






Beomjun Kim
Department of
麻省理工学院
地址
kimbj@mit.edu
Kangyeon Kim
电气工程学院
韩国科学技术院
大田市尤松区大학路291号,邮编34141,韩国
kky3528@kaist.ac.kr
Sunwoo Kim
统计系
首尔国立大学
首尔冠岳区冠岳路1号,邮编08826,韩国
ksunw0209@snu.ac.kr
Heejin Ahn
电气工程学院
韩国科学技术院
大田市尤松区大학路291号,邮编34141,韩国
heejin.ahn@kaist.ac.kr
摘要
确保AI系统的安全性最近已成为实际部署中的关键优先事项,特别是在物理AI应用中。目前的AI安全方法通常解决预定义的领域特定安全条件,限制了其在不同上下文中的泛化能力。我们提出了一种新颖的AI安全框架,该框架确保AI系统符合任何用户定义的约束条件,以任何所需的概率,并跨越各种领域。在此框架中,我们将AI组件(例如神经网络)与优化问题相结合,生成响应以最小化目标函数,同时以超过用户定义阈值的概率满足用户定义的约束条件。为了评估AI组件的可信度,我们提出了内部测试数据,即一组补充的安全标记数据,以及提供使用内部测试数据统计有效性的保守测试方法。我们还介绍了一种损失函数的近似方法及其梯度计算方法用于训练。我们在特定、温和的条件下数学证明了概率约束满足性,并证明了安全性和内部测试数据数量之间的缩放定律。通过在不同领域的实验,我们展示了我们框架的有效性:生产决策需求预测、SafetyGym模拟器内的安全强化学习以及AI聊天机器人输出防护。通过这些实验,我们证明了我们的方法可以保证用户指定的约束条件的安全性,在低安全阈值区域比现有方法高出几个数量级,并且相对于内部测试数据的数量具有良好的可扩展性。
1 引言
随着AI系统越来越多地部署在从医疗保健到交通运输等关键领域,确保其安全性已从技术偏好演变为社会必需。尽管取得了显著进展García和Fernández [2015],Ribeiro等人[2016],Mehrabi等人[2021],
当前的方法通常解决预定义的领域特定安全条件,限制了其在不同上下文中的泛化能力。
在本文中,我们提出了一种框架,将任何AI模型转换为一个确保安全的系统,定义为以用户指定的概率阈值满足所有用户指定的约束条件。我们的方法引入了一个优化问题,该问题接受AI模型的输出并生成动作以优化目标函数,同时满足约束条件。一个关键创新是能够处理非确定性约束——那些无法确定性评估的约束,例如在聊天机器人示例中,文本输出是否“无害”——通过将它们公式化为随机控制理论中的机会约束。
非确定性约束对确保AI在实际应用中的安全性提出了重大挑战,因为大多数现代AI模型是数据驱动的,因此其输出本质上是概率性的。
机会约束编码约束满足概率保持在用户指定的阈值之上。为了评估约束满足概率,
我们引入安全分类模型并使用内部测试数据(补充的安全标记数据)来评估其可信度。它可以是训练数据的一部分或强化学习中的重放缓冲区 Mnih 等人 [2015]。由于这种内部测试数据影响训练并产生统计有效性挑战,我们提出了保守测试,这是一种利用AI模型的Lipshitz连续性属性以可靠地高估约束满足概率的新方法。
我们在特定条件下数学证明了我们的方法保证概率约束满足,并证明我们可以估计损失函数的梯度用于训练。通过涵盖生产决策制定、强化学习和自然语言生成的实验,我们证明了我们的框架在不同领域中提供了可证明的安全性,同时保持性能。值得注意的是,即使在极低的安全阈值下,我们的框架仍能保持有意义的性能,这是以前方法无法实现的能力。在最低阈值级别,我们的方法在相似或更优的性能下实现了高达
28
,
412
,
3.7
28,412,3.7
28,412,3.7 倍的安全性提升。此外,我们证明了内部测试数据数量与安全性保证之间的缩放定律。特别是,我们证明所需内部测试数据的数量与期望的安全阈值成反比。据我们所知,这是AI安全研究中首次证明的缩放定律。此结果也通过强化学习和自然语言生成实例中的实验得到了验证。
我们提出的通用领域、数学上有保障的安全框架具有缩放特性,为在关键应用中部署AI系统奠定了基础。我们的贡献可以总结如下。
- 我们提出了一种通用领域的安全AI框架,通过我们新颖的内部测试数据和保守测试方法处理非确定性约束。
-
- 我们介绍了如何在框架中通过引入损失函数的近似和其梯度计算来训练此类安全AI。
-
- 我们数学上定义并证明了安全性的缩放定律。
-
- 我们通过实验证明了安全性和性能。
2 相关工作
随着现代AI系统的巨大成功Amodei等人 [2016],AI安全成为一个重要的研究领域。AI安全研究涵盖了对对抗性扰动的鲁棒性Goodfellow等人 [2015]、安全强化学习García和Fernández [2015]、可解释性和解释性Ribeiro等人 [2016]、公平性和偏差缓解Mehrabi等人 [2021]以及使高级系统与人类价值观对齐Amodei等人 [2016]。
此外,由于某些应用需要正式证明AI的安全性,因此有努力正式验证神经网络的行为。Reluplex引入了一种基于SMT的过程,该过程通过在ReLU激活上进行情况拆分来增强经典的Simplex算法,从而为前馈网络的行为提供证明或反例Katz等人 [2017]。Ehlers将分段线性网络的验证重新表述为混合整数线性规划问题,表明MILP求解器可以对适度规模网络的安全属性给出精确的“是/否”答案,同时在属性失败时提供对抗性反例Ehlers [2017]。Huang等人提出了一个可达性分析框架,传播每层输出的几何过度逼近以保证从给定输入集到达的所有状态满足指定的安全属性Huang等人 [2017]。在本文中,我们采用可达性分析的思想设计保守测试以高估后验概率,假设网络是Lipchitz连续的。
另一方面,有一种名为Predict-and-optimize的决策聚焦学习框架,其中机器学习模型预测优化问题的输入参数,并训练以最大化由此产生的决策质量而不是仅仅预测准确性Donti等人 [2017],Kotary等人 [2021]。该框架的关键方法包括将求解器嵌入神经网络的可微优化层Amos和Kolter [2017]、通过组合优化进行反向传播的决策聚焦训练Wilder等人 [2019],以及对齐预测与最终目标(例如智能“预测然后优化”损失)的代理损失函数Elmachtoub和Grigas [2022]。一些方法甚至将优化器本身视为模型的一部分——例如,混合整数程序可以作为网络层包含Ferber等人 [2020],或者为复杂的组合目标学习线性代理Ferber等人 [2023]。该框架还通过专门的微分技术扩展到黑盒组合求解器Vlastelica等人 [2020]。我们在补充材料第1部分的第4节和第5节中将此框架扩展到处理没有机会约束的一般连续优化问题。然后,在正文部分,我们重点重新推广它以处理非确定性约束。
强化学习安全性已从单约束调整发展到形式化基础、移位鲁棒控制。受约束策略优化提供了每次更新的保证Achiam等人 [2017];时间逻辑屏蔽消除了运行时违规Alshiekh等人 [2018]。Safety Gym基准了安全探索Ray等人 [2019a],而风险敏感的SAC Enders等人 [2024] 和条件约束策略Yao等人 [2023] 在分布移位下适应配额。
3 方法
我们提出的框架将AI模型与优化问题结合起来,确保输出满足用户指定的约束条件。这种方法将predict+optimize框架Amos和Kolter [2017]推广到处理不可避免的非确定性安全约束,这是由于AI模型预测中的固有不确定性造成的。为此,我们引入了两个关键创新:用于可信度评估的内部测试数据和用于稳健概率估计的保守测试。我们还介绍了计算损失函数梯度的方法,以实现端到端训练。
3.1 总体框架
假设给定一个AI模型 f f f,其训练权重为 w 0 ∈ R n w 1 \mathbf{w}_{0} \in \mathbb{R}^{n_{w} 1} w0∈Rnw1,它以未知环境状态 s ∈ S ⊂ R n s 1 × Z n s 2 \mathbf{s} \in \mathcal{S} \subset \mathbb{R}^{n_{s 1}} \times \mathbb{Z}^{n_{s 2}} s∈S⊂Rns1×Zns2 的测量值 y ∈ Y ⊂ R n y \mathbf{y} \in \mathcal{Y} \subset \mathbb{R}^{n_{y}} y∈Y⊂Rny 作为输入,并输出一个连续向量 f ( y ; w 0 ) ∈ R n f f\left(\mathbf{y} ; \mathbf{w}_{0}\right) \in \mathbb{R}^{n_{f}} f(y;w0)∈Rnf。输出 f ( y ; w 0 ) f\left(\mathbf{y} ; \mathbf{w}_{0}\right) f(y;w0) 经过后处理以生成连续和离散预测(或动作) u ∈ U ⊂ R n u 1 × Z n u 2 \mathbf{u} \in \mathcal{U} \subset \mathbb{R}^{n_{u 1}} \times \mathbb{Z}^{n_{u 2}} u∈U⊂Rnu1×Znu2。我们说AI模型
1
R
n
∗
{ }^{1} \mathbb{R}^{n_{*}}
1Rn∗ 是
n
∗
n_{*}
n∗ 维实向量的空间,
Z
n
