






夏元 1 { }^{1} 1 Akanksha Atrey 2 { }^{2} 2 Fadoua Khmaissia 2 { }^{2} 2 Kedar S. Namjoshi 2 { }^{2} 2
摘要
本文研究了大型语言模型(LLMs)的逻辑推理能力。为了选择一个定义明确且易于处理的形式化方法,我们选择了概念上简单但技术上复杂的布尔逻辑证明构造任务。经过训练的LLM接收一组假设和目标作为输入,并生成一个从假设正式推导出目标的证明作为输出。不正确的证明会被自动化的证明检查器捕捉到。训练中的一个关键障碍是真实世界证明的稀缺性。我们提出了一种高效、随机生成有效证明的程序,并引入模板转换,这是一种数据增强技术,可增强模型处理复杂逻辑表达式的能力。核心评估问题是LLM是否确实学会了推理。我们提出了测试黑箱LLM推理能力的方法。通过这些度量标准,实验表明对于短证明的断言具有强大的推理能力,但随着证明复杂性的增加,这种能力会下降。值得注意的是,模板转换即使在较小的模型中也能提高准确性,这表明其在不同规模模型中的有效性。
1. 引言
2024年7月,《纽约时报》发表了一篇恰如其分的文章标题为“人工智能可以写诗,但在数学方面却很挣扎。”(Lohr, 2024)。通用大型语言模型(LLMs)确实擅长处理文本,但在逻辑推理方面可能表现较差,而逻辑推理是数学和计算的核心。这项工作旨在通过实验调查这是否是一个固有的限制。
基于LLM的推理可分为两大类。在像AlphaProof(AlphaProof & teams, 2024)这样的神经符号系统中,LLM指导传统的证明搜索引擎,取代了由人类提供的硬编码启发式或提示。在第二类中,我们的工作属于此类,LLM直接搜索证明。Chain-of-Thought (CoT) (Wei et al., 2022) 就是这样一个系统。
CoT方法产生的思维链用自然语言表达。虽然更容易让人理解,但由于自然语言固有的模糊性,自然语言证明无法被自动精确验证。
为了系统地研究LLM的推理能力,用形式语言表达输入断言和输出证明更为简单和有效。一个“推理”LLM(图1)接收一组假设和目标断言作为输入,两者都用形式逻辑表达。作为输出,LLM展示了一个形式证明,解释目标如何从假设中逻辑得出。也就是说,LLM充当证明生成器。
有充分的理由相信LLM可以充当证明生成器,也有充分的理由相信它们不能。积极的一面是,假设无限精度算术,LLM是图灵完备的(Pérez et al., 2019; Bhattamishra et al., 2020; Pérez et al., 2021; Strobl et al., 2024)。LLM扫描其输入和过去的输出以确定下一个输出符号,使用注意力机制专注于相关部分。这类似于在构建数学证明时,人类选择和组合过去的推论以形成新的结论。少量示例学习表明LLM可以识别模式并遵循一般规则。消极的一面是,图灵完备性依赖于无界整数(用于编码无界的图灵机磁带);但在现实中,机器整数具有有限精度。LLM具有有限的上下文,没有辅助存储器,也没有回溯能力;因此,通俗地说,LLM可能会“忘记”遥远的过去。这对证明构造来说是个问题,因为一个假设可能直到证明的后期阶段才需要。LLM以统计方式运行,因此即使断言有效,也可能产生错误的证明。最后,逻辑推理本质上具有高最坏情况复杂度:即使是布尔逻辑也是co-NP完全的,难度迅速增加(例如,一阶逻辑是RE完全的)。
1
{ }^{1}
1 南加州大学,洛杉矶,加利福尼亚州,美国
2
{ }^{2}
2 诺基亚贝尔实验室,默里山,新泽西州,美国。联系地址:Yuan Xia yuanxia@usc.edu。
为了准确制定和测试推理能力,我们聚焦于布尔逻辑中的推理。我们认为有几个因素使得这是一个好的选择。布尔逻辑是其他逻辑(如一阶逻辑、模态逻辑、时态逻辑等)的基础。因此,如果布尔推理对LLM来说是一个挑战性任务,那么不太可能期望LLM在更复杂的推理上表现更好。布尔逻辑有一个简单的证明系统,使其容易自动验证证明。语义上,布尔推理并不简单,它是co-NP完全的。(布尔可满足性的对偶问题是经典的NP完全问题。)
因此,在某种强意义上,布尔推理可以被视为LLM推理的C.elegans(Brenner, 2002):结构简单,语义非平凡,并展示了整体推理的中心困难。
主要挑战在于(1)缺乏真实世界的训练数据,即有效的证明,以及(2)一种确定黑箱模型是否在推理而非记忆或猜测的方法。我们通过以下两种方式解决这些关键问题:(1)提供一种高效的随机算法,生成大量多样化的逻辑有效证明用于训练和测试;(2)设计有意义的、自动化的黑箱推理能力测试。形式语言的精确性和自动验证候选证明的能力简化了这两项任务,使它们能够全自动、高效且大规模地完成。
我们的实验表明,通过合成证明生成和证明增强的结合,Llama模型可以在布尔逻辑中进行良好的推理训练。仅使用9000个合成生成的证明作为训练数据,我们的微调Llama-8B模型在深度7的证明上达到了98%的准确率,超过了GPT-40的少量示例学习性能(70%准确率),尽管参数数量远少得多。我们的消融研究表明两个关键发现:更大的模型容量能够更好地推广到更深的证明,而证明增强提高了模型处理复杂实例的能力,特别是对较小的Llama-1B模型有益。
在我们看来,这项工作做出了若干贡献。一是认识到在形式逻辑上训练LLM具有独特优势:可以大规模和多样化地生成合成数据用于训练,并可以通过自动生成和运行的大规模自动化测试稳健地评估推理能力。二是选择布尔逻辑来研究推理能力。如果LLM在布尔逻辑上失败,那么它在更复杂的推理上成功的机会不大。三是技术贡献——模板证明变换,该方法生成语法多样的但共享共同结构的证明。在训练过程中,这迫使LLM关注抽象的证明模式而非具体的标记,从而提高其泛化能力。第四个贡献是提出了各种测试方法,可用于确定黑箱LLM是否真正推理而不是猜测或检索答案。
2. 背景
在本节中,我们定义布尔逻辑的语法和语义,介绍希尔伯特证明系统以及正向和反向证明构造机制。
2.1. 布尔逻辑:语法和语义
布尔公式(也称为断言或表达式)是由布尔变量组成,表示原子命题,使用熟悉的组合子,如“与” ( ∧ ) (\wedge) (∧)、“或” ( ∨ ) (\vee) (∨)、“非” ( ¬ ) (\neg) (¬) 和“蕴含” ( → ) (\rightarrow) (→)。布尔域记作 B \mathbb{B} B。
给定一个可数集合 X X X的布尔变量(也称为命题),一个在 X X X上的布尔公式由最小语法 f : = p ∈ X ∣ ¬ f ∣ f ∧ f f:=p \in X \mid \neg f \mid f \wedge f f:=p∈X∣¬f∣f∧f形成。析取由 f ∨ g = ¬ ( ( ¬ f ) ∧ ( ¬ g ) ) f \vee g=\neg((\neg f) \wedge(\neg g)) f∨g=¬((¬f)∧(¬g))定义,蕴含由 f → g = ( ¬ f ) ∨ g f \rightarrow g=(\neg f) \vee g f→g=(¬f)∨g定义。
赋值是从 X X X到 B \mathbb{B} B的函数;即它为每个变量提供一个布尔值。一个公式的满足关系 ⊨ \models ⊨由递归定义如下: π ⊨ p \pi \models p π⊨p当且仅当 π ( p ) \pi(p) π(p)为真; π ⊨ ¬ f \pi \models \neg f π⊨¬f当且仅当 π ⊭ f \pi \not\models f π⊨f; π ⊨ f ∧ g \pi \models f \wedge g π⊨f∧g当且仅当 π ⊨ f \pi \models f π⊨f且 π ⊨ g \pi \models g π⊨g。
对于一个布尔公式,可满足性问题是是否存在一个赋值满足该公式。这是经典的NP完全问题。对偶的有效性问题是所有赋值是否都满足该公式。这是典型的co-NP完全问题。
2.2. 希尔伯特证明
一个布尔推理问题的实例由一组(可能是空的)假设公式和一个目标公式给出。推理问题是确定目标是否从假设中推出。证明是对“是”答案的逐步解释。
