






胡星
∘
{ }^{\circ}
∘ 陈志轩
∘
{ }^{\circ}
∘ 杨大伟
aa
∘
{ }^{\text {aa }}{ }^{\circ}
aa ∘
许祖康
1
{ }^{1}
1 徐晨
1
{ }^{1}
1 袁志航
1
{ }^{1}
1 周思帆
12
{ }^{12}
12 余江勇
1
{ }^{1}
1
摘要
混合专家(MoE)大语言模型(LLMs),利用动态路由和稀疏激活来提高效率和可扩展性,在降低计算成本的同时实现了更高的性能。然而,这些模型面临显著的内存开销,限制了其实际部署和更广泛的采用。后训练量化(PTQ),一种广泛用于压缩LLMs的方法,在应用于MoE模型时会遇到严重的精度下降和泛化性能减弱问题。本文研究了MoE的稀疏和动态特性对量化的影响,并确定了两个主要挑战:(1)专家间不平衡,指样本在不同专家之间的分布不均,导致较少使用的专家校准不足且有偏差;(2)专家内不平衡,源于MoE独特的聚合机制,导致不同样本与分配给它们的专家之间的相关程度不同。为了解决这些挑战,我们提出了MoEQuant,一种专为MoE LLMs设计的新型量化框架。MoEQuant包括两种新技术:1)专家平衡自采样(EBSS),这是一种高效采样方法,通过利用标记概率和专家平衡度量作为指导因素,构建具有均衡专家分布的校准集。2)亲和力引导量化(AGQ),它将样本与专家之间的亲和力纳入量化过程,从而准确评估单个样本对MoE层中不同专家的影响。实验
表明,MoEQuant实现了显著的性能提升(在4位量化下DeepSeekMoE-16B的人类评估中提升了超过10点的准确率)并提高了效率。
1. 引言
自然语言处理的最新进展深受大语言模型(LLMs)成功的影响。其中,混合专家(MoE)LLMs通过利用MoE层的动态路由机制和可扩展能力,表现出卓越的性能并取得了最先进的成果,引起了研究界的广泛关注(Jiang等人,2024;Qwen,2024;Liu等人,2024b)。然而,在部署过程中,MoE LLMs不仅面临与传统LLMs相同的内存带宽限制(Kim等人,2023;Dettmers等人,2022),还面临显著更高的存储需求。例如,在Qwen-MoE-A2.7B-14B(Qwen,2024)中,生成阶段仅激活2.7亿参数,但所有14亿参数必须驻留在内存中,显著增加了推理成本。此外,MoE层占变压器块中参数足迹的主要部分:考虑激活专家时约为80%,包含所有专家时高达97%。因此,压缩MoE LLMs,特别是其MoE层,对于减少推理成本和在资源受限设备上部署至关重要,这些设备具有有限的内存容量和带宽。
后训练量化(PTQ),通过将权重量化为低精度格式,有效减少了模型大小和内存占用,在传统的大型语言模型(LLMs)中取得了显著成功。例如,AWQ(Lin等人,2023)和GPTQ(Frantar等人,2022)无需额外训练即可将模型权重压缩多达四倍,同时几乎无损性能。然而,当这些方法直接应用于MoE LLMs时,通常会导致过拟合和显著的性能退化,特别是在泛化方面。这是因为它们专注于逐层量化,而忽略了MoE架构的独特性。
1 { }^{1} 1 同等贡献 1 { }^{1} 1 Houmo AI 2 { }^{2} 2 东南大学。联系地址:Dawei Yang dawei.yang@houmo.ai.
第$41^{\text {st }}$届国际机器学习会议论文集,加拿大温哥华。PMLR 267,2025。版权所有2025由作者保留。

图1:应用MoEQuant前后,GPTQ在各种模型上的相对精度增益展示于两个生成任务HumanEval和GSM8k中。后缀"I"表示指令微调版本。
MoE,它将样本路由到有限数量的专家并通过加权组合聚合其输出。此外,它们未能考虑到MoE结构引入的固有稀疏性和异质性。
我们对影响MoE LLMs量化性能的关键因素进行了全面分析,并确定了MoE架构中的两个固有不平衡为主要贡献者。首先,不同专家之间的样本分布存在不平衡。正如DeepSeek(Liu等人,2024b)所强调的那样,已经开发了各种技术以保持专家之间的负载平衡,这在校准阶段同样关键。然而,校准集通常是领域特定的,门控机制可能导致某些专家过载,而其他专家则未充分利用。未充分利用的专家自然会收到不足的校准,导致显著的量化误差。如图2所示,两个最常用的校准集都表现出这种不平衡。其次,样本与其分配专家之间的亲和力存在不平衡。与传统LLMs中所有样本均由单一前馈网络处理不同,MoE架构使用门控机制将输出表示为多个专家结果的加权和。因此,从每个专家的角度来看,样本表现出不同程度的亲和力,定义为样本与其分配专家之间的相关性。现有的PTQ方法(Xiao等人,2022;Lin等人,2023;Ashkboos等人,2024)在专家量化过程中未能考虑到这种亲和力。例如,GPTQ(Frantar等人,2022)在收集Hessian信息时忽略了门控单元的影响,导致对每个样本对专家的重要性评估不准确。这种疏忽扭曲了Hessian信息,显著降低了量化模型的性能。
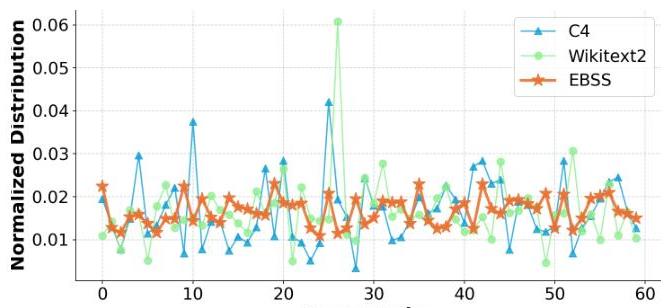
图2:Qwen-MoE-A2.7B-14B在不同校准集上的第一个MoE层的样本分布。对于C4和WikiText2,采样了 128 × 512 128 \times 512 128×512个标记,对于我们的EBSS,样本是通过模型的自采样方法生成的。
为了解决上述两种不平衡,本文介绍了两种方法:专家平衡自采样(EBSS)和亲和力引导量化(AGQ)。EBSS基于LLMs的自采样能力构建校准集,并结合累积概率和专家平衡度量来指导采样过程。这种引导显著降低了搜索复杂度。此外,它确保校准样本在专家之间均匀分布并与预训练数据分布一致。AGQ通过将亲和力集成到逐层校准中并构建加权量化误差,解决了专家量化过程中令牌-专家亲和力的不平衡问题。这种方法适应MoE的动态特性,能够更准确地计算量化误差和敏感度。通过整合这两种方法,我们提出了MoEQuant,一个将现有量化技术与MoE架构相结合的框架,朝着协调量化系统的效率与MoE LLMs独特要求的方向迈出了重要一步。如图1所示,MoEQuant在不同模型上实现了不同程度的性能改进,突显了其有效性和广泛适用性,以增强MoE语言模型。我们的贡献总结如下:
- 我们识别出MoE模型量化中的两个关键不平衡:专家间和专家内的不平衡——即专家间的样本分布不平衡和令牌-专家亲和力不平衡。
-
- 我们提出专家平衡自采样,以高效生成均衡的校准数据集,确保所有专家的公平利用。我们还提出亲和力引导量化,将令牌-专家亲和力引入量化过程,从而提高权重更新的准确性并减少量化误差。
-
- 我们开发了MoEQuant,将EBSS和AGQ与现有PTQ方法无缝集成,显著增强了MoE LLMs的量化性能。作为该领域首批研究之一,我们将
- 发布代码以鼓励进一步探索并推动该领域的发展。
2. 相关工作
2.1. 混合专家大语言模型
混合专家(MoE)模型最初由(Jacobs等人,1991)和(Jordan & Jacobs,1994)引入,并在各种背景下得到了广泛研究(Eigen等人,2013;Theis & Bethge,2015;Deisenroth & Ng,2015;Aljundi等人,2017)。在MoE LLMs中,每个MoE层包含多个专家网络和一个门控网络。门控网络通常实现为带有softmax函数的线性层,将输入导向适当的专家网络并聚合其输出。不同的模型采用各种配置。例如,SwitchTransformer(Fedus等人,2022)引入了top-1门控策略,在特定模型规模下实现了竞争性结果。Mixtral-8x7B(Jiang等人,2024)将MoE与基础设施创新相结合,每层使用两个专家,以较低的计算成本实现卓越性能。DeepSeekMoE(Dai等人,2024)通过细分FFN的中间隐藏维度细化专家分割,增加专家数量并激活更多专家以改善知识分解和捕捉。它还引入共享专家,这些专家始终被激活以巩固跨上下文的共同知识,减少路由特定专家的参数冗余。DeepSeekv2(Liu等人,2024a)和DeepSeekv3(Lu,2025)通过优化设计进一步提升性能。Qwen-Moe(Qwen,2024)完全用MoE层取代传统FFN层,使用四个共享专家和从60个池中选择的四个非共享专家。在训练过程中,Qwen-MoE首先调整现有的Qwen-1.8B模型以创建Qwen1.5-MoE-A2.7B-16B,从而实现更好的整体预训练性能。
2.2. 大语言模型的后训练量化
