






玛塔·克里文 (marta.kryven@dal.ca)
计算机科学系
达尔豪斯大学
艾丹·柯蒂斯 (curtisa@mit.edu)
计算机科学与人工智能实验室
麻省理工学院
科尔·韦特 (cwyeth@uwaterloo.ca)
计算机科学系
滑铁卢大学
凯文·埃利斯 (kellis@cornell.edu)
计算机科学系
康奈尔大学
摘要
理解和应对世界依赖于构建简化的心理表征,这些表征抽象了现实的某些方面。这种认知映射原则对资源有限的主体具有普遍性。生物体、人类和算法都面临在各种计算约束下形成功能性世界表征的问题。在这项工作中,我们探讨了这样一个假设:人类资源高效的规划可能源于将世界表示为可预测结构的能力。基于概念即程序的隐喻,我们提出认知地图可以采取生成性程序的形式,利用可预测性和冗余性,而不是直接编码空间布局。我们通过行为实验表明,在结构化空间中导航的人依赖于与程序化地图表示一致的模块化规划策略。我们描述了一种计算模型,该模型可以在各种结构化场景中预测人类行为。此模型推断出一个关于可能的程序化认知地图的小分布,该分布以人类对世界的先验知识为条件,并使用该分布生成资源高效的计划。我们的模型利用大型语言模型作为人类先验知识的嵌入,通过在大量人类数据上训练隐式学习。我们的模型展示了改进的计算效率,需要显著更少的内存,并且在预测人类行为方面优于具有认知约束的非结构化规划算法,这表明人类规划策略依赖于程序化认知地图。
关键词:导航、规划、认知地图、计算建模、大型语言模型。
引言
当前的人工智能将规划形式化为在可能行动和结果的决策树中的搜索。此树可以通过多种方式编码,例如学习的神经策略 [Liu et al., 2020]、显式的树结构 [Russell and Norvig, 2016] 或神经符号模型 [Tang et al., 2024]。底层决策树的大小决定了问题的计算成本,或其难度。然而,此类模型的规范难度很少与人类经验一致,因为人们通常能够轻松解决理论上难以处理的实际问题。例如,人们可以在不了解街道网络每个链接的确切位置的情况下高效地在城市中导航(图1a)[Bongiorno et al., 2021],并规划涉及数千个动作的建设项目(图1b)。
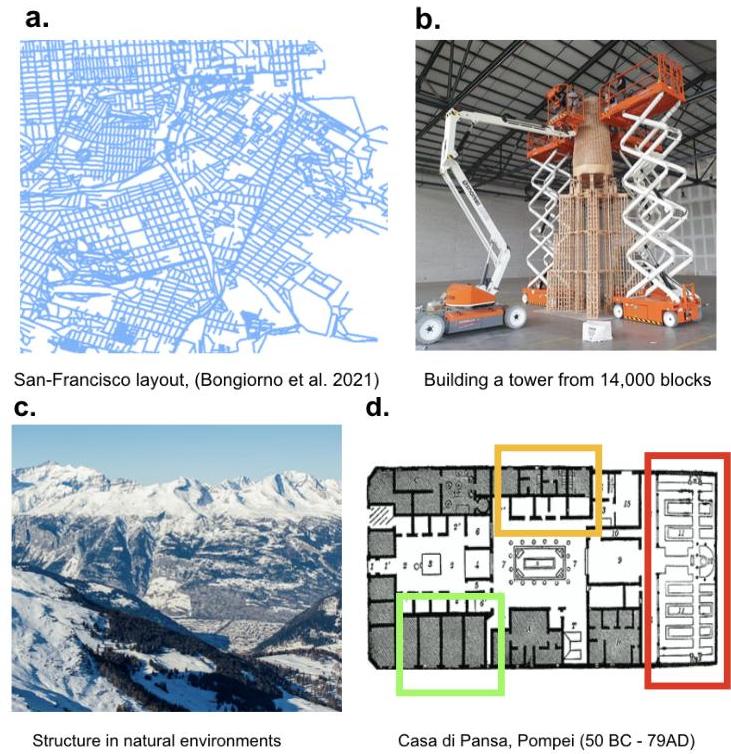
图1:现实世界的规划往往发生在具有可预测结构的领域中,例如街道网络(a)、模块化建筑(b,d)和自然模式化的景观(c)。
这种在现实生活规划中的卓越效率与实验室中的经常低效表现形成鲜明对比。在各种背景下,人们偏离最优计划,包括基于多臂老虎机的任务 [Keramati et al., 2016, Huys et al., 2015]、象棋等游戏 [Ferreira, 2013] 和许多旨在检查规划行为的实验范式 [Unterrainer et al., 2004, Kryven et al., 2024, Callaway et al., 2022]。这种偏离最优性的常见解释是限制规划范围 [Ferreira, 2013, Kryven et al., 2024, van Opheusden et al., 2023] 和感知的低级约束 [Kryven et al., 2024]。然而,大多数基于实验室的任务明显缺乏现实生活中无处不在的可预测和规则化问题结构,例如自然中的丘陵和山谷(图1c)以及模块化布局(图1d)。此外,经典实验范式通常明确避免创建结构,以隔离感兴趣的变量,例如规划深度。
在这里,我们测试了这样一个假设:人类规划利用了关于世界的先验知识,特别是对世界高度结构化的期望。鉴于此,认知地图可以表示为程序,因为程序可以捕捉诸如对称性和重复部分等结构。
程序结构的地图解决了关键的计算问题:在部分观察到的环境中进行规划是不可行的 [Madani et al., 2003]。需要近似。程序结构的地图有助于解决困难的规划问题,因为反复生成相同地图片段的程序允许重用成功的策略,从而本质上分解决策问题。这给出了局部最优(在代码片段内)但全局次优的计划。关键是发现部分观察到的地图中重复结构的片段,并只为每个重复片段规划一次策略。然后,当遇到每个片段时,我们通过重用预先计算的策略来避免昂贵的信念空间规划。我们探究人类在多大程度上类似地在重复代码片段之间重用成功策略,发现他们的计划与此次优特征相符。我们展示了人类在结构化环境中的规划由我们的生成地图模型预测,并且不能用基于非结构化规划的认知约束模型来解释。
背景
