






Jiuqiang Tang* Raman Sarokin* George LLC Google LLC
Juhyun Lee* Google LLC
Ekaterina Ignasheva † { }^{\dagger} † Meta Platforms, Inc.
Grant Jensen Google LLC
林晨
Google LLC
摘要
受生成式AI的进步驱动,大型机器学习模型已经革新了图像处理、音频合成和语音识别等领域。尽管基于服务器的部署仍然是性能峰值的核心,但由于隐私和效率方面的考虑,设备端推理的需求依然存在。鉴于GPU是覆盖范围最广的设备端ML加速器,我们提出了ML Drift——一个优化框架,扩展了最先进的GPU加速推理引擎的能力。ML Drift实现了包含比现有设备端生成AI模型多10到100倍参数的生成AI工作负载的设备端执行。ML Drift解决了与跨GPU API开发相关的复杂工程挑战,并确保在移动和桌面/笔记本平台上的广泛兼容性,从而促进了资源受限设备上显著更复杂的模型的部署。我们的GPU加速的ML/AI推理引擎相对于现有的开源GPU推理引擎实现了数量级的性能提升。
1. 引言
过去十年见证了大型生成模型的迅速普及,这些模型彻底改变了图像合成和自然语言处理等领域,特别是在服务器端。尽管基于服务器的部署提供了大量的计算资源,但设备端执行对于用户隐私、降低延迟、离线功能和减少服务器成本仍然至关重要。在流行的设备端处理单元中,如CPU、GPU和NPU,移动GPU因其广泛的可用性和内在的计算能力而脱颖而出,因此为这些复杂模型的部署提供了一个普遍适用的解决方案。然而,现代生成模型以其巨大的规模著称,其参数通常比前一代模型大10到100倍,这给移动GPU上的部署带来了重大工程挑战。现有的设备端推理框架难以管理增加的内存和计算需求,这可能是一到两个数量级的增长,导致性能瓶颈和有限的可扩展性。
本文介绍了ML Drift,这是一种优化的推理框架,旨在解决大型生成模型在GPU上的部署挑战。关键创新包括:(1) 张量虚拟化,将逻辑索引与物理GPU索引解耦,并通过坐标转换实现灵活的内存布局和内核优化;(2) 针对不同GPU的全面优化,包括通过后端特定着色器实现设备专业化、内存管理、操作融合和阶段感知LLM优化。此外,本文还展示了ML Drift在移动(Arm和Qualcomm)、桌面(Intel和NVIDIA)和Apple GPU上的详尽性能评估,显示相对于现有开源引擎的数量级改进。
2. 相关工作
边缘设备的资源受限特性给机器学习模型的有效部署带来了重大挑战。这种限制促使了大量研究,旨在优化这些环境中的推理性能。这些努力可以大致分为利用通用GPU、专用推理框架以及最近针对边缘设备部署大型生成模型的复杂性进行的研究。
通用GPU推理 大部分现有的GPU加速推理工作依赖于厂商特定的库,如TensorRT [41] 和ROCm [3]。虽然这些解决方案在各自硬件平台上最大化性能方面非常有效,但它们本质上受到架构特异性的限制,降低了在多样化GPU生态系统中的可移植性。ML Drift通过优先考虑在广泛后端上的性能优化而区别于其他解决方案,例如OpenCL [1], Metal [20], OpenGL ES [27], Vulkan [2], 和WebGPU [53],超出了其他解决方案[26, 31] 的范围。
异构边缘设备的推理引擎 针对边缘设备优化推理引擎,特别是利用异构硬件(CPU、GPU和NPU),一直是主要的研究重点。硬件和操作系统供应商响应这一需求,提供了专门的SDK,旨在最大化其专有硬件上的推理性能。值得注意的例子包括Apple CoreML [6], Arm Compute Library [7], 华为HiAI Engine [19], Intel OpenVINO [21], MediaTek NeuroPilot [32], Microsoft DirectML [35], 和Qualcomm Neural Processing SDK [44]。虽然这些SDK在其指定生态系统内提供了显著的性能优势,但其固有的厂商依赖性引发了对跨平台可移植性和部署灵活性的关注。相比之下,各种跨平台框架已出现,旨在提供更广泛的硬件和平台覆盖。这些框架力求抽象掉硬件复杂性并提供更通用的部署解决方案。突出的例子包括ExecuTorch [33], ONNX Runtime Mobile [36], MACE [55], MNN [24], NCNN [51], 和TensorFlow Lite [18]。此外,基于IR的运行时,如IREE [23], TVM [8], 和XLA [48],专注于通过中间表示将机器学习模型降低到硬件特定代码来优化。
大型生成模型推理 最近大型生成模型的出现进一步加剧了机器学习推理的需求。对此,机器学习推理社区提出了专门针对服务器端部署的库,包括LMDeploy [10], SGLang [59], 和vLLM [25]。同时,正在努力实现大型生成模型的有效边缘推理,正如llama.cpp [16], ollama [42], 和torchchat [50] 所示。MLC LLM [38] 利用TVM运行时和WebLLM [47] 来促进跨多种GPU后端的大语言模型推理。针对移动GPU上大型扩散模型的具体实现级优化也在探索中[9]。其他推理加速研究[4, 56-58] 关注与我们的工作正交的挑战,包括DRAM限制、NPU/CPU协调、模型协作等。模型压缩技术[13, 29, 54] 设计用于改善边缘部署,与我们的方法兼容且协同。
3. 扩展GPU推理以适应大型模型
为了应对在各种GPU架构上部署大型生成模型的挑战,ML Drift扩展了成熟的GPU加速ML推理引擎的基本架构[26]。我们引入了一种新方法,在运行时从手动优化的着色器模板生成动态代码,将ML Drift归类为一种优化数据布局和内核选择的专用推理框架。为便于优化和性能探索,我们引入了张量虚拟化,这种方法将物理GPU对象从逻辑张量表示中抽象出来,允许不同的内存布局和内核配置,然后结合坐标转换,实现对这些不同内存布局的灵活访问。进一步的优化包括减少足迹的内存管理策略、操作融合、阶段感知LLM推理优化和专用KV缓存布局。这种架构范式使ML Drift能够在广泛的GPU平台上增强性能和可扩展性。
3.1. 逻辑张量和物理GPU对象
在本文的上下文中,逻辑张量指的是具有语义意义轴的多维数组,通常在数学或机器学习背景下构思。另一方面,物理GPU对象是实际的GPU内存缓冲区或存储结构,实现了这个逻辑张量,例如GPU缓冲区、图像缓冲区、纹理数组、2D纹理和3D纹理。
