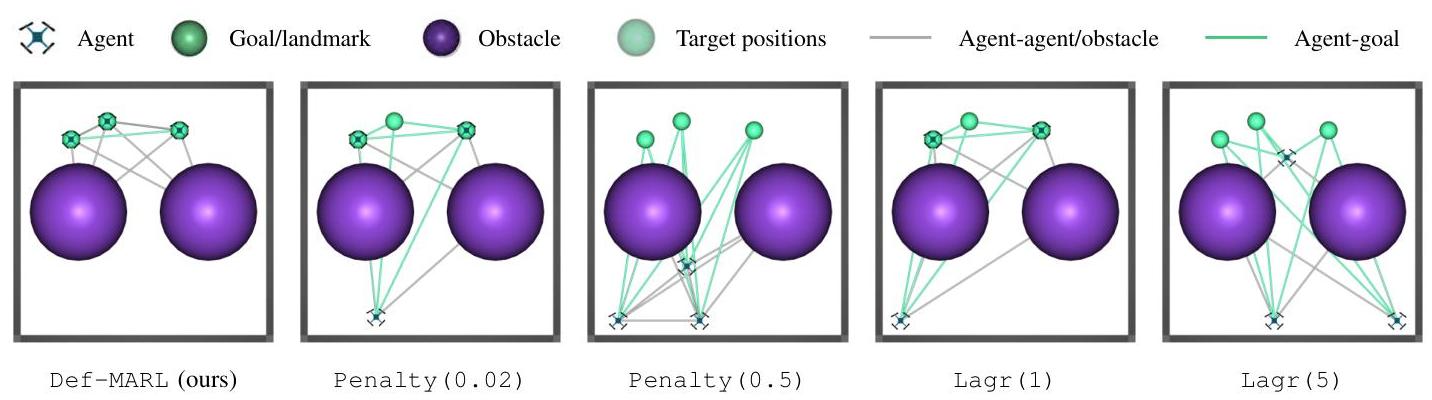
图5:走廊中的收敛状态。Def-MARL实现了全局最小值,而其他基线则部分收敛到不同的最优解。
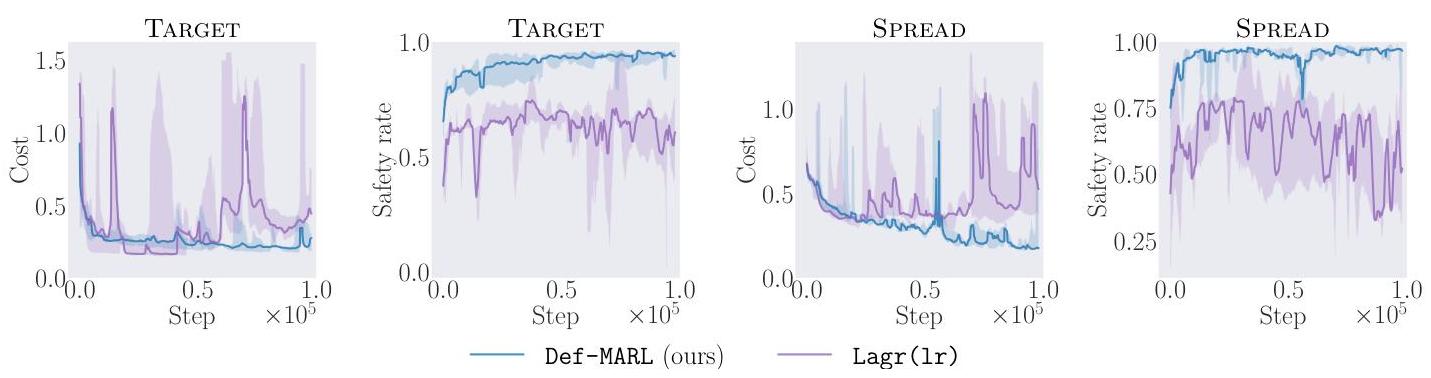
图6:目标和扩散中的训练曲线。Def-MARL相比Lagr (lr) 具有更平滑、更稳定的训练曲线。我们绘制了平均值并用 ± 1 \pm 1 ±1标准差着色。
表I: 策略泛化。在TARGET任务中测试Def-MARL,训练时使用 N = 8 N=8 N=8个智能体。
| 智能体数 | 32 | 128 | 512 |
|---|---|---|---|
| 安全率 | 99.8 ± 0.2 99.8 \pm 0.2 99.8±0.2 | 99.6 ± 0.4 99.6 \pm 0.4 99.6±0.4 | 99.5 ± 0.3 99.5 \pm 0.3 99.5±0.3 |
| 成本 | − 0.387 ± 0.029 -0.387 \pm 0.029 −0.387±0.029 | − 0.408 ± 0.015 -0.408 \pm 0.015 −0.408±0.015 | − 0.410 ± 0.009 -0.410 \pm 0.009 −0.410±0.009 |
(Q3): Def-MARL的训练更加稳定。为了比较Def-MARL和拉格朗日方法Lagr (lr) 的训练稳定性,我们在图6中绘制了它们在训练过程中的成本和安全率。Def-MARL的曲线比Lagr (lr) 更平滑,支持我们在III-B节中的理论分析。由于篇幅限制,其他环境和其他基线方法的图表在附录E-D中提供。
(Q4): Def-MARL可以在维持高性能和安全的同时扩展到更多智能体,但由于集中训练受到GPU内存的限制。我们在FORMATION和LINE任务中通过比较所有方法来测试Def-MARL在训练期间对智能体数量的限制,其中
N
=
5
,
7
N=5,7
N=5,7;在TARGET任务中测试
N
=
8
,
12
,
16
N=8,12,16
N=8,12,16(图7)。由于使用集中训练导致GPU内存限制,我们无法进一步增加
N
N
N。在这个实验中,我们省略了Lagr (lr),因为它在MPE中使用
N
=
3
N=3
N=3时表现最差。Def-MARL在所有环境中都最接近左上角,并且其性能不会随着
智能体数量的增加而下降。
(Q5): 来自Def-MARL的训练策略可以推广到更大的MAS。为了测试Def-MARL的推广能力,我们在TARGET任务上训练了一个包含
N
=
8
N=8
N=8个智能体的策略,并在包含多达
N
=
512
N=512
N=512个智能体的更大规模MAS上进行测试,保持相同的智能体密度以避免分布偏移。尽管应用于比训练时多64倍智能体的MAS,Def-MARL仍然保持高安全率和低成本。
C. 消融研究
在这里我们对 z i z_{i} zi的通信进行消融研究,并研究Def-MARL的超参数敏感性。
是否需要通信 z i z_{i} zi?正如在第四节C部分介绍的那样,理论上所有相连的智能体都应该通信并就 z = max i z i z=\max _{i} z_{i} z=maxizi达成共识。然而,我们在第五节B部分观察到,即使智能体取 z ← z i z \leftarrow z_{i} z←zi而不进行通信以计算最大值,它们也可以很好地执行。我们在MPE ( N = 3 N=3 N=3) 上进行实验以理解这种近似的影響,结果见表II,发现使用这种近似并不会导致性能差异显著。
在外层问题中改变
ξ
\xi
ξ。为了使我们的方法对
V
h
V^{h}
Vh的估计误差更具鲁棒性,我们通过修改(15b)至
V
ψ
h
(
o
i
,
z
i
)
≤
−
ξ
V_{\psi}^{h}\left(o_{i}, z_{i}\right) \leq-\xi
Vψh(oi,zi)≤−ξ (第四节C部分) 来求解一个稍显保守的
z
i
z_{i}
zi。我们现在进行实验
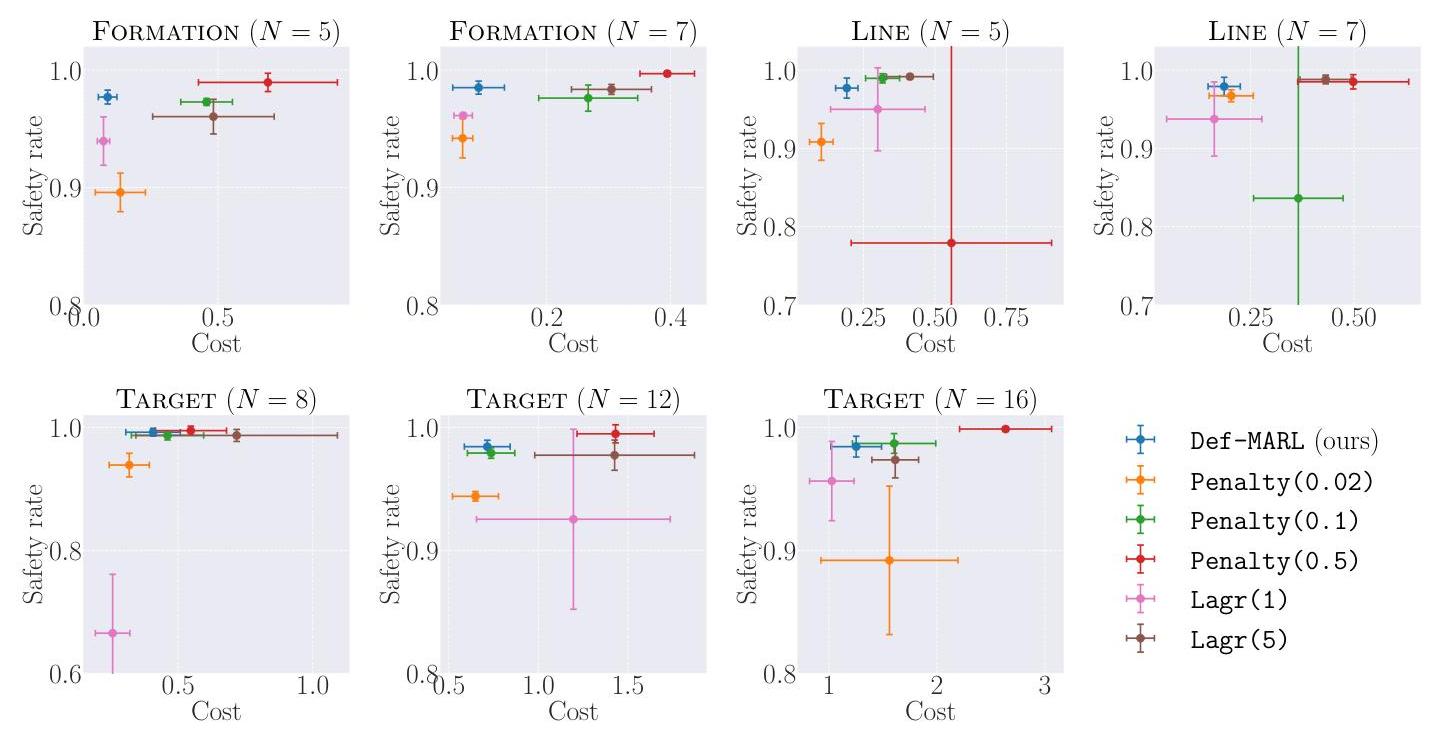
图7:大规模修改后的MPE对比。即使智能体数量增加,Def-MARL仍保持在左上角。点表示平均值,误差条表示一个标准差。
表II:不同环境下 z i z_{i} zi通信的效果(第四节C部分)。