从幼儿到狩猎采集者,人们都会强加结构于世界以解决问题 [Pitt et al., 2021, Lake and Piantadosi, 2020]。例如,人们自发地推断空间相邻位置之间的奖励相关性 [Schulz et al., 2018],并分层表示空间——被可见边界 [Kosslyn et al., 1974]、地理 [Stevens and Coupe, 1978] 或子区域 [Hirtle and Jonides, 1985] 划分的空间。组成问题表示的行为证据扩展到了听觉 [Verhoef et al., 2014]、视觉 [Tian et al., 2020] 和抽象概念领域 [Schulz et al., 2017]——这表明组成推理可能是对日常生活中遇到的自然结构的一种进化适应 [Johnston et al., 2022]。
最近的一项研究发现,人们形成认知地图以促进规划 [Ho et al., 2022],仅选择性地表示与目标导向路线相关的地图部分。认知地图也可能取决于对世界的先验期望,导致人们即使事先未被告知新环境的规律性也能预期这些规律性 [Sharma et al., 2022]。在自然主义设置中,适应性规划依赖于复杂的概念先验知识,包括关于代理和对象如何交互的知识,通常称为核心知识 [Acquaviva et al., 2022, Spelke and Kinzler, 2007, Dehaene et al., 2006]。学习这些自然先验仍然是认知AI中的一个重要问题 [Kumar et al., 2022, Li et al., 2024, Binz et al., 2024]。
计算领域的平行发展长期以来一直致力于构建能够解决一般性过程任务的智能系统的目标 [Chollet et al., 2025, Veness et al., 2011]。强化学习(RL)模型通过将一起执行的动作表达为选项 [Sutton et al., 1999]、学习具有共享奖励的相似马尔可夫决策过程(MDP)家族 [Wilson et al., 2012] 以及通过识别导致相同观察的动作来构建高效的状态空间 [Singh et al., 2012] 来抽象问题表示。通用规划框架可以找到解决任务多个实例的算法类策略 [Curtis et al., 2022],尽管它们处理不确定性的能力仍然有限。一种基于旋转和反射对称性对围棋盘状态进行分组的原则被用来优化围棋中的表示 [Silver et al., 2017],尽管这项工作不考虑自动发现结构化表示。
因此,对认知建模和工程通用智能的核心挑战都是学习和利用自然先验 [Feldman, 2013]。AI如何学习使人们在现实生活中如此高效的核心知识和常识期望?新兴的研究线利用LLM,在工程 [Tang et al., 2024] 和行为领域 [Correa et al., 2023] 中制定计划。虽然LLM直接生成计划的应用有限,但研究已成功利用LLM的程序合成能力,在OpenAI Gym领域生成用于规划的转换函数的程序化表示 [Tang et al., 2024, Towers et al., 2024],并合成规划域定义语言(PDDL)规范 [Xie et al., 2023]。我们的计算框架采用类似的方法,假设通过这样做,我们可以隐式访问嵌入在LLM训练使用的语言和代码中的世界人类先验知识。
方法
行为实验
为了测试人们的自然规划策略,我们改编了一个版本的迷宫搜索任务(MST),以前曾用于评估计算模型对人类在空间领域中的规划和计划感知 [Kryven et al., 2024, Kryven et al., 2021]。MST 的目标是在一系列部分可观测的二维网格世界迷宫中导航,寻找隐藏在每个迷宫中的出口。由于迷宫是部分可观测的,出口最初放置在一个随机未观测的位置内。图2b 显示了参与者在 MST 中看到的一系列视图 1 { }^{1} 1。人们通过点击他们角色(一个圆形脸图标)旁边的任何未占用的网格单元格来在相邻单元格之间移动以搜索迷宫。黑色隐藏
1
{ }^{1}
1 我们鼓励读者在此尝试实验:http:// 18.25.132.241/fragments/int_exp.php
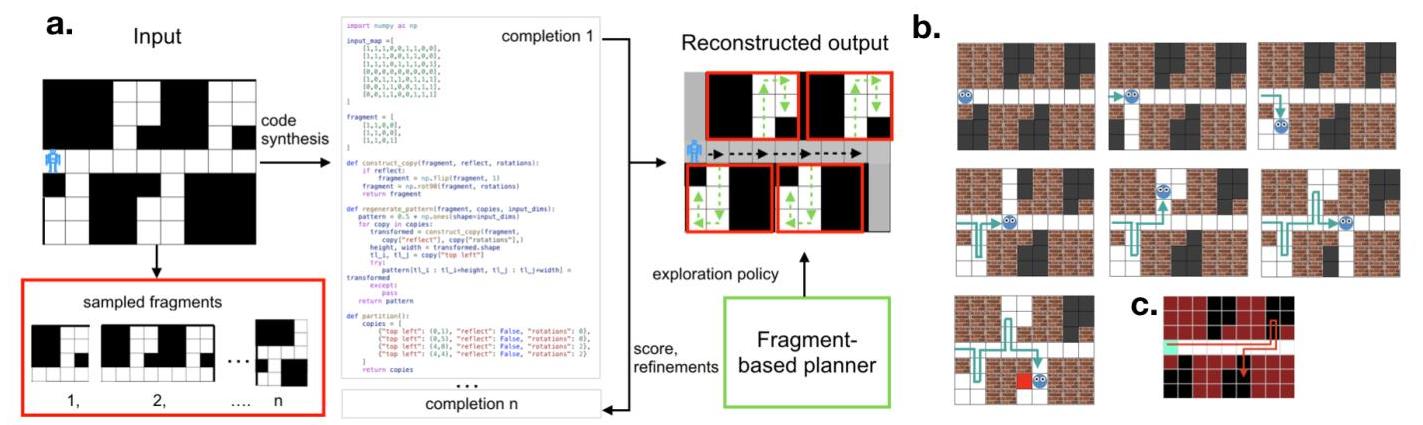
