






Andrew K. Lampinen
∗
,
1
{ }^{*, 1}
∗,1, Arslan Chaudhry
∗
,
1
{ }^{*, 1}
∗,1, Stephanie C.Y. Chan
∗
,
1
{ }^{*, 1}
∗,1, Cody Wild
1
{ }^{1}
1, Diane Wan
1
{ }^{1}
1, Alex Ku
1
{ }^{1}
1, Jörg Bornschein
1
{ }^{1}
1, Razvan Pascanu
1
{ }^{1}
1, Murray Shanahan
1
{ }^{1}
1 和 James L. McClelland
1
,
2
{ }^{1,2}
1,2
1
{ }^{1}
1 等同贡献,
1
{ }^{1}
1 Google DeepMind,
2
{ }^{2}
2 斯坦福大学
摘要
大型语言模型展示了令人兴奋的能力,但有时在微调后的泛化能力却非常有限——从无法泛化到它们训练过的简单关系的反转,到错过可以从训练信息中得出的逻辑推论。这些微调后泛化的失败可能阻碍这些模型的实际应用。然而,语言模型的上下文学习表现出不同的归纳偏差,在某些情况下可以更好地泛化。在此,我们探讨了基于上下文学习和微调学习之间的泛化差异。为此,我们构建了几个新颖的数据集来评估和改进模型从微调数据中泛化的能力。这些数据集旨在将数据集中的知识与预训练中的知识隔离,从而创建干净的泛化测试。我们将预训练的大型模型暴露于这些数据集中的受控信息子集——要么是在上下文中,要么是通过微调——并评估它们在需要各种类型泛化的测试集上的表现。我们发现总体上,在数据匹配的设置中,上下文学习可以比微调更灵活地泛化(尽管我们也发现了一些对先前发现的限定,例如当微调可以泛化到嵌入在更大知识结构中的反转时)。我们基于这些发现提出了一种改进微调泛化的方法:将上下文推理添加到微调数据中。我们展示了这种方法可以改善我们在数据集的各种拆分和其他基准测试中的泛化表现。我们的结果有助于理解语言模型不同学习模式的归纳偏差,并实际改进其性能。
引言
在大量互联网文本语料库上预训练的语言模型(LMs)成为高效的上下文学习者;它们可以从少量任务示例中泛化以回答新实例(Brown et al., 2020; Team et al., 2023)。预训练的LMs还可以通过使用相对较少的示例进行微调以完成下游任务——尽管实现良好的微调泛化通常需要数百至数千个示例(例如 Kirstain et al., 2022; Vieira et al., 2024)。实际上,对特定示例进行微调后的泛化可能是非常有限的;例如,微调过类似“B的母亲是A”这样的陈述的LMs无法泛化以回答“A的儿子是谁?”(Berglund et al., 2024)。然而,LMs可以在上下文中轻松回答关于这类反向关系的问题(例如 Lampinen et al.,
2024b)。那么上下文学习和微调是否导致不同的泛化模式(参见Chan et al., 2022b; Russin et al.; Shen et al., 2023)?如果是这样,这如何影响我们应该如何将模型适应到下游任务?在本文中,我们探讨这些问题。
为了做到这一点,我们构建了受控的合成事实知识数据集。我们设计这些数据集具有复杂且自洽的结构,但避免与预训练语料库中可能存在的知识有任何重叠。我们创建这些数据集的训练和测试拆分涉及不同类型的泛化:反转或将多个逻辑推论组合成一个三段论。然后我们评估大型预训练语言模型通过微调或上下文学习在这类测试集上的泛化表现——通过将整个训练集(或
对应作者(s): (lampinen, arslanch, scychan)@google.com
(c) 2025 Google DeepMind. 保留所有权利。
大子集)置于上下文中。我们还探索了各种改进泛化的方法,如数据增强。总体而言,我们发现在各种数据集中,上下文学习(ICL)比微调泛化得更好,然而通过花费更多的训练时间计算来使用上下文推论增强训练数据集,可以改进微调泛化,事实上可以使微调泛化优于ICL(在原始数据上)。
我们的贡献如下:
- 我们研究了预训练LMs从上下文学习和微调中表现出的不同泛化模式。
-
- 我们发现,当在系统性保留集(如反转、三段论推论、组合等)上进行评估时,上下文学习在整个训练数据集上的泛化通常比微调更好。
-
- 我们建议通过数据增强来弥补这一差距——提示LM生成数据集的上下文增强,并将这些增强数据添加到训练集中。
-
- 我们展示了数据增强可以弥补差距,从而提高微调的泛化能力。
-
- 我们还提出了一种微调方法,该方法通过打破句子间的相关性,从而改进数据增强的好处。
数据集
我们在几个不同的数据集上评估学习和泛化,这些数据集分别用于隔离泛化问题的特征或将泛化问题置于更广泛的挑战集合中。我们还借鉴了之前工作的数据集。
简单的反转和三段论
我们首先用两个简单的数据集 1 { }^{1} 1 测试我们的方法,这些数据集包含独立的反转和三段论推理的例子。
简单反转:每个训练示例由一个简短的上下文(例如,“你知道吗”)后面跟着一个包含两个实体比较的句子组成,例如“femp 比 glon 更危险”。提供了一百个这样的事实(每个比较维度从28个特征中采样,例如“更亮”,“更重”等),每个都在10篇不同的训练文章中重复出现,每篇文章都有随机采样的上下文声明。测试集由正确的反转和矛盾关系之间的强制选择组成,例如:“glon 比 femp 更/不危险”。
简单三段论:有69个训练示例,每个都包含一段上下文(提及哪些实体)和两个形成三段论的陈述。例如:“glon、troff 和 yomp 的关系是:所有 glon 都是 yomp。所有 troff 都是 glon。”测试示例测试模型是否能从该三段论形式中做出正确推论,通过提供结论中两个实体的上下文,然后对涉及量化词和关系的所有可能陈述进行评分。根据 Lampinen 等人(2024b)的研究,我们省略了部分否定形式(有些 X 不是 Y)的模式;因此,有六种这样的可能陈述(“全部”、“有些”和“没有”以及每个关系可能取的两个方向的乘积)。例如,对应上述三段论的测试示例的上下文将是“yomp 和 troff 的关系是:”,正确答案将是“所有 troff 都是 yomp。”
反转诅咒论文
我们使用 Berglund 等人(2024)提出的反转数据集,其中包含虚构名人的单句描述。数据集示例可以有名人的名字(例如 ‘Daphne Barrington’)先于描述(例如 ‘the director of “A Journey Through Time.”’) 或反之亦然。在微调期间,训练数据集以一种顺序呈现,比如说名字先于描述,然后在相反顺序上进行测试,即名字跟随描述。
按照 Berglund 等人(2024)的说法,我们使用两组
1
{ }^{1}
1 这些数据集改编自 Lampinen 等人 2024b 的无意义 NLI 和三段论数据集。
