






Tyler McDonald
计算机科学系
布罗克大学
圣凯瑟琳,安大略省
tmcdonald3@brocku.ca
摘要
随着大型语言模型(LLMs)在日常任务中的不断应用,提示工程仍然是计算语言学领域内一个活跃的研究方向,特别是在需要专业知识的领域,如算术推理。尽管这些LLMs针对多种任务进行了优化,但它们的广泛使用可能会对小型团队带来计算或财务上的负担。此外,完全依赖专有的、封闭源代码的模型通常会限制定制和适应性,从而在研究和应用可扩展性方面带来重大挑战。相反,通过利用参数量在70亿及以下的开源模型,我们可以在优化资源使用的同时,仍能观察到相较于标准提示方法的巨大收益。为了培养这一理念,我们引入了思维轨迹提示,这是一种简单、零样本的提示工程技术,它指导LLMs创建可观察的子问题,采用关键的问题解决策略,专门设计用于增强算术推理能力。当应用于与GPT-4结合使用的开源模型时,我们观察到思维轨迹不仅允许深入了解问题解决过程,而且在参数量为70亿及以下的语言模型上带来了高达125%的性能提升。这种方法强调了开源倡议在民主化AI研究和提高高质量计算语言学应用的可访问性方面的潜力。我们的代码,包括数据分析和测试脚本,可以在这里获取。
1 引言
提示工程已成为自然语言处理(NLP)领域内的一个重要研究方向,各种高效的方法迅速涌现(Wei等人,2023;Wang等人,2023;Yao等人,2023;Kojima
Ali Emami
计算机科学系
布罗克大学
圣凯瑟琳,安大略省
aemami@brocku.ca
等人,2023;Huang等人,2022a;Zou等人,2023)。随着这些方法在研究社区中越来越受到关注,纯粹的性能已成为众多数据集上的主导基准。然而,这些方法将推理视为一种“全有或全无”的过程,直到事后评估才能看到这些步骤。缺乏透明的推理意味着常见的、容易解决的错误可能在整个问题解决过程中传播,降低性能并可能鼓励贪婪解决方案,同时在问题解决过程中没有额外的机会来改进推理(Saparov和He,2023)。
此外,随着各种小规模语言模型被微调以完成特定任务,用户在自己的消费级硬件上部署模型进行问题解决变得显著更容易(Touvron等人,2023;Xu等人,2023;Tunstall等人,2023;Jiang等人,2023,等)。这种对一系列本地模型的控制带来了通过开源语言建模实现可访问性的范式转变。虽然易于部署和访问,这些语言模型在常见任务上可能会遇到困难,例如文本和多模态算术推理,这要求改进其关键的问题解决技能(Hendrycks等人,2021b;Shao等人,2024;Lu等人,2024)。
通过认识到混合部署的潜力以及在多模态环境中同时使用大规模和小规模模型的优势,我们可以努力弥补每种方法的缺陷。虽然大型、封闭源代码的语言模型计算密集,但我们可以从这些模型中提取关键推理优势,将其注入小规模模型中(Shridhar等人,2023;Chen等人,2023a)。通过利用这种蒸馏,我们可以将计算负载转移到商业可用的硬件上,
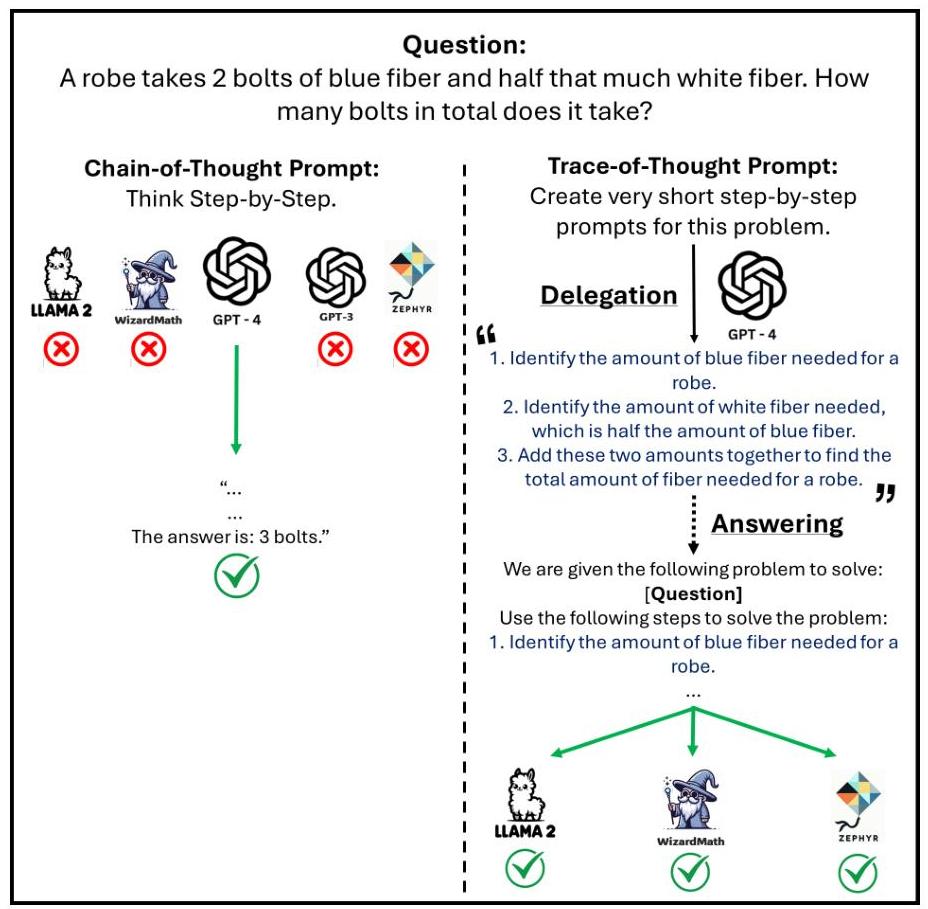
图1:标准零样本链式思维提示与我们的思维轨迹提示策略在GSM8K问题实例上的比较。
而不是使用封闭源API,这样既可以灵活部署模型,又能通过直接访问底层机制确保可靠的服务质量。
鉴于这些挑战和机遇,我们提出了思维轨迹,这是一种新颖的提示策略,将复杂问题解决分解为可观察的推理步骤,作为对NLP领域更透明、高效和可访问的问题解决机制需求的直接回应。图1展示了在GSM8K(Cobbe等人,2021)问题实例上的比较示例,突显了使思维轨迹特别适合于通常在更复杂的推理链上挣扎的小型模型的简化和简洁的推理路径。
我们通过引入思维轨迹做出的贡献有三方面:
- 透明度。思维轨迹提供了一个可观察的框架,在其中由问答模型执行的步骤在执行前已为人所知。这使得人类监督者不仅可以更明智地推断当前问题,还可以了解执行委托任务的模型的优点,而无需等待事后分析。
-
- 开源问题解决。通过用更大、封闭源模型的指令加强开源模型,我们观察到性能的巨大提升,展示了小型模型作为竞争性问题解决者的实用性。通过使用开源模型作为解决方案模型,我们观察到这些模型的性能相比其他流行方法提高了超过125%。此外,像WizardMath-7B这样的模型在超出GPT-3.5-Turbo链式思维至少10%的情况下,运用思维轨迹是一种可行的替代方案。这种令人鼓舞的表现表明,小型开源语言模型可能继续发展为封闭源模型的适当替代品。
-
- 上下文知识蒸馏。通过使用由大型语言模型(如GPT-4)生成的高质量指令,我们能够利用知识蒸馏的概念,并以无需预先微调的方式在上下文中应用它(Hinton等人,2015;Huang等人,2022b;OpenAI等人,2023)。通过简单的委派和回答提示,我们利用了GPT-4作为高级推理者的持续成功,并将这种推理扩散到较少赋能的模型中,通过典型的人类互动(Espejel等人,2023)。这创造了对大型封闭源模型的依赖,不是为了全面解决方案,而是为了基于指令的推理和任务识别。
2 相关工作
开源语言建模。自然语言处理的民主化因开源语言模型的出现而得到了极大的推动。这些模型,如Zephyr-7B、Llama 2-7B Chat和WizardMath-7B,证明了该领域的进步,提供了挑战大型专有模型霸主地位的领域特定功能(Touvron等人,2023;Olausson等人,2023;Li等人,2023b)。我们的工作建立在这个基础上,通过实证评估展示了如何通过思维轨迹提示进一步增强这些模型的能力,使其以一小部分计算成本接近其较大对手的效率。这不仅展示了它们作为独立解决方案的潜力,还强调了开源模型在促进竞争性和多样化的NLP生态系统中的重要性,特别是通过利用这些开源替代方案(Chen等人,2023b)。
