






刘宇航*
浙江大学 liuyuhang@zju.edu.cn
胡泽维尔
浙江大学 xavier.hu.research@gmail.com
李鹏翔
大连理工大学 lipengxiang@gmail.dlut.edu.cn
韩晓天 xiaotian.sky.han@gmail.com
谢聪凯
Reallm 实验室 xieck13@gmail.com
张盛钰
†
{ }^{\dagger}
†
浙江大学 sy_zhang@zju.edu.cn
杨红霞
香港理工大学
hongxia.yang@polyu.edu.hk
摘要
多模态大语言模型(MLLMs)已经为图形用户界面(GUI)代理提供了动力,展示了在计算设备上自动化的潜力。近期的研究已经开始探索GUI任务中的推理,并取得了令人鼓舞的结果。然而,许多当前的方法依赖于手动设计的推理模板,这可能导致在复杂GUI环境中不够稳健和适应性的推理。同时,一些现有的代理仍然作为反应型演员运行,主要依赖隐式推理,这种推理可能缺乏足够的深度来应对需要规划和错误恢复的复杂GUI任务。我们认为,推进这些代理需要从反应性行为向基于深思熟虑推理的行为转变。为了促进这一转型,我们引入了InfiGUI-R1,这是一个基于MLLM的GUI代理,通过我们的Actor2Reasoner框架开发,该框架是一个以推理为中心的两阶段训练方法,旨在逐步将代理从反应型演员转变为深思熟虑的推理者。第一阶段,推理注入,专注于建立基本推理器。我们采用空间推理蒸馏技术,通过具有明确推理步骤的轨迹,将教师模型的空间推理能力转移到MLLM中,使模型能够在生成动作之前将GUI视觉-空间信息与逻辑推理相结合。第二阶段,深思熟虑增强,使用强化学习将基本推理器精炼为深思熟虑的推理器。本阶段引入了两种方法:子目标引导,奖励模型生成准确的中间子目标;错误恢复场景构建,从已识别的易出错步骤创建失败和恢复训练场景。这些方法增强了代理的规划能力和自我修正能力。实验结果证实,InfiGUI-R1在跨平台GUI定位和轨迹任务中表现出色,即使与参数量显著更大的先前代理相比也具有竞争力。资源可在https://github.com/Reallm-Labs/InfiGUI-R1获得。
关键词
GUI代理,MLLMs,强化学习
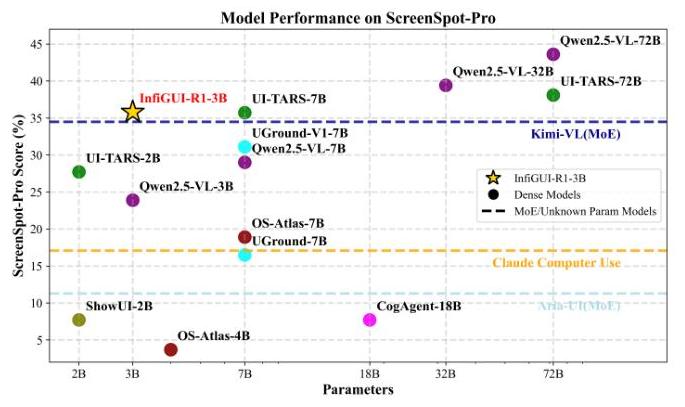
图1:各种GUI代理在ScreenSpot-Pro基准上的性能比较。我们的模型InfiGUI-R1-3B用星号标记,显示出与参数量更大的模型竞争的能力。
1 引言
图形用户界面(GUI)代理,随着多模态大语言模型(MLLMs)的发展而日益强大 [5, 22, 28, 39, 48],在自动化移动电话和计算机等计算设备上的广泛任务方面展现出巨大潜力 [9, 42]。这些代理通过视觉界面与数字环境交互,旨在提高用户生产力并扩展自动化任务完成的范围。
近期的研究开始探索GUI任务中的推理,并取得了令人鼓舞的结果。然而,许多当前的方法要么依赖于手动设计的推理模板,要么缺乏针对GUI的优化,这可能导致在复杂GUI环境中不够稳健和适应性的推理。同时,许多现有的基于MLLM的GUI代理继续作为
*两位作者对本研究的贡献相同。
${ }^{\dagger}$ 对应作者。
反应型演员 [10, 29],主要依赖隐式推理。这种隐式推理通常缺乏处理复杂的、多步骤GUI任务所需的足够深度,这些任务需要复杂的规划和自适应错误恢复。此类任务不仅需要精确理解密集视觉布局的空间结构,还需要有效整合跨模态信息(将视觉-空间理解融入文本推理)并参与深思熟虑的过程,这对于稳健的长期任务执行至关重要。
我们认为,从根本上提升GUI代理能力需要范式的转变:超越反应性执行,迈向作为深思熟虑推理者的代理。这些代理应在感知与行动之间明确纳入推理过程(感知 $\rightarrow$ 推理 $\rightarrow$ 行动),使它们能够提前规划、分解复杂目标、深入理解空间关系,并反思过去的行动以纠正错误。这种转变对于处理真实世界GUI环境的复杂性和动态性质至关重要。
为了实现这一转变,我们引入了Actor2Reasoner框架,这是一种以推理为中心的方法,旨在逐步将GUI代理从反应型演员转变为深思熟虑的推理者。我们的框架最终产生了InfiGUI-R1-3B,这是一种基于MLLM的代理,展示了增强的推理和稳健性。Actor2Reasoner框架解决了两个核心挑战:1)可靠地注入基础推理能力,特别是弥合视觉-空间感知与文本推理之间的关键跨模态差距,以实现从演员到推理者的初步飞跃;以及2)精炼和提升此基础推理器的推理质量,以灌输高级规划和反思能力,最终达到深思熟虑的阶段。
Actor2Reasoner框架分为两个不同的阶段:
-
第一阶段:推理注入(为推理奠定基础):本阶段重点关注从演员到推理者的重大转变。我们采用空间推理蒸馏技术,利用来自强大推理教师模型的轨迹,这些轨迹包含明确的空间推理步骤。通过监督微调(SFT)对该蒸馏数据进行训练,引导基础MLLM打破直接的感知 → \rightarrow → 行动链接,并明确纳入推理,特别是对GUI任务至关重要的空间推理。这建立了基础的(感知 → \rightarrow → 推理 → \rightarrow → 行动)模式,克服了标准MLLM在将其视觉-空间理解融入推理流中的关键限制。
-
- 第二阶段:深思熟虑增强(精炼为深思熟虑的推理者):在此基础上建立第一阶段确立的推理器,本阶段使用强化学习(RL)将推理能力精炼至深思熟虑。这种精炼战略性地提升了深思熟虑推理的两个核心方面:规划和反思。两项关键创新驱动这一过程:
-
- 子目标引导:为了增强代理的前瞻性规划和任务分解能力,我们在其推理过程中引导它生成明确的中间子目标。这些生成的子目标与真实情况的一致性提供了一个中间奖励信号,有效地训练了代理的主动性规划能力(“总目标 → \rightarrow → 子目标 → \rightarrow → 行动”)。
-
- 错误恢复场景构建:补充规划重点,这一创新培养了代理的回顾和通过反思自我修正的能力——这是深思熟虑的标志。我们积极构建模拟错误状态或恢复时刻(例如,刚刚执行了错误的动作或需要“回到正轨”)的RL环境中的场景。在这些场景中进行训练,并使用有针对性的奖励,迫使代理学习适应策略,如逃离错误状态(例如,使用“返回”动作)和在认识到错误后调整计划。这直接塑造了代理反思其行动和从失败中恢复的能力,增强了其稳健性。
-
综上所述,我们的框架提供了一条途径,赋予GUI代理必要的推理、规划和反思能力,用于任务自动化。我们通过一系列旨在评估核心GUI代理能力的具有挑战性的基准测试验证了InfiGUI-R1-3B的有效性。这些包括要求在不同平台上精确定位GUI元素的任务(例如,ScreenSpot,ScreenSpot-Pro [21, 24])以及需要复杂、长期任务执行与规划和适应的任务(例如,AndroidControl[26])。我们的实验结果表明了显著的改进。InfiGUI-R1-3B在参数数量相当的模型中实现了最先进的跨平台定位能力(ScreenSpot平均87.5%)和强大的复杂、长期任务执行能力(AndroidControl-High成功率71.1%)。这些发现证实了我们框架培养复杂规划和反思能力的能力,极大地提升了代理在深思熟虑、稳健和有效的GUI任务自动化方面的能力。
我们的主要贡献有三个方面: -
我们提出了Actor2Reasoner框架,这是一种新颖的两阶段训练方法,旨在通过逐步注入和精炼推理能力,系统地将基于MLLM的GUI代理从反应型演员转变为深思熟虑的推理者。