图2:(a) GMP框架。从输入地图中恢复的生成地图表示构成碎片列表和一个近似重构输入的程序。这些碎片被规划模块用于为每个碎片规划搜索政策。(b) 实验中一个人看到的一系列屏幕。黑块最初是隐藏的,当它们进入视线时会显示出来。出口在最后一个屏幕上可见,显示为红色方块。箭头指示参与者的路径,以模块化方式(单位到单位)搜索迷宫。© 在这个迷宫中,最小化到达随机放置出口所需步骤的最优路径是非模块化的。
单元格在进入视线范围内时会显示出来。当显示时,出口会显示为红色方块。一旦角色移动到出口上,试验就结束。
程序 在开始实验之前,人们给予知情同意并完成了一系列练习迷宫,随后进行了指导测验。之后,他们完成了一个包含21个生成结构化迷宫的MST版本,出口位置在设计时随机选择。在一个迷宫中,出口随机放置在视线范围内,并从分析中排除。完成MST后,人们完成了认知反思测试(CRT)[Frederick, 2005],此前已证明该测试与分配给规划的认知资源相关联[Kryven et al., 2021]。由于原始CRT已被广泛使用,我们的CRT版本提供了一个新颖背景下的类似问题集[Chandler et al., 2014]。最后,我们进行了一个实验后问卷调查,要求人们描述他们使用的任何搜索策略,并提供人口统计信息。由于我们的目标是观察人们的自然规划,我们没有提供基于性能的激励措施。人们被告知出口可能在任何隐藏的方块中,并被指示在每个迷宫中找到它。
参与者 我们在Prolific上招募了30名(13名女性,17名男性,
M
(
M(
M(年龄
)
=
36.7
,
S
D
(
)=36.7, S D(
)=36.7,SD(年龄
)
=
13.5
)
)=13.5)
)=13.5)讲英语的参与者,每小时支付9英镑。没有人被排除在外。平均而言,实验需要10分钟才能完成。初步试点实验揭示了模块化效应的强烈影响,使我们得出结论,小样本足以确认这一效应。
计算模型
问题公式化 部分可观测下的决策制定可以通过部分可观测马尔可夫
决策过程(POMDP)进行建模。等价地,它可以被视为完全可观测的信念空间搜索,其中每个信念是一个可能状态的概率分布。解决POMDPs是出了名的困难 [Madani et al., 2003],因此理解人们如何接近这些问题对于认知科学和人工智能具有深远的重要性。
正式地,一个POMDP是一个元组 ⟨ Δ ( S ) , A , τ , r , b 0 , γ ⟩ \langle\Delta(S), A, \tau, r, b_{0}, \gamma\rangle ⟨Δ(S),A,τ,r,b0,γ⟩,其中 Δ ( S ) \Delta(S) Δ(S)是状态空间 S S S上的概率分布空间, A A A是动作集, τ \tau τ是信念更新函数, r r r是奖励函数, b 0 b_{0} b0是初始信念, γ \gamma γ是折扣因子。信念状态通过 τ \tau τ确定性地演化,反映代理的动作和观察。
在本工作中,每个状态 s ∈ S s \in S s∈S被表示为一个 N × M N \times M N×M网格,其单元格标记为{wall, empty, exit, agent } 。整体状态空间 \}。整体状态空间 }。整体状态空间S 由所有包含恰好一个代理和一个出口的此类网格组成。信念 由所有包含恰好一个代理和一个出口的此类网格组成。信念 由所有包含恰好一个代理和一个出口的此类网格组成。信念b \in \Delta(S) 因此是这些网格上的概率分布,编码代理对真实状态的不确定性。最初, 因此是这些网格上的概率分布,编码代理对真实状态的不确定性。最初, 因此是这些网格上的概率分布,编码代理对真实状态的不确定性。最初,b_{0} 假设代理和墙壁是已知的,而出口在所有有效、未见单元格上均匀分布。动作空间 假设代理和墙壁是已知的,而出口在所有有效、未见单元格上均匀分布。动作空间 假设代理和墙壁是已知的,而出口在所有有效、未见单元格上均匀分布。动作空间A 包含四个可能的移动(上、下、左、右)。观察 包含四个可能的移动(上、下、左、右)。观察 包含四个可能的移动(上、下、左、右)。观察o \in O 揭示代理周围的网格可见子集,每个可见单元格标记为 { w a l l , e m p t y , e x i t } ,任何超出代理视野范围 揭示代理周围的网格可见子集,每个可见单元格标记为\{wall, empty, exit\},任何超出代理视野范围 揭示代理周围的网格可见子集,每个可见单元格标记为{wall,empty,exit},任何超出代理视野范围r 的单元格标记为未见。观察与真实状态 的单元格标记为未见。观察与真实状态 的单元格标记为未见。观察与真实状态s \in S$的网格结构一致。
