






已完成的研究论文
Jonas Bokstaller,列支敦士登大学,瓦杜兹,列支敦士登,jonas.bokstaller@uni.li
Julia Altheimer,列支敦士登大学,瓦杜兹,列支敦士登,julia.altheimer@uni.li
Julian Dormehl,慕尼黑工业大学,慕尼黑,德国,julian.dormehl@tum.de
Alina Buss,慕尼黑工业大学,慕尼黑,德国,alina.buss@tum.de
Jasper Wiltfang,慕尼黑工业大学,慕尼黑,德国,jasper.wiltfang@tum.de
Johannes Schneider,列支敦士登大学,瓦杜兹,列支敦士登,johannes.schneider@uni.li
Maximilian Röglinger,拜罗伊特大学,拜罗伊特,德国,maximilian.roeglinger@fim-rc.de
摘要
在各个行业中,可解释的人工智能(XAI)应用势头强劲,因为主流机器学习(ML)模型的黑箱化日益明显。同时,大规模语言模型(LLMs)在理解和识别复杂模式方面的能力显著提升。通过结合两者,本文提出了一种新的参考架构,用于通过交互式聊天机器人解释XAI,该聊天机器人由微调后的LLM驱动。我们在电池健康状态(SoH)预测的背景下实例化参考架构,并在多次评估和演示轮次中验证其设计。评估结果表明,所实现的原型增强了人类对ML的理解,特别是对于较少经验的XAI用户。
关键词:可解释的人工智能,大规模语言模型,微调,电池健康状态
1 引言
人工智能被视为一种难以解释的变革性技术(Berente等人,2021)。可解释的人工智能(XAI)旨在通过向最终用户提供解释来增强机器学习(ML)预测的可解释性(Meske等人,2022)。XAI的一个主要目标是使人类能够彻底理解并有效与人工智能(AI)模型互动,这对于将开发过程从试错转变为更有针对性以及确保AI的适当功能(如通过认证机构)至关重要(Meske等人,2022)。因此,XAI可以帮助减轻安全风险。然而,当前可解释性的研究现状被普遍认为效率低下(Räuker等人,2023),并且许多问题仍然存在(Schneider,2024)。例如,在交互式和更定制(或个性化)解释方面进展甚微(Schneider,2024)。与此同时,大规模语言模型(LLMs)最近展示了显著的交互和定制能力。只有少数方法尝试构建结合XAI和LLMs的系统(Gao等人,2022;Slack等人,2023;Nguyen等人,2023)。所有这些方法都没有针对任务调整模型,而是围绕它进行构建,即它们倾向于依赖规则、模板和问题库,而不是调整或增强模型本身。因此,当涉及到推理能力时,例如不仅仅显示重要性值,而是将其与领域特定知识以文本形式连接起来,它们的结果虽然有希望但尚未令人信服。我们的研究旨在回答研究问题(RQ):“如何利用LLM来增强现有XAI输出以提高人类理解?”实现这一目标的一种方法是微调,它可以使得模型掌握领域特定的细微差别,并生成更准确和上下文相关的解释。与静态基于规则的方法不同,微调允许LLMs超越通用模式,提供更丰富、更具洞察力的重要性值解释。
作为LLM的数据源,有各种XAI库可用,每个库都旨在为ML模型提供事后评估。我们呈现的成果兼容广泛使用的XAI库;然而,在本文中,我们重点强调SHapley Additive exPlanations(SHAP)(Lundberg & Lee, 2017),因为它支持分类输入特征。SHAP通过博弈论方法提供模型特征如何贡献到最终ML预测的精细分析。然而,解释SHAP输出需要数据科学和统计概念方面的领域特定专业知识。尽管XAI技术(如SHAP)具有巨大的潜力来增加可解释性,但对于缺乏解释SHAP结果所需知识的用户来说,理解XAI技术可能会很困难,这限制了其应用范围仅限于领域专家(Kaur等人,2020)。通过在交互式聊天机器人中利用SHAP值,用户可以进行对话驱动的模型预测探索,从而有可能使更多用户群体能够使用XAI技术的功能。因此,我们旨在通过设计一个具有XAI翻译能力的交互式聊天机器人来弥合这一差距,以促进人类用户对ML模型的解释。我们遵循Hevner等人(2004)和Peffers等人(2007)改编的设计科学研究(DSR)方法,整合Venable等人(2016)的设计科学评价框架(FEDS)。我们推导并制定相关的设计目标(DOs),并通过专家访谈评估其重要性。基于这些充分论证的DOs,我们迭代开发和评估一个概述微调LLM与SHAP交互以提高ML模型可解释性的成果。在此过程中,我们开发了一个包含三个连续微调步骤的LLM微调流程,以增强其理解和分析领域特定用户问题的能力。我们证明领域特定的微调在所有评估指标上都有显著改进。我们还通过在电池健康状态(SoH)预测的背景下实施和演示一个原型来评估和展示我们成果的实际适用性。这个用例不仅对于信息原因很重要,而且对于健康和安全也至关重要。一项在线调查总结了我们的研究,确认了我们的成果在增强ML模型可解释性方面的优势。我们的成果利用LLM,可以将纯数字形式的SHAP值与领域特定背景相结合,最终为最终用户提供易于理解的信息。这降低了最终用户的知识要求,使更多受众能够理解模型预测。
2 理论背景
2.1 大型语言模型
大型语言模型(LLMs)已从早期的统计语言模型和深度神经网络中的词嵌入发展到现代基于转换器的架构(Vaswani,2017),显著提高了自然语言理解和生成能力。同时,XAI领域在过去几年迅速发展(Meske等人,2022),但仍处于活跃研究中(Schneider,2024)。最初,这些模型通过无监督训练技术在大规模数据集上进行训练,以从原始文本中获得广泛的语言理解。虽然这种广泛的语料库对于一般语言理解至关重要,但它并不总是适用于专门任务或特定领域。微调则是随后的过程,将这种通用知识适应特定应用。在微调过程中,模型的权重根据特定领域的数据集进行调整,完善模型的理解并提高其在特定任务上的性能。例如,当在金融数据上进行微调时,BloombergGPT在金融任务中的表现显著增强,而不会失去其通用能力(Wu等人,2023)。
本文已被接受在ECIS 2025会议上发表。
最终版本将在ECIS 2025会议记录中提供。