-
- 我们在该框架内引入了三个关键技术创新:空间推理蒸馏以建立基础的跨模态推理,子目标引导以增强规划推理,以及通过有针对性的RL构建错误恢复场景以培养反思性错误校正能力。
-
- 我们开发了InfiGUI-R1-3B,这是一种基于MLLM的GUI代理,通过我们的框架进行训练,并通过全面的实验展示了其有效性。
2 相关工作
2.1 多模态LLMs
大型语言模型(LLMs)[6, 13, 47, 53] 显著增强了AI系统在处理广泛任务中的能力 [17, 25],这得益于它们卓越的处理复杂语义和上下文信息的能力。LLMs的非凡力量还激发了对其处理多模态数据(如图像)潜力的探索。通常,多模态大型语言模型(MLLMs)的架构由三个主要组成部分构成:预训练的大语言模型、训练过的模态编码器以及连接LLM与编码模态特征的模态接口。各种视觉编码器,如ViT
[12], CLIP [41], 和 ConvNeXt [34] 提取视觉特征,并通过适配器网络 [31]、交叉注意力层 [3] 和视觉专家模块 [49] 等技术进行整合。这些方法促进了高性能MLLMs的发展,如Qwen-VL [7], GPT-4 Vision [36], BLIP-2 [23] 和 InfiMM [32],从而为LLMs在处理GUI任务中开辟了新的途径。
2.2 基于MLLM的GUI代理
代理是感知其环境、做出决策并采取行动以完成特定任务的AI系统。具备人类水平推理能力的LLMs的出现显著推动了代理的发展。对于GUI任务,早期系统依赖于LLMs来读取和解释HTML代码等结构化表示 [50]。然而,最近的研究表明,直接与GUI的视觉形式交互可以带来更好的性能 [16]。因此,提出了基于MLLM的GUI代理,结合视觉感知和语言理解。
几个代表性系统开创了这一领域。ILuvUI [20] 微调了LLaVA以增强通用GUI理解,而AppAgent [58] 则通过自主交互探索了移动应用的使用。CogAgent [15] 引入了高分辨率编码器以更好地捕捉UI细节,Ferret-UI-anyres [57] 支持灵活的屏幕分辨率以处理多样化的设备设置。
更近期的工作引入了模块化和轻量级架构,旨在改善泛化和部署效率。InfiGUIAgent [33] 提出了一个两阶段方法,结合在定位和问答任务上的通用预训练与合成微调以实现分层规划和推理。UI-TARS [40] 进一步扩展了这种方法,通过在移动、Web和桌面环境中使用统一的视觉-语言接口,并结合反思和里程碑跟踪机制以提高任务成功率。与此同时,AgentS2 [1] 采用了通才-专家框架,将高层次推理与领域特定的定位模块解耦,并通过混合定位机制实现长期规划。
在输入方面,最近的代理优先考虑截图级别的视觉理解,可选地通过布局或OCR为基础的文本提示加以增强。诸如集合提示 [54] 和链式推理 [38] 等技术已被用于改进定位精度和任务规划。为进一步提高交互效率,像UI-R1 [35], GUI-R1 [52] 这样的代理用基于规则的强化学习替代大规模监督,以最少的专家数据实现竞争性性能。
此外,为了支持实际可用性,较新的代理在日益复杂的环境中接受测试。UI-TARS和AgentS2报告在OSWorld和AndroidWorld基准上表现强劲,显示了稳健的跨平台泛化能力。GUI-Xplore [44] 进一步引入了一次性适应设置,鼓励代理通过自主探索构建结构化UI地图后再执行任务。
3 Actor2Reasoner
我们介绍Actor2Reasoner框架,这是一个以推理为中心的渐进式训练方法,旨在系统地增强多模态大语言模型(MLLM)
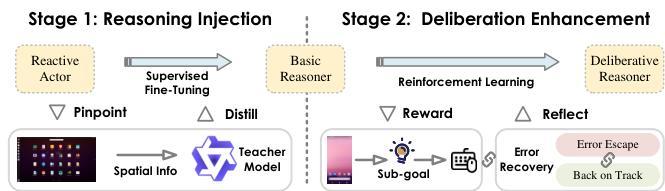
图2:Actor2Reasoner框架概述,一种两阶段方法,逐步将反应型演员转变为深思熟虑的推理者。第一阶段:推理注入使用监督微调(SFT)与空间推理蒸馏——识别推理瓶颈(Pinpoint)并利用教师模型(Distill)——灌输基础的跨模态推理能力,并将代理转化为基础推理器(感知
→
\rightarrow
→ 推理
→
\rightarrow
→ 行动)。第二阶段:深思熟虑增强应用RL精炼规划和反思能力,使用子目标引导(
R
e
R e
Re ward)进行前瞻性任务分解和错误恢复场景构建(Reflect)进行回顾性自我修正,最终形成深思熟虑的推理者。
基于GUI代理。核心目标是将代理从反应性行为转向深思熟虑的推理,以实现GUI任务自动化。该框架包含两个阶段,首先建立基础推理能力,然后将其精炼为高级深思熟虑。第3.1节详细介绍了第一阶段的方法,重点是通过空间推理蒸馏进行推理注入。随后,第3.2节详细介绍了第二阶段的方法,其中使用RL通过子目标引导和错误恢复场景构建来增强深思熟虑。
3.1 第一阶段:推理注入
第一阶段的主要目标是实现从反应型演员(感知 → \rightarrow → 行动)到基础推理器(感知 → \rightarrow → 推理 → \rightarrow → 行动)的根本转变。这一转变至关重要,因为标准MLLM往往难以有效将GUI截图中丰富的视觉-空间信息融入其文本推理过程中。这一限制阻碍了它们处理需要精确空间理解和定位的GUI任务的能力。为此,第一阶段采用空间推理蒸馏技术,旨在明确将空间推理能力注入代理。
空间推理蒸馏利用强大教师模型的推理能力生成高质量的推理轨迹,然后用于训练目标MLLM(学生)。核心思想是引导学生模型不仅学习正确的动作,还要学习导致该动作的中间推理步骤——尤其是涉及空间逻辑的那些步骤。这一过程通过以下步骤实现:
3.1.1 确定推理瓶颈样本。为了最大化蒸馏效率,我们首先确定基础MLLM失败最可能是由于缺乏推理而非基本感知或动作执行缺陷的交互步骤。我们将这些称为推理瓶颈样本。这一
识别采用每一步
s
s
s的两步准则:
(i) 当前MLLM
M
M
M,在给定当前GUI截图
I
s
I_{s}
Is和总体任务目标
G
G
G的情况下,未能预测正确动作。设
a
high
=
M
(
I
s
,
G
)
a_{\text {high }}=M\left(I_{s}, G\right)
ahigh =M(Is,G)。
(ii) 然而,当提供该特定步骤的额外真实子目标
g
s
g_{s}
gs时,同一模型
M
M
M成功预测了正确动作。设
a
low
=
M
(
I
s
,
G
,
g
s
)
a_{\text {low }}=M\left(I_{s}, G, g_{s}\right)
alow =M(Is,G,gs)。
正式地,推理瓶颈步骤集
S
bottleneck
S_{\text {bottleneck }}
Sbottleneck 定义为:
S
bottleneck
=
S_{\text {bottleneck }}=
Sbottleneck =
{ s ∣ IsCorrect ( a high ) = False ∧ IsCorrect ( a low ) = True } \left\{s \mid \text { IsCorrect }\left(a_{\text {high }}\right)=\text { False } \wedge \text { IsCorrect }\left(a_{\text {low }}\right)=\text { True }\right\} {s∣ IsCorrect (ahigh )= False ∧ IsCorrect (alow )= True }
