






You Peng
1
∗
{ }^{1 *}
1∗, Youhe Jiang
1
∗
{ }^{1 *}
1∗, Chen Wang
2
{ }^{2}
2, 和 Binhang Yuan
11
{ }^{11}
11
1
{ }^{1}
1 香港科技大学
2
{ }^{2}
2 清华大学
摘要
最近在利用大规模语言模型(LLMs)的代理范式方面的进展显著增强了文本到SQL的能力,使没有专门数据库知识的用户能够直观地查询数据。然而,在生产环境中部署这些基于代理LLM的文本到SQL系统存在重大挑战,因为它们具有多阶段的工作流程、严格的延迟约束以及企业环境中可能存在的异构GPU基础设施。当前的LLM服务框架缺乏有效的机制来处理相互依赖的推理任务、动态延迟变化和资源异构性,导致性能不佳并频繁违反服务水平目标(SLO)。本文介绍了Hexgen-Text2SQL,这是一种专门为在异构GPU集群上调度和执行基于代理多阶段LLM的文本到SQL工作流而设计的新框架,用于处理多租户端到端查询。Hexgen-Text2SQL引入了一种分层调度方法,结合全局工作负载平衡任务分发和本地自适应紧迫性导向优先级排序,由对代理文本到SQL工作流的系统分析指导。此外,我们提出了一种轻量级的基于模拟的方法来调整关键调度超参数,进一步增强其鲁棒性和适应性。我们在现实的文本到SQL基准上的广泛评估表明,Hexgen-Text2SQL显著优于最先进的LLM服务框架。具体来说,与vLLM相比,Hexgen-Text2SQL在多样化的现实工作负载条件下最多可减少 1.67 × 1.67 \times 1.67× 的延迟期限(平均值为 1.41 × 1.41 \times 1.41×),并将系统吞吐量提高多达 1.75 × 1.75 \times 1.75×(平均值为 1.65 × 1.65 \times 1.65×)。我们的代码可在Relaxed-SystemLab/Hexgen-Flow获取。
1 引言
最近在大型语言模型(LLMs)方面的进展带来了文本到SQL领域的重大突破——即将自然语言问题转化为SQL查询的任务 [1, 2, 3, 4]。此类进展有潜力通过赋予非专家用户直观查询数据的能力,而无需手动编写复杂的SQL语句,从而实现关系数据库高级使用的民主化。然而,在生产环境中部署基于代理LLM的文本到SQL系统需要的不仅仅是利用最先进的LLM [5, 6, 7, 8, 9] 和先进的代理推理时间扩展算法 [10, 11]——还需要一个高效的推理服务基础设施。具体而言,这种基础设施必须管理包含多个相互依赖的LLM推理请求的工作流,并满足严格的延迟和吞吐量需求,特别是在部署于展现某些计算异构性的企业GPU集群时。在本文中,我们解决了在计算异构、多租户服务环境中高效调度和执行基于代理多阶段LLM的文本到SQL工作负载的挑战。
对于基于代理LLM的文本到SQL工作流,一个高效的服务基础设施对于实际部署至关重要,尤其是在以严格的服务级别目标(SLOs)为特征的企业生产环境中。满足这些SLOs具有挑战性,这是由于基于代理LLM的文本到SQL范式的固有多阶段特性,其中每个用户发出的文本到SQL查询都会触发多个相互依赖的LLM推理请求和后续的数据库交互。例如,单个自然语言查询可能会同时生成多个候选SQL语句,每个语句都是通过不同的LLM提示产生的。如果发生执行错误,系统会迭代调用LLM来改进查询,有时可能需要多达十次迭代。虽然这种多阶段管道对于实现高精度是必不可少的,但它显著增加了计算复杂性、延迟敏感性和调度复杂性。
因此,服务于大量并发端到端文本到SQL查询的生产级系统必须有效地将不同阶段的LLM推理请求调度到异构GPU资源上,这些资源包含多个可能具有不同处理能力的LLM模型实例。这样的调度器必须明智地分配任务,确定LLM推理请求分配给适当的GPU实例及其在每个模型实例内的执行顺序,以确保遵守每条查询的截止日期,同时最大化整体系统吞吐量。解决这一调度挑战至关重要:不良的调度决策会大幅降低响应时间,影响用户体验,并削弱自然语言驱动的数据库接口的实际效用。该调度问题是固有的非平凡问题,因为适用于较简单工作负载的简单调度方法无法管理文本到SQL服务中固有的动态依赖、延迟变化和资源异构性。
优化基于代理文本到SQL工作负载的LLM推理请求调度特别具有挑战性,原因在于以下几个相互关联的复杂性,如我们所列举的:
- LLM推理请求依赖性:最先进的文本到SQL代理本质上涉及多个相互依赖的阶段,每个阶段都具有不同的紧急程度。后期任务,例如最终的SQL验证,只有在前期阶段完成后才能开始。因此,早期推理阶段的延迟减少了后续任务的可用余地,增加了端到端截止日期违规的风险。
-
- LLM推理请求的异构性:文本到SQL工作流中的LLM推理请求在不同阶段表现出显著的变化,这由查询提示的长度和生成的输出令牌数量差异驱动。这种异构性使得执行延迟难以预测,从而复杂化了有效调度。
-
- 模型实例服务容量的异构性:企业生产环境通常利用具有不同计算能力的异构GPU。因此,LLM推理请求的吞吐量和延迟会因执行模型实例的GPU规格而显著不同。
-
- 多租户场景中的SLO约束:生产部署必须处理来自多个用户的连续端到端文本到SQL查询流,每个查询都有相应的不同SLO。因此,调度策略必须能够在生产环境中适应各种优先级。
由于这些相互交织的因素,简单的调度方法,如轮询调度或先到先服务(FCFS)队列,由流行的LLM服务系统实施,在实践中将是无效的。这些幼稚的方法忽略了关键任务依赖、延迟变化和GPU异构性,导致资源利用率低下、频繁违反SLO以及在现实工作负载下系统响应能力下降。
- 多租户场景中的SLO约束:生产部署必须处理来自多个用户的连续端到端文本到SQL查询流,每个查询都有相应的不同SLO。因此,调度策略必须能够在生产环境中适应各种优先级。
需要注意的是,现有的LLM服务框架主要针对独立的LLM推理任务,忽视了具有多个阶段及其内在依赖的复杂端到端工作流。通用调度程序通常单独处理请求,缺乏对依赖子任务的有效协调或强制执行端到端截止日期。近期探索自适应批处理 [16]、优先级感知请求分配 [17, 18] 和GPU负载均衡 [19] 的工作通常假设LLM推理任务之间的独立性,未能充分解决异构工作流。因此,需要避免违反截止日期的任务抢占场景仍未得到解决。基于代理LLM的文本到SQL服务中独特的多阶段管道依赖和GPU资源异构性的组合仍很大程度上未被探索,突显了当前服务基础设施中的关键差距。为了解决这些挑战,我们提出了HEXGEN-TEXT2SQL,这是一个专为在异构GPU服务环境中高效调度和执行基于代理的文本到SQL工作负载而设计的新框架,支持多租户查询。我们的贡献可以总结如下:
贡献1. 我们提出了HEXGEN-TEXT2SQL,一种基于代理LLM的文本到SQL服务框架,由对工作流的仔细分析指导。该设计明确考虑了文本到SQL管道的多阶段性质,管理跨阶段依赖关系,同时利用独立子任务之间的并行性。通过构建支持代理LLM推理循环的HEXGEN-TEXT2SQL结构,我们实现了顺序和并行推理任务的有效推进,减少了依赖阶段之间的空闲时间。该架构包括一个全局协调层和每个实例的执行管理,以无缝编排跨异构GPU资源的任务流动。这种分析驱动的设计为在多租户环境中满足严格的SLO建立了坚实的基础。
贡献2. 我们设计了一种新颖的两级调度算法,该算法可以有效地协调由多个LLM模型服务实例组成的池中的LLM推理请求,这些实例具有不同的LLM请求处理能力。在全局层面,一个工作负载平衡的调度器将每个传入的LLM推理任务分配给最适合的模型实例,考虑到该模型实例的处理能力和当前负载。每个模型实例中的本地优先队列采用一种自适应紧迫性引导的排队策略,根据剩余的截止日期余地和估计的执行时间动态优先化任务。这种分层调度策略确保必要的推理阶段可以在必要时抢占不太重要的任务,从而使HEXGEN-TEXT2SQL即使在重多租户工作负载下也能满足严格的每查询SLO。我们还采用模拟驱动的方法来确定一些关键超参数,使算法在多样化的工作负载模式下保持稳健。一起,这些调度创新使HEXGEN-TEXT2SQL能够充分利用异构硬件并行性,同时实现持续低延迟和高吞吐量。
贡献3. 我们对HEXGEN-TEXT2SQL进行了全面的实验评估,以展示其在现实的基于代理LLM的文本到SQL工作负载上的性能。我们的实验在异构GPU集群上部署HEXGEN-TEXT2SQL,并将其与最先进的LLM服务系统进行比较。结果表明,HEXGEN-TEXT2SQL始终满足严格的服务级别目标,显著减少了查询响应时间和提高了吞吐量,与现有解决方案相比。具体来说,与vLLM相比,HEXGEN-TEXT2SQL在多样化的现实工作负载条件下最多可减少
1.67
×
1.67 \times
1.67× 的延迟期限(平均值为
1.41
×
1.41 \times
1.41×),并将系统吞吐量提高多达
1.75
×
1.75 \times
1.75×(平均值为
1.65
×
1.65 \times
1.65×)。我们还观察到,HEXGEN-TEXT2SQL的调度策略确保了在查询复杂度各异的多租户场景下高效利用资源和稳健的性能。总体而言,该研究证实了HEXGEN-TEXT2SQL的架构和算法在端到端文本到SQL服务性能方面取得了实质性的改进。
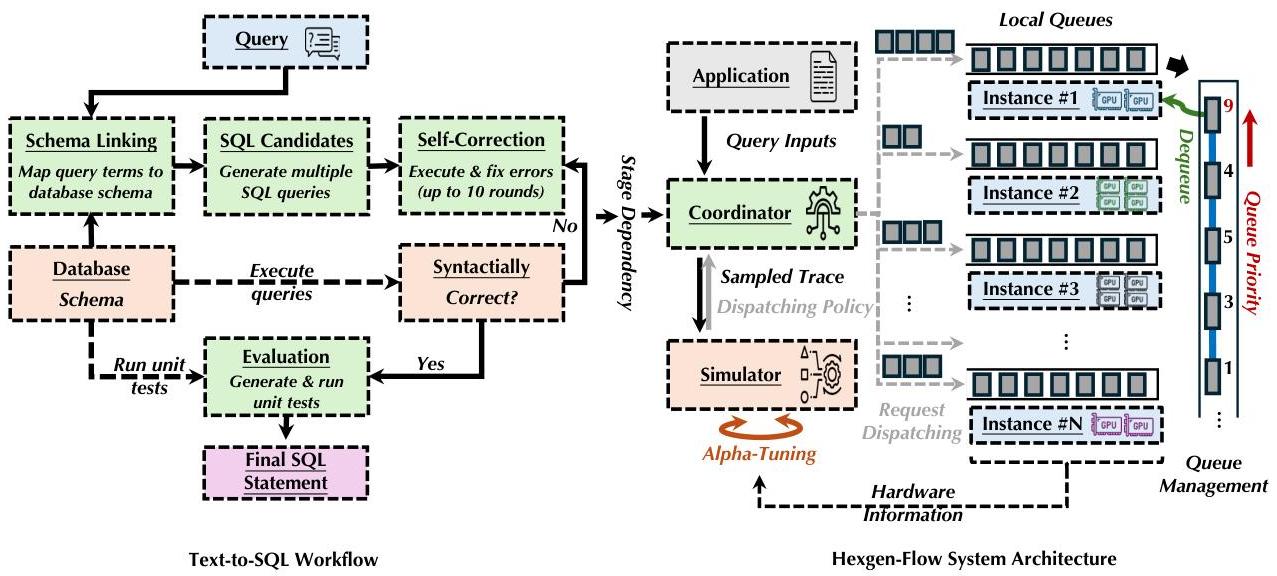
图1:文本到SQL工作流和Hexgen-Text2SQL系统架构。文本到SQL工作流提供了跨阶段依赖关系。传入的LLM推理请求由全局协调器根据工作负载平衡和任务适用性分派给模型实例。每个模型实例使用紧迫性引导的优先机制管理其队列。
2 基础知识
最先进的文本到SQL服务系统在提供端到端延迟敏感查询时面临独特挑战,要求在多个阶段内协调执行相互依赖的LLM推理请求。在本节中,我们首先形式化服务系统设计的关键概念:第2.1节将文本到SQL工作流分解为其组成阶段,强调序列依赖和多阶段模式,这需要专门的调度;第2.2节分析现有LLM服务系统中调度和排队策略的局限性,说明为什么通用调度器无法满足基于代理LLM的文本到SQL工作流的端到端延迟要求。
2.1 基于代理LLM的文本到SQL工作流
基于代理LLM的文本到SQL工作流涉及几个关键阶段,以将自然语言查询转换为可执行的SQL语句。如图1所示,我们将最新的代理文本到SQL范式(主要遵循Chess [20])的关键阶段总结如下:
- 模式链接:给定每个表的元数据和详细列描述,LLM识别并匹配用户自然语言查询中提到的实体与数据库模式中的相关表和列。此步骤对于准确地将用户的查询定位到基础数据库结构中至关重要。
-
- SQL候选生成:利用前一阶段的模式对齐,LLM从自然语言查询生成候选SQL查询。多个LLM推理请求并行执行,使用不同的提示和示例,以生成一组多样的候选查询。这种并行方法旨在捕捉用户意图的多种可能解释。
-
- 自我修正:候选SQL查询在数据库上执行,任何出现的执行错误都会触发后续LLM调用的迭代细化。系统可以迭代
- 修正查询,直到达到预定义的限制(例如,10次迭代),系统性地提高其准确性和正确性。
- 评估:自我修正确保语法正确后,LLM基于从原始查询衍生的自然语言生成多个单元测试。最终的SQL候选将在这些测试中进行评估,选择成功通过最多案例的查询。这些测试验证SQL候选的语义准确性和功能正确性,确保与用户原始意图的一致性。
2.2 LLM服务队列管理
当前流行的LLM服务框架,如vLLM [21]、Hugging Face的文本生成推理(TGI)[22]和NVIDIA的TensorRT-LLM [23],采用了各种优化的调度和队列策略,适用于通用的LLM服务。例如,vLLM利用连续批量处理 [24] 并采用先进先出(FCFS)策略,允许新的LLM推理请求在解码过程中加入正在进行的批次。TGI根据提示长度和生成参数对传入的LLM推理请求进行分组,以优化批次形成。TensorRT-LLM实现“飞行中”批量处理策略,通过Triton [25] 实现的调度策略管理并发的LLM推理请求,包括FIFO和基于优先级的排队。尽管这些框架对标准的LLM任务有效,但它们并非天生设计用于处理像文本到SQL这样的多阶段、依赖感知的代理工作流。
高级排队方法,如LLM服务队列管理(QLM)[26] 和虚拟令牌计数器(VTC)[27],已被提出以解决特定的性能和公平性要求 - QLM引入优先级调度以通过优先处理紧急的LLM推理请求来满足服务级别目标(SLO),并采用诸如抢占和状态交换等技术;VTC通过跟踪已服务的令牌数量并优先处理消耗较低的用户来确保资源分配的公平性。然而,这些机制仍然不能内在地考虑文本到SQL管道的细微差别,如不同阶段的计算成本差异或查询延迟对下游数据库性能的影响。
具体来说,我们总结了现有排队策略应用于代理文本到SQL工作流时面临的局限性:
- 缺乏LLM推理依赖意识:当前的排队系统不管理顺序阶段之间的依赖关系(例如,在SQL生成之前的模式链接),这可能导致多阶段查询处理效率低下。
-
- 请求调度忽略异构性:现有的排队策略统一对待所有LLM推理请求,未能考虑不同文本到SQL查询和不同计算能力的模型实例之间不同的资源需求,这可能导致资源利用不足和难以满足SLO。
-
- 在多租户环境中SLO管理不足:通用的LLM队列通常缺乏细粒度控制,无法在文本到SQL工作流中优先处理异构LLM推理请求,这使得在多租户设置中满足每个文本到SQL查询的SLO变得困难。
为了解决这些挑战,有必要设计一种专门针对文本到SQL多阶段和依赖感知性质的新型排队方法。这样的系统应优化端到端性能,并确保在多租户环境中严格遵守SLO。
- 在多租户环境中SLO管理不足:通用的LLM队列通常缺乏细粒度控制,无法在文本到SQL工作流中优先处理异构LLM推理请求,这使得在多租户设置中满足每个文本到SQL查询的SLO变得困难。
3 Hexgen-Text2SQL
在本节中,我们首先介绍文本到SQL LLM代理工作流的设计原则,然后展示框架设计。
3.1 文本到SQL服务的设计原则
鉴于第2.2节对现有LLM服务系统的局限性的分析,我们讨论了基于代理LLM的文本到SQL系统的设计原则,每个原则都针对代理文本到SQL工作流中固有的关键挑战。
原则1. 明确的多阶段依赖管理。代理文本到SQL工作流将每个端到端用户查询分解为顺序和并行阶段,包括模式链接、候选生成、自我修正和评估,每个阶段都会触发单个或多个LLM推理请求。这些请求在不同阶段的有效协调对于确保正确性和优化性能至关重要。一个高效的系统应该明确建模跨阶段依赖关系,在启动依赖任务之前确保前提阶段的完成。对于可并行化的任务,这样的系统应该能够并发分发子任务,并有效地管理其完成,从而最小化空闲时间并提高吞吐量。这种结构化的方法应该能够缓解无序执行的错误,并解决多阶段工作流编排的复杂性。
原则2. 考虑异构性的LLM推理请求分配。在生产环境中,硬件异构性非常普遍——部署通常涵盖具有不同计算能力、内存容量和性能特性的GPU混合体。这种多样性可能源于逐步的硬件升级或成本考虑。因此,有效的资源利用需要一种意识到多个LLM服务模型实例之间这些差异的调度策略。我们假设多个模型实例的分配可以通过现有系统 [28, 29, 30] 有效确定,其中分配可以优化在一组异构GPU上的端到端SLO或吞吐量,而每个模型实例可能表现出不同的服务容量。一个高效的系统可以通过将全局任务分配与本地执行管理分离来解决这个问题。例如,一个全局协调器可以评估每个任务的计算需求,如内存占用、预期执行时间和并行潜力,并将它们分配给最合适的硬件资源。这种全局视角确保最佳负载平衡并防止资源争用。在本地层面,每个模型实例可以管理任务优先级和执行,适应实时工作负载波动。这种调度确保高容量和低容量硬件都能得到有效利用,最大化整体系统吞吐量和性能。
原则3. SLO保证。在生产级别的文本到SQL服务系统中,遵守每个端到端SLO对于确保一致且可预测的性能尤为重要,尤其是在多租户环境中,多种工作负载共存。正如我们在第2.1节中所述,代理文本到SQL工作流的每个阶段都会对用户经历的整体延迟产生贡献。因此,管理并调度这些阶段时必须意识到它们对SLO的个别和集体影响。理想的LLM推理请求调度应能根据每个端到端文本到SQL查询的剩余时间预算和预计执行持续时间进行优先级排序。此外,在多租户场景中,不同的用户或应用程序可能有不同的SLO要求。理想的服务系统应通过维护每个SLO的跟踪并调整调度策略来满足这些差异化的目标。这种细粒度的控制应能防止某一租户的性能下降影响其他租户的情况,从而在整个系统中保持公平性和可预测性。
综上所述,我们认为这些原则使我们能够有效地管理复杂的工作流,优化资源利用,并满足性能保证,从而解决了现有文本到SQL服务系统中的关键局限性。
3.2 框架设计
遵循前面介绍的设计原则,HEXGEN-TEXT2SQL是一个分布式系统,旨在高效地在异构GPU集群中服务多阶段、基于LLM的文本到SQL推理工作负载。图1提供了所提议系统的概述。HEXGEN-TEXT2SQL的服务架构围绕一个集中式的全局协调器和多个GPU支持的LLM模型实例构建,反映了系统的三个指导原则。作为一个分布式文本到SQL服务系统,HEXGEN-TEXT2SQL明确设计用于在异构GPU部署下处理多阶段推理工作流,同时满足严格的每查询SLO截止日期。为了实现这些目标,HEXGEN-TEXT2SQL通过两级调度设计智能地分发和优先处理LLM推理任务。首先,一个全局协调器根据LLM请求的计算估算和每个模型实例的可用性(即排队状态)的变化,将每个传入的LLM推理请求分配给适当的模型服务实例。其次,每个模型实例管理自己的优先队列,根据紧迫性动态排序待处理的推理步骤。
接下来,我们将详细介绍每个原则如何体现在HEXGEN-TEXT2SQL的设计中,以及它为何对正确的和高效的文本到SQL执行至关重要。
多阶段依赖管理。端到端文本到SQL查询作为包含多个依赖阶段的代理工作流执行(例如,模式链接、SQL生成、错误校正、验证),这些阶段必须按照其继承的依赖关系依次进行——后期阶段无法开始,除非早期阶段完成,而且早期阶段的任何延迟都会削减后期阶段的时间预算。为了处理这些严格的跨阶段依赖关系,HEXGEN-TEXT2SQL将每个传入的端到端文本到SQL查询视为一系列相互依赖的LLM推理请求,而不是孤立的一个。全局协调器维护每个查询的流水线状态的显式表示,仅在前置任务完成后才调度LLM推理请求执行,确保正确的执行顺序。例如,一旦查询的模式链接步骤完成,协调器立即调度下一阶段(即生成SQL候选);如果某个阶段涉及可并行化的子任务,则它会在可用的模型服务实例上并发调度所有这些子任务,以加速该阶段的完成。这种显式的依赖关系追踪保证了正确性(每个LLM步骤都能看到从前置步骤来的适当输入),并防止浪费资源在由于未满足先决条件而最终无效的任务上。HEXGEN-TEXT2SQL监控每个端到端文本到SQL查询的进度,并在每个阶段完成后更新调度参数。特别是,查询的剩余端到端截止日期会被传播到其挂起的阶段——缩小这些阶段在分配模型实例中的本地优先队列中的允许执行窗口,从而增加它们在系统中的优先级。通过这种方式动态适应工作流的状态,HEXGEN-TEXT2SQL最小化了阶段间的空闲间隙,并确保下游任务不会因为上游延迟而错过截止日期。这种对多阶段依赖关系的原则性管理最终提高了性能和可靠性:通过避免不必要的等待,查询更快完成,同时大大降低了级联截止日期违规的风险。
LLM推理请求分配。用于LLM服务的生产GPU集群通常是异构的,其中标准调度算法 [29, 30, 28] 应该能够组织多个模型实例,从而实现最优的全局SLO或吞吐量,而每个模型实例可能表现出不同的LLM服务容量。另一方面,代理文本到SQL工作流中的LLM推理请求在资源需求上也是天然异构的:根据输入和输出长度的不同,从不同阶段发起的LLM推理请求可能具有广泛变化的执行时间。HEXGEN-TEXT2SQL通过一种考虑异构性的调度策略,明智地将每个LLM推理请求分配给最适合的模型实例来解决这种变异性。与其采用天真的轮询或FIFO分配(这将忽略硬件速度或当前负载的关键差异并导致SLO违规),HEXGEN-TEXT2SQL中的集中协调器采用一种工作负载平衡的分发策略。对于每个传入的LLM推理请求(可能对应某个端到端文本到SQL查询的阶段),协调器评估所有可用的模型实例,并根据两个因素选择目标实例:(i) 给定该模型实例的请求处理能力,该任务在此模型实例上的预期执行时间,以及 (ii) 该实例当前的工作负载(例如,队列长度或利用率)。具体来说,HEXGENTEXT2SQL的调度器为每种类型的GPU和文本到SQL推理步骤维护一个经验性能模型。HEXGEN-TEXT2SQL估计给定的LLM推理请求(例如,一定长度的提示和输出长度的预测)在每个候选模型实例上的运行速度,并且它知道每个设备的工作积压。利用这些信息,协调器为每个模型实例计算一个综合适合度分数,平衡将任务发送到最快可能模型实例的愿望与避免过载任何单一模型实例的需求。任务被派遣到得分最高的模型实例,即提供最低预期延迟和当前负载之间最佳权衡的那个。通过以这种考虑异构性的方式动态路由LLM推理请求,HEXGEN-TEXT2SQL比静态或负载无关的方案实现了更好的资源利用率和尾部延迟控制。较重或延迟敏感的查询倾向于在更强大的模型实例上运行,而较轻的任务可以填补较慢或较忙设备上的容量,从而实现集群工作负载的平衡。这种全局协调不仅提高了整体吞吐量,还有助于符合SLO,因为它防止了缓慢模型实例成为瓶颈或快速模型实例闲置的情况,从而减少了由于不适当的放置而导致查询错过截止日期的可能性。总之,考虑异构性的调度使HEXGEN-TEXT2SQL能够利用可用硬件多样性来提升性能,同时确保没有任何端到端查询的延迟SLO因不当分配而受到威胁。