信念更新函数 τ \tau τ由下式给出:
b ′ ( s ′ ) ∝ Z ( o ∣ s ′ ) ∑ s ∈ S T ( s ′ , a , s ) b ( s ) b^{\prime}\left(s^{\prime}\right) \propto Z\left(o \mid s^{\prime}\right) \sum_{s \in S} T\left(s^{\prime}, a, s\right) b(s) b′(s′)∝Z(o∣s′)s∈S∑T(s′,a,s)b(s)
其中 T ( s ′ , a , s ) T\left(s^{\prime}, a, s\right) T(s′,a,s)是转移函数, Z ( o ∣ s ′ ) Z\left(o \mid s^{\prime}\right) Z(o∣s′)是观察似然度。转移函数 T ( s ′ , a , s ) T\left(s^{\prime}, a, s\right) T(s′,a,s)指定执行动作 a a a后从状态 s s s过渡到状态 s ′ s^{\prime} s′的概率。这里,会使代理移动到墙上的动作会导致代理停留在当前位置,而向出口状态的过渡则终止过程。观察函数 Z ( o ∣ s ′ ) Z\left(o \mid s^{\prime}\right) Z(o∣s′)编码观察 o o o给定 s ′ s^{\prime} s′的似然度,其中观察反映了代理位置范围内可见的网格子集。墙壁阻挡视线,使得墙壁后的单元格被标记为未见。最后,奖励函数 r ( b , a ) r(b, a) r(b,a)是在信念 b b b下的预期奖励。由于代理总能在到达出口前看到出口,若动作 a a a引导代理到已知出口,则 r ( b , a ) = 1 r(b, a)=1 r(b,a)=1,否则为0。
预期效用 这个POMDP的最优策略可以通过信念空间树搜索找到 [Kaelbling et al., 1998]。搜索在一颗树上进行,其中每个节点代表一个信念 b ∈ Δ ( S ) b \in \Delta(S) b∈Δ(S),边对应于动作-观察对 ( a , o ) (a, o) (a,o)。从根节点 b 0 b_{0} b0开始,通过模拟动作 a ∈ A a \in A a∈A并使用信念更新函数 τ \tau τ更新信念来扩展树。对于每个动作 a a a,代理考虑所有可能的观察 o ∈ O o \in O o∈O,每个观察的可能性由观察函数 Z ( o ∣ s ′ ) Z\left(o \mid s^{\prime}\right) Z(o∣s′)确定。在每个节点,信念的价值通过贝尔曼方程递归计算:
V ( b ) = max a ∈ A [ r ( b , a ) + γ ∑ o ∈ O P ( o ∣ b , a ) V ( τ ( b , a , o ) ) ] V(b)=\max _{a \in A}\left[r(b, a)+\gamma \sum_{o \in O} P(o \mid b, a) V(\tau(b, a, o))\right] V(b)=a∈Amax[r(b,a)+γo∈O∑P(o∣b,a)V(τ(b,a,o))]
其中 P ( o ∣ b , a ) P(o \mid b, a) P(o∣b,a)是在信念 b b b下采取动作 a a a后接收到观察 o o o的概率。最优策略 π ∗ \pi^{*} π∗通过选择在每个信念节点最大化预期价值的动作来导出。有关此实现的更多细节,请参见[Kryven et al., 2024]。
尽管这是最优策略,但先前研究表明,人类行为有时会偏离其预测 [Kryven et al., 2024],这种偏离的程度因人而异,可以用人们分配给规划的认知资源量来解释 [Kryven et al., 2021]。以往关于MST的研究以及相关的非空间规划任务 [Huys et al., 2015] 发现,人们对最优轨迹的偏离最容易用有限的规划范围(折扣因子 γ < 1 \gamma<1 γ<1在公式1中)来解释。在本节的其余部分中,我们将描述替代的计算假设,说明人类在这种环境下如何通过推理结构模式来做决策。
生成模块化规划(GMP) 我们首先描述一个模型,该模型形式化了基于自动发现的状态空间潜在结构的规划策略。我们的模型由两个模块组成:生成地图模块(GMM)和基于片段的规划(FP)模块。请参见图2a以获取此架构的高层次概述。GMM恢复观察到的状态空间的程序化表示,作为片段单元的组合。然后FP使用规划器为每个片段规划一次分段策略,而不是全局策略,从而节省计算