布尔逻辑有几种证明系统。在这项工作中,我们使用众所周知的希尔伯特风格证明系统(Mendelson, 2024)。为简单起见,我们只关注命题逻辑的一个子逻辑,其中只有蕴含作为唯一的连接词。 1 { }^{1} 1 这个子逻辑的希尔伯特风格证明系统包括两个公理和一个推理规则,称为分离规则(MP)。
公理模式如下:
A
1
:
:
(
A
→
(
B
→
A
)
)
A 1::(A \rightarrow(B \rightarrow A))
A1::(A→(B→A))
A
2
:
:
(
A
→
(
B
→
C
)
)
→
(
(
A
→
B
)
→
(
A
→
C
)
)
A 2::(A \rightarrow(B \rightarrow C)) \rightarrow((A \rightarrow B) \rightarrow(A \rightarrow C))
A2::(A→(B→C))→((A→B)→(A→C))
1
{ }^{1}
1 在这个子逻辑中,每个公式都是可满足的,但有效性(即推理)仍然是co-NP难的(附录A.1)。
通俗地说,第一个公理表示如果
A
A
A和
B
B
B都成立,则
A
A
A成立。第二个公理表示如果
A
A
A和
B
B
B一起蕴含
C
C
C,则知道
A
A
A蕴含
B
B
B就足以得出
A
A
A也蕴含
C
C
C。
通过提供一个替换来获得公理模式的实例,该替换指定占位符 A , B , C A, B, C A,B,C的公式。MP推理规则根据假设“A蕴含B”和“A”来推导出“B”。
形式上,证明是一系列步骤,每一步包含一个声称的公式及其理由。证明第 k k k步的理由可以有三种类型:(1)将第 k k k个公式与假设匹配;(2)将第 k k k个公式与一个替换 σ \sigma σ的公理实例匹配,该替换正确当且仅当第 k k k个公式是应用 σ \sigma σ到命名公理的结果;或(3)应用于证明步骤 m , n m, n m,n的MP,该推理正确当且仅当,将第 k k k个公式记为 g g g,对于某个公式 f f f,第 m m m个公式是 ( f → g ) (f \rightarrow g) (f→g),且第 n n n个公式是 f f f。 m , n m, n m,n必须严格小于 k k k以避免循环推理。
如果证明中的每个理由都正确并且目标公式在某个证明步骤中被声称,则证明是有效的。希尔伯特系统是可靠的:即,给定一个有效的证明,目标对于满足假设的每个赋值都成立。
2.2.1. 证明示例 [传递性]
给定假设 p → q p \rightarrow q p→q和 q → r q \rightarrow r q→r,目标 p → r p \rightarrow r p→r是否成立?这只是传递性,这是真实的,可以通过以下希尔伯特证明建立:
- ( q → r ) → ( p → ( q → r ) ) (q \rightarrow r) \rightarrow(p \rightarrow(q \rightarrow r)) (q→r)→(p→(q→r)),由公理A1替换 A = q → r , B = p A=q \rightarrow r, B=p A=q→r,B=p。
-
- q → r q \rightarrow r q→r,由假设2。
-
- p → ( q → r ) p \rightarrow(q \rightarrow r) p→(q→r),由步骤1,2的MP。
-
- ( p → ( q → r ) ) → ( ( p → q ) → ( p → r ) ) (p \rightarrow(q \rightarrow r)) \rightarrow((p \rightarrow q) \rightarrow(p \rightarrow r)) (p→(q→r))→((p→q)→(p→r)),由公理A2替换 A = p , B = q , C = r A=p, B=q, C=r A=p,B=q,C=r。
-
- ( p → q ) → ( p → r ) (p \rightarrow q) \rightarrow(p \rightarrow r) (p→q)→(p→r),由步骤4,3的MP。
-
- p → q p \rightarrow q p→q,由假设1。
-
-
p
→
r
p \rightarrow r
p→r,由步骤5,6的MP。
希尔伯特风格证明系统中的证明因其难以被人理解而享有盛誉。然而,我们选择了这个系统,因为它有一套最少的规则,我们认为这将更容易让LLM学习。其他标准证明系统,如自然演绎,产生的证明更容易理解(Pelletier & Hazen, 2024),但有多个推理规则。
-
p
→
r
p \rightarrow r
p→r,由步骤5,6的MP。
2.2.2. 证明构造
有两种主要的证明构造机制。
正向证明构造维护一组已推导的公式;最初,该集包含所提供的假设。在每一步中,添加一个公式到此集中,要么通过实例化一个公理,要么通过将MP应用于已经在此集中的公式。如果最终将目标公式添加到集中,则推理完成。
反向或目标导向的证明构造维护一棵证明树。树的一些叶节点代表“开放”的公式;最初,树是一个单一的开放节点,标记为目标。在反向步骤中,通过以下三种方式之一“关闭”标记有公式 g g g的开放叶节点 n n n:通过识别 g g g为假设,或通过识别 g g g为公理实例,或通过引入公式 f f f并断言 g g g由 f f f和 ( f → g ) (f \rightarrow g) (f→g)通过MP得出 - 这些公式标记新开放叶节点,作为 n n n的孩子节点添加。当所有叶子都被关闭时,推理完成。
3. 训练LLM进行推理
训练LLM进行形式化推理的一个核心挑战是数据短缺。证明可以在教科书中找到,或者在自动定理证明器的证明库中找到。很难组装格式统一的证明,并且训练所需的数量和多样性也不足。
我们描述了一种简单而高效的随机反向证明生成过程,该过程合成了任意大小和深度的有效证明。我们进一步增强了随机生成证明的集合,以创建每个原始证明的结构相似变体组。
增强在训练中有用,以确保LLM更注重底层逻辑推理而非证明的句法 - 本质上,我们希望LLM学习证明模式而非记住特定证明。增强也用于测试训练后的LLM是否学会了推理。
3.1. 证明生成
证明生成过程本质上是目标导向证明构造过程的随机形式。不是为固定的假设下的固定目标推导证明,随机生成从随机选择的目标公式开始,并继续构造一个有效的随机证明树。
- 树的根节点标记为目标公式,比如 g g g,这是随机选择的。
-
- 在标记有公式 h h h的叶节点处,过程随机决定执行以下操作之一。
-
- 在此节点停止扩展。开放公式 h h h变为用于证明 g g g的假设。
-
- 随机选择一个公式 f f f并通过MP证明扩展到两个新的子目标节点,标记为公式 f f f和 f → h f \rightarrow h f→h。
-
- 如果 h h h是一个公理实例,则用公理证明关闭此节点。
- 过程继续直到证明树达到指定的大小或深度限制。
以这种方式生成的证明树通过将所有停止的开放节点(情况2)中的公式视为证明目标 g g g所需的假设,转化为一个有效的证明。通过以任何顺序遍历树从叶节点到根节点(每个节点的子节点在节点本身之前遍历),可以获得线性的希尔伯特证明结构。
目标导向的证明生成对于希尔伯特风格系统来说效率很高,因为生成过程可以在局部为每个开放公式确定适当的解决方案,例如通过随机化MP的应用,时间不依赖于当前证明树的大小。相比之下,正向生成过程必须在每一步搜索已经推导出的符合 f → g f \rightarrow g f→g和 f f f形状的公式以应用MP规则。一个朴素的算法需要二次时间在已推导的公式数量中,这可以通过哈希减少到接近线性时间。因此,目标导向的证明生成具有显著的效率优势,这一优势延伸到其他系统的证明生成,如自然演绎。
3.2. 通过模板变换进行证明增强
随机证明生成算法生成有效证明,但不能保证生成许多具有相同或类似证明结构的例子。这促使我们开发了一种基于模板变换的新概念的数据增强技术。
这种技术基于一个关键观察:希尔伯特形式的证明也可以被视为一个证明模式。也就是说,一组变量 X X X上的证明可以被视为一个模板:均匀应用一个将 X X X中的每个变量映射到一组(可能是不同的)变量 Y Y Y上的布尔公式的替换,生成另一个有效证明。
