






丹尼尔·N·尼桑尼 (Nissensohn)
dnissani@post.bgu.ac.il
摘要
自从大型语言模型(LLMs)的非凡出现以来,关于它们是否能够理解世界以及捕捉所参与对话意义的能力的讨论一直在热烈进行。这些讨论基于思想实验、人类与LLMs之间的轶事对话、统计语言分析、哲学思考等提出了各种论点和反驳论点。在本文中,我们通过一个思想实验和半形式化的考虑提出了一种反驳意见,认为存在一种固有的模糊性障碍,阻止了LLMs对其流畅对话的实际意义有任何理解。
1. 引言
大型语言模型(以下简称LLMs)的出现及其令人惊叹且出乎意料的流畅性,立即在研究界(以及公众中)引发了关于这些模型智能的讨论,特别是关于其语言理解和对世界的理解。
在这场争论的支持方,认为LLMs至少部分理解它们所交流词语的意义的研究包括关于物理世界属性的工作(例如Abdou等人,2021年);对人类与LLMs之间轶事对话的分析(例如Aguera y Arcas,2021年);思想和现实生活中的实验(例如Sogaard,2023年);访谈和文章(Hinton,2024年;Manning,2022年)。
在反对方,我们再次发现思想实验(例如Bender和Koller,2020年);文章(Browning和LeCun,2022年;Marcus,2022年;Bisk等人,2020年;Mahowald等人,2024年);形式化论证(例如Merrill等人,2021年);统计语言学分析结果(例如Niven和Kao,2019年),以及其他更多内容。
描述“辩论现状”的综述也已发表(Mitchell和Krakauer,2023年;Michael等人,2022年),这些综述表明研究界成员的意见大致分为50/50。
大约三十年前的一系列开创性实验(Fried等人,1997年;Kreiman等人,2000年;Quiroga等人,2005年)揭示了人类大脑中的一个区域,该区域作为“抽象概念中心”运作:神经细胞对该特定抽象概念(如著名的Jennifer Aniston细胞)的各种模态刺激选择性地强烈响应。更近期的结果(Bausch等人,2021年)提供了证据,证明还有其他神经细胞编码概念对之间的关系(如“更大?”、“更贵?”等)。
这些发现启发我们在本文中提出一个简单但有用的语言模型,详见第2节,该模型可以应用于参与交流的人类。然后我们在第3节展示了为什么这个相同的语言模型不能应用于交流中的LLMs(假设其当前最先进的架构和训练协议)。这最终通过一个思想实验和半形式化论证引出了一个固有的模糊性障碍,该障碍阻止了LLMs将词语与明确的抽象概念联系起来,从而无法理解其对话的意义。我们在第4节讨论并总结了我们的结果。
2. 语言模型
在此文中,我们采用了一个模型,其中语言是一对映射, L L L 和其逆映射 L − 1 L^{-1} L−1,它们在有限的概念抽象表示集 K = { k i } \mathrm{K}=\left\{\mathrm{k}_{\mathrm{i}}\right\} K={ki}(简称为概念)和词汇表(即有限的单词集 W = { w i } \mathrm{W}=\left\{\mathrm{w}_{\mathrm{i}}\right\} W={wi},大小为 i = 1 , 2 , … N = ∣ W ∣ = ∣ K ∣ \mathrm{i}=1,2, \ldots \mathrm{~N}=|\mathrm{W}|=|\mathrm{K}| i=1,2,… N=∣W∣=∣K∣)之间:
| L: | K | → \rightarrow → | W | (1a),以及 |
|---|---|---|---|---|
| L − 1 : \mathrm{L}^{-1}: L−1: | W | → \rightarrow → | K | (1b) |
概念集 K K K 及其相关实体包含了代理理解世界的所需全部内容。这些相关实体包括 K K K 元素自身之间以及它们与“接地”的物理世界之间的庞大而复杂的关联集。映射 L L L 和 L − 1 L^{-1} L−1 看似平凡,但实际上并非如此。特别地,在没有 L L L 和 L − 1 L^{-1} L−1 的情况下,集合 W W W 中的词没有任何意义:任何缺乏这些映射的人类都无法理解 W W W 元素的含义,正如任何听不懂外语的人都能证明的那样。因此, K K K 是上述抽象“概念中心”的简单模型(Fried等人,1997年)。为了我们的目的,无需使这些陈述比这更具体。
由于
K
K
K 元素的意义和前述的关系集(并且受到语言语法规则的影响),句子中的下一个词(或新句子的第一个词),记为
w
i
w_{i}
wi,实际上由条件概率矩阵约束:
Pr
{
W
=
w
i
∣
c
j
∈
C
}
≡
P
i
j
\operatorname{Pr}\left\{W=w_{i} \mid c_{j} \in C\right\} \equiv P_{i j}
Pr{W=wi∣cj∈C}≡Pij
其中
c
j
c_{j}
cj 是一个上下文,它限制了随机变量
W
W
W 的实现,即单词
w
i
w_{i}
wi(注意我们略微滥用符号:在这里,
W
W
W 可以代表一个随机变量或我们的词汇集)。该上下文
c
j
=
[
s
j
1
,
s
j
2
,
…
.
