






Silvia García-Méndez
信息技术组 - atlanTTic
维戈大学
维戈,西班牙
sgarcia@gti.uvigo.es - 0000-0003-0533-1303
Francisco de Arriba-Pérez
信息技术组 - atlanTTic
维戈大学
维戈,西班牙
farriba@gti.uvigo.es - 0000-0002-1140-679X
© 2024 IEEE。允许个人使用此材料。所有其他用途均需获得IEEE许可,包括在任何当前或未来的媒体中重新印刷/重新发布此材料以用于广告或宣传目的、创建新的集体作品、转售或重新分发到服务器或列表,或在其他作品中重复使用本工作的任何受版权保护的组成部分。
摘要
社交媒体平台实现了即时和无处不在的连接,并且是我们技术社会中社交互动和交流的核心部分。除了其优势外,这些平台还引发了在线社区中的负面行为,即所谓的网络欺凌。尽管最近涉及生成人工智能(AI)的作品很多,但仍有机会研究其性能,而不仅仅是零样本/少量样本学习策略。因此,我们提出了一种创新的实时解决方案,用于网络欺凌检测,该方案利用了基于流的机器学习(ML)模型,能够增量处理传入样本,并利用大型语言模型(LLMs)进行特征工程,以应对在线滥用和仇恨言论的演变性质。提供了一个可解释性仪表板,以促进系统的可信度、可靠性和问责制。实验数据上的结果显示,在所有评估指标上表现接近90%,并且超过了文献中竞争作品的结果。最终,我们的提案通过及时检测滥用行为来防止长期骚扰并减少对社会的负面影响,从而为在线社区的安全做出了贡献。
关键词-网络欺凌和不当行为,可解释性,大型语言模型,机器学习,安全与信任,社交网络,流式/实时分析
I. 引言
由于新社区和网络的激增,在线交流已成为社交互动的重要特征[1]。更具体地说,2023年全球有49亿人报告使用社交媒体,预计到2027年这一数字将增至58.5亿[1]。尽管这些
平台实现了即时、无处不在的连接,但它们也引发了诸如欺凌、种族主义、性别歧视和网络钓鱼等负面行为[2]。根据世界卫生组织在欧洲的网络欺凌统计数据[2],大约12%的青少年报告骚扰他人。相比之下,15%的人经历了与分享敏感或私人内容、收到威胁性评论和信息或成为虚假信息和谣言传播目标相关的虐待。
网络欺凌的后果从低自尊、消极情绪状态增加、抑郁、自我伤害和睡眠模式改变到自杀念头不等[3],[4],[5]。即使孤立用户偶尔使用侮辱性和仇恨语言,也可能触发在线社区的重复行为,不幸的是,这会导致上述网络欺凌[6]。因此,它对用户的心理健康有直接的负面影响[1],[7]。
为了解决这种令人不安的情况,社交媒体公司采用了举报策略。例如,x[3]通过DCMA索赔,可能导致账户暂停或委派,类似于TikTok[4]的做法。此外,Instagram[5]测试了负面和不适当评论和消息,使用其隐藏词功能。不幸的是,这是由于近期这些流行平台上在线骚扰或网络欺凌的激增。然而,上述依赖用户的预防机制(例如,屏蔽、删除和举报)可能因被动和手动性质而变得无效[8]。
对于社交媒体数据分析,应考虑社交媒体内容的连续节奏,即以流式方式。同时,线上用户表达自己的方式也在不断变化。后者对于正确分析社交媒体中的攻击行为尤为重要[6]。鉴于数字时代这一普遍关注的问题,网络欺凌检测吸引了学术界的注意[1]。需要注意的是,检测网络欺凌是一项复杂且具有挑战性的任务,仅使用人工智能(AI)方法如机器学习(ML)模型可能不足以解决问题[9],[10]。
在这方面,大型语言模型(LLMs)代表了一种新兴的方法,具有在自然语言处理(NLP)领域中的广阔前景。然而,在许多领域中,如网络欺凌检测,将LLMs与其他技术(如ML或图像识别)结合仍处于起步阶段[7]。更具体地说,像OpenAI开发的LLMs(例如GPT-4)[6]具有生成类人类文本的能力,这得益于其底层由数百万参数组成的神经网络架构跨越数百层[11]。由于它们是用多样化的互联网数据训练的,这些模型可以学习检测各种语言模式和上下文见解[7]。
尽管最近涉及生成AI的作品很多,但仍有机会研究其性能,而不仅仅是将其作为最终解决方案,即要求模型对社交媒体内容进行分类。相反,我们建议利用它们提取高层次推理特征,这些特征可以被具有可解释能力的ML模型利用以检测网络欺凌。此外,请注意,虽然传统ML模型受益于LLMs的文本模式分析能力,但后者生成的AI可能对分类问题的理解有限,我们计划通过监督学习来规避这一点。
不幸的是,包括通过文本挖掘进行网络欺凌检测在内的数据分析AI技术是不透明的,这不仅影响算法的内在可解释性和可信度以及所提供结果的可靠性与问责制,还影响社交媒体平台、政策制定者和在线用户对这些解决方案的接受和采用[12]。相应地,可解释人工智能(XAI)似乎适合描述自主机器决策模型的工作原理,因为这些模型对公众和开发者来说主要表现为黑箱[13]。在XAI模型中,应考虑DeepLIFT、逐层相关性传播和LIME [14]。简而言之,XAI技术促进了关于为何特定消息被标记的互操作性、透明性和公平性[12]。
最终,及时检测社交网络中的滥用行为对于防止长期骚扰和减少社区中的负面影响至关重要[8]。总结一下,我们提出了一种创新的实时解决方案,用于网络欺凌检测,该方案利用基于流的ML和LLMs进行特征工程,以应对在线滥用和仇恨言论的演变性质。更具体地说,它可以增量处理样本,增强模型的适应能力。