大多数LLMs建立在Transformer(Vaswani等人,2017)架构之上,本质上是内存密集型的。后训练量化(PTQ)已成为一种广泛采用的压缩LLMs方法,有效地减少了内存消耗同时保持模型精度。两种突出的PTQ方法,GPTQ(Frantar等人,2022)和AWQ(Lin等人,2023),已被深入研究。GPTQ采用基于Hessian的误差补偿以最小化量化误差并实现高压缩率。另一方面,AWQ考虑激活分布对权重量化的影响,从而提升量化性能。除此之外,还出现了几种先进技术以进一步增强PTQ。Quarot(Ashkboos等人,2024)应用
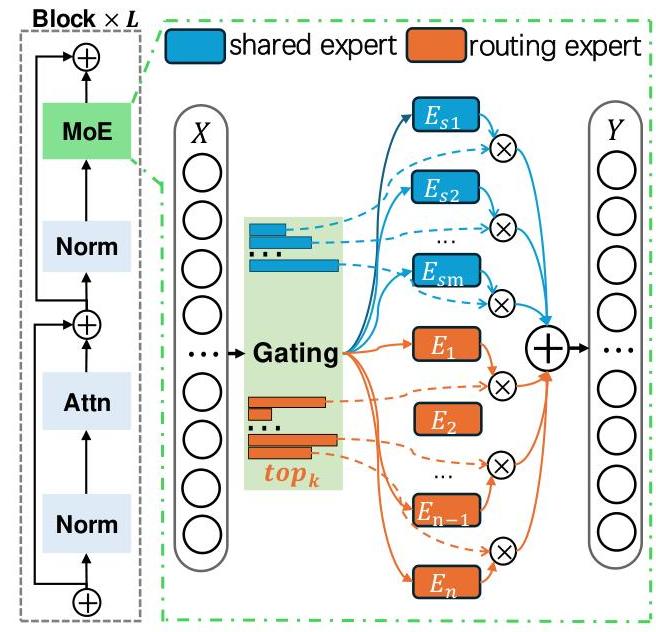
图3:LLMs中的MoE结构。路由器选择所有非共享专家和 k k k个置信度最高的共享专家。然后将所有专家的预测进行聚合和加权。
Hadamard变换以去除异常值而不改变输出,从而增强GPTQ的效果。GPTVQ(van Baalen等人,2024)从向量角度探索非均匀量化方案,提供更好的权重分布适应性。
然而,这些方法忽视了MoE架构带来的独特挑战,导致显著的精度下降。我们提出的MoEQuant基于校准样本与专家之间的关系,与现有PTQ方法正交,能够无缝集成以有效量化基于MoE的LLMs。
3. 预备知识
如图3所示,一个MoE层由 m m m个共享专家和 n n n个路由专家组成,以及一个将不同专家及其相应概率分配给每个标记的门控网络。只使用具有最高亲和力的前 k k k个共享专家。对于给定的输入标记 x \boldsymbol{x} x,输出 y \boldsymbol{y} y被计算为来自前 k k k个路由专家和所有共享专家的输出的加权和:
y = ∑ i = 1 m E i s ( x ) g i ( x ) ⏟ 共享专家 + ∑ j ∈ K E j c ( x ) g j ( x ) ⏟ 前 k 路由专家 y=\underbrace{\sum_{i=1}^{m} E_{i}^{s}(\boldsymbol{x}) g_{i}(\boldsymbol{x})}_{\text {共享专家 }}+\underbrace{\sum_{j \in \mathcal{K}} E_{j}^{c}(\boldsymbol{x}) g_{j}(\boldsymbol{x})}_{\text {前 } k \text { 路由专家 }} y=共享专家 i=1∑mEis(x)gi(x)+前 k 路由专家 j∈K∑Ejc(x)gj(x)
其中
K
=
top
k
(
{
g
i
(
x
)
∣
i
∈
{
1
,
…
,
m
}
}
)
,
g
i
(
x
)
\mathcal{K}=\operatorname{top} k\left(\left\{g_{i}(\boldsymbol{x}) \mid i \in\{1, \ldots, m\}\right\}\right), g_{i}(\boldsymbol{x})
K=topk({gi(x)∣i∈{1,…,m}}),gi(x) 表示分配给第
i
i
i个专家的权重。
困惑度(PPL)是衡量语言模型质量的常见指标。较低的PPL表示更好的预测准确性和更接近模型真实分布的对齐。对于由
n
n
n个标记组成的序列
D
=
(
d
1
,
d
2
,
…
d
n
)
\mathcal{D}=\left(d_{1}, d_{2}, \ldots d_{n}\right)
D=(d1,d2,…dn),相对于模型
M
\mathcal{M}
M的困惑度定义为:
PPL ( D ∣ M ) = exp ( − 1 N ∑ i = 1 N log P M ( d i ∣ d 1 , d 2 , … , d i − 1 ) ) \operatorname{PPL}(\mathcal{D} \mid \mathcal{M})=\exp \left(-\frac{1}{N} \sum_{i=1}^{N} \log P_{\mathcal{M}}\left(d_{i} \mid d_{1}, d_{2}, \ldots, d_{i-1}\right)\right) PPL(D∣M)=exp(−N1i=1∑NlogPM(di∣d1,d2,…,di−1))
其中 P ( d i ∣ d 1 , d 2 , … , d i − 1 ) P\left(d_{i} \mid d_{1}, d_{2}, \ldots, d_{i-1}\right) P(di∣d1,d2,…,di−1) 表示模型在给定上下文 d 1 , d 2 , … , d i − 1 d_{1}, d_{2}, \ldots, d_{i-1} d1,d2,…,di−1的情况下对 d i d_{i} di的预测概率。
专家平衡通过所有层中专家使用频率的标准差来评估。我们将其定义为:
σ = ∑ l = 1 L σ l L σ l = 1 E − 1 ∑ e = 1 E ( u l e − u ^ l ) 2 \begin{aligned} \sigma & =\frac{\sum_{l=1}^{L} \sigma_{l}}{L} \\ \sigma_{l} & =\sqrt{\frac{1}{E-1} \sum_{e=1}^{E}\left(u_{l}^{e}-\hat{u}_{l}\right)^{2}} \end{aligned} σσl=L∑l=1Lσl=E−11e=1∑E(ule−u^l)2
其中 L L L表示MoE模型中的层数, E E E表示一层中的专家总数, σ l \sigma_{l} σl指的是第 l l l层的标准差,它是根据每个专家的使用频率 u l e u_{l}^{e} ule和平均频率 u ^ l \hat{u}_{l} u^l计算得出的。
量化通常涉及将浮点数映射到离散区间,使用整数值。对于权重量化,我们关注最常用的按通道对称均匀量化。量化过程表示如下:
Q ( W ) = clamp ( ∥ W s ∥ , q min , q max ) \mathcal{Q}(\boldsymbol{W})=\operatorname{clamp}\left(\left\|\frac{\boldsymbol{W}}{\boldsymbol{s}}\right\|, q_{\min }, q_{\max }\right) Q(W)=clamp( sW ,qmin,qmax)
其中 W ∈ R o × c \boldsymbol{W} \in \mathbb{R}^{o \times c} W∈Ro×c代表权重矩阵, s ∈ R o \boldsymbol{s} \in \mathbb{R}^{o} s∈Ro表示按通道量化的步长, q min , q max q_{\min }, q_{\max } qmin,qmax表示量化范围。为了便于量化误差的评估,我们通常执行去量化操作:
W ^ = Q ( W ) ⋅ s \hat{\boldsymbol{W}}=\mathcal{Q}(\boldsymbol{W}) \cdot \boldsymbol{s} W^=Q(W)⋅s
对于一个线性层,量化 W \boldsymbol{W} W造成的损失可以公式化为
L ( W ^ ) = ∥ W X − W ^ X ∥ F 2 \mathcal{L}(\hat{\boldsymbol{W}})=\left\|\boldsymbol{W} \boldsymbol{X}-\hat{\boldsymbol{W}} \boldsymbol{X}\right\|_{F}^{2} L(W^)= WX−W^X F2
其中 X ∈ R b × c \boldsymbol{X} \in \mathbb{R}^{b \times c} X∈Rb×c表示该层校准数据的激活。AWQ(Lin等人,2023)利用方程7指导平滑系数的选择和权重修剪。GPTQ(Frantar等人,2022)遵循OBQ(LeCun等人,1989),使用Hessian补偿量化误差。结合方程7,Hessian可以有效地计算为:
H = X X ⊤ \boldsymbol{H}=\boldsymbol{X} \boldsymbol{X}^{\top} H=XX⊤
4. 方法
4.1. MoEQuant
在本文中,我们提出了MoEQuant,这是一个专为高效量化利用MoE架构的LLMs设计的框架。MoEQuant解决了量化过程中出现的关键挑战,即专家间的不平衡和专家内部的不平衡。MoEQuant从两个角度解决这种不平衡:生成专家均衡的校准数据集和专家校准时的令牌-专家相关性。相应地,它包含了两种解决方案:专家平衡自采样(EBSS)和亲和力引导量化(AGQ)。EBSS生成校准样本,确保MoE架构中所有专家的均衡参与。另一方面,AGQ解决了MoE层中门控单元引入的样本相关性差异。