这些样本代表从总体目标(
G
G
G)推断即时任务(
g
s
g_{s}
gs)的主要困难在于根据视觉上下文
(
I
s
)
\left(I_{s}\right)
(Is),使其成为推理注入的理想候选。我们使用如Qwen2.5-VL-3B-Instruct这样的基础MLLM进行此过滤过程。
3.1.2 生成空间推理轨迹。对于每个步骤
s
∈
s \in
s∈
S
bottleneck
S_{\text {bottleneck }}
Sbottleneck ,我们使用高性能教师模型生成详细的推理轨迹。这涉及:
空间信息提取与压缩。我们从与GUI截图 I s I_{s} Is相关联的可访问性树(a11y树)中提取相关的结构和空间信息(例如,元素类型、文本内容、坐标、层次结构)。过滤掉无关属性和元素。然后使用强大的MLLM(例如,Qwen2.5-VL-32BInstruct)将此处理后的信息压缩成简洁的文本描述 D spatial D_{\text {spatial }} Dspatial ,其中包括GUI页面的详细描述,所有相关元素的坐标信息和特定步骤的描述,捕捉到基本的空间布局和关键元素细节。
推理轨迹生成。将压缩的空间描述
D
spatial
D_{\text {spatial }}
Dspatial 、可用动作空间描述和总体目标
G
G
G作为输入提供给具有强大推理能力的强大大型语言模型(例如,QwQ-32B [46])。此教师模型被提示生成明确的推理文本
R
teacher
R_{\text {teacher }}
Rteacher 和相应的动作
a
teacher
a_{\text {teacher }}
ateacher 。重要的是,
R
teacher
R_{\text {teacher }}
Rteacher 被引导阐述逻辑步骤,包括使用
D
spatial
D_{\text {spatial }}
Dspatial 中的空间信息进行元素定位、关系评估和动作理由说明。
3.1.3 通过SFT注入推理。生成的对(
R
teacher
R_{\text {teacher }}
Rteacher ,
a
teacher
a_{\text {teacher }}
ateacher )首先通过基于预测动作
a
teacher
a_{\text {teacher }}
ateacher 的正确性进行拒绝采样来确保质量。高质量对随后用于微调基础MLLM。SFT目标训练学生模型在给定GUI截图和总体目标时预测教师的推理和动作:
(
I
s
,
G
)
→
(
R
teacher
,
a
teacher
)
\left(I_{s}, G\right) \rightarrow\left(R_{\text {teacher }}, a_{\text {teacher }}\right)
(Is,G)→(Rteacher ,ateacher )。通过在输出动作之前显式生成或隐式模拟这些推理步骤,学生模型内部化了感知
→
\rightarrow
→ 推理
→
\rightarrow
→ 动作模式。
完成第一阶段后,所得模型是一个基础推理器,配备了增强的空间理解和通过中间推理过程连接感知与动作的基本能力。
3.2 第二阶段:深思熟虑增强
在第一阶段建立的基础推理器之上,第二阶段的目标是精炼其能力,将其转化为深思熟虑的推理器。本阶段采用基于规则奖励的强化学习(RL)作为主要增强机制。核心理念是通过特别针对两个方面——前瞻性规划和回顾性反思/校正——培养代理进行更复杂、“深思熟虑”的决策制定。这两个关键创新集成到RL过程中:子目标引导(详见第3.2.2节)以加强规划和任务分解,以及错误恢复场景构建(详见第3.2.3节)以促进自我校正和稳健性。
3.2.1 强化学习设置。我们利用RL进一步优化代理的策略,超越监督学习。具体来说,我们采用REINFORCE Leave-One-Out (RLOO)算法 [2],该算法通过使用同一批次中其他样本的平均奖励作为当前样本的基线,有效减少策略梯度估计的方差。这种“leave-one-out”基线策略消除了单独训练价值或批评模型的需要,从而简化了训练架构。RLOO策略梯度
∇
θ
J
(
θ
)
\nabla_{\theta} J(\theta)
∇θJ(θ)估计如下:
∇ θ J ( θ ) ≈ 1 k ∑ i = 1 k [ R ( y ( i ) , x ) − 1 k − 1 ∑ j ≠ i R ( y ( j ) , x ) ] ∇ θ log π θ ( y ( i ) ∣ x ) \begin{aligned} & \nabla_{\theta} J(\theta) \approx \\ & \quad \frac{1}{k} \sum_{i=1}^{k}\left[R\left(y_{(i)}, x\right)-\frac{1}{k-1} \sum_{j \neq i} R\left(y_{(j)}, x\right)\right] \nabla_{\theta} \log \pi_{\theta}\left(y_{(i)} \mid x\right) \end{aligned} ∇θJ(θ)≈k1i=1∑k R(y(i),x)−k−11j=i∑R(y(j),x) ∇θlogπθ(y(i)∣x)
其中 k k k是从当前策略 π θ \pi_{\theta} πθ给定输入 x x x抽样的输出序列 y ( i ) y_{(i)} y(i)的数量, R ( y , x ) R(y, x) R(y,x)是评估输出 y y y质量的奖励函数。
奖励函数 R ( y , x ) R(y, x) R(y,x)的设计对于指导代理的学习轨迹至关重要。我们的总奖励 R total R_{\text {total }} Rtotal 整合了输出格式正确性和任务执行准确性的评估:
R total = w f ⋅ R format + w a ⋅ R acc R_{\text {total }}=w_{f} \cdot R_{\text {format }}+w_{a} \cdot R_{\text {acc }} Rtotal =wf⋅Rformat +wa⋅Racc
这里, R format R_{\text {format }} Rformat 检查模型的输出 y y y是否符合预期格式(例如,在 标签内放置推理过程),如果有效则得1,否则得0。 R acc R_{\text {acc }} Racc 衡量内容的准确性,仅在 R format = 1 R_{\text {format }}=1 Rformat =1时计算,确保代理首先学会生成结构上有效的输出。 w f w_{f} wf和 w a w_{a} wa是权重超参数 ( w f + w a = 1 ) \left(w_{f}+w_{a}=1\right) (wf+wa=1)。
准确性奖励
R
acc
R_{\text {acc }}
Racc 根据具体任务类型定制:
代理轨迹任务奖励(Ragent):对于评估GUI动作序列,我们通过结合动作类型及其参数的奖励提供细粒度反馈:
R agent = w t ⋅ R type + w p ⋅ R param R_{\text {agent }}=w_{t} \cdot R_{\text {type }}+w_{p} \cdot R_{\text {param }} Ragent =wt⋅Rtype +wp⋅Rparam
其中
w
t
+
w
p
=
1.