我们的工作贡献还包括可解释性能力,以促进社会对AI的信任。
本文其余部分分为以下章节。第二章总结了网络欺凌检测的主要文献。第三章详细介绍了我们的系统架构,第四章展示了我们方法学的结果,并与文献中的其他作品进行了比较。最后,第五章总结了这项工作的主要结论,并提出了未来的研究方向。
II. 文献综述
最简单的网络欺凌检测方法是基于关键词过滤[12]。然后,早期研究集中在ML分类器[15],随后是深度学习模型,特别是卷积神经网络(CNN)和循环神经网络(RNN),[16],[17]。更具体地说,传统的ML模型利用文本内容和社会网络结构中的语言模式[1],[7]。在这方面,文献支持在考虑效率和有效性时,前者的传统ML架构表现出色[18]。深度学习框架的主要问题是其对计算和数据资源的高要求[12]。
大多数文献中的作品比较了LLMs与基线ML模型和深度学习的性能。例如,S. Paul和S. Saha(2022)[16]研究了微调版BERT在使用Twitter、Wikipedia和Formspring数据检测网络欺凌方面的性能。此外,K. Verma等人(2022)[4]比较了传统ML模型(即支持向量机)与LLMs(例如BERT)。关于深度学习方法,A. Muneer等人(2023)[10]分析了微调版BERT模型的性能。最终,类似于S. Paul和S. Saha(2022)[16]、K. Verma等人(2022)[4]和A. Muneer等人(2023)[10]的结果,在T. H. Teng和K. D. Varathan(2023)[8]以及K. Saifullah等人(2024)[2]的更近期作品中,LLMs和ML模型的性能相当,这启发我们利用它们的组合。
此外,在那些结合LLMs和ML解决网络欺凌检测问题的文献解决方案中,Y. Yan等人(2023)[19]使用ChatGPT提取全局知识以输入K-Nearest Neighbor (KNN)算法。与我们的提议不同,未提取高层次推理知识。事实上,前沿研究表明,仅仅依赖文本衍生特征会限制解决方案的性能,因为语言的多样性和复杂性(例如讽刺、讽刺)[20]。因此,应考虑从词嵌入中提取细微情境细节的困难[1]。如前所述,我们通过利用LLMs提取专家用户的特征来训练ML模型,避免了这一问题。主要的是,使用LLMs减少了先前研究对人工构建特征的依赖和低泛化性,这是因为传统NLP策略(例如词袋模型)建模语言多样性能力有限[10]。
6
{ }^{6}
6 可用网址 https://openai.com, 2024年10月。
表I
相关解决方案的比较。
| 作者 | 方法 | 运行方式 | 可解释性 |
|---|---|---|---|
| H. Herodotou 等(2020)[6] | ML | 流式 | x \boldsymbol{x} x |
| M.S. Islam 和 R. I. Rafiq(2023)[1] | LLMs | 批量 | x \boldsymbol{x} x |
| A. Sadek 等(2023)[21] | LLMs | 批量 | x \boldsymbol{x} x |
| Y. Yan 等(2023)[19] | ML + LLMs | 批量 | x \boldsymbol{x} x |
| E. A. Nina-Gutiérrez 等(2024)[22] | LLMs | 批量 | x \boldsymbol{x} x |
| 我们的提议 | ML + LLMs | 流式 | ✓ \checkmark ✓ |
请注意,上述所有网络欺凌检测方法都是基于批量部署的,这影响了模型随时间的适应能力,并限制了对社交媒体内容的持续监控[23]。据我们所知,唯一的例外是H. Herodotou 等(2020)[6] 的工作。作者提出了一种实时的Twitter攻击检测解决方案,通过利用基于流的机器学习模型实现。作者使用了霍夫丁树、自适应随机森林和流式逻辑回归模型。然而,他们并未使用LLMs进行特征提取,而是采用了词袋方法。相比之下,我们提出了一种基于流的ML框架,能够增量处理传入样本,并利用LLMs应对在线仇恨言论和辱骂语言的演变特性。请注意,系统能够被最终用户理解,这得益于可解释性模块,这是我们的研究另一重要贡献。
当涉及到生成型AI对此任务的适用性时,M.S. Islam 和 R. I. Rafiq(2023)[1] 研究了LLMs在Instagram上检测网络欺凌的有效性。为此,作者探索了不同的模型(例如ChatGPT 3.5 Turbo和Text-davinci-003)、学习策略(例如零样本和单样本)和提示符。特别值得一提的是A. Sadek 等(2023)[21] 的工作,他们研究了传统ML模型和LLMs(例如BERT和ChatGPT)在阿拉伯语网络欺凌检测中的性能。然而,结果表明,像ChatGPT这样的模型单独解决分类问题的性能有限。尽管如此,正如我们在研究中所做的那样,它们可以与其他技术(如标准ML模型)结合使用。此外,E. A. Nina-Gutiérrez 等(2024)[22] 使用了微调版GPT3.5来检测仇恨言论和冒犯性语言。与A. Sadek 等(2023)[21] 的工作类似,作者未探索LLMs超出其作为最终决策者直接应用的局限性,缺乏对分类问题的深入情境理解。
