






付松辰
1
,
2
{ }^{1,2}
1,2,陈思昂
3
{ }^{3}
3,赵少靖
1
,
2
{ }^{1,2}
1,2,白乐天
1
,
2
{ }^{1,2}
1,2,李塔
1
,
2
,
2
{ }^{1,2,2}
1,2,2,颜永红
1
,
2
{ }^{1,2}
1,2
1
{ }^{1}
1 中国科学院声学研究所语音与智能信息处理实验室
2
{ }^{2}
2 中国科学院大学
3
{ }^{3}
3 清华大学电子工程系
fusongchen@hccl.ioa.ac.cn, lita@hccl.ioa.ac.cn
摘要
在现实世界的多智能体系统(MASs)中,观测延迟是普遍存在的,阻碍了智能体根据环境的真实状态做出决策。单个智能体的局部观测通常由来自其他智能体或环境中动态实体的多个组件组成。这些具有不同延迟特性的离散观测组件对多智能体强化学习(MARL)构成了重大挑战。本文首先通过扩展标准的Dec-POMDP提出了去中心化的随机个体延迟部分可观测马尔可夫决策过程(DSID-POMDP)。然后,我们提出了彩虹延迟补偿(RDC),这是一种针对随机个体延迟的MARL训练框架,并提供了其组成模块的推荐实现方式。我们在标准的MARL基准测试中实现了DSID-POMDP的观测生成模式,包括MPE和SMAC。实验表明,在固定和非固定的延迟条件下,基线MARL方法性能严重下降。RDC增强的方法缓解了这一问题,在某些延迟场景中显著达到了理想的无延迟性能,同时保持了泛化能力。我们的工作为多智能体延迟观测问题提供了一个新的视角,并提供了一个有效的解决方案框架。
1 引言
多智能体强化学习(MARL)已广泛应用于多人游戏 [27, 18]、机器人控制 [13, 14]、智能体通信 [5, 39] 和量化交易 [36] 等领域。然而,除了MARL本身固有的挑战,如非平稳性、部分可观测性、信用分配和维度灾难 [37, 12] 外,观测延迟问题往往被忽视。从生物系统中的信号传输 [11] 到大规模群体中的通信 [28],延迟问题在实际场景中普遍存在,并且通常对大多数系统产生不利影响。由于环境、盟友智能体和其他智能体(对手或目标)的耦合影响,多智能体系统(MASs)表现出比单智能体系统更普遍和复杂的观测延迟情况。
早期关于系统延迟问题的研究主要植根于控制理论 [1, 22],其中解决方案高度依赖于固定的转换模型——这一假设在复杂的MASs中经常被违反 [24]。引入扩充状态空间 [2,31] 标志着一个关键转变,使强化学习方法能够通过基于模型的状态估计来处理确定性延迟 [9, 7]。尽管这些方法推动了单智能体系统的发展,但它们在多智能体设置中的扩展仍然表
面化,通常仅限于固定延迟场景 [7, 32, 20]。近期在延迟观测马尔可夫决策过程(DOMDPs)[33] 方面的进展正式化了随机延迟建模,但现有工作主要集中于单智能体领域。多智能体解决方案 [35, 34] 在通信和反馈层面建立了理论基础和算法创新。然而,MASs中随机部分可观测性的根本挑战仍未解决。鉴于实际多智能体应用中固有的异步性和网络引发的不确定性,这一疏忽尤为重要。
以往的研究主要集中在单智能体系统的延迟问题上,而MARL研究主要是单智能体延迟理论的简单扩展。然而,多智能体环境中的延迟并非恒定,每个智能体的观测组件可能经历不同的延迟。我们的工作为MASs中的延迟观测提供了更深入的理解,并提出了一种通用的算法框架来应对相关挑战。这意味着从业者可以通过选择和集成适合不同场景的算法来定制框架,从而实现最佳性能。本文的主要贡献如下:
- 我们定义了去中心化的随机个体延迟POMDP(DSID-POMDP),为具有延迟观测的MASs提供了一个通用的数学模型。
-
- 我们提出了彩虹延迟补偿(RDC)训练框架,通过无延迟观测重建、课程学习和知识蒸馏减轻延迟观测的影响。
-
- 基于DSID-POMDP,我们创新性地引入了两种补偿器操作模式(Echo和Flash),并基于Transformer和门控循环单元(GRU)网络实现了两种模型。
-
- 我们将两种经典的MARL算法,VDN [29] 和QMIX [26],集成到RDC框架中。所提出的方法在两个常见的MARL基准测试中进行了测试,在固定和非固定延迟条件下表现出显著的性能改进,接近无延迟性能水平。
2 相关工作
最近的研究探索了深度强化学习(DRL)方法以解决单智能体系统中的延迟问题。Walsh等人 [31] 提出了常延迟马尔可夫决策过程(CDMDP),通过扩展动作序列将固定延迟纳入观测和奖励中。然而,由此产生的状态空间扩展遭受指数级增长,限制了纯状态基解决方案的可行性。为克服这一点,他们提出了基于模型的仿真(MBS)适用于离散环境和模型参数近似(MPA)适用于连续环境,开创了无延迟状态估计的基于模型的方法。Firoiu等人 [9] 使用环境预测模型减少游戏中固定动作延迟带来的性能退化。Bouteiller等人 [4] 开发了一种部分轨迹重采样方法,以解决随机延迟环境中的信用分配挑战。Liotet等人 [19] 实施模仿学习以使延迟智能体与专家动作分布对齐,但仅限于固定延迟。Wang等人 [33] 结合状态扩充和状态预测与延迟协调训练进行单独的演员-评论家优化,在随机延迟场景中表现出显著改进。
在解决MARL中的延迟挑战方面也取得了显著进展。Chen等人 [6] 开发了延迟感知多智能体强化学习(DAMARL)框架,通过集中训练使用辅助信息减轻固定观测延迟。随后,Yuan等人 [35] 引入TimeNet动态优化智能体的等待时间以进行延迟通信,从而提高协作效率。对于奖励延迟场景,Zhang等人 [38] 提出了延迟自适应多智能体V-学习(DAMAVL),在有限和无限延迟条件下证明了收敛性。实际应用展示了前景,如Liu等人 [20] 在合作自适应巡航控制系统(CACC)中成功实施DAMARL。虽然Wang等人 [32] 通过状态预测预测动作效果推进了该领域,但当前方法仍限于固定延迟场景,通常忽略观测延迟的异步性。
3 预备知识
3.1 去中心化的部分可观测马尔可夫决策过程
去中心化的部分可观测马尔可夫决策过程(Dec-POMDP)是一种为MASs中的协调和决策设计的模型。在这个框架中,POMDP引入了一个“观测”变量,使决策者能够在每个时间步骤只观察系统状态的一部分,建立在原始MDP之上。Dec-POMDP通过引入额外的联合变量将这一概念扩展到多智能体场景。它可以形式化定义为一个7元组 ( I , S , A , Z , P , R , O ) (\mathcal{I}, \mathcal{S}, \mathcal{A}, \mathcal{Z}, \mathcal{P}, \mathcal{R}, \mathcal{O}) (I,S,A,Z,P,R,O),其中 I \mathcal{I} I表示有限的智能体集合。 S \mathcal{S} S表示包含所有可能环境状态的状态系统集合。 A \mathcal{A} A和 Z \mathcal{Z} Z分别是每个智能体的动作和观测空间,有 A = A i \mathcal{A}=\mathbf{A}_{i} A=Ai和 Z = Z i , P , R \mathcal{Z}=\mathbf{Z}_{i}, \mathcal{P}, \mathcal{R} Z=Zi,P,R,以及 O \mathcal{O} O定义为 P ( s ′ ∣ s , a ) , R ( r ′ ∣ s , a ) \mathcal{P}\left(\mathbf{s}^{\prime} \mid \mathbf{s}, \mathbf{a}\right), \mathcal{R}\left(\mathbf{r}^{\prime} \mid \mathbf{s}, \mathbf{a}\right) P(s′∣s,a),R(r′∣s,a),和 O ( o ∣ s ) \mathcal{O}(\mathbf{o} \mid \mathbf{s}) O(o∣s),分别表示执行联合动作 a \mathbf{a} a后从状态 s \mathbf{s} s转移到状态 s ′ \mathbf{s}^{\prime} s′,获得奖励 r ′ \mathbf{r}^{\prime} r′,以及获得观测 o \mathbf{o} o的概率。这种表述捕捉了MASs中去中心化决策的本质,即智能体必须基于环境的部分观测来协调他们的行动。
3.2 去中心化的随机个体延迟部分可观测马尔可夫决策过程
虽然延迟观测MDPs代表了POMDPs的一个特殊情况,我们在本文中清楚地区分了延迟观测和部分观测。在典型的多智能体环境中,每个智能体的观测由三个部分组成:(1) 自身状态信息(通常由于内部传输延迟最小),(2) 其他智能体的状态(通过感知或通信获得),(3) 环境状态。由于观察其他智能体和环境状态的延迟遵循相似的原则,我们将这些观测源统称为“实体”,以清晰表达。来自其他实体的观测延迟通常
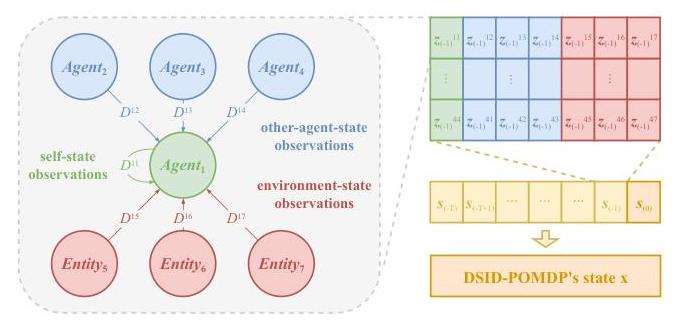
图1:DSID-POMDP中扩展状态和延迟观测的简单示例。左侧描述了智能体
1
_{1}
1 的观测组成部分,并标注了它们的延迟值分布。右上方矩阵显示了扩展状态中
s
(
−
1
)
s_{(-1)}
s(−1)的内容。
与它们的相对距离正相关。受此现象启发,我们可以将智能体
i
_{i}
i 观测中不同实体的可能延迟值建模为多个用户定义的概率分布,而不仅仅是与距离相关的那些。因此,我们提出了去中心化的随机个体延迟POMDP(DSID-POMDP)。
定义1. DSID-POMDP
=
(
I
,
X
,
A
,
Z
,
D
,
P
D
,
R
D
,
O
D
)
=(\mathcal{I}, \mathcal{X}, \mathcal{A}, \mathcal{Z}, \mathcal{D}, \mathcal{P}_{\mathcal{D}}, \mathcal{R}_{\mathcal{D}}, \mathcal{O}_{\mathcal{D}})
=(I,X,A,Z,D,PD,RD,OD) 扩展了Dec-POMDP
=
=
=
(
I
,
S
,
A
,
Z
,
P
,
R
,
O
)
(\mathcal{I}, \mathcal{S}, \mathcal{A}, \mathcal{Z}, \mathcal{P}, \mathcal{R}, \mathcal{O})
(I,S,A,Z,P,R,O),使得
- I D = I ∪ J \mathcal{I}_{\mathcal{D}}=\mathcal{I} \cup \mathcal{J} ID=I∪J 其中 J \mathcal{J} J是环境实体集合,
-
- X = S T + 1 \mathcal{X}=\mathcal{S}^{T+1} X=ST+1 其中 T T T表示最大可能延迟值,
-
- A D = A \mathcal{A}_{\mathcal{D}}=\mathcal{A} AD=A,
-
- Z D = Z \mathcal{Z}_{\mathcal{D}}=\mathcal{Z} ZD=Z,
-
- KaTeX parse error: Expected '\right', got 'EOF' at end of input: …athcal{D}\left( 智能体 i _{i} i, 实体KaTeX parse error: Expected 'EOF', got '\right' at position 21: …\mid \mathbf{x}\̲r̲i̲g̲h̲t̲), i \in \mathc…,
-
- P D ( x ′ ∣ x , a ) = P ( s ′ ∣ s , a ) ∏ t = 1 T δ ( s ( − t ) ′ − s ( − t + 1 ) ) , s ( − t ) ′ ∈ x ′ , s ( − t + 1 ) ∈ x \mathcal{P}_{\mathcal{D}}\left(\mathbf{x}^{\prime} \mid \mathbf{x}, \mathbf{a}\right)=\mathcal{P}\left(s^{\prime} \mid s, \mathbf{a}\right) \prod_{t=1}^{T} \delta\left(s_{(-t)}^{\prime}-s_{(-t+1)}\right), s_{(-t)}^{\prime} \in \mathbf{x}^{\prime}, s_{(-t+1)} \in \mathbf{x} PD(x′∣x,a)=P(s′∣s,a)∏t=1Tδ(s(−t)′−s(−t+1)),s(−t)′∈x′,s(−t+1)∈x,
-
- R D ( x , a ) = R ( s , a ) \mathcal{R}_{\mathcal{D}}(\mathbf{x}, \mathbf{a})=\mathcal{R}(s, \mathbf{a}) RD(x,a)=R(s,a),
-
-
O
D
(
z
∣
x
)
=
∏
t
∈
I
∏
j
∈
I
D
∑
t
=
0
T
p
(
d
i
j
=
t
)
δ
(
z
i
j
−
s
(
−
t
)
i
j
)
O
(
o
i
j
=
z
i
j
∣
s
(
−
t
)
)
\mathcal{O}_{\mathcal{D}}(\mathbf{z} \mid \mathbf{x})=\prod_{t \in \mathcal{I}} \prod_{j \in \mathcal{I}_{\mathcal{D}}} \sum_{t=0}^{T} p\left(d^{i j}=t\right) \delta\left(z^{i j}-s_{(-t)}^{i j}\right) \mathcal{O}\left(o^{i j}=z^{i j} \mid s_{(-t)}\right)
OD(z∣x)=∏t∈I∏j∈ID∑t=0Tp(dij=t)δ(zij−s(−t)ij)O(oij=zij∣s(−t)).
DSID-POMDP在每个系统实体暴露的信息仅包含自身信息的条件下建立。新元素,个体延迟分布 D i j D^{i j} Dij,表示实体 j _{j} j在智能体 i _{i} i观测中的延迟值分布。一个自然且直观的约束是延迟值 d i i j d_{i}^{i j} diij必须满足条件: d i i j < min ( d i − 1 i j + 1 , T ) d_{i}^{i j}<\min \left(d_{i-1}^{i j}+1, T\right) diij<min(di−1ij+1,T)。为了结合延迟状态,DSID-POMDP的状态扩展为包括无延迟状态和前 T T T个状态,即 x = { s ( − T ) , s ( − T + 1 ) , … , s ( − 1 ) , s } \mathbf{x}=\left\{s_{(-T)}, s_{(-T+1)}, \ldots, s_{(-1)}, s\right\} x={s(−T),s(−T+1),…,s(−1),s}。为了保持符号的一致性,我们也用无延迟状态 s s s表示 s ( 0 ) s_{(0)} s(0)。在观测函数中, p ( d i j = t ) p\left(d^{i j}=t\right) p(dij=t)表示延迟值 d i j d^{i j} dij等于 t t t的概率,而 s ( − t ) i j s_{(-t)}^{i j} s(−t)ij表示智能体 i _{i} i在状态 s ( − t ) s_{(-t)} s(−t)中从实体 j _{j} j的角度获取的状态信息。图1提供了个体延迟分布和观测函数的更直观解释。
-
O
D
(
z
∣
x
)
=
∏
t
∈
I
∏
j
∈
I
D
∑
t
=
0
T
p
(
d
i
j
=
t
)
δ
(
z
i
j
−
s
(
−
t
)
i
j
)
O
(
o
i
j
=
z
i
j
∣
s
(
−
t
)
)
\mathcal{O}_{\mathcal{D}}(\mathbf{z} \mid \mathbf{x})=\prod_{t \in \mathcal{I}} \prod_{j \in \mathcal{I}_{\mathcal{D}}} \sum_{t=0}^{T} p\left(d^{i j}=t\right) \delta\left(z^{i j}-s_{(-t)}^{i j}\right) \mathcal{O}\left(o^{i j}=z^{i j} \mid s_{(-t)}\right)
OD(z∣x)=∏t∈I∏j∈ID∑t=0Tp(dij=t)δ(zij−s(−t)ij)O(oij=zij∣s(−t)).