| 环境 | 不通信 ( z ← z i ) \left(z \leftarrow z_{i}\right) (z←zi) | 通信 ( z = max i z i ) \left(z=\max _{i} z_{i}\right) (z=maxizi) | ||
|---|---|---|---|---|
| 安全率 | 成本 | 安全率 | 成本 | |
| TARGET | 97.9 ± 1.5 97.9 \pm 1.5 97.9±1.5 | 0.196 ± 0.108 0.196 \pm 0.108 0.196±0.108 | 96.9 ± 3.0 96.9 \pm 3.0 96.9±3.0 | 0.214 ± 0.141 0.214 \pm 0.141 0.214±0.141 |
| SPREAD | 99.0 ± 0.9 99.0 \pm 0.9 99.0±0.9 | 0.162 ± 0.144 0.162 \pm 0.144 0.162±0.144 | 98.6 ± 1.3 98.6 \pm 1.3 98.6±1.3 | 0.171 ± 0.128 0.171 \pm 0.128 0.171±0.128 |
| FORMATION | 98.3 ± 1.0 98.3 \pm 1.0 98.3±1.0 | 0.123 ± 0.940 0.123 \pm 0.940 0.123±0.940 | 98.3 ± 1.8 98.3 \pm 1.8 98.3±1.8 | 0.126 ± 0.100 0.126 \pm 0.100 0.126±0.100 |
| LINE | 98.6 ± 0.5 98.6 \pm 0.5 98.6±0.5 | 0.117 ± 0.540 0.117 \pm 0.540 0.117±0.540 | 98.3 ± 0.5 98.3 \pm 0.5 98.3±0.5 | 0.121 ± 0.630 0.121 \pm 0.630 0.121±0.630 |
| CORRIDOR | 97.9 ± 1.8 97.9 \pm 1.8 97.9±1.8 | 0.247 ± 0.390 0.247 \pm 0.390 0.247±0.390 | 98.6 ± 1.9 98.6 \pm 1.9 98.6±1.9 | 0.255 ± 0.470 0.255 \pm 0.470 0.255±0.470 |
| CONNECTSPREAD | 97.9 ± 1.7 97.9 \pm 1.7 97.9±1.7 | 0.324 ± 0.187 0.324 \pm 0.187 0.324±0.187 | 99.0 ± 0.8 99.0 \pm 0.8 99.0±0.8 | 0.339 ± 0.201 0.339 \pm 0.201 0.339±0.201 |
表III:对于LINE ( N = N= N= 3) 在固定 ν = 0.5 \nu=0.5 ν=0.5下的不同 ξ \xi ξ选择效果。
| ξ \xi ξ | 安全率 | 成本 |
|---|---|---|
| 0.5 | 100.0 ± 0.0 100.0 \pm 0.0 100.0±0.0 | 0.127 ± 0.061 0.127 \pm 0.061 0.127±0.061 |
| 0.4 | 98.6 ± 0.5 98.6 \pm 0.5 98.6±0.5 | 0.117 ± 0.540 0.117 \pm 0.540 0.117±0.540 |
| 0.2 | 96.5 ± 0.5 96.5 \pm 0.5 96.5±0.5 | 0.108 ± 0.044 0.108 \pm 0.044 0.108±0.044 |
| 0.0 | 93.4 ± 0.020 93.4 \pm 0.020 93.4±0.020 | 0.102 ± 0.035 0.102 \pm 0.035 0.102±0.035 |
结果表明,更高的 ξ \xi ξ值会导致更高的安全率和略高的成本,而较小的 ξ \xi ξ值则反之。这与我们的直觉相符,即修改(15b)可以帮助改善约束满足度,当学到的 V h V^{h} Vh存在估计误差时。因此,我们建议选择接近 ν \nu ν的 ξ \xi ξ。我们还在附录E中提供了更多超参数的敏感性分析。
VI. 硬件实验
最后,我们在一群Crazyflie (CF) 无人机[27]上进行硬件实验,展示Def-MARL在现实世界中安全协调智能体完成复杂协作任务的能力。我们考虑以下两项任务。
- 走廊。一群无人机协同穿过狭窄的走廊并到达一组目标,无需明确分配无人机到目标。
-
- 检测。两架无人机协同保持与按照八字路径移动的目标无人机直接视觉接触,同时避开目标无人机的避障区。只有当视线未被障碍物阻挡时才会发生视觉接触。