最终,关于使用可解释模型或解释性技术,我们必须提到M. Wich 等(2021)[20] 的早期工作。他们使用SHapley Additive exPlanations(SHAP)评估了基于BERT的解决方案在滥用语言分类中的脆弱性。同样,T. Ahmed 等(2022)[24] 使用了GPT-2和其他LLMs(例如BERT)提取嵌入,通过集成学习检测网络欺凌。关于解释性,仅提供了BERT模型的单词重要性指数。
另一个SHAP使用的代表性例子是P. Aggarwal 和 R. Mahajan(2023)[25] 的研究,他们结合BERT和超级向量机(SVM)进行多类别网络欺凌分类。此外,H. Mehta 和 K. Passi [14] 以及V. Pawar 等(2022)[26] 利用局部可解释模型无关解释(LIME)为仇恨言论检测提供可解释数据,类似于Shakil 和 M. G. R. Alam [27] 的方法。此外,V. U. Gongan 等(2023)[13] 比较了神经网络模型(例如CNN、BiLSTM 和 BERT)的性能,并利用LIME对其结果进行补充。最终,M. Umer 等(2024)[28] 结合RoBERTa模型与主成分分析(PCA)和全局词向量表示(GLOVE)提取词嵌入特征。然后,作者使用LIME提供可解释结果。不幸的是,后者的可解释技术(即SHAP和LIME)仅提供促使模型决策的特征的概率得分,这对最终用户来说仍然难以理解。
A. 研究贡献
表I显示了最相关的解决方案,以便轻松比较和评估我们的贡献。如文献综述所述,大多数作品是在批量基础上执行网络欺凌检测,除了H. Herodotou 等(2020)[6] 的工作。然而,这项工作完全依赖于词袋方法进行文本挖掘,这在建模语言多样性方面的能力非常有限。此外,Y. Yan 等(2023)[19] 是唯一利用LLMs进行特征工程的作品,这是我们工作的新贡献,因为后者仅用于提取全局知识(即LLMs被要求总结帖子的主要方面)。此外,在所选作品中没有任何可解释性。
总结起来,所提出的网络欺凌检测领域的解决方案的主要贡献如下:
- 一种基于流的框架,能够增量处理样本,增强模型的适应能力。
-
- 使用LLMs提取高级推理特征以训练ML模型。
-
- 提供可解释性仪表板,促进可信度、可靠性和问责制。
III. 方法论
图1显示了所提解决方案的架构,包含(i)预处理模块,用于从社交媒体帖子中移除无意义的数据;(ii)特征工程模块,通过结合传统NLP和提示工程技术生成新特征,充分利用LLMs的语言建模能力;(iii)特征分析和选择模块,从中提取相关数据以训练(iv)分类模块中的ML模型;以及(v)可解释性模块,用于生成系统提供的预测的自然语言描述。
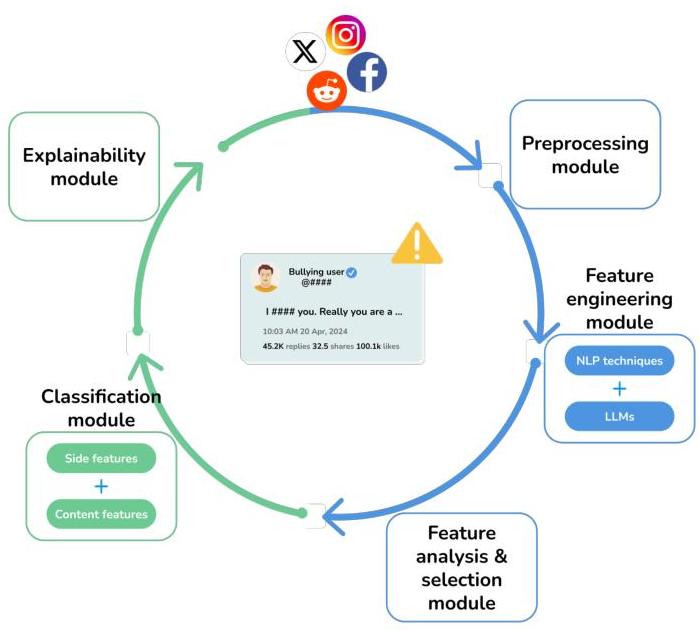
图1. 系统方案。
此外,系统存在两个阶段:(i)冷启动(见图1中该阶段的蓝色表示)和(ii)流设置。更具体地说,在初始冷启动阶段,第一个样本(见第III-C节和第IV-D节)用于优化分类器的超参数并选择初始的相关特征集,这最小化了流操作中的计算负载。当这个阶段结束时,系统维持图1中所有模块的恒定数据流。
A. 预处理模块
在使用NLP技术进行特征工程之前,实验数据由社交媒体帖子组成并进行处理(见第III-B节的技术信息)。值得注意的是,使用正则表达式,系统移除了数字、标点字符、链接、空格、双字母单词和特殊字符。此外,停用词被移除,内容被分词和词形还原。最后,孤立字符也被移除。
B. 特征工程模块
表II列出了系统中使用的所有特征。特征1-7是通过对LLM模型应用提示工程计算得出的布尔信息(见第IV-D节的实现细节)。发送给模型进行分析的文本未经预处理,包含了所有原始
原始信息。此外,特征8-16是通过对预处理内容应用传统NLP技术计算得出的(见第III-A节)。
虽然特征1-7是描述网络欺凌帖子的备注,有助于解释对话者的意图,特征8-15与语言特征相关。两者都被视为辅助特征,独立于内容,因此更加灵活。我们的研究将后者与从词矩阵方法派生的内容相关特征16进行比较。
C. 特征分析与选择模块
流式系统需要较高的计算能力,因为在每次交互时,模型都会根据新标注的输入样本进行调整。因此,这种方法不能像批量分析那样评估那么多特征,使得分类问题更具挑战性。出于这个原因,我们的系统结合了两种特征选择方法。第一种是在冷启动期间应用的元转换器包装ML模型。该分类器基于平均纯度下降(MDI)技术[29]选择最重要的特征。第二种过滤器在冷启动阶段结束后应用,旨在消除方差较低的特征。这减少了无关特征和模型大小,提高了性能。在我们的分析中,我们使用了这两种选择器的默认参数,进一步描述见第IV-D节。
D. 分类模块
我们的实验中有两种评估场景。
- 场景1使用仅侧边特征(表II中的1-15)评估ML模型。它研究了基于提示工程和NLP从帖子中提取相关信息的质量,独立于其显式内容(即特征16中的词嵌入)。
-