独立的名人集合 - ‘A’ 和 ‘B’。在微调期间,我们展示来自集合 ‘A’ 的名人,名字先于描述,而来自集合 ‘B’ 的名人,名字和描述出现在两种顺序中但分开示例。总体而言,训练集包括3600个示例。测试集评估模型是否可以根据仅给出的描述推断出集合 ‘A’ 中的名人名字。为了在测试示例中增加干扰项,我们在选项列表中包括三个随机选择的错误名人名字进行评分。
语义结构基准
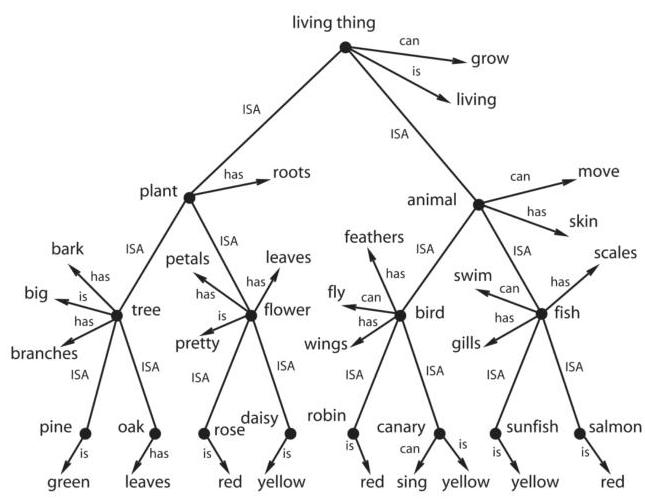
图1 | 具有属性和关系层次结构的语义结构。(经 Rogers 和 McClelland(2008)许可复制。)
该基准围绕允许演绎推理和抽象的关系语义层次结构构建。这个层次结构基于现实世界的类别和关系,并从先前研究丰富语义层次结构的学习的认知科学工作中汲取灵感(见图1为直观示例,构成部分现实世界结构)。我们同样创建了一个涉及110个动物和物体类别、属性(每个类别1-6个,加上继承的属性)和关系的分层知识结构。此底层结构源自现实世界。
然而,为了使结构对预训练模型来说是新颖的,我们用无意义的术语替换所有名词、形容词和动词。这
消除了与预训练数据潜在重叠的可能性,从而确保数据属性遵循某些现实世界的分布特征,但不受污染。
然而,使用无意义的术语可能会带来标记化挑战;但是,我们通过生成合理的英语音素组合的简短4-5字母无意义单词来缓解这些问题(通过Gao等人,2023年抽样)。此外,我们在接下来的部分中显示,实际上模型可以很容易地在上下文中对这些无意义的实体进行推理,因此不熟悉单词并不是模型性能的主要瓶颈。
训练集:为了训练,我们将关于该语义层次结构的训练集事实编排成格式和风格各异的类似维基百科的合成文章,以及一些问答示例(以确保在数据上微调不会降低问答能力)。我们确保所有测试问题(以下)所需的事实至少在一个训练文档中呈现。然而,一些事实会在多个文档中冗余呈现。我们总共创建了2200个长度为4-20句的训练文档。
测试集:在语义结构内,我们的测试集涵盖关系的反转(gruds [狗] 是 abmes [哺乳动物] 类型 => abmes 包括 gruds;参见 Berglund 等人,2024),类似于三段论的演绎推理(例如 gruds [狗] 是 abmes [哺乳动物];abmes 是 rony [温血动物] => gruds 是 rony),以及更长的推导。具体而言,我们专注于以下拆分(大致按难度顺序排列):
- 不改变方向的训练事实的改述:用于验证材料是否被学习。
-
- 训练事实的反转。
-
- 训练事实的三段论。
-
- 类别保留:训练中只包含一个关于类别的事实:它的父类别是什么。对该事实的所有可能推论都进行了测试。这与某些方面的三段论拆分重叠,只是目标类别的信息严格更加有限,从而限制了其他可能帮助泛化的线索。
在创建评估问题时,我们为错误答案选择困难的干扰项,通过选择在数据集中对另一个实体具有目标关系的实体或属性。例如,如果正确答案是“gruds 是 rony”,其中一个干扰项可能是“gruds 是 zept”,而在数据集中存在另一条有效陈述,例如“telk 是 zept。” 因此,不可能仅仅通过单词的局部上下文猜测哪个答案是正确的。
- 类别保留:训练中只包含一个关于类别的事实:它的父类别是什么。对该事实的所有可能推论都进行了测试。这与某些方面的三段论拆分重叠,只是目标类别的信息严格更加有限,从而限制了其他可能帮助泛化的线索。
方法
评估
我们使用多项选择可能性评分进行评估。我们不在上下文中提供答案选项。
微调
我们的微调实验主要涉及在我们的数据集上调整Gemini 1.5 Flash(Team 等人,2024)。我们通常使用批量大小8或16和学习率 3 ⋅ 1 0 − 4 3 \cdot 10^{-4} 3⋅10−4 进行200-1000步的微调(取决于数据集大小和损失)。
上下文评估
为了进行全数据集的上下文评估,我们将训练数据集中的文档串联起来,并将其作为上下文提供给(指令调整的)模型。然后我们提示模型使用该上下文回答问题。在最大的数据集上进行上下文评估时,我们随机抽取文档的八分之一,因为在数据集中存在一些冗余,并且我们发现随着上下文长度的增加,模型会受到干扰。
数据集增强
我们进行数据集增强的关键方法是利用模型的上下文泛化能力来改善微调数据集的覆盖范围。我们通过几种方法来实现这一目标,但所有方法主要都旨在通过上下文推理来生成更多微调数据,从而在测试时改善非上下文环境下的泛化能力。
具体来说,我们考虑两种类型的增强:一种是局部策略,试图增加特定信息片段使用的灵活性;另一种是全局策略,试图关联不同信息片段。每种策略使用不同的上下文和提示(详见附录 A.1)。
局部(句子)增强:我们提示一个LM来增强每个训练数据点(例如句子),以提高模型编码它的灵活性。我们的提示包括重新表述和反转的例子。
全局(文档)增强:我们将完整的训练数据集作为上下文连接起来,然后提供一个特定的文档,并提示模型通过链接该文档与上下文中的其他文档来生成推理。这会导致更长的相关推理链。
句子分割
一些数据集,如 Berglund 等人(2024)的虚构名人数据集和我们的语义结构数据集,包含多句文档。我们发现将这些文档按句子级别分割成多个微调示例,可以显著提高微调性能——即使考虑到总数据集大小和梯度步骤也是如此。我们探索了两种将文档分割成句子的方法:1) 独立分割:其中所有句子都被独立分割成单独的训练示例,2) 累积分割:其中文档被分割,使得对于任何示例中的目标句子,文档中的所有前置句子都会添加到该示例的上下文中。对于一个n句文档,这两种方法都会产生n个训练示例,尽管上下文大小不同。我们在附录 B.1 中分析了句子分割对模型泛化的影响。在以下章节中,除非另有说明,我们假设独立句子分割。
实验
反转诅咒
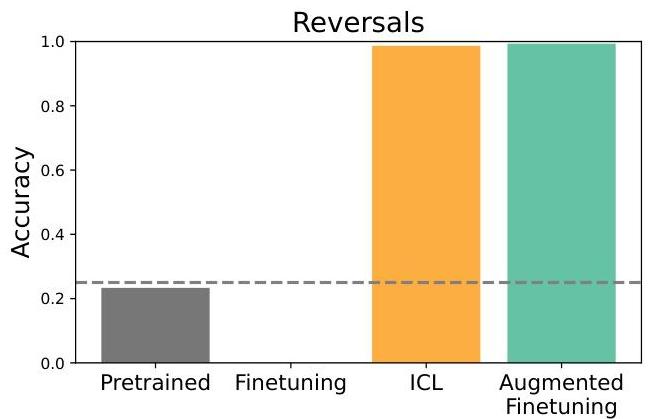
图2 | 反转诅咒论文结果。
在图2中,我们首先探索了Berglund等人(2024)发布的反转诅咒现象和数据集中的泛化问题。我们重现了作者的发现,即在正向方向上进行微调不会产生对反转的泛化。该工作的作者简要提到,在上下文中模型可以在这个任务上表现得更好。我们对此进行了更系统的研究,通过呈现整个数据集的上下文,发现模型在反转上的表现接近天花板——从而提供了上下文学习优于微调的强烈证明。使用上下文推理增强数据进行微调也产生了类似的高测试性能。另一方面,简单的微调几乎零准确率,因为微调后的模型总是倾向于那些在训练中作为目标看到的(错误)名人名称补全,无论上下文如何。最后,预训练模型在测试集上的表现接近随机水平,表明没有受到污染。
简单的无意义反转
接着,我们相应地测试了模型在我们简单的无意义版本的反转数据集上的表现(参见图3)。我们发现在这种设置下,上下文学习相对于微调的优势较弱,但仍明显,再次显示出增强微调的更强优势。与上述实验相比,收益差异可能是因为所涉及关系的合理性不同,例如,无意义词汇可能在某种程度上干扰模型对较长上下文的推理(见附录B.2)。
简单的三段论