3.3 经典MARL算法
RDC框架的操作依赖于基线算法。MARL算法的分类与深度强化学习(DRL)类似,可以根据其基本原理分为基于价值的和基于策略的方法。综合考虑算法性能和特性后,我们在框架中采用了两种基于价值的算法,VDN [29] 和 QMIX [26],它们在离散动作空间任务中表现出色。VDN通过简单的线性分解方法扩展了DQN [23],分解团队价值函数。在训练过程中,VDN从回放缓冲区采样批次并通过最小化TD误差更新参数,其损失函数定义为:
L r l ( θ ) = E ‾ b [ ( r + γ max u ′ Q total ( s ′ , u ′ ; θ − ) − Q total ( s , u ; θ ) ) 2 ] \mathcal{L}_{\mathrm{rl}}(\theta)=\overline{\mathbb{E}}_{b}\left[\left(r+\gamma \max _{\mathbf{u}^{\prime}} Q_{\text {total }}\left(s^{\prime}, \mathbf{u}^{\prime} ; \theta^{-}\right)-Q_{\text {total }}(s, \mathbf{u} ; \theta)\right)^{2}\right] Lrl(θ)=Eb[(r+γu′maxQtotal (s′,u′;θ−)−Qtotal (s,u;θ))2]
其中
θ
−
\theta^{-}
θ−表示目标网络的参数。目标网络周期性复制(硬更新)或逐渐加权(软更新)评估网络的参数
θ
\theta
θ。
E
‾
b
\overline{\mathbb{E}}_{b}
Eb表示对有限批次样本的期望。
基于VDN,QMIX使用混合网络将单个智能体的局部Q值聚合为集中的全局Q值,同时满足单调性约束:
∂
Q
total
∂
Q
j
i
≥
0
,
∀
i
\frac{\partial Q_{\text {total }}}{\partial Q_{j}^{i}} \geq 0, \forall i
∂Qji∂Qtotal ≥0,∀i。这确保了全局和局部Q值之间的一致性。这一修改赋予QMIX一个参数化的批评家,而VDN仅依赖于简单的求和操作。这种区别服务于验证RDC对不同RL算法框架的适应性。
4 方法
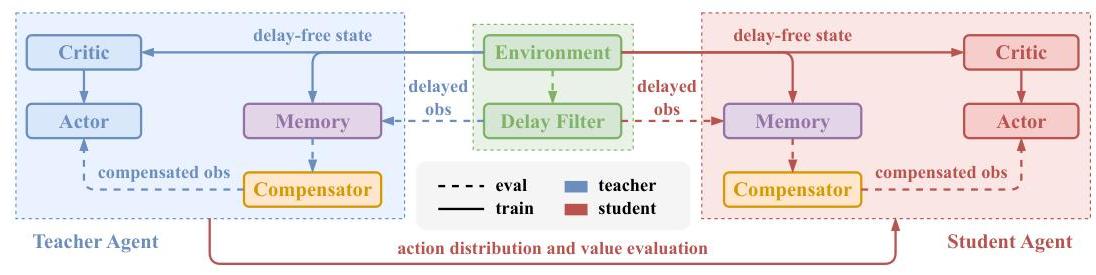
图2:DA-MARL框架的内部结构。
在本节中,我们介绍了RDC的架构细节。如图2所示,该框架通过加入四个关键组件扩展了传统的MARL算法:1)补偿模块,2)延迟协调的批评家,3)演员的课程学习,4)策略知识蒸馏。不同颜色和样式的箭头表示各个阶段的数据流。蓝色箭头属于教师模型,红色箭头属于学生模型。实箭头表示训练阶段,虚箭头表示推理阶段。推理阶段涉及的数据流可以在训练阶段使用。虽然我们描述了几种可行的实现和相应算法,但这并不代表框架内可能性的详尽列举。该框架保持了广泛的兼容性——大多数主流的演员-批评家算法可以无缝适应RDC。同时,其他MARL方法通常可以通过选择性移除特定框架组件来适应。补偿器可以采用任何具备序列预测能力的架构,课程学习和知识蒸馏机制都可以由研究人员根据特定的策略网络和任务需求进行定制。
4.1 多智能体系统中的观测延迟发生及补偿过程
由于MASs中智能体之间的动作延迟相互独立,并且每个智能体的动作都会影响全局状态,因此延迟等效定理 [33] 不再适用。本文专注于延迟观测,并假设智能体仅向外部传输自己的信息——这一假设与研究界中大多数多智能体环境配置一致。因此,从单个智能体的角度来看,来自不同实体的信息更新是相对独立的。这一原则导致了观测的其他部分不属于同一时间步的现象。图3展示了一个简单的延迟观测示例。数字表示智能体当前观测的每个部分源自的时间步——较小的数字对应较旧的信息。左侧展示了智能体 i _{i} i 在系统时钟步骤0到3期间的观测信息更新。相比之下,右侧显示了无延迟情况下对应的观测补偿过程。来自第二个智能体的观测在第3步仍包含第0步的信息,这部分需要最多的补偿步骤。
4.2 延迟补偿器
基于观测延迟的发生过程,我们直观设计了两种延迟补偿器模式——Flash和Echo——以重建无延迟观测。Flash利用可用信息进行简单补偿并直接输出重建结果。它通过内部模型设计隐式处理观测中的不同延迟问题。Echo是一个自回归模型,基于每一步补偿时已知的数据逐步输出下一步信息。在掩码层的控制下,Echo的第 T T T次输出产生最终的重建观测。图5展示了两种补偿器并行的工作流程。理论上,Flash提供更快的重建速度和更低的资源消耗,使其适用于延迟变化轻微且对决策速度要求较高的场景。Echo的操作模式完全符合图3所示的理想延迟补偿过程,可以适应可变延迟值和未知延迟模式。我们认为随着智能体策略的迭代和更新,数据分布会发生变化,可能导致补偿器性能显著波动。因此,两种补偿器都与强化学习同步训练,这意味着RDC框架保持完整的在线训练过程。
充分有效的输入数据使补偿器能够实现更好的性能。基于DSID-POMDP的定义,我们自然将当前观测扩展为包含历史观测的观测序列。此外,借鉴现有的增强方法 [6,7,33,32],我们经验性地将过去
T
T
T时间步的动作序列纳入。与之前的
方法不同,本文中的延迟步数表示为一个向量,其长度对应于观测中包含的其他实体的数量。我们使用GRU [8] 和Transformer [30] 网络实现两种类型的补偿器,这些网络擅长处理序列数据。图4展示了不同模型结构下扩展观测输入的形式。固定输入是指在第一个输入步骤中馈入模型的预连接序列数据。相反,序列输入表示在模型的自回归过程中增量增加的输入信息。对于Echo,我们将延迟值向量转换为二进制(0或1)向量以增强历史和自回归输入之间的一致性。
此外,我们设计了双头残差补偿器以处理观测中的不同类型数据。我们对分类任务使用交叉熵损失函数,对回归任务使用均方误差。残差输出可以进一步提高补偿器的重建精度。两种补偿器的损失函数如下:
L flash ( ϕ ) = L C E ( I T , I ( Z T − G T − Z ) ) + L M S E ( F T , F ( Z T − G T − Z ) ) L echo ( ϕ ) = 1 T ∑ k = 1 T [ L C E ( I k , I ( Z k − G T − Z k − 1 ) ) + L M S E ( F k , F ( Z k − G T − Z k − 1 ) ) ] \begin{aligned} & \mathcal{L}_{\text {flash }}(\phi)=\mathcal{L}_{\mathrm{CE}}\left(\mathbf{I}^{T}, \mathbf{I}\left(Z^{T_{-} G T}-Z\right)\right)+\mathcal{L}_{\mathrm{MSE}}\left(\mathbf{F}^{T}, \mathbf{F}\left(Z^{T_{-} G T}-Z\right)\right) \\ & \mathcal{L}_{\text {echo }}(\phi)=\frac{1}{T} \sum_{k=1}^{T}\left[\mathcal{L}_{\mathrm{CE}}\left(\mathbf{I}^{k}, \mathbf{I}\left(Z^{k_{-} G T}-Z^{k-1}\right)\right)+\mathcal{L}_{\mathrm{MSE}}\left(\mathbf{F}^{k}, \mathbf{F}\left(Z^{k_{-} G T}-Z^{k-1}\right)\right)\right] \end{aligned} Lflash (ϕ)=LCE(IT,I(ZT−GT−Z))+LMSE(FT,F(ZT−GT−Z))Lecho (ϕ)=T1k=1∑T[LCE(Ik,I(Zk−GT−Zk−1))+LMSE(Fk,F(Zk−GT−Zk−1))]
其中 I k = I ( Z k − Z k − 1 ) , F k = F ( Z k − Z k − 1 ) \mathbf{I}^{k}=\mathbf{I}\left(Z^{k}-Z^{k-1}\right), \mathbf{F}^{k}=\mathbf{F}\left(Z^{k}-Z^{k-1}\right) Ik=I(Zk−Zk−1),Fk=F(Zk−Zk−1),并且 I ( ⋅ ) \mathbf{I}(\cdot) I(⋅)和 F ( ⋅ ) \mathbf{F}(\cdot) F(⋅)分别表示从目标中提取整型内容和浮点型内容。 Z Z Z表示智能体 t _{t} t在时间 t t t获得的观测(公式中省略)。 Z k − G T Z^{k_{-} G T} Zk−GT表示经过 k k k步补偿后的延迟观测的真实值。 ϕ \phi ϕ表示补偿器的模型参数。
4.3 延迟协调的批评家和课程学习的演员
Wang等人 [33] 首次引入了延迟协调的概念以解决单智能体延迟观测问题。他们的关键见解是,在集中训练期间向批评家提供无延迟的全局状态可以减轻延迟的影响。由于批评家在模型推理期间无需参与,延迟协调的批评家可以无缝集成到集中训练与分散执行(CTDE)范式中。
除了接收补偿后的观测外,演员在面对复杂场景时可能会出现收敛不良的情况。这是因为补偿器的在线训练也需要时间,而在早期训练阶段补偿器的输出可能显著偏离无延迟观测。实际上,强化学习训练初期的探索阶段通常起着至关重要的作用,即使在此期间奖励值可能没有明显的改善。然而,与仅在训练期间运行的批评家不同,最终模型必须依赖于现实中可用的观测作为输入。课程学习 [3] 提供了解决这一挑战的方法。在初始训练阶段,我们向演员提供无延迟的观测
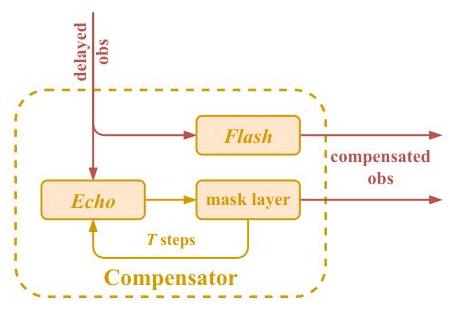
图5:Flash和Echo的工作流程。
(即补偿器的真实值),并随着训练的进行逐渐降低使用无延迟观测的概率,直到演员完全依赖于补偿后的观测。我们在实验中使用线性退火策略,当然也可以使用更复杂或自适应的退火方法。对于较不复杂的任务(例如MPE),演员的课程学习并不是严格必要的。
4.4 知识蒸馏
尽管经过所有的设计和优化努力,补偿观测与无延迟真实值之间仍然存在不可避免的差异。然而,相同场景下的智能体策略可以通过定量指标客观评估。当使用延迟观测进行训练时,高性能策略模型的指导可以使模型更准确地优化策略或估计值,从而加速收敛。基于这一见解,我们将知识蒸馏 [15] 纳入RDC框架。尽管存在多种蒸馏方法,我们通过实验识别出一种有效的方法。在高延迟环境下训练目标模型之前,我们首先在低延迟条件下训练教师模型。正如预期的那样,教师模型在高延迟场景中比独立训练的学生模型表现得更接近理想的无延迟训练。在学生模型训练期间,我们将补偿后的观测输入教师模型,并利用它指导学生演员和批评家的隐藏表示和输出决策。相应的损失函数定义为:
L k d ( θ s ) = L C E ( action t , action s ) + β 1 ⋅ L M S E ( Q t , Q s ) + β 2 L M S E ( θ t c , θ s c ) L r d c − r l ( θ s ) = α L r l ( θ s ) + ( 1 − α ) L k d ( θ s ) \begin{gathered} \mathcal{L}_{k d}\left(\theta_{s}\right)=\mathcal{L}_{\mathrm{CE}}\left(\text { action }_{t}, \text { action }_{s}\right)+\beta_{1} \cdot \mathcal{L}_{\mathrm{MSE}}\left(Q_{t}, Q_{s}\right)+\beta_{2} \mathcal{L}_{\mathrm{MSE}}\left(\theta_{t}^{c}, \theta_{s}^{c}\right) \\ \mathcal{L}_{r d c_{-} r l}\left(\theta_{s}\right)=\alpha \mathcal{L}_{r l}\left(\theta_{s}\right)+(1-\alpha) \mathcal{L}_{k d}\left(\theta_{s}\right) \end{gathered} Lkd(θs)=LCE( action t, action s)+β1⋅LMSE(Qt,Qs)+β2LMSE(θtc,θsc)Lrdc−rl(θs)=αLrl(θs)+(1−α)Lkd(θs)
其中 β 1 \beta_{1} β1和 β 2 \beta_{2} β2表示知识蒸馏损失函数中的权重因子,而 α \alpha α决定知识蒸馏损失和强化学习损失之间的相对权重。
我们不对补偿器应用知识蒸馏或在学生训练期间加载教师的补偿器。这一设计选择源于两个关键考虑:第一,在在线学习场景中,补偿器的性能应随策略改进而进化,通过蒸馏直接转移教师的补偿器知识不一定能促进学生策略训练。第二,这种方法允许更明确地展示纯粹策略指导的效果,我们将在实验部分详细说明。遵循与课程学习类似的原理,我们为知识蒸馏过程实现了相同的退火策略。
5 实验
场景选择:我们在两个最流行的多智能体强化学习环境中进行实验——MPE[21] 和 SMAC [27]。总体而言,由于状态和动作空间更为复杂,SMAC任务比MPE任务更具挑战性。我们在MPE中选择了simple-tag (TAG), simple-spread (SPREAD),和 simple-reference (REFERENCE),在SMAC中选择了三个逐步难度递增的场景: 3 s _ v s _ 5 z , 5 m _ v s _ 6 m 3 \mathrm{~s} \_\mathrm{vs} \_5 \mathrm{z}, 5 \mathrm{~m} \_\mathrm{vs} \_6 \mathrm{~m} 3 s_vs_5z,5 m_vs_6 m,和 6 h _ v s _ 8 z 6 \mathrm{~h} \_\mathrm{vs} \_8 \mathrm{z} 6 h_vs_8z。这两个基准都是离散环境,因此我们将价值函数分解算法整合到RDC框架中。MPE中每项任务获得的奖励值是唯一的评估指标。尽管SMAC还提供了具体的奖励值,但由于目标是取得胜利,胜率是一个更重要的指标。
实验方案:我们使用DSID-POMDP重新表述了MASs中的延迟观测问题,并将其扩展到常用的基准测试中。因此,我们在RDC框架中实现了以前的解决方案,如延迟协调的批评家和增强的观测输入,以便进行更公平的比较。对于基线RL算法,我们选择了代码级别优化的FT-QMIX和FT-VDN [16],它们表现出
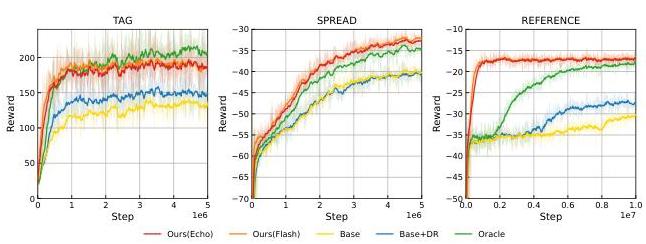
图6:MPE上的训练结果对比。
相对于原版QMIX和VDN的显著改进,后者在离散任务上的性能已被多次验证 [17, 10]。为了简化展示,以下实验结果部分将使用以下缩写:Oracle,Base,Echo,Flash,DR(延迟协调的批评家),H(历史输入),C(课程学习的演员),和KD(知识蒸馏)。只有Oracle是在无延迟环境中使用基线算法训练的,获得了不受延迟影响的理想性能,代表了算法的能力。在正文部分,所有呈现的结果都是基于使用FT-QMIX作为基线算法,并使用Transformer网络实现补偿器。
测试设置:每10,000个训练步骤,我们进行一次测试,每次测试包含64或32个回合,并记录模型性能。测试期间禁用epsilon-greedy策略。模型训练完成后,我们在固定和非固定延迟条件下进行广泛的测试,每个设置运行1,280个回合。
5.1 训练
图6和图7展示了FT-QMIX在延迟观测下的训练性能。结果揭示了所有六个场景中严重的性能退化,特别是在 5 m _ 5 \mathrm{~m} \_ 5 m_ vs. 6 m 和 6 h _ 6 \mathrm{~h} \_ 6 h_ vs. 8 z 任务中,胜率接近零。我们的消融研究使用课程学习(Base+C)和延迟协调训练(Base+DR)而不使用补偿机制,结果表明在复杂场景中,单独的课程学习或仅仅向批评家提供无延迟状态都不能充分抵消失去观测对学习过程的不利影响。这些发现表明延迟观测从根本上损害了初始收敛和整体策略优化。
RDC增强模型在大多数场景中表现出显著更快的收敛速度,这表明尽管知识蒸馏过程需要顺序训练教师和学生模型,但它增加了极少的额外训练开销。这种效率优势来自于在低延迟条件下的加速训练以及学生模型所需不到三分之一的原始训练迭代次数。值得注意的是,增强模型的性能达到或略微超过了无延迟Oracle的性能。这种边际改进归因于额外的训练步骤,正如在SPREAD和REFERENCE场景结束时Oracle持续性能提升所证明的那样。