∗
\mathbb{Z}^{n_{*}}
Zn∗ 是
n
∗
n_{*}
n∗ 维整数向量的空间。
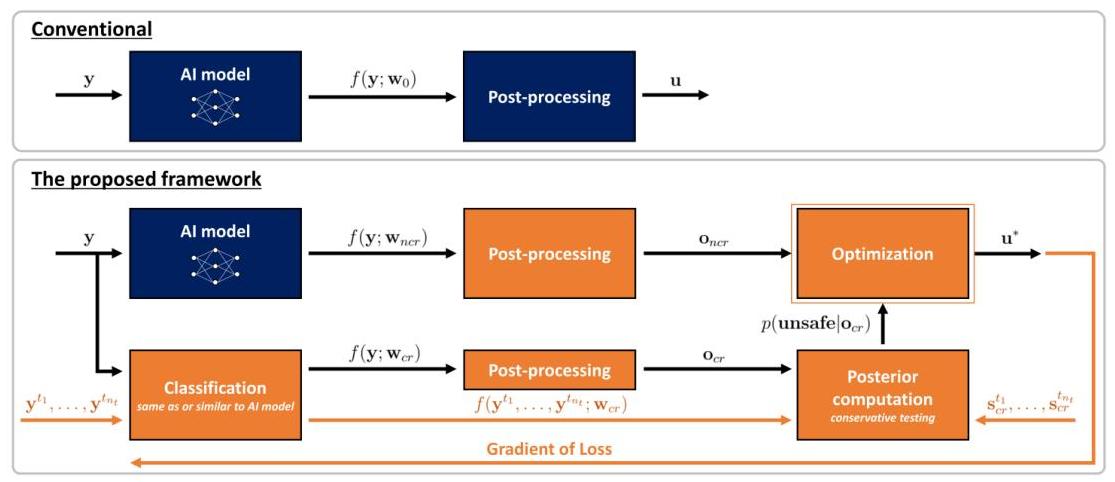
图1:我们提出的框架
如果所有动作都满足用户指定的约束条件
c
i
(
u
;
s
,
r
)
≥
0
c_{i}(\mathbf{u} ; \mathbf{s}, \mathbf{r}) \geq 0
ci(u;s,r)≥0 对于
i
=
1
,
…
,
n
c
i=1, \ldots, n_{c}
i=1,…,nc 在环境状态
s
\mathbf{s}
s 和用户给定参数
r
∈
R
n
c
\mathbf{r} \in \mathbb{R}^{n_{c}}
r∈Rnc 下,则保证安全。
由于AI模型通常由于其数据驱动的性质无法保证安全,我们引入了一个优化组件,强制动作满足安全约束条件,同时保持高性能。目标是最小化目标函数
J
(
u
;
s
,
r
)
J(\mathbf{u} ; \mathbf{s}, \mathbf{r})
J(u;s,r) 同时满足约束条件
c
(
u
;
s
,
r
)
≥
0
\mathbf{c}(\mathbf{u} ; \mathbf{s}, \mathbf{r}) \geq 0
c(u;s,r)≥0,其中
J
:
U
→
R
J: \mathcal{U} \rightarrow \mathbb{R}
J:U→R 和
c
:
U
→
R
n
c
\mathbf{c}: \mathcal{U} \rightarrow \mathbb{R}^{n_{c}}
c:U→Rnc 由用户指定,因此是已知的。然而,由于我们不完全知道环境状态
s
\mathbf{s}
s,我们不能确定性地保证约束条件满足。
我们将这种非确定性约束条件表示为机会约束条件,将违反概率限定如下:
Pr ( c i ( u ; s , r ) < 0 ) ≤ r t , i , i = 1 , … , n c \operatorname{Pr}\left(c_{i}(\mathbf{u} ; \mathbf{s}, \mathbf{r})<0\right) \leq r_{t, i}, \quad i=1, \ldots, n_{c} Pr(ci(u;s,r)<0)≤rt,i,i=1,…,nc
其中
r
t
,
i
∈
R
r_{t, i} \in \mathbb{R}
rt,i∈R 是用户给定的阈值,
n
c
n_{c}
nc 是约束条件的数量。
根据约束条件,我们将环境状态分为两部分
s
=
(
s
c
r
,
s
n
c
r
)
\mathbf{s}=\left(\mathbf{s}_{c r}, \mathbf{s}_{n c r}\right)
s=(scr,sncr),其中
s
c
r
∈
S
c
r
\mathbf{s}_{c r} \in \mathcal{S}_{c r}
scr∈Scr 是确定安全约束条件
c
\mathbf{c}
c 所需的环境状态必要部分,
s
n
c
r
∈
S
n
c
r
\mathbf{s}_{n c r} \in \mathcal{S}_{n c r}
sncr∈Sncr 是剩余部分。由于环境状态
s
\mathbf{s}
s 是未观测变量,我们需要使用测量值
y
\mathbf{y}
y 来估计环境状态。为了获得其估计值
o
∈
O
\mathbf{o} \in \mathcal{O}
o∈O,我们引入了两个AI模型,一个用于生成估计
o
c
r
\mathbf{o}_{c r}
ocr,另一个用于生成估计
o
n
c
r
\mathbf{o}_{n c r}
oncr。实际上,我们使用与给定AI模型相同的结构
f
f
f 或其简化变体,但具有不同的权重
w
c
r
∈
R
n
w
\mathbf{w}_{c r} \in \mathbb{R}^{n_{w}}
wcr∈Rnw 和
w
n
c
r
∈
R
n
w
\mathbf{w}_{n c r} \in \mathbb{R}^{n_{w}}
wncr∈Rnw,并对输出进行后处理以分别生成估计
o
c
r
\mathbf{o}_{c r}
ocr 和
o
n
c
r
\mathbf{o}_{n c r}
oncr。具体来说,
o
c
r
\mathbf{o}_{c r}
ocr 是
f
(
y
;
w
c
r
)
f\left(\mathbf{y} ; \mathbf{w}_{c r}\right)
f(y;wcr) 的后处理结果,
o
n
c
r
\mathbf{o}_{n c r}
oncr 是
f
(
y
;
w
n
c
r
)
f\left(\mathbf{y} ; \mathbf{w}_{n c r}\right)
f(y;wncr) 的后处理结果。为简单起见,我们假设
s
c
r
\mathbf{s}_{c r}
scr 和
o
c
r
\mathbf{o}_{c r}
ocr 取离散值——例如,在聊天机器人应用中将文本分类为“有害”或“无害”。因此,我们称
f
(
y
;
w
c
r
)
f\left(\mathbf{y} ; \mathbf{w}_{c r}\right)
f(y;wcr) 为安全分类模型。
现在我们使用这些估计值重新制定优化问题:
min u ∈ U J ˉ ( u ; o , r ) subject to c ˉ i ( u ; o , r ) ≥ 0 , i = 1 , … , n c \begin{array}{ll} \min _{\mathbf{u} \in \mathcal{U}} & \bar{J}(\mathbf{u} ; \mathbf{o}, \mathbf{r}) \\ \text { subject to } & \bar{c}_{i}(\mathbf{u} ; \mathbf{o}, \mathbf{r}) \geq 0, \quad i=1, \ldots, n_{c} \end{array} minu∈U subject to Jˉ(u;o,r)cˉi(u;o,r)≥0,i=1,…,nc
这里,约束条件 c ˉ i \bar{c}_{i} cˉi 是使用估计值 o c r \mathbf{o}_{c r} ocr 重写的机会约束条件,
c ˉ i ( u ; o , r ) ≥ 0 ⇔ Pr ( c i ( u ; s c r , r ) < 0 ∣ o c r ) ≤ r t , i , i = 1 , … , n c \bar{c}_{i}(\mathbf{u} ; \mathbf{o}, \mathbf{r}) \geq 0 \Leftrightarrow \operatorname{Pr}\left(c_{i}\left(\mathbf{u} ; \mathbf{s}_{c r}, \mathbf{r}\right)<0 \mid \mathbf{o}_{c r}\right) \leq r_{t, i}, \quad i=1, \ldots, n_{c} cˉi(u;o,r)≥0⇔Pr(ci(u;scr,r)<0∣ocr)≤rt,i,i=1,…,nc
这个概率表示在分类输出
o
c
r
\mathbf{o}_{c r}
ocr 给定的情况下约束条件违反的后验概率。目标函数
J
ˉ
\bar{J}
Jˉ 是类似于
J
J
J 的函数,但用估计值
o
\mathbf{o}
o 表示;例如,
J
ˉ
(
u
;
o
,
r
)
=
E
s
c
r
[
J
(
u
;
s
c
r
,
o
n
c
r
,
r
)
∣
o
c
r
]
\bar{J}(\mathbf{u} ; \mathbf{o}, \mathbf{r})=E_{\mathbf{s}_{c r}}\left[J\left(\mathbf{u} ; \mathbf{s}_{c r}, \mathbf{o}_{n c r}, \mathbf{r}\right) \mid \mathbf{o}_{c r}\right]
Jˉ(u;o,r)=Escr[J(u;scr,oncr,r)∣ocr]。为了在实践中估计(3)中的后验概率,我们将在下一小节中介绍内部测试数据。有关此公式化的更多详细信息,请参阅补充材料第一部分的第2-3节。
示例1。在一个生产决策示例中,测量值
y
\mathbf{y}
y 是历史需求数据,动作
u
\mathbf{u}
u 是生产决策,约束条件
c
\mathbf{c}
c 可以指定原料限制并防止生产低需求产品。
示例2。在一个RL在SafetyGym示例中,测量值
y
\mathbf{y}
y 是通过(模拟)RIDAR和IMU获得的观察数据,动作
u
\mathbf{u}
u 是代理的加速度或旋转,约束条件
c
\mathbf{c}
c 可以指定代理不应进入或碰撞到不安全区域。
示例3。在一个聊天机器人示例中,测量值
y
\mathbf{y}
y 是用户提供的提示,动作
u
\mathbf{u}
u 是聊天机器人的响应,约束条件
c
\mathbf{c}
c 可以指定响应应该是无害的。
3.2 内部测试和保守测试
在本小节中,我们介绍了计算(3)中的后验概率
Pr
(
c
i
(
u
;
s
c
r
,
r
)
<
\operatorname{Pr}\left(c_{i}(\mathbf{u} ; \mathbf{s}_{c r}, \mathbf{r})<\right.
