






奇异科学:第一部分.ii
Kola Ayonrinde
†
{ }^{\dagger}
†
Louis Jaburi
†
{ }^{\dagger}
†
英国人工智能安全研究所
摘要
机械可解释性(MI)旨在通过因果解释来理解神经网络。尽管MI有许多生成解释的方法,但由于缺乏通用的解释评估方法,进展受到限制。在这里,我们分析了“什么是好的解释?”这一基本问题。我们引入了一个多元的解释美德框架,该框架基于科学哲学中的四种视角——贝叶斯、库恩、德意志和诺莫逻辑——系统地评估并改进MI中的解释。我们发现紧凑证明考虑了许多解释美德,因此是一种有前途的方法。由我们的框架暗示的富有成果的研究方向包括(1)明确定义解释的简洁性,(2)关注统一解释,以及(3)推导神经网络的普遍原则。改进的MI方法增强了我们监控、预测和引导AI系统的能力。
1 引言
机械可解释性是研究生成人工神经网络因果科学解释的学科。好的解释使我们能够监控和理解AI系统,同时提供转向和调试的便利。但什么是好的解释?
Wu等人(2024)观察到以下问题:当分析相同的算法任务时,Chughtai等人(2023)和Stander等人(2024)产生了看似对同一模型有效的两种MI解释。然而,他们提出的机制相互矛盾。如果没有系统的选择标准,很难给出充分的理由来判断哪种解释更好。如果没有充分理由选择,研究人员可能会暂停判断或诉诸不同的主观偏好。
同样,Bolukbasi等人(2021)、Friedman等人(2024)和Makelov等人(2024)发现解释可能是误导性的。虽然生成的解释最初可能看起来合理,但它们可能不完整——或者更糟的是,完全虚构的解释,与模型内部结构不符。这样的解释仅提供了对模型理解的幻觉。我们希望有一个明确的指南,说明哪些解释可能忠实于模型内部结构(Ayonrinde & Jaburi, 2025),反之哪些解释即使看似合理也可能不忠实。
1
{ }^{1}
1
近期工作已经开发了针对特定方法(Karvonen等人,2024)或特定合成任务(Gupta等人,2024;Thurnherr & Scheurer,2024)的可解释性评估指标。然而,没有一个统一的框架可以让我们在各种任务中比较不同的解释方法。
†
{ }^{\dagger}
† 对应联系: koayon@gmail.com, louis.yodj@gmail.com
1
{ }^{1}
1 在这个意义上,解释评估对于避免解释性研究人员被解释性幻觉愚弄是有用的。正如费曼(1974)所说:“首要原则是你不能欺骗自己——而你是最容易被欺骗的人。”
为了解决这个问题,我们引入了解释美德框架,它回答了以下问题:给定两个竞争的解释理论,我们应该优先选择哪一个?我们的框架借鉴了科学哲学,特别是贝叶斯、库恩、德意志和诺莫逻辑解释理论,并将这些理论的选择标准应用于MI方法。我们分别通过理论分析和案例研究,探讨我们在好解释中应该寻求和实际寻求的品质。使用我们的解释美德框架,我们分析了四种机械可解释性方法:聚类、稀疏自编码器(SAEs)、因果电路分析和紧凑证明。我们发现,当前MI方法中经常忽视的解释美德包括简洁性、统一性、共同解释和诺莫逻辑原则。因此,我们建议追求这些美德作为有前途的研究方向。
解释美德框架为评估MI方法和增加对AI系统的理解提供了系统方法。这种理解对AI安全、AI伦理和AI认知科学(Bengio等人,2025;Anwar等人,2024;Chalmers,2025)以及调试和改进神经网络(Lindsay & Bau,2023;Sharkey等人,2025;Amodei,2025)都很有用。
贡献。我们的贡献如下:
- 首先,我们提供了MI中解释美德的统一账户。这可以被视为对“什么是好的解释?”这一问题的回答。
-
- 其次,我们根据这些美德分析和比较MI方法。
-
- 最后,我们提出了超越当前技术水平的发展MI解释的新方向。
论文结构。本文组织如下:在第2节中,我们概述了机械可解释性中有效解释的定义,区分MI与其他可解释性范式。在第3节中,我们分析了选择一种解释而非另一种的原因,并介绍了解释美德框架。在第4节中,我们根据这些解释美德对MI方法进行了批判性分析。我们在第5节中讨论了解释学中的方法论前沿,并强调了我们认为有助于发展更可靠的MI解释的美德。
- 最后,我们提出了超越当前技术水平的发展MI解释的新方向。
系列结构。本文是名为《奇异科学:机械可解释性》系列的第二篇,涉及机械可解释性的哲学。
见Ayonrinde & Jaburi(2025)(第一部分.i)关于机械可解释性作为一种实践的哲学基础及其局限性的讨论。另见Ayonrinde(2025)(第一部分.iii),该文提出了通过教授人类机器概念来增强人类的方法。
2 机械可解释性中的有效解释
神经网络可解释性(以下简称可解释性)是使用科学方法理解人工神经网络的过程。在本文中,我们重点关注机械可解释性(MI)。按照Ayonrinde & Jaburi(2025)的观点,我们将机械可解释性与其他形式的可解释性区分开来,指出机械可解释性产生模型层面、本体论、因果-机械性和可证伪的解释。
2.1 机械可解释性中的解释
良好的科学解释回答了为什么的问题。通常,科学解释会回答“为什么现象发生?”这个问题,一个好的解释会使听者更好地理解现象。解释旨在获取知识。由于压缩和理解密切相关(Wilkenfeld,2019),良好的解释通过利用数据中的规律性来压缩观察结果。
神经网络传统上被视为黑箱预测机器(Lipton,2018)。然而,Ayonrinde & Jaburi(2025)描述了一种替代的解释观点,强调深度神经网络包含可以解释其行为的表示和机制。随着模型学习泛化,它们发展出压缩世界信息的内部结构。良好的解释应揭示这些内部结构。
2.2 定义机械可解释性
根据Olah等人(2020);Olsson等人(2022),Ayonrinde & Jaburi(2025)定义了机械可解释性如下 2 { }^{2} 2 :
机械可解释性的技术定义(Ayonrinde & Jaburi,2025)
如果解释是模型层面、本体论、因果-机械性和可证伪的,则它们是有效的机械可解释性解释。
- 模型层面:解释应专注于理解神经网络,而不是采样方法或其他系统级属性(Arditi,2024;Zaharia等人,2024)。
-
- 本体论:解释应指代模型内的真实实体(Salmon,1984)。
-
- 可证伪性:解释应产生可测试的预测(Popper,1935)。
-
- 因果-机械性:解释应识别从原因到现象的连续因果链,而不是统计相关或一般法则(Woodward,2003;Salmon,1989;Bechtel & Abrahamsen,2005)。
3 好解释的美德
“在两个竞争的解释理论之间,我们应该选择哪一个?”这是理论选择的问题(Kuhn,1981;Schindler,2018;Kuhn,1962)。为了回答这个问题,我们可以看看解释的性质。
在科学中,包括在可解释性的奇异科学中,不可能有一份完整的充分证明标准清单。解释理论无法被证明为真,只能被证伪(Popper,1935)。然而,解释理论确实具有促进真理的性质。我们将这些促进真理的解释性质称为解释美德。解释美德是指可靠指示真理的性质。因此,解释美德是我们优先选择一种解释理论而非另一种的好理由。
某个性质是否为解释美德是一个规范性负载的问题;我们应该认识性地优先选择体现解释美德的解释,因为这样的解释更有可能为真,而科学解释的目标是追求真理。
3
{ }^{3}
3 相反,我们描述性地称科学家在实践中重视的解释性质为解释价值。
我们可以通过增加解释的美德来改进我们的解释理论。任何单一理论可能并不具备所有解释美德,但在其他条件相同的情况下,我们应当优先选择具备更多解释美德的理论。类似地,我们可以通过将我们的解释价值与解释美德对齐来提高机械可解释性科学共同体的认识美德(Sosa,1991);也就是说,通过适当重视解释中好的(即促进真理的)方面。
在本节中,我们讨论了解释美德——机器学习研究人员应重视的性质。我们评估了四种解释理论:库恩主义、贝叶斯主义、德意志主义和诺莫逻辑理论。如果这些理论正确识别了我们应该重视的性质,那么这些性质的集合就是解释美德。这些性质将
2
{ }^{2}
2 见Ayonrinde & Jaburi(2025)以获得更全面的阐述。另见附录D.1中的直观解释类型示例。
3
{ }^{3}
3 Schindler(2018)讨论了我们所讨论的美德的真理促进性。
形成我们的多元解释美德框架。我们为每个解释美德提供数学定义,以确保有统一且规范的方式来计算每个美德,从而允许对解释进行更客观的比较。
4
{ }^{4}
4 然后在第4节中,我们将讨论MI研究人员在实践中实际重视的内容,即机械可解释性中的解释价值。我们提供了我们多元解释美德框架的总结以及美德之间的关系图1。
符号。我们将所考虑的解释表示为 E ∈ E E \in \mathcal{E} E∈E,其中 E \mathcal{E} E 是所有可能解释的集合, B B B 表示背景理论。 x T \mathbf{x}_{T} xT 表示用于拟合解释的观测数据(训练数据)。我们假设 x T x_{T} xT 来自可能的观测数据集 X \mathcal{X} X。 x l \mathbf{x}_{l} xl 表示在解释制作时间不可用的未来观测数据(推理时间数据)。 x T , i x_{T, i} xT,i 是 x T \mathbf{x}_{T} xT 中的第 i i i 个数据点。我们用 k k k 表示复杂度度量(例如,柯尔莫哥洛夫复杂度),用 ∣ E ∣ B |E|_{B} ∣E∣B 表示在背景理论 B B B 下解释 E E E 的描述长度(以比特为单位)。
3.1 贝叶斯理论美德
Wojtowicz & DeDeo(2020)描述了一种贝叶斯最佳解释推理方法(Henderson,2014)。在这里,解释美德是理论的信任提升性质。这些美德可以分为两类:理论美德(蓝色),这些是解释中不依赖于已观察或尚未观察数据的性质,以及经验美德(橙色),这些是相对于已观察数据定义的解释性质。
准确性、精确性和先验概率。贝叶斯美德是经验解释美德的准确性、理论解释美德的精确性和某些解释在背景理论下的先验概率。
准确性代表给定解释下真实数据的概率。对数似然是准确性的对数。同样,精确性是给定解释为真的情况下数据条件的期望对数似然。精确性表示解释预测集中在一个特定区域的程度。更高的精确性意味着解释在其预测中更具约束性,如果解释正确的话,它做出的风险且有用的预测排除了其他可能性。
5
{ }^{5}
5
我们将准确性和精确性进一步分解为更多的解释美德。
描述性和共解释性。给定许多数据点
x
=
{
x
1
,
x
2
,
…
,
x
n
}
\mathbf{x}=\left\{x_{1}, x_{2}, \ldots, x_{n}\right\}
x={x1,x2,…,xn},我们希望了解解释如何单独解释每个数据点以及如何一起解释多个数据点。因此,我们将描述性定义为孤立考虑数据观察的对数似然成分,而共解释性则定义为对数似然的成分,重点在于解释如何解释多个数据点,超出其单独预测任何单个观察的能力。
力量和统一性。类似地,我们可以将精确性分解为我们的理论美德——力量和统一性,它们被类似地定义。其中力量衡量解释单个数据点的能力,而统一性衡量连接多个不同观察结果的能力。
4
{ }^{4}
4 我们认为规范定义很重要,因为机械可解释性之前有过几个定义,被不同研究人员不一致地使用,使得直接比较方法变得困难。读者可以检查文本定义的直观理解是否与数学定义一致。我们还在表2中包括了一个评估解释方法的评分表。我们在附录D.2中进一步包括了直观示例来说明解释美德。
5
{ }^{5}
5 注意这里的精确性定义与机器学习中的’精确率-召回率’分析中的精确性度量略有不同(Hastie等人,2009)。在那里,精确性是预测为正例中的真正例比例。这里,我们所说的精确性意味着更精确的解释对其预测更具约束性。
(
Acc
(
E
)
=
P
(
x
T
∣
E
)
)
(\operatorname{Acc}(E)=\mathbb{P}\left(\mathbf{x}_{T} \mid E\right))
(Acc(E)=P(xT∣E))
(
Prec
(
E
)
=
E
x
T
∼
X
[
log
(
P
(
x
T
∣
E
)
)
]
)
(\operatorname{Prec}(E)=\mathbb{E}_{x_{T} \sim \mathcal{X}}\left[\log \left(\mathbb{P}\left(\mathbf{x}_{T} \mid E\right)\right)\right])
(Prec(E)=ExT∼X[log(P(xT∣E))])
(
Prior
(
E
)
=
P
(
E
∣
B
)
)
(\operatorname{Prior}(E)=\mathbb{P}(E \mid B))
