






阿卜杜勒卡林·埃尔-哈贾米
[
9909
−
0004
−
7053
−
3264
]
{ }^{[9909-0004-7053-3264]}
[9909−0004−7053−3264] 和卡米尔·萨利内西
[
9000
−
0002
−
1957
−
0519
]
{ }^{[9000-0002-1957-0519]}
[9000−0002−1957−0519]
巴黎第一大学潘théon-索邦,巴黎,法国
{abdelkarim.el-hajjami, camille.salinesi}@univ-paris1.fr
摘要
尽管现代需求工程(RE)高度依赖自然语言处理和机器学习(ML)技术,但它们的有效性受到高质量数据集稀缺的限制。本文介绍了Synthline,这是一种产品线(PL)方法,利用大型语言模型系统地为基于分类的应用场景生成合成RE数据。通过在使用ML识别需求规范缺陷的背景下进行的实证评估,我们研究了生成数据的多样性和其对下游模型训练的实用性。我们的分析表明,尽管合成数据集的多样性低于真实数据,但它们足以作为可行的训练资源。此外,我们的评估显示,结合合成数据和真实数据可以显著提高性能。具体而言,混合方法在精度上可达到 85 % 85 \% 85% 的提升,并且召回率相比仅用真实数据训练的模型增加了两倍。这些发现展示了基于PL的合成数据生成在解决RE领域数据稀缺问题上的潜力。我们公开发布了我们的实现代码和生成的数据集,以支持可重复性和推动该领域的进步。
关键词:需求工程 ⋅ \cdot ⋅ 合成数据 ⋅ \cdot ⋅ 大型语言模型 ⋅ \cdot ⋅ 产品线
1 引言
需求工程(RE)主要通过自然语言(NL)进行操作,这是捕捉、指定和验证各种类型需求的主要媒介 [1]。尽管这种对NL的依赖促进了自然语言处理(NLP)技术和人工智能(AI)模型在RE中的广泛应用 [9,10],但其有效性仍然取决于多样化高质量数据集的可用性。即使随着大型语言模型(LLMs)中引入的情境学习范式转变 [7],实现最佳性能仍需要足够的高质量训练数据和额外的微调 [8]。因此,缺乏免费可用的RE特定数据集仍然是一个主要瓶颈 [9],[17],阻碍了进展并限制了AI模型在RE中的有效应用。
然而,获取高质量数据面临重大挑战。它既昂贵又耗时,数据标注阶段通常费力且容易出错 [12]。此外,公司往往不愿意分享敏感和私人数据,这限制了此类数据在生产组织外部的研究用途。因此,合成数据作为一种有前途的解决方案应运而生。
数据合成可以采取多种形式:敏感数据的匿名化 [16];用于监督学习的标注 [12];通过文本变换(如单词删除或同义词替换)进行增强 [46];以及从头生成全新的样本 [19]。我们的研究遵循最后一种方法,利用LLMs先进的文本生成和多语言能力 [2] 来解决RE中的数据稀缺问题。这种方法不仅实现了大规模、成本效益高的数据生成,还提供了对数据属性的系统控制,支持多样化的RE应用场景并解决具体挑战,例如数据不平衡 [15] 和非英语资源的稀缺 [9]。
为了实现系统的可控性,我们提出了一种生成方法,使用特征模型(FM)形式化RE应用场景及其特定需求的变异性。本研究代表了一个更广泛的设计科学周期的第一轮迭代 [3],其中我们设计并评估了一个最小的合成数据产品线(PL),专为基于分类的RE应用场景设计。在此范围内,我们探讨了以下研究问题:
- RQ1. 合成数据的多样性与真实数据相比如何?
-
- RQ2. 使用合成数据进行训练相对于仅使用真实数据进行训练如何影响模型性能?
贡献。(1)我们提出了Synthline,这是一种最小且可配置的方法,用于系统地控制基于LLM的数据生成。(2)我们在识别需求规范缺陷的应用场景中评估了我们的方法。评估从两个维度展开:数据多样性和下游模型性能。(3)我们提供了生成的数据集和我们的实现代码作为开放访问资源,以支持RE社区更广泛的采用和可重复性 1 { }^{1} 1。
- RQ2. 使用合成数据进行训练相对于仅使用真实数据进行训练如何影响模型性能?