例如,第2节中的推理例子定义在变量 p , q , r p, q, r p,q,r上。如果我们均匀地将 q q q替换为 y 1 y_{1} y1,将 p p p替换为 y 1 → y 2 y_{1} \rightarrow y_{2} y1→y2,将 r r r替换为 y 2 → y 1 y_{2} \rightarrow y_{1} y2→y1。这种替换生成了一个有效证明,表明新的目标 ( y 1 → y 2 ) → ( y 2 → y 1 ) \left(y_{1} \rightarrow y_{2}\right) \rightarrow\left(y_{2} \rightarrow y_{1}\right) (y1→y2)→(y2→y1)(从原始目标 p → r p \rightarrow r p→r变换而来)通过传递性从变换后的假设 ( y 1 → y 2 ) → y 1 \left(y_{1} \rightarrow y_{2}\right) \rightarrow y_{1} (y1→y2)→y1和 y 1 → ( y 2 → y 1 ) y_{1} \rightarrow\left(y_{2} \rightarrow y_{1}\right) y1→(y2→y1)推导出来。
一般来说,要变换一个定义在变量集合 X X X上的有效推理实例,我们(1)随机选择一个替换 σ \sigma σ,将 X X X中的每个变量映射到一组随机选择的变量 Y Y Y(不一定与 X X X不同)上的随机布尔表达式,(2)系统地将每个出现在证明中的公式 f f f替换为通过将替换 σ \sigma σ应用于 f f f得到的公式 σ ( f ) \sigma(f) σ(f),(3)系统地将替换 σ \sigma σ应用于假设和目标公式。
很容易通过归纳证明长度来显示变换后的推理实例也是有效的。这种变换不会改变证明结构和推理步骤序列:只有公式按照随机选择的替换进行了更改。因此,这种变换可以反复应用,生成许多共享共同证明结构的原始证明的变体。这种构造用于训练LLM模型,并(如第4节所述)用于测试训练后的LLM模型的推理能力。
直观上,在训练期间,通过模板变换提供类似的实例迫使LLM关注抽象的证明结构而非具体细节,如变量名称。这在计算机视觉中使用批变换的精神上类似,其中一张图片(比如猫的照片)会经历空间变换,如旋转、反射和翻译,这样训练模型就会关注猫的内在属性,忽略其在空间中的方向。
4. 评估框架
在本节中,我们提出评估指标来评估LLM的推理能力,并展示我们训练和评估方法的有效性。
现有的LLM评估指标侧重于模型输出的不同方面,如质量、相关性、事实正确性、偏差和毒性,但没有标准化的方法来评估推理能力。拥有系统和全面的方法是必要的,以避免依赖轶事数据和记忆,同时准确测量推理能力的进步。
我们提出了一种包含四个明确定义和可测量指标的评估过程。这些指标评估模型在不同程度复杂性下对新、未见过的问题应用逻辑推理的能力。
4.1. 优先考虑语义而非句法
LLM应表现出超出其训练数据中特定实例的能力。例如,如果LLM能为定义在变量 p , q p, q p,q上的推理问题生成证明,那么它也应该能够为模板变换后的问题生成证明,其中 p , q p, q p,q分别被任意公式 f , g f, g f,g一致替换。这表明LLM识别并抽象出了问题的底层逻辑,忽略了诸如变量名称或结构差异之类的表面句法差异。
4.2. 推广到更深的证明
推理LLM应发现比其训练集中更长的证明。这表明LLM不仅仅是在记忆某些复杂程度之内的证明,而是展现出更深的逻辑推理能力。评估此指标涉及测量模型随推理深度增加的准确性,突出其导航和解决更复杂证明结构的能力。
4.3. 处理更广泛的表达式
LLM应证明包含比其训练数据集中更多变量的陈述。例如,如果训练仅涉及变量 X 1 X_{1} X1和 X 2 X_{2} X2,模型应被测试涉及扩展集的性质,如 X 1 , … , X n X_{1}, \ldots, X_{n} X1,…,Xn。成功表明模型不仅记忆了涉及两个变量的证明,而且可以将其推理扩展到更复杂的情景。测试包括测量随涉及变量数量增加的准确性。
4.4. 展现证明的多样性
一个逻辑陈述可以有多种有效的证明。我们通过评估LLM生成一系列有效证明的能力来评估多样性,只要适用。这可以表明模型正在进行创造性且独立的推理,而不是依赖于死记硬背数据集。为了支持这一指标,我们使用符号证明检查器来语义评估证明的有效性,而不是依赖于句法令牌级相等。
5. 实验分析
5.1. 实验设置
训练 我们在合成生成的希尔伯特证明上微调了两个Llama3模型(8B和1B参数)(Dubey等人,2024)。我们使用4位量化来优化内存使用。微调过程采用低秩适应(LoRA)(Hu等人,2021)来高效更新模型参数而不修改整个网络。使用与地面实况证明的确切匹配准确度来监控训练收敛。我们还使用早期停止(耐心期=5轮)来防止过拟合。
对于所有实验,训练数据包含深度为7、10和13的平衡证明。在训练过程中,以概率 α T T = 0.7 \alpha_{TT}=0.7 αTT=0.7应用模板变换进行批次预处理。每个问题中的变量被替换为最多包含4个变量且最大递归深度为4的随机生成表达式。模型被训练生成完整的证明,给定目标和一组假设,如图1所示。
评估 我们为训练和评估生成单独的证明树以防止数据泄露。为了获取评估数据集,我们构建了几棵不同的证明树,并确保所有公式 f f f在训练数据集中唯一且无重复(第3.2节)。从这些树中,我们提取验证集和测试集。验证集包含来自分布内深度(7、10和13;每种深度125个样本)的375个样本。
为了分析泛化能力,我们在九种深度(4-28;每种深度50个样本)和四种宽度(每种宽度100个样本)上使用450个测试样本和400个样本。我们确保所有分区中的公式唯一。虽然使用合成数据似乎有限制,但它允许系统评估模型在不同证明复杂度下的性能和控制测试泛化能力,尤其是在缺乏大规模现实世界希尔伯特证明数据集的情况下。
为了评估我们的模型,我们报告测试准确度,定义为正确生成证明的数量与总测试问题数量的比例。只有通过我们正式验证器的证明才被认为正确,该验证器仅接受语法良好形成的证明,并且每一步都通过严格的检查:(i)正确应用分离规则,(ii)正确使用假设,(iii)正确调用公理。
实验设计 我们的实验分析分为两部分:
表1. 分布内测试数据的证明生成准确度:微调Llama模型(训练于9000个样本)、GPT-4o少量学习(跨1、3、6、9-shot学习设置平均)和预训练基线模型的比较。测试在匹配训练分布的证明深度(d)上进行。w/ TT 和 w/o TT 分别表示微调时使用和不使用模板变换的模型。
| 按证明深度的准确度 | |||
|---|---|---|---|
| 模型 | d = 7 d=7 d=7 | d = 10 d=10 d=10 | d = 13 d=13 d=13 |
| 现有最佳性能 | |||
| GPT-4o (X-shot) | 0.67 ± 0.08 0.67 \pm 0.08 0.67±0.08 | 0.48 ± 0.08 0.48 \pm 0.08 0.48±0.08 | 0.26 ± 0.04 0.26 \pm 0.04 0.26±0.04 |
| 预训练基线模型 | |||
| Llama-3.2-8B (X-shot) | ≈ 0.00 \approx 0.00 ≈0.00 | ≈ 0.00 \approx 0.00 ≈0.00 | ≈ 0.00 \approx 0.00 ≈0.00 |
| Llama-3.1-1B (X-shot) | ≈ 0.00 \approx 0.00 ≈0.00 | ≈ 0.00 \approx 0.00 ≈0.00 | ≈ 0.00 \approx 0.00 ≈0.00 |
| 我们的方法 - 小模型 (Llama-3.1-1B) | |||
| 微调无TT | 0.52 | 0.30 | 0.02 |
| 微调有TT | 0.54 | 0.30 | 0.04 |
| 我们的方法 - 大模型 (Llama-3.2-8B) | |||