(Prior(E)=P(E∣B))
(
Desc
(
E
)
=
∑
i
log
(
P
(
x
T
,
i
∣
E
)
)
)
(\operatorname{Desc}(E)=\sum_{i} \log \left(\mathbb{P}\left(x_{T, i} \mid E\right)\right))
(Desc(E)=∑ilog(P(xT,i∣E)))
(
CoEx
(
E
)
=
log
(
A
c
c
(
E
)
)
−
Desc
(
E
)
=
log
(
P
(
x
T
∣
E
)
∏
i
P
(
x
T
,
i
∣
E
)
)
)
(\operatorname{CoEx}(E)=\log (A c c(E))-\operatorname{Desc}(E)=\log \left(\frac{\mathbb{P}\left(\mathbf{x}_{T} \mid E\right)}{\prod_{i} \mathbb{P}\left(x_{T, i} \mid E\right)}\right))
(CoEx(E)=log(Acc(E))−Desc(E)=log(∏iP(xT,i∣E)P(xT∣E)))
(
Power
(
E
)
=
E
x
T
∼
X
[
∑
i
log
(
P
(
x
T
,
i
∣
E
)
)
]
)
(\operatorname{Power}(E)=\mathbb{E}_{x_{T} \sim \mathcal{X}}\left[\sum_{i} \log \left(\mathbb{P}\left(x_{T, i} \mid E\right)\right)\right])
(Power(E)=ExT∼X[∑ilog(P(xT,i∣E))])
(准确性)
(精确性)
(先验概率)
(描述性)
(共同解释性)
(统一性)
3.2 库恩理论美德
库恩(1981)列出了五个理论美德作为理论选择的基础:准确性、(内部)一致性、范围(统一性)、简单性和丰硕性。我们在第3.1节中已经探讨了统一性(范围)和准确性。
准确性和丰硕性。准确性是指解释与当时创建此类解释时可用数据的契合程度。我们可以将其视为解释的“平凡经验成功”,这与解释的“新颖经验成功”或其丰硕性(Lakatos,1978)形成对比。机器学习研究人员可能会将准确性视为训练/验证集上的性能度量,而丰硕性则是测试集上的性能度量。
6
{ }^{6}
6 丰硕的解释具有扩展性:它们在解决解释设计的原始问题之外的上下文中也有用。
解释性研究人员常常测试MI方法的一个特别重要的丰硕性类型是实用性,即局部解释在某些感兴趣的下游任务中有用的能力(Marks,2025)。例如,研究人员已经测试了稀疏自动编码器特征在下游任务中的表现,如遗忘(Karvonen等人,2024),探测Wu等人(2025),构建鲁棒分类器Gao等人(2024),以及构建稀疏特征电路Marks等人(2024)。分析下游实用性确保MI方法在研究人员关心的任务中直接有用(Lindsay & Bau,2023;Amodei,2025)。
一致性。理论成为良好解释的一个必要标准是其内部一致性。也就是说,解释不应包含任何逻辑矛盾。
简单性。简单性被认为是科学解释的关键美德(White,2005;Qu,2023;MacKay,2003)。然而,可以选择多种形式的简单性,这些形式可能会对解释进行不同的排名(Lakatos,1970)。我们考虑了主要三种简单性度量形式:简约性、简洁性和复杂性。简约性计数
6
{ }^{6}
6 这里我们允许测试集从与训练集相同的分布中抽取,或者代表分布偏移。在科学中,训练集和测试集来自相同分布的类比,如果解释也适合新数据,我们之前没有观察到这些数据,但我们可能已经观察到了。分布偏移的类比是,如果有新的解释促使我们对抗性地寻找新观察以尝试证伪我们的解释理论。在后一种情况下,我们不太可能在制作解释之前观察到这些新数据点。
解释所假设的实体数量(Wojtowicz & DeDeo,2020)。
7
{ }^{7}
7 简洁性是对解释中信息的香农复杂度度量,由描述长度给出(Shannon,1948;MacKay,2003),(K-)复杂性是对解释的柯尔莫哥洛夫复杂度度量,由生成它的最短程序给出(Kolmogorov,1965;Hutter等人,2024)。对于所有简单性度量,较低值更受青睐。
库恩美德词汇表

3.3 德意志理论美德
可证伪性和难变性。波普尔(1935)写道,科学的关键标准是其理论应该是可证伪的——也就是说,我们的解释应附带一组明确的可测试预测。德意志(2011)进一步认为,除了可证伪性外,我们还应寻求本身难变的解释。直观上,我们可以认为解释E是难变的,如果它不能轻易修改以适应与解释相矛盾的传入数据。更确切地说,考虑对解释E的修改Δ,其中Δ是由E中的符号插入、删除、替换和转置组成的列表操作。|Δ|是Δ中的此类操作的数量。
然后难变性准则捕捉了这样的直觉:如果你向解释E添加一些修改或“本轮”Δ,那么新解释E’的新型经验成功应低于E(复杂度加权)。相反,如果我们可以在不增加复杂度的情况下向解释添加修改,并且新解释具有更高的平凡和新型经验成功,那么我们应该更喜欢新解释。 8 { }^{8} 8
对于某种复杂度度量k,我们可以说解释E是难变的,如果它是函数hv(E) = log(Acc(E)) - k(E)的局部最大值。 9 { }^{9} 9
难变性
解释E是难变的,如果它是函数
h v ( E ) = log ( Acc ( E ) ) − k ( E ) (难变性) hv(E) = \log (\operatorname{Acc}(E)) - k(E) \quad \text { (难变性) } hv(E)=log(Acc(E))−k(E) (难变性)
的局部最大值。
3.4 诺莫逻辑理论美德
在亨佩尔&奥本海姆(1948)的演绎-诺莫逻辑(DN)解释模型中,科学解释是一个健全的演绎论证,其中至少有一个前提是“普遍定律”。就我们的目的而言,我们可以将普遍定律视为“对于所有”陈述,这些陈述是真的且不是偶然真的。普遍定律描述了世界的必然而非偶然事实。例如,“所有气体在恒压下加热时膨胀”
7
{ }^{7}
7 实践中,简约性难以很好地定义,因为我们并不总是清楚什么算作一个实体。更糟糕的是,简约性可能将直观上高度复杂的对象和非常简单的对象都同等视为“实体”,并简单地计数它们而不加细致区分。Baker(2022)讨论了简约性作为简单性度量的缺点。
8
{ }^{8}
8 我们在附录E中提供了一个补充的临时性度量。
9
{ }^{9}
9 我们非正式地认为两个解释接近,如果它们之间的编辑操作数很小。
是一条普遍定律,而“1964年格林斯伯里学校董事会的所有成员都是秃头”可能是真实的,但只是巧合,如此而已。
诺莫逻辑性。尽管我们不要求我们的解释严格遵循DN解释模型,但解释的诺莫逻辑性(或合法性),即解释是否引用普遍定律或推导出普遍原则,是一项解释美德。 10 { }^{10} 10
诺莫逻辑性
解释E如果引用普遍定律或神经网络的普遍原则,则是诺莫逻辑的。
3.5 机械可解释性的解释美德
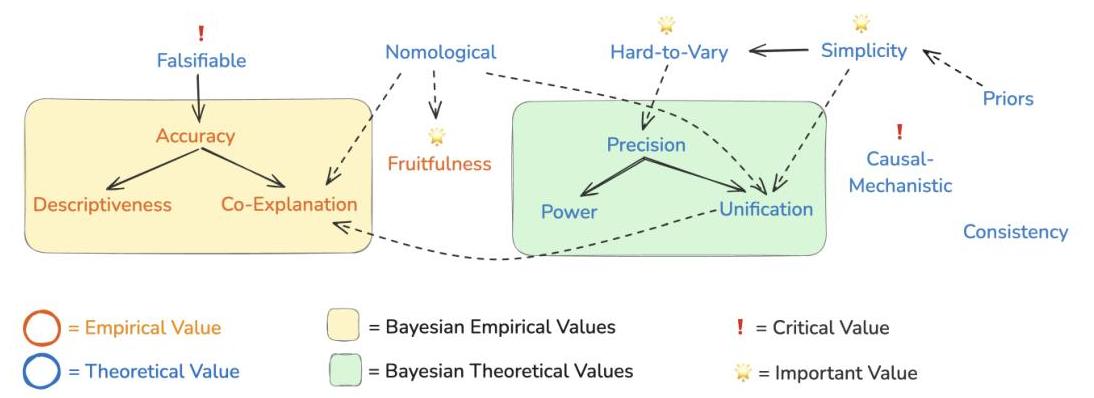
图1:解释美德框架的有向无环图表示,显示了美德之间的关系。经验美德用橙色表示,理论美德用蓝色表示。我们用粗箭头 ( → ) (\rightarrow) (→)表示直接依赖的美德,用虚线箭头 ( − → ) (-\rightarrow) (−→)表示高度相关的美德。对任何科学解释(可证伪性和因果-机械性)有效的解释美德用感叹号标记;决定解释(简单性、难变性和丰硕性)最重要的美德用星号标记。附录A详细说明了评估解释方法的评分表。附录B提供了一个例子,说明简单性作为解释美德的重要性。
我们提供了多元解释美德框架的摘要以及这些美德如何相互关联的图1。这些解释美德不一定穷尽也不一定完全独立。
11
{ }^{11}
11 有些美德可能彼此冲突。例如,在某些情况下,准确性可能与简单性相抵触。在这种情况下,我们的目标可能是达到这种折衷的帕累托边界上的最佳点。
我们希望读者能同意我们的解释美德既是(1)评估解释的重要考虑因素,也是(2)促进真理的。
12
{ }^{12}
12 因此,这些美德可以
10
{ }^{10}
10 Myers(2012)将诺莫逻辑解释与机制解释相对比,认为前者是更高层次的解释,后者是更低层次的解释。然而,Ayonrinde & Jaburi(2025)指出这是一个错误的二分法:机制解释中的实体可以是涌现实体,引用普遍定律可以帮助解释和统一低层次现象。
11
{ }^{11}
11 我们在附录F中详细说明了另一个可能的美德。
12
{ }^{12}
12 也就是说,在其他条件相同的情况下,体现这些美德的解释更可能是正确的。我们推荐读者阅读Schindler(2018),以详细了解我们讨论的许多美德的真理促进性。
作为理论选择的有用指南,更广泛地说,可以辅助新解释方法的发展。我们认为,机械可解释性研究人员应该重视解释美德。
为了让一个解释在机械可解释性中成为一个好的解释,它首先必须是一个有效的MI解释。在第2.2节中,我们将有效的MI解释定义为模型层面、本体论、因果-机械性、可证伪的解释。有效性要求上述四个有效性条件全部满足。然后,解释美德允许我们评估有效MI解释的质量,并提供认识论理由来优先选择一个解释而非另一个。
野外的解释:机械可解释性的案例研究
在第3节中,我们探讨了解释美德。这些价值包括理论解释美德:精确性、力量、统一性、一致性、简单性、诺莫逻辑性、可证伪性和难变性,以及经验解释美德:(平凡)准确性、描述性、共解释性和丰硕性。我们现在考虑这些美德如何在机械可解释性研究人员实际使用的方法中实现。也就是说,我们考虑每种解释美德在MI方法中的重视程度。
本节讨论的方法的视觉总结可以在附录C中找到。
4.1 示例
4.1.1 聚类(激活或输入)
一种原始形式的神经网络解释是对模型输入或激活进行聚类。对于复杂模型,这种解释通常不会非常准确。然而,这种解释是对整体模型性能的简化。这里我们可以想象找到输入/激活空间的一些分区,将给定输入 x \mathbf{x} x映射到其所属的聚类,理想情况下, x \mathbf{x} x是该聚类的典型成员。然后我们可以将聚类(以及可能模型在某些聚类代表上的输出)作为模型行为的代理。 13 { }^{13} 13
尽管在这种情况下这种解释显然不够充分,我们注意到它确实对输入空间进行了一些压缩,我们可以通过改变聚类数量来控制解释的简单性。同样,这里生成的解释是可证伪的;我们可以测试我们的聚类模型对原始模型行为的预测能力。然而,这种解释显然由于不具备因果-机械性,且如果该过程容易受到异常值影响,解释的丰硕性可能较低。
4.1.2 稀疏自动编码器对表示/激活的解释
稀疏自动编码器(SAEs)可用于将神经激活的表示分解为稀疏激活、解耦和单义潜在变量的线性组合(Bricken等人,2023;Huben等人,2024)。尽管提出了许多SAEs的评估方案(Karvonen等人,2024;Wu等人,2025),但SAE解释的主要评估轴是经验准确性和简单性。这里的准确性代表要么是局部无监督准确度度量,如重建误差,要么是当SAE重建被修补到模型中代替原始激活时,解释模型的下游性能。
MDL-SAEs。Ayonrinde等人(2024)提供了一个有用的案例研究,说明在不同背景下不同类型的简单性度量可能更为或不那么有原则性。在MDLSAE框架内,SAE解释在准确性、新颖经验成功和简洁性方面进行评估,其中简洁性是简单性的信息理论度量(见第3.2节)。这与经典SAE框架形成对比,其中简单性度量是SAE潜在稀疏性,这是一种简约度量。在这种情况下,将
13
{ }^{13}
13 我们可以将聚类解释视为对输入空间执行某种“商”操作,等价关系是属于同一个聚类。
简单性度量从稀疏性(简约性)改为描述长度(简洁性)解决了SAE的三个关键问题:避免不必要的特征分裂,实现SAE宽度的原则性选择,以及确保基于特征的解释的独特性(Ayonrinde,2024)。
SAE解释的解释美德。像大多数ML方法一样,SAE解释重视可证伪性和新颖经验成功(超出训练集的预测)。还有一些共解释性,因为应该使用相同的特征字典来解释任何激活(至少来自模型的同一层)。然而,SAE解释可能是临时性的且不容易变化。正如Braun等人(2024)指出的那样,SAE训练用于重建的特征激活对模型的下游性能可能几乎没有影响。因此,相应的特征激活实际上是自由参数。同样,倾向于扩大特征字典(即增加SAE宽度)或向解释中添加额外的活跃特征(即增加特征激活向量的 i th i^{\text {th }} ith 范数)而没有明确理由,表明解释中存在隐含的临时性。MDL-SAEs提供了一些指导,防止特征字典不断增大,但仍需解决如何确保SAE解释真正难变且挑选出与模型下游行为因果相关的特征(Leask等人,2025)。
4.1.3 电路的因果抽象解释