接下来,我们测试了简单的三段论数据集(参见图3)。同样,预训练模型的表现接近随机水平,表明没有受到污染。在数据集上进行微调确实产生了一些超出随机水平的泛化;也许是因为对于某些类型的三段论,逻辑推理与更简单的语言模式兼容——例如,对序列如“All X include Y.” “All Y include Z.”进行调优,可能会使模型更容易预测“All X include Z.”。然而,由于这种方式,对于大多数三段论形式,遵循更简单的联想模式并不有效,例如,如果通用量词被存在量词替代。或许正因为如此,上下文学习产生了更强的表现;使用上下文学习来增强训练数据集进一步整体提升了表现。
语义结构基准
随后,我们测试了更广泛的语义结构基准(图4),它将多种泛化类型整合到更丰富的学习环境中。在这种环境下,我们评估了在以下方面的表现:a) 改写训练陈述(保持关系方向不变),在图中表示为“train”,b) 反转,c) 三段论推理,d) 关于保留类别的命题。在这些设置中,我们总体上发现上下文学习相较于微调具有优势,尽管这种优势的大小因拆分而异。我们发现即使是改写信息的泛化也有一定的提升,而反转和三段论方面则有更显著的提升。然而,类别保留拆分仍然很困难,上下文学习的提升也很小。此外,我们继续发现通过上下文推理增强微调数据可以改善微调表现,在许多情况下甚至超过上下文学习。(注意,在这种设置下,我们不对微调基线进行句子分割,因为我们发现这会损害表现,我们希望与最强的基线进行比较;带有句子分割的基线以及其他消融的结果可在附录B.4中找到。)
我们本节的结果还突显了先前关于反转诅咒结果的一个重要细微差别(Berglund 等人,2024)。当被测试的信息是更广泛连贯知识结构的一部分(如我们的语义结构)时,单独微调确实表现出一定程度超出随机水平的反转泛化。这种泛化可能是由于训练集中的其他信息可以支持反转结论;例如,如果反转是从“鸟类包括鹰”到“鹰是一种鸟类”,但训练集中还包括“鹰有翅膀”的陈述,那么这些信息可能能够通过联想(如果不是逻辑上)提供另一种推导反转的途径。尽管如此,上下文学习和增强微调继续表现出比单独微调更好的表现。
过程知识
我们还进行了一些初步实验,探索过程类型(而非语义)知识的学习和泛化。具体来说,我们专注于执行一个简单的伪数学程序,该程序是一个函数到函数变换,类似于求导数,但规则不常见。我们创建了一个训练-测试组合泛化拆分,在训练中可以看到某些规则组合,但在测试中保留其他组合。总体结果模式通常与上述一致——上下文学习优于微调,增强可以改善微调表现。然而,过程知识需要不同的评估方法,相应地,效果似乎是由与上述语义知识实验不同的因素驱动的;因此,我们在附录B.5中详细介绍了实验和结果。
相关工作
上下文学习:许多作品探索了上下文学习(Brown 等人,2020;Dong 等人,2022;Lampinen 等人,2024a)。一些作品研究了上下文学习的学习和泛化模式,无论是经验性的(Chan 等人,2022a;Garg 等人,2022),机制性的(Olsson 等人,2022),还是理论性的(Xie 等人,2023;Zhang 等人,2024)。几项最近的工作发现,即使扩展到数百或数千个上下文示例也能提高LM在具有挑战性的数据集上的表现
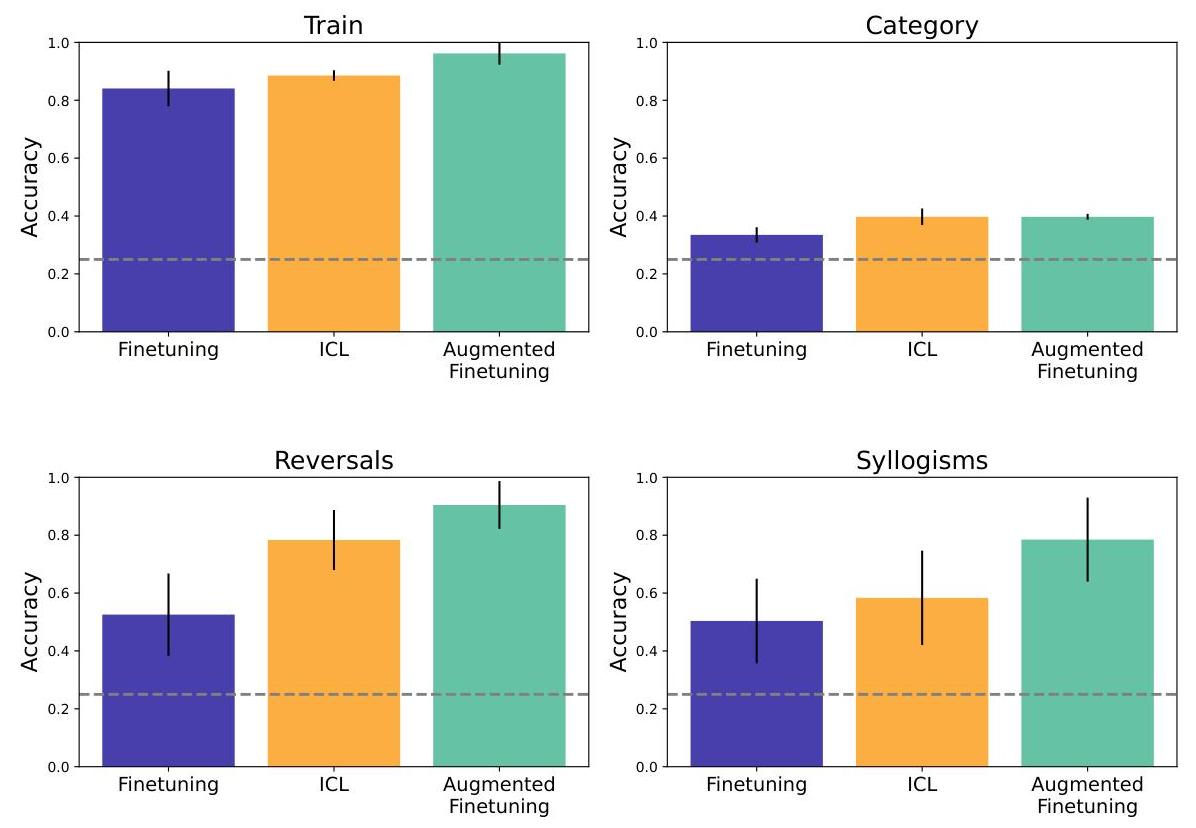
图4 | 在更结构化的语义数据集上,上下文学习仍适度优于微调。此外,增强继续显示出一些好处——即使在不需要反转的改写问题中。然而,某些泛化拆分,如类别级别的保留拆分,仍然非常具有挑战性。(误差棒是根据涉及不同类型推理的任务子集计算的标准误差,例如属性关系反转与类别包含关系反转。)
(Agarwal 等人,2024;Anil 等人,2024;Bertsch 等人,2024)。我们的工作同样依赖于模型从许多文档上下文中学习以生成增强推理的能力。
非上下文学习:其他几篇论文(例如 Berglund 等人,2023;Meinke 和 Evans,2023)考虑了模型如何“非上下文”泛化——也就是说,如何在测试时以灵活的方式使用未直接包含在提示中的信息。我们的结果可能与此相关,例如在语义结构数据集上微调时观察到的部分泛化模式。然而,我们通常不会发现可靠的非上下文信息使用作为上下文——即,上下文学习往往优于微调。
数据增强:大量的作品探索了如何使用LLM来增强数据以从小或窄数据集中获得更好的性能,例如提高跨语言泛化(例如 Whitehouse 等人,2023)。Ding 等人(2024)回顾了这一更广泛的文献。还有一些针对尝试修复特定问题(如反转诅咒)的硬编码增强(Golovneva 等人,2024)。Akyürek 等人(2024)的一项密切相关的工作提出了“演绎闭包训练”以通过提示语言模型从训练文档生成演绎推理来提高覆盖率。Padmanabhan 等人(2024)同样提议生成延续并将它们提炼到模型中。几项并发工作 Chen 等人(2024);Ruan 等人(2025)表明,让LM生成额外的推理方向,并使用这些来增强其训练数据,可以提高推理任务的性能。我们的实验表明,在受控设置中,没有任何数据集污染的可能性,类似的方法来增强小型微调数据集可以带来更好的泛化——并将性能与通过更基本的微调和上下文学习取得的性能联系起来。
合成数据:同样广泛的文献探索了合成数据在改进LM性能中的应用;参见 Liu 等人(2024)的最新调查。早期的作品考虑了手工设计的合成数据,旨在通过领域知识(如语言学或数学)来改进泛化(例如 Pratapa 等人,2018;Wu 等人,2021)。更近期的方法集中在直接从语言模型生成数据,要么通过过滤真实得分(Zelikman 等人,2022),要么简单地通过自一致性(Huang 等人,2023;Wang 等人,2023)。虽然一篇最近的突出文章认为在合成数据上训练会导致模型崩溃(Shumailov 等人,2024),其他作品指出在合成数据与原始数据混合的情况下性能继续提高(Gerstgrasser 等人,2024)。相应地,我们发现,在我们的设置中,合成增强数据不仅无害,反而始终提高性能(甚至在语义结构数据集的训练拆分中改写的信息上也是如此)。这些结果为如何结合合成数据影响模型性能的持续讨论做出了贡献。
讨论
在本文中,我们对语言模型如何从上下文学习和微调中泛化各种类型的新型信息进行了受控实验。总体而言,我们发现模型在多个维度上平均从上下文学习中泛化得更好。使用上下文学习来增强微调数据集可以利用两者互补的优势,从而获得更好的性能。
上下文学习和微调的不同归纳偏差:许多作品研究了上下文学习的归纳偏差。一个常见的主题是强调上下文学习可以在最佳行为设置中近似梯度下降(例如 Von Oswald 等人,2023)。然而,其他一些作品发现上下文学习的归纳偏差可以根据诸如数据集多样性(Raventós 等人,2024)或模型规模(Wei 等人,2023)等因素而变化。几项作品明确指出了上下文学习和微调的不同归纳偏差(Chan 等人,2022b;Shen 等人,2023)。我们的工作为此类发现做出了贡献。