这两种方法都是即插即用的,可以与其他量化技术无缝集成,以提高MoE LLMs的性能。详细描述见第4.2节和第4.3节。
4.2. 专家平衡自采样
当前的PTQ方法通常依赖于领域特定的校准数据集,例如WikiText-2。虽然这些校准数据集可以为标准LLMs保留合理的泛化能力,但它们直接应用于MoE LLMs时往往会导致显著的性能下降。这种下降发生是因为领域特定的校准数据集导致专家之间样本分布不均。如图2所示,依赖单一校准集通常会在不同专家之间产生长尾样本分布。
一种直观的方法是通过从多个领域采样数据来构建领域均衡的校准集。然而,可能领域的数量几乎是无限的,使得实现真正的领域均衡既复杂又不切实际。此外,如图4所示,即使高质量的数据集也常常表现出高困惑度,表明选定的数据与模型的内在分布不匹配。
问题定义 根据以上内容,目标是找到满足以下两个关键属性的数据集 D ∗ \mathcal{D}^{*} D∗:
- 低困惑度。 D ∗ \mathcal{D}^{*} D∗中的样本应与模型 M \mathcal{M} M的内在分布紧密对齐,这对应于最小化困惑度。
-
- 专家平衡。样本应在MoE LLMs的专家之间均匀分布,确保没有专家被过度使用或使用不足。
这一双重要求可以表述为联合优化问题,具体表述为:
- 专家平衡。样本应在MoE LLMs的专家之间均匀分布,确保没有专家被过度使用或使用不足。
D ∗ = arg min D { PPL ( M , D ) ⋅ exp ( σ ( M , D ) τ ) } \mathcal{D}^{*}=\underset{\mathcal{D}}{\arg \min }\left\{\operatorname{PPL}(\mathcal{M}, \mathcal{D}) \cdot \exp \left(\frac{\sigma(\mathcal{M}, \mathcal{D})}{\tau}\right)\right\} D∗=Dargmin{PPL(M,D)⋅exp(τσ(M,D))}
其中 exp ( σ ( M , D ) τ ) \exp \left(\frac{\sigma(\mathcal{M}, \mathcal{D})}{\tau}\right) exp(τσ(M,D))表示归一化不平衡的倒数, exp \exp exp用于归一化 σ \sigma σ, τ \tau τ是一个控制专家不平衡影响的超参数。
困惑度优化对应于最优子集选择问题,而专家平衡类似于负载平衡问题。两者都是NP难的,使得直接求解在计算上不可行。为了实现实用分析,问题可以通过结合方程2重新表述为
D ∗ = arg min D { − 1 N ∑ i = 1 n ( log ( P ( D i ∣ D 1 : i − 1 ) ) ) + σ ( M , D ) τ } subject to D ∈ = V ⊗ V n ⊗ ⋯ ⏟ n times \begin{aligned} & \mathcal{D}^{*}=\underset{\mathcal{D}}{\arg \min }\left\{\frac{-1}{N} \sum_{i=1}^{n}\left(\log \left(P\left(\mathcal{D}_{i} \mid \mathcal{D}_{1: i-1}\right)\right)\right)+\frac{\sigma(\mathcal{M}, \mathcal{D})}{\tau}\right\} \\ & \text { subject to } \mathcal{D} \in=\underbrace{\mathcal{V} \otimes \mathcal{V}_{n} \otimes \cdots}_{n \text { times }} \end{aligned} D∗=Dargmin{N−1i=1∑n(log(P(Di∣D1:i−1)))+τσ(M,D)} subject to D∈=n times V⊗Vn⊗⋯
其中 V = { v 1 , v 2 , … , v m } \mathcal{V}=\left\{v_{1}, v_{2}, \ldots, v_{m}\right\} V={v1,v2,…,vm}表示包含 m m m个标记的词汇表, P P P表示由 M \mathcal{M} M预测的概率。 n n n是序列长度, ⊗ \otimes ⊗表示笛卡尔积。在这种情况下,优化可以视为在 n n n维词汇空间中寻找最佳路径。
挑战。一个挑战在于可用数据集的数量有限。由于通常只能访问少量数据用于校准,很难确保理想的领域平衡或与预训练分布的对齐,这可能会影响最终的量化性能。另一个挑战是搜索潜在校准集的巨大空间的计算成本。蛮力搜索需要探索 m n m^{n} mn种可能性,这是不可行的。贪婪搜索策略虽然更高效,但可能会陷入局部最优,凸显了对更复杂但高效的搜索方法的需求。
自采样。为了解决数据可用性的挑战,我们利用LLMs的自采样能力构建校准数据。这种数据无关的方法仅依赖于模型的词汇表,并且自然与模型学习的语言分布一致(Liu等人,2023)。此外,在自采样过程中,历史概率和专家分布会被缓存,消除了困惑度和专家平衡度量的冗余计算。我们将序列 S S S的历史累积对数概率定义为:
R S = ∑ i = 1 n log ( P ( S i ∣ S 1 : i − 1 ) R_{S}=\sum_{i=1}^{n} \log \left(P\left(S_{i} \mid S_{1: i-1}\right)\right. RS=i=1∑nlog(P(Si∣S1:i−1)
其中 n n n是 S S S的长度。在采样阶段,通过 R S R_{S} RS和预测概率 P ( v ∣ S ) P(v \mid S) P(v∣S)可以轻松计算困惑度:
PPL ( M , S ∥ v ) = exp ( − 1 n + 1 ( R s + P ( v ∣ S ) ) ) \operatorname{PPL}(\mathcal{M}, S \| v)=\exp \left(\frac{-1}{n+1}\left(R_{\boldsymbol{s}}+P(v \mid S)\right)\right) PPL(M,S∥v)=exp(n+1−1(Rs+P(v∣S)))
其中
∥
\|
∥表示连接。
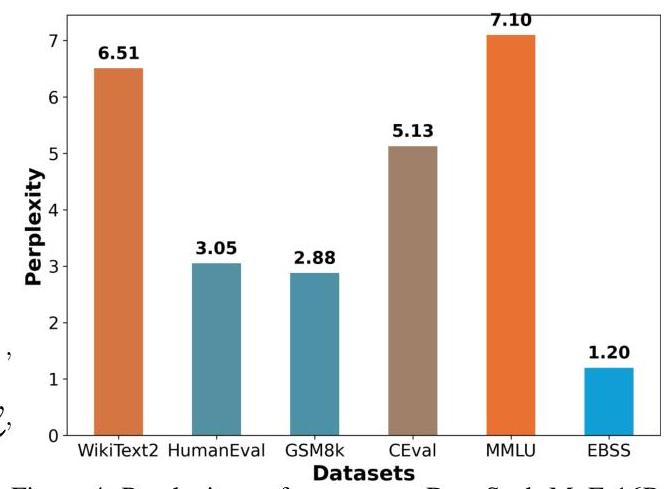
图4:不同数据集在DeepSeek-MoE-16B上的困惑度表现。
概率引导路径剪枝。在自采样方法中预测下一个标记时,头部层输出所有可能候选者的概率,这些概率通常呈现多峰分布。低概率的标记往往导致连贯性差或语义错误的序列。基于此观察,我们提出了一种概率引导的路径剪枝方法,以有效提高搜索效率。核心思想是在搜索过程中忽略低概率分支。
具体而言,在校准数据集搜索期间,我们仅保留 w w w个分支 S = { S 1 , S 2 , … , S w } \mathcal{S}=\left\{S^{1}, S^{2}, \ldots, S^{w}\right\} S={S1,S2,…,Sw},每个分支长度为 l l l。当生成长度为 l + 1 l+1 l+1的候选序列时,每个分支 S i S^{i} Si扩展到空间 S i ⊗ V S^{i} \otimes V Si⊗V中的潜在序列。这些序列的剪枝评估指标定义为:
score ( S ∥ v ) = − 1 l + 1 ( R S + log P ( v ∣ S ) ) + σ ( M , S ) τ subject to v ∈ V \begin{aligned} \operatorname{score}(S \| v)=\frac{-1}{l+1}\left(R_{S}+\log P(v \mid S)\right)+\frac{\sigma(\mathcal{M}, S)}{\tau} \\ \text { subject to } v \in V \end{aligned} score(S∥v)=l+1−1(RS+logP(v∣S))+τσ(M,S) subject to v∈V