R
type
w_{t}+w_{p}=1 . R_{\text {type }}
wt+wp=1.Rtype 如果预测的动作类型(例如,‘click’, ‘type’)与真实值匹配,则给予奖励1,否则为0。
R
param
R_{\text {param }}
Rparam 提供更严格的奖励,只有当动作类型及其所有参数都与真实值匹配时才给予奖励1,否则为0。(注意:此奖励在第3.2.2节的子目标引导中进一步细化)。
定位任务奖励:对于评估GUI元素定位:
-
点定位奖励( R point R_{\text {point }} Rpoint ):给定预测点坐标 ( x p , y p ) \left(x_{p}, y_{p}\right) (xp,yp)和目标元素的真实边界框 B g t B_{\mathrm{gt}} Bgt,如果点落在框内,则奖励为1,否则为0:
R point = I ( ( x p , y p ) ∈ B g t ) R_{\text {point }}=\mathbb{I}\left(\left(x_{p}, y_{p}\right) \in B_{\mathrm{gt}}\right) Rpoint =I((xp,yp)∈Bgt) -
边界框奖励( B bbox B_{\text {bbox }} Bbbox ):我们计算预测边界框 B pred B_{\text {pred }} Bpred 与真实边界框 B g t B_{\mathrm{gt}} Bgt的交并比(IoU)。为了避免过度惩罚小偏差,同时鼓励显著重叠,我们使用阈值 τ IoU \tau_{\text {IoU }} τIoU 。如果IoU达到或超过阈值,则奖励为1;否则,奖励为IoU除以阈值:
R bbox = { 1 if IoU ( B pred , B g t ) ≥ τ I o U IoU ( B pred , B g t ) τ I o U if IoU ( B pred , B g t ) < τ I o U R_{\text {bbox }}=\left\{\begin{array}{ll} 1 & \text { if } \operatorname{IoU}\left(B_{\text {pred }}, B_{\mathrm{gt}}\right) \geq \tau_{\mathrm{IoU}} \\ \frac{\operatorname{IoU}\left(B_{\text {pred }}, B_{\mathrm{gt}}\right)}{\tau_{\mathrm{IoU}}} & \text { if } \operatorname{IoU}\left(B_{\text {pred }}, B_{\mathrm{gt}}\right)<\tau_{\mathrm{IoU}} \end{array}\right. Rbbox ={1τIoUIoU(Bpred ,Bgt) if IoU(Bpred ,Bgt)≥τIoU if IoU(Bpred ,Bgt)<τIoU
其他任务奖励( R other R_{\text {other }} Rother ):对于潜在包含在训练组合中的辅助任务(例如,VQA、多项选择题),我们使用与真实值 y g t y_{\mathrm{gt}} ygt的完全匹配(EM)或数学表达式验证来确定正确性:
R other = I ( ExactMatch ( y ans , y g t ) ∨ MathVerify ( y ans , y g t ) ) R_{\text {other }}=\mathbb{I}\left(\text { ExactMatch }\left(y_{\text {ans }}, y_{\mathrm{gt}}\right) \vee \text { MathVerify }\left(y_{\text {ans }}, y_{\mathrm{gt}}\right)\right) Rother =I( ExactMatch (yans ,ygt)∨ MathVerify (yans ,ygt))
为了确保代理在增强其特定于GUI的深思熟虑技能的同时不损害其一般的多模态理解和视觉定位基础,RL训练阶段使用了多样化数据混合。这包括核心GUI轨迹数据(例如,来自AndroidControl [26]),GUI元素定位数据(例如,来自控件标题数据集 [27]),一般用途的多模态问答数据集和对象检测数据集(例如,来自COCO [30])。
遵循既定的引出推理实践 [43, 56],我们采用系统提示,明确指示模型先在其内部独白中阐述推理过程,然后再提供最终答案。使用的具体提示为:
系统提示以进行推理
你首先要思考推理过程作为一个内部独白,然后提供最终答案。
推理过程必须包含在 标签内。
3.2.2 子目标引导。为了将基础推理器提升为能够进行复杂规划的深思熟虑推理器,第二阶段的一个核心方面集中在增强其任务分解能力。标准MLLM在复杂GUI环境中独立从高层次目标推导必要中间步骤时常会失败。子目标引导专门设计为在RL框架内激励代理制定和追求准确的子目标,从而促进更有结构和更有效的规划。这是通过评估代理推理过程内隐含子目标的质量来实现的。
子目标质量评估。我们通过将其评估整合到代理的奖励结构中来激励准确的子目标制定。我们评估推理文本内隐含生成的子目标的质量。
在训练期间,对于每一步,我们使用轻量级评分LLM分析代理的推理输出( … 标签内的文本),并尝试提取隐含的子目标,记为 s g extracted s_{g}^{\text {extracted }} sgextracted 。然后将提取的子目标 s g extracted s_{g}^{\text {extracted }} sgextracted 与相应的真实子目标 s g g t s_{g}^{\mathrm{gt}} sggt(从数据集注释 1 { }^{1} 1中获取)进行比较。根据 s g extracted s_{g}^{\text {extracted }} sgextracted 与 s g g t s_{g}^{\mathrm{gt}} sggt之间的语义匹配程度,分配原始分数 S raw S_{\text {raw }} Sraw ,范围为1到10。如果评分LLM无法从推理文本中提取子目标,则 S raw S_{\text {raw }} Sraw 设为0。然后将原始分数归一化到范围 [ 0 , 1 ] [0,1] [0,1]以产生最终的子目标奖励:
R subgoal = S raw 10 R_{\text {subgoal }}=\frac{S_{\text {raw }}}{10} Rsubgoal =10Sraw
这个归一化分数, R subgoal R_{\text {subgoal }} Rsubgoal ,作为反映代理当前步骤规划质量的中间奖励信号。为了在最终动作执行失败时仍能特别鼓励正确规划,我们将 R subgoal R_{\text {subgoal }} Rsubgoal 整合到代理轨迹任务奖励 R agent R_{\text {agent }} Ragent (见第3.2.1节)中。公式修改如下,加入专用权重 w s : w_{s}: ws:
R agent = { w t ⋅ R type + w p ⋅ R param if R param = 1 w t ⋅ R type + w s ⋅ R subgoal if R param = 0 R_{\text {agent }}=\left\{\begin{array}{ll} w_{t} \cdot R_{\text {type }}+w_{p} \cdot R_{\text {param }} & \text { if } R_{\text {param }}=1 \\ w_{t} \cdot R_{\text {type }}+w_{s} \cdot R_{\text {subgoal }} & \text { if } R_{\text {param }}=0 \end{array}\right. Ragent ={wt⋅Rtype +wp⋅Rparam wt⋅Rtype +ws⋅Rsubgoal if Rparam =1 if Rparam =0
其中
w
t
,
w
p
,
w
s
w_{t}, w_{p}, w_{s}
wt,wp,ws是非负权重,通常
w
s
w_{s}
ws低于
w
p
w_{p}
wp,以优先实现完整的动作正确性。这种条件奖励结构在代理难以准确执行动作时提供针对性的规划质量反馈,从而引导学习过程朝着更好的中间推理和任务分解方向发展。
3.2.3 错误恢复情景构建。虽然子目标引导增强了前瞻性的规划,但培养深思熟虑的推理器还需要具备反思和从错误中恢复的能力——这是标准GUI代理常常缺乏且容易导致不可恢复失败的能力。为了培养稳健性和适应性,我们利用错误恢复情景构建技术,通过在RL训练过程中整合特定的失败-恢复情景,直接针对代理的反思和矫正推理能力。这一机制通过加强代理的回溯调整能力来补充规划。
识别易出错步骤:为了最大限度地提高训练效率,我们首先识别代理表现出不稳定性的交互步骤。对于给定的步骤 s s s,我们使用基础模型(例如,Qwen2.5-VL-3B-Instruct)以较高的温度 T T T采样 N sample N_{\text {sample }} Nsample 动作序列。成功率 P success ( s ) P_{\text {success }}(s) Psuccess (s)介于0和1之间的步骤( 0 < P success ( s ) < 1 0<P_{\text {success }}(s)<1 0<Psuccess (s)<1)被指定为易出错步骤,形成集合KaTeX parse error: Expected 'EOF', got '_' at position 16: S_{\text {error_̲prone }}。这些步骤表明代理具备正确动作的能力,但也容易出错,为学习矫正策略提供了最佳机会。对代理始终掌握或始终失败的步骤进行训练在学习恢复方面效率较低;前者
1 { }^{1} 1 https://github.com/google-research/google-research/tree/master/android_control
| 模型 | 准确率 (%) | 平均 | |||||
|---|---|---|---|---|---|---|---|
| 移动端 | 桌面端 | 网页端 | |||||
| 文本 | 图标 | 文本 | 图标 | 文本 | 图标 | ||
| 专有模型 | |||||||
| GPT-4o [37] | 30.5 | 23.2 | 20.6 | 19.4 | 11.1 | 7.8 | 18.8 |
| Claude 计算机使用 [4] | - | - | - | - | - | - | 83.0 |
| Gemini 2.0(Project Mariner)[11] | - | - | - | - | - | - | 84.0 |
| 通用开源模型 | |||||||
| Qwen2-VL-7B [48] | 61.3 | 39.3 | 52.0 | 45.0 | 33.0 | 21.8 | 42.9 |