对于这两项任务,所有无人机都有与其他无人机和静态障碍物碰撞的约束。我们在图8中可视化了这些任务。
- 检测。两架无人机协同保持与按照八字路径移动的目标无人机直接视觉接触,同时避开目标无人机的避障区。只有当视线未被障碍物阻挡时才会发生视觉接触。
基线。Def-MARL在仿真实验中已经表现出优于RL方法的性能。因此,我们不将RL方法作为硬件实验的基线。相反,我们对Def-MARL和模型预测控制(MPC)进行比较分析,后者是一种在实际机器人应用中广泛采用的技术。值得注意的是,MPC需要模型动力学知识,而Def-MARL不需要。我们将Def-MARL与以下两种MPC基线进行比较。
- 分散式。我们考虑一种分散式MPC方法(DMPC),其中每架无人机试图单独最小化总成本,并通过假设当前测量的速度为常速运动模型来防止与其他受控无人机碰撞。
-
- 集中式。我们还测试了一种集中式MPC(CMPC)方法,以便更好地区分现象与数值非线性优化和执行分散控制的关系。这种方法使用与Def-MARL相同的成本函数。
- 两种MPC方法都在CasADi [4] 中使用SNOPT非线性优化器实现[28]。硬件设置和实验视频的详细信息请参阅附录F。
A. 走廊
我们从16个随机初始条件运行每种算法,并使用任务成功率衡量其性能。如果所有目标都被智能体覆盖且所有智能体在整个任务期间保持安全,则任务被认为是成功的。
相应地,成功率定义为成功任务的数量除以16。在我们的测试中,Def-MARL、CMPC和DMPC的成功率分别为 100 % 100 \% 100%、 0 % 0 \% 0%和 62.5 % 62.5 \% 62.5%。为了分析这一结果,我们在图9中可视化了Def-MARL的轨迹以及某些基线的失败案例。
CMPC容易陷入局部最小值。我们首先比较Def-MARL与CMPC。由于我们将每个目标到最近无人机的距离相加,所以在此任务中的成本函数非常非凸。因此,CMPC会产生次优解,其中只有离目标最近的无人机尝试到达目标,其余无人机留在另一侧。为了缓解这一问题,尽管原任务没有明确的目标分配,但我们为CMPC方法提供了一个帮助,并使用明确分配给每个无人机的目标重新运行实验。这简化了优化问题,通过去除目标分配的离散性质。我们将这个基线命名为CMPCwA(带分配的CMPC)。然而,即使有明确的目标分配,我们仍然看到有时团队中的某个无人机会卡在走廊后面,导致成功率为
87.5
%
87.5 \%
87.5%。相比之下,Def-MARL不会陷入这个局部最小值,并以
100
%
100 \%
100%的成功率完成任务。
DMPC有不安全的情况。如图9所示,DMPC在中间任务中出现不安全情况,因为智能体穿越了不安全半径,导致MPC问题变得不可行,因此无法到达目标。
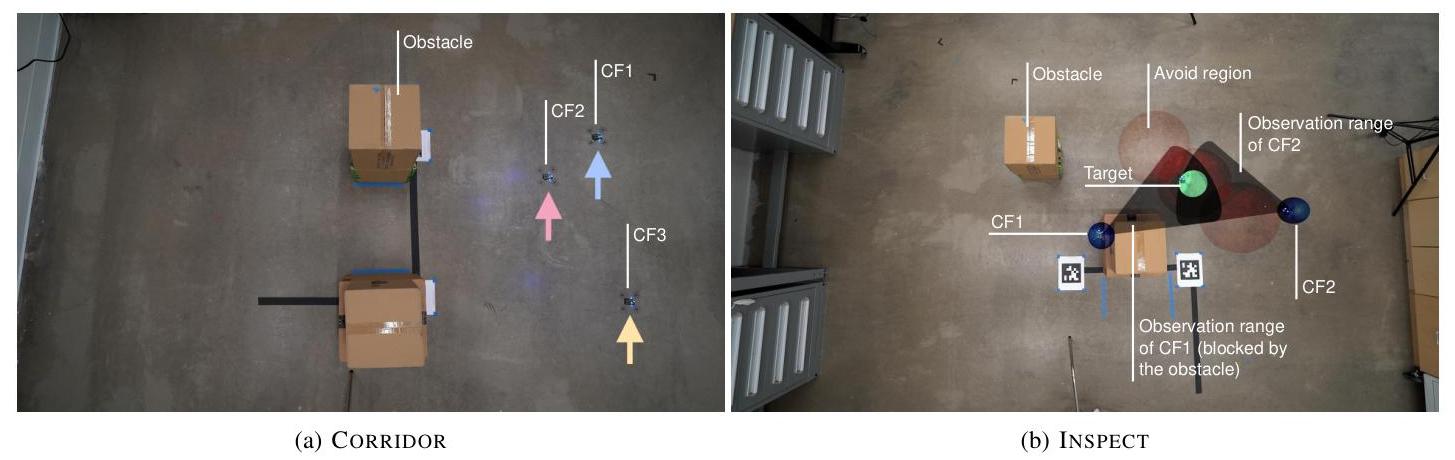
图8:硬件任务。我们在CF无人机群上进行硬件实验,涉及CORRIDOR和INSPECT任务。在CORRIDOR中,团队必须穿过狭窄的走廊并集体覆盖一组目标,无需事先分配。在INSPECT中,团队必须在保持远离目标无人机的避障区域的情况下,与目标无人机保持直接视觉接触。

图9:CORRIDOR任务的硬件结果(
N
=
3
N=3
N=3)。从左到右:不同算法生成的轨迹关键帧。不同颜色的箭头表示不同无人机的位置。Def-MARL(顶部)以
100
%
100 \%
100%的成功率完成任务,因为无人机学会了逐一穿越走廊。CMPC和CMPCwA(中部)有时会陷入局部最小值,无法完成任务,因为成本函数高度非凸。DMPC(底部)有不安全的情况,智能体穿越了不安全半径,因此无法到达目标,因为MPC问题变得不可行。
CORRIDOR中的任务成功率较高。我们从16个随机初始条件运行每种算法,并使用任务成功率衡量其性能。任务定义为成功,如果所有目标都被智能体覆盖并且所有智能体在整个任务中保持安全。
因此,成功率定义为成功任务数量除以16。在我们的测试中,Def-MARL、CMPC和DMPC的成功率分别为 100 % 100 \% 100%、 0 % 0 \% 0%和 62.5 % 62.5 \% 62.5%。为了分析这一结果,我们在图9中可视化了Def-MARL的轨迹和一些基线的失败案例。