正如神经科学中一样,可解释性研究人员解释神经网络行为的一种自然方式是将网络分解为电路(Olah等人,2020;Kandel等人,2000)。电路可以通过网络与某些已知高层次因果模型之间的对应关系正式指定,使用因果抽象理论(Geiger等人,2023;Woodward,2003;Beckers & Halpern,2019;Pearl,2009)。特别是,通常引用的抽象类型是构造抽象(Beckers & Halpern,2019)。引述自Geiger等人(2021),高层次模型(可理解的因果模型)是低层次模型的构造抽象,如果我们可以对低层次模型中的变量(例如神经网络神经元)进行分区,使得:
- 每个低层次分区单元可以分配给一个高层次变量。
-
- 干预低层次分区单元与干预高层次变量之间存在系统对应关系。
电路分析的因果抽象框架显然关注解释的可证伪性和解释对底层因果模型的忠实性(干预下的经验准确性和新颖成功)。为了鼓励解释的简单性, 14 { }^{14} 14,我们还可以在电路解释中寻求完整性和最小性(Wang等人,2023)。(行为)忠实性、完整性和最小性被称为电路解释的FCM标准。
- 干预低层次分区单元与干预高层次变量之间存在系统对应关系。
电路的FCM标准。对于提出的电路
C
C
C和模型
M
M
M,完整性标准指出,对于每个子集
K
⊂
C
K \subset C
K⊂C,不完整性得分
∣
F
(
C
\
K
)
−
F
(
M
\
K
)
∣
|F(C \backslash K)-F(M \backslash K)|
∣F(C\K)−F(M\K)∣应该很小。直观地说,如果电路和模型在消融后功能保持相似,则电路是完整的。相反,最小性标准指出,对于每个节点
v
∈
C
v \in C
v∈C,存在一个子集
K
⊆
C
\
{
v
}
K \subseteq C \backslash\{v\}
K⊆C\{v},其最小性得分
∣
F
(
C
\
(
K
∪
|F(C \backslash(K \cup
∣F(C\(K∪
{
v
}
)
)
−
F
(
C
\
K
)
∣
\{v\}))-F(C \backslash K) \mid
{v}))−F(C\K)∣很高。直观地说,如果电路不包含对电路功能不必要的组件,则电路是最小的。
算法如ACDC(Conmy等人,2023)找到(近似)满足FCM标准的电路。然而,众所周知(Wang等人,2023),FCM标准是相互矛盾的,不可能同时满足所有三个标准。在
14
{ }^{14}
14 毕竟,当网络本身可以被视为因果模型时,如果忽略了简单性标准,高度复杂的抽象有何意义尚不清楚。
实践中,找到电路是一个计算挑战性问题,电路发现算法通常只找到近似最优的电路(Adolfi等人,2024)。
15
{ }^{15}
15
电路解释的解释美德。尽管这些方法有优点,但它们在统一性、共解释性和诺莫逻辑性方面表现不佳。无论是手动还是自动电路发现方法,大部分注意力都集中在个别电路上,而不是子电路之间的关系和组成。共享内部组件的相关任务的电路解释通常未被优先考虑。同样,通常没有一般的定律或原则详细说明网络中可能出现哪些电路,以及这些电路在不同上下文中的关系。
4.2 紧凑证明
上述聚类、SAEs和电路的例子是创建解释和评估所创建解释的方法。紧凑证明方法(Gross等人,2024;Wu等人,2024;Jaburi等人,2025)是一种评估通过其他方法获得的任何因果-机械解释的方法。在紧凑证明框架中,解释被转换为一个正式保证,允许研究人员评估解释的准确性和简单性。
给定数据分布
D
\mathcal{D}
D和权重
θ
∈
W
\theta \in \mathcal{W}
θ∈W的模型
M
θ
M_{\theta}
Mθ,我们希望获得模型在
D
\mathcal{D}
D上的准确率下限.
16
{ }^{16}
16 正式地,我们构建一个验证程序
V
(
θ
,
E
)
V(\theta, E)
V(θ,E),其中
E
E
E是解释。
V
V
V的目标是以尽可能紧的方式返回模型性能的最坏情况界限,同时保证证明的有效性尽可能高效。我们可以将计算效率视为证明简单性的度量(Xu等人,2020)。请注意,这两个目标,界值的紧密性(准确性)和证明(解释)的紧凑性(简单性),是相互矛盾的。一个好的解释应该推动(紧密性,紧凑性)帕累托前沿。
17
{ }^{17}
17
Gross等人(2024)表明,忠实的机械解释导致更紧的性能界限和更高效的(即更简单的)证明。非正式地,我们可以说紧凑证明允许我们将好的MI解释转化为更紧和更紧凑的证明界限。我们注意到这种方法允许找到和评估满足许多解释美德的解释:精确的解释允许更紧的界限,准确性和简单性直接优化,而因果-机械解释通常需要非空洞的界限。
18
{ }^{18}
18
4.3 解释价值的讨论
表1显示了一些解释美德在不同方法中一直受到高度重视。然而,所有当前的可解释性方法都可以在某些维度上改进,以更有可能产生人类可理解且有用的解释。特别是,我们建议生产或参考诺莫逻辑原则以及统一神经网络行为账户的方法可能越来越成功。
15
{ }^{15}
15 Shi等人(2024)提供了电路的假设检验,测试等效性、独立性和最小性的相关标准。他们的方法是评估电路解释的实际方法。
16
{ }^{16}
16 一般来说,我们可能对需要最小化的指标(如损失)感兴趣,而不是最大化的指标(如准确率和奖励)。在这种情况下,我们可能寻求上限而不是下限,但论证是类似的。
17
{ }^{17}
17 附录B提供了一个基本证明策略的例子,该策略计算成本高但提供了紧的界限。这种策略被称为暴力证明(Gross等人,2024),对应于直接的实现级别解释(Ayonrinde & Jaburi,2025)。
18
{ }^{18}
18 目前还不知道如何将紧凑证明方法扩展到更大的模型,并在附加叠加噪声的情况下仍获得有意义的非空洞界限。这仍然是一个开放问题和评估解释的黄金标准。
| 解释美德 | 重要性 | 聚类 | (MDL) SAEs | 电路 | 紧凑证明 |
|---|---|---|---|---|---|
| 有效性 因果- 机械性 | ! | x x x | - | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
| 贝叶斯 | |||||
| 精确性 | - | - | ✓ \checkmark ✓ | ✓ \checkmark ✓ | |
| 先验概率 | - | - | x x x | x x x | |
| 描述性 | - | - | ✓ \checkmark ✓ | ✓ \checkmark ✓ | |
| 共解释性 | x x x | x x x | x x x | - | |
| 力量 | - | - | ✓ \checkmark ✓ | ✓ \checkmark ✓ | |
| 贝叶斯&库恩 | |||||
| 准确性 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | |
| 统一性 | x x x | x x x | x x x | x x x | |
| 库恩 | |||||
| 一致性 | - | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | |
| 简单性 | * | - | ✓ \checkmark ✓ | - | ✓ \checkmark ✓ |
| 丰硕性 | * | - | - | x x x | - |
| 德意志 | |||||
| 可证伪性 | ! | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
| 难变性 | * | - | - | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
| 诺莫逻辑性 | x x x | x x x | x x x | - | |
| 诺莫逻辑性 |
表1:根据第3节中的解释美德框架对MI解释方法的评估。不可或缺于有效机械可解释性解释的美德用!突出显示。我们认为对良好解释最重要的美德用*突出显示。指标按其哲学基础分组:德意志、库恩、贝叶斯或诺莫逻辑。蓝色指标表示经验标准,而橙色指标表示理论标准。绿色勾号、橙色圆圈和红色叉号分别表示该方法充分考虑、适度考虑或较差考虑某项美德。在第4节中对这些方法的描述中,我们提供了更详细的分析,说明我们如何评估每种方法的美德,并在表2中提供了我们的完整评估评分表。
5 前路展望
“科学是由事实建立起来的,就像房子是由石头建造的一样;但是事实的积累并不能构成科学,就像一堆石头不能构成房子一样。”
- Poincaré(1905)
机械可解释性领域由Olah等人(2020)创立,以区别于先前的神经网络可解释性方法。这些先前的方法未能充分基于因果抽象,也未能适当将模型内部视为需要揭示的内在结构解释(Ayonrinde & Jaburi, 2025; Saphra & Wiegreffe, 2024)。可解释性中的“机械转向”是朝着围绕忠实和可证伪模型解释统一社区的一步。解释美德框架是这一方向的进一步步骤,提供了统一的标准来评估解释方法。特别是,专注于以下三个美德将构成该领域的方法论进步:
- 简洁性和压缩性。Swinburne(1997)认为简洁性是良好解释的关键美德,并可以为理论的真实性提供证据。然而,适当地表征解释的简洁性度量目前仍是可解释性领域的一个开放问题。 19 { }^{19} 19 在紧凑证明文献(Gross等人,2024)和基于归因的参数分解(Braun等人,2025)中可以找到早期探索理解压缩作为解释关键功能的研究。围绕简洁性概念凝聚起来将允许不同解释在(准确性,简洁性)帕累托曲线上进行严格比较,这在许多应用中直接有用。这样的定义也可能自然鼓励对神经网络及其解释中模块化影响的进一步研究(Clune等人,2013;Filan等人,2021;Baldwin & Clark,1999)。
-
- 统一性和共解释性。Hempel(1966)认为统一性是科学进步的核心驱动力。 20 { }^{20} 20 确实,我们可以将统一性视为一种驱动解释压缩的现象,其中要解释的现象集合较大(Bassan等人,2024;Bhattacharjee & von Luxburg,2024)。目前,大多数可解释性方法并不寻求使用相同的构建块共同解释许多现象。机械可解释性(MI)社区试图理解表示和算法在许多模型中的普遍性(或否则),结果喜忧参半(Olah等人,2020;Olsson等人,2022;Chughtai等人,2023)。然而,我们还可能对模块化的组合解释感兴趣,其中解释单元不仅在不同模型之间共享,而且在同一模型内的不同任务和领域之间共享。例如,有证据表明归纳头在模型内用于许多任务,并执行共解释功能(Olsson等人,2022)。
-
- 诺莫逻辑原则。培根(1620)写道,任何科学首先从观察开始。之后,大多数领域必须在温德尔班德(1894)所称的诺莫逻辑和意象两种(非排他性的)路径之间做出选择。诺莫逻辑方法旨在迅速将这些早期观察综合成具有诺莫逻辑原则的一般解释理论,这些原则有助于预测。相反,意象方法侧重于分类和描述越来越详尽的观察集合,而不一定寻求一般定律来解释它们。 21 { }^{21} 21 物理学是一个典型的诺莫逻辑科学;生物学通常被认为是一种意象科学。 22 { }^{22} 22 意象方法往往倾向于描述而非解释。例如,我们可能会怀疑,可解释性研究人员统计和分类给定模型潜在空间中的所有特征是否与生物学家命名和描述生态系统中所有甲虫物种而不学习这些物种的进化或它们在环境中的相互作用有很大区别。
- 诺莫逻辑原则可以简化解释并帮助为机械可解释性提供统一范式。发育可解释性(Hoogland等人,2024)、智能物理学(Allen-Zhu & Li,2024)、计算力学(Shai等人,2024)和深度学习科学(Lubana等人,2023;AllenZhu & Li,2023)的努力也可能产生MI社区在其解释中采用的有用诺莫逻辑原则。
- 机械可解释性已经开始凝聚成一个真正的领域,出现了综述论文(Bereska & Gavves,2024)和(主要会议)研讨会(Barez等人,2024)。许多机械可解释性社区成员采纳了原则、问题和方法,尽管仍有许多开放问题和方法论争议需要解决。虽然库恩意义上的正常科学范式不需要采取诺莫逻辑方法(Kuhn,1962),但历史上具有法律和原则测试和批评的诺莫逻辑导向领域往往看到了更快的科学进步。我们可以将机械可解释性解释向更成熟的科学迈进视为迈向更成熟科学的一种表现。深度学习科学领域寻求发展神经网络原则的努力可能为机械可解释性提供诺莫逻辑原则的基础。
- Shimi(2024)写道:“每门科学的开始都有一个人在编目岩石。” 我们可以补充说:“然后事实证明,我们可以利用这些观察来建立理论。” 我们不应该永远只是编目岩石;实际上,我们必须在某个时候建立理论!