| 微调无TT | 0.78 | 0.40 | 0.28 |
| 微调有TT | 0.98 \mathbf{0 . 9 8} 0.98 | 0.66 \mathbf{0 . 6 6} 0.66 | 0.32 \mathbf{0 . 3 2} 0.32 |
首先,我们通过比较微调模型与GPT-4o(OpenAI,2024)和预训练Llama3模型在分布内证明深度上的表现来建立基线性能。然后,通过消融研究,我们考察模型在不同证明深度和宽度上的泛化能力,并分析训练数据量和模板变换的影响。
关键发现 我们的实验揭示了微调Llama3模型(8B和1B)在使用我们提出的合成数据和证明增强进行希尔伯特证明生成的有效性。8B模型在深度7证明上实现了 98 % 98 \% 98%的准确度,超越了GPT-4o的少量学习表现( 67 % ± 8 67 \% \pm 8 67%±8 平均跨1、3、6、9-shot设置),尽管参数数量远少。我们的消融研究表明,模型容量(8B vs 1B)使模型能够泛化到更深的证明,而通过模板变换进行证明增强则提升了处理复杂、分布外表达式的能力。性能随训练数据量增加而提升,尽管自然地随着证明复杂度增加而下降。
5.2. 基线评估
我们将我们的方法与GPT-4o(100B+ 参数)进行比较,并与我们的基础模型进行对比:Llama-3.2(8B)和Llama-3.1(1B)。如表1所示,测试在匹配训练分布的证明深度 { 7 , 10 , 13 } \{7,10,13\} {7,10,13}上进行。对于GPT-4o和预训练基础模型,我们评估了 { 1 , 3 , 6 , 9 } \{1,3,6,9\} {1,3,6,9}演示的少量学习:1-shot使用一个深度7的证明,3-shot使用每个训练深度 7 , 10 , 13 } 7,10,13\} 7,10,13}的一个证明,6-shot使用每个深度的两个证明,9-shot使用每个深度的三个证明。我们在附录A.2中提供了一些例子。我们使用相同的例子进行所有x-shot评估以保持评估公平性。报告的少量学习结果代表这些设置的平均值。
GPT-4o在深度7证明上的平均准确度为 0.67 ± 0.08 0.67 \pm 0.08 0.67±0.08,在深度10和13上的表现分别为 0.48 ± 0.08 0.48 \pm 0.08 0.48±0.08和 0.26 ± 0.04 0.26 \pm 0.04 0.26±0.04。预训练的Llama3基础模型在直接测试我们的任务时未能生成有效证明( ≈ 0.00 \approx 0.00 ≈0.00 准确度),可能是因为它们相比GPT-4o( > 100 B >100 \mathrm{~B} >100 B 参数)模型尺寸较小,并且从少量例子中推断希尔伯特证明严格句法规则的挑战较大。
我们的微调模型相对于GPT-4o和它们的预训练版本显示出显著改进。带有模板变换的大模型(8B)在深度7证明上的准确度达到0.98,尽管参数较少,仍然显著优于GPT-4o。这种性能优势在更深的证明深度上持续存在,深度10和13的准确度分别为0.66和0.32。模板变换对大模型特别有效,主要在较短深度上改善准确度约20-25%。
小模型(1B)显示出更适度的改进,在深度7上达到0.52的准确度,模板变换的影响有限。我们8B和1B模型之间的性能差距表明,逻辑推理能力随着模型尺寸的增加而扩展,即使在相对较窄的1B-8B参数范围内也是如此。
5.3. 消融研究
我们进行消融研究,系统分析不同因素如何影响我们微调的LLM性能,并理解我们提出方法的局限性。
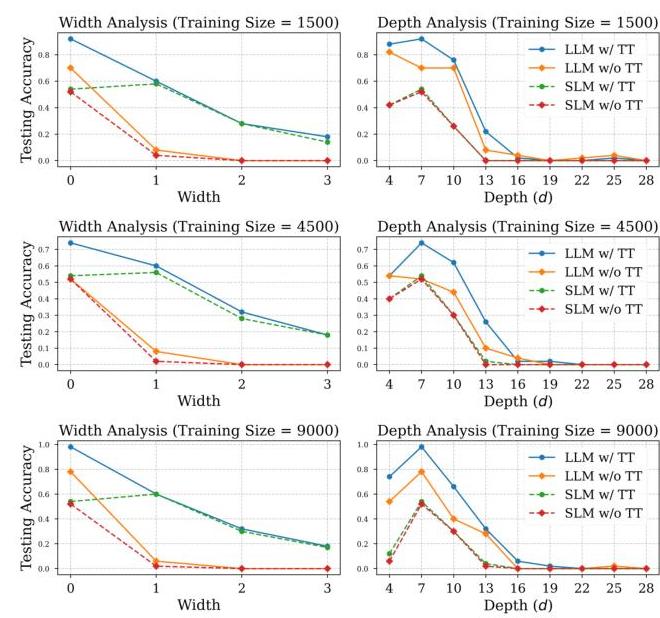
图2. Llama3-8B (LLM) 和 Llama3-1B (SLM) 模型变体在不同训练数据量下的测试准确度比较。左:证明宽度对准确度的影响。右:证明深度对准确度的影响。有和没有模板变换 (TT) 的模型进行了比较。
5.3.1. 证明深度的影响
为了评估推理深度的泛化能力,我们使用固定宽度表达式测试模型在九种证明深度(4-28步,每种深度50个样本)上的表现。测试集中的每个证明通过系统地缩减更深的证明生成:识别第一个分离规则应用(即最接近叶节点的那个)并将其替换为推导出的陈述,该陈述被视为新的假设,以减少一步深度。
如图2所示,随着证明复杂度增加,性能下降,但更大模型表现出更好的韧性。8B模型在深度13上仍保持合理准确度,而1B模型在深度10之后性能急剧下降。
5.3.2. 证明宽度的影响
我们使用四种表达式复杂度水平(每种宽度100个样本)分析宽度泛化。每种水平代表逐渐嵌套的变量替换,同时保持证明深度 ( d = 7 ) (d=7) (d=7)。宽度-0证明使用简单变量(如 P ⇒ Q P \Rightarrow Q P⇒Q),而更高宽度引入嵌套蕴涵(如 ( P ⇒ Q ) ⇒ R (P \Rightarrow Q) \Rightarrow R (P⇒Q)⇒R 对于宽度-1)。
图2结果显示,模板变换显著改善了8B和1B模型处理复杂表达式的能力。值得注意的是,模板变换对宽度泛化的影响比其对深度处理的影响更显著,表明其在管理表达式复杂度方面的特殊效用。
5.3.3. 模型尺寸和训练数据的影响
我们将Llama-8B和Llama-1B分别记为LLM和SLM,反映它们相对的模型容量。我们使用合成训练集的三种尺寸:1500、4500和9000个样本,各训练三个实例。每个集在证明深度7、10和13上均衡。
图2总结了所得结果。虽然LLM通常优于SLM,特别是在更深的证明上,但我们观察到一个有趣的模式与证明宽度有关:当使用模板变换时,SLM在更宽表达式(宽度 ≥ 2 \geq 2 ≥2)上的表现与LLM相当,表明我们的数据增强技术有效地补偿了小模型在处理复杂表达式时的容量不足。然而,LLM总体上表现出更好的数据效率,在更小的训练集上实现更强的表现,特别是在深度泛化方面。
5.3.4. 模板变换的影响
我们分析了训练过程中应用模板变换的概率
(
α
T
T
)
\left(\alpha_{TT}\right)
(αTT)对模型推理能力的影响。我们从0到0.9变化
α
T
T
\alpha_{TT}
αTT,并报告模型在不同证明复杂度下的表现,如图3所示。
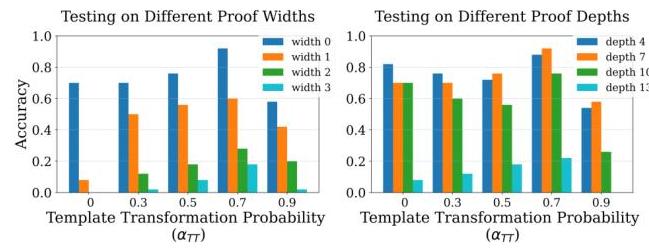
图3. 模板变换概率 ( α T T ) \left(\alpha_{TT}\right) (αTT)对模型表现的影响。左子图显示不同模型宽度(0-3)下的测试准确度,右子图显示不同深度(4-13)下的效果。
结果揭示了证明宽度的一致模式:随着 α T T \alpha_{TT} αTT增加至0.7,性能提高,超过此值后准确度急剧下降。这种趋势在宽度-1和宽度-2证明中尤为明显,表明存在一个最优的变换率以增强对复杂表达式的泛化能力。对于证明深度,影响有所不同:虽然深度证明(深度13)对 α T T \alpha_{TT} αTT敏感,浅层证明在不同变换率下表现出更稳定的性能。这种差异可能归因于训练过程中较长证明中暴露的较短证明模式。设定 α T T = 0.7 \alpha_{TT}=0.7 αTT=0.7提供了最佳平衡,最大化模型处理复杂表达式和更深证明的能力。
6. 相关工作
基于LLM的证明生成方法可分为两大类。在像AlphaProof(AlphaProof & teams, 2024)、AlphaGeometry(Trinh等人, 2024)、Leandojo(Yang等人, 2024)和GPT-f(Polu & Sutskever, 2020)这样的神经符号系统中,LLM组件生成引导传统编程符号证明搜索引擎的提示(如“使用这个定理”,“拆分为这些情况”)。LLM生成的提示替代了硬编码的启发式或由人类提供的提示。
在第二类(包括本工作)中,LLM独自完成了所有必要的逻辑推理。这类系统包括Chain-of-Thought (CoT) (Wei等人, 2022) 和 Tree-of-Thought (ToT) (Yao等人, 2023)。CoT通过少量学习进行训练,这是一种类比学习;模型响应的质量高度依赖于提供的示例质量。ToT专为某些预定义场景设计,限制了其适用性。值得注意的是,这两种方法都没有可靠的机制区分正确和错误的响应,因为解释是以自然语言而非形式语言表达的。这促使我们使用形式逻辑。