由于神经网络中的中间张量通常对其轴没有内在含义,我们隐含地赋予它们语义。具体来说,我们按轴分配以下语义(对于最多5D的张量):
- 0D: 标量
-
- 3D: H W C H W C HWC
-
- 1D: 线性
-
- 4D: B H W C B H W C BHWC
-
- 2D: H W H W HW
-
- 5D:
B
H
W
D
C
B H W D C
BHWDC
其中 B , H , W , D B, H, W, D B,H,W,D, 和 C C C分别代表批次、高度、宽度、深度和通道。5D张量的 D D D轴仅用于3D卷积,对于其他网络, D D D通常设置为1。我们在离线测试期间为每个边缘设备确定了最佳的GPU对象。在初始化过程中,根据检测到的硬件,我们为每个GPU内核选择预定的最佳GPU对象。根据所选的GPU对象,张量元素以不同的内存布局存储,因此需要不同的索引方法来访问相应的张量元素。
- 5D:
B
H
W
D
C
B H W D C
BHWDC
受PHWC4内存布局[26]的启发,该布局通过将数据组织成连续的4通道切片以优化GPU缓冲区和纹理的4元素SIMD,我们采用了多种4元素切片感知的内存布局。例如,考虑一个大小为 ( B , H , W , D , C ) (B, H, W, D, C) (B,H,W,D,C)的5D张量。当使用2D纹理实现时,我们使用内存布局 H S W B D C 4 H S W B D C_{4} HSWBDC4,其中 S S S代表切片( [ C / 4 ] [C / 4] [C/4])和 C 4 C_{4} C4代表切片内的索引( C m o d 4 C \bmod 4 Cmod4),以对 H H H维度应用自动零钳位。为了确保与4元素SIMD的兼容性,通道数不是4的倍数的张量会被零填充。
我们对权重张量进行了类似的探索,以确定最佳的GPU对象和内存布局。最常用于卷积和全连接层权重的布局是 O H W I O H W I OHWI 或 O H W D I O H W D I OHWDI,其中 I I I和 O O O分别是输入通道数和输出通道数,根据内核设计重新排列为 ( G , S O , O 4 , H W D , S I , I 4 ) \left(G, S_{O}, O_{4}, H W D, S_{I}, I_{4}\right) (G,SO,O4,HWD,SI,I4)布局。这里, S I S_{I} SI代表 I I I轴的切片数, O 4 O_{4} O4和 I 4 I_{4} I4分别代表 O O O和 I I I轴切片内的元素。虽然 G G G和 S O S_{O} SO的具体值取决于内核设计,但它们的乘积 G ⋅ S O G \cdot S_{O} G⋅SO始终对应于 O O O轴的切片数。
通过战略性地选择权重张量的最佳内存布局,我们实现了矩阵乘法操作高达20%的速度提升,这对于卷积和全连接层都是基本的。这种权重张量布局优化是高性能矩阵乘法的基础,也是ML Drift性能优势的主要驱动力。
3.2. 张量虚拟化
依赖单一统一布局处理所有张量可能会对某些GPU内核不理想,因为其内存访问偏离了原本预期的模式。为了解决这一局限性,我们引入了“张量虚拟化”,这是一种受虚拟内存启发的新技术。张量虚拟化将张量的逻辑表示与其在GPU上的物理存储解耦,允许张量使用各种类型的GPU内存对象(纹理、缓冲区等)来实现。一个抽象层管理逻辑张量索引与物理GPU对象索引之间的映射,处理底层张量数据的碎片化和分布。这使得内核作者无需担心低级内存管理问题,能够专注于算法逻辑。
这种虚拟化为张量表示提供了显著的灵活性。传统上,一个尺寸为 ( 1 , 2 , 3 , 5 ) (1,2,3,5) (1,2,3,5)的张量会严格约束在PHWC4格式下,要求一个RGBA纹理大小为 ( 2 , 3 × (2,3\times (2,3× ⌈ 5 / 4 ⌉ ) = ( 2 , 6 ) \lceil 5 / 4\rceil)=(2,6) ⌈5/4⌉)=(2,6)。我们的方法允许这个逻辑张量被任意映射到各种内存布局。如图1所示,它可以被实现为一个大小为 ( 2 , 3 , ⌈ 5 / 4 ⌉ ) = ( 2 , 3 , 2 ) (2,3,\lceil 5 / 4\rceil)=(2,3,2) (2,3,⌈5/4⌉)=(2,3,2)的3D纹理,一个大小为 ( 2 × ⌈ 5 / 4 ⌉ , 3 ) = ( 4 , 3 ) (2 \times\lceil 5 / 4\rceil, 3)=(4,3) (2×⌈5/4⌉,3)=(4,3)的2D纹理,或者作为一个具有 2 × 3 × ⌈ 5 / 4 ⌉ = 12 2 \times 3 \times\lceil 5 / 4\rceil=12 2×3×⌈5/4⌉=12像素的1D图像缓冲区,具体取决于特定内核实现的效率。这种适应性对于优化具有不同并行特征的多样内核的性能至关重要。
| 存储类型 | 存储坐标 |
|---|---|
| 1D 缓冲区 | ( ( s ⋅ ((s \cdot ((s⋅ 高度 + y ) ⋅ +y) \cdot +y)⋅ 宽度 + x ) ⋅ +x) \cdot +x)⋅ 批次 + b +b +b |
| 2D 纹理 | ( x ⋅ (x \cdot (x⋅ 批次 + b , y ⋅ +b, y \cdot +b,y⋅ 切片 + s ) +s) +s) |
| 3D 纹理 | ( x ⋅ (x \cdot (x⋅ 批次 + b , y , s ) +b, y, s) +b,y,s) |
表1. 从逻辑坐标 ( b , x , y , s ) (b, x, y, s) (b,x,y,s)到 B H W C B H W C BHWC张量的GPU内存对象坐标的坐标转换,考虑到其批次大小、宽度、高度、切片数和存储类型。
张量虚拟化也促进了单个张量需要由多个GPU对象表示的情况下的高效处理。例如,我们的通用卷积内核需要同时从多个纹理读取以优化内存缓存使用。我们的抽象层无缝支持这一点,允许一个大小为 ( 5 , 2 , 1 , 7 ) (5,2,1,7) (5,2,1,7)的张量使用四个大小为 ( 4 , 2 ) (4,2) (4,2)的纹理表示,每个纹理保存张量的一个切片,如图2所示。这使得复杂操作得以实现,这些操作可能无法通过张量和GPU对象之间刚性的逐一映射来完成。