同样,GitHub Copilot在代码生成方面进行了微调,可以根据自然语言描述生成多种编程语言的代码(Nguyen & Nadi,2022)。这些例子展示了微调如何将知识从广泛的语言环境转移到更小众的领域,优化性能而无需从头开始重新训练。值得注意的是参数高效微调(Hu等人,2023)以及更具体的低秩适应(LoRa),这有助于主流模型更有效地将知识从源任务转移到目标任务,只需少量内存,并通过仅拟合少量参数减少灾难性遗忘问题(Hu等人,2022)。微调可以通过监督或非监督方式进行。非监督微调允许模型发现与领域相关的潜在模式和结构。它增强了领域特定文本生成的适应性和鲁棒性。另一方面,监督微调利用带有明确任务相关注释的结构化数据来指导学习过程。这使模型与任务目标对齐,并提高生成文本输出的准确性(Gunel等人,2021)。虽然之前的文献主要解决了LLMs的技术方面,但研究已扩展到包括社会技术视角(Chakraborty等人,2017;Lehmann,2022;Jussupow等人,2020)。这些研究关注用户的需求和与AI系统的互动。
2.2 可解释的人工智能
XAI区分局部和全局解释。局部解释涉及数据集中特定实例的预测或决策。全局解释则提供对整个数据集中底层模型的整体理解。其次,XAI技术根据它们是否提供事后解释或内在解释进行区分。事后解释指的是模型做出预测后提供的解释。相比之下,内在解释包括本质上可解释的ML模型,例如决策树或朴素贝叶斯分类器(Arrieta等人,2020;Brasse等人,2023)。一种流行的XAI方法是SHAP,它代表事后解释技术(Lundberg & Lee,2017)。解释是在模型做出预测后提供的。最初来源于合作博弈论领域,并适应到XAI环境中,以量化黑盒ML模型中单个特征的贡献,从而确定单个特征对预测的重要性(Van den Broeck等人,2022)。通过计算特征对模型预测的影响,可以计算出SHAP值,并通过提供的可视化方式使模型及其特征更加易懂(Lundberg & Lee,2017)。
2.3 相关工作
在筛选文献时,我们确定了四篇将LLMs集成以增强ML模型可解释性的论文。Gao等人(2022)提出了一种聊天机器人解释框架,可以为最终用户提供不同用途。作为一个用例,他们实现了一个与ML模型交互以检测火车票预订系统异常的聊天机器人。聊天机器人是通过Watson Assistant Service(IBM,2024)构建并集成到生产力工具(例如Slack应用程序)中。Slack等人(2023)介绍了TalkToModel。这是一个交互式对话系统,允许用户通过自然语言对话了解ML模型。用户输入首先通过LLM解析成结构化查询编程语言。基于解析输入,TalkToModel通过填充预定义模板生成响应,这些模板定义了ML模型的具体操作。模板的响应合并成最终响应并显示给用户。预定义模板确保可信的响应并减少LLM的幻觉(Yao等人,2023)。Nguyen等人(2023)使用LLM模型专注于AI解释。他们构建了问题短语库和基于模板的答案,使用来自ML模型的信息。因此,LLM受特定规则和回答模板的约束。问题是处理成标准格式,其中占位符由用户提供的信息填充。在匹配用户输入到相应的参考问题和模板后,需要检索模型预测的相关信息。检索到的SHAP值用于解释特定预测输出的原因。总的来说,据作者所知,目前还没有其他论文发表过利用微调LLM的神经能力来解释AI并提供聊天机器人交互以供人类理解。当前相关工作的状态主要集中在预定义模板或问题短语库上,这限制了适应复杂、不可预见场景或提供个性化解释的能力。通过利用不受这些约束的LLM,我们使模型能够生成更动态、上下文丰富的响应,以更好地满足每次交互的具体需求和细微差别,提供更大的灵活性和深入解释。
3 研究设计
我们使用DSR(Hevner等人,2004;Peffers等人,2007)来解决我们的RQ,即如何利用LLM来增强现有的XAI输出以提高人类理解。我们的研究产生了一个参考架构,详细说明了XAI评估的ML模型与微调的LLM模型之间的交互以增强人类可解释性。参考架构区分了参与的参与者:用户、系统和开发者。在参与者、活动和数据之间,参考架构概述了所需的信息流和交互。此外,参考架构在自然环境中实现,通过提供物理实现形式的原型实例来评估我们提出的成果的有效性,并迭代改进其设计。在我们成果的设计中,我们遵循Peffers等人(2007)的增量和迭代DSR过程,包括六个阶段:1. 问题识别,2. 定义DOs,3. 设计和开发,4. 展示,5. 评估,和6. 沟通。在问题识别的背景下,我们识别并详细阐述了研究问题,以确保我们的DSR项目目标针对相关的业务问题(Hevner等人,2004)。因此,我们从问题规范和XAI及LLM领域的初步文献筛查中推导出DOs。我们将DSR项目结构化为搜索过程,该过程在DOs定义的解决方案空间内进行,以实现原型的适当现实世界实例化(Hevner等人,2004;Peffers等人,2007)。我们迭代开发抽象参考架构,详细说明XAI评估的ML模型与微调LLM模型之间的交互,通过具体化DOs并在电池健康的用例中启动现实世界的原型。我们将展示和评估阶段结合起来,因为在开发过程中纳入多个评估活动(Hevner等人,2004;Peffers等人,2007),并采用FEDS框架以减少设计过程中的不确定性和风险,并支撑所开发成果的有效性(Venable等人,2016)。FEDS框架沿功能目的和评估背景结构化设计阶段和评估事件,以确保成果的实用性、质量和有效性可以严格评估。此外,我们通过Sonnenberg和Vom Brocke(2012)的DSR评估框架中选定的组件扩展FEDS。在FEDS的背景下,我们遵循技术和有效性策略,因为我们预期的成果代表技术导向模型,要求通过真实用户在其人工背景下的验证来满足所概述的研究需求。我们将评估策略分为三个阶段:1. 预评估,2. 中期评估,和3. 后评估(Venable等人,2016)。预评估在研究项目开始后立即进行,符合形成性评估以改进预期研究结果的评估(Venable等人,2016)。操作上,评估阶段改编自Sonnenberg和Vom Brocke(2012)的EVAL1。因此,我们调查了现有文献并进行了专家访谈,以突出我们研究和定义的DOs的重要性与新颖性。中期评估是一个迭代程序,旨在提高成果的预期适用性,并提供对成果在自然主义背景下的初始行为的见解。操作上,此评估阶段结合了Sonnenberg和Vom Brocke(2012)的EVAL2和EVAL3指南,包括竞争性成果分析和向学科相关观众展示原型的初始演示。在后评估中,我们旨在通过评估研究成果的影响来提供成果在不同背景下的总结性评估(Venable等人,2016)。操作上,评估阶段改编自Sonnenberg和Vom Brocke(2012)的EVAL4,重点关注通过真实用户展示成果的实际好处。为此,我们在案例研究背景下对n=61名参与者进行了调查。据我们所知,这份手稿代表了首次尝试沟通我们研究在开发和实现使用微调LLMs的交互式聊天机器人以翻译XAI结果方面的成果。我们的原型源代码可通过以下GitHub存储库公开获取:https://github.com/bktllr/llm_explainable_ai