中间推理。诸如算术推理领域的任务需要仔细计划的步骤来创造强大的输出,未能正确识别子问题可能会导致基本错误(Stolfo等人,2023)。零样本和少量样本链式思维提示方法有助于这种刻意推理;然而,这些推理路径在运行时之前是隐藏的,并不能提供任何关于潜在不正确推理的洞察(Li等人,2023a)。同样,即使拥有强大的链式思维推理,后续输出也可能与所使用的推理不符(Lyu等人,2023;Lanham等人,2023)。像Least-to-Most提示方法可以让中间推理可见,并鼓励忠实表现,但可能因非常长的输入提示而牺牲效率和可读性以换取性能(Zhou等人,2023b)。在实施思维轨迹时,我们希望将问题解决严格约束为由模型生成和分配的步骤,同时保持强大性能,所有这些都在一个紧凑的提示中。
问题分解。先前的工作通过递归提示或作为微调方法学习中间步骤模式来探索问题分解(Qi等人,2023;Yao等人,2023;Shridhar等人,2023)。然而,这些方法侧重于问题分解作为训练数据的功能,以时间复杂度换取性能提升,或需要额外的人工参与才能成功(Radhakrishnan等人,2023;Patel等人,2022;V等人,2023)。思维轨迹作为一种高效的原地提示方法不同于这些工作,因为完整的对话默认不超过两个提示。此外,思维轨迹不要求模型在使用问题分解策略的训练数据上进行训练。通过从现有的训练语料库中提取趋势和优势——这里展示了一系列广泛的模型——用户只需添加提示前缀和后缀即可在其自身工作中使用思维轨迹。
3 模型混合性
GPT-4等LLM的使用已在多个领域产生了变革性影响,展示了处理复杂任务的独特推理能力(OpenAI等人,2023)。尽管它们表现出色,但对这种封闭源模型的依赖引入了可访问性、定制化以及长期可用性的潜在担忧(Bubeck等人,2023)。这些限制凸显了计算语言学领域内更加民主化解决方案的需求。
为应对行业标准模型的专有性质,NLP社区见证了开源替代方案的发展和采用激增。这些模型,如WizardMath和DeepSeekMath,不仅在算术推理基准上达到了与GPT-3.5相当的水平,还在逐渐缩小与GPT-4的差距(Shao等人,2024;Hendrycks等人,2021a,b;Liu等人,2023)。这种向开源解决方案的趋势正在重塑格局,提供可行且具有成本效益的替代方案,使高质量NLP工具的访问民主化。
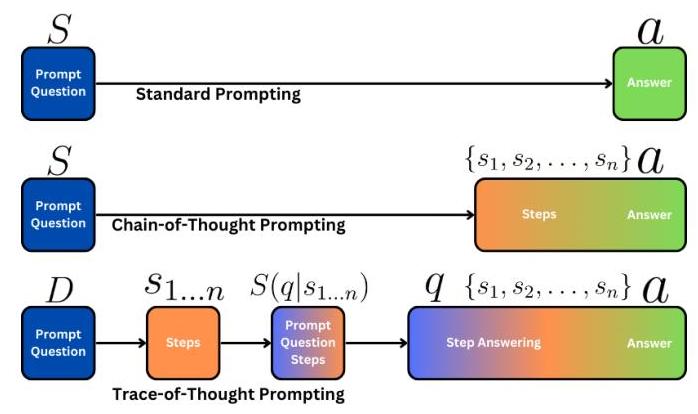
图2:思维轨迹提示工作流程与其他两种方法——链式思维提示和标准提示的工作流程对比。
解决方案是提供可行且具有成本效益的替代方案,使高质量NLP工具的访问民主化。
我们在此提出的概念——模型混合性——在这种不断发展的环境中应运而生。这种方法不仅仅是为了利用各种模型的个别优势以提高性能;更是为了促进它们之间的协同关系。模型混合性结合了LLM的关键推理能力和较小开源模型的敏捷性和可访问性,旨在构建一个整体大于部分之和的复合体(Madaan等人,2023;Chen等人,2023b)。
通过将模型视为合作者,我们充分利用它们的独特优势——无论是LLM的深刻、细致的理解,还是小型模型的专业知识和效率。这种协作集成不仅增强了性能,还确保了在快速变化的应用领域中的韧性和适应性。此外,通过摒弃开发作为性能竞赛的理念,我们鼓励未来工作关注于可访问且强大的语言建模,同时强调来自研究人员和开发者社区合作的好处。
通过思维轨迹提示,我们力求体现模型混合性的原则,提出一种打破传统线性和递归结构的提示方法。该方法旨在最大化开源模型的效用,引导它们与从更大模型中提取的推理能力协同工作。这也是朝着以集合为导向的未来迈出的一步,其中多样化模型的集体智能为计算语言学中的创新问题解决策略铺平了道路。
4 思维轨迹提示
考虑这样一个场景:一个复杂问题不是由单一实体解决,而是通过协作努力,汲取各个参与者的专业能力。这就是思维轨迹提示的本质——一种旨在将问题解决过程分为两个透明、可管理阶段的方法,充分发挥不同语言模型的优势。
让我们定义一个语言模型 D D D ,它接收一个可分割的问题 q q q ,这是一个可以分解成一系列较简单中间子问题的查询。这个模型 D D D 在单个上下文中产生一系列推理步骤 s 1 … n s_{1 \ldots n} s1…n :
D ( q ) → s 1 , s 2 , … , s n D(q) \rightarrow s_{1}, s_{2}, \ldots, s_{n} D(q)→s1,s2,…,sn
关键是, s 1 … n s_{1 \ldots n} s1…n 不是孤立的输出,而是顺序生成的,提供了一条清晰的逐步解决问题的路径。
接下来,一个解算器 S S S 利用这些中间步骤计算最终答案 a a a :
S ( q ∣ s 1 , s 2 , … , s n ) → a S\left(q \mid s_{1}, s_{2}, \ldots, s_{n}\right) \rightarrow a S(q∣s1,s2,…,sn)→a
重要的是,解算器 S S S 可以是一个与 D D D 不同的模型或实例,为问题解决过程提供了灵活性。
思维轨迹方法包含两个不同的阶段:
- 委托 ( D ( q ) ) (D(q)) (D(q)) :此阶段涉及生成一套简明的分步指示来解决问题。用户可以在进入解答阶段之前手动或使用
- | 提示类型 | 模板 |
- | :-- | :-- |
- | 标准 | “<问题>.” |
- | 链式思维 | “<问题>。一步一步思考。” |
- | 思维轨迹 - 委托 | “为以下问题创建非常简短的分步提示:<问题>。
格式为列表。不要解决问题。” | - | 思维轨迹 - 解决 | “我们给出以下问题:<问题>。使用以下步骤来
解决问题:<步骤>。” |
表1:实验评估中使用的提示模板。
验证模型进行验证和细化。这种明确的分割确保过程早期可以纠正任何不准确之处(Ling等人,2023)。 - 回答