- 机械可解释性发现因果抽象理论是一个有用的起点。我们认为,机械可解释性的进一步范式应该认真对待良好解释的美德。解释美德使我们能够迭代地构建更好的可解释性方法,并生成对神经网络越来越好的解释。
- 机械可解释性的进展可能为AI系统提供洞见,这些洞见对于提高广泛部署和/或在关键应用中使用的系统的透明度和安全性很有用(Bengio等人,2025;Rivera等人,2024;Sharkey等人,2025)。我们认为,我们的解释美德框架可以帮助研究人员设计出导致更可靠和更有用的神经系统解释的方法。
致谢
感谢Nora Belrose、Matthew Farr、Sean Trott、Evžen Wybitul、Andy Artiti、Owen Parsons、Kristaps Kallaste和Egg Syntax对初稿的评论。感谢Elsie Jang、Alexander Gietelink Oldenziel、Jacob Pfau、Catherine Fist、Lee Sharkey、Michael Pearce、Mel Andrews、Daniel Filan、Jason Gross、Samuel Schindler、Dashiell Stander、Geoffrey Irving以及ICML MechInterp Social与会者的有益讨论。我们感谢Kwamina Orleans-Pobee、Will Kirby和Aliya Ahmad提供的额外支持。本项目部分由Foresight Institute AI Safety Grant资助。
可重复性声明
表1中呈现的解释方法的比较评估可以通过应用表2中详细说明的解释美德评分表来重现。该评分表提供了明确的标准,以评估不同的机制可解释性方法在多大程度上体现了每个解释美德。通过遵循三级评估框架(高度美德、弱度美德、不具美德)及其相应的指标( ✓ \boldsymbol{\checkmark} ✓、 ⊗ \boldsymbol{\otimes} ⊗、 X \boldsymbol{X} X),研究人员可以系统地根据解释美德框架评估解释方法。评分表的结构化方法确保评估基于一致的标准,而不是主观偏好,从而允许在机制可解释性中对不同的解释方法进行可重复的比较。
伦理声明
本工作重点在于开发评估神经网络机制可解释性的哲学框架。作为一种理论贡献,我们的框架本身并未直接引发通常与经验AI研究相关的伦理问题,如数据隐私、偏差或直接影响社会的问题。然而,我们认识到机制可解释性的进步具有重要的伦理意义。
我们的框架旨在鼓励更好的AI系统解释,这可以促进AI系统的透明性、问责制和信任。我们注意到,通过对神经网络的更好理解,机制可解释性可能有助于AI安全、AI伦理和在关键应用中负责任地部署AI系统。通过提供系统评估解释的标准,我们的工作支持负责任地开发可解释且人类可理解的AI。
我们希望这项工作有助于实现开发人类可有意义理解、监控和引导的AI系统这一更广泛的目标。
参考文献
Federico Adolfi, Martina G Vilas, 和 Todd Wareham. 内部可解释性的电路发现的计算复杂性. arXiv预印本arXiv:2410.08025, 2024.
Zeyuan Allen-Zhu 和 Yuanzhi Li. 语言模型的物理:第3.1部分,知识存储和提取. arXiv预印本arXiv:2309.14316, 2023.
Zeyuan Allen-Zhu 和 Yuanzhi Li. 语言模型的物理:第3.1部分,知识存储和提取. 第四十一届国际机器学习会议,2024.
Dario Amodei. 解释的紧迫性,2025. URL https://www.darioamodei.com/ post/the-urgency-of-interpretability.
Usman Anwar, Abulhair Saparov, Javier Rando, Daniel Paleka, Miles Turpin, Peter Hase, Ekdeep Singh Lubana, Erik Jenner, Stephen Casper, Oliver Sourbut等. 确保大型语言模型对齐和安全的基础挑战. arXiv预印本arXiv:2404.09932, 2024.
Andy Arditi. AI作为系统,而不仅仅是模型,2024. URL https://www.lesswrong.com/posts/ 2po6bp2gCHzxaccNz/ai-as-systems-not-just-models.
Kola Ayonrinde. 标准SAEs可能不连贯:一个选择问题和一个"简洁"解决方案. 博客文章, 2024. URL https://www.lesswrong.com/posts/vNCAQLcJSzTgjPaW5/ standard-saes-might-be-incoherent-a-choosing-problem-and-a.
Kola Ayonrinde. 观点:可解释性是一个双向沟通问题. ICLK 2025双向人机对齐研讨会, 2025. URL https://openreview. net/forum?id=04LaRH4zSI.
Kola Ayonrinde 和 Louis Jaburi. 机械可解释性中解释的数学哲学:奇异科学第一部分I.i, 2025. 即将出版.
Kola Ayonrinde, Michael T. Pearce, 和 Lee Sharkey. 可解释性作为压缩:重新考虑使用MDL-SAEs解释神经激活的SAE解释,2024. URL https: //arxiv.org/abs/2410.11179.
Francis Bacon. 新工具. 克拉伦登出版社, 伦敦, 1620. URL https://en. wikipedia.org/wiki/Novum_Organum. 是《伟大的复兴》的一部分.
Alan Baker. 简单性. 在Edward N. Zalta (ed.), 《斯坦福哲学百科全书》. Metaphysics Research Lab, 斯坦福大学, 夏季2022版, 2022.
Carliss Y Baldwin 和 Kim B Clark. 设计规则:模块化的力量 第1卷. MIT出版社, 1999.
Fazl Barez, Mor Geva, Lawrence Chan, Atticus Geiger, Kayo Yin, Neel Nanda, 和 Max Tegmark. ICML 2024 机械可解释性研讨会, 2024. URL https: //icml2024mi. pages.dev/.
Shahaf Bassan, Guy Amir, 和 Guy Katz. 局部与全局可解释性:计算复杂性视角. arXiv预印本arXiv:2406.02981, 2024.
William Bechtel 和 Adele Abrahamsen. 解释:一种机制替代方案. 历史与科学哲学研究杂志C部分:历史与生物与生物医学科学哲学研究, 36(2):421-441, 2005. doi:10.1016/j.shpsc.2005.03.010.
Sander Beckers 和 Joseph Y. Halpern. 抽象因果模型. 第33届AAAI人工智能会议论文集, 第2678-2685页. 2019.
Yoshua Bengio, Sören Mindermann, Daniel Privitera, Tamay Besiroglu, Rishi Bommasani, Stephen Casper, Yejin Choi, Philip Fox, Ben Garfinkel, Danielle Goldfarb等. 国际AI安全报告. arXiv预印本arXiv:2501.17805, 2025.
Leonard Bereska 和 Efstratios Gavves. 机械可解释性在AI安全中的应用 - 综述, 2024年4月. URL http://arxiv.org/abs/2404.14082. arXiv:2404.14082 [cs].
J. Bernal. 科学的社会功能. 哲学评论, 49(n/a):377, 1940. doi:10.2307/2180883.
Robi Bhattacharjee 和 Ulrike von Luxburg. 审核局部解释很困难. 第三十八届年度神经信息处理系统会议, 2024. URL https://openreview.net/forum?id=ybHrn4tdn0.
Steven Bills, Nick Cammarata, Dan Mossing, Henk Tillman, Leo Gao, Gabriel Goh, Ilya Sutskever, Jan Leike, Jeff Wu, 和 William Saunders. 语言模型可以解释语言模型中的神经元. https://openaipublic.blob.core.windows.net/ neuron-explainer/paper/index.html, 2023.
Tolga Bolukbasi, Adam Pearce, Ann Yuan, Andy Coenen, Emily Reif, Fernanda Viégas, 和 Martin Wattenberg. BERT的可解释性错觉,2021年4月. URL http: //arxiv.org/abs/2104.07143. arXiv:2104.07143 [cs].
Dan Braun, Jordan Taylor, Nicholas Goldowsky-Dill, 和 Lee Sharkey. 使用端到端稀疏字典学习识别功能性重要特征,2024年5月. URL http://arxiv.org/abs/2405.12241. arXiv:2405.12241 [cs].
Dan Braun, Lucius Bushnaq, Stefan Heimersheim, Jake Mendel, 和 Lee Sharkey. 参数空间中的可解释性:通过基于归因的参数分解最小化机械描述长度. arXiv预印本arXiv:2501.14926, 2025.
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, 和 Christopher Olah. 向单义性迈进:使用字典学习分解语言模型. Transformer Circuits Thread, 2023.
David J Chalmers. 人工智能中的命题可解释性. arXiv预印本arXiv:2501.15740, 2025.
Bilal Chughtai, Lawrence Chan, 和 Neel Nanda. 通用性玩具模型:逆向工程网络如何学习群操作. 国际机器学习会议, 第6243-6267页. PMLR, 2023.
Jeff Clune, Jean-Baptiste Mouret, 和 Hod Lipson. 模块化的进化起源. 皇家学会学报B: 生物科学, 280(1755):20122863, 2013.
Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, 和 Adrià Garriga-Alonso. 机械可解释性的自动电路发现. 2023. URL https://arxiv.org/abs/2304.14997.
Francis Crick. 分子生物学的中心法则. 自然, 227(5258):561-563, 1970.
David Deutsch. 开始无穷:改变世界的解释. penguin uK, 2011.
Frank Watson Dyson, Arthur Stanley Eddington, 和 Charles Davidson. IX. 从1919年5月29日的日全食观测中确定太阳引力场对光的偏折. 皇家学会哲学汇刊A系列, 包含数学或物理性质的论文, 220(571-581):291-333, 1920.