4 设计规范
我们定义并展示了我们推导的DOs,指定解决方案空间,并引入参考架构,该架构使用微调的LLM来增强人类对XAI的理解。这是我们研究的核心成果,包含了上述DOs。
4.1 设计目标
为了指导我们的成果开发,我们根据研究问题的识别和现有文献的筛查推导出DOs作为基本解决方案组件(Peffers等人,2007)。推导出的见解被综合成反映解决关键问题特性的DOs,同时与该领域的既定知识保持一致。我们的目标是解决XAI个性化解释的空白(Schneider,2024),同时增强其对人类用户的可解释性(Kaur等人,2020)。以下是介绍和证明推导出的DOs:
DO1 - 易于理解的解释,改善XAI解释的努力-效益比:
先前关于利用LLM增强ML模型可解释性的研究表明,易于理解的解释如何帮助人们理解主流ML模型的工作原理的重要性(Dhanorkar等人,2021;Gao等人,2022;Liao等人,2020)。基于这一基础,我们的成果旨在将生成的ML模型预测的文本描述与相应的XAI可视化集成。这样,人们应该能够通过阅读聊天机器人生成的解释来理解主流ML模型的最新预测,同时还能以视觉方式参考所获得的见解。文本和视觉结合的方式可以增加认知负担(Mayer & Moreno,2003)。然而,研究表明,这种结合也可以促进学习和参与(Sweller等人,2019)。例如,聊天机器人生成的解释可以帮助用户更好地理解特征的重要性及其对ML模型输出的贡献(正面与负面)。这对不熟悉XAI术语的用户特别有益,确保其更广泛的可访问性和理解(Gao等人,2022;Slack等人,2023)。虽然文本和可视化的组合可能需要比单独的XAI可视化等传统方法稍微多一点时间来进行人类解释,但在不同的用户群体中,XAI的可解释性应显著提高——无论是XAI专家还是非专家。
DO2 - 交互式和情境感知的用户体验,促进个性化理解
XAI:
现有研究表明,聊天机器人结合用户反馈进行个性化解释和使用自然语言进行交互的重要性(Schneider & Handali,2019;Schneider,2024;Schwalbe & Finzel,2023;Tenney等人,2020)。这些能力被认为是确保聊天机器人持续接受的关键(Slack等人,2023;Feine等人,2020)。为了实现这一点,成果应具备在用户界面中考虑聊天历史引用先前交互的能力。此外,为了使用户间接与主流ML模型生成的预测进行交互,聊天机器人应在生成响应时引用用户界面中的现有XAI可视化。这应使用户能够交互地探索XAI可视化,将人类解释过程与其在该领域的现有知识对齐。
DO3 - 推理答案生成,能够识别主流ML模型应用领域的全新见解:
虽然推理答案生成方面在底层文献中很少被提及(Finch等人,2021;Mazumder等人,2018),但从作者的角度来看,考虑到这一点对于确保聊天机器人在实际应用中的有用性至关重要。因此,设想中的聊天机器人不仅应能回答从其训练数据中获取的一般知识的问题,还应能处理需要推理的问题。这些推理应考虑关于特定ML模型预测、现有XAI可视化和用户聊天中提供的上下文的推理,解释为何做出某些预测。这种方法旨在为用户提供相关见解,激发解决实际挑战的灵感。
4.2 模型成果
在设计和开发阶段,我们根据DOs逐步指定和构建成果及其原型实例。图1提供了成果的示意图。
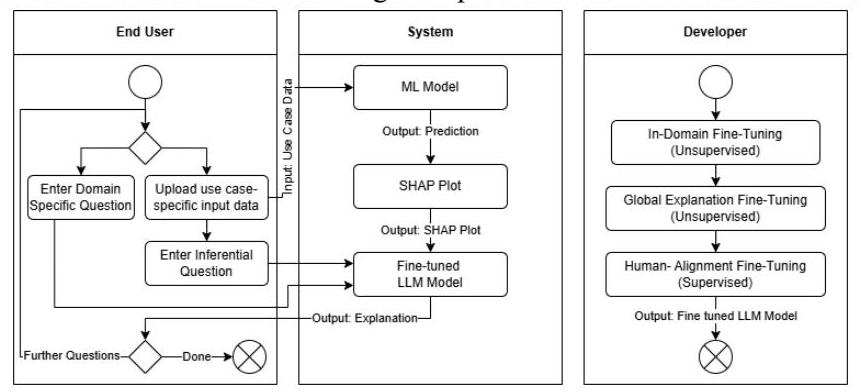
图1. 我们提出的成果使用微调的LLM来增强ML模型的可解释性,可视化为UML活动图(Dumas等人,2001)。
最初,开发人员通过三个步骤微调选择的通用LLM,以提高其处理和响应领域特定内容的能力,从而满足DOs。在应用中,用户首先决定是使用聊天机器人进行领域特定问题还是推理问题。系统提示包括有关预期问题、答案清晰简洁以及聊天机器人相应领域的信息,以向用户提供关于某个领域特定用例的深刻知识。用户从微调的LLM接收答案,并可以继续向系统提出新问题。对于推理问题,用户首先需要向系统上传用例特定输入数据以触发新的ML预测。在我们的用例中,ML预测通过预训练的CatBoost模型(Prokhorenkova等人,2018)进行。然后自动使用XAI技术分析新预测,以确定相应的SHAP重要性得分。然后将模型预测和XAI值集成到信息提示中,用户提交新问题时会自动提供给微调的LLM。用户从聊天机器人界面接收到微调LLM的答案,并可以继续向系统提出新问题。所展示的成果以其在特定领域内解释、交互和检索ML模型见解的独特能力脱颖而出。这是通过无缝集成XAI技术、ML模型和微调的LLM模型实现的。它可以作为其他领域系统设计的蓝图,需要不同的XAI技术、ML模型和微调的LLM模型。
本文已被接受在ECIS 2025会议上发表。
最终版本将在ECIS 2025会议记录中提供。
4.3 实例化
4.3.1 用例
我们基于物联网电池健康用例实现和测试了我们成果的原型,以提高SoH的可访问性。电池的SoH是一种指示电池当前状态相对于其原始状态的指标。它提供了对电池容量和性能随时间降级程度的见解(Bokstaller等人,2023)。因此,电池健康指数(BHI)监控是一种使用预测模型的新方法,该方法基于关键数据源实现持续的SoH监控(Bokstaller等人,2024)。底层预测模型是一个预训练的CatBoost模型(Prokhorenkova等人,2018),该模型基于电池特定因素和环境方面(如电池类型、外部影响或使用行为)预测物联网电池的SoH,这些因素在特征中表示。鉴于BHI监控对确保可靠电池运行的高度相关性,我们利用这个预训练模型来测试成果关于其提供个别模型特征及其相互作用对电池SoH影响的有意义解释的能力。
4.3.2 实现
