






刘科、马静和赖恩德·M-K,新西兰奥克兰理工大学数据科学与人工智能系
本文提出了一种自适应动态属性和规则(ADAR)框架,旨在解决高维数据在神经模糊推理系统中带来的挑战。通过集成双重加权机制——为属性和规则分配自适应的重要性权重——以及自动增长和修剪策略,ADAR能够自适应地简化复杂的模糊模型,同时不牺牲性能或可解释性。通过对四个不同数据集的实验评估——Auto MPG(7个变量)、北京PM2.5(10个变量)、波士顿房价(13个变量)和家电能耗(27个变量)——显示基于ADAR的模型相比最先进的基线方法实现了更低的均方根误差(RMSE)。例如,在北京PM2.5数据集中,ADAR-SOFENN达到了九条规则下的56.87 RMSE,超越了传统的ANFIS [12] 和 SOFENN [16] 模型。同样,在高维家电能耗数据集中,ADAR-ANFIS在九条规则下达到了83.25的RMSE,优于已建立的模糊逻辑方法和专注于可解释性的方法如APLR。消融研究进一步揭示了结合规则级和属性级权重分配显著减少了模型重叠,同时保留了关键特征,从而增强了可解释性。这些结果突显了ADAR在动态平衡规则复杂性和特征重要性方面的有效性,为适用于各种实际场景的可扩展、高精度和透明的神经模糊系统铺平了道路。
额外关键词和短语:ADAR框架、神经模糊推理系统、高维数据、模型可解释性
ACM参考格式:
Ke Liu, Jing Ma, and Edmund M-K Lai. 2018. 高维数据模糊推理系统的动态模糊规则与属性管理框架。1, 1(2018年4月),23页。https://doi.org/XXXXXXX.XXXXXXX
1 引言
神经模糊系统(NFS)首次于1990年代提出,试图将模糊IF-THEN规则的可解释性与人工神经网络的学习能力相结合[26]。不同类型NFS已成功应用于工业过程控制[2, 18]、医学模式识别[7, 9, 24]和金融预测[15, 30]等领域。然而,与其他许多机器学习系统一样,NFS随着输入特征数量的增加也遭受“维度灾难”的困扰。有人尝试通过使用手动定义的规则或固定特征子集来解决这一缺陷[32]。但这些方法通常缺乏适应实际应用中数据异质性的自适应机制[35]。
尽管在处理高维数据方面取得了显著进展,但仍存在几个关键挑战。首先,诸如自编码器[11]、粒子群优化(PSO)[13]和模块化NFS设计[12]等技术提高了鲁棒性和计算效率。但它们往往没有一个统一的框架自适应地整合特征选择、规则管理和性能优化。这导致了分散的、特定领域的解决方案,难以在异构数据集或动态变化环境中进行推广。
其次,像Fuzzy-ViT [17]和GFAT [8]等模型在模型中采用了重要性加权机制,以更强调关键输入特征。然而,这些模型仍主要限制在特定应用中,如医学成像、癌症转移预测和海洋波高预报[1, 8, 17]。此外,它们缺乏明确的动态规则和属性管理机制,限制了在处理高维和动态数据时的透明度和可解释性。因此,这些基于权重的方法难以提供一个能在不同领域中平衡预测准确性和模型可解释性的可扩展解决方案。
第三,当前处理高维数据的策略缺乏系统化的机制来一致地调节规则复杂性和特征重要性。许多方法仍然依赖于手动定义的规则或简单的剪枝算法,这对于捕捉随时间演变的真实世界数据分布及其多个属性之间的潜在交互是不够的[21, 31, 33]。这不仅削弱了模型的可解释性,还对数据特征和操作条件快速变化的领域中的性能产生了负面影响。
在本文中,我们提出了自适应动态属性和规则(ADAR)框架,以应对上述挑战。它集成了双重重要性加权机制,分别作用于属性和规则,不同于现有的单独处理方案。通过这种方式,ADAR能够在单一连贯框架内调节规则复杂性和特征重要性。这确保了跨不同数据集的可扩展性和透明性,填补了神经模糊研究中的关键空白。据我们所知,这是首次将自适应规则和特征加权、动态结构调节和神经模糊逻辑整合到单一框架中。ADAR具有以下关键特性:
(1) 双重加权机制:通过为属性和规则分配重要性权重,所提出的框架能够精确控制模型复杂性,提高性能和可解释性。
(2) 规则和属性的自适应管理:自动增长和修剪策略使模型能够根据数据集的复杂性调整规则和属性的数量,克服固定或手动定义结构的限制。
(3) 应对高维数据的挑战:属性修剪和指导学习有效缓解了“维度灾难”,允许模糊逻辑系统应用于复杂、高维环境。
(4) 提高模型可解释性:通过明确突出每个属性和规则的重要性,ADAR框架增强了决策过程中的透明度,从而推动了可解释人工智能的发展。
2 神经模糊系统中的高维数据管理
当NFS应用于大型数据集时,管理模型参数的指数增长一直是一个问题。早期的努力主要集中在扩展传统模糊逻辑架构以处理增加的维度。但这些方法通常导致过于复杂的模型,难以训练和解释[5]。随着数据集规模和多样性的增长,研究人员开始引入降维方法,如主成分分析(PCA)
和自编码器,将高维输入投影到低维子空间[34]。例如,Pirmoradi等人[19]提出了一种用于肾癌亚型分类的自组织深度神经模糊推理系统,该方法解决了高维miRNA基因组数据的挑战。该方法结合了基于相关性的过滤器进行特征选择,利用算术-几何平均离散度度量,并采用深度自编码器压缩作为NFS输入的高维数据。这种方法显著减少了计算复杂度,同时保持了稳健的预测准确性。类似地,R.K. Sevakula和N.K. Verma [23]利用深度自编码器进行降维。深度自编码器的输出充当NFS的输入数据的压缩表示。Afshin Shoeibi等人[27]结合自编码器和PCA作为降维技术,用于自适应神经模糊推理系统(ANFIS)预测癫痫发作。虽然这些预处理技术有助于减轻计算需求,但它们通常将转换过程与模糊推理层分开,导致丢失对有效规则生成至关重要的有价值信息。
近期的研究越来越强调将优化算法与神经模糊模型集成以提高高维任务中的性能。一个显著的例子是由Shahaboddin等人[25]引入的基于粒子群优化(PSO)的ANFIS模型。该模型利用PSO算法优化模糊系统中的隶属函数参数,实现了在建模复杂非线性问题时改进的鲁棒性和准确性。同时,它还能减少模型复杂性。
另一种方法利用分层和模块化的NFS框架。高维输入空间被划分为较小、可管理的子空间,在这些子空间中独立进行局部模糊推理,然后将结果组合成最终预测。与传统的全局建模相比,这些策略在可解释性和性能优化方面提供了明显优势。Siminski等人[28]通过整合模糊双聚类扩展了这一概念,该方法同时对对象和特征进行聚类以创建特定子空间的模糊规则。这样可以强调在特定维度中重要的特征。
另一个有希望的方向是集成高效的特征处理技术以增强高维环境中的适应性。例如,Sajid等人[22]引入了NF-RVFL模型,该模型结合随机向量功能链接网络(RVFL)与NFS。它采用K-means和模糊C-means等聚类方法提供模糊集中心的初始值,并利用随机投影和直接连接策略。通过利用高维输入中的冗余同时保留关键原始特征信息,该模型增强了特征多样性表示和训练效率。这种创新在复杂数据分布下平衡了计算复杂性和模型性能。
尽管上述策略显著提升了NFS在高维场景中的性能,但将这些方法集成到灵活且可扩展的统一框架中仍然是一个挑战。它们通常关注局部优化和降维技术,缺乏一种有效整合分层建模、特征选择和优化算法的方式。这常常导致适应性有限的碎片化模型。此外,随着应用场景的多样化,需要能够管理跨子空间规则交互并支持实时更新的模型。当前方法难以系统地实现性能、可解释性和可扩展性之间的动态平衡。
3 ADAR框架
我们提出了自适应动态属性和规则(ADAR)框架,以克服现有NFS的不足。它旨在提升现有NFS如ANFIS [12]的性能和可解释性。在NFS的训练过程中引入了属性和规则的可学习加权机制。同时,还引入了规则增长和修剪过程以及属性修剪过程。因此,此框架中的三个主要元素是:(1)初始化,(2)属性加权和修剪,以及(3)规则增长和修剪。图1展示了集成在ANFIS结构中的ADAR框架。它呈现了从输入到输出的架构流程,重点说明了如何嵌入属性加权机制和规则加权机制以促进可解释和高效的模型行为。
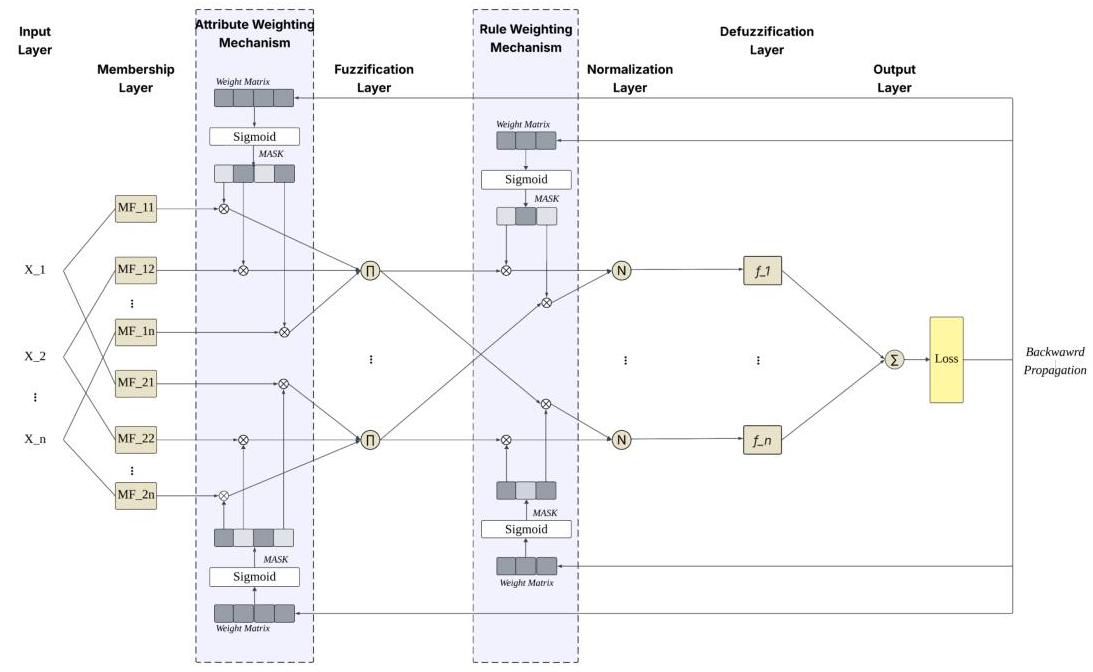
图1. ADAR-ANFIS框架架构
3.1 初始化
初始化涉及确定模糊规则的初始数量和参数,以及数据属性和模糊规则的重要性权重。归一化的训练数据首先通过K均值聚类划分为簇。然后使用每个簇的质心作为每个规则的高斯隶属函数均值的初始值。由每簇数据点的特征标准差初始化规则的形状和支持,这些由高斯函数的标准差量化。这允许每个隶属函数的宽度反映局部数据离散程度,为模糊划分提供数据驱动的、规则特定的基础。初始属性重要性权重从高斯分布中随机采样,引入各维度的初始变异性。规则权重通常初始化为1,表示所有规则在开始时具有相等贡献。
3.2 带加权机制的神经模糊系统
在训练期间,两类重要性权重都被视为完全可微参数并通过反向传播更新。模型进一步对这些权重应用L1正则化以促进稀疏性——自动抑制无关输入特征和冗余规则。这一策略通过选择性放大信息模式增强了模型的可解释性,同时在训练过程中实现了自动结构剪枝。结果,模型演变为更加紧凑、高效且语义意义更强的模糊推理系统。
在训练迭代期间,属性修剪(AP)机制定期激活。AP利用属性重要性权重识别并移除持续贡献较低的属性,从而简化模型结构并增强可解释性。修剪后,评估性能变化以确定修剪是否显著降低性能。如果确实如此,则恢复先前的结构以维持复杂性和准确性之间的平衡。
ADAR还采用规则增长和修剪(RG&P)策略,定期调整规则库的大小。规则修剪通过评估其重要性权重并消除那些持续影响较低的规则来去除冗余规则。相反,规则增长识别高预测误差的未充分表示区域,促使创建新规则以有效捕获这些复杂数据模式。每当发生结构修改时,优化器重新初始化以使参数优化与当前模型架构对齐。这些过程将在以下部分详细描述。
3.3 属性加权机制
在ADAR框架下,每个规则 l l l中的每个属性 i i i关联一个可学习的重要权重 α l , i \alpha_{l, i} αl,i。
这些权重反映了每个特征在其关联模糊规则内的相对重要性。通过在训练过程中学习此类权重,模型有效地过滤输入特征空间,聚焦于显著影响预测任务的属性,而忽略那些贡献极小的属性。
引入了一个可训练参数矩阵
W
a
∈
R
L
×
D
\mathbf{W}_{a} \in \mathbb{R}^{L \times D}
Wa∈RL×D
其中
L
L
L是规则数,
D
D
D是输入属性数。这个矩阵捕获属性权重logits,每个元素
α
l
,
i
\alpha_{l, i}
αl,i代表特征
i
i
i在规则
l
l
l下的原始(前激活)重要性得分。这些logits通过sigmoid激活函数转换为最终的重要性权重,这些权重进一步由一个二进制属性掩码调制,以在规则级别强制稀疏性。
重要权重 α l , i \alpha_{l, i} αl,i按以下公式计算:
α l , i = σ ( w a , l , i ) ⋅ m l , i \alpha_{l, i}=\sigma\left(w_{a, l, i}\right) \cdot m_{l, i} αl,i=σ(wa,l,i)⋅ml,i
这里, σ ( ⋅ ) \sigma(\cdot) σ(⋅)代表sigmoid函数,确保 α l , i \alpha_{l, i} αl,i保持在范围 [ 0 , 1 ] [0,1] [0,1]内。变量 m l , i m_{l, i} ml,i用作属性掩码,初始化为所有属性的1,并在修剪过程中更新。当一个属性从规则中修剪时,其掩码设置为0,保证该属性不再影响模糊推理过程。
项 w a , l , i w_{a, l, i} wa,l,i是一个可训练参数,直接控制激活前特征 i i i在规则 l l l中的重要性。它通过梯度下降端到端学习,其大小决定了特征 i i i在规则 l l l中的影响。 w a , l , i w_{a, l, i} wa,l,i的较大正值导致 α l , i \alpha_{l, i} αl,i接近1,表示高度相关,而较大的负值则推动 α l , i \alpha_{l, i} αl,i接近0,表示低重要性。
