






梅悦文
同济大学交通工程系 上海,中国
meiyuewen@tongji.edu.cn
聂 tong
土木与环境工程系
香港理工大学
香港特别行政区,中国
tong.nie@connect.polyu.hk
孙健
同济大学交通工程系 上海,中国 sunjian@tongji.edu.cn
田野
同济大学交通工程系
上海,中国
tianye@tongji.edu.cn
摘要
基于仿真的测试对于验证自动驾驶车辆(AVs)至关重要,但现有的场景生成方法要么过度拟合常见的驾驶模式,要么以离线、非交互的方式运行,无法暴露罕见的安全关键边缘案例。本文介绍了一种基于在线检索增强的大语言模型(LLMs)框架,用于生成安全关键的驾驶场景。我们的方法首先使用基于LLM的行为分析器从观察到的状态中推断背景车辆最危险的意图,然后查询其他LLM代理以合成可行的对抗性轨迹。为了缓解灾难性遗忘并加速适应,我们通过动态记忆和检索库增强了该框架,当出现新的意图时,自动扩展其行为库。使用Waymo开放运动数据集进行的评估表明,我们的模型将平均最小碰撞时间从 1.62 \mathbf{1 . 6 2} 1.62减少到 1.08 s \mathbf{1 . 0 8} \mathbf{s} 1.08s,并且导致了 75 % \mathbf{7 5 \%} 75%的碰撞率,显著优于基线。
索引术语-安全关键场景生成,大语言模型,自动驾驶,检索增强生成,记忆机制
I. 引言
仿真对于开发和测试自动驾驶车辆(AVs)是不可或缺的,因为现实世界中的道路测试无法实际遇到可能驾驶条件的巨大空间。一个核心挑战是生成能够捕捉复杂多智能体交互的真实且多样化的交通场景。早期的模拟器使用基于规则或手工制作的模型,但这些模型缺乏人类般的变异性 [1]。数据驱动的方法,如从驾驶日志中学习的模仿学习(IL)[2] 或生成模型 [3] 已经变得流行,可以更真实地建模智能体行为。然而,这些方法往往过度拟合自然驾驶分布:它们倾向于重现常见交通模式,而对稀有或对抗性事件表示不足。例如,IL 方法通常学习一种策略,使用真实轨迹作为监督来重建真实的驾驶行为。同样,生成模型
如 GANs 或扩散模型可以合成新场景,但其输出仍锚定在训练分布上 [4]。实际上,这意味着安全关键的边缘案例,即稀有事件的长尾部分,往往被忽略,使得 AVs 在最终必须处理的情况下未经过测试。
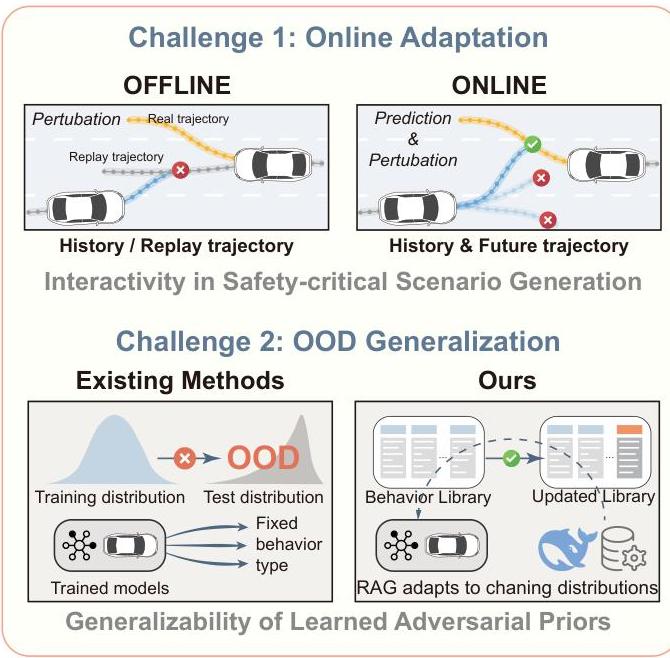
图 1. 交互式安全关键场景生成的挑战。本文强调了安全关键场景生成中的两个基本挑战:(1)在线适应,其中对抗性先验必须与智能体未来不断演变的行为进行互动;(2)分布外(OOD)泛化,其中学习到的先验必须在新的测试分布下保持有效。现有的离线方法仅在固定的行为分布下扰动历史轨迹。我们提出的框架在线生成场景,并持续更新安全关键行为库,利用 LLMs 实现。
为了解决安全关键场景生成中的“稀有性诅咒”问题 [5],最近的研究开发了对抗方法,有意生成此类场景 [6]-[13]。然而,现有方法主要集中在复杂的优化过程上,这通常是计算密集型和静态设计的。基于对抗学习、搜索扰动或风险驱动行为建模的方法在构建具有挑战性的场景方面显示出潜力;然而,它们通常需要预训练,并依赖于固定的客观目标或手工设计的启发式方法。这限制了它们在真实驾驶环境中连续适应自动驾驶车辆演变行为的灵活性。
大型语言模型(LLMs)的最新进展为场景生成提供了一种新范式 [14],[15],特别是在感兴趣的场景中。通过解释丰富的自然语言提示和世界知识,LLMs 可以灵活地组合超出训练集的交通场景。例如,ChatScene [16] 利用带有知识检索模块的 LLM 将文本场景描述翻译成特定领域的模拟代码,以重现稀有事件。这些由 LLM 驱动的方法可以在人类语言指令的引导下生成多样甚至安全关键的场景。
总之,尽管取得了这些进展,现有方法仍然存在两个重大局限性,如图 1 所示。首先,大多数场景生成器,无论是基于 IL 还是基于 LLM 的,都是离线操作的:它们生成一组固定的场景来执行,而不适应 AV 的实时行为。如果没有在线互动能力,这些生成器可能会错过意外的失败模式,最终降低安全验证的有效性 [4]。其次,虽然一些研究已经探索了在线方法(例如,使用强化学习编辑场景参数或将行为模型引入 [9],[13],[17]),但它们大多以单独的离线过程获得对抗性行为先验,例如学习分布或规定的行为主导词典。因此,当前方法在分布外(OOD)泛化方面可能存在困难,在测试期间无法连续调整和适应新场景。解决这些问题需要一种新方法,能够在在线生成高风险场景的同时,动态调整以应对不断变化的行为,从而更严格地压力测试鲁棒性。
虽然目前基于 LLM 的场景生成器仅以有限方式闭合循环。将 LLM 灵活集成到在线和交互式场景生成中的挑战依然存在。为此,本文提出了在线安全关键场景生成方法的机会。具体而言,我们提出了一种代理框架,利用检索增强 LLM 的力量。通过分析历史场景中的行为意图,初始 LLM 输出危险行为类型和所需参数。这些条件用于提示其他 LLM 代理生成并优化可行的未来对抗性轨迹,从而形成交互式和安全关键场景。为了进一步使模型适应测试期间熟悉和新颖的场景,开发了一种动态记忆和检索机制。
我们的贡献总结如下:
- 提出了一种基于 LLM 的代理框架,用于在线生成交互式和安全关键场景。
- 开发了一种记忆和检索机制,以连续适应 LLM 至变化的场景。
- 使用 Waymo 开放运动数据集进行的实验展示了对抗性轨迹生成和记忆-检索方法的有效性。
本文其余部分组织如下。第二部分回顾相关工作。第三部分阐述方法论。第四部分进行实验以验证所提方法论的有效性。第五部分总结全文。
II. 相关工作
A. 数据驱动的真实交通场景生成
大量工作集中于从数据中学习驾驶行为。模仿学习(行为克隆、GAIL 等)使用自然驾驶日志来训练交通代理的策略 [2],[18],[19]。这些方法可以独立捕获类似人类的动作,但在多智能体协调方面表现不佳。联合轨迹优化或逆强化学习(IRL)可以显式建模交互,但这些方法通常不适用于通用场景,并需要复杂成本设计。生成模型已应用于拓宽场景多样性。GAN 和变分模型可以合成新轨迹或交通场景。例如,条件 GAN 已被用于推导高速公路车道变换场景 [20]。然而,GAN 计算成本高昂且高度依赖于训练数据。扩散模型也被提出用于交通生成 [3],[21]。它们可以迭代精炼场景并允许可控编辑,但训练这样的扩散策略仍然具有挑战性,并且输出仍锚定在训练分布上。特别是,如果边缘案例在数据中稀疏或缺失,学习到的生成器将简单地不会产生它们。总之,数据驱动的生成器往往复制它们训练上的自然分布,因此很少产生真正新颖或危险的事件。