A. Einstein. 广义相对论基础. 1916.
Richard P. Feynman. 货拜文化科学. 工程与科学, 37(7):10-13, 1974. ISSN 0013-7812. URL http://resolver.caltech.edu/CaltechES:37.7.CargoCult.
Daniel Filan, Stephen Casper, Shlomi Hod, Cody Wild, Andrew Critch, 和 Stuart Russell. 神经网络的集群能力. arXiv预印本arXiv:2103.03386, 2021.
Dan Friedman, Andrew Lampinen, Lucas Dixon, Danqi Chen, 和 Asma Ghandeharioun. 简化模型泛化的可解释性错觉. 第41届国际机器学习会议论文集, ICML’24. JMLR.org, 2024.
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, 和 Jeffrey Wu. 稀疏自编码器的扩展与评估, 2024年6月. URL http://arxiv.org/abs/2406.04093. arXiv:2406.04093 [cs] 版本: 1.
Atticus Geiger, Hanson Lu, Thomas Icard, 和 Christopher Potts. 神经网络的因果抽象. M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, 和 J. Wortman Vaughan (eds.), 高级神经信息处理系统进展, 第34卷, 第9574-9586页. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper_ files/paper/2021/file/4f5c422f4d49a5a807eda27434231040-Paper.pdf.
Atticus Geiger, Chris Potts, 和 Thomas Icard. 因果抽象:忠实模型解释. arXiv预印本arXiv:2301.04709, 2023.
Google Developers. 聚类算法. https://developers.google.com/ machine-learning/clustering/clustering-algorithms, 2025. 访问日期: 2025-02-23.
Jason Gross, Rajashree Agrawal, Thomas Kwa, Euan Ong, Chun Hei Yip, Alex Gibson, Soufiane Noubir, 和 Lawrence Chan. 通过机械可解释性验证模型性能的紧凑证明. 第三十八届年度神经信息处理系统会议, 2024.
Rohan Gupta, Iván Arcuschin, Thomas Kwa, 和 Adrià Garriga-Alonso. Interpbench: 半合成变压器用于评估机械可解释性技术. A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, 和 C. Zhang (eds.), 高级神经信息处理系统进展, 第37卷, 第92922-92951页. Curran Associates, Inc., 2024. URL https://proceedings.neurips.cc/paper_files/paper/2024/file/ a8f7d43ae092d9a5295775eb17f3f4f7-Paper-Datasets_and_Benchmarks_Track.pdf.
T. Hastie, R. Tibshirani, 和 J.H. Friedman. 统计学习要素:数据挖掘、推理和预测. Springer系列统计学. Springer, 2009. ISBN 9780387848846. URL https://books.google.co.uk/books?id=eBSgoAEACAAJ.
Carl G. Hempel 和 Paul Oppenheim. 解释逻辑研究. 科学哲学, 15(2):135-175, 1948. ISSN 00318248, 1539767X. URL http://www.jstor.org/ stable/185169.
Carl Gustav Hempel. 自然科学哲学. Prentice-Hall, Englewood Cliffs, N.J., 1966.
Leah Henderson. 贝叶斯主义与最佳解释推论. 英国科学哲学杂志, 2014.
Jesse Hoogland, George Wang, Matthew Farrugia-Roberts, Liam Carroll, Susan Wei, 和 Daniel Murfet. 上下文学习的发展景观. arXiv预印本arXiv:2402.02364, 2024.
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, 和 Lee Sharkey. 稀疏自编码器在语言模型中找到高度可解释的特征. 第十二届国际学习表征会议, 2024. URL https://openreview.net/ forum?id=F76bwRSLeK.
M. Hutter, E. Catt, 和 D. Quarel. 普遍人工智能简介. Chapman & Hall/CRC人工智能与机器人系列. Chapman & Hall/CRC Press, 2024. ISBN 9781003460299. URL https://books.google.co.uk/books?id=cfg60AEACAAJ.
Louis Jaburi, Ronak Mehta, Soufiane Noubir, 和 Jason Gross. 细调神经网络以匹配其解释:迈向缩放紧凑证明, 2025. 即将出版.
E.R. Kandel, J.H. Schwartz, 和 T. Jessell. 神经科学原理,第四版. McGrawHill Companies,Incorporated, 2000. ISBN 9780838577011. URL https://books.google. co.uk/books?id=yzEFK7Xc87YC.
Adam Karvonen, Can Rager, Johnny Lin, Curt Tigges, Joseph Bloom, David Chanin, YeuTong Lau, Eoin Farrell, Arthur Conmy, Callum McDougall, Kola Ayonrinde, Matthew Wearden, Samuel Marks, 和 Neel Nanda. Saebench: 稀疏自编码器的全面基准测试,2024. URL https://www. neuronpedia.org/sae-bench/info.
D. Kennefick. 不留疑问:1919年的日食确认爱因斯坦的相对论. Princeton University Press, 2021. ISBN 9780691217154. URL https://books. google.co.uk/books?id=_Eb8DwAAQBAJ.
Philip Kitcher. 解释的统一. 科学哲学, 48(4):507-531, 1981.
Andrei N Kolmogorov. 信息定量定义的三种方法. 信息传输问题, 1(1):1-7, 1965.
Thomas S. Kuhn. 客观性、价值判断和理论选择. 在David Zaret (ed.), 托马斯·S·库恩《基本张力:科学传统与变化选集》, 第320-39页. Duke University Press, 1981.
Thomas Samuel Kuhn. 科学革命的结构. University of Chicago Press, Chicago, 1962.
Imre Lakatos. 证伪与科学研究纲领方法论. 在Imre Lakatos 和 Alan Musgrave (eds.), 批判与知识增长, 第91-196页. Cambridge University Press, 1970.
Imre Lakatos. 科学研究纲领方法论. Cambridge University Press, New York, 1978.
Patrick Leask, Bart Bussmann, Michael Pearce, Joseph Bloom, Curt Tigges, Noura Al Moubayed, Lee Sharkey, 和 Neel Nanda. 稀疏自编码器无法找到分析单位的规范单元. arXiv预印本arXiv:2502.04878, 2025.
Grace W. Lindsay 和 David Bau. 测试神经系统理解方法. 认知系统研究, 82:101156, 2023年12月. URL https://doi.org/10.1016/j.cogsys.2023. 101156 .
Zachary C Lipton. 模型可解释性的神话:在机器学习中,可解释性概念既重要又模糊. Queue, 16(3):31-57, 2018.
Ekdeep Singh Lubana, Eric J Bigelow, Robert P Dick, David Krueger, 和 Hidenori Tanaka. 机械模式连接. 第40届国际机器学习会议论文集, 第22965-23004页, 2023.
David JC MacKay. 信息论、推理和学习算法. Cambridge university press, 2003.
Aleksandar Makelov, Georg Lange, Atticus Geiger, 和 Neel Nanda. 这是你在寻找的子空间吗?子空间激活修补的可解释性错觉. 第十二届国际学习表征会议, 2024. URL https://openreview. net/forum?id=Ebt7JgMHv1.
Sam Marks. 下游应用作为可解释性进展的验证, 2025年3月. URL https://www.lesswrong.com/posts/wGRnzCFcowRCrpX4Y/ downstream-applications-as-validation-of-interpretability.
Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, 和 Aaron Mueller. 稀疏特征电路:发现和编辑语言模型中的可解释因果图, 2024年3月. URL http://arxiv.org/abs/2403.19647. arXiv:2403.19647 [cs].
James Myers. 两种认知科学的认知风格. 在Proceedings of the Annual Meeting of the Cognitive Science Society, volume 34, 2012.
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, 和 Shan Carter. 放大镜:电路介绍. Distill, 5(3):e00024-001, 2020.
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen等. 上下文学习和归纳头. arXiv预印本arXiv:2209.11895, 2022.
Gonçalo Paulo, Alex Mallen, Caden Juang, 和 Nora Belrose. 自动解释大型语言模型中的数百万特征. arXiv预印本arXiv:2410.13928, 2024.
Philip Kitcher. 解释统一. 科学哲学, 48(4):507-531, 1981.
Andrei N Kolmogorov. 信息的定量定义的三种方法. 信息传输问题, 1(1):1-7, 1965.
Thomas S. Kuhn. 客观性、价值判断和理论选择. 在David Zaret (ed.), 托马斯·S·库恩《基本张力:科学传统与变化选集》, 第320-39页. Duke University Press, 1981.
Thomas Samuel Kuhn. 科学革命的结构. University of Chicago Press, Chicago, 1962.
Imre Lakatos. 证伪与科学研究纲领方法论. 在Imre Lakatos 和 Alan Musgrave (eds.), 批判与知识增长, 第91-196页. Cambridge University Press, 1970.
Imre Lakatos. 科学研究纲领方法论. Cambridge University Press, New York, 1978.
Patrick Leask, Bart Bussmann, Michael Pearce, Joseph Bloom, Curt Tigges, Noura Al Moubayed, Lee Sharkey, 和 Neel Nanda. 稀疏自编码器未找到分析单位的规范单元. arXiv预印本arXiv:2502.04878, 2025.
Grace W. Lindsay 和 David Bau. 测试神经系统的理解方法. 认知系统研究, 82:101156, 2023年12月. URL https://doi.org/10.1016/j.cogsys.2023. 101156 .
Zachary C Lipton. 模型可解释性的神话:在机器学习中,可解释性概念既重要又模糊. Queue, 16(3):31-57, 2018.
Ekdeep Singh Lubana, Eric J Bigelow, Robert P Dick, David Krueger, 和 Hidenori Tanaka. 机械模式连接. 第40届国际机器学习会议论文集, 第22965-23004页, 2023.
David JC MacKay. 信息理论、推理和学习算法. Cambridge university press, 2003.
Aleksandar Makelov, Georg Lange, Atticus Geiger, 和 Neel Nanda. 这是你在寻找的子空间吗?子空间激活修补的可解释性错觉. 第十二届国际学习表征会议, 2024. URL https://openreview. net/forum?id=Ebt7JgMHv1.
Sam Marks. 下游应用作为可解释性进展的验证, 2025年3月. URL https://www.lesswrong.com/posts/wGRnzCFcowRCrpX4Y/ downstream-applications-as-validation-of-interpretability.
Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, 和 Aaron Mueller. 稀疏特征电路:发现和编辑语言模型中的可解释因果图, 2024年3月. URL http://arxiv.org/abs/2403.19647. arXiv:2403.19647 [cs].
James Myers. 认知科学中的认知风格. 在Proceedings of the Annual Meeting of the Cognitive Science Society, volume 34, 2012.
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, 和 Shan Carter. 放大镜:电路介绍. Distill, 5(3):e00024-001, 2020.
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. 上下文学习和归纳头. arXiv预印本arXiv:2209.11895, 2022.
Gonçalo Paulo, Alex Mallen, Caden Juang, 和 Nora Belrose. 自动解释大型语言模型中的数百万个特征. arXiv预印本arXiv:2410.13928, 2024.
Judea Pearl. 因果关系. Cambridge university press, 2009.
H. Poincaré. 科学与假设. 图书馆哲学、心理学和科学方法. Science Press, 1905. URL https://books.google.co.uk/books?id=5nQSAAAAYAAJ.
Karl R. Popper. 科学发现的逻辑. Routledge, London, England, 1935.
Hsueh Qu. 谦虚论理论简单性. Philosophers’ Imprint, 23(1), 2023. doi:10.3998/phimp. 1521.
Juan-Pablo Rivera, Gabriel Mukobi, Anka Reuel, Max Lamparth, Chandler Smith, 和 Jacquelyn Schneider. 语言模型在军事和外交决策中的升级风险. 第2024 ACM公平性、责任和透明度会议论文集, FAccT '24, 第836-898页, 纽约, NY, USA, 2024. Association for Computing Machinery. ISBN 9798400704505. doi:10.1145/3630106.3658942. URL https: //doi.org/10.1145/3630106.3658942.
Wesley Salmon. 四十年的科学解释. 1989. URL https://api. semanticscholar.org/CorpusID:46466034.
Wesley C. Salmon. 科学解释与世界的因果结构. Princeton University Press, 1984. ISBN 9780691101705.
Naomi Saphra 和 Sarah Wiegreffe. 机械可解释性?, 2024. URL https://arxiv.org/abs/2410. 09087.
Samuel Schindler. 科学中的理论美德:通过理论揭示现实. Cambridge University Press, Cambridge, 2018.