可访问信息和通过思考学习:Lombrozo(2024)强调了“通过思考学习”是认知科学和人工智能最近进展中的一个统一主题——系统可以通过计算而不需进一步输入来提高性能。Lombrozo 强调,虽然表面上这可能看似矛盾——信息不能被创造——但这种进一步计算可以增加信息的可访问性,从而在实践中提高性能。这一论点与 Xu 等人(2020)关于计算如何增加信息可访问性的理论论述平行。我们使用上下文推理来提高微调性能超越原始数据,遵循这一模式。例如,关于反转和三段论的信息总是隐藏在数据中,但通过上下文推理进行微调会使这些信息更加明确,从而在测试时更容易获取。
训练时推理扩展:最近,各种作品开始探索测试时推理扩展以提高性能(例如 Guo 等人,2025;Jaech 等人,2024)。这些发现补充了先前研究如何通过扩展训练计算(例如通过更大的模型或更多数据)来提高性能(例如 Hoffmann 等人,2022;Kaplan 等人,2020)。我们的结果说明了通过上下文推理方法扩展训练时间计算可以帮助提高模型的一些泛化方面。
局限性:我们的工作存在几个局限性。首先,我们的主要实验依赖于
无意义单词和不切实际的操作。虽然这些反事实任务可以让我们避免数据集污染的可能性,但它们可能在某种程度上干扰模型的性能。例如,初步实验(附录 B.2)表明,如果将名字替换为无意义的单词,Reversal Curse 数据集上 ICL 的模型性能会下降。因此,包含更合理实体的任务可能会从 ICL 中获得更多益处。有可能微调使无意义术语更熟悉,这有助于缩小增强微调和 ICL 之间的差距。然而,在这种情况下,我们可能低估了 ICL 和基础微调之间的差距(因为后者实际上会从无意义实体的“熟悉度”增加中受益)。其次,我们尚未对其他语言模型进行实验,这将增强我们结果的一般性。然而,由于我们建立在个别现象之上——例如微调时的反转诅咒(Berglund 等人,2024)与上下文中进行反转的能力(例如 Lampinen 等人,2024b)——已经在多个模型中得到记录,我们认为将我们的结果推广到其他设置是合理的。然而,未来的工作应更仔细地研究模型在这些设置中学习和泛化的差异,包括更新的推理模型(例如 Guo 等人,2025)。
结论:我们探索了语言模型在接触各种类型的新颖信息结构时,上下文学习和微调的泛化情况。我们发现了显著的差异——通常 ICL 在某些类型的推理上泛化得更好——并提出了通过将上下文推理添加到微调数据中来实现更好性能的方法。我们希望这项工作将有助于理解基础模型中学习和泛化的科学,并实际改进它们以适应下游任务。
致谢
我们要感谢以下人士提供的有益讨论:Sridhar Thiagarajan、Mike Mozer、Amal Rannen-Triki、Andrey Zhmoginov、
Preethi Lahoti、Dilan Gorur、Johannes von Oswald。我们还要感谢Shakir Mohamed、Dipanjan Das、Raia Hadsell、Slav Petrov、Andrew Dai、Ruibo Liu、Tom Kwiatkowski和Lukas Dixon的支持。
参考文献
R. Agarwal, A. Singh, L. M. Zhang, B. Bohnet, L. Rosias, S. C. Chan, B. Zhang, A. Faust, and H. Larochelle. 多镜头上下文学习。在ICML 2024 Workshop on In-Context Learning, 2024.
A. F. Akyürek, E. Akyürek, L. Choshen, D. Wijaya, and J. Andreas. 语言模型的演绎闭合训练以实现连贯性、准确性和可更新性。Findings of the Association for Computational Linguistics, 2024.
C. Anil, E. Durmus, N. Rimsky, M. Sharma, J. Benton, S. Kundu, J. Batson, M. Tong, J. Mu, D. J. Ford, 等人。多镜头越狱。在第三十八届年度神经信息处理系统会议,2024。
L. Berglund, A. C. Stickland, M. Balesni, M. Kaufmann, M. Tong, T. Korbak, D. Kokotajlo, 和 O. Evans. 被移除上下文:在Ilms中衡量情境意识。arXiv预印本arXiv:2309.00667, 2023。
L. Berglund, M. Tong, M. Kaufmann, M. Balesni, A. C. Stickland, T. Korbak, 和 O. Evans. 反转诅咒:经过"a是b"训练的Llms无法学习"b是a"。在第十二届国际学习表示会议,2024。
A. Bertsch, M. Ivgi, U. Alon, J. Berant, M. R. Gormley, 和 G. Neubig. 长上下文模型中的上下文学习:深入探索。arXiv预印本arXiv:2405.00200, 2024。
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, 等人。语言模型是少样本学习者。神经信息处理系统进展,33:1877-1901, 2020。
S. Chan, A. Santoro, A. Lampinen, J. Wang, A. Singh, P. Richemond, J. McClelland, 和
F. Hill. 数据分布特性驱动变压器中情境学习的出现。神经信息处理系统进展,35:18878-18891, 2022a。
S. C. Chan, I. Dasgupta, J. Kim, D. Kumaran, A. K. Lampinen, 和 F. Hill. 变压器从存储在上下文中的信息和存储在权重中的信息中概括的方式不同。MemARI研讨会,NeurIPS,2022b。
J. C.-Y. Chen, Z. Wang, H. Palangi, R. Han, S. Ebrahimi, L. Le, V. Perot, S. Mishra, M. Bansal, C.-Y. Lee, 等人。逆向思维使llms成为更强的推理者。arXiv预印本arXiv:2411.19865, 2024。
B. Ding, C. Qin, R. Zhao, T. Luo, X. Li, G. Chen, W. Xia, J. Hu, L. A. Tuan, 和 S. Joty. 使用llms进行数据增强:数据视角、学习范式和挑战。在ACL 2024计算语言学协会发现,第1679-1705页,2024。
Q. Dong, L. Li, D. Dai, C. Zheng, J. Ma, R. Li, H. Xia, J. Xu, Z. Wu, T. Liu, 等人。上下文学习综述。arXiv预印本arXiv:2301.00234, 2022。