Pr(ci(u;scr,r)<
0
∣
o
c
r
0 \mid \mathbf{o}_{c r}
0∣ocr ) 的方法。由于AI模型(尤其是神经网络)可能训练得不完美,我们不能完全信任其输出,必须评估其可信度——具体来说,约束相关输出
o
c
r
\mathbf{o}_{c r}
ocr 和环境状态
s
c
r
\mathbf{s}_{c r}
scr 之间的关系。为了解决这一挑战,我们引入了内部测试数据:一个带有安全标签的数据集,帮助评估模型可靠性。约束相关的环境状态
s
c
r
\mathbf{s}_{c r}
scr 在此数据集中被提供为安全标签,因为一旦
s
c
r
\mathbf{s}_{c r}
scr 被指定,约束条件就被确定。
我们将可能的约束相关环境状态集合表示为
S
c
r
=
{
s
‾
1
,
…
,
s
‾
n
s
c
r
}
\mathcal{S}_{c r}=\left\{\overline{\mathbf{s}}_{1}, \ldots, \overline{\mathbf{s}}_{n_{s c r}}\right\}
Scr={s1,…,snscr},可能的输出集合表示为
O
c
r
=
{
o
‾
1
,
…
,
o
‾
n
o
c
r
}
\mathcal{O}_{c r}=\left\{\overline{\mathbf{o}}_{1}, \ldots, \overline{\mathbf{o}}_{n_{o c r}}\right\}
Ocr={o1,…,onocr}。我们的内部测试数据包括测量值
y
t
1
,
…
,
y
t
n
t
\mathbf{y}^{t_{1}}, \ldots, \mathbf{y}^{t_{n_{t}}}
yt1,…,ytnt,每个测量值分别与环境状态标签
s
c
r
t
1
,
…
,
s
c
r
t
n
t
\mathbf{s}_{c r}^{t_{1}}, \ldots, \mathbf{s}_{c r}^{t_{n_{t}}}
scrt1,…,scrtnt 相关联。
为了计算后验概率,我们使用安全分类模型
f
(
y
t
k
;
w
c
r
)
f\left(\mathbf{y}^{t_{k}} ; \mathbf{w}_{c r}\right)
f(ytk;wcr) 评估内部测试数据,并进行后处理(在这种情况下,argmax操作)以获得
o
c
r
t
k
\mathbf{o}_{c r}^{t_{k}}
ocrtk。具体来说,我们通过应用贝叶斯规则 Bayes 和 Price [1763],结合给定的先验
p
(
s
c
r
=
s
‾
i
)
p\left(\mathbf{s}_{c r}=\overline{\mathbf{s}}_{i}\right)
p(scr=si) 和以下从内部测试数据估计的似然函数来计算每对
(
i
,
j
)
(i, j)
(i,j) 的后验
p
(
s
c
r
=
s
‾
i
∣
o
c
r
=
o
‾
j
)
p\left(\mathbf{s}_{c r}=\overline{\mathbf{s}}_{i} \mid \mathbf{o}_{c r}=\overline{\mathbf{o}}_{j}\right)
p(scr=si∣ocr=oj)
p ( o c r = o ‾ j ∣ s c r = s ‾ i ) ≈ ∑ k = 1 n t 1 ( s c r t k , s ‾ i ) 1 ( o c r t k , o ‾ j ) ∑ k = 1 n t 1 ( s c r t k , s ‾ i ) p\left(\mathbf{o}_{c r}=\overline{\mathbf{o}}_{j} \mid \mathbf{s}_{c r}=\overline{\mathbf{s}}_{i}\right) \approx \frac{\sum_{k=1}^{n_{t}} \mathbf{1}\left(\mathbf{s}_{c r}^{t_{k}}, \overline{\mathbf{s}}_{i}\right) \mathbf{1}\left(\mathbf{o}_{c r}^{t_{k}}, \overline{\mathbf{o}}_{j}\right)}{\sum_{k=1}^{n_{t}} \mathbf{1}\left(\mathbf{s}_{c r}^{t_{k}}, \overline{\mathbf{s}}_{i}\right)} p(ocr=oj∣scr=si)≈∑k=1nt1(scrtk,si)∑k=1nt1(scrtk,si)1(ocrtk,oj)
其中
1
(
x
1
,
x
2
)
\mathbf{1}\left(x_{1}, x_{2}\right)
1(x1,x2) 是指示函数,当
x
1
=
x
2
x_{1}=x_{2}
x1=x2 时等于1,否则等于0。此估计本质上是对在我们的内部测试数据中,当环境状态为
s
‾
i
\overline{\mathbf{s}}_{i}
si 时,输出
o
‾
j
\overline{\mathbf{o}}_{j}
oj 出现的频率进行计数。
这种方法面临的一个关键挑战是:我们持续训练AI模型,而此训练过程会纳入来自内部测试数据的梯度。与传统的测试数据不同,我们的内部测试数据通过这些梯度影响模型,从而在第一个epoch之后泄露到模型中。尽管存在这种泄露,我们仍在后续epoch中继续使用相同的数据点,从而产生了统计有效性问题,即内部测试数据点不再是从输入分布中独立同分布抽样的样本。
为了解决这一数据泄露问题,我们提出了一种称为保守测试的新方法。这种方法确保在内部测试数据分布足够接近输入分布的前提下,我们高估约束违反的后验概率,而无需要求其为独立同分布。该方法利用AI模型的Lipshitz连续性属性,该属性确保相似输入产生相似输出且差异有限。然后,AI模型对输入数据的输出与其对内部测试数据的输出相似且差异有限,因此我们可以基于内部测试数据的输出获得保守界限。
在保守测试中,我们考虑以
f
(
y
t
k
;
w
c
r
)
f\left(\mathbf{y}^{t_{k}} ; \mathbf{w}_{c r}\right)
f(ytk;wcr) 为中心半径为
ξ
\xi
ξ 的一组输出,定义为
B ( f ( y t k ; w c r ) ) : = { ϕ : ∥ ϕ − f ( y t k ; w c r ) ∥ ≤ ξ } \mathcal{B}\left(f\left(\mathbf{y}^{t_{k}} ; \mathbf{w}_{c r}\right)\right):=\left\{\boldsymbol{\phi}:\left\|\boldsymbol{\phi}-f\left(\mathbf{y}^{t_{k}} ; \mathbf{w}_{c r}\right)\right\| \leq \xi\right\} B(f(ytk;wcr)):={ϕ: ϕ−f(ytk;wcr) ≤ξ}
然后,我们定义两种版本的指示函数
1 + ξ ( f ( y t k ; w c r ) , o ‾ j ) : = max ϕ ∈ B ( f ( y t k ; w c r ) ) 1 ( argmax ( ϕ ) , o ‾ j ) 1 − ξ ( f ( y t k ; w c r ) , o ‾ j ) : = min ϕ ∈ B ( f ( y t k ; w c r ) ) 1 ( argmax ( ϕ ) , o ‾ j ) \begin{aligned} \mathbf{1}^{+\xi}\left(f\left(\mathbf{y}^{t_{k}} ; \mathbf{w}_{c r}\right), \overline{\mathbf{o}}_{j}\right) & :=\max _{\boldsymbol{\phi} \in \mathcal{B}\left(f\left(\mathbf{y}^{t_{k}} ; \mathbf{w}_{c r}\right)\right)} \mathbf{1}\left(\operatorname{argmax}(\boldsymbol{\phi}), \overline{\mathbf{o}}_{j}\right) \\ \mathbf{1}^{-\xi}\left(f\left(\mathbf{y}^{t_{k}} ; \mathbf{w}_{c r}\right), \overline{\mathbf{o}}_{j}\right) & :=\min _{\boldsymbol{\phi} \in \mathcal{B}\left(f\left(\mathbf{y}^{t_{k}} ; \mathbf{w}_{c r}\right)\right)} \mathbf{1}\left(\operatorname{argmax}(\boldsymbol{\phi}), \overline{\mathbf{o}}_{j}\right) \end{aligned} 1+ξ(f(ytk;wcr),oj)1−ξ(f(ytk;wcr),oj):=ϕ∈B(f(ytk;wcr))max1(argmax(ϕ),oj):=ϕ∈B(f(ytk;wcr))min1(argmax(ϕ),oj)