其中 S S S是 S \mathcal{S} S中的一个, R S R_{S} RS对应于方程11中定义的累积概率。生成一组新的 w w w个候选序列 S ^ = \hat{S}= S^= { S ^ 1 , S ^ s 1 , … , S ^ w , } \left\{\hat{S}^{1}, \hat{S}_{s}^{1}, \ldots, \hat{S}^{w},\right\} {S^1,S^s1,…,S^w,}的过程表示为:
S ^ = arg topk S ∥ v ( w , score ( S ∥ v ) ) subject to v ∈ V and S ∈ { S i , S 2 , … , S w } \begin{gathered} \hat{\mathcal{S}}=\underset{S \| v}{\arg \operatorname{topk}}(w, \operatorname{score}(S \| v)) \\ \text { subject to } v \in V \text { and } S \in\left\{S^{i}, S^{2}, \ldots, S^{w}\right\} \end{gathered} S^=S∥vargtopk(w,score(S∥v)) subject to v∈V and S∈{Si,S2,…,Sw}
其中
arg
topk
x
(
f
(
w
,
x
)
\arg \operatorname{topk}_{x}(f(w, x)
argtopkx(f(w,x)表示最大化
f
(
x
)
f(x)
f(x)的
x
x
x的
w
w
w个值。
如方程14和图5所示,来自相同输入序列
S
S
S的候选序列得分受到LLM产生的概率分布的影响。此外,专家平衡度量影响从
S
S
S衍生的所有候选序列。通过引入有效的校准集搜索方法,搜索复杂度从
O
(
m
n
)
O\left(m^{n}\right)
O(mn)显著降低到
O
(
w
n
)
O(\mathrm{wn})
O(wn),并且有效缓解了局部最优的风险。
延迟专家不平衡计算。需要注意的是,在剪枝过程中,如方程14所示,评估指标并未将候选标记 v v v纳入专家平衡评估。这种做法有几个原因:
- 不像可以直接从LLM输出的概率分布计算的困惑度,计算词汇表中每个标记的专家分布需要遍历所有可能的标记,这是一个计算昂贵的过程。由于当前序列的分布已知,延迟计算只会带来极小的额外成本。
-
- 剪枝过程主要依赖于LLM预测的概率,而不是专家平衡。在剪枝下一个标记时包含专家分布是不合适的,因为它可能导致语义错位或不连贯。
-
- 如方程14所示,延迟计算实际上执行的是分支级别的剪枝,从而在保持困惑度的前提下确保创建专家均衡的校准集。
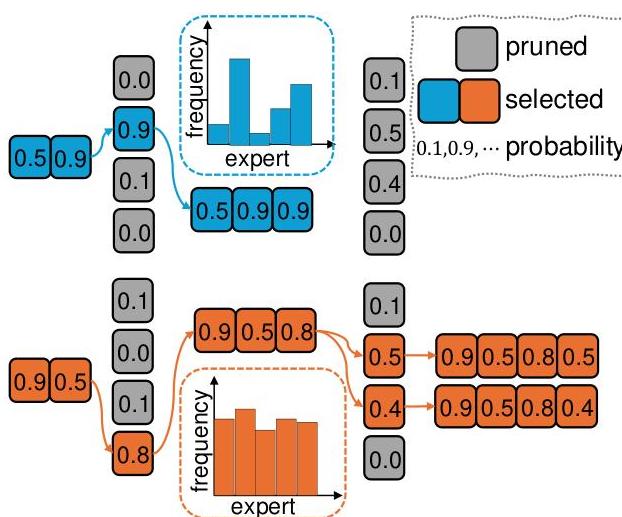
图5:EBSS的说明图。专家分布和累积概率共同指导路径搜索。
4.3. 亲和力引导量化
在MoE层中,门控网络根据输入为每个专家分配一个概率分数。选择最相关的专家并根据其分配的概率对其输出进行加权。传统的逐层量化使用方程1统一最小化量化误差,但忽略了样本与专家之间的概率。我们将这种校正定义为亲和力,主张它同样重要,并应在量化过程中予以考虑。
设 E E E为一个特定的专家,记路由到该专家的 b b b个标记集合为 X = { x 1 , x 2 , … , x b } \boldsymbol{X}=\left\{\boldsymbol{x}_{\mathbf{1}}, \boldsymbol{x}_{\mathbf{2}}, \ldots, \boldsymbol{x}_{\boldsymbol{b}}\right\} X={x1,x2,…,xb},相应的亲和力分数为 c = { c 1 , c 2 , … , c b } \boldsymbol{c}=\left\{c_{1}, c_{2}, \ldots, c_{b}\right\} c={c1,c2,…,cb},由门控网络提供。由该专家处理的第 i i i个标记的输出可以表示为
y i = c i E ( x i ) \boldsymbol{y}_{i}=c_{i} E\left(\boldsymbol{x}_{i}\right) yi=ciE(xi)
E E E是一个前馈神经网络(FFN),可以扩展为一系列线性层和激活函数如ReLU。这里,我们考虑一个代表性的FFN结构,得到:
y i = c i { ( ( x W u p ) ⊙ f ( x W g a t e ) ) W d o w n } \boldsymbol{y}_{\boldsymbol{i}}=c_{i}\left\{\left(\left(\boldsymbol{x} \boldsymbol{W}^{u p}\right) \odot f\left(\boldsymbol{x} \boldsymbol{W}^{g a t e}\right)\right) \boldsymbol{W}^{d o w n}\right\} yi=ci{((xWup)⊙f(xWgate))Wdown}
其中 f f f表示激活函数, W \boldsymbol{W} W表示参数矩阵。由于FFN主要是线性的性质和 f f f的准线性特性,上述表达式可以重新表述为:
y i = ( ( c i x W u p ) ⊙ f ( x W g a t e ) ) W d o w n y i = ( ( x W u p ) ⊙ f ( x W g a t e ) ) ( c i W d o w n ) y i ≈ ( ( x W u p ) ⊙ f ( c i x W g a t e ) ) W d o w n \begin{aligned} & \boldsymbol{y}_{\boldsymbol{i}}=\left(\left(c_{i} \boldsymbol{x} \boldsymbol{W}^{u p}\right) \odot f\left(\boldsymbol{x} \boldsymbol{W}^{g a t e}\right)\right) \boldsymbol{W}^{d o w n} \\ & \boldsymbol{y}_{\boldsymbol{i}}=\left(\left(\boldsymbol{x} \boldsymbol{W}^{u p}\right) \odot f\left(\boldsymbol{x} \boldsymbol{W}^{g a t e}\right)\right)\left(c_{i} \boldsymbol{W}^{d o w n}\right) \\ & \boldsymbol{y}_{\boldsymbol{i}} \approx\left(\left(\boldsymbol{x} \boldsymbol{W}^{u p}\right) \odot f\left(c_{i} \boldsymbol{x} \boldsymbol{W}^{g a t e}\right)\right) \boldsymbol{W}^{d o w n} \end{aligned} yi=((cixWup)⊙f(xWgate))Wdownyi=((xWup)⊙f(xWgate))(ciWdown)yi≈((xWup)⊙f(cixWgate))Wdown
这表明令牌-专家亲和力
c
i
c_{i}
ci传播到专家网络的每一层。当专注于特定的线性层时,
c
i
c_{i}
ci可以直接集成到该层的操作中。换句话说,不同的令牌对同一专家的权重施加门控感知的影响,
c
i
c_{i}
ci作为一个缩放因子,调节每个令牌输入特征对线性层的贡献。
亲和力感知量化误差。传统的LLMs量化方法尚未考虑亲和力感知特性。在这里,我们首次通过重新定义
W
\boldsymbol{W}
W的量化损失,将门控系数纳入逐层校准中:
L ( W ~ ) = ∑ i = 0 n c i ⋅ ∥ W x i − W ~ x i ∥ F 2 \mathcal{L}(\tilde{\boldsymbol{W}})=\sum_{i=0}^{n} c_{i} \cdot\left\|\boldsymbol{W} \boldsymbol{x}_{i}-\tilde{\boldsymbol{W}} \boldsymbol{x}_{i}\right\|_{F}^{2} L(W~)=i=0∑nci⋅ Wxi−W~xi F2
对于基于量化误差的PTQ方法,如AWQ,方程18将令牌-专家亲和力纳入量化过程。与原始实现相比,后者在校准期间平等对待所有令牌,我们的亲和力感知度量强调高亲和力的令牌,从而减少对影响大的令牌的整体量化误差。