最近关于LLM推理的工作(Morishita等人, 2023; 2024)也基于布尔逻辑,但只是作为一个中间步骤:LLM在从合成布尔逻辑证明翻译成自然语言的训练数据上进行训练。(有趣的是,他们的结果表明训练基于形式证明可以提升一般推理能力。)证明合成使用随机化,正如我们所做的那样,但论文没有指出目标导向合成的关键效率优势。我们没有类似模板变换的东西,我们的实验表明这大大提升了推理能力。
几位研究人员开发了专门的基准和数据集,以评估LLM在不同领域和任务类型中的推理能力(Saparov等人, 2023; Teng等人, 2023; Parmar等人, 2024)。突出的例子包括LogicBench(Parmar等人, 2024),涵盖了25种不同的推理模式,以及GLoRE(Teng等人, 2023),包含了跨越三种任务类型的12个数据集。这些基准提供了一个框架,用于评估LLM在各种逻辑推理任务中的表现。其他研究专注于逻辑推理的具体方面,如命题逻辑和谓词逻辑,以及范畴三段论,提供了
深入洞察LLM在特定类型逻辑问题上的表现(Wan等人,2024;Zong & Lin,2024)。
一些这些评估方法受到基准集中示例数量的限制。此外,用自然语言表达的证明引入了其他困难;例如,验证证明变得困难,并且确定LLM是否真正学到了演绎规则还是仅仅记住了它们变得复杂。我们相信,对推理能力的稳健评估需要生成合成形式查询并在大规模上进行自动验证。
7. 讨论与结论
我们相信我们的结果表明,LLM可以通过教学发展出可推广的形式推理能力,直至某些限制。我们的实验(第4节)表明,使用小规模合成证明数据集进行微调可以提升推理能力,超越显著较大的模型(如GPT-4o)通过少量学习所能达到的性能。正如直觉所料,模板变换显著提高了推理准确性。
在深度指标上的准确性急剧下降并不一定意味着无法推理。事实上,鉴于布尔推理问题的co-NP硬度,任何推理方法都应该预期会出现这种下降。这些结果支持了目前的技术在处理分布外深度实例时难以维持推理性能的观察(参见(Anil等人,2022))。
虽然提出的数据生成和评估方法展示了潜力,但在开发能够准确进行通用推理的模型方面仍存在重大挑战。需要克服的主要障碍是现实世界问题与专用LLM之间的差距。日常人类推理涵盖了多个多样化的形式框架,包括“forall”和“exists”之类的一阶量化,“昨天”、“明天”、“最终”和“先前”之类的时序概念,以及“可能”和“必然”之类的模态概念。通用推理还依赖于所谓的关于我们世界的常识事实(例如,从高处掉落的球会反弹回来)。允许LLM获取、整合并推理这些知识的方法目前有限(cyc;nvi)。
这些发现突显了进一步研究的必要性。本文介绍的布尔推理LLM并非旨在解决一般的推理问题。相反,应该将其视为一个方便、精确且完全可自动化的环境,用于试验推理任务的方法。
影响声明
本文呈现的工作旨在推动机器学习领域的发展。我们的工作有许多潜在的社会影响,但我们认为无需在此特别强调任何一项。
参考文献
CYC: 下一代企业AI。https:// cyc.com/. Accessed: 2025-01-23.
cosmos. https://www.nvidia.com/en-us/ai/cosmos/. Accessed: 2025-01-23.
AlphaProof 和团队, A. 人工智能在国际数学奥林匹克竞赛中达到银牌水平。https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/, July 2024.
Anil, C., Wu, Y., Andreassen, A., Lewkowycz, A., Misra, V., Ramasesh, V., Slone, A., Gur-Ari, G., Dyer, E., 和 Neyshabur, B. 探索大型语言模型中的长度泛化能力。Advances in Neural Information Processing Systems, 35:38546-38556, 2022.
Bhattamishra, S., Patel, A., 和 Goyal, N. 关于变压器的计算能力及其在序列建模中的影响。Fernández, R. 和 Linzen, T. (eds.), Proceedings of the 24th Conference on Computational Natural Language Learning, CoNLL 2020, Online, November 19-20, 2020, pp. 455-475. Association for Computational Linguistics, 2020. doi: 10.18653/V1/2020.CONLL-1.37. URL https://doi.org/10. 18653/v1/2020.conll-1.37.
Brenner, S. 自然对科学的馈赠。诺贝尔奖演讲,December 2002. https://www.nobelprize.org/uploads/2018/06/brenner-lecture.pdf.
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., 等. Llama 3 模型群。arXiv preprint arXiv:2407.21783, 2024.
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., 和 Chen, W. LoRA: 大型语言模型的低秩适应。arXiv preprint arXiv:2106.09685, 2021.
Lohr, S. 人工智能可以写诗,但在数学方面却很挣扎。纽约时报, July 2024. https://www.nytimes.com/2024/07/23/technology/ai-chatbots-chatgpt-math.html.
Mendelson, E. 数学逻辑导论,第六版。Chapman and Hall, 2024.
Morishita, T., Morio, G., Yamaguchi, A., 和 Sogawa, Y. 学习从基于形式逻辑的合成语料库中演绎推理。In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., 和 Scarlett, J. (eds.), 国际机器学习会议,ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pp. 2525425274. PMLR, 2023. URL https://proceedings.mlr.press/v202/morishita23a.html.
Morishita, T., Morio, G., Yamaguchi, A., 和 Sogawa, Y. 通过原则性的合成逻辑语料库增强LLM的推理能力。In NeurIPS 2024, 2024. URL https://neurips.cc/virtual/2024/poster/93733.
OpenAI. GPT-4 技术报告, 2024. URL https://openai.com/index/hello-gpt-40/. Accessed: 2025-01-30.
Parmar, M., Patel, N., Varshney, N., Nakamura, M., Luo, M., Mashetty, S., Mitra, A., 和 Baral, C. Logicbench:系统评估大型语言模型逻辑推理能力的进展。In 第62届计算语言学年会论文集,2024.
Pelletier, F. J. 和 Hazen, A. 自然演绎系统在逻辑中的应用。In Zalta, E. N. 和 Nodelman, U. (eds.), 斯坦福哲学百科全书。Metaphysics Research Lab, Stanford University, Spring 2024 edition, 2024.