CMPC容易陷入局部最小值。我们首先比较Def-MARL与CMPC。由于我们将每个目标到最近无人机的距离相加,因此此任务中的成本函数非常非凸。因此,CMPC产生非常次优的解,其中只有离目标最近的无人机尝试到达目标,其余无人机留在另一侧。为了缓解这一问题,尽管原任务没有明确的目标分配,但我们为CMPC方法提供了一个帮助,并使用明确分配给每个无人机的目标重新运行实验。这通过删除目标分配的离散性质简化了优化问题。我们将这个基线命名为CMPCwA(带分配的CMPC)。然而,即使有了明确的目标分配,我们仍然看到有时团队中的某个无人机会卡在走廊后面,导致成功率为 87.5 % 87.5 \% 87.5%。相比之下,Def-MARL不会陷入这个局部最小值,并以 100 % 100 \% 100%的成功率完成任务。
DMPC有不安全的情况。由于DMPC在没有目标分配的情况下也会遇到与CMPC类似的问题,我们选择为此基线分配目标。这导致了一个更简单的问题,如上所述。然而,与CMPCwA不同,使用DMPC的智能体不知道其他智能体的实际动作,只能基于他们的观察做出预测,因为DMPC具有分散性。因此,如果其他智能体的行为与预测有很大差异,可能会发生碰撞。在图9的DMPC行中,智能体在任务中间发生碰撞,导致MPC优化问题变得不可行,阻止智能体到达目标。我们还测试了Def-MARL在相同环境中的7个CF无人机的可扩展性。值得注意的是,环境大小保持不变,因此环境变得更加拥挤,从而更具挑战性。我们使用9个不同的随机初始条件测试Def-MARL,它保持了 100 % 100 \% 100%的成功率。我们在图10中可视化了一条轨迹。由于我们只有7个可用的无人机,这里仅限于7个无人机。然而,鉴于仿真结果,我们希望Def-MARL能够扩展到更大的硬件群体。
B. InsPECT
我们还从16个不同的随机初始条件运行每种算法。请注意,智能体在第一步可能无法在其初始位置观察到目标。在这种环境中,两架无人机应最大化至少一架无人机观察到目标的时间。通过测量目标不可见的时间步数来评估任务性能,我们获得Def-MARL、CMPC和DMPC的性能分别为 85.5 ± 42.9 , 206 ± 53.2 85.5 \pm 42.9, 206 \pm 53.2 85.5±42.9,206±53.2和 251 ± 59.1 251 \pm 59.1 251±59.1。我们还报告了安全率,
1
6
{ }^{6}
6 为了我们的安全,无人机的安全半径大于其实际半径。这里,我们指的是它们进入了彼此的安全半径,尽管实际上并未发生碰撞。
VII. 结论
为了构建真实世界多智能体系统的安全分布式策略,本文引入了Def-MARL用于多智能体安全最优控制问题,该问题将安全性定义为零约束违反。Def-MARL利用原问题的表观形式来解决拉格朗日方法在零约束违反设置下的训练不稳定性。我们提供了一个理论结果,表明集中式的表观形式可以通过每个智能体以分布式方式解决,这使得Def-MARL能够在分布式执行中实现。MPE和Safe Multiagent MuJoCo环境上的仿真结果表明,与基线方法不同,Def-MARL在所有环境中使用一组恒定的超参数,并且实现了与最保守基线相似的安全率,同时实现了与优先考虑性能但违反安全约束的基线类似的性能。Crazyflie无人机上的硬件结果展示了Def-MARL在现实世界中安全解决复杂协作任务的能力。
VIII. 局限性
第四节C部分的理论分析表明,连接的智能体必须通信 z z z并达成一致。如果禁用 z z z的通信,尽管我们的实验显示智能体仍然表现相似,但理论上的最优性保证可能不再有效。此外,该框架未考虑动态中的噪声、干扰或智能体之间的通信延迟。最后,作为一种安全RL方法,虽然在最优价值函数和策略下可以理论上保证安全性,但在损失不精确最小化的情况下并不成立。我们留待未来工作解决这些问题。
致谢
这项工作部分由国防部研究与工程副部长根据空军合同号FA8702-15-D-0001资助。此外,张、So和范得到了MIT-DSTA项目的资助。本出版物中表达的任何意见、发现、结论或建议均为作者的观点,并不一定反映赞助方的观点。
© 2025 麻省理工学院。
交付给美国政府时享有无限权利,如DFARS Part 252.227-7013或7014(2014年2月)所定义。除非另有具体授权,使用本作品可能违反存在的版权。
参考文献
[1] Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. Constrained policy optimization. In International Conference on Machine Learning, pages 22-31. PMLR, 2017.