表1:RTN、AWQ、GPTQ和我们的MoEQuant在Qwen-MoE14B、DeepSeek-MoE-16B和Mixtral-8x7B上的4位权重量化结果,其中+表示基于AWQ的MoEQuant,++表示基于GPTQ的MoEQuant。值得注意的是,除了我们提出的MoEQuant外,其他方法使用Wikitext2作为校准数据集,这导致了在Wikitext2上的过拟合。在C4数据集上测量的困惑度更准确地反映了不同方法的性能。
| MODEL | METHOD | PPL | ACCURACY | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WIKI TEXT2 | C4 | MMLU | HUMAN EVAL | GSM8k | BOOLQ | HELLA SWAG | OPEN BOOKQA | MATH QA | AVG. | |||
| QWEN- MoE-14B | FP | 7.22 | 9.30 | 59.60 | 32.32 | 62.55 | 79.82 | 57.96 | 30.40 | 35.77 | 51.20 | |
| RTN | 10.83 | 12.49 | 48.10 | 14.63 | 16.07 | 72.11 | 51.42 | 25.80 | 30.08 | 36.89 | ||
| AWQ | 8.59 | 10.93 | 51.63 | 20.73 | 36.77 | 71.96 | 54.78 | 30.40 | 31.39 | 42.52 | ||
| MOEQuant + { }^{+} + | 8.77 | 10.67 | 52.33 | 22.10 | 42.22 | 74.52 | 54.92 | 30.40 | 33.44 | 44.27 | ||
| GPTQ | 7.43 | 10.11 | 57.90 | 28.05 | 56.25 | 78.77 | 56.54 | 29.00 | 36.48 | 49.00 | ||
| MOEQuant + + { }^{++} ++ | 7.55 | 9.62 | 58.30 | 29.87 | 58.38 | 78.04 | 56.87 | 30.20 | 35.50 | 49.59 | ||
| DEEPSEEK- MoE-16B | FP | 6.51 | 9.04 | 44.60 | 26.83 | 20.16 | 72.72 | 58.06 | 32.20 | 31.49 | 40.86 | |
| RTN | 7.47 | 10.01 | 36.10 | 18.90 | 10.54 | 70.21 | 55.76 | 30.60 | 28.87 | 35.85 | ||
| AWQ | 6.80 | 9.50 | 40.57 | 25.00 | 17.06 | 71.65 | 56.42 | 32.20 | 31.76 | 39.23 | ||
| MOEQuant + { }^{+} + | 6.94 | 9.32 | 41.20 | 25.00 | 18.90 | 71.98 | 56.79 | 32.12 | 31.82 | 39.68 | ||
| GPTQ | 6.66 | 9.39 | 40.60 | 22.56 | 19.18 | 72.17 | 57.03 | 30.60 | 30.95 | 39.01 | ||
| MOEQuant + + { }^{++} ++ | 6.78 | 9.22 | 42.20 | 25.00 | 19.18 | 73.49 | 57.20 | 31.40 | 31.66 | 40.01 | ||
| FP | 3.84 | 6.87 | 70.50 | 32.93 | 65.88 | 85.23 | 64.88 | 35.80 | 42.41 | 56.80 | ||
| RTN | 5.41 | 8.13 | 62.20 | 28.05 | 27.90 | 80.85 | 61.73 | 32.20 | 37.35 | 47.18 | ||
| MIXTRAL- | AWQ | 5.01 | 7.98 | 62.75 | 25.00 | 38.67 | 79.97 | 62.11 | 33.60 | 38.43 | 48.64 | |
| 8x7B | MOEQuant + { }^{+} + | 5.15 | 7.84 | 64.66 | 25.45 | 50.66 | 81.03 | 62.73 | 34.00 | 39.77 | 51.19 | 68.50 |
| GPTQ | 4.03 | 7.67 | MOEQuant + + { }^{++} ++ | 4.12 | 7.34 | 69.60 | 32.15 | 61.79 | 84.98 | 64.05 | 33.60 |
门控感知Hessian统计。与方程7假设所有标记对Hessian的贡献相等不同,亲和力感知量化损失(方程18)导致更合理的Hessian计算:
H = ( X ⋅ c ) ( X ⋅ c ) ⊤ = ( X ⋅ c ) X ⊤ \boldsymbol{H}=(\boldsymbol{X} \cdot \sqrt{\boldsymbol{c}})(\boldsymbol{X} \cdot \sqrt{\boldsymbol{c}})^{\top}=(\boldsymbol{X} \cdot \boldsymbol{c}) \boldsymbol{X}^{\top} H=(X⋅c)(X⋅c)⊤=(X⋅c)X⊤
对于基于Hessian的PTQ方法(例如GPTQ),改进的Hessian纳入了标记特定的加权以更好地捕捉MoE层的操作动态。结果是,具有更高门控系数的标记在计算敏感度指标时施加更大的影响,这些指标指导权重更新并帮助最小化量化误差。
5. 实验
5.1. 设置
我们使用对称均匀量化进行LLMs的权重量化,粒度为每通道。所有实验均在NVIDIA A6000 GPU上进行。由于MoEQuant是一个高效的后训练量化(PTQ)框架,因此无需任何微调。
模型和数据集。我们在DeepSeek-MoE-16B (Dai等人, 2024)、Qwen-MoE14B (Qwen, 2024) 和Mixtral-8x7B (Jiang等人, 2024) 上进行实验。此外,我们还比较指令微调模型以展示我们方法的有效性。除了在Wikitext2 (Merity, 2016) 和C4 (Raffel等人, 2020) 上的标准困惑度评估外,我们还在各种推理任务上评估提出的MoEQuant,包括MMLU (Hendrycks等人, 2020)、BoolQ (Clark等人, 2019)、HellaSwag (Zellers等人, 2019)、Openbookqa (Mihaylov等人, 2018) 和MathQA (Amini等人, 2019)。此外,我们使用HumanEval (Chen等人, 2021) 和GSM8k (Cobbe等人, 2021) 评估MoEQuant。HumanEval评估代码生成能力,而GSM8k评估多步数学推理技能。
基线。我们的主要基线包括纯RTN和LLMs的PTQ方法:AWQ (Lin等人, 2023) 和GPTQ (Frantar等人, 2022)。对于校准,选择Wikitext2数据集中的128段。提供浮点结果作为参考。
实现细节。对于三个复杂的推理任务,即MMLU、GSM8k和HumanEval,我们根据其官方存储库进行评估。对于几个其他零样本任务,我们使用开源工具lm-evaluation-harness (版本0.4.4) (Gao等人, 2024) 进行评估。在涉及AWQ的实验中,我们调整其官方存储库以支持三种MoE模型。对于GPTQ,我们首先通过等效的Hadamard变换消除权重中的异常值,这与QuaRot (Ashkboos等人, 2024) 中的实现一致,同时避免任何在线变换。
5.2. 结果