本文结构如下:第2节回顾了与我们研究相关的现有工作。第3节介绍方法论,详细描述了我们的PL方法及其通过Synthline的实现。第4节展示了我们评估数据多样性和实用性的方法。第5节讨论了实验结果。第6节检查了有效性威胁。最后,第7节总结了论文并概述了未来的研究方向。
2 相关工作
LLMs激发了许多研究探索不同的合成数据生成方法。早期方法依赖于简单的上下文感知提示,要么在零样本设置中仅使用任务说明 [13],要么在少量样本设置中由少量示例引导 [11]。近期研究探索了属性提示,通过纳入明确的属性来控制生成过程并解决信息不足和冗余的问题 [19]。此外,多步骤生成方法将工作流程分解为顺序步骤,生成多个数据系列以确保更大的多样性 [18]。这些研究强调了受控生成对于数据多样性和质量的重要性。
在RE领域,合成数据研究主要集中在数据增强。Malik等人 [4] 使用回译、释义和RE特定替换(如名词动词或行为动作)等技术改进不平衡数据集中冲突和重复检测。类似地,Majidzadeh等人 [5] 引入了基于代码的增强方法,如变量重命名和运算符交换,以增强需求追踪性,从而提高了精确度、召回率和
1
{ }^{1}
1 https://github.com/abdelkarim-elhajjami/synthline/tree/v0.0.0
F1分数。据我们所知,Cheng等人 [6] 是唯一使用LLMs(GPT-J)进行RE数据增强的研究者;他们在三个行业案例研究中展示了分类性能的提升。然而,这些增强方法存在几个关键限制。首先,它们依赖于现有的数据集,在严重数据稀缺的情况下效果不佳。其次,它们的转换通常生成接近原始领域和分布的数据,限制了真正新颖数据的潜力。第三,它们通常对数据属性(如语言或领域变化)的控制有限。相比之下,我们的研究重点是通过功能模型(FM)指导,完全生成新的合成数据集。
3 Synthline方法概览
本研究构成了一个更广泛的设计科学周期的第一轮迭代,其中设计问题和知识问题通过设计改进和实证调查的循环得到逐步解决 [3]。我们选择了产品线(PL)方法,根据不同的RE应用场景系统地控制和配置合成数据集的生成。PL方法提供了一种系统定制公共平台的形式,可以从该平台衍生出多个变体 [21]。这种范式在我们的合成数据生成环境中提供了两个重要好处。首先,它实现了系统定制,确保每个变体符合其RE应用场景的具体需求和约束条件。其次,它有助于提高生成数据的质量,因为平台的共性可以在多个数据集中系统地检查和测试。这种方法包括两个主要阶段:领域工程和应用工程。在领域工程中,我们从领域分析开始,定义基于分类的RE应用场景的范围和变异性,形成FM。然后通过开发名为Synthline的可配置生成工作流作为我们的共享平台来实施领域实现。在应用工程期间,我们从FM中选择和配置特性以满足特定RE应用场景的需求,然后使用Synthline生成相应数据。
3.1 领域工程
特征模型 PL方法的第一步是领域分析,通常会产生一个FM [22]。FM是一种广泛使用的符号,用于描述PL的变异性 [22]。标准FM符号可以表示具体的和抽象的特征,并将其标记为可选或必需。符号还定义了特征之间的约束,以防止无效或冲突的配置。它还支持特征的“或”和“异或”分解,允许从给定的特征集中选择多个子特征(至少一个),或者限制只能选择一个子特征。
为了构建FM,我们采用了反应式方法,从一个或多个具体变体开始,然后将其概括为FM。这种方法可以增量完成,逐步细化模型并随时间引入新特征,降低初始成本,但可能需要更长时间才能达到稳定的平台 [23]。尽管我们的最终目标是涵盖所有可以用ML自动化的RE应用场景,但一次性实现如此广泛的覆盖是不现实的。因此,我们的增量反应式方法在本研究中仅从一部分RE应用场景开始。我们打算在未来的工作中扩展覆盖范围到其他应用场景。
为了确定合适的起点,我们依赖于最近关于ML在RE中的系统文献综述 [10],该综述指出分类是RE领域中最常用的ML任务,远远超过聚类和回归等其他任务。区分作为ML任务的分类和作为RE应用场景的需求分类很重要。作为RE应用场景的需求分类特指将需求分类为预定义的类型(例如,功能性与非功能性需求)。而作为ML任务的分类不仅支持需求分类,还支持可以表述为分类问题的其他RE应用场景,例如识别需求规范缺陷,其中需求根据与缺陷相关的标签进行分类。另一个关键见解来自 [10],即文本需求工件是大多数RE相关ML研究的主要数据来源,与其他数据类型如设计文档、领域知识、用户反馈或政策和法规相比。基于这些发现,我们将本研究中PL的范围定义为专注于基于分类的RE应用场景,以文本需求为主要工件。我们围绕四个核心特征构建了FM:生成器、工件、ML任务和输出。
模型的第一个特征是生成器,它定义了LLM生成器的配置。它包括LLM、温度和TopP特征。LLM子特征支持两个选项:GPT-40和DeepSeek-V3模型。温度调节生成过程中的随机性,较低值产生更确定的输出,较高值允许更大的创造性。TopP启用核采样,提供对输出多样性的精细控制同时保持连贯性。