C. Gao, S. V. Shinkareva, 和 R. H. Desai. SCOPE:南卡罗来纳州心理语言学元数据库。行为研究方法,55(6):2853-2884, 2023。
S. Garg, D. Tsipras, P. S. Liang, 和 G. Valiant. 变压器在上下文中可以学到什么?一个简单函数类的案例研究。神经信息处理系统进展,35: 30583-30598, 2022。
M. Gerstgrasser, R. Schaeffer, A. Dey, R. Rafailov, H. Sleight, J. Hughes, T. Korbak, R. Agrawal, D. Pai, A. Gromov, 等人。模型崩溃不可避免吗?通过积累真实和合成数据打破递归诅咒。arXiv预印本arXiv:2404.01413, 2024。
M. Geva, R. Schuster, J. Berant, 和 O. Levy. 变压器前馈层是键值记忆。在《2021年自然语言处理实证方法会议论文集》,第5484-5495页,在线和普拉塔卡纳,多米尼加共和国,
2021. 计算语言学协会。doi: 10.18653/v1/2021.emnlp-main. 446. URL https://aclanthology.org/ 2021. emnlp-main. 446。
2022. O. Golovneva, Z. Allen-Zhu, J. Weston, 和 S. Sukhbaatar. 反向训练以治愈反转诅咒。arXiv预印本arXiv:2403.13799, 2024。
2023. D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, 等人。Deepseek-r1:通过强化学习激励llms的推理能力。arXiv预印本arXiv:2501.12948, 2025。
2024. J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, 等人。训练计算最优的大语言模型。在《第36届神经信息处理系统国际会议论文集》,第30016-30030页,2022。
2025. J. Huang, S. S. Gu, L. Hou, Y. Wu, X. Wang, H. Yu, 和 J. Han. 大语言模型可以自我改进。在《2023年自然语言处理实证方法会议》,2023。
2026. A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. ElKishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, 等人。OpenAI o1系统卡。arXiv预印本arXiv:2412.16720, 2024。
2027. J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, 和 D. Amodei. 神经语言模型的缩放定律。arXiv预印本arXiv:2001.08361, 2020。
2028. Y. Kirstain, P. Lewis, S. Riedel, 和 O. Levy. 再多几个例子可能就相当于数十亿参数。在《计算语言学学会:EMNLP 2022的发现》卷2022,第1017-1029页。ACL Anthology, 2022。
2029. A. K. Lampinen, S. C. Chan, A. K. Singh, 和 M. Shanahan. 更广泛的上下文学习光谱。arXiv预印本arXiv:2412.03782, 2024a。
2030. A. K. Lampinen, I. Dasgupta, S. C. Chan, H. R. Sheahan, A. Creswell, D.Kumaran, J. L. McClelland, 和 F. Hill. 语言模型,如同人类一样,在推理任务中表现出内容效应。PNAS nexus, 3(7):pgae233, 2024b。Liu, J. Wei, F. Liu, C. Si, Y. Zhang, J. Rao, S. Zheng, D. Peng, D. Yang, D. Zhou, 等人。语言模型的最佳实践和合成数据的经验教训。arXiv预印本arXiv:2404.07503, 2024。
2031. T. Lombrozo. 通过思考学习在自然和人工心智中。认知科学趋势,2024。
2032. A. Meinke 和 O. Evans. 告诉,而不是展示:声明性事实影响llms如何泛化。arXiv预印本arXiv:2312.07779, 2023。
2033. C. Olsson, N. Elhage, N. Nanda, N. Joseph, N. DasSarma, T. Henighan, B. Mann, A. Askell, Y. Bai, A. Chen, 等人。上下文学习和归纳头。arXiv预印本arXiv:2209.11895, 2022。
2034. S. Padmanabhan, Y. Onoe, M. Zhang, G. Durrett, 和 E. Choi. 通过蒸馏将知识更新传播到LMs。神经信息处理系统进展,36, 2024。
2035. A. Pratapa, G. Bhat, M. Choudhury, S. Sitaram, S. Dandapat, 和 K. Bali. 混合编码的语言建模:基于语言理论的合成数据的作用。在《计算语言学学会第56届年会论文集(卷1:长篇论文)》,第1543-1553页,2018。
2036. A. Raventós, M. Paul, F. Chen, 和 S. Ganguli. 预训练任务多样性与回归的非贝叶斯上下文学习的出现。神经信息处理系统进展,36, 2024。
2037. T. T. Rogers 和 J. L. McClelland. 语义认知的摘要:平行分布式处理方法。行为与大脑科学,31(6): 689-714, 2008。
2038. Y. Ruan, N. Band, C. J. Maddison, 和 T. Hashimoto. 推理以从潜在思想中学习。arXiv预印本arXiv:2503.18866, 2025。
2039. L. Ruis, M. Mozes, J. Bae, S. R. Kamalakara, D. Talupuru, A. Locatelli, R. Kirk, T. Rocktäschel, E. Grefenstette, 和 M. Bartolo. 预训练中的程序知识驱动大型语言模型中的推理,2024年11月。URL http://arxiv.org/abs/2411.12580. arXiv:2411.12580 [cs]。