对比结果。我们对不同LLMs和数据集上的量化性能进行了全面比较。如表1所示,九个任务的结果表明,我们的方法MoEQuant在MoE LLMs上表现出优于其他方法的性能。值得注意的是,尽管GPTQ在Wikitext2上实现了较低的困惑度(可能是因为使用Wikitext2进行校准而导致过拟合),其在C4和其他任务上的表现明显较弱。相比之下,MoEQuant在大多数任务中超越了GPTQ和AWQ,显示出在困惑度和任务特定分数方面的显著提升。平均而言,MoEQuant在所有三个模型上超过了原始性能的1%,这是通过七个任务的平均分数衡量的。特别是在HumanEval和GSM8k上,其他方法在量化后降低了模型的推理能力,而集成MoEQuant有效地保留了这种能力,在生成任务中取得了与全精度模型相当的结果。这一点尤为重要,因为在像HumanEval这样的复杂任务中推理对于实际应用至关重要,进一步突显了MoEQuant性能的实际相关性。
表2:RTN、AWQ、GPTQ和MoEQuant在Qwen、DeepSeek和Mixtral MoE指令微调模型上的4位权重量化结果,其中+表示基于AWQ的MoEQuant,++表示基于GPTQ的MoEQuant。
| MODEL | METHOD | MMLU | HUMAN EVAL | GSM8K |
|---|---|---|---|---|
| QWEN- MoE-14B- CHAT | FP | 59.00 | 21.34 | 30.71 |
| RTN | 43.00 | 7.32 | 9.70 | |
| AWQ | 52.06 | 12.20 | 17.74 | |
| MoEQuant + { }^{+} + | 53.22 | 18.92 | 22.34 | |
| GPTQ | 57.30 | 15.24 | 26.08 | |
| MoEQuant + + { }^{++} ++ | 58.00 | 21.95 | 29.11 | |
| FP | 48.90 | 24.39 | 54.28 | |
| DEEPSEEK- MoE-16B- CHAT | RTN | 41.40 | 10.41 | 28.88 |
| AWQ | 46.33 | 18.90 | 39.88 | |
| MoEQuant + { }^{+} + | 46.80 | 19.20 | 47.42 | |
| GPTQ | 46.60 | 13.41 | 47.08 | |
| MoEQuant + + { }^{++} ++ | 47.60 | 21.95 | 48.97 |
指令微调模型实验。指令微调可以显著提高模型的应用能力,并已成为在不同场景下部署LLMs的必要过程。指令微调模型的量化通常比基础模型更具挑战性。我们在Qwen-MoE-14B-Chat (Qwen, 2024) 和DeepSeek-MoE-16B-Chat (Dai等人, 2024) 上进行基准测试,涵盖三个任务。对于Qwen-MoE-14B-Chat,MoEQuant + + { }^{++} ++持续保持超过94%的全精度性能,大部分原始推理能力得到有效恢复。如表2所示,先前的方法在指令微调模型的代码生成和数学推理任务上面临更显著的准确率下降。例如,GPTQ在Qwen-MoE-14B-Chat的人类评估中经历了29%的准确率下降。通过集成MoEQuant + + { }^{++} ++,准确率甚至超过了全精度模型,进一步证明了EBSS和GAQ在提高量化性能方面的有效性。更多关于困惑度和推理任务的详细结果可以在附录表8中找到。
消融结果。MoEQuant通过两种主要方法增强MoE LLMs的泛化能力和推理能力:EBSS和AGQ。我们进行分解实验。为了评估这些方法,我们进行分解实验。对于EBSS,我们进行消融研究以检查两个关键超参数的影响:温度 τ \tau τ和分支数 w w w。当 τ \tau τ设置为1.2时达到最佳性能,我们将 w w w设置为4以平衡有效性和效率。更多详细结果请参见附录A.1。
表3:DeepSeek和Mixtral MoE模型在3位下的平均得分,其中+表示基于AWQ的MoEQuant,++表示基于GPTQ的MoEQuant
| MODEL | BITWIDTH | METHOD | AVG. |
|---|---|---|---|
| DEEPSEEK- MoE-16B | FP | 40.86 | |
| 3 | RTN | 20.17 | |
| 3 | AWQ | 22.20 | |
| 3 | MoEQuant + { }^{+} + | 26.65 | |
| 3 | GPTQ | 35.85 | |
| 3 | MoEQuant + + { }^{++} ++ | 36.47 | |
| FP | 56.80 | ||
| 3 | RTN | 18.64 | |
| MIXTRAL- 8x7B | 3 | AWQ | 36.05 |
| 3 | MoEQuant + { }^{+} + | 39.30 | |
| 3 | GPTQ | 45.03 | |
| 3 | MoEQuant + + { }^{++} ++ | 49.75 |
低比特宽度。我们在DeepSeek-MoE16B和Mixtral-8x7B的低比特宽度设置下评估我们的方法的通用性。如表3所示,在测试的方法中,MoEQuant + { }^{+} +和MoEQuant + + { }^{++} ++始终获得最高的平均得分。这些发现表明,MoEQuant相比其他量化方法提供了优越的性能,在较低比特宽度下仍能有效保持较高的准确性。完整结果见附录3。
加速和内存节省。MoEQuant的动机是将MoE LLMs压缩到更低的比特宽度,从而在推理过程中减少延迟和GPU内存使用,同时最大程度地保留准确性,确保实际适用性。如表4所示,
表4:3种MoE LLMs的速度提升和内存节省,比较我们的4位实现与FP16。所有测试均在Nvidia A6000 GPU上进行。
| MODEL | DECODER SPEED (TOKENS/SEC) | ||
|---|---|---|---|
| FP | QUANTIZED | SPEED UP \begin{gathered} \text { SPEED } \\ \text { UP } \end{gathered} SPEED UP | |
| QWEN-MOE-14B | 8.35 | 10.60 | 1.27 |
| DeEPSEEK-MOE-16B | 20.81 | 24.45 | 1.17 |
| Mixtral-8x7B | 10.24 | 21.25 | 2.08 |
| MODEL | MEMORY USE (GB) | ||
| FP | QUANTIZED | MEMORY SAVING | |
| QWEN-MOE-14B | 27.88 | 8.51 | 3.28 |
| DEEPSEEK-MOE-16B | 32.23 | 9.87 | 3.27 |
| Mixtral-8x7B | 89.64 | 23.97 | 3.74 |
MoEQuant实现了平均超过1.2倍的推理加速和超过3.2倍的内存节省,展示了显著的推理效率提升。这些进展使得MoE LLMs能够在消费者级设备(如Nvidia 4090 GPU)上部署。
6. 结论
我们提出了MoEQuant,一个专为解决MoE LLMs独特量化挑战设计的框架。通过整合专家平衡自采样和亲和力引导量化,MoEQuant扩展了传统量化方法,能够有效处理校准样本在专家之间的不均衡分布以及由门控单元引入的令牌-专家亲和力变化问题。实验结果表明,MoEQuant即使在低比特量化下也能实现接近浮点精度的性能,并显著提高了泛化能力,尤其是在指令微调模型中。这些结果突显了其大幅减少模型大小和计算需求的潜力,使MoE LLMs在资源受限环境中部署更加可行。
影响声明
MoEQuant通过解决混合专家(MoE)LLMs的独特量化挑战,应对专家间和专家内的不平衡问题,确保高效低比特量化的同时保留模型精度。通过整合专家平衡自采样(EBSS)和亲和力引导量化(AGQ),MoEQuant显著增强了校准平衡和令牌-专家交互建模,在泛化和推理任务中超越现有的PTQ方法。实验结果表明,MoEQuant实现了3.2倍的内存节省、1.2倍的推理加速和显著的精度提升,使MoE LLMs在消费级GPU(如Nvidia RTX 4090)上部署更加实用。这项工作推进了MoE模型的可扩展性和可访问性,弥合了高性能语言建模与高效部署之间的差距。
参考文献
Aljundi, R., Chakravarty, P., and Tuytelaars, T. Expert gate: Lifelong learning with a network of experts. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3366-3375, 2017.