B. 安全关键场景生成
另一条平行的工作线明确关注生成稀有的安全关键场景,以进行自动驾驶车辆(AVs)的对抗性测试。为了明确针对高风险案例,一些方法将场景生成表述为搜索或优化问题。这些“边缘案例”生成器通常使用对抗性或搜索方法 [6]-[10],[12],[13]。例如,Hao 等人 [10] 结合自然驾驶模型与基于 RL 的对抗性训练循环。他们从真实数据中校准标准的人类驾驶行为,然后对其进行微调以生成现实的对抗性场景。然而,它仍然以离线方式进行:RL 代理一次训练后,随后生成场景以供后续测试。其他工作将场景生成表述为轨迹扰动或影响最大化(例如对抗性代理 [9],SEAL [12]),强调最坏情况的驾驶条件。特别是,Zhang 等人 [9] 提出了一个闭环框架,用于对抗性行为生成。他们通过计算碰撞可能性来确定对抗性代理的行为,然后优化代理参数以达到这些边界条件。
尽管取得这些进展,大多数安全关键生成器仍然主要处于离线或计算繁重状态。许多方法被表述为优化或 RL,需要广泛的训练。它们通常依赖于手动调整的先验或优化目标,这可能仍然会遗漏不可预见的极端情况。此外,很少有方法完全与 AVs 在线整合。然而,AV 测试理想情况下应该是自适应的:场景应根据自我车辆的行为演变。脚本或回放式场景本质上无法适应,即使封闭形式的 RL 生成器也不会实时与 AV 互动。非交互式测试无法充分暴露 AV 的弱点。在实践中,缺乏一种能连续响应 AV 动作的在线安全关键场景生成方法。
C. 增强型 LLM 场景生成
新兴工作使用 LLM 来促进场景设计。这些方法利用 LLM 的世界知识和灵活推理能力,从高级指令或演示中合成场景。例如,LLMScenario [14] 设计链式思维提示以生成场景并对其真实性与稀有性评分,明确针对不常见事件。OmniTester [22] 使用 LLM 提示结合工具如 SUMO 来生成可控测试用例。这些方法强调 LLM 能够解释用户规范和世界知识以创建多样化、结构化的场景。值得注意的是,一些作品将 LLM 与知识检索框架集成,以桥接语言和模拟。ChatScene [16] 使用带有检索数据库的 LLM 代理,首先生成高层次的对抗性场景描述,然后将其转换为可执行的模拟代码。RealGen [23] 检索类似的交通示例并在上下文中学习以组成新的场景布局。这些基于 LLM 的方法拓宽了场景生成的范围。它们可以通过混合和匹配示例或创造新的叙述来组合未见的场景变化,潜在地减轻纯 IL 方法的过拟合问题。
然而,几乎所有现有的 LLM 驱动方法仍然主要以离线方式运行:LLM 生成一个场景(或代码),然后在模拟中运行,但场景本身并未在循环中适应。Mei 等人的近期工作 [13] 开始关闭这个循环。然而,这是闭环生成的一个初步步骤,尚未结合检索增强的知识。
D. 挑战总结
在这些领域中,出现了几个共同的局限性。(a) 过度拟合自然数据:在真实驾驶数据上训练的生成器重现常见场景,但很少采样到保障安全所需的稀有边缘案例。(b) 离线生成:传统和基于 LLM 的方法通常提前生成场景。除了少数例外,它们在模拟运行期间不适应场景,这意味着 AV 并没有以真正的交互方式进行测试。© 缺乏闭环互动:没有统一的框架可以根据 AV 的
实时行为动态调整场景参数。现有的对抗性和自适应方法要么需要手工制作,要么需要大量计算,并且没有充分利用丰富的外部知识。
III. 方法论
在本节中,我们提出了一种在线、意图驱动的框架,用于安全关键场景生成。我们的方法分为三个阶段:(1) 安全关键背景车辆行为推断,其中 LLM 分析历史状态以分配意图标签;(2) 基于意图的轨迹合成,其中基于 LLM 的代码代理根据意图生成危险轨迹的规划者;以及 (3) 动态记忆和检索,这通过先前生成的规划者的结构化缓存增强 LLM,以减轻遗忘并加速在线操作。这些组件一起实现了危险但可行的背景车辆机动的自适应生成,使我们将安全驾驶历史转化为在线的安全关键未来场景。
A. 问题公式化
定义 1(交通场景):我们在时间 t t t 处考虑一个自动驾驶场景,定义为
X = ( W , S 1 : t e g o , S 1 : t b a c ) X=\left(W, S_{1: t}^{e g o}, \mathbf{S}_{1: t}^{b a c}\right) X=(W,S1:tego,S1:tbac)
其中 W W W 表示静态道路几何形状(车道中心线等), S 1 : t e g o = ( s 1 e g o , s 2 e g o , … , s t e g o ) S_{1: t}^{e g o}=\left(s_{1}^{e g o}, s_{2}^{e g o}, \ldots, s_{t}^{e g o}\right) S1:tego=(s1ego,s2ego,…,stego) 是自我车辆直到时间 t t t 的观测状态, S 1 : t b a c = { S 1 : t i } i = 1 M \mathbf{S}_{1: t}^{b a c}=\left\{S_{1: t}^{i}\right\}_{i=1}^{M} S1:tbac={S1:ti}i=1M 收集了 M M M 个背景车辆直到时间 t t t 的轨迹。
从 t t t 到视野 T T T 的未来轨迹表示为:
Y e g o = S 1 : T e g o , Y b a c = { Y i } i = 1 M Y^{e g o}=S_{1: T}^{e g o}, \quad \mathbf{Y}^{b a c}=\left\{Y^{i}\right\}_{i=1}^{M} Yego=S1:Tego,Ybac={Yi}i=1M
其中
Y
i
=
S
1
:
T
i
Y^{i}=S_{1: T}^{i}
Yi=S1:Ti.