算法1 从2D数组生成程序
需要:
(
I
)
(I)
(I) : 输入地图,
(
t
)
(t)
(t) : 阈值,
(
C
)
(C)
(C) : 完成次数
确保:
(
λ
)
(\lambda)
(λ) 生成程序, 片段
(
S
′
←
0
)
(S^{\prime} \leftarrow 0)
(S′←0)
初始化片段
(
←
)
(\leftarrow)
(←)
(
λ
←
)
(\lambda \leftarrow)
(λ←) “”
while
(
S
′
<
t
)
(S^{\prime}<t)
(S′<t) do
从
(
I
)
(I)
(I) 和片段生成提示
发送提示并接收
(
C
)
(C)
(C) 个完成
提取程序
(
{
λ
1
,
λ
2
,
…
,
λ
C
}
)
(\left\{\lambda_{1}, \lambda_{2}, \ldots, \lambda_{C}\right\})
({λ1,λ2,…,λC})
for all
(
λ
i
∈
{
λ
1
,
λ
2
,
…
,
λ
C
}
)
(\lambda_{i} \in\left\{\lambda_{1}, \lambda_{2}, \ldots, \lambda_{C}\right\})
(λi∈{λ1,λ2,…,λC}) do
if
(
λ
i
)
(\lambda_{i})
(λi) 运行成功 then
(
S
i
←
S
(
λ
i
)
)
(S_{i} \leftarrow S\left(\lambda_{i}\right))
(Si←S(λi))
end if
end for
(
S
′
,
i
←
max
(
S
i
)
)
(S^{\prime}, i \leftarrow \max \left(S_{i}\right))
(S′,i←max(Si))
(
λ
←
λ
i
)
(\lambda \leftarrow \lambda_{i})
(λ←λi) 最高得分
片段
(
←
)
(\leftarrow)
(←) 片段
(
i
)
(_{i})
(i)
end while
返回
(
λ
i
)
(\lambda_{i})
(λi) 片段
成本。重要的是,这种重建的程序化表示是一种受认知启发的状态空间压缩。虽然这种重建可能匹配真实的规划状态空间,但它不需要精确。理论上,结合自动结构发现与结构感知规划的认知原则可以应用于任何领域,作为一个概念验证,我们专注于空间任务。
生成地图模块 我们使用基于LLM的程序合成为GPT4搜索可以生成认知地图的程序(见算法1)。为此,我们提示LLM识别输入地图中可能重复的片段,并合成一个Python程序,根据这些片段近似重构输入。提示包括Python代码,其中包含允许片段变换的帮助函数,以及评分函数,用于评估地图(如下所述)。在我们的实现中,输入地图是一个网格世界,由Python中的数值数组指定,其中每个网格单元与一个数字相关联(例如,墙=1,地板=0)。此操作的结果是一些可能近似重构地图的程序。这种重构允许输出的部分保持未定义。
我们通过对网格级相似性和最小描述长度(MDL)原则([Rissanen, 1978])的加权组合对每个候选地图补全进行评分,以产生重建地图的排名。MDL方法通过大小惩罚片段,因为形状和每个条目都必须指定。MDL还通过指定片段到地图转换所需的比特数来惩罚每次用于重建地图的出现:平移(作为左上角的位置)、旋转和反射。这意味着无信息片段(例如,包含墙或开放空间的单元块)不会形成地图的简约解释,尽管它们当然会发生很多次。这可以看作是对简单生成程序的偏好,额外的结构要求是生成程序使用编码对称性的原始变换,这对规划相关。排名最高的地图程序然后由规划模块用于生成策略。正式地,得分为
S = w 1 M ⋅ N ∑ x = 1 M ∑ y = 1 N ( I ( x , y ) − O ( x , y ) ) 2 − w 2 ∣ λ ∣ S=\frac{w_{1}}{M \cdot N} \sum_{x=1}^{M} \sum_{y=1}^{N}(I(x, y)-O(x, y))^{2}-w_{2}|\lambda| S=M⋅Nw1x=1∑My=1∑N(I(x,y)−O(x,y))2−w2∣λ∣