(
S
(
q
∣
s
1
,
s
2
,
…
,
s
n
)
)
\left(S\left(q \mid s_{1}, s_{2}, \ldots, s_{n}\right)\right)
(S(q∣s1,s2,…,sn)) :在第二阶段,解算器模型使用委派步骤解决原始问题。该模型专注于提供的步骤,不会被提示进行额外推理,从而紧密遵循既定计划。图2对比了这种精简的过程与之前方法可能更为复杂的路径。
思维轨迹提示不仅增强了推理过程的可见性,还赋予用户利用一系列模型的专项能力,尤其是在算术推理等领域。这促进了资源的有效利用,并为模型根据其强项充当专注的问题解决者或熟练的委派者铺平了道路(Zhang等人,2023)。
通过遵循模型混合性的原则,思维轨迹提示倡导多样化的合作问题解决景观。它标志着迈向集合导向方法的一步,其中不同模型优势的融合带来了强大、适应性强且高度胜任的NLP系统。
5 实验设置
5.1 基准
本文考虑了两项算术推理任务:
- GSM8K:一个包含8500道小学数学文字题的数据集(Cobbe等人,2021)。GSM8K因其结合了大、小规模计算和常识推理的问题而被选中,同时仍保持入门级基准的地位。
-
- 启发式数学能力测试 (MATH):一个包含12500道具有挑战性的竞赛数学问题的数据集(Hendrycks等人,2021b)。MATH是一个历史上在未采用代码解决方案的模型上表现较低的数据集,被选中以评估较长形式的推理和一些模型(如WizardMath-7B)范围之外的任务推理(Zhou等人,2023a)。
从每个数据集中,我们选择前200个问题,如果可用则从数据集主体或测试拆分中选择。
- 启发式数学能力测试 (MATH):一个包含12500道具有挑战性的竞赛数学问题的数据集(Hendrycks等人,2021b)。MATH是一个历史上在未采用代码解决方案的模型上表现较低的数据集,被选中以评估较长形式的推理和一些模型(如WizardMath-7B)范围之外的任务推理(Zhou等人,2023a)。
5.2 模型
我们考虑了各种闭源和开源模型进行比较:
GPT-4(大小未知,闭源):由OpenAI创建的闭源模型。使用06/13快照。
GPT-3.5-Turbo(大小未知,闭源):GPT-4的前身系列的一部分,由OpenAI创建。使用06/13快照。
WizardMath-7B(7B,开源):由WizardLM生产的开源模型套件,基于Mistral训练,并在GSM8K数据集上进行了微调。使用强化学习从人类反馈(RLHF)的新扩展,强化进化指令(RLEIF)进行训练。
Llama 2-7B Chat(7B,开源):Meta生产的一套开源模型的一部分,并针对对话目的进行了微调。
Zephyr-7B(7B,开源):由HuggingFace的H4团队开发的开源模型,使用直接偏好优化(Rafailov等人,2023)在合成数据上进行训练。
5.3 提示方法
我们在所有数据集上比较三种主要的提示方法,均在零样本环境下——选择这种提示环境是为了模拟最公平的人机交互形式:
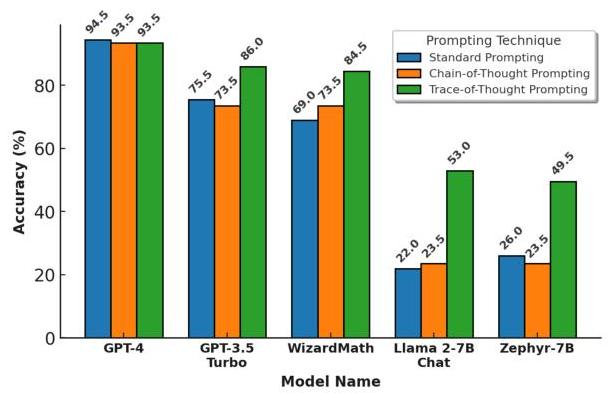
图3:使用三种提示方法在GSM8K上的各种模型准确性。
标准提示:模型被提示以数据集的确切内容,未经修改。
链式思维提示:模型被给予一个问题,并被指示“一步一步思考”,没有任何先验的情境示例。
思维轨迹提示:选择一个委派模型和一个解算模型,并执行思维轨迹的委派和解答工作流。再次说明,没有任何先验的情境示例。对于委派,我们在每种思维轨迹实例中都使用GPT-4。 1 { }^{1} 1
为了说明这些提示方法的操作差异,图2提供了一个比较工作流图,可以通过参考来获得每种方法结构的视觉理解。有关提示模板的详细比较,请参见表1。
5.4 评估
答案通过与数据集标签的精确匹配进行评估;除非模型四舍五入,“接近”答案不予考虑。结果,包括问题、模型和数据集答案,以及对于思维轨迹的步骤和答案,记录在一个CSV文件中。每个响应由内部注释员标记为真或假。
如果模型得出正确答案,但添加了不必要的额外结果或后续问题,我们将答案标记为正确,但记录发生情况以便进一步分析。此外,在模糊情况下,模型正确推理了答案,但在答案格式化过程中可能返回了不同的答案,我们会将问题标记为正确,并附上进一步分析的指示。例如,如果模型在推理过程中得出结果为5,但错误地说“答案是:6”,我们认可推理为5,而不认可格式化答案为6。
6 结果
6.1 GSM8K
图3描绘了每种模型在GSM8K ( n = 200 ) (n=200) (n=200) 上使用所有三种方法的性能。
随着模型尺寸减小,我们观察到通过使用思维轨迹提示方法带来的相对性能提升更大,具有统计显著性。尽管GPT-4总体损失最小,GPT-3.5-Turbo的准确性提升了17%,Llama 2-7B Chat的准确性提升了超过125%,而其他模型的准确性提升范围从14%到50%不等。同样,在表2和表3中,我们看到了更窄的准确性范围、更高的平均值和高度一致的准确性提升,显示出各模型总体准确性提升的令人鼓舞趋势。当使用思维轨迹提示方法结合WizardMath时,我们观察到接近GPT-4的提升,这是利用GPT-4推理能力和WizardMath算术微调的一个强有力例子。
GSM8K的表格结果和统计显著性测试分别可以在附录表5和表7中找到。
1 { }^{1} 1 我们使用GPT-4作为委派模型是基于其已被证明的推理能力和对我们研究的便利性,而不是对模型必须大或封闭源的要求。鼓励未来的工作调查思维轨迹的开源替代方案,以提高语言建模的成本效益。
| 模型 | 最高替代方案 | 思维轨迹 | % 变化 | 模型 | 最高替代方案 | 思维轨迹 | % 变化 |
|---|---|---|---|---|---|---|---|