Adam Shai, Paul M. Riechers, Lucas Teixeira, Alexander Gietelink Oldenziel, 和 Sarah Marzen. 变压器在残差流中表示信念状态几何. 第三十八届年度神经信息处理系统会议, 2024. URL https: //openreview.net/forum?id=YIB7REL8UC.
Richard Swinburne. 简单性作为真理的证据. Marquette University Press, Milwaukee, 1997.
Hannes Thurnherr 和 Jérémy Scheurer. Tracrbench: 使用大型语言模型生成可解释性测试平台, 2024. URL https://arxiv.org/abs/2409.13714.
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, 和 Jacob Steinhardt. 野外解释:GPT-2小型模型中的间接对象识别电路. 第十一届国际学习表征会议, 2023.
Roger White. 为什么青睐简单性? Analysis, 65(3):205-210, 2005. doi:10.1093/analys/65.3.205.
Daniel A Wilkenfeld. 理解为压缩. 哲学研究, 176(10):28072831, 2019.
Wilhelm Windelband. 历史与自然科学. 应届毕业生就职演讲,斯特拉斯堡威廉皇帝大学,1894年5月1日. Heitz, 1894.
Zachary Wojtowicz 和 Simon DeDeo. 从概率到共识:解释值如何实施贝叶斯推理. Trends in Cognitive Sciences, 24(12):981-993, 2020.
Adam Shai, Paul M. Riechers, Lucas Teixeira, Alexander Gietelink Oldenziel, 和 Sarah Marzen. 变压器在残差流中表示信念状态几何. 第三十八届年度神经信息处理系统会议, 2024. URL https: //openreview.net/forum?id=YIB7REL8UC.
Claude Elwood Shannon. 通信的数学理论. The Bell system technical journal, 27(3):379-423, 1948.
Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeff Wu, Lucius Bushnaq, Nicholas Goldowsky-Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Bloom, Stella Biderman, Adria Garriga-Alonso, Arthur Conmy, Neel Nanda, Jessica Rumbelow, Martin Wattenberg, Nandi Schoots, Joseph Miller, Eric J. Michaud, Stephen Casper, Max Tegmark, William Saunders, David Bau, Eric Todd, Atticus Geiger, Mor Geva, Jesse Hoogland, Daniel Murfet, 和 Tom McGrath. 机械可解释性中的开放问题, 2025. URL https://arxiv.org/abs/2501.16496.
Claudia Shi, Nicolas Beltran-Velez, Achille Nazaret, Carolina Zheng, Adrià Garriga-Alonso, Andrew Jesson, Maggie Makar, 和 David Blei. 在LLM中假设检验电路假说. ICML 2024机械可解释性研讨会, 2024. URL https:// openreview.net/forum?id=ibSNv9cldu.
Adam Shimi. 科学美德的黄金均值, 2024. URL https://formethods. substack.com/p/the-golden-mean-of-scientific-virtues.
Ernest Sosa. 知识视角:认识论论文选集. Cambridge University Press, New York, 1991.
Dashiell Stander, Qinan Yu, Honglu Fan, 和 Stella Biderman. 使用陪集理解群乘法. 在Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, 和 Felix Berkenkamp (eds.), 第41届国际机器学习会议论文集, 第235卷, 第46441-46467页. PMLR, 2024年7月21日至27日. URL https://proceedings.mlr.press/ v235/stander24a.html.
Richard Swinburne. 简单性作为真理的证据. Marquette University Press, Milwaukee, 1997.
Hannes Thurnherr 和 Jérémy Scheurer. Tracrbench: 使用大型语言模型生成可解释性测试平台, 2024. URL https://arxiv.org/abs/2409.13714.
Wilson Wu, Louis, Jacob Drori, 和 Jason Gross. 统一和验证机械解释:群操作案例研究. arXiv预印本arXiv:2410.07476, 2024.
Zhengxuan Wu, Aryaman Arora, Atticus Geiger, Zheng Wang, Jing Huang, Dan Jurafsky, Christopher D. Manning, 和 Christopher Potts. Axbench: 引导ILMs?即使简单的基线也优于稀疏自编码器, 2025. URL https://arxiv.org/abs/2501. 17148 .
Yilun Xu, Shengjia Zhao, Jiaming Song, Russell Stewart, 和 Stefano Ermon. 计算约束下的可用信息理论. 国际学习表征会议, 2020. URL https://openreview.net/forum?id=r1eBeyHFDH.
Sergey Yekhanin 等人. 局部可解码码. Foundations and Trends® in Theoretical Computer Science, 6(3):139-255, 2012.
Matei Zaharia, Omar Khattab, Lingjiao Chen, Jared Quincy Davis, Heather Miller, Chris Potts, James Zou, Michael Carbin, Jonathan Frankle, Naveen Rao, 和 Ali Ghodsi. 从模型到复合AI系统. https://bair.berkeley.edu/blog/2024/02/ 18/compound-ai-systems/, 2024.
A 解释美德评分表
表2:评估给定解释(见图1和第3节)的解释美德评分表。我们使用此评分表对解释进行结构化评估,如表1所示。
| 解释 美德 | 高度美德 | 弱度美德 | 不具美德 |
|---|---|---|---|
| 图标 | ✓ \checkmark ✓ | ⊙ \odot ⊙ | χ \chi χ |
| 因果- 机械性 | 生成端到端因果解释 | 解释网络的一部分并可用作因果机械解释的一部分 | 生成的解释未用于生成端到端因果解释 |
| 精确性 | 奖励提供可量化方式精确和冒险预测的解释 | 部分考虑解释中的精确性,可能是定性的 | 未能惩罚(甚至支持)过于宽泛或模糊的预测 |
| 先验概率 | 明确地在方法中包含与背景理论先验的比较 | 隐含地在评估解释时包含背景理论先验 | 未能适当地包含背景理论先验 |
| 描述性 | 偏向于清晰分析详细、组件级预测质量的高度保真解释,捕捉每个数据点的基本特征 | 仅部分间接分析个别数据点拟合,主要关注整体聚合拟合 | 完全不分析数据点如何单独拟合解释 |
| 共解释性 | 评估解释对多个观察结果一起解释的能力,奖励强调综合联合预测性能的措施 | 有可能结合一些联合解释方面,但目前实践中并未充分奖励连贯整合多样的数据点 | 单独评估每个数据点,忽略链接多个观察结果的价值 |
| 力量 | 强烈重视生成高度约束预测的方法(特别是关于单独考虑的观察),惩罚允许太多合理替代方案的方法 | 对约束预测提供适度重视,允许一定程度的不确定性 | 对解释的预测力不赋予权重 |
| 准确性 | 定量奖励以最小误差拟合数据的解释,特别是在相关情况下参考精度和召回率 | 定性奖励主观上似乎很好地拟合数据的解释 | 无法区分拟合数据良好的解释和拟合数据差的解释,导致容忍显著误差的评估 |
表2:评估解释美德的评分表(续)
| 解释 美德 | 高度美德 | 弱度美德 | 不具美德 |
|---|---|---|---|
| 统一性 | 衡量单一评估框架能够解释多样观察的程度,强调综合统一的解释 | 有可能识别某种统一性,即使是以有限或碎片化的方式,或者这不是该方法的典型应用 | 不重视统一账户,而是重视不一致账户 |
| 一致性 | 要求解释内部连贯,并多次运行相同解释方法 | 大部分内部一致,但可能会提供不一致的解释 | 不重视生成解释的内部一致性 |
| 简单性 | 根据简洁性或K-复杂性简单性度量评估解释,奖励更简单的解释 | 部分考虑简约形式的简单性 | 忽视简单性因素,鼓励极其复杂和繁琐的解释 |
| 丰硕性 | 奖励预测新、可测试现象的解释,即使测试数据是从接近的数据分布中对抗性选择的 | 奖励从相同数据分布中预测新颖现象的解释 | 仅评估当前数据拟合,完全没有训练-验证-测试分割 |
| 可证伪性 | 要求解释产生明确、可测试的预测,并惩罚那些在反事实数据下无法被反驳的解释 | - | 未能考虑解释是否可以经验性反驳,奖励不可证伪的评估 |
表2:评估解释美德的评分表(续)
| 解释 美德 | 高度美德 | 弱度美德 | 不具美德 |
|---|---|---|---|
| 诺莫逻辑性 | 明确整合 已建立 的定律和原则, 偏向于连接到更广泛的 诺莫逻辑框架的评估 或在解释理论中重复使用定律 | 隐含引用 某些非通用定律 但这种联系可能间接且未充分利用 | 忽略与普遍 原则的联系,试图专注于解释 数据而不参考更一般的 理论原则 |
B 直截了当的解释
根据(Ayonrinde & Jaburi,2025),我们将神经网络的直截了当解释定义如下。给定一个神经网络
f
:
X
→
Y
f: X \rightarrow Y
f:X→Y 和
x
∈
X
x \in X
x∈X,使得
f
(
x
)
=
y
f(x)=y
f(x)=y,那么直截了当的解释由网络在输入
x
\mathrm{x}
x 上的计算轨迹给出.
23
{ }^{23}
23 我们注意到,对于任何神经网络
f
f
f 和子分布
D
⊆
D
D \subseteq \mathcal{D}
D⊆D,都存在
f
f
f 在
D
D
D 上的直截了当解释。然而,这种直截了当的解释通常不是一个好的解释,因为这些解释不够简洁或富有启发性。相反,我们希望得到基于网络在训练过程中学到的特征(或概念)的神经网络解释,并且这些解释应该是紧凑且有用的。
鉴于第3节和附录A,我们可以使用解释美德框架来评估神经网络的直截了当解释。
- 因果-机械性:直截了当的解释是因果-机械性的。它将模型分解为由神经网络架构给出的计算图。
-
- 精确性、描述性、准确性、力量&可证伪性:直截了当的解释满足所有这些标准,因为它是对模型的完整表示。
-
- 共解释性&统一性:直截了当的解释不满足这些标准,因为它独立对待所有输入。
-
- 先验概率:直截了当的解释在其解释中不涉及先验概率。
-
- 一致性:直截了当的解释是一致的。
-
- 简单性:直截了当的解释非常复杂。解释中没有从原始权重中压缩出来。
-
- 丰硕性:直截了当的解释不是丰硕的,因为它不提供新的预测。
-
- 难变性:直截了当的解释不是难变的;通过少量修改模型的某些部分(例如单个权重)通常不会显著改变模型性能。
-
- 诺莫逻辑性:直截了当的解释不是诺莫逻辑的,因为它不提供普遍定律或原则。
我们注意到,直截了当的解释是一个有效的神经网络解释:它是模型层面的、本体论的、因果-机械性的和可证伪的。此外,直截了当
- 诺莫逻辑性:直截了当的解释不是诺莫逻辑的,因为它不提供普遍定律或原则。
23
{ }^{23}
23 实际上,这个解释是等式
f
(
x
)
=
y
f(x)=y
f(x)=y 的正式证明。
的解释体现了许多解释价值。然而,我们希望读者会同意,直截了当的解释不是一个好的解释。正如在第5节中所指出的,不是所有的解释价值都是同等重要的,因此一种解释可能体现了一些美德,但仍不是好的解释。
正在解释神经网络的研究人员可能有不同的用例,他们希望获得模型行为的解释。为了考虑这些不同的目标,研究人员可以在他们最看重的解释美德之间做出权衡。
24
{ }^{24}
24 然而,总体而言,我们认为,为了成为一个好的解释,简单性和丰硕性以及难变性是最重要的价值,缺乏这些价值很难有一个好的解释。在这种情况下,直截了当的解释在简单性美德上失败了。
C 野外的解释,视觉上
本节是第4节的视觉补充。我们展示了一系列图表,以阐明每种解释形式的含义,以及如何根据这种方法在两种解释之间进行选择(即理论选择(Schindler,2018))。
C. 1 聚类(激活或输入)
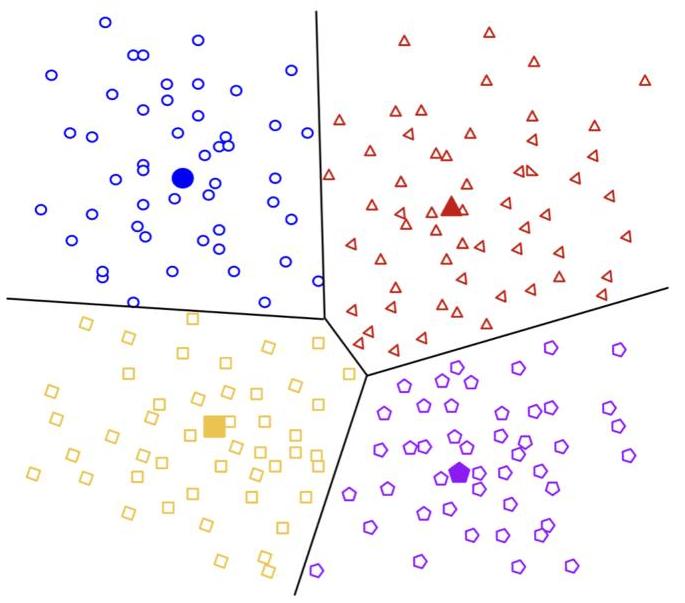
图2:给定一些(可能是中间层的)嵌入(x),可以通过将 x \mathbf{x} x分配到一个聚类 C i C_{i} Ci来生成聚类解释,其中n个聚类将输入空间划分为不相交的区域。这里 C 1 ∪ C 2 ∪ … ∪ C n = R N C_{1} \cup C_{2} \cup \ldots \cup C_{n}=\mathbb{R}^{N} C1∪C2∪…∪Cn=RN 并且 C i ∩ C j = ∅ ∀ i ≠ j C_{i} \cap C_{j}=\varnothing \forall i \neq j Ci∩Cj=∅∀i=j。解释然后通过取模型在某个聚类代表或质心 μ i ∈ C i \mu_{i} \in C_{i} μi∈Ci上的行为给出。我们可以直观地将其视为对输入空间执行商操作,其中模型行为由逐段常数函数近似。[图像来自Google Developers(2025)].