为了实现原型,我们选择了Llama-2-13b-chat-hf(Touvron等人,2023)作为LLM,它是Meta开发的Llama系列的一部分,提供了质量与性能之间的良好平衡(Meta,2023)。该系列代表当时最先进的开源模型,产生的结果与OpenAI的商业GPT 3.5相似(Touvron等人,2023)。为了以可访问和交互的方式初始化我们的LLM,我们利用Gradio框架(Abid等人,2019)构建了一个聊天机器人界面,无缝集成了后端微调的Llama-2。此外,我们使用SHAP作为XAI技术,因为我们有分类特征。
4.3.3 微调
我们分三个步骤微调Llama-2,使用Oobabooga text-generation-webui(Oobabooga,2024),该工具支持LoRa训练、监督微调、非监督微调、困惑度评估和评估损失计算。这三个微调步骤的目标是首先为模型提供广泛的、基础的知识,然后逐步缩小到更领域特定和实例特定的知识,逐步完善模型的理解。在每次微调步骤之后,我们使用困惑度分数(Goldberg等人,2017)和损失指标定量评估LLM的性能。这三个微调步骤是:
- 领域内微调 1 { }^{1} 1 专注于丰富LLM在特定领域的知识。此微调步骤以无监督的方式在非结构化数据上进行,鼓励基础LLM发现目标领域的潜在模式。我们指定了两个领域类别“SHAP”和“电池”,并通过在Google和Google Scholar上进行广泛探索从网络中收集这些类别的非结构化文本文件。从搜索结果中,我们选择了每类别十个文档,这些文档从网站、文章和论文中检索而来,包含重要信息且被频繁引用。我们将这些文档转换为文本文件,并进行了简要的手动精炼。在每个类别中,一个文档被标记为评估此微调步骤对模型性能影响的困惑度分数,从而在每个类别中产生了九个训练文档和一个评估文档。微调过程的结果是1. 领域内微调模型,每个类别评估一次。
-
- 全局解释微调 2 { }^{2} 2 旨在通过考虑从广泛分析SHAP值得出的一般模型发现来增强LLM的用例特定知识。此微调步骤也以无监督的方式进行。因此,我们手动分析了SHAP值并将发现总结在一个非结构化文本文档中,然后提供给LLM。我们执行了以下三个SHAP分析步骤,利用SHAP库(Lundberg & Lee,2017):a) 使用所有可用数据的SHAP摘要图来评估输入特征对SoH的影响,b) 用于15个最重要输入特征的SHAP依赖图以识别特征之间的依赖关系和影响(Lundberg & Lee,2017),c) 按电池类型划分的SHAP摘要图以获取电池特定信息。虽然此微调步骤没有带来显著的新改进,但它帮助LLM更深入地理解了SHAP概念和电池SoH预测过程。有关上述各图的更多信息,请参见Lundberg和Lee(2017)。生成的信息被总结在一个非结构化训练文档中以进行2. 全局解释微调。
-
- 人类对齐微调 3 { }^{3} 3 旨在提高LLM为最终用户提供可解释和易于理解的模型解释的能力。此微调步骤以监督的方式在类似未来使用的结构化数据上进行,从而使微调后的LLM生成的输出更精确地与期望的任务目标对齐。在这种情况下,LLM被训练以准确解释SHAP值与模型预测和特定用户查询的关系。为了支持这一过程,我们自动生成了一个包含指令、与查询相关的简要数据描述、20个最重要的特征及其值和SHAP值以及正确输出的结构化JSON文档(Touvron等人,2023)。使用相同的方法,我们生成了一个评估文档(上下文问答)以匹配训练和评估提示。最后,我们在损失评估中针对评估文档进行了测试,以评估3. 人类对齐微调的影响。
4.3.4 微调结果
表1按三个微调步骤的形式展示了每份评估文档的定量评估结果,形式为消融研究。
| 微调步骤 | 1. SHAP 在 领域 | 1. 电池 在 领域 | 2. 全局 解释 | 3. 人类- 对齐 |
|---|---|---|---|---|
| 测试文档 | 综合 SHAP 指南 | 维基百科电池 SoH 文章 | 改写 结果摘要 | 上下文 Q&A 数据集 |
| 评估类型 | 困惑度 | 困惑度 | 困惑度 | 损失 |
| Llama-2 (基准) | 5.76 | 8.94 | 11.44 | 2.56 |
| + 领域内 微调 | 5.32 ( 7.6 % ) 5.32(7.6 \%) 5.32(7.6%) | 7.91 ( 11.5 % ) 7.91(11.5 \%) 7.91(11.5%) | 9.94 | 2.31 |
| + 全局 解释 | 5.32 | 7.93 | 9.81 ( 1.3 % ) 9.81(1.3 \%) 9.81(1.3%) | 2.31 |
| + 人类- 对齐 (最终模型) | 5.35 | 7.92 | 9.93 | 1.12 ( 51.5 % ) 1.12(51.5 \%) 1.12(51.5%) |
表1. Llama-2微调步骤的概述,用于驱动电池SoH聊天机器人,其中(x.xx%)指由于微调导致的评估指标改进百分比。
表1显示,领域内微调在每个类别的主要评估文档中带来了显著改进。这表明微调对于在特定领域中实现所需的准确性和上下文理解水平至关重要,而这仅通过提示工程无法充分实现。相反,全局解释微调对困惑度的影响较小。其中一个原因是,在全局解释微调的数据准备阶段分析SHAP值并未带来显著的新见解。
1
{ }^{1}
1 训练轮数: 3; 学习率: 0.0003; LoRA Rank: 8; LoRA Alpha: 16; 批量大小: 128; 微批量大小: 4
2
{ }^{2}
2 训练轮数: 3; 学习率: 0.0003; LoRA Rank: 8; LoRA Alpha: 16; 批量大小: 128; 微批量大小: 4
本文已被接受在ECIS 2025会议上发表。
最终版本将在ECIS 2025会议记录中提供。
因此,全球解释微调期间发现的所有内容已经在领域内微调期间转移给了LLM,这可以解释积极的溢出效应。人类对齐微调在评估其主要评估文档时对损失有最显著的影响。然而,表1揭示了之前微调的LLMs的困惑度值略有增加。
3
{ }^{3}
3 训练轮数: 20; 学习率: 0.0003; LoRA Rank: 8; LoRA Alpha: 16; 批量大小: 128; 微批量大小: 4
本文已被接受在ECIS 2025会议上发表。
最终版本将在ECIS 2025会议记录中提供。
因此,所有在全局解释微调期间发现的内容已经通过领域内微调转移到LLM,这可以解释积极的溢出效应。人类对齐微调在评估其主要评估文档时对损失有最显著的影响。然而,表1揭示了之前微调的LLMs的困惑度值略有增加。
5 评估