自适应多租户优先级调度。为了在多租户环境中满足严格的SLO,HEXGEN-TEXT2SQL将其智能调度与按查询紧迫性感知的调度相结合。每个LLM服务模型实例运行一个自适应优先队列,根据任务的紧迫性不断重新排序待处理的LLM推理请求。而不是严格按照到达顺序处理LLM请求,每个模型实例总是执行最紧迫的任务——根据端到端文本到SQL查询的截止日期和剩余执行时间来定义。这种设计直接强制执行每个端到端文本到SQL查询的SLO保证:当系统处于负载下时,那些最接近违反其端到端时间预算的LLM推理请求将首先得到服务,以最小化错过截止日期的数量。具体来说,当一个新的文本到SQL查询进入系统时,HEXGEN-TEXT2SQL根据其SLO为其分配一个目标截止日期。这个总截止日期随后被分配到查询的多个阶段,以得出每个LLM推理请求的个体时间预算。预算分配考虑了每个步骤的平均预期持续时间,例如,计算密集型阶段将获得较大份额的总时间。模型实例中的优先队列使用这一点来计算任务的紧迫性,随着任务的等待时间增加或其截止日期临近,紧迫性也会增长。端到端文本到SQL查询如果有很少的空闲时间和非平凡的执行长度,将具有最高的紧迫值。优先队列在实时中连续更新每个任务的紧迫性:当一个LLM推理请求在队列中等待时,其空闲时间减少(增加SLO压力),并且每当同一查询的前一步骤完成时,后续步骤的剩余子截止日期将被重新计算以弥补失去的时间。在这种自适应策略下,最紧迫的LLM推理请求始终在模型实例可以接受新LLM推理请求时位于队列的前端。这种紧迫性驱动的调度机制对于在多租户场景下的重负载和不可预测条件下满足延迟目标至关重要。因此,HEXGEN-TEXT2SQL可以在尽可能多地保持模型实例繁忙的同时,保证高SLO达成率——绝大多数查询在截止日期前完成。全局考虑异构性的分发和局部紧迫性感知执行的结合-
使HEXGEN-TEXT2SQL能够提供可靠的性能,即满足每个端到端文本到SQL查询的截止日期。
通过系统地将这些原则嵌入其设计中,HEXGEN-TEXT2SQL提供了可靠、高效和可扩展的文本到SQL推理服务,直接应对了生产级基于LLM的工作流的独特需求。
4 调度算法
在本节中,我们将深入介绍全局协调器和本地优先队列的公式化和实现。我们首先将调度问题公式化如下:
问题公式化。正式地,考虑一系列文本到SQL查询
{
Q
1
,
Q
2
,
…
}
\left\{Q_{1}, Q_{2}, \ldots\right\}
{Q1,Q2,…},它们按照某种分布
P
Q
\mathbb{P}_{Q}
PQ到达,即
Q
i
∼
P
Q
Q_{i} \sim \mathbb{P}_{Q}
Qi∼PQ;每个查询
Q
i
Q_{i}
Qi包含一组LLM推理请求,表示为
{
q
i
,
1
,
q
i
,
2
,
…
,
q
i
,
j
,
…
q
i
,
n
i
}
\left\{q_{i, 1}, q_{i, 2}, \ldots, q_{i, j}, \ldots q_{i, n_{i}}\right\}
{qi,1,qi,2,…,qi,j,…qi,ni},以及一个端到端SLO,记为
T
i
SLO
T_{i}^{\text {SLO }}
TiSLO 。给定一组
N
N
N个模型实例,
M
=
{
m
1
,
m
2
,
…
m
N
}
\mathbf{M}=\left\{m_{1}, m_{2}, \ldots m_{N}\right\}
M={m1,m2,…mN},其中模型实例
m
m
m可以以不同的处理时间
t
i
,
j
m
t_{i, j}^{m}
ti,jm(包括分配给模型实例
m
m
m的排队时间和计算时间)处理LLM请求
q
i
,
j
q_{i, j}
qi,j,我们的调度问题的目标是找到某种LLM请求分配
ϕ
\phi
ϕ,其中LLM推理请求
q
i
,
j
q_{i, j}
qi,j由模型实例
m
i
,
j
∈
M
m_{i, j} \in \mathbf{M}
mi,j∈M执行,其中
ϕ
(
q
i
,
j
)
=
m
i
,
j
\phi\left(q_{i, j}\right)=m_{i, j}
ϕ(qi,j)=mi,j,以最大化从分布
P
Q
\mathbb{P}_{Q}
PQ到达的每个端到端文本到SQL查询
Q
i
Q_{i}
Qi在SLO之前被处理的概率:
arg max ϕ P ( ∑ i i , j t i , j ϕ ( q i , j ) ≤ T i S L O ∣ Q i ∼ P Q ) \arg \max _{\phi} \mathbb{P}\left(\sum_{i_{i, j}} t_{i, j}^{\phi\left(q_{i, j}\right)} \leq T_{i}^{\mathrm{SLO}} \mid Q_{i} \sim \mathbb{P}_{Q}\right) argϕmaxP ii,j∑ti,jϕ(qi,j)≤TiSLO∣Qi∼PQ
不幸的是,确定这种调度问题的最佳排队策略通常是计算上不可行的——作业特性的固有不确定性需要在没有完整信息的情况下进行动态决策,这使得调度问题成为NP难问题 [31]。因此,为了在异构GPU集群和多租户环境中实现稳健和高效的文本到SQL服务,我们提出了一种基于启发式的解决方案,其中我们引入了一种分层的两级调度算法,将全局任务分发与本地截止日期驱动的优先级结合在一起。具体来说,我们的设计包括以下组件:
- 在全局协调级别(见第4.1节),我们引入了一个工作负载平衡的调度器,该调度器动态地将每个传入的LLM推理请求分配给最适合的模型实例。此调度器共同考虑了:(i) LLM请求处理能力和(ii) 模型实例的当前工作负载分配和排队状态,有效地平衡计算负载并最大化GPU资源利用率。
-
- 在每个LLM服务模型实例的本地优先队列级别(见第4.2节),我们采用了一种高级的自适应优先队列方法,根据一个基于截止日期的紧迫性指标不断重新排序任务。这种优先级排列使高紧迫性任务——那些接近其端到端截止日期的任务——可以抢占不太重要的任务,显著减少SLO违规的风险。
-
- 此外,我们纳入了一种基于模拟的调整机制(见第4.3节),该机制定期调整全局分发协调的超参数,在不同的运行时条件下平衡硬件任务对齐与工作负载分布。
这些设计元素一起确保(i) 最大限度地利用异构模型实例的服务能力,以及(ii) 在动态、多租户部署中可靠地遵守严格的每查询延迟目标。
- 此外,我们纳入了一种基于模拟的调整机制(见第4.3节),该机制定期调整全局分发协调的超参数,在不同的运行时条件下平衡硬件任务对齐与工作负载分布。
4.1 工作负载平衡分发策略
为了在异构GPU集群上高效服务文本到SQL工作负载,HEXGEN-TEXT2SQL采用了一种工作负载平衡分发策略,将每个LLM推理请求分配给最适合的LLM服务模型实例。该策略共同考虑了(i) 每个实例对传入LLM推理请求的执行效率和(ii) 每个模型实例的当前排队推理工作负载。此外,引入了一个可调超参数
α
∈
[
0
,
1
]
\alpha \in[0,1]
α∈[0,1],以动态平衡这两个因素之间的权衡。我们将在第4.3节讨论如何调整
α
\alpha
α。
推断计算成本。对于每个传入的LLM推理请求
q
i
,
j
q_{i, j}
qi,j,我们首先通过函数
L
^
out
(
q
i
,
j
)
\hat{L}_{\text {out }}\left(q_{i, j}\right)
L^out (qi,j)估计其输出长度,该函数由其输入长度导出——我们的实现基于Zheng等人[32]介绍的预测方法。基于该估计,我们通过以下方程得到
q
i
,
j
q_{i, j}
qi,j在模型实例
m
m
m上的预测计算执行成本,记为
t
comp
i
,
j
m
t_{\text {comp }_{i, j}^{m}}
tcomp i,jm:
t comp i , j m = t prefil m ( L ( q i , j ) ) + t decode m ( L ^ out ( q i , j ) ) t_{\text {comp }_{i, j}^{m}}=t_{\text {prefil }}{ }^{m}\left(L\left(q_{i, j}\right)\right)+t_{\text {decode }}{ }^{m}\left(\hat{L}_{\text {out }}\left(q_{i, j}\right)\right) tcomp i,jm=tprefil m(L(qi,j))+tdecode m(L^out (qi,j))
其中
t
prefil
m
(
L
(
q
i
,
j
)
)
t_{\text {prefil }}{ }^{m}\left(L\left(q_{i, j}\right)\right)
tprefil m(L(qi,j))和
t
decode
m
(
L
^
out
(
q
i
,
j
)
)
t_{\text {decode }}{ }^{m}\left(\hat{L}_{\text {out }}\left(q_{i, j}\right)\right)