尽管张量虚拟化增加了实现的复杂性,但其性能开销可以忽略不计。具体来说,逻辑和物理索引之间的映射是在初始化过程中生成着色器代码时建立的,从而最小化运行时延迟。
3.3. 坐标转换
为了使生产着色器程序具备上述灵活性,消费着色器程序必须具备读写具有灵活内存布局的张量的能力。换句话说,我们在着色器代码生成中引入了一个预处理阶段,带有辅助函数,例如args.src.Read (b, x, y, s),它将请求的张量元素的坐标转换为实际GPU内存对象的坐标,如表1所示。这使得实现神经网络操作符的着色器可以抽象访问GPU缓冲区和纹理中的张量元素,并简化了编写着色器程序的过程,而无需担心内存布局组合的爆炸性增长。
类似于张量虚拟化,坐标转换过程也在着色器代码生成过程中执行。这种预处理方法避免了在执行GPU内核时添加任何运行时延迟。
3.4. 设备专业化
为了促进在不同GPU架构上的执行,我们为各种GPU后端(如OpenCL、Metal、WebGPU)开发了一系列着色器生成器,将平台无关的抽象转换为目标GPU语言。通过对目标GPU属性的运行时分析,特别是识别支持的厂商扩展并确定最佳GPU对象存储类型,生成器对每个GPU操作符执行一系列转换。这些转换包括:
- 自适应内核选择:从一组候选方案中选择最适合特定GPU API和设备的最快实现。可以使用专业化的内核,如Winograd快速卷积,以获得更好的性能。
-
- 利用厂商特定扩展:利用厂商扩展,如专用矩阵乘法扩展cl_arm_matrix_multiply。
-
- 语法转换:将ML Drift表示转换为特定语言的着色器代码。
-
- 权重转换:预处理权重并将它们存储在具有最佳内存布局的GPU内存中。
3.5. 内存管理
大型生成模型的内存占用主要受到模型权重和中间张量的影响。虽然模型权重大小是整体内存消耗的主要决定因素,但运行时内存的有效管理至关重要。先前关于中间张量管理的研究表明,由于神经网络的顺序执行范式,这些张量不需要同时占用内存。因此,实施有效的内存缓冲区复用方法是一种显著减少运行时内存占用的方式[43]。内存共享可以通过两种主要方法实现:将内存缓冲区分配给生命周期不重叠的张量,或预先分配一大块内存并在其中为张量分配偏移量。这些策略利用了神经网络的有向无环图表示和顺序执行。
以Stable Diffusion 1.4为例,半精度浮点(FP16)激活需要4.31 GB的运行时内存。Greedy by Size策略将运行时内存占用减少到387 MB(节省93%),如图3所示。
3.6. 操作融合
操作融合是一种常见的优化方法,将多个内存绑定操作合并到一个内核中,以减少内核启动开销和内存传输。如图4所示,当ML Drift检测到一系列逐元素操作、张量重新排序操作或残差连接时,会自动应用操作融合。除了自动化优化策略外,我们还结合了分析来识别性能瓶颈,并手动实现优化以实现高效的大型模型推理。在一个具体的注意力块内,我们创建了一个自定义内核,将旋转嵌入与查询(Q)、键(K)和值(V)投影的布局转换结合起来。这包括将查询投影从初始布局 ( B , 1 , S , h q ⋅ d h ) \left(B, 1, S, h_{q} \cdot d_{h}\right) (B,1,S,hq⋅dh)转换为结果布局 ( B ⋅ h k v , S ⋅ h q / h k v , d h ) \left(B \cdot h_{k v}, S \cdot h_{q} / h_{k v}, d_{h}\right) (B⋅hkv,S⋅hq/hkv,dh)。这里, B B B表示批次大小, h k v h_{k v} hkv表示KV头数, S S S表示序列长度, h q h_{q} hq表示查询头数, d h d_{h} dh表示头维度。这种优化的QKV布局对于高效推理各种注意力机制至关重要,包括多头、多查询和分组查询注意力。
3.7. 阶段感知的大语言模型推理优化
尽管使用相同的位于GPU内存中的权重,ML Drift区分了大语言模型推理的预填充和解码阶段,这种区分是由它们根本不同的性能特征决定的。对于涉及外部权重的操作,如计算查询、键、值、输出投影以及前馈网络中的线性层,计算密集型的预填充阶段受益于专用的GPU量化内核。该内核将浮点输入激活转换为8位整数并计算所需的量化参数,从而使后续内核能够利用带有预量化权重的快速int8指令,并对输出激活进行反量化。相反,内存绑定的解码阶段通过将输入激活量化直接集成到操作内核中得到优化,这种方法减轻了内存传输开销,从而提高了总体性能。此外,ML Drift根据输入数据的特性选择专门的GPU内核。处理较长输入序列的预填充阶段受益于高度优化的卷积内核,而以迭代生成单个标记为特征的解码阶段则更适合全连接内核。
3.8. GPU优化的KV缓存布局
ML Drift在LLM推理中使用卷积内核进行矩阵乘法。KV缓存作为卷积权重,存储在与QKV布局转换(第3.6节)兼容的布局中。K缓存使用 O H W I O H W I OHWI布局( O = O= O= 缓存大小, I = d h I=d_{h} I=dh),表示 K T K^{T} KT用于 Q K T Q K^{T} QKT计算。V缓存使用 O H W I O H W I OHWI布局,但维度反转 ( O = d h , I = \left(O=d_{h}, I=\right. (O=dh,I= 缓存大小 ) ) ),确保涉及V的卷积产生所需的注意力输出布局 ( B ⋅ h k v , S ⋅ h q / h k v , d h ) \left(B \cdot h_{k v}, S \cdot h_{q} / h_{k v}, d_{h}\right) (B⋅hkv,S⋅hq/hkv,dh)。
4. 性能评估
本节呈现了ML Drift在大型文本到图像模型和大型语言模型上的综合性能评估,涵盖了多种平台。我们详细提供了ML Drift的OpenCL、Metal和Web-
GPU后端在一系列硬件上的基准测试,包括移动GPU(Arm Mali和Qualcomm Adreno)、桌面/笔记本GPU(Intel和NVIDIA)和Apple Silicon。
4.1. 大型扩散模型
我们使用开源模型Stable Diffusion 1.4评估了我们的OpenCL、Metal和WebGPU后端的性能,配置为FP16推理和FP16权重。该流水线包括文本编码器、UNet和VAE解码器。基准测试在来自Apple、Arm、Intel和Qualcomm的一系列GPU上进行。