- 场景2评估内容相关特征(表II中的16)对分类器评估指标的影响。尽管这些特征在文献中广泛使用[24],[28],但无论分类方法如何(即批量或流式基础),它们都极其耗时,并减少了解决方案对不同实验数据的泛化能力,特别是在高度变化的布局(如社交媒体知识挖掘)中尤其相关。此外,据报道此类数据无法捕捉细微的情境细节[1]。
- 此外,为了评估解决方案,选择了以下分类器:
-
- 高斯朴素贝叶斯(GNB)[30],使用高斯概率来最小化预测误差。
-
- 霍夫丁自适应树分类器(HATC)[31],是批量设置中决策树(DT)的流式等效物。预测基于特征值数据计算。
-
- 自适应随机森林分类器(ARFC)[32],是批量设置中随机森林(RF)的流式等效物。
- 表II
- 用于网络欺凌检测的特征工程。
| 技术 | 类别 | ID | 名称 | 描述 |
| :–: | :–: | :–: | :–: | :–: |
| | | 1 | 贬义言论 | 表示帖子是否包含侮辱性语言。 |
| | | 2 | 辱骂性语言 | 表示帖子是否包含羞辱性和去人格化的表达。 |
| | | 3 | 种族歧视术语 | 表示明确提及种族歧视术语。 |
| | | 4 | 讽刺术语 | 表示帖子是否讽刺。 |
| LLM | 辅助 | 5 | 性相关术语 | 表示帖子是否包含性相关术语。 |
| | | 6 | 威胁言论 | 表示帖子是否包含威胁性表达。 |
| | | 7 | 暴力术语 | 表示帖子是否包含提倡暴力的术语。 |
| | | 8 | 复杂词汇计数器 | 统计复杂术语的数量。 |
| | | 9 | 情感负载 | 表示愤怒、恐惧、快乐、悲伤和惊讶的程度。 |
| | | 10 | Flesch分数 | 表示帖子的可读性水平。 |
| | | 11 | McAlpine分数 | 表示非母语英语使用者的可读性评分。 |
| NLP | 辅助 | 12 | 极性 | 表示负面、中立或正面负载。 |
| | | 13 | POS计数器 | 表示形容词、限定词、名词、代词、标点符号和动词相对于总词汇的比例。 |
| | | 14 | 阅读时间 | 表示帖子阅读时间的估计值。 |
| | | 15 | 词数 | 表示帖子中的词数。 |
| | 内容 | 16 | 单词n-gram | 表示帖子中单词n-gram的频率。 |
操作。该模型包含可配置数量的DT模型,预测基于多数投票得出。
E. 可解释性模块
每个预测的自然语言解释是使用提示工程强化的LLMs生成的。表II中的1-7辅助特征是高层次推理特征,通过检测语言模式、语言使用和深层语义意义来捕获用户的专家信息,利用这些模型的理解能力。最终,LLM生成的自然语言解释来源于特征值、帖子内容本身、ML模型预测及其置信度,生成网络欺凌检测的全面解释。
IV. 结果与讨论
本节展示了在利用(i) 辅助特征和(ii) 内容相关特征分别评估两种场景下获得的结果。分析是在具有以下规格的计算机上进行的:
- 操作系统 (OS): Ubuntu 18.04.2 LTS 64位
-
- 处理器: IntelCore i9-10900K 2.80 GHz
-
- 内存: 96 GB DDR4
-
- 磁盘存储: 480 GB NVME + 500 GB SSD
A. 实验数据
使用的数据集[7]由从X中提取并根据网络欺凌
是否存在进行标注的社会媒体帖子组成。表III总结了其统计信息[8]。
样本平均包含21.25 ± 14.19个单词,在进行预处理后减少到9.64 ± 7.14个单词。后者通过减少文本输入数据量(即限制表II中特征16的大小和计算特征8-15所需的时间)提高了ML的性能。请注意,这种减少并不会降低解决方案的性能,因为完整的原始内容由LLM(特征1-7)进行分析。因此,结合两种特征工程方法的优势得以体现。
表III
数据集分布。
| 网络欺凌 | 样本数 |
|---|---|
| 缺失 | 7945 |
| 存在 | 7945 |
| 总数 | 15890 |
B. 预处理模块
我们使用正则表达式(见清单1)去除无意义元素,详见第III-A节。为去除停用词,我们使用NLTK库[9],并使用spaCy库[10]中的en_core_web_md核心模型对内容进行词形还原。
1
7
{ }^{7}
7 可用网址 https://www.kaggle.com/datasets/andrewmvd/cyberbullying-classification, 2024年10月。
清单1. 预处理的正则表达式。
数字
=
r
′
\
d
×
[
A
−
Z
a
−
z
]
+
=\mathrm{r}^{\prime} \backslash \mathrm{d} \times[\mathrm{A}-\mathrm{Za}-\mathrm{z}]+
=r′\d×[A−Za−z]+ ’
标点字符
=
r
′
{
\
,
{
\
}
{
\
}
{
\
}
{
\
−
}
−
]
+
=\mathrm{r}^{\prime}\{\backslash,\{\backslash\}\{\backslash\}\{\backslash\}\{\backslash-\}-]+
=r′{\,{\}{\}{\}{\−}−]+ ’
URLs
=
r
′
(
?
