






Ishan Kavathekar*
IIIT-Hyderabad
Hyderabad, India
ishan.kavathekar@research.iiit.ac.in
Ponnurangam Kumaraguru
IIIT-Hyderabad
Hyderabad, India
pk.guru@iiit.ac.in
摘要
函数调用是一项复杂且应用广泛的任务,在信息检索、软件工程和自动化等领域具有重要意义。例如,查询预订2024年1月15日从纽约到伦敦的最短航班需要识别正确的参数以生成准确的函数调用。大型语言模型(LLMs)可以自动化这一过程,但计算成本高且在资源受限的环境中不切实际。相比之下,小型语言模型(SLMs)能够高效运行,提供更快的响应时间和更低的计算需求,使其成为边缘设备上执行函数调用的潜在候选者。在这项探索性的实证研究中,我们评估了SLMs在零样本、少量样本和微调方法下跨多个领域生成函数调用的有效性,同时进行了有无提示注入的实验,并提供了微调后的模型以促进未来应用。此外,我们通过一系列指标分析模型响应,捕捉函数调用生成的各个方面。我们还在边缘设备上进行实验,评估其在延迟和内存使用方面的性能,为其实用性提供了有价值的见解。我们的研究发现表明,尽管SLMs从零样本到少量样本有所改进并在微调后表现最佳,但在遵循给定输出格式方面存在显著困难。提示注入实验进一步表明,这些模型通常具有较强的鲁棒性,性能下降幅度较小。虽然SLMs在函数调用生成任务中展现出潜力,但我们的结果也指出了需要进一步改进以实现实时功能的领域。
Raghav Donakanti*
IIIT-Hyderabad
Hyderabad, India raghav.donakanti@students.iiit.ac.in
Karthik Vaidhyanathan
IIIT-Hyderabad
Hyderabad, India
karthik.vaidhyanathan@iiit.ac.in
CCS概念
- 软件及其工程; ⋅ \cdot ⋅ 计算方法 → \rightarrow → 人工智能; ⋅ \cdot ⋅ 综述与参考 → \rightarrow → 实证研究;
关键词
小型语言模型,函数调用,边缘AI,可靠性
ACM参考格式:
Ishan Kavathekar, Raghav Donakanti, Ponnurangam Kumaraguru 和 Karthik Vaidhyanathan。2025。小型模型,大型任务:关于小型语言模型生成函数调用的探索性实证研究。在第29届国际软件工程评估与评估会议(EASE 2025)论文集。ACM,纽约州纽约市,美国,11页。https://doi.org/XXXXXXXX.XXXXXXX
1 引言
大语言模型(LLMs)的进步使它们在广泛的任务中表现出色 [26, 45, 59]。它们越来越多地被应用于软件工程任务,如代码生成 [4,36]、调试 [48] 和 API 集成 [58],以及任务自动化的系统中。一个关键的应用是函数调用和执行。LLMs 通常依赖于庞大的基于云的基础设施,引发了对隐私、延迟和高计算开销的担忧 [12,55]。因此,SLMs 正作为现实世界应用中的强大替代方案出现,可以在本地高效执行特定任务,使其在响应性和数据安全性至关重要的环境中成为理想选择 [38, 49]。
SLMs 有可能在函数调用应用中充当用户输入和后端系统之间的桥梁,将自然语言查询转换为结构化的函数调用 [49]。尽管函数调用不如总结或翻译等 NLP 任务常见,但对于解释和执行用户命令至关重要。它使 SLMs 能够执行现实世界的操作,在需要及时准确响应的行业中尤为重要,如医疗保健、金融、汽车系统、电信和智能家居自动化。然而,这个结合函数调用与 SLMs 的领域相对较少被探索和开发。
为此,我们开展了一项探索性实证研究,评估 SLMs 生成函数调用的能力。我们系统地选择了 5 个 SLMs,基于编码能力评估基准和模型中的参数数量,并在涵盖多样领域的 60,000 个样本的综合数据集上进行评估。
*两位作者对本工作贡献相同。
[^1]
允许为了个人或课堂教学目的免费制作本文的数字或硬拷贝,前提是复印件不得用于盈利或商业优势,并且复印件上须带有此通知和首页的完整引用。必须尊重不属于作者(s)的本作品组件的版权。允许带信用摘要。除此之外的复制、再出版、服务器发布或列表重新分发均需事先获得具体许可和/或支付费用。请向 permissions@acm.org 请求权限。
EASE 2025, 伊斯坦布尔,土耳其
© 2025 版权由作者(s)持有。出版权已授权给 ACM。ACM ISBN 978-1-4503-XXXX-X/2018/06
https://doi.org/XXXXXXXX.XXXXXXX
功能性领域,如技术、娱乐、金融等。我们使用三种推理策略评估 SLMs:零样本、少样本和微调,并通过不同指标评估它们的表现,这些指标捕捉了函数调用生成的多个维度。我们的指标评估语法正确性、语义准确性以及模型在各种场景中生成结构化输出的能力。此外,我们进行提示注入实验,评估模型对用户提示中细微扰动的鲁棒性。此外,我们在边缘设备上进行实验,考察模型在计算资源受限环境中的实际适用性,并分析模型的内存占用与延迟之间的关系。总之,我们的贡献包括:(i) 使用各种提示技术(包括提示注入)进行函数调用的 SLM 分析,(ii) 微调后的 SLM 及其性能分析,突出改进领域,以及 (iii) 在边缘设备上的实验以评估效率。
我们的研究发现表明某些 SLMs 在各种方法中表现出令人鼓舞的能力。此外,我们的分析揭示了有趣的见解,为未来的进一步研究开辟了新的方向。我们提供微调后的模型以支持进一步的研究和应用。我们研究的复制包在这里
1
{ }^{1}
1。
2 背景
2.1 小型语言模型 (SLMs)