| Qwen2.5-VL-3B [8] | - | - | - | - | - | - | 55.5 |
| Qwen2.5-VL-7B [8] | - | - | - | - | - | - | 84.7 |
| GUI 特定模型 | |||||||
| CogAgent [15] | 67.0 | 24.0 | 74.2 | 20.0 | 70.4 | 28.6 | 47.4 |
| SeeClick [10] | 78.0 | 52.0 | 72.2 | 30.0 | 55.7 | 32.5 | 53.4 |
| UGround-7B [14] | 82.8 | 60.3 | 82.5 | 63.6 | 80.4 | 70.4 | 73.3 |
| OS-Atlas-7B [51] | 93.0 | 72.9 | 91.8 | 62.9 | 90.9 | 74.3 | 82.5 |
| ShowUI-2B [29] | 92.3 | 75.5 | 76.3 | 61.1 | 81.7 | 63.6 | 75.1 |
| Aguvis-7B [18] | 95.6 | 77.7 | 93.8 | 67.1 | 88.3 | 75.2 | 84.4 |
| UI-R1-3B [35] | - | - | 90.2 | 59.3 | 85.2 | 73.3 | - |
| GUI-R1-3B [52] | - | - | 93.8 | 64.8 | 89.6 | 72.1 | - |
| GUI-R1-7B [52] | - | - | 91.8 | 73.6 | 91.3 | 75.7 | - |
| UI-TARS-2B [40] | 93.0 | 75.5 | 90.7 | 68.6 | 84.3 | 74.8 | 82.3 |
| 我们的模型 | |||||||
| InfiGUI-R1-3B | 97.1 | 81.2 | 94.3 | 77.1 | 91.7 | 77.6 | 87.5 |
表1:在不同平台(移动端、桌面端、网页端)上ScreenSpot的表现。所有实验均使用原始截图信息进行。加粗标记的结果代表最佳表现,下划线标记的结果代表次佳表现。
无需纠正,而后者可能表明存在更深的问题,可能因简单的恢复训练而混淆。
构建恢复情景:对于每个易出错步骤KaTeX parse error: Expected 'EOF', got '_' at position 22: …S_{\text {error_̲prone }},我们构建两种不同类型的RL训练情景,每种设计用于教授特定方面的错误处理:错误逃脱情景。主要目标是训练代理识别进入错误状态并执行适当的“逃脱”动作(例如,按下返回按钮)。为此,我们选择在识别阶段采样的错误动作
a
s
err
a_{s}^{\text {err }}
aserr ,该动作导致意外的后续观察
P
s
+
1
err
\mathrm{P}_{s+1}^{\text {err }}
Ps+1err 。然后将此错误观察
I
s
+
1
err
I_{s+1}^{\text {err }}
Is+1err 连同修改的历史
H
s
err
=
H
s
−
1
⊕
a
s
err
H_{s}^{\text {err }}=H_{s-1} \oplus a_{s}^{\text {err }}
Hserr =Hs−1⊕aserr (其中
H
s
−
1
H_{s-1}
Hs−1是步骤
s
s
s之前的历史,
⊕
\oplus
⊕表示连接)呈现给RL代理。在这种情况下,代理的期望行为是输出预定义的逃脱动作
a
escape
a_{\text {escape }}
aescape 。
重回正轨情景。此情景旨在训练反思调整,使代理在从错误中恢复后重新执行预定任务流程。我们假设代理刚刚从错误状态执行了逃脱动作
a
escape
a_{\text {escape }}
aescape ,将其带回在步骤
s
s
s遇到的原始观察
I
s
I_{s}
Is。代理将看到此原始观察
I
s
I_{s}
Is,但其历史反映了最近的绕道:
H
s
recover
=
H
s
−
1
⊕
a
s
err
⊕
a
escape
H_{s}^{\text {recover }}=H_{s-1} \oplus a_{s}^{\text {err }} \oplus a_{\text {escape }}
Hsrecover =Hs−1⊕aserr ⊕aescape 。在“重回正轨”状态下,代理的期望行为是在步骤
s
s
s执行原本正确的动作
a
s
′
a_{s}^{\prime}
as′,展示其重新评估情况并正确进行的能力,尽管之前失败。
构建的“错误逃脱”和“重回正轨”情景样本被纳入第二阶段RL训练的数据中。当代理在这些情景中遇到输入 x x x并生成输出 y y y时,其表现使用相同的综合奖励函数 R total ( y , x ) R_{\text {total }}(y, x) Rtotal (y,x)进行评估。通过在第一类情景中奖励成功的逃脱动作和在第二类情景中奖励正确的后续动作,RL过程特别强化了代理处理失败的适应策略。这种针对性训练巩固了代理向深思熟虑推理器的转变,同时具备任务分解能力。
4 实验
在本节中,我们详细描述用于训练和评估我们提出的InfiGUI-R1-3B代理的实验设置。我们描述实现细节、用于评估的基准以及与现有最先进方法相比的全面结果分析。
4.1 设置
实现细节。我们的模型InfiGUI-R1-3B基于Qwen2.5-VL-3B-Instruct构建,并使用提议的Actor2Reasoner框架进行训练,该框架包括两个主要阶段。对于RL奖励函数$R_{\text {total }}=w_{f} $cdot R_{\text {format }}+w_{a} \cdot R_{\text {acc }}
,我们设置权重
,我们设置权重
,我们设置权重w_{f}=0.1
和
和
和w_{a}=0.9
。在代理轨迹准确性奖励
。在代理轨迹准确性奖励
。在代理轨迹准确性奖励R_{\text{acc_agent }}
中,权重为类型匹配的
中,权重为类型匹配的
中,权重为类型匹配的w_{t}=0.2
和精确参数匹配的
和精确参数匹配的
和精确参数匹配的w_{p}=0.8$。对于边界框
| 模型 | CAD | | | 开发 | | | 创意| | | 科学 | | | 办公 | | | 操作系统 | | | 平均值 | |
| — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — |
| | 文本 | 图标 | 平均值 | 文本 | 图标 | 平均值 | 文本 | 图标 | 平均值 | 文本 | 图标 | 平均值 | 文本 | 图标 | 平均值 | 文本 | 图标 | 平均值 | 文本 | 图标 | 平均值 |
| 专有模型 | | | | | | | | | | | | | | | | | | | | | |
| GPT-4o [19] | 2.0 | 0.0 | 1.5 | 1.3 | 0.0 | 0.7 | 1.0 | 0.0 | 0.6 | 2.1 | 0.0 | 1.2 | 1.1 | 0.0 | 0.9 | 0.0 | 0.0 | 0.0 | 1.3 | 0.0 | 0.8 |
| Claude 计算机使用 [4] | 14.5 | 3.7 | 11.9 | 22.0 | 3.9 | 12.6 | 25.9 | 3.4 | 16.8 | 33.9 | 15.8 | 25.8 | 30.1 | 16.3 | 26.9 | 11.0 | 4.5 | 8.1 | 23.4 | 7.1 | 17.1 |
| 通用开源模型 | | | | | | | | | | | | | | | | | | | | | |
| Qwen2-VL-7B [48] | 0.5 | 0.0 | 0.4 | 2.6 | 0.0 | 1.3 | 1.5 | 0.0 | 0.9 | 6.3 | 0.0 | 3.5 | 3.4 | 1.9 | 3.0 | 0.9 | 0.0 | 0.5 | 2.5 | 0.2 | 1.6 |
| Qwen2.5-VL-3B [8] | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 23.9 |
| Qwen2.5-VL-7B [8] | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 29.0 |
| Kimi-VL [45] | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 34.5 |
| GUI 特定模型 | | | | | | | | | | | | | | | | | | | | | |
| SeeClick [10] | 2.5 | 0.0 | 1.9 | 0.6 | 0.0 | 0.3 | 1.0 | 0.0 | 0.6 | 3.5 | 0.0 | 2.0 | 1.1 | 0.0 | 0.9 | 2.8 | 0.0 | 1.5 | 1.8 | 0.0 | 1.1 |
| CogAgent-18B [15] | 7.1 | 3.1 | 6.1 | 14.9 | 0.7 | 8.0 | 9.6 | 0.0 | 5.6 | 22.2 | 1.8 | 13.4 | 13.0 | 0.0 | 10.0 | 5.6 | 0.0 | 3.1 | 12.0 | 0.8 | 7.7 |
| Aria-UI [55] | 7.6 | 1.6 | 6.1 | 16.2 | 0.0 | 8.4 | 23.7 | 2.1 | 14.7 | 27.1 | 6.4 | 18.1 | 20.3 | 1.9 | 16.1 | 4.7 | 0.0 | 2.6 | 17.1 | 2.0 | 11.3 |
| OS-Atlas-4B [51] | 2.0 | 0.0 | 1.5 | 7.1 | 0.0 | 3.7 | 3.0 | 1.4 | 2.3 | 9.0 | 5.5 | 7.5 | 5.1 | 3.8 | 4.8 | 5.6 | 0.0 | 3.1 | 5.0 | 1.7 | 3.7 |
| OS-Atlas-7B [51] | 12.2 | 4.7 | 10.3 | 33.1 | 1.4 | 17.7 | 28.8 | 2.8 | 17.9 | 37.5 | 7.3 | 24.4 | 33.9 | 5.7 | 27.4 | 27.1 | 4.5 | 16.8 | 28.1 | 4.0 | 18.9 |
| ShowUI-2B [29] | 2.5 | 0.0 | 1.9 | 16.9 | 1.4 | 9.4 | 9.1 | 0.0 | 5.3 | 13.2 | 7.3 | 10.6 | 15.3 | 7.5 | 13.5 | 10.3 | 2.2 | 6.6 | 10.8 | 2.6 | 7.7 |
| UGround-7B [14] | 14.2 | 1.6 | 11.1 | 26.6 | 2.1 | 14.7 | 27.3 | 2.8 | 17.0 | 31.9 | 2.7 | 19.3 | 31.6 | 11.3 | 27.0 | 17.8 | 0.0 | 9.7 | 25.0 | 2.8 | 16.5 |