[2] Akshat Agarwal, Sumit Kumar, Katia Sycara, and Michael Lewis. Learning transferable cooperative behavior in multi-agent team. In International Conference on Autonomous Agents and Multiagent Systems (AAMAS’2020). IFMAS, 2020.
[3] Eitan Altman. Constrained Markov decision processes. Routledge, 2004.
[4] Joel AE Andersson, Joris Gillis, Greg Horn, James B Rawlings, and Moritz Diehl. Casadi: a software framework for nonlinear optimization and optimal control. Mathematical Programming Computation, 11:1-36, 2019.
[5] Somil Bansal, Mo Chen, Sylvia Herbert, and Claire J Tomlin. Hamilton-jacobi reachability: A brief overview and recent advances. In 2017 IEEE 56th Annual Conference on Decision and Control (CDC), pages 2242-2253. IEEE, 2017.
[6] Dimitri Bertsekas. Dynamic programming and optimal control: Volume I, volume 4. Athena scientific, 2012.
[7] Suda Bharadwaj, Roderik Bloem, Rayna Dimitrova, Bettina Konighofer, and Ufuk Topcu. Synthesis of minimum-cost shields for multi-agent systems. In ACC. IEEE, 2019.
[8] Vivek S Borkar. An actor-critic algorithm for constrained markov decision processes. Systems & Control Letters, 54(3):207-213, 2005.
[9] Vivek S Borkar. Stochastic Approximation: A Dynamical Systems Viewpoint, volume 48. Springer, 2009.
[10] Stephen P Boyd and Lieven Vandenberghe. Convex optimization. Cambridge university press, 2004.
[11] Zhiyuan Cai, Huanhui Cao, Wenjie Lu, Lin Zhang, and Hao Xiong. Safe multi-agent reinforcement learning through decentralized multiple control barrier functions. arXiv preprint arXiv:2103.12553, 2021.
[12] Tirupathi R Chandrupatla. A new hybrid quadratic/bisection algorithm for finding the zero of a nonlinear function without using derivatives. Advances in Engineering Software, 28(3):145-149, 1997.
[13] Yu Fan Chen, Michael Everett, Miao Liu, and Jonathan P How. Socially aware motion planning with deep reinforcement learning. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1343-1350. IEEE, 2017.
[14] Yu Fan Chen, Miao Liu, Michael Everett, and Jonathan P How. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning. In 2017 IEEE International Conference on Robotics and Automation (ICRA), pages 285-292. IEEE, 2017.
[15] Ziyi Chen, Yi Zhou, and Heng Huang. On the duality gap of constrained cooperative multi-agent reinforcement learning. In The Twelfth International Conference on Learning Representations, 2024.
[16] Christian Conte, Tyler Summers, Melanie N Zeilinger, Manfred Morari, and Colin N Jones. Computational aspects of distributed optimization in model predictive control. In 2012 IEEE 51st IEEE conference on decision and control (CDC), pages 6819-6824. IEEE, 2012.
[17] Philip Dames, Pratap Tokekar, and Vijay Kumar. Detecting, localizing, and tracking an unknown number of moving targets using a team of mobile robots. The International Journal of Robotics Research, 36(13-14): 1540-1553, 2017.
[18] Dongsheng Ding, Xiaohan Wei, Zhuoran Yang, Zhaoran Wang, and Mihailo Jovanovic. Provably efficient generalized lagrangian policy optimization for safe multi-agent reinforcement learning. In Learning for Dynamics and Control Conference, pages 315-332. PMLR, 2023.
[19] Ingy ElSayed-Aly, Suda Bharadwaj, Christopher Amato, Rüdiger Ehlers, Ufuk Topcu, and Lu Feng. Safe multi-agent reinforcement learning via shielding. arXiv preprint arXiv:2101.11196, 2021.
[20] Ingy ElSayed-Aly, Suda Bharadwaj, Christopher Amato, Rüdiger Ehlers, Ufuk Topcu, and Lu Feng. Safe multiagent reinforcement learning via shielding. AAMAS '21, 2021.
[21] Michael Everett, Yu Fan Chen, and Jonathan P How. Motion planning among dynamic, decision-making agents with deep reinforcement learning. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3052-3059. IEEE, 2018.
[22] Giuseppe Fedele and Giuseppe Franzè. A distributed model predictive control strategy for constrained multiagent systems: The uncertain target capturing scenario. IEEE Transactions on Automation Science and Engineering, 2023.
[23] Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
[24] Milan Ganai, Zheng Gong, Chenning Yu, Sylvia Herbert, and Sicun Gao. Iterative reachability estimation for safe reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024.
[25] Kunal Garg, Songyuan Zhang, Oswin So, Charles Dawson, and Chuchu Fan. Learning safe control for multirobot systems: Methods, verification, and open challenges. Annual Reviews in Control, 57:100948, 2024.
[26] Nan Geng, Qinbo Bai, Chenyi Liu, Tian Lan, Vaneet Aggarwal, Yuan Yang, and Mingwei Xu. A reinforcement learning framework for vehicular network routing under peak and average constraints. IEEE Transactions on Vehicular Technology, 2023.