第二个核心特征工件通过三个必填子特征定义生成数据的特征。需求子特征目前是唯一支持的工件类型,与我们的初始范围一致,包含需求内容的核心规格。领域指定上下文,语言控制输出语言。在当前需求特征内,定义了四个关键方面。需求类型子特征遵循IEEE 830中定义的分类,包括外部接口(例如,用户界面、硬件接口)、功能、性能需求、逻辑数据库规范、设计约束和系统属性(例如,可靠性、安全性、可维护性)。规范级别允许区分高级别规范和详细规范,从而实现不同粒度级别的生成。需求来源标识需求的利益相关者来源,如终端用户、业务经理、开发团队或监管机构。最后,规范格式支持不同的标注标准,包括自然语言(NL)、受限自然语言(ConstrainedNL)、用例(UseCase)和用户故事(UserStory)。
第三个核心特征ML任务指定将应用于生成数据的ML任务特征。在我们当前的范围内,我们关注分类子特征,它需要两个必填组件:标签定义目标分类类别,标签描述提供这些类别的详细规格。
最后一个核心特征输出定义生成数据的格式和大小。它由两个不同的子特征组成:输出格式,结构化为替代组,要求在CSV或JSON格式之间进行选择;子集大小,允许控制每次运行生成的数据量。完整的FM图形表示见附录7。
Synthline架构 我们对设计科学方法论的应用使我们能够迭代设计Synthline。Synthline是一个基于PL的合成数据生成工作流,适用于可以表述为AI分类任务的RE应用场景。Synthline的架构如图1所示,通过一系列组件将我们为此目的设计的FM配置转换为合成数据。
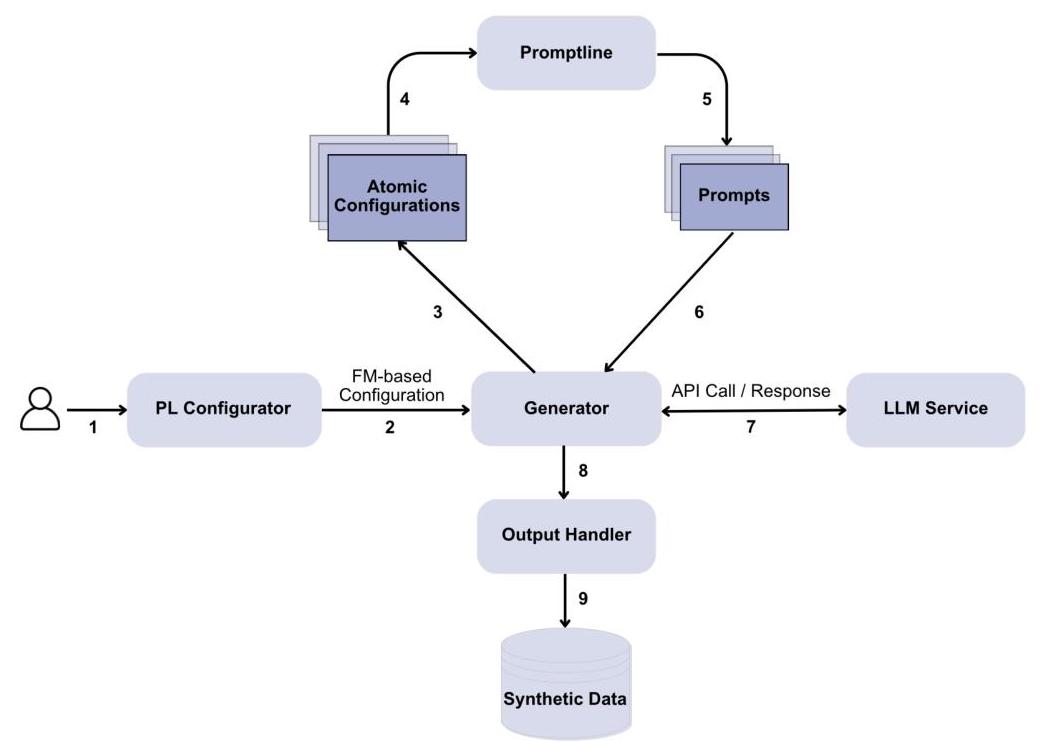
图1. Synthline的高层架构。
工作流从PL配置器开始,它将我们的FM实现为一个用于特征选择的图形界面。该界面直接反映了我们FM的分层结构,将控件分为四个部分,对应我们的核心特征。对于需要从预定义选项中选择的特征选择,例如在CSV和JSON之间选择输出格式,界面提供下拉菜单。对于温度或子集大小等数值参数,实现文本输入字段并进行适当验证。此设计确保用户只能创建有效配置,同时保持选择的灵活性。
生成器将此基于FM的配置转换为原子配置,其中原子配置表示特征值的独特组合。
Promptline组件使用标准化模板将每个原子配置转换为提示,基于[34]中证明有效的结构化提示模式,其内容如下:
生成一个需求,该需求:
- 被分类为 {label}(描述:{label_description})
-
- 类型为 {requirement_type}
-
- 用 {language} 编写
-
- 用于 {domain} 系统
-
- 从 {requirement_source} 角度出发
-
- 遵循 {specification_format} 格式
-
- 在 {specification_level} 层次编写
- 重要:仅生成需求文本。不要添加任何额外的上下文。
生成器管理请求样本数量均匀分布在所有原子配置中的分配,调整无法完美分割的情况。然后它通过异步API调用与LLM服务接口进行文本生成。生成的内容流向输出处理器,后者以指定格式持久化合成数据及其配置元数据。
3.2 应用工程
需求规范缺陷的识别 为了演示和评估我们的合成数据PL方法,我们选择了识别需求规范缺陷作为主要应用场景。
需求规范缺陷在软件开发中呈现关键挑战,因为它们可能导致后期开发阶段的重大问题,这些问题变得越来越难以解决且成本高昂 [24]。自动化方法识别这些缺陷显示出减少人工努力和提高缺陷检测准确性的潜力 [25|26|27]。
需求缺陷的识别可以有效地表述为分类问题,其中每个需求被分析以确定是否存在特定类型的缺陷。RE社区的几位研究人员已经确定了不同类型的需求规范缺陷。Berry和Kamsties [28] 突出了模糊性作为主要问题,而其他研究则强调了其他关键缺陷类别,如不可测量性、非原子性和不确定性 [25]。
表1详细列出了Fazelnia等人定义的常见需求规范缺陷 [25]。我们关注这些缺陷,因为我们能够访问他们公开可用的数据集 2 { }^{2} 2,其中需求被标记为这六个类别。
表1. 需求缺陷类别及其定义 [25]
| 类别 | 定义 |
|---|---|
| 模糊需求 | 需求规范不清楚、不精确,且有多重解释的可能性。 |
| 指令性需求 | 指导开发者参考需求之外的其他来源(例如,引用图表或表格)。 |
| 不可测量需求 | 需求不可测量或不可测试,包含无法量化或测量的定性值(例如,“一些”、“大”、“长”)。 |
| 可选项需求 | 包含可能以多种方式解释的术语,并将如何实施需求的选择留给开发者(例如,“可以”、“可能”、“可选地”、“按需”、“至少”、“任一”、“最终”、“如合适”、“如情况所需”、“如有必要”)。 |
| 不确定需求 | 包含未充分定义的定性值(例如,“好”、“坏”、“强”、“容易”),或可能包含未充分引用的元素(例如,“符合标准(哪些?)”)。 |