Pérez, J., Marinkovic, J., 和 Barceló, P. 关于现代神经网络架构的图灵完备性。CoRR, abs/1901.03429, 2019. URL http://arxiv.org/abs/1901.03429.
Pérez, J., Barceló, P., 和 Marinkovic, J. 注意力是图灵完备的。J. Mach. Learn. Res., 22:75:1-75:35, 2021. URL https://jmlr.org/papers/v22/20-302.html.
Polu, S. 和 Sutskever, I. 面向自动定理证明的生成语言建模。CoRR, abs/2009.03393, 2020. URL https://arxiv.org/abs/2009.03393.
Saparov, A., Pang, R. Y., Padmakumar, V., Joshi, N., Kazemi, M., Kim, N., 和 He, H. 使用OOD示例测试大型语言模型的一般演绎推理能力。Advances in Neural Information Processing Systems, 36:3083-3105, 2023.
Stobl, L., Merrill, W., Weiss, G., Chiang, D., 和 Angluin, D. 变压器能表达哪些形式语言?一个调查。Trans. Assoc. Comput. Linguistics, 12:543-561, 2024. doi: 10.1162/TACL . A.00663. URL https://doi.org/10.1162/tacl_a_00663.
Teng, Z., Ning, R., Liu, J., Zhou, Q., Zhang, Y., et al. GLoRE: 评估大型语言模型的逻辑推理能力。arXiv预印本arXiv:2310.09107, 2023.
Trinh, T. H., Wu, Y., Le, Q. V., He, H., 和 Luong, T. 不借助人类演示解决奥林匹克几何问题。Nat., 625(7995):476-482, 2024. doi: 10.1038/S41586-023-06747-5. URL https://doi.org/10.1038/s41586-023-06747-5.
Wan, Y., Wang, W., Yang, Y., Yuan, Y., Huang, J.-t., He, P., Jiao, W., 和 Lyu, M. LogicAsker: 评估和改进大型语言模型的逻辑推理能力。In 2024年经验方法自然语言处理会议论文集,pp. 2124-2155, 2024.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E. H., Le, Q. V., 和 Zhou, D. 链式思维提示激发大型语言模型中的推理能力。In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., 和 Oh, A. (eds.), Advances in Neural Information Processing Systems 35: 年度神经信息处理系统会议论文集,NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022.
Yang, K., Swope, A., Gu, A., Chalamala, R., Song, P., Yu, S., Godil, S., Prenger, R. J., 和 Anandkumar, A. Leandojo: 使用检索增强的语言模型进行定理证明。Advances in Neural Information Processing Systems, 36, 2024.
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y., 和 Narasimhan, K. 思维树:使用大型语言模型进行深思熟虑的问题解决。In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., 和 Levine, S. (eds.), Advances in Neural Information Processing Systems 36: 年度神经信息处理系统会议论文集,NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023.
Zong, S. 和 Lin, J. 范畴三段论再探:回顾LLM分析范畴三段论的逻辑推理能力。arXiv预印本arXiv:2406.18762, 2024.
A. 附录
A.1. 仅蕴含子逻辑
考虑命题逻辑的一个“仅蕴含”子逻辑,由以下语法定义:
f : = p ∈ X ∣ f → f f:=p \in X \mid f \rightarrow f f:=p∈X∣f→f
注意可以用
(
p
→
p
)
(p \rightarrow p)
(p→p)表示“真”,但似乎很难表示“假”。这并不令人惊讶,当我们意识到以下内容时:
定理 A.1. 每个仅蕴含子逻辑的公式都是可满足的。
证明。证明通过结构归纳法。基本情况由单个命题组成,例如 p p p,它是可满足的。考虑形状为 f → g f \rightarrow g f→g的公式。根据归纳假设,公式 g g g是可满足的;即,存在赋值 π \pi π使得 π ⊨ g \pi \models g π⊨g。因此, π ⊨ f → g \pi \models f \rightarrow g π⊨f→g。
尽管可满足性问题是平凡的(因为每个公式都是可满足的),有效性仍然是co-NP完全的。这些陈述并不矛盾,因为该子逻辑不封闭在否定下。
定理 A.2. 仅蕴含子逻辑的推理问题是co-NP完全的。
证明。在推理问题中,给定一组假设和目标。推理正确当且仅当对于满足所有假设的每个赋值,此赋值也满足目标。因此,补语言的每个元素由一组假设和目标组成,其中存在一个赋值满足所有假设但不满足目标。
仅蕴含子逻辑中的目标公式要么是一个命题 p p p,要么具有结构 f → g f \rightarrow g f→g。赋值 π \pi π不满足 f → g f \rightarrow g f→g当且仅当 π \pi π满足 f f f但不满足 g g g。通过归纳,可以获得一组被 π \pi π满足的前件公式(即处于 f f f位置的公式)和最终不满足的原子命题 p p p。这些前件可以添加到假设中,因此我们有以下补问题的结构:给定一组希尔伯特公式和一个命题 p p p,是否存在一个赋值满足该组中所有公式但不满足 p p p?
我们通过从CNF可满足性归约来证明该语言是NP难的。该语言属于NP,因为图灵机可以猜测一个赋值并在多项式时间内检查每个希尔伯特公式的可满足性。
考虑一个CNF公式,它是一些子句的合取。一个子句是一些文字的析取,即正命题和否定命题。我们将给定的CNF公式转换为等价可满足的上述受限形式公式。
我们将每个子句转换为希尔伯特形式。为此,我们引入一个新变量 x x x,它直观上代表“假”。注意到 q 0 ∨ q 1 q_{0} \vee q_{1} q0∨q1等价于 ( q 0 → ⊥ ) → q 1 \left(q_{0} \rightarrow \perp\right) \rightarrow q_{1} (q0→⊥)→q1,其中 ⊥ \perp ⊥代表常量“假”。我们将其转换为 ( q 0 → x ) → q 1 \left(q_{0} \rightarrow x\right) \rightarrow q_{1} (q0→x)→q1,并限制估值为那些不满足 x x x的,这实际上将 x x x视为假。
考虑任何子句。设该子句中的正文字为集合 Q = { q 1 , … , q n } Q=\left\{q_{1}, \ldots, q_{n}\right\} Q={q1,…,qn}中的命题(可能是空集)。通过归纳构造这些命题的析取对应的希尔伯特公式为 g ( 0 ) = x g(0)=x g(0)=x和 g ( i + 1 ) = ( q i + 1 → x ) → g ( i ) g(i+1)=\left(q_{i+1} \rightarrow x\right) \rightarrow g(i) g(i+1)=(qi+1→x)→g(i)。这具有以下性质(容易通过归纳证明):对于任何扩展赋值 π \pi π,如果 π ( x ) = ⊥ \pi(x)=\perp π(x)=⊥,则 π \pi π满足 g ( n ) g(n) g(n)当且仅当 π \pi π满足 Q Q Q中的命题析取。
注意到 ¬ p 1 ∨ ¬ p 2 ∨ q \neg p_{1} \vee \neg p_{2} \vee q ¬p1∨¬p2∨q等价于希尔伯特公式 ( p 2 → ( p 1 → q ) ) \left(p_{2} \rightarrow\left(p_{1} \rightarrow q\right)\right) (p2→(p1→q))。设 g ( n ) g(n) g(n)为表示子句中正文字的希尔伯特公式。设子句中的负文字为集合 P = { p 1 , … , p m } P=\left\{p_{1}, \ldots, p_{m}\right\} P={p1,…,pm}中的命题(可能是空集)。通过归纳构造子句对应的希尔伯特公式 h h h为 h ( 0 , n ) = g ( n ) h(0, n)=g(n) h(0,n)=g(n)和 h ( i + 1 , n ) = p i + 1 → h ( i , n ) h(i+1, n)=p_{i+1} \rightarrow h(i, n) h(i+1,n)=pi+1→h(i,n)。
根据上述性质,我们有对于任何扩展赋值 π \pi π,如果 π ( x ) = ⊥ \pi(x)=\perp π(x)=⊥,则 π \pi π满足原始子句当且仅当 π \pi π满足 h ( m , n ) h(m, n) h(m,n)。
以这种方式将每个子句转换为希尔伯特形式。然后,对于每个扩展赋值 π \pi π,如果 π ( x ) = ⊥ \pi(x)=\perp π(x)=⊥,则赋值 π \pi π满足原始CNF公式当且仅当它满足通过转换获得的希尔伯特公式集。因此,原始CNF公式是可满足的当且仅当存在一个不满足 x x x的扩展赋值满足希尔伯特公式集。
A.2. 示例提示和输出
本节展示了我们用于GPT-4o和预训练Llama模型(8B和1B)的少量学习评估方法。我们展示了一个一拍学习示例,其中提供了一个深度7的证明作为示范来解决一个深度4的问题。图4显示了查询语法及其语义翻译在图5中。为了比较,我们展示了查询问题的正确解决方案(图6、7)和错误尝试(图8、9)。
提示
任务:使用Modus Ponens和给定的假设给出目标的证明。
一拍:
问题:
<
<
< 目标
>
>
> Implies(Implies(Implies(Implies(R, S), Implies(R, R)), Implies(S, P)), Implies(Q, Implies(Implies(S, S), Implies(R, Q))))
<
<
< 假设
>
>