[27] Wojciech Giernacki, Mateusz Skwierczyński, Wojciech Witwicki, Paweł Wroński, and Piotr Kozierski. Crazyflie 2.0 quadrotor as a platform for research and education in robotics and control engineering. In 2017 22nd International Conference on Methods and Models in Automation and Robotics (MMAR), pages 37-42. IEEE, 2017.
[28] Philip E Gill, Walter Murray, and Michael A Saunders. Snopt: An sqp algorithm for large-scale constrained optimization. SIAM review, 47(1):99-131, 2005.
[29] Lars Grne and Jrgen Pannek. Nonlinear model predictive control: theory and algorithms. Springer Publishing Company, Incorporated, 2013.
[30] Shangding Gu, Jakub Grudzien Kuba, Munning Wen, Ruiqing Chen, Ziyan Wang, Zheng Tian, Jun Wang, Alois Knoll, and Yaodong Yang. Multi-agent constrained policy optimisation. arXiv preprint arXiv:2110.02793, 2021.
[31] Shangding Gu, Long Yang, Yali Du, Guang Chen, Florian Walter, Jun Wang, Yaodong Yang, and Alois Knoll. A review of safe reinforcement learning: Methods, theory and applications. arXiv preprint arXiv:2205.10330, 2022.
[32] Shangding Gu, Jakub Grudzien Kuba, Yuanpei Chen, Yali Du, Long Yang, Alois Knoll, and Yaodong Yang. Safe multi-agent reinforcement learning for multi-robot control. Artificial Intelligence, 319:103905, 2023.
[33] Carlos Guestrin, Michail Lagoudakis, and Ronald Parr. Coordinated reinforcement learning. In ICML, volume 2, pages 227-234. Citeseer, 2002.
[34] Matthew Hausknecht and Peter Stone. Deep recurrent q-learning for partially observable mdps. In 2015 aaai fall symposium series, 2015.
[35] Tairan He, Weiye Zhao, and Changliu Liu. Autocost: Evolving intrinsic cost for zero-violation reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 14847-14855, 2023.
[36] Weidong Huang, Jiaming Ji, Chunhe Xia, Borong Zhang, and Yaodong Yang. Safedreamer: Safe reinforcement learning with world models. In The Twelfth International Conference on Learning Representations, 2024.
[37] Ajay Kattepur, Hemant Kumar Rath, Anantha Simha, and Arijit Mukherjee. Distributed optimization in multi-agent
robotics for industry 4.0 warehouses. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, pages 808-815, 2018.
[38] Chenyi Liu, Nan Geng, Vaneet Aggarwal, Tian Lan, Yuan Yang, and Mingwei Xu. Cmix: Deep multiagent reinforcement learning with peak and average constraints. In Machine Learning and Knowledge Discovery in Databases. Research Track: European Conference, ECML PKDD 2021, Bilbao, Spain, September 13-17, 2021, Proceedings, Part I 21, pages 157-173. Springer, 2021.
[39] Pinxin Long, Tingxiang Fan, Xinyi Liao, Wenxi Liu, Hao Zhang, and Jia Pan. Towards optimally decentralized multi-robot collision avoidance via deep reinforcement learning. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 6252-6259. IEEE, 2018.
[40] Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. Multi-agent actorcritic for mixed cooperative-competitive environments. Advances in neural information processing systems, 30, 2017.
[41] Songtao Lu, Kaiqing Zhang, Tianyi Chen, Tamer Başar, and Lior Horesh. Decentralized policy gradient descent ascent for safe multi-agent reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 8767-8775, 2021.
[42] Carlos E Luis and Angela P Schoellig. Trajectory generation for multiagent point-to-point transitions via distributed model predictive control. IEEE Robotics and Automation Letters, 4(2):375-382, 2019.
[43] Carlos E Luis, Marijan Vukosavljev, and Angela P Schoellig. Online trajectory generation with distributed model predictive control for multi-robot motion planning. IEEE Robotics and Automation Letters, 5(2):604-611, 2020.
[44] John Lygeros. On reachability and minimum cost optimal control. Automatica, 40(6):917-927, 2004.
[45] Hang Ma, Jiaoyang Li, TK Kumar, and Sven Koenig. Lifelong multi-agent path finding for online pickup and delivery tasks. arXiv preprint arXiv:1705.10868, 2017.
[46] Kostas Margellos and John Lygeros. Hamilton-jacobi formulation for reach-avoid differential games. IEEE Transactions on automatic control, 56(8):1849-1861, 2011.
[47] Pierre-François Massiani, Steve Heim, Friedrich Solowjow, and Sebastian Trimpe. Safe value functions. IEEE Transactions on Automatic Control, 68(5): 2743-2757, 2023.
[48] Daniel Melcer, Christopher Amato, and Stavros Tripakis. Shield decentralization for safe multi-agent reinforcement learning. In Advances in Neural Information Processing Systems, 2022.
[49] Ian M Mitchell, Alexandre M Bayen, and Claire J Tomlin. A time-dependent hamilton-jacobi formulation of reachable sets for continuous dynamic games. IEEE
Transactions on automatic control, 50(7):947-957, 2005.
[50] Simon Muntwiler, Kim P Wabersich, Andrea Carron, and Melanie N Zeilinger. Distributed model predictive safety certification for learning-based control. IFACPapersOnLine, 53(2):5258-5265, 2020.
[51] Siddharth Nayak, Kenneth Choi, Wenqi Ding, Sydney Dolan, Karthik Gopalakrishnan, and Hamsa Balakrishnan. 可扩展多智能体强化学习通过智能信息聚合. 在国际机器学习会议,页面 25817-25833. PMLR, 2023.
[52] Angelia Nedić 和 Ji Liu. 分布式优化用于控制. 年度控制、机器人和自主系统评论,1:77-103, 2018.
[53] Jorge Nocedal 和 Stephen J Wright. 数值优化. Springer, 1999.
[54] Bei Peng, Tabish Rashid, Christian Schroeder de Witt, Pierre-Alexandre Kamienny, Philip Torr, Wendelin Böhmer, 和 Shimon Whiteson. FACMAC: 因子多智能体集中策略梯度. 高级神经信息处理系统进展,34:12208-12221, 2021.
[55] Marcus A Pereira, Augustinos D Saravanos, Oswin So, 和 Evangelos A Theodorou. 去中心化安全多智能体随机最优控制使用深度 FBSDEs 和 ADMM. arXiv 预印本 arXiv:2202.10658, 2022.