移动GPU ML Drift的OpenCL后端是Android平台的主要执行引擎。在搭载Qualcomm Adreno 740 GPU的三星S23 Ultra上,我们实现了生成 512 × 512 512 \times 512 512×512图像(20次迭代)的端到端延迟为10.96秒。这比之前报告的低于12秒的基准提高了8%[9],比另一项测量的14.42秒提高了26%[46]。图5详细说明了Android上Stable Diffusion 1.4的延迟,展示了各种移动GPU上各个模型组件的性能。ML Drift OpenCL在搭载Qualcomm Adreno 750的三星S24上将延迟减少到不到9秒。
| ML Drift OpenCL | ML Drift WebGPU | ONNX Runtime DirectML | |
|---|---|---|---|
| 每次迭代 | 0.64 | 1.28 | 1.75 |
| 端到端 | 13.5 | 27.9 | 37.0 |
表3. Stable Diffusion 1.4在Intel Meteor Lake Ultra 7165 U上的性能(秒)。
桌面/笔记本GPU 在配备Intel Meteor Lake Ultra 7 165U的Windows笔记本电脑上,我们的OpenCL和WebGPU后端表现出明显优于使用DirectML的ONNX Runtime的性能[37]。具体来说,如表3所述,ML Drift OpenCL实现了2.7倍的速度提升,而WebGPU实现了1.3倍的速度提升。
为进一步突出ML Drift的能力,我们将其实力与Intel在较新的Lunar Lake Ultra 7 288V上的报告性能进行了针对性比较[22]。在我们最接近的可用平台上,即Lunar Lake Ultra 7 258V,ML Drift OpenCL生成了 512 × 512 512 \times 512 512×512图像(20次迭代)仅需3.4秒,比Intel报告的288 V的3.89秒快了14.4%。
Apple Silicon ML Drift的Metal后端在Apple Silicon上提供了优化执行,从而加快了扩散模型推理。使用Stable Diffusion 1.4在M1 Ultra和MacBook Pro M4 Pro(20核GPU)上的性能测试分别产生了3.86秒和5.34秒的运行时间。这些数字明显优于Apple的CoreML Stable Diffusion [5]观察到的5.03秒和6.16秒。
4.2. 大型语言模型
为了评估ML Drift在大型语言模型上的推理性能,我们使用了四个开源权重模型进行基准测试:Gemma 2B [15], Gemma2 2B [14], Llama 3.2 3B [34], 和 Llama 3.1 8B [30]。这些评估涵盖了移动和桌面平台,使我们能够与已建立的LLM GPU推理解决方案进行比较,如llama.cpp [16], ollama [42], torchchat [50], MLC LLM [38], 和 MLX LM [39]。ML Drift主要使用FP16进行激活,例外是NVIDIA平台,由于OpenCL驱动程序限制,使用单精度浮点(FP32)。ML Drift实现了两种量化策略:q8(所有权重的每通道int8量化)和8/4/4(混合精度每通道量化,int8用于注意力,int4用于嵌入/前馈权重)。相比之下,其他开源解决方案
| Adreno 830 | Adreno 750 | Adreno 740 | Immortalis-G720 | Mali-G715 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 预填充 | 解码 | 预填充 | 解码 | 预填充 | 解码 | 预填充 | 解码 | 预填充 | 解码 | |
| Gemma 2B q8 | 1440 | 22.8 | 1440 | 23.1 | 1120 | 20.4 | 1280 | 18.2 | 796 | 11.9 |
| Gemma 2B 8/4/4 | 1490 | 42.5 | 1480 | 42.7 | 1150 | 38.1 | 1380 | 32.5 | 813 | 12.2 |
| Gemma2 2B q8 | 1220 | 20.8 | 1290 | 21.3 | 1010 | 18.3 | 1170 | 15.7 | 700 | 11.2 |
| Gemma2 2B 8/4/4 | 1250 | 37.0 | 1370 | 37.1 | 1040 | 32.4 | 1250 | 27.3 | 729 | 18.4 |
| Llama3.2 3B q8 | 960 | 17.1 | 917 | 17.5 | 720 | 15.4 | 791 | 12.5 | 507 | 8.71 |
| Llama3.2 3B 8/4/4 | 983 | 30.4 | 959 | 30.3 | 741 | 26.8 | 850 | 21.2 | 516 | 15.0 |
| Llama3.1 8B q8 | 389 | 7.70 | - | - | - | - | 270 | 4.72 | - | - |
| Llama3.1 8B 8/4/4 | 413 | 13.4 | 412 | 12.7 | 325 | 10.7 | 378 | 8.88 | 240 | 6.46 |
表2. Qualcomm和Arm GPU上Gemma和Llama模型的LLM性能(token/s)。Llama 3.1 8B q8因Adreno 750、Adreno 740和Mali-G715设备的内存限制而终止。
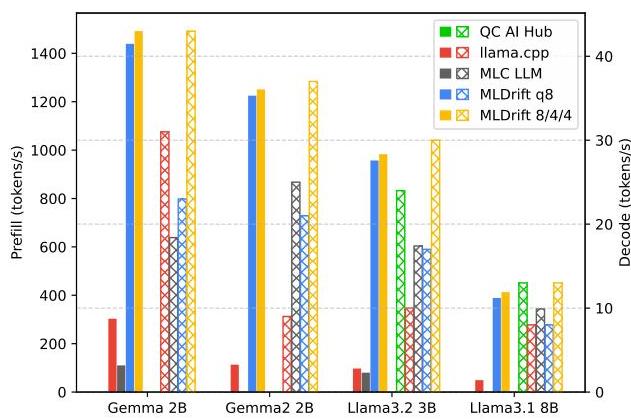
图6. Adreno 830上不同推理解决方案的LLM性能(token/s)的比较分析。预填充性能(实心条形图,左纵轴)和解码性能(交叉条纹条形图,右纵轴)被展示。当数据不可用、非公开或不合理时,条形图缺失。
通常使用GGUF [17] q4组量化,产生的模型大小介于ML Drift的q8和8/4/4方法之间。对于LLM基准测试,ML Drift实现关闭了投机解码 [28] 和闪电注意力 [11],并在每次生成token后执行CPU/GPU同步。所有评估都使用固定的上下文长度为1280个token,包括1024个预填充和256个生成token。