3.4 属性修剪(AP)
高维特征空间通常包含对预测任务贡献最小的属性,即使有了属性加权机制也是如此。虽然重要性权重有助于识别规则内每个属性的重要性,但一些属性可能始终未被充分利用。AP的主要目标是去除那些尽管最初被包括在内,但始终未能表现出显著重要性的属性。经过属性加权机制的充分训练以调整重要性权重后,具有持续低权重值的属性从相应的规则中修剪掉。这一过程减少了规则的有效输入空间维度,缓解过拟合并提高了计算效率。
设 α l , i \alpha_{l, i} αl,i为规则 l l l中属性 i i i的重要性权重,如属性权重机制所定义。如果规则 l l l中的属性 i i i持续保持低于预定义修剪阈值 θ attr \theta_{\text {attr }} θattr 的重要性权重:
α l , i < θ a t t r \alpha_{l, i}<\theta_{\mathrm{attr}} αl,i<θattr
在较长时间或经过指定数量的训练周期后,对应的属性掩码 m l , i m_{l, i} ml,i被设置为零,有效排除属性 i i i参与规则 l l l的推理过程:
m l , i = 0 if α l , i < θ a t t r m_{l, i}=0 \quad \text { if } \quad \alpha_{l, i}<\theta_{\mathrm{attr}} ml,i=0 if αl,i<θattr
这里, θ attr \theta_{\text {attr }} θattr 是一个小超参数,定义了属性相关性的最低可接受水平。这一准则确保只有具有足够重要性的属性在模型中保持活跃状态。
3.5 规则加权机制
随着模糊神经网络复杂性的增长,管理大量规则变得日益具有挑战性。虽然属性加权机制优先考虑每个规则中最相关的特征,但规则加权机制旨在动态评估和强调整个规则的重要性。通过为每个规则分配和学习不同的重要性权重,这一机制引导模型专注于对预测贡献显著的规则,同时淡化或消除提供有限或冗余信息的规则。
规则加权机制为每个规则 l l l引入了一个可学习参数 β l \beta_{l} βl。直观上, β l \beta_{l} βl表示规则 l l l在推理过程中的整体重要性。持续无法减少残差误差的规则将保持低重要性权重,表明其对模型决策的贡献最小。相反,捕捉有意义模式或增强预测的规则将获得更高的重要性权重,确保其对最终输出的影响得到适当放大。
对于每个规则 l l l,引入了一个可学习参数 w r , l w_{r, l} wr,l。为了确保规则重要性权重 β l \beta_{l} βl保持在范围 [ 0 , 1 ] [0,1] [0,1]内,应用了sigmoid激活函数:
β l = σ ( w r , l ) \beta_{l}=\sigma\left(w_{r, l}\right) βl=σ(wr,l)
这里, σ ( ⋅ ) \sigma(\cdot) σ(⋅)代表sigmoid函数。较高的 β l \beta_{l} βl值表示更具影响力的规则,而较低的 β l \beta_{l} βl值表示重要性减弱。在训练期间,通过基于梯度的优化更新 w r , l w_{r, l} wr,l,允许模型根据数据动态调整每个规则的重要性。
3.6 规则增长和修剪(RG&RP)
虽然属性加权机制和属性修剪(AP)步骤细化了每个规则内的输入空间,但模糊推理系统的整体复杂性也受到规则数量的影响。规则太少可能会限制模型的表现力,而规则太多则可能导致冗余、过拟合和可解释性降低。为了平衡这些因素,我们将动态规则增长和修剪(RG&RP)策略纳入ADAR框架。RG&RP动态调整规则库,以在模型复杂性和表示能力之间保持平衡。当现有规则不足以覆盖输入空间的复杂区域或解决持续存在的错误时,模型引入新规则以更好地表示这些具有挑战性的数据子集。相反,持续显示低重要性——反映在其规则重要性权重——或在属性修剪后变得冗余的规则被删除以简化模型结构。规则增长和修剪(RG&RP)机制基于规则加权机制中学习到的规则重要性权重 { β I } \left\{\beta_{I}\right\} {βI}。RG&RP不是重新定义这些权重,而是利用它们以及其他性能指标动态调整规则库,确保高效有效的适应。
规则修剪标准:如果规则 l l l的重要性权重 β I \beta_{I} βI在较长时间内保持低于预定义阈值 θ r \theta_{\mathrm{r}} θr,则认为该规则未被充分利用,可能会被移除。这种修剪步骤帮助模型的复杂性与其实际需求相匹配,仅保留对预测贡献显著的规则。
正式地说,如果:
β I < θ r \beta_{I}<\theta_{\mathrm{r}} βI<θr
则标记规则
l
l
l为待移除,前提是此条件在多个训练周期内成立。
规则增长标准:另一方面,如果验证误差在特定耐心期内没有改善——尽管之前进行了属性修剪和训练——这表明现有规则可能不足以覆盖某些数据区域。在这种情况下,模型添加新规则以更好地覆盖输入空间并提高预测准确性。
如果:
验证误差在
p
p
p个周期内无改善且
L
<
L
max
L<L_{\max }
L<Lmax
(其中
p
p
p是耐心参数,
L
max
L_{\max }
Lmax是允许的最大规则数),模型选择训练集中高误差样本初始化新规则的隶属函数参数。新规则旨在捕捉以前未解释的模式并减少残差误差。
3.7 模糊推理模块
在ADAR框架中,模糊推理模块作为中央计算层,将输入数据转换为相关规则激活并生成最终预测。虽然基于权重的机制和动态结构调整侧重于识别最重要的属性和规则,模糊推理过程则控制这些元素如何相互作用,使模型能够有效管理不确定性、非线性和高维复杂性。
模糊推理模块的主要功能是使用模糊集表示输入特征并通过模糊规则组合它们以生成可靠预测。通过为每个规则中的每个属性使用参数化隶属函数(例如高斯函数),此模块自然有效地处理现实世界数据中的渐变过渡和不确定性。计算规则激发强度后,将其聚合和规范化以产生清晰输出。这种方法确保模型将学到的结构(规则和属性)与这些组件的重要性导向权重相结合,从而实现准确且可解释的预测。
考虑一组
L
L
L个模糊规则,每个规则都与每个输入属性的参数化隶属函数相关联。对于规则
l
l
l和属性
i
i
i,设
μ
l
,
i
(
x
i
)
\mu_{l, i}\left(x_{i}\right)
μl,i(xi)表示输入
x
i
x_{i}
xi对由规则
l
l
l定义的模糊集的隶属度。ADAR中常见的选择是高斯隶属函数:
μ l , i ( x i ) = exp ( − ( x i − v l , i ) 2 2 s l , i 2 ) \mu_{l, i}\left(x_{i}\right)=\exp \left(-\frac{\left(x_{i}-v_{l, i}\right)^{2}}{2 s_{l, i}^{2}}\right) μl,i(xi)=exp(−2sl,i2(xi−vl,i)2)
其中
v
l
,
i
v_{l, i}
vl,i和
s
l
,
i
s_{l, i}
sl,i是高斯集的可学习中心和宽度参数。
对于每个规则
l
l
l,通过汇总所有活动属性的隶属度计算组合激发强度。设
D
D
D为规则中的属性数:
激发强度 ( R l ) = ∏ i = 1 D μ l , i ( x i ) ⋅ α l , i \text { 激发强度 }\left(R_{l}\right)=\prod_{i=1}^{D} \mu_{l, i}\left(x_{i}\right) \cdot \alpha_{l, i} 激发强度 (Rl)=i=1∏Dμl,i(xi)⋅αl,i
其中 α l , i \alpha_{l, i} αl,i是属性重要性权重,确保较少重要的属性对规则的激活影响减小。
计算所有规则的激发强度后,通过规则重要性权重 β l \beta_{l} βl对其进行加权,反映每个规则的整体重要性:
f ^ l = 激发强度 ( R l ) ⋅ β l \widehat{f}_{l}=\text { 激发强度 }\left(R_{l}\right) \cdot \beta_{l} f l= 激发强度 (Rl)⋅βl
然后规范化规则激活为:
w l = f ^ l ∑ m = 1 L f ^ m + ϵ w_{l}=\frac{\widehat{f}_{l}}{\sum_{m=1}^{L} \widehat{f}_{m}+\epsilon} wl=∑m=1Lf m+ϵf l
其中
ϵ
\epsilon
ϵ是一个小常数,防止除以零。
最后,每个规则输出其结论部分中选定属性的线性组合:
y l = ∑ i ∈ A l c l , i x i y_{l}=\sum_{i \in \mathcal{A}_{l}} c_{l, i} x_{i} yl=i∈Al∑cl,ixi
其中 A l \mathcal{A}_{l} Al是规则 l l l中的活动属性集合, c l , i c_{l, i} cl,i是结论参数。最终预测是规则输出的加权和:
y = ∑ l = 1 L w l y l y=\sum_{l=1}^{L} w_{l} y_{l} y=l=1∑Lwlyl
3.8 与SOFENN的集成
ADAR框架与SOFENN的集成遵循类似于基于ANFIS实现的自适应训练原则,共享核心组件,包括属性加权机制、属性修剪(AP)、规则加权机制、规则增长和修剪(RG&RP),以及模糊推理模块。然而,由于SOFENN具有独特的结构特征,集成在初始化策略、规则演化和自适应优化方法上表现出显著差异。
具体来说,ADAR-SOFENN实现通过聚类方法初始化模糊规则,但强调更灵活的在线式结构调整。与主要细化固定模糊规则集的ANFIS不同,SOFENN本质上以更动态、数据驱动的方式支持增量规则构建和修剪。这自然与ADAR的动态属性和规则调整能力相契合,增强了SOFENN在自适应捕捉演化数据分布方面的优势。
在训练期间,SOFENN的属性级重要性加权机制同样根据动态计算的重要性权重指导周期性属性修剪。然而,独特的是,ADAR-SOFENN利用SOFENN固有的模块化架构,以更频繁和精细的属性级调整而不引起显著计算开销或结构不稳定。通过RG&RP进行的规则级调整与ANFIS集成也略有不同,因为SOFENN允许增量规则添加连续发生而非在离散间隔,从而实现对新兴数据模式的更平稳适应。
在两种框架中,属性和规则修剪程序包括严格的性能检查,当检测到过度性能退化时恢复结构更改。然而,ADARSOFENN独特地受益于SOFENN的增量优化策略,允许更无缝地集成新添加或移除的规则,通常比ADAR-ANFIS需要更少的完整优化器重新初始化。
总体而言,ADAR-SOFENN利用SOFENN的动态和增量结构,在模型复杂性和预测性能之间实现增强的平衡,特别适合展示非平稳或演化特性的数据集。
4 实验设计
ADAR的有效性将通过一系列计算实验进行评估。ADAR可以与ANFIS [12] 和 SOFENN [16] 结合使用,后者是一种统计在线模糊极限神经网络。因此,它们的性能将与传统的ANFIS和SOFENN进行比较。此外,我们还将与以下模型进行比较:
-
FuBiNFS [28]:一种新颖的模糊双边神经模糊系统,通过在子空间中构造模糊规则来增强泛化能力和可解释性。
-
- ANFIS-PSO [25]:集成粒子群优化(PSO)的ANFIS模型,用于优化参数并提高预测准确性。
-
- RVFL (Neuro-Fuzzy RVFL) [22]:一种将随机向量功能链接网络与神经模糊系统集成的模型,增强了模型的透明性和泛化能力。
-
- APLR [29]:自动分段线性回归模型具有高度可解释性,是模糊逻辑域之外的关键可解释性算法。
-
- DecisionTreeRegressor [3]:决策树回归模型具有高度可解释性,是模糊逻辑域之外的代表性算法。
-
- ADAR-ANFIS 和 ADAR-SOFENN:本论文中提出的ADAR框架增强了ANFIS和SOFENN模型。
-