| UGround-V1-7B [14] | - | - | 13.5 | - | - | 35.5 | - | - | - | 27.8 | - | - | 38.8 | - | - | 48.8 | - | - | 26.1 | - | - | 31.1 |
| UI-R1-3B [35] | 11.2 | 6.3 | - | 22.7 | 4.1 | - | 27.3 | 3.5 | - | 42.4 | 11.8 | - | 32.2 | 11.3 | - | 13.1 | 4.5 | - | - | - | 17.8 |
| GUI-R1-3B [52] | 26.4 | 7.8 | - | 33.8 | 4.8 | - | 40.9 | 5.6 | - | 61.8 | 17.3 | - | 53.6 | 17.0 | - | 28.1 | 5.6 | - | - | - | - |
| GUI-R1-7B [52] | 23.9 | 6.3 | - | 49.4 | 4.8 | - | 38.9 | 8.4 | - | 55.6 | 11.8 | - | 58.7 | 26.4 | - | 42.1 | 16.9 | - | - | - | - |
| UI-TARS-2B [40] | 17.8 | 4.7 | 14.6 | 47.4 | 4.1 | 26.4 | 42.9 | 6.3 | 27.6 | 56.9 | 17.3 | 39.8 | 50.3 | 17.0 | 42.6 | 21.5 | 5.6 | 14.3 | 39.6 | 8.4 | 27.7 |
| UI-TARS-7B [40] | 20.8 | 9.4 | 18.0 | 58.4 | 12.4 | 36.1 | 50.0 | 9.1 | 32.8 | 63.9 | 31.8 | 50.0 | 63.3 | 20.8 | 53.5 | 30.8 | 16.9 | 24.5 | 47.8 | 16.2 | 35.7 |
| 我们的模型 | | | | | | | | | | | | | | | | | | | | | |
| InfiGUI-R1-3B | 33.0 | 14.1 | 28.4 | 51.3 | 12.4 | 32.4 | 44.9 | 7.0 | 29.0 | 58.3 | 20.0 | 41.7 | 65.5 | 28.3 | 57.0 | 43.9 | 12.4 | 29.6 | 49.1 | 14.1 | 35.7 |
表2:基于ScreenSpot-Pro文本、图标和平均得分的不同代理模型在各类任务中的性能比较。加粗标记的结果代表最佳表现,下划线标记的结果代表次佳表现。
奖励(
R
libox
R_{\text {libox }}
Rlibox ),IoU阈值为
τ
IoU
=
0.7
\tau_{\text {IoU }}=0.7
τIoU =0.7。当使用子目标相似性作为奖励(
R
subgoal
R_{\text {subgoal }}
Rsubgoal )且动作参数不正确(
R
param
=
0
R_{\text {param }}=0
Rparam =0)时,我们使用权重
w
s
=
0.2
w_{s}=0.2
ws=0.2。
训练数据。为了确保强大的GUI能力和一般的多模态理解,我们在一个多样化的数据集组合上训练InfiGUI-R1-3B:AndroidControl(10k轨迹+2k专注于反思的轨迹)、GUI定位数据(从RicoSCA、Widget Caption等汇总的5k样本)、MathV360K(11k用于一般推理的样本)以及COCO(4k用于一般视觉定位和理解的样本)。
训练参数。所有实验均使用16块NVIDIA H800 GPU进行。对于SFT阶段(第一阶段),我们使用学习率为 2.0 e − 6 2.0 \mathrm{e}-6 2.0e−6,全局批次大小为32,预热比率为0.1。对于RL阶段(第二阶段),我们使用学习率为 1.0 e − 6 1.0 \mathrm{e}-6 1.0e−6,训练更新批次大小为256,策略探索期间每样例生成16个rollout。
4.2 评估基准
为了全面评估InfiGUI-R1-3B,我们使用了几个关键基准来针对不同方面的GUI代理能力:
ScreenSpot & ScreenSpot-Pro:这些基准评估了跨不同平台(移动设备、桌面端、网页端)的基本GUI理解和元素定位准确性。ScreenSpot-Pro特别通过复杂的桌面应用程序和高分辨率屏幕增加了难度。
AndroidControl:此基准评估代理在现实的Android环境中执行复杂、多步骤任务的能力。它们直接测试对长期交互轨迹中规划和状态跟踪至关重要的高级推理能力。我们在AndroidControl的低级(Low)和高级(High)分割上报告结果。
4.3 结果
我们将InfiGUI-R1-3B与一系列最先进的开源和专有GUI代理进行比较。结果展示了我们的Actor2Reasoner框架在推动GUI代理向深思熟虑推理发展的有效性。
ScreenSpot上的表现。表1总结了ScreenSpot基准上的结果,评估了在移动设备、桌面端和网页端平台上定位的表现。InfiGUI-R1-3B在所有对比模型中,包括Gemini 1.5 Pro和Claude等专有模型,表现出最先进水平,平均准确率令人印象深刻地达到 87.5 % \mathbf{8 7 . 5 \%} 87.5%。它在所有平台和基于文本及图标的定位任务中始终排名第一(移动设备:97.1/81.2,桌面端:94.3/77.1,网页端:91.7/77.6)。这种卓越表现
| 模型 | AndroidControl-Low | AndroidControl-High | ||||
|---|---|---|---|---|---|---|
| 类型 | 定位 | 成功率 | 类型 | 定位 | 成功率 | |
| Claude ∗ { }^{*} ∗ | 74.3 | 0.0 | 19.4 | 63.7 | 0.0 | 12.5 |
| GPT-40 | 74.3 | 0.0 | 19.4 | 66.3 | 0.0 | 20.8 |
| Aria-UI | - | 87.7 | 67.3 | - | 43.2 | 10.2 |
| OS-Atlas-4B | 91.9 | 83.8 | 80.6 | 84.7 | 73.8 | 67.5 |
| Aguvis-7B | - | - | 80.5 | - | - | 61.5 |
| Aguvis-72B | - | - | 84.4 | - | - | 66.4 |
| UI-R1 | 94.3 | 82.6 | - | - | - | - |
| GUI-R1-3B | - | - | - | 58.0 | 56.2 | 46.6 |
| GUI-R1-7B | - | - | - | 71.6 | 65.6 | 51.7 |
| UI-TARS-2B | 98.1 | 87.3 | 89.3 | 81.2 | 78.4 | 68.9 |
| 我们的模型 | ||||||
| InfiGUI-R1-3B | 96.0 | 93.2 | 92.1 | 82.7 | 74.4 | 71.1 |
表3:不同代理模型在AndroidControl基准上的性能比较。SR代表成功率。加粗标记的结果代表最佳表现,下划线标记的结果代表次佳表现。
突显了InfiGUI-R1-3B视觉理解和定位能力的稳健性和泛化能力。
ScreenSpot-Pro上的表现。如表2所示,InfiGUI-R1-3B在要求严格的Screen-Spot-Pro基准上表现出竞争力,该基准专注于复杂的高分辨率桌面GUI定位。总体平均得分为35.7,其表现可与较大的UI-TARS-7B模型(35.7)相媲美,并显著优于其他基线,如OS-Atlas-7B(18.9)和UGround-7B(16.5)。我们的模型在CAD(28.4平均分)、Office(57.0平均分)和操作系统(29.6平均分)类别中表现出色,即使在专业软件环境中也展现出强大的定位能力。尽管并非在每个类别中都全面超越顶级模型,但其强劲的整体表现验证了我们方法的有效性。
AndroidControl上的表现。表3展示了AndroidControl基准上的结果。InfiGUI-R1-3B在AndroidControl-Low上取得了92.1%的成功率,在AndroidControl-High上取得了71.1%的成功率。这超过了参数数量相似的先前最先进模型UI-TARS-2B(成功率:89.3%/68.9%)。此外,它还超越了更大的GUI特定模型,如Aguvis-72B(成功率:84.4%/66.4%)。这突显了我们在第二阶段专注于规划能力训练的有效性。
总之,跨AndroidControl、ScreenSpot-Pro和ScreenSpot的实验结果表明,InfiGUI-R13B显著提升了GUI代理的能力。我们的Actor2Reasoner框架结合空间推理蒸馏和基于RL的深思熟虑增强(子目标引导、错误恢复),成功将基础MLLM转化为更有效的深思熟虑推理器,在具有类似参数量的模型中达到了轨迹任务和跨平台、分辨率元素定位的最先进水平,即使是一个相对较小的3B参数模型也是如此。
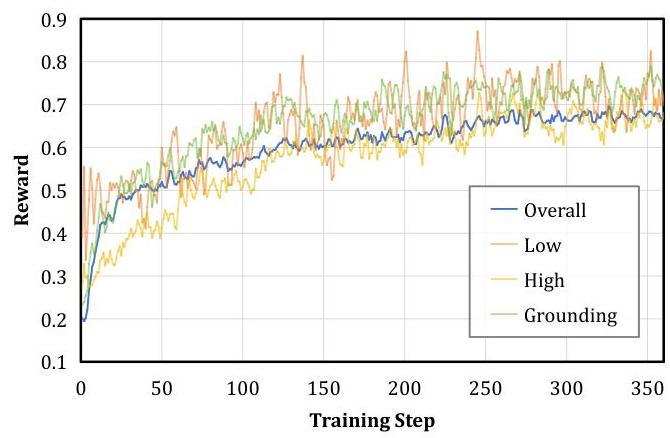
图3:强化学习训练期间的奖励曲线。该图显示了整个训练步骤中的总体奖励和个别任务类型的奖励(低级、高级、定位)。
4.4 可视化
图3展示了在整个强化学习训练过程中的奖励进展。它显示了代理积累的总体奖励以及不同任务类别的具体奖励——低级任务、高级任务和定位任务。从曲线观察到,随着训练的进行,代理整体性能的奖励以及每个单独任务类型的奖励都显示出一致的上升趋势。这表明代理在RL训练阶段有效学习并提高了其在所有GUI任务中的表现。
5 结论
我们介绍了InfiGUI-R1-3B,这是一个弥合反应性执行与深思熟虑推理之间差距的多模态GUI代理。通过Actor2Reasoner框架,我们的方法系统地在两个阶段注入和精炼推理能力:通过空间推理蒸馏构建基础的跨模态推理,以及通过强化学习进行深思熟虑增强以支持子目标规划和错误恢复。实证结果表明,InfiGUI-R1-3B不仅在定位准确性方面与更大模型相当或超越,还在具备稳健规划和反思的情况下,在长期任务执行中表现出色。
参考文献
[1] Sasket Agade, Kyle Wong, Vincent Tu, Jiachen Yang, Ang Li, and Xin Eric Wang. 2025. Agent 52: A Compositional Generalist-Specialist Framework for Computer Use Agents. arXiv:2504.00906 [cs.AI] https://arxiv.org/abs/2504.00906
[2] Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. 2024. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms. arXiv preprint arXiv:2402.14740 (2024).