tdecode m(L^out (qi,j))分别表示基于输入令牌数量和估计输出令牌数量在模型实例
m
m
m上的预填充和解码阶段的估计执行时间。
(最大)排队成本的公式化。
q
i
,
j
q_{i, j}
qi,j在实例
m
m
m上的预期排队时间成本,记为
t
queue
i
,
j
m
t_{\text {queue }_{i, j}^{m}}
tqueue i,jm,通过将模型实例
m
m
m队列
Θ
m
\Theta^{m}
Θm中所有任务的执行成本相加估计得出:
t queue i , j m = ∑ q i ′ , j ′ ∈ Θ m t comp i ′ , j ′ m t_{\text {queue }_{i, j}^{m}}=\sum_{q_{i^{\prime}, j^{\prime}} \in \Theta^{m}} t_{\text {comp }_{i^{\prime}, j^{\prime}}^{m}} tqueue i,jm=qi′,j′∈Θm∑tcomp i′,j′m
注意,
t
queue
i
,
j
m
t_{\text {queue }_{i, j}^{m}}
tqueue i,jm捕获了如果
q
i
,
j
q_{i, j}
qi,j被分派到模型实例
m
m
m,它在执行开始前所可能等待的最长的时间。
选择服务模型实例。给定推理计算时间和排队时间的估计,理想实例在这两方面的估计都较低。然而,这两者的线性组合存在问题——执行时间相对可预测,而排队时间可以根据我们在每个本地优先队列中实现的紧迫性进行积极调整。因此,我们定义以下非线性组合作为启发式评分:
Score ( q i , j , m ) = ( 1 − α ) ⋅ β t queue i , j m − α ⋅ t comp i , j m \text { Score }\left(q_{i, j}, m\right)=(1-\alpha) \cdot \frac{\beta}{t_{\text {queue }_{i, j}^{m}}}-\alpha \cdot t_{\text {comp }_{i, j}^{m}} Score (qi,j,m)=(1−α)⋅tqueue i,jmβ−α⋅tcomp i,jm
对于LLM推理请求 q i , j q_{i, j} qi,j和模型实例 m − q i , j m-q_{i, j} m−qi,j,将被分派到得分最高的实例。请注意,此启发式评分中有两个超参数( α \alpha α和 β \beta β);在我们的部署中,我们通过一些试验固定 β \beta β的值,而在服务期间动态在线调整 α \alpha α。权重因子 α \alpha α决定了分发偏向快速执行还是负载平衡的程度。当 α = 1 \alpha=1 α=1时,只考虑执行速度;当 α = 0 \alpha=0 α=0时,只考虑队列深度。我们通过模拟经验确定最优的 α \alpha α,评估不同负载和配置下的系统级SLO达成情况(见第4.3节)。
4.2 本地优先队列
在工作负载平衡分发策略将LLM推理请求分配给模型实例之后,每个实例使用本地优先队列策略管理其请求。该优先队列根据其对应的端到端文本到SQL查询的紧迫性和实时排队条件动态重新排名LLM推理请求,启用多阶段工作流的及时进展。正式地,为了确定本地队列中每个LLM推理请求的优先级,我们根据执行成本和剩余端到端截止日期为 q i , j q_{i, j} qi,j分配一个每请求SLO预算 t i , j S L O t_{i, j}^{\mathrm{SLO}} ti,jSLO:
t i , j S L O = ( T i S L O − τ elapsed i ) ⋅ t ˉ comp i , j ∑ k = j n i t ˉ comp i , k t_{i, j}^{\mathrm{SLO}}=\left(T_{i}^{\mathrm{SLO}}-\tau_{\text {elapsed }}^{i}\right) \cdot \frac{\bar{t}_{\text {comp }_{i, j}}}{\sum_{k=j}^{n_{i}} \bar{t}_{\text {comp }_{i, k}}} ti,jSLO=(TiSLO−τelapsed i)⋅∑k=jnitˉcomp i,ktˉcomp i,j
其中 τ elapsed i \tau_{\text {elapsed }}^{i} τelapsed i是从 Q i Q_{i} Qi到达全局协调器以来经过的时间,而 t ˉ comp i , k \bar{t}_{\text {comp }_{i, k}} tˉcomp i,k是LLM推理 q i , j q_{i, j} qi,j在所有模型实例上的平均执行成本,即,
t ˉ comp i , j = 1 N ∑ m ∈ M t comp i , j m \bar{t}_{\text {comp }_{i, j}}=\frac{1}{N} \sum_{m \in \mathbf{M}} t_{\text {comp }_{i, j}^{m}} tˉcomp i,j=N1m∈M∑tcomp i,jm
这种比例分配确保为成本较高的下游LLM推理请求分配更多时间。
紧迫性指标的公式化。假设LLM推理请求
q
i
,
j
q_{i, j}
qi,j被分派到模型实例
m
m
m,我们定义
q
i
,
j
q_{i, j}
qi,j的紧迫性
U
i
,
j
U_{i, j}
Ui,j为它的执行成本与剩余SLO余量之间的差值:
U i , j = t comp i , j m − ( t i , j S L O − τ i , j ) U_{i, j}=t_{\text {comp }_{i, j}^{m}}-\left(t_{i, j}^{\mathrm{SLO}}-\tau_{i, j}\right) Ui,j=tcomp i,jm−(ti,jSLO−τi,j)
其中
t
comp
i
,
j
m
t_{\text {comp }_{i, j}^{m}}
tcomp i,jm是我们定义在方程2中的任务在实例
m
m
m上的估计执行成本,而
τ
i
,
j
\tau_{i, j}
τi,j表示本地优先队列自
q
i
,
j
q_{i, j}
qi,j进入本地队列以来实际的排队延迟。注意,更高的紧迫性意味着更大的SLO违规风险。
本地优先队列策略。我们实现了一种动态优先级调整方法,其中紧迫性得分会不断更新以反映系统动态:
- 排队老化: τ i , j \tau_{i, j} τi,j随着时间的推移而增长,因为LLM推理请求在队列中等待。
-
- 工作流进展:当
q
i
,
j
−
1
q_{i, j-1}
qi,j−1完成时,
τ
elapsed
i
\tau_{\text {elapsed }}^{i}
τelapsed i会更新,影响未来的SLO分配。
因此,模型实例 m m m始终从本地队列中选择紧迫性最高的LLM推理请求:
- 工作流进展:当
q
i
,
j
−
1
q_{i, j-1}
qi,j−1完成时,
τ
elapsed
i
\tau_{\text {elapsed }}^{i}
τelapsed i会更新,影响未来的SLO分配。
q ∗ = arg max q i , j ∈ Θ m U i , j q^{*}=\arg \max _{q_{i, j} \in \Theta^{m}} U_{i, j} q∗=argqi,j∈ΘmmaxUi,j
其中 Θ m \Theta^{m} Θm是模型实例 m m m当前排队的LLM推理请求集合。这种自适应策略优先考虑有可能错过其SLO的请求,并考虑到实例特定的执行特性。
4.3 α \alpha α-调整过程
派遣得分函数(方程4)中的超参数
α
\alpha
α控制执行成本和排队成本之间的权衡。为了响应实时工作负载条件自适应地调整
α
\alpha
α,我们实现了一种基于平均查询延迟的轻量级在线参数调整过程。
初始化。在系统启动时,将
α
\alpha
α初始化为0,优先考虑队列长度最小化。在操作的前100秒内,Hexgen-Text2SQL使用此策略来服务传入的文本到SQL查询。同时,系统收集每个LLM推理请求的执行跟踪,例如到达时间、队列延迟和各阶段持续时间。然后利用这些信息即时模拟各种
α
\alpha
α值,并根据端到端文本到SQL查询的平均完成时间选择表现最佳的
α
∗
\alpha^{*}
α∗值。
基于滑动窗口的监控和更新。初始化后,HEXGEN-TEXT2SQL假设短间隔内的工作负载是平稳的,并继续使用当前的
α
∗
\alpha^{*}
α∗。系统在一个100秒的滑动窗口中监控平均延迟。在每个滑动窗口结束时,它计算该期间所有服务查询的平均端到端
延迟
T
ˉ
new
\bar{T}_{\text {new }}
Tˉnew ,并与前一个窗口的基线延迟
T
ˉ
ref
\bar{T}_{\text {ref }}
Tˉref 进行比较。
为了确定延迟是否显著恶化,我们进行了一次单侧两样本 t t t检验:
H 0 : T ˉ new = T ˉ ref vs. H 1 : T ˉ new > T ˉ ref H_{0}: \bar{T}_{\text {new }}=\bar{T}_{\text {ref }} \quad \text { vs. } \quad H_{1}: \bar{T}_{\text {new }}>\bar{T}_{\text {ref }} H0:Tˉnew =Tˉref vs. H1:Tˉnew >Tˉref
如果
p
p
p值低于0.01,则拒绝原假设,表明统计上显著的延迟回归。这触发了一个重新调整过程,使用最近100秒的跟踪记录。
模拟引导优化。重新调整通过一个跟踪驱动的模拟器进行,该模拟器重放历史文本到SQL查询并评估不同
α
\alpha
α值下的性能。通过最小化模拟的平均延迟来选择最优的
α
∗
\alpha^{*}
α∗:
α ∗ = arg min α ∈ [ 0 , 1 ] 1 N ∑ i = 1 N T i ( α ) \alpha^{*}=\arg \min _{\alpha \in[0,1]} \frac{1}{N} \sum_{i=1}^{N} T_{i}(\alpha) α∗=argα∈[0,1]minN1i=1∑NTi(α)