4.0.1 数据集。我们选择了四个具有不同特征数和复杂性的数据集,以涵盖广泛的应用场景:
-
- Auto MPG [20](7个特征):用于预测汽车的每加仑英里数(MPG)。
-
- 北京PM2.5 [6](10个特征):用于预测空气中PM2.5的浓度。
-
- 波士顿房价 [10](13个特征):用于预测中位数房价。
-
- 家电能耗 [4](27个特征):用于预测家用电器的能耗。
每个数据集都经历了基本的数据预处理步骤,包括处理缺失值(如有必要)和标准化或归一化。这些措施确保一致的输入尺度并促进更可靠的模型比较。
注意:APLR和DecisionTreeRegressor的结构不涉及规则数量设置,因此其性能不受规则数量变化的影响。
4.0.2 评估指标。我们使用以下三个指标来评估模型的预测性能和结构优化:
- 家电能耗 [4](27个特征):用于预测家用电器的能耗。
-
均方根误差(RMSE):RMSE衡量模型预测值与实际值之间的平均偏差。较低的RMSE表示更高的预测准确性。它计算如下:
RMSE = 1 N ∑ i = 1 N ( y ^ i − y i ) 2 \text { RMSE }=\sqrt{\frac{1}{N} \sum_{i=1}^{N}\left(\hat{y}_{i}-y_{i}\right)^{2}} RMSE =N1i=1∑N(y^i−yi)2
其中 N N N是样本数, y ^ i \hat{y}_{i} y^i是预测值, y i y_{i} yi是实际值。
- 平均重叠指数
(
I
o
v
\left(I_{o v}\right.
(Iov ) [28]:衡量模糊规则库中规则的重叠程度。
I
o
v
I_{o v}
Iov计算每个属性下所有规则对的高斯隶属函数的最大重叠面积并取平均值:
I o v ( L ) = 1 D ∑ d = 1 D [ max i , j = 1 i ≠ j L max ∫ − ∞ + ∞ min ( μ A d ( I ) 1 ( x ) , μ A d ( I ) j ( x ) ) d x min ( ∫ − ∞ + ∞ μ A d ( I ) 1 ( x ) d x , ∫ − ∞ + ∞ μ A d ( I ) j ( x ) d x ) ] I_{o v}(L)=\frac{1}{D} \sum_{d=1}^{D}\left[\max _{\substack{i, j=1 \\ i \neq j}}^{\substack{L} \text { max }} \frac{\int_{-\infty}^{+\infty} \min \left(\mu_{A_{d}}^{(I)_{1}}(x), \mu_{A_{d}}^{(I)_{j}}(x)\right) d x}{\min \left(\int_{-\infty}^{+\infty} \mu_{A_{d}}^{(I)_{1}}(x) d x, \int_{-\infty}^{+\infty} \mu_{A_{d}}^{(I)_{j}}(x) d x\right)}\right] Iov(L)=D1d=1∑D i,j=1i=jmaxL max min(∫−∞+∞μAd(I)1(x)dx,∫−∞+∞μAd(I)j(x)dx)∫−∞+∞min(μAd(I)1(x),μAd(I)j(x))dx
其中
D
D
D是属性数,
L
L
L是规则数,
μ
A
d
(
I
)
(
x
)
\mu_{A_{d}}^{(I)}(x)
μAd(I)(x)表示第
l
l
l条规则在属性
d
d
d上的隶属函数。
较低的
I
o
v
I_{o v}
Iov值表示规则间重叠减少和规则库内更好的区分性,这通过最小化模糊规则间的歧义提高了模型的泛化能力和可解释性。
- 平均模糊集位置指数
(
I
f
s
p
\left(I_{f s p}\right.
(Ifsp ) [14]:
I
f
s
p
I_{f s p}
Ifsp通过计算相邻模糊集的位置和形状差异来评估模糊集的覆盖情况:
I f s p ( L ) = 1 L D ∑ d = 1 D ∑ l = 1 L − 1 [ 2 ⋅ ( 0.5 − ϕ A d ( I ) , A d ( l + 1 ) + ψ A d ( I ) , A d ( l + 1 ) ) ] I_{f s p}(L)=\frac{1}{L D} \sum_{d=1}^{D} \sum_{l=1}^{L-1}\left[2 \cdot\left(0.5-\phi_{A_{d}^{(I)}, A_{d}^{(l+1)}}+\psi_{A_{d}^{(I)}, A_{d}^{(l+1)}}\right)\right] Ifsp(L)=LD1d=1∑Dl=1∑L−1[2⋅(0.5−ϕAd(I),Ad(l+1)+ψAd(I),Ad(l+1))]
其中
ϕ A d ( I ) , A d ( l + 1 ) = exp [ − 1 2 ( v d ( I ) − v d ( l + 1 ) s d ( I ) + s d ( l + 1 ) ) 2 ] ψ A d ( I ) , A d ( l + 1 ) = exp [ − 1 2 ( v d ( I ) − v d ( l + 1 ) s d ( I ) − s d ( l + 1 ) ) 2 ] \begin{aligned} & \phi_{A_{d}^{(I)}, A_{d}^{(l+1)}}=\exp \left[-\frac{1}{2}\left(\frac{v_{d}^{(I)}-v_{d}^{(l+1)}}{s_{d}^{(I)}+s_{d}^{(l+1)}}\right)^{2}\right] \\ & \psi_{A_{d}^{(I)}, A_{d}^{(l+1)}}=\exp \left[-\frac{1}{2}\left(\frac{v_{d}^{(I)}-v_{d}^{(l+1)}}{s_{d}^{(I)}-s_{d}^{(l+1)}}\right)^{2}\right] \end{aligned} ϕAd(I),Ad(l+1)=exp −21(sd(I)+sd(l+1)vd(I)−vd(l+1))2 ψAd(I),Ad(l+1)=exp −21(sd(I)−sd(l+1)vd(I)−vd(l+1))2
在这些公式中,
A
d
(
I
)
A_{d}^{(I)}
Ad(I)是第
l
l
l条规则在属性
d
d
d上的高斯模糊集,
v
d
(
I
)
v_{d}^{(I)}
vd(I)和
s
d
(
I
)
s_{d}^{(I)}
sd(I)分别表示模糊集的均值(中心)和标准差(宽度)。模糊集按其均值
v
v
v排序,
v
d
(
I
)
v_{d}^{(I)}
vd(I)和
v
d
(
l
+
1
)
v_{d}^{(l+1)}
vd(l+1)表示排序后两个连续相邻的模糊集。
较低的
I
f
s
p
I_{f s p}
Ifsp值反映了模糊集在输入空间中更准确的定位和更合理的覆盖,增强了模型的可解释性和泛化能力。
4.0.3 模型配置和超参数。在所有实验中,除非另有说明,以下超参数始终保持一致以确保结果的可比性:
- 学习率:0.01
-
- 批量大小:512
-
- 训练迭代次数:1500
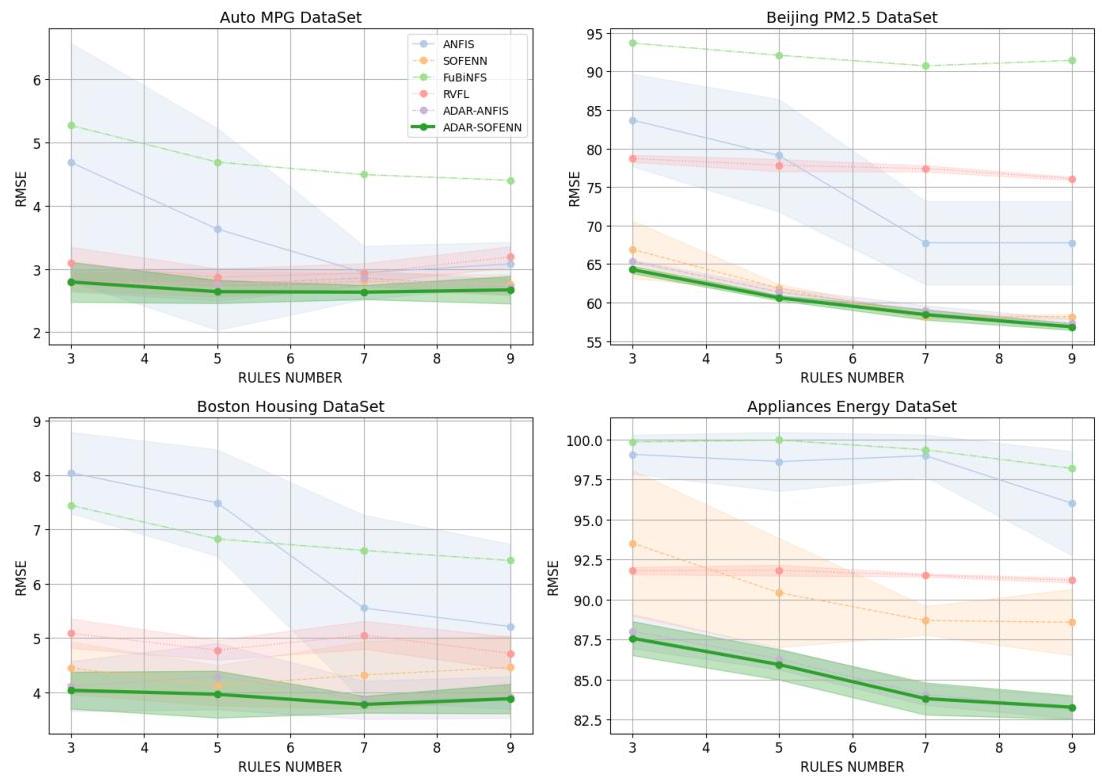
图2. 不同数据集和规则数量下的可解释性算法比较
对于基于规则的模型,最大规则数量测试为3、5、7和9,以评估规则数量对模型性能的影响。
4.1 实验结果与讨论
在本节中,我们介绍并分析了来自各种实验的结果。我们首先对不同算法在多个数据集上的表现进行广泛比较,以突出ADAR框架的优势。接下来,我们讨论ADAR框架的动态规则和属性管理机制,然后是消融研究的结果,最后是一个全面的参数敏感性分析。
不同数据集上算法的比较。表1和表2总结了每个算法在四个数据集上的RMSE(均方根误差)表现。对于基于规则的模型,结果显示了在不同最大规则数量下的表现。由于ANFIS-PSO的规则设计与其他模糊逻辑算法不同,且APLR和DecisionTreeRegressor的结果独立于规则数量,它们的结果合并到表2中。
ADAR框架在复杂数据集上的优势。实验结果表明,基于ADAR框架的模型(ADAR-ANFIS和ADAR-SOFENN)在所有数据集上均表现出更好的性能,特别是在特征数量较多的复杂数据集上。这凸显了ADAR框架在处理高维数据和复杂的非线性关系方面的强大能力。
表1. 不同规则下的数据集RMSE比较
| 数据集 | 算法 | RULE-3 | RULE-5 | RULE-7 | RULE-9 |
|---|---|---|---|---|---|
| Auto MPG (Variable=7) | ANFIS | 4.6879 ± 1.8879 4.6879 \pm 1.8879 4.6879±1.8879 | 3.6324 ± 1.5975 3.6324 \pm 1.5975 3.6324±1.5975 | 2.9424 ± 0.4225 2.9424 \pm 0.4225 2.9424±0.4225 | 3.0815 ± 0.3451 3.0815 \pm 0.3451 3.0815±0.3451 |
| SOFENN | 2.8008 ± 0.1373 2.8008 \pm 0.1373 2.8008±0.1373 | 2.7614 ± 0.2003 2.7614 \pm 0.2003 2.7614±0.2003 | 2.8046 ± 0.1312 2.8046 \pm 0.1312 2.8046±0.1312 | 2.7513 ± 0.1600 2.7513 \pm 0.1600 2.7513±0.1600 | |
| FuBiNFS | 5.2729 ± 0.0000 5.2729 \pm 0.0000 5.2729±0.0000 | 4.6923 ± 0.0000 4.6923 \pm 0.0000 4.6923±0.0000 | 4.4941 ± 0.0000 4.4941 \pm 0.0000 4.4941±0.0000 | 4.4049 ± 0.0000 4.4049 \pm 0.0000 4.4049±0.0000 | |
| RVFL | 3.0897 ± 0.2582 3.0897 \pm 0.2582 3.0897±0.2582 | 2.8711 ± 0.1346 2.8711 \pm 0.1346 2.8711±0.1346 | 2.9358 ± 0.1559 2.9358 \pm 0.1559 2.9358±0.1559 | 3.1911 ± 0.1668 3.1911 \pm 0.1668 3.1911±0.1668 | |
| ADAR-ANFIS | 2.8108 ± 0.1675 2.8108 \pm 0.1675 2.8108±0.1675 | 2.7587 ± 0.2589 2.7587 \pm 0.2589 2.7587±0.2589 | 2.8580 ± 0.1219 2.8580 \pm 0.1219 2.8580±0.1219 | 2.7128 ± 0.1230 2.7128 \pm 0.1230 2.7128±0.1230 | |
| ADAR-SOFENN | 2.7948 ± 0.3171 2.7948 \pm 0.3171 2.7948±0.3171 | 2.6418 ± 0.1823 2.6418 \pm 0.1823 2.6418±0.1823 | 2.6332 ± 0.1122 2.6332 \pm 0.1122 2.6332±0.1122 | 2.6699 ± 0.2173 2.6699 \pm 0.2173 2.6699±0.2173 | |
| Beijing PM2.5 (Variable=10) | ANFIS | 83.6791 ± 5.9950 83.6791 \pm 5.9950 83.6791±5.9950 | 79.0816 ± 7.3014 79.0816 \pm 7.3014 79.0816±7.3014 | 67.7683 ± 5.4045 67.7683 \pm 5.4045 67.7683±5.4045 | 67.7683 ± 5.4045 67.7683 \pm 5.4045 67.7683±5.4045 |