为了对预期的成果进行严格的评估,我们将FEDS整合到DSR方法中,进行三个评估阶段:前评估、中间评估和后评估。
5.1 前评估
我们在设计和开发阶段之前进行前评估,以验证我们研究问题和确定的DOs的重要性(Venable等人,2016)。研究问题源于一个实际的行业问题。在确定问题和研究空白后,我们从对XAI和LLM的初步文献筛选中得出了一个用于设计成果以解决给定研究问题的DOs集合。为了评估研究问题(RQ)和DOs的重要性与相关性,我们进行了16次专家访谈,这些专家在机器学习(ML)和信息系统(IS)方面经验丰富。专家们在ML方面有2至15年的经验,在IS方面有2至20年的经验。每位专家都进行了单独访谈,平均访谈时间为30分钟。首先,专家被要求使用从1(“不重要”)到5(“极其重要”)的五点李克特量表对给定的RQ和DOs的重要性进行评分。接下来,他们通过在这些DOs之间分配10分的预算来对DOs的重要性进行排名。
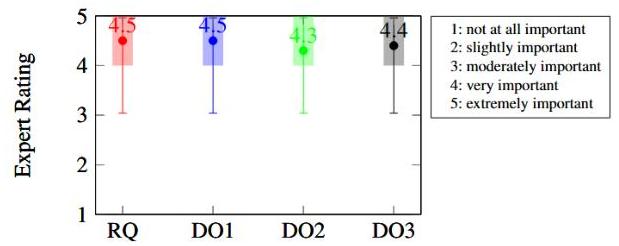
图2. 前评估以对研究问题(RQ)和DOs的重要性进行评分。
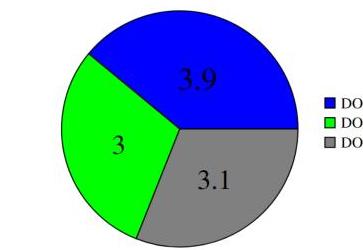
图3. 前评估以对DOs的重要性进行排名。
图2总结了专家组对重要性的评分。RQ被评为高度重要,平均评分为4.53(满分5分),突显了这项研究的重要性。此外,所有DOs都获得了超过4.4(满分5分)的高重要性评分。图3总结了专家组对重要性的排名。平均而言,专家组将DO1评为最重要,其次是DO3和DO2,所有DOs彼此接近,这与重要性评分一致。专家提到,很难对DOs进行排名,因为所有DOs都很重要。在访谈中,他们强调了可理解的解释(DO1)和推理答案生成(DO3)是聊天机器人设计的核心要求。对于这两个DOs,专家强调其功能需求因用户类型而异。他们指出,有限XAI知识的用户以及从事决策支持角色的用户,比拥有更深XAI专业知识或主要参与执行运营流程的用户更能从这些特性中受益。基于此反馈,
本文已被接受在ECIS 2025会议上发表。
最终版本将在ECIS 2025会议记录中提供。
我们完善了DOs以澄清其预期影响。DO1旨在提高对XAI的理解效率,特别是对于有限XAI知识的用户,而DO3旨在为参与决策支持的用户提供对现实世界解决方案的洞察。大多数专家预计互动体验(DO2)将成为聊天机器人用于简洁理解的必要功能,但通常被视为附加功能。然而,专家们仍提到澄清XAI可视化后续问题和个人化支持的潜力。在作者团队内部,我们决定专家额外提到的方面,如安全或可扩展性,不代表开发成果的核心,而是代表与实现相关的问题。总之,结果突显了我们研究的重要性,验证了DOs。我们得出结论,前评估证明了我们的研究问题和DOs,这是后续设计成果的基础。
5.2 中间评估
中间评估代表一个迭代过程,旨在通过初步接触自然主义设置来获取关于成果行为的知识(Venable等人,2016)。
5.2.1 竞争成果分析
我们通过将成果的DOs与当前前沿文献进行基准比较进行了竞争成果分析。更具体地说,我们确定了现有作品是否满足我们的DOs。竞争成果分析导致了几个关于我们提出的成果(图1)差异化能力的发现,这些发现总结在表2中。
| 方法 | 本文的主要成果 | Gao等人(2022) | Nguyen等人(2023) | Slack等人(2023) |
|---|---|---|---|---|
| DO1: 提高XAI解释的努力-效益比的可理解解释 | 提供直观解释的支持XAI可视化的底层ML模型 | 提供一般解释的主流AI并给出其置信水平的指示 | 通过解释特征重要性等,使用自然语言对话理解给定ML模型的XAI可视化 | 通过数据驱动见解使用自然语言对话理解ML模型 |
| DO2: 促进个性化理解的交互式和情境感知用户体验 | 通过引用生成的XAI可视化促进持续的人机对话 | 由于预定义的对话流程,人机对话互动有限 | 通过聊天历史支持持续互动,同时将聊天机器人接地到生成的XAI可视化 | 通过聊天历史支持持续互动,同时将聊天机器人接地到ML模型使用的数据及其预测 |
| DO3: 能够识别应用领域新见解的推理答案生成 | 将XAI评估得出的见解与LLM微调中获得的领域知识连接起来 | 响应依赖于预定义的交互 | 响应依赖于构建的问题短语库,启用基于模板的答案 | 响应依赖于预定义模板,规定ML模型的操作 |
表2. 竞争成果分析
在表2中,圆圈代表对设计目标的完全、部分或未考虑。因此,我们提出的成果对DO1和DO2完全考虑,对DO3部分考虑。实例化的原型能够根据生成的XAI图通过微调中获得的领域知识进行推理。然而,根据提出的问题,聊天机器人有时
本文已被接受在ECIS 2025会议上发表。
最终版本将在ECIS 2025会议记录中提供。
难以应对幻觉和使用领域特定术语。相关工作在至少部分保证可理解解释(DO1)和实现交互用户体验(DO2)方面做出了重大努力。我们提出的成果与以前的工作相比的核心差异在于推理答案生成(DO3)。在此之前,没有任何论文包括基于聊天机器人中传递的数据生成推理答案,而是依赖于预定义模板或构造的问题短语库。竞争成果分析显示了我们成果在当前文献中的独特设计。
5.2.2 原型演示
我们根据每周讨论中的反馈迭代开发了成果和基于此反馈的原型,这些讨论组由六名成员组成,他们在XAI、LLM、ML、物联网电池技术和信息系统方面具有跨学科经验。此外,原型(如图4所示)两次向约20人的较大受众进行了演示,这些演示是在定期会议中进行的,会议的重点是分享和讨论信息系统、机器学习和数字技术领域的新解决方案。因此,参与者在这些领域具有跨学科背景,促进了对原型的多样化视角。第一次原型演示是在初始实现管道后进行的,这意味着在这个阶段,我们初始化了一个通用的LLM而没有进行微调。我们利用Gradio框架构建了一个聊天机器人界面,无缝集成了后端的Llama-2。初始原型展示了基本的XAI翻译能力,以促进人类用户对ML模型的理解,并作为验证成果有效性的第一个证据。然而,在最初的演示中,观众指出聊天机器人似乎在处理详细和转移问题时遇到困难。因此,我们优先考虑进一步微调以进行下一步开发。
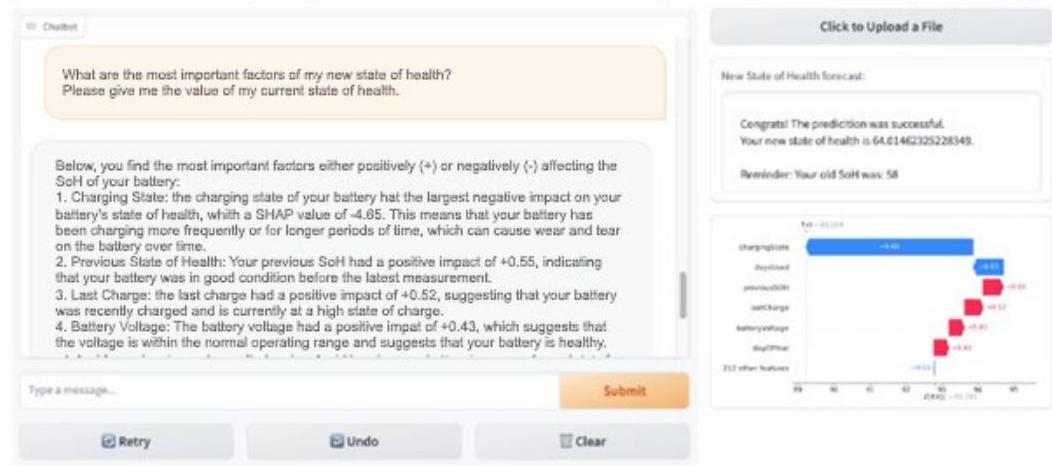
图4. 聊天机器人界面快照。
观众赞赏了互动功能的加入,例如能够上传电池数据并允许用户在聊天机器人对话中提出个性化问题。聊天机器人通过微调获得的广泛领域特定知识及其在响应用户查询时展示这种知识的能力受到了高度赞扬。
5.