5.2 不同延迟设置下的性能
固定延迟测试允许更精确地观察性能的逐步退化,并更好地评估模型的泛化能力。如图8和图9所示,基线算法FT-QMIX(Oracle)随着延迟的增加表现出显著的性能下降。Base和Base+DR方法在延迟为
0
−
2
0-2
0−2时的性能下降表明,尽管在训练期间成功收敛,但在测试期间无法泛化到未见过的延迟条件。相比之下,RDC增强模型在所有场景中保持优越性能,在SPREAD和REFERENCE任务中尤其表现出对延迟的强大适应性,即使在延迟增加的情况下,奖励稳定性依然保持。
我们在两种非固定延迟条件下评估模型性能:分布内(在训练延迟范围内)和半分布外(新的延迟范围)。如图10所示,基于Transformer的补偿器的RDC增强模型在分布外测试中仅表现出轻微的性能下降,同时保持接近Oracle的性能(绿色虚线)。消融研究表明每个模块的贡献:Flash+DR由于输入信息有限而表现不佳,而Flash+H+DR通过结合历史观测显示出显著改进。Echo的自回归设计提供了更丰富的输入信息,导致从历史数据中获益较小。使用低延迟Teacher模型的知识蒸馏被证明是有效的,尽管我们排除了Flash+DR,因为它的基线性能较差。
5.3 进一步结果和分析
尽管Flash和Echo表现出相当的性能,它们的基本区别是什么?我们的实验结果显示,随着延迟幅度的增加,Flash通常表现出比Echo更明显的性能下降,尤其是在处理分布外延迟时。如图11所示,保持相同的输入历史序列长度和训练配置对于实现最优性能至关重要
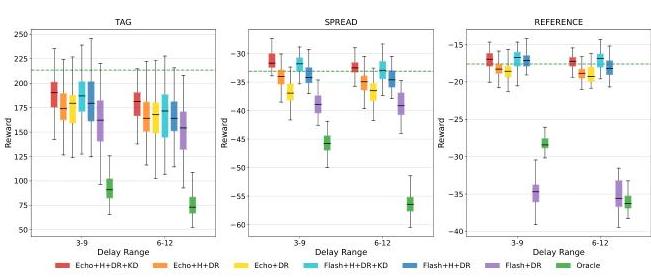
图10:MPE上非固定延迟测试结果对比。
Flash补偿器。这表明通过一次性补偿恢复无延迟观测违背了人类直觉,并对神经网络同样具有挑战性。尽管在泛化能力和灵活性方面的局限性令人不快,我们必须强调其在训练效率和推理速度方面的显著优势,这在特定场景中可能是决定性因素。在固定延迟为6的TAG场景中,Echo和Flash的补偿器推理时间分别约为0.02秒和0.004秒。
由于基线算法使用FTQMIX且补偿器网络在Transformer上达到最佳性能,主文中呈现的所有结果均使用此配置。我们已在附录D中包含了所有实验结果,其中包括使用FT-VDN作为基线算法的附加实验,以及基于GRU的补偿器网络和补充解释。虽然这些替代配置保持了预期的相对性能趋势,但整体性能有所下降。这验证了RDC框架与非演员-评论家算法的兼容性,并表明选择更优的基线算法和补偿器架构可以显著提高结果。
6 结论
本文中,我们提出了RDC框架,并证明了其各模块在解决MASs中延迟观测的有效性。补偿器作为框架的核心组件,直接尝试重建无延迟观测。课程学习的演员和延迟感知的批评家在模型训练期间提供更高质量的数据。来自低延迟教师模型的知识蒸馏显著提高了收敛速度和模型性能。整合这些模块的算法在固定和非固定延迟条件下实现了出色的结果(接近或理想无延迟性能)。此外,在复杂场景中增强模型对分布外延迟的泛化能力将是我们的下一个研究方向,潜在解决方案包括对补偿器架构和知识蒸馏技术进行更深入的研究。总的来说,我们的研究不仅提出了能够应对延迟观测的多智能体强化学习算法,还提供了一个实用的训练框架,为未来的研究奠定了坚实的基础。
参考文献
[1] Zvi Artstein. 线性系统带延迟控制: 减少. IEEE Transactions on Automatic control, 27(4):869-879, 1982.
[2] James L Bander 和 Chelsea C White III. 带噪声干扰和延迟状态观测的马尔可夫决策过程. Journal of the Operational Research Society, 50(6):660-668, 1999.
[3] Yoshua Bengio, Jérôme Louradour, Ronan Collobert, 和 Jason Weston. 课程学习. In Proceedings of the 26th annual international conference on machine learning, pages 41-48, 2009.
[4] Yann Bouteiller, Simon Ramstedt, Giovanni Beltrame, Christopher Pal, 和 Jonathan Binas. 带随机延迟的强化学习. In International conference on learning representations, 2020.
[5] Marwa Chafii, Salmane Naoumi, Reda Alami, Ebtesam Almazrouei, Mehdi Bennis, 和 Merouane Debbah. 多智能体强化学习中未来的无线网络新兴通信. IEEE Internet of Things Magazine, 6(4):18-24, 2023.
[6] Baiming Chen, Mengdi Xu, Zuxin Liu, Liang Li, 和 Ding Zhao. 延迟感知的多智能体强化学习用于合作和竞争环境. arXiv preprint arXiv:2005.05441, 2020.
[7] Baiming Chen, Mengdi Xu, Liang Li, 和 Ding Zhao. 延迟感知的基于模型的强化学习用于连续控制. Neurocomputing, 450:119-128, 2021.
[8] Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, 和 Yoshua Bengio. 使用RNN编码器-解码器进行统计机器翻译的短语表示学习. arXiv preprint arXiv:1406.1078, 2014.
[9] Vlad Firoiu, Tina Ju, 和 Josh Tenenbaum. 以人类速度:带动作延迟的深度强化学习. arXiv preprint arXiv:1810.07286, 2018.
[10] Songchen Fu, Shaojing Zhao, Ta Li, 和 Yonghong Yan. 通过异构和同质价值分解增强多智能体合作策略. Neural Networks, 184:107093, 2025.
[11] Marcus Gerwig, Karim Hajjar, Albena Dimitrova, Matthias Maschke, Florian P Kolb, Markus Frings, Alfred F Thilmann, Michael Forsting, Hans Christoph Diener, 和 Dagmar Timmann. 小脑患者的条件眼睑反应时间受损. Journal of Neuroscience, 25(15):3919-3931, 2005.
[12] Sven Gronauer 和 Klaus Diepold. 多智能体深度强化学习:综述. Artificial Intelligence Review, 55(2):895-943, 2022.
[13] Shangding Gu, Jakub Grudzien Kuba, Yuanpei Chen, Yali Du, Long Yang, Alois Knoll, 和 Yaodong Yang. 安全多智能体强化学习用于多机器人控制. Artificial Intelligence, 319:103905, 2023.
[14] Shangding Gu, Dianye Huang, Muning Wen, Guang Chen, 和 Alois Knoll. 真实机器人控制中带有软约束策略优化的安全多智能体学习. IEEE Transactions on Industrial Informatics, 2024.
[15] Geoffrey Hinton, Oriol Vinyals, 和 Jeff Dean. 蒸馏神经网络的知识. arXiv preprint arXiv:1503.02531, 2015.
[16] Jian Hu, Siyang Jiang, Seth Austin Harding, Haibin Wu, 和 Shih wei Liao. 再思合作多智能体强化学习中的实现技巧和单调性约束. 2021.
[17] HAO Jianye, Xiaotian Hao, Hangyu Mao, Weixun Wang, Yaodong Yang, Dong Li, Yan Zheng, 和 Zhen Wang. 使用置换不变和置换等变网络提升多智能体强化学习. In The Eleventh International Conference on Learning Representations, 2022.
[18] Karol Kurach, Anton Raichuk, Piotr Stańczyk, Michał Zając, Olivier Bachem, Lasse Espeholt, Carlos Riquelme, Damien Vincent, Marcin Michalski, Olivier Bousquet, 等. Google研究足球:一种新的强化学习环境. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 4501-4510, 2020.
[19] Pierre Liotet, Davide Maran, Lorenzo Bisi, 和 Marcello Restelli. 通过模仿进行延迟强化学习. In International conference on machine learning, pages 13528-13556. PMLR, 2022.
[20] Jiaqi Liu, Ziran Wang, Peng Hang, 和 Jian Sun. 带模型增强稳定性的合作自适应巡航控制的延迟感知多智能体强化学习. arXiv preprint arXiv:2404.15696, 2024.
[21] Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, 和 Igor Mordatch. 混合合作-竞争环境中的多智能体演员-评论家. Neural Information Processing Systems (NIPS), 2017.
[22] Miroslav R Matausek 和 AD Micic. 修改后的Smith预测器用于控制具有积分器和长死区的过程. IEEE Transactions on Automatic Control, 44(8):16031606, 1999.
[23] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, 和 Martin Riedmiller. 使用深度强化学习玩Atari游戏. arXiv preprint arXiv:1312.5602, 2013.
[24] Silviu-Iulian Niculescu. 延迟对稳定性的影响: 一种鲁棒控制方法, volume 269. Springer, 2003.
[25] Georgios Papoudakis, Filippos Christianos, Lukas Schäfer, 和 Stefano V Albrecht. 多智能体深度强化学习算法在合作任务中的基准测试. arXiv preprint arXiv:2006.07869, 2020.
[26] Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, 和 Shimon Whiteson. 深度多智能体强化学习中的单调价值函数分解. Journal of Machine Learning Research, 21(178):1-51, 2020.
[27] Mikayel Samvelyan, Tabish Rashid, Christian Schroeder De Witt, Gregory Farquhar, Nantas Nardelli, Tim GJ Rudner, Chia-Man Hung, PhilipHS Torr, Jakob Foerster, 和 Shimon Whiteson. 星际争霸多智能体挑战. arXiv preprint arXiv:1902.04043, 2019.
[28] Andrew C Singer, Jill K Nelson, 和 Suleyman S Kozat. 水下声学通信的信号处理. IEEE Communications Magazine, 47(1):90-96, 2009.
[29] Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, 等. 合作多智能体学习的价值分解网络. arXiv preprint arXiv:1706.05296, 2017.
[30] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, 和 Illia Polosukhin. 注意力就是你所需要的. Advances in neural information processing systems, 30, 2017.
[31] Thomas J Walsh, Ali Nouri, Lihong Li, 和 Michael L Littman. 在延迟反馈环境中学习和规划. Autonomous Agents and Multi-Agent Systems, 18:83-105, 2009.
[32] Fanshuo Wang, Hui Zhang, 和 Ya Zhang. 解决动作延迟:基于状态预测的多智能体强化学习. In Chinese Intelligent Systems Conference, pages 552-563. Springer, 2024.
[33] Wei Wang, Dongqi Han, Xufang Luo, 和 Dongsheng Li. 深度强化学习中解决信号延迟问题. In The Twelfth International Conference on Learning Representations, 2023.
[34] Yunchang Yang, Han Zhong, Tianhao Wu, Bin Liu, Liwei Wang, 和 Simon S Du. 一种基于约简的序列决策框架,适用于延迟反馈情况. Advances in Neural Information Processing Systems, 36:46362-46389, 2023.
[35] Tingting Yuan, Hwei-Ming Chung, Jie Yuan, 和 Xiaoming Fu. Dacom:学习延迟感知的多智能体强化学习通信. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 11763-11771, 2023.
[36] Hengxi Zhang, Zhendong Shi, Yuanquan Hu, Wenbo Ding, Ercan E Kuruoğlu, 和 Xiao-Ping Zhang. 使用多智能体强化学习优化量化市场中的交易策略. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 136-140. IEEE, 2024.
[37] Kaiqing Zhang, Zhuoran Yang, 和 Tamer Başar. 多智能体强化学习:理论与算法的选择性综述. Handbook of reinforcement learning and control, pages 321-384, 2021.
[38] Yuyang Zhang, Runyu Zhang, Yuantao Gu, 和 Na Li. 奖励延迟下的多智能体强化学习. In Learning for Dynamics and Control Conference, pages 692-704. PMLR, 2023.
[39] Changxi Zhu, Mehdi Dastani, 和 Shihan Wang. 带通信的多智能体深度强化学习综述. Autonomous Agents and Multi-Agent Systems, 38(1):4, 2024.