| 非原子需求 | 描述了需要采取的多个行动,通常包含连词,如“和”。 |
2
{ }^{2}
2 数据集可在 https://zenodo.org/records/11000349 获取
该数据集结合了来自真实软件系统的实际需求,包括美国卫生与公众服务部的电子健康记录系统和学生项目SysRS文档中的高质量需求。两位拥有超过20年和10年经验的主题专家进行了严格的三阶段审查过程,包括语法分析、缺陷标注和最终同行评审,以确保高质量注释 [25]。
该数据集包含6个缺陷类别的131个总样本,其中模糊需求最为常见(34个样本),指令性需求最少(4个样本)。该数据集存在两个显著限制:严重的类别不平衡及其相对较小的规模,这限制了在不冒过拟合风险的情况下对AI模型的有效训练或微调。
表2. 需求规范缺陷的分布
| 类别 | 样本数 |
|---|---|
| 模糊 | 34 |
| 指令性 | 4 |
| 不可测量 | 18 |
| 可选项 | 31 |
| 不确定 | 16 |
| 非原子 | 28 |
数据生成 我们的合成数据生成方法使用每个LLM生成六个类别特定的子集,这些子集与表1中定义的缺陷类别一致,使用其文本定义作为标签描述符。这与多步骤生成方法一致,该方法在单独运行中创建多个数据子集,提供更多控制 [18]。我们的生成过程配置设置详见表3。
我们选择了GPT-4o和DeepSeek-V3作为主要的LLM选项。选择GPT-4o基于其前代在生成高质量合成数据方面的有效性 [19],[29],[12]。对于开源替代方案,我们选择了截至实验日期(2025年1月5日)最先进的DeepSeek-V3模型,经验评估表明它在大多数基准测试中超越了包括GPT-4o和Claude 3.5 Sonnet在内的领先专有模型 [2]。根据[19]和[29],选择了温度为1.0和TopP为1.0,因为这些设置已被证明能生成高质量的合成数据。选择了医疗保健领域,以直接与美国卫生与公众服务部的电子健康记录系统的真实数据集对齐,同时选择了餐厅运营管理作为第二个领域,以反映数据集中与餐厅员工注册、菜单管理和运营功能相关的要求。同样,我们选择了受限自然语言格式和英语语言,以确保我们的合成需求与真实数据集的语言特征相匹配。选择了CSV输出格式,因其简单性和与真实数据集格式的兼容性。我们有意使我们的合成数据特征与真实数据集对齐,因为合成模型的评估将在真实数据的一个保留子集上进行,以确保对其性能的公平评估。此外,我们包括了所有可用的需求类型、规范层次和需求来源子特征。这种全面的选择确保了多样性,避免了可能偏倚数据集的系统排除。
表3. 控制多步骤生成运行的配置参数,按LLM和合成数据子集的缺陷类别应用。
| 特征 | 值 | 原子 配置数 |
|---|---|---|
| 温度 | 1 | 1 |
| TopP | 1 | 1 |
| 需求类型 | 外部接口、功能、性能、逻辑 数据库、设计约束、系统属性 | 7 |
| 规范层次 | 高级规范、详细规范 | 2 |
| 需求来源 | 终端用户、业务经理、开发团队、 监管机构 | 4 |
| 规范格式 | 受限自然语言 | 1 |
| 语言 | 英语 | 1 |
| 领域 | 医疗保健、餐厅运营管理 | 2 |
| 输出格式 | CSV | 1 |
| 子集大小 | 1120 | 1 |
| 总原子配置数 | 112 |
对于每个LLM(GPT-4o和DeepSeek-V3),我们为每个缺陷类别生成了1,120个需求,每种模型生成6,720个合成样本,总计13,440个样本。
4 评估
正如最近的一项调查 [14] 所强调的,合成数据的评估方法可以大致分为直接和间接两种方法。直接评估侧重于生成数据本身的属性。一个常被研究的方面是数据多样性,通常使用词汇统计(例如词汇量和N-gram频率)或语义变异指标(如余弦相似度)进行评估 [19]。另一方面,间接评估主要评估合成数据对下游模型训练后的性能影响,通常应用“在合成数据上训练、在真实数据上测试”的范式 [19]。在我们的研究中,我们关注这两个互补维度,以全面评估我们生成的数据。
多样性评估 为了全面评估合成数据集相对于真实数据的多样性,我们在去重后 3 { }^{3} 3 对合成数据集(GPT4o和DeepSeek)进行了这项评估。我们使用了几种互补的指标来捕捉文本多样性的不同方面。我们从两个基于词汇的测量开始:绝对词汇量,定义为每个数据集中独特术语的数量;以及归一化的词汇量,考虑了数据集大小的变化。这些指标提供了词汇丰富性的基本指示,较大的词汇量表明更高的语言多样性和潜在更丰富的表达方式。
为了评估语义多样性,我们使用Sentence-BERT [31] 的嵌入计算了文本对之间的余弦相似度。平均成对相似度(APS)衡量了整个数据集中样本的整体
3
{ }^{3}
3 去重包括去除偶尔由LLMs多次生成的相同需求。
语义相似度。较低的APS值表示整体语义多样性更高。另一方面,类内APS衡量同一缺陷类别内的样本之间的语义相似度。较低的类内APS值表明同类缺陷的更多样例子,表明类内冗余较少。