SLMs 是能够理解、处理并根据用户提示生成文本的生成模型。与 LLMs 相比,这些模型在规模上小得多。与拥有数十亿参数的 LLMs 不同,SLMs 使用的参数数量从数百万到数十亿不等。这种较低的内存和计算需求使得模型的效率更高、更易访问、可定制性更强、推理时间更快。这些特性使得 SLMs 成为比 LLMs 更好的域特定、受限和低资源设置的替代方案。
2.2 零样本、少样本和微调推理方法
零样本方法涉及利用模型的预训练并直接提示模型而不提供任何其他任务信息。相比之下,少样本方法涉及在提示中提供一个或多个任务-答案响应示例。模型使用这些示例来理解任务并生成所需的输出 [46]。由于这些示例被提供到模型的上下文中,少样本方法也被称为情境学习。提示中提供的示例数量根据任务而异。这一选择还受到单个示例长度和模型上下文大小的影响。零样本和少样本推理不需要额外的模型训练,这使得它们成为计算高效的技巧。微调是指在特定任务数据上重新训练模型以提高其在该任务上的性能。然而,由于需要额外的训练,微调的计算成本较高,这涉及到更新模型参数和增加内存使用。为了解决这个问题,
采用了一些技术,如 LoRA [22]、提示微调 [27] 和前缀微调 [28]。这些方法显著降低了计算成本,同时几乎保持相同的性能。
2.3 GGUF 模型
GGUF [16] 是一种存储格式,用于在计算受限设备上高效存储和运行量化的大语言模型(LLMs)。量化是一种压缩过程,将模型权重从高精度表示转换为低数据精度表示,以减少内存使用并提高计算效率 [14]。这种格式支持具有不同大小和量化级别的模型,显著降低其内存占用而不会大幅降低性能。GGUF 是 GGML [15] 格式的继任者,具有改进的量化方法和元数据管理。随着更大模型的发布,GGUF 格式的模型变体相比之前的半精度模型和 GGML 格式成为更好的选择。
2.4 提示注入
提示注入指的是操纵用户提示以改变生成模型的输出 [33]。这包括在初始提示后附加某些特殊字符、指令或对抗性文本,导致有毒、有偏见和不希望的输出。提示注入可分为两种类型:(i) 直接提示注入和 (ii) 间接提示注入。直接提示注入涉及直接更改模型的输入 [8, 52],而间接提示注入修改模型生成时可访问的外部数据 [17, 54]。在这项研究中,我们主要关注直接提示注入,因为我们仅关注函数调用生成而不涉及外部数据。
3 相关工作
近年来,大型语言模型(LLMs)越来越多地被应用于各种软件工程(SE)任务,如自动代码生成和修复 [25, 29, 37]、需求分析与设计 [10, 41]、智能项目管理 [5, 31] 等,反映了它们在各种应用中的广泛应用。其中一项任务是函数调用。多年来,研究人员探索了多种策略以使 LLMs 能够生成准确的函数调用。这些方法大致可分为两类主要策略。第一类涉及有效地提示模型以利用其在训练期间获取的知识。这可以通过情境学习 [51] 或使用 ReAct [57] 等技术来实现,这些技术结合推理和行动以指导模型生成更好的响应。第二类策略涉及在多样化的数据集或特定领域的数据集上微调模型以增强其性能。像 Gorilla [42], Nous-Hermes-13b [39], ToolLlama [44] 和 ToolAlpaca [47] 这样的模型是在由 GPT-4 和 GPT-3.5 生成的合成数据上训练的。另一方面,Granite-20B [1] 已在 API-Blend [7] 上进行了微调,该数据集包含五个多样的 API 数据集。
已经引入了几个基准测试来评估 LLMs 的函数调用能力,如 ToolBench [20], ComplexFuncBench [61], Berkeley 函数调用排行榜 (BFCL) [56]。这些基准测试评估了诸如真实 API 响应、多步函数调用等多个因素。
1
{ }^{1}
1 https://github.com/Raghav010/Small-Models-Big-Tasks
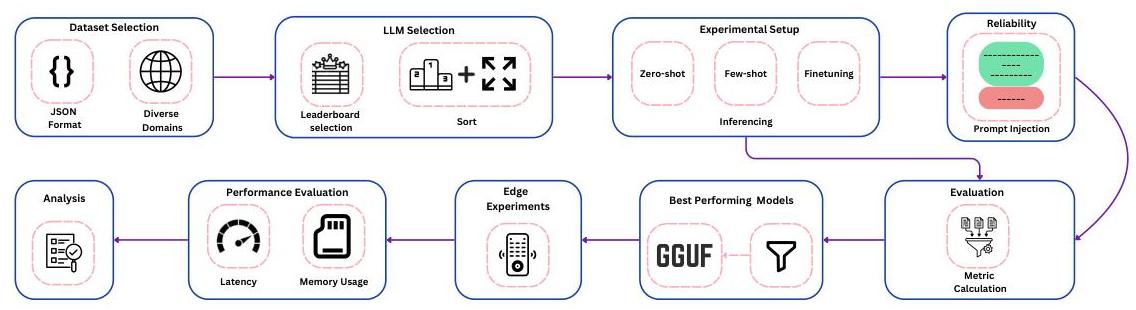
图1:研究设计概述,说明研究方法的不同组成部分。
然而,以往的工作主要集中在微调大型模型和未专门设计用于评估小型模型相关挑战的基准上。我们的工作通过针对SLMs进行细致的实证研究,分析其性能,并提供微调的小型模型来弥补这一空白。
4 研究设计
4.1 目标
本文旨在理解当呈现一组函数描述和用户查询时(如图1所示),SLMs在生成函数调用方面的有效性。我们采用目标-问题-度量方法 [11] 来正式定义目标如下:
分析小型语言模型在生成函数调用方面的有效性,考虑到准确性、可靠性和鲁棒性,从研究人员和开发者的角度来看,在函数调用任务的背景下。
4.2 研究问题
在本节中,我们探讨了关键的研究问题,旨在评估SLMs在生成函数调用方面的鲁棒性和实用性。我们试图回答以下研究问题:
RQ1: 在零样本设置中,SLMs是否可以成功用于生成给定任务和情景下的函数调用?
通过这个问题,我们旨在评估SLMs是否能够在没有接触任务的情况下生成准确和精确的函数调用。这让我们有机会仅基于它们的预训练知识来评估SLMs的内在能力。
RQ2: 少样本方法如何影响SLMs生成函数调用的能力?
在提示中提供类似问题的例子可以提高生成模型的性能。这些例子帮助SLM理解任务的细微差别,并引导其生成适当的任务响应。我们检查提供任务-响应对的例子如何影响SLMs的性能。
RQ3: 微调SLMs是否能增强其生成函数调用的能力?
在特定任务数据上微调模型已被证明可以显著提高其能力。因此,我们检查它如何影响SLMs在生成函数调用任务中的性能。
通过对前三个研究问题中的SLMs性能进行检查,我们还旨在识别提示注入如何影响零样本 ( R Q 1 ) \left(R Q_{1}\right) (RQ1)、少样本 ( R Q 2 ) \left(R Q_{2}\right) (RQ2) 和微调 ( R Q 3 ) \left(R Q_{3}\right) (RQ3) 结果的鲁棒性。成功的提示注入鲁棒性演示表明SLMs可以在动态环境中保持其功能完整性和适应性,最终支持其在自动化系统中的可靠 2 { }^{2} 2 集成。
RQ4: 当部署在边缘设备上时,SLMs在生成函数调用方面的表现如何?