定义 2(安全关键场景):给定一个观测场景
X
X
X,完整场景表示为:
τ = ( X , Y e g o , Y b a c ) \tau=\left(X, Y^{e g o}, \mathbf{Y}^{b a c}\right) τ=(X,Yego,Ybac)
我们定义 τ \tau τ 为安全关键场景,如果在未来轨迹展开中,自我车辆与至少一个背景车辆发生碰撞:
C ( Y e g o , Y b a c ) = I [ ∃ i , ∃ κ ∈ { t , … , T } : ∥ y κ e g o − y κ i ∥ ≤ ϵ ] = 1 \begin{aligned} C\left(Y^{e g o}, \mathbf{Y}^{b a c}\right) & =\mathbb{I}\left[\exists i, \exists \kappa \in\{t, \ldots, T\}: \left\|y_{\kappa}^{e g o}-y_{\kappa}^{i}\right\| \leq \epsilon\right] \\ & =1 \end{aligned} C(Yego,Ybac)=I[∃i,∃κ∈{t,…,T}: yκego−yκi ≤ϵ]=1
其中 ∥ ⋅ ∥ \|\cdot\| ∥⋅∥ 是欧几里得距离, I \mathbb{I} I 是指示函数, ϵ \epsilon ϵ 是碰撞阈值。
等价地,从概率角度看,碰撞可以表示为:
P ( C = 1 ∣ X , Y e g o , Y b a c ) \mathbb{P}\left(C=1 \mid X, Y^{e g o}, \mathbf{Y}^{b a c}\right) P(C=1∣X,Yego,Ybac)
定义 3(基于扰动的安全关键场景生成):给定当前状态 X X X,任务是找到适当的背景车辆未来轨迹 Y ~ b a c \tilde{\mathbf{Y}}^{b a c} Y~bac,以根据方程 4 的定义引发安全关键事件。
Y
~
b
a
c
=
arg
max
Y
b
a
c
P
(
C
=
1
∣
X
,
Y
e
g
o
,
Y
b
a
c
)
\tilde{\mathbf{Y}}^{b a c}=\arg \max _{\mathbf{Y}^{b a c}} \mathbb{P}\left(C=1 \mid X, Y^{e g o}, \mathbf{Y}^{b a c}\right)
Y~bac=argYbacmaxP(C=1∣X,Yego,Ybac)
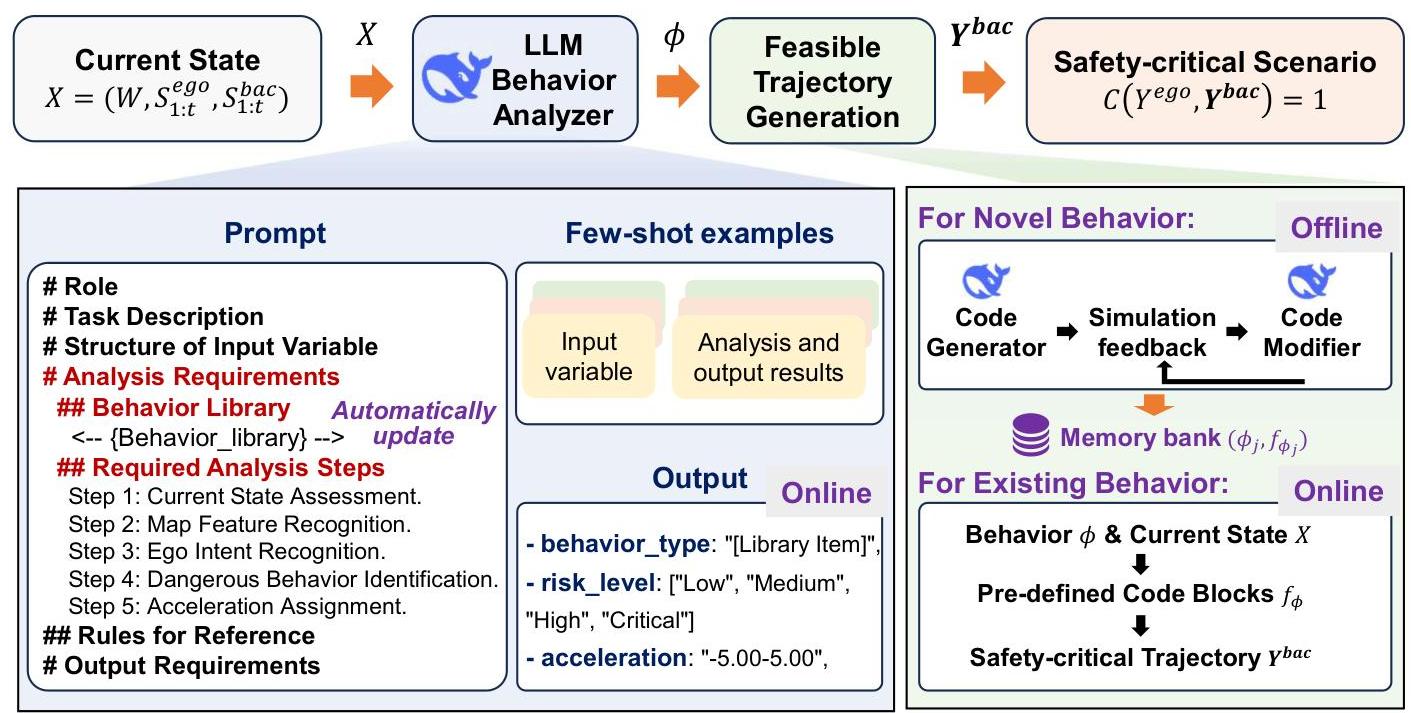
图 2. 所提出的基于 LLM 的框架概述,用于安全关键场景生成。给定当前状态 X = ( W , S 1 : I ego , S 1 : I bac ) X=\left(W, S_{1: I}^{\text {ego }}, S_{1: I}^{\text {bac }}\right) X=(W,S1:Iego ,S1:Ibac ),基于 LLM 的行为分析器使用结构化提示和少量示例来推断危险行为类型、风险水平和加速度配置文件。这些用于生成可行的轨迹并引发安全关键场景,其中 C ( Y ego , Y bac ) = 1 C\left(Y^{\text {ego }}, Y^{\text {bac }}\right)=1 C(Yego ,Ybac )=1。离线时,通过模拟生成和细化行为类型的代码块;在线时,这些记忆与实时行为匹配并检索,以增强类似场景的生成。
B. 总体框架
基于上述公式化,我们详细介绍了利用 LLM 的生成能力和显式记忆和检索过程的安全关键场景生成方法。直接提示 LLM 生成原始轨迹可能具有挑战性,因为 LLM 在文本语料库中训练,处理数值数据的效果较差。在我们的方法中,我们进一步将 Y ~ bac \tilde{\mathbf{Y}}^{\text {bac }} Y~bac 的生成分解为两个阶段:
- 行为意图推断:我们使用基于 LLM 的行为分析代理 g θ g_{\theta} gθ 来分析观测历史,为背景车辆分配离散意图标签:
ϕ = g θ ( X ) , ϕ ∈ Ψ \phi=g_{\theta}(X), \quad \phi \in \Psi ϕ=gθ(X),ϕ∈Ψ
其中
Ψ
\Psi
Ψ 是危险行为意图类型的库。
2) 安全关键轨迹生成:基于意图
ϕ
\phi
ϕ 和当前状态
X
X
X,我们生成安全关键的未来轨迹:
Y ~ bac = f ω ( ϕ , X ) \tilde{\mathbf{Y}}^{\text {bac }}=f_{\omega}(\phi, X) Y~bac =fω(ϕ,X)
其中 f ω f_{\omega} fω 表示基于 ϕ \phi ϕ 条件的轨迹生成器,选择使其最大化与自我车辆的碰撞可能性。
总体而言,我们的在线目标可以写为:
max θ , ω P ( C = 1 ∣ X , Y ego , f ω ( g θ ( X ) , X ) ) \max _{\theta, \omega} \mathbb{P}\left(C=1 \mid X, Y^{\text {ego }}, f_{\omega}\left(g_{\theta}(X), X\right)\right) θ,ωmaxP(C=1∣X,Yego ,fω(gθ(X),X))
这样,正常的历史通过意图引导的轨迹合成转化为安全关键场景。
方程 9 可以扩展为迭代方式,以动态与自我车辆互动,这可以建立一个闭环测试环境 [13]。我们将在以下部分详细说明每个组件的实现。
C. 基于 LLM 的安全关键行为意图分析器
为了自动识别可能威胁测试中自我车辆的背景车辆危险行为,我们设计了一个基于 LLM 的行为分析器。此模块利用带有精心设计的提示和推理过程的 LLM 输出给定场景中最安全关键的行为意图。
如图 2 所示,提示结构分为六个块:角色、任务描述、输入变量结构、分析要求、参考规则和输出要求。角色和任务描述赋予 LLM 安全行为分析器的角色,并指导模型预测系统提示中的行为意图。
输入变量结构澄清了输入格式,包括自我和周围车辆的状态特征以及道路布局。最近的研究表明,LLM 的空间推理和识别能力有限 [24]。为了帮助它们在统一框架内处理任意地图几何形状,我们将所有位置转换为自我为中心的框架。坐标转换表示为:
s
~
=
R
(
−
θ
t
=
0
ego
)
(
s
−
s
t
=
0
ego
)
\tilde{s}=R\left(-\theta_{t=0}^{\text {ego }}\right)\left(s-s_{t=0}^{\text {ego }}\right)
s~=R(−θt=0ego )(s−st=0ego )
其中
s
∈
R
2
s \in \mathbb{R}^{2}
s∈R2 是全局二维点,
s
t
=
0
e
g
o
s_{t=0}^{e g o}
st=0ego 和
θ
t
=
0
e
g
o
\theta_{t=0}^{e g o}
θt=0ego 是自我车辆的初始位置和航向,
R
(
α
)
R(\alpha)
R(α) 是角度
α
\alpha
α 的二维旋转矩阵。
分析要求包括行为库、自动更新库的规则以及五个必要的分析步骤。受到链式思维提示方法的启发 [25],LLM 被引导通过五步推理过程。它首先解释两辆车的当前状态,然后将这些状态置于地图拓扑中。基于自我车辆推断出的意图,模型评估库中哪种行为最可能导致高风险互动。最后,它分配一个适当的加速度 y a c c y_{a c c} yacc 以在下游场景生成中模拟这种行为。
D. 基于行为先验的可行轨迹生成
我们现在解释方程 8 的实现。为了合成背景车辆真实且具有威胁性的运动模式,我们提出了一种由行为级先验指导的三步轨迹生成管道。
- 危险终点推断:给定推断出的意图标签 ϕ \phi ϕ,我们旨在推断背景车辆在这种行为下的可能未来终点。基于 LLM 的代码生成器用于生成可执行代码块 f ϕ f_{\phi} fϕ,根据当前车辆状态和行为语义计算终点坐标 y T b a c y_{T}^{b a c} yTbac:
y T b a c = f ϕ ( y t b a c , y a c c , T ) y_{T}^{b a c}=f_{\phi}\left(y_{t}^{b a c}, y_{a c c}, T\right) yTbac=fϕ(ytbac,yacc,T)
- 插值轨迹规划:为了生成目标轨迹,我们首先调用基于 LLM 的代码生成器以生成专用轨迹规划器:
C ( ψ ) ↦ f t r a j = Planner ψ ( ⋅ ) \mathcal{C}(\psi) \mapsto f_{t r a j}=\operatorname{Planner}_{\psi}(\cdot) C(ψ)↦ftraj=Plannerψ(⋅)
其中 C : Ψ → C \mathcal{C}: \Psi \rightarrow \mathcal{C} C:Ψ→C 将用户指令映射到可执行规划器代码块,而 ψ \psi ψ 指定了规划器所需的特性和约束。