为了评估短语级多样性,我们计算了跨样本N-gram频率(INGF),该指标衡量生成文本中的重复模式。此指标计算数据集中所有样本的n-gram平均频率,较低的值表示较少的重复,因此短语构造更加多样。这些指标共同提供了数据集多样性的多维视图,从词汇丰富性到语义变异和短语级独特性。
合成数据集的统计信息汇总在表4中,显示了去重后的总样本数及其在缺陷类别中的分布。
表4. 去重后合成数据集的统计信息。
| 缺陷类别 | DeepSeek样本数 | GPT-4o样本数 |
|---|---|---|
| 模糊 | 1,007 | 1,117 |
| 指令性 | 1,015 | 1,120 |
| 非原子 | 828 | 1,118 |
| 不可测量 | 701 | 1,117 |
| 可选项 | 934 | 1,119 |
| 不确定 | 828 | 1,112 |
| 总样本数 | 5 , 313 \mathbf{5 , 3 1 3} 5,313 | 6 , 703 \mathbf{6 , 7 0 3} 6,703 |
效用评估 为了实现合成数据和真实数据性能的直接比较,我们将BERT-base-uncased [20] 作为骨干网络进行微调,并默认使用标准交叉熵损失。对于超参数选择,我们遵循了文献中的建议 [30],没有使用验证集进行模型选择。表5详细列出了我们实验中使用的超参数。
表5. 训练超参数。
| 超参数 | 值 |
|---|---|
| 学习率 | 5 e − 5 5 \mathrm{e}-5 5e−5 |
| 批量大小 | 32 |
| 训练轮数 | 6 |
| 权重衰减 | 1 e − 4 1 \mathrm{e}-4 1e−4 |
| 预热比例 | 6 % 6 \% 6% |
我们的评估方法遵循“在合成数据上训练,在真实数据上测试”的范式 [19]。我们保留了由真实数据组成的30%的测试集,该测试集在所有实验中保持不变,以确保一致的评估。剩余的70%真实数据仅用于训练真实数据基线模型。对于合成数据实验,我们在纯合成数据或合成与真实训练数据的组合上训练模型。这种方法使我们能够直接比较合成数据与真实数据的有效性,以及合成数据与真实数据结合的效果。
为了确保稳健的评估,我们针对每种配置进行了多次训练运行,考虑到模型训练中的固有变异性。我们使用宏平均精度和召回率指标评估模型性能。
5 结果
5.1 RQ1: 生成数据的多样性与真实数据相比如何?
如表6所示,尽管GPT-4o和DeepSeek生成的数据集具有更大的绝对词汇量(分别为4,874和3,659个术语)相较于真实数据集(566个术语),这主要是由于它们的样本量更大。当按样本数量归一化时,合成数据集表现出显著较低的词汇密度,GPT-4o和DeepSeek分别为每样本0.73和0.69个词,而真实数据为每样本4.32个词。这种 6.2 − 6.3 × 6.2-6.3 \times 6.2−6.3×的词汇密度下降表明,尽管合成数据可以访问更广泛的词汇范围,但它们倾向于使用更受限的词汇。
表6. 数据集间的词汇量分析。
| 数据集 | 词汇量 | 归一化词汇量 |
|---|---|---|
| 真实数据 | 566 | 4.32 |
| DeepSeek | 3,659 | 0.69 |
| GPT-4o | 4,874 | 0.73 |
通过表7观察语义多样性,我们发现合成数据集生成的语义内容更为同质化。两个合成数据集均表现出较高的整体APS值(DeepSeek: 0.649, GPT-4o: 0.612),相较于真实数据(0.544)。这种模式在类内分析中尤为明显,合成数据显示出显著更高的相似度得分(DeepSeek: 0.729, GPT-4o: 0.689),而真实数据为0.587。如图2所示,合成数据的余弦相似度分布向更高值偏移,并表现出较窄的分布范围。
表7. 语义相似度和短语重复指标。
| 数据集 | APS | 类内 | APS | INGF |
|---|---|---|---|---|
| 真实数据 | 0.544 | 0.587 | 1.214 | |
| DeepSeek | 0.649 | 0.729 | 5.086 | |
| GPT-4o | 0.612 | 0.689 | 2.472 |
表7显示,从短语层面来看,合成数据表现出显著更高的n-gram重复率,INGF值比真实数据高出2-4倍(DeepSeek: 5.086, GPT-4o: 2.472, vs. 真实数据: 1.214)。这种增加的重复率可能归因于我们在生成过程中选择的受限自然语言规范格式,这鼓励了更标准化的短语构造。
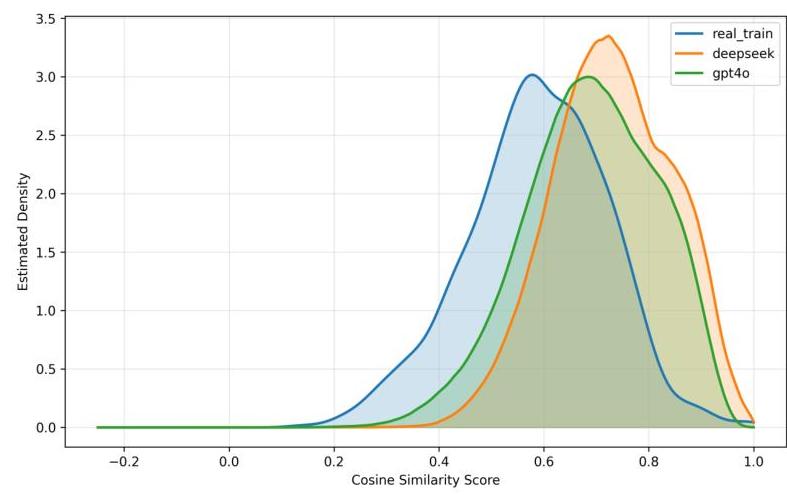
图2. 从同一类别中抽样的文本对的余弦相似度分布。