移动GPU 我们在Android设备上对标了ML Drift的OpenCL实现与llama.cpp的基准工具和MLC Chat演示应用程序,评估了五种移动GPU的性能:Qualcomm Adreno 830(小米15 Pro 16GB RAM),Adreno 750(三星S24 8GB RAM),Adreno 740(三星S23 Ultra 8GB RAM),Arm Immortalis-G720(Vivo X100 Pro 16GB RAM),和Arm Mali-G715(谷歌Pixel 9 12GB RAM)。
在Qualcomm Adreno GPU上,如图6所示,ML Drift的OpenCL后端在与其他开源LLM推理解决方案相比时,token预填充速度提高了5到11倍。此外,ML Drift的OpenCL后端在Llama 3.2 3B的token生成速度上比Qualcomm AI Hub基准 [45] 提高了29%,使用了相同的8/4/4量化方案。同样,在Arm Mali GPU上,目前不支持llama.cpp的情况下,ML Drift在预填充和生成阶段都显示出相当的加速。例如,运行Llama3.2 3B时,ML Drift在q8量化下平均达到了791 tokens/s的预填充速度和12.5 tokens/s的解码速度,而MLC LLM分别达到了89.2和11.2 tokens/s的q4f16速度。
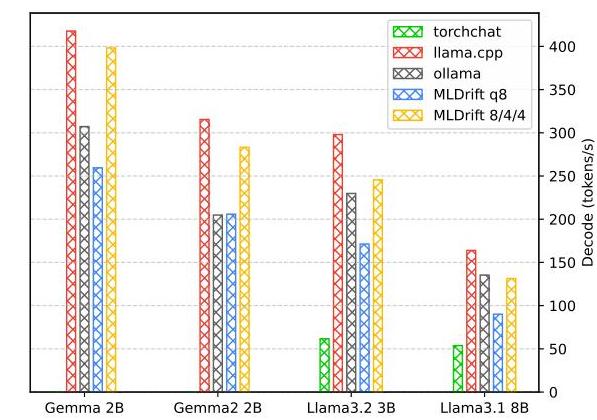
图7. NVIDIA GeForce RTX 4090上不同推理解决方案的LLM解码性能(tokens/s)的比较分析。排除了预填充性能,因为NVIDIA Tensor Cores主导CUDA中的预填充阶段,但无法通过OpenCL API访问,无法进行有意义的比较。
token预填充速度几乎不受量化方案的影响,表明这是一个计算密集型过程。然而,token生成速度在量化优化后显示出了高达1.9倍的性能提升,表明这是一个内存密集型阶段,其中内存带宽是一个关键限制。表2提供了各种GPU和模型的综合性能指标。
桌面/笔记本GPU 超越移动平台,ML Drift通过OpenCL和WebGPU(通过Dawn [52]实现原生执行)接口促进了集成和独立GPU的执行。尽管这些GPU中存在专门的矩阵乘法加速单元,如NVIDIA的Tensor Cores [40],当前的ML Drift实现受限于这些硬件特性的利用,这是由于厂商在OpenCL和WebGPU中对这些功能的支持有限所致。因此,计算密集型的token预填充阶段经历了四到七倍的性能下降,如经验观察所示。尽管存在这一限制,ML Drift仍保持了竞争力的token生成速度,证明了即使没有硬件加速也具有鲁棒性。具体而言,如图7所示,在NVIDIA GeForce RTX 4090上,ML Drift的OpenCL实现(使用FP32精度)与llama.cpp的基准工具测量相比,性能下降了5%到25%。然而,当使用CUDA后端进行q4f16量化模型推理时,ML Drift的OpenCL仍优于ollama和torchchat。对于支持8位合作矩阵扩展的GPU,例如Intel Ultra 7平台,ML Drift表现出更快的token预填充速度,如表4所示。
ML Drift的WebGPU后端通过支持RTX 4090上的FP16和FP32精度提供了操作灵活性。比较评估显示,WebGPU后端在模型推理时相对于ML Drift的OpenCL实现存在明显的性能下降。需要进一步研究以调查这种性能下降的根本原因,并探索潜在的优化策略。
Apple Silicon 对于配备了专有Apple Silicon芯片的Apple设备,ML Drift通过其Metal后端促进了LLM推理,通常采用FP16精度。ML Drift在Apple M4 Pro 20核GPU上的性能经过了严格的分析,详细结果如图8所示。所得结果表明,ML Drift的Metal实现具有token预填充阶段的性能优势。值得注意的是,对于Gemma2 2B,ML Drift相较于llama.cpp基准提升了14%,相较于MLX LLM提升了20%。ML Drift在所有测试模型的token生成中一致超越了llama.cpp和ollama,并且在Gemma模型中也比MLX LLM更快。
与移动平台上的经验观察一致,在比较q8和8/4/4量化模型时,预填充阶段出现了性能差异。尽管量化方法之间的性能差异仍然存在,但在Apple M4 Pro上与移动平台相比,其幅度有所减弱。Apple Silicon架构较高的内存带宽有助于缓解性能差异。
5. 结论
在这项工作中,我们介绍了ML Drift,这是一种新颖的推理框架,旨在促进大型生成模型在广泛GPU上的高效部署。通过张量虚拟化将逻辑张量索引与物理GPU索引分离,ML Drift在内存布局和内核优化方面实现了前所未有的灵活性。结合设备专业化、内存管理策略和操作融合,我们的框架实现了显著的性能提升。在包括移动、桌面和Apple Silicon GPU在内的各种硬件平台上的全面评估验证了ML Drift的有效性,展示了相对于现有开源解决方案的数量级改进。ML Drift展示了执行比最新最先进的GPU推理引擎大一到两个数量级的工作负载的能力。
未来的工作将集中在通过纳入先进的量化技术(如子通道量化)和稀疏性来扩展ML Drift的能力。随着移动GPU越来越多地集成专用于ML工作负载的指令,包括通过厂商扩展访问的点积和矩阵乘法,深入探索这些特性对于进一步的性能提升至关重要。为了促进ML Drift对各种模型的优化,将进行消融研究以量化每个优化组件的开销和个别贡献。此外,评估将扩展到更近期的扩散模型如Stable Diffusion 3.5 [49]和基于变压器的架构[12],这将涉及调查为这些模型类型定制的先进最新构建模块的集成。还将探索与异构处理器的高效互操作性和零拷贝缓冲区的混搭操作。
参考文献
[1] OpenCL C++ 1.0 Specification. The Khronos Group Inc., 2019. 2
[2] Vulkan 1.4.309 - A Specification(with all registered extensions). The Khronos Group Inc., 2025. 2
[3] Advanced Micro Devices, Inc. AMD ROCm Software. https://www.amd.com/en/products/ software/rocm.html. [Online; accessed March 17, 2025]. 2