最后,规划器 f t r a j f_{t r a j} ftraj(例如多显示样条或多项式插值器)合成一个时间平滑且运动学可行的轨迹,连接起点 y t b a c y_{t}^{b a c} ytbac 和推断出的终点 y T b a c y_{T}^{b a c} yTbac :
Y ~ b a c = ( y t + 1 b a c , y t + 2 b a c , … , y T b a c ) = f t r a j ( y t b a c , y T b a c ) \tilde{\mathbf{Y}}^{b a c}=\left(y_{t+1}^{b a c}, y_{t+2}^{b a c}, \ldots, y_{T}^{b a c}\right)=f_{t r a j}\left(y_{t}^{b a c}, y_{T}^{b a c}\right) Y~bac=(yt+1bac,yt+2bac,…,yTbac)=ftraj(ytbac,yTbac)
- 基于模拟的代码细化:生成的轨迹
Y
~
b
a
c
\tilde{\mathbf{Y}}^{b a c}
Y~bac 进一步在自我车辆的模拟测试中进行评估。如果合成的轨迹未能引发有意义的安全关键事件,则将其送回代码修改器,这是一个细化模块,根据反馈调整原始代码块
f
ϕ
f_{\phi}
fϕ。这种细化持续进行,直到合成的轨迹满足预定义的风险阈值,确保生成的场景确实是具有对抗性和行为一致性的。
E. 通过动态记忆和检索实现在线场景生成
由于本文考虑在线场景生成,所使用的 LLM 代理(如行为标识符和轨迹生成器)应快速生成与之前遇到的场景相似的场景。然而,由于 LLM 在上下文非常长时会发生灾难性遗忘,因此需要额外的记忆和检索机制来解决这一问题。因此,我们设计了一种动态记忆和检索机制,允许 LLM 对之前遇到的场景类型进行分类,并形成生成轨迹生成器代码的结构化记忆。当遇到新场景时,如果 LLM 将其识别为相似的行为意图,则会基于意图标签检索,并直接采用之前生成的轨迹生成器,从而加快推理过程。
为了克服 LLM 的长上下文遗忘并加速在线生成,我们维护了一个不断增长的记忆库:
M = { ( ϕ j , f ϕ j ) } j = 1 K \mathcal{M}=\left\{\left(\phi_{j}, f_{\phi_{j}}\right)\right\}_{j=1}^{K} M={(ϕj,fϕj)}j=1K
其中每个条目将行为意图标签 ϕ j ∈ Ψ \phi_{j} \in \Psi ϕj∈Ψ 与其之前生成的规划器 f ϕ j f_{\phi_{j}} fϕj 配对, K K K 是历史中处理过的场景数量。给定这样一个记忆库,生成过程可以通过检索加以增强:
- 基于意图的检索:在时间 t t t,给定一个新的推断意图
ϕ t ′ = g θ ( S 1 : t e g o ′ , S 1 : t b a c ′ ) \phi_{t}^{\prime}=g_{\theta}\left(S_{1: t}^{e g o^{\prime}}, \mathbf{S}_{1: t}^{b a c^{\prime}}\right) ϕt′=gθ(S1:tego′,S1:tbac′)
我们在 M \mathcal{M} M 中搜索最接近的存储标签:
j ∗ = arg min 1 ≤ j ≤ K d ( ϕ t ′ , ϕ j ) j^{*}=\arg \min _{1 \leq j \leq K} d\left(\phi_{t}^{\prime}, \phi_{j}\right) j∗=arg1≤j≤Kmind(ϕt′,ϕj)
其中 d ( ⋅ , ⋅ ) d(\cdot, \cdot) d(⋅,⋅) 是合适的标签相似性度量,例如意图标签文本嵌入之间的余弦相似性。如果 d ( ϕ t ′ , ϕ j ∗ ) ≤ ϵ ret d\left(\phi_{t}^{\prime}, \phi_{j^{*}}\right) \leq \epsilon_{\text {ret }} d(ϕt′,ϕj∗)≤ϵret ,那么我们检索并重用现有的规划器:
f ~ t = f ϕ j ∗ \tilde{f}_{t}=f_{\phi_{j^{*}}} f~t=fϕj∗
这避免了重新生成代码以应对已经见过的意图。
2) 通过发现新意图扩展:此外,由于 LLM 可能遇到以前未见过的场景,我们还提示 LLM 主动探索新的行为意图可能性。如果 LLM 认为当前场景中的行为意图不在行为记忆库中,LLM 需要理解和生成新的行为意图标签,以及生成相应的轨迹规划器代码并将其添加到记忆库中作为新记忆。