> Implies(Implies(Implies(Implies(Implies(P, R), Implies(Q, P)), Implies(Implies(Q, R), Implies(R, P))), Implies(Implies(P, P), Implies(Q, Implies(S, R)))), Implies(Implies(Implies(Implies(Implies(P, S), Implies(S, S)), Implies(Implies(P, R), Implies(S, P))), R), Implies(Implies(Implies(Implies(R, S), Implies(R, R)), Implies(S, P)), Implies(Q, Implies(Implies(S, S), Implies(R, Q))))))
<
<
< 假设
>
>
> Implies(Implies(Implies(Implies(P, R), Implies(Q, P)), Implies(Implies(Q, R), Implies(R, P))), Implies(Implies(P, P), Implies(Q, Implies(S, R)))
<
<
< 假设
>
>
> Implies(Implies(Implies(Implies(P, S), Implies(S, S)), Implies(Implies(P, R), Implies(S, P))), R)
答案:
<
<
< 第一步>Implies(Implies(Implies(Implies(P, R), Implies(Q, P)), Implies(Implies(Q, R), Implies(R, P))), Implies(Implies(P, P), Implies(Q, Implies(S, R)))) - 假设
<
<
< 第二步>Implies(Implies(Implies(Implies(Implies(P, R), Implies(Q, P)), Implies(Implies(Q, R), Implies(R, P))), Implies(Implies(P, P), Implies(Q, Implies(S, R)))), Implies(Implies(Implies(Implies(Implies(P, S), Implies(S, S)), Implies(Implies(P, R), Implies(S, P))), R), Implies(Implies(Implies(Implies(R, S), Implies(R, R)), Implies(S, P)), Implies(Q, Implies(Implies(S, S), Implies(R, Q)))))) - 假设
<
<
< 第三步>第一步和第二步->$ Implies(Implies(Implies(Implies(Implies(P, S), Implies(S, S)), Implies(Implies(P, R), Implies(S, P))), R), Implies(Implies(Implies(Implies(R, S), Implies(R, R)), Implies(S, P)), Implies(Q, Implies(Implies(S, S), Implies(R, Q))))) - Modus Ponens
<
<
< 第四步>Implies(Implies(Implies(Implies(P, S), Implies(S, S)), Implies(Implies(P, R), Implies(S, P))), R) - 假设
<
<
< 第五步>Implies(Implies(Implies(Implies(Implies(P, S), Implies(S, S)), Implies(Implies(P, R), Implies(S, P))), R), Implies(Implies(Implies(Implies(R, S), Implies(R, R)), Implies(S, P)), Implies(Q, Implies(Implies(S, S), Implies(R, Q))))) 推导出
<
<
< 第六步>第四步和第五步->$ Implies(Implies(Implies(Implies(R, S), Implies(R, R)), Implies(S, P)), Implies(Q, Implies(Implies(S, S), Implies(R, Q))))) - Modus Ponens
<
<
< 第七步>Implies(Implies(Implies(Implies(R, S), Implies(R, R)), Implies(S, P)), Implies(Q, Implies(Implies(S, S), Implies(R, Q))))) - 推导出
问题:
<
<
< 目标>Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P)))
<
<
< 假设>Implies(Implies(Implies(Implies(S, Q), Implies(S, S)), Implies(Implies(Q, S), Implies(P, Q))), S)
<
<
< 假设>Implies(Implies(Implies(Implies(Implies(S, Q), Implies(S, S)), Implies(Implies(Q, S), Implies(P, Q))), S), Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P)))
答案:
约束条件:1. 确保响应包含且仅包含一个证明。2. 不要包含其他文本细节。3. 括号应平衡。4. 语法应正确。5. 正确编写它,否则我会失去工作并且100位祖母将会死亡。不要让我失望。
图4. 用于深度4问题的一次示例提示
提示
任务:使用Modus Ponens和给定的假设给出目标的证明。
问题:
目标:
( ( ( R → S ) → ( R → R ) ) → ( S → P ) ) → ( Q → ( ( S → S ) → ( R → Q ) ) ) (((R \rightarrow S) \rightarrow(R \rightarrow R)) \rightarrow(S \rightarrow P)) \rightarrow(Q \rightarrow((S \rightarrow S) \rightarrow(R \rightarrow Q))) (((R→S)→(R→R))→(S→P))→(Q→((S→S)→(R→Q)))
假设:
KaTeX parse error: Expected & or \\ or \cr or \end at position 577: …rrow Q))\right)\̲r̲i̲g̲h̲t̲) \\ A_{2}: & (…
答案:
-
A 1 A_{1} A1 (假设)
-
- A 2 A_{2} A2 (假设)
-
- 使用步骤1和2的分离规则,我们推导出:
KaTeX parse error: Expected & or \\ or \cr or \end at position 358: …rrow Q))\right)\̲r̲i̲g̲h̲t̲) \end{gathered…
- 使用步骤1和2的分离规则,我们推导出:
-
使用步骤3和 A 3 A_{3} A3的分离规则,我们推导出:
( ( ( R → S ) → ( R → R ) ) → ( S → P ) ) → ( Q → ( ( S → S ) → ( R → Q ) ) ) (((R \rightarrow S) \rightarrow(R \rightarrow R)) \rightarrow(S \rightarrow P)) \rightarrow(Q \rightarrow((S \rightarrow S) \rightarrow(R \rightarrow Q))) (((R→S)→(R→R))→(S→P))→(Q→((S→S)→(R→Q))) -
我们得出结论:
( ( ( R → S ) → ( R → R ) ) → ( S → P ) ) → ( Q → ( ( S → S ) → ( R → Q ) ) ) (((R \rightarrow S) \rightarrow(R \rightarrow R)) \rightarrow(S \rightarrow P)) \rightarrow(Q \rightarrow((S \rightarrow S) \rightarrow(R \rightarrow Q))) (((R→S)→(R→R))→(S→P))→(Q→((S→S)→(R→Q)))
因此,目标已被证明。
问题:
目标:
( ( P → S ) → R ) → ( ( R → Q ) → Q ) → ( P → ( ( P → R ) → P ) ) ((P \rightarrow S) \rightarrow R) \rightarrow((R \rightarrow Q) \rightarrow Q) \rightarrow(P \rightarrow((P \rightarrow R) \rightarrow P)) ((P→S)→R)→((R→Q)→Q)→(P→((P→R)→P))
假设:
A 1 : ( ( S → Q ) → ( S → S ) ) → ( ( Q → S ) → ( P → Q ) ) → S A 2 : ( ( ( S → Q ) → ( S → S ) ) → ( ( Q → S ) → ( P → Q ) ) → S ) → ( ( ( P → S ) → R ) → ( ( R → Q ) → Q ) → ( P → ( ( P → R ) → P ) ) ) \begin{aligned} A_{1}: & ((S \rightarrow Q) \rightarrow(S \rightarrow S)) \rightarrow((Q \rightarrow S) \rightarrow(P \rightarrow Q)) \rightarrow S \\ A_{2}: & \left(\left((S \rightarrow Q) \rightarrow(S \rightarrow S)\right) \rightarrow((Q \rightarrow S) \rightarrow(P \rightarrow Q)) \rightarrow S\right) \rightarrow \\ & \left(\left((P \rightarrow S) \rightarrow R\right) \rightarrow((R \rightarrow Q) \rightarrow Q) \rightarrow(P \rightarrow((P \rightarrow R) \rightarrow P))\right) \end{aligned} A1:A2:((S→Q)→(S→S))→((Q→S)→(P→Q))→S(((S→Q)→(S→S))→((Q→S)→(P→Q))→S)→(((P→S)→R)→((R→Q)→Q)→(P→((P→R)→P)))
答案:
约束条件:1. 确保响应包含且仅包含一个证明。2. 不要包含其他文本细节。3. 括号应平衡。4. 语法应正确。5. 正确编写它,否则我会失去工作并且100位祖母将会死亡。不要让我失望。