[4] Keivan Alizadeh, Iman Mirzadeh, Dmitry Belenko, Karen Khatamifard, Minsik Cho, Carlo C Del Mundo, Mohammad Rastegari, and Mehrdad Farajtabar. LLM in a flash: Efficient Large Language Model Inference with Limited Memory, 2024. 2
[5] Apple Inc. Core ML Stable Diffusion. https:// github.com/apple/ml-stable-diffusion. [Online; accessed March 17, 2025]. 6
[6] Apple Inc. Core ML. https://developer.apple. com/documentation/coreml. [Online, accessed March 17, 2025]. 2
[7] Arm Ltd. Compute Library. https://www.arm. com/products/development-tools/embedded-and-software/compute-library. [Online; accessed March 17, 2025]. 2
[8] Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy. TVM: An automated End-to-End optimizing compiler for deep learning. In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 578-594, Carlsbad, CA, 2018. USENIX Association. 2
[9] Yu-Hui Chen, Raman Sarokin, Juhyun Lee, Jiuqiang Tang, Chuo-Ling Chang, Andrei Kulik, and Matthias Grundmann. Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations, 2023. 2, 6
[10] LMDeploy Contributors. LMDeploy: A Toolkit for Compressing, Deploying, and Serving LLM. https:// github.com/InternLM/lmdeploy, 2023. 2
[11] Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, 2022. 7
[12] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. CoRR, abs/2010.11929, 2020. 8
[13] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, 20------
23. 2
24. [14] Gemma Team. Gemma 2: Improving Open Language Models at a Practical Size, 2024. 6
25. [15] Gemma Team. Gemma: Open Models Based on Gemini Research and Technology, 2024. 6
26. [16] ggml.ai. llama.c
27. ------pp. https://github.com/ggml-org/11ama.cpp. [Online; accessed March 17, 2025]. 2, 6
28. [17] ggml.ai. GGUF. https://github.com/ggml-org/ggml/blob/master/docs/gguf.md. [Online; accessed March 17, 2025]. 7
29. [18] Google LLC. LiteRT Overview. https://ai.google.dev/edge/1itert. [Online, accessed March 17, 2025]. 2
30. [19] Huawei Technologies Co., Ltd. Huawei HiAI. https://developer.huawei.com/consumer/en/hiai. [Online; accessed March 17, 2025]. 2
31. [20] Apple Inc. Metal. https://developer.apple.com/documentation/metal. [Online; accessed March 17, 2025]. 2
32. [21] Intel Corporation. OpenVINO. https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html. [Online; accessed March 17, 2025]. 2
33. [22] Intel Corporation. Intel Core Ultra Series 2 Media Deck. https://download.intel.com/newsroom/2024/client-computing/Intel-Core-Ultra-Series-2-Media-Deck.pdf, 2024. 6
34. [23] IREE Organization. IREE. https://iree.dev/. [Online, accessed March 17, 2025]. 2
35. [24] Xiaotang Jiang, Huan Wang, Yiliu Chen, Ziqi Wu, Lichuan Wang, Bin Zou, Yafeng Yang, Zongyang Cui, Yuezhi Cai, Tianhang Yu, Chengfei Lv, and Zhihua Wu. MNN: A Universal and Efficient Inference Engine. ArXiv, abs/2002.12418, 2020. 2