| GPT-4 | 94.5 | 93.5 | − 1.06 % -1.06 \% −1.06% | GPT-4 | 66 | 70.5 | + 6.82 % +6.82 \% +6.82% |
| GPT-3.5-Turbo | 75.5 | 86 | + 13.91 % +13.91 \% +13.91% | GPT-3.5-Turbo | 75.5 | 86 | + 12.5 % +12.5 \% +12.5% |
| WizardMath-7B | 73.5 | 84.5 | + 14.97 % +14.97 \% +14.97% | WizardMath-7B | 44.5 | 40.5 | − 8.99 % -8.99 \% −8.99% |
| Llama 2-7B Chat | 23.5 | 53 | + 125.53 % +125.53 \% +125.53% | Llama 2-7B Chat | 7.5 | 8.5 | + 13.33 % +13.33 \% +13.33% |
| Zephyr-7B | 12 | 18 | + 50 % +50 \% +50% | Zephyr-7B | 26 | 49.5 | + 90.38 % +90.38 \% +90.38% |
表2:在GSM8K和MATH( n = 200 n=200 n=200)上测试模型的准确性提升比较。
| 方法 | 最小值 | 最大值 | 平均值 |
|---|---|---|---|
| 标准提示 | 22 | 94.5 \mathbf{9 4 . 5} 94.5 | 57.4 |
| 链式思维 | 23.5 | 93.5 | 57.5 |
| 思维轨迹 | 49.5 \mathbf{4 9 . 5} 49.5 | 93.5 | 73.3 \mathbf{7 3 . 3} 73.3 |
表3:使用GSM8K( n = 200 n=200 n=200)对每种提示方法的准确性进行中心趋势测量。
6.2 MATH
图4描绘了每种模型在MATH ( n = 200 ) (n=200) (n=200) 上使用所有三种方法的性能。
尽管在GPT-4和GPT-3.5等闭源模型上的提升缺乏统计显著性,但它们的改进——尤其是GPT-4通过自我提示得到的改进——表明了使用思维轨迹作为一种通用解决方案在提高准确性方面的强劲趋势,即使是在大型闭源模型上也是如此。此外,尽管思维轨迹未能在WizardMath-7B上达到与其他方法相当的效果,但我们仍然在历史上表现不佳的模型Llama 2 Chat和Zephyr上看到了提升。MATH数据集的使用保持了类似的紧致准确性范围和性能提升趋势,如表2和表4所示。这种初始版本的思维轨迹能在多大程度上应用仍有待观察,但这些结果有力支持了在困难问题数据集上至少部分增强算术问题解决能力的概念。
MATH的表格结果和统计显著性测试分别可以在附录表6和表8中找到。
7 扩展分析
7.1 推理增强
在使用思维轨迹与小规模语言模型时,我们观察到了两个与小规模模型通过自身推理增强所提供步骤相关的有趣趋势。
首先,如图6所示,开源语言模型识别并随后忽略了冗余步骤,保留了透明性,同时保留了推理并减少了幻觉的可能性。通过识别出无净增益的不必要过程或过程,模型展示了比单纯指令跟随更深入的问题解决,而是将步骤用作监督框架的问题解决方式。
此外,当模型遇到给定必要信息——无论是从前一步骤还是从问题上下文中观察到——可进一步细分的步骤时,它可以选择通过进一步的推理链来增强所提供的步骤,类似于递归推理链,如图5所示(Lee和Kim,2023)。通过引入局部推理,模型填补了空白,或添加了其认为必要的问题上下文。
尽管先前的研究已将类似步骤评估作为事后方法进行调查,但这种现象利用了与答案生成相同的上下文;通过就地分析和修正步骤,无需额外的事后验证,模型可以根据需要进行调整(Miao等人,2023)。
7.2 自反思维轨迹
当在MATH数据集上使用GPT-4作为委派模型和解算模型时,尽管未使用其他模型进行该系列测试,我们观察到了显著的准确性提升(图4)。这种自反使用GPT-4,尽管不具备统计显著性,却阐述了无论使用何种模型进行任务,精心推理所带来的好处。
这种方法,我们称之为自反思维轨迹,更注重模型集成的能力,而不是利用有意问题解决方法(如思维树)之前应用的精心问题解决力量(Yao等人,
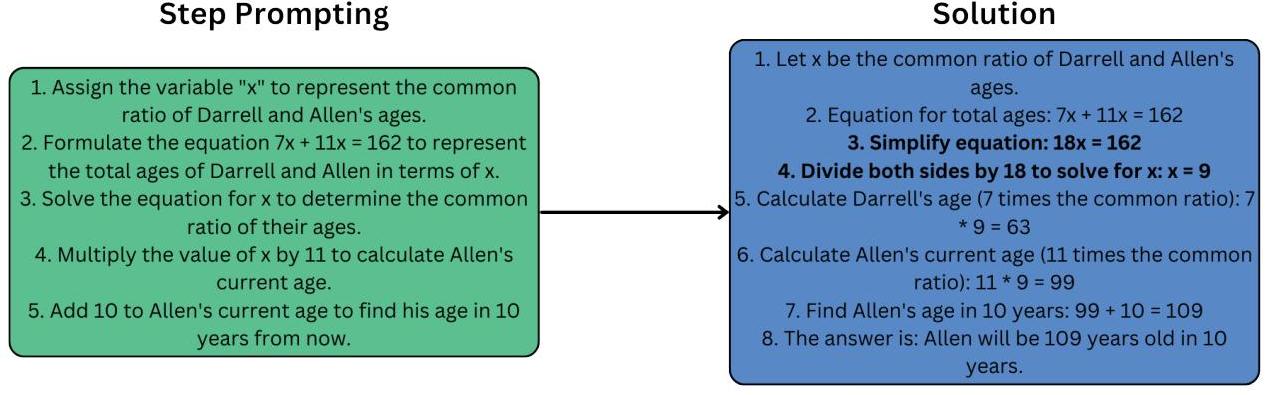
图5:Zephyr-7B通过步骤增强执行局部推理链——即在解方程时。
步骤提示
解决方案
- 确定函数 g ( x ) = 3 g(x)=3 g(x)=3。
-
- 注意示例中 x x x 的值为 2。
-
- 在函数中将 x x x 替换为 2,以形成 g ( 2 ) g(2) g(2)。
-
- 如果有必要,简化以得到最终答案。
解决方案
- 给定的函数是 $$ g(x)=3 $$。
-
- 在这个例子中, x x x 的值是 2。
-
- 将 x x x 替换为 2 在函数中,我们有:$$ g(2)=3 $$(由于括号内的值被替换为 2)。
-
- 不需要进一步简化,因为答案已经是最简形式。
- 总之,$$ g(2) $ 5$ 的值是 3。
图6:Zephyr-7B通过识别冗余步骤忽略无用工作——即在简化结果时。
2023)。增量成功使用自反思维轨迹所带来的启示进一步考虑了使用较大的开源模型进行委派和问题回答任务。这种远离封闭源建模解决方案的转变是计算语言学中的一个关键范式,赋予研究公司开发模型不仅用于问题解决,还用于有意推理和指令生成。
7.3 透明推理
尽管现有的方法如链式思维提示鼓励逐步推理,但很难将这些步骤恰当地划分为解决方案的整体部分。我们发现思维轨迹提示鼓励模型遵循定义的步骤结构,包括将解决方案与步骤编号对齐以提高可观察性,即使步骤是冗余或缺失的。