]
c_{j}=\left[s_{j 1}, s_{j 2}, \ldots.\right]
cj=[sj1,sj2,….],属于庞大的上下文集
C
C
C,由一系列语法和语义有效的句子组成,每个句子
s
j
k
=
[
w
j
k
1
,
w
j
k
2
,
…
]
s_{j k}=\left[w_{j k 1}, w_{j k 2}, \ldots\right]
sjk=[wjk1,wjk2,…],由一系列有限的单词组成,表达为语音或文本符号。
为简化起见,我们忽略了同义词、同音异义词及其他词汇问题。这种简化使得 L L L(和 L − 1 \mathrm{L}^{-1} L−1)成为双射函数,如上式(1b)所示。
词汇元素 w i w_{i} wi 和语言语法规则由同一社区内的代理约定俗成定义,相当随意。智能且具有沟通能力的代理学会 L L L 和 L − 1 L^{-1} L−1,同时学习集合 K K K 和 W W W(以及条件概率矩阵 P i j P_{i j} Pij)。智能但不具有沟通能力的代理仅学习 K K K。
我们模型的示意图如图1所示。
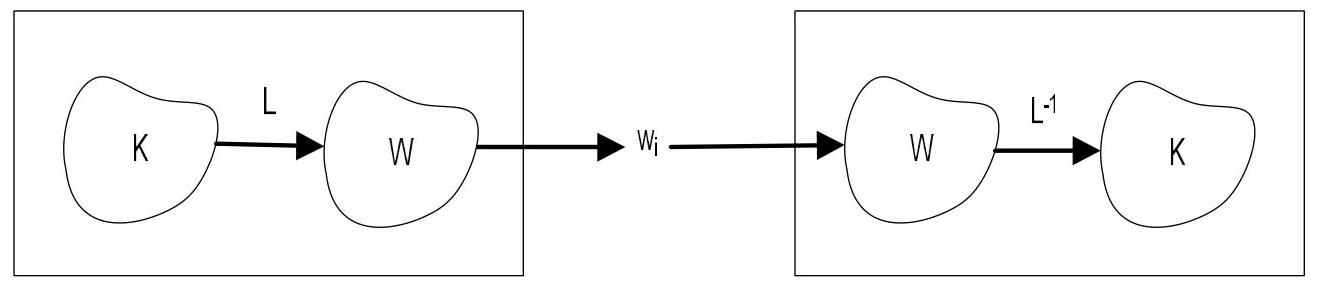
图1. 发送代理(左侧)将从集合 K K K 中选择的概念抽象表示映射为集合 W W W 中的词。这些词被接收代理(右侧)接收,并重新映射回概念集合 K K K。两个集合 K K K 和 W W W 以及语言功能已被学习并存储在代理的大脑中。这是一个理想化但有用的视角(参见正文)。
候选概念是否包含在集合 K K K 中取决于代理的感觉能力、本能、兴趣和动机,以及其世界或环境的特性。我们假设具有相同性质、文化和环境的代理,即属于同一社区的代理,将学习完全相同的语言功能及其逆映射,相同的 K K K 和 W W W 集合,以及相同的条件概率矩阵 P i j \mathrm{P}_{\mathrm{ij}} Pij;这严格来说很少成立,因为单个代理的学习通常不完美且近似,但这是一种有用的简化。
有人可能认为(例如Havlik,2024年),抽象表示集合的基本元素是思想(而不是如上所述的概念),相应的基本词汇元素是句子(而不是单词)。这可能是(也可能不是)真的。然而,采用这种方法会不必要地增加我们的符号负担,而不会显著改变我们的论点和结论。
3. 大型语言模型的情况
与上述描述的代理不同,LLMs 不学习函数 L L L 和 L − 1 \mathrm{L}^{-1} L−1,也不学习集合 K K K。相反,词汇集合 W W W 提供给 LLM(通常以单词的部分形式,即所谓的标记,出于实现效率的原因),巨大的矩阵 P i j P_{i j} Pij 被设置为目标函数,并通过自监督方式学习,方法是向其展示大量由智能且具有沟通能力的代理创建的选定语言语料库,并反复要求它预测下一个(或被遮盖的)单词。
LLMs生成对话的非凡流畅性、类似人类的质量及其看似推理能力,使许多人相信或支持这样的观点(如第1节所述),即这些模型“知道它们在说什么”,而不仅仅是“随机鹦鹉”(Bender等人,2021年)。支持这一论点的主要论据之一是“你将通过它所处的环境来了解一个词”的格言(Firth,1957年),这是分布语义学的一个激励性陈述。
我们打算提供一个半形式化的证明,说明这一论点是错误的:与人类和其他假设的智能且具有沟通能力的代理不同,LLMs 对其对话的意义没有任何理解,也无法理解。
我们将利用一个模糊性论点,反复利用一个简单但深刻的真理:“存在的就是可能的”(Boulding,1957年)。
为了证明我们的主张,我们转向一个简单的思想实验。考虑生活在完全不同世界中的两组非常不同的代理。这些可以是,例如,两个人类(如亚马逊的Waorani人和阿拉斯加的因纽特人);或者一个人类和一只假设的智能且具有沟通能力的蚂蚁;或者一个人类和生活在其他星球上的智能生物。第一个代理(在这些任意一对中)将学习其自己的概念集合 K K K、其自己的词汇 W W W、其自己的语言映射 L L L(及其逆映射),以及其条件概率矩阵 P i j \mathrm{P}_{\mathrm{ij}} Pij。第二个代理将学习其自己的 K ′ , W ′ , L ′ \mathrm{K}^{\prime}, \mathrm{W}^{\prime}, \mathrm{L}^{\prime} K′,W′,L′(及其逆映射)和 P i j ′ \mathrm{P}_{\mathrm{ij}}{ }^{\prime} Pij′。特别地,我们可以设想一种情况,由于它们生活在一个极端不同的世界中,它们的概念集合 K K K 和 K ′ \mathrm{K}^{\prime} K′ 是不相交的:没有任何概念是共享的。它们的世界观完全不同。