正式地说,如果没有近似匹配(即 d ( ϕ t , ϕ j ∗ ) > ϵ ret d\left(\phi_{t}, \phi_{j^{*}}\right)>\epsilon_{\text {ret }} d(ϕt,ϕj∗)>ϵret ),LLM 分析器提出一个新的意图标签 ϕ K + 1 \phi_{K+1} ϕK+1,扩展标签集。然后,通过代码生成代理生成相应的规划器 f ϕ K + 1 f_{\phi_{K+1}} fϕK+1。最后,更新记忆:
M ← M ∪ { ( ϕ K + 1 , f ϕ K + 1 ) } , K ← K + 1 \mathcal{M} \leftarrow \mathcal{M} \cup\left\{\left(\phi_{K+1}, f_{\phi_{K+1}}\right)\right\}, \quad K \leftarrow K+1 M←M∪{(ϕK+1,fϕK+1)},K←K+1
传统的对抗性生成方法,如 [6],[7],[21],通过拟合训练分布生成安全关键场景。一旦模型经过训练,预期的
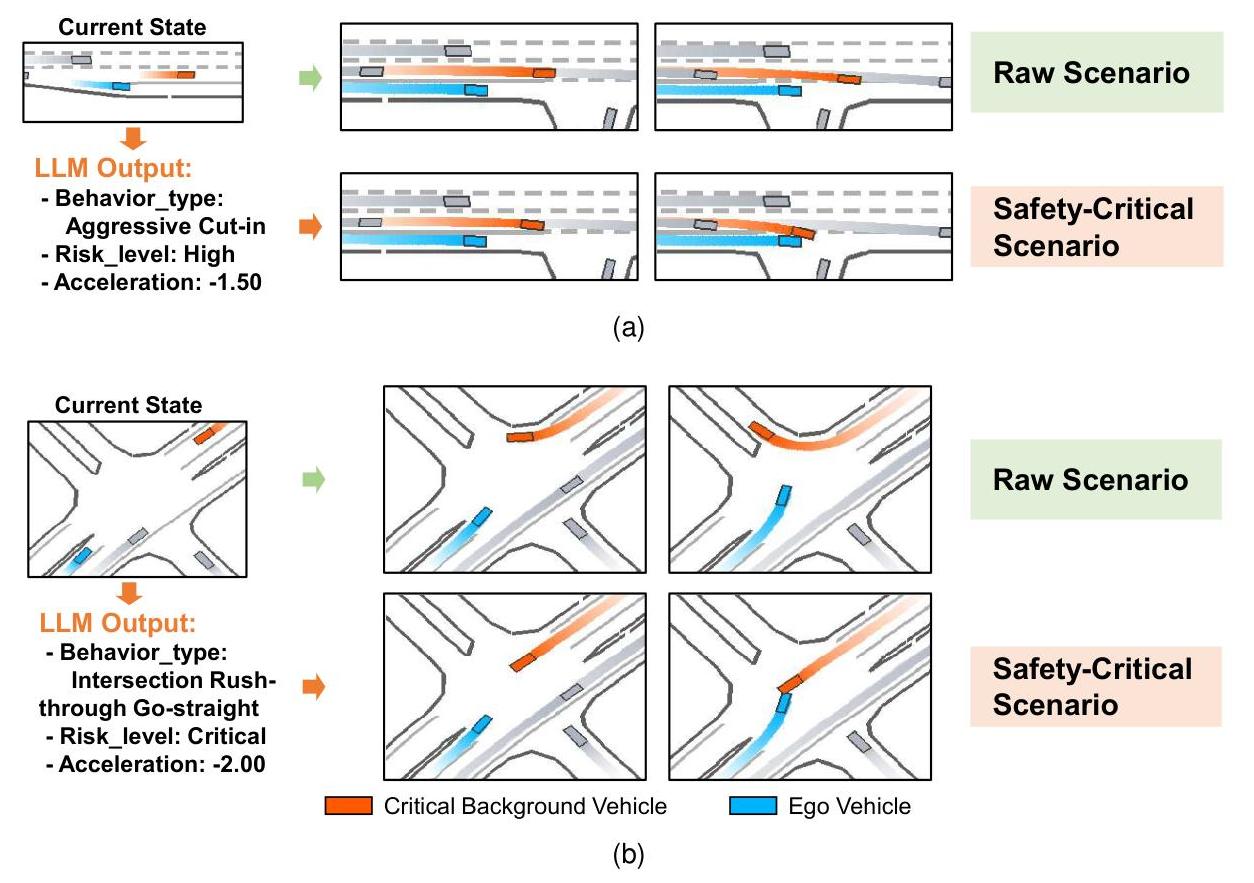
图 3. 生成的安全关键场景示例。(a) 在直路场景中,LLM 识别出强行切入是最危险的行为。生成的轨迹增加了切入的严重程度,并导致碰撞。(b) 在交叉路口场景中,LLM 修改了背景车辆的轨迹,从右转改为直行,导致与左转的自我车辆冲突。
行为生成类型是固定的。这限制了它们在处理动态变化场景中的有效性,而在现实驾驶环境中这种情况很常见。相反,我们的方法提供了一种灵活的替代方案,可以有效地使模型适应新场景。
3) 完整的在线循环:结合检索和生成,对于每个场景:
f ^ t = { f ϕ j ∗ , d ( ϕ t , ϕ j ∗ ) ≤ ϵ r e t f ϕ K + 1 , otherwise (with memory update \widehat{f}_{t}= \begin{cases}f_{\phi_{j^{*}}}, & d\left(\phi_{t}, \phi_{j^{*}}\right) \leq \epsilon_{\mathrm{ret}} \\ f_{\phi_{K+1}}, & \text { otherwise (with memory update }\end{cases} f t={fϕj∗,fϕK+1,d(ϕt,ϕj∗)≤ϵret otherwise (with memory update
检索或新生成的规划器 f ^ ϕ \widehat{f}_{\phi} f ϕ 然后被调用来为当前背景车辆生成对抗性轨迹:
Y ^ b a c = f t r a j ( y t b a c , f ^ ϕ ( y t b a c , y a c c , X ) ) \widehat{\mathbf{Y}}^{b a c}=f_{t r a j}\left(y_{t}^{b a c}, \widehat{f}_{\phi}\left(y_{t}^{b a c}, y_{a c c}, X\right)\right) Y bac=ftraj(ytbac,f ϕ(ytbac,yacc,X))
每种行为类型的规划器代码块生成是一个离线过程。所有经过验证的行为及其对应的终点计算代码块都被存档在 M \mathcal{M} M 中以供在线使用。这种动态记忆和检索机制确保熟悉的意图立即由缓存的规划器处理,而真正的新型互动则促使 LLM 扩展其行为库。
IV. 实验
本节介绍了我们提出的框架的实验设置和评估结果。我们首先描述
数据集和实施细节。接下来,我们评估基于 LLM 的行为分析器在识别危险行为方面的准确性。最后,我们根据它们生成高风险情境的能力比较不同的场景生成方法。
A. 数据集和实验设置
我们在 Waymo 开放运动数据集 [26] 的基础上进行实验。总共导入了 81 个场景,包括 50 个直路场景和 31 个交叉口场景。每个场景包含一辆自我车辆、一辆关键背景车辆和多辆其他周围的车辆。我们的框架采用了 DeepSeek-V3 和 DeepSeek-R1 模型,通过 API 访问。
B. 安全关键行为识别
应用基于 LLM 的行为分析器来识别背景车辆的安全关键行为。识别出七种类型的安全关键行为:紧急刹车、近距离跟随、强行切入、反向入侵、交叉口抢左转、交叉口抢直行和直道换道。我们还手动标注了每个 81 个场景中关键背景车辆的最危险行为,作为基于 LLM 的行为分析器的地面实况。
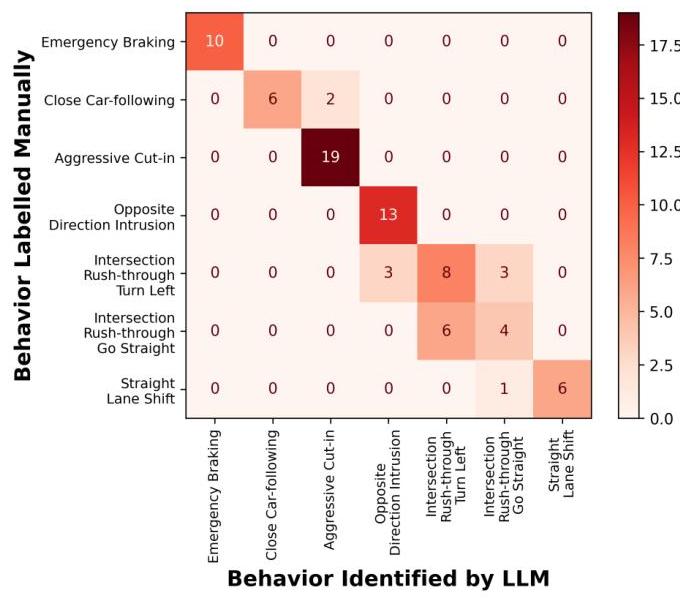