图7(附录)中的案例展示了在使用GPT-3.5-Turbo时,两种方法在透明度上的差异。至关重要的是,思维轨迹鼓励遵守提供的步骤指南进行推理。虽然链式思维在答案呈现时发展这种推理链,但思维轨迹对解决方案模型设定了明确的期望,即使步骤可以更改,也要遵循结构和所需的步骤。
这种清晰的推理窗口不仅允许判断解决方案模型在某些目标任务上的有效性,还可以提供一些关于委派模型生成的一些步骤必要性的见解。结合解决方案模型有时可以完全省略这些冗余步骤,这是一个强有力的趋势,鼓励对委派过程进行仔细和精细的调整。
8 结论
我们介绍了思维轨迹提示,这是一种新颖的提示方法,旨在将问题分解为委派和回答步骤,并分析了其在使用GPT4进行委派时应用于小规模语言模型的性能。思维轨迹提示寻求鼓励向可访问和开源语言建模的范式转变,并表明像GPT-4这样的大型语言模型可能在未来作为委派者而非问题解决者具有实用价值。我们的研究结果敦促社区考虑可访问、包容和民主化研究的优势,并在开发未来方法时将开源模型置于首要考虑位置。
局限性
提示敏感性。当省略委派或回答提示的某些部分时可能导致性能下降的潜在风险尚未被充分研究。我们鼓励对这些提示的结构进行全面的显著性研究,以防止这种下降。
抽象推理。ARC和ACRE等数据集探讨了抽象推理任务,目标是在极少数据的情况下泛化并应用一个共同的模式(Xu等人,2024;Gendron等人,2024)。由于其抽象性质和原始问题缺乏可观测划分,尚不清楚思维轨迹是否是进行诸如一般模式识别或常识推理等任务的有效和有用框架。
财务影响。由于需要额外的提示来为解决方案模型生成步骤,以及实现这种效果所需的较长输入提示,在主要使用闭源设置中应用思维轨迹可能会导致额外成本和受限资源(如API信用额度)使用率的提高。
委派模型的解决方案扩散。类似于提示敏感性,用户应注意过于强烈地提示其委派模型鼓励解决方案可能导致生成的步骤是先前工作的结果,而不是解决方案模型的方向,从而导致下游结果污染。
模型依赖性和可扩展性。思维轨迹的有效性很大程度上依赖于所选模型的能力,这可能限制其在模型缺乏特定知识或推理技能领域的应用。此外,该方法的计算和资源需求可能在资源受限的环境中带来可扩展性挑战。
参考文献
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, 和 Yi Zhang. 2023. 人工通用智能的火花:GPT-4的早期实验。
Hongzhan Chen, Siyue Wu, Xiaojun Quan, Rui Wang, Ming Yan, 和 Ji Zhang. 2023a. MCC-KD:多COT一致性知识蒸馏。
Lingjiao Chen, Matei A. Zaharia, 和 James Y. Zou. 2023b. Frugalgpt:如何在降低成本和提高性能的同时使用大型语言模型。ArXiv, abs/2305.05176。
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, 和 John Schulman. 2021. 训练验证器以解决数学文字问题。
Jessica López Espejel, El Hassane Ettifouri, Mahaman Sanoussi Yahaya Alassan, El Mehdi Chouham, 和 Walid Dahhane. 2023. GPT-3.5, GPT-4 或 Bard?评估LLM在零样本设置下的推理能力及通过提示提升性能。
Gaël Gendron, Qiming Bao, Michael Witbrock, 和 Gillian Dobbie. 2024. 大型语言模型并非强大的抽象推理者。
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, 和 Jacob Steinhardt. 2021a. 测量大规模多任务语言理解。
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, 和 Jacob Steinhardt. 2021b. 使用数学数据集测量数学问题解决能力。
Geoffrey Hinton, Oriol Vinyals, 和 Jeff Dean. 2015. 蒸馏神经网络中的知识。
Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, 和 Jiawei Han. 2022a. 大型语言模型可以自我改进。
Yukun Huang, Yanda Chen, Zhou Yu, 和 Kathleen McKeown. 2022b. 上下文学习蒸馏:转移预训练语言模型的少样本学习能力。
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, 和 William El Sayed. 2023. Mistral 7b。
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, 和 Yusuke Iwasawa. 2023. 大型语言模型是零样本推理者。
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamilè Lukošiūtė, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Larson, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Shannon Yang, Thomas Henighan, Timothy Maxwell, Timothy Telleen-Lawton, Tristan Hume, Zac Hatfield-Dodds, Jared Kaplan, Jan Brauner, Samuel R. Bowman, 和