| SOFENN | 66.9002 ± 3.7310 66.9002 \pm 3.7310 66.9002±3.7310 | 61.8837 ± 0.5297 61.8837 \pm 0.5297 61.8837±0.5297 | 58.1916 ± 0.2862 58.1916 \pm 0.2862 58.1916±0.2862 | 58.1916 ± 0.2862 58.1916 \pm 0.2862 58.1916±0.2862 | |
| FuBiNFS (2021) | 93.6840 ± 0.0000 93.6840 \pm 0.0000 93.6840±0.0000 | 92.1008 ± 0.0000 92.1008 \pm 0.0000 92.1008±0.0000 | 90.7340 ± 0.0000 90.7340 \pm 0.0000 90.7340±0.0000 | 91.4465 ± 0.0000 91.4465 \pm 0.0000 91.4465±0.0000 | |
| RVFL (2024) | 78.6992 ± 0.4646 78.6992 \pm 0.4646 78.6992±0.4646 | 77.8190 ± 0.8003 77.8190 \pm 0.8003 77.8190±0.8003 | 77.3965 ± 0.4112 77.3965 \pm 0.4112 77.3965±0.4112 | 76.0913 ± 0.2162 76.0913 \pm 0.2162 76.0913±0.2162 | |
| ADAR-ANFIS | 65.3408 ± 0.2019 65.3408 \pm 0.2019 65.3408±0.2019 | 61.3989 ± 0.5540 61.3989 \pm 0.5540 61.3989±0.5540 | 58.9481 ± 0.6897 58.9481 \pm 0.6897 58.9481±0.6897 | 57.3199 ± 0.5940 57.3199 \pm 0.5940 57.3199±0.5940 | |
| ADAR-SOFENN | 64.2827 ± 0.4883 64.2827 \pm 0.4883 64.2827±0.4883 | 60.6262 ± 0.3478 60.6262 \pm 0.3478 60.6262±0.3478 | 58.4496 ± 0.6825 58.4496 \pm 0.6825 58.4496±0.6825 | 56.8668 ± 0.4113 56.8668 \pm 0.4113 56.8668±0.4113 | |
| Boston Housing (Variable=13) | ANFIS | 8.0455 ± 0.7479 8.0455 \pm 0.7479 8.0455±0.7479 | 7.4894 ± 0.9818 7.4894 \pm 0.9818 7.4894±0.9818 | ------ | |
| 5.5524 ± 1.7124 5.5524 \pm 1.7124 5.5524±1.7124 | 5.2112 ± 1.5201 5.2112 \pm 1.5201 5.2112±1.5201 | ||||
| SOFENN | 4.4443 ± 0.4845 4.4443 \pm 0.4845 4.4443±0.4845 | 4.1290 ± 0.3700 4.1290 \pm 0.3700 4.1290±0.3700 | |||
| 4.3192 ± 0.6223 4.3192 \pm 0.6223 4.3192±0.6223 | 4.4596 ± 0.5837 4.4596 \pm 0.5837 4.4596±0.5837 | ||||
| FuBiNFS | 7.4459 ± 0.0000 7.4459 \pm 0.0000 7.4459±0.0000 | $6.8265 \pm 0.000 | |||
| ------0$ | 6.6156 ± 0.0000 6.6156 \pm 0.0000 6.6156±0.0000 | 6.4289 ± 0.0000 6.4289 \pm 0.0000 6.4289±0.0000 | |||
| RVFL | 5.0860 ± 0.2700 5.0860 \pm 0.2700 5.0860±0.2700 | 4.7784 ± 0.1817 4.7784 \pm 0.1817 4.7784±0.1817 | 5.0550 ± 0.2580 5.0550 \pm 0.2580 5.0550±0.2580 | 4.7192 ± 0.3001 4.7192 \pm 0.3001 4.7192±0.3001 | |
| ADAR-ANFIS | 4.1125 ± 0.4632 4.1125 \pm 0.4632 4.1125±0.4632 | 4.2964 ± 0.6100 4.2964 \pm 0.6100 4.2964±0.6100 | 3.8586 ± 0.3517 3.8586 \pm 0.3517 3.8586±0.3517 | 3.9099 ± 0.3828 3.9099 \pm 0.3828 3.9099±0.3828 | |
| ADAR-SOFENN | 4.0378 ± 0.3398 4.0378 \pm 0.3398 4.0378±0.3398 | 3.9641 ± 0.4319 3.9641 \pm 0.4319 3.9641±0.4319 | 3.7770 ± 0.1541 3.7770 \pm 0.1541 3.7770±0.1541 | 3.8831 ± 0.2713 3.8831 \pm 0.2713 3.8831±0.2713 | |
| 家电能耗 (Variable=27) | ANFIS | 99.0577 ± 1.2197 99.0577 \pm 1.2197 99.0577±1.2197 | 98.6092 ± 1.8407 98.6092 \pm 1.8407 98.6092±1.8407 | 98.9762 ± 1.3135 98.9762 \pm 1.3135 98.9762±1.3135 | 95.9975 ± 3.2503 95.9975 \pm 3.2503 95.9975±3.2503 |
| SOFENN | 93.5092 ± 4.5456 93.5092 \pm 4.5456 93.5092±4.5456 | 90.4177 ± 3.4090 90.4177 \pm 3.4090 90.4177±3.4090 | 88.6798 ± 0.8949 88.6798 \pm 0.8949 88.6798±0.8949 | 88.5745 ± 2.0701 88.5745 \pm 2.0701 88.5745±2.0701 | |
| FuBiNFS | 99.8365 ± 0.0000 99.8365 \pm 0.0000 99.8365±0.0000 | 99.9557 ± 0.0000 99.9557 \pm 0.0000 99.9557±0.0000 | 99.3492 ± 0.0000 99.3492 \pm 0.0000 99.3492±0.0000 | 98.1800 ± 0.0000 98.1800 \pm 0.0000 98.1800±0.0000 | |
| RVFL | 91.7919 ± 0.2311 91.7919 \pm 0.2311 91.7919±0.2311 | 91.8162 ± 0.3387 91.8162 \pm 0.3387 91.8162±0.3387 | 91.5115 ± 0.0933 91.5115 \pm 0.0933 91.5115±0.0933 | 91.1958 ± 0.1544 91.1958 \pm 0.1544 91.1958±0.1544 | |
| ADAR-ANFIS | 88.0047 ± 1.0725 88.0047 \pm 1.0725 88.0047±1.0725 | 86.2727 ± 0.6647 86.2727 \pm 0.6647 86.2727±0.6647 | 84.0432 ± 0.6443 84.0432 \pm 0.6443 84.0432±0.6443 | 83.2472 ± 0.6939 83.2472 \pm 0.6939 83.2472±0.6939 | |
| ADAR-SOFENN | 87.5710 ± 1.0646 87.5710 \pm 1.0646 87.5710±1.0646 | 85.9295 ± 0.9476 85.9295 \pm 0.9476 85.9295±0.9476 | 83.8022 ± 1.0049 83.8022 \pm 1.0049 83.8022±1.0049 | 83.2657 ± 0.7424 83.2657 \pm 0.7424 83.2657±0.7424 | |
| 表2. 各算法和数据集的最佳RMSE比较 |
| 数据集 | 算法 | 最佳RMSE | 规则数 |
|---|---|---|---|
| Auto MPG (Variable=7) | ANFIS-PSO | 2.8578 ± 0.1956 2.8578 \pm 0.1956 2.8578±0.1956 | 14 |
| APLR | 2.7572 ± 0.1336 2.7572 \pm 0.1336 2.7572±0.1336 | - | |
| DecisionTreeRegressor | 3.6448 ± 0.4722 3.6448 \pm 0.4722 3.6448±0.4722 | - | |
| ADAR-ANFIS | 2.7128 ± 0.1230 2.7128 \pm 0.1230 2.7128±0.1230 | 9 | |
| ADAR-SOFENN | 2.6332 ± 0.1122 2.6332 \pm 0.1122 2.6332±0.1122 | 7 | |
| Beijing PM2.5 (Variable=10) | ANFIS-PSO | 85.0095 ± 1.3883 85.0095 \pm 1.3883 85.0095±1.3883 | 20 |
| APLR | 57.11896 ± 0.1718 57.11896 \pm 0.1718 57.11896±0.1718 | - | |
| DecisionTreeRegressor | 55.81432 ± 0.9817 55.81432 \pm 0.9817 55.81432±0.9817 | - | |
| ADAR-ANFIS | 57.3199 ± 0.5940 57.3199 \pm 0.5940 57.3199±0.5940 | 9 | |
| ADAR-SOFENN | 56.8668 ± 0.4113 56.8668 \pm 0.4113 56.8668±0.4113 | 9 | |
| Boston Housing (Variable=13) | ANFIS-PSO | 8.6875 ± 0.2733 8.6875 \pm 0.2733 8.6875±0.2733 | 26 |
| APLR | 3.4227 ± 0.4218 3.4227 \pm 0.4218 3.4227±0.4218 | - | |
| DecisionTreeRegressor | 5.1525 ± 0.4114 5.1525 \pm 0.4114 5.1525±0.4114 | - | |
| ADAR-ANFIS | 3.8586 ± 0.3517 3.8586 \pm 0.3517 3.8586±0.3517 | 7 | |
| ADAR-SOFENN | 3.7770 ± 0.1541 3.7770 \pm 0.1541 3.7770±0.1541 | 7 | |