尽管合成数据集提供了更广泛的绝对词汇覆盖率,但它们在所有测量维度上都表现出比真实数据更低的多样性——表现为词汇密度低6倍,语义相似度高(0.612-0.649 vs 0.544),以及短语重复率增加(2-4倍更高的INGF值)。
5.2 RQ2: 使用合成数据进行训练相对于仅使用真实数据如何影响模型性能?
我们考察了三种关键训练方法下的模型性能:仅使用合成数据、结合真实和合成数据的混合训练以及合并的合成数据集。首先,仅使用合成数据训练的模型表现优于真实数据基线。如表8所示,基于DeepSeek的模型在精度上提高了37%(0.425 vs 0.310),而基于GPT-4o的模型提高了20%(0.372 vs 0.310)。这表明在真实数据稀缺的情况下,仅使用合成数据可以提供有希望的可行训练替代方案。
表8. 使用不同训练数据组合的模型性能。所有实验使用相同的模型架构,仅在训练数据上有所不同。
| 训练数据 | 精度 | 召回率 |
|---|---|---|
| 仅真实数据(基线) | 0.310 ± 0.050 0.310 \pm 0.050 0.310±0.050 | 0.256 ± 0.043 0.256 \pm 0.043 0.256±0.043 |
| 仅DeepSeek | 0.425 ± 0.083 0.425 \pm 0.083 0.425±0.083 | 0.334 ± 0.025 0.334 \pm 0.025 0.334±0.025 |
| 仅GPT-4o | 0.372 ± 0.060 0.372 \pm 0.060 0.372±0.060 | 0.329 ± 0.080 0.329 \pm 0.080 0.329±0.080 |
| GPT-4o + DeepSeek | 0.308 ± 0.037 0.308 \pm 0.037 0.308±0.037 | 0.297 ± 0.015 0.297 \pm 0.015 0.297±0.015 |
| 真实 + DeepSeek | 0.456 ± 0.027 0.456 \pm 0.027 0.456±0.027 | 0.431 ± 0.042 0.431 \pm 0.042 0.431±0.042 |
| 真实 + GPT-4o | 0.575 ± 0.229 0.575 \pm 0.229 0.575±0.229 | 0.512 ± 0.166 0.512 \pm 0.166 0.512±0.166 |
| 真实 + GPT-4o + DeepSeek | 0.469 ± 0.121 0.469 \pm 0.121 0.469±0.121 | 0.427 ± 0.089 0.427 \pm 0.089 0.427±0.089 |
然而,最显著的性能提升来自于结合真实和合成数据的混合训练方法。真实和GPT-4o合成数据的组合产生了最佳的整体性能,相较于真实数据基线,精度提升了85%(0.575 vs. 0.310)。这一显著提升表明真实和合成训练数据之间存在强烈的互补性。有趣的是,我们观察到不同合成数据源的性能稳定性存在显著差异。使用DeepSeek合成数据训练的模型表现出更一致的性能(精度标准差: ± 0.027 \pm 0.027 ±0.027),而使用GPT-4o数据训练的模型( ± 0.229 \pm 0.229 ±0.229)则不然。这种稳定性差异在实际应用中性能一致性重要的情况下可能具有重要意义。特别值得注意的是,结合多个合成数据集(GPT-4o + DeepSeek)实际上降低了性能,甚至低于单个合成数据集的表现。即使加入真实数据(真实 + GPT-4o + DeepSeek: 0.469 vs. 真实 + GPT-4o: 0.575),这种负面协同效应依然存在,这表明精心策划合成数据源可能比单纯增加合成数据量更重要。
所有配置的相对较低性能指标可归因于我们选择使用推荐的超参数 [30] 而未进行数据集特定的调优。虽然超参数优化可能会提高绝对性能,但在所有实验中使用固定配置确保了不同训练数据组合之间的公平比较,使得任何相对改进可以直接归因于数据质量。
合成数据不仅能够匹配,而且在训练下游模型以分类需求缺陷时显著超越真实数据,混合方法尤其显示出前景。然而,成功似乎高度依赖于合成数据源的具体组合和策划,而不是仅仅增加数据量。
6 有效性威胁
我们在内部、外部、构念和结论有效性的四个标准维度上识别了若干有效性威胁。内部而言,我们的模型性能可能受到所选特定训练超参数设置的影响。尽管我们遵循了先前研究 [30] 中的既定建议,但不同的超参数配置可能会产生不同的结果。我们评估方法依赖BERT-base-uncased作为骨干模型可能引入偏差,因为其他预训练模型在合成数据上的表现可能不同。此外,尽管我们遵循了[19]中的结构化提示模式,但合成数据质量本质上依赖于提示设计选择,即使是模板结构或措辞的细微变化也可能系统性地影响生成样本的特性。关于构念有效性,我们的多样性指标(词汇量、APS、INGF)可能无法完全捕捉自然语言生成输出的所有多样性方面。尽管这些指标在合成数据评估中广泛使用 [14, 19] 并提供了有用的定量措施,但它们在表示高质量多样文本的细腻特性方面可能存在固有限制。