其中
T
i
(
α
)
T_{i}(\alpha)
Ti(α)表示在参数
α
\alpha
α下查询
Q
i
Q_{i}
Qi的模拟完成时间。搜索遵循粗到细的策略:初始扫描
α
∈
{
0.0
,
0.2
,
…
,
1.0
}
\alpha \in\{0.0,0.2, \ldots, 1.0\}
α∈{0.0,0.2,…,1.0},然后在最佳候选周围的0.1增量范围内进行更精细的搜索。
调整开销讨论。模拟器完全在CPU上执行,与实际服务相比仅产生可忽略不计的开销成本。在实践中,除非工作负载模式发生突然变化,否则相邻时间窗口中的调优
α
∗
\alpha^{*}
α∗值保持稳定。这使得对不断变化的服务条件进行稳健且低开销的适应成为可能,确保持续的低延迟性能。
5 评估
为了评估Hexgen-Text2SQL的设计,我们提出以下问题以分析我们框架的端到端性能以及每个组件对整体效率提升的贡献:
- 我们的针对文本到SQL的专用HEXGEN-TEXT2SQL与通用推理服务系统相比,端到端性能如何?
-
- 调度算法的每个组件的有效性如何?
-
-
α
\alpha
α-调优过程的收益和成本是什么?
我们在第5.1节中陈述实验设置,并分别在第5.2节、第5.3节和第5.4节中回答每个问题。
-
α
\alpha
α-调优过程的收益和成本是什么?
5.1 实验设置
运行时间。每个端到端文本到SQL查询按照一个多代理框架CHESS处理,在本研究时点,该框架代表了文本到SQL工作流的最新技术 [20]。我们在以下设置中进行评估:
- 异构-1:此设置包含两种类型的GPU,A100和A6000,每种负责服务两个模型实例。
-
- 异构-2:此设置包含三种类型的GPU:A100、L40和A6000。A100 GPU负责服务两个实例,而L40和A6000 GPU各负责服务一个实例。
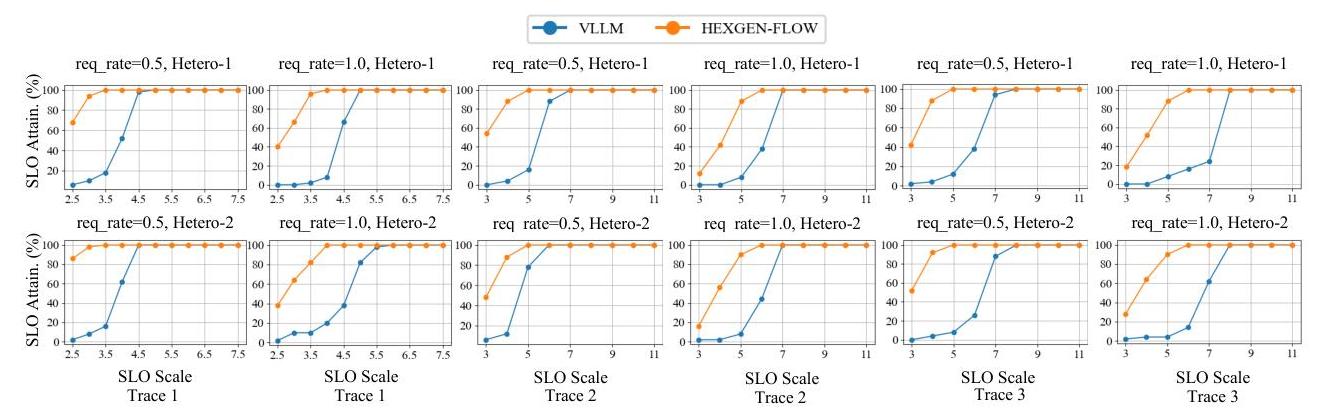
图2:端到端SLO达成率比较。
注意由于模型参数数量庞大,我们采用vLLM [21] 的张量并行度八来服务所有模型实例,并且所有模型实例在推理过程中采用连续批处理。
模型和数据集。CHESS [20] 工作流中的所有LLM推理请求都使用Llama3.1-70B模型,这是一个具有代表性和流行的开源变压器模型。我们遵循先前的工作,基于BIRD-bench [33] 开发集生成三个工作负载跟踪,这是一个专门为文本到SQL评估设计的跨域数据集。我们的测试跟踪从与金融和F1赛车数据库相关的查询中抽样,包括简单和复杂的查询。特别是,Trace 1纯粹从金融数据库中抽样查询,Trace 2从F1赛车数据库中抽样查询,Trace 3包含来自两个数据库的查询。根据查询的复杂性,工作流可能需要零到十轮修订来完善SQL查询。为了模拟用户文本到SQL查询的随机到达模式,我们使用泊松过程发送查询,到达率为每秒0.5个查询和每秒1.0个查询。这种方法捕捉了用户交互的固有随机性,并与先前研究 [18] 中采用的方法一致。
基准。为了评估端到端性能,我们将Hexgen-Text2SQL与基准vLLM进行比较,vLLM是一种广泛采用的推理服务系统,使用先进先出(FCFS)管理本地队列。对于基准,我们基于轮询策略分发LLM推理请求。这种幼稚的方法在现有的推理服务系统中被普遍使用 [34, 35]。在消融研究中,我们将Hexgen-Text2SQL与两个基准系统进行比较:(i) RR+PQ:从我们框架中衍生的一种中间设计,实施轮询分发策略与本地优先队列结合。(ii) WB+FCFS:另一种从我们Hexgen-Text2SQL架构中衍生的中间设计,实施工作负载平衡(WB)分发与本地队列上的FCFS处理。我们将这两种设计作为基准,以独立于其他增强功能评估我们工作负载平衡分发和本地优先队列的影响。
评估指标。遵循现有LLM服务框架 [36, 37] 的评估设置,我们根据SLO达成和服务吞吐量评估系统性能。SLO基于单个查询处理延迟经验确定,我们将其缩放到不同的倍数(图2中的SLO Scale),以评估在不同操作严格程度下的性能。我们专注于识别系统在达到95%和完全(100%)SLO达成所需的最低SLO Scale。
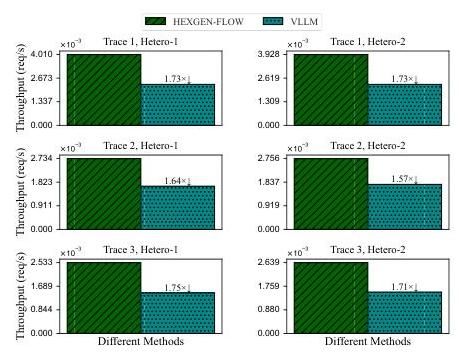
图3:端到端系统吞吐量比较。
5.2 端到端性能增益
我们通过将其端到端性能与广泛采用的推理服务系统vLLM进行比较,评估Hexgen-Text2SQL的有效性,后者采用先进先出(FCFS)本地队列。比较集中在两个关键指标上:SLO达成和持续吞吐量,涉及多样化的部署跟踪和查询到达率。
SLO达成。图2展示了多个跟踪和异构配置下,每秒0.5和1.0查询工作负载的SLO达成曲线。在所有测试条件下,HEXGENTEXT2SQL相对于vLLM在95% SLO达成时最多降低1.67倍延迟截止期,平均降低1.41倍;在99% SLO达成时最多降低1.60倍延迟截止期,平均降低1.35倍。例如,在Trace 3每秒1.0查询的情况下,HEXGENText2SQL实现95%和99% SLO达成所需的最短延迟分别为550秒和600秒,而vLLM则需要790秒和800秒,分别高出43%和33%。
吞吐量比较。图3报告了两系统在固定每秒1.0查询到达率下的持续吞吐量。HEXGEN-FLOW在所有跟踪和硬件配置下始终提供更高的吞吐量。改进范围为vLLM的1.57倍至1.75倍,突显了我们工作负载平衡分发和紧急意识本地调度的有效性。例如,在Hetero-1下的Trace 3,HEXGEN-TEXT2SQL的吞吐量比vLLM高出1.75倍。
总结。这些结果共同表明,HEXGEN-TEXT2SQL在95%和99% SLO达成方面实现了显著更低的延迟截止期,并且相对于基准推理服务系统几乎将吞吐量翻倍。这些收益归因于工作负载平衡任务分发和自适应紧迫性指导队列的统一设计,使我们的框架能够充分利用LLM支持的文本到SQL服务中的并行性和异构性。
5.3 消融研究:调度的有效性
这项消融研究量化了我们两个关键调度创新的个别贡献:工作负载平衡(WB)分发策略和本地优先队列(PQ)。通过在两个异构GPU部署(Hetero-1和Hetero-2)和不同的负载条件(每秒0.5-1.0查询)下进行受控实验,我们展示了这两个组件的有效性,以及它们对调度顺序的影响。
分发策略的性能。为了检查我们分发策略的贡献,我们将WB+PQ和RR+PQ实现95%和99% SLO达成所需的最短延迟进行比较。图4显示,用我们的工作负载平衡分发策略替换轮询路由策略,在假设两者都采用本地优先队列管理实例等待列表的情况下,带来了显著的服务效率提升。在Hetero-1和Hetero-2部署下,无论是每秒0.5查询还是1.0查询到达率,WB+FCFS曲线相较于RR+FCFS曲线始终向较低的SLO规模值移动。在所有测试条件下,WB+PQ相较于RR+PQ在95% SLO达成时最多降低1.38倍延迟截止期,平均降低1.18倍;在99% SLO达成时最多降低1.4倍延迟截止期,平均降低1.24倍。例如,在Hetero-1下的Trace 3每秒0.5查询情况下,所有查询在WB+PQ下均在500秒内完成,而在RR+PQ下则需要700秒。这相当于尾部延迟减少了约40%。这些结果证实,我们的分发策略既减少了尾部延迟,又提高了文本到SQL工作负载中的GPU利用率。
分发策略的影响。对于每个到达的LLM推理请求,我们的分发策略考虑每个模型实例对该任务的适用性及其所承载的工作负载。我们通过调整
α
\alpha
α的值(如
§
4.3
\S 4.3
§4.3所述)来控制适用性和工作负载之间的权衡,并检查相应的SLO达成变化。我们通过基准测试任务分布在应用策略前后的情况,展示我们的工作负载平衡分发策略的效果。如第1节所示,在应用策略之前,任务均匀分布于所有实例。应用策略后,不同实例间的任务分配相应改变。具体来说,A100 GPU(实例1和2)主要处理来自"SQL Candidates"(27.9%)、“Self-Correction”(47.9%)和"Evaluation"(23.3%)阶段的LLM推理请求。A6000 GPU(实例3)主要处理来自"Self-Correction"阶段的任务(71.5%),而L40 GPU(实例4)则集中于"Schema Linking"阶段(32.3%)和"Evaluation"阶段(56.3%)。因此,这一优化导致不同实例间任务分配更加专业化,使分发策略能够在平衡实例间负载的同时将请求路由到适当的模型实例,从而提高整体系统性能。
本地优先队列的性能。为了研究本地优先队列的消融效果,我们让两种调度都采用工作负载平衡分发,并比较WB+FCFS和WB+PQ的性能。在图4中,保持工作负载平衡调度不变,WB+PQ曲线在所有三条跟踪中都优于WB+FCFS曲线,无论查询到达率如何。在所有测试条件下,WB+PQ在95% SLO达成时最多降低1.5倍延迟截止期,平均降低1.2倍;在99% SLO达成时最多降低1.4倍延迟截止期,平均降低1.2倍,相较于WB+FCFS。例如,在两种部署设置下,当查询以每秒0.5查询到达时,WB+PQ策略在Trace 3中实现95%和99% SLO达成所需的最短延迟约为400秒和500秒,而WB+FCFS策略则需要600秒和700秒,
表1:分发策略对任务分布的影响。阶段1-4代表上述文本到SQL阶段;I1-I4代表不同的GPU实例,其中I1和I2是A100实例,I3是一个A6000实例,I4是一个L40实例。
| 阶段 | WB分发 | I 1 ( % ) \mathbf{I 1}(\%) I1(%) | I 2 ( % ) \mathbf{I 2}(\%) I2(%) | I 3 ( % ) \mathbf{I 3}(\%) I3(%) | I 4 ( % ) \mathbf{I 4}(\%) I4(%) |
|---|---|---|---|---|---|
| 1 | 之前 | 20.8 | 23.1 | 19.9 | 26.8 |
| 之后 | 0.9 | 0.5 | 6.1 | 32.3 | |
| 2 | 之前 | 10.3 | 7.8 | 10.6 | 9.6 |