:
{
pic.
{
http
{
new
{
\
w
+
}
?
\
:
(
/
/
)
+
}
\
S
+
=\mathrm{r}^{\prime}(?:\{\text { pic. }\{\text { http }\{\text { new }\{\backslash w+\} ? \backslash:(/ /)+\} \backslash \mathbf{S}+
=r′(?:{ pic. { http { new {\w+}?\:(//)+}\S+ ’
空格
=
r
′
(
\
s
∣
\
t
∣
\
\
n
∣
\
n
)
+
=\mathrm{r}^{\prime}(\backslash s|\backslash t| \backslash \backslash n|\backslash n)+
=r′(\s∣\t∣\\n∣\n)+ ’
特殊字符
=
r
′
(
\
s
∣
\
{
∣
\
}
∣
=
∣
\
t
∣
\
)
∣
\
S
∣
\
′
′
∣
\
}
∣
\
{
∣
\
∣
∣
\
+
∣
A
∣
C
}
=\mathrm{r}^{\prime}(\backslash s|\backslash\{|\backslash\}|=|\backslash t|\backslash)|\backslash S|\backslash^{\prime \prime}|\backslash\}|\backslash\{|\backslash||\backslash+|\mathbf{A}| \mathbf{C}\}
=r′(\s∣\{∣\}∣=∣\t∣\)∣\S∣\′′∣\}∣\{∣\∣∣\+∣A∣C} KaTeX parse error: Expected 'EOF', got '\right' at position 31: …{\prime \prime}\̲r̲i̲g̲h̲t̲)+ ’
两字母单词
=
r
′
\
b
[
a
−
z
A
−
Z
\
−
}
{
2
,
}
\
b
=\mathrm{r}^{\prime} \backslash \mathrm{b}[\mathrm{a}-\mathrm{zA}-\mathrm{Z} \backslash-\}\{2,\} \backslash \mathrm{b}
=r′\b[a−zA−Z\−}{2,}\b
C. 特征工程模块
为了生成NLP特征,使用了以下库:
- textstat[11] 生成表II中的特征8,10,11,14,15。
-
- text2emotion[12] 生成特征9。
-
- spaCy[13] 生成特征12和13。
-
- ChatGPT的GPT-40-mini模型[14] 生成特征1-7。系统通过OpenAI API[15] 发送请求,提示符如清单2所示,温度参数值为0[16]。
-
- scikit-learn Python库中的CountVectorizer[17] 生成特征16。该库使用数据的10%(约我们实验数据集中的前1500个样本)创建词频向量。配置参数如下:ngrams_max_df = 0.7,ngrams_min_df = 0.01,ngrams_ngram_range = (1,1)。这些值是从实验测试中选择的,以最小化计算负载,同时不影响流式环境下的性能。
清单2. ChatGPT提示符进行特征工程。
- scikit-learn Python库中的CountVectorizer[17] 生成特征16。该库使用数据的10%(约我们实验数据集中的前1500个样本)创建词频向量。配置参数如下:ngrams_max_df = 0.7,ngrams_min_df = 0.01,ngrams_ngram_range = (1,1)。这些值是从实验测试中选择的,以最小化计算负载,同时不影响流式环境下的性能。
这段文字来自社交媒体。请分析是否包含贬义、侮辱、种族歧视、讽刺、性、威胁或暴力言论、术语和语言,并返回1如果存在,否则返回0。按照此JSON格式。不要添加任何解释:
{“derogatory”:0,
“humiliating”:0,
“racist”:0,
“sarcasm”:0,
“sexual”:0,
“threatening”:0,
“violence”:0
}
<
<
< 帖子
>
>
>
D. 特征分析与选择模块
为了减少流式系统中的特征数量,我们使用scikit-learn库中的SelectFromModel[18] 结合RF分类器[19] 作为元变换器包装选择器。此分析在冷启动阶段(前1500个样本)进行,分别在场景1和场景2中从原始集合中选择36%和18%的特征。此过程在实验开始时仅执行一次。
冷启动后,特征通过VarianceThreshold[20] 方法进行评估。该函数分析方差变化,并丢弃方差为0的特征。此过程允许从冷启动期间的第一个选择过程中选择最相关的特征。请注意,所选特征集会根据流生命周期中的方差值变化。
E. 分类模块
我们的方法分析了GNB[21]、HATC[22] 和 ARFC[23] ML模型在流式环境中的性能。
每个分类器的超参数在冷启动阶段通过应用针对流式操作的GridSearchCV[24] 方法的定制版本计算。此方法在Listings 3和4定义的参数范围内评估HATC和ARFC[25] 模型,选定的参数以粗体标记。
清单3. HATC超参数集。
depth
=
[
None,
50
,
100
,
200
]
=[\text { None, } 50,100,200]
=[ None, 50,100,200]
tiethreshold
=
[
0.9
,
0.5
,
0.05
,
0.005
]
=[0.9,0.5,0.05,0.005]
=[0.9,0.5,0.05,0.005]
maxsize
=
[
15
,
50
,
100
,
200
]
=[15,50,100,200]
=[15,50,100,200]
清单4. ARFC超参数集。
n_models
=
[
10
,
25
,
50
,
75
,
100
]
=[10,25,50,75,100]