Ethan Perez. 2023. 测量链式思维推理的忠实性。
Soochan Lee 和 Gunhee Kim. 2023. 思维递归:使用语言模型进行多情境推理的分而治之方法。
Yifei Li, Zeqi Lin, Shizhuo Zhang, Qiang Fu, Bei Chen, Jian-Guang Lou, 和 Weizhu Chen. 2023a. 步骤感知验证器让语言模型成为更好的推理者。第61届计算语言学年会论文集(第1卷:长篇论文),第5315-5333页,加拿大多伦多。计算语言学协会。
Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, 和 Yin Tat Lee. 2023b. 文本书就是你所需要的II:Phi-1.5技术报告。
Zhan Ling, Yunhao Fang, Xuanlin Li, Zhiao Huang, Mingu Lee, Roland Memisevic, 和 Hao Su. 2023. 演绎验证链式思维推理。
Wentao Liu, Hanglei Hu, Jie Zhou, Yuyang Ding, Junsong Li, Jiayi Zeng, Mengliang He, Qin Chen, Bo Jiang, Aimin Zhou, 和 Liang He. 2023. 数学语言模型:综述。
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, KaiWei Chang, Michel Galley, 和 Jianfeng Gao. 2024. MathVista:评估基础模型在视觉上下文中的数学推理能力。
Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, 和 Chris Callison-Burch. 2023. 忠实的链式思维推理。
Aman Madaan, Pranjal Aggarwal, Ankit Anand, Srividya Pranavi Potharaju, Swaroop Mishra, Pei Zhou, Aditya Gupta, Dheeraj Rajagopal, Karthik Kappaganthu, Yiming Yang, Shyam Upadhyay, Mausam, 和 Manaal Faruqui. 2023. AutoMix:自动混合同一语言模型。
Ning Miao, Yee Whye Teh, 和 Tom Rainforth. 2023. SelfCheck:使用LLM零样本检查自身的逐步骤推理。
Theo Olausson, Alex Gu, Ben Lipkin, Cedegao Zhang, Armando Solar-Lezama, Joshua Tenenbaum, 和 Roger Levy. 2023. LINC:结合语言模型与一阶逻辑证明器的神符号方法。2023年经验方法在自然语言处理会议论文集。计算语言学协会。
OpenAI, :, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mo Bavarian, Jeff Belgium, Irwan Bello,
Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Ben Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux, Thomas Degry, Noah Deutsch, Damien Deville, Arka Dhar, David Dohan, Steve Dowling, Sheila Dunning, Adrien Ecoffet, Atty Eleti, Tyna Eloundou, David Farhi, Liam Fedus, Niko Felix, Simón Posada Fishman, Juston Forte, Isabella Fulford, Leo Gao, Elie Georges, Christian Gibson, Vik Goel, Tarun Gogineni, Gabriel Goh, Rapha Gontijo-Lopes, Jonathan Gordon, Morgan Grafstein, Scott Gray, Ryan Greene, Joshua Gross, Shixiang Shane Gu, Yufei Guo, 魏晨, 杰西·韩, 杰夫·哈里斯, 余辰, 迈克·希顿, 约翰内斯·海德克, 克里斯·赫斯, 艾伦·希基, 沃德·希基, 彼得·霍舍勒, 布兰登·霍顿, 康尼·许, 胡盛利, 胡欣, 乔斯特·胡伊辛加, 山坦努·贾恩, 雪恩·贾因, 乔安妮·张, 安吉拉·江, 罗杰·江, 金浩准, 殿殿金, 新井树, 比莉·琼, 许慧武, 汤姆·考夫坦, 卢卡斯·凯撒, 阿里·卡马利, 英格玛·卡尼切德, 尼蒂什·谢里什·凯斯卡尔, 塔巴克·汗, 洛根·基尔帕特里克, 郑宗宇, 金美琳, 金永植, 汉德里克·基尔纳, 杰米·基罗斯, 马特·奈特, 达尼尔·科塔贾洛, 卢卡斯·康德拉丘克, 安德鲁·孔德里奇, 阿里斯·康斯坦丁尼迪斯, 凯尔·科西克, 格雷琴·克鲁格, 吴士浩, 迈克尔·兰佩, 艾克·兰, 特德·李, 简·莱克, 翟玲, 丹尼尔·列维, 李查明, 杨雪, 毛莉·林, 斯蒂芬妮·林, 马特乌什·利特温, 特蕾莎·洛佩兹, 瑞安·洛, 帕特丽夏·吕, 安娜·马坎朱, 金马法辛尼, 山姆·曼宁, 托多尔·马尔科夫, 亚尼夫·马尔科夫斯基, 白佳·马丁, 凯蒂·梅耶, 安德鲁·梅恩, 鲍勃·麦格鲁, 斯科特·梅尔·麦金尼, 克里斯汀·麦克利维, 