图 4. 基于 LLM 行为分析器的安全关键行为识别混淆矩阵。基于 LLM 的行为分析器在识别 81 个场景中关键背景车辆的最危险行为时达到了 81.5% 的准确率。该矩阵反映了七种类别行为的分类性能。
表 I
安全关键场景生成方法的比较
| MEAN Min TTC ↓ \downarrow ↓ | 碰撞率 ↑ \uparrow ↑ | |
|---|---|---|
| 原始数据 | 1.62 | 0.00 |
| Transformer ∗ { }^{*} ∗ | 1.73 | 0.41 |
| LLM-F (V3) | 2.03 | 0.22 |
| LLM-A (V3) | 1.09 | 0.65 |
| LLM-A (R1) | 1.08 \mathbf{1 . 0 8} 1.08 | 0.75 \mathbf{0 . 7 5} 0.75 |
*: 由基于 Transformer 的候选轨迹预测模型在 [27] 中实现。
分类结果的混淆矩阵如图 4 所示。DeepSeek-R1 的整体准确率达到 81.5%,证明了分析器可以可靠地预测哪个背景行为会对自我车辆构成最高风险。同时,DeepSeek-V3 的准确率为 74.1 % 74.1 \% 74.1%。
C. 安全关键场景生成
在行为识别之后,根据由 1 lm 代码生成器预先定义的代码计算可行的未来轨迹。为了评估生成场景的安全关键特性,我们使用两个指标:碰撞时间(TTC)和 81 个场景中的碰撞率。我们报告平均最小 TTC 和发生碰撞的场景比例。
我们比较了以下三种方法:1)基于 Transformer 的运动预测模型。使用多模态运动预测模型 [27] 为背景车辆生成候选未来轨迹,并选择最危险的一个。2)具有固定行为库的 LLM(LLM-F)。LLM 只能从固定的行为集合中选择:
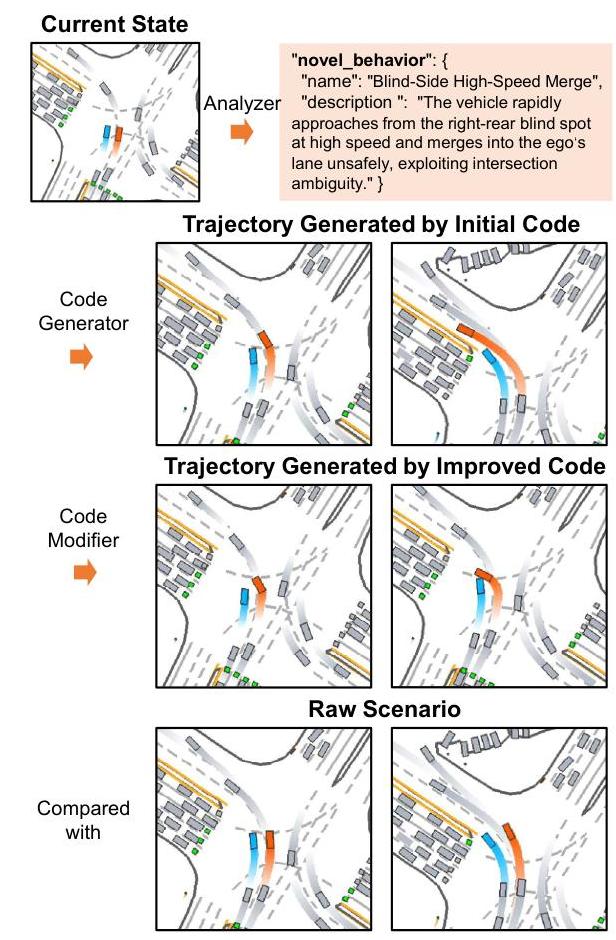
图 5. 发现新的危险行为。LLM 识别出双左转场景中高速侧合并的新高风险行为。初始生成的轨迹增加威胁但避免碰撞。经过代码修改器的改进后,轨迹导致故意合并和碰撞。
近距离跟随和紧急刹车。3)具有自动更新行为库的 LLM(LLM-A)。LLM 从完整且自动更新的行为库中选择和生成行为。
评估结果如表 I 所示。使用 DeepSeek-R1 的 LLM-A 方法将平均最小 TTC 从 1.62 秒减少到 1.08 秒,并在 75 % 75 \% 75% 的场景中引发碰撞,表明场景的关键性更高。
图 3 显示了生成场景的两个代表性例子。在图 3a 中,场景是一条直路。LLM 识别出强行切入是最危险的行为。生成的轨迹特征更加突然和尖锐的切入,导致与未能及时刹车的自我车辆发生碰撞。在图 3b 中,原始交叉口场景中自我车辆左转,背景车辆从对面方向右转。经过修改后,背景车辆改为直行,导致与转弯的自我车辆发生冲突。
此外,图 5 显示了 LLM 行为分析器发现的一种新型危险行为的例子,该行为未包含在初始行为库中。在这种情况下,两辆车都在左转。LLM 识别出背景车辆的盲侧高速合并操作会造成危险。然后,代码生成器输出可执行代码以创建相应的轨迹。最初,生成的行为增加了威胁级别但未导致碰撞。经过代码修改器的改进后,轨迹变得更加激进,背景车辆故意合并到自我车辆的路径中,导致碰撞。
V. 结论
在这项工作中,我们提出了一种新的框架,用于利用检索增强的 LLM 进行在线安全关键场景生成。通过将任务分解为行为意图推断、轨迹合成和记忆-检索机制,我们的方法支持动态适应不断演变的自动驾驶车辆行为和新的驾驶情境。实验表明,我们的方法能够以超过 80 % 80 \% 80% 的准确率识别最危险的背景行为,并生成比数据驱动和固定库基线方法具有显著更高碰撞率的场景。
有几个方向可以进一步增强交互式场景生成。首先,可以集成意图推断中的不确定性。其次,扩展记忆库以支持层次意图和多智能体协调可能会产生更复杂的对抗性互动。
生成式人工智能和人工智能辅助技术在写作过程中的声明
在准备这项工作的过程中,作者使用了 ChatGPT(一种人工智能辅助工具)来提高语言清晰度和可读性。使用该工具后,作者根据需要审查和编辑内容,并对发表文章的内容承担全部责任。
参考文献
[1] D. Chen, M. Zhu, H. Yang, X. Wang, and Y. Wang, “Data-driven traffic simulation: A comprehensive review,” IEEE Transactions on Intelligent Vehicles, 2024.