其中
argmax
(
ϕ
)
\operatorname{argmax}(\phi)
argmax(ϕ) 是安全分类模型的后处理算子,返回
ϕ
\phi
ϕ 中最大值对应的类别。正指示函数
1
+
ξ
\mathbf{1}^{+\xi}
1+ξ 等于1,如果
ξ
\xi
ξ-球中的任何点被分类为
o
‾
j
\overline{\mathbf{o}}_{j}
oj,而负指示函数
1
−
ξ
\mathbf{1}^{-\xi}
1−ξ 等于1,仅当
ξ
\xi
ξ-球中的所有点被分类为
o
‾
j
\overline{\mathbf{o}}_{j}
oj 时。
使用这些指示函数,我们推导出条件概率的保守上下界
p ± ξ ( o c r = o ‾ j ∣ s c r = s ‾ i ) : = ∑ k = 1 n i 1 ( s c r t k , s ‾ i ) 1 ± ξ ( f ( y t k ; w c r ) , o ‾ j ) ∑ k = 1 n i 1 ( s c r t k , s ‾ i ) p^{ \pm \xi}\left(\mathbf{o}_{c r}=\overline{\mathbf{o}}_{j} \mid \mathbf{s}_{c r}=\overline{\mathbf{s}}_{i}\right):=\frac{\sum_{k=1}^{n_{i}} \mathbf{1}\left(\mathbf{s}_{c r}^{t_{k}}, \overline{\mathbf{s}}_{i}\right) \mathbf{1}^{ \pm \xi}\left(f\left(\mathbf{y}^{t_{k}} ; \mathbf{w}_{c r}\right), \overline{\mathbf{o}}_{j}\right)}{\sum_{k=1}^{n_{i}} \mathbf{1}\left(\mathbf{s}_{c r}^{t_{k}}, \overline{\mathbf{s}}_{i}\right)} p±ξ(ocr=oj∣scr=si):=∑k=1ni1(scrtk,si)∑k=1ni1(scrtk,si)1±ξ(f(ytk;wcr),oj)
这些界限的有效性在以下定理中形式化。
定理1. 当测量空间
Y
\mathcal{Y}
Y 具有温和条件,且
ξ
\xi
ξ 足够大时,我们可以限定条件概率
p
(
o
c
r
=
o
‾
j
∣
s
c
r
=
s
‾
i
)
p\left(\mathbf{o}_{c r}=\overline{\mathbf{o}}_{j} \mid \mathbf{s}_{c r}=\overline{\mathbf{s}}_{i}\right)
p(ocr=oj∣scr=si) 如下:
p − ξ ( o c r = o ‾ j ∣ s c r = s ‾ i ) ≤ p ( o c r = o ‾ j ∣ s c r = s ‾ i ) ≤ p + ξ ( o c r = o ‾ j ∣ s c r = s ‾ i ) p^{-\xi}\left(\mathbf{o}_{c r}=\overline{\mathbf{o}}_{j} \mid \mathbf{s}_{c r}=\overline{\mathbf{s}}_{i}\right) \leq p\left(\mathbf{o}_{c r}=\overline{\mathbf{o}}_{j} \mid \mathbf{s}_{c r}=\overline{\mathbf{s}}_{i}\right) \leq p^{+\xi}\left(\mathbf{o}_{c r}=\overline{\mathbf{o}}_{j} \mid \mathbf{s}_{c r}=\overline{\mathbf{s}}_{i}\right) p−ξ(ocr=oj∣scr=si)≤p(ocr=oj∣scr=si)≤p+ξ(ocr=oj∣scr=si)
定理中使用的正式条件在补充材料第一部分的第4节中提供,定理的证明也在该节中提供。 ξ \xi ξ 的大小取决于内部测试数据的质量(我们在补充材料中称之为 ζ \zeta ζ-信息性)和AI模型的Lipshitz常数。
有了似然函数的上下界,我们可以基于贝叶斯规则计算后验概率 p ( s c r = s ‾ i ∣ o c r = o ‾ j ) p\left(\mathbf{s}_{c r}=\overline{\mathbf{s}}_{i} \mid \mathbf{o}_{c r}=\overline{\mathbf{o}}_{j}\right) p(scr=si∣ocr=oj) 的上界(注意 p ( s c r = s ‾ i ) p\left(\mathbf{s}_{c r}=\overline{\mathbf{s}}_{i}\right) p(scr=si) 是用户给定的参数(包含在 r \mathbf{r} r 中)):
p ξ ( s c r = s ‾ i ∣ o c r = o ‾ j ) : = p + ξ ( o c r = o ‾ j ∣ s c r = s ‾ i ) p ( s c r = s ‾ i ) ∑ k = 1 N c p − ξ ( o c r = o ‾ j ∣ s c r = s ‾ k ) p ( s c r = s ‾ k ) p^{\xi}\left(\mathbf{s}_{c r}=\overline{\mathbf{s}}_{i} \mid \mathbf{o}_{c r}=\overline{\mathbf{o}}_{j}\right):=\frac{p^{+\xi}\left(\mathbf{o}_{c r}=\overline{\mathbf{o}}_{j} \mid \mathbf{s}_{c r}=\overline{\mathbf{s}}_{i}\right) p\left(\mathbf{s}_{c r}=\overline{\mathbf{s}}_{i}\right)}{\sum_{k=1}^{N_{c}} p^{-\xi}\left(\mathbf{o}_{c r}=\overline{\mathbf{o}}_{j} \mid \mathbf{s}_{c r}=\overline{\mathbf{s}}_{k}\right) p\left(\mathbf{s}_{c r}=\overline{\mathbf{s}}_{k}\right)} pξ(scr=si∣ocr=oj):=∑k=1Ncp−ξ(ocr=oj∣scr=sk)p(scr=sk)p+ξ(ocr=oj∣scr=si)p(scr=si)
3.3 训练的近似损失
对于AI模型的输出 o \mathbf{o} o 和优化问题的最优解 u \mathbf{u} u,我们需要评估损失函数 L ( u , o ; s , r ) L(\mathbf{u}, \mathbf{o} ; \mathbf{s}, \mathbf{r}) L(u,o;s,r) 并计算其关于模型权重 w c r \mathbf{w}_{c r} wcr 和 w n c r \mathbf{w}_{n c r} wncr 的梯度。然而,这带来了挑战,因为最优动作 u \mathbf{u} u 可能相对于 o \mathbf{o} o 不连续。此外,当存在多个最优解时,它们可能导致不同的损失值。这些特性使得损失函数相对于模型权重不连续,阻止直接应用基于梯度的训练方法。为了克服这一障碍,我们必须开发损失函数的连续近似。
我们提出了一种适用于一般具有连续目标和约束的优化问题的近似损失函数。这是先前工作 Vlastelica 等人 [2020] 的扩展,该工作提出了具有线性目标函数的无约束问题的近似损失函数。我们构建了一些参数 λ ∈ R \lambda \in \mathbb{R} λ∈R 和 β ∈ R n c \boldsymbol{\beta} \in \mathbb{R}^{n_{c}} β∈Rnc 的近似损失函数如下:
L ~ ( o ; s , r , β , λ ) : = 1 λ ( min u ∈ U ( λ L ( u , o ; s , r ) + J ˉ ( u ; o , r ) − β ⊤ min ( c ‾ ( u ; o , r ) , 0 ) ) − min u ∈ U ( J ˉ ( u ; o , r ) − β ⊤ min ( c ‾ ( u ; o , r ) , 0 ) ) ) \begin{aligned} & \tilde{L}(\mathbf{o} ; \mathbf{s}, \mathbf{r}, \boldsymbol{\beta}, \lambda):=\frac{1}{\lambda}\left(\min _{\mathbf{u} \in \mathcal{U}}(\lambda L(\mathbf{u}, \mathbf{o} ; \mathbf{s}, \mathbf{r})+\bar{J}(\mathbf{u} ; \mathbf{o}, \mathbf{r})-\boldsymbol{\beta}^{\top} \min (\overline{\mathbf{c}}(\mathbf{u} ; \mathbf{o}, \mathbf{r}), \mathbf{0}))\right. \\ & \left.-\min _{\mathbf{u} \in \mathcal{U}}\left(\bar{J}(\mathbf{u} ; \mathbf{o}, \mathbf{r})-\boldsymbol{\beta}^{\top} \min (\overline{\mathbf{c}}(\mathbf{u} ; \mathbf{o}, \mathbf{r}), \mathbf{0})\right)\right) \end{aligned} L~(o;s,r,β,λ):=λ1(u∈Umin(λL(u,o;s,r)+Jˉ(u;o,r)−β⊤min(c(u;o,r),0))−u∈Umin(Jˉ(u;o,r)−β⊤min(c(u;o,r),0)))
近似损失函数是两个最优目标之间的缩放差值,其中一个包含权重为 λ \lambda λ 的损失函数 L L L,另一个仅包含优化问题。为了处理约束条件,我们通过惩罚项 β \boldsymbol{\beta} β 将其纳入目标函数。这种构造确保了近似损失函数 L ~ \tilde{L} L~ 相对于 o \mathbf{o} o 是连续的,并且当 λ \lambda λ 足够小时接近真实的损失函数 L L L。
以下定理保证了 (9) 相对于
o
\mathbf{o}
o 是连续的,并且接近
L
∗
(
o
;
s
,
r
)
L^{*}(\mathbf{o} ; \mathbf{s}, \mathbf{r})
L∗(o;s,r),后者定义为当
u
∗
\mathbf{u}^{*}
u∗ 是 (2) 的最优解时的
L
(
u
∗
,
o
;
s
,
r
)
L\left(\mathbf{u}^{*}, \mathbf{o} ; \mathbf{s}, \mathbf{r}\right)
L(u∗,o;s,r)。
2
{ }^{2}
2
定理2. 当
J
ˉ
(
u
;
o
,
r
)
,
c
‾
(
u
;
o
,
r
)
,
L
(
u
,
o
;
s
,
r
)
\bar{J}(\mathbf{u} ; \mathbf{o}, \mathbf{r}), \overline{\mathbf{c}}(\mathbf{u} ; \mathbf{o}, \mathbf{r}), L(\mathbf{u}, \mathbf{o} ; \mathbf{s}, \mathbf{r})
Jˉ(u;o,r),c(u;o,r),L(u,o;s,r) 相对于
u
\mathbf{u}
u 和
o
3
\mathbf{o}^{3}
o3 是连续的,在
U
\mathcal{U}
U 的轻微条件下,
L
~
(
o
;
s
,
r
,
β
,
λ
)
\tilde{L}(\mathbf{o} ; \mathbf{s}, \mathbf{r}, \boldsymbol{\beta}, \lambda)
L~(o;s,r,β,λ) 相对于
o
\mathbf{o}
o 是连续的,并且当
β
\boldsymbol{\beta}
β 足够大且
λ
\lambda
λ 足够小时接近
L
∗
(
o
;
s
,
r
)
L^{*}(\mathbf{o} ; \mathbf{s}, \mathbf{r})
L∗(o;s,r)。
我们计算 L ~ ( o ; s , r , β , λ ) \tilde{L}(\mathbf{o} ; \mathbf{s}, \mathbf{r}, \boldsymbol{\beta}, \lambda) L~(o;s,r,β,λ) 关于 o \mathbf{o} o 的梯度,然后计算关于 w c r \mathbf{w}_{c r} wcr 和 w n c r \mathbf{w}_{n c r} wncr 的梯度,并将其反向传播以训练AI模型。定理2的证明和梯度计算的详细信息分别在补充材料第一部分的第4节和第5节中提供。
2
{ }^{2}
2 当存在多个最优解时,我们考虑
u
∗
\mathbf{u}^{*}
u∗ 为使
L
(
u
∗
,
o
;
s
,
r
)
L\left(\mathbf{u}^{*}, \mathbf{o} ; \mathbf{s}, \mathbf{r}\right)
L(u∗,o;s,r) 最小的最优解。
3
{ }^{3}
3 我们仅考虑
o
\mathbf{o}
o 的连续部分的连续性。
4 缩放定律
传统的深度学习缩放定律描述了计算需求或性能指标如何随着训练数据量的变化而变化。然而,对于AI安全系统,我们必须同时优化性能并确保安全。这种多目标性质使得为AI安全定义缩放定律变得非平凡。
为了解决这一挑战,我们从识别动作空间 U \mathcal{U} U 内的“安全集”角度概念化问题。我们框架中的安全组件的主要目标是准确地将动作分类为安全或不安全。一旦完成此分类,系统就可以在被认为安全的动作中选择性能最高的动作。
我们根据可靠安全集识别的数据需求定义缩放定律。具体来说,我们量化需要多少内部测试数据点来限制两类错误分类:将不安全动作分类为安全(I型错误)和将安全动作分类为不安全(II型错误)。以下定理形式化了这种关系。
定理3. 设
α
\alpha
α 为I型错误和II型错误概率的上限。在安全集的轻微条件下,并假设安全分类模型是一个通用逼近器,则所需内部测试数据的期望数量
N
reqit
N_{\text {reqit }}
Nreqit 随着
N reqit ≤ A α − n y N_{\text {reqit }} \leq A \alpha^{-n_{y}} Nreqit ≤Aα−ny
增长,其中
A
A
A 为常数,
n
y
n_{y}
ny 为测量空间
Y
\mathcal{Y}
Y 的维度。
此定理建立了误差边界
α
\alpha
α 与所需内部测试数据点数量之间的逆幂律关系,指数由测量空间的维度决定。条件的正式定义和完整证明在补充材料第一部分的第6节中提供。
5 实验结果
在本节中,我们展示了实验结果。为了展示领域的无关性,我们在三个不同领域验证了我们的框架:需求预测的生产计划、Safetygym中的强化学习和自然语言生成。在每个领域中,我们使用传统AI模型(有时是简化版用于安全分类)作为我们框架的神经网络架构,并使用相同的网络作为基线,以进行公平比较。
我们的框架有一个有用的扩展,可以帮助在不同于训练使用的阈值下获得高性能。请参阅补充材料第一部分的第7节。我们在实验中利用了这一特性。对于所有领域,我们只用一个阈值值训练我们的框架,并用多个阈值进行验证,从而生成描述性能与安全之间关系的散点图。
由于篇幅限制,实验细节在补充材料第二部分中说明,而非本节。
5.1 带需求预测的生产计划
作为我们的第一个例子,我们将我们的框架应用于带需求预测的生产计划。在这个场景中,一家公司必须根据不确定的未来需求 s ∈ R 4 \mathbf{s} \in \mathbb{R}^{4} s∈R4 确定四种产品的最佳生产数量 u ∈ R 4 \mathbf{u} \in \mathbb{R}^{4} u∈R4,以最大化收入,同时满足材料约束并避免在需求过低时进行生产。
约束条件:系统面临两种类型的约束条件。首先,确定性的材料限制被公式化为
A
u
+
∣
u
∣
≤
b
A \mathbf{u}+|\mathbf{u}| \leq \mathbf{b}
Au+∣u∣≤b,其中
A
A
A 和
b
\mathbf{b}
b 是代表材料消耗率和可用性限制的固定矩阵和向量。元素级绝对值
∣
u
∣
|\mathbf{u}|
∣u∣ 创建了对消耗率不确定性的鲁棒性,处理实际消耗可能偏离名义值
A
A
A 的最坏情况。这种鲁棒公式可以表示为二阶锥约束。其次,我们引入非确定性约束条件:当第
i
i
i 种产品的需求过低
(
s
i
<
3
\left(s_{i}<3\right.