这里 N , M N, M N,M 是地图尺寸, I I I 是输入, O O O 是输出(重建)地图, λ \lambda λ 是程序, w 1 , w 2 w_{1}, w_{2} w1,w2 是权重,模型的自由参数。在一般情况下,输入 I I I 和输出 O O O 是实值2D图像数组。在我们当前的实现中,输入 I I I 取值0和1 ,输出 0 ≤ O ( x , y ) ≤ 1 0 \leq O(x, y) \leq 1 0≤O(x,y)≤1。
我们不使用原始的Python程序 λ \lambda λ 来衡量其复杂性,而是使用片段的压缩编码和用于重构地图的变换。这里压缩LLM生成的片段和变换类似于重构合成的程序。由于LLM生成代码的长度可能会受到注入注释和代码冗余的影响,重构输出获得了一个去噪的复杂性指标。例如,只需两位即可指定副本的旋转,一位即可指定是否反射。
图3显示了实验中使用的三个地图示例,分别有4、2和5个结构片段,用红色突出显示。
基于片段的规划模块 在当前实现中,我们将来自[Kryven et al., 2024]的最佳预期效用模型(
π
∗
\pi^{*}
π∗ 的实现)改编为在片段内规划。
这种建模选择的含义是假设人们在局部是最优的但在全局是次优的,这是能精确解决小问题并然后重用它们的模型的自然结果。为了在片段之间规划(在输出未定义的部分),FP通过局部求解马尔可夫决策过程(使用值迭代)朝最近的片段移动,假设找到出口的先验概率在各片段间是均匀的。当这样的先验是非均匀时,可以在任何规划算法中解决片段之间的规划问题。
这种方法是资源高效的,因为我们的规划器只为每个片段计算一次决策(子)树,并在每次遇到该片段时重新使用它。而不是为整个地图计算决策树,我们的模型维护几个较小的决策树,以及一个描述如何从它们重建全局地图的生成程序。原则上,由于地图重建是近似的,规划器可能会遇到与重建地图不符的观察结果。当这种情况发生时,恢复到非模块化规划(例如,使用预期效用规划[Kryven et al., 2024])以确保算法的鲁棒性。虽然我们选择规划器是出于与先前工作比较结果的动机,但我们的框架并不严重依赖内部非模块化规划器的选择,并且可以与其他实现集成。
替代模型 我们将GMP与一组现有模型进行比较,这些模型以前用于解释人类在MST中的行为[Kryven et al., 2024]。这些模型将迷宫搜索视为路径最小化问题——这是参与者在实验后问卷调查中自发报告的隐含目标。在这里,我们将人们与之前工作的一个子集模型进行比较——预期效用(最佳规划器)和折现效用(总体最佳拟合规划器,假设 γ = 0.7 \gamma=0.7 γ=0.7,规划范围有限)[Kryven et al., 2024]。为了便于比较,我们设计环境,使这些现有模型要么预测非模块化策略,要么在模块化和非模块化搜索之间无差别。每当一个现有模型在某个环境中对模块化和非模块化路径无差别时,该模型采取模块化路径的概率最多为0.25。
结果
我们引入以下指标来比较行为与我们的模型。首先,我们定义了一种保守的模块化路径定义,即按顺序访问所有片段,总是移动到下一个最近的片段。这种模块化的定义与我们GMP的实现一致,然而,它低估了模块化的实际比率,因为将地图表示为模块化的人可能对哪些片段“有益”持有非均匀的先验信念。例如,人们可能假设出口倾向于在第二个或第三个片段中,跳过地图的一些部分。我们使用这个定义来计算模块化——
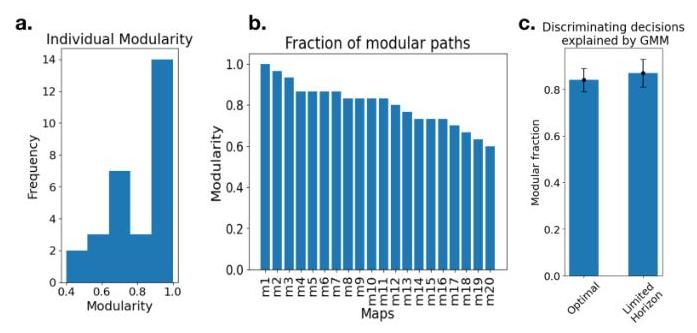
图4:根据保守定义,人们表现出高度模块化。(a)参与者模块化直方图。(b)每位参与者使用模块化轨迹搜索的分数,针对20张地图中的每一张。(c)汇总个体决策和人群。每个条形图显示每个参与者在区分决策中的比例,其中参与者的决策被我们的模型预测,但未被替代模型预测。误差条为95%CI。
图4a和4b中对个体和特定地图模块化的检查显示,人们与我们的模型高度一致,展示了跨所有环境和参与者的模块化规划特征。相比之下,根据我们的实验设计,替代模型预测迷宫应以非模块化方式搜索。此外,GMM比最优规划器或之前展示解释人类在MST中行为的有限范围规划更好地预测人们(图4)。
为了测试模块化规划是否是减少认知成本的资源高效适应,我们计算了人们CRT得分与模块化率的线性回归。尽管我们在试点期间发现了这些得分之间的负相关关系,但这种相关性在当前结果中并不显著。这种无法复制很可能是因为我们对模块化的保守定义低估了人们以不同顺序搜索片段的真实比率。
讨论