保罗·麦克米兰, 杰克·麦克尼尔, 大卫·梅迪纳, 阿洛克·梅塔, 杰克布·梅尼克, 卢克·梅茨, 安德烈·米申科, 帕梅拉·米什金, 文尼·莫纳科, 埃文·莫里卡瓦, 达尼尔·莫斯宁, 穆同穆, 米拉·穆拉提, 奥列格·穆尔克, 大卫·梅利, 阿什文·奈尔, 雷一彻罗·那卡诺, 拉吉夫·奈克, 阿文德·尼拉卡坦, 理查德·恩戈, 徐贤宇, 赵龙, 库伦·奥基夫, 雅库布·帕乔斯基, 亚历克斯·派诺, 乔·帕拉默, 阿什利·潘图利阿诺, 吉安巴蒂斯塔·帕拉斯坎多洛, 乔尔·帕里什, 艾米·帕普里塔, 亚历克斯·帕索斯, 米哈伊尔·帕夫洛夫, 安德鲁·彭, 亚当·佩雷尔曼, 菲利普·德·阿维拉·贝尔布特·佩雷斯, 迈克尔·彼得罗夫, 亨里克·庞德·德·奥利维拉·平托, 迈克尔, 波科尔尼, 米歇尔·波克拉塞, 维切尔·庞, 托利·鲍威尔, 阿莱西亚·鲍尔, 玻利斯·鲍尔, 伊丽莎白·普罗尔, 劳尔·普里, 艾力克·拉福德, 杰克·雷, 阿迪亚·拉梅什, 坎贝尔·雷蒙德, 弗朗西斯·瑞尔, 昌达·林巴赫, 卡尔·罗斯, 鲍勃·罗斯特德, 亨利·鲁塞, 尼克·赖德尔, 马里奥·萨尔塔雷利, 泰德·桑德斯, 希芭尼·桑特卡尔, 吉里什·萨斯特里, 海瑟·施密特, 戴维·施耐尔, 约翰·舒尔曼, 达尼尔·塞尔萨姆, 凯拉·希伯德, 托基·舍尔巴科夫, 杰西卡·希, 萨拉·肖克, 普拉纳夫·夏姆, 施蒙·西多, 埃里克·锡格勒, 玛迪·西门斯, 乔丹·西特金, 卡塔琳娜·斯拉马, 伊恩·索尔, 本杰明
索科洛夫斯基, 杨松, 纳塔莉·施塔达赫, 菲利佩·佩特罗斯基·苏奇, 纳塔莉·萨默斯, 伊利亚·苏茨克弗, 唐洁, 尼古拉斯·泰扎克, 玛德琳·汤普森, 菲尔·蒂尔特, 阿明·图托尼亚, 伊丽莎白·曾格, 普雷斯顿·塔格尔, 尼克·特雷利, 杰里·特沃雷克, 胡安·费利佩·塞隆·乌里贝, 安德里亚·瓦洛内, 阿伦·维杰亚韦尔吉亚, 切尔西·沃斯, 卡罗尔·韦恩赖特, 刚杰·王, 阿尔文·王, 本·王, 乔纳森·沃德, 杰森·韦, CJ 温曼, 阿基拉·韦利亨达, 彼得·韦林德, 王家义, 威廉·王, 马特·威斯霍夫, 戴夫·威尔纳, 克莱门斯·温特, 萨缪尔·沃尔里奇, 汉娜·王, 劳伦·沃克曼, 舒仁吴, 杰夫·吴, 迈克尔·吴, 肖晓, 韶智旭, 凯文·俞, 齐明元, 伍杰·扎雷姆巴, 罗文·泽勒斯, 庄俊堂, 威廉·朱克, 巴雷特·佐夫. 2023. GPT-4技术报告。
普鲁特维·帕特尔, 斯瓦鲁普·米什拉, 米希尔·帕尔马, 和 奇塔·巴拉尔. 2022. 问题分解单元是否是我们所需的一切?
景远齐, 郑志宏, 沈颖, 刘敏谦, 王启帆, 黄立福. 2023. 苏格拉底提问的艺术:使用大型语言模型进行递归思考。
安什·拉德哈克里希南, 卡丽娜·阮, 安娜·陈, 卡罗尔·陈, 卡森·丹尼森, 丹尼·赫尔南德斯, 艾辛·杜尔穆斯, 伊万·休宾格, 杰克逊·科尼翁, 卡米尔·卢科什尤特, 牛顿·程, 尼古拉斯·约瑟夫, 尼古拉斯·谢菲尔, 奥利弗·劳施, 山姆·麦坎德利什, 希尔·埃尔肖克, 提摩太·麦克斯韦, 文卡塔斯·钱德拉塞卡兰, 杰德·卡普兰, 简·布拉纳, 楚门·R·鲍曼, 和 艾坦·佩雷斯. 2023. 问题分解提高了模型生成推理的忠实性。
拉斐尔·拉法伊洛夫, 阿奇特·沙玛, 埃里克·米切尔, 斯蒂芬诺·埃尔蒙, 克里斯托弗·D·曼宁, 和 切尔西·芬恩. 2023. 直接偏好优化:你的语言模型实际上是一个奖励模型。
阿布尔海尔·萨帕罗夫 和 贺何. 2023. 语言模型是贪婪的推理者:链式思维的系统形式分析。
沈鸿钟, 王培怡, 朱其昊, 徐润新, 宋俊潇, 张明川, 李玉坤, 吴轶, 郭大禹. 2024. DeepSeekMath:推动开源语言模型中数学推理的极限。
库马尔·施里达尔, 亚历山德罗·斯托尔福, 和 Mrinmaya Sachan. 2023. 将推理能力蒸馏到更小的语言模型中。
亚历山德罗·斯托尔福, 靳之京, 库马尔·施里达尔, Bernhard Schölkopf, 和 Mrinmaya Sachan. 2023. 使用语言模型进行数学推理的因果框架量化其稳健性。
雨果·图弗龙, 提博·拉维尔, 高帝埃·伊扎卡德, 夏维尔·马尔坦, 玛丽安娜·拉绍, 蒂莫西·拉克罗伊克斯, 巴普蒂斯特·罗济尔, 纳曼·戈亚尔, 埃里克·汉布罗, 法伊萨尔·阿兹哈尔, 奥雷利安·罗德里格斯, 阿曼德·朱利安, 爱德华
格雷夫和纪尧姆·兰普尔。2023年。Llama:开放且高效的基语言模型。
刘易斯·图恩斯特尔,爱德华·比钦,内森·兰伯特,纳兹内恩·拉贾尼,卡什夫·拉苏尔,尤尼斯·贝拉达,盛义黄,勒内德·冯·沃拉,克莱门汀·富里耶,内森·哈比卜,内森·萨拉赞,奥马尔·桑塞维罗,亚历山大·M·拉什和托马斯·沃尔夫。2023年。Zephyr:直接蒸馏Im对齐。
Venktesh V,Sourangshu Bhattacharya和Avishek Anand。2023年。复杂问答中问题分解的上下文能力转移。
薛子王、孙青峰、郑凯、耿溪波、赵浦、周杰、冯嘉展、陶崇阳、姜大昕。2023年。WizardLM:赋予大型语言模型遵循复杂指令的能力。
徐宇东、李文豪、帕修坦·瓦伊兹普尔、斯科特·桑纳和艾利亚斯·B·哈利尔。2024年。LLMs与抽象和推理语料库:成功、失败及基于对象表示的重要性。
顺宇姚、田迪安、赵杰弗里、Izhak Shafran、Thomas L. Griffiths、袁超和Karthik Narasimhan。2023年。思维树:利用大型语言模型进行深思熟虑的问题解决。
张志弘、王书航、余文豪、许亦聪、丹·迭代、曾庆凯、刘洋、朱成光、蒋萌。2023年。Auto-Instruct:黑盒语言模型的自动指令生成和排名。
敖君周、王可、陆自牧、石伟兴、罗思春、秦梓鹏、卢思春、贾雅、宋林奇、战明杰、李洪生。2023a。使用GPT-4代码解释器和基于代码的自我验证解决具有挑战性的数学文字问题。