A 证明
这里我们证明DSID-POMDP中定义的状态转移函数和观测函数表达式的正确性。首先,状态x包含T个历史状态:
x = { s , s ( − 1 ) , … , s ( − T ) } \mathbf{x}=\left\{s, s_{(-1)}, \ldots, s_{(-T)}\right\} x={s,s(−1),…,s(−T)}
扩展新状态转移函数的表达式:
P D ( x ′ ∣ x , a ) = P D ( s ′ , s ( − 1 ) ′ , … , s ( − T ) ′ ∣ s , s ( − 1 ) , … , s ( − T ) , a ) \mathcal{P}_{\mathcal{D}}\left(\mathbf{x}^{\prime} \mid \mathbf{x}, \mathbf{a}\right)=\mathcal{P}_{\mathcal{D}}\left(s^{\prime}, s_{(-1)}^{\prime}, \ldots, s_{(-T)}^{\prime} \mid s, s_{(-1)}, \ldots, s_{(-T)}, \mathbf{a}\right) PD(x′∣x,a)=PD(s′,s(−1)′,…,s(−T)′∣s,s(−1),…,s(−T),a)
观察这两个序列可以发现历史状态 s ( − t ) ′ = s ( − t + 1 ) s_{(-t)}^{\prime}=s_{(-t+1)} s(−t)′=s(−t+1)的转移过程,因此可以将其分解为当前状态转移和历史状态转移。由于马尔可夫性质,原始状态中最旧的状态可以直接丢弃。
P D ( x ′ ∣ x , a ) = P D ( s ′ , s ( − 1 ) ′ , … , s ( − T ) ′ ∣ s , s ( − 1 ) , … , s ( − T ) , a ) = P ( s ′ ∣ s , a ) ∏ t = 1 T δ ( s ( − t ) ′ − s ( − t + 1 ) ) \begin{aligned} \mathcal{P}_{\mathcal{D}}\left(\mathbf{x}^{\prime} \mid \mathbf{x}, \mathbf{a}\right) & =\mathcal{P}_{\mathcal{D}}\left(s^{\prime}, s_{(-1)}^{\prime}, \ldots, s_{(-T)}^{\prime} \mid s, s_{(-1)}, \ldots, s_{(-T)}, \mathbf{a}\right) \\ & =\mathcal{P}\left(s^{\prime} \mid s, \mathbf{a}\right) \prod_{t=1}^{T} \delta\left(s_{(-t)}^{\prime}-s_{(-t+1)}\right) \end{aligned} PD(x′∣x,a)=PD(s′,s(−1)′,…,s(−T)′∣s,s(−1),…,s(−T),a)=P(s′∣s,a)t=1∏Tδ(s(−t)′−s(−t+1))
换句话说,当历史序列的转移确定时,DSID-POMDP的状态转移函数变得与POMDP相同。观测函数有效性的基本假设是来自不同实体的观测相互独立。虽然这个假设在大多数场景中成立,但在特定情况下可能不满足,例如单信道通信系统中不同实体的信号可能会干扰。对于智能体 i _{i} i,如果实体 y j y_{j} yj对应的观测延迟值为 t t t,可以表示为 z i j = s ( − t ) i j z^{i j}=s_{(-t)}^{i j} zij=s(−t)ij。因此,该智能体从实体 y j y_{j} yj获得观测 z i j z^{i j} zij的概率为:
O D ( z i j ∣ x ) = ∑ t = 0 T p ( d i j = t ) δ ( z i j − s ( − t ) i j ) O ( o i j = z i j ∣ s ( − t ) ) \mathcal{O}_{\mathcal{D}}\left(z^{i j} \mid \mathbf{x}\right)=\sum_{t=0}^{T} p\left(d^{i j}=t\right) \delta\left(z^{i j}-s_{(-t)}^{i j}\right) \mathcal{O}\left(o^{i j}=z^{i j} \mid s_{(-t)}\right) OD(zij∣x)=t=0∑Tp(dij=t)δ(zij−s(−t)ij)O(oij=zij∣s(−t))
其中 O ( o i j = z i j ∣ s ( − t ) ) \mathcal{O}\left(o^{i j}=z^{i j} \mid s_{(-t)}\right) O(oij=zij∣s(−t))表示在原始POMDP中给定状态 s ( − t ) s_{(-t)} s(−t)获得观测 z i j z^{i j} zij的概率。由于独立性假设,此定义可以通过因式分解扩展到联合观测:
O D ( z ∣ x ) = ∏ i ∈ I ∏ j ∈ L D ∑ t = 0 T p ( d i j = t ) δ ( z i j − s ( − t ) i j ) O ( o i j = z i j ∣ s ( − t ) ) \mathcal{O}_{\mathcal{D}}(\mathbf{z} \mid \mathbf{x})=\prod_{i \in \mathcal{I}} \prod_{j \in \mathcal{L}_{\mathcal{D}}} \sum_{t=0}^{T} p\left(d^{i j}=t\right) \delta\left(z^{i j}-s_{(-t)}^{i j}\right) \mathcal{O}\left(o^{i j}=z^{i j} \mid s_{(-t)}\right) OD(z∣x)=i∈I∏j∈LD∏t=0∑Tp(dij=t)δ(zij−s(−t)ij)O(oij=zij∣s(−t))
B 场景介绍
simple-tag: 这是一个竞争性的捕食者-猎物模拟,好的智能体必须躲避较慢但更具攻击性的对手。好的智能体速度更快,但每次与对手碰撞都会受到惩罚,而对手则因成功击中它们而获得奖励。地形包括阻止移动的静态障碍物。为了防止好的智能体无限逃离,根据预定义的边界函数,它们会因离开指定区域而受到惩罚。默认情况下,场景开始时有一个好的智能体、三个对手和两个障碍物,创建了动态平衡的追逐和逃避。在我们的实验中,好的智能体策略固定为一个使用MADDPG [21]预先训练的模型,与Papoudakis等人一致 [25]。算法仅控制对手,将对抗环境转变为合作环境。
simple-spread: 在这个合作多智能体场景中,N个智能体(默认:3)必须学会高效覆盖N个地标,同时避免碰撞。智能体根据覆盖所有地标的程度集体获得奖励,这由每个地标与其最近的智能体之间的最小距离之和衡量。智能体必须最小化这个全局距离指标以最大化共享奖励。为了防止鲁莽行为,每个智能体因与其他智能体碰撞而单独受到惩罚。通过local_ratio参数调整全局覆盖与碰撞避免之间的权衡,可以精细控制智能体协调策略。
simple-reference: 此场景涉及两个合作智能体导航至三个颜色独特的地标,每个都有隐藏的目标分配。关键在于,一个智能体的目标地标只被另一个智能体知道,需要实时通信来解决不确定性。两个智能体都作为说话者和倾听者,交换信息以推断彼此的目标,同时导航。
表1: 平均环境参数。
| MPE | SMAC | ||
|---|---|---|---|
| 参数 | 值 | 参数 | 值 |
| time_limit | 25 | difficulty | 7 |
| obs_agent_id | True | obs_agent_id | True |
| obs_last_action | False | obs_last_action | True |
| state_last_action | True | ||
| state_timestamp_number | False | ||
| contc_low | False |
SMAC: 不同于MPE,所有SMAC场景的目标都是取得胜利,唯一的方法是完全消灭敌方力量。场景名称明确指出了盟军和敌方单位的力量组成——例如,6 h_vs_8z 表示六个Hydralisks对抗八个Zealots。这种环境强调智能体间的短期协作和有效利用单位特定优势。
C 实现细节
C. 1 延迟观测实现
(a)
(b)
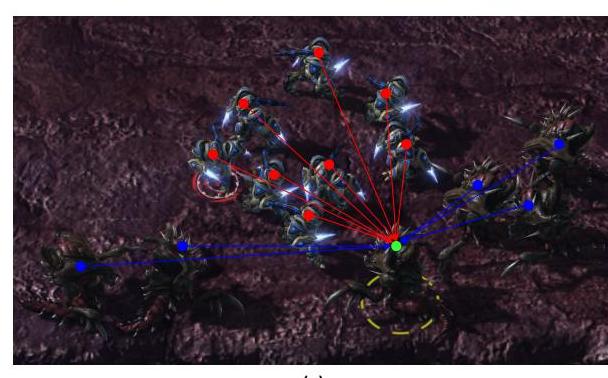
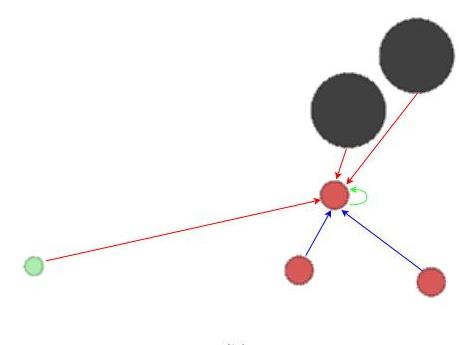
图12: DSID-POMDP在SMAC的6h_vs_8z和MPE的simple-tag中的应用。
我们为SMAC和MPE开发了延迟过滤器,以模拟现实世界的感知和通信延迟,实现了四种不同的模式:无延迟(none)、固定延迟(f)、部分固定延迟(pf)和非固定延迟(uf)。固定延迟模式设置一个固定的延迟值并应用于所有观测。部分非固定延迟模式使用固定的延迟值,但不一定延迟所有观测内容。非固定延迟模式在延迟值和哪些内容被延迟方面引入随机性。虽然延迟过滤器支持实体和智能体之间不同的分布或基于距离的延迟计算,但我们的实验对所有随机变量使用统一分布,不失一般性。延迟实现机制主要为每个智能体维护历史观测记录,并根据特定的延迟策略在当前时间步从过去观测中检索信息。
我们将智能体的观测分为四类,基于其延迟特性:运动特征(实时更新信息)、敌方特征(环境实体数据,排除盟友)、盟友特征(来自盟友的信息)和自身特征(智能体的状态)。实际上,命名这些特征并不重要——我们的主要区别在于它们的延迟特性。例如,在SMAC的6 h_vs_8z场景中,观测包括运动能力(4维),8个敌方状态(每个6维),5个盟友状态(每个5维),以及自身属性(1维)。我们的实现仅延迟敌方和盟友特征,同时保持运动和自身特征的实时更新。这反映了现实情况,即智能体可以立即访问自己的状态,但经历环境感知延迟。
系统在每集开始时初始化观测历史,并持续记录无延迟观测。在生成延迟观测时,它根据配置的延迟参数检索历史数据。例如,在MPE的simple-tag场景中,捕食者可能使用延迟2个时间步的位置跟踪逃逸者,从而降低追逐效率。同样,在SMAC中,部队对敌方移动表现出响应滞后。系统通过确保延迟观测始终从有效的历史状态中抽取,同时保留原始环境动态,维持时间一致性。这种实现允许系统地研究各种延迟模式(固定、非固定或距离依赖),同时保持底层多智能体决策过程的完整性。模块化设计允许灵活配置延迟参数,无需修改核心环境逻辑。
此外,延迟过滤器强制执行时间一致性约束,确保步骤 t t t观察到的信息不能比步骤 t − 1 t-1 t−1更旧。当未使用延迟协调批评家时,全局状态通过连接所有智能体的观测形成。通过在现有模拟环境中实现延迟过滤器,我们建立了一个可靠且灵活的实验平台,用于研究延迟观测对MAS性能的影响。
C. 2 补偿器实现
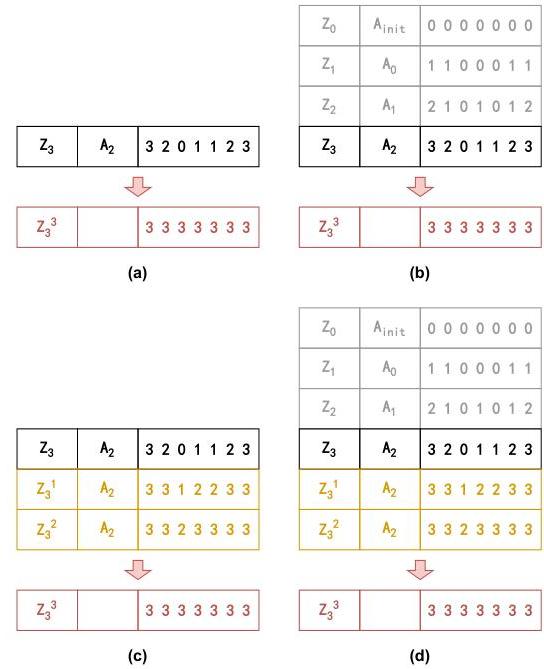
图13: 补偿器的输入和输出。(a): Flash无历史输入。(b): Flash有历史输入。©: Echo无历史输入。(d): Echo有历史输入。
我们利用基于深度学习的补偿器减轻MAS中观测延迟的影响,并采用基于GRU和Transformer的架构从历史数据中预测无延迟观测。补偿器实现包括输入序列构建、标签生成和掩码生成。补偿器处理从过去观测和动作构建的输入序列,可选T步历史上下文(不足时填充)。图13遵循图3的例子。Flash+H和Echo+H模型获得额外信息。值得注意的是,Echo的自回归推理与历史序列处理紧密对齐,这有助于模型理解延迟与观测之间的关系。图中直观表示延迟值序列为其对应的实际环境时间步序列。在实际实现中,我们为Flash输入延迟值序列,为Echo输入指示延迟存在的二进制(0或1)序列。
我们采用监督学习框架,其中标签生成模块从存储的无延迟观测中创建真实值,使用理想的延迟值作为参考。掩码生成
表2: 平均训练参数。
| MPE | SMAC | ||
|---|---|---|---|
| 参数 | 值 | 参数 | 值 |
| t_max | 5e6/1e7 | t_max | 6 e 6 |
| test_nepisode | 64 | test_nepisode | 32 |
| batch_size | 32 | batch_size | 128 |
| epsilon_anneal_time | 5 e 4 | epsilon_anneal_time | 1e5/5e6 |
| standardise_rewards | True | standardise_rewards | False |
| actor_model | GRU | actor_model | GRU |
| target_update_interval | 200 | target_update_interval | 200 |
| mixing_embed_dim | 32 | mixing_embed_dim | 32 |
| hypernet_embed | 64 | hypernet_embed | 64 |
| actor_hidden_dim | 64 | actor_hidden_dim | 64 |
| td_lambda | 0.6 | td_lambda | 0.6/0.3 |
| rf_learning_rate | 1 e − 3 1 \mathrm{e}-3 1e−3 | rf_learning_rate | 1 e − 3 1 \mathrm{e}-3 1e−3 |
| compensator_model | GRU/Transformer | compensator_model | GRU/Transformer |
| compensator_hidden_dim | 64 | compensator_hidden_dim | 64 |
| compensator_mode | None/Flash/Echo | compensator_mode | None/Flash/Echo |
| compensator_learning_rate | 1 e − 3 1 \mathrm{e}-3 1e−3 | compensator_learning_rate | 1 e − 3 1 \mathrm{e}-3 1e−3 |
| delay_type | unfixed | delay_type | unfixed |
| delay_value | 6 | delay_value | 3 |
| delay_scope | 3 | delay_scope | 3 |
| use_history | True/False | use_history | True/False |
| history_length | 9 | history_length | 6 |
| delay_reconciled | True/False | delay_reconciled | True/False |
| curriculum_start_value | 0 | curriculum_start_value | 1/0 |
| curriculum_end_value | 0 | curriculum_end_value | 0 |
| curriculum_start_step | 1e6 | curriculum_start_value | 1e6 |
| curriculum_end_step | 3e6 | curriculum_end_step | 4e6 |
| distillation_start_value | 1/0 | distillation_start_value | 1/0 |
| distillation_end_value | 0 | distillation_end_value | 0 |
| distillation_start_step | 2e6/3e6 | distillation_start_value | 2e6 |
| distillation_end_step | 4e6/7e6 | distillation_end_step | 4e6 |
模块通过掩码防止Echo中的错误传播。我们的混合损失函数结合了连续特征(如位置)的均方误差(MSE)与离散特征(如单位状态)的加权交叉熵(CE),平衡其数值尺度。为了提高训练效率和稳定性,我们实现了教师强迫——最初以100%的概率使用真实观测作为下一步输入,训练过程中逐渐减少到0%,帮助模型学会依赖其预测。如表3所示,教师强迫训练模式相较于不使用教师强迫没有显著优势。因此,默认情况下我们在训练中禁用此选项。
C. 3 训练细节
在本节中,我们展示了不同任务的超参数设置。表1和表2分别详细说明了关键的环境和训练参数。在确保算法性能的同时,我们尽可能保持超参数的一致性。所有演员网络使用GRU架构,而QMIX的批评家采用两层超网络。GRU补偿器由一层GRU层和三层线性层组成,而Transformer补偿器仅使用一对编码器-解码器层,并支持纯编码器结构。回放缓冲区大小固定为5000,MPE的批次大小设为32,SMAC设为128。在训练初始化期间, ϵ = 1 \epsilon=1 ϵ=1并线性退火至 ϵ = 0.05 \epsilon=0.05 ϵ=0.05。MPE的默认训练步数设为5e6。然而,我们在REFERENCE上观察到大约2e6步后出现显著性能提升,5e6步时性能仍呈上升趋势。因此,我们将训练步数延长至1e7,为每个算法提供足够的收敛时间。相应地,知识蒸馏的起始和结束步数也有所增加。
我们并未完全忽视MPE场景中的课程学习选项。然而,早期实验表明,这种技术对MPE无效,而在SMAC中不可或缺。这一结果表明,课程学习演员可以显著缓解复杂任务中因随机种子导致的收敛问题。仔细观察收敛曲线可以发现,SMAC任务中性能提升通常不在初始训练阶段发生。相反,在MPE任务中,性能改进紧随训练开始。这种时间差异可能解释了为什么课程学习演员在SMAC场景中表现尤为出色。
教师模型在所有任务中训练1e7步,延迟设置为1-3。我们尝试直接使用Oracle作为教师模型,在学生模型训练期间,Oracle接收无延迟观测并提供即时指导。这种方法未能成功,可能是因为无延迟观测和补偿观测之间存在固有差异。具体来说,当学生模型接收补偿观测时,基于无延迟观测的决策虽然客观上更优,但可能会扰乱学生模型的判断。我们通过低延迟教师模型解决了这个问题,取得了优异表现。我们鼓励其他研究人员探索我们框架内的进一步变化。
D 补充结果
表3: 启用和禁用教师强迫的性能比较。
| 固定延迟值 | 0 | 3 | 6 | 9 | 12 | |||
|---|---|---|---|---|---|---|---|---|