| 家电能耗 (Variable=27) | ANFIS-PSO | 100.2024 ± 0.2374 100.2024 \pm 0.2374 100.2024±0.2374 | 54 |
| APLR | 83.9781 ± 1.1202 83.9781 \pm 1.1202 83.9781±1.1202 | - | |
| DecisionTreeRegressor | 98.7506 ± 2.3485 98.7506 \pm 2.3485 98.7506±2.3485 | - | |
| ADAR-ANFIS | 83.2472 ± 0.6939 83.2472 \pm 0.6939 83.2472±0.6939 | 9 | |
| ADAR-SOFENN | 83.2657 ± 0.7424 83.2657 \pm 0.7424 83.2657±0.7424 | 9 |
与传统模型的比较。与传统的ANFIS和SOFENN模型相比,ADAR框架通过引入属性和规则加权机制来自动检测并优先处理重要特征和规则,从而提高了预测准确性。例如,在家电能耗数据集中,ADAR-SOFENN在9条规则(RULE=9)的情况下实现了83.2657的RMSE,显著优于传统模型。这种性能的提升主要是由于ADAR框架能够动态调整属性和规则,使模型更好地捕捉数据中的关键模式。
与高级模糊逻辑模型的比较。与FuBiNFS和ANFIS-PSO等高级模糊逻辑模型相比,尽管这些模型在某些情况下表现出更好的结果,但通常仍逊色于基于ADAR框架的模型。FuBiNFS通过在子空间内创建模糊规则来提高泛化能力,但缺乏动态分配特征和规则重要性的权重,限制了其在高维数据集上的表现。ANFIS-PSO使用粒子群优化算法全局优化模型参数,导致一些性能改进。然而,其固定结构限制了模型根据数据复杂性动态调整的能力。
与可解释性算法的比较。模糊逻辑领域之外的可解释性算法,如APLR和DecisionTreeRegressor,在特定数据集上表现出强劲的性能。例如,APLR在波士顿房价数据集上实现了3.4227的RMSE,而DecisionTreeRegressor在北京PM2.5数据集上达到了55.8143的RMSE。然而,在大多数情况下,基于ADAR框架的模型要么超越或匹配这些算法,同时提供更好的可解释性。
4.2 ADAR框架的规则和属性管理
我们在家电能耗数据集上结合ANFIS评估ADAR框架,以分析训练期间规则增长、规则修剪和属性修剪的动态过程。模型从两条模糊规则开始,并在批大小为64的情况下进行500轮训练。属性修剪和规则修剪的阈值分别设置为0.1和0.25。这种方法旨在简化模型,同时保持或提高其预测性能。
结果与分析。在早期训练阶段(大约第50到150轮),模型检测到之前未学习的数据模式,并动态引入新规则,将规则数量从初始的2增加到14。这种增长伴随着验证损失的显著减少,从大约1.1降至0.7。新添加的规则有效捕获高误差数据点并细化决策边界,增强了模型的预测准确性。
同时,模型利用属性加权机制动态修剪无关输入特征。重要性权重低于0.1的属性逐渐被停用,最小化每个规则输入中的冗余。到第200轮时,大多数无关属性已被移除,平均每条规则保留约15个活动属性。值得注意的是,这种修剪并未对验证损失产生负面影响;相反,它增强了模型的泛化能力。
在后期训练阶段(超过第350轮后),应用规则修剪机制以增强可解释性和计算效率。重要性权重低于0.25的规则被消除,将活动规则数量从14减少到10。尽管如此,验证损失保持稳定,表明模型有效地去除了冗余规则,同时保留了其基本决策能力。
图3展示了训练过程中验证损失和规则数量的动态变化。实线代表验证损失的趋势,虚线表示模型中规则的总数。在早期训练阶段,随着新规则的引入,验证损失急剧下降。当模型进入微调阶段时,规则数量和验证损失趋于稳定,表明动态调整过程完成。
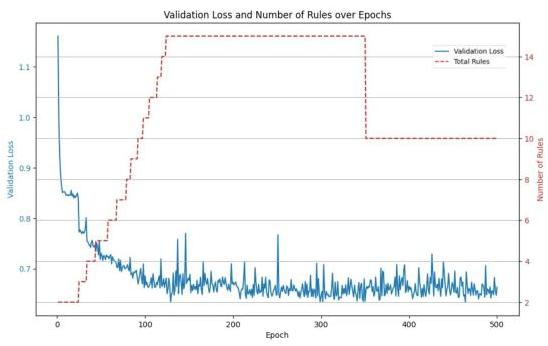
图3. ADAR框架中的动态规则增长和验证损失收敛
4.3 消融研究结果分析
为了全面评估自适应动态属性和规则(ADAR)框架中每个组件对模型性能和结构优化的影响,我们对基于ADAR框架的两种模糊神经网络模型进行了系统消融研究:ADAR-SOFENN(具有自适应动态属性和规则的自组织模糊神经网络)和ADAR-ANFIS(基于自适应动态属性和规则的ANFIS)。该研究旨在量化规则增长和修剪(RG&RP)以及属性修剪(AP)组件对模型的贡献,特别强调权重机制在属性选择和规则细化中的作用。
实验设计和配置。实验使用了UCI机器学习存储库中的北京PM2.5数据集。选择了十个特征变量:年份、月份、日期、小时、露点温度(DEWP)、温度(TEMP)、压力(PRES)、累积风速(Iws)、累积小时数(Is)和累积降水量(Ir),PM2.5浓度作为目标变量。为保证数据质量,处理了缺失值并对数据集进行了标准化。
数据集分为80%的训练集和20%的测试集。训练集进一步分为80%的训练子集和20%的验证集用于模型训练和评估。模型使用以下参数进行训练:1500轮,批大小为512,学习率为0.01,每25轮进行一次属性修剪,属性和规则的修剪阈值分别为0.1和0.25。
对于模型配置,我们为每个模型建立了四种不同的实验设置:
- 基础模型(SOFENN和ANFIS):此设置排除了优化组件,禁用了RG&RP和AP,并未包含加权机制。模型依赖固定的规则和属性,没有自适应调整能力。
-
- 基础模型 + RG&RP:仅启用规则增长和修剪组件,禁用属性修剪组件。此配置包含规则加权机制,允许模型动态调整规则的重要性数量。通过学习规则重要性权重,模型可以识别并移除不太重要的规则,同时根据需要引入新规则以适应数据复杂性。
-
- 基础模型 + AP:仅启用属性修剪(AP)组件,禁用规则增长和修剪(RG&RP)组件。此配置包含属性加权机制以动态调整输入特征的相关性和权重。通过学习属性重要性权重,模型可以优先考虑重要属性,同时抑制冗余或相关性较低的特征,增强泛化性能。
-
- 完整模型(基础模型 + RG&RP + AP,即ADAR-SOFENN和ADAR-ANFIS):同时启用规则增长和修剪(AP)和属性修剪(RG&RP)组件。此设置整合了规则加权和属性加权机制,允许对模型结构进行全面优化。
- 每种配置的最大规则限制为3、5、7和9,每个实验重复五次以确保可靠性和统计意义。当启用RG&RP组件时,模型可以动态添加或移除规则,但不会超过预定义的最大值。对于评估,我们使用RMSE、
l
o
v
l_{o v}
lov和
I
f
s
p
I_{f s p}
Ifsp作为评估指标。较低的
l
o
v
l_{o v}
lov表示规则重叠减少,增强可解释性。而较低的
I
f
s
p
I_{f s p}
Ifsp意味着更精确的模糊集定位,改善覆盖范围和可解释性。
实验结果与分析。表3和表4展示了不同最大规则数量下的消融结果。
表3. ADAR-SOFENN的消融研究结果
| 模型配置 | 最大规则数 | RMSE ( ± \pm ± Std) | l o v ( ± l_{o v}(\pm lov(± Std) | I f s p ( ± I_{f s p}(\pm Ifsp(± Std) |
|---|---|---|---|---|
| SOFENN | 3 | 66.9002 ± 3.7310 66.9002 \pm 3.7310 66.9002±3.7310 | 2.3862 ± 0.3029 2.3862 \pm 0.3029 2.3862±0.3029 | 0.8611 ± 0.1099 0.8611 \pm 0.1099 0.8611±0.1099 |
| 5 | 61.8837 ± 0.5297 61.8837 \pm 0.5297 61.8837±0.5297 | 2.7036 ± 0.3439 2.7036 \pm 0.3439 2.7036±0.3439 | 0.8968 ± 0.0962 0.8968 \pm 0.0962 0.8968±0.0962 | |
| 7 | 60.1431 ± 0.9294 60.1431 \pm 0.9294 60.1431±0.9294 | 3.1246 ± 0.3581 3.1246 \pm 0.3581 3.1246±0.3581 | 1.0148 ± 0.0377 1.0148 \pm 0.0377 1.0148±0.0377 | |
| 9 | 58.1916 ± 0.2862 58.1916 \pm 0.2862 58.1916±0.2862 | 3.8300 ± 0.5557 3.8300 \pm 0.5557 3.8300±0.5557 | 1.0067 ± 0.0707 1.0067 \pm 0.0707 1.0067±0.0707 | |
| SOFENN + RG&RP | 3 | 65.7658 ± 2.3611 65.7658 \pm 2.3611 65.7658±2.3611 | 2.8810 ± 0.3328 2.8810 \pm 0.3328 2.8810±0.3328 | 0.7608 ± 0.0554 0.7608 \pm 0.0554 0.7608±0.0554 |
| 5 | 61.7878 ± 0.5831 61.7878 \pm 0.5831 61.7878±0.5831 | 2.6595 ± 0.1973 2.6595 \pm 0.1973 2.6595±0.1973 | 0.9107 ± 0.0697 0.9107 \pm 0.0697 0.9107±0.0697 | |
| 7 | 59.0466 ± 0.5816 59.0466 \pm 0.5816 59.0466±0.5816 | 3.1668 ± 0.4685 3.1668 \pm 0.4685 3.1668±0.4685 | 0.9276 ± 0.0739 0.9276 \pm 0.0739 0.9276±0.0739 | |
| 9 | 58.0395 ± 0.7897 58.0395 \pm 0.7897 58.0395±0.7897 | 3.0303 ± 0.1364 3.0303 \pm 0.1364 3.0303±0.1364 | 0.9932 ± 0.0569 0.9932 \pm 0.0569 0.9932±0.0569 | |
| SOFENN + AP | 3 | 64.7029 ± 0.5744 64.7029 \pm 0.5744 64.7029±0.5744 | 1.4909 ± 0.1728 1.4909 \pm 0.1728 1.4909±0.1728 | 0.4680 ± 0.1428 0.4680 \pm 0.1428 0.4680±0.1428 |
| 5 | 61.1893 ± 0.3582 61.1893 \pm 0.3582 61.1893±0.3582 | 1.5838 ± 0.2418 1.5838 \pm 0.2418 1.5838±0.2418 | 0.6776 ± 0.1207 0.6776 \pm 0.1207 0.6776±0.1207 | |
| 7 | 59.4569 ± 0.4296 59.4569 \pm 0.4296 59.4569±0.4296 | 1.8413 ± 0.2813 1.8413 \pm 0.2813 1.8413±0.2813 | 0.6461 ± 0.1128 0.6461 \pm 0.1128 0.6461±0.1128 | |
| 9 | 57.6671 ± 0.3984 57.6671 \pm 0.3984 57.6671±0.3984 | 1.9144 ± 0.3762 1.9144 \pm 0.3762 1.9144±0.3762 | 0.7434 ± 0.1471 0.7434 \pm 0.1471 0.7434±0.1471 | |