36. [25] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient Memory Management for Large Language Model Serving with PagedAttention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. 2
37. [26] Juhyun Lee, Nikolay Chirkov, Ekaterina Ignasheva, Yury Pisarchyk, Mogan Shieh, Fabio Riccardi, Raman Sarokin, Andrei Kulik, and Matthias Grundmann. On-Device Neural Net Inference with Mobile GPUs. In Proceedings of the CVPR Workshop on Efficient Deep Learning for Computer Vision, 2019. 2, 3
38. [27] Jon Leech, editor. OpenGL ES Version 3.1. The Khronos Group Inc., 2016. 2
39. [28] Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast Inference from Transformers via Speculative Decoding, 2023. 7
40. [29] Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, WeiMing Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. In MLSys, 2024. 2
41. [30] Llama Team. The Llama 3 Herd of Models, 2024. 6
42. [31] Huynh Nguyen Loc, Youngki Lee, and Rajesh Krishna Balan. DeepMon: Mobile GPU-based Deep Learning Framework for Continuous Vision Applications. Proceedings of the 15th Annual International Conference on Mobile Systems, Applications, and Services, 2017. 2
43. [32] MediaTek Inc. NeuroPilot. https://neuropilot.mediatek.com. [Online; accessed March 17, 2025]. 2
44. [33] Meta Platforms, Inc. ExecuTorch. https://pytorch.org/executorch-overview. [Online; accessed March 17, 2025]. 2
45. [34] Meta Platforms, Inc. Llama 3.2: Revolutionizing edge AI and vision with open, customizable models. https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/. [Online; accessed March 17, 2025]. 6
46. [35] Microsoft Corporation, Inc. DirectML Overview. https://learn.microsoft.com/en-us/windows/ai/directml/dml. [Online; accessed March 17, 2025]. 2
47. [36] Microsoft Corporation, Inc. Get started with ONNX Runtime Mobile. https://onnxruntime.ai/docs/get-started/with-mobile.html. [Online; accessed March 17, 2025]. 2
48. [37] Microsoft Corporation Inc. Stable Diffusion Optimization with DirectML. https://github.com/microsoft/Olive/tree/main/examples/directml/stable_diffusion. [Online; accessed March 17, 2025]. 6
49. [38] MLC team. MLC-LLM. https://github.com/mlcai/mlc-llm. [Online; accessed March 17, 2025]. 2, 6
50. [39] MLX Community. MLX LM. https://github.com/ml-explore/mlx-lm. [Online; accessed March 17, 2025]. 6
51. [40] NVIDIA Corporation. NVIDIA Tensor Cores. https://www.nvidia.com/en-us/data-center/tensor-cores. [Online; accessed March 17, 2025]. 7
52. [41] NVIDIA Corporation. TensorRT. https://developer.nvidia.com/tensorrt-gettingstarted. [Online; accessed March 17, 2025]. 2
53. [42] ollama. ollama. https://github.com/ollama/ollama. [Online; accessed March 17, 2025]. 2, 6