------3 后评估
为了作为后评估来评估我们方法的有效性,我们进行了一项在线调查。我们的目标是衡量与我们的聊天机器人互动时的整体可解释性和清晰度,并了解不同熟练程度参与者之间的理解差异。我们接触了超过100名参与者,他们的ML概念熟悉程度各不相同,特别是SHAP值。我们通过向行业中的个人和团队发送调查链接(根据其专业职位和AI知识水平选择低和高),以及不同的社会和学生群体,以确保多样化的代表性,招募了参与者。从这个样本池中,我们收到了61份回复,这些回复构成了我们分析的基础。调查分为四个主要部分:人口统计信息、SHAP可解释性评估、非微调聊天机器人提供的解释评估,以及对我们微调的XAI聊天机器人的清晰度、可解释性和认知努力的评估。首先,我们想衡量用户对ML和SHAP值的熟练程度。我们通过询问诸如“您对AI概念的熟悉程度如何”和“您在日常生活中与AI技术交互的频率如何?”等问题来做到这一点。这种分类有助于区分用户。参与者首先与一个电池SoH预测的SHAP瀑布图互动,该图附有对SHAP值和特征的基本解释(基线1)。然后他们回答了关于理解图表所需清晰度、可解释性和认知努力的问题。同样的评估程序应用于非微调聊天机器人生成的解释截图(基线2),然后是我们提出的将相同的SHAP值转化为更用户友好的文本的微调XAI聊天机器人。为了最小化顺序效应,所有参与者首先评估了SHAP图,然后是聊天机器人生成的解释(Doshi-Velez & Kim, 2017)。为了评估我们聊天机器人的性能,我们将两个基线与我们提出的微调XAI聊天机器人进行了比较。我们的研究结果如图5所示,表明我们的解决方案在所有三个评估指标上都超过了传统的SHAP瀑布图和非微调聊天机器人(数值越高表示结果越好)。无论熟练程度如何,参与者都喜欢由微调XAI聊天机器人提供的用户友好型解释,因为缺乏领域知识使得SHAP生成的图和非微调聊天机器人相形见绌。
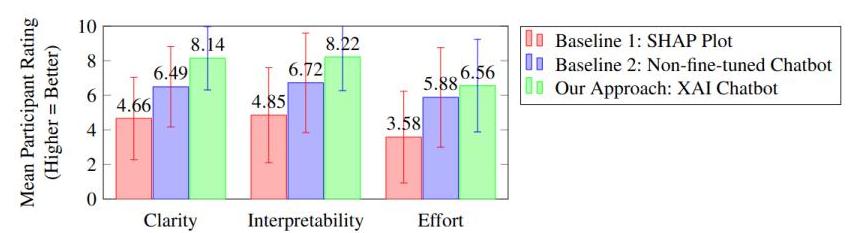
图5. 调查结果关于整体可解释性和清晰度。
此外,我们比较了两个基线与我们微调的XAI聊天机器人在不同参与者熟练程度(低、中、高)下的评分。我们从调查的人口统计部分获取了熟练程度水平。对于每个熟练程度水平,我们计算了基线值与我们的聊天机器人在三个指定类别上的差异。正差异表示偏好我们的解决方案,而负差异则表示基线解决方案的可用性更高。如图6所示,我们的解决方案在所有熟练程度水平下始终优于两个基线。然而,值得注意的是,随着参与者的熟练程度提高,所有三个评估类别的差异会减小。这一趋势可以归因于更熟练用户的增强分析能力和对SHAP图的熟悉程度。熟练程度较低的用户在有效解释SHAP图方面遇到挑战。这正是我们解决方案的优势所在。聊天机器人可以将SHAP图翻译成即使是熟练程度较低的参与者也能理解的文本。因此,我们的分析确认,与熟练程度较高的参与者相比,熟练程度较低的参与者对我们聊天机器人的偏好更强。
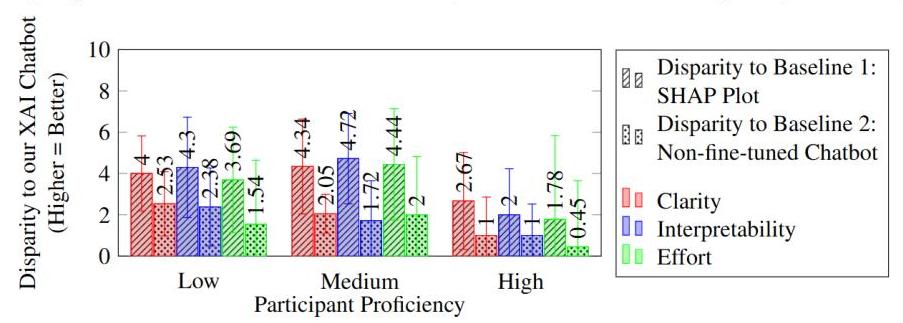
图6.