| ADAR-SOFENN | 3 | 64.2827 ± 0.4883 64.2827 \pm 0.4883 64.2827±0.4883 | 0.5263 ± 0.0756 0.5263 \pm 0.0756 0.5263±0.0756 | 0.4028 ± 0.0340 0.4028 \pm 0.0340 0.4028±0.0340 |
| 5 | 60.6262 ± 0.3478 60.6262 \pm 0.3478 60.6262±0.3478 | 0.8624 ± 0.0246 0.8624 \pm 0.0246 0.8624±0.0246 | 0.6639 ± 0.0808 0.6639 \pm 0.0808 0.6639±0.0808 | |
| 7 | 58.4496 ± 0.6825 58.4496 \pm 0.6825 58.4496±0.6825 | 0.9425 ± 0.0129 0.9425 \pm 0.0129 0.9425±0.0129 | 0.6326 ± 0.0380 0.6326 \pm 0.0380 0.6326±0.0380 | |
| 9 | 57.2381 ± 0.4417 57.2381 \pm 0.4417 57.2381±0.4417 | 0.9676 ± 0.0076 0.9676 \pm 0.0076 0.9676±0.0076 | 0.7978 ± 0.0603 0.7978 \pm 0.0603 0.7978±0.0603 |
基线模型的性能。基线模型(SOFENN和ANFIS)在所有最大规则数量下表现出相对较高的RMSE值,随着最大规则数量的增加,RMSE逐渐降低。例如,ADAR-SOFENN的RMSE从最大规则数量为3时的
66.90
±
3.73
66.90 \pm 3.73
66.90±3.73降低到最大规则数量为9时的
58.19
±
0.29
58.19 \pm 0.29
58.19±0.29。类似地,ADAR-ANFIS从
88.18
±
5.39
88.18 \pm 5.39
88.18±5.39降低到
66.93
±
3.58
66.93 \pm 3.58
66.93±3.58。这表明增加规则数量
表4. ADAR-ANFIS的消融研究结果
| 模型配置 | 最大规则数 | RMSE ( ± \pm ± Std) | l o v ( ± l_{o v}(\pm lov(± Std) | l f s p ( ± l_{f s p}(\pm lfsp(± Std) |
|---|---|---|---|---|
| ANFIS | 3 | 88.1843 ± 5.3894 88.1843 \pm 5.3894 88.1843±5.3894 | 12.4502 ± 10.2629 12.4502 \pm 10.2629 12.4502±10.2629 | 0.7066 ± 0.0818 0.7066 \pm 0.0818 0.7066±0.0818 |
| 5 | 79.0816 ± 7.3014 79.0816 \pm 7.3014 79.0816±7.3014 | 20.0718 ± 3.9651 20.0718 \pm 3.9651 20.0718±3.9651 | 0.7989 ± 0.0364 0.7989 \pm 0.0364 0.7989±0.0364 | |
| 7 | 70.3829 ± 7.7170 70.3829 \pm 7.7170 70.3829±7.7170 | 27.8611 ± 7.4576 27.8611 \pm 7.4576 27.8611±7.4576 | 0.8690 ± 0.0404 0.8690 \pm 0.0404 0.8690±0.0404 | |
| 9 | 66.9279 ± 3.5835 66.9279 \pm 3.5835 66.9279±3.5835 | 24.3194 ± 6.5254 24.3194 \pm 6.5254 24.3194±6.5254 | 0.9146 ± 0.0238 0.9146 \pm 0.0238 0.9146±0.0238 | |
| ANFIS + RG&RP | 3 | 66.8949 ± 2.1634 66.8949 \pm 2.1634 66.8949±2.1634 | 2.8815 ± 0.9386 2.8815 \pm 0.9386 2.8815±0.9386 | 0.8243 ± 0.1218 0.8243 \pm 0.1218 0.8243±0.1218 |
| 5 | 62.7235 ± 1.1389 62.7235 \pm 1.1389 62.7235±1.1389 | 3.1181 ± 0.2536 3.1181 \pm 0.2536 3.1181±0.2536 | 0.9718 ± 0.0584 0.9718 \pm 0.0584 0.9718±0.0584 | |
| 7 | 60.6018 ± 0.7743 60.6018 \pm 0.7743 60.6018±0.7743 | 5.2207 ± 1.5654 5.2207 \pm 1.5654 5.2207±1.5654 | 1.0168 ± 0.0866 1.0168 \pm 0.0866 1.0168±0.0866 | |
| 9 | 59.5692 ± 0.8444 59.5692 \pm 0.8444 59.5692±0.8444 | 6.6771 ± 2.3137 6.6771 \pm 2.3137 6.6771±2.3137 | 1.0322 ± 0.0576 1.0322 \pm 0.0576 1.0322±0.0576 | |
| ANFIS + AP | 3 | 65.9599 ± 0.6826 65.9599 \pm 0.6826 65.9599±0.6826 | 1.2917 ± 0.2949 1.2917 \pm 0.2949 1.2917±0.2949 | 0.4769 ± 0.1595 0.4769 \pm 0.1595 0.4769±0.1595 |
| 5 | 62.7266 ± 0.7535 62.7266 \pm 0.7535 62.7266±0.7535 | 1.7280 ± 0.2759 1.7280 \pm 0.2759 1.7280±0.2759 | 0.6823 ± 0.1729 0.6823 \pm 0.1729 0.6823±0.1729 | |
| 7 | 60.7769 ± 0.6910 60.7769 \pm 0.6910 60.7769±0.6910 | 1.8385 ± 0.3599 1.8385 \pm 0.3599 1.8385±0.3599 | 0.8217 ± 0.0807 0.8217 \pm 0.0807 0.8217±0.0807 | |
| 9 | 58.6765 ± 0.7500 58.6765 \pm 0.7500 58.6765±0.7500 | 2.0903 ± 0.3281 2.0903 \pm 0.3281 2.0903±0.3281 | 0.8006 ± 0.0971 0.8006 \pm 0.0971 0.8006±0.0971 | |
| ADAR-ANFIS | 3 | 65.3408 ± 0.2019 65.3408 \pm 0.2019 65.3408±0.2019 | 0.6854 ± 0.1114 0.6854 \pm 0.1114 0.6854±0.1114 | 0.4727 ± 0.0925 0.4727 \pm 0.0925 0.4727±0.0925 |
| 5 | 61.3989 ± 0.5540 61.3989 \pm 0.5540 61.3989±0.5540 | 0.8742 ± 0.0754 0.8742 \pm 0.0754 0.8742±0.0754 | 0.5872 ± 0.1514 0.5872 \pm 0.1514 0.5872±0.1514 | |
| 7 | 58.9481 ± 0.6897 58.9481 \pm 0.6897 58.9481±0.6897 | 0.9447 ± 0.0181 0.9447 \pm 0.0181 0.9447±0.0181 | 0.7257 ± 0.1630 0.7257 \pm 0.1630 0.7257±0.1630 | |
| 9 | 57.3199 ± 0.5940 57.3199 \pm 0.5940 57.3199±0.5940 | 0.9503 ± 0.0144 0.9503 \pm 0.0144 0.9503±0.0144 | 0.7253 ± 0.1146 0.7253 \pm 0.1146 0.7253±0.1146 |
基线模型的性能。基线模型(SOFENN和ANFIS)在所有最大规则数量下表现出相对较高的RMSE值,随着最大规则数量的增加,RMSE逐渐降低。例如,ADAR-SOFENN的RMSE从最大规则数量为3时的
66.90
±
3.73
66.90 \pm 3.73
66.90±3.73降低到最大规则数量为9时的
58.19
±
0.29
58.19 \pm 0.29
58.19±0.29。类似地,ADAR-ANFIS从
88.18
±
5.39
88.18 \pm 5.39
88.18±5.39降低到
66.93
±
3.58
66.93 \pm 3.58
66.93±3.58。这表明增加规则数量
可以一定程度上提高预测性能。然而,基线模型的
I
o
v
I_{o v}
Iov值仍然相对较高,特别是对于ANFIS,其中
I
o
v
I_{o v}
Iov从最大规则数量为3时的
12.45
±
10.26
12.45 \pm 10.26
12.45±10.26增加到最大规则数量为9时的
24.32
±
6.53
24.32 \pm 6.53
24.32±6.53。这表明基线模型中存在显著的规则重叠和冗余,这会对泛化能力和可解释性产生负面影响。
添加RG&RP组件的影响。在仅启用规则增长和修剪(RG&RP)组件的配置中,RMSE值显著降低,突显了RG&RP组件对预测准确性的积极影响。例如,ADAR-SOFENN + RG&RP的RMSE从最大规则数量为3时的 66.90 ± 3.73 66.90 \pm 3.73 66.90±3.73降至 65.77 ± 2.36 65.77 \pm 2.36 65.77±2.36,展示了RG&RP组件在优化预测性能方面的有效性。同样,ADAR-ANFIS + RG&RP显示出更大的改进,RMSE从相同条件下的 88.18 ± 88.18 \pm 88.18± 5.39降至 66.89 ± 2.16 66.89 \pm 2.16 66.89±2.16,进一步证实了RG&RP组件显著减少预测误差的能力。
在ADAR-SOFENN + RG&RP配置中,最大规则数量为3时, I o v I_{o v} Iov值从 2.3862 ± 0.3029 2.3862 \pm 0.3029 2.3862±0.3029略微增加到 2.8810 ± 0.3328 2.8810 \pm 0.3328 2.8810±0.3328。这种轻微增加可归因于SOFENN基线模型中已经较低的 I o v I_{o v} Iov值,这表明规则重叠较少。启用RG&RP后,模型可能添加了新规则以更好地拟合数据。这些规则的添加导致与现有规则的一些重叠,从而使 I o v I_{o v} Iov值略有上升。然而,这种增加很小,且 I o v I_{o v} Iov值仍然较低,表明规则重叠仍然可控。
相比之下,在ADAR-ANFIS + RG&RP配置中,最大规则数量为3时,
I
o
v
I_{o v}
Iov值从
12.4502
±
10.2629
12.4502 \pm 10.2629
12.4502±10.2629显著降低到
2.8815
±
0.9386
2.8815 \pm 0.9386
2.8815±0.9386。这是由于ANFIS基线模型表现出高度的规则重叠和低规则区分度。启用RG&RP组件后,模型通过修剪冗余规则和
调整规则参数有效减少了重叠,导致
I
o
v
I_{o v}
Iov值持续下降。这表明RG&RP组件对优化ANFIS模型的规则库结构有更持久的影响。