23
{ }^{23}
23 实际上,这个解释是等式
f
(
x
)
=
y
f(x)=y
f(x)=y 的正式证明。
解释体现了许多解释价值。然而,我们希望读者能同意,直接解释并不是一个好的解释。由于如第5节所述,并非所有解释价值都同样重要,一个解释可能具备某些美德,却仍不是一个好的解释。
解释神经网络的研究人员可能有不同的用途,因此需要对模型行为进行解释。为了考虑这些不同目标,研究人员可以在他们最重视的解释美德之间进行权衡。
24
{ }^{24}
24 然而,总的来说,为了让一个解释成为好的解释,我们认为简单性、丰硕性和难变性是最重要的价值,缺少这些价值就很难有一个好的解释。在这种情况下,直接解释在简单性美德上失败了。
C 野外的解释,视觉上
本节是第4节的视觉补充。我们展示了一系列图表,以阐明我们所说的每种解释形式及其如何在给定方法的情况下选择两个解释之间的差异(即理论选择(Schindler,2018))。
C. 1 聚类(激活或输入)
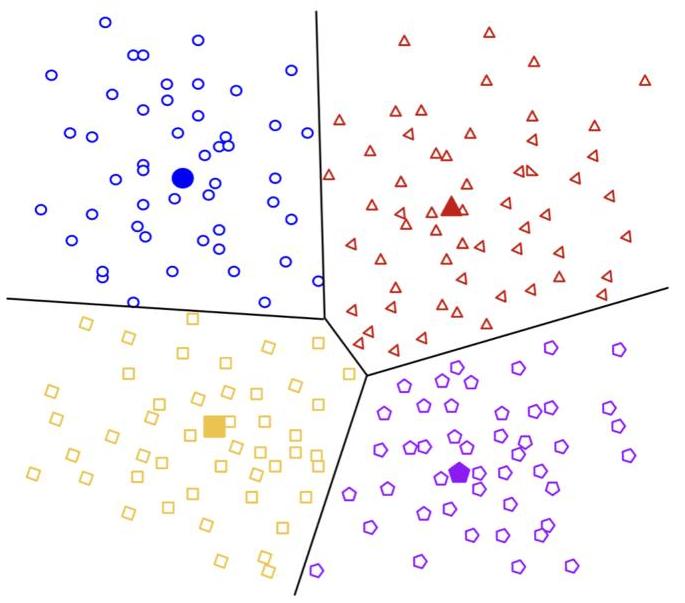
图2:给定一些(可能是中间的)嵌入(x),可以通过将 x \mathbf{x} x分配到一个聚类 C i C_{i} Ci来生成聚类解释,其中n个聚类将输入空间划分为不相交的区域。这里 C 1 ∪ C 2 ∪ … ∪ C n = R N C_{1} \cup C_{2} \cup \ldots \cup C_{n}=\mathbb{R}^{N} C1∪C2∪…∪Cn=RN并且 C i ∩ C j = ∅ ∀ i ≠ j C_{i} \cap C_{j}=\varnothing \forall i \neq j Ci∩Cj=∅∀i=j。解释随后通过取模型在某些聚类代表或质心 μ i ∈ C i \mu_{i} \in C_{i} μi∈Ci上的行为给出。我们可以直观地将其视为对输入空间执行商操作,其中模型行为由逐段常数函数近似。[图像来自Google Developers(2025)]。
23
{ }^{23}
23 实际上,这个解释是等式
f
(
x
)
=
y
f(x)=y
f(x)=y的形式证明。
解释体现了许多解释价值。然而,我们希望读者能同意,直接解释并非一个好的解释。由于如第5节所述,并非所有解释价值都同样重要,一个解释可能具备某些美德,却仍不是一个好的解释。
解释神经网络的研究人员可能有不同的用例,因此希望获得模型行为的解释。为了考虑这些不同目标,研究人员可以在他们最重视的解释美德之间进行权衡。
24
{ }^{24}
24 然而,总的来说,为了让一个解释成为好的解释,我们认为简单性、丰硕性和难变性是最重要的价值,缺少这些价值就很难有一个好的解释。在这种情况下,直接解释在简单性美德上失败了。
C 解释在野外,视觉上
本节是第4节的视觉补充。我们展示了系列图表,以阐明我们所说的每种解释形式及如何根据这种方法在两种解释之间进行选择(即理论选择(Schindler,2018))。
C.1 聚类(激活或输入)
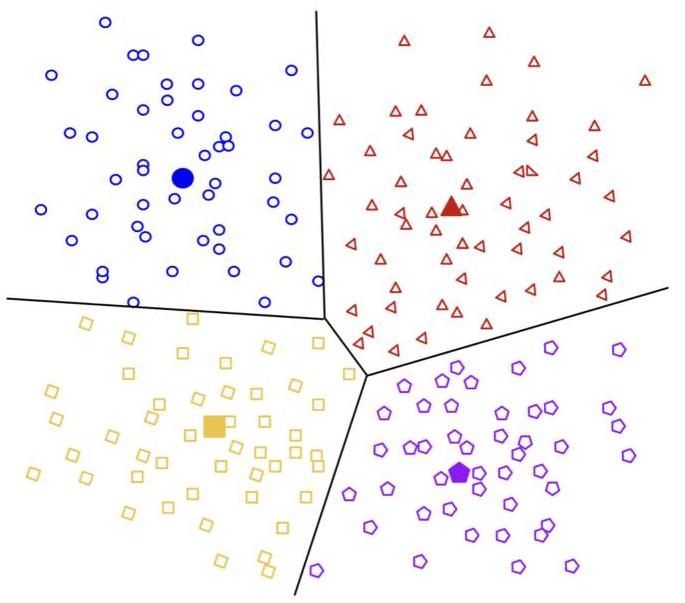
图2:给定一些(可能是中间的)嵌入(x),可以通过将 x \mathbf{x} x分配到一个聚类 C i C_{i} Ci来生成聚类解释,其中n个聚类将输入空间划分为不相交的区域。这里 C 1 ∪ C 2 ∪ … ∪ C n = R N C_{1} \cup C_{2} \cup \ldots \cup C_{n}=\mathbb{R}^{N} C1∪C2∪…∪Cn=RN并且 C i ∩ C j = ∅ ∀ i ≠ j C_{i} \cap C_{j}=\varnothing \forall i \neq j Ci∩Cj=∅∀i=j。解释随后通过取模型在某些聚类代表或质心 μ i ∈ C i \mu_{i} \in C_{i} μi∈Ci上的行为给出。我们可以直观地将其视为对输入空间执行商操作,其中模型行为由逐段常数函数近似。[图像来自Google Developers(2025)]。
24 { }^{24} 24 选择正确的解释是一项带有价值观的任务(Ayonrinde & Jaburi,2025)。
C.2 稀疏自动编码器对表示/激活的解释
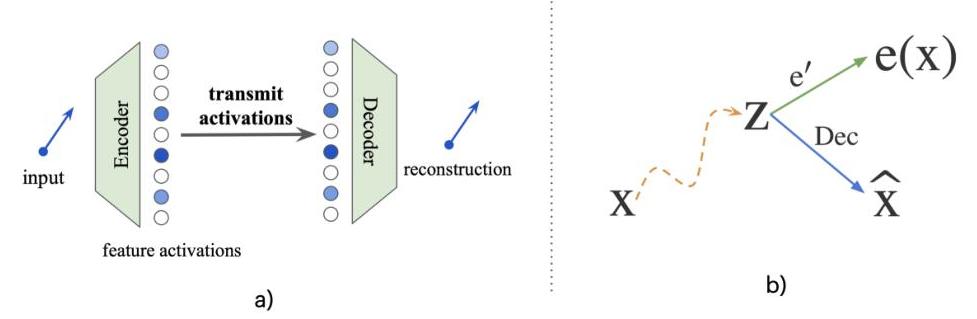
图3:(a) SAE架构。编码器提供特征基础中的某些潜在变量(或特征激活)。我们有一些解码映射Dec,这是特征字典列的线性组合,按稀疏潜在变量加权。我们非正式地说,如果在解码映射下Dec,这些潜在变量对应于输入激活。 (b) 如果 x \mathbf{x} x和 z \mathbf{z} z以上述意义相对应,则输入激活 x \mathbf{x} x的自然语言解释为 e ( x ) = e ′ ( z ) e(\mathbf{x})=e^{\prime}(\mathbf{z}) e(x)=e′(z);即使用自动化可解释性过程 e ′ ( z ) e^{\prime}(\mathbf{z}) e′(z)对潜在变量的解释(Paulo等人,2024;Karvonen等人,2024;Bills等人,2023;Ayonrinde,2024)。我们可以将解释 e ( x ) e(\mathbf{x}) e(x)的数学描述长度(简洁性)测量为描述潜在变量 z \mathbf{z} z所需的比特数(Ayonrinde等人,2024)。[图像来自Ayonrinde等人(2024);Ayonrinde(2024)]
C.3 电路的因果抽象解释
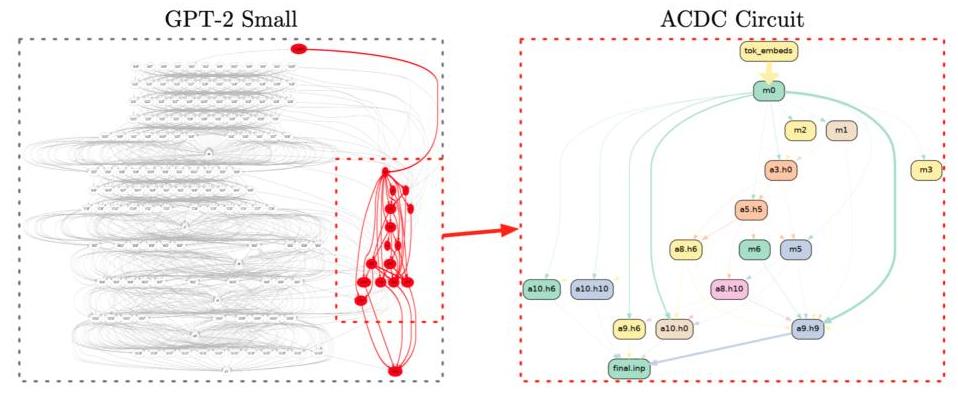
图4:电路解释是一种因果-机械解释,使得电路C是神经网络计算图M的构造抽象,如果存在M中的变量分区,使得C中的每个高层次变量对应M中的低层次分区单元,并且对M的干预对应于对C的干预。例如,在图4左(Conmy等人,2023)中,IOI电路(Wang等人,2023)(以红色突出显示)从GPT-2小型模型的计算图中恢复。[图像来自(Conmy等人,2023)].