| 之后 | 27.9 | 29.6 | 16.5 | 3.1 | |
| 3 | 之前 | 26.5 | 23.0 | 25.5 | 21.7 |
| 之后 | 47.9 | 46.6 | 71.5 | 8.3 | |
| 4 | 之前 | 42.3 | 46.0 | 44.1 | 41.8 |
| 之后 | 23.3 | 23.3 | 5.8 | 56.3 |
分别是1.5倍和1.4倍更高。此外,当查询速率为每秒0.5查询时,采用本地优先队列的策略比FCFS策略快约20%完成95%的查询。尽管优先队列带来的改进程度可能因不同的异构设置和跟踪而异,但WB+PQ的优势表明,根据剩余紧迫性动态优先化推理任务显著减少了头部阻塞和错过截止日期的情况,确保在不同负载条件下提供稳定、高质量的服务。
表2:处理下一个LLM调用前本地队列的状态快照。Arrive-at表示LLM调用到达的时间戳。
| 请求ID | 1 \mathbf{1} 1 | 2 \mathbf{2} 2 | 3 \mathbf{3} 3 | 4 \mathbf{4} 4 | 5 \mathbf{5} 5 | 6 \mathbf{6} 6 | 7 \mathbf{7} 7 |
|---|---|---|---|---|---|---|---|
| Arrive-at (s) | 22.4 | 46.3 | 52.3 | 62.4 | 62.8 | 64.4 | 65.0 |
| Urgency | 14.5 | 13.2 | 19.0 | 13.1 | 19.0 | 26.9 | 21.9 |
本地优先队列的影响。为了突出优先队列的影响,我们展示了在评估期间某个实例上的本地优先队列状态。表2中的快照是在实例即将处理下一个LLM推理请求之前捕获的。从表中可以看出,LLM推理请求Request #6在64.4到达,并且具有最高的紧迫性26.9,因此它将由我们的本地优先队列首先处理。相比之下,FCFS策略会首先处理Request #1,因为它最早到达时间为22.4,尽管它的紧迫性得分为14.5,小于Request #6。根据预测的执行成本,Request #1需要26.7秒完成,而Request #6只需要3.2秒完成。同时,分配给Request #1的SLO为30.4秒,大于其预测的执行成本。另一方面,Request #6分配的SLO为3.3秒,相对Request #1更为紧迫。这一观察结果与我们的紧迫性评分一致。总之,本地优先队列优先处理最紧迫的请求,并尽可能最大化满足其SLO的请求比例。
5.4 α \alpha α-调优的经验分析
我们的评估展示了动态
α
\alpha
α-调优如何适应硬件异构性和工作负载特征以优化系统性能。通过在三种不同的工作负载跟踪和两种异构GPU部署下的受控实验,我们分析了:(1) 良好调优的
α
\alpha
α值如何提高95% SLO达成率,以及 (2) 基于模拟的调优在实时服务中的实际可行性。所有实验在查询到达率为每秒0.5查询的情况下保持不变,同时改变
α
\alpha
α
从0(纯工作负载平衡)到0.5(均衡加权)。
α
\alpha
α-调优的影响。图5展示了在其他超参数相同的情况下,不同
α
\alpha
α值对性能变化的影响。所有实验都在三个跟踪上进行,假设文本到SQL查询以每秒0.5个查询的速度到达。Trace 1上的两个实验显示,分别在Hetero-1和Hetero-2设置下,取
α
=
0.1
\alpha=0.1
α=0.1和0.3可以获得最佳结果。同样,Trace 2上的实验结果表明,在Hetero-1部署下
α
=
0.2
\alpha=0.2
α=0.2表现更好,而在Hetero-2情况下
α
=
0.3
\alpha=0.3
α=0.3表现更佳。对于Trace
3
3
3,当只有两种类型的GPU时,
α
=
0.2
\alpha=0.2
α=0.2胜过其他值。在Hetero-2设置下,值得注意的是,当
α
=
0.4
\alpha=0.4
α=0.4时,95%的查询比仅考虑工作负载平衡因子的调度快14%完成。从这三组结果中,我们得出结论,虽然任务适用性的影响不如工作负载平衡因素重要,但它仍然可以进一步提升性能。此外,
α
\alpha
α的最佳值不仅取决于异构设置,还取决于传入的文本到SQL查询的工作负载。因此,如果相关开销可管理,通过模拟确定
α
\alpha
α的最佳值有助于提升系统性能。
表3:不同实验设置和跟踪的alpha调优开销。
| 设置 | Trace 1 | Trace 2 | Trace 3 |
|---|---|---|---|
| (Hetero-2, req_rate = 0.5 =0.5 =0.5 ) | 124.6 s 124.6 \mathrm{~s} 124.6 s | 122.3 s 122.3 \mathrm{~s} 122.3 s | 142.2 s 142.2 \mathrm{~s} 142.2 s |
| (Hetero-2, req_rate = 1.0 =1.0 =1.0 ) | 133.3 s 133.3 \mathrm{~s} 133.3 s | 137.8 s 137.8 \mathrm{~s} 137.8 s | 149.7 s 149.7 \mathrm{~s} 149.7 s |
| (Hetero-3, req_rate = 0.5 =0.5 =0.5 ) | 124.7 s 124.7 \mathrm{~s} 124.7 s | 141.3 s 141.3 \mathrm{~s} 141.3 s | 158.0 s 158.0 \mathrm{~s} 158.0 s |
| (Hetero-3, req_rate = 1.0 =1.0 =1.0 ) | 115.6 s 115.6 \mathrm{~s} 115.6 s | 133.4 s 133.4 \mathrm{~s} 133.4 s | 154.2 s 154.2 \mathrm{~s} 154.2 s |
α
\alpha
α-调优的开销。我们评估
α
\alpha
α-调优模拟的时间成本,以评估其在实时文本到SQL推理服务中的可行性。每次模拟系统测试不同的
α
\alpha
α值,
遵循
§
4.3
\S 4.3
§4.3中提到的
α
\alpha
α-调优过程。如表3所示,在各种异构设置和工作负载跟踪下,
α
\alpha
α-调优模拟时间范围从115秒到158秒。这种开销在实践中是可以接受的,因为相比于现实世界工作负载变化通常发生的小时级别时间尺度,这个开销要短得多 [37]。
6 相关工作
在本节中,我们简要概述了基于LLM的文本到SQL方法的最新进展(第6.1节),然后讨论了一些LLM推理请求的服务系统设计和实现(第6.2节)。
6.1 LLM在文本到SQL方面的进展
LLMs已成为文本到SQL任务的革命性范式 [38, 1],其中核心技术在于有效的SQL生成和模式链接。
SQL生成。一些早期研究集中于更好的提示策略和LLM适应以提高文本到SQL性能。Gu等人 [39] 提出了一种基于结构和内容的提示学习方法,以增强少量示例的文本到SQL翻译,而Li等人 [40] 构建了一个专门用于SQL生成的开源LLM。其他方法通过微调或约束LLM输出来提高准确性:Ren等人 [41] 提出了Purple,它改进了一般的LLM,使其成为一个更有效的SQL编写者,Sun等人 [42] 将预训练模型(PaLM)专门用于文本到SQL任务,实现了更高的执行准确性。此外,Xie等人 [43] 提出了OpenSearch-SQL,它从查询档案中动态检索少量示例,并强制一致性检查以使LLM的输出与数据库模式一致。
除了简单的LLM适应外,最近的代理方法利用多个LLM推理请求协同完成文本到SQL任务。Fan等人 [44] 结合一个小语言模型和一个大模型来处理文本到SQL的不同子任务,从而提高了零样本鲁棒性。类似地,Pourreza等人 [45] 探索了跨模型的任务分解:DTS-SQL将问题分解为由小型LLM依次处理的阶段,他们的DIN-SQL方法通过迭代自我修正 [46] 在提示中改进自己的输出。另一条研究路线增强了LLM的推理过程以生成正确的SQL。一种策略是在推理过程中加入中间步骤或推理框架。Zhang等人 [47] 应用ReAct范式 [48] 到表格问答中,鼓励LLM生成并推理中间动作(如分解或计算)后再最终确定SQL查询。Mao等人 [49] 提出重写用户问题以澄清,并使用执行反馈迭代细化生成的SQL(执行导向细化)。为了提高生成正确查询的机会,Pourreza等人 [50] 引入了一种多路径推理方法(ChaseSQL),生成多样化的SQL候选并使用偏好模型对其进行排名,而Li等人 [51] 提出了Alpha-SQL,它采用蒙特卡罗树搜索在零样本设置下探索不同的查询构造。还有人探索了优化给LLM的上下文的方法:Talaei等人 [20] 提出了CHESS,它有效地利用上下文信息来指导LLM的SQL合成,而不增加模型大小或复杂性。
模式链接。将数据库模式知识和领域特定信息集成到LLM驱动的文本到SQL中是另一个重要步骤。Eyal等人 [52] 将自然语言问题和相应的SQL查询分解为语义子单元,提高了模型对问题子句与模式元素对齐的理解。Dou等人 [53] 将外部知识(如业务规则或公式)纳入解析过程,以处理需要超出数据库内容的事实的查询。一些作品特别针对LLM时代的模式链接挑战。Liu等人 [54] 提出了SolidSQL,它使用增强的上下文示例来使LLM在生成过程中更稳健地匹配问题术语与模式。为了在开放领域的文本到SQL中即时提供相关的模式上下文,Zhang等人 [55] 开发了一种检索方法,找到相关表并在SQL生成之前提供给LLM。Yang等人 [56] 采取了不同的方法来辅助模式链接:他们生成初步的SQL(SQL-to-schema)以识别可能涉及的模式项,然后利用该信息指导最终查询的生产。
6.2 LLM推理请求调度
高效调度LLM推理请求在现代AI基础设施中至关重要,对于满足延迟和吞吐量要求尤其重要,特别是在系统约束变化的情况下。