| TF | DR | H | TAG | |||||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 190.9 ± 26.0 190.9 \pm 26.0 190.9±26.0 | 175.8 ± 29.7 175.8 \pm 29.7 175.8±29.7 | 168.8 ± 23.4 168.8 \pm 23.4 168.8±23.4 | 161.7 ± 25.4 161.7 \pm 25.4 161.7±25.4 | 158.5 ± 25.9 158.5 \pm 25.9 158.5±25.9 |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 185.9 ± 23.4 185.9 \pm 23.4 185.9±23.4 | 175.1 ± 30.3 175.1 \pm 30.3 175.1±30.3 | 176.9 ± 29.9 176.9 \pm 29.9 176.9±29.9 | 167.3 ± 24.0 167.3 \pm 24.0 167.3±24.0 | 155.5 ± 25.4 155.5 \pm 25.4 155.5±25.4 | |
| TF | DR | H | SPREAD | |||||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 34.2 ± 2.2 -34.2 \pm 2.2 −34.2±2.2 | − 34.1 ± 1.9 -34.1 \pm 1.9 −34.1±1.9 | − 34.2 ± 2.0 -34.2 \pm 2.0 −34.2±2.0 | − 35.3 ± 2.2 -35.3 \pm 2.2 −35.3±2.2 | − 35.4 ± 2.1 -35.4 \pm 2.1 −35.4±2.1 |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 33.6 ± 1.7 -33.6 \pm 1.7 −33.6±1.7 | − 33.8 ± 2.2 -33.8 \pm 2.2 −33.8±2.2 | − 34.3 ± 1.5 -34.3 \pm 1.5 −34.3±1.5 | − 35.4 ± 1.9 -35.4 \pm 1.9 −35.4±1.9 | − 36.6 ± 1.7 -36.6 \pm 1.7 −36.6±1.7 |
表4: MPE固定延迟测试结果(奖励)使用基线算法FT-QMIX。
| 固定延迟值 | 0 | 3 | 6 | 9 | 12 | |||
|---|---|---|---|---|---|---|---|---|
| DR | H | KD | TAG | |||||
| Oracle | 213.4 ± 33.5 213.4 \pm 33.5 213.4±33.5 | 136.2 ± 23.0 136.2 \pm 23.0 136.2±23.0 | 84.5 ± 16.9 84.5 \pm 16.9 84.5±16.9 | 70.1 ± 11.1 70.1 \pm 11.1 70.1±11.1 | 66.1 ± 13.3 66.1 \pm 13.3 66.1±13.3 | |||
| Base | 110.2 ± 17.7 110.2 \pm 17.7 110.2±17.7 | 135.2 ± 22.5 135.2 \pm 22.5 135.2±22.5 | 125.4 ± 22.8 125.4 \pm 22.8 125.4±22.8 | 112.6 ± 20.7 112.6 \pm 20.7 112.6±20.7 | 101.5 ± 19.6 101.5 \pm 19.6 101.5±19.6 | |||
| Base | ✓ \checkmark ✓ | 135.1 ± 26.7 135.1 \pm 26.7 135.1±26.7 | 156.9 ± 23.2 156.9 \pm 23.2 156.9±23.2 | 142.3 ± 22.3 142.3 \pm 22.3 142.3±22.3 | 120.9 ± 20.8 120.9 \pm 20.8 120.9±20.8 | 111.7 ± 17.5 111.7 \pm 17.5 111.7±17.5 | ||
| Flash | ✓ \checkmark ✓ | 176.6 ± 27.7 176.6 \pm 27.7 176.6±27.7 | 177.5 ± 34.2 177.5 \pm 34.2 177.5±34.2 | 150.4 ± 22.5 150.4 \pm 22.5 150.4±22.5 | 132.8 ± 21.6 132.8 \pm 21.6 132.8±21.6 | 127.8 ± 23.7 127.8 \pm 23.7 127.8±23.7 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 188.0 ± 26.6 188.0 \pm 26.6 188.0±26.6 | 180.4 ± 24.7 180.4 \pm 24.7 180.4±24.7 | 166.7 ± 29.0 166.7 \pm 29.0 166.7±29.0 | 168.5 ± 28.2 168.5 \pm 28.2 168.5±28.2 | 149.9 ± 26.3 149.9 \pm 26.3 149.9±26.3 | |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 213.7 ± 30.8 213.7 \pm 30.8 213.7±30.8 | 194.8 ± 27.5 194.8 \pm 27.5 194.8±27.5 | 182.5 ± 32.0 182.5 \pm 32.0 182.5±32.0 | 169.8 ± 23.9 169.8 \pm 23.9 169.8±23.9 | 150.9 ± 24.1 150.9 \pm 24.1 150.9±24.1 |
| Echo | ✓ \checkmark ✓ | 194.2 ± 29.0 194.2 \pm 29.0 194.2±29.0 | 187.6 ± 29.0 187.6 \pm 29.0 187.6±29.0 | 173.8 ± 22.6 173.8 \pm 22.6 173.8±22.6 | 160.7 ± 30.1 160.7 \pm 30.1 160.7±30.1 | 163.7 ± 27.5 163.7 \pm 27.5 163.7±27.5 | ||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 185.9 ± 23.4 185.9 \pm 23.4 185.9±23.4 | 175.1 ± 30.3 175.1 \pm 30.3 175.1±30.3 | 176.9 ± 29.9 176.9 \pm 29.9 176.9±29.9 | 167.3 ± 24.0 167.3 \pm 24.0 167.3±24.0 | 155.5 ± 25.4 155.5 \pm 25.4 155.5±25.4 | |
| TF | DR | H | SPREAD | |||||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 34.2 ± 2.2 -34.2 \pm 2.2 −34.2±2.2 | − 34.1 ± 1.9 -34.1 \pm 1.9 −34.1±1.9 | − 34.2 ± 2.0 -34.2 \pm 2.0 −34.2±2.0 | − 35.3 ± 2.2 -35.3 \pm 2.2 −35.3±2.2 | − 35.4 ± 2.1 -35.4 \pm 2.1 −35.4±2.1 |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 33.6 ± 1.7 -33.6 \pm 1.7 −33.6±1.7 | − 33.8 ± 2.2 -33.8 \pm 2.2 −33.8±2.2 | − 34.3 ± 1.5 -34.3 \pm 1.5 −34.3±1.5 | − 35.4 ± 1.9 -35.4 \pm 1.9 −35.4±1.9 | − 36.6 ± 1.7 -36.6 \pm 1.7 −36.6±1.7 |
表4: 使用基线算法FT-QMIX的MPE固定延迟测试结果(奖励)。
| 固定延迟值 | 0 | 3 | 6 | 9 | 12 | |||
|---|---|---|---|---|---|---|---|---|
| DR | H | KD | TAG | |||||
| Oracle | 213.4 ± 33.5 213.4 \pm 33.5 213.4±33.5 | 136.2 ± 23.0 136.2 \pm 23.0 136.2±23.0 | 84.5 ± 16.9 84.5 \pm 16.9 84.5±16.9 | 70.1 ± 11.1 70.1 \pm 11.1 70.1±11.1 | 66.1 ± 13.3 66.1 \pm 13.3 66.1±13.3 | |||
| Base | 110.2 ± 17.7 110.2 \pm 17.7 110.2±17.7 | 135.2 ± 22.5 135.2 \pm 22.5 135.2±22.5 | 125.4 ± 22.8 125.4 \pm 22.8 125.4±22.8 | 112.6 ± 20.7 112.6 \pm 20.7 112.6±20.7 | 101.5 ± 19.6 101.5 \pm 19.6 101.5±19.6 | |||
| Base | ✓ \checkmark ✓ | 135.1 ± 26.7 135.1 \pm 26.7 135.1±26.7 | 156.9 ± 23.2 156.9 \pm 23.2 156.9±23.2 | 142.3 ± 22.3 142.3 \pm 22.3 142.3±22.3 | 120.9 ± 20.8 120.9 \pm 20.8 120.9±20.8 | 111.7 ± 17.5 111.7 \pm 17.5 111.7±17.5 | ||
| Flash | ✓ \checkmark ✓ | 176.6 ± 27.7 176.6 \pm 27.7 176.6±27.7 | 177.5 ± 34.2 177.5 \pm 34.2 177.5±34.2 | 150.4 ± 22.5 150.4 \pm 22.5 150.4±22.5 | 132.8 ± 21.6 132.8 \pm 21.6 132.8±21.6 | 127.8 ± 23.7 127.8 \pm 23.7 127.8±23.7 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 188.0 ± 26.6 188.0 \pm 26.6 188.0±26.6 | 180.4 ± 24.7 180.4 \pm 24.7 180.4±24.7 | 166.7 ± 29.0 166.7 \pm 29.0 166.7±29.0 | 168.5 ± 28.2 168.5 \pm 28.2 168.5±28.2 | 149.9 ± 26.3 149.9 \pm 26.3 149.9±26.3 | |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 213.7 ± 30.8 213.7 \pm 30.8 213.7±30.8 | 194.8 ± 27.5 194.8 \pm 27.5 194.8±27.5 | 182.5 ± 32.0 182.5 \pm 32.0 182.5±32.0 | 169.8 ± 23.9 169.8 \pm 23.9 169.8±23.9 | 150.9 ± 24.1 150.9 \pm 24.1 150.9±24.1 |
| Echo | ✓ \checkmark ✓ | 194.2 ± 29.0 194.2 \pm 29.0 194.2±29.0 | 187.6 ± 29.0 187.6 \pm 29.0 187.6±29.0 | 173.8 ± 22.6 173.8 \pm 22.6 173.8±22.6 | 160.7 ± 30.1 160.7 \pm 30.1 160.7±30.1 | 163.7 ± 27.5 163.7 \pm 27.5 163.7±27.5 | ||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 185.9 ± 23.4 185.9 \pm 23.4 185.9±23.4 | 175.1 ± 30.3 175.1 \pm 30.3 175.1±30.3 | 176.9 ± 29.9 176.9 \pm 29.9 176.9±29.9 | 167.3 ± 24.0 167.3 \pm 24.0 167.3±24.0 | 155.5 ± 25.4 155.5 \pm 25.4 155.5±25.4 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 206.5 ± 34.0 206.5 \pm 34.0 206.5±34.0 | 197.9 ± 28.5 197.9 \pm 28.5 197.9±28.5 | 184.7 ± 32.4 184.7 \pm 32.4 184.7±32.4 | 175.6 ± 22.9 175.6 \pm 22.9 175.6±22.9 | 165.2 ± 28.0 165.2 \pm 28.0 165.2±28.0 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 209.8 ± 32.3 209.8 \pm 32.3 209.8±32.3 | 200.8 ± 25.1 200.8 \pm 25.1 200.8±25.1 | 182.9 ± 36.6 182.9 \pm 36.6 182.9±36.6 | 176.2 ± 24.8 176.2 \pm 24.8 176.2±24.8 | 160.5 ± 29.5 160.5 \pm 29.5 160.5±29.5 |
| DR | H | KD | SPREAD | |||||
| Oracle | − 33.1 ± 2.0 -33.1 \pm 2.0 −33.1±2.0 | − 37.6 ± 2.2 -37.6 \pm 2.2 −37.6±2.2 | − 48.8 ± 2.0 -48.8 \pm 2.0 −48.8±2.0 | − 59.9 ± 2.9 -59.9 \pm 2.9 −59.9±2.9 | − 67.2 ± 3.2 -67.2 \pm 3.2 −67.2±3.2 | |||
| Base | − 40.4 ± 2.2 -40.4 \pm 2.2 −40.4±2.2 | − 38.1 ± 1.8 -38.1 \pm 1.8 −38.1±1.8 | − 40.3 ± 2.4 -40.3 \pm 2.4 −40.3±2.4 | − 44.2 ± 2.2 -44.2 \pm 2.2 −44.2±2.2 | − 46.5 ± 2.3 -46.5 \pm 2.3 −46.5±2.3 | |||
| Base | ✓ \checkmark ✓ | − 41.1 ± 2.4 -41.1 \pm 2.4 −41.1±2.4 | − 39.2 ± 1.8 -39.2 \pm 1.8 −39.2±1.8 | − 41.0 ± 2.5 -41.0 \pm 2.5 −41.0±2.5 | − 44.7 ± 2.0 -44.7 \pm 2.0 −44.7±2.0 | − 49.2 ± 2.9 -49.2 \pm 2.9 −49.2±2.9 | ||
| Flash | ✓ \checkmark ✓ | − 37.7 ± 1.7 -37.7 \pm 1.7 −37.7±1.7 | − 37.8 ± 2.3 -37.8 \pm 2.3 −37.8±2.3 | − 39.3 ± 1.9 -39.3 \pm 1.9 −39.3±1.9 | − 40.1 ± 2.1 -40.1 \pm 2.1 −40.1±2.1 | − 40.0 ± 2.3 -40.0 \pm 2.3 −40.0±2.3 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 33.9 ± 1.8 -33.9 \pm 1.8 −33.9±1.8 | − 34.2 ± 2.0 -34.2 \pm 2.0 −34.2±2.0 | − 33.1 ± 1.9 -33.1 \pm 1.9 −33.1±1.9 | − 34.4 ± 1.8 -34.4 \pm 1.8 −34.4±1.8 | − 35.8 ± 1.8 -35.8 \pm 1.8 −35.8±1.8 | |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 31.7 ± 2.0 -31.7 \pm 2.0 −31.7±2.0 | − 32.0 ± 1.6 -32.0 \pm 1.6 −32.0±1.6 | − 32.4 ± 2.3 -32.4 \pm 2.3 −32.4±2.3 | − 33.2 ± 2.3 -33.2 \pm 2.3 −33.2±2.3 | − 35.4 ± 2.0 -35.4 \pm 2.0 −35.4±2.0 |
| Echo | ✓ \checkmark ✓ | − 36.3 ± 2.2 -36.3 \pm 2.2 −36.3±2.2 | − 36.6 ± 2.3 -36.6 \pm 2.3 −36.6±2.3 | − 36.2 ± 1.9 -36.2 \pm 1.9 −36.2±1.9 | − 36.8 ± 1.7 -36.8 \pm 1.7 −36.8±1.7 | − 37.4 ± 2.2 -37.4 \pm 2.2 −37.4±2.2 | ||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 33.6 ± 1.7 -33.6 \pm 1.7 −33.6±1.7 | − 33.8 ± 2.2 -33.8 \pm 2.2 −33.8±2.2 | − 34.3 ± 1.5 -34.3 \pm 1.5 −34.3±1.5 | − 35.4 ± 1.9 -35.4 \pm 1.9 −35.4±1.9 | − 36.6 ± 1.7 -36.6 \pm 1.7 −36.6±1.7 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 32.2 ± 1.6 -32.2 \pm 1.6 −32.2±1.6 | − 33.0 ± 2.3 -33.0 \pm 2.3 −33.0±2.3 | − 33.3 ± 1.8 -33.3 \pm 1.8 −33.3±1.8 | − 33.3 ± 2.2 -33.3 \pm 2.2 −33.3±2.2 | − 33.9 ± 1.9 -33.9 \pm 1.9 −33.9±1.9 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 31.8 ± 1.9 -31.8 \pm 1.9 −31.8±1.9 | − 32.0 ± 2.0 -32.0 \pm 2.0 −32.0±2.0 | − 32.3 ± 1.9 -32.3 \pm 1.9 −32.3±1.9 | − 33.1 ± 2.1 -33.1 \pm 2.1 −33.1±2.1 | − 33.2 ± 2.2 -33.2 \pm 2.2 −33.2±2.2 |