[56] Zengyi Qin, Kaiqing Zhang, Yuxiao Chen, Jingkai Chen, 和 Chuchu Fan. 学习安全多智能体控制与去中心化神经屏障证书. 在国际学习表示会议,2021.
[57] Tabish Rashid, Gregory Farquhar, Bei Peng, 和 Shimon Whiteson. 加权 QMIX: 扩展单调价值函数分解以实现深度多智能体强化学习. 高级神经信息处理系统进展,33:10199-10210, 2020.
[58] Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, 和 Shimon Whiteson. 单调价值函数分解以实现深度多智能体强化学习. 机器学习研究杂志,21(178):1-51, 2020.
[59] Herbert Robbins 和 Sutton Monro. 一种随机逼近方法. 数学统计年鉴,页面 400-407, 1951.
[60] Harsh Satija, Philip Amortila, 和 Joelle Pineau. 约束马尔可夫决策过程通过反向价值函数. 在国际机器学习会议,页面 8502-8511. PMLR, 2020.
[61] John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, 和 Philipp Moritz. 信任区域策略优化. 在国际机器学习会议,页面 1889-1897. PMLR, 2015.
[62] John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, 和 Pieter Abbeel. 使用广义优势估计的高维连续控制. arXiv 预印本 arXiv:1506.02438, 2015.
[63] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, 和 Oleg Klimov. 近端策略优化算法. arXiv 预印本 arXiv:1707.06347, 2017.
[64] Samaneh Hosseini Semnani, Hugh Liu, Michael Everett, Anton De Ruiter, 和 Jonathan P How. 通过深度强化学习实现密集动态环境下的多智能体运动规划. IEEE 机器人与自动化快报,5(2):3221-3226, 2020.
[65] Yunsheng Shi, Zhengjie Huang, Shikun Feng, Hui Zhong, Wenjin Wang, 和 Yu Sun. 被掩码标签预测:统一消息传递模型用于半监督分类. arXiv 预印本 arXiv:2009.03509, 2020.
[66] Oswin So 和 Chuchu Fan. 解决稳定避免最优控制问题通过表观形式和深度强化学习. 在机器人科学与系统会议录,2023.
[67] Oswin So, Cheng Ge, 和 Chuchu Fan. 使用强化学习解决最小成本到达避免问题. 在第三十八届年度神经信息处理系统会议录,2024.
[68] Enrica Soria, Fabrizio Schiano, 和 Dario Floreano. 杂乱环境中空中群体的预测控制. 自然机器智能,3(6):545-554, 2021.
[69] Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, 等人. 价值分解网络用于合作多智能体学习. arXiv 预印本 arXiv:1706.05296, 2017.
[70] Chen Tessler, Daniel J. Mankowitz, 和 Shie Mannor. 奖励约束策略优化. 在国际学习表示会议,2019.
[71] Claire J Tomlin, John Lygeros, 和 S Shankar Sastry. 混合系统的控制器设计的游戏理论方法. IEEE学报,88(7):949-970, 2000.
[72] Charbel Toumieh 和 Alain Lambert. 使用模型预测控制和时间感知安全走廊的去中心化多智能体规划. IEEE 机器人与自动化快报,7(4):11110-11117, 2022.
[73] Panagiotis Tsiotras, Efstathios Bakolas, 和 Yiming Zhao. 飞机着陆轨迹优化的初始猜测生成. 在 AIAA 制导、导航和控制会议,页面 6689, 2011.
[74] Jianhao Wang, Zhizhou Ren, Terry Liu, Yang Yu, 和 Chongjie Zhang. QPLEX: 复杂双斗多智能体 Q 学习. arXiv 预印本 arXiv:2008.01062, 2020.
[75] Peng Wang 和 Baocang Ding. 具有碰撞规避的同质多智能体系统分布式模型预测控制的综合方法. 国际控制期刊,87(1):52-63, 2014.
[76] Tong Wu, Pan Zhou, Kai Liu, Yali Yuan, Xiumin Wang, Huawei Huang, 和 Dapeng Oliver Wu. 车辆网络中用于城市交通灯控制的多智能体深度强化学习. IEEE 车辆技术交易,69(8):8243-8256, 2020.
[77] Wenli Xiao, Yiwei Lyu, 和 John Dolan. 基于模型的动态屏蔽以实现安全高效的多智能体强化学习. arXiv 预印本 arXiv:2304.06281,
2023.
[78] Tengyu Xu, Yingbin Liang, 和 Guanghui Lan. CRPO: 一种具有收敛性保证的安全强化学习新方法. 在国际机器学习会议,页面 11480-11491. PMLR, 2021.
[79] Yaodong Yang, Jianye Hao, Ben Liao, Kun Shao, Guangyong Chen, Wulong Liu, 和 Hongyao Tang. QATTEN: 一种用于合作多智能体强化学习的通用框架. arXiv 预印本 arXiv:2002.03939, 2020.
[80] Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, 和 Yi Wu. 合作多智能体游戏中的近似 PPO 的惊人有效性. 高级神经信息处理系统进展,35: 24611-24624, 2022.
[81] Dongjie Yu, Haitong Ma, Shengbo Li, 和 Jianyu Chen. 可达性约束强化学习. 在国际机器学习会议,页面 25636-25655. PMLR, 2022.
[82] Mario Zanon 和 Sébastien Gros. 使用鲁棒 MPC 的安全强化学习. IEEE 自动控制交易,66(8):3638-3652, 2020.
[83] Kaiqing Zhang, Zhuoran Yang, Han Liu, Tong Zhang, 和 Tamer Basar. 完全去中心化的多智能体强化学习与网络智能体. 在国际机器学习会议,页面 5872-5881. PMLR, 2018.
[84] Kaiqing Zhang, Zhuoran Yang, 和 Tamer Başar. 多智能体强化学习:理论和算法的选择性概述. 强化学习与控制手册,页面 321-384, 2021.
[85] Songyuan Zhang, Kunal Garg, 和 Chuchu Fan. 神经图控制屏障函数引导的分布防撞多智能体控制. 在机器人学习会议,页面 2373-2392. PMLR, 2023.
[86] Songyuan Zhang, Oswin So, Mitchell Black, 和 Chuchu Fan. 离散 GCBF 近端策略优化用于多智能体安全最优控制. 在第十三届国际学习表示会议,2025.
[87] Songyuan Zhang, Oswin So, Kunal Garg, 和 Chuchu Fan. GCBF+: 一种用于分布安全多智能体控制的神经图控制屏障函数框架. IEEE 机器人交易,41:1533-1552, 2025.