=[10,25,50,75,100]
max_features
=
[
s
q
r
t
,
4
,
10
,
25
]
=[\mathrm{sqrt}, 4,10,25]
=[sqrt,4,10,25]
lambda_value
=
[
2
,
6
,
10
,
25
]
=[2,6,10,25]
=[2,6,10,25]
表IV 显示了场景1和场景2的结果。ARFC表现最佳,在场景1中所有指标超过80%,在场景2中大多数指标接近90%。更具体地说,ARFC在网络欺凌召回率指标上与GBN和HATC相比分别高出5%和7%。关于场景2,HATC和ARFC模型在所有指标上均超过80%。然而,在这种情况下,模型之间的差异更为显著,ARFC在无网络欺凌召回率指标上比GNB高出17%。鉴于ARFC是最好的模型,两个场景之间
1
1
)
{ }^{1)}
1) 可用网址 https://pypi.org/project/textstat, 2024年10月。
12
{ }^{12}
12 可用网址 https://pypi.org/project/text2emotion, 2024年10月。
13
{ }^{13}
13 可用网址 https://spacy.io, 2024年10月。
14
{ }^{14}
14 可用网址 https://platform.openai.com/docs/models/gpt-4o-mini, 2024年10月。
15
{ }^{15}
15 可用网址 https://openai.com/api, 2024年10月。
16
{ }^{16}
16 这可以防止模型对相同输入生成随机响应。
17
{ }^{17}
17 可用网址 https://scikit-learn.org/stable/modules/generated/sklearn.feat ure_extraction.text.CountVectorizer.html, 2024年10月。
18
{ }^{18}
18 可用网址 https://scikit-learn.org/stable/modules/generated/sklearn.feat ure_selection.SelectFromModel.html, 2024年10月。
我们的结果与表I中选出的前沿解决方案相比有了显著改进:比M.S. Islam和R. I. Rafiq(2023)[1]的网络欺凌召回率高出41%,比A. Sadek等(2023)[21]的网络欺凌精确率高出22%,比E. A. Nina-Gutiérrez等(2024)[22]的宏召回率高出11%。
关于最相关的研究,H. Herodotou等(2020)[6] 提出了一种没有可解释性的流式ML系统。请注意,他们的方法完全依赖于内容相关特征。在这方面,不考虑泛化和偏差限制的情况下获得了更好的性能。此外,我们的系统收敛速度更快(使用前4000个样本,宏F-measure高出39%)。最终,Y. Yan等(2023)[19] 是唯一结合ML和LLMs的提案,但为批量设置且不具备可解释性能力。我们的结果在宏精度指标上比后者的解决方案高出13%。
F. 可解释性模块
我们应用第III-E节中描述的方法生成ARFC模型预测的自然语言解释。清单5显示了用于指导GET-40-mini模型的OpenAI API的提示模板。模板包括预测类别、Predict_Proba_One函数[26]给出的置信百分比、特征值和帖子内容。图2显示了一个带有收集帖子列表和预期类别的仪表板(见底部)。当前由LLM生成的描述位于屏幕顶部,右侧是预测类别(红色表示网络欺凌存在,绿色表示不存在)以及置信区间。
V. 结论
新型社交媒体网络和平台的普及源于现代社会对虚拟互动和通信的日益增长的使用。尽管它们提供了即时和无处不在的连接,但也促进了不受限制地接触其他成员,可能包括分享敏感内容、发送威胁信息或传播虚假信息和谣言等负面行为。在这些负面后果中,网络欺凌值得关注,因为它对人们的健康有直接的负面影响。
清单5. ChatGPT可解释性提示。
生成一个少于500个字符的解释,说明为什么这篇帖子被归类为[网络欺凌/非网络欺凌],置信度为[xx%]。请注意,生成预测的模型使用的特征是:贬义=[0/1],
羞辱=[0/1],种族主义=[0/1],讽刺=[0/1],
性相关=[0/1],威胁=[0/1],暴力=[0/1]。
<帖子内容>
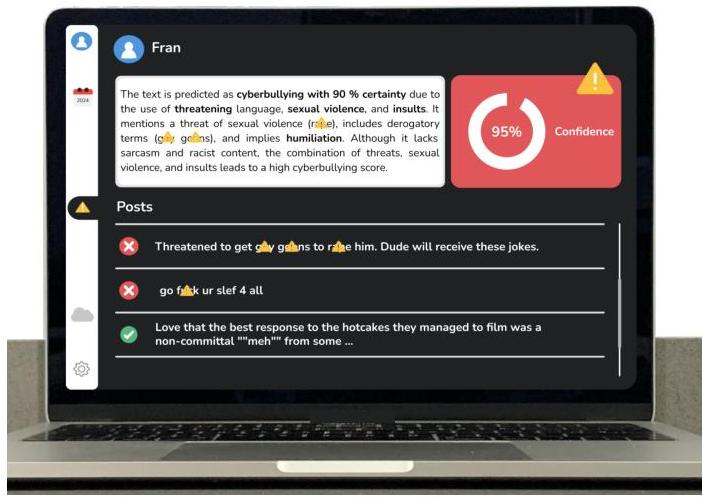
图2. 可解释性仪表板。
我们在网络欺凌文献中发现了一个显著的空白,即实时解决方案(即在流式环境中运行的解决方案)。此外,很少有研究联合利用LLMs的语言理解能力和使用高度准确的检测方法如ML。最终,缺乏可解释和可解释的解决方案也值得提及。因此,我们提出了一种创新的实时网络欺凌检测解决方案,结合了基于流的ML和LLMs。我们工作的贡献包括一个可解释的仪表板,提供分类预测背后的理由及其置信度。
实验数据显示,在所有评估指标上表现接近90%,超越了文献中竞争作品的结果。最终,我们的提案促进了可信度、可靠性、问责制和在线安全,有助于缓解网络欺凌的负面影响。在未来的工作中,我们计划采用多标签方法标记不同滥用行为(如种族歧视、性别歧视)的评论,并应用基于滑动窗口的特征工程、分析和选择,以考虑用户过去的行为。此外,我们希望对非人类生成的数据进行实验,以对抗在线社区中仇恨机器人(hate bots)的扩散。还将考虑多模态数据(如图像)。最终目标是分析所提出的在线解决方案的长期适应性和性能,提供个性化和有针对性的干预措施,并评估其在偏见和歧视脆弱性方面的结果。
竞争利益声明
作者声明与本文内容无关的竞争利益。
致谢
这项工作得到了加利西亚自治区政府资助的部分支持,资助编号为ED481B-2022-093 和 ED481D 2024/014,西班牙。
26
{ }^{26}
26 可用网址 https://riverml.xyz/0.11.1/api/base/Classifier, 2024年10月。
表IV
分类结果。