边缘设备在受限资源上运行并本地处理输入,从而降低模型的延迟和内存使用。我们旨在评估将这些SLMs部署到边缘设备对其性能的影响。
4.3 实验主体
研究中考虑的模型
我们评估了五种SLMs在其跨各种设置生成函数调用的能力。这些模型是从EvalPlus基准测试 [32] 3 { }^{3} 3 中选出的,这是一个代码合成评估框架。该基准可能反映了一个模型准确组成函数的能力,因为代码合成和函数调用生成的范式密切相关。选取了最多4B参数的前五名模型进行研究。这一选择是考虑到在边缘设备上进行的实验。EvalPlus基准是一个不断发展的排行榜,根据我们的要求,研究中评估的模型在进行研究时排名前五位。表1总结了HuggingFace上选定模型的详细信息。
数据集
Salesforce XLAM 函数调用数据集 [34] 可在 Hugging Face 上获取,专为函数调用任务设计的高质量资源。它包含 60,000 个样本,提供覆盖广泛领域和场景的大量和多样化数据集。该数据集源自 ToolBench [44] 数据集,得益于精心策划,反映真实的函数调用背景,增强了我们研究成果的实际应用价值。数据集中的每个数据点包含三个部分:(i) 查询:问题陈述,(ii) 工具:可用函数的名称、描述和
2
{ }^{2}
2 在本研究中,可靠指的是SLMs生成的响应的可靠性,而非系统本身的可靠性。
3
{ }^{3}
3 https://evalplus.github.io/leaderboard.html

图2:来自 Salesforce-XLAM 函数调用数据集的样本数据点,展示了其组成部分:用户查询、可用工具和答案。
参数,以及 (iii) 答案:正确的函数调用。图2展示了一个数据集中的示例。
| 模型 | 大小 | 上下文长度 |
|---|---|---|
| Deepseek-coder-1.5B-instruct [19] | 1.35B | 120 K |
| Phi-3-mini-4k instruct [2] | 3.82B | 4 K |
| Phi-2 [24] | 2.78B | 2048 |
| Starcoder2-3B [35] | 3.03B | 16 K |
| Stable-code-3B [43] | 2.8B | 16 K |
表1:研究中使用的SLMs及其参数大小和上下文长度。
该数据集遵循JSON格式的优势为我们研究提供了关键优势。结构化的JSON格式有助于自动处理和评估模型输出,简化我们的研究流程。此外,JSON的独立于语言的性质使其可转换为各种编程语言,增强了我们函数调用解决方案的多样性。
为确保与我们较小的变压器模型(1.35B-3.82B参数)的上下文长度限制兼容,我们为每个模型的限制内整理了Salesforce XLAM函数调用数据集的一个子集(表1)以进行公平的性能比较。然后我们将此数据集分为测试集(5,000个样本)和微调集(55,000个样本)。
4.4 实验程序
在本小节中,我们提供了一个全面的实验设置和方法概述。除了边缘部署外的所有推断都在单GPU设置上进行,使用GTX 1080 Ti或RTX 2080 Ti在测试集上以float 16精度进行。零样本方法:对于零样本提示实验,我们使用标准化的提示模板来组织查询、工具和预期答案,确保所有样本的输入格式一致。此外,提示还包括明确的指令,要求模型以指定的JSON格式生成输出,以便生成结构化和机器可读的响应。实验在温度设置为0的情况下进行,以最小化随机性并确保确定性输出。
零样本方法的提示
任务指示:系统提示和函数调用生成任务的描述
工具描述:完成用户查询所需的所有工具的描述
格式指示:生成输出所需的结构和格式
用户查询
少样本方法:对于少样本提示实验,我们使用与零样本设置相同的标准化提示模板,包括明确的指令,要求模型以指定的JSON格式生成输出。除了查询、工具和预期答案外,提示还附有三个特定任务示例(3-shot提示),以引导模型理解期望的行为。提供少量示例(2-5个)可以显著提高模型性能 [9]。考虑到数据集的大小和模型的上下文长度限制,我们通过评估模型和示例的上下文长度提供三个示例。这些示例经过精心挑选,以涵盖测试集中的代表性场景并保持不变。实验在与零样本相同的温度设置下进行。
少样本方法的提示
任务指示:系统提示和函数调用生成任务的描述
工具描述:完成用户查询所需的所有工具的描述
格式指示:生成输出所需的结构和格式
示例样例:函数调用生成任务的三个查询-响应示例
<SAMPLE EXAMPLE 1> <SAMPLE EXAMPLE 2> <SAMPLE EXAMPLE 3>
用户查询
微调:对于微调实验,我们使用单GPU RTX A5000设置,并采用LoRA(低秩适配)有效调整模型参数,同时保持最少的额外开销。LoRA配置包括秩8,这指定了用于参数更新的低秩矩阵的维度,使学习在不修改整个模型的情况下更加高效。缩放因子(alpha)设置为8,放大低秩空间中的更新以平衡学习的稳定性和有效性。LoRA权重施加了0.05的丢弃率,以引入正则化并减轻过拟合。
LoRA应用于模型中的所有线性层,包括查询和值投影层。
微调过程在55,000个样本子集上进行2个周期。训练使用每个设备2个批量大小,评估使用4个批量大小,梯度累积步骤设置为4以有效增加整体批量大小。学习率为
2
e
−
5
2 \mathrm{e}-5
2e−5. 训练在bf16精度下进行,以加快计算速度并减少内存使用。所有微调模型及代码都提供在补充材料中以供再现。
提示注入:我们通过执行提示注入来评估SLMs在零样本、少样本和微调设置下的鲁棒性。这包括在用户提示中追加一串无意义的随机字符(包括字母数字、特殊和Unicode字符)。通过这样做,我们评估模型遵守原始任务和忽略输入中任何噪声的能力。
提示注入实验的提示
任务指示:系统提示和函数调用生成任务的描述
工具描述:完成用户查询所需的所有工具的描述
格式指示:生成输出所需的结构和格式
(示例仅在少样本实验中包括)
示例样例:函数调用生成任务的三个查询-响应示例
«SAMPLE EXAMPLE 1»
«SAMPLE EXAMPLE 2»
«SAMPLE EXAMPLE 3»
用户查询 $+I 3_{u} q-a^{*}<: 11|E>3 o n 8 I s d e F $ r n j Q &$
边缘设备实验:由于其在边缘设备的内存和计算约束内工作的能力,我们使用所选模型的GGUF变体进行边缘实验。我们使用Q4_K_M格式进行4位量化,因为它在紧凑性和性能之间达到了理想的平衡。对于边缘实验,我们选择Qualcomm QIDK(Qualcomm Innovation Development Kit)
4
{ }^{4}
4,配备了Snapdragon
®
8
{ }^{\circledR} 8
®8 Gen 2处理器和Adreno GPU。它具有驱动各种商用智能手机的片上系统(SoC)。
我们在边缘设备上进行了两组实验。对于第一组实验,我们从上述实验(零样本、少样本和微调)中选择表现最佳的模型-设置对。我们将这些模型转换为GGUF格式以部署在边缘设备上。我们排除了边缘设置中的提示注入实验。由于边缘设备的计算限制,我们使用测试集的100个数据点子集。这些数据点是从数据集中随机选择的,以确保选择的公正性。另一组实验涉及计算这些GGUF模型的平均延迟和内存使用,并与半精度模型进行比较,用于函数调用任务。
4.5 指标
尽管代码评估取得了进展,但尚无全面评估函数调用生成的指标。虽然存在如ROUGE [30]、BLEU分数 [40] 和 METEOR [6] 等评估结构正确性和代码相似性的指标,但它们不能满足我们研究的目的,因为我们专注于函数调用生成。抽象语法树(AST)特别用于分析代码不同组件之间的结构关系。然而,由于我们的研究完全专注于函数调用生成而非完整的函数生成,我们不包括AST分析。因此,为了评估模型在函数调用任务中的表现,我们引入了五个新指标。这些指标旨在评估模型输出的语法正确性和函数调用、参数和值的语义准确性。
JSON可解析性衡量模型的输出是否符合有效的预期JSON结构。JSON可解析性确保输出的语法正确性,这对于依赖结构化数据的下游任务至关重要。