[3] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgcaud, Andy Brock, Aida Nemutzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karen Simonyan. 2022. Flamingo: a Visual Language Model for Few-Shot Learning. In Advances in Neural
Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, WexilPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, Samni Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh (Eds.). http://papers.nips.cc/paper_files/paper/2022/hash/ 9t0a172bc7fb8f177ccc6b411a7d800-Abstract-Conférence.html
[4] Anthropic. 2024. Developing a computer use model. https://www.anthropic.com/ news/developing-computer-use. Accessed: 2025-04-12.
[5] Anas Awadalla, Irena Gao, Josh Gardner, Jack Heasel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, et al. 2023. Openflamingo: An open-source framework for training large autoregressive vision-language models. arXiv preprint arXiv:2308.01390 (2023).
[6] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenhang Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Jianyang Lin, Runji Lin, Daysheng Lin, Gao Liu, Chengqiang Lu, K. Lu, Jianxiu Ma, Rui Men, Xingshang Ren, Xuansheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jiu Xu, An Tang, Hao Tang, Jian Yang, Jian Yang, Shunheng Yang, Yang Yao, Bowen Yu, Yu Bowen, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xing Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. 2025. Qwen Technical Report. ArXiv (2025). https://doi.org/10.48550/arXiv.2309.16609
[7] Jinze Bai, Shuai Bai, Shunheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Jianyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL: A Frontier Large Vision-Language Model with Versatile Abilities. ArXiv (2023). https://doi.org/10.48550/ arXiv. 2308.12966
[8] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. 2025. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025).
[9] Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, et al. 2024. Windows agent arena: Evaluating multi-modal os agents at scale. arXiv preprint arXiv:2409.08264 (2024).
[10] Kaoshi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. 2024. Swolick: Harnessing gui grounding for advanced visual gui agents. arXiv preprint arXiv:2401.10935 (2024).
[11] Google DeepMind. 2024. Gemin/2.0 (Project Mariner). https://deepmind.google/ technologies/project-mariner. Accessed: 2025-04-12.
[12] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mustafa Debghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Unzkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum? id=YicbFdNTTy
[13] Luciano Floridi and Massimo Chiriatti. 2020. GPT-5: Its nature, scope, limits, and consequences. Minds and Machines 30 (2020), 681-694.
[14] Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. 2024. Navigating the digital world as human-do Universal visual grounding for gui agents. arXiv preprint arXiv:2410.05243 (2024).
[15] Wenyi Hong, Weiham Wang, Qingyong Lv, Jiazheng Xu, Wenneng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. 2024. Cogagent: A visual language model for gui agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. (4281-14290.
[16] Xueyu Hu, Tao Xiong, Biao Yi, Zizho Wei, Ruizuan Xiao, Yurun Chen, Jiasheng Ye, Meiling Tao, Xiangxin Zhou, Ziyu Zhao, Yuhuai Li, Shengze Xu, Shawn Wang, Xinchen Xu, Shuofei Qiao, Kun Kuang, Tieyong Zeng, Liang Wang, Jiwei Li, Yuchen Eleanor Jiang, Wangchuanhu Zhou, Guoyin Wang, Keting Yin, Zhou Zhao, Hongxia Yang, Fan Wu, Shengyu Zhang, and Fei Wu. 2024. OS Agents: A Survey on MLLM-Based Agents for General Computing Devices Use. Preprints (December 2024). doi:10.20944/preprints202412.2294.v1
[17] Xueyu Hu, Ziyu Zhao, Shuang Wei, Ziwei Chai, Qiushi Ma, Guoyin Wang, Xuewi Wang, Jing Su, Jingjing Xia, Ming Zhu, Yao Cheng, Jianbo Yuan, Jiwei Li, Kun Kuang, Yang Tang, Hongxia Yang, and Fei Wu. 2024. InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks. arXiv preprint arXiv:2401.05507 (2024).
[18] Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. 2024. Understanding the planning of LLM agents: A survey. arXiv preprint arXiv:2402.02716 (2024).
[19] Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, Aj Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpr-4o system card. arXiv preprint arXiv:2410.21276 (2024).
[20] Yue Jiang, Eldon Schoop, Amanda Swerangin, and Jeffrey Nichols. 2023. ILuvUI: Instruction-tuned LangPage-Vision modeling of UIs from Machine Conversations. arXiv preprint arXiv:2310.04869 (2023).
[21] Marko Jurmu, Sebastian Boring, and Jukka Riekki. 2008. ScreenSpot: Multidimensional resource discovery for distributed applications in smart spaces. In Proceedings of the 5th Annual International Conference on Mobile and Ubiquitous Systems Computing, Networking, and Services. 1-9.