邓尼·周、纳塔纳尔·沙尔利、侯乐、韦森、内森·斯凯尔斯、王雪芝、戴尔·舒尔曼斯、克莱尔·崔、奥利维尔·布斯凯特、乐谷、埃德·奇。2023b。最少至最多提示使大型语言模型能够进行复杂推理。
安妮·祖、张卓盛、赵海、唐翔如。2023年。Meta-COT:在混合任务场景下使用大型语言模型进行可推广的链式思维提示。
A 附录
n = 200 , GSM8K测试数据拆分,主集。 n=200, \text { GSM8K测试数据拆分,主集。 } n=200, GSM8K测试数据拆分,主集。
| 模型 | 标准提示 | 链式思维提示 | 思维轨迹提示(GPT-4委派) |
|---|---|---|---|
| GPT-4 | 94.5 \mathbf{9 4 . 5} 94.5 | 93.5 | 93.5 |
| GPT-3.5-Turbo | 75.5 | 73.5 | 86 \mathbf{8 6} 86 |
| WizardMath-7B | 69 | 73.5 | 84.5 \mathbf{8 4 . 5} 84.5 |
| Llama 2-7B Chat | 22 | 23.5 | 53 \mathbf{5 3} 53 |
| Zephyr | 26 | 23.5 | 49.5 \mathbf{4 9 . 5} 49.5 |
表5:使用三种提示方法在GSM8K上各种模型准确性的表格结果。
n
=
200
\mathrm{n}=200
n=200,MATH测试数据拆分。
| 模型 | 标准提示 | 链式思维提示 | 思维轨迹提示(GPT-4委派) |
|---|---|---|---|
| GPT-4 | 57.5 | 66 | 70.5 \mathbf{7 0 . 5} 70.5 |
| GPT-3.5-Turbo | 46.5 | 52 | 58.5 \mathbf{5 8 . 5} 58.5 |
| WizardMath-7B | 44.5 \mathbf{4 4 . 5} 44.5 | 33.5 | 40.5 |
| Llama 2-7B Chat | 6.5 | 7.5 | 8.5 \mathbf{8 . 5} 8.5 |
| Zephyr | 7 | 12 | 18 \mathbf{1 8} 18 |
表6:使用三种提示方法在MATH上各种模型准确性的表格结果。
两样本Z检验比例——显著结果加粗,并标明其显著水平。
| 模型 | 思维轨迹 ( x ˉ T o T ) \left(\bar{x}_{T o T}\right) (xˉToT) | 最高性能替代方案 ( x ˉ H P A ) \left(\bar{x}_{H P A}\right) (xˉHPA) | z z z | p p p |
|---|---|---|---|---|
| GPT-4 | 93.5 | 94.5 | -0.4211 | 0.67448 |
| GPT-3.5-Turbo | 86 | 75.5 | 2.6632 | 0.00774 ( p < 0.01 ) \mathbf{0 . 0 0 7 7 4}(p<0.01) 0.00774(p<0.01) |
| WizardMath-7B | 84.5 | 73.5 | 2.7007 | 0.00694 ( p < 0.01 ) \mathbf{0 . 0 0 6 9 4}(p<0.01) 0.00694(p<0.01) |
| Llama 2-7B Chat | 52.5 | 23.5 | 5.9746 | < 0.00001 ( p < 0.01 ) \mathbf{< 0 . 0 0 0 0 1}(p<0.01) <0.00001(p<0.01) |
| Zephyr-7B | 56 | 26 | 6.0996 | < 0.00001 ( p < 0.01 ) \mathbf{< 0 . 0 0 0 0 1}(p<0.01) <0.00001(p<0.01) |
表7:使用两样本Z检验比例在GSM8K数据集上比较思维轨迹性能与最高性能替代方案跨模型的统计对比。
两样本Z检验比例——显著结果加粗,并标明其显著水平。
| 模型 | 思维轨迹 ( x ˉ T o T ) \left(\bar{x}_{T o T}\right) (xˉToT) | 最高性能替代方案 ( x ˉ H P A ) \left(\bar{x}_{H P A}\right) (xˉHPA) | z z z | p p p |
|---|---|---|---|---|
| GPT-4 | 70.5 | 66 | 0.9667 | 0.33204 |
| GPT-3.5-Turbo | 58.5 | 52 | 1.3072 | 0.1902 |
| WizardMath-7B | 40.5 | 44.5 | -0.8092 | 0.41794 |
| Llama 2-7B Chat | 8.5 | 7.5 | 0.3686 | 0.71138 |
| Zephyr-7B | 18 | 12 | 1.6803 | 0.09296 ( p < 0.10 ) \mathbf{0 . 0 9 2 9 6}(p<0.10) 0.09296(p<0.10) |
表8:使用两样本Z检验比例在MATH数据集上比较思维轨迹性能与最高性能替代方案跨模型的统计对比。
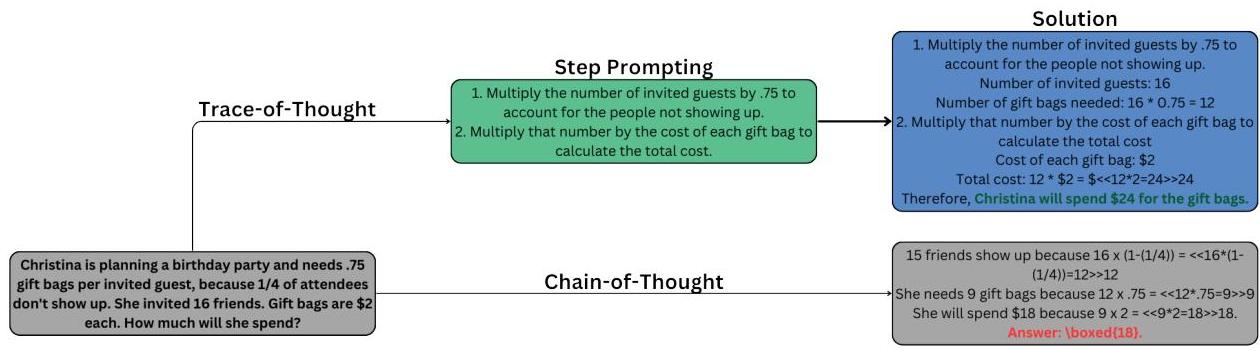
图7:GPT-3.5-Turbo使用链式思维与思维轨迹解决GSM8K问题——思维轨迹提供可观察的推理框架。
参考论文:https://arxiv.org/pdf/2504.20946



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