[2] L. Feng, Q. Li, Z. Peng, S. Tan, and B. Zhou, “Trafficgen: Learning to generate diverse and realistic traffic scenarios,” in 2023 IEEE international conference on robotics and automation (ICRA). IEEE, 2023, pp. 3567-3575.
[3] E. Pronovost, M. R. Ganesina, N. Hendy, Z. Wang, A. Morales, K. Wang, and N. Roy, “Scenario diffusion: Controllable driving scenario generation with diffusion,” Advances in Neural Information Processing Systems, vol. 36, pp. 68 873-68 894, 2023.
[4] W. Ding, C. Xu, M. Arief, H. Lin, B. Li, and D. Zhao, “A survey on safety-critical driving scenario generation-a methodological perspective,” IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 7, pp. 6971-6988, 2023.
[5] H. X. Liu and S. Feng, “Curse of rarity for autonomous vehicles,” nature communications, vol. 15, no. 1, p. 4808, 2024.
[6] W. Ding, B. Chen, M. Xu, and D. Zhao, “Learning to collide: An adaptive safety-critical scenarios generating method,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 2243-2250.
[7] J. Wang, A. Pun, J. Tu, S. Manivasagam, A. Sadat, S. Casas, M. Ren, and R. Urtasun, “Advsim: Generating safety-critical scenarios for selfdriving vehicles,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9909-9918.
[8] D. Rempe, J. Philion, L. J. Guibas, S. Fidler, and O. Litany, “Generating useful accident-prone driving scenarios via a learned traffic prior,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 305-17315.
[9] L. Zhang, Z. Peng, Q. Li, and B. Zhou, “Cat: Closed-loop adversarial training for safe end-to-end driving,” in Conference on Robot Learning. PMLR, 2023, pp. 2357-2372.
[10] K. Hao, W. Cui, Y. Luo, L. Xie, Y. Bai, J. Yang, S. Yan, Y. Pan, and Z. Yang, “Adversarial safety-critical scenario generation using naturalistic human driving priors,” IEEE Transactions on Intelligent Vehicles, 2023.
[11] Y. Mei, T. Nie, J. Sun, and Y. Tian, “Bayesian fault injection safety testing for highly automated vehicles with uncertainty,” IEEE Transactions on Intelligent Vehicles, 2024.
Francis, and J. Oh, “Seal: Towards safe autonomous driving via skill-enabled adversary learning forclosed-loop scenario generation,” arXiv preprint arXiv:2409.10320, 2024.
[13] Y. Mei, T. Nie, J. Sun, and Y. Tian, “Llm-attacker: Enhancing closed-loop adversarial scenario generation for autonomous driving with large language models,” arXiv preprint arXiv:2501.15850, 2025.
[14] C. Chang, S. Wang, J. Zhang, J. Ge, and L. Li, “Llmscenario: Large language model driven scenario generation,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2024.
[15] T. Nie, J. Sun, and W. Ma, “Exploring the roles of large language models in reshaping transportation systems: A survey, framework, and roadmap,” arXiv preprint arXiv:2503.21411, 2025.
[16] J. Zhang, C. Xu, and B. Li, “Chatscene: Knowledge-enabled safety-critical scenario generation for autonomous vehicles,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 459-15 469.
[17] J. Ransiek, J. Plaum, J. Langner, and E. Sax, “Goose: Goal-conditioned reinforcement learning for safety-critical scenario generation,” arXiv preprint arXiv:2406.03870, 2024.
[18] S. Tan, K. Wong, S. Wang, S. Manivasagam, M. Ren, and R. Urtasun, “Scenegen: Learning to generate realistic traffic scenes,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 892-901.
[19] S. Choi, J. Kim, and H. Yeo, “Trajgail: Generating urban vehicle trajectories using generative adversarial imitation learning,” Transportation Research Part C: Emerging Technologies, vol. 128, p. 103091, 2021.
[20] Y. Li, F. Zeng, C. Han, and S. Feng, “Vehicle lane-changing scenario generation using time-series generative adversarial networks with an adaptative parameter optimization strategy,” Accident Analysis & Prevention, vol. 205, p. 107667, 2024.
[21] C. Xu, A. Petiushko, D. Zhao, and B. Li, “Diffscene: Diffusion-based safety-critical scenario generation for autonomous vehicles,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 8, 2025, pp. 8797-8805.
[22] Q. Lu, X. Wang, Y. Jiang, G. Zhao, M. Ma, and S. Feng, “Multimodal large language model driven scenario testing for autonomous vehicles,” arXiv preprint arXiv:2409.06450, 2024.
[23] W. Ding, Y. Cao, D. Zhao, C. Xiao, and M. Pavone, “Realgen: Retrieval augmented generation for controllable traffic scenarios,” in European Conference on Computer Vision. Springer, 2024, pp. 93-110.
[24] B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Sadigh, L. Guibas, and F. Xia, “Spatialvlm: Endowing vision-language models with spatial reasoning capabilities,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 455-14 465.
[25] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou et al., “Chain-of-thought prompting elicits reasoning in large language models,” Advances in neural information processing systems, vol. 35, pp. 24 824-24 837, 2022.
[26] S. Ettinger, S. Cheng, B. Caine, C. Liu, H. Zhao, S. Pradhan, Y. Chai, B. Sapp, C. R. Qi, Y. Zhou, Z. Yang, A. Chouard, P. Sun, J. Ngiam, V. Vasudevan, A. McCauley, J. Shlens, and D. Anguelov, “Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2021, pp. 9710-9719.
[27] Z. Zhou, L. Ye, J. Wang, K. Wu, and K. Lu, “Hivt: Hierarchical vector transformer for multi-agent motion prediction,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 8823-8833.
参考论文:https://arxiv.org/pdf/2505.00972



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