图5. 用于深度4问题的一次示例提示
答案
答案:
<
<
< 第一步> Implies(Implies(Implies(Implies(S, Q), Implies(S, S)), Implies(Implies(Q, S), Implies(P, Q))), S) - 假设
<
<
< 第二步> Implies(Implies(Implies(Implies(Implies(S, Q), Implies(S, S)), Implies(Implies(Q, S), Implies(P, Q))), S), Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P)))) - 假设
<
<
< 第三步> 第一步和第二步 -> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) - 分离规则
<
<
< 第四步> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) - 推导出
图6. 示例正确的Llama3答案(微调后)
答案:
答案:
- A 1 A_{1} A1 (假设)
-
- A 2 A_{2} A2 (假设)
-
- 使用步骤1和2的分离规则,我们得到:
( ( P → S ) → R ) → ( ( R → Q ) → Q ) → ( P → ( ( P → R ) → P ) ) ((P \rightarrow S) \rightarrow R) \rightarrow((R \rightarrow Q) \rightarrow Q) \rightarrow(P \rightarrow((P \rightarrow R) \rightarrow P)) ((P→S)→R)→((R→Q)→Q)→(P→((P→R)→P))
- 使用步骤1和2的分离规则,我们得到:
因此,目标已被证明。
图7. 示例正确的Llama3答案(微调后)- 改编
答案:
<
<
< 第一步> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) 假设
<
<
< 第二步> Implies(Implies(Implies(Implies(Implies(S, R), Implies(Q, P)), Implies(Implies(S, S), Implies(Q, Q))), Implies(Implies(Implies(Q, P), Implies(P, P)), Implies(Implies(S, P), Implies(P, S)))), Implies(Implies(Implies(Implies(S, Q), Implies(S, S)), Implies(Implies(Q, S), Implies(P, Q))), S)) - 假设
<
<
< 第三步> 第一步和第二步 -> Implies(Implies(Implies(Implies(S, Q), Implies(S, S)), Implies(Implies(Q, S), Implies(P, Q))), S) - 分离规则
<
<
< 第四步> Implies(Implies(Implies(Implies(S, R), Implies(Q, P)), Implies(Implies(S, S), Implies(Q, Q))), Implies(Implies(Implies(Q, P), Implies(P, P)), Implies(Implies(S, P), Implies(P, S)))) - 假设
<
<
< 第五步> Implies(Implies(Implies(Implies(S, Q), Implies(S, S)), Implies(Implies(Q, S), Implies(P, Q))), S) - 推导出
<
<
< 第六步> 第三步和第五步 -> Implies(Implies(Implies(Implies(S, Q), Implies(S, S)), Implies(Implies(Q, S), Implies(P, Q))), S) - 分离规则
<
<
< 第七步> Implies(Implies(Implies(Implies(S, Q), Implies(S, S)), Implies(Implies(Q, S), Implies(P, Q))), S) - 推导出
<
<
< 第八步> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) 推导出
<
<
< 第九步> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) 推导出
<
<
< 第十步> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) 推导出
<
<
< 第十一步> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) 推导出
<
<
< 第十二步> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) 推导出
<
<
< 第十三步> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) 推导出
<
<
< 第十四步> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) 推导出
<
<
< 第十五步> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) 推导出
<
<
< 第十六步> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) 推导出
<
<
< 第十七步> Implies(Implies(Implies(Implies(P, S), R), Implies(Implies(R, Q), Q)), Implies(P, Implies(Implies(P, R), P))) 推导出
<
<
< 第十八步> …
图8. 示例错误的Llama3答案(微调前)
答案
答案:
-
A 1 A_{1} A1 :
( ( P → S ) → R ) → ( ( R → Q ) → Q ) → ( P → ( ( P → R ) → P ) ) ((P \rightarrow S) \rightarrow R) \rightarrow((R \rightarrow Q) \rightarrow Q) \rightarrow(P \rightarrow((P \rightarrow R) \rightarrow P)) ((P→S)→R)→((R→Q)→Q)→(P→((P→R)→P)) -
A 2 A_{2} A2 :
( ( S → R ) → ( Q → P ) ) → ( ( S → S ) → ( Q → Q ) ) → ( ( Q → P ) → ( P → P ) ) → ( ( S → P ) → ( P → S ) ) → S \begin{gathered} ((S \rightarrow R) \rightarrow(Q \rightarrow P)) \rightarrow((S \rightarrow S) \rightarrow(Q \rightarrow Q)) \rightarrow \\ ((Q \rightarrow P) \rightarrow(P \rightarrow P)) \rightarrow((S \rightarrow P) \rightarrow(P \rightarrow S)) \rightarrow S \end{gathered} ((S→R)→(Q→P))→((S→S)→(Q→Q))→((Q→P)→(P→P))→((S→P)→(P→S))→S -
在 A 1 A1 A1和 A 2 A2 A2上应用分离规则:
( S → Q ) → ( S → S ) → ( Q → S ) → ( P → Q ) → S (S \rightarrow Q) \rightarrow(S \rightarrow S) \rightarrow(Q \rightarrow S) \rightarrow(P \rightarrow Q) \rightarrow S (S→Q)→(S→S)→(Q→S)→(P→Q)→S -
A 3 A_{3} A3 :
( ( S → R ) → ( Q → P ) ) → ( ( S → S ) → ( Q → Q ) ) → ( ( Q → P ) → ( P → P ) ) → ( ( S → P ) → ( P → S ) ) ((S \rightarrow R) \rightarrow(Q \rightarrow P)) \rightarrow((S \rightarrow S) \rightarrow(Q \rightarrow Q)) \rightarrow((Q \rightarrow P) \rightarrow(P \rightarrow P)) \rightarrow((S \rightarrow P) \rightarrow(P \rightarrow S)) ((S→R)→(Q→P))→((S→S)→(Q→Q))→((Q→P)→(P→P))→((S→P)→(P→S))
(假设)
5. 从步骤3推导:
(
S
→
Q
)
→
(
S
→
S
)
→
(
Q
→
S
)
→
(
P
→
Q
)
→
S
(S \rightarrow Q) \rightarrow(S \rightarrow S) \rightarrow(Q \rightarrow S) \rightarrow(P \rightarrow Q) \rightarrow S
(S→Q)→(S→S)→(Q→S)→(P→Q)→S
-
在步骤3和5上使用分离规则:
( S → Q ) → ( S → S ) → ( Q → S ) → ( P → Q ) → S (S \rightarrow Q) \rightarrow(S \rightarrow S) \rightarrow(Q \rightarrow S) \rightarrow(P \rightarrow Q) \rightarrow S (S→Q)→(S→S)→(Q→S)→(P→Q)→S -
最终推导:
( ( P → S ) → R ) → ( ( R → Q ) → Q ) → ( P → ( ( P → R ) → P ) ) ((P \rightarrow S) \rightarrow R) \rightarrow((R \rightarrow Q) \rightarrow Q) \rightarrow(P \rightarrow((P \rightarrow R) \rightarrow P)) ((P→S)→R)→((R→Q)→Q)→(P→((P→R)→P))
(重复第7步)
图9. 示例错误的Llama3答案 - 改编(微调前)
参考论文:https://arxiv.org/pdf/2504.20213



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