(si<3,需求归一化为
[
0
,
10
]
[0,10]
[0,10] )时,应停止生产
(
u
i
=
0
)
\left(u_{i}=0\right)
(ui=0),因为低效的分销网络。我们将违反此约束条件的概率限制在用户指定的阈值
r
t
r_{t}
rt 以下。
AI模型:对于AI模型,我们使用LSTM架构处理过去24个时间步的历史需求数据 y,并预测产品的需求估计
o
n
c
r
=
(
o
n
c
r
,
1
,
…
,
o
n
c
r
,
4
)
\mathbf{o}_{n c r}=\left(o_{n c r, 1}, \ldots, o_{n c r, 4}\right)
oncr=(oncr,1,…,oncr,4)。对于安全分类模型,我们使用相同的LSTM架构生成
o
c
r
=
(
o
c
r
,
1
,
…
,
o
c
r
,
4
)
∈
{
0
,
1
}
4
\mathbf{o}_{c r}=\left(o_{c r, 1}, \ldots, o_{c r, 4}\right) \in\{0,1\}^{4}
ocr=(ocr,1,…,ocr,4)∈{0,1}4,其中
o
c
r
,
i
=
1
o_{c r, i}=1
ocr,i=1 表示预测
s
i
<
3
s_{i}<3
si<3。
内部测试数据:我们使用数据的四分之一作为训练数据,另一份四分之一作为训练中使用的内部测试数据,再一份四分之一作为验证数据,其余四分之一作为验证的内部测试数据。然后我们应用保守测试以计算给定分类器输出时低需求的可靠上界。
优化:当此界限超过用户指定的阈值
r
t
r_{t}
rt 时,生产数量被设置为零;否则,优化以最大化收入。考虑到市场价格受供需影响,收入公式化为
∑
i
=
1
4
(
p
i
−
k
i
(
u
i
−
s
i
)
)
⋅
u
i
\sum_{i=1}^{4}\left(p_{i}-k_{i}\left(u_{i}-s_{i}\right)\right) \cdot u_{i}
∑i=14(pi−ki(ui−si))⋅ui,其中标准价格
(
p
1
,
p
2
,
p
3
,
p
4
)
\left(p_{1}, p_{2}, p_{3}, p_{4}\right)
(p1,p2,p3,p4) 和价格敏感参数
(
k
1
,
k
2
,
k
3
,
k
4
)
\left(k_{1}, k_{2}, k_{3}, k_{4}\right)
(k1,k2,k3,k4) 是给定常数。
结果:图2说明了性能与约束违反之间的权衡。x轴显示尽管需求低(约束违反)仍继续生产的案例百分比,y轴显示8,760个时间步的总收入。请注意,约束违反仅发生在关于低需求的非确定性约束条件下,因为我们的方法保证完全满足确定性约束。在此实验中,我们使用
r
t
=
0.001
r_{t}=0.001
rt=0.001 进行训练,使用
0.001
−
1.0
0.001-1.0
0.001−1.0 进行验证。结果表明,我们的方法在需要严格约束满足(低违反百分比)时显著提高了收入。我们与“MeanVar”(基于历史需求均值和方差的生产决策)、“Twostage”(独立学习需求预测)和“End-to-End”(从历史数据直接学习到生产决策)进行比较。由于现有的预测和优化方法无法处理二阶锥约束,这些替代方法代表了可用的最佳基线。这个例子展示了我们的框架在实际优化场景中处理确定性和非确定性约束的同时实现卓越性能的能力。
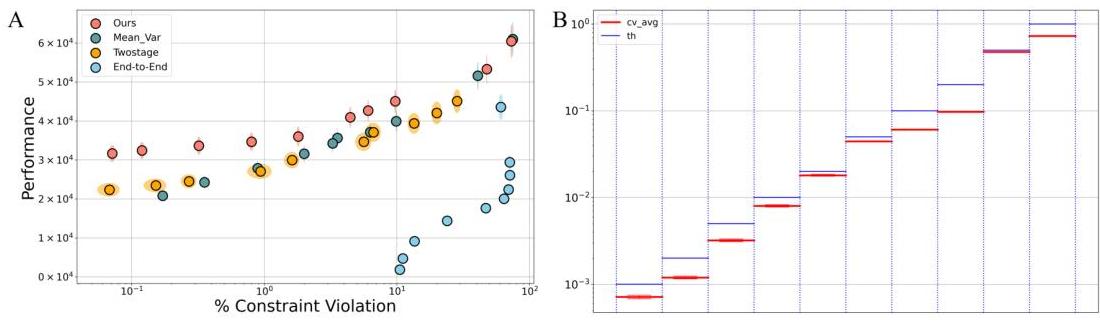
图2:生产计划性能与约束违反的关系。x轴显示尽管实际需求低于30%时仍有非零生产的百分比,y轴表示8,760个时间步的总收入。所提出的方法相比基线方法实现了显著更高的收入,特别是在低约束违反百分比的情况下。
5.2 Safetygym中的强化学习
为了证明我们提出的框架可以在强化学习(RL)中提供安全性保证,我们将它应用于标准RL方法,并在SafetyGym模拟器Ray等人 [2019b] 中评估性能。特别地,我们在两个SafetyGym环境中实现我们的框架:Safexp-PointGoal1-v0和Safexp-Cargoall-v0,其中未知状态
s
\mathbf{s}
s 包括代理速度和代理、目标及不安全区域的确切位置,
s
c
r
\mathbf{s}_{c r}
scr 是每个离散化动作候选(稍后解释)是否安全,测量值
y
\mathbf{y}
y 是LIDAR和IMU传感器的输出。目标是计算代理的动作
u
\mathbf{u}
u 以到达目标位置而不进入不安全区域。
AI模型:我们将我们的方法与标准RL方法结合,包括近端策略优化(PPO)Schulman等人 [2017] 和PPO-Lagrangian Jayant [2022]。这些算法提供了动作分布的均值和方差
o
n
c
r
=
(
μ
,
σ
)
\mathbf{o}_{n c r}=(\mu, \sigma)
oncr=(μ,σ),我们用它们构建推荐的动作分布作为一个正态分布
π
=
N
(
μ
,
σ
)
\pi=\mathcal{N}(\mu, \sigma)
π=N(μ,σ)。我们的方法将连续动作空间离散化,使得
U
=
{
u
‾
1
,
…
u
‾
n
sccd
}
\mathcal{U}=\left\{\overline{\mathbf{u}}_{1}, \ldots \overline{\mathbf{u}}_{n_{\text {sccd }}}\right\}
U={u1,…unsccd } 并评估每个离散化动作候选的安全性。具体来说,我们使用一个安全分类模型(原始模型的尺寸缩减形式)来生成
o
c
r
=
(
o
‾
1
,
…
,
o
‾
n
sccd
)
\mathbf{o}_{c r}=\left(\overline{\mathbf{o}}_{1}, \ldots, \overline{\mathbf{o}}_{n_{\text {sccd }}}\right)
ocr=(o1,…,onsccd ),其中如果
u
‾
i
\overline{\mathbf{u}}_{i}
ui 不安全则
o
‾
i
=
1
\overline{\mathbf{o}}_{i}=1
oi=1,否则为0。我们使用分类模型、内部测试数据和保守测试估计每个离散化动作候选的碰撞概率。
内部测试数据:我们预训练PPO代理10,000个epoch,并使用由此产生的检查点通过代理-环境交互收集内部测试案例。与监督学习不同,在监督学习中可以从现有标记数据集中直接选择内部测试案例,在RL中我们通过模拟生成内部测试案例。每个内部测试案例包括观察值
y
\mathbf{y}
y、动作
u
\mathbf{u}
u 和安全标签
s
c
r
\mathbf{s}_{c r}
scr,指示代理在60个时间步内是否进入危险区域。
优化:我们根据以下优化问题在离散化动作候选中采样动作:
min u = π d J ˉ ( u ) subject to log p ξ ( s c r = 1 ∣ o c r = o ) ≤ log r t \begin{aligned} \min _{\mathbf{u}=\pi^{d}} & \bar{J}(\mathbf{u}) \\ \text { subject to } & \log p^{\xi}\left(\mathbf{s}_{c r}=1 \mid \mathbf{o}_{c r}=o\right) \leq \log r_{t} \end{aligned} u=πdmin subject to Jˉ(u)logpξ(scr=1∣ocr=o)≤logrt
其中
π
d
\pi^{d}
πd 是
π
\pi
π 限制在离散化动作候选
U
\mathcal{U}
U 和默认动作
d
‾
\overline{\mathbf{d}}
d(最大制动)。我们使用
log
\log
log 操作来处理极低阈值,例如
r
t
=
1
0
−
4
r_{t}=10^{-4}
rt=10−4。我们让
J
ˉ
(
d
‾
)
>
0
\bar{J}(\overline{\mathbf{d}})>0
Jˉ(d)>0 并且对所有其他动作候选
J
ˉ
(
u
‾
i
)
=
0
\bar{J}\left(\overline{\mathbf{u}}_{i}\right)=0