设 O i O_{i} Oi 表示第 i i i 个数据点的输出, J ( O i ) \mathcal{J}\left(O_{i}\right) J(Oi) 是一个指示函数,如果 O i O_{i} Oi 是有效的JSON对象,则为1,否则为0。总体JSON可解析性指标计算公式为:
JSON Parsability = 1 N ∑ i = 1 N J ( O i ) \text { JSON Parsability }=\frac{1}{N} \sum_{i=1}^{N} \mathcal{J}\left(O_{i}\right) JSON Parsability =N1i=1∑NJ(Oi)
其中 N N N 是数据点的总数。以下所有指标仅在 J ( O i ) \mathcal{J}\left(O_{i}\right) J(Oi) 为1的数据点上计算。
任务准确性评估给定任务/查询下函数调用的整体正确性。任务准确性涵盖了函数的广泛方面,捕获了函数选择和构建的正确性,反映了其他指标单独关注的区域的性能。本质上,它评估模型正确理解任务并生成适当函数调用的能力。
对于给定的数据点,设: T true T_{\text {true }} Ttrue 为真实函数调用集(地面真相), T pred T_{\text {pred }} Tpred 为预测的函数调用集。任务准确性定义为 T pred T_{\text {pred }} Tpred 和 T true T_{\text {true }} Ttrue 之间的F1分数。总体任务准确性是所有数据点的平均值。
正确比例作为对模型性能的更严格评估,通过测量任务准确性恰好为1的数据点的比例,使其成为模型交付完全正确输出能力的指标。与其他更广泛的指标不同,正确比例仅考虑预测函数调用在函数选择和构建方面完美匹配地面真相且无错误或遗漏的情况。
函数选择性能(FSP)衡量模型从给定的可用函数集中选择正确函数的能力。通过专注于函数选择,FSP 隔离了模型正确解释任务意图并将其映射到正确工具或函数的能力。设 F true F_{\text {true }} Ftrue 为地面真相中的函数名称集, F pred F_{\text {pred }} Fpred 为模型预测的函数名称集。给定数据点的 FSP 计算公式为:
F S P = ∣ F true ∩ F pred ∣ ∣ F true ∣ \mathrm{FSP}=\frac{\left|F_{\text {true }} \cap F_{\text {pred }}\right|}{\left|F_{\text {true }}\right|} FSP=∣Ftrue ∣∣Ftrue ∩Fpred ∣
4
{ }^{4}
4 https://www.qualcomm.com/developer/hardware/qualcomm-innovators-development-kit
其中
∣
F
true
∩
F
pred
∣
\left|F_{\text {true }} \cap F_{\text {pred }}\right|
∣Ftrue ∩Fpred ∣ 表示正确预测的函数名称数量。总体 FSP 是所有数据点的平均值。
参数完整性评分 (ACS) 评估模型在其函数调用中包含必要参数名称的能力。较高的 ACS 表明模型理解了函数要求的全部范围。
设: A true A_{\text {true }} Atrue 为地面真相中的参数名称集, A pred A_{\text {pred }} Apred 为预测的参数名称集。
某个函数的 ACS 是 A true A_{\text {true }} Atrue 和 A pred A_{\text {pred }} Apred 之间的 F1 分数。总体 ACS 是所有属于 ∣ F true ∩ F pred ∣ \left|F_{\text {true }} \cap F_{\text {pred }}\right| ∣Ftrue ∩Fpred ∣ 的函数在所有数据点上的平均值。
参数值正确性 (AVC) 进一步细化评估,通过测量分配给参数的值的正确性。虽然 ACS 评估是否提供了正确的参数名称,AVC 则评估模型是否为这些参数分配了正确的值。AVC 是模型对任务细节理解的更严格衡量。
对于已正确预测的参数(由 ACS 识别),设 o true ( a ) \mathrm{o}_{\text {true }}(a) otrue (a) 和 o pred ( a ) \mathrm{o}_{\text {pred }}(a) opred (a) 分别为参数 a a a 的地面真相值和预测值。某个函数的 AVC 由下式给出:
A V C = 1 ∣ A correct ∣ ∑ a ∈ A correct Σ ( o true ( a ) , o pred ( a ) ) \mathrm{AVC}=\frac{1}{\left|A_{\text {correct }}\right|} \sum_{a \in A_{\text {correct }}} \Sigma\left(\mathrm{o}_{\text {true }}(a), \mathrm{o}_{\text {pred }}(a)\right) AVC=∣Acorrect ∣1a∈Acorrect ∑Σ(otrue (a),opred (a))
其中 A correct A_{\text {correct }} Acorrect 是正确预测的参数名称集, Σ ( ⋅ ) \Sigma(\cdot) Σ(⋅) 是指示函数,若值匹配则为1,否则为0。总体 AVC 是所有属于 ∣ F true ∩ F pred ∣ \left|F_{\text {true }} \cap F_{\text {pred }}\right| ∣Ftrue ∩Fpred ∣ 的函数在所有数据点上的平均值。
5 结果
RQ1: 在零样本设置下,给定任务和场景,SLMs 是否可以成功用于生成函数调用?在测试模型的零样本设置中,我们观察到大多数模型即使在输入提示中明确提到 JSON 格式后仍无法生成符合 JSON 格式的响应。如表2所示,只有 Deepseek-Coder-1.3b-instruct 在 JSON 可解析性方面取得非零值,使我们能够进一步分析响应。
Deepseek-Coder 以仅 7.34 % 7.34 \% 7.34% 的成功率生成可解析的 JSON 响应。我们观察到它在准确选择正确的函数、参数和参数值方面存在困难,导致任务准确率仅为 1.11 % 1.11 \% 1.11%。手动检查表2中产生零值的模型的200个响应显示,这些SLMs在不受控制的生成方面存在困难。虽然一些示例生成了正确答案,但它们经常发起一个新的无关查询。其他实例未能生成适当的 JSON 结构,导致错误的函数调用。我们将在第6节进一步讨论这一点。
结果表明,提示注入会影响模型的响应。尽管某些情况下 JSON 可解析性和 ACS 指标有所下降,值得注意的是 FSP、AVC 和总体任务准确率显示出改善。
RQ1的主要发现:在零样本设置下,SLMs无法生成准确的函数调用。大多数模型无法生成符合给定格式的响应,使响应不可解析且不正确。Deepseek-Coder是唯一生成可解析JSON响应的模型,但此类响应的数量非常有限。提示注入实验显示出性能略有下降,但鉴于基线性能较差,总体影响仍然很小。
RQ2: 少样本方法如何影响SLM生成函数调用的能力?
表2突显了提供少量任务特定示例对函数调用生成的影响。Deepseek-Coder表现出显著改进,JSON可解析性、FSP、ACS和AVC等指标提高了67-80%,任务准确率达到55.65%。然而,Phi-3-Mini、Phi-2和StarCoder继续在生成可解析JSON响应方面挣扎。Stablecode表现不佳,任务准确率仅为0.11%。
提示注入显著降低了Deepseek-Coder模型的性能达13-16%。输入中的小扰动破坏了模型选择函数、参数和参数值的能力。因此,任务准确率下降了13%,突显了模型对提示中小改动的脆弱性。
RQ2的主要发现:在少样本设置下可以观察到显著的性能提升。然而,许多模型即使在提供示例后也无法表现得更好。提示注入导致模型性能显著下降。
RQ3: 微调SLMs是否能增强其生成函数调用的能力?