我们测试了这样一个假设:人们可能通过生成程序表示认知地图,这些程序基于对世界的概念先验知识。我们利用一个以前用于研究人类规划的实验任务,设计部分可观测环境布局以区分模块化规划、遵循最优计算预期效用的规划以及之前展示描述有限范围规划的模型。我们发现,人们遵循高度模块化的策略,这些策略在环境和个体间具有普遍性,支持我们的假设。我们通过一个结合LLM程序合成用于地图生成与模块化规划的计算模型来解释我们的结果,表明该模型在预测行为方面高度准确。这一结果表明,人们在结构化环境中偏离最优计划至少部分是由于对环境结构的推理。
我们在科学和工程领域做出了三项贡献。首先,我们在科学上有所贡献,表明人们做出的适应性计划与程序化表示的认知地图一致。其次,我们通过展示如何引出人类关于空间决策的归纳偏差,推进了对LLM潜在认知能力的理解。第三,我们贡献了一个实现,展示了如何将这些原则融入一个工作系统。我们的GMP模型不同于现有的层次模型(将复杂问题划分为可管理的块),因为它还可以在重复片段之间重用计算。它也不同于现有的PDDL中指定的可推广任务和运动模型,因为它容忍不确定性。通过使用LLM进行程序合成,我们的工作比传统的枚举搜索(暴力搜索)方法 [Sharma et al., 2022, Veness et al., 2011] 更实用和可扩展,用于发现结构形式。
值得注意的是,我们发现个体之间和地图之间的行为差异并未被我们对模块化规划的保守定义所解释。这种变异性很大程度上来自于人们跳过片段,这表明未来模型版本应包括对哪些片段人们认为有益的非均匀先验。未来研究还应考虑潜在的认知因素,如学习、注意力和可用的认知资源,如何影响人们模块化和表示地图的方式。
由于地图重建是近似的,规划器可能会遇到与重建地图不一致的观察结果。我们目前通过恢复到非模块化规划器来处理这种情形,但此解决方案与人们的契合度仍需通过实验进行评估。需要更多的研究来了解当人们的期望失败时,他们如何处理认知地图与现实之间的差异。未来的研究还应考察在可能目标的背景下,被视为同一类别实例的片段之间变异的程度,因为认知地图可能依赖于目标 [Ho et al., 2022]。
虽然规划认知已经被广泛研究,但现实世界的规划领域仍然探索不足。我们的工作为人类先验知识如何指导资源高效的计划提供了正式的计算见解,并为正在兴起的
是否LLMs可以捕获自然主义归纳偏差(例如,[Tang et al., 2024])的调查做出了贡献,提供了在空间领域的见解。通过以计算术语表达我们的发现,我们的GMP模型朝着将人类规划背后的认知机制转化为AI应用的方向迈进。
参考文献
[Acquaviva et al., 2022] Acquaviva, S., Pu, Y., Kryven, M., Sechopoulos, T., Wong, C., Ecanow, G., Nye, M., Tessler, M., and Tenenbaum, J. (2022). Communicating natural programs to humans and machines. Advances in Neural Information Processing Systems, 35:3731-3743.
[Binz et al., 2024] Binz, M., Akata, E., Bethge, M., Brändle, F., Callaway, F., Coda-Forno, J., Dayan, P., Demircan, C., Eckstein, M. K., Éltető, N., Griffiths, T. L., Haridi, S., Jagadish, A. K., Ji-An, L., Kipnis, A., Kumar, S., Ludwig, T., Mathony, M., Mattar, M., Modirshanechi, A., Nath, S. S., Peterson, J. C., Rmus, M., Russek, E. M., Saanum, T., Scharfenberg, N., Schubert, J. A., Buschoff, L. M. S., Singhi, N., Sui, X., Thalmann, M., Theis, F., Truong, V., Udandarao, V., Voudouris, K., Wilson, R., Witte, K., Wu, S., Wulff, D., Xiong, H., and Schulz, E. (2024). Centaur: a foundation model of human cognition.