Jˉ(ui)=0。这样,当所有动作都有危险时,我们应用默认动作
d
‾
\overline{\mathbf{d}}
d。给定分类输出
o
o
o,后验概率
p
ξ
(
s
c
r
=
1
∣
o
c
r
=
o
)
p^{\xi}\left(\mathbf{s}_{c r}=1 \mid \mathbf{o}_{c r}=o\right)
pξ(scr=1∣ocr=o) 由(8) 使用内部测试数据和保守测试计算。我们对所有情况使用
ξ
=
1
0
5
n
t
\xi=\frac{10^{5}}{n_{t}}
ξ=nt105。
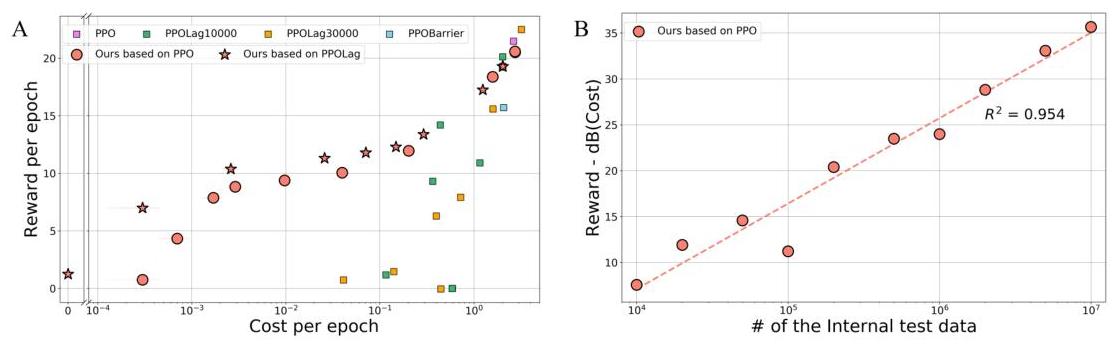
图3:(A) RL安全性与性能。x轴是每轮平均碰撞次数,y轴是每轮平均奖励。我们在这些实验中使用 1 0 7 10^{7} 107 内部测试数据。对于基线,我们报告训练10,000个epoch的PPO检查点(紫色),训练10,000个epoch的PPO-Barrier检查点(蓝色),以及通过改变成本限制从0到2并训练10,000个epoch(绿色)或30,000个epoch(黄色)获得的几个PPO-Lag检查点。我们的方法相比基线显著降低了碰撞率,达到低于 1 0 − 5 10^{-5} 10−5 的同时保持具有竞争力的性能。(B) RL缩放定律。x轴显示内部测试数据的数量 n t n_{t} nt,y轴表示前一图中展示的奖励减去成本的分贝。所提出的方法显示出内部测试数据数量与奖励最大化和成本最小化的综合性能之间清晰的缩放定律。
结果:图3说明了我们在RL实验中安全性与性能之间的权衡。x轴(每轮成本)表示每轮(1,000个时间步)的平均危险遭遇次数(每次成本为1)。y轴显示每轮的平均奖励,代理在每一步根据其向目标的进展获得奖励,并在到达目标时获得1的奖励。在此实验中,我们使用
r
t
=
1
0
−
4
r_{t}=10^{-4}
rt=10−4 进行训练,并使用10个不同的值在
[
1
0
−
5
,
1
+
1
0
−
5
]
\left[10^{-5}, 1+10^{-5}\right]
[10−5,1+10−5] 进行验证。我们的框架在安全性方面显著优于所有基线方法,在某些阈值设置下实现低于
1
0
−
5
10^{-5}
10−5 的碰撞率——这是其他方法无法达到的安全水平——同时保持具有竞争力的性能。这种超低碰撞率代表了对自动驾驶等关键应用的重要进步,因为在这些应用中,即使极其罕见的失败也可能导致灾难性后果。
图?? 显示了内部测试数据数量与奖励最大化和成本最小化的综合性能之间的清晰缩放定律。x轴显示内部测试数据的数量,y轴显示奖励(前一图中的y轴值)减去成本的分贝(前一图中的x轴值)。这种线性关系与前一节介绍的缩放定律相符。
5.3 自然语言生成
大型语言模型(LLMs)已被用于各种正在成为许多人生活方式关键部分的应用中,从商业聊天机器人(如GPT-4、Claude)到临床决策支持Singhal等人 [2022] 和教育支持Wang等人 [2024]。随着这些系统深入嵌入社会,它们的安全性变得至关重要。例如,聊天机器人和教育代理必须避免错误信息、歧视性内容和不道德的影响。LLMs面临从训练数据中潜在学习和复制有害内容的固有安全挑战Su等人 [2024]。虽然指导调优方法在使LLMs与人类偏好对齐方面取得了进展,既有助于有用性Li等人 [2024] 又有助于无害性Ji等人 [2023],但它们缺乏在部署中概率保证安全水平的机制。
为了解决这一挑战,我们将我们的框架适应于在最大化有用响应的同时保证任意安全水平,提供一种数学严谨的方法来实现LLM输出的概率安全保证,并使从业者能够在不同的部署环境中指定和维持所需的阈值。
我们的机会约束优化框架可以与任何现有的LLM对齐方法集成,包括SFT Ouyang等人 [2022]、PPO Schulman等人 [2017]、Ouyang等人 [2022]、DPO Rafailov等人 [2024] 和PPO-lag Wu等人 [2023]。
在这个例子中,我们固定AI模型,因此将其表示为 π \pi π 而不是 f ( y ; w n ε r ) f\left(\mathbf{y} ; \mathbf{w}_{n \varepsilon r}\right) f(y;wnεr),因为我们不对其进行训练,并将其与安全分类模型 f ( y ; w c r ) f\left(\mathbf{y} ; \mathbf{w}_{c r}\right) f(y;wcr) 串联连接。对于固定的 π \pi π,状态是16个答案候选( s n ε r \mathbf{s}_{n \varepsilon r} snεr)以及它们是否安全( s c r \mathbf{s}_{c r} scr:16维二进制向量)。在这个例子中,答案候选人 o n ε r \mathbf{o}_{n \varepsilon r} onεr 在原则上等同于 s n ε r \mathbf{s}_{n \varepsilon r} snεr。它们从 π \pi π 获得,然后与输入 y \mathbf{y} y 拼接并进入安全分类模型。
给定一个使用任何对齐方法微调的基础模型 π \pi π,我们添加一个使用训练好的安全分类模型的拒绝采样层以确保安全保证。为此,我们将拒绝采样视为一个简单的优化问题如下:
arg min i 1 s.t. c ˉ ( y i ; x ) ≥ 0 \begin{aligned} & \arg \min _{i} 1 \\ & \text { s.t. } \quad \bar{c}\left(y_{i} ; x\right) \geq 0 \end{aligned} argimin1 s.t. cˉ(yi;x)≥0
其中 y i ∼ π ( ⋅ ∣ x ) y_{i} \sim \pi(\cdot \mid x) yi∼π(⋅∣x) 给定提示 x x x 和 c ˉ \bar{c} cˉ 是由安全分类模型给出的机会约束。
图4显示,无论基础生成器模型如何,使用我们方法生成的输出始终满足目标安全阈值,而所有基线方法在低于10的情况下都无法满足安全阈值。
6 讨论
在本文中,我们提出了一种领域无关的框架,该框架基于AI模型构建了一个输出安全且高性能动作的系统。我们基于理论构造和三个不同领域的实验展示了我们框架的有效性和性能。与现有方法相比,我们方法内部评估安全性并提供定制梯度以获得安全且高性能动作的特点使我们的框架能够获得更安全的系统。鉴于有足够的内部测试数据,我们的系统可以根据保守测试提供的理论保证采用定制的训练梯度和大量的训练周期。这允许在安全性方面比现有方法额外增加训练容量,现有方法在防止过拟合时需要额外小心地运行训练。
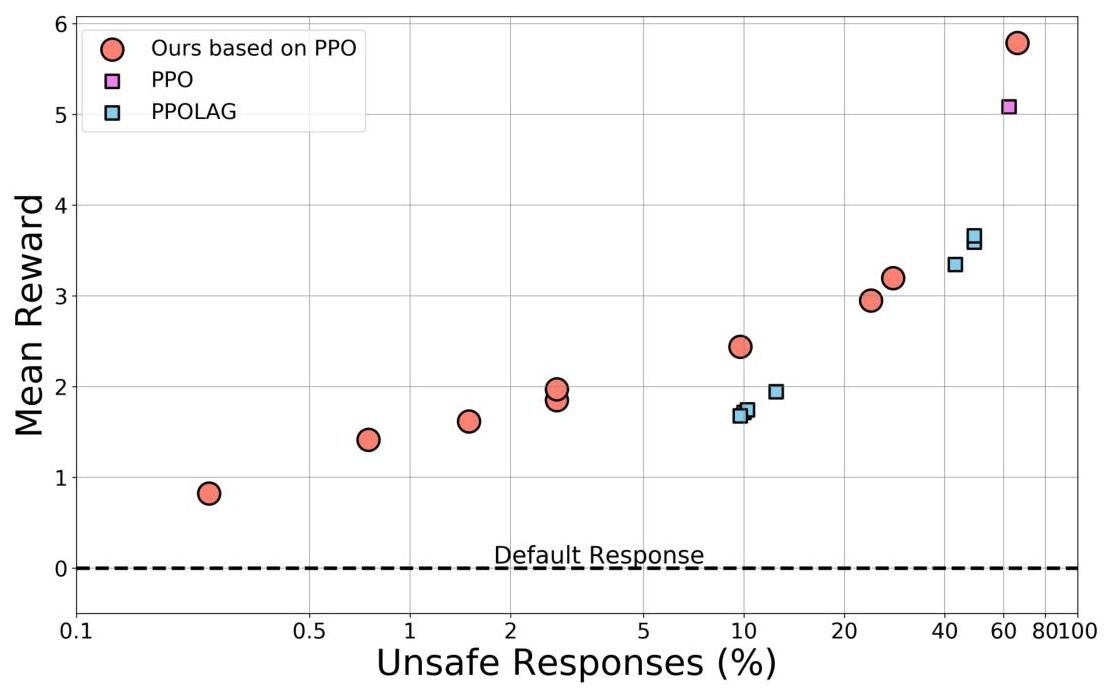
图4:自然语言生成性能:x轴表示安全响应的百分比。y轴表示400个提示的平均奖励。所提出的方法获得了显著更安全的响应。
在实验中,通过所有实验领域的测试,我们的框架在最低阈值情况下实现了至少3.7倍至数量级的安全性改进,同时在类似或更优的性能下表现优异。这些结果表明,该框架在这些领域中具有大幅提高安全性的潜力。
我们的框架不仅遵守用户定义的安全约束和阈值,还能在保持操作透明度的同时适应用户偏好。用户可以灵活地调整约束、阈值、目标函数和参数,以根据特定需求定制系统。当用户更改这些元素并对系统重新训练时,它会基于优化目标在指定约束下更新AI模型和安全分类模型。用户可以通过监控AI模型和分类模型的输出来检查系统如何解释情况,并通过监控优化输入和输出来了解系统如何做出决策。因此,我们的方法实现了可定制性和透明性。
基于理论保证、性能及其领域无关的方式,该框架可以成为各种关键安全领域的游戏规则改变者。此外,可定制性和透明性使该框架成为增强AI对齐性的一种合适方法,除了安全性之外。因此,我们预计这种方法将成为安全且与人类对齐的AI和相关机器人部署的关键里程碑。为了最大限度地提高实用性,我们提供了一个组织良好的框架实现套件,可以与各种应用中的任何AI模型集成,供非商业用途使用。
参考文献
Javier García 和 Fernando Fernández. 安全强化学习的全面调查。Journal of Machine Learning Research, 16(42):1437-1480, 2015. 2,100次引用 (Google Scholar, 2025年4月).