| DR | H | KD | REFERENCE | |||||
| Oracle | − 17.6 ± 1.2 -17.6 \pm 1.2 −17.6±1.2 | − 22.5 ± 1.2 -22.5 \pm 1.2 −22.5±1.2 | − 31.1 ± 1.1 -31.1 \pm 1.1 −31.1±1.1 | − 38.2 ± 1.5 -38.2 \pm 1.5 −38.2±1.5 | − 43.7 ± 1.9 -43.7 \pm 1.9 −43.7±1.9 | |||
| Base | − 29.5 ± 1.5 -29.5 \pm 1.5 −29.5±1.5 | − 28.6 ± 1.5 -28.6 \pm 1.5 −28.6±1.5 | − 30.3 ± 1.7 -30.3 \pm 1.7 −30.3±1.7 | − 34.3 ± 1.5 -34.3 \pm 1.5 −34.3±1.5 | − 36.8 ± 1.8 -36.8 \pm 1.8 −36.8±1.8 | |||
| Base | ✓ \checkmark ✓ | − 28.9 ± 1.8 -28.9 \pm 1.8 −28.9±1.8 | − 26.1 ± 1.6 -26.1 \pm 1.6 −26.1±1.6 | − 27.7 ± 1.7 -27.7 \pm 1.7 −27.7±1.7 | − 30.9 ± 1.7 -30.9 \pm 1.7 −30.9±1.7 | − 34.7 ± 1.6 -34.7 \pm 1.6 −34.7±1.6 | ||
| Flash | ✓ \checkmark ✓ | − 34.5 ± 2.1 -34.5 \pm 2.1 −34.5±2.1 | − 34.2 ± 2.0 -34.2 \pm 2.0 −34.2±2.0 | − 34.8 ± 2.1 -34.8 \pm 2.1 −34.8±2.1 | − 34.9 ± 2.3 -34.9 \pm 2.3 −34.9±2.3 | − 35.1 ± 2.2 -35.1 \pm 2.2 −35.1±2.2 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 17.1 ± 1.3 -17.1 \pm 1.3 −17.1±1.3 | − 17.4 ± 1.5 -17.4 \pm 1.5 −17.4±1.5 | − 17.3 ± 1.2 -17.3 \pm 1.2 −17.3±1.2 | − 18.0 ± 1.5 -18.0 \pm 1.5 −18.0±1.5 | − 20.0 ± 1.2 -20.0 \pm 1.2 −20.0±1.2 | |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 16.8 ± 1.3 -16.8 \pm 1.3 −16.8±1.3 | − 17.0 ± 1.3 -17.0 \pm 1.3 −17.0±1.3 | − 16.7 ± 1.1 -16.7 \pm 1.1 −16.7±1.1 | − 17.6 ± 1.1 -17.6 \pm 1.1 −17.6±1.1 | − 19.6 ± 1.7 -19.6 \pm 1.7 −19.6±1.7 |
| Echo | ✓ \checkmark ✓ | − 19.1 ± 1.4 -19.1 \pm 1.4 −19.1±1.4 | − 18.0 ± 1.4 -18.0 \pm 1.4 −18.0±1.4 | − 19.0 ± 1.4 -19.0 \pm 1.4 −19.0±1.4 | − 19.0 ± 1.4 -19.0 \pm 1.4 −19.0±1.4 | − 19.1 ± 1.6 -19.1 \pm 1.6 −19.1±1.6 | ||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 18.4 ± 1.2 -18.4 \pm 1.2 −18.4±1.2 | − 18.5 ± 1.5 -18.5 \pm 1.5 −18.5±1.5 | − 18.5 ± 1.1 -18.5 \pm 1.1 −18.5±1.1 | − 18.7 ± 1.4 -18.7 \pm 1.4 −18.7±1.4 | − 20.2 ± 1.4 -20.2 \pm 1.4 −20.2±1.4 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 20.6 ± 1.2 -20.6 \pm 1.2 −20.6±1.2 | − 20.9 ± 1.4 -20.9 \pm 1.4 −20.9±1.4 | − 21.3 ± 1.3 -21.3 \pm 1.3 −21.3±1.3 | − 22.2 ± 1.1 -22.2 \pm 1.1 −22.2±1.1 | − 22.2 ± 1.2 -22.2 \pm 1.2 −22.2±1.2 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | − 16.7 ± 1.4 -16.7 \pm 1.4 −16.7±1.4 | − 16.9 ± 1.1 -16.9 \pm 1.1 −16.9±1.1 | − 16.9 ± 1.2 -16.9 \pm 1.2 −16.9±1.2 | − 17.6 ± 1.2 -17.6 \pm 1.2 −17.6±1.2 | − 18.7 ± 1.4 -18.7 \pm 1.4 −18.7±1.4 |
我们的实验结果主要通过图表和表格展示,并附有详细解释。我们首先在MPE上进行了广泛的实验,随后在SMAC上进行了选择性验证。MPE的消融研究比较了两种基线算法:FT-QMIX 和 FT-VDN。如表所示,
表5: 使用基线算法FT-QMIX的MPE非固定延迟测试结果(奖励)。
| 延迟范围 | 3-9 | 6-12 | 3-9 | 6-12 | 3-9 | 6-12 | |||
|---|---|---|---|---|---|---|---|---|---|
| DR H KD | TAG | SPREAD | REFERENCE | ||||||
| Oracle | 92.3 ± 15.2 92.3 \pm 15.2 92.3±15.2 | 74.8 ± 13.5 74.8 \pm 13.5 74.8±13.5 | − 45.9 ± 1.8 -45.9 \pm 1.8 −45.9±1.8 | − 56.4 ± 2.1 -56.4 \pm 2.1 −56.4±2.1 | − 28.3 ± 1.2 -28.3 \pm 1.2 −28.3±1.2 | − 36.1 ± 1.4 -36.1 \pm 1.4 −36.1±1.4 | |||
| Base | 127.0 ± 18.8 127.0 \pm 18.8 127.0±18.8 | 113.6 ± 19.9 113.6 \pm 19.9 113.6±19.9 | − 39.6 ± 2.0 -39.6 \pm 2.0 −39.6±2.0 | − 42.2 ± 2.5 -42.2 \pm 2.5 −42.2±2.5 | − 29.9 ± 1.6 -29.9 \pm 1.6 −29.9±1.6 | − 33.2 ± 2.0 -33.2 \pm 2.0 −33.2±2.0 | |||
| Base | ✓ \checkmark ✓ | 144.6 ± 21.1 144.6 \pm 21.1 144.6±21.1 | 132.4 ± 19.7 132.4 \pm 19.7 132.4±19.7 | − 40.5 ± 2.2 -40.5 \pm 2.2 −40.5±2.2 | − 44.0 ± 2.3 -44.0 \pm 2.3 −44.0±2.3 | − 27.4 ± 1.6 -27.4 \pm 1.6 −27.4±1.6 | − 30.4 ± 1.9 -30.4 \pm 1.9 −30.4±1.9 | ||
| Flash | ✓ \checkmark ✓ | 161.5 ± 20.4 161.5 \pm 20.4 161.5±20.4 | 151.4 ± 27.4 151.4 \pm 27.4 151.4±27.4 | − 38.8 ± 2.3 -38.8 \pm 2.3 −38.8±2.3 | − 39.2 ± 2.6 -39.2 \pm 2.6 −39.2±2.6 | − 34.9 ± 2.0 -34.9 \pm 2.0 −34.9±2.0 | − 35.2 ± 2.0 -35.2 \pm 2.0 −35.2±2.0 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 180.3 ± 28.3 180.3 \pm 28.3 180.3±28.3 | 165.4 ± 26.1 165.4 \pm 26.1 165.4±26.1 | − 33.7 ± 2.0 -33.7 \pm 2.0 −33.7±2.0 | − 34.5 ± 1.9 -34.5 \pm 1.9 −34.5±1.9 | − 17.1 ± 1.1 -17.1 \pm 1.1 −17.1±1.1 | − 18.2 ± 1.3 -18.2 \pm 1.3 −18.2±1.3 | |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 188.6 ± 31.1 \mathbf{1 8 8 . 6} \pm \mathbf{3 1 . 1} 188.6±31.1 | 166.9 ± 30.9 \mathbf{1 6 6 . 9} \pm \mathbf{3 0 . 9} 166.9±30.9 | − 32.0 ± 1.0 -\mathbf{3 2 . 0} \pm \mathbf{1 . 0} −32.0±1.0 | − 33.0 ± 2.3 -\mathbf{3 3 . 0} \pm \mathbf{2 . 3} −33.0±2.3 | − 17.0 ± 1.4 -\mathbf{1 7 . 0} \pm \mathbf{1 . 4} −17.0±1.4 | − 17.2 ± 1.4 -\mathbf{1 7 . 2} \pm \mathbf{1 . 4} −17.2±1.4 | |
| Echo | ✓ \checkmark ✓ | 175.1 ± 25.0 175.1 \pm 25.0 175.1±25.0 | 165.5 ± 24.5 165.5 \pm 24.5 165.5±24.5 | − 36.7 ± 2.2 -36.7 \pm 2.2 −36.7±2.2 | − 36.9 ± 2.2 -36.9 \pm 2.2 −36.9±2.2 | − 18.6 ± 1.3 -18.6 \pm 1.3 −18.6±1.3 | − 18.9 ± 1.3 -18.9 \pm 1.3 −18.9±1.3 | ||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 177.1 ± 21.9 177.1 \pm 21.9 177.1±21.9 | 166.8 ± 27.4 166.8 \pm 27.4 166.8±27.4 | − 34.2 ± 2.0 -34.2 \pm 2.0 −34.2±2.0 | − 35.1 ± 1.9 -35.1 \pm 1.9 −35.1±1.9 | − 18.3 ± 1.2 -18.3 \pm 1.2 −18.3±1.2 | − 18.9 ± 1.2 -18.9 \pm 1.2 −18.9±1.2 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 178.9 ± 27.0 178.9 \pm 27.0 178.9±27.0 | 180.0 ± 20.7 180.0 \pm 20.7 180.0±20.7 | − 32.1 ± 2.2 -32.1 \pm 2.2 −32.1±2.2 | − 33.2 ± 1.9 -33.2 \pm 1.9 −33.2±1.9 | − 21.4 ± 1.0 -21.4 \pm 1.0 −21.4±1.0 | − 21.6 ± 1.3 -21.6 \pm 1.3 −21.6±1.3 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 189.2 ± 22.3 \mathbf{1 8 9 . 2} \pm \mathbf{2 2 . 3} 189.2±22.3 | 178.3 ± 21.1 \mathbf{1 7 8 . 3} \pm \mathbf{2 1 . 1} 178.3±21.1 | − 31.4 ± 1.0 -\mathbf{3 1 . 4} \pm \mathbf{1 . 0} −31.4±1.0 | − 32.5 ± 1.4 -\mathbf{3 2 . 5} \pm \mathbf{1 . 4} −32.5±1.4 | − 17.0 ± 1.2 -\mathbf{1 7 . 0} \pm \mathbf{1 . 2} −17.0±1.2 | − 17.4 ± 1.1 -\mathbf{1 7 . 4} \pm \mathbf{1 . 1} −17.4±1.1 |
表6: 使用基线算法FT-QMIX的SMAC固定延迟测试结果(胜率)。
| 固定延迟值 | 0 | 2 | 4 | 6 | 8 | ||||
|---|---|---|---|---|---|---|---|---|---|
| C DR H KD | |||||||||
| Oracle | 99.7 ± 1.2 \mathbf{9 9 . 7} \pm \mathbf{1 . 2} 99.7±1.2 | 64.6 ± 9.3 64.6 \pm 9.3 64.6±9.3 | 26.6 ± 7.9 26.6 \pm 7.9 26.6±7.9 | 1.9 ± 2.4 1.9 \pm 2.4 1.9±2.4 | 0.1 ± 0.5 \pm 0.5 ±0.5 | ||||
| Base | 82.9 ± 6.2 82.9 \pm 6.2 82.9±6.2 | 79.3 ± 8.1 79.3 \pm 8.1 79.3±8.1 | 84.9 ± 6.1 84.9 \pm 6.1 84.9±6.1 | 69.9 ± 9.1 69.9 \pm 9.1 69.9±9.1 | 65.0 ± 9.1 65.0 \pm 9.1 65.0±9.1 | ||||
| Base | ✓ \checkmark ✓ | 97.0 ± 2.6 97.0 \pm 2.6 97.0±2.6 | 95.5 ± 2.9 95.5 \pm 2.9 95.5±2.9 | 95.1 ± 3.6 95.1 \pm 3.6 95.1±3.6 | 93.8 ± 4.5 93.8 \pm 4.5 93.8±4.5 | 88.4 ± 4.8 88.4 \pm 4.8 88.4±4.8 | |||
| Base | ✓ \checkmark ✓ | 97.0 ± 2.7 97.0 \pm 2.7 97.0±2.7 | 98.0 ± 2.0 98.0 \pm 2.0 98.0±2.0 | 92.3 ± 5.8 92.3 \pm 5.8 92.3±5.8 | 74.8 ± 8.3 74.8 \pm 8.3 74.8±8.3 | 33.0 ± 10.5 33.0 \pm 10.5 33.0±10.5 | |||
| Base | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 92.4 ± 3.6 92.4 \pm 3.6 92.4±3.6 | 96.8 ± 2.8 96.8 \pm 2.8 96.8±2.8 | 80.6 ± 5.9 80.6 \pm 5.9 80.6±5.9 | 44.5 ± 8.9 44.5 \pm 8.9 44.5±8.9 | 4.5 ± 3.4 4.5 \pm 3.4 4.5±3.4 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 95.0 ± 4.3 95.0 \pm 4.3 95.0±4.3 | 96.6 ± 3.0 96.6 \pm 3.0 96.6±3.0 | 91.4 ± 5.0 91.4 \pm 5.0 91.4±5.0 | 78.1 ± 6.2 78.1 \pm 6.2 78.1±6.2 | 37.7 ± 10.2 37.7 \pm 10.2 37.7±10.2 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 98.8 ± 2.1 98.8 \pm 2.1 98.8±2.1 | 97.3 ± 2.9 97.3 \pm 2.9 97.3±2.9 | 93.4 ± 4.5 93.4 \pm 4.5 93.4±4.5 | 83.6 ± 6.5 83.6 \pm 6.5 83.6±6.5 | 43.5 ± 7.9 43.5 \pm 7.9 43.5±7.9 | |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 99.8 ± 0.7 \mathbf{9 9 . 8} \pm \mathbf{0 . 7} 99.8±0.7 | 99.3 ± 1.9 \mathbf{9 9 . 3} \pm \mathbf{1 . 9} 99.3±1.9 | 99.4 ± 1.2 \mathbf{9 9 . 4} \pm \mathbf{1 . 2} 99.4±1.2 | 94.9 ± 3.4 \mathbf{9 4 . 9} \pm \mathbf{3 . 4} 94.9±3.4 | 82.9 ± 5.4 \mathbf{8 2 . 9} \pm \mathbf{5 . 4} 82.9±5.4 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 96.3 ± 2.8 96.3 \pm 2.8 96.3±2.8 | 97.1 ± 2.7 97.1 \pm 2.7 97.1±2.7 | 94.6 ± 3.8 94.6 \pm 3.8 94.6±3.8 | 83.6 ± 6.3 83.6 \pm 6.3 83.6±6.3 | 24.7 ± 8.5 24.7 \pm 8.5 24.7±8.5 | ||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 98.5 ± 2.2 98.5 \pm 2.2 98.5±2.2 | 98.8 ± 1.8 98.8 \pm 1.8 98.8±1.8 | 96.6 ± 2.8 96.6 \pm 2.8 96.6±2.8 | 84.2 ± 6.7 84.2 \pm 6.7 84.2±6.7 | 60.9 ± 8.0 60.9 \pm 8.0 60.9±8.0 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 99.8 ± 0.8 \mathbf{9 9 . 8} \pm \mathbf{0 . 8} 99.8±0.8 | 99.8 ± 0.7 \mathbf{9 9 . 8} \pm \mathbf{0 . 7} 99.8±0.7 | 99.8 ± 0.8 \mathbf{9 9 . 8} \pm \mathbf{0 . 8} 99.8±0.8 | 97.1 ± 2.7 \mathbf{9 7 . 1} \pm \mathbf{2 . 7} 97.1±2.7 | 80.0 ± 8.1 \mathbf{8 0 . 0} \pm \mathbf{8 . 1} 80.0±8.1 | |