微调在各模型间产生了混合的性能改进。虽然Deepseek-Coder和Phi-3-mini表现出显著的性能提升,但其他模型未能达到非零值。
如表2所示,Deepseek-Coder在JSON可解析性方面实现了显著提升,从零样本设置的7.34%提高到少样本设置的89.38%,再到微调后的99.44%。同样,Phi-3-mini也显示出显著提升,JSON可解析性从零样本和少样本设置的0%提高到微调后的99.62%。此外,Phi-3-mini能够正确选择函数调用的参数,这反映在较高的FSP、ACS和AVC指标上。然而,其他模型如Phi-2、Starcoder和Stable-code在微调后性能依然为零。这可以归因于其输出结构中的持续错误,使其JSON响应不可解析。值得注意的是,尽管Deepseek-Coder在零样本和少样本设置中表现更好,但Phi-3-mini在任务准确率上超过了Deepseek-Coder。这一结果突显了在特定任务数据上微调模型的影响。
此外,我们观察到微调提高了对提示注入攻击的鲁棒性。例如,我们观察到微调后的模型在各项指标上的性能下降仅为1-2%,而在少样本设置中下降了10-15%。
| 指标 | 模型 | 零样本 | 少样本 | 微调 | |||
|---|---|---|---|---|---|---|---|
| 无提示注入 | 有提示注入 | 无提示注入 | 有提示注入 | 无提示注入 | 有提示注入 | ||
| JSON 可解析性 | Deepseek-coder-1.3B-instruct | 0.0734 | 0.0140 | 0.8938 | 0.7268 | 0.9944 | 0.9906 |
| Phi-3-mini-4k-instruct | 0.0000 | 0.0000 | 0.0000 | 0.0084 | 0.9962 | 0.9939 | |
| Phi-2 | 0.0000 | 0.0000 | 0.0000 | 0.0002 | 0.0000 | 0.0000 | |
| Starcoder2-3B | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| Stable-code-3B | 0.0000 | 0.0000 | 0.0058 | 0.0060 | 0.0000 | 0.0000 | |
| 任务准确性 | Deepseek-coder-1.3B-instruct | 0.0111 | 0.0527 | 0.5565 | 0.4289 | 0.8543 | 0.8404 |
| Phi-3-mini-4k-instruct | 0.0000 | 0.0000 | 0.0000 | 0.0012 | 0.8727 | 0.8598 | |
| Phi-2 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| Starcoder2-3B | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| Stable-code-3B | 0.0000 | 0.0000 | 0.0011 | 0.0009 | 0.0000 | 0.0000 | |
| 正确比例 | Deepseek-coder-1.3B-instruct | 0.0470 | 0.0098 | 0.468 | 0.3384 | 0.8074 | 0.7866 |
| Phi-3-mini-4k-instruct | 0.0000 | 0.0000 | 0.0010 | 0.0008 | 0.8328 | 0.8210 | |
| Phi-2 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| Starcoder2-3B | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| Stable-code-3B | 0.0000 | 0.0000 | 0.001 | 0.0006 | 0.0000 | 0.0000 | |
| FSP | Deepseek-coder-1.3B-instruct | 0.0139 | 0.0723 | 0.8846 | 0.7209 | 0.9918 | 0.9859 |
| Phi-3-mini-4k-instruct | 0.0000 | 0.0000 | 0.0000 | 0.0031 | 0.9936 | 0.9901 | |
| Phi-2 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| Starcoder2-3B | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| 稳定代码-3B | 0.0017 | 0.0016 | 0.0000 | 0.0000 |
表2:模型在不同指标和配置下的性能,包括提示注入和不提示注入的情况。
RQ3的主要发现:微调后的模型在零样本和少样本设置下表现显著更好。这些模型能够准确选择函数参数,从而提高任务准确率和正确比例。此外,提示注入对模型性能的影响很小。
RQ 4 _{4} 4 : 在边缘设备上部署时,SLMs在生成函数调用方面的表现如何?
对于边缘设备实验,由于资源限制,我们使用了100个提示的子集来评估模型。如表3所示,在少样本设置中,Deepseek-Coder在任务准确率达到44.97%的情况下表现出最佳性能,超过了其零样本(32.5%)和微调(35.7%)配置。这一趋势在所有指标中都很明显,包括正确比例。在边缘设备上,模型表现出显著的延迟,如表5所示。Deepseek-Coder在所有设置中的延迟最低,范围从61.10秒到70.55秒。相比之下,Phi-3-mini在零样本设置中需要364.51秒,在少样本设置中需要335.58秒。其他模型表现出中间的延迟值,在不同设置下范围从140.29秒到267.65秒。值得注意的是,与服务器部署相比,边缘设备上的延迟显著更高。例如,Deepseek-Coder在服务器上进行零样本推理需要5.59秒,少样本推理需要3.22秒,但在边缘设备上部署时延迟增加了超过10秒。此外,不同设置之间的延迟趋势有所不同。虽然微调模型在服务器上由于处理复杂性的增加而表现出更高的延迟,但少样本设置在边缘设备上导致更大的延迟。
| 模型及 设置 | JSON 可解析性 | 正确 比例 | FSP | ACS | AVC | 任务 准确性 |
|---|---|---|---|---|---|---|
| Deepseek-coder-1.3B-instruct | 0.4000 | 0.3000 | 0.4000 | 0.3871 | 0.3633 | 0.3250 |
| 零样本 | 0.6000 | 0.4000 | 0.6000 | 0.5859 | 0.5312 | 0.4497 |
| Deepseek-coder-1.3B-instruct 微调 | 0.4100 | 0.3200 | 0.4067 | 0.4012 | 0.3743 | 0.3570 |
| Phi-3-mini-4k-instruct 微调 | 0.3900 | 0.3200 | 0.3800 | 0.3689 | 0.3517 | 0.3417 |
表3:在边缘设备上表现最佳的模型-设置对的模型性能。
除了延迟,内存限制进一步影响边缘部署。如表4所示,模型在服务器上消耗的内存显著更多,Deepseek-Coder需要5385.89 MB,而在边缘设备上仅需1678.18 MB。类似的趋势适用于大多数其他模型,在边缘设备上部署时内存使用减少约5秒。
RQ4的主要发现:边缘设备部署显示Deepseek-Coder在性能、延迟和内存使用之间取得了最佳平衡。尽管少样本学习产生了更好的准确性指标,但与其他设置相比,它带来了稍高的延迟。我们还观察到,由于GGUF的原因,模型在边缘设备上的内存消耗比在服务器上少了约5秒。
包含代码、提示模板和数据的复制包可在此处获得
5
{ }^{5}
5。

图3:Deepseek-Coder和Phi-3-mini在不同设置下的响应,突出错误(红色)和正确(绿色)输出。
6 讨论
经验教训:我们的研究揭示了SLMs在函数调用能力方面的几个关键见解。首先,所有评估模型的零样本和少量样本性能普遍较差,只有Deepseek-Coder可以生成结构化的函数调用。微调模型显著提高了模型性能。然而,我们仍然在表2中观察到许多模型的零值。图3展示了Deepseek-Coder和Phi-3-mini在不同设置下的响应示例。在不同设置下常见的问题包括不受控制的生成以及模型无法以指定格式生成响应。图3(b),3(e) 和 3(f) 展示了模型生成正确答案但未能遵循所需的JSON格式或继续超出答案生成文本的实例。
然而,这些响应没有显示出任何模式,使得难以提出系统化的方法来处理这些响应以供进一步使用。因此,我们不再深入研究这一点。
此外,模型在少量样本设置下对提示注入的脆弱性仍然是一个关注点,因为细微的扰动会导致性能下降。另一方面,微调模型对提示扰动表现出更强的鲁棒性,表明在遵守结构化响应方面有所改进。这需要围绕构建能够处理这些扰动的小型模型以及探索使用输入验证器在将提示传递给模型之前清理不准确内容的方法进行更多工作。这需要结合软件工程和自然语言处理的专业知识才能实现。
在边缘设备上部署SLMs需要在延迟、内存和性能之间取得平衡。如图4所示,边缘延迟通常比服务器延迟高出一个数量级,这需要模型优化和高效的推理技术,如闪存注意力 [13] 或硬件加速。持续使用还面临功率和温度限制,这可以通过神经处理单元(NPUs)和专用加速器来缓解,以提高效率和热管理。
未来NLP研究方向:我们的研究结果突显了改进SLMs用于生成任务的几个研究方向。
不受控制的生成和不正确的格式问题需要在解码策略方面取得进展。研究受限解码技术 [23, 50],如语法约束采样和结构化输出模型,可以帮助缓解这些问题。