在硬件和模型设置一致的环境中,调度技术集中在优化延迟和吞吐量。Patke等人 [17] 引入了QLM,这是一种估计请求等待时间以优先处理任务的系统,确保在负载条件下满足SLO。Gong等人 [57] 提出了未来调度器,它使用历史工作负载模式和预测建模做出明智的调度决策,履行SLA保证。Fu等人 [58] 将LLM调度视为学习排序问题,训练模型对排队请求进行排序以优化端到端延迟和吞吐量,超越传统启发式方法。Agrawal等人 [16] 提出了Sarathi-Serve,该系统调整批处理和资源分配以平衡吞吐量和延迟,特别适用于高优先级与低优先级请求。在硬件能力和模型类型不同的设置中,最近提出的调度策略适应资源异构性:Wan等人 [59] 开发了BROS,该系统区分实时和尽力而为的LLM查询,确保交互查询得到优先处理而不影响后台批处理。Jain等人 [19] 引入了一种性能感知负载均衡器,监控查询特征和系统负载以动态将请求分发到模型副本和GPU节点。Gao等人 [60] 提出了Apt-Serve,它采用混合缓存结合GPU内存和较低层级存储以扩展LLM服务,同时将常用模型状态保留在更快的内存中。Ao等人 [61] 提出了一种基于流体模型引导的调度器,将推理任务分配以接近理想的GPU内存流体公平份额,从而在内存压力下提高吞吐量并减少尾部延迟。Sun等人 [62] 提出了Llumnix,一种动态调度系统,随着查询负载模式的变化实时调整LLM服务的资源配置,展示了单模型场景下的好处。尽管在无阶段LLM服务方面取得了显著进展,但多阶段管道仍较少被探索。最近,Fang等人 [63] 在离线设置中调查了多LLM应用管道的效率,使用采样和模拟优化涉及多个LLM或顺序模型调用的工作流推理计划。
尽管如此,协调具有多个依赖LLM请求服务阶段的端到端管道的调度策略存在明显的差距。我们的方法建立在现有见解的基础上,如紧迫性感知优先级和硬件敏感分配,但有效地扩展了它们,以管理严格的延迟要求和系统异构性下的复杂、多阶段文本到SQL工作流,显著提升了性能。
7 结论
本文介绍了Hexgen-Text2SQL,这是一种新型推理服务框架,专为在异构GPU集群中高效调度和执行多阶段代理文本到SQL工作负载而设计,处理多租户请求。通过对这些工作负载的独特特性进行系统分析——包括阶段依赖、任务变异性、资源异构性和严格的延迟限制——我们制定了一种分层调度解决方案,由全局工作负载平衡调度器和每个LLM服务模型实例中的本地紧迫性驱动队列组成。这种两级
调度策略显著提高了资源利用率,并有效缓解了违反截止期限的问题。全面的实验表明,HEXGEN-TEXT2SQL始终优于现有的最先进的LLM服务框架,在真实的生产工作负载下显著减少了查询延迟并显著提高了系统吞吐量——与vLLM相比,HEXGEN-TEXT2SQL在多样化的现实工作负载条件下最多可减少
1.67
×
1.67 \times
1.67× 的延迟截止期(平均值为
1.41
×
1.41 \times
1.41×),并将系统吞吐量提高多达
1.75
×
1.75 \times
1.75×(平均值为
1.65
×
1.65 \times
1.65×)。总体而言,HEXGEN-TEXT2SQL提供了一种高效的基础设施解决方案,使基于代理LLM的文本到SQL系统能够在真实的企业环境中实用且高效地部署。
参考文献
[1] Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. Text-to-sql empowered by large language models: A benchmark evaluation. Proceedings of the VLDB Endowment, 17(5):1132-1145, 2024.
[2] Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, and Nan Tang. The dawn of natural language to sql: Are we fully ready? Proceedings of the VLDB Endowment, 17(11):3318-3331, 2024.
[3] Shuaichen Chang, Jun Wang, Mingwen Dong, Lin Pan, Henghui Zhu, Alexander Hanbo Li, Wuwei Lan, Sheng Zhang, Jiarong Jiang, Joseph Lilien, et al. Dr. spider: A diagnostic evaluation benchmark towards text-to-sql robustness. In The Eleventh International Conference on Learning Representations.
[4] Han Fu, Chang Liu, Bin Wu, Feifei Li, Jian Tan, and Jianling Sun. Catsql: Towards real world natural language to sql applications. Proceedings of the VLDB Endowment, 16(6):1534-1547, 2023.
[5] OpenAI. Openai gpt-4o, 2024.
[6] Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
[7] Anthropic. The claude 3 model family: Opus, sonnet, haiku, 2024.
[8] Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088, 2024.
[9] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
[10] Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314, 2024.
[11] Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling. arXiv preprint arXiv:2407.21787, 2024.
[12] Nvidia. Nvidia reinvents computer graphics with turing architecture, 2018.
[13] Nvidia. Nvidia’s new ampere data center gpu in full production, 2020.
[14] Nvidia. Nvidia announces hopper architecture, the next generation of accelerated computing, 2022.
[15] Nvidia. Nvidia blackwell platform arrives to power a new era of computing, 2024.
[16] Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming {Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 117-134, 2024.
[17] Archit Patke, Dhemath Reddy, Saurabh Jha, Haoran Qiu, Christian Pinto, Chandra Narayanaswami, Zbigniew Kalbarczyk, and Ravishankar Iyer. Queue management for slo-oriented large language model serving. In Proceedings of the 2024 ACM Symposium on Cloud Computing, pages 18-35, 2024.
[18] Zhibin Wang, Shipeng Li, Yuhang Zhou, Xue Li, Rong Gu, Nguyen Cam-Tu, Chen Tian, and Sheng Zhong. Revisiting slo and goodput metrics in llm serving. arXiv preprint arXiv:2410.14257, 2024.
[19] Kunal Jain, Anjaly Parayil, Ankur Mallick, Esha Choukse, Xiaoting Qin, Jue Zhang, Íñigo Goiri, Rujia Wang, Chetan Bansal, Victor Rühle, et al. Performance aware llm load balancer for mixed workloads. In Proceedings of the 5th Workshop on Machine Learning and Systems, pages 19-30, 2025.
[20] Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, and Amin Saberi. Chess: Contextual harnessing for efficient sql synthesis. arXiv preprint arXiv:2405.16755, 2024.
[21] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, pages
611
−
626
,
2023
611-626,2023
611−626,2023.
[22] HuggingFace. Text generation inference. https://huggingface.co/docs/text-generat ion-inference/index, 2023.
[23] Nvidia. Tensorrt-llm. https://github.com/NVIDIA/TensorRT-LLM, 2023.