[88] Wenbo Zhang, Osbert Bastani, 和 Vijay Kumar. MAMPS: 使用模型预测屏蔽的安全多智能体强化学习. arXiv 预印本 arXiv:1910.12639, 2019.
[89] Weiye Zhao, Tairan He, 和 Changliu Liu. 不需要模型的安全控制用于零违反强化学习. 在第五届年度机器人学习会议,2021.
[90] Youpeng Zhao, Yaodong Yang, Zhenbo Lu, Wengang Zhou, 和 Houqiang Li. 策略空间中的多智能体一阶约束优化. 高级神经信息处理系统进展,36, 2024.
[91] Dingjiang Zhou, Zijian Wang, Saptarshi Bandyopadhyay,
和 Mac Schwager. 快速在线避碰方法使用缓冲 Voronoi 细胞. IEEE 机器人与自动化快报,2(2):1047-1054, 2017.
[92] Edward L Zhu, Yvonne R Stürz, Ugo Rosolia, 和 Francesco Borrelli. 使用去中心化学习模型预测控制的非线性多智能体系统轨迹优化. 在 2020 59th IEEE 决策与控制会议 (CDC),页面 6198-6203. IEEE, 2020.
证明:在动力学
x
k
+
1
=
f
(
x
k
,
π
(
x
k
)
)
x^{k+1}=f\left(x^{k}, \pi\left(x^{k}\right)\right)
xk+1=f(xk,π(xk)) 下,我们有
V ( x k , z k ; π ) = max { max p ≥ k h ( x p ) , ∑ p ≥ k l ( x p , π ( x p ) ) − z k } = max { max { h ( x k ) , max p ≥ k + 1 h ( x p ) } , ∑ p ≥ k + 1 l ( x p , π ( x p ) ) + l ( x k , π ( x k ) ) − z k } = max { max { h ( x k ) , max p ≥ k + 1 h ( x p ) } , ∑ p ≥ k + 1 l ( x p , π ( x p ) ) − [ z k − l ( x k , π ( x k ) ) ] ⏟ : = z k + 1 } = max { h ( x k ) , max { max p ≥ k + 1 h ( x p ) , ∑ p ≥ k + 1 l ( x p , π ( x p ) ) − z k + 1 } } = max { h ( x k ) , V ( x k + 1 , z k + 1 ; π ) } \begin{aligned} V\left(x^{k}, z^{k} ; \pi\right) & =\max \left\{\max _{p \geq k} h\left(x^{p}\right), \sum_{p \geq k} l\left(x^{p}, \pi\left(x^{p}\right)\right)-z^{k}\right\} \\ & =\max \left\{\max \left\{h\left(x^{k}\right), \max _{p \geq k+1} h\left(x^{p}\right)\right\}, \sum_{p \geq k+1} l\left(x^{p}, \pi\left(x^{p}\right)\right)+l\left(x^{k}, \pi\left(x^{k}\right)\right)-z^{k}\right\} \\ & =\max \left\{\max \left\{h\left(x^{k}\right), \max _{p \geq k+1} h\left(x^{p}\right)\right\}, \sum_{p \geq k+1} l\left(x^{p}, \pi\left(x^{p}\right)\right)-\underbrace{\left[z^{k}-l\left(x^{k}, \pi\left(x^{k}\right)\right)\right]}_{:=z^{k+1}}\right\} \\ & =\max \left\{h\left(x^{k}\right), \max \left\{\max _{p \geq k+1} h\left(x^{p}\right), \sum_{p \geq k+1} l\left(x^{p}, \pi\left(x^{p}\right)\right)-z^{k+1}\right\}\right\} \\ & =\max \left\{h\left(x^{k}\right), V\left(x^{k+1}, z^{k+1} ; \pi\right)\right\} \end{aligned} V(xk,zk;π)=max⎩ ⎨ ⎧p≥kmaxh(xp),p≥k∑l(xp,π(xp))−zk⎭ ⎬ ⎫=max⎩ ⎨ ⎧max{h(xk),p≥k+1maxh(xp)},p≥k+1∑l(xp,π(xp))+l(xk,π(xk))−zk⎭ ⎬ ⎫=max⎩ ⎨ ⎧max{h(xk),p≥k+1maxh(xp)},p≥k+1∑l(xp,π(xp))−:=zk+1 [zk−l(xk,π(xk))]⎭ ⎬ ⎫=max⎩ ⎨ ⎧h(xk),max⎩ ⎨ ⎧p≥k+1maxh(xp),p≥k+1∑l(xp,π(xp))−zk+1⎭ ⎬ ⎫⎭ ⎬ ⎫=max{h(xk),V(xk+1,zk+1;π)}
其中我们在第三个等式中定义了 z k + 1 = z k − l ( x k , π ( x k ) ) z^{k+1}=z^{k}-l\left(x^{k}, \pi\left(x^{k}\right)\right) zk+1=zk−l(xk,π(xk))。
附录B
参考论文:https://arxiv.org/pdf/2504.15425
7 { }^{7} 7 一些基于MPC的方法可以解决CORRIDOR环境[43, 68],但假设目标已预先分配。此外,这些方法需要额外的方法来进行碰撞规避(例如Buffered Voronoi Cells[91],按需碰撞规避方法[42]),这需要更多的领域知识。
定义为所有智能体保持安全的任务比例,分别为 100 % 100 \% 100%、 100 % 100 \% 100%和 43.75 % 43.75 \% 43.75%。我们在图11中可视化了不同方法的轨迹。
使用Def-MARL的智能体有更好的协作。设计INSPECT是为了确保智能体之间必须协作才能在没有任何停机时间的情况下观察目标。单个智能体无法独自持续观察目标,因为它的观察可能会被障碍物阻挡。它也不能简单地跟随目标,因为存在避障区域。使用Def-MARL,智能体学会了在障碍物的两侧等待,并在目标出现在它们一侧时轮流观察目标。然而,MPC方法并没有这样的全局最优行为,而是陷入局部最小值。例如,CMPC只移动离目标最近的无人机,让另一架无人机静止不动,而DMPC则让两架无人机追逐目标而不协作。因此,两种MPC方法都有短暂的时间段内两架无人机都没有视觉接触目标。此外,类似于CORRIDOR,我们观察到DMPC有时由于缺乏协调而导致碰撞。 ↩︎



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