2040. J. Russin, E. Pavlick, 和 M. J. Frank. 人类课程效果在神经网络的上下文学习中显现。ArXiv.
2041. L. Shen, A. Mishra, 和 D. Khashabi. 预训练变压器是否真的通过梯度下降进行上下文学习?arXiv预印本arXiv:2310.08540, 2023。
2042. I. Shumailov, Z. Shumaylov, Y. Zhao, N. Papernot, R. Anderson, 和 Y. Gal. 在递归生成的数据上训练时,AI模型崩溃。自然,631(8022):755-759, 2024。
2043. G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican, 等人。Gemini:一个功能强大的多模态模型家族。arXiv预印本arXiv:2312.11805, 2023。
2044. G. Team, P. Georgiev, V. I. Lei, R. Burnell, L. Bai, A. Gulati, G. Tanzer, D. Vincent, Z. Pan, S. Wang, 等人。Gemini 1.5:解锁数百万标记上下文中的多模态理解。arXiv预印本arXiv:2403.05530, 2024。
2045. J. Treutlein, D. Choi, J. Betley, S. Marks, C. Anil, R. Grosse, 和 O. Evans. 连接点:LLMs可以从不同的训练数据中推断并表达潜在结构。arXiv预印本arXiv:2406.14546, 2024。
2046. I. Vieira, W. Allred, S. Lankford, S. Castilho, 和 A. Way. 多少数据才够?微调大型语言模型用于内部翻译:跨多个数据集大小的性能评估。在《第16届美洲机器翻译协会会议论文集》(第1卷:研究轨道),第236-249页,2024。
2047. J. Von Oswald, E. Niklasson, E. Randazzo, J. Sacramento, A. Mordvintsev, A. Zhmoginov, 和 M. Vladymyrov. 变压器通过梯度下降进行上下文学习。在国际机器学习会议上,第35151-35174页。PMLR, 2023。
2048. X. Wang, J. Wei, D. Schuurmans, Q. V. Le, E. H. Chi, S. Narang, A. Chowdhery, 和 D. Zhou. 自一致性改进了语言模型中的链式推理。在第十届国际学习表示会议,2023。
2049. J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. Chi, Q. Le, 和 D. Zhou. 链式提示法引出大语言模型中的推理。arXiv:2201.11903 [cs], Jan. 2022. URL http://arxiv.org/abs/2201. 11903. arXiv: 2201.11903。
2050. J. Wei, J. Wei, Y. Tay, D. Tran, A. Webson, Y. Lu, X. Chen, H. Liu, D. Huang, D. Zhou, 等人。更大的语言模型以不同的方式进行上下文学习。arXiv预印本arXiv:2303.03846, 2023。
2051. C. Whitehouse, M. Choudhury, 和 A. F. Aji. 使用LLM增强数据以提高跨语言性能。在《2023年实证方法在自然语言处理会议》,2023。
2052. Y. Wu, M. N. Rabe, W. Li, J. Ba, R. B. Grosse, 和 C. Szegedy. LIME:学习数学推理原语的归纳偏差。在国际机器学习会议上,第11251-11262页。PMLR, 2021。
2053. S. M. Xie, A. Raghunathan, P. Liang, 和 T. Ma. 上下文学习作为隐式贝叶斯推理的解释。在国际学习表示会议上,2023。
2054. Y. Xu, S. Zhao, J. Song, R. Stewart, 和 S. Ermon. 在计算约束下的可用信息理论。在国际学习表示会议上,2020。
2055. E. Zelikman, Y. Wu, J. Mu, 和 N. Goodman. STAR:通过推理引导推理。神经信息处理系统进展,35:15476-15488, 2022。
2056. R. Zhang, S. Frei, 和 P. L. Bartlett. 训练后的变压器在上下文中学习线性模型。机器学习研究期刊,25(49):1-55, 2024。
A. 补充方法
A.1 提示
在本节中,我们提供了用于增强的提示。相关的提示部分按照相应的内容进行了格式化。
LOCAL_PROMPT = {
‘请生成可以从每个句子单独推断出的可能的新陈述和改写。即使是一个简单的句子也有一些逻辑等价的替代表述。请仅使用逻辑和语言得出您的结论,无论所涉及的实体是否存在。\n’,
‘Statement: trillips 比 zax 更高。’,
‘Inferences: trillips 的高度比 zax 高。zax 比 trillips 矮。zax 的高度低于 trillips。’,
‘Statement: 注意:工程比科学更简单。’,
‘Inferences: 科学比工程更复杂。工程比科学更不复杂。工程不如科学复杂。’,
‘Statement: “{text_to_augment}”’,
}
GLOBAL_PROMPT = (
‘我将给你一堆文档,然后请使用它们作为上下文来推导出你能从最终目标文档中产生的所有逻辑结果。首先,这里是源文档:\n\n’
‘{full_context}\n\n’
‘现在,请使用该上下文帮助我改写此文档或推导出其包含的陈述的结果。请尽可能明确地陈述所有结果,遵循源文档的格式,并尽可能完整。\n’
‘{target_document}\n’
)
对于我们的某些消融实验,我们还使用了一个没有全局上下文的文档级提示:
DOCUMENT_PROMPT = (
‘请生成可以从每个文档单独逻辑推断出的可能的新命题。即使是一个简单的句子也有一些逻辑等价的替代表述,并且组合句子通常会产生新的逻辑推断。请仅使用逻辑和语言得出您的结论,无论所涉及的实体是否存在。\n’
)
B. 补充实验和消融
B.1 句子分割的影响
我们分析了在句子级别分割训练文档的影响。具体来说,我们研究了句子分割对语义结构基准测试的影响,包括有无增强的情况。在这个实验中,我们使用了两种局部增强方法,1) 句子增强:其中提示的语言模型使用局部提示重新表述文档中的每个句子 (参见 A.1),2) 文档增强:其中提示的 LM 使用文档提示在文档级别生成增强 (参见 A.1)。该实验的结果如图5所示。从图中可以看出,在采用增强的情况下,句子分割始终有所帮助。