54. [43] Yury Pisarchyk and Juhyun Lee. Efficient Memory Management for Deep Neural Net Inference. In Proceedings of the MLSys Workshop on Resource-Constrained Machine Learning, 2020. 4
55. [44] Qualcomm Inc. Snapdragon Neural Processing Engine SDK. https://www.qualcomm.com/developer/software/neural-processing-sdk-for-a. [Online; accessed March 17, 2025]. 2
56. [45] Qualcomm Inc. QualComm AI Hub Llama-v3.2-3B-Chat. https://aihub.qualcomm.com/models/llama_v3_2_3b_chat_quantized. [Online; accessed March 17, 2025]. 7
57. [46] Qualcomm Inc. World’s first on-device demonstration of Stable Diffusion on an Android phone. https://www.qualcomm.com/news/onq/2023/02/worlds-first-on-device-demonstration-of-stable-diffusion-on-android. [Online; accessed March 17, 2025]. 6
58. [47] Charlie F. Ruan, Yucheng Qin, Xun Zhou, Ruihang Lai, Hongyi Jin, Yixin Dong, Bohan Hou, Meng-Shiun Yu, Yiyan Zhai, Sudeep Agarwal, Hangrui Cao, Siyuan Feng, and Tianqi Chen. WebLLM: A High-Performance In-Browser LLM Inference Engine, 2024. 2
59. [48] Amit Sabne. XLA: Compiling Machine Learning for Peak Performance, 2020. 2
60. [49] Stability AI, Ltd. Introducing Stable Diffusion 3.5. https://stability.ai/news/introducing-stable-diffusion-3-5. [Online; accessed March 17, 2025]. 8
61. [50] Team PyTorch. Introducing torchchat: Accelerating Local LLM Inference on Laptop, Desktop and Mobile. https://pytorch.org/blog/torchchat-local-llminference. [Online; accessed March 17, 2025]. 2, 6
62. [51] Tencent Holdings Ltd. NCNN. https://github.com/Tencent/ncnn. [Online; accessed March 17, 2025]. 2
63. [52] The Dawn and Tint Authors. Dawn, a WebGPU implementation. https://dawn.googlesource.com/dawn?pli=1. [Online; accessed March 17, 2025]. 7
64. [53] W3C. WebGPU. https://www.w3.org/TR/webgpu. [Online; accessed March 17, 2025]. 2
65. [54] Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. In Proceedings of the 40th International Conference on Machine Learning, 2023. 2
66. [55] Xiaomi Corporation. MACE. https://github.com/XiaoMi/mace. [Online; accessed March 17, 2025]. 2
67. [56] Daliang Xu, Wangsong Yin, Xin Jin, Ying Zhang, Shiyun Wei, Mengwei Xu, and Xuanzhe Liu. LLMCad: Fast and Scalable On-device Large Language Model Inference, 2023. 2
68. [57] Daliang Xu, Hao Zhang, Liming Yang, Ruiqi Liu, Gang Huang, Mengwei Xu, and Xuanzhe Liu. Fast On-device LLM Inference with NPUs. In International Conference on Architectural Support for Programming Languages and Operating Systems, 2024.
69. [58] Zhenliang Xue, Yixin Song, Zeyu Mi, Le Chen, Yubin Xia, and Haibo Chen. PowerInfer-2: Fast Large Language Model Inference on a Smartphone. ArXiv, abs/2406.06282, 2024. 2
70. [59] Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient Execution of Structured Language Model Programs, 2024. 2
参考论文:https://arxiv.org/pdf/2505.00232



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