| C DR H KD | |||||||||
| Oracle | 84.8 ± 6.7 \mathbf{8 4 . 8} \pm \mathbf{6 . 7} 84.8±6.7 | 0.0 ± 0.0 0.0 \pm 0.0 0.0±0.0 | 0.0 ± 0.0 0.0 \pm 0.0 0.0±0.0 | 0.0 ± 0.0 0.0 \pm 0.0 0.0±0.0 | 0.0 ± 0.0 0.0 \pm 0.0 0.0±0.0 | ||||
| Base | 0.5 ± 1.1 0.5 \pm 1.1 0.5±1.1 | 0.4 ± 1.0 0.4 \pm 1.0 0.4±1.0 | 0.9 ± 1.6 0.9 \pm 1.6 0.9±1.6 | 0.5 ± 1.3 0.5 \pm 1.3 0.5±1.3 | 0.1 ± 0.5 0.1 \pm 0.5 0.1±0.5 | ||||
| Base | ✓ \checkmark ✓ | 1.1 ± 1.6 1.1 \pm 1.6 1.1±1.6 | 2.7 ± 2.9 2.7 \pm 2.9 2.7±2.9 | 3.4 ± 3.5 3.4 \pm 3.5 3.4±3.5 | 2.3 ± 2.8 2.3 \pm 2.8 2.3±2.8 | 0.7 ± 1.6 0.7 \pm 1.6 0.7±1.6 | |||
| Base | ✓ \checkmark ✓ | 7.3 ± 5.1 7.3 \pm 5.1 7.3±5.1 | 15.9 ± 6.2 15.9 \pm 6.2 15.9±6.2 | 12.1 ± 5.4 12.1 \pm 5.4 12.1±5.4 | 0.4 ± 1.0 0.4 \pm 1.0 0.4±1.0 | 0.1 ± 0.5 0.1 \pm 0.5 0.1±0.5 | |||
| Base | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 58.1 ± 9.0 58.1 \pm 9.0 58.1±9.0 | 80.2 ± 7.1 80.2 \pm 7.1 80.2±7.1 | 57.2 ± 10.8 57.2 \pm 10.8 57.2±10.8 | 20.5 ± 8.1 20.5 \pm 8.1 20.5±8.1 | 3.0 ± 2.8 3.0 \pm 2.8 3.0±2.8 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 83.2 ± 6.4 83.2 \pm 6.4 83.2±6.4 | 80.6 ± 7.4 80.6 \pm 7.4 80.6±7.4 | 73.7 ± 7.7 73.7 \pm 7.7 73.7±7.7 | 59.9 ± 9.5 59.9 \pm 9.5 59.9±9.5 | 36.6 ± 8.4 36.6 \pm 8.4 36.6±8.4 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 84.8 ± 4.4 84.8 \pm 4.4 84.8±4.4 | 81.9 ± 6.4 81.9 \pm 6.4 81.9±6.4 | 78.4 ± 6.4 78.4 \pm 6.4 78.4±6.4 | 43.9 ± 7.8 43.9 \pm 7.8 43.9±7.8 | 5.8 ± 4.3 5.8 \pm 4.3 5.8±4.3 | |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 85.5 ± 5.7 \mathbf{8 5 . 5} \pm \mathbf{5 . 7} 85.5±5.7 | 84.6 ± 6.8 \mathbf{8 4 . 6} \pm \mathbf{6 . 8} 84.6±6.8 | 82.5 ± 6.1 \mathbf{8 2 . 5} \pm \mathbf{6 . 1} 82.5±6.1 | 62.3 ± 7.7 \mathbf{6 2 . 3} \pm \mathbf{7 . 7} 62.3±7.7 | 40.1 ± 9.8 \mathbf{4 0 . 1} \pm \mathbf{9 . 8} 40.1±9.8 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 81.9 ± 7.2 81.9 \pm 7.2 81.9±7.2 | 78.4 ± 7.1 78.4 \pm 7.1 78.4±7.1 | 74.7 ± 7.3 74.7 \pm 7.3 74.7±7.3 | 58.4 ± 10.2 58.4 \pm 10.2 58.4±10.2 | 44.7 ± 8.3 44.7 \pm 8.3 44.7±8.3 | ||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 73.4 ± 7.1 73.4 \pm 7.1 73.4±7.1 | 65.2 ± 7.9 65.2 \pm 7.9 65.2±7.9 | 63.1 ± 9.8 63.1 \pm 9.8 63.1±9.8 | 39.8 ± 7.8 39.8 \pm 7.8 39.8±7.8 | 23.4 ± 7.7 23.4 \pm 7.7 23.4±7.7 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 86.3 ± 6.5 \mathbf{8 6 . 3} \pm \mathbf{6 . 5} 86.3±6.5 | 85.2 ± 5.0 \mathbf{8 5 . 2} \pm \mathbf{5 . 0} 85.2±5.0 | 79.9 ± 7.7 \mathbf{7 9 . 9} \pm \mathbf{7 . 7} 79.9±7.7 | 65.2 ± 8.9 \mathbf{6 5 . 2} \pm \mathbf{8 . 9} 65.2±8.9 | 51.8 ± 8.6 \mathbf{5 1 . 8} \pm \mathbf{8 . 6} 51.8±8.6 | |
| C DR H KD | |||||||||
| Oracle | 92.0 ± 4.0 \mathbf{9 2 . 0} \pm \mathbf{4 . 0} 92.0±4.0 | 0.5 ± 1.2 0.5 \pm 1.2 0.5±1.2 | 0.0 ± 0.0 0.0 \pm 0.0 0.0±0.0 | 0.0 ± 0.0 0.0 \pm 0.0 0.0±0.0 | 0.0 ± 0.0 0.0 \pm 0.0 0.0±0.0 | ||||
| Base | 0.6 ± 1.2 0.6 \pm 1.2 0.6±1.2 | 1.0 ± 1.9 1.0 \pm 1.9 1.0±1.9 | 0.7 ± 1.5 0.7 \pm 1.5 0.7±1.5 | 0.1 ± 0.5 0.1 \pm 0.5 0.1±0.5 | 0.0 ± 0.0 0.0 \pm 0.0 0.0±0.0 | ||||
| Base | ✓ \checkmark ✓ | 4.4 ± 3.1 4.4 \pm 3.1 4.4±3.1 | 3.8 ± 3.5 3.8 \pm 3.5 3.8±3.5 | 2.4 ± 2.6 2.4 \pm 2.6 2.4±2.6 | 1.4 ± 1.8 1.4 \pm 1.8 1.4±1.8 | 0.7 ± 1.5 0.7 \pm 1.5 0.7±1.5 | |||
| Base | ✓ \checkmark ✓ | 3.1 ± 2.5 3.1 \pm 2.5 3.1±2.5 | 4.1 ± 3.8 4.1 \pm 3.8 4.1±3.8 | 2.1 ± 2.7 2.1 \pm 2.7 2.1±2.7 | 0.4 ± 1.0 0.4 \pm 1.0 0.4±1.0 | 0.2 ± 1.0 0.2 \pm 1.0 0.2±1.0 | |||
| Base | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 50.8 ± 9.1 50.8 \pm 9.1 50.8±9.1 | 70.6 ± 9.2 70.6 \pm 9.2 70.6±9.2 | 12.7 ± 6.1 12.7 \pm 6.1 12.7±6.1 | 2.7 ± 3.5 2.7 \pm 3.5 2.7±3.5 | 0.3 ± 0.9 0.3 \pm 0.9 0.3±0.9 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 77.5 ± 6.6 77.5 \pm 6.6 77.5±6.6 | 70.7 ± 9.0 70.7 \pm 9.0 70.7±9.0 | 29.7 ± 10.9 29.7 \pm 10.9 29.7±10.9 | 4.6 ± 3.6 4.6 \pm 3.6 4.6±3.6 | 0.5 ± 1.4 0.5 \pm 1.4 0.5±1.4 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 85.3 ± 7.1 85.3 \pm 7.1 85.3±7.1 | 72.1 ± 8.6 72.1 \pm 8.6 72.1±8.6 | 30.6 ± 7.9 30.6 \pm 7.9 30.6±7.9 | 5.9 ± 4.4 5.9 \pm 4.4 5.9±4.4 | 1.2 ± 2.4 1.2 \pm 2.4 1.2±2.4 | |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 90.6 ± 5.1 \mathbf{9 0 . 6} \pm \mathbf{5 . 1} 90.6±5.1 | 81.6 ± 6.1 \mathbf{8 1 . 6} \pm \mathbf{6 . 1} 81.6±6.1 | 43.1 ± 8.7 \mathbf{4 3 . 1} \pm \mathbf{8 . 7} 43.1±8.7 | 12.6 ± 6.1 \mathbf{1 2 . 6} \pm \mathbf{6 . 1} 12.6±6.1 | 3.4 ± 3.4 \mathbf{3 . 4} \pm \mathbf{3 . 4} 3.4±3.4 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 86.6 ± 7.2 86.6 \pm 7.2 86.6±7.2 | 82.0 ± 7.3 82.0 \pm 7.3 82.0±7.3 | 40.8 ± 9.6 40.8 \pm 9.6 40.8±9.6 | 11.2 ± 5.6 11.2 \pm 5.6 11.2±5.6 | 2.9 ± 3.1 2.9 \pm 3.1 2.9±3.1 | ||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 86.7 ± 6.2 86.7 \pm 6.2 86.7±6.2 | 71.0 ± 8.2 71.0 \pm 8.2 71.0±8.2 | 19.1 ± 6.8 19.1 \pm 6.8 19.1±6.8 | 5.1 ± 4.3 5.1 \pm 4.3 5.1±4.3 | 0.6 ± 1.2 0.6 \pm 1.2 0.6±1.2 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 94.1 ± 4.1 \mathbf{9 4 . 1} \pm \mathbf{4 . 1} 94.1±4.1 | 89.3 ± 6.3 \mathbf{8 9 . 3} \pm \mathbf{6 . 3} 89.3±6.3 | 57.6 ± 10.7 \mathbf{5 7 . 6} \pm \mathbf{1 0 . 7} 57.6±10.7 | 10.5 ± 6.7 \mathbf{1 0 . 5} \pm \mathbf{6 . 7} 10.5±6.7 | 6.2 ± 5.1 \mathbf{6 . 2} \pm \mathbf{5 . 1} 6.2±5.1 |
表7: 使用基线算法FT-QMIX的SMAC非固定延迟测试结果(胜率)。
| 延迟范围 | 0-6 | 3-9 | 0-6 | 3-9 | 0-6 | 3-9 | ||
|---|---|---|---|---|---|---|---|---|
| C DR H KD | 3 x − y − 3 z 3 \mathrm{x}_{-} \mathrm{y}_{-} \mathrm{3z} 3x−y−3z | |||||||
| Oracle | 62.2 ± 7.8 62.2 \pm 7.8 62.2±7.8 | 16.2 ± 6.4 16.2 \pm 6.4 16.2±6.4 | 0.0 ± 0.0 0.0 \pm 0.0 0.0±0.0 | 0.0 ± 0.0 0.0 \pm 0.0 0.0±0.0 | 2.9 ± 3.2 2.9 \pm 3.2 2.9±3.2 | 0.0 ± 0.0 0.0 \pm 0.0 0.0±0.0 | ||
| Base | 83.4 ± 6.5 83.4 \pm 6.5 83.4±6.5 | 77.5 ± 6.4 77.5 \pm 6.4 77.5±6.4 | 0.7 ± 1.3 0.7 \pm 1.3 0.7±1.3 | 0.5 ± 1.4 0.5 \pm 1.4 0.5±1.4 | 0.5 ± 1.2 0.5 \pm 1.2 0.5±1.2 | 0.4 ± 1.0 0.4 \pm 1.0 0.4±1.0 | ||
| Base | ✓ \checkmark ✓ | 95.9 ± 3.1 95.9 \pm 3.1 95.9±3.1 | 94.8 ± 3.7 94.8 \pm 3.7 94.8±3.7 | 2.1 ± 2.1 2.1 \pm 2.1 2.1±2.1 | 2.0 ± 2.3 2.0 \pm 2.3 2.0±2.3 | 5.5 ± 3.9 5.5 \pm 3.9 5.5±3.9 | 1.3 ± 1.7 1.3 \pm 1.7 1.3±1.7 | |
| Base | ✓ \checkmark ✓ | 98.1 ± 1.7 98.1 \pm 1.7 98.1±1.7 | 84.8 ± 6.2 84.8 \pm 6.2 84.8±6.2 | 15.2 ± 7.6 15.2 \pm 7.6 15.2±7.6 | 4.1 ± 3.2 4.1 \pm 3.2 4.1±3.2 | 2.3 ± 2.7 2.3 \pm 2.7 2.3±2.7 | 0.9 ± 1.4 0.9 \pm 1.4 0.9±1.4 | |
| Base | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 97.0 ± 2.6 97.0 \pm 2.6 97.0±2.6 | 74.7 ± 7.4 74.7 \pm 7.4 74.7±7.4 | 79.0 ± 8.4 79.0 \pm 8.4 79.0±8.4 | 45.4 ± 8.5 45.4 \pm 8.5 45.4±8.5 | 68.6 ± 11.8 68.6 \pm 11.8 68.6±11.8 | 7.2 ± 5.4 7.2 \pm 5.4 7.2±5.4 |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 96.5 ± 3.7 96.5 \pm 3.7 96.5±3.7 | 92.4 ± 5.4 92.4 \pm 5.4 92.4±5.4 | 78.5 ± 6.3 78.5 \pm 6.3 78.5±6.3 | 71.1 ± 7.8 71.1 \pm 7.8 71.1±7.8 | 67.1 ± 8.1 67.1 \pm 8.1 67.1±8.1 | 13.7 ± 6.6 13.7 \pm 6.6 13.7±6.6 |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 97.2 ± 2.9 97.2 \pm 2.9 97.2±2.9 | 90.6 ± 4.8 90.6 \pm 4.8 90.6±4.8 | 83.7 ± 6.6 83.7 \pm 6.6 83.7±6.6 | 73.5 ± 7.8 73.5 \pm 7.8 73.5±7.8 | 73.8 ± 6.4 73.8 \pm 6.4 73.8±6.4 | 22.3 ± 8.1 22.3 \pm 8.1 22.3±8.1 |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 90.7 ± 0.9 90.7 \pm 0.9 90.7±0.9 | 98.2 ± 2.6 98.2 \pm 2.6 98.2±2.6 | 83.0 ± 7.0 83.0 \pm 7.0 83.0±7.0 | 76.6 ± 7.0 76.6 \pm 7.0 76.6±7.0 | 80.7 ± 7.1 80.7 \pm 7.1 80.7±7.1 | 28.9 ± 7.6 28.9 \pm 7.6 28.9±7.6 |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 98.9 ± 2.0 98.9 \pm 2.0 98.9±2.0 | 95.5 ± 3.8 95.5 \pm 3.8 95.5±3.8 | 80.2 ± 7.8 80.2 \pm 7.8 80.2±7.8 | 66.9 ± 8.6 66.9 \pm 8.6 66.9±8.6 | 78.8 ± 7.1 78.8 \pm 7.1 78.8±7.1 | 27.5 ± 9.4 27.5 \pm 9.4 27.5±9.4 |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 98.9 ± 1.6 98.9 \pm 1.6 98.9±1.6 | 96.2 ± 3.3 96.2 \pm 3.3 96.2±3.3 | 74.5 ± 7.1 74.5 \pm 7.1 74.5±7.1 | 59.5 ± 8.8 59.5 \pm 8.8 59.5±8.8 | 79.5 ± 7.9 79.5 \pm 7.9 79.5±7.9 | 17.3 ± 6.8 17.3 \pm 6.8 17.3±6.8 |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 90.8 ± 0.7 \mathbf{9 0 . 8} \pm \mathbf{0 . 7} 90.8±0.7 | 98.8 ± 1.8 \mathbf{9 8 . 8} \pm \mathbf{1 . 8} 98.8±1.8 | 84.5 ± 6.3 \mathbf{8 4 . 5} \pm \mathbf{6 . 3} 84.5±6.3 | 76.0 ± 6.8 \mathbf{7 6 . 0} \pm \mathbf{6 . 8} 76.0±6.8 | 89.3 ± 5.3 \mathbf{8 9 . 3} \pm \mathbf{5 . 3} 89.3±5.3 |