C.4 紧凑证明
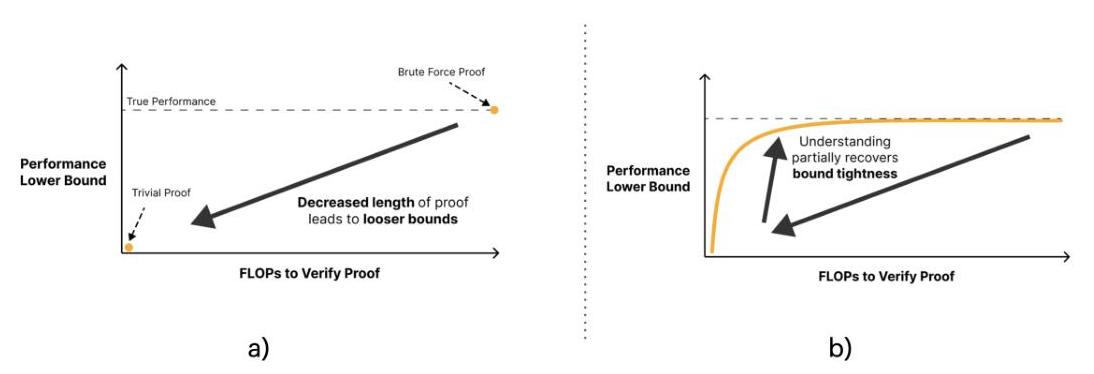
图5:(a) 紧凑证明根据两个指标评估解释,其紧凑性(验证证明所需的FLOPs)和其准确性(模型性能下限)。这两个指标可以在帕累托边界上进行评估。(b) 一个好的解释应该推动边界向左上方移动(即更准确和紧凑的证明)。[图像来自Gross等人(2024)。]
D 解释示例
在本节中,我们提供了一些符合上述标准的解释示例和非示例。第4节中的案例研究是机械可解释性和机器学习领域内的示例;这里的示例是非技术说明。
D.1 解释类型示例
D.1.1 本体论解释
问题:为什么钢笔从桌子上掉了下来?
因果-机械性但非本体论解释。
钢笔掉下桌子是因为以太推了瓶子,然后瓶子又把钢笔推下了桌子。
这种解释在因果-机械意义上是有道理的,因为一件事情发生后引起另一件事情的发生。然而,如果我们不相信以太是一个真实存在的实体,那么这个解释就不能被视为本体论解释。
问题:为什么立方体很重?
本体论但非因果-机械性解释。
立方体很重因为它是由钨原子构成的。
这个解释是本体论的,因为解释中涉及的实体是真实存在的实体。然而,它不是因果-机械性的,因为没有逐步解释,没有填补空白。
D.1.2 统计相关解释
考虑以下解释:
冰淇淋销量在鲨鱼袭击更多的日子更高。如果有鲨鱼袭击报告,我们可以以85%的信心预测当天的冰淇淋销量高于平均水平。
这种解释纯粹基于统计相关性而非因果关系。没有对任何潜在因果机制进行解释,这可能涉及到两者都是炎热天气和/或更多海滩游客的下游结果。我们可以进行干预以测试这一假设。
D.1.3 诺莫逻辑解释
问题:为什么金属棒加热时会膨胀?
诺莫逻辑但非因果-机械性解释。
棒材膨胀因为它遵循所有金属加热时都会膨胀的自然法则,如热膨胀系数所述。
这种解释引用了一条自然法则,而没有深入探讨底层机制。
因果-机械性解释。
棒材膨胀是因为其金属原子受热后振动更剧烈,增加了它们的平均间距。这种增加的间距导致棒材整体长度的增加。
这详细说明了导致膨胀的物理机制。
D.2 解释价值示例
在本节中,我们提供了一些符合上述标准的解释示例和非示例。第4节中的案例研究是在机械可解释性和机器学习领域的示例;这里的示例是非技术说明。
D.2.1 精确性、力量和统一性
考虑一下物体掉落时会发生什么的解释:
当一个物体被放下时,由于重力的作用,它会落到地面。
与更精确的解释相比:
物体以每秒9.8米的速度向地球坠落,具体速度取决于海拔和纬度略有不同。
后者排除的可能性比前者更多。当我们看到一个物体被放下时,有了第二种解释,我们就能排除物体以不同速率坠落的可能性,也能排除物体升空的可能性。
精确的解释做出狭窄且有风险的预测。
统一性。如果一个解释声称解释多个不同的观察结果,那么这个解释就是统一的。分子生物学中的中心法则表明遗传信息只在一个方向流动,从DNA到RNA再到蛋白质,或者直接从RNA到蛋白质(Crick,1970)。这个理论作为一个统一解释,缩小了广泛生物现象的可能性范围。
D.2.2 一致性
一致的解释不含内部矛盾。
问题:为什么爱丽丝今天早上错过了重要的会议?
不一致的解释。爱丽丝是个健忘的人,忘记了会议正在进行,同时爱丽丝故意跳过会议以避免冲突。
一致的解释。爱丽丝外出度假不在办公室,所以错过了会议。
随着解释的统一性/范围增加,我们有时会引入不一致性。例如,当我们试图统一量子力学和广义相对论时,这两个各自内部一致的解释发现它们彼此不一致。
D.2.3 简单性
奥卡姆剃刀原则指出,面对相互竞争的解释,我们应该选择最简单的那个。这个启发式规则最初以简约的形式表述,但我们也可以将简单性的概念扩展到简洁性(香农复杂度)或K-复杂性(柯尔莫哥洛夫复杂度)作为更合适的简单性度量。
托勒密解释:
地球位于宇宙的中心,行星、太阳和恒星围绕地球运转。有许多本轮解释行星的逆行运动(行星在天空中向后移动)。
比哥白尼解释更复杂:
太阳位于太阳系的中心,行星以椭圆轨道绕太阳运转。
尽管两种解释都能拟合数据,但我们应该根据奥卡姆剃刀原则和我们的解释美德简单性来优先选择哥白尼模型。
Wojtowicz & DeDeo(2020)通过分析阴谋论的例子,警示了在解释中不充分重视简单性的危险。这类理论常常“异常共解释和描述…,解释了在官方解释下不太可能的事实…,揭示了日常生活中看似随意的事实如何通过隐藏事件相关联…,并描述了一个统一的宇宙,其中一切通过隐藏共同原因网络相关。” 这些阴谋论通常不是好解释的主要原因是它们不够简单:往往有大量的复杂性和临时推理来解释矛盾证据以及掩盖尚未被揭露的原因。
D.3 可证伪性和难变性
波普尔(1935)反对马克思、弗洛伊德和阿德勒的伪科学理论,理由是它们不可证伪。也就是说,不存在任何可能作出的观察会与理论矛盾并导致其支持者放弃它。为了使一个理论可证伪,它必须对世界作出一些原则上可以测试的具体预测。
考虑以下三种解释季节变化的原因(改编自德意志(2011)):
不可证伪。
季节变化取决于宙斯的意愿。
这个解释不可证伪,因为它不做任何预测。如果某一年没有季节变化,那也不会对该理论构成反对。
可证伪但不难变。
得墨忒耳(希腊女神)与哈迪斯达成协议,她的女儿珀耳塞福涅每年访问哈迪斯一次。当珀耳塞福涅与哈迪斯在一起而不是与她母亲在一起时,得墨忒耳悲伤,世界变得寒冷。
这个解释确实做出了具体预测:季节每年只会改变一次。另一个随之而来的预测是,冬天(珀耳塞福涅与哈迪斯在一起的寒冷时期)应该在地球上所有地方同时发生。这个解释被澳大利亚和雅典的季节时间不同这一事实所否定。然而,这个解释并不难变。我们可以很容易地更改理论中涉及的任何角色或机制,同时保持相同的预测。
可证伪且难变。
地球的自转轴相对于其绕太阳公转的平面倾斜。因此,每年的一半时间北半球朝向太阳,而南半球远离太阳,另一半时间情况则相反。每当太阳光线垂直照射一个半球(从而为单位面积表面提供更多热量)时,它们就会斜射另一个半球(从而提供较少热量)。
这个解释既可证伪又难变。理论的所有细节都在功能上起作用,不能轻易改变。轴倾角理论还(正确地)预测了南北半球季节相反的事实。
D.4 (平凡)准确性和丰硕性(新颖成功)
解释在某种程度上正确解释了它们旨在解释的现象,具有平凡准确性。相反,如果解释预测新的、解释者当时不知道的现象,则解释是丰硕的。能够预测和解释后来被证实的新现象(如同丰硕性)通常被认为比仅仅解释已知现象(如同平凡准确性)更有价值。
爱因斯坦的广义相对论预测光会在大质量物体如太阳附近弯曲(爱因斯坦,1916)。1919年,在一次日食期间,亚瑟·爱丁顿观察到经过太阳附近的星光确实按照爱因斯坦预测的精确程度发生了偏折(Dyson等人,1920;Kennefick,2021)。鉴于大质量物体周围光弯曲的现象之前未知,这对爱因斯坦的理论来说是一次新颖的经验成功。这可以增加我们对爱因斯坦理论的信心,因为预测是在观察之前作出的,精确且定量地处于未知领域,并且观察结果与预测高度一致。
D.5 共解释性和描述性
解释可以是纯粹描述性的,在这种情况下,它们很好地解释了它们旨在解释的现象,但不与其他解释相连。或者,解释可以是共解释性的,统一以前被认为是不同的现象。
描述性但不共解释性。
电涉及电荷的移动并产生静电吸引、闪电和电流等效应。另一方面,磁性涉及某些材料如磁石和铁之间的吸引或排斥,并表现为指南针指向北方的行为。
共解释性。
电和磁是单一基本电磁力的不同表现形式。变化的电场会产生磁场,变化的磁场会产生电场。移动的电荷创建磁场,而移动的磁铁会感应电流。
E 一致性公式化的临时性
(Schindler, 2018) 还给出了一个临时性测试,可以识别那些是添加到容易变动的解释中的事后epicycle的结果。对于Schindler,如果修改Δ对应于某些额外假设H(我们可以认为是为了适应难以解释的数据 x I \mathbf{x}_{I} xI而添加的),并且满足两个条件,则该解释是临时的:
- H解释 x I \mathbf{x}_{I} xI。即 P ( x I ∣ E , H ) > P ( x I ∣ E ) \mathbb{P}\left(\mathbf{x}_{I} \mid E, H\right)>\mathbb{P}\left(\mathbf{x}_{I} \mid E\right) P(xI∣E,H)>P(xI∣E)。
-
- 原始解释E或背景理论B都不为H提供证据。即
P
(
H
∣
E
,
B
)
<
P
(
H
)
\mathbb{P}(H \mid E, B)<\mathbb{P}(H)
P(H∣E,B)<P(H)。
我们将临时性度量定义为 Adhoc = P ( H ) − P ( H ∣ E , B ) \operatorname{Adhoc}=\mathbb{P}(H)-\mathbb{P}(H \mid E, B) Adhoc=P(H)−P(H∣E,B),其中更大的临时性值更临时且不受欢迎。
- 原始解释E或背景理论B都不为H提供证据。即
P
(
H
∣
E
,
B
)
<
P
(
H
)
\mathbb{P}(H \mid E, B)<\mathbb{P}(H)
P(H∣E,B)<P(H)。
F 本地可解码性作为一种解释美德
另一种我们可能考虑的高统一性解释美德是本地可解码性。本地可解码解释允许检索和使用解释的小片段,而无需查询整个解释,类似于局部可解码纠错码(Yekhanin等人,2012)。这很重要,因为我们不仅希望解释具有信息压缩(简洁表示),还希望具有信息可访问性(快速检索特定子部分的能力)。实际上,一个被压缩但不可本地解码的网络解释需要大量的计算资源才能查询,并且对人类理解没有用处。 25 { }^{25} 25 Ayonrinde等人(2024)的独立加法性条件是机械可解释性中的一个本地可解码性条件示例。V-Information(Xu等人,2020)为机器学习中的本地可解码性提供了有用的类比。
25 { }^{25} 25 本地可解码性以查询复杂度衡量:恢复消息(解释)1位所需的查询次数。简洁性和查询复杂度已知成反比,但它们关系的确切基本限制目前尚不清楚。
参考论文:https://arxiv.org/pdf/2505.01372



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