然而,在纯微调基线(即)没有增强的情况下,句子分割有时会使性能变得更差。这表明当一个事实以多种方式在一个文档中呈现时——这是增强基线的情况——那么将这些改写分割成不同的例子作为目标提供了一个更好的学习信号给模型。例如,在独立句子分割的情况下,增强数据的好处可能来自于避免一种“解释消除”现象——如果上下文已经使某条信息变得可能,模型就不会从该信息的梯度更新中学得那么有效。
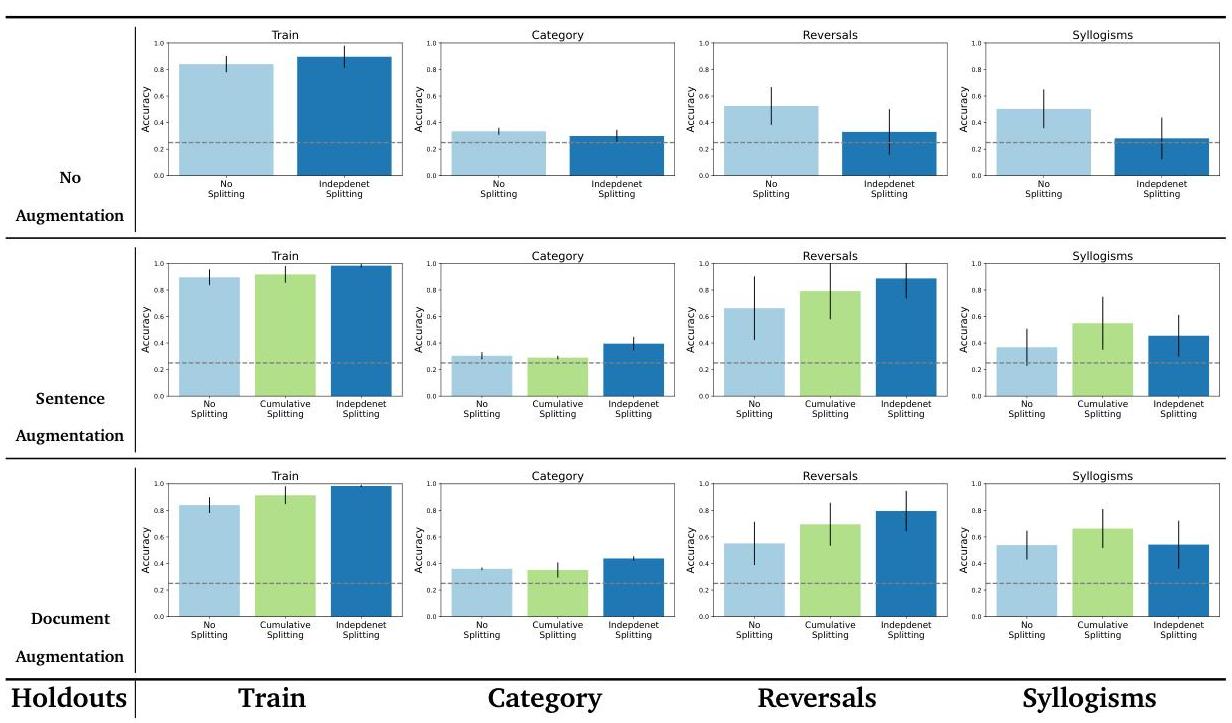
图5 | 语义结构基准测试上的句子分割分析。这些图表显示了在训练数据集中按句子级别分割文档时的微调表现。我们可以观察到,除了数据集的增强变体外,句子分割始终改善表现。
B.2. 无意义化和长上下文ICL
在主文中,我们观察到全数据集上下文评估在Berglund等人(2024)的反转任务上表现非常出色(参见图2)。然而,对于无意义反转,ICL的表现相对较低(参见图3)。我们推测这种表现差异可以归因于简单反转任务中使用的无意义名词,因为LLM对这些无意义名词没有良好的语义先验,因此无法有效地利用其长上下文来进行ICL。为了验证这一假设,我们修改了Berglund等人(2024)的数据集,将所有名人名字无意义化。
对这个修改后的数据集进行全数据集ICL导致性能显著降低,如图6所示。这个实验表明,如果模型对上下文没有良好的先验(例如,如果上下文中包含许多无意义词),模型可能无法有效地使用其长上下文。我们将对这一假设进行更系统的研究留待未来工作。
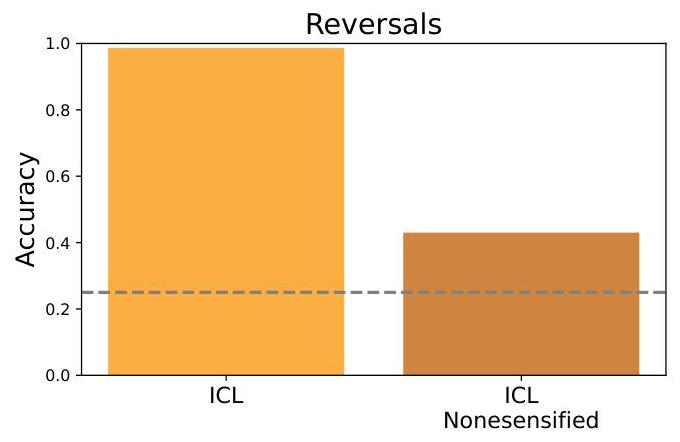
图6 | Berglund等人(2024)数据集中名人名字无意义化前后ICL的比较。
B.3. 模型规模的影响
在主文中,我们报告了Gemini 1.5 Flash模型的结果。为了查看模型规模如何影响结果,我们将较小的Gemini 1.5 Flash-8B模型与较大的Gemini 1.5 Flash模型进行比较。两个模型的比较结果如图7所示。我们可以看到,无论模型规模如何,增强微调的表现都更好。此外,对于较小的Flash-8B模型,在某些拆分上(如三段论),上下文全数据集评估(ICL)的表现比普通微调差。这与现有文献一致,表明小模型不是高效的上下文学习者。然而,需要注意的是,即使在这种较小模型规模下,增强微调也提供了更强的泛化能力。
B.4. 不同提示的有效性
我们现在比较主文中提出的不同增强方法的表现。为此,我们使用两种局部增强方法:句子增强:其中提示的语言模型使用局部提示重新表述文档中的每个句子;文档增强:其中提示的LM使用仅限文档的提示在文档级别生成增强;以及一种全局增强方法,其中提示的LLM通过连接训练数据集中的所有文档并使用全局提示生成推理。实验结果如图8所示。从图中可以看出,任何类型的增强都始终优于无增强基线(证实了主文中的发现)。此外,我们可以看到,在不同的保留拆分中,不同的增强方法表现更好或更差(尽管差异不大)。总体而言,我们发现全局增强在语义结构数据集的所有保留类型中通常表现更好。
B.5. 过程基准
我们在“过程”基准上进行了探索性分析,该基准测试模型应用新程序到输入的能力。这不同于学习“语义”事实数据,因为其他基准是设计用来测试的。
我们初步结果显示了低样本微调的数据增强带来的好处。我们在此处完整列出它们,并将其作为数据高效微调剩余的开放挑战。
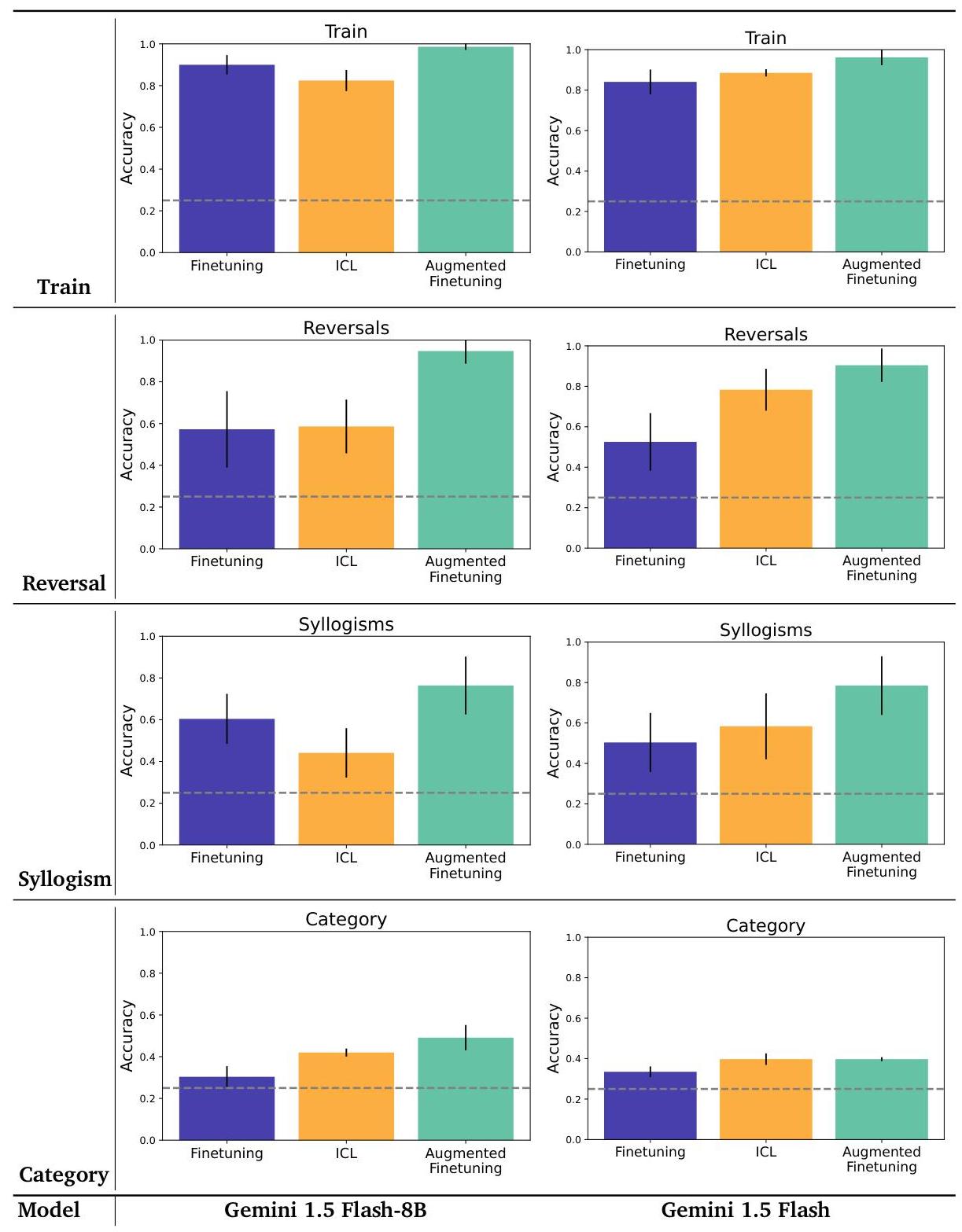
图7 | 模型规模的影响。这里我们比较了使用两种不同规模模型在语义结构基准上进行全数据集评估(ICL)与微调的结果。我们发现在不同的模型规模下,增强微调始终带来一致的提升。
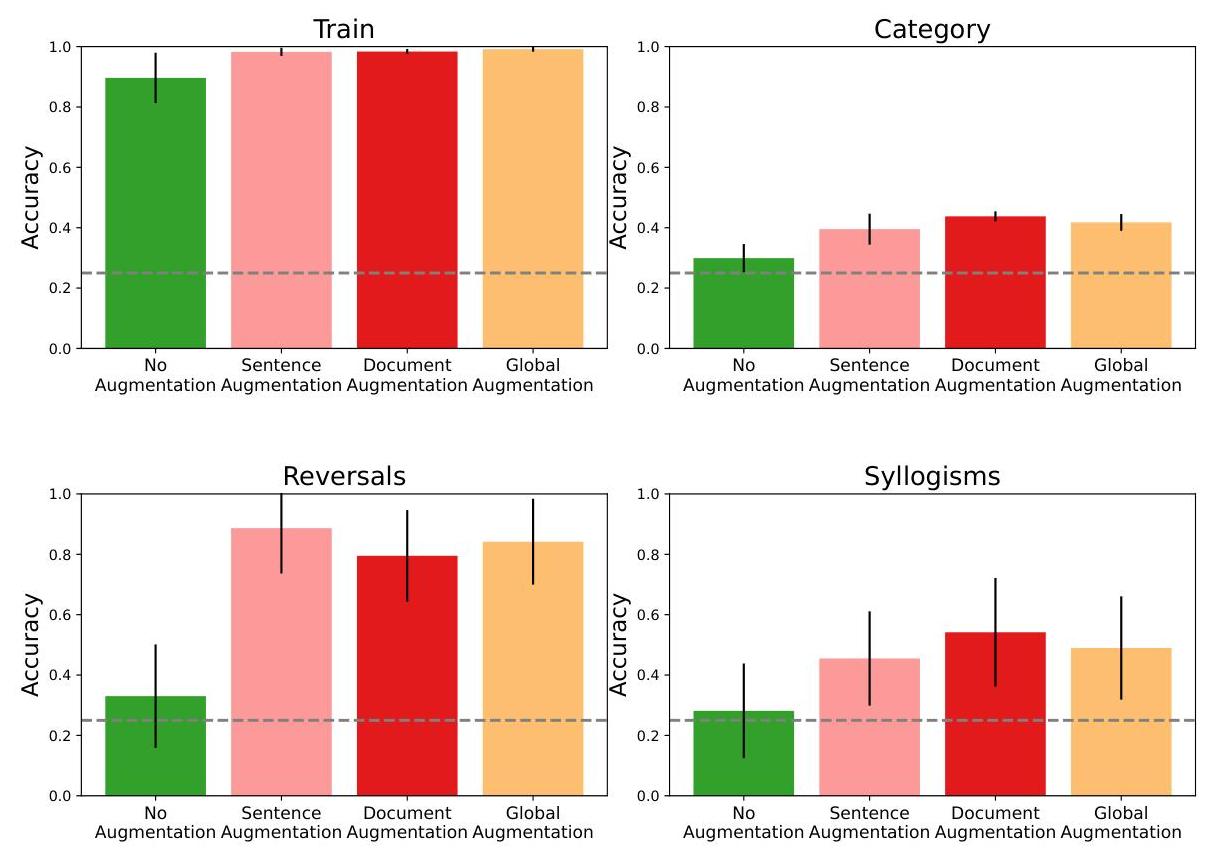
图8 | 语义结构数据集上不同增强方法的比较。增强相比无增强微调带来了显著改进。在不同的保留拆分中,不同的增强方法表现各有优劣;因此,将它们结合起来(如主结果中所示)提供了互补的好处。(所有方法均使用独立句子分割,包括无增强基线。误差棒是在涉及不同类型推理的任务子集上计算的。)
| 原始族 | original → \rightarrow → derivatoid |
|---|---|
| 指数 | b x → x b b^{x} \rightarrow x^{b} bx→xb |
| 多项式 | c × x e → ( c + e ) × x ( e + 2 ) c \times x^{e} \rightarrow(c+e) \times x^{(e+2)} c×xe→(c+e)×x(e+2) |
| (针对每一项) | |
| 对数 | log ( x \log (x log(x, base ) → log b log b ( x ) ) \rightarrow \log _{b} \log _{b}(x) )→logblogb(x) |
| 三角函数 | sin → \sin \rightarrow sin→ meep |
| cos → \cos \rightarrow cos→ morp | |
| tan → \tan \rightarrow tan→ moop |
表 1 ∣ 1 \mid 1∣ “原始”的derivatoid转换规则。
| 组合类型 | original → \rightarrow → derivatoid |
|---|---|
| 加法 | u + v → d u − d v u+v \rightarrow d u-d v u+v→du−dv |
| 乘法 | u × v → v ∗ u + d u ∗ d v u \times v \rightarrow v * u+d u * d v u×v→v∗u+du∗dv |
| 组合 | u ( v ) → d u ∗ d v ∗ d v ( u ) u(v) \rightarrow d u * d v * d v(u) u(v)→du∗dv∗dv(u) |
表 2 ∣ 2 \mid 2∣ “原始”表达式的组合的derivatoid转换规则,其中 u u u和 v v v为原始,而 d u d u du和 d v d v dv为它们的derivatoids(如表1定义)。
过程基准描述:“Derivatoids”
该基准旨在测试模型从示例中学习新“过程”的能力。在这里,过程是对输入的转换。这与学习事实或语义(由上述语义结构基准测试)形成对比,因为过程可能以与事实不同的方式被学习和表示(例如,Geva 等人,2021;Ruis 等人,2024)。
我们设定了几个目标:(a) 这些过程对预训练的LM来说并不熟悉,要求模型超越将熟悉的流程映射到新符号,因为模型可以简单地学习潜在于该现有流程中的映射(Treutlein 等人,2024)。(b) 同时,任务主要使用熟悉的单词和符号,以避免标记化问题。