Marco Tulio Ribeiro, Sameer Singh 和 Carlos Guestrin. “我为什么要信任你?”: 解释任何分类器的预测。In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1135-1144, 2016. doi: 10.1145/2939672.2939778.
Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman 和 Aram Galstyan. 关于机器学习中的偏差和公平性的调查。ACM Computing Surveys, 54(6):1-35, 2021. doi:
10.1145
/
3457607
10.1145 / 3457607
10.1145/3457607.
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg 和 Demis Hassabis. 通过深度强化学习实现人类级别的控制。Nature, 518(7540):529-533, 2015年2月. ISSN 1476-4687. doi: 10.1038/nature14236. URL https://doi.org/10.1038/nature14236.
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman 和 Dan Mané. AI安全中的具体问题。arXiv preprint arXiv:1606.06565, 2016. 超过3,000次引用 (Google Scholar, 2025年4月).
Ian J. Goodfellow, Jonathon Shlens 和 Christian Szegedy. 解释和利用对抗性样本。International Conference on Learning Representations (ICLR), 2015.
Guy Katz, Clark Barrett, David L. Dill, Kyle Julian 和 Mykel J. Kochenderfer. Reluplex: 一种有效的SMT求解器用于验证深度神经网络。In Proceedings of the 29th International Conference on Computer Aided Verification (CAV), pages 97-117, 2017. doi: 10.1007/978-3-319-63387-9_5.
Rüdiger Ehlers. 分段线性前馈神经网络的形式验证。In Proceedings of the 15th International Symposium on Automated Technology for Verification and Analysis (ATVA), volume 10482 of Lecture Notes in Computer Science, pages 269-286, 2017. 600次引用 (Google Scholar, 2025年4月).
Xin Huang, Marta Kwiatkowska, Sen Wang 和 Min Wu. 深度神经网络的安全验证。In Proceedings of the 29th International Conference on Computer Aided Verification (CAV), pages 3-29, 2017. 1,200次引用 (Google Scholar, 2025年4月).
Priya L. Donti, Brandon Amos 和 J. Zico Kolter. 基于任务的端到端模型学习在随机优化中。In Advances in Neural Information Processing Systems (NeurIPS), pages 5484-5494, 2017.
James Kotary, Ferdinando Fioretto, Pascal Van Hentenryck 和 Bryan Wilder. 端到端约束优化学习综述。In Proceedings of the 30th International Joint Conference on Artificial Intelligence (IJCAI), pages 4475-4482, 2021.
Brandon Amos 和 J. Zico Kolter. OptNet: 作为神经网络层的可微优化。In Proceedings of the 34th International Conference on Machine Learning (ICML), volume 70 of Proceedings of Machine Learning Research, pages 136-145, 2017.
Bryan Wilder, Bistra Dilkina 和 Milind Tambe. 整合数据-决策管道:专注于组合优化的决策导向学习。In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 1658-1665, 2019.
Adam N. Elmachtoub 和 Paul Grigas. 智能“先预测,后优化”。Management Science, 68(1): 9 − 26 , 2022 9-26,2022 9−26,2022.
Aaron Ferber, Bryan Wilder, Bistra Dilkina 和 Milind Tambe. MIPaaL: 混合整数程序作为一种层。In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 1504-1511, 2020.
Aaron M. Ferber, Taoan Huang, Daochen Zha, Martin Schubert, Benoit Steiner, Bistra Dilkina 和 Yuandong Tian. SurCo: 学习组合非线性优化问题的线性代理。In Proceedings of the 40th International Conference on Machine Learning (ICML), volume 202 of Proceedings of Machine Learning Research, pages 10034-10052, 2023.
Marin Vlastelica, Anselm Paulus, Vít Musil, Georg Martius 和 Michal Rolínek. 黑盒组合求解器的微分。In International Conference on Learning Representations (ICLR), 2020.
Joshua Achiam, David Held, Aviv Tamar 和 Pieter Abbeel. 受限策略优化。In 国际机器学习会议 (ICML), 2017.
Mohammad Alshiekh, Roderick Bloem, Ruediger Ehlers 等人. 强化学习中的屏蔽安全方法。In AAAI人工智能会议, 2018.
Alex Ray, Joshua Achiam 和 Dario Amodei. 深度强化学习中安全探索的基准测试。技术报告, OpenAI, 2019a.
Tobias Enders, James Harrison 和 Maximilian Schiffer. 鲁棒深度强化学习下的分布移位风险敏感软演员评论家。arXiv:2402.09992, 2024.
Yiming Yao 等人. 多功能安全强化学习的约束条件策略优化。In NeurIPS, 2023.
Mr. Bayes 和 Mr. Price. 解决机会理论问题的论文。已故Rev. Mr. Bayes, F. R. S. 通过Mr. Price通信给John Canton, A. M. F. R. S. 哲学汇刊, 53:370-418, 1763. ISSN 02607085.
Alex Ray, Joshua Achiam 和 Dario Amodei. 深度强化学习中安全探索的基准测试。2019b.
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford 和 Oleg Klimov. 近端策略优化算法, 2017. URL https://arxiv.org/abs/1707.06347.
Ashish Kumar Jayant. Ppo lagrangian pytorch, 2022. URL https://github.com/akjayant/ PPOLagrangianPyTorch.
Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, Perry Payne, Martin Seneviratne, Paul Gamble, Chris Kelly, Nathaneal Scharli, Aakanksha Chowdhery, Philip Mansfield, Blaise Aguera y Arcas, Dale Webster, Greg S. Corrado, Yossi Matias, Katherine Chou, Juraj Gottweis, Nenad Tomasev, Yun Liu, Alvin Rajkomar, Joelle Barral, Christopher Semturs, Alan Karthikesalingam 和 Vivek Natarajan. 大型语言模型编码临床知识, 2022年12月. URL http://arxiv.org/abs/2212.13138. arXiv:2212.13138 [cs].
Shen Wang, Tianlong Xu, Hang Li, Chaoli Zhang, Joleen Liang, Jiliang Tang, Philip S. Yu 和 Qingsong Wen. 大型语言模型在教育中的应用:综述与展望, 2024. URL https://arxiv.org/abs/2403.18105.
Jingtong Su, Julia Kempe 和 Karen Ullrich. 使命不可能:破解LLMs的统计视角, 2024年8月. URL http://arxiv.org/abs/2408.01420. arXiv:2408.01420 [cs].
Bolian Li, Yifan Wang, Ananth Grama 和 Ruqi Zhang. 级联奖励采样以实现高效解码时间对齐, 2024年6月. URL http://arxiv.org/abs/2406.16306. arXiv:2406.16306 [cs, stat].
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Chi Zhang, Ruiyang Sun, Yizhou Wang 和 Yaodong Yang. BeaverTails:通过人类偏好数据集改善LLM的安全对齐, 2023年7月. URL http://arxiv.org/abs/2307.04657. arXiv:2307.04657 [cs].
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike 和 Ryan Lowe. 使用人类反馈训练语言模型以遵循指令, 2022年3月. URL http://arxiv.org/abs/2203.02155. arXiv:2203.02155 [cs].
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning 和 Chelsea Finn. 直接偏好优化:你的语言模型实际上是一个奖励模型, 2024. URL https://arxiv.org/abs/2305.18290.
Tianhao Wu, Banghua Zhu, Ruoyu Zhang, Zhaojin Wen, Kannan Ramchandran 和 Jiantao Jiao. 成对近端策略优化:利用相对反馈进行LLM对齐, 2023. URL https://arxiv.org/abs/2310.00212.
参考论文:https://arxiv.org/pdf/2504.20924



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