因此,RG&RP组件在不同模型中的影响有所不同:对于初始 I o v I_{o v} Iov值较低的SOFENN,由于新规则引入的少量重叠, I o v I_{o v} Iov值略有增加;对于初始 I o v I_{o v} Iov值较高的ANFIS,RG&RP组件有效减少了规则重叠,导致 I o v I_{o v} Iov值显著下降。
此外,RG&RP组件在各种最大规则数量下优化了 I f s p I_{f s p} Ifsp指标。例如,在ADAR-SOFENN + RG&RP中, I f s p I_{f s p} Ifsp从最大规则数量为3时的 0.8611 ± 0.1099 0.8611 \pm 0.1099 0.8611±0.1099降至0.7608 ± 0.0554 \pm 0.0554 ±0.0554,表明模糊集定位得到改善。这些改进表明,通过调整规则数量和参数,RG&RP组件提高了输入空间中模糊集分布的准确性,最终增强了模型的泛化能力和预测性能。
添加AP组件的影响。在仅启用属性修剪(AP)组件的配置中,模型的RMSE和 I o v I_{o v} Iov值显著降低,且 I f s p I_{f s p} Ifsp指标得到了有效优化。例如,ADAR-SOFENN + AP在最大规则数量为3时实现了 64.70 ± 0.57 64.70 \pm 0.57 64.70±0.57的RMSE, I o v I_{o v} Iov为 1.4909 ± 0.1728 1.4909 \pm 0.1728 1.4909±0.1728, I f s p I_{f s p} Ifsp显著降至 0.4680 ± 0.1428 0.4680 \pm 0.1428 0.4680±0.1428。这表明,由属性加权机制支持的属性修剪机制成功抑制了无关特征,提高了模型的简单性和泛化能力。对于ADAR-ANFIS + AP,RMSE从 88.18 ± 5.39 88.18 \pm 5.39 88.18±5.39降至 65.96 ± 0.68 , I o v 65.96 \pm 0.68, I_{o v} 65.96±0.68,Iov从 12.45 ± 10.26 12.45 \pm 10.26 12.45±10.26降至 1.2917 ± 0.2949 1.2917 \pm 0.2949 1.2917±0.2949, I f s p I_{f s p} Ifsp从 0.7066 ± 0.0818 0.7066 \pm 0.0818 0.7066±0.0818降至 0.4769 ± 0.1595 0.4769 \pm 0.1595 0.4769±0.1595,在相同条件下,突显了AP组件对模型性能的重大影响。
属性加权机制使模型能够通过为每个规则中的输入属性分配权重来动态调整属性的重要性。这有助于抑制冗余或无关特征,提高输入空间中模糊集的定位准确性,进一步优化 I f s p I_{f s p} Ifsp指标。结果,模型的预测准确性得以提高,同时其可解释性和可靠性也得到了提升。
完整模型的优势。在完整模型配置(ADAR-SOFENN和ADAR-ANFIS)中,同时启用了规则增长和修剪(RG&RP)和属性修剪(AP)组件,从而在所有指标上实现最佳性能。这表明RG&RP和AP组件的协同效应共同提供了对模型结构和性能的全面优化。具体而言,规则加权机制动态精炼规则库结构,最小化冗余和过度重叠,而属性加权机制则选择性地调整输入特征,简化模型结构并提高模糊集的定位准确性。
完整模型在所有最大规则数量下始终表现出低RMSE、低 I o v I_{o v} Iov和低 I f s p I_{f s p} Ifsp值,表明在预测准确性和规则库结构及模糊集定位优化方面都有显著改进。例如,ADAR-SOFENN在最大规则数量为9时实现了 57.24 ± 0.44 , I o v 57.24 \pm 0.44, I_{o v} 57.24±0.44,Iov为 0.9676 ± 0.0076 0.9676 \pm 0.0076 0.9676±0.0076, I f s p I_{f s p} Ifsp为 0.7978 ± 0.0603 0.7978 \pm 0.0603 0.7978±0.0603。同样,ADAR-ANFIS在相同条件下实现了 57.32 ± 0.59 , I o v 57.32 \pm 0.59, I_{o v} 57.32±0.59,Iov为 0.9503 ± 0.0144 0.9503 \pm 0.0144 0.9503±0.0144, I f s p I_{f s p} Ifsp为 0.7253 ± 0.1146 0.7253 \pm 0.1146 0.7253±0.1146。这些结果清楚地展示了ADAR框架在优化规则库、保持低规则重叠和确保不同规则数量下模糊集定位优化方面的优势,显著提高了模型的预测准确性和泛化能力。
4.4 参数敏感性分析
为了探索超参数对ADAR框架的影响,我们通过对ADAR-ANFIS改变阈值和修剪频率进行了参数敏感性分析。该分析的目标是评估不同参数配置如何影响模型的预测准确性和可解释性,最终确定提高模型性能的最佳参数组合。表5总结了每次参数设置在三次独立实验中的平均结果。
敏感性实验设置。敏感性分析检查了ADAR-ANFIS模型的五个关键超参数:
- 生长阈值(G_Thres):调节规则生长机制的灵敏度,测试值为 5 × 1 0 − 5 5 \times 10^{-5} 5×10−5和 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4。
-
- 剪枝规则阈值(PR_Thres):根据重要性权重确定剪枝规则的阈值,测试值为0.05和0.1。
-
- 剪枝规则频率(PR_Freq):定义规则剪枝操作之间的间隔(以轮数计),测试值为50和100轮。
-
- 剪枝属性阈值(PA_Thres):确定规则内剪枝属性的阈值,测试值为0.05和0.1。
-
- 剪枝属性频率(PA_Freq):指定属性剪枝的频率(以轮数计),测试值为25和50轮。
总共测试了32种独特配置,每种配置代表上述参数的组合。对于每种配置,模型独立训练和评估三次以考虑随机变化,结果取平均值。
- 剪枝属性频率(PA_Freq):指定属性剪枝的频率(以轮数计),测试值为25和50轮。
结果与分析。使用以下指标评估超参数对模型性能的影响:
- 平均测试RMSE:测试集上的均方根误差,表示模型的预测准确性。较低的值更优。
-
- 平均 I o v I_{o v} Iov:模糊集的平均重叠指数,反映模糊隶属函数之间的重叠程度。较低的 I o v I_{o v} Iov值更好,表示规则间重叠减少和更好的区分性,这增强了模型的泛化能力和可解释性。
-
- 平均 I f s p I_{f s p} Ifsp:模糊集位置指数的平均值,表示模糊集中心的分散情况。较低的 I f s p I_{f s p} Ifsp值更好,表示输入空间中模糊集的定位更准确,导致更好的覆盖和改进的可解释性和泛化能力。
-
- 平均最终规则:最终模型中的平均规则数量。
-
- 平均最终属性:所有规则中包括的属性的平均总数量。
生长阈值的影响。比较两个生长阈值 5 × 1 0 − 5 5 \times 10^{-5} 5×10−5和 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4的结果显示,较低的生长阈值通常会导致模型具有略低的平均测试RMSE和最终规则数量。例如,参数组合G5e-05_PR0.1_PF50_PA0.05_PAF25实现了最低的平均测试RMSE为0.8034,平均最终规则数量为9.00。这表明较低的生长阈值使模型生成更多规则,使其能够捕捉更复杂的模式,从而提高预测性能。
- 平均最终属性:所有规则中包括的属性的平均总数量。
然而,较低的生长阈值也可能导致较高的 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值,表示规则间的重叠增加和模糊集定位不准确。例如,G5e-05系列配置的 I o v I_{o v} Iov值范围为0.64至0.68, I f s p I_{f s p} Ifsp值范围为0.58至0.67。较高的 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值可能会降低模型的区分能力和可解释性。
表5. 参数敏感性实验结果——三次重复的平均值
| 参数集 | 平均测试RMSE | 平均 l o v l_{o v} lov | 平均 l f s p l_{f s p} lfsp | 平均最终规则 | 平均最终属性 |
|---|---|---|---|---|---|
| G5e-05_PR0.05_PF50_PA0.05_PAF25 | 0.816705 | 0.659805 | 0.581153 | 7.0 | 189.0 |
| G5e-05_PR0.05_PF50_PA0.05_PAF50 | 0.821961 | 0.674249 | 0.536936 | 7.0 | 189.0 |
| G5e-05_PR0.05_PF50_PA0.1_PAF25 | 0.810586 | 0.679352 | 0.577585 | 9.33 | 249.0 |
| G5e-05_PR0.05_PF50_PA0.1_PAF50 | 0.809774 | 0.640174 | 0.636667 | 8.67 | 232.0 |
| G5e-05_PR0.05_PF100_PA0.05_PAF25 | 0.822867 | 0.668093 | 0.577141 | 6.67 | 179.67 |
| G5e-05_PR0.05_PF100_PA0.1_PAF25 | 0.816463 | 0.629675 | 0.633326 | 8.33 | 222.33 |
| G5e-05_PR0.05_PF100_PA0.1_PAF50 | 0.825841 | 0.603897 | 0.667261 | 5.33 | 141.33 |
| G5e-05_PR0.1_PF50_PA0.05_PAF25 | 0.803431 | 0.644519 | 0.630471 | 9.0 | 241.33 |
| G5e-05_PR0.1_PF50_PA0.05_PAF50 | 0.825825 | 0.627980 | 0.642903 | 6.0 | 162.0 |
| G5e-05_PR0.1_PF50_PA0.1_PAF25 | 0.819882 | 0.655016 | 0.591918 | 7.33 | 192.67 |
| G5e-05_PR0.1_PF50_PA0.1_PAF50 | 0.802829 | 0.673278 | 0.604944 | 10.33 | 278.0 |
| G5e-05_PR0.1_PF100_PA0.05_PAF25 | 0.811259 | 0.600041 | 0.719270 | 6.67 | 178.0 |
| G5e-05_PR0.1_PF100_PA0.05_PAF50 | 0.826052 | 0.659374 | 0.583199 | 6.33 | 170.33 |
| G5e-05_PR0.1_PF100_PA0.1_PAF25 | 0.805895 | 0.647840 | 0.656270 | 9.33 | 248.67 |
| G5e-05_PR0.1_PF100_PA0.1_PAF50 | 0.823679 | 0.606701 | 0.674123 | 6.33 | 167.33 |
| G0.0001_PR0.05_PF50_PA0.05_PAF25 | 0.825171 | 0.612779 | 0.668276 | 7.33 | 183.33 |
| G0.0001_PR0.05_PF50_PA0.05_PAF50 | 0.831590 | 0.669550 | 0.553278 | 4.67 | 125.67 |