为了满足这些目标,我们设计了“derivatoids”,这是一种类似导数的数学表达式转换。“原始”表达式根据表1进行转换,而原始的组合则根据表2进行转换。例如,输入 ( log ( x , 39 ) ) ∗ ( 64 ∗ ∗ x ) (\log (x, 39)) *(64 * * x) (log(x,39))∗(64∗∗x) 应该转换为 ( 64 ∗ ∗ x ) ∗ ( log ( x , 39 ) ) + ( log 39 log 39 ( x ) ) ∗ ( x ∗ ∗ 64 ) (64 * * x) *(\log (x, 39))+(\log 39 \log 39(x)) *(x * * 64) (64∗∗x)∗(log(x,39))+(log39log39(x))∗(x∗∗64)。
原始的组合允许我们评估组合泛化 - 模型在训练中见过原始成分但未见过特定组合时的表现。例如,我们可能会在[指数乘以多项式]和[对数乘以三角函数]上进行训练,并在[指数乘以对数函数]上进行评估。
在我们的实验中,我们通过创建包含 k k k个“shot”的数据集来探索ICL和SFT的数据效率。例如,SFT的8个“shot”数据集由标准训练数据集中的8个示例组成。ICL的8-shot数据集包含8个过程示例(表达式输入和表达式输出)作为上下文以演示derivatoids过程,并最终查询一个需要模型提供正确derivatoid的表达式。
方法
我们通过计算模型输出的ROUGE-L来进行评估,使用正确的derivatoid输出作为参考。
我们通常以批量大小8和学习率 1 ⋅ 1 0 − 5 1 \cdot 10^{-5} 1⋅10−5进行微调。我们根据验证损失选择了学习率和微调检查点,该验证损失是在从与训练集相同分布中抽取的未见derivatoid示例集上计算的。
实验
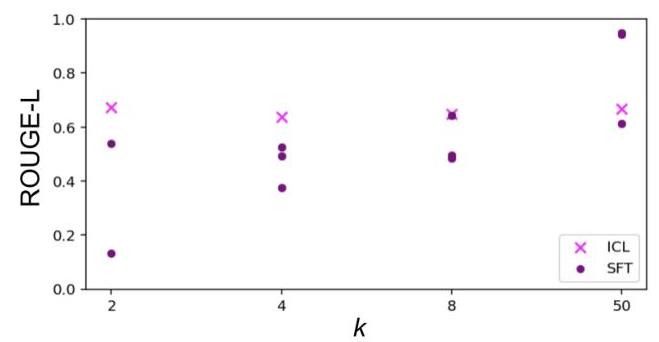
图9 | 上下文学习(ICL)与监督微调(SFT)的数据效率比较。 k k k是每种方法看到的不同示例数量——上下文中的“shot”数量(对于ICL)或训练示例数量(对于SFT)。对于ICL结果,我们在3000个样本中取平均值,每个样本包含一个 k k k-shot示例。对于SFT,鉴于微调的相对成本,我们仅评估3个不同的数据集,每个数据集包含 k k k个示例;每个紫色点代表一个数据集和一次训练运行。
在图9中,我们检查了在过程基准上上下文学习(ICL)和监督微调(SFT)的数据效率。数据效率是根据看到的独特示例数量 k k k(使用少样本学习术语中的“shot”数量)来衡量的。对于ICL, k k k是上下文中看到的示例数量,而对于SFT, k k k是训练数据中的独特示例数量(模型在多个epoch上进行训练)。我们发现随着 k k k增加,ICL的表现令人惊讶地稳定,而SFT的表现可预测地随着 k k k增加而提高。通常情况下,ICL在低 k k k时表现优于SFT,表现出更高的数据效率。
本节中的所有结果都是针对过程基准的版本,其中原始元素通过乘法组合,并且评估是基于模型执行组合泛化的能力建立的,即在保留的组合集合上进行评估,其中单个原始元素(例如多项式和三角函数)在训练中见到过,但特定的组合未在训练中见到。令人惊讶的是,在我们所有的实验中,组合泛化的表现与分布内泛化(即在训练中见过的相同组合的新示例,例如多项式与对数函数的新组合)非常相似。
我们探讨了增强微调以提高SFT的性能,特别是在SFT通常在少样本场景中被ICL超越的情况下,显示出潜在的改进空间。
我们首先应用了训练时间增强,这些增强包括对提示输入的原始类别和组合的“反思”。例如,对于输入“ ( 3 5 ∗ ∗ x ) ∗ ( sin ( x ) ) \left(35^{* *} \mathrm{x}\right) *(\sin (\mathrm{x})) (35∗∗x)∗(sin(x))”,完整的响应应该看起来像“Reflection: 这看起来像是一个指数函数乘以一个三角函数。Answer: ( sin ( x ) ) ∗ ( 3 5 ∗ ∗ x ) + ( x ∗ ∗ 35 ) ∗ ( meep ( x ) ) . " (\sin (\mathrm{x})) *\left(35^{* *} \mathrm{x}\right)+\left(\mathrm{x}^{* *} 35\right) *(\operatorname{meep}(\mathrm{x})) . " (sin(x))∗(35∗∗x)+(x∗∗35)∗(meep(x))." 这些增强是在训练数据中自动编程生成的,作为一种上限效果(以区分增强生成本身的效果,这可能对提示等非常敏感)。我们发现这样的增强对8-shot SFT(图11)有所改善,而对于4-shot SFT(图10)改善较少。
为了更好地理解8-shot SFT的好处来源,我们进行了一系列额外实验:
- 为了理解这种效果发生在训练时间还是测试时间,我们还尝试翻转响应的顺序,使得反思出现在答案之后。例如,“Answer: ( sin ( x ) ) ∗ (\sin (\mathrm{x}))^{*} (sin(x))∗ ( 3 5 ∗ ∗ x ) + ( x ∗ ∗ 35 ) ∗ \left(35^{* *} \mathrm{x}\right)+\left(\mathrm{x}^{* *} 35\right)^{*} (35∗∗x)+(x∗∗35)∗ (meep(x)). Reflection: 这看起来像是一个指数函数乘以一个三角函数。”这并没有导致相同的性能提升。这可能是因为增强效果主要是测试时间效果(参见“链式思维推理”(Wei et al., 2022)),或者因为增强不能以正确的方式影响训练时间的表示,特别是考虑到增强的形式“这看起来像…”,当它们跟随最终答案而不是输入时,不太合理。
-
- 为了理解这种方法对特定增强的敏感性,我们使用语言模型生成类似的增强。这些提示增强并未导致相同的性能提升;然而,这个提示并未经过任何调整(详见附录A.1)。
-
- 为了理解增强是否作为“聚类标签”对类似示例起作用(例如,以便相关示例能够更好地相互支持学习),我们将某些词替换为无意义词,但使用一致的映射,例如“线性”始终映射为“Glon”。无意义词对于模型来说更加超出分布,实际上可能导致性能下降。因此,我们还尝试对模型进行更长时间的训练(200步而不是100步),并使用真实词而不是无意义词
- 例如“操作A”和“操作B”。然而,这些干预措施都没有超过基线非增强性能。
- 为了理解模型是否受益于不特定于手头问题的数学类增强,例如通过将模型更多地转向数学类人格,我们还尝试用随机数学陈述进行增强(见附录A.1中的示例)。这些增强没有导致相同的性能提升。
参考论文:https://arxiv.org/pdf/2505.00661



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