另一个需要注意的点是我们尝试了一种简单的提示注入攻击,并观察到模型性能显著下降。更复杂的攻击如多轮提示注入 [3] 有可能操纵模型泄露敏感系统信息。因此,开发强大的防御机制以减轻此类攻击的影响是至关重要的。
构建特定任务的微调模型可能在不同函数调用领域中的通用性方面面临挑战。未来的研究可以探索跨任务适用性,并利用合成数据生成针对特定领域的数据集。
| 模型 | 服务器 (fp16) | 边缘 (GGUF) |
|---|---|---|
| Deepseek-coder-1.3B-instruct | 2,570.24 | 1,678.18 |
| Phi-3-mini-4k-instruct | 7,642.16 | 3,990.97 |
| Phi-2 | 5,304.32 | 2,443.01 |
| Starcoder2-3B | 5,775.36 | 2,051.05 |
| Stable-code-3B | 5,335.04 | 3,058.95 |
表4:各设置下模型的内存使用情况(MB)。
未来SE研究方向:SLMs为软件工程提供了高效且可扩展解决方案的有希望机会。微调模型在函数调用任务中表现出强劲性能,突显了其在实际应用中的潜力。此外,我们的研究表明提示注入对其有效性的影响最小。研究人员应专注于开发更具鲁棒性的微调SLMs,以应对各种场景,确保在函数调用生成中的更大可靠性和适应性。关于在不同SE生命周期任务中的通用性和对各种攻击的抗性进一步研究可以增强这些模型的鲁棒性,使其更适合实际部署。这项研究将有助于弥合实验与实际应用之间的差距。
SLMs还在重新设想模型与软件系统的集成方面提供了一个机会,以使其更加高效。
3
{ }^{3}
3 https://github.com/Raghav010/Small-Models-Big-Tasks
大多数由LLM驱动的应用依赖于单一LLM来处理和解决多种任务。相比之下,SLM研究集中于构建执行专门功能的任务特定模型,效率更高。这可以用来通过分解大型复杂任务并将它们路由到各种专门的SLMs,保持整体性能的同时显著降低计算成本,从而设计出可持续的软件系统。
| 设置 | 模型 | 零样本 | 少样本 | 微调 |
|---|---|---|---|---|
| 服务器 (I测) | Despoork-coder-1.3B-instruct | 3.59 | 3.22 | 3.91 |
| Phi-3-mini-4k-instruct | 35.23 | 39.14 | 32.88 | |
| Pln-2 | 22.19 | 28.97 | 62.40 | |
| Starcodez2-3B | 32.05 | 33.25 | 60.32 | |
| Stable-code-3B | 22.95 | 27.67 | 31.91 | |
| 边缘 (GGOF) | Despoork-coder-1.3B-instruct | 64.87 | 70.55 | 61.10 |
| Phi-3-mini-4k-instruct | 364.51 | 335.38 | 124.76 | |
| Pln-2 | 133.67 | 250.77 | 140.29 | |
| Starcodez2-3B | 246.63 | 262.92 | 267.65 | |
| Stable-code-3B | 214.89 | 265.90 | 175.77 |
表5:各设置下模型的延迟(秒)。
这种向任务特定SLMs的转变不仅增强了效率,还为混合部署策略[21]开辟了途径。诸如边缘-云协作等技术,其中初始推理在设备上进行,复杂查询卸载到云端,可以减少延迟同时保持稳健性。诸如模型压缩 [62]、量化 [14] 和知识蒸馏 [18] 等技术可以帮助优化计算效率,支持更快推理并减少对云资源的依赖。然而,这些技术在软件工程任务中的有效性尚未得到充分研究,为未来研究指明了方向。
实践意义:我们的研究结果表明,在实际应用中部署SLMs进行函数调用需要仔细考虑性能、可靠性和集成挑战。真实环境对性能和可靠性提出了更高的期望,因为应用程序开发者需要能够安全集成到生产系统的模型。尽管如此,SLMs在实时应用中具有独特优势,尤其是在延迟至关重要的情况下。这不仅降低了推理成本,还通过降低能源消耗和碳足迹支持了AI绿化倡议,与基于大型云的模型相比更为环保。然而,一个挑战依然存在——对结构化格式的不一致遵守,这对集成到生产系统构成了挑战。大多数模型不符合指定格式,需要工程解决方案来增强适应性。诸如强制结构化输出的包装器、响应格式检查器和护栏等方法可以帮助缓解不良输出。精心设计指令以与模型特定的提示格式对齐的提示工程可以改善结构化输出生成。然而,通过提示注入攻击对提示的扰动可能会使输出不可用。相比之下,Typechat 6 { }^{6} 6 和 Guidance 7 { }^{7} 7 等工具可以用来引导生成模型生成结构化输出。TypeChat 启用了基于 TypeScript 的模型交互,使用重新提示和 TypeScript 编译器进行输出验证。相比之下,Guidance 结合了提示工程、受约束的标记生成和重新提示,以提高模型响应的控制和精度。我们相信开发人员可以从这些工具中大大受益
来生成更好的响应并改进不良的响应。
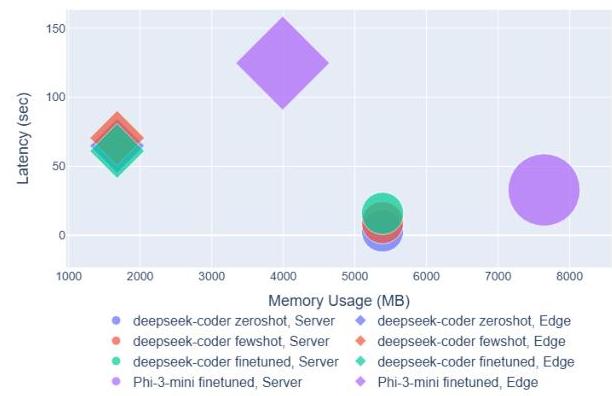
图4:模型在边缘和服务器环境下的延迟(秒)和内存使用(MB)比较。
一个关键的部署考虑因素是在少量样本提示和微调之间进行选择。少量样本提示提供了灵活性,允许通过提示修改轻松适应后端更新。微调增强了任务性能和对提示扰动的鲁棒性,但需要更高的计算和维护成本。选择取决于在适应性与性能需求之间取得平衡。
尽管SLMs在函数调用系统中的潜力巨大,但由于缺乏有效的部署框架以及边缘计算设备的异构性,其采用仍受到限制,这使得将这些模型集成到实际系统中变得复杂 [60]。此外,在动态、资源受限环境中确保可靠的性能和低延迟执行仍然是一个持续的障碍。解决这些挑战需要SE和NLP社区之间更强的合作。
7 对有效性的威胁
在本节中,我们讨论了我们研究的有效性威胁。我们遵循Wohlin等人提供的分类 [53] 并解释我们如何尝试减轻这些威胁。
内部有效性:从EvalPlus排行榜中选择模型是基于它们所展示的编码能力,减少了模型选择中的偏见风险。这确保了我们的分析集中在最先进的模型上。研究中使用的度量标准可能会对有效性构成威胁。据我们所知,目前尚无标准度量标准可以全面评估函数调用。现有的ROUGE、BLEU和METEOR等度量标准侧重于文本语法和语义,不适合我们的用例。因此,我们定义了评估函数定义各个方面的新度量标准。
外部有效性:新型SLMs的快速发布使得不可能考虑所有模型进行研究。因此,我们仔细选择了符合我们要求的EvalPlus排行榜上的顶级模型。另一种有效性威胁是模型可能在训练期间接触过测试数据。然而,由于
6
{ }^{6}
6 https://microsoft.github.io/TypeChat/
7
{ }^{7}
7 https://github.com/guidance-ai/guidance
大多数模型不会公开披露其训练数据的详细信息,我们无法缓解此数据泄露问题。我们仅考虑QIDK设备进行我们的边缘实验。然而,其他具有不同硬件配置的边缘设备的性能结果可能会有所不同。未来的工作可以探索这些模型在更广泛的边缘设备上的表现。
构建有效性:使用的数据集可能会对构建有效性构成潜在威胁。为了减轻这一点,我们选择了包含来自金融、技术、医疗保健、体育等多个领域的真实世界函数调用的salesforce-xlam函数调用数据集。我们从数据集中选择了100个数据点进行边缘设备实验。如果子集不能代表整个数据集,这可能会对有效性构成威胁。为了减轻这一点,我们随机选择数据点以确保平衡样本。此外,研究中使用的度量标准旨在捕捉函数调用生成的各个方面,提供了对模型能力的多维度综合评估。
8 结论
在这项研究中,我们探讨了小型语言模型生成函数调用的能力。我们评估了EvalPlus排行榜上排名前五的SLMs在零样本、少样本、微调和边缘设备等各种实验设置下的表现。此外,我们通过进行提示注入实验评估了这些模型的鲁棒性。我们发现SLMs在自主生成函数调用方面存在困难,其性能通过后期处理有所改善,但因提示注入而有所下降。此外,我们观察到模型在服务器上的高性能并不一定转化为边缘设备设置。此外,我们提供了本研究中的微调模型,并概述了NLP和SE社区在实际场景中增强函数调用生成的前进路径。
未来的工作可以涉及将本研究扩展到特定语言的函数调用生成,提供有关模型在各种编程语言中的表现的见解。探索其他边缘设备并评估各种对抗性攻击将提供更全面的鲁棒性评估。另一个潜在方向是利用基于LLM的代理和多代理系统生成函数调用并执行它们。
致谢
我们衷心感谢Qualcomm Inc.和AlphaGrep通过支持IIITHyderabad, India为我们这项研究提供的慷慨资助和支持。我们还要感谢Sujay Belsare和Ananth Yegavakota在边缘设备实验中的帮助。此外,我们要感谢Kunal Bhosikar、Hiya Bhatt、Shrikara A、以及SERC和Precog小组的其他成员,IIIT-Hyderabad,他们提供了宝贵的反馈。
参考文献
[1] Ibrahim Abdelaziz, Kinjal Basu, Mayank Agarwal, Sadhana Kumaravel, Matthew Stallone, Rameswar Panda, Yara Rizk, GP Bhargav, Maxwell Crouse, Cholaka Gunasekara, et al. 2024. Granite-function calling model: Introducing function calling abilities via multi-task learning of granular tasks. arXiv preprint arXiv:2407.00121 (2024).