| G0.0001_PR0.05_PF50_PA0.1_PAF25 | 0.816230 | 0.639937 | 0.661261 | 7.67 | 204.0 |
| G0.0001_PR0.05_PF50_PA0.1_PAF50 | 0.800953 | 0.669415 | 0.604870 | 10.33 | 278.0 |
| G0.0001_PR0.05_PF100_PA0.05_PAF25 | 0.833910 | 0.660353 | 0.558622 | 6.0 | 162.0 |
| G0.0001_PR0.05_PF100_PA0.05_PAF50 | 0.815831 | 0.629507 | 0.670356 | 7.0 | 188.67 |
| G0.0001_PR0.05_PF100_PA0.1_PAF25 | 0.846509 | 0.599343 | 0.616923 | 3.67 | 95.67 |
| G0.0001_PR0.05_PF100_PA0.1_PAF50 | 0.806566 | 0.619445 | 0.689826 | 8.0 | 211.33 |
| G0.0001_PR0.1_PF50_PA0.05_PAF25 | 0.812810 | 0.647198 | 0.627898 | 11.33 | 305.33 |
| G0.0001_PR0.1_PF50_PA0.05_PAF50 | 0.824287 | 0.647859 | 0.628169 | 7.67 | 206.33 |
| G0.0001_PR0.1_PF50_PA0.1_PAF25 | 0.816196 | 0.632600 | 0.662316 | 10.0 | 264.0 |
| G0.0001_PR0.1_PF50_PA0.1_PAF50 | 0.829588 | 0.631592 | 0.594863 | 6.67 | 178.67 |
| G0.0001_PR0.1_PF100_PA0.05_PAF25 | 0.812394 | 0.617858 | 0.681755 | 6.33 | 170.67 |
| G0.0001_PR0.1_PF100_PA0.05_PAF50 | 0.812964 | 0.628225 | 0.655215 | 8.0 | 215.0 |
| G0.0001_PR0.1_PF100_PA0.1_PAF25 | 0.819645 | 0.649383 | 0.616592 | 7.67 | 205.33 |
| G0.0001_PR0.1_PF100_PA0.1_PAF50 | 0.826528 | 0.594279 | 0.681473 | 5.33 | 143.0 |
另一方面,较高的生长阈值 ( 1 0 − 4 ) \left(10^{-4}\right) (10−4)倾向于生成较少的规则,且 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值相对较低。例如,配置G0.0001_PR0.05_PF100_PA0.1_PAF25具有 I o v I_{o v} Iov为 0.5993 , I f s p 0.5993, I_{f s p} 0.5993,Ifsp为0.6169,仅有3.67条规则。然而,过高的生长阈值可能限制模型学习复杂关系的能力,导致预测准确性下降,平均测试RMSE为0.8465。这表明选择适当的生长阈值需要在预测性能与 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值之间取得平衡。
剪枝规则阈值和频率的影响。较高的剪枝规则阈值(0.1)通常会导致模型中的规则数量减少,因为更多规则被剪枝。然而,这并不总是带来更好的性能。例如,参数组合G5e-05_PR0.05_PF50_PA0.05_PAF25的平均测试RMSE为0.8167,略高于G5e-05_PR0.1_PF50_PA0.05_PAF25的0.8034。这可能是因为较高的剪枝阈值减少了模型复杂性,同时保留了更重要的规则,从而降低了 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值。具体来说,PR_Thres = 0.1 =0.1 =0.1的配置通常具有较低的 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值,提高了模型的区分能力和可解释性。
关于剪枝规则频率,更频繁的剪枝( P R − F r e q = 50 \mathrm{PR}_{-} \mathrm{Freq}=50 PR−Freq=50 )有助于快速消除不重要的规则,进一步降低 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值,增强模型的泛化能力。在RMSE性能方面,剪枝频率为50轮的配置往往显示出比剪枝频率为100轮的配置稍低的RMSE值。
属性剪枝阈值和频率的影响。属性剪枝阈值显著影响模型复杂性以及 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值。较高的属性剪枝阈值(0.1)减少了模型中的属性数量,同时降低了 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值。例如,PA_Thres = 0.1 =0.1 =0.1的配置通常表现出较低的 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值,表明模糊集之间的重叠减少且定位更准确。然而,对RMSE性能的影响是混合的。在某些情况下,较高的属性剪枝阈值可能会略微增加RMSE,表明过度的属性剪枝可能移除重要的输入特征。同样,应考虑属性剪枝频率的影响。更频繁的属性剪枝( P A F = 25 \mathrm{PAF}=25 PAF=25 )有助于快速消除不重要的属性,导致 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值减少。然而,对RMSE性能的影响不一致,强调了在剪枝频率和预测准确性之间取得平衡的重要性。
参数之间的相互作用。综合考虑所有参数,低生长阈值与中等剪枝规则阈值和适当的属性剪枝阈值相结合可以保持良好的预测性能,同时减少 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值。例如,参数组合G5e-05_PR0.1_PF50_PA0.1_PAF25实现了平均测试RMSE为 0.8199 , I o v 0.8199, I_{o v} 0.8199,Iov为 0.6550 , I f s p 0.6550, I_{f s p} 0.6550,Ifsp为0.5919 ,平均规则数量为7.33。这表明最佳参数组合可以在预测性能和模型可解释性之间取得平衡。然而,值得注意的是,过度减少 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值(即过度减少规则重叠和模糊集分散)可能阻止模型捕捉复杂的数据模式,潜在影响预测性能。因此,在同时优化RMSE、 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值时,找到这些参数之间的正确平衡至关重要。
重叠指数和模糊集位置指数。虽然较低的 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值增强了模型的区分能力和可解释性,但在实际应用中必须在减少 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值与保持良好的预测性能之间取得平衡。实验结果表明, I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值过低的配置(如G0.0001_PR0.1_PF100_PA0.1_PAF50,其中 I o v = 0.5943 I_{o v}=0.5943 Iov=0.5943和 I f s p = 0.6815 I_{f s p}=0.6815 Ifsp=0.6815)的预测性能(RMSE = 0.8265 =0.8265 =0.8265 )可能劣于那些具有较适中的 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值的配置(如G5e-05_PR0.1_PF50_PA0.05_PAF25, I o v = 0.6445 , I f s p = 0.6305 I_{o v}=0.6445, I_{f s p}=0.6305 Iov=0.6445,Ifsp=0.6305, RMSE = 0.8034 =0.8034 =0.8034)。这表明适度的 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值可能对模型的整体性能更有利。
因此,在调整模型时,重要的是不要仅仅专注于最小化 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值。相反,应该考虑RMSE性能,并寻找在预测准确性和可解释性之间取得最佳平衡的参数组合。
讨论和建议。参数敏感性分析显示,ADAR-ANFIS模型的性能高度依赖于超参数的选择,特别是生长阈值、剪枝规则阈值和剪枝属性参数。这些参数不仅影响模型的预测准确性(RMSE),还在确定模糊集之间的重叠程度 ( I o v ) \left(I_{o v}\right) (Iov)和模糊集定位精度 ( I f s p ) \left(I_{f s p}\right) (Ifsp)方面起着关键作用。
较低的生长阈值提高了预测性能,但可能导致较高的 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值,这可能对模型的区分能力和可解释性产生负面影响。适当提高剪枝规则和属性阈值可以帮助减少 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值,同时维持甚至改善模型的预测性能。
参数之间的相互作用在决定模型性能方面起着至关重要的作用。最优性能并非由单一参数的极端值实现,而是通过考虑它们集体影响的平衡组合实现。这些组合影响模型结构和学习动态,需要在模型复杂性、预测性能和结构特征之间取得平衡。
基于实验结果,提出以下ADAR-ANFIS模型的配置建议:
- 选择中等生长阈值(如 5 × 1 0 − 5 5 \times 10^{-5} 5×10−5)以确保模型生成足够的规则来捕捉数据模式,同时防止 I o v I_{o v} Iov和 I f s p I_{f s p} Ifsp值过高。
-
- 适当提高剪枝规则阈值(如0.1)以有效消除不太重要的规则,减少 I o v I_{o v} Iov值并增强规则库的区分能力。
-
- 设置合理的剪枝规则和属性频率(如剪枝规则频率为50轮,剪枝属性频率为25至50轮)以实现及时剪枝,减少 I f s p I_{f s p} Ifsp值并确保模糊集定位准确。
-
- 适度提高剪枝属性阈值(如0.1)以最小化不必要的属性,同时保留关键特征,提高模型的可解释性和泛化能力。
-
- 持续监控
I
o
v
I_{o v}
Iov和
I
f
s
p
I_{f s p}
Ifsp指标以确保它们保持在适当水平,维持预测性能和模型结构之间的最佳平衡。
参考论文:https://arxiv.org/pdf/2504.19148
- 持续监控
I
o
v
I_{o v}
Iov和
I
f
s
p
I_{f s p}
Ifsp指标以确保它们保持在适当水平,维持预测性能和模型结构之间的最佳平衡。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