| 场景 | 模型 | 准确率 | 精确率 | 召回率 | F-measure | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 宏平均 | 缺失 | 存在 | 宏平均 | 缺失 | 存在 | 宏平均 | 缺失 | |||
| 1 | GNB | 83.03 | 83.67 | 79.25 | 88.10 | 82.97 | 89.91 | 76.04 | 82.93 | 84.24 |
| HATC | 84.01 | 85.37 | 78.67 | 92.06 | 83.93 | 93.72 | 74.14 | 83.83 | 85.54 | |
| ARFC | 85.00 | 85.20 | 82.74 | 87.67 | 84.97 | 88.78 | 81.15 | 84.97 | 85.66 | |
| 2 | GNB | 84.46 | 85.18 | 90.44 | 79.92 | 84.52 | 77.37 | 91.67 | 84.40 | 83.40 |
| HATC | 85.77 | 86.06 | 83.03 | 89.09 | 85.73 | 90.23 | 81.23 | 85.73 | 86.48 | |
| ARFC | 90.55 | 90.84 | 87.63 | 94.06 | 90.52 | 94.63 | 86.40 | 90.53 | 91.00 |
参考文献
[1] M. S. Islam 和 R. I. Rafiq, “比较GPT模型在社交媒体平台线程中检测网络欺凌的分析,” 在年度国际信息管理和大数据会议论文集。Springer, 2023, 第331-346页。
[2] K. Saifullah, M. I. Khan, S. Jamal 和 I. H. Sarker, “基于深度学习和基于转换器的语言模型的网络欺凌文本识别,” EAI认可的工业网络与智能系统交易期刊, 卷11, 第1-12页, 2024年。
[3] M. Arisanty 和 G. Wiradharma, “社交媒体中作为网络欺凌行为的火焰攻击者动机研究,” 传播学杂志, 卷10, 第215页, 2022年。
[4] K. Verma, T. Milosevic, K. Cortis 和 B. Davis, “基准语言模型用于从社交媒体文本中识别和分类网络欺凌,” 在语言资源和评估会议论文集 - 公平、包容和安全社会的语言技术和资源研讨会。欧洲语言资源协会, 2022, 第26-31页。
[5] H. Saini, H. Mehra, R. Rani, G. Jaiswal, A. Sharma 和 A. Dev, “增强网络欺凌检测:集成CNN-SVM和BERT模型的比较研究,” 社交网络分析与挖掘, 卷14, 第1-18页, 2023年。
[6] H. Herodotou, D. Chatzakou 和 N. Kourtellis, “在线推特攻击检测的流式机器学习框架,” 在IEEE国际大数据会议论文集。IEEE, 2020, 第5056-5067页。
[7] P. Vanpech, K. Peerabenjakul, N. Suriwong 和 S. Fugkeaw, “使用语言学习模型检测社交网络中的网络欺凌,” 在国际知识与智能技术会议论文集。IEEE, 2024, 第161-166页。
[8] T. H. Teng 和 K. D. Varathan, “社交网络中网络欺凌检测:机器学习和迁移学习方法的比较,” IEEE Access, 卷11, 第55 533-55 560页, 2023年。
[9] L. Cheng, R. Guo, Y. N. Silva, D. Hall 和 H. Liu, “使用分层注意力网络建模网络欺凌检测的时间模式,” ACM/IMS 数据科学交易, 卷2, 第1-23页, 2021年。
[10] A. Muneer, A. Alwadain, M. G. Ragab 和 A. Alqushaibi, “使用堆叠集成学习和增强BERT进行社交网络中的网络欺凌检测,” 信息, 卷14, 第467页, 2023年。
[11] R. Daniel, T. S. Murthy, C. D. V. P. Kumari, E. L. Lydia, M. K. Ishak, M. Hadjouni 和 S. M. Mostafa, “用于社交网络中网络欺凌检测的集成学习与锦标赛选择萤火虫群优化算法,” IEEE Access, 卷11, 第123 392-123 400页, 2023年。
[12] S. G. Tesfagergish 和 R. Damaševičius, 用于对抗网络欺凌的可解释人工智能。Springer, 2024, 卷2030, 第54-67页。
[13] V. U. Gongane, M. V. Munot 和 A. Anuse, “可靠检测网络欺凌的可解释人工智能,” 在IEEE浦那分会国际会议论文集。IEEE, 2023, 第1-6页。
[14] H. Mehta 和 K. Passi, “使用可解释人工智能(XAI)检测社交媒体仇恨言论,” 算法, 卷15, 第291313页, 2022年。
[15] E. Balkir, I. Nejadgholi, K. Fraser 和 S. Kritichenko, “文本分类器的必要性和充分性解释:仇恨言论检测案例研究,” 在北美计算语言学协会年会论文集:人类语言技术。计算语言学协会, 2022, 第2672-2686页。
[16] S. Paul 和 S. Saha, “CyberBERT:用于网络欺凌识别的BERT,” 多媒体系统, 卷28, 第1897-1904页, 2022年。
[17] A. C. Mazari 和 H. Kheddar, “基于深度学习的阿尔及利亚方言数据集目标仇恨言论、冒犯性语言和网络欺凌分析,” 国际计算与数字系统杂志, 卷13, 第965-972页, 2023年。