不同熟练程度水平下的可理解性差异调查结果。
6 结论
遵循设计科学的研究方法,本研究开发并展示了一种新型成果,旨在解决解释机器学习模型的挑战。随着机器学习模型复杂性的增加,通常被最终用户视为“黑箱”,我们的解决方案通过结合XAI与微调的大规模语言模型(LLMs),使用户能够通过自然语言交互查询和理解模型决策,从而增强了可解释性。这对于需要安全操作机器学习模型的各种实际应用尤为重要,因为可解释性有助于评估透明性、公平性、数据隐私、可靠性、鲁棒性和信任等要求是否得到满足(Doshi-Velez & Kim, 2017)。我们的实证调查结果强调了可解释性的显著提升,特别是对于不太熟悉XAI的用户。通过将SHAP嵌入到对话界面中,我们成功地将复杂的SHAP图转换为高层次、易于理解的见解,从而降低了最终用户的知识要求。因此,这项研究通过提供可理解的解释、提供交互式用户体验以及基于机器学习模型预测响应领域特定问题和推理问题,显著促进了XAI的发展,弥合了复杂机器学习模型与人类理解之间的差距。与以往工作不同,我们不是使用基于模板的答案和响应匹配,而是基于SHAP值输入应用微调的LLM。据作者所知,我们是第一篇详细介绍如何调整LLM以与SHAP值配合工作的论文,并发布相应代码。虽然我们为电池健康状态(SoH)用例展示了成果的原型实例,使用SHAP值,但其潜力远远超出了这个具体应用。我们成果的多功能设计使其可以推广到其他各种领域,显著增强信任、透明度和可靠性(Javed等人,2023)。例如,在智慧城市解决方案中,XAI可以提高洪水检测、排水监控(Thakker等人,2020)和事故预防(Lavrenovs & Graf,2021)等领域的透明度。在医疗领域,为机器决策和预测提供清晰且可解释的解释能力对于确保其可靠性和建立信任至关重要(Tjoa & Guan,2021)。因此,拥有一个可以在各个部门应用的适应性强且通用的成果非常重要。未来的工作可以实施并扩展我们的成果到此类用例和不同的XAI技术,以研究其性能。进一步扩展成果可能包括集成无监督机器学习模型和不同技术以超越当前展示的微调技术。我们的LLM针对电池和SHAP领域的特定知识进行了微调,提供了一个可在这些领域使用的可转移方法。然而,对于其他具有有限共同知识的应用领域,LLM可能需要更广泛的微调才能实现有效的推理推理,特别是在与预训练模型中已嵌入大量相关知识的成熟领域相比时。由于获取足够的领域特定数据用于微调可能会很困难,替代或补充方法可能是集成检索增强生成(RAG)。通过纳入相关外部信息,RAG可以缓解LLM出现幻觉的情景,从而减少错误信息生成的实例。我们的研究存在以下限制:首先,我们的成果基于当前技术和它们的内部工作机制构建和评估,如SHAP、ML和LLM,因此受限于它们当前的能力。本研究使用SHAP作为一种成熟的XAI技术,为ML模型提供事后解释以增强模型可解释性。其次,为了确保不仅是透明而且是值得信赖的ML模型,将我们的成果扩展以整合预测置信度分数可能是一个有前景的研究方向。第三,深入了解用户不断变化的需求需要长期评估。尽管当前评估通过访谈和面向更广泛受众的在线调查捕捉到了快照,但随着时间推移扩展评估可以提供关于用户体验和适应性的更深入见解。
参考文献
Abid, A., Abdalla, A., Abid, A., Khan, D., Alfozan, A., & Zou, J. (2019). Gradio: Hassle-free sharing and testing of ml models in the wild. ArXiv, abs/1906.02569.
Arrieta, A. B., Diaz-Rodriguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., Garcia, S., Gil-Lopez, S., Molina, D., Benjamins, R., et al. (2020). Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information Fusion, 58, 82-115.
Berente, N., Gu, B., Recker, J., & Santhanam, R. (2021). Managing Artificial Intelligence. MIS Quarterly. 45(3), 1433-1450.
Bokstaller, J., Schneider, J., Lux, S., & vom Brocke, J. (2024). Battery Health Index: Combination of Physical and ML-based SoH for continuous Health Tracking. IEEE Internet of Things Journal. 11(20), 33624-33641
Bokstaller, J., Schneider, J., & vom Brocke, J. (2023). Estimating SoC, SoH, or RuL of rechargeable batteries via IoT: A review. IEEE Internet of Things Journal. 11(5), 7559-7582
Brasse, J., Broder, H., & Forster, M. e. a. (2023) Explainable artificial intelligence in information systems: A review of the status quo and future research directions. Electronic Markets, 33(1), 26.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
Chakraborty, S., Tomsett, R., Raghavendra, R., Harborne, D., Alzantot, M., Cerutti, F. (2017). Interpretability of deep learning models: A survey of results. Proceedings of 2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Atlanta, GA, USA, 1-6.
Dhanorkar, S., Wolf, C. T., Qian, K., Xu, A., Popa, L., & Li, Y. (2021). Who needs to know what, when?: Broadening the Explainable AI (XAI) Design Space by Looking at Explanations Across the AI Lifecycle. Proceedings of the 2021 ACM Designing Interactive Systems Conference, Virtual Event USA, 1591-1602.
Doshi-Velez, F., & Kim, B. (2017). Towards A Rigorous Science of Interpretable Machine Learning arXiv preprint arXiv:1702.08608.
Dumas, M., Hofstede, A. (2001). UML Activity Diagrams as a Workflow Specification Language. Proceedings of the UML 2001 - The Unified Modeling Language. Modeling Languages, Concepts, and Tools, Toronto, Kanada, 76-90.
Feine, J., Morana, S., & Maedche, A. (2020). Designing Interactive Chatbot Development Systems. Proceedings of the 41st International Conference on Information Systems(ICIS), Hyderabad, India.
Finch, S. E., Finch, J. D., Huryn, D., Hutsell, W., Huang, X., He, H., & Choi, J. D. (2021). An Approach to Inference-Driven Dialogue Management within a Social Chatbot. ArXiv,
a
b
s
/
2111.00570
a b s / 2111.00570
abs/2111.00570.
Gao, M., Liu, X., Xu, A., & Akkiraju, R. (2022). Chat-XAI: A New Chatbot to Explain Artificial Intelligence. Intelligent Systems and Applications. Proceedings of SAI Intelligent Systems Conference, Amsterdam, The Netherlands, 125-134.
Gunel, B., Du, J., Conneau, A., & Stoyanov, V. (2021). Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning. Proceedings of the Ninth International Conference on Learning Representations, Vienna, Austria.
Goldberg, Y. (2017). Neural Network Methods in Natural Language Processing. Morgan & Claypool Publishers.
Hevner, A. R., March, S. T., Park, J., & Ram, S. (2004). Design Science in Information Systems Research. MIS Quarterly, 28, 75-105.
本文已被接受在ECIS 2025会议上发表。
最终版本将在ECIS 2025会议记录中提供。
Hu, E. J., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al. (2022). Lora: Low-Rank Adaptation of Large Language Models. Proceedings of the Tenth International Conference on Learning Representations, Virtual Event, Austria.
Hu, Z., Wang, L., Lan, Y., Xu, W., Lim, E.-P., Bing, L., Xu, X., Poria, S., & Lee, R. K.-W. (2023). LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 5254-5276.
IBM. (2024). IBM Watson Assistant X. Retrieved March 05, 2024 from https://www.ibm.com/ products/watsonx-assistant
Javed, A. R., Ahmed, W., Pandya, S., Maddikunta, P. K. R., Alazab, M., & Gadekallu, T. R. (2023). A Survey of Explainable Artificial Intelligence for Smart Cities. Electronics, 12(4).