我们现在首次应用我们的“存在的就是可能的”真理:既然存在大小为 N N N 的概念集合 K K K,我们必须接受另一种可能性,即我们的第二个(不相交的)集合 K ′ \mathrm{K}^{\prime} K′ 也可以具有相同的大小。我们假设 ∣ K ∣ = ∣ K ′ ∣ = N |K|=\left|K^{\prime}\right|=N ∣K∣=∣K′∣=N。记住,我们正在处理可能性,无论概率多么小;仅仅因为某个社区已经发展出大小为 N N N 的概念集合,并不妨碍任何其他社区这样做。现在,由于 L L L 是一个双射映射(见上面的公式1),我们立即得出 ∣ W ∣ = ∣ W ′ ∣ = N |W|=\left|W^{\prime}\right|=N ∣W∣=∣W′∣=N。我们继续第二次应用这种存在/可能性推理,并同样得出条件概率矩阵可能存在(近似)相等的可能性。我们在这里只能期望达到某种任意误差范围内的近似值,因为这些矩阵的值是实数,但对于我们的目的,我们可以认为它们相等。因此,我们假设 P i j ≅ P i j ′ P_{i j} \cong P_{i j}{ }^{\prime} Pij≅Pij′。
再进一步,回想一下上面提到的,词汇 W W W 实现为语音或文本符号 w i \mathrm{w}_{\mathrm{i}} wi 是任意的,并由社区成员共同约定。因此,我们可以更新所有 W ′ \mathrm{W}^{\prime} W′ 的元素,使得 w i ′ = w i ∀ i = 1 , 2 , … N \mathrm{w}_{\mathrm{i}}{ }^{\prime}=\mathrm{w}_{\mathrm{i}} \forall \mathrm{i}=1,2, \ldots \mathrm{~N} wi′=wi∀i=1,2,… N,而不产生实质性影响。
总结一下,我们现在有两个处于不同世界中的社区,拥有两个大小相等但互不相交的概念集、相同的词汇和相同的条件概率矩阵。
接下来,回到我们的LLM,我们让它学习例如我们第一个代理的条件概率矩阵 P i j P_{i j} Pij(在预设词汇 W W W 下)。根据我们的LLM训练协议,简要描述如下,在此过程中既不学习概念集 K K K 也不学习语言映射 L L L。
完成 P i j P_{i j} Pij 学习后,我们可以问我们的LLM任何一个词 w m ∈ W w_{m} \in W wm∈W 的意义是什么。但是这个问题遇到了本质上模糊的情况:由于 P i j ≅ P i j ′ P_{i j} \cong P_{i j}{ }^{\prime} Pij≅Pij′ 和 W = W ′ W=W^{\prime} W=W′,没有办法让我们的LLM确定 w m \mathrm{w}_{\mathrm{m}} wm 是指属于第一个世界概念集 K K K 的概念还是指属于第二个世界概念集 K ′ \mathrm{K}^{\prime} K′ 的完全不同概念。即使假设我们的LLM可以根据“它所处的环境”为任何词分配意义(并且我们忽略同音异义词等问题,如上所述),它也没有线索应该选择哪个意义,来自 K K K 还是来自 K ′ \mathrm{K}^{\prime} K′。需要注意的是,一个智能且具有沟通能力的代理,不仅学习了 P i j P_{i j} Pij 和 W W W,还学习了 K K K 和 L L L(其自身世界中的两者),就没有这种模糊性问题。
因此,似乎别无选择,只能得出结论:LLM 所学习的词与其概念完全脱离,作为推论,也脱离了其意义。
4. 讨论
我们认为在本文(短小且谦逊)中提供了一个半形式化的证明,即无论LLMs看起来对我们人类而言多么智能、流畅和复杂,它们都无法真正理解其对话的意义。
有人说(例如Elman,1990年,以及其他学者),人类不可能仅仅通过听广播(或等价地说,仅仅通过阅读文本)来学习语言的意义。由于“阅读文本”是LLMs训练过程中的唯一活动,我们得出LLMs无法实现语言理解的结论不应让我们感到惊讶。