图14和图15中,FT-VDN在固定和非固定延迟设置下表现出略逊于FT-QMIX的性能,特别是在REFERENCE任务中。值得注意的是,尽管缺乏批评网络,RDC增强的FT-VDN仍保持合理的延迟抗性,证实了该框架与非演员-评论家方法的兼容性,同时保留了基线性能特征。架构比较(图14-17)显示,基于GRU的补偿器通常不如Transformer变体表现好,除了在5m_vs_6m场景中。为了简洁起见,表4-9省略了竞争力较弱的FT-VDN和基于GRU的结果。在SMAC实验中,我们使用课程学习确保演员收敛,如前所述。
表8: 使用基线算法FT-QMIX的SMAC固定延迟测试结果(奖励)。
| 固定延迟值 | 0 | 2 | 4 | 6 | 8 | ||||
|---|---|---|---|---|---|---|---|---|---|
| C | DR | H | KD | 3 s_vs_5z | |||||
| Oracle | 21.0 ± 0.1 21.0 \pm 0.1 21.0±0.1 | 21.3 ± 0.4 21.3 \pm 0.4 21.3±0.4 | 19.0 ± 0.7 19.0 \pm 0.7 19.0±0.7 | 12.6 ± 0.6 12.6 \pm 0.6 12.6±0.6 | 9.6 ± 0.6 9.6 \pm 0.6 9.6±0.6 | ||||
| Base | 21.9 ± 0.5 21.9 \pm 0.5 21.9±0.5 | 21.8 ± 0.4 21.8 \pm 0.4 21.8±0.4 | 21.5 ± 0.4 21.5 \pm 0.4 21.5±0.4 | 21.6 ± 0.5 21.6 \pm 0.5 21.6±0.5 | 21.4 ± 0.6 21.4 \pm 0.6 21.4±0.6 | ||||
| Base | ✓ \checkmark ✓ | 21.6 ± 0.2 21.6 \pm 0.2 21.6±0.2 | 21.7 ± 0.2 21.7 \pm 0.2 21.7±0.2 | 21.5 ± 0.2 21.5 \pm 0.2 21.5±0.2 | 21.4 ± 0.2 21.4 \pm 0.2 21.4±0.2 | 21.8 ± 0.3 21.8 \pm 0.3 21.8±0.3 | |||
| Base | ✓ \checkmark ✓ | 21.7 ± 0.2 21.7 \pm 0.2 21.7±0.2 | 21.6 ± 0.2 21.6 \pm 0.2 21.6±0.2 | 22.1 ± 0.3 22.1 \pm 0.3 22.1±0.3 | 21.9 ± 0.5 21.9 \pm 0.5 21.9±0.5 | 17.7 ± 1.1 17.7 \pm 1.1 17.7±1.1 | |||
| Base | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 21.4 ± 0.2 21.4 \pm 0.2 21.4±0.2 | 21.4 ± 0.2 21.4 \pm 0.2 21.4±0.2 | 21.5 ± 0.3 21.5 \pm 0.3 21.5±0.3 | 19.5 ± 0.7 19.5 \pm 0.7 19.5±0.7 | 13.5 ± 0.7 13.5 \pm 0.7 13.5±0.7 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 21.4 ± 0.2 21.4 \pm 0.2 21.4±0.2 | 21.4 ± 0.2 21.4 \pm 0.2 21.4±0.2 | 21.4 ± 0.3 21.4 \pm 0.3 21.4±0.3 | 21.4 ± 0.4 21.4 \pm 0.4 21.4±0.4 | 19.3 ± 0.8 19.3 \pm 0.8 19.3±0.8 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 21.2 ± 0.2 21.2 \pm 0.2 21.2±0.2 | 21.4 ± 0.1 21.4 \pm 0.1 21.4±0.1 | 21.5 ± 0.2 21.5 \pm 0.2 21.5±0.2 | 21.8 ± 0.3 21.8 \pm 0.3 21.8±0.3 | 19.7 ± 0.6 19.7 \pm 0.6 19.7±0.6 | |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 21.1 ± 0.1 21.1 \pm 0.1 21.1±0.1 | 21.1 ± 0.1 21.1 \pm 0.1 21.1±0.1 | 21.3 ± 0.1 21.3 \pm 0.1 21.3±0.1 | 21.8 ± 0.3 21.8 \pm 0.3 21.8±0.3 | 21.8 ± 0.3 21.8 \pm 0.3 21.8±0.3 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 21.2 ± 0.2 21.2 \pm 0.2 21.2±0.2 | 21.2 ± 0.2 21.2 \pm 0.2 21.2±0.2 | 21.3 ± 0.2 21.3 \pm 0.2 21.3±0.2 | 21.2 ± 0.3 21.2 \pm 0.3 21.2±0.3 | 17.9 ± 0.8 17.9 \pm 0.8 17.9±0.8 | ||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 21.2 ± 0.1 21.2 \pm 0.1 21.2±0.1 | 21.3 ± 0.1 21.3 \pm 0.1 21.3±0.1 | 21.4 ± 0.2 21.4 \pm 0.2 21.4±0.2 | 21.7 ± 0.3 21.7 \pm 0.3 21.7±0.3 | 20.5 ± 0.4 20.5 \pm 0.4 20.5±0.4 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 21.0 ± 0.1 21.0 \pm 0.1 21.0±0.1 | 21.1 ± 0.1 21.1 \pm 0.1 21.1±0.1 | 21.2 ± 0.1 21.2 \pm 0.1 21.2±0.1 | 21.3 ± 0.1 21.3 \pm 0.1 21.3±0.1 | 21.3 ± 0.4 21.3 \pm 0.4 21.3±0.4 | |
| C | DR | H | KD | 5 m_vs_6m | |||||
| Oracle | 18.5 ± 0.6 18.5 \pm 0.6 18.5±0.6 | 4.8 ± 0.1 4.8 \pm 0.1 4.8±0.1 | 4.0 ± 0.1 4.0 \pm 0.1 4.0±0.1 | 3.7 ± 0.1 3.7 \pm 0.1 3.7±0.1 | 3.4 ± 0.1 3.4 \pm 0.1 3.4±0.1 | ||||
| Base | 8.5 ± 0.2 8.5 \pm 0.2 8.5±0.2 | 8.4 ± 0.2 8.4 \pm 0.2 8.4±0.2 | 8.4 ± 0.3 8.4 \pm 0.3 8.4±0.3 | 8.3 ± 0.3 8.3 \pm 0.3 8.3±0.3 | 8.0 ± 0.2 8.0 \pm 0.2 8.0±0.2 | ||||
| Base | ✓ \checkmark ✓ | 8.4 ± 0.3 8.4 \pm 0.3 8.4±0.3 | 9.1 ± 0.4 9.1 \pm 0.4 9.1±0.4 | 9.2 ± 0.4 9.2 \pm 0.4 9.2±0.4 | 8.9 ± 0.4 8.9 \pm 0.4 8.9±0.4 | 8.4 ± 0.3 8.4 \pm 0.3 8.4±0.3 | |||
| Base | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 18.0 ± 0.7 18.0 \pm 0.7 18.0±0.7 | 15.8 ± 1.1 15.8 \pm 1.1 15.8±1.1 | 12.0 ± 0.8 12.0 \pm 0.8 12.0±0.8 | 9.2 ± 0.4 9.2 \pm 0.4 9.2±0.4 | |||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 18.3 ± 0.7 18.3 \pm 0.7 18.3±0.7 | 18.1 ± 0.8 18.1 \pm 0.8 18.1±0.8 | 17.4 ± 0.8 17.4 \pm 0.8 17.4±0.8 | 16.1 ± 0.9 16.1 \pm 0.9 16.1±0.9 | 13.7 ± 0.9 13.7 \pm 0.9 13.7±0.9 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 18.5 ± 0.4 18.5 \pm 0.4 18.5±0.4 | 18.1 ± 0.7 18.1 \pm 0.7 18.1±0.7 | 17.8 ± 0.7 17.8 \pm 0.7 17.8±0.7 | 14.4 ± 0.8 14.4 \pm 0.8 14.4±0.8 | 9.9 ± 0.5 9.9 \pm 0.5 9.9±0.5 | |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 18.6 ± 0.5 18.6 \pm 0.5 18.6±0.5 | 18.5 ± 0.7 18.5 \pm 0.7 18.5±0.7 | 18.3 ± 0.6 18.3 \pm 0.6 18.3±0.6 | 16.3 ± 0.7 16.3 \pm 0.7 16.3±0.7 | 13.9 ± 1.0 13.9 \pm 1.0 13.9±1.0 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 18.2 ± 0.7 18.2 \pm 0.7 18.2±0.7 | 17.8 ± 0.7 17.8 \pm 0.7 17.8±0.7 | 17.5 ± 0.7 17.5 \pm 0.7 17.5±0.7 | 15.8 ± 1.0 15.8 \pm 1.0 15.8±1.0 | 14.3 ± 0.9 14.3 \pm 0.9 14.3±0.9 | ||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 17.4 ± 0.7 17.4 \pm 0.7 17.4±0.7 | 16.6 ± 0.8 16.6 \pm 0.8 16.6±0.8 | 16.3 ± 1.0 16.3 \pm 1.0 16.3±1.0 | 13.8 ± 0.8 13.8 \pm 0.8 13.8±0.8 | 11.9 ± 0.8 11.9 \pm 0.8 11.9±0.8 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 18.6 ± 0.7 18.6 \pm 0.7 18.6±0.7 | 18.6 ± 0.5 18.6 \pm 0.5 18.6±0.5 | 18.0 ± 0.8 18.0 \pm 0.8 18.0±0.8 | 16.5 ± 0.9 16.5 \pm 0.9 16.5±0.9 | 15.1 ± 0.9 15.1 \pm 0.9 15.1±0.9 | |
| C | DR | H | KD | 6 m_vs_8z | |||||
| Oracle | 10.6 ± 0.2 10.6 \pm 0.2 10.6±0.2 | 11.1 ± 0.3 11.1 \pm 0.3 11.1±0.3 | 9.2 ± 0.2 9.2 \pm 0.2 9.2±0.2 | 8.7 ± 0.2 8.7 \pm 0.2 8.7±0.2 | 8.4 ± 0.2 8.4 \pm 0.2 8.4±0.2 | ||||
| Base | 12.7 ± 0.3 12.7 \pm 0.3 12.7±0.3 | 12.9 ± 0.3 12.9 \pm 0.3 12.9±0.3 | 12.5 ± 0.2 12.5 \pm 0.2 12.5±0.2 | 11.9 ± 0.2 11.9 \pm 0.2 11.9±0.2 | 11.0 ± 0.2 11.0 \pm 0.2 11.0±0.2 | ||||
| Base | ✓ \checkmark ✓ | 14.0 ± 0.3 14.0 \pm 0.3 14.0±0.3 | 14.0 ± 0.3 14.0 \pm 0.3 14.0±0.3 | 13.6 ± 0.3 13.6 \pm 0.3 13.6±0.3 | 13.2 ± 0.2 13.2 \pm 0.2 13.2±0.2 | 12.9 ± 0.3 12.9 \pm 0.3 12.9±0.3 | |||
| Base | ✓ \checkmark ✓ | 12.6 ± 0.3 12.6 \pm 0.3 12.6±0.3 | 12.6 ± 0.4 12.6 \pm 0.4 12.6±0.4 | 11.9 ± 0.3 11.9 \pm 0.3 11.9±0.3 | 11.0 ± 0.2 11.0 \pm 0.2 11.0±0.2 | 10.4 ± 0.2 10.4 \pm 0.2 10.4±0.2 | |||
| Base | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 17.4 ± 0.6 17.4 \pm 0.6 17.4±0.6 | 18.5 ± 0.5 18.5 \pm 0.5 18.5±0.5 | 14.5 ± 0.5 14.5 \pm 0.5 14.5±0.5 | 12.8 ± 0.3 12.8 \pm 0.3 12.8±0.3 | 11.5 ± 0.3 11.5 \pm 0.3 11.5±0.3 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 18.9 ± 0.3 18.9 \pm 0.3 18.9±0.3 | 18.5 ± 0.4 18.5 \pm 0.4 18.5±0.4 | 16.0 ± 0.8 16.0 \pm 0.8 16.0±0.8 | 13.3 ± 0.4 13.3 \pm 0.4 13.3±0.4 | 11.9 ± 0.3 11.9 \pm 0.3 11.9±0.3 | ||
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 19.3 ± 0.3 19.3 \pm 0.3 19.3±0.3 | 18.6 ± 0.5 18.6 \pm 0.5 18.6±0.5 | 16.1 ± 0.5 16.1 \pm 0.5 16.1±0.5 | 13.6 ± 0.5 13.6 \pm 0.5 13.6±0.5 | 12.4 ± 0.4 12.4 \pm 0.4 12.4±0.4 | |
| Flash | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 19.6 ± 0.2 19.6 \pm 0.2 19.6±0.2 | 19.1 ± 0.3 19.1 \pm 0.3 19.1±0.3 | 16.9 ± 0.5 16.9 \pm 0.5 16.9±0.5 | 14.4 ± 0.5 14.4 \pm 0.5 14.4±0.5 | 13.0 ± 0.4 13.0 \pm 0.4 13.0±0.4 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 19.4 ± 0.3 19.4 \pm 0.3 19.4±0.3 | 19.2 ± 0.4 19.2 \pm 0.4 19.2±0.4 | 16.8 ± 0.6 16.8 \pm 0.6 16.8±0.6 | 14.3 ± 0.5 14.3 \pm 0.5 14.3±0.5 | 13.0 ± 0.4 13.0 \pm 0.4 13.0±0.4 | ||
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 19.4 ± 0.3 19.4 \pm 0.3 19.4±0.3 | 18.6 ± 0.5 18.6 \pm 0.5 18.6±0.5 | 15.1 ± 0.6 15.1 \pm 0.6 15.1±0.6 | 13.2 ± 0.4 13.2 \pm 0.4 13.2±0.4 | 12.0 ± 0.3 12.0 \pm 0.3 12.0±0.3 | |
| Echo | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 19.7 ± 0.2 19.7 \pm 0.2 19.7±0.2 | 19.5 ± 0.3 19.5 \pm 0.3 19.5±0.3 | 17.8 ± 0.5 17.8 \pm 0.5 17.8±0.5 | 15.3 ± 0.5 15.3 \pm 0.5 15.3±0.5 | 13.6 ± 0.5 13.6 \pm 0.5 13.6±0.5 |
参考论文:https://arxiv.org/pdf/2505.03586



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