[2] Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, and Arash Bakhtiari et al. 2024. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv:2404.14219 [cs.CL] https://arxiv.org/abs/2404.14219
[3] Divyandı Agarwal, Alexander Fablet, Ben Risher, Philippe Laban, Shafiq Joty, and Chien-Sheng Wu. 2024. Prompt Leakage effect and mitigation strategies for multiturn LLM Applications. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, Franck Dernoncourt, Daniel Preoţiuc-Pietro, and Anastasia Shimorina (Eds.). Association for Computational Linguistics, Miami, Florida, US, 1255-1275. doi:10.18633/v1/2024.emnlp-industry. 94
[4] Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. 2021. Unified pre-training for program understanding and generation. arXiv preprint arXiv:2103.06333 (2021).
[5] Muhammad Azeem Akbar, Arif Ali Khan, Najmul Islam, and Sajjad Mahmood. 2024. DevOps project management success factors: A decision-making framework. Software: Practice and Experience 54, 2 (2024), 257-280.
[6] Satanjeev Banerjee and Alon Lavie. 2004. Meteor: an automatic metric for MT evaluation with high levels of correlation with human judgments. Proceedings of ACL-WMT (2004), 65-72.
[7] Kinjal Basu, Ibrahim Abdelaziz, Subhajit Chaudhury, Soham Dan, Maxwell Crouse, Asim Munawar, Sadhana Kumaravel, Vinod Muthusamy, Pavan Kapanipathi, and Luis A Lautraz. 2024. API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs. arXiv preprint arXiv:2402.15491 (2024).
[8] Herekiah J Branch, Jonathan Rodriguez Cefalo, Jeremy McHugh, Leyla Hujer, Aditya Bahl, Daniel del Castillo Iglesias, Ron Heichman, and Ramesh Darwishi. 2022. Evaluating the susceptibility of pre-trained language models via handcrafted adversarial examples. arXiv preprint arXiv:2209.02128 (2022).
[9] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, and et al. 2020. Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems (Vancouver, BC, Canada) (NIPS’20). Curran Associates Inc., Red Hook, NY, USA, Article 159, 25 pages.
[10] Saheed A Busari and Emmanuel Letier. 2017. Radar: A lightweight tool for requirements and architecture decision analysis. In 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE). IEEE, 552-562.
[11] Victor B Basili1 Gianluigi Caldera and H Dieter Rombach. 1994. The goal question metric approach. Encyclopedia of software engineering (1994), 528-532.
[12] Xiang Chen, Chaoyang Gao, Chunyang Chen, Guangbei Zhang, and Yong Liu. 2025. An Empirical Study on Challenges for LLM Application Developers. arXiv:2408.05002 [cs.SE] https://arxiv.org/abs/2408.05002
[13] Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. arXiv:2205.14135 [cs.LG] https://arxiv.org/abs/2205.14135
[14] Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. Gpt3. int8 (3. 8-bit matrix multiplication for transformers at scale. Advances in Neural Information Processing Systems 35 (2022), 30318-30332.
[15] Georgi Gerganov. [n. d.]. GGML. https://github.com/ggerganov/ggml
[16] Georgi Gerganov. 2023. GGUF. https://github.com/ggerganov/ggml/blob/master/ docs/gguf.md
[17] Kai Greshale, Sahar Abdelnahi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not what you’ve signed up for: Compromising realworld llm-integrated applications with indirect prompt injection. In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, 79-90.
[18] Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. 2023. Knowledge distillation of large language models. arXiv preprint arXiv:2306.08543 (2023).
[19] Daya Guo, Qihuo Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence. arXiv:2401.14196 [cs.SE] https: //arxiv.org/abs/2401.14196
[20] Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, and Yang Liu. 2024. StableToolBench: Towards Stable LargeScale Benchmarking on Tool Learning of Large Language Models. arXiv preprint arXiv:2403.07714 (2024).
[21] Zren Hao, Huiajang Jiang, Shiaj Jiang, Ju Ren, and Ting Cao. 2024. Hybrid SLM and LLM for Edge-Cloud Collaborative Inference. Proceedings of the Workshop on Edge and Mobile Foundation Models (2024). https://api.semanticscholar.org/ CorpusID:270405086
[22] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lorx: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021).
[23] J. Edward Hu, Huda Khayrallah, Ryan Culkin, Patrick Xia, Tongfei Chen, Matt Post, and Benjamin Van Durme. 2019. Improved Lexically Constrained Decoding for Translation and Monolingual Rewriting. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burstein, Christy Doran, and Thamar Solorio (Eds.). Association for Computational Linguistics, Minneapolis, Minnesota, 839-850. doi:10.18655/v1/Xl19-1090
[24] Mojan Javaherigi, Sébastien Bubeck, Marah Abdin, Jyoti Aneja, Sebastien Bubeck, Caio César Teodoro Mendes, Weizhu Chen, Allie Del Giorno, Ronen Eldan, Sivakanth Gopi, et al. 2023. Phi-2: The surprising power of small language models. Microsoft Research Blog 1, 3 (2023), 3.
[25] Nan Jiang, Thibaud Luteiller, and Lin Tan. 2021. Cure: Code-aware neural machine translation for automatic program repair. In 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 1161-1173.
[26] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems 35 (2022), 22199-22213.
[27] Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Marie-Francine Moens, Xuoxiang Huang, Lucia Specia, and Scott Wen-tau Yih (Eds.). Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 30453059. doi:10.18653/v1/2021.emnlp-main. 243
[28] Xiang Lisu Li and Percy Liang. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (Eds.). Association for Computational Linguistics, Online, 4582-4597. doi:10.18653/v1/2021.acl-long. 353
[29] Zongjie Li, Chaosheng Wang, Zhibu Liu, Haoruan Wang, Dong Chen, Shuai Wang, and Cuiyun Gao. 2023. Cctest: Testing and repairing code completion systems. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1238-1250.