理解世界是理解语言的前提(而非结果)。正如现在已经显而易见的那样,理解世界显然需要在有机体的大脑或LLMs架构中存在一组概念的抽象表示,包括它们之间的相互关系。这样的集合显然在任何现有的LLM架构中都缺失。相比之下,这样的集合存在于人类大脑中,这一点已被证明(Fried等人,1997年),并且很可能(如果开发出适当的实验技术)也会存在于任何智能的(不一定具有沟通能力的)有机体的大脑中。
那些支持LLMs确实理解语言这一论点的人可能会争辩说,语言并不是我们在此假设的那么简单,其精细结构(包括语法规则及长长的例外列表、同义词、同音异义词等)对于意义获取确实很重要。例如,他们可能会声称,同音异义词的选定意义完全取决于“它的同伴”(对此我们表示同意)。然而,与此同时,如果我们忽略本文中未涉及的语言特征,却将这些特征归因于LLMs理解的核心支柱,我们会感到非常惊讶。
对LLMs能够理解语言的错误信念,归根结底可能是(如Bender和Koller,2020年;Sejnowski,2022年;及其他学者所建议的那样)我们对自己理解LLMs所说内容的“心智理论”反映——即所谓Eliza效应(Weizenbaum,1966年)的错觉案例。在上述思想实验中,当我们聪明且具有沟通能力的蚂蚁和人类同时聆听同一个LLM的论述时,他们会各自体验到一种独特的Eliza效应,每个人都按照自己独特的一套世界概念解释信息,彼此完全不同。
最后,如果希望朝着类似人类的世界和语言理解方向取得进展,我们应该继续探索,第一步应包括一个尚未发现的重大范式转变。
参考文献
Abdou, M., Kulmizev, A., Hershcovich, D., Frank, S., Pavlick, E., Sogaard, A., ‘Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color’, 在计算自然语言学习会议(CoNLL),2021年
Aguera y Arcas, B., ‘Do Large Language Models Understand Us?’, 在《Daedalus》,美国艺术与科学院期刊,2022年
Bausch, M., Niediek, J., Reber, T.P., Mackay, S., Bostrom, J., Elger, C.E., Mormann, F., ‘Concept neurons in the human medial temporal lobe flexibly represent abstract relations between concepts’, 在《Nature Communications》,2021年
Bender, E.M., Koller, A., ‘Climbing towards NLU: On Meaning, Form and Understanding in the Age of Data’, 在计算语言学协会(ACL),2020年
Bender, E.M., Timnit, G., McMillan-Major, A., Shmitchell, S, ‘On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?’, 在2021 ACM公平性、问责制和透明度会议论文集,2021年
Bisk, Y., Holtzman, A., Thomason, J., Andreas, J., Bengio, Y., Chai, J., Lapata, M., Lazaridou, A., May, J., Nisnevich, A., Pinto, N., Turian, J., ‘Experience Grounds Language’, 在经验方法在自然语言处理会议,2020年
Boulding, K.E., ‘Segments of the economy, 1956’, 在第五届经济学行动项目研讨会,1957年
Browning, J., LeCun, Y., ‘AI and The Limits Of Language’, 在伯格鲁恩研究所的《NOEMA》,2022年
Elman, J.L., ‘Finding structure in time’, 在认知科学杂志,1990年
Firth, J.R., ‘A Synopsis of Linguistic Theory, 1930-1955’, 在《语言学分析研究》,Basil-Blackwell-Oxford,1957年