Jussupow, E., Benbasat, I., Heinzl, A. (2020). Why are we averse towards algorithms? A comprehensive literature review on algorithm aversion. Proceedings of the European Conference on Information Systems - A Virtual AIS Conference.
Kaur, H., Nori, H., Jenkins, S., Caruana, R., Wallach, H., & Wortman Vaughan, J. (2020). Interpreting Interpretability: Understanding Data Scientists’ Use of Interpretability Tools for Machine Learning. Proceedings of the 2020 CHI: Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 1-14.
Lakkaraju, H., Slack, D., Chen, Y., Tan, C., & Singh, S. (2022). Rethinking Explainability as a Dialogue: A Practitioner’s Perspective. Proceedings of the NeurIPS Workshop on Human Centered AI, online.
Lavrenovs, A., & Graf, R. (2021). Explainable AI for Classifying Devices on the Internet. Proceedings of the 13th International Conference on Cyber Conflict (CyCon), Tallinn, Estonia, 291-308.
Lehmann, C., Haublitz, C., Fügener, A., Thonemann, U. (2022). The risk of algorithm transparency: How algorithm complexity drives the effects on the use of advice. Production and Operations Management, 3419-3434.
Liao, V., Gruen, D., & Miller, S. (2020). Questioning the AI: Informing Design Practices for Explainable AI User Experiences. Proceedings of the 2020 CHI: Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 1-15.
Liu, W., Wang, Z., Liu, X., Zeng, N., Liu, Y., & Alsaadi, F. E. (2017). A survey of deep neural network architectures and their applications. Neurocomputing, 234, 11-26.
Lundberg, S. M., & Lee, S.-I. (2017). A Unified Approach to Interpreting Model Predictions. Advances in Neural Information Processing Systems, 30, 4768- 4777.
Mayer, R. E. & Moreno R. (2010). Nine Ways to Reduce Cognitive Load in Multimedia Learning. Educational Psychlogist, 38(1), 43 - 52.
Mazumder, S., Ma, N., & Liu, B. (2018). Towards a Continuous Knowledge Learning Engine for Chatbots. ArXiv, abs/1802.06024.
Meske, C., Bunde, E., Schneider, J., & Gersch, M. (2022). Explainable Artificial Intelligence: Objectives, Stakeholders, and Future Research Opportunities. Information Systems Management, 39(1), 53-63.
Meta. (2023). Llama 2: Open source, free for research and commercial use. Retrieved April 10, 2024 from https://llama.meta. com/llama2/.
Nguyen, N., & Nadi, S. (2022). An empirical evaluation of GitHub copilot’s code suggestions. Proceedings of the 19th International Conference on Mining Software Repositories, Pittsburgh, Pennsylvania, US, 1-5.
Nguyen, V. B., Schlötterer, J., & Seifert, C. (2023). From Black Boxes to Conversations: Incorporating XAI in a Conversational Agent. Proceedings of the World Conference on eXplainable Artificial Intelligence, Lisbon, Portugal, 71-96.
Oobabooga. (2024). Text-generation-webui. Retrieved April 10, 2024 from https://github.com/ oobabooga/text-generation-webui).
本文已被接受在ECIS 2025会议上发表。
最终版本将在ECIS 2025会议记录中提供。
Peffers, K., Tuunanen, T., Rothenberger, M. A., & Chatterjee, S. (2017). A Design Science Research Methodology for Information Systems Research. Journal of Management Information Systems, 24(3), 45-77.
Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. (2018). Catboost: unbiased boosting with categorical features. Advances in Neural Information Processing Systems, 31.
Räuker, T., Ho, A., Casper, S., & Hadfield-Menell, D. (2023). Toward Transparent AI: A Survey on Interpreting the Inner Structures of Deep Neural Networks. Proceedings of the 2023 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), Raleigh, NC, USA, 464-483.
Schneider, J. (2024). Explainable Generative AI (GenXAI): A survey, conceptualization, and research agenda. Artificial Intelligence Review, 57(11), 289.
Schneider, J., & Handali, J. (2019). Personalized explanation in machine learning: A conceptualization. Proceedings of the European Conference on Information Systems (ECIS), Stockholm, Sweden.
Schwalbe, G., & Finzel, B. (2023). A comprehensive taxonomy for explainable artificial intelligence: A systematic survey of surveys on methods and concepts. Data Mining and Knowledge Discovery, 1-59.
Slack, D., Krishna, S., Lakkaraju, H., & Singh, S. (2023). Explaining machine learning models with interactive natural language conversations using TalkToModel. nature machine intelligence, 5(8), 873-883.
Sonnenberg, C., & Vom Brocke, J. (2012). Evaluations in the Science of the ArtificialReconsidering the Build-Evaluate Pattern in Design Science Research. Design Science Research in Information Systems. International Conference on Design Science Research in Information Systems and Technology, Las Vegas, NV, USA, 381-397.
Sweller, J., van Merriënboer, J.J.G. & Paas, F. (2019). Cognitive Architecture and Instructional Design: 20 Years Later. Educational Psychology Review, 31, 261-292.
Tenney, I., Wexler, J., Bastings, J., Bolukbasi, T., Coenen, A., Gehrmann, S., Jiang, E., Pushkarna, M., Radebaugh, C., Reif, E., et al. (2020). The language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 107-118.
Thakker, D., Mishra, B. K., Abdullatif, A., Mazumdar, S., & Simpson, S. (2020). Explainable Artificial Intelligence for Developing Smart Cities Solutions. Smart Cities, 3(4), 1353-1382.
Tjoa, E., & Guan, C. (2020). A Survey on Explainable Artificial Intelligence (XAI): Toward Medical XAI. IEEE Transactions on Neural Networks and Learning Systems, 32(11), 47934813.
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. (2023). LLaMA: Open and efficient Foundation Language Models. ArXiv, abs/2302.13971.
Van den Broeck, G., Lykov, A., Schleich, M., & Suciu, D. (2022). On the Tractability of SHAP Explanations. Journal of Artificial Intelligence Research, 74, 851-886.
Vaswani, A. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30.
Venable, J., Pries-Heje, J., & Baskerville, R. (2016). FEDS: a framework for evaluation in design science research. European Journal of Information Systems, 25(1), 77-89.
Wu, S., Irsoy, O., Lu, S., Dabravolski, V., Dredze, M., Gehrmann, S., Kambadur, P., Rosenberg, D., & Mann, G. (2023). BloombergGPT: A Large Language Model for Finance. arXiv, abs /2303.17564.
Yao, J.-Y., Ning, K.-P., Liu, Z.-H., Ning, M., & Yuan, L. (2023). LLM Lies: Hallucinations are not Bugs, but Features as Adversarial Examples. ArXiv, abs/2310.01469.
参考论文:https://arxiv.org/pdf/2505.02859



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