Amini, A., Gabriel, S., Lin, P., Koncel-Kedziorski, R., Choi, Y., and Hajishirzi, H. Mathqa: Towards interpretable math word problem solving with operation-based formalisms. arXiv preprint arXiv:1905.13319, 2019.
Ashkboos, S., Mohtashami, A., Croci, M. L., Li, B., Jaggi, M., Alistarh, D., Hoefler, T., and Hensman, J. Quarot: Outlier-free 4-bit inference in rotated llms. arXiv preprint arXiv:2404.00456, 2024.
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins, M., and Toutanova, K. Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044, 2019.
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
Dai, D., Deng, C., Zhao, C., Xu, R., Gao, H., Chen, D., Li, J., Zeng, W., Yu, X., Wu, Y., et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. arXiv preprint arXiv:2401.06066, 2024.
Deisenroth, M. and Ng, J. W. Distributed gaussian processes. In International conference on machine learning, pp. 1481-1490. PMLR, 2015.
Dettmers, T., Lewis, M., Belkada, Y., and Zettlemoyer, L. Llm. int8 (): 8-bit matrix multiplication for transformers at scale. arXiv preprint arXiv:2208.07339, 2022.
Eigen, D., Ranzato, M., and Sutskever, I. Learning factored representations in a deep mixture of experts. arXiv preprint arXiv:1312.4314, 2013.
Fedus, W., Zoph, B., and Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1-39, 2022.
Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. Gptq: Accurate post-training quantization for generative pretrained transformers. arXiv preprint arXiv:2210.17323, 2022.
Gao, L., Tow, J., Abbasi, B., Biderman, S., Black, S., DiPofi, A., Foster, C., Golding, L., Hsu, J., Le Noac’h, A., Li, H., McDonell, K., Muennighoff, N., Ociepa, C., Phang, J., Reynolds, L., Schoelkopf, H., Skowron, A., Sutawika, L., Tang, E., Thite, A., Wang, B., Wang, K., and Zou, A. A framework for few-shot language model evaluation, 07 2024. URL https://zenodo.org/records/12608602.
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
Jacobs, R. A., Jordan, M. I., Nowlan, S. J., and Hinton, G. E. Adaptive mixtures of local experts. Neural computation, 3(1):79-87, 1991.
Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., Casas, D. d. 1., Hanna, E. B., Bressand, F., et al. Mixtral of experts. arXiv preprint arXiv:2401.04088, 2024.
Jordan, M. I. and Jacobs, R. A. Hierarchical mixtures of experts and the em algorithm. Neural computation, 6(2): 181-214, 1994.
Kim, S., Hooper, C., Gholami, A., Dong, Z., Li, X., Shen, S., Mahoney, M. W., and Keutzer, K. Squeezellm: Dense-and-sparse quantization. arXiv preprint arXiv:2306.07629, 2023.
Langley, P. Crafting papers on machine learning. In Langley, P. (ed.), Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp. 1207-1216, Stanford, CA, 2000. Morgan Kaufmann.
LeCun, Y., Denker, J., and Solla, S. Optimal brain damage. In Advances in Neural Information Processing Systems, 1989.
Lin, J., Tang, J., Tang, H., Yang, S., Dang, X., and Han, S. Awq: Activation-aware weight quantization for llm compression and acceleration. arXiv preprint arXiv:2306.00978, 2023.
Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., Guo, D., et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434, 2024a.
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseekv3 technical report. arXiv preprint arXiv:2412.19437, 2024b.
Liu, Z., Oguz, B., Zhao, C., Chang, E., Stock, P., Mehdad, Y., Shi, Y., Krishnamoorthi, R., and Chandra, V. Llm-qat:
Data-free quantization aware training for large language models. arXiv preprint arXiv:2305.17888, 2023.
Lu, C.-P. The race to efficiency: A new perspective on ai scaling laws. arXiv preprint arXiv:2501.02156, 2025.
Merity, S. The wikitext long term dependency language modeling dataset. Salesforce Metamind, 9, 2016.
Mihaylov, T., Clark, P., Khot, T., and Sabharwal, A. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789, 2018.
Qwen. Qwen1.5-moe-a2.7b. https://huggingface.co/ Qwen/Qwen1.5-MoE-A2.7B, 2024. Accessed: [n. d.].
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 2020.
Theis, L. and Bethge, M. Generative image modeling using spatial lstms. Advances in neural information processing systems, 28, 2015.
van Baalen, M., Kuzmin, A., Nagel, M., Couperus, P., Bastoul, C., Mahurin, E., Blankevoort, T., and Whatmough, P. Gptvq: The blessing of dimensionality for llm quantization. arXiv preprint arXiv:2402.15319, 2024.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Attention is all you need. Advances in neural information processing systems, 2017.
Xiao, G., Lin, J., Seznec, M., Demouth, J., and Han, S. Smoothquant: Accurate and efficient post-training quantization for large language models. arXiv preprint arXiv:2211.10438, 2022.
Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., and Choi, Y. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.
A. 附录
A.1. 消融研究
在本节中,我们提供了我们方法EBSS和AGQ的完整结果比较。如表5所示,以DeepSeek-MoE-16B为例,单独应用时,EBSS带来了几乎1.3%的改进,而AGQ带来了约2%的改进。当两种技术结合使用时,性能显著提高了2.6%,这在Qwen-MoE-14B上也类似。这证明了结合EBSS和AGQ的好处,因为组合方法的表现优于单独的两种方法。不可避免的是,对于Mixtral 8x7b,AGQ的结果不如传统的GPTQ好,但组合结果仍然是最优的。
表5:在Qwen、DeepSeek和Mixtral MoE模型的9项任务上,我们的方法消融研究的完整比较,基线方法是GPTQ。
| MODEL | EBSS | AGQ | PPL | SCORE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WIKI TEXT2 | C4 | MMLU | HUMAN EVAL | GSM8K | BOOLQ | HELLA SWAG | OPEN BOOKQA | MATH QA | AVG. | |||
| QWEN- MoE-14B | × \times × | × \times × | 7.22 | 9.30 | 59.60 | 32.32 | 62.55 | 79.82 | 57.96 | 30.40 | 35.77 | 51.20 |
| × \times × | × \times × | 7.43 | 10.11 | 57.90 | 28.05 | 56.25 | 78.77 | 56.54 | 29.00 | 36.48 | 49.00 | |