[Bongiorno et al., 2021] Bongiorno, C., Zhou, Y., Kryven, M., Theurel, D., Rizzo, A., Santi, P., Tenenbaum, J., and Ratti, C. (2021). Vector-based pedestrian navigation in cities.
[Callaway et al., 2022] Callaway, F., van Opheusden, B., Gul, S., Das, P., Krueger, P. M., Griffiths, T. L., and Lieder, F. (2022). Rational use of cognitive resources in human planning. Nature Human Behaviour, 6(8):1112-1125.
[Chandler et al., 2014] Chandler, J., Mueller, P., and Paolacci, G. (2014). Nonnaivete among amazon mechanical turk workers: Consequences and solutions for behavioral researchers. Behavior research methods, 46(1):112-130.
[Chollet et al., 2025] Chollet, F., Knoop, M., Kamradt, G., and Landers, B. (2025). Arc prize 2024: Technical report.
[Correa et al., 2023] Correa, C. G., Sanborn, S., Ho, M. K., Callaway, F., Daw, N. D., and Griffiths, T. L. (2023). Exploring the hierarchical structure of human plans via program generation. arXiv preprint arXiv:2311.18644.
[Curtis et al., 2022] Curtis, A., Silver, T., Tenenbaum, J. B., Lozano-Pérez, T., and Kaelbling, L. (2022). Discovering state and action abstractions for generalized task and motion planning. In Proceedings of the AAAI conference on artificial intelligence, volume 36, pages 5377-5384.
[Dehaene et al., 2006] Dehaene, S., Izard, V., Pica, P., and Spelke, E. (2006). Core knowledge of geometry in an amazonian indigene group. Science, 311(5759):381-384.
[Feldman, 2013] Feldman, J. (2013). Tuning your priors to the world. Topics in cognitive science, 5(1):13-34.
[Ferreira, 2013] Ferreira, D. R. (2013). The impact of the search depth on chess playing strength. ICGA journal, 36(2):67-80.
[Frederick, 2005] Frederick, S. (2005). Cognitive reflection and decision making. The Journal of Economic Perspectives, 19(4):25-42.
[Hirtle and Jonides, 1985] Hirtle, S. C. and Jonides, J. (1985). Evidence of hierarchies in cognitive maps. Memory & cognition, 13(3):208-217.
[Ho et al., 2022] Ho, M. K., Abel, D., Correa, C. G., Littman, M. L., Cohen, J. D., and Griffiths, T. L. (2022). People construct simplified mental representations to plan. Nature, 606(7912):129-136.
[Huys et al., 2015] Huys, Q. J., Lally, N., Faulkner, P., Eshel, N., Seifritz, E., Gershman, S. J., Dayan, P., and Roiser, J. P. (2015). Interplay of approximate planning strategies. Proceedings of the National Academy of Sciences, 112(10):3098-3103.
[Johnston et al., 2022] Johnston, I. G., Dingle, K., Greenbury, S. F., Camargo, C. Q., Doye, J. P., Ahnert, S. E., and Louis, A. A. (2022). Symmetry and simplicity spontaneously emerge from the algorithmic nature of evolution. Proceedings of the National Academy of Sciences, 119(11):e2113883119.
[Kaelbling et al., 1998] Kaelbling, L. P., Littman, M. L., and Cassandra, A. R. (1998). Planning and acting in partially observable stochastic domains. Artificial intelligence, 101(1-2):99-134.
[Keramati et al., 2016] Keramati, M., Smittenaar, P., Dolan, R. J., and Dayan, P. (2016). Adaptive integration of habits into depth-limited planning defines a habitual-goaldirected spectrum. Proceedings of the National Academy of Sciences, 113(45):12868-12873.
[Kosslyn et al., 1974] Kosslyn, S. M., Pick Jr, H. L., and Fariello, G. R. (1974). Cognitive maps in children and men. Child development, pages 707-716.
[Kryven et al., 2021] Kryven, M., Ullman, T. D., Cowan, W., and Tenenbaum, J. B. (2021). Plans or outcomes: How do we attribute intelligence to others? Cognitive Science, 45(9):13-41.
[Kryven et al., 2024] Kryven, M., Yu, S., Kleiman-Weiner, M., Ullman, T., and Tenenbaum, J. (2024). Approximate planning in spatial search. PLOS Computational Biology, 20(11):e1012582.
[Kumar et al., 2022] Kumar, S., Correa, C. G., Dasgupta, I., Marjieh, R., Hu, M., Hawkins, R. D., Cohen, J., Daw, N., Narasimhan, K. R., and Griffiths, T. L. (2022). Using natural language and program abstractions to instill human inductive biases in machines.语言和程序抽象以在机器中灌输人类归纳偏见。
参考论文:https://arxiv.org/pdf/2504.20628



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