我们选择在整个合成数据生成过程中使用受限自然语言规范格式,这本质上限制了语言变化和多样性潜力,可能影响我们对方法生成多样化输出能力的评估。此外,我们的方法依赖Fazelnia等人 [25] 的缺陷类别定义作为标签描述来指导LLM生成,像“不可测量”这样的类别可能具有主观解释边界,可能影响LLM对每种缺陷类型的解释和生成示例的方式。外部而言,我们的发现可能无法推广到识别需求规范缺陷以外的其他基于分类的RE应用场景。我们的方法有效性主要在医疗保健和餐厅运营管理领域得到了证明,不同的应用领域可能提出我们当前评估未涉及的独特挑战。此外,我们的结果基于GPT-4o和DeepSeek-V3模型,不同LLM版本或替代模型的性能特征可能会有所不同。最后,结论有效性可能受到我们测试集规模较小的影响,这可能影响我们性能比较的统计显著性。此外,模型训练的变异性由于随机初始化和随机优化过程引入了潜在的不稳定性,尽管我们通过针对每种配置进行多次训练运行来尝试缓解这一点。
7 结论
本文介绍了Synthline,这是一种利用LLMs在产品线策略内生成合成数据的方法,用于控制基于分类的RE应用场景的合成数据生成。通过专注于识别需求规范缺陷的实证评估,我们发现合成数据,特别是与真实数据结合时,可以显著提高下游分类器的性能。具体而言,我们的实验显示,与仅使用真实数据的基线相比,精度提高了多达 85 % 85 \% 85%,召回率提高了两倍。此外,尽管合成数据集的多样性低于真实数据,但结果确认,精心策划的合成样本在真实数据有限时可作为可行的——并且在许多情况下更优越的——训练资源。
未来,我们计划扩大Synthline的范围以支持更多的RE应用场景,并改进生成技术以进一步提高合成数据质量。我们还将开发一个更全面的评估框架,超越多样性和效用,使我们能够更深入地理解合成数据如何为RE中的强大可靠AI解决方案做出贡献。
参考文献
- X. Franch, C. Palomares, C. Quer, P. Chatzipetrou, and T. Gorschek, “The state-of-practice in requirements specification: an extended interview study at 12 companies”, Requirements Engineering, pp. 1-33, 2023. doi: 10.1007/s00766-023-00399-7.
-
- DeepSeek-AI, “DeepSeek-V3 Technical Report”, arXiv:2412.19437 [cs.CL], 2024.
-
- R. Wieringa, “Design science as nested problem solving”, in Proc. 2009 ACM Int. Conf., New York, NY, USA, 2009. doi: 10.1145/1555619.1555630.
-
- G. Malik, M. Cevik, and A. Başar, “Data Augmentation for Conflict and Duplicate Detection in Software Engineering Sentence Pairs”, arXiv:2305.09608 [cs.SE], 2023.
-
- A. Majidzadeh, M. Ashtiani, and M. Zakeri-Nasrabadi, “Multi-type requirements traceability prediction by code data augmentation and fine-tuning MS-CodeBERT”, Computer Standards & Interfaces, vol. 90, Article 103850, 2024. doi: 10.1016/j.csi.2024.103850.
-
- I. Gräßler, D. Preuß, L. Brandt, and M. Mohr, “Efficient Extraction of Technical Requirements Applying Data Augmentation”, in Proc. 2022 IEEE International Symposium on Systems Engineering (ISSE), Vienna, Austria, 2022, pp. 1-8. doi: 10.1109/ISSE54508.2022.10005452.
-
- T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, 和 D. M. Ziegler, “语言模型是少量样本学习者”,arXiv:2005.14165 [cs.CL], 2020.