[24] Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for {Transformer-Based } generative models. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 521-538, 2022.
[25] Nvidia. Nvidia triton inference server, 2025.
[26] Archit Patke, Dhemath Reddy, Saurabh Jha, Haoran Qiu, Christian Pinto, Chandra Narayanaswami, Zbigniew Kalbarczyk, and Ravishankar Iyer. Queue management for slo-oriented large language model serving. In Proceedings of the 2024 ACM Symposium on Cloud Computing, pages 18-35, 2024.
[27] Ying Sheng, Shiyi Cao, Dacheng Li, Banghua Zhu, Zhuohan Li, Danyang Zhuo, Joseph E Gonzalez, and Ion Stoica. Fairness in serving large language models. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 965-988, 2024.
[28] Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, and Rashmi Vinayak. Helix: Serving large language models over heterogeneous gpus and network via max-flow。在第30届ACM国际架构支持编程语言和操作系统会议论文集,第1卷,页586-602,2025年。
[29] Youhe Jiang, Ran Yan,Xiaozhe Yao, Yang Zhou, Beidi Chen, 和 Binhang Yuan. Hexgen: 在异构环境中生成性推理大型语言模型。在国际机器学习会议论文集,页21946-21961。PMLR,2024年。
[30] Youhe Jiang, Ran Yan, 和 Binhang Yuan. Hexgen-2: 在异构环境中分离生成性推理LLMs。arXiv预印本 arXiv:2502.07903, 2025.
[31] U Narayan Bhat. 排队论导论:应用中的建模与分析,第36卷。Springer, 2008.
[32] Zheng Zangwei, Ren Xiaozhe, Xue Fuzhao, Luo Yang, Jiang Xin, 和 You Yang. 响应长度感知与序列调度:基于LLM的LLM推理管道。神经信息处理系统进展,36:65517-65530, 2023.
[33] Li Jinyang, Hui Binyuan, Qu Ge, Yang Jiaxi, Li Binhua, Li Bowen, Wang Bailin, Qin Bowen, Geng Ruiying, Huo Nan, 等. LLM是否已经可以作为数据库接口?一个大规模数据库支持文本到SQL的大规模基准测试。神经信息处理系统进展,36:42330-42357, 2023.
[34] Douglas G. Down 和 Rong Wu. 并行服务器的多层轮询路由。排队系统,53(4):177-188, 2006年8月。
[35] Isaac Grosof, Ziv Scully, 和 Mor Harchol-Balter. 负载均衡护栏:让您的重流量保持低响应时间的道路。arXiv预印本 arXiv:1905.03439, 2019.
[36] Zhuohan Li, Lianmin Zheng, Zhong Yinmin, Liu Vincent, Sheng Ying, Jin Xin, Huang Yanping, Chen Zhifeng, Zhang Hao, Joseph E Gonzalez, 等. {AlpaServe}: 深度学习服务中的统计复用与模型并行。在第17届USENIX操作系统设计与实现研讨会 (OSDI 23),页663-679, 2023.
[37] Zhong Yinmin, Liu Shengyu, Chen Junda, Hu Jianbo, Zhu Yibo, Liu Xuanzhe, Jin Xin, 和 Zhang Hao. {DistServe}: 分离预填充和解码以优化大型语言模型服务的良好吞吐量。在第18届USENIX操作系统设计与实现研讨会 (OSDI 24),页193-210, 2024.
[38] George Katsogiannis-Meimarakis 和 Georgia Koutrika. 文本到SQL深度学习方法综述。VLDB期刊,32(4):905-936, 2023.
[39] Zihui Gu, Ju Fan, Nan Tang, Lei Cao, Bowen Jia, Sam Madden, 和 Xiaoyong Du. 少样本文本到SQL翻译使用结构和内容提示学习。ACM数据管理杂志,1(2):1-28, 2023.
[40] Haoyang Li, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, 和 Hong Chen. CODES: 朝着构建开源文本到SQL语言模型迈进。ACM数据管理杂志,2(3):1-28, 2024.
[41] Tonghui Ren, Yuankai Fan, Zhenying He, Ren Huang, Jiaqi Dai, Can Huang, Yinan Jing, Kai Zhang, Yifan Yang, 和 X Sean Wang. Purple: 让大语言模型成为更好的SQL编写者。在2024年IEEE第40届国际数据工程大会 (ICDE)论文集,页15-28。IEEE, 2024.
[42] Ruoxi Sun, Sercan O Arik, Alexandre Muzio, Lesly Miculicich, Satya Kesav Gundabathula, Pengcheng Yin, Hanjun Dai, Hootan Nakhost, Rajarishi Sinha, Zifeng Wang, 等. SQL-PALM: 改进的大型语言模型适应于文本到SQL。机器学习研究交易。
[43] Xiangjin Xie, Guangwei Xu, Lingyan Zhao, 和 Ruijie Guo. Opensearch-SQ1: 使用动态少样本和一致性对齐增强文本到SQ1。arXiv预印本 arXiv:2502.14913, 2025.
[44] Ju Fan, Zihui Gu, Songyue Zhang, Yuxin Zhang, Zui Chen, Lei Cao, Guoliang Li, Samuel Madden, Xiaoyong Du, 和 Nan Tang. 结合小语言模型和大语言模型进行零样本NL2SQ1。VLDB会刊,17(11):2750-2763, 2024.
[45] Mohammadreza Pourreza 和 Davood Rafiei. DTS-SQ1: 使用小型大型语言模型分解文本到SQ1。在计算语言学协会发现:EMNLP 2024论文集,页8212-8220, 2024.
[46] Mohammadreza Pourreza 和 Davood Rafiei. DIN-SQ1: 带有自我修正的分解上下文学习文本到SQ1。神经信息处理系统进展,36:36339-36348, 2023.
[47] Yunjia Zhang, Jordan Henkel, Avrilia Floratou, Joyce Cahoon, Shaleen Deep, 和 Jignesh M Patel. Reactable: 增强表问答的React。VLDB会刊,17(8):1981-1994, 2024.
[48] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, 和 Yuan Cao. React: 在语言模型中协同推理和行动。在第十一届国际学习表示会议。
[49] Wenxin Mao, Ruiqi Wang, Jiyu Guo, Jichuan Zeng, Cuiyun Gao, Peiyi Han, 和 Chuanyi Liu. 通过问题重写和执行引导细化增强文本到SQ1解析。在计算语言学协会ACL 2024发现论文集,页2009-2024, 2024.
[50] Mohammadreza Pourreza, Hailong Li, Ruoxi Sun, Yeounoh Chung, Shayan Talaei, Gaurav Tarlok Kakkar, Yu Gan, Amin Saberi, Fatma Ozcan, 和 Sercan O Arik. Chase-SQ1: 文本到SQ1中的多路径推理和偏好优化候选选择。arXiv预印本 arXiv:2410.01943, 2024.
[51] Boyan Li, Jiayi Zhang, Ju Fan, Yanwei Xu, Chong Chen, Nan Tang, 和 Yuyu Luo. Alpha-SQ1: 使用蒙特卡罗树搜索实现零样本文本到SQ1。arXiv预印本 arXiv:2502.17248, 2025.
[52] Ben Eyal, Amir Bachar, Ophir Haroche, Moran Mahabi, 和 Michael Elhadad. 文本到SQ1解析的语义分解问题和SQ1。在2023年计算语言学协会发现:EMNLP 2023论文集,页13629-13645。计算语言学协会 (ACL), 2023.
[53] Longxu Dou, Yan Gao, Xuqi Liu, Mingyang Pan, Dingzirui Wang, Wanxiang Che, Dechen Zhan, Min-Yen Kan, 和 Jian-Guang Lou. 面向知识密集型文本到SQ1语义解析的公式化知识。在2022年经验方法自然语言处理会议论文集,页5240-5253, 2022.
[54] Geling Liu, Yunzhi Tan, Ruichao Zhong, Yuanzhen Xie, Lingchen Zhao, Qian Wang, Bo Hu, 和 Zang Li. Solid-SQ1: 增强模式链接的上下文学习以实现稳健的文本到SQ1。在第31届国际计算语言学会议论文集,页9793-9803, 2025.
[55] Xuanliang Zhang, Dingzirui Wang, Longxu Dou, Qingfu Zhu, 和 Wanxiang Che. Murre: 开放域文本到SQ1的多跳表检索与移除。在第31届国际计算语言学会议论文集,页5789-5806, 2025.
[56] Sun Yang, Qiong Su, Zhishuai Li, Ziyue Li, Hangyu Mao, Chenxi Liu, 和 Rui Zhao. SQL-to-schema增强了文本到SQL中的模式链接。在数据库与专家系统应用国际会议论文集,页139-145。Springer, 2024.
[57] Ruihao Gong, Shihao Bai, Siyu Wu, Yunqian Fan, Zaijun Wang, Xiuhong Li, Hailong Yang, 和 Xianglong Liu. 过去未来调度器用于LLM服务下的SLA保证。在第30届ACM国际架构支持编程语言和操作系统会议论文集,第2卷,页798-813, 2025.
[58] Yichao Fu, Siqi Zhu, Runlong Su, Aurick Qiao, Ion Stoica, 和 Hao Zhang. 通过学习排序实现高效的LLM调度。在第三十八届年度神经信息处理系统会议论文集。
[59] Borui Wan, Juntao Zhao, Chenyu Jiang, Chuanxiong Guo, 和 Chuan Wu. 在混合实时和尽力而为请求上的高效LLM服务。arXiv预印本 arXiv:2504.09590, 2025.
[60] Shihong Gao, Xin Zhang, Yanyan Shen, 和 Lei Chen. Apt-Serve: 在混合缓存上的自适应请求调度以实现可扩展的LLM推理服务。arXiv预印本 arXiv:2504.07494, 2025.
[61] Ruicheng Ao, Gan Luo, David Simchi-Levi, 和 Xinshang Wang. 优化LLM推理:带内存约束的流体引导在线调度。arXiv预印本 arXiv:2504.11320, 2025.
[62] Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, 和 Wei Lin. Llumnix: 大型语言模型服务的动态调度。在第18届USENIX操作系统设计与实现研讨会 (OSDI 24),页173-191, 2024.
[63] Jingzhi Fang, Yanyan Shen, Yue Wang, 和 Lei Chen. 基于采样和模拟改进多LLM应用程序的离线推理端到端效率。arXiv预印本 arXiv:2503.16893, 2025.
参考论文:https://arxiv.org/pdf/2505.05286



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