Fried, I., MacDonald, K.A., Wilson, C., ‘Single neuron activity in human hippocampus and amygdale during recognition of faces and objects’, 在《Neuron》,1997年
Havlik, V., ‘Meaning and understanding in large language models’, 在《Synthese》,Springer Link,2024年
Hinton, G., 在Reddit采访中,2024年 https://www.reddit.com/r/OpenAI/comments/1cveifd/geoffrey hinton says ai language mo dels_arent/?rdt=55810
Kreiman, G., Koch, C., Fried, I., ‘Category specific visual responses of single neurons in the human medial temporal lobe’, 在《Nature Neuroscience》,2000年
Mahowald, K., Ivanova, A.A., Blank, I.A., Kanwisher, N., Tenenbaum, J.B., Fedorenko, E., ‘Dissociating Language and Thought in Large Language Models’, 在《Trends in Cognitive Sciences》,2024年
Manning, C.D., ‘Human Language Understanding & Reasoning’, 在《Daedalus》,美国艺术与科学院期刊,2022年
Marcus, G., ‘Deep Learning Alone isn’t Getting Us To Human-Like AI’, 在伯格鲁恩研究所的《NOEMA》,2022年
Merrill, W., Goldberg, Y., Schwartz, R., Smith, N.A., ‘Provable Limitations of Acquiring Meaning from Ungrounded Form: What Will Future Language Models Understand?’, 在计算语言学协会事务,2021年
Michael, J., Holtzman, A., Parrish, A., Mueller, A., Wang, A., Chen, A., Madaan, D., Nangia, N., Pang, R.Y., Phang, J., Bowman, S.R., ‘What do NLP Researchers Believe? Results of the NLP Community Metasurvey’, 在计算语言学协会第61届年会论文集,2023年
Mitchell, M., Krakauer, D.C., ‘The debate over understanding in AI’s large language models’, 在PNAS,2023年
Niven, T., Kao, H, ‘Probing Neural Network Comprehension of Natural Language Arguments’, 在计算语言学协会第57届年会论文集,2019年
Sejnowski, T., ‘Large Language Models and the Reverse Turing Test’, 在神经计算,2022年
Sogaard, A., ‘Grounding the Vector Space of an Octopus: Word Meaning fro Raw Text’, 在《心灵与机器》,2023年
Weizenbaum, J., ‘A Computer program for the study of natural language communication between men and machines’, 在《ACM通讯》,1966年
参考论文:https://arxiv.org/pdf/2505.00654


















 2985
2985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