[22] Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. 2024. Llava-onevision: Easy
visual task transfer. arXiv preprint arXiv:2408.03326 (2024).
[23] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hui. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, PMLR, 19730-19742.
[24] Kaixin Li, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, Tat-Seng Chua, et al. 2025. Screenspot-pro: Gui grounding for professional highresolution computer use. In Workshop on Reasoning and Planning for Large Language Models.
[25] Linyi Li, Shijie Geng, Zhenwen Li, Yibo He, Hao Yu, Ziyue Hua, Guanghan Ning, Siewi Wang, Tao Xie, and Hongxia Yang. 2024. InffBench: Evaluating the Question-Answering Capabilities of Code Large Language Models. arXiv preprint arXiv:2404.07940 (2024).
[26] Wei Li, William Bishop, Alice Li, Chris Rawles, Folawiyo Campbell-Ajala, Divya Tyanagundlu, and Oriana Riva. 2024. On the effects of data scale on computer control agents. arXiv e-prints (2024). arXiv: 2406.
[27] Yang Li, Luhong Li, Gangaand He, Jingjie Zheng, Hong Li, and Zhiwei Guan. 2020. Widget Captioning: Generating Natural Language Description for Mobile User Interface Elements. arXiv preprint arXiv:2010.04295 (2020).
[28] Zijing Liang, Yanjie Xu, Yifan Hong, Fenghui Shang, Qi Wang, Qiang Fu, and Ke Liu. 2024. A Survey of Multimodal Large Language Models. In Proceedings of the 3rd International Conference on Computer, Artificial Intelligence and Control Engineering. 405-409.
[29] Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Zechen Bai, Weixian Lei, Lijuan Wang, and Mike Zheng Shou. 2024. Showwit: One vision-languageaction model for generalist gui agent. In WexilPS 2024 Workshop on Open-World Agents.
[30] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. In Computer vision-ECCV 2014, 15th European conference, eurich, Switzerland, September 6-12, 2014, proceedings, part v 13, Springer, 740755 .
[31] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruction: Tuning. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, WexilPS 2023, New Orleans, LA, USA, December 10 - 16, 2023. Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Haedt, and Sergey Levine (Eds.). http://papers.nips.cc/paper_files/paper/2023/hash/ 64bf277ea32ce3288914faE9e9b6d6b-Abstract-Conférence.html
[32] Haogeng Liu, Quanzeng You, Yaji Wang, Xiaotian Han, Bohan Zhai, Yongfei Liu, Wentao Chen, Yiren Jian, Yunzhe Tao, Jianbo Yuan, Ran He, and Hongxia Yang. 2024. InfMIM: Advancing Multimodal Understanding with an Open-Sourced Visual Language Model. In Annual Meeting of the Association for Computational Linguistics.
[33] Yuhang Liu, Pengxiang Li, Zizho Wei, Congkai Xie, Xueyu Hu, Xinchen Xu, Shengyu Zhang, Xiaotian Han, Hongxia Yang, and Fei Wu. 2025. InfiGUIAgent: A Multimodal Generalist GUI Agent with Native Reasoning and Reflection. arXiv preprint arXiv:2501.04575 (2025).
[34] Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. 2022. A conrnet for the 2020s. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11976-11986.
[35] Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Guanjing Xiong, and Hongzheng Li. 2025. UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement Learning. arXiv preprint arXiv:2503.21620 (2025).
[36] OpenAI. 2023. GPT 4V(ision) System Card. https://cib.openai.2023/GPTV_System_Card.pdf
[37] OpenAI. 2024. GPT-4o. https://openai.com/index/hello-gpt-4o/ 访问日期:2025-01-03。
[38] Zhenyu Pan, Haozheng Luo, Manling Li, 和 Han Liu. 2024. Chain-of-action: 通过大型语言模型实现忠实且多模态的问题回答。arXiv preprint arXiv:2403.17939 (2024)。
[39] Zhilang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, 和 Furu Wei. 2023. Kosmos-2: 将多模态大语言模型与世界对齐。arXiv preprint arXiv:2306.14824 (2023)。
[40] Yuja Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiabao Li, Yunxin Li, Shijue Huang, 等人. 2025. UI-TARS: 使用原生代理开创自动化的GUI交互。arXiv preprint arXiv:2501.12326 (2025)。
[41] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askedl, Pamela Mishkin, Jack Clark, 等人. 2021. 学习可转移的视觉模型进行自然语言监督。在国际机器学习会议,PMLR,8748-8763。
[42] Christopher Rawles, Sarah Clinekemallie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, 等人. 2024. Androidworld: 自主代理的动态基准环境。arXiv preprint arXiv:2405.14573 (2024)。
[43] Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xihiu Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, 和 Chuan Wu. 2024. HybridFlow: 一种灵活高效的强化学习框架。arXiv preprint arXiv:2409.19256 (2024)。
[44] Yuchen Sun, Shanhui Zhao, Tao Yu, Hao Wen, Samith Va, Mengwei Xu, Yuanchun Li, 和 Chongyang Zhang. 2025. GUI-Splore: 通过一次探索赋予通用GUI代理能力。arXiv preprint arXiv:2505.17709 (2025)。
[45] Kimi 团队, Angang Du, Bohong Yin, Bowet Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Cherizhuang Du, Chu Wei, 等人. 2025. Kimi-VL 技术报告。arXiv preprint arXiv:2504.07491 (2025)。
[46] Qwen 团队. 2025. QwQ-52B: 拥抱强化学习的力量。https://qwenlm.github.io/blog/qwq-52b/
[47] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothy Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, 和 Guillaume Lample. 2025. LLaMA: 开放且高效的基语言模型。ArXiv (2025). https://doi.org/10.48550/arXiv.2502.13971
[48] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, 等人. 2024. Qwen2-vl: 增强任何分辨率下视觉语言模型的世界感知。arXiv preprint arXiv:2409.12191 (2024)。
[49] Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhunyi Yang, Lei Zhao, Xiraian Song, 等人. 2023. Cogvlm: 预训练语言模型的视觉专家。arXiv preprint arXiv:2311.03079 (2023)。
[50] Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, 和 Yunxin Liu. 2023. AutoDroid: LLM驱动的Android任务自动化。arXiv preprint arXiv:2308.15272 (2023)。
[51] Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, 等人. 2024. Osatlas: 通用GUI代理的基础动作模型。arXiv preprint arXiv:2410.25218 (2024)。
[52] Xiaobo Xia 和 Run Luo. 2025. GUI-R1: 适用于GUI代理的通才R1风格视觉-语言动作模型。arXiv preprint arXiv:2504.10458 (2025)。
[53] Chaojun Xiao, Xueyu Hu, Zhiyuan Liu, Cunchao Tu, 和 Maozong Sun. 2021. Lawformer: 用于中文法律长文档的预训练语言模型。AI Open 2 (2021), 79-84。
[54] Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, 和 Jianfeng Gao. 2023. Set-of-mark 提示释放了GPT-4V中的非凡视觉定位能力。arXiv preprint arXiv:2310.11441 (2023)。
[55] Yuhao Yang, Yue Wang, Dongxu Li, Ziyang Luo, Bei Chen, Chao Huang, 和 Junnan Li. 2024. Aria-UI: GUI指令的视觉定位。arXiv preprint arXiv:2412.16256 (2024)。
[56] Shenzhi Wang Zhangchi Feng Dongdong Kuang Yuwen Xiong Yaowei Zheng, Junting Lu. 2025. EasyR1: 一个高效、可扩展、多模态的RL训练框架。https://github.com/hiyouga/EasyR1。
[57] Keen You, Haotian Zhang, Eldon Schoop, Floris Weers, Amanda Swarengin, Jeffrey Nichols, Yinfei Yang, 和 Zhe Gan. 2025. Ferret-ui: 使用多模态LLMs进行基于地面的移动UI理解。在欧洲计算机视觉会议上,Springer,240-255。
[58] Chi Zhang, Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zelsao Huang, Bin Fu, 和 Gang Yu. 2023. Appagent: 多模态代理作为智能手机用户。arXiv preprint arXiv:2312.13771 (2023)。
参考论文:https://arxiv.org/pdf/2504.14239



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