[30] Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out. 74-81.
[31] Yishuai Lin, Philippe Descamps, Nicolas Gaud, Vincent Hilaire, and Abderrafisa Koukam. 2015. Multi-agent system for intelligent scrum project management. Integrated Computer-Aided Engineering 22, 3 (2015), 281-296.
[32] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. In Thirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=1qvx610Cu7
[33] Yupei Liu, Yuqi Jia, Bunpeng Geng, Jinyuan Jia, and Neil Zhengiang Gong. 2024. Formalizing and benchmarking prompt injection attacks and defenses. In 33rd USENIX Security Symposium (USENIX Security 24). 1831-1847.
[34] Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Shirley Kokane, Juntao Tan, Weiran Yao, Zhiwei Liu, Yibao Feng, Rithesh Murthy, Liangwei Yang, Silvio Savarese, Juan Carlos Niebles, Huan Wang, Shelby Heinecke, and Caiming Xiong. 2024. APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets. arXiv:2406.18518 [cs.CL] https://arxiv.org/abs/2406. 18518
[35] Anton Leshkov, Raymond Li, Loubna Ben Allal, Federico Cassano, and et al. 2024. StarCoder 2 and The Stack v2: The Next Generation. arXiv:2402.19173 [cs.SE] https://arxiv.org/abs/2402.19173
[36] Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, et al. 2021. Codesglue: A machine learning benchmark dataset for code understanding and generation. arXiv preprint arXiv:2102.04664 (2021).
[37] Fangwen Mu, Xiao Chen, Lin Shi, Song Wang, and Qing Wang. 2023. Developerintent driven code comment generation. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 768-780.
[38] Chien Van Nguyen, Xuan Shen, Ryan Aponte, Yu Xia, Samyadeep Basu, Zhengmian Hu, Jian Chen, Mihir Parmar, Sasidhar Kunapuli, Joe Barrow, Junda Wu, Ashish Singh, Yu Wang, Jiusiang Gu, Franck Dernoncourt, Neseem K. Ahmed, Nedim Lipka, Ruiyi Zhang, Xiang Chen, Tong Yu, Sungchul Kim, Hanieh Deilamsalehy, Nanyong Park, Mike Rimer, Zhehao Zhang, Huanrui Yang, Ryan A. Rossi, and Thien Huu Nguyen. 2024. A Survey of Small Language Models. arXiv:2410.20011 [cs.CL] https://arxiv.org/abs/2410.20011
[39] NoueResearch. 2023. Nous-Hermes-13b. https://huggingface.co/NousResearch/ Nous-Hermes-13b
[40] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics. 311-318.
[41] Eugenio Parra, Jose Luis de la Vara, and Luis Alonso. 2018. Analysis of requirements quality evolution. In Proceedings of the 40th International Conference on Software Engineering: Companion Proceedings. 199-200.
[42] Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. 2023. Gcrilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334 (2023).
[43] Nikhil Pinnaparaju, Reshinth Adithyao, Duy Phung, Jonathan Tow, James Baicoianu, and Nathan Cooper. [n. d.]. Stable Code 5B. https://huggingface.co/ stabilityai/stable-code-3b
[44] Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. 2023. Toollim: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789 (2023).
[45] Murray Shunahan. 2024. Talking about large language models. Commun. ACM 67, 2 (2024), 68-79.
[46] Yisheng Song, Ting Wang, Puyu Cai, Subrota K Mondal, and Jyoti Prakash Sahoo. 2025. A comprehensive survey of few-shot learning: Evolution, applications,
challenges, and opportunities. Comput. Surveys 55, 136 (2025), 1-40.
[47] Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Bosi Cao, and Le Sun. 2023. Toolapace: Generalized tool learning for language models with 8000 simulated cases. arXiv preprint arXiv:2306.05301 (2023).
[48] Runchu Tian, Yining Ye, Yujia Qin, Xin Cong, Yankai Lin, Yinxu Pan, Yesai Wu, Haotian Hui, Weichuan Liu, Zhiyuan Liu, et al. 2024. Debugbench: Evaluating debugging capability of large language models. arXiv preprint arXiv:2403.04621 (2024).
[49] Fali Wang, Zhiwei Zhang, Xianren Zhang, Zongyu Wu, Tzuhao Mo, Qiuhao Lu, Wanjing Wang, Rui Li, Junjie Xu, Xianfeng Tang, Qi He, Yao Ma, Ming Huang, and Suhang Wang. 2024. A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness. arXiv:2411.03350 [cs.CL] https: //arxiv.org/abs/2411.03350
[50] Yiwei Wang, Muhao Chen, Nanyun Peng, and Kai-Wei Chang. 2024. DeepEdit: Knowledge Editing as Decoding with Constraints. arXiv:2401.10471 [cs.CL]
[51] Yaqing Wang, Quanning Yao, James T Kwok, and Lionel M Ni. 2020. Generalizing from a few examples:少量样本学习的综述。ACM计算调查(CRAN) 53, 3 (2020), 1-34.
[52] Simon Willison. 2023. 分隔符无法保护你免受提示注入攻击。https://simonwillison.net/2023/May/11/delimiters-wont-save-you/
[53] Clare Woldin, Per Runeson, Martin Höst, Magnus C Ohlsson, Björn Regnell, Anders Wesslén 等. 2012. 软件工程中的实验。第236卷。Springer出版社。
[54] Fangzhou Wu, Ning Zhang, Someeb Jha, Patrick McDaniel, 和 Chaowei Xiao. 2024. 大型语言模型安全的新时代:探索现实世界基于LLM系统的安全问题。arXiv:2402.18649 [cs.CR] https://arxiv.org/abs/2402.18649
[55] Biwei Yan, Kun Li, Minghui Xu, Yueyan Dong, Yue Zhang, Zhaochun Ren, 和 Xiuzhen Cheng. 2024. 论保护大型语言模型的数据隐私:一项综述。arXiv预印本 arXiv:2403.05156 (2024).
[56] Fanjia Yan, Huanzhi Mao, Charlie Cheng-Jie Ji, Tianjun Zhang, Shishir G. Patil, Ion Stoica, 和 Joseph E. Gonzalez. 2024. Berkeley 函数调用排行榜。https://gorilla.cs.berkeley.edu/blogs/5_berkeley_function_calling_leaderboard.html.
[57] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, 和 Yuan Cao. 2022. React: 在语言模型中协同推理与行动。arXiv预印本 arXiv:2210.03629 (2022).
[58] Kechi Zhang, Huangzhao Zhang, Ge Li, Jia Li, Zhuo Li, 和 Zhi Jin. 2023. Toolcoder: 教授代码生成模型使用API搜索工具。arXiv预印本 arXiv:2305.04032 (2023).
[59] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong 等. 2023. 大型语言模型的综述。arXiv预印本 arXiv:2305.18223 (2023).
[60] Yue Zheng, Yuhao Chen, Bin Qian, Xinfang Shi, Yuanchao Shu, 和 Jining Chen. 2024. 边缘大语言模型综述:设计、执行与应用。arXiv:2410.11845 [cs.DC] https://arxiv.org/abs/2410.11845
[61] Lucen Zhong, Zhengxiao Du, Xiaohan Zhang, Haiyi Hu, 和 Jie Tang. 2025. ComplexFuncBench:探索长上下文场景下的多步骤和约束函数调用。arXiv预印本 arXiv:2501.10132 (2025).
[62] Xunyu Zhu, Jian Li, Yong Liu, Can Ma, 和 Weiping Wang. 2024. 大型语言模型压缩技术综述。计算语言学协会会刊 12 (2024), 1556-1577.
参考论文:https://arxiv.org/pdf/2504.19277



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