[18] D. Chatzakou, I. Leontiadis, J. Blackburn, E. D. Cristofaro, G. Stringhini, A. Vakali 和 N. Kourtellis, “社交网络中网络欺凌和网络攻击的检测,” ACM Web事务期刊, 卷13, 第1-51页, 2019年。
[19] Y. Yan, W. Du, Y. Sun 和 D. Yin, “KNCD:用于网络欺凌检测的知识增强网络,” 在智能计算与人机交互国际会议论文集。IEEE, 2023, 第443-447页。
[20] M. Wich, E. Mosca, A. Gorniak, J. Hingerl 和 G. Groh, 利用用户和网络数据的可解释性辱骂语言分类。Springer, 2021, 卷12979 LNAI, 第481-496页。
[21] A. Sadek, M. I. Khalil 和 C. Salama, “使用机器学习和ChatGPT检测阿拉伯语网络欺凌,” 在新兴科学新型智能和领先会议论文集。IEEE, 2023, 第242-245页。
[22] E. A. Nina-Gutièrrez, J. E. Pacheco-Alanya 和 J. C. Morales-Azevalo, “使用微调GPT-3.5模型进行多语言社交网络中的网络欺凌检测,” 在深度学习理论与应用国际会议论文集。Springer, 2024, 第252-263页。
[23] R. I. Rafiq, H. Hosseinmardi, R. Han, Q. Lv 和 S. Mishra, “在线社交网络中可扩展且及时的网络欺凌检测,” 在年度ACM应用计算会议论文集。计算机协会, 2018, 第1738-1747页。
[24] T. Ahmed, S. Ivan, M. Kabir, H. Mahmud 和 K. Hasan, “基于变压器架构及其集成检测特征型网络欺凌的性能分析,” 社交网络分析与挖掘, 卷12, 第1期, 第99-115页, 2022年。
[25] P. Aggarwal 和 R. Mahajan, “保护社交媒体:BERT和SVM联合用于网络欺凌检测与分类,” 信息系统与信息学杂志, 卷6, 第2期, 第607-623页, 2024年。
[26] V. Pawar, D. V. Jose 和 A. Patil, “网络欺凌检测的可解释人工智能方法,” 在IEEE移动网络与无线通信国际会议论文集。IEEE, 2022, 第1-4页。
[27] M. H. Shakil 和 M. G. R. Alam, “通过可解释的人工智能实现NLP和CNN结合机器学习算法的仇恨言论分类,” 在IEEE地区研讨会论文集。IEEE, 2022, 第1-6页。
[28] M. Umer, E. A. Alabdulqader, A. A. Alarfaj, L. Cascone 和 M. Nappi, “使用PCA提取的GLOVE特征和RoBERTaNet变换学习模型进行网络欺凌检测,” IEEE计算社会科学系统汇刊, 第10-10页, 2024年。
[29] N. Burkart 和 M. F. Huber, “监督机器学习可解释性的综述,” 人工智能研究杂志, 卷70, 第245-317页, 2021年。
[30] S. Xu, “贝叶斯朴素贝叶斯分类器用于文本分类,” 信息科学杂志, 卷44, 第48-59页, 2018年。
[31] A. I. Weinberg 和 M. Last, “EnHAT - 树基集成与霍夫丁自适应树协同作用于动态数据流挖掘,” 信息融合, 卷89, 第397-404页, 2023年。
[32] W. Zhang, A. Bifet, X. Zhang, J. C. Weiss 和 W. Nejdl, FARF: 公平且自适应随机森林分类器。Springer, 2021, 卷12713 LNAI, 第245-256页。
[33] J. Wang, K. Fu 和 C.-T. Lu, “SOSNet: 细粒度网络欺凌检测的图卷积网络方法,” 在IEEE国际大数据会议论文集。IEEE, 2020, 第1699-1708页。
参考论文:https://arxiv.org/pdf/2505.03746
19 { }^{19} 19 可用网址 https://scikit-learn.org/stable/modules/generated/sklearn.en semble.RandomForestClassifier.html, 2024年10月。
20 { }^{20} 20 可用网址 https://riverml.xyz/0.11.1/api/feature-selection/VarianceThr eshold, 2024年10月。
21 { }^{21} 21 可用网址 https://riverml.xyz/dev/api/naive-bayes/GaussianNB, 2024年10月。
22 { }^{22} 22 可用网址 https://riverml.xyz/0.11.1/api/tree/HoeffdingAdaptiveTreeC lassifier, 2024年10月。
23 { }^{23} 23 可用网址 https://riverml.xyz/0.11.1/api/ensemble/AdaptiveRandomFo restClassifier, 2024年10月。
24 { }^{24} 24 可用网址 https://scikit-learn.org/stable/modules/generated/sklearn.mo del_selection.GridSearchCV.html, 2024年10月。
25 { }^{25} 25 GNB没有需要调整的超参数。
的表现差异约为5%,这促使我们放弃基于内容的特征,并得到文献分析的支持。 ↩︎ ↩︎



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