| × \times × | ✓ \checkmark ✓ | 7.44 | 10.09 | 57.30 | 29.27 | 56.41 | 76.45 | 56.86 | 31.00 | 35.87 | 49.02 | |
| ✓ \checkmark ✓ | × \times × | 7.56 | 9.62 | 58.80 | 27.44 | 56.71 | 78.77 | 56.73 | 30.80 | 35.27 | 49.21 | |
| ✓ \checkmark ✓ | ✓ \checkmark ✓ | 7.55 | 9.68 | 58.30 | 29.87 | 58.38 | 78.04 | 56.87 | 30.20 | 35.50 | 49.59 | |
| DEEPSEEK- MoE-16B | × \times × | × \times × | 6.51 | 9.04 | 44.60 | 26.83 | 20.16 | 72.72 | 58.06 | 32.20 | 31.49 | 40.86 |
| × \times × | × \times × | 6.66 | 9.39 | 40.60 | 22.56 | 19.18 | 72.17 | 57.03 | 30.60 | 30.95 | 39.01 | |
| × \times × | ✓ \checkmark ✓ | 6.66 | 9.38 | 41.60 | 23.17 | 17.89 | 74.52 | 57.30 | 31.20 | 30.88 | 39.50 | |
| ✓ \checkmark ✓ | × \times × | 6.77 | 9.22 | 44.00 | 23.78 | 18.19 | 73.24 | 57.21 | 31.80 | 30.92 | 39.87 | |
| ✓ \checkmark ✓ | ✓ \checkmark ✓ | 6.78 | 9.25 | 42.20 | 25.00 | 19.18 | 73.49 | 57.20 | 31.40 | 31.66 | 40.01 | |
| MIXTRAL- 8x7B | × \times × | × \times × | 4.03 | 7.67 | 68.50 | 27.60 | 57.92 | 84.22 | 64.08 | 30.60 | 41.07 | 53.42 |
| × \times × | ✓ \checkmark ✓ | 4.04 | 7.64 | 68.30 | 29.54 | 60.12 | 83.36 | 64.04 | 32.80 | 41.54 | 54.24 | |
| ✓ \checkmark ✓ | × \times × | 4.10 | 7.38 | 69.10 | 31.19 | 60.50 | 84.83 | 64.21 | 34.20 | 42.01 | 55.15 | |
| ✓ \checkmark ✓ | ✓ \checkmark ✓ | 4.12 | 7.38 | 69.60 | 32.15 | 61.79 | 84.98 | 64.05 | 33.60 | 42.95 | 55.58 |
在EBSS中,我们进行了一项消融研究,以检查两个关键超参数的影响:温度 τ \tau τ和分支数 w w w。 τ \tau τ控制专家平衡在句子概率分布中的重要性,而 w w w决定生成句子的多样性。虽然增加 w w w可以提高句子多样性,但它也会带来更高的计算成本。实验在DeepSeek-MoE-16B上跨七项任务进行,如表6和表7所示。当 τ \tau τ设置为1.2时,跨数据集的平均得分最大化。同样,将 w w w设置为4会产生最佳结果,进一步增加 w w w只会带来边际得分改善,但会显著增加生成时间。
表6:在DeepSeek-MoE-16B上,不同 τ \tau τ对7项任务平均得分的影响,使用MoEQuant + + { }^{++} ++。
| τ \tau τ | 1.0 | 1.1 | 1.2 | 1.3 | 1.4 | 1.5 |
|---|---|---|---|---|---|---|
| AVG. | 39.82 | 39.89 | 40.01 | 39.98 | 39.69 | 39.71 |
表7:在DeepSeek-MoE-16B上,不同分支数 w w w对7项任务平均得分的影响,使用MoEQuant++。
| w w w | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 20 | 30 | 40 | 50 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AVG. | 39.77 | 39.80 | 40.01 | 39.98 | 40.01 | 40.00 | 40.00 | 40.01 | 40.00 | 40.10 | 40.07 | 40.08 | 40.11 |
A.2. 完整结果
在本节中,我们提供了一个完整的展示,涵盖了各种数据集上的结果,以补充主论文。具体来说,结果包括以下内容:
- 在指令调优MoE LLMs上的两困惑度和七准确度任务的完整比较:Qwen-MoE-14Bchat和DeepSeek-MoE-16B-chat。
-
- 在DeepSeek-MoE-16B和Mixtral8x7B上的两困惑度和七准确度任务的完整比较,采用较低比特。
表8:在Qwen、DeepSeek和Mixtral MoE指令调优模型上,RTN、AWQ、GPTQ和我们的MoEQuant在9项任务上的4位权重量化完整比较,其中+表示基于AWQ的MoEQuant,++表示基于GPTQ的MoEQuant。
- 在DeepSeek-MoE-16B和Mixtral8x7B上的两困惑度和七准确度任务的完整比较,采用较低比特。
| MODEL | METHOD | PPL | SCORE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WIKI TEXT2 | C4 | MMLU | HUMAN EVAL | GSM8k | BOOLQ | HELLA SWAG | OPEN BOOKQA | MATH QA | AVG. | |||
| QWEN- MoE-14B- CHAT | FP | 8.07 | 9.74 | 59.0 | 21.34 | 30.71 | 81.31 | 59.33 | 31.00 | 34.91 | 45.37 | |
| RTN | 12.81 | 14.03 | 43.00 | 7.32 | 9.70 | 71.13 | 51.41 | 24.40 | 28.81 | 33.68 | ||
| AWQ | 9.97 | 11.90 | 52.06 | 12.20 | 17.74 | 74.74 | 55.37 | 30.40 | 31.46 | 39.1------ | ||
| 4 | ||||||||||||
| MOEQuant + { }^{+} + | 10.12 | 11.55 | 55.34 | 13.60 | 20.87 | 76.22 | 56.64 | 30.60 | 32.82 | |||
| GPTQ | 8.38 | 10.78 | 57.30 | 15.24 | 26.08 | 78.92 | 58.72 | 31.40 | 34.17 | 4 | ||
| ------3.19 | ||||||||||||
| MOEQuant + + { }^{++} ++ | 8.65 | 10.21 | 58.00 | 21.95 | 29.11 | 79.11 | 58.53 | 33.20 | 34.77 | 44.95 | ||
| DEEPSEEK- MoE-16B- CHAT | FP | 7.35 | 9.96 | 48.90 | 24.39 | 54.28 | 79.81 | 60.69 | 35.40 | 34.27 | 47.96 | |
| RTN | 8.63 | 11.06 | 41.40 | 10.41 | 28.88 | 75.84 | 57.59 | 31.40 | 29.04 | 39.22 | ||
| AWQ | 7.72 | 10.49 | 46.33 | 18.90 | 39.88 | 78.20 | 58.97 | 33.80 | 32.86 | 44.13 | ||
| MOEQuant + { }^{+} + | 7.85 | 10.23 | 46.40 | 18.90 | 45.41 | 78.20 | 59.03 | 33.60 | 33.14 | 44.95 | ||
| GPTQ | 7.55 | 10.24 | 46.60 | 13.41 | 47.08 | 78.87 | 59.64 | 33.20 | 32.76 | 44.50 | ||
| MOEQuant + + { }^{++} ++ | 7.70 | 10.08 | 47.60 | 21.95 | 48.97 | 79.20 | 59.30 | 33.80 | 32.60 | 46.20 |
表9:在DeepSeek和Mixtral MoE模型上的低比特完整结果,其中+表示基于AWQ的MoEQuant,++表示基于GPTQ的MoEQuant。
| MODEL | BIT | METHOD | PPL | SCORE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WIDTH | WIKI TEXT2 | C4 | MMLU | HUMAN EVAL | GSM8k | BOOLQ | HELLA SWAG | OPEN BOOKQA | MATH QA | AVG. | ||
| DEEPSEEK- MoE-16B | FP | 6.51 | 9.04 | 44.60 | 26.83 | 20.16 | 72.72 | 58.06 | 32.20 | 31.49 | 40.86 | |
| 3BIT | RTN | 26352 | 32357 | 24.8 | 0.00 | 1.59 | 51.62 | 26.18 | 15.60 | 21.44 | 20.17 | |
| 3BIT | AWQ | 4622 | 5505 | 27.80 | 1.90 | 2.88 | 53.20 | 27.97 | 17.80 | 23.86 | 22.20 | |
| 3BIT | MOEQuant + { }^{+} + | 5100 | 4924 | 33.20 | 8.72 | 10.44 | 59.24 | 29.22 | 20.60 | 25.14 | 26.65 | |
| 3BIT | GPTQ | 7.17 | 11.66 | 37.30 | 17.68 | 11.60 | 72.31 | 53.68 | 27.80 | 29.72 | 35.85 | |
| 3BIT | MOEQuant + + { }^{++} ++ | 7.55 | 10.88 | 40.00 | 20.12 | 12.81 | 69.72 | 54.09 | 29.00 | 29.61 | 36.47 | |
| FP | 3.84 | 6.87 | 70.50 | 32.93 | 65.88 | 85.23 | 64.88 | 35.80 | 42.41 | 56.80 | ||
| 3BIT | RTN | 44944 | 51241 | 25.30 | 0.00 | 0.00 | 41.52 | 25.61 | 18.40 | 19.66 | 18.64 | |
| MIXTRAL- 8x7B | 3BIT | AWQ | 7.38 | 13.13 | 45.80 | 10.37 | 10.39 | 75.23 | 53.04 | 28.00 | 29.55 | 36.05 |
| 3BIT | MOEQuant + { }^{+} + | 8.77 | 11.44 | 49.40 | 14.44 | 17.29 | 77.22 | 54.29 | 30.10 | 32.34 | 39.30 | |
| 3BIT | GPTQ | 4.64 | 9.12 | 57.80 | 22.56 | 22.59 | 79.82 | 61.30 | 30.40 | 40.80 | 45.04 | |
| 3BIT | MOEQuant + + { }^{++} ++ | 4.90 | 8.24 | 64.10 | 28.05 | 43.21 | 82.81 | 60.07 | 31.20 | 38.82 | 49.75 |
参考论文:https://arxiv.org/pdf/2505.03804



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