- M. Mosbach, T. Pimentel, S. Ravfogel, D. Klakow, 和 Y. Elazar, “少量样本微调与情境学习:公平的比较与评估”,在 Findings of the Association for Computational Linguistics: ACL 2023, 多伦多,加拿大,第12284-12314页,2023. 计算语言学协会。
- L. Zhao, W. Alhoshan, A. Ferrari, K. J. Letsholo, M. A. Ajagbe, E.-V. Chioasca, 和 R. T. BatistaNavarro, “需求工程中的自然语言处理:系统映射研究”,ACM Computing Surveys, 第54卷,第3期,文章55,第1-41页,2022年4月。
- T. Li, X. Zhang, Y. Wang, Q. Zhou, Y. Wang, 和 F. Dong, “需求工程中的机器学习(ML4RE):系统文献综述补充了来自Stack Overflow的从业者声音”,Information and Software Technology, 第172卷,文章107477,2024年。
- Z. Li, H. Zhu, Z. Lu, 和 M. Yin, “使用大型语言模型生成合成数据进行文本分类:潜力与局限性”,在 Proc. 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023年。
- F. Gilardi, M. Alizadeh, 和 M. Kubli, “ChatGPT在文本标注任务中优于众包工人”,在 Proc. National Academy of Sciences, 第120卷,第30期,文章e2305016120, 2023年。
- J. Ye, J. Gao, Q. Li, H. Xu, J. Feng, Z. Wu, T. Yu, 和 L. Kong, “ZeroGen:通过数据集生成实现高效的零样本学习”,arXiv:2202.07922 [cs.CL], 2022年。
- L. Long, R. Wang, R. Xiao, J. Zhao, X. Ding, G. Chen, 和 H. Wang, “关于LLMs驱动的合成数据生成、策划和评估:综述”,arXiv:2406.15126 [cs.CL], 2024年。
- A. El-Hajjami, N. Fafin, 和 C. Salinesi, “哪种AI技术更适合分类需求?SVM、LSTM和ChatGPT实验”,arXiv:2311.11547 [cs.AI], 2024年。
- J. Yoon, J. Jordon, 和 M. van der Schaar, “PATE-GAN:具有差分隐私保证的合成数据生成”,在 Proc. International Conference on Learning Representations (ICLR), 2019年。
- S. Abualhaija, F. B. Aydemir, F. Dalpiaz, D. Dell’Anna, A. Ferrari, X. Franch, 和 D. Fucci, “需求工程中的复制:RE中的NLP案例”,arXiv:2304.10265 [cs.SE], 2024年。
- Z. Shao, Y. Gong, Y. Shen, M. Huang, N. Duan, 和 W. Chen, “合成提示:为大型语言模型生成链式思维演示”,arXiv:2302.00618 [cs.CL], 2023年。
- Y. Yu, Y. Zhuang, J. Zhang, Y. Meng, A. Ratner, R. Krishna, J. Shen, 和 C. Zhang, “作为属性训练数据生成器的大规模语言模型:多样性与偏差的故事”,在 Proc. Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023年。
- J. Devlin, M.-W. Chang, K. Lee, 和 K. Toutanova, “BERT: 预训练深度双向Transformer用于语言理解”,在 Proc. 2019 North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), J. Burstein, C. Doran, 和 T. Solorio 编辑,明尼苏达州明尼阿波利斯:计算语言学协会,2019年,第4171-4186页。doi: 10.18653/v1/N19-1423。
- K. Pohl, G. Böckle, 和 F. Van Der Linden, Software Product Line Engineering: Foundations, Principles, and Techniques, 第1卷,柏林,德国:Springer, 2005年。
- S. Apel, D. Batory, C. Kästner, 和 G. Saake, Feature-Oriented Software Product Lines: Concepts and Implementation, Springer, 柏林,海德堡,2013年。
- L. Northrop, “软件产品线基础”, 匹兹堡:SEI卡内基梅隆大学, 2008年。
- S. Lauesen 和 O. Vinter, “防止需求缺陷:过程改进实验”, 在《需求工程期刊》, 第6卷,第1期,第37-50页,2001年。
- M. Fazelnia, V. Koscinski, S. Herzog, 和 M. Mirakhorli, “自然语言推理(NLI)在需求工程任务中的应用教训”, 在《IEEE国际需求工程会议( RE )论文集》,2024年。
- S. Goyal 等人, “SDP-BB: 使用BiLSTM和基于BERT的语义特征的软件缺陷预测模型”, 在《IEEE软件工程事务》,2022年。
- A. Dautovic, R. Plösch, 和 M. Saft, “软件开发文档中的自动质量缺陷检测”, 在《第五届国际软件质量管理会议论文集》,2011年。
- D. M. Berry 和 E. Kamsties, “需求规范中的模糊性”, 在《需求工程:实践状态》,M. Leite 和 J. Doorn 编辑,波士顿,MA: Springer US, 2004年,第7-44页。
- B. Peng, C. Li, P. He, M. Galley, 和 J. Gao, “使用GPT-4进行指令调整”, arXiv:2304.03277 [cs.CL], 2023年。
- E. Perez, D. Kiela, 和 K. Cho, “语言模型的真实少量样本学习”, 在 Proc. Advances in Neural Information Processing Systems, A. Beygelzimer, Y. Dauphin, P. Liang, 和 J. Wortman Vaughan 编辑,2021年。
- N. Reimers 和 I. Gurevych, “Sentence-BERT: 使用孪生BERT网络的句子嵌入”, 在 Proc. 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), K. Inui, J. Jiang, V. Ng, 和 X. Wan 编辑,中国香港:计算语言学协会,2019年,第3982-3992页。doi: 10.18653 / v 1 / D 19 − 1410 10.18653 / \mathrm{v} 1 / \mathrm{D} 19-1410 10.18653/v1/D19−1410。
附录:FM的图形表示

参考论文:https://arxiv.org/pdf/2505.03265



